Università Degli Studi Di Parma Facoltà di Scienze MM.FF.NN Dottorato in Scienze Chimiche (XX ciclo) Synthesis and Applications of PNA and Modified PNA in Nanobiotechnology Relatori: Prof.ssa Rosangela Marchelli Prof. Roberto Corradini Coordinatore: Prof.ssa Marta Catellani Dottorando: Dott. Filbert Totsingan Triennio 2005-2007

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Università Degli Studi Di Parma
Facoltà di Scienze MM.FF.NN
Dottorato in Scienze Chimiche
(XX ciclo)
Synthesis and Applications of PNA and Modified
PNA in Nanobiotechnology
Relatori: Prof.ssa Rosangela Marchelli
Prof. Roberto Corradini
Coordinatore: Prof.ssa Marta Catellani
Dottorando:
Dott. Filbert Totsingan
Triennio 2005-2007


Index
3
General Index
Introduction.................................................................................................................5
I.1. Supramolecular Chemistry and Nano(bio)technology……………………….5
I.2. Nucleic acids as biological and supramolecular entities…………………..…6
I.3. DNA mimics……………………………………...………………………….8
I.4. Peptide Nucleic Acids (PNAs)………………………………………...……10
I.4.1. Structure……………………………………………............................10
I.4.2 Binding properties and sequence-selectivity of PNAs………………...11
I.5. Synthesis of PNA monomers and oligomers…………….…………………15
I.6. Chemical modification of the PNA backbone………………………….…..20
I.7. Chiral acyclic PNAs and the influence of chirality……………………..….22
I.8. Applications of PNAs in molecular biology and medicine………….…......25
I.9. PNA as tool for molecular devices and in nanobiotechnology…………….28
I.9.1 PNA-based biosensors………………………………………………...28
I.9.2. Conjugation of PNA with micro- and nanofabricated systems………30
I.10. PNA:PNA duplexes as tunable nanomaterials: Sergeant and soldiers
behaviour………………………………………………………………………..31
I.11. PNA as model for prebiotic chemistry………………………….…………35
I.12. References…………………………………………………………………38
Aim of the work…………………………………………………………………...46
Chapter 1. PNA Beacons in Label-Free Selective Detection of DNA by
Fluorimetry and by Ion Exchange HPLC……………………………….….....47
1.1. Introduction………………………………………………………………...47
1.2. Results and Discussion……………………………………………………..49
1.3. Conclusions………………………………………………………………...49
1.4. Experimental section…………………………...…………………………..56

Index
4
1.5. References………………………………………………………………….58
Chapter 2. Design and Synthesis of a PNA Beacon Modified with a
Chiral Monomer Linker……………………………………………….................60
2.1. Introduction………………………………………………………………...60
2.2. Results and Discussion……………………………………………………..62
2.3. Conclusions………………………………………………………………...69
2.4. Experimental section…………………………...…………………………..69
2.5. References………………………………………………………………….77
Chapter 3. Insights into the Propagation of Helicity in PNA:PNA
Duplexes as a Model for Nucleic Acid Cooperativity...................................79
3.1. Introduction………………………………………………………………...79
3.2. Results ……………………………………………………………………..81
3.3. Discussion……………………………………………………………….....96
3.4. Conclusions……………………………………………………………….106
3.5. Experimental section…………………………...……………………...….107
3.6. References…………………………………………………………...……115
Chapter 4. PNA as tools for molecular computers ………………………..117
4.1. Introduction………………………………………………………….........117
4.2. Results and Discussion……………………………………………………119
4.3. Conclusions…………….………………………………………………....126
4.4. Experimental section…………………………...…………………………126
4.5. References…………………………………………………...……………131

