Orquestrando Hadoop, Cassandra e MongoDB com o Pentaho Big Data Analytics. Trilha: Big Data Palestrante: Marcio Junior Vieira [email protected]

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Orquestrando Hadoop, Cassandra e MongoDB com o Pentaho Big Data Analytics.
Trilha: Big DataPalestrante: Marcio Junior [email protected]

Marcio Junior Vieira
● 16 anos de experiência em informática, vivência em desenvolvimento e análise de sistemas de Gestão empresarial.
● Trabalhando com Free Software e Open Source desde 2000 com serviços de consultoria e treinamento.
● Graduado em Tecnologia em Informática(2004) e pós-graduado em Software Livre(2005) ambos pela UFPR.
● Palestrante em Congressos relacionados a FLOSS tais como: CONISLI, SOLISC, FISL, LATINOWARE, SFD, JDBR, Campus Party, Pentaho Day, TDC São Paulo.
● Organizador Geral do Pentaho Day 2015 e apoio nas edições 2013 e 2014.● CEO da Ambiente Livre.● Data Scientist, Instrutor e Consultor de Big Data

Nosso Ecosistema● Fundada em 2004 com atuação em
consultoria para o mercado de gestão empresarial com Free Software/Open Source.
● 14 soluções para geração de negócios.
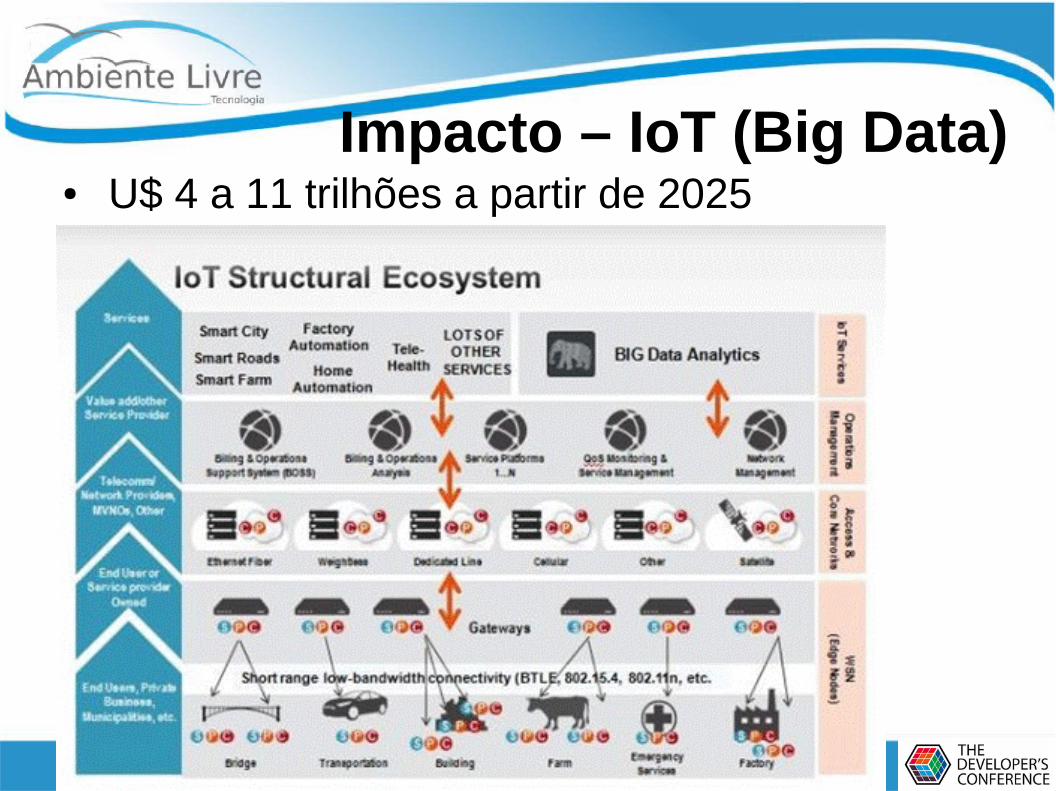
Impacto – IoT (Big Data)● U$ 4 a 11 trilhões a partir de 2025

Sensores de Voo

Fundação Apache
● Big Data = Apache = Open Source● Apache é líder e Big Data!● ~31 projetos de Big Data incluindo “Apache
Hadoop” e “Spark” e “Apache Cassandra”

Hadoop
● O Apache Hadoop é um projeto de software open-source escrito em Java. Escalável, confiável e com processamento distribuído.
● Filesystem Distribuído.● Inspirado Originalmente pelo GFS e MapReduce da Google
( Modelo de programação MapReduce)● Utiliza-se de Hardware Comum (Commodity cluster computing )● Framework para computação distribuída● infraestrutura confiável capaz de lidar com falhas (hardware,
software, rede)

Ecosistema - Hadoop

MapReduceProgramação Distribuída
● modelo de programação para processar grandes volumes de dados em paralelo, dividindo o trabalho em um conjunto de tarefas independentes.

MongoDB
● Banco de dados não relacional ( NoSQL ) Orientado a Documentos
● Baseado am JSON onde os documentos (registros) são representados por “chave:valor“ BSON
● Escrito em C++ e Open Source● Schema Dinâmico: Permite dados complexos não
estruturados● Documentos auto-contidos e arrays reduzem a
necessidade de join’s● Multiplataforma e com Alta Performance

MongoDB Inc
● 10 Milhões de Downloads.● Mais de 1.000 parceiros.● Milhares e clientes!

