Elena Landaburu Jiménez 1 Tema 1 Estadística Descriptiva I Generalmente se pueden distinguir dos fases en la realización de cualquier experimento. Una primera, que consiste en la observación y análisis de los hechos que acontecen, y otra segunda, de interpretación y obtención de soluciones. Cuando la experiencia se realiza en un contexto de incertidumbre, los resultados dependen del azar y nos encontramos ante lo que se denomina fenómeno aleatorio. 1. Estadística Descriptiva. Conceptos Generales. Cuando se analiza un fenómeno aleatorio, ya sea de ingeniería o de otra rama del conocimiento humano, aparecen resultados del mismo que han de ser tratados de forma conveniente para conocer mejor los propios resultados obtenidos y el fenómeno en cuestión. Para ello será necesario emplear los resultados de la Estadística Descriptiva, cuya definición se presenta a continuación. DEFINICION Se entiende por Estadística Descriptiva el conjunto de conceptos y técnicas que proporcionan una descripción numérica, ordenada y simplificada, a veces con la ayuda de representaciones gráficas, de la información obtenida en la observación y recogida de datos de un fenómeno aleatorio. Además, proporciona la base necesaria para construir los modelos matemáticos teóricos de los fenómenos aleatorios. En la observación y recogida de datos de un fenómeno aleatorio subyacen los siguientes conceptos.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Elena Landaburu Jiménez
1
Tema 1
Estadística Descriptiva I
Generalmente se pueden distinguir dos fases en la realización de cualquier experimento. Una primera, que consiste en la observación y análisis de los hechos que acontecen, y otra segunda, de interpretación y obtención de soluciones. Cuando la experiencia se realiza en un contexto de incertidumbre, los resultados dependen del azar y nos encontramos ante lo que se denomina fenómeno aleatorio. 1. Estadística Descriptiva. Conceptos Generales.
Cuando se analiza un fenómeno aleatorio, ya sea de ingeniería o de otra rama del conocimiento humano, aparecen resultados del mismo que han de ser tratados de forma conveniente para conocer mejor los propios resultados obtenidos y el fenómeno en cuestión. Para ello será necesario emplear los resultados de la Estadística Descriptiva, cuya definición se presenta a continuación.
DEFINICION Se entiende por Estadística Descriptiva el conjunto de conceptos y técnicas que proporcionan una descripción numérica, ordenada y simplificada, a veces con la ayuda de representaciones gráficas, de la información obtenida en la observación y recogida de datos de un fenómeno aleatorio. Además, proporciona la base necesaria para construir los modelos matemáticos teóricos de los fenómenos aleatorios.
En la observación y recogida de datos de un fenómeno aleatorio subyacen los siguientes conceptos.

Elena Landaburu Jiménez
2
Población Estadística es cualquier conjunto de personas, animales, objetos o acontecimientos sometido a estudio estadístico y que debe estar perfectamente definido, tanto en el tiempo como en el espacio.
Individuo o Unidad Estadística es cada uno de los elementos que componen una población estadística. Puede ser descrito por uno o varios caracteres, dependiendo de cual sea el objeto del estudio estadístico.
Cualquier carácter o característica que se vaya a analizar en las unidades estadísticas presentará dos o más niveles exhaustivos e incompatibles, de forma que cada unidad estadística de la población presente uno y solamente uno de los niveles del carácter. Además, los caracteres se pueden clasificar en:
Cualitativos: también denominados atributos. Los niveles de un atributo se llaman modalidades.
Cuantitativos: también denominados variables estadísticas. Los niveles de una variable estadística se llaman valores observados.
Dentro de las variables estadísticas los caracteres pueden ser de dos tipos:
Discretos: si hay una cantidad finita o infinita numerable de valores observados de la variable.
Continuos. Si la variable puede tomar cualquier valor de un intervalo.
Muestra es cualquier subconjunto observado de

Elena Landaburu Jiménez
3una población estadística, cuyo número de elementos se llama tamaño de la muestra. Censo es la observación de todos los elementos de una población estadística. EJEMPLOS
o En la población estadística de vehículos fabricados en una determinada factoría durante un día, se puede analizar el carácter cualitativo color, que presentará varias modalidades así como los caracteres cuantitativos o variables: número de defectos en las pruebas finales a realizar en los vehículos antes de enviarlos al mercado (discreto) y consumo de combustible en una prueba simulada de circulación urbana (continuo).
o En la población estadística de estudiantes
matriculados en un curso se puede analizar el carácter cualitativo sexo, que presenta dos modalidades; así como los caracteres cuantitativos edad (discreto) y estatura (continuo).
1.1 Organización de un Conjunto de Datos de una Variable Estadística en una Tabla de
Frecuencias Supongamos que se ha recogido un conjunto de datos sobre un carácter de las unidades de un colectivo. Por ejemplo, salarios de un grupo de trabajadores, número de horas que han estado 1000 vehículos aparcados en un aparcamiento, número de televisores vendidos cada día en una tienda a lo largo de un año, duración de una serie de bombillas, consumo de electricidad en una vivienda durante un trimestre, rendimiento de una máquina eléctrica, etc…Es