Introduction
5
I.1. Supramolecular Chemistry and Nano(bio)technology
Chemistry began when man started to use and transform natural inorganic and organic
materials such as rock, wood, and pigments for specific purposes. Since then, the
development of new materials from atoms or molecules has strongly influenced our
life. Very recently, two major research areas have transformed our vision of the
chemistry of molecules as well as materials sciences: Supramolecular Chemistry
was established in the 1970s and is concerned with the study of the interaction
between molecules, and Nanotechnology emerged in the 1990s and involves the
research and development of technology at the nanometer level (1–100 nm).
Based on supramolecular concepts, molecules can interact with other molecules
through weak interactions (0.1-5 kcal/mole), such as hydrogen- bonding, van der
Waals, or dispersive forces, which are collectively know as non-covalent interactions.
Such interactions play a key role in fundamental biological processes, such as protein
folding or the expression and transfer of genetic information. These non-covalent
interactions are useful tool in the preparation of complex molecular assemblies and
offers differences in strength, binding kinetics, directionality and useful media that
allow one to pick and choose the appropriate interaction for the desired purpose.
During the last past years, Supramolecular Chemistry has extended the knowledge
about type of elementary non-covalent interaction, with the description of recognition
motifs such as C-H-π or cation- π interactions, but has also produced a massive effort
for the generation of tailor-made systems devoted to specific technological
applications, in what is now generally recognized as “molecular engineering”.
In figure I.1 some of the applications of Supramolecular Chemistry described in the
last decades are illustrated. On one hand supramolecular interactions can be used to
generate functions that are similar to those of macroscopic objects at a molecular level
(molecular devices), and on the other hand, new materials with programmed special
properties can be prepared through nanostructuring and self-assembly.
For example many supramolecular sensors, based on the transmission of a recognition
event to a measurable signal have been described.1 Signaling of the presence of
analytes can be accomplished in a number of ways, but is commonly based on a
change in color, fluorescence, or a redox potential. In molecular chemosensors, the
signaling process usually comprises two steps: 1) selective coordination of the guest

Introduction
6
by a binding site and 2) transduction of that event by modulation of a photophysical or
electrochemical process within the probe. One of the key tasks in this field is to seek
out new and effective chemical sensors that show enhanced performance with respect
to selectivity and sensitivity, for example, by signal amplification and a reduction in
the detection limit.
The Supramolecular Chemistry approach has also found interesting applications in
molecular logic gates and switches for computation in which the input and output
events are well-distinguished.2 Other objects such as molecular motors and molecular
machines have been the subject of many studies in recent years.3
The combination of nanomaterials as solid supports and supramolecular concepts has
also led to the development of hybrid materials with improved functionalities4. These
“hetero-supramolecular” ideas provide a means of bridging the gap between molecular
chemistry, materials sciences, and nanotechnology.
.
Figure I.1. Various applications of supramolecular concepts
I.2. Nucleic acids as biological and supramolecular entities
More than fifty years ago, Watson and Crick proposed the double-helical model for
the 3D structure of DNA5. The biological implications of the model were already
stated in the paper, although not overemphasized, because the molecular basis of
SupramolecularChemistry
Supramolecular Devices
SwitchesSensors Nanostructures
Supramolecular Materials
Logic Gates Self-assemblyMachines

Introduction
7
genetics and reproduction came as a consequence of the complementary pairing of the
two DNA strands. Probably at that time it was not so obvious to predict the revolution
that would be launched in bioorganic chemistry following the elegant simple strategy
of hydrogen bond-mediated molecular recognition of specific nucleic acid sequences.
Nucleic acids occupy a position of central importance in biological systems.
Remarkably, even though based on relatively simple nucleotide monomers, these
biopolymers participate in an impressive array of complex cellular functions. For
example, from DNA double-stranded structure, genetic information is stored,
accessed, and replicated as a linear nucleotide code. In partnership with DNA, RNA is
an essential biopolymer which, among other functions, transports genetic information
from DNA to the site of protein manufacturing, the ribosome6. The flow of genetic
information: DNA transcribed into RNA which is ultimately translated into proteins,
constitutes the so-called “central dogma of molecular biology”.
The foregoing comments underscore the importance of nucleic acids in the processes
that permit life as we know it and, perhaps, in the origin and evolution of life itself.
Giving their importance, it should not be surprising that nucleic acids constitute a
primary target for binding or chemical modification by several classes of molecules.
These agents can take the form of gene regulatory proteins which are necessary to
repress or stimulate the natural flow of genetic information through DNA and RNA7,8
Alternatively, low molecular weight species from extracellular sources may also
artificially alter or inhibit the activities of RNA or DNA. These exogenous agents can
be based on organic9 or inorganic10 species and may be associated noncovalently or
induce the strand scission of nucleic acids. Such molecules, accessible from either
natural sources or by synthesis, have played a major role in the development of
chemotherapeutic regimens and have also contributed to our understanding of the
molecular recognition of nucleic acids.
However, in another more recent approach, nucleic acid molecules can be viewed as
highly programmable molecules able to perform many of the above mentioned
functions typical of supramolecular systems. For example, DNA and DNA-like
materials offer the opportunity of preparing controlled self-assembled architectures.
The interaction between two DNA strands is primarily mediated by four nucleobases
(A; C; G; T). The two anti-parallel strands of DNA are held together by A-T and G-C