Apache Cassandra
● É um tipo de banco NoSQL que originalmente foi criado pelo Facebook e atualmente é mantido pela Apache e outras empresas.
● Banco de dados distribuído baseado no modelo BigTable do Google e no Dynamo da Amazon

Características
● Nenhum ponto único de falha● Escreve em Tempo Real ( real-time) com análise de
dados operacional ao vivo● Modelos de dados, facilmente alterados flexíveis● Horizontalmente Escala ( Near-linear ) entre os
servidores de commodities● Replicação de confiança entre data centers distribuídos● Esquema de tabela claramente definido em um
ambiente NoSQL

CassandraEscalabilidade Linear
● A Capacidade pode ser facilmente aumentada simplesmente por adicionar novos nós.
● Exemplo: Se 2 nós pode lidar com 100.000 transações por segundo, 4 nós apoiará 200.000 transações/s e 8 nós vai enfrentar 400.000 transações/s
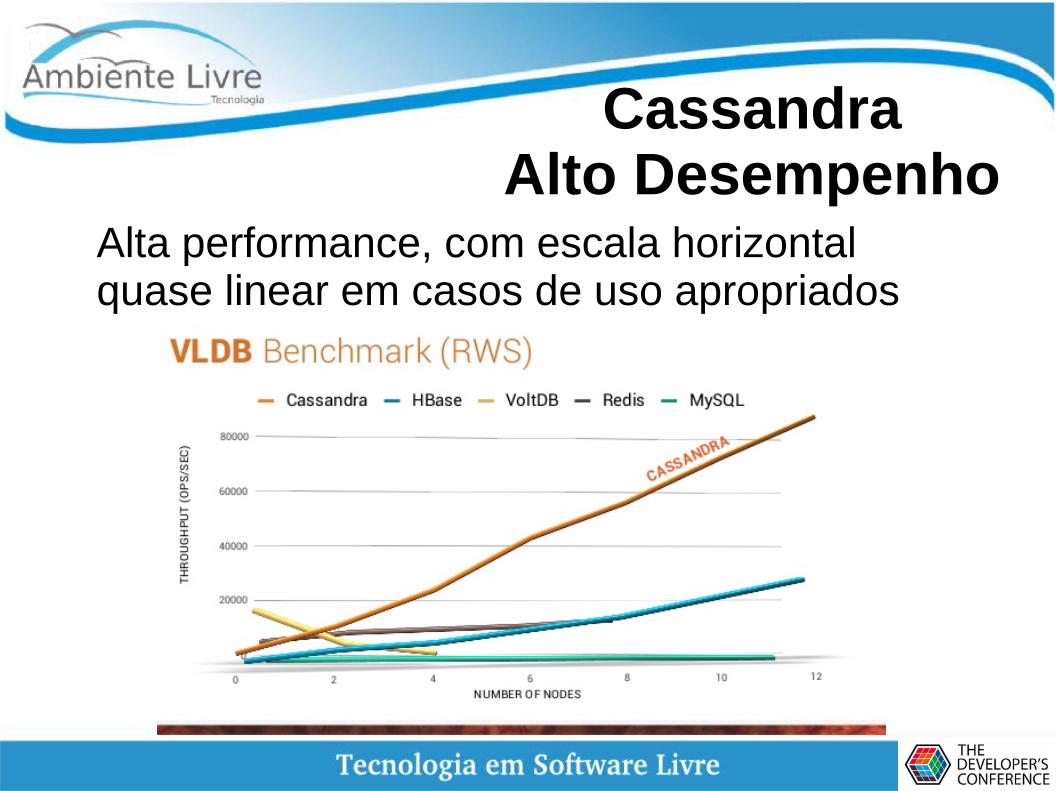
CassandraAlto Desempenho
Alta performance, com escala horizontal quase linear em casos de uso apropriados

Modelagem de Dados
Cassandra Query Language (CQL)● Fornece uma, linha-coluna, a abordagem SQL-like
familiarizado: CREATE, ALTER, DROP, SELECT, INSERT, UPDATE, DELETE
● Substituiu o complexoThrift API (utilizado em versões anteriores)
● Fornece definições de esquema claros num contextoflexível esquema (NoSQL)

CAP Theorem
● Consistência● Disponibilidade● Particionamento

Pentaho
● Plataforma completa para Business Intelligence e Business Analytics e Big Data Analytics.
● ETL, Reporting, Data Mining, OLAP e Dashbards.
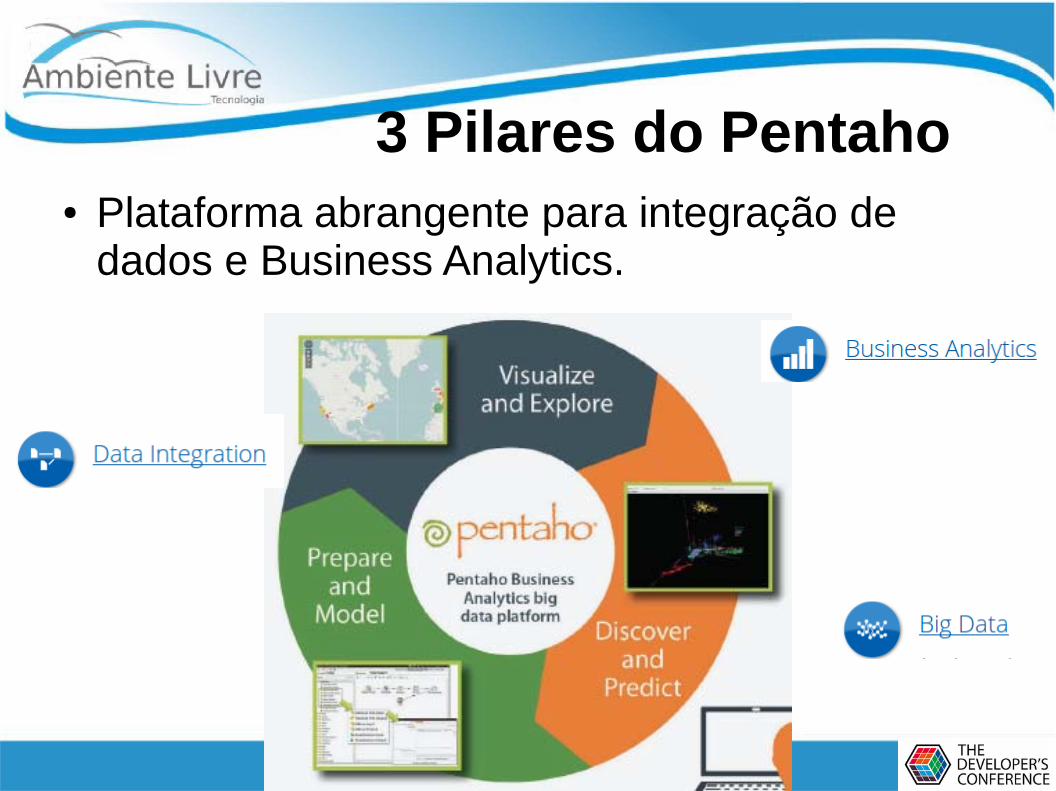
3 Pilares do Pentaho● Plataforma abrangente para integração de
dados e Business Analytics.