Elena Landaburu Jiménez
4necesario digerir y procesar tal información de manera que podamos extraer conclusiones sobre el comportamiento de dicho colectivo y, a veces, compararlo con el de otro colectivo con respecto a la misma variable. Consideremos x1,…,xN los datos recogidos de una variable estadística, y x1,…,xk los diferentes valores observados de la variable. Designamos por ni al número de veces que aparece el dato xi, lo que se denomina frecuencia absoluta del valor xi, siendo i=1,…,k. Designamos por fi, a la proporción de veces que aparece el valor xi, entre los N datos, lo que se llama frecuencia relativa del valor xi. Es decir, el cociente entre la frecuencia absoluta y el número total de observaciones realizadas
Nnf i
i = con i=1,…,k
Llamamos frecuencia absoluta acumulada en el valor xi a la suma de las frecuencias absolutas de los valores inferiores o iguales a él y es denotada por Ni.
iiij
ji nNnN +== −≤∑ 1 con i=1,…,k
Es claro que N1=n1 y que Nk=N. Llamamos frecuencia relativa acumulada en el valor xi al cociente entre la frecuencia absoluta acumulada y el número de observaciones realizadas, es denotada por Fi
∑≤
==ij
ji
i fNNF
Se llama tabla de frecuencias o distribución de frecuencias a una tabla con cinco filas o columnas en la que la primera fila o columna contiene los

Elena Landaburu Jiménez
5valores diferentes en observación, ordenados de menor a mayor, la segunda contiene las frecuencias absolutas de dichos valores, la tercera las frecuencias relativas, en la cuarta las frecuencias absolutas acumuladas y en la última las frecuencias relativas acumuladas. Su estructura será, por tanto, la siguiente: Si se utilizan filas:
xi x1,…,xk
ni n1,…,nk
fi f1,…,fk
Ni Ni,…,Nk
Fi F1,…,Fk
O bien si se utilizan columnas:
xi ni fi Ni Fi
x1
. . . xk
n1
. . . nk
f1. . . fk
N1
. . . Nk
F1
. . . Fk
En las observaciones realizadas puede ocurrir que la variable estadística tome pocos valores diferentes, ya sea grande o pequeño el tamaño muestral, o bien puede pasar que la variable tome muchos valores diferentes, lo cual suele ocurrir para tamaños muestrales grandes. En el primer caso confeccionaremos la tabla de frecuencias como hemos visto anteriormente. En la segunda situación trataremos de agrupar los valores de la variable estadística en intervalos. Agrupación de un conjunto de datos en intervalos Los intervalos cuando agrupamos datos se denominan intervalos de clase, los extremos de los intervalos se