Introduction
8
base pairs to form a doubled helix. While the selectivity of these base- pair interactions
is controlled mainly by hydrogen bonding, both π− π stacking and hydrophobic effects
also play a role in stabilizing the resulting structure. There is a considerable growing
interest in the use of DNA as building blocks for non-covalent synthesis11, as
pioneered by the work of Seeman et al.12 Short pieces of DNA can be regarded as stiff
building blocks, a feature essential for the formation of well-defined assemblies. Other
attractive properties of DNA-based self-assembly are the readily automated synthesis,
the easy modification with functional groups, and the mild conditions under which
self-assembly occurs. Geometrically organized nanostructures, such as a cube13, fully
composed of polynucleotides have been synthesized.
More recently, the use of DNA has been spectacularly applied in the creation of highly
organized structures, named “DNA origami” in which the control of shape, 3-D
structure, and information content can be fully programmed by the appropriate choice
of DNA sequences.14
Molecular machines based on DNA assembly processes have been described and are
among the most promising tools for the conversion of chemical signals into
mechanical motions. For example, the transition between quadruplex and duplex DNA
structures has been driven in a cyclic way in order to create a “motor-like” behaviour3
These examples illustrate one of the possible approaches to “nanobiotechnology” that
is to use the genetic code as a programmable entity for the control of structures and
functions at the molecular level.
I.3. DNA mimics
After it became clear that the genetic information was encoded in the double-strand
DNA and transcribed into single-stranded mRNA, it was possible to use it as a target
for biochemical manipulation and potential therapeutic intervention. For example, this
can be made by inserting new information or correct mutations in order to modify the
original DNA structure or by using selective techniques able to suppress the
expression of unwanted genes. Selective gene inhibition is theoretically possible by
taking advantage of the known hydrogen bonding interactions which take place
between complementary bases of nucleic acids. Selective gene inhibition is possible
by taking advantage of the two most important characteristic of the DNA: the

Introduction
9
specificity and the reversibility of the hydrogen bonding between complementary base
pair (A---T and G---C). These properties give the opportunity to design synthetic
oligomers, which can hybridize complementary sequence of DNA/RNA target
forming a double helix complex in the same fashion as natural DNA.
Over the past two decades synthetic oligonucloetides have shown great promise and
have been extremely useful in gene activation and repression strategies, however
several factors have limited their potential, most importantly the susceptibility to
nuclease digestion.
To overcome this drawback and with the aim of introducing chemical modifications to
improve binding and selectivity, many new DNA analogues were designed. The
antisense oligonucleotides of “the first generation” were phosphothioates15
oligonucleotide methylphosphonates16 while the second generation includes analogues
like: 2’-carbohydrate-modified nucleic acids17 N3’-P5’ phosphoramidate DNA18,
morpholino-DNA 19 and locked nucleic acids (LNA) 20. Some of these oligonucleotide
analogues are reported in Figure I.2.
OR
O Base
O
PO O
O
O Base
O
PO O
O
OBase
O
PO O
RO
X
X
X
OR
O Base
NH
PO O
O
OBase
NH
PO O
RO
OR
OBase
O
PCH3
O
O
O Base
O
PCH3
O
RO
OR
O Base
O
PS O
O
O Base
O
PS O
RO
N
O
O
PO N
OR
N
O
RO
PO N
Base
Base
O
OR
O Base
O
PO O
O
OBase
O
PO O
RO
O
OO
OR
OBase
O
PO O
O
O Base
O
PO O
RO
OO
X=H DNAX=OH RNA
N3'-P5' phosphoramidateMethylphosphonatePhosphorothioate
MorpholinoLocked Nuceic Acid
LNA2'-O-(2-methoxyetil)-RNA
MOE
Figure I.2. Few examples of synthetic oligonucleotide analogues