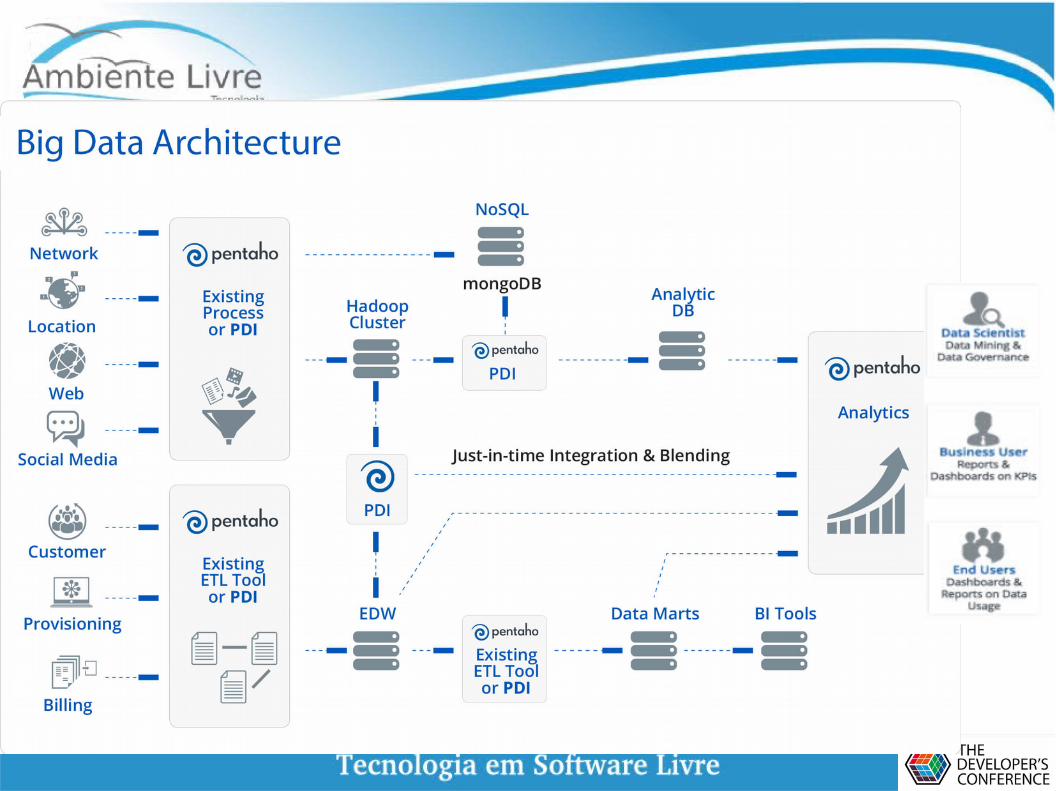
Arquitetura Big Data Analytics

Pentaho Data Integration
● Ferramenta completa de ETL● “Programação e Fluxo Visual”● Aproximadamente 350 steps diferentes

