Tema 1: Introducció Eduard Ayguadé i Josep Llosa These slides have been prepared using some material which is part of the teaching material of Prof. Mateo Valero at the Computer Architecture Departament and Barcelona Supercomputing Center. Some processor diagrams have been extracted from the “Microprocessor Report journal, Copyright In/Stat&MDR.” Other material available through the internet has also been used to prepare this chapter’s slides. Why do we need high-performance computing? Why do we need high-performance computing? Computational Needs of Technical, Scientific, Digital Media and Business Applications CFD Wing Simulation 512x64x256 Grid (8.3 x10e6 mesh points) 5000 FLOPS per mesh point, 5000 time steps/cycles 2.15x10e14 FLOPS CFD Full Plane Simulation 512x64x256 Grid (3.5 x10e17 mesh points) 5000 FLOPS per mesh point, 5000 time steps/cycles 8.7x10e24 FLOPS Source: A. Jameson, et al Materials Science Magnetic Material: Current: 2000 atoms; 2.64 TF/s, 512 GB Future: HDD Simulation - 30 TF/s, 2 TB Electronic Structures: Current: 300 atoms; 0.5 TF/s, 100 GB Future: 3000 atoms; 50 TF/s, 2TB Source: D. Balley, NERSC Digital Movies and Special Effects ~1e14 FLOPs per frame 50 frames/sec 90 minute movie - 2.7e19 FLOPs Source: Pixar Spare Parts Inventory Planning Modelling the optimized deployment of 10000 part numbers across 100 part depots and requries: - 2x10e14 FLOP/s (12 hours on 10, 650 MHz CPUs) - 2.4 PetaFlop/s sust. performance (1 hour turn-around time) Industry trend to rapid, frequent modeling for timely business decision support driver higher sustained performance Source: B. Dietrich, IBM

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Tema 1: Introducció
Eduard Ayguadé i Josep Llosa
These slides have been prepared using some material which is part of the teaching material of Prof. Mateo Valero at the ComputerArchitecture Departament and Barcelona Supercomputing Center. Some processor diagrams have been extracted from the“Microprocessor Report journal, Copyright In/Stat&MDR.” Other material available through the internet has also been used toprepare this chapter’s slides.
Why do we need high-performance computing?Why do we need high-performance computing?
Computational Needs of Technical, Scientific, Digital Media and Business Applications
CFD Wing Simulation512x64x256 Grid(8.3 x10e6 mesh points)5000 FLOPS per mesh point,5000 time steps/cycles2.15x10e14 FLOPS
CFD Full Plane Simulation512x64x256 Grid(3.5 x10e17 mesh points)5000 FLOPS per mesh point,5000 time steps/cycles8.7x10e24 FLOPSSource: A. Jameson, et al
Materials Science
Magnetic Material:Current: 2000 atoms; 2.64 TF/s, 512 GBFuture: HDD Simulation - 30 TF/s, 2 TB
Electronic Structures:Current: 300 atoms; 0.5 TF/s, 100 GBFuture: 3000 atoms; 50 TF/s, 2TB
Source: D. Balley, NERSC
Digital Movies and Special Effects
~1e14 FLOPs per frame50 frames/sec90 minute movie- 2.7e19 FLOPs
Source: Pixar
Spare Parts Inventory Planning
Modelling the optimized deployment of 10000 part numbers across 100 part depots and requries:- 2x10e14 FLOP/s (12 hours on 10, 650 MHz CPUs)
- 2.4 PetaFlop/s sust. performance(1 hour turn-around time)
Industry trend to rapid, frequent modeling for timely business decision support driver higher sustained performanceSource: B. Dietrich, IBM

2
Operations and execution timeOperations and execution time
1012 1019
Digital movies
1014
CFD Wing Simulation
1024
CFD Full Plane
1 Tflop/s
1 Gflop/s1 Mflop/s
1012 1010 104 102 101109 108
1.5 minutes3 hours
32 years320 years
40 months
32000 years
Operationsper second
Time
1 Pflop/s
1.2 days
105
4 months
107
Current high-end microprocessorsCurrent high-end microprocessors
Frequency: 2.2 GHzPeak: 8.8 GFlops
PowerPC 970FX