Elena Landaburu Jiménez
6llaman extremos de clase y los puntos medios de los intervalos reciben el nombre de marcas de clase. A la hora de construir una tabla de frecuencias con datos agrupados se debe intentar seguir los siguientes pasos:
La tabla de frecuencias no puede presentar intervalos de clase con frecuencia nula, ya que supondría una ruptura artificial en la representación de la frecuencia, fruto de una inadecuada agrupación por intervalos, que no se correspondería, con la manera en que se presenta la frecuencia de aparición de la variable estudiada. Es decir, no puede haber intervalos vacíos.
Siempre que sea posible las clases deberán tener la misma longitud, con el fin de no enmascarar la realidad del fenómeno. No obstante, cuando se manejan datos de una magnitud económica este criterio no suele ser posible cumplirlo y hay que plantear intervalos de longitud diferente.
El extremo superior del último intervalo debe ser mayor que el mayor valor observado.
Cuando el dato más pequeño (resp. grande) se encuentra muy alejado del resto, se dirá que se trata de una observación anómala o extrema, (outlier).
Se recomienda elegir los intervalos de clase de forma que sus marcas de clase coincidan con datos observados.
Los extremos de clase de los intervalos se deben definir con precisión, de forma que los intervalos sean contiguos, pero no solapados. Así, una observación queda perfectamente encasillada en sólo un intervalo. Generalmente los intervalos se cierran por los extremos inferiores.
Elena Landaburu Jiménez
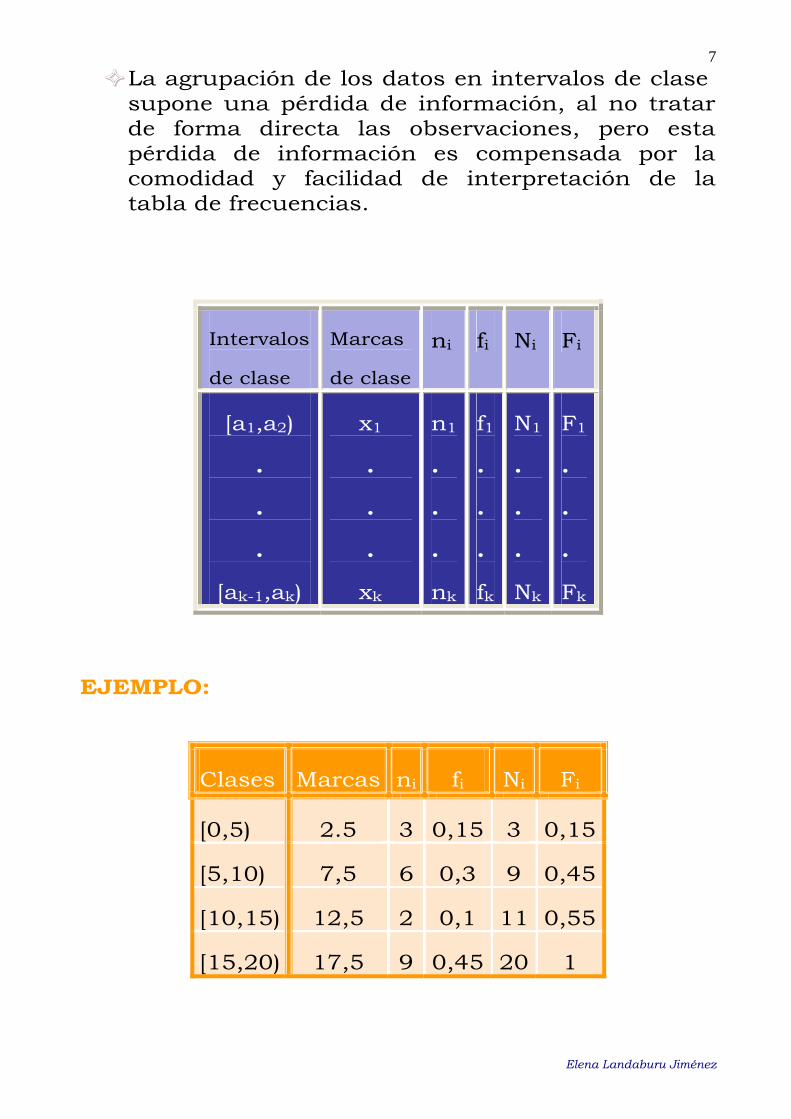
7 La agrupación de los datos en intervalos de clase supone una pérdida de información, al no tratar de forma directa las observaciones, pero esta pérdida de información es compensada por la comodidad y facilidad de interpretación de la tabla de frecuencias.