Pentaho Report Designer
● Web● Assistente de relatório● Amplo suporte de fonte de dados, incluindo
relacionais, OLAP, XMLe Pentaho Analysis, arquivos flat, objetos Java e ...
● Big Data Reports ( integra-se com PDI )
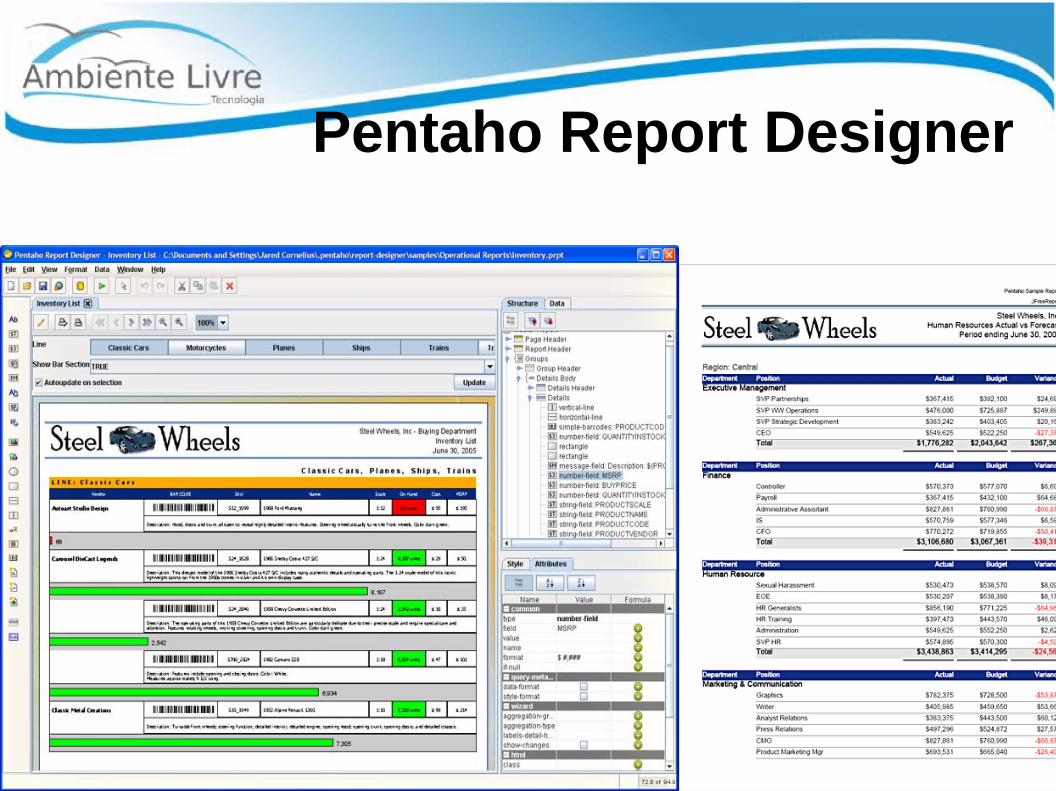
Pentaho Report Designer
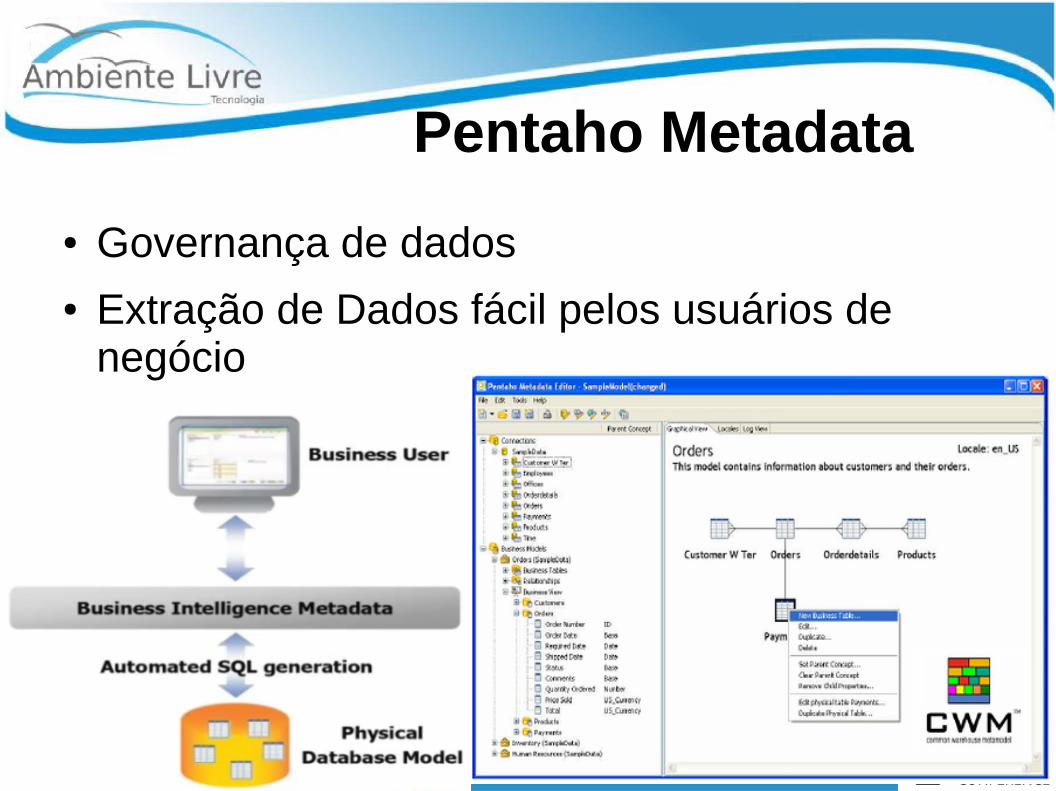
Pentaho Metadata
● Governança de dados● Extração de Dados fácil pelos usuários de
negócio●
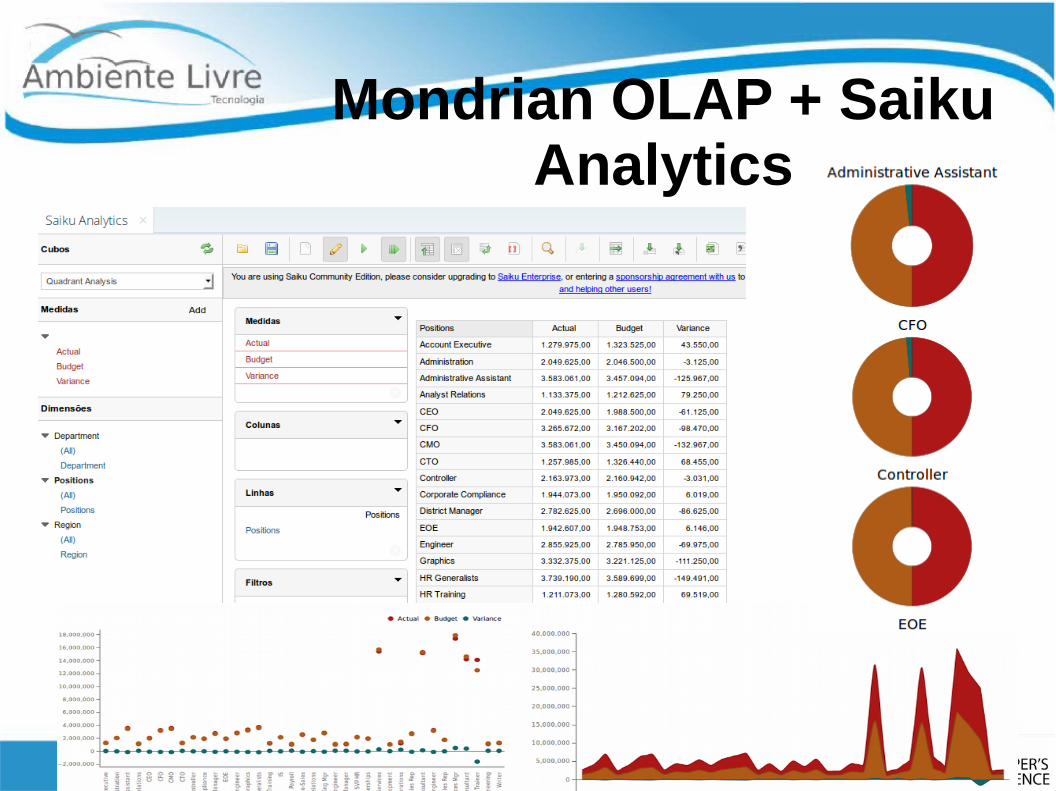
Mondrian OLAP + Saiku Analytics