3
Current multi-core architecturesCurrent multi-core architectures
IBM’s triple-core processor forXbox 360 videogame console
8 multithreading processors on a 333 milliontransistor chip for Raza Microelectronicsnetwork processor
Intel Core Duo processor with twocores, a unified 2 MB L2 cache, and152 million transistors
Current multi-core architecturesCurrent multi-core architectures
Intel Pentium D (dual core) and eXtreme Edition (dualCore, multithreaded), 2 x 1MB L2 cache, up to 3.2 GHz
Sun Niagara 1 (UltraSPARC T1) package and block diagram, running at 1.0 and 1.2 GHz, packaging 4, 6 and 8 active cores

4
Current multi-core architecturesCurrent multi-core architectures
Cell processor architecture with 1 PowerPC (PPU) core and 8 Synergistic Processing Units (SPU, 32 GFlops each), 256 GFlops
Current multi-core architecturesCurrent multi-core architectures
IBM Power 5Dual-core SMT processor
8-way superscalar SMT cores 276M transistors, 389 mm2 dieOperating in lab at 1.8GHz & 1.3V1.9MB L2 cache – point of coherencyOn-chip L3 directory, memory
controller
Technology130nm lithography, SOICu wiring, 8 layers of metal
High-speed elastic bus interfaceI/Os: 2313 signal, 3057 power

5
Current multi-core architecturesCurrent multi-core architectures
IBM Power5 multi-chip module
95mm x 95mm
Four POWER5 chips2 processors per chip2-way simultaneous multithreaded
Four L3 cache chips
4,491 signal I/Os
89 layers of metalMemoryI/OJTAG
On-BookOff-Book
POW
ER
5
L3 POWER5
L3
POWER5
L3
POW
ER
5
L3
Current high-performance µP (8/06)Current high-performance µP (8/06)

6
Current high-performance µP (8/06)Current high-performance µP (8/06)
Operations and execution timeOperations and execution time
1012 1019
Digital movies
1014
CFD Wing Simulation
1024
CFD Full Plane
256 Gflop/s
1012 1010 104 102 101109 108
4 minutes125000 years
Operationsper second
Time
105
4 months
107 1061011 1031013

7
www.top500.org (november 2005)www.top500.org (november 2005)
GFlops
MareNostrum: 4564 cpu, 40 TFlopsMareNostrum: 4564 cpu, 40 TFlops

8
MareNostrum: 4812 cpu, 42 TFlopsMareNostrum: 4812 cpu, 42 TFlops
JS20 Processor Blade2-way PPC970FX symmetric multiprocessor (SMP)4 GB memory, shared memory40 GBytes local IDE diskMyrinet network adapter and 2 Gigabit ports
MareNostrum 1.5MareNostrum 1.5
PowerPC 970MP

9
Blade Center• 14 blades per chassis (7U)
• 28 processors• 56GB memory
• Gigabit ethernet switch
6 chassis in a rack (42U)• 168 processors(1.4 TFlops)
• 336GB memory
MareNostrum: 4812 cpu, 42 TFlopsMareNostrum: 4812 cpu, 42 TFlops
MareNostrum: 4812 cpu, 42 TFlopsMareNostrum: 4812 cpu, 42 TFlops
Myrinet Clos256+256 switch

10
Clos 256x256Clos 256x256
Clos 256x256Clos 256x256
Clos 256x256Clos 256x256
Clos 256x256Clos 256x256
Clos 256x256Clos 256x256
Spine 1280 Spine 1280
256 links (1 to each node)250MB/s each direction
128 Links
MareNostrum: 4812 cpu, 42 TFlopsMareNostrum: 4812 cpu, 42 TFlops