Intervalos
de clase
Marcas
de clase
ni fi Ni Fi
[a1,a2)
.
.
.
[ak-1,ak)
x1
.
.
.
xk
n1
.
.
.
nk
f1
.
.
.
fk
N1
.
.
.
Nk
F1
.
.
.
Fk
EJEMPLO:
Clases Marcas ni fi Ni Fi
[0,5) 2.5 3 0,15 3 0,15
[5,10) 7,5 6 0,3 9 0,45
[10,15) 12,5 2 0,1 11 0,55
[15,20) 17,5 9 0,45 20 1
Elena Landaburu Jiménez
8
1.2 Representaciones gráficas de una Tabla de frecuencias
Caso de un Atributo
••• Diagrama de rectángulos
Para proceder a su representación se colocan, en primer lugar, las modalidades por orden decreciente de la frecuencia, y a continuación se levantan rectángulos de altura proporcional a la frecuencia
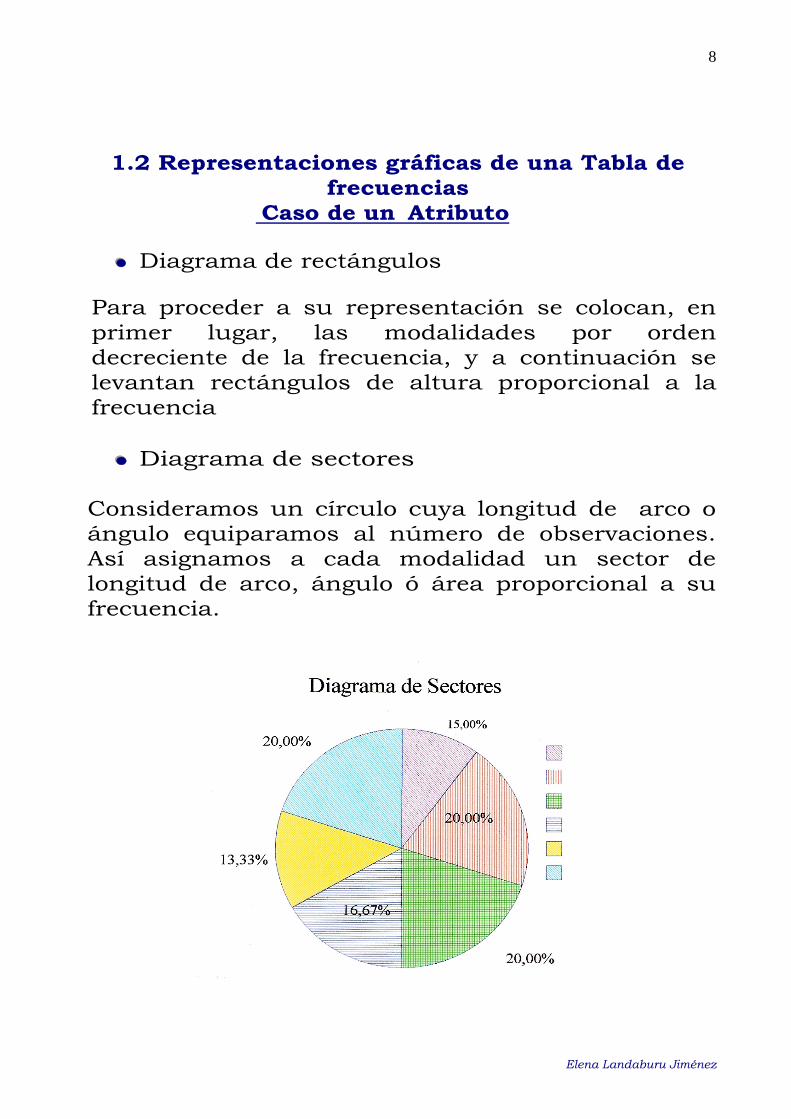
••• Diagrama de sectores
Consideramos un círculo cuya longitud de arco o ángulo equiparamos al número de observaciones. Así asignamos a cada modalidad un sector de longitud de arco, ángulo ó área proporcional a su frecuencia.
Elena Landaburu Jiménez
9
Caso de una Variable Discreta
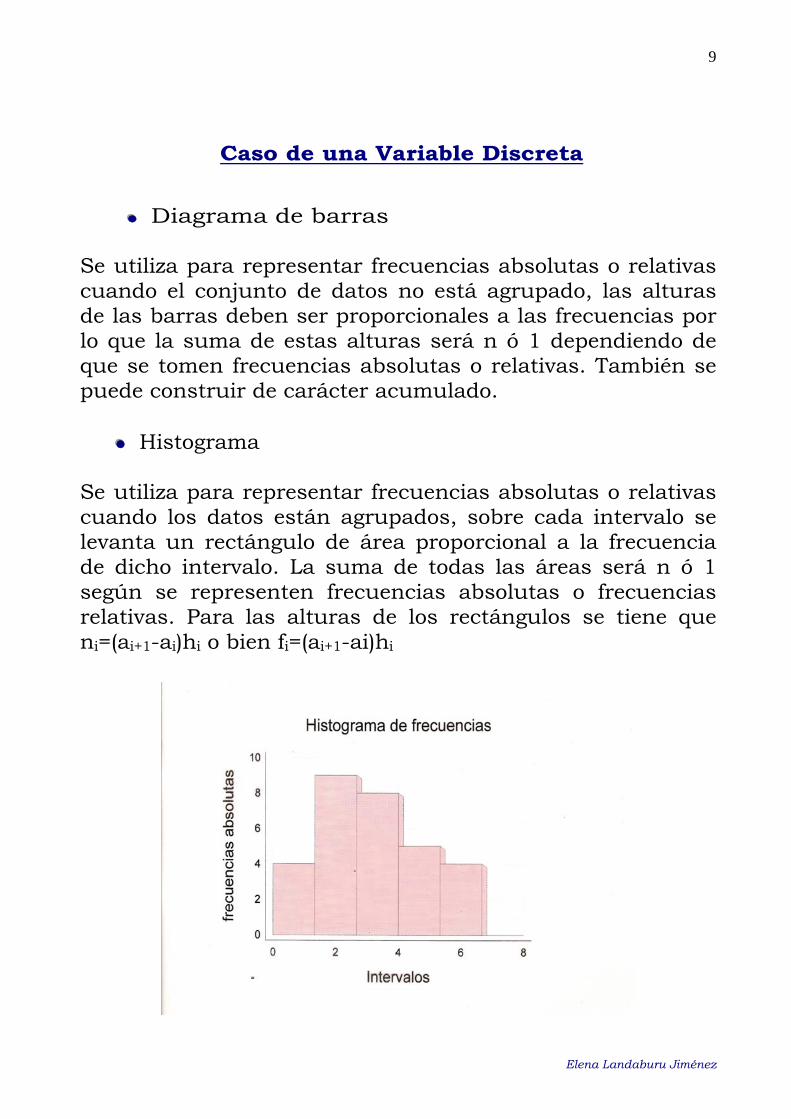
••• Diagrama de barras Se utiliza para representar frecuencias absolutas o relativas cuando el conjunto de datos no está agrupado, las alturas de las barras deben ser proporcionales a las frecuencias por lo que la suma de estas alturas será n ó 1 dependiendo de que se tomen frecuencias absolutas o relativas. También se puede construir de carácter acumulado.
••• Histograma Se utiliza para representar frecuencias absolutas o relativas cuando los datos están agrupados, sobre cada intervalo se levanta un rectángulo de área proporcional a la frecuencia de dicho intervalo. La suma de todas las áreas será n ó 1 según se representen frecuencias absolutas o frecuencias relativas. Para las alturas de los rectángulos se tiene que ni=(ai+1-ai)hi o bien fi=(ai+1-ai)hi