CTools - Dashboards
● CTools – Tem um conjunto de Ferramentas para Desenvolvimento de Dashboars
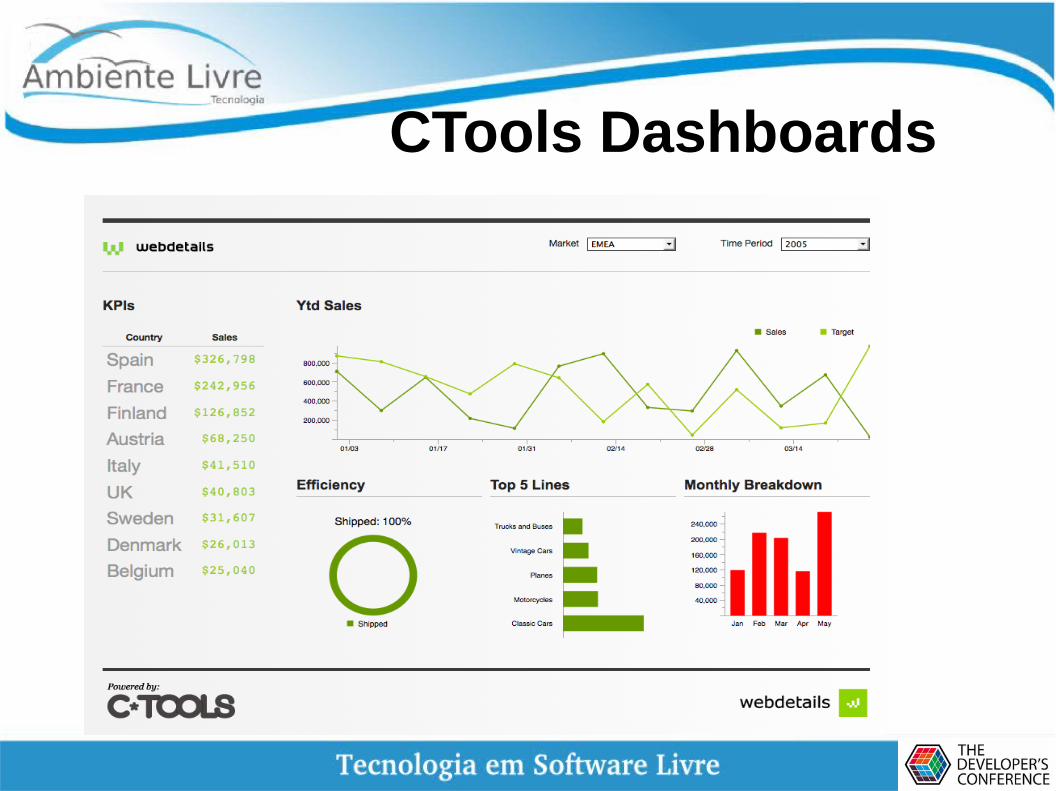
CTools Dashboards

CDE ( CTools )
● Editor de Dashboards

Pentaho Data Mining
● Solução completa para Machine Learning● 79 Algorítimos
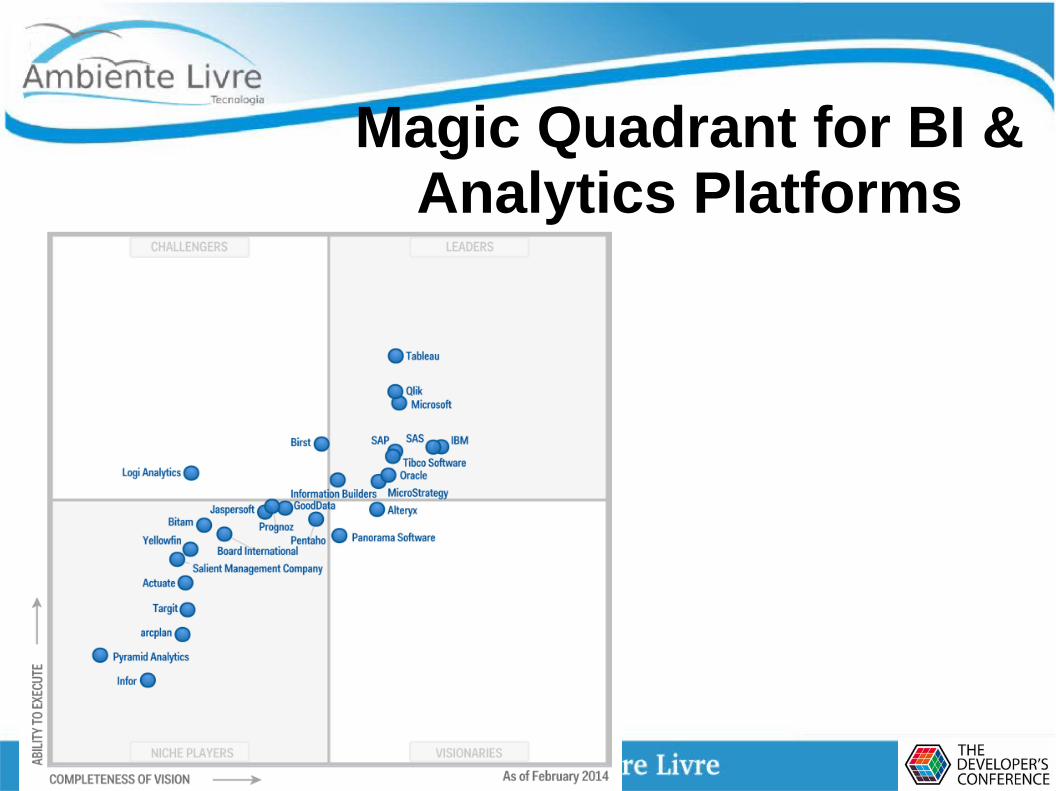
Magic Quadrant for BI & Analytics Platforms