11
Blade centers
Myrinet racks
Storage servers
Operations rack
Gigabit switch
10/100 switches
MareNostrum: 4812 cpu, 42 TFlopsMareNostrum: 4812 cpu, 42 TFlops
NASA Columbia SupercomputerNASA Columbia Supercomputer
Global shared memory across 4 cpus, 8 Gigabyte
4 Itanium2 per C-Brick

12
NASA Columbia SupercomputerNASA Columbia Supercomputer
Global shared memory across 64 cpus, 128 Gigabyte
NASA Columbia SupercomputerNASA Columbia Supercomputer
Global shared memory across 512 cpus, 1 Terabyte

13
NASA Columbia SupercomputerNASA Columbia Supercomputer
20 SGI® Altix™ 3700 superclusters, each with 512 Itanium2 processors (1.5 GHz, 6 MB cache)
Infiniband network to connect superclusters
35 years of microprocessor history35 years of microprocessor history4004 8008 8080 8085
Pentium804868038680286
8086
Pentium IIPentium III Pentium 4 Pentium D

14
35 years of microprocessor history35 years of microprocessor history
Integration scale has increasedFeature size: 10 microns in 1971 to 0.10 microns in 2005
Technology: SIA roadmapTechnology: SIA roadmap
Year 1999 2002 2005 2008 2011 2014
Feature size (nm) 180 130 100 70 50 35
Logic trans/cm2 6.2M 18M 39M 84M 180M 390M
Cost/trans (mc) 1.735 .580 .255 .110 .049 .022
#pads/chip 1867 2553 3492 4776 6532 8935
Clock (MHz) 1250 2100 3500 6000 10000 16900
Chip size (mm2) 340 430 530 620 750 900
Wiring levels 6-7 7 7-8 8-9 9 10
Power supply (V) 1.8 1.5 1.2 0.9 0.6 0.5
High-perf pow (W) 90 130 160 170 175 183

15
35 years of microprocessor history35 years of microprocessor history
•• 13X due to process 13X due to process technologytechnology
•• Additional 4X due to Additional 4X due to microarchitecturemicroarchitecture
10
100
1.000
10.000
1.0µ 0.7µ 0.5µ 0.35µ 0.25µ 0.18µ
Frequency (MHz)
Freq (uArch)Freq (Process)
13X
4X
i486Pentium® proc
Pentium® 4 proc
Pentium® II and III proc
Frequency Increased 50XFrequency Increased 50X
1
10
100
1.0µ 0.7µ 0.5µ 0.35µ 0.25µ 0.18µ
Relative Performance
RelativePerformanceRelativeFrequency
13X
6X
i486
Pentium® proc
Pentium® 4 proc
Pentium® II and III proc
•• 13X due to frequency13X due to frequency
•• Additional >6X due Additional >6X due to microarchitectureto microarchitectureand designand design
Performance Increased >75XPerformance Increased >75X
*Note: Performance measured using *Note: Performance measured using SpecINTSpecINTand and SpecFPSpecFP
Basic conceptsBasic concepts
Instruction types:Load/StoreOperationControl
ControlUnit
Memory
Instructions + Data
. . .
Register File
Instructionsload Rx := M[]store M[] := Rx
Ri := Rj op Rk
Branch (cond.)
Processor

