Scalable Matrix Multiplication for the 16 Core Epiphany Co- Processor Louis Loizides May 2 nd 2015

Term Project Presentation (4)
Aug 18, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Scalable Matrix Multiplicationfor the 16 Core Epiphany Co-Processor
Louis LoizidesMay 2nd 2015

Parallella Board
16 core MIMD EpiphanyCo-Processor
Zync ARM processor / FPGA
Image from Adapteva

Epiphany Versions
32 GFLOPS16 core Epiphany on
Parallella
5 TFLOPS?4096 core Epiphany
Graphic from Adapteva

Compiling
*.c gcc Hostprog
HAL
Execution:
*.c e-gcc *.elf
ELDF
e-objcopy
Device prog
*.srec
Hardware definition file

Challenges• Hard to code. Need for very
manual memory allocation and management makes complex coding difficult.
• Hard to debug. Epiphany doesn’t share memory with Linux
• Temperature. After a week of frustration I realized I needed to put a fan over it.
• Documentation. SDK and examples are poor and frequently broken. Few beginner examples. Small community of users.
My “thermal management solution”

Process Synchronization
• Each core runs a process, not a thread– Every core can run a different process– “Workgroups” can be created in SDK
• Functions exist in OpenCL, COPRTHR and eSDK for synchronizing processes– Mutexes only provided between cores– SDK examples tend to use wait for single bits to change for
synchronization• MPI, OpenMP currently not supported for coprocessor
– Some “community” projects in works… not much of a community though

Memory Management
• “Shared” DRAM– Memory allocated specifically for Epiphany using e_alloc– 160 MB/s (https://parallella.org/forums/viewtopic.php?f=10&t=1978)
• SRAM in each core– Only 32kB available– 4 GB/s (1 GB/s in practice per DMA channel)– Use DMA channel functions to transfer memory between cores– Can’t use malloc!!! – must keep track manually– Have to know addresses on other cores you want to send data to– Must watch out for both code size and stack growth
32kB of memory
Prog. Stack(matrix buffers go here… essentially the heap)D
ebug
ging

Chip Architecture
• 32kb SRAM per core for program + stack• ~2 GB/s DMA transfers between cores• ~150 MB/s to transfer to/from shared DRAM
DMA engine frees up processor
Graphic from Adapteva
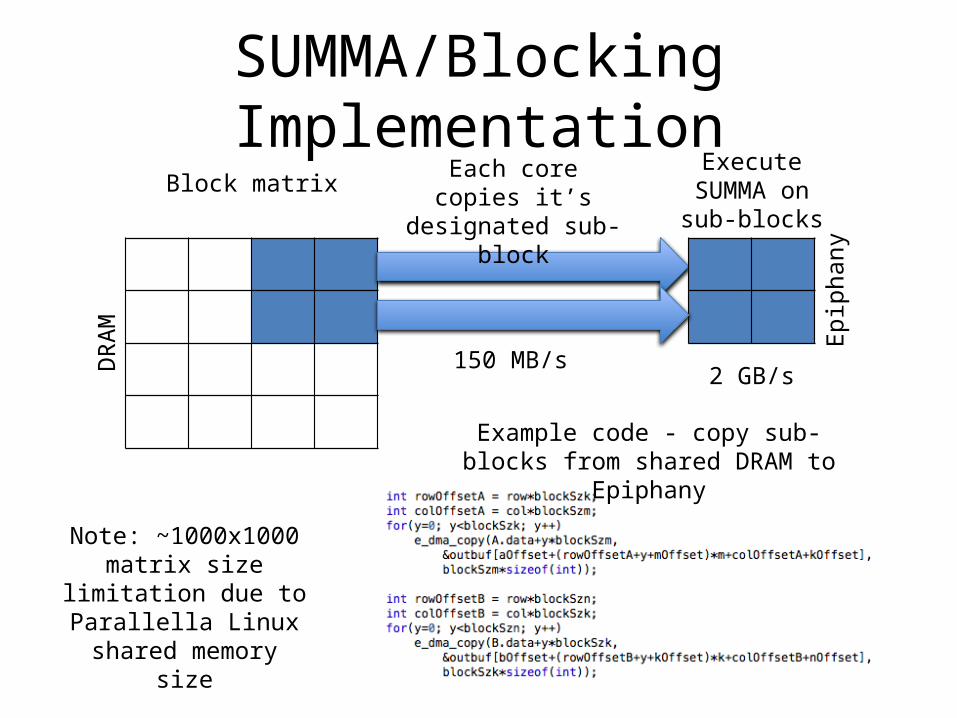
SUMMA/Blocking ImplementationBlock matrix
Execute SUMMA on sub-blocks
Each core copies it’s designated sub-block
Example code - copy sub-blocks from shared DRAM to Epiphany
Epip
hany
DRA
M
Note: ~1000x1000 matrix size limitation due to
Parallella Linux shared memory size
150 MB/s2 GB/s

Results
0 200 400 600 800 10000
50
100
150
200
250
300
350
Matrix Multiplication Execution Times
Single Epiphany Core
2x2 Core Grid
3x3 Core Grid
4x4 Core Grid
ARM Naive
ARM Blocked
Matrix Side Size
Exec
ution
Tim
e (s
)

Epiphany Version Grid Side Size Epiphany
Time (s)Speedup vs. Single Core
1 317.2 1 2 80.9 3.92 3 35.43 8.95
E16G3 4 21.5 14.76E64G4 8 7.7 41.24
E256G4 16 1.98 160.02E1KG4 32 0.51 620.96E4KG4 64 0.13 2409.56
Speedup(vs. single core)
More cores -> Larger Blocks -> Exponentially Less Blocking
1 2 3 40
2
4
6
8
10
12
14
16
f(x) = 1.00827869658563 x^1.95623152724166R² = 0.999495920088555
Speedups vs. Grid Side Size
Grid Side Size
Spee
dup
(vs S
ingl
e Co
re)
Estimated

Conclusions
• Potentially powerful device, especially in embedded AI applications with large search spaces– Needs passive cooling
• 32kB SRAM is extremely limiting– Needs either L2 cache or just some kind of faster near-
chip shared memory– Really limitation of Parallella architecture, not Epiphany
• Incredibly difficult to code– SDK & Documentation needs improvement– Better debugging tools needed ASAP!
Related Documents