Comunidade Brasileira

Comunidade Brasileira● Maior comunidade do Mundo!● Lista de Discussão com + de 1900 membros● Organiza a 5 anos o Pentaho Day Brasil● Composta por desenvolvedores, usuários , empresas e
acadêmia.● Utilizado em mais de 185 países.● +10.000 Produtos desenvolvidos sobre a plataforma Pentaho. ● + 4 milhões de Downloads● Em 2015 +- 60.000 downloads dia

Ecosistema Big Data

O Profissional“Data Scientist”
Novo profissional: Cientista de Dados

Competências
● Fonte http://www.datascientist.com.br/Artigo.aspx?ID=Competencia_de_um_cientista_de_dados_um_breve_exemplo_de_uma_analise_de_redes

Pentaho e Hadoop
● O Uso de Pentaho em projetos com Hadoop e Big Data pode diminuir em 15x o tempo do Projeto.
Codificação Java ETL com Pentaho
X

Pentaho e Hadoop

HDFS e Pentaho
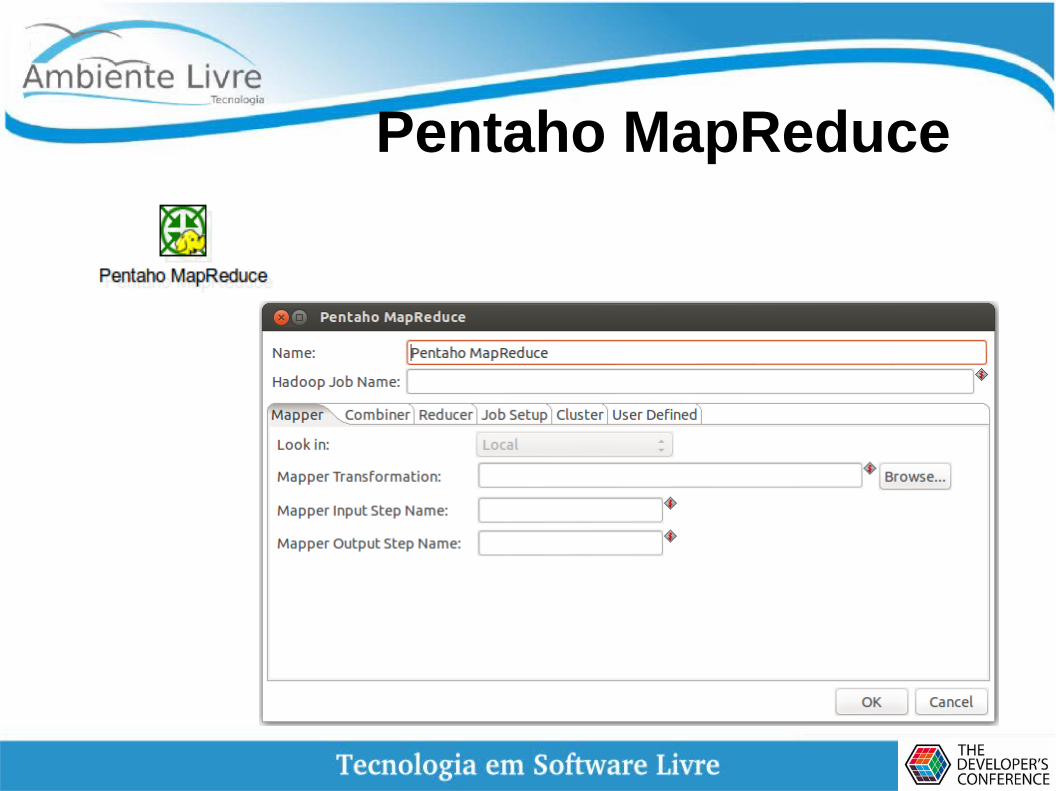
Pentaho MapReduce
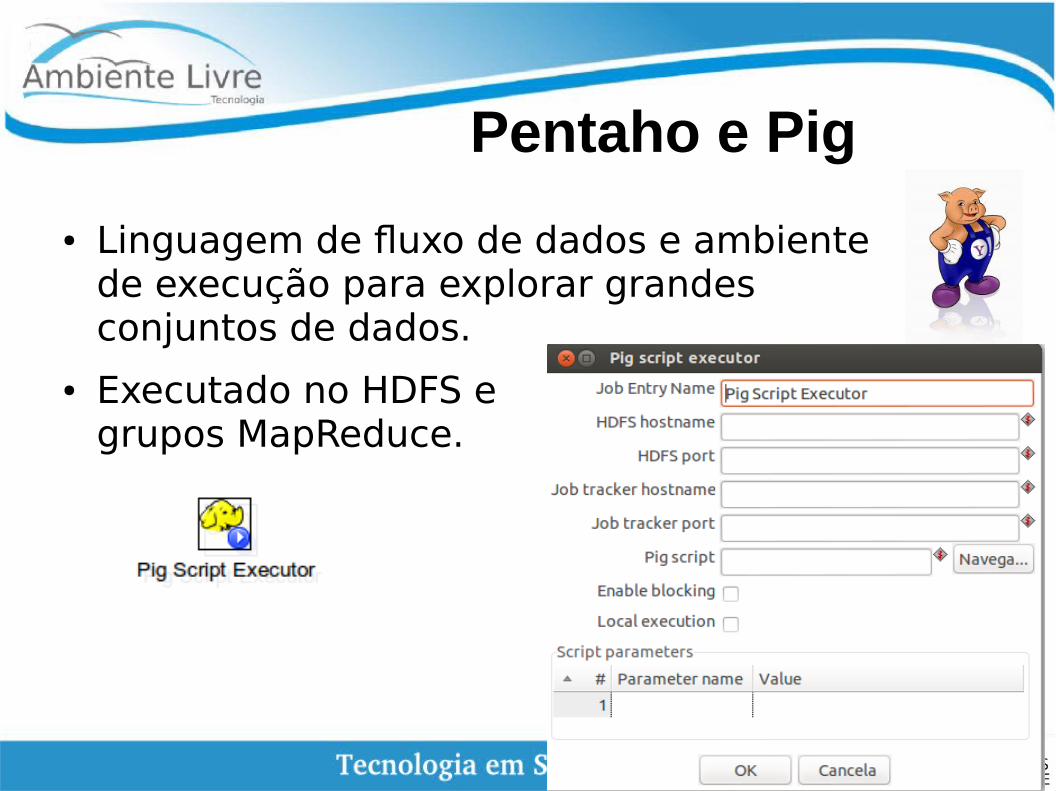
Pentaho e Pig
● Linguagem de fluxo de dados e ambiente de execução para explorar grandes conjuntos de dados.
● Executado no HDFS e grupos MapReduce.

