TESTING WITHOUT WRITING TESTS HAVING FUN WITH POSTCODES AND LIES VICTOR MUNOZ

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

TESTING WITHOUTWRITING TESTS
HAVING FUN WITH POSTCODES AND LIESVICTOR MUNOZ

WHAT'S IN APOSTCODE?

A typical British postcode has a clearly definedstructure......but many possible variationsWriting a correct regular expression is feasible, but trickySo, so many cases to test against

W1 6LS
N1C 4AQ
N17 6LA
SW8 1UQ
WC2H 7LT
HU12 0AR

THE BAD, THE WRONGAND THE UGLY

There is a list of official rules
Even a (wrong) regexp in an official document

THE WRONG(̂[Gg][Ii][Rr] 0[Aa]{2}) |( ( ([A-Za-z][0-9]{1,2}) | ( ([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2}) | ( ([AZa-z][0-9][A-Za-z]) | ([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]) ) ) ) [0-9][A-Za-z]{2})$
No, this is not LISP. Promise.

THE BAD(̂ ([gG][iI][rR] {0,}0[aA]{2}) | ( ( ([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y]?[0-9][0-9]?) | ( ([a-pr-uwyzA-PR-UWYZ][0-9][a-hjkstuwA-HJKSTUW]) | ([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y][0-9][abehmnprv-yABEHMNPRV-Y]) ) ) {0,}[0-9][abd-hjlnp-uw-zABD-HJLNP-UW-Z]{2} ))$

THE UGLY(̂?P<postcode> (?P<girobank>gir\s*0aa) | # Girobank. ( (?P<first> ((?![qvx])[a-z][a-hk-y]?[0-9][0-9]?) | # First part. ((?![qvx])[a-z][0-9][a-hjkpstuw]) | # First part. ((?![qvx])[a-z][a-hk-y][0-9][abehmnprvwxy]) # First part. )\s*(?P<second>[0-9](?![cikmov])[a-z]{2})? # Second part. ))$
...but it's my ugly.

HOW DO I TEST THAT?

CarefullyCreate lots of casesCover all possibilities of success and failureTL; DR: Hell

CAN I HAVE SOMEMAGIC?
Since you ask nicely...Let's use pytest to generate tests from the test datasetNote for testing nerds: Yes, this is just a semi-magic formof table-driven tests.

TESTING STRATEGY (I)1. Check if the postcode matches2. Check it matches the right thing3. Check the first part is matched correctly4. Check the second part is matched correctly
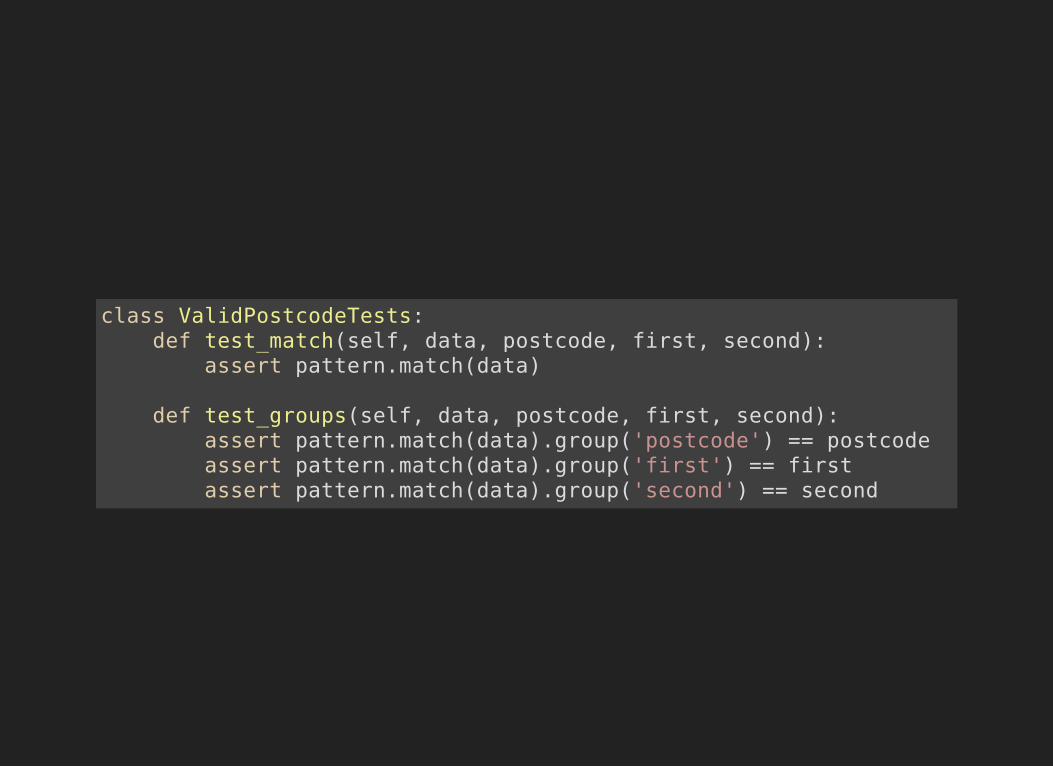
class ValidPostcodeTests: def test_match(self, data, postcode, first, second): assert pattern.match(data)
def test_groups(self, data, postcode, first, second): assert pattern.match(data).group('postcode') == postcode assert pattern.match(data).group('first') == first assert pattern.match(data).group('second') == second