16
Execution of a programExecution of a program
• N – Number of instructions• Architecture: CISC, RISC, vector• Compiler
• CPI – cycles to execute one instruction• Architecture: CISC, RISC, pipelined,
superscalar, vector• Computer structure
• tc – processor cycle time• Computer Structure• Technology
T = N * CPI * tc
Pipelined processorsPipelined processors
Von Neumann (IPC = 1/5)
Pipelined (IPC <= 1)
F D R E W F D R E W F D R E WInstructioni-1 Instructioni Instructioni+1
F D R E W
F D R E W
F D R E W
F D R E W
F D R E W
F D R E W
Time
T = N * * tc1
IPC
17
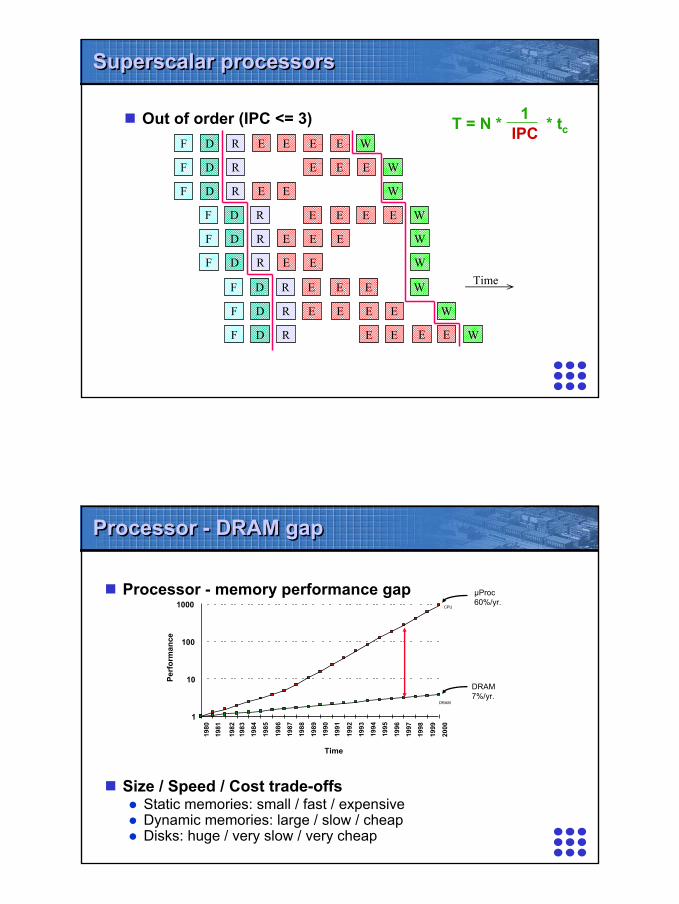
Superscalar processorsSuperscalar processors
Out of order (IPC <= 3)
F D R W
F D R E W
F D R W
F D R E W
F D R E W
F D R E W
F D R E W
F D R E W
F D R W
E
E
E
E
E
E
E
E
E
E
E
E
E E
E
E
E
E
E
E
E E E
Time
T = N * * tc1
IPC
Processor - DRAM gapProcessor - DRAM gap
Processor - memory performance gap
Size / Speed / Cost trade-offsStatic memories: small / fast / expensiveDynamic memories: large / slow / cheapDisks: huge / very slow / very cheap
µProc60%/yr.
DRAM7%/yr.
1
10
100
1000
1980
1981
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
DRAM
CPU
1982
Perf
orm
ance
Time

18
Solution: memory hierarchySolution: memory hierarchy
Earth Simulator (Japan)Earth Simulator (Japan)
640 nodes, each node with 8 NEC SX vector processors (8 Gflop/s peak per processor), 2 ns tc
Total of 5104 total processors, 40 TFlop/s peak

19
Vector processorVector processor
ControlUnit
Main Memory
Instructions (scalar + vector) + Data
Ri := Rj op Rk
Branch (cond.)
Instr.. . .
Vector Reg.
. . .
Scalar Reg.
Vector dataScalar data VR[i] := VR[j] op VR[k]
Evaluating computer system performanceEvaluating computer system performance
Which metrics can be used to evaluate computer system performance?Execution time
Also known as wall clock time, elapsed time, response timeTotal time to complete a taskExample: hit RETURN, how long until the answer appears on the screen
ThroughputAlso known as bandwidthTotal number of operations (such as instructions, memory requests, programs) completed per unit time (rate)
Performance improves when execution time is reduced or throughput is increased