Pentaho e Hbase
● BD colunar e distribuído.
● Usa o HDFS para armazenamentoe suporta os cálculosusando MapReduce e pontos de consultas
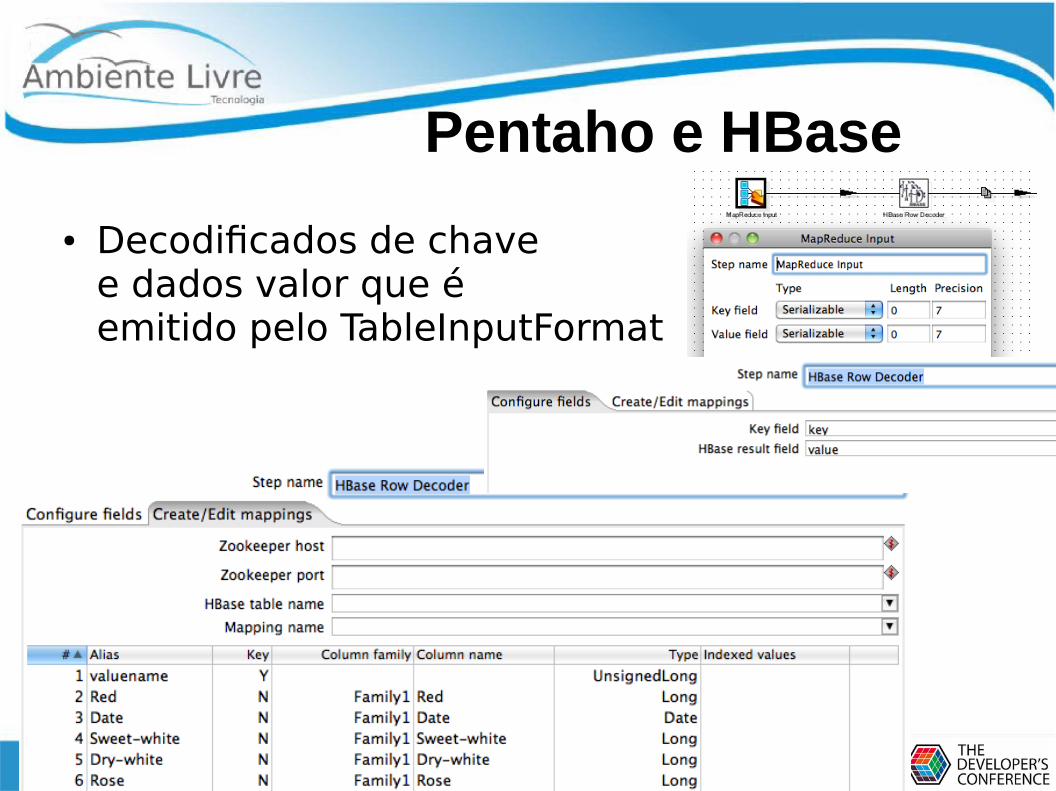
Pentaho e HBase
● Decodificados de chave e dados valor que é emitido pelo TableInputFormat

Pentaho e Hive
● interface SQL-like para dados estruturados armazenados no HDFS
● facilita a consulta e gerenciamento ● de grandes conjuntos de dados que
residem em armazenamento distribuído.
● Hive fornece um mecanismo para projetar a estrutura para esses dados e consultar os dados usando uma linguagem SQL, chamado HiveQL