Elena Landaburu Jiménez
10 El histograma también puede representar frecuencias acumuladas, en este caso se construye levantando sobre cada intervalo un rectángulo de altura proporcional a la frecuencia que se acumula en dicho intervalo, tanto si los intervalos tienen la misma amplitud como si es distinta.
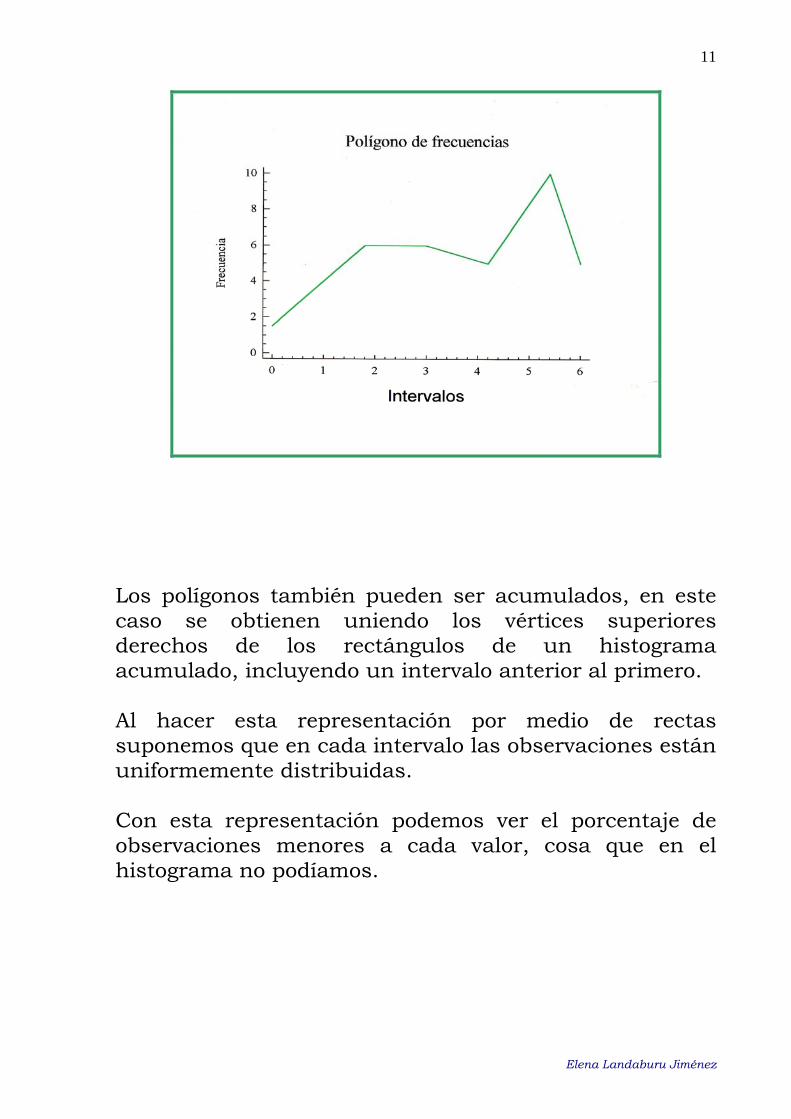
••• Polígono de frecuencias Los polígonos de frecuencias se construyen uniendo los extremos de las barras de un diagrama de barras (frecuencias relativas o absolutas) si los datos están sin agrupar, o bien, si los datos están agrupados y todos los intervalos de clase tienen la misma amplitud, uniendo los puntos medios de la bases superiores de los rectángulos de un histograma sin acumular incluyendo un intervalo anterior al primero y un intervalo posterior al último, de modo que la figure quede cerrada. Si los datos están sin agrupar, la suma de las alturas será n ó 1, según sean las frecuencias absolutas o relativas. Si los datos están agrupados y todos los intervalos tienen la misma amplitud, entonces el área encerrada por el polígono será n ó 1, dependiendo de que la frecuencia representada sea absoluta o relativa.
Elena Landaburu Jiménez
11
Los polígonos también pueden ser acumulados, en este caso se obtienen uniendo los vértices superiores derechos de los rectángulos de un histograma acumulado, incluyendo un intervalo anterior al primero. Al hacer esta representación por medio de rectas suponemos que en cada intervalo las observaciones están uniformemente distribuidas. Con esta representación podemos ver el porcentaje de observaciones menores a cada valor, cosa que en el histograma no podíamos.
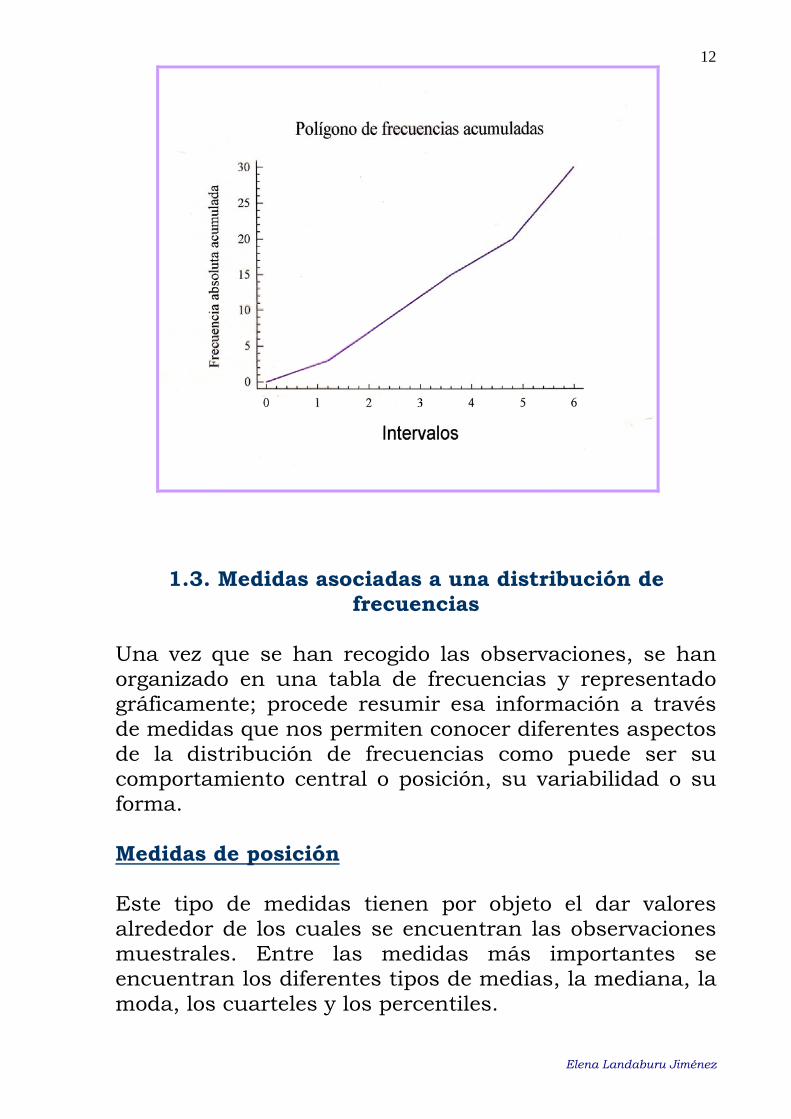
Elena Landaburu Jiménez
12
1.3. Medidas asociadas a una distribución de frecuencias
Una vez que se han recogido las observaciones, se han organizado en una tabla de frecuencias y representado gráficamente; procede resumir esa información a través de medidas que nos permiten conocer diferentes aspectos de la distribución de frecuencias como puede ser su comportamiento central o posición, su variabilidad o su forma. Medidas de posición Este tipo de medidas tienen por objeto el dar valores alrededor de los cuales se encuentran las observaciones muestrales. Entre las medidas más importantes se encuentran los diferentes tipos de medias, la mediana, la moda, los cuarteles y los percentiles.