20
CPU time breakdownCPU time breakdown
CPU_Time = cycles x tc
cycles: total cycles to execute the programtc: clock cycle time (clock period)
1/frequency
cycles = INST x CPI / WINST: total number of instructions executedCPI: average number of clock cycles executed per instruction
Total clock cycles divided by total instructions executed (CYCLES/INST)Different instruction types (add, divide, etc.) may take different numbers of clock cycles to execute
W: number of instructions executed per cycle
CPU time breakdownCPU time breakdown
CPU_Time = Σ (INSTi x CPIi) x W-1 x tcINSTi: number of instructions of type i executedCPIi: numbers of clock cycles to execute an instruction of type I
Is it a good metric?INST is influenced by the compiler and its optimizationsThe whole system is evaluated (CPU, memory, I/O)

21
The INST-CPI tradeoffThe INST-CPI tradeoff
In creating a machine code equivalent to a HLL construct, the compiler writer may have several choices that differ in INST and CPI
Best solution may involve more, simpler instructions
Example: multiply by constant 5:
or
See Exercise 3
muli $2, $4 , 5 4 cycles
sll $2, $4 , 2 1 cycleadd $2, $2, $4 1 cycle
CPU metricsCPU metrics
tc is not a good metric to compare processors:Example: Pentium and Pentium III, both running at 500 MHz
CPI is not a good metric to compare processors:Intel Pentium: 5 cycles integer data pathIntel Pentium Pro (basis for Pentium II and III): 14 cycles integerdata pathPentium IV: 20 cycles integer data path
What’s behind high CPI values?
Can both be combined in a single metric?

22
CPU metricsCPU metrics
MIPS: Millions of Instructions Per Second:INST x 10-6 / CPU_Time = (CPI / W x tc)-1
MFLOP: Millions of FLOating Point operations per second:INST (only FP) x 10-6 / CPU_Time
Peak metrics:MIPSpeak = IPC x W x f (f in MHz)
MFLOPpeak = IPC (only FP) x W (only FP) x fIPC: maximum number of instructions completed per cycle
CPU metrics: examplesCPU metrics: examples
f = 200 MHz, 1 integer FU, 1 floating-point FUW=1 → 200 MIPS, 200 MFLOPsW=2 → 400 MIPS, 200 MFLOPs
Consider the following program:
which is executed in a machine with W=1, f=100MHz. Compute CPI, MIPS and MFLOPs if CPU_Time=8µs.
real a[64], b[64], c[64]; /* 8 bytes each */integer i;…for (i=1; i<=64; i++)
c[i] = a[i] + b[i];…

23
Evaluating computer system performanceEvaluating computer system performance
A workload is a collection of programs
Ideally, a user needs to evaluate the performance of its workload on a given machine before deciding whether to purchase it
This is impractical because:There are too many unique workloads to evaluatePrograms may be compiled for a different system and the source code may not be available or easily portable (get to run on a different machine)
So how can we as customers make purchase decisions without being able to run our programs on different machines?
BenchmarksBenchmarks
Benchmarks are programs specifically chosen to measure performance
Benchmark suites attempt to mimic the workloads of particular user communities
Scientific benchmarks, business benchmarks, consumer benchmarks, etc.
Computer manufacturers report performance results for benchmarks to aid users in making machine comparisons
The hope is that most user workloads can be represented well enough by a modest set of benchmark suites

24
Example: SPEC CPU2000Example: SPEC CPU2000
Comprised of SPECint2000 and SPECfp2000 benchmarks
SPECint2000 programs164.gzip: Data compression utility175.vpr: FPGA circuit placement and routing176.gcc: C compiler181.mcf: Minimum cost network flow solver186.crafty: Chess program197.parser: Natural language processing252.eon: Ray tracing253.perlbmk: Perl254.gap: Computational group theory255.vortex: Object-oriented database256.bzip2: Data compression utility300.twolf: Place and route simulator
Example: SPEC CPU2000Example: SPEC CPU2000
SPECfp2000 programs168.wupwise: Quantum chromodynamics171.swim: Shallow water modeling172.mgrid: Multi-grid solver in 3D potential field173.applu: Parabolic/elliptic partial differential equations177.mesa: 3D graphics library178.galgel: Fluid dynamics: analysis of oscillatory instability179.art: Neural network simulation: adaptive resonance theory183.equake: Finite element simulation: earthquake modeling187.facerec: Computer vision: recognizes faces188.ammp: Computational chemistry189.lucas: Number theory: primality testing191.fma3d: Finite-element crash simulation200.sixtrack: Particle accelerator model301.apsi: Solves problems regarding temperature, wind, distribution of pollutants