Introduction
10
Other DNA analogues are currently being intensely investigated and their properties
and interaction with DNA or RNA could provide a better understanding of the
structural features of natural DNA. At the beginning of 1990s, a new class of DNA
analogues, named peptide nucleic acids (PNAs). disclosed to the scientific community
that this process could go even further, by changing the type of bond between the
nucleotide units and using acyclic structures in place of the sugar moiety, still
maintaining (and improving) the DNA binding ability.
I.4. Peptide Nucleic Acids (PNAs)
I.4.1. Structure
In 1991, Nielsen et al. first described what is one of the most interesting of the new
DNA mimics, the peptide nucleic acids, in which the sugar-phosphate backbone was
replaced by an N-(2-aminoethyl)glycine unit covalently linked to the nucleobases 21.
The astonishing discovery that these polyamide bind with higher affinity to
complementary nucleic acid strands and their natural counterparts22, and obey to
Watson- Crick base-pairing rules resulted in the rapid development of a new branch of
research focused on diagnostic and therapeutic applications of this highly interesting
class of compounds.23, 24
The success of PNAs made it clear that oligonucleotide analogues could be obtained
with drastic changes from the natural model, provided that some important structural
features were preserved. The PNA scaffold has served as a model for the design of
new compounds able to perform DNA recognition. Synthetic organic chemistry has
played a fundamental role in the achievement of these goals, by allowing to obtain
new structures for the PNA monomers, and by developing novel strategies for
oligomer synthesis. One important aspect of this type of research is that the design of
new molecules and the study of their performances are strictly interconnected,
inducing organic chemists to collaborate with biologists, physicians and biophysicists.

Introduction
11
*O O
P
*O
OO
B
n
*
NH
N
*
O
n
O
B
DNA PNA
Figure I.3. Schematic structures of DNA and PNA
With the exception of the nucleobases, PNAs and DNA have no functional group in
common. As a result of this, the stability of the compounds are completely different .
In contrast with DNA, which depurinates on treatment with strong acids, PNAs are
very stable to acids. It is thus possible to synthesize PNAs by using standard
protecting groups from peptide chemistry which require cleavage with
trifluoromethanesulfonic acid or anydrous HF.25 Another interesting property of
PNAs, which is useful in biological applications, is their stability to both nucleases
and peptidases, since their “unnatural” skeleton prevents recognition by natural
enzymes, making them more persistent in biological fluids.26
The PNA backbone, which is composed by repeating N-(2-aminoethyl)glycine units,
is constituted by six atoms for each repeating unit and by a two atom spacer between
the backbone and the nucleobase, similarly to the natural DNA. However, the PNA
skeleton is neutral, allowing the binding to complementary polyanionic DNA to occur
without repulsive electrostatic interactions, which are present in the DNA:DNA
duplex. As a result, the thermal stability of the PNA:DNA duplexes (measured by their
melting temperature) is higher than that of the natural the DNA:DNA double helix of
the same length. Furthermore, while DNA:DNA is stabilized by a high ionic strength
medium, the PNA:DNA is much less affected by it.
I.4.2 Binding properties and sequence-selectivity of PNAs
In DNA:DNA duplexes the two strands are always in an antiparallel orientation (with
the 5’-end of one strand opposed to the 3’- end of the other), while PNA:DNA

Introduction
12
adducts can be formed in two different orientations, arbitrarily termed parallel and
antiparallel (Figure I.4), both adducts being formed at room temperature, with the
antiparallel orientation showing higher stability.
Figure I.4. Parallel and antiparallel orientation of the PNA:DNA duplexes
One of the most important features of the PNA:DNA duplexes is that the stability is
highly affected by the presence of a single mismatched base pair. For example,
considering a 15-mer DNA sequence (3’-TGTACGTCACAACTA-5’),22 a T-G substitution
on the target DNA causes a decrease of only 4 °C in the DNA:DNA melting
temperature, whereas the melting temperature of PNA:DNA (antiparallel) drops of 13
°C. Thus, PNA probes are very sequence-selective and are superior to DNA probes in
recognizing single-base mispairing.
The thermal stability of the full-matched antiparallel PNA:DNA duplexes known has
been analyzed statistically and an empirical model is now available for calculating the
Tm of the duplex formed by a given PNA sequence; according to this model, the
thermal stability increases, as expected, with the G-C contents when the purines are on
the PNA strand27.
Targeting a double-strand DNA with PNA can occur via at least four different binding
modes. Three of these modes: triplex formation, duplex invasion and triplex invasion,
require homopurine/homopyrimidine DNA targets, whereas double duplex invasion
requires the use of modified non self complementary bases and targets of at least 50%
of A-T contents. The base pairing in triplexes occurs via Watson-Crick and Hoogsteen
hydrogen bonds (Figure I.5). In the case of triplex formation, the stability of these type
of structures is very high: for example, a T10 PNA can bind to A10 DNA forming a
triplex with a melting temperature of 72 °C. If the target sequence is present in a long
dsDNA tract, the PNA can displace the opposite strand by opening the double helix in
PNA
DNA
N-ter C-term
5' 3'
PNA
DNA
N-term C-term.
3' 5'
Parallel Antiparallel