Elena Landaburu Jiménez
13Media aritmética: es el promedio de las observaciones muestrales.
∑∑==
==k
1iii
k
1iii xfxn
n1x
donde x1, x2, …,xk son los diferentes valores observados, n1, n2, …,nk las frecuencias absolutas de los mismos y f1, f2, …,fk las frecuencias relativas. Si consideramos las n observaciones x1, x2, …,xn sin tener en cuenta si están repetidas o no, entonces la expresión anterior se puede poner en la forma siguiente:
∑=
=n
1iix
n1x
PROPIEDAD 1 Si yi=axi+b, entonces bxay += PROPIEDAD 2 Sean r muestras de una población siendo r1 x..., ,x las respectivas medias aritméticas, con n1, …,nr el número de observaciones en las muestras respectivas. La media en el total de las r muestras es
∑
∑
=
== r
1ii
r
1iii
T
n
xnx

Elena Landaburu Jiménez
14Observación.- Las ventajas de la media son: ••• Definición objetiva. ••• Utilización de todas las observaciones. ••• Tiene un significado concreto y una interpretación
sencilla e inmediata. ••• Es fácil de calcular. ••• Se presta a manipulaciones algebraicas.
También presenta un gran inconveniente y es que se ve afectada por las fluctuaciones muestrales. Es decir, resulta muy sensible a las observaciones anómalas.
Media geométrica: se usa cuando los datos evolucionan en progresión geométrica o se rigen por leyes de crecimiento exponencial.
k..., 1,i ,0con x xx ink
1i
niG
i =∀>= ∏=
Observación.- el logaritmo de la media geométrica es la media aritmética de los logaritmos de los datos. Media armónica: se usa con datos tipo cociente (metros/segundo, euros/litro, …) o precios donde asociado a cada dato haya información del numerador (velocidades-distancias, precios-dinero gastado, …)
∑=
= k
1i i
iH
xn
nx
Observación.- el inverso de la media armónica es la media aritmética de los inversos de las observaciones. PROPIEDAD
xxx GH ≤ ≤