25
SpeedUpSpeedUp
How faster we go when a new feature is added to oursystem:
Sideal = CPU_Time (ref) / CPU_Time (enhanced) == (CPIref / Wref x tcref) / (CPIenhanced / Wenhanced x tcenhanced) == αref / αenhanced
Amdhal’s law:Performance improvement of an enhancement is limited by the fraction of time the enhancement is used, e.g. ϕ:
S = (N x αref) / ((N x (1-ϕ) x αref) + (N x ϕ x αenhanced))= 1 / ((1-ϕ) + ϕ/Sideal)
Amdahl’s law exampleAmdahl’s law example
Assume an enhancement with Sideal=1000, and that it can be applied 80% of the total time:
S = 1 / (0.2 + 0.8/1000) ≅ 5
Or even worse, you got it!!! Sideal = ∞, then
S = 1 / (1 - ϕ)

26
Capacity metricsCapacity metrics
How is memory capacity measured?
How much is 1K? 103 or 210
How much is 1 KHz?
and 1 Mbit/s?
and 1 Gbyte?
What is bigger? 1 Gbyte of disk or 1 Gbyte of memory?
☺ ¿Qué pesa más, un kilo de hierro o un kilo de paja? ☺
Capacity metricsCapacity metrics
1027290Xenta/Xora/Bronto1024280YYotta1021270ZZetta1018260EExa1015250PPeta1012240TTera109230GGiga106220MMega103 =1000210 =1024KKiloBase 10Base 2SymbolName
Names and Symbols for different magnitudes

27
Capacity metricsCapacity metrics
The difference grows with the order of magnitude (2.4% for Kilo, 20.8% for Yotta)
THE PROBLEM: the same word is used for both powers of 2 and powers of 10. Either of them is used depending on the context:
Hertz (Hz) are measured in powers of 10a processor running at 1 Gigahertz (GHz) runs at 1.000.000.000 Hz.
Transmission speed is measured in powers of 10a 128 Kbit/s mp3 stream, transfers 128.000 bits per seconda 1 Mbit/s ADSL connection, transfers at most 1.000.000 bits per second
Bus bandwidth is also measured in powers of 10RAM memory is measured in powers of 2
1MB of RAM is 220 bytes of RAM.
What about storage devices?
Capacity metricsCapacity metrics
Hard Disks (HD) are measured in powers of 10.A HD of 30GB has 30x109 bytes (28x230 aprox. )
It is not marketing, but tradition: the physical structure of a disk (plates, tracks, sectors) is not required to be a power of 2.
However, the operating system shows disk capacity in powers of 2.
It seems to be done for coherence between RAM capacity and HD capacity.Therefore, a laptop that has, according to the vendor, 1GB of RAM and 30 GB of HD, will be seen under Windows as 1GB of RAM and 28 GB of HD
Can things be more confusing? Of course, yes !!!

28
Capacity metricsCapacity metrics
Some devices use hybrid measurement systems:A floppy disc of 1,44 MB is not 1,44x106 nor 1,44x220, but 1,44x1000x1024 bytes (1,406 MB in base 2 or 1,475 MB in base 10)
Finally: CDs and DVDs also use different measurementsCD capacity is given in powers of 2
a 700MB CD =“80 minutes” has 700x220 bytesDVD capacity is given in powers of 10
a DVD of 4.7 GB has 4.7x109 bytes = 4.38x230 bytes
Related Documents