TESTING STRATEGY(II)For invalid postcodes, just check it doesn't match
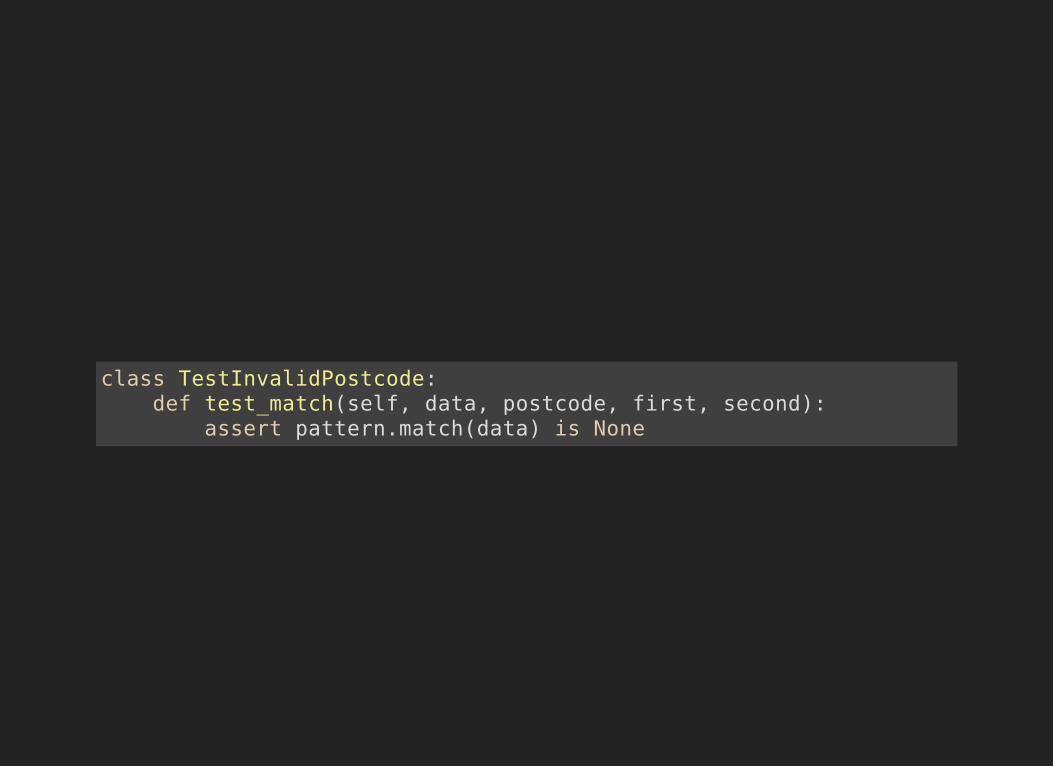
class TestInvalidPostcode: def test_match(self, data, postcode, first, second): assert pattern.match(data) is None

TESTING STRATEGY (III)Test for variations as well:
Lowercase postcodesPostcodes without space separatorPartial postcodesAny combination of those

transforms = { "lowercase": partial( _transform_factory, lambda k: k.lower() if k else k ), "nospace": partial( _transform_factory, lambda k: k.replace(' ', '') if k else k ),}

Once you have all the combinations, generate tests.class DataGenerator: def generate_data(self): for item in self.dataset: for transform in self._get_transform_combinations(): yield self._transform_data(item, *transform)
def generate_ids(self): for item in self.dataset: for transform in self._get_transform_combinations(): yield "{}-{}".format( item[0].replace(" ", "_"), "_".join(transform) or "original" )

Finally, hook that into pytestdef pytest_generate_tests(metafunc): if metafunc.cls: gen = DataGenerator(metafunc.cls.postcodes)
metafunc.parametrize( 'data,postcode,first,second', list(gen.generate_data()), ids=list(gen.generate_ids()), scope='class' )

Your test cases should look like this:class TestFullPostcodes(ValidPostcodeTests): postcodes = ( ("W1 6LS", "W1 6LS", "W1", "6LS",), ("N1C 4UQ", "N1C 4UQ", "N1C", "4UQ",), ("N1P 4AA", "N1P 4AA", "N1P", "4AA",), ("N17 6LA", "N17 6LA", "N17", "6LA",), ("SW8 1UQ", "SW8 1UQ", "SW8", "1UQ",), ("CW3 9SS", "CW3 9SS", "CW3", "9SS",), ("SE5 0EG", "SE5 0EG", "SE5", "0EG",), ("WC2H 7LT", "WC2H 7LT", "WC2H", "7LT",), ("WC1N 2PL", "WC1N 2PL", "WC1N", "2PL",), ("HU12 0AR", "HU12 0AR", "HU12", "0AR"), )

I WANT TO COVEREVERYTHING

OS CODEPOINT1.7M+ postcodesCovers pretty much everything

First, extract the useful bits in a useful formatdef get_postcodes(datadir): for fn in listdir(datadir): with open(datadir + fn) as f: for row in reader(f): yield row[0]
if __name__ == '__main__': datadir = 'tests/data/Data/CSV/' postcodes = list(get_postcodes(datadir))
with open("tests/OSpostcodes.db", "wb") as f: pickle.dump(postcodes, f, pickle.HIGHEST_PROTOCOL)

Then, generate millions of testsdef pytest_generate_tests(metafunc): if pytest.config.getoption("osdb"): with open("tests/OSpostcodes.db", "rb") as f: metafunc.parametrize("postcode", pickle.load(f)) else: metafunc.parametrize("postcode", pytest.skip([]))
def test_OS_postcodes(postcode): assert pattern.match(postcode)

QUESTIONS?COMMENTS?

@vmberti
github.com/bolsote/ukpcre
Related Documents