Introduction
13
order to form a triplex with the other, thus inducing the formation of a structure
defined as “P-loop”, in a process which has been defined as “strand invasion” (Figure
I.6).28
H N
O
N
N
H
*
H
NO N+
N
H
*
H
O
O
H
HN
N
N
H
N
N
O3
5
*
*
O
G
C+
C
a)
HoogsteenH-bonds
Watson-CrickH-bonds
HN
H
N
N
N
N
O3
5
O
O
*
*
O
H N
N
O *
OH
N
N
O
*
T
T
A
b)
HoogsteenH-bonds
Watson-CrickH-bonds
Figure I.5. Hydrogen bonding in triplex PNA2/DNA: C+GC (a) and TAT (b)
Figure I.6. Mechanism of strand invasion of double stranded DNA by triplex formation.
TTTTTTTTT
TTTTTTTTTT
TTTTTTTTT
TAAAAAAAAAA
TTTTTTTTTT
TTTTTTTTT
AAAAAAAAAA
TTTTTTTTT
TTTTTTTTTT
TTTTTTTTT
TTTTTTTTTT
TTTTTTTTTT
TTTTTTTTT
TTTTTTTTTT
TTTTTTTTTT
TTTTTTTTT
T
PNA PNA
dsDNA
“P-loop”
Strand invasion

Introduction
14
This process can be very useful when trying to target double strand -DNA, but the P-
loop can be formed only by a limited number of sequences (homopyrimidine PNAs).
Although the rate of formation of the PNA:DNA duplexes is fast and comparable to
that of DNA:DNA, the formation of PNA:DNA:PNA triplexes has a complex kinetic
pathway and is much slower. For these reasons, melting curves of triplexes show a
typical hysteresis pattern.29
Recently “Tail-clamp” PNAs composed of a short (hexamer) homopyridine triplex
forming domain and a decamer mixed sequence duplex forming extension, have been
designed.30 These PNAs display significantly increased binding to single-stranded
DNA as compared to PNAs without duplex-forming extension; binding with double-
strand DNA occurred by combined triplex formation and duplex invasion. From these
results “Tail-clamp” PNAs seem to be really useful in P-loop technology.
PNAs containing complementary sequences can also form PNA:PNA duplexes of very
high stability,31 which are interesting structures as tools for assembling components
for nanotechnologies by non-covalent interactions.
Three-dimensional structures have been determined for the major families of PNA
complexes by different techniques. a PNA-RNA32 and PNA-DNA33 duplex were
characterized by NMR in solution, while the structures of a PNA2DNA triplex34 and
PNA-PNA duplexes35 were solved by X-ray crystallography.
The PNA was found to prefer a unique helix form, different from all other nucleic acid
duplex, named the P-helix, which was characterized in the PNA2DNA triplex and is
developed in PNA-PNA duplexes. This helix is characterized by a small twist angle, a
large x-displacement, and a wide, deep major groove.
The structural analysis in solution of the PNA-RNA and PNA-DNA duplexes showed
that PNA, when hybridized to RNA, adopts an A-like helix, whereas, when hybridized
to a complementary DNA, it adopts a conformation that is different from both the A
and the B forms.
However, the crystal structure of the duplex formed by a modified PNA (chiral box,
vide infra) with DNA showed characteristics similar to those of P-helix (for example,
with 16 bp per turn), suggesting that PNA, when involved in duplex formation, acts as
a more rigid entity than DNA (Table I.1). Accordingly, the DNA conformation is
distorted, being partially in the A- and partly in B-conformations.