Elena Landaburu Jiménez
15Momentos respect r: es una extensión del concepto de promedio de los datos al
o al origen de orden
promedio de los datos al cuadrado, al cubo, …. Es decir, considerar
∑∑ ==1i
rii
1i
riir xfxn
na
Mediana: es el valor de la variable estadística (observado o no) que deja igual número e observaciones por debajo
==
kk1
dy por encima de ella, ordenadas las observaciones en forma creciente. Si el número de observaciones es impar se trata del dato central, si el número de observaciones es par se toma el promedio de los centrales. Por tanto,
impar esn si xMe =
par esn si 2
xx
Me1
2n
2n
12n
⎟⎠⎞
⎜⎝⎛ +⎟
⎠⎞
⎜⎝⎛
⎟⎟⎠
⎞⎜⎜⎝
⎛+⎥⎦⎤
⎢⎣⎡
+
=
Siempre que los datos no estén agrupados. EEjjeemmpplloo::
5 5.5
i los datos están agrupados, la mediana se calcula de la rma siguiente:
5, 4, 6 → 4, 5, 6; Me=5, 7, 6, 4 → 4, 5, 6, 7; Me= Sfo
( )i
i1ii n2aaaMe −+= +
1-iNn−
Centil de orden K: es el valor no necesariamente observado de la variable est dística que deja las k/100 a

Elena Landaburu Jiménez
16partes de las observaciones por debajo o igual que él, con k=1, 2, …, 99, una vez ordenadas de forma creciente las observaciones. Si los datos no están agrupados:
⎪⎪⎩
⎪⎨⎪
∈
+
∉
=⎟⎠⎞
⎜⎝⎛ +⎟
⎠⎞
⎜⎝⎛
⎟⎟⎠
⎜⎜⎝
⎥⎦⎢⎣
Zkn si 2
xx
Zkn
C1
100kn
100kn
100
k
Si los datos están agrupados:
⎧ ⎞⎛ ⎤⎡si x kn
+1
( )i
i1iik n100aaaC −+= +
1-iNkn−
Cuartiles: es el valor no necesariamente observado de la variable que deja las k/4 partes de las observaciones por
observado de la ariable que deja las k/10 partes de las observaciones
debajo o igual que él, con k=1, 2, 3, una vez que las observaciones están ordenadas de forma creciente. Se tiene que Q1=C25, Q2=C50=Me y Q3=C75. Deciles: es el valor no necesariamentevpor debajo o igual que él, con k=1, 2, …, 9, una vez que las observaciones están ordenadas de forma creciente. Se tiene que D1=C10, …, D9=C90. Observación.- Las ventajas de la mediana, centiles, uarteles y deciles son: c
••• Definición objetiva. ••• ignificado directo y sencillo. Interpretación y s••• o, aunque no tanto a nivel Sencillez de cálcul
computacional. ••• Robustez. No influyen las observaciones extremas
o anómalas.

Elena Landaburu Jiménez
17Tam étodas l d
le que tiene máxima ecuencia. No tiene por qué ser única; así, si hay dos
ominamos intervalo modal al intervalo de
( )
bi n presenta los inconvenientes de que no utiliza as observaciones, así como no presentar facilida
para la manipulación algebraica. Moda: es el valor de la variabfrmodas, la distribución se llama bimodal, si tres, trimodal, etc. En una distribución de frecuencia agrupada por intervalos, denmayor frecuencia, como una primera aproximación se puede tomar la marca de clase como la moda. De una forma más exacta se suele tomar la moda de la forma siguiente:
21 dd +
1i1ii
daaaMo −+= +
Observación.- existen las siguientes relaciones entre la media, mediana y moda:
••• Distribución simétrica unimodal: MoMex == ••• trica unimodal: Distribución asimé MoMex ≠≠ ••• que Empíricamente se ha comprobado
Me-x3Mo-x ≅ .en distribuciones a Psimétricas. or
MMMeeedddiiidddaa
tanto, conociendo dos de estas medidas podemos enos la tercera.
as
conocer más o m
ss dddeee dddiiissspppeeerrrsssiiióóónnn Las medidas de dispersión tienen como objeto el uantificar si los datos están próximos o separados entre
ecto a la media o momento entral: es el promedio de potencias de las diferencias
entre las observaciones y la media.
csí o respecto algún punto. Momento de orden r respc