Mongo DB
● Acessível via PDI (ETL)● Acessível via PRD
( Report )● Suporte a Mongo 3.0
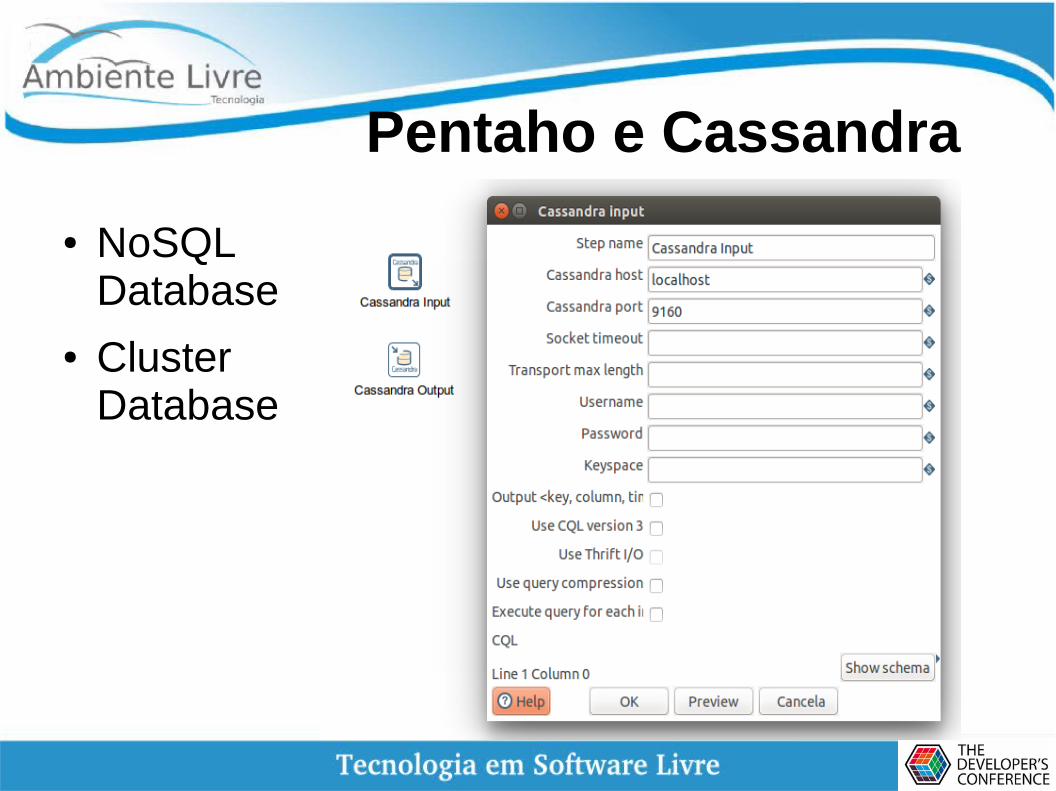
Pentaho e Cassandra
● NoSQL Database
● Cluster Database

Pentaho e CounchDB
● Foca na facilidade de usoe na filosofia de ser "um banco de dados que abrange a Web"
● NoSQL, usa JSON para armazenar os dados,

Pentaho e Amazon
● MapReduce sob Demanda●
●
●
● Amazon RedShift

Pentaho e Amazon
● Input e Output no S3
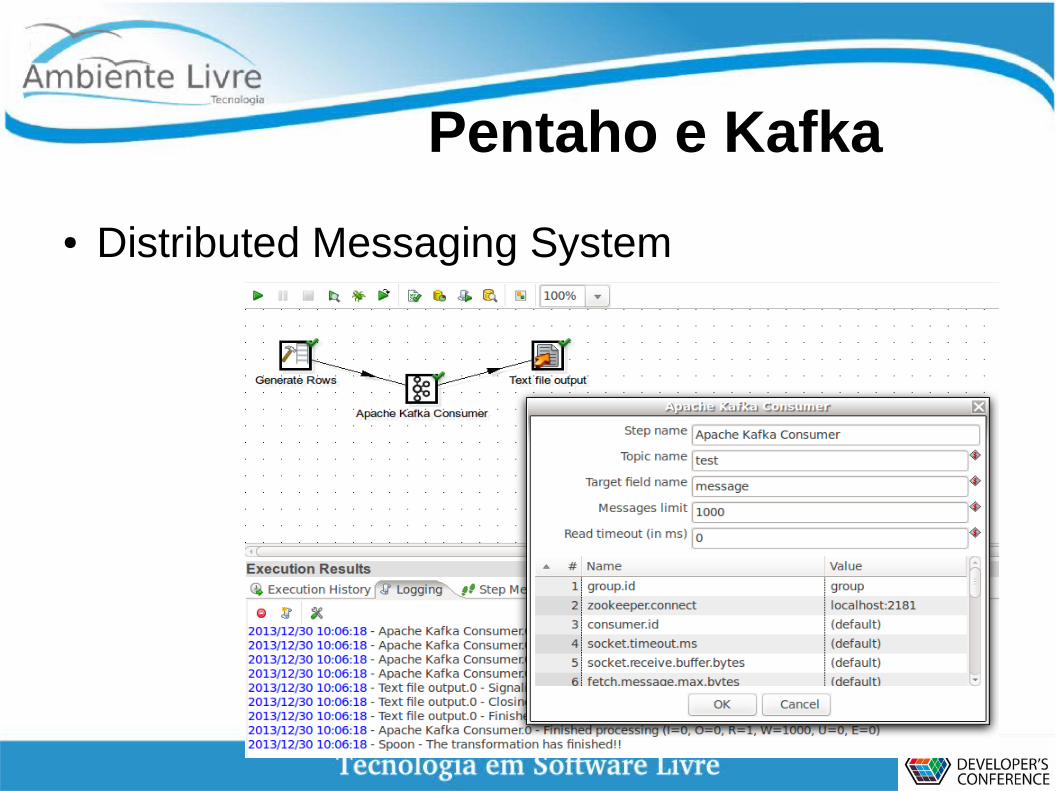
Pentaho e Kafka
● Distributed Messaging System

Pentaho e ElasticSearch
● Query via REST● Bulk Insert

Pentaho e Apache Sqoop
● Permite copiar dados em tabelas de banco de dados para HDFS

Pentaho e Apache Flume
● Coletor de dados escalável que leva dados de vários servidores e agrega-os ao Hadoop Data Lake.

Pentaho e Storm
● Distributed real-time computation system● https://github.com/pentaho/kettle-storm ●

Pentaho e Apache Avro
● Data serialization system

Pentaho com Spark
● Spark é um mecanismo de processamento na memória que podem ser agrupados / escalado usando Hadoop.

Pentaho Sparkl
● App Builder que permite desenvolver plugins de Big Data Analytics e outros em alguns passos.

Exemplo Big Data em D3.js


Baixe agora....
● http://sourceforge.net/projects/pentaho/ ● Entre em nossa comunidade!● [email protected]

Contatos
● www.ambientelivre.com.br ● marcio @ ambientelivre.com.br ● http://twitter.com/ambientelivre● @ambientelivre ou @marciojvieira● Blog
blogs.ambientelivre.com.br/marcio● Facebook/ambientelivre
Related Documents