Introduction
15
Table I.1. Helical parameters (average) of duplexes involving PNA compared with canonical DNA.
Duplex Twist (°)
Rise (Å)
Displacement (Å)
Bases per turn
Chiral box PNA:DNA36 23.2 3.5 -3.8 16 PNA-PNA35,37 19.8 3.2 -8.3 18
PNA2-DNA triplex34 22.9 3.4 -6.8 16 PNA-DNA33 28.0 3.3 -3.8 13
DNA-DNA (A)38 32.7 2.6 -4.5 11 DNA-DNA (B)38 36.0 3.4 -0.1 10
I.5. Synthesis of PNA monomers and oligomers
The monomeric unit (backbone) is constituted by N-(2-aminoethyl)glycine protected
at the terminal amino group, which is essentially a pseudopeptide with a reduced
amide bond (ψ-CH2). Several retrosynthetic routes have been described for this simple
unit (Figure I.7). SN2 reaction on α-bromoacetic acid or its esters (route a) is one of the
most convenient and unexpensive method. Reductive amination is also a simple way
of producing the C-N bond, either using glyoxalic esters and ethylenediamine (b) or
glycinal and glycine (c). The last approach requires more steps, but it is useful for the
production of modified PNAs or isotopically labelled monomers using the
corresponding commercially available enriched glycine unit. N-protected glycinal can
be obtained by reduction of N-methyl-N-methoxy amide (Weinreb amide)39 of the
protected glycine or, more conveniently, by oxydation of Boc-3-aminopropane-1,2-
diol with potassium periodate40.
Figure I.7. Retrosynthesis of a PNA monomer
R1NH
NOH
OO
Base
R1NH
NH
O
O
R2
O
Base
OH
R1NH
NH2
O
O
R2Br+
R1NH
O
NH2
O
O
R2+
R1NH
NH2
O
O
R2
O
+
PNA
+
R1= H, Boc, Fmoc, MmtR2= H, Me, Et, tBu, Bz, All
a
b
c

Introduction
16
The synthesis of PNA monomers is then performed by coupling a nucleobase-
modified acetic acid with the secondary amino group of the backbone by using
standard peptide coupling reagents: such as N,N'-dicyclohexylcarbodiimide in the
presence of 1-hydroxybenzotriazole (HOBt). Temporary masking of the carboxylic
group as alkyl or allyl ester is also necessary during the coupling reactions. The
protected monomer is then selectively deprotected at the carboxyl group to produce
the monomer ready for oligomerization. The choice of the protecting groups on the
amino group and on the nucleobases depends on the strategy used for oligomer
synthesis.
The similarity of the PNA monomers with the amino acids allow the synthesis of the
PNA polymer with the same synthetic procedures commonly used for peptides, mainly
based on solid phase methodologies. The most common strategies used in peptide
synthesis involve the Boc and the Fmoc protecting groups. Some “tactics”, on the
other hand, are necessary in order to circumvent particularly difficult steps during the
synthesis (i.e. difficult sequences, side reactions, epimerization, etc.).
In Figure I.8, a general scheme for the synthesis of PNA oligomers on solid-phase
is described. The elongation takes place by deprotecting the N-terminus of the
anchored monomer and by coupling to it the following N-protected monomer. The
coupling reactions are carried out with coupling reagents such as HBTU or, better, its
7-aza analogue HATU23 which gives rise to yields above 99%. Exocyclic amino
groups present on cytosine, adenine and guanine may interfere with the synthesis and
therefore need to be protected with semi-permanent groups orthogonal to the main N-
terminal protecting group.