aburu Jiménez
18
Elena Land
( )∑=
Observación.-
−=k
1i
riir xxn
n1m
Se tiene que m0=1
es el momento central de or Varianza: den 2.
( )k
2 1∑=
−== 2ii2 xxnms
Desviación típica: varianza.
1in
es la raíz cuadrada positiva de la
2ss +=
PROPIEDAD 1 La varianza se puede escribir
como
∑=
−=−=k
212
22ii aaxxn1s
2
1in
Es decir, la varianza es la diferencia entre la media de los cuadrados y el cuadrado de la media.
PROPIEDAD 2
ión óptima, ya que os proporciona el mínimo de los promedios de los
ferencias a cualquier valor a.
La varianza es una medida de dispersncuadrados de di
( ) xaen alcanza se axnn1
mink
1i
2ii
a=−∑
=

Elena Landaburu Jiménez
19PROPIEDAD 3
Si yi=axi+b, entonces sasy sas 222 == xyxy
bio de origen no influye en la varianza y n cambio de escala si.
Es decir, un camu Observación.- las ventajas de la varianza son:
• ••• Definición objetiva. •• Utilización de todas las observaciones. ••• rla computacionalmente. Es fácil de obtene•••
ervaciones anómalas, aunque su mayoapar Coef medida de
Se presta a manipulación algebraica. Sin embargo, resulta muy sensible a las obs
r inconveniente es que ece en unidades al cuadrado.
iciente de variación de Pearson: es unadispersión relativa, no conlleva unidades. Su expresión es la siguiente:
0x si x
CV >= s
irve para medir la variabilidad relativa una vez
Observación.-
Seliminado el efecto de la unidad utilizada.
•• Al realizar un cambio de escala no varía, en •
cambio si lo hace con un cambio de origen. ••• ersión. A menores valores de CV menor disp••• la dispersión o variabilidad
Recorr valor obse
Sirve para compararentre varios conjuntos de datos.
ido: es la diferencia entre el máximo rvado y el mínimo.
R=x(n)-x(1)

Elena Landaburu Jiménez
20
Observación.- ••• Medida fácil de obtener. ••• Medida de vari ontroles rápidos. ••• La presencia de observaciones extremas o muy
alejadas distorsiona mucho la medida.
Reco diferencia entre el tercero cuar e un interobserv
ero. Nos da idea de la longitud de un tervalo central de valores que contiene el 80% de las
observaciones.
etría
ilidad en cab
rrido intercuartílico: es la til y el primero. Nos da idea de la longitud dvalo central de valores que contiene el 50% de las
aciones.
RI=Q3-Q1
Recorrido interdecílico: es la diferencia entre el noveno decil y el primin
RID=D9-D1
Medidas de sim
que lado de la curva, a o derecha, se encuentra la cola de de la distribución, así como su magnitud.
e dice que la distribución es asimétrica por la derecha
Los coeficientes de asimetría permiten caracterizar hacia
izquierd
So positiva cuando:
xMeMo ≤≤ , En estos casos las frecuencias tienden a descender más lentamente por la derecha.
Se dice que la di asimétrica por la quierda o negativa cuando:
stribución es
iz

Elena Landaburu Jiménez
21
xMeMo ≥≥ , En estos casos las frecuencias tienden a descender más
e dice que la distribución es simétrica cuando:
lentamente por la izquierda. S
xMeMo = = ,
as tienden a descender por mbos lados de una forma similar.
En estos casos las frecuencia
Histograma
Asimetría positiva
frecu
enci
a
0 1 2 3 4 5 60
2
4
8
6
Histograma
Asimetría negativa
frecu
enci
a
0 1 2 3 4 5 60
2
4
6
8

Elena Landaburu Jiménez
22
Diagrama de Puntos
Simetría
Frec
uenc
ia
0 1 2 3 4 5 60
7
Coeficiente de asimetría de Pearson:
sMo-xAP =
Observación.-
••• Es adimensional. ••• Si es >0 distribución asimétrica a la derecha. ••• Si es <0 distribución asimétrica a la izquierda. ••• Si es =0 distribución simétrica.
oeficiente de asimetría de Fisher: C
33
1 sg =
m
Su forma de actuar es la misma que el caso anterior.
Medidas de apuntamiento
Toman unid esulta que hay
istogramas y diagramas de barras con forma (mesocúrticas), otras
do como origen de coordenadas la media y comoad de medida la desviación típica r
hacampanada denominada normal

Elena Landaburu Jiménez
23parecen puntiagudas (leptocúrticas) y otras dan sensación de estar aplastadas (platicúrticas).
Coeficiente de exceso, apuntamiento o curtosis:
3s
g 4
m4 −=
2
Observación.- ••• si el coeficiente es positivo la distribución es
leptocúrtica. ••• Si el coeficiente es nulo la distribución es
mesocúrtica. ••• bución es
platicúrtica.
Si el coeficiente es negativo la distri
Related Documents