Introduction
17
NH
NNH
2
O
H
O
Base
n
NH2
Resin
First monomerloading
NH
NNH
OO
Base
NNH
OO
Base
NH
NNH
OO
Base
Resin
NH2
NNH
OO
Base
PGt
PGs
= Temporary protecting group
= Semi-permanent protecting group
NH
NOH
OO
BasePGs
PGt
NH
NOH
OO
BasePGs
PGt
Deprotection
Coupling
Repeat deprotectionand coupling
n times
Final cleavage
PNA
PGt
PGs PGs
Resin
PGt
PGs
PGs
Resin
Figure I.8. Typical scheme for solid phase PNA synthesis
Parallel solid-phase synthesis is also becoming part of PNA chemistry. An impressive
solid phase synthesis of PNA libraries was recently reported by Matysiak et al.41
through an automated parallel approach using commercially available Fmoc-
monomers. 1536 PNA oligomers were obtained on a 8x12 cm polyoxymethylene
support and then used for hybridization assays either directly on the solid support or in
solution after cleavage.
The Boc strategy was first applied to the synthesis of homothymine PNAs21,28 and
subsequently optimized for efficient mixed sequences23. The solid phase is usually a
methylbenzhydryl amine (MBHA) derivatized polystirene (PS) resin to which the first
PNA monomer is linked as an amide. The amino groups on nucleobases are protected
as benzyloxycarbonyl derivatives (Cbz) and actually this protecting group
combination is often referred to as the Boc/Cbz strategy. The Boc group is deprotected
with trifluoroacetic acid (TFA) and the final cleavage of PNA from the resin, with
simultaneous deprotection of exocyclic amino groups in the nucleobases, is carried out

Introduction
18
with HF or with a mixture of trifluoroacetic and trifluoromethanesulphonic acids
(TFA/TFMSA).
In the Fmoc strategy, the Fmoc protecting group is cleaved under mild basic
conditions with piperidine, and is therefore compatible with resin linkers, such as
MBHA-Rink amide or chlorotrityl groups. which can be cleaved under less acidic
conditions (TFA). In the first paper reporting the use of a Fmoc strategy,42 Cbz groups
were used for nucleobases, but a subsequent paper43 conveniently introduced
monomethoxytrityl (Mmt) protecting group, which is easily removed during the TFA
cleavage. Commercial available Fmoc monomers are currently protected on
nucleobases with the benzhydryloxycarbonyl (Bhoc) groups, also easily removed by
TFA. A strategy including acyl protecting groups for nucleobases was also
described.44 PNA synthesis by the Fmoc protocol was carried out successfully on a
variety of solid-phase supports common to peptide and DNA chemistry45. Optimal
results, as far as yield and purity, were obtained on PEG-PS supports with the use of
XAL as a synthesis handle.
Manual solid phase PNA synthesis has been sometimes replaced by automated
synthetic procedures adapted to commercially available synthesizers. PNA synthesis
has been developed for both continuous flow instruments and batch synthesizers by
using both Fmoc- or Boc-strategies.
Both strategies, with the right set of protecting group and the opportune cleavage
condition, allow the synthesis of different type of PNA-conjugated. Two examples of
this are the synthesis of PNA-DNA conjugates and PNA-peptide conjugates.
In the first case, strong acid conditions for the cleavage should be avoided, because it
would lead to depurination of the nucleotides. For the synthesis of PNA-DNA
chimeras the Fmoc strategy with acyl groups for the protection of nucleobase amino
group can be used on controlled pore glass (CPG)46 solid support. The chimera can be
cleaved by strong basic conditions (concentrated ammonia). PNA-peptide conjugates
can usually be assembled with the same strategy for both the PNA and the peptide
part. However, not all the strategies presented above are compatible with peptide
chemistry: in particular, the use of acyl protecting groups for nucleobases, requiring
strong basic conditions for the cleavage, is not suitable for PNA bearing amino acid
residues either at the C- or at the N-terminus.

Introduction
19
Table I.2. Strategies used for PNA synthesis, types of PNAs obtained and compatibility with peptide or oligonucleotide conjugation47
Strategy Resin linker (cleavage reagents)
PNA obtained PNA C-term Compatibility
Boc/Cbz MBHA (TFMSA or HF) free amide peptide
HYCRON (Pd(0) + morpholine)
Cbz acid peptide
Dts/Cbz PAL-PEG (TFA) Cbz and N-Dts amide peptide
Fmoc/Cbz MBHA (HF) N-Fmoc amide peptide
Fmoc/Mmt MBHA rink amide (TFA) Free or N-Fmoc amide peptide
Fmoc/Bhoc MBHA rink amide (TFA) Free or N-Fmoc acid peptide
Chlorotrityl (TFA) Free or N-Fmoc amide peptide
Fmoc/Acyl hydroxyalkyl-CPG (conc. NH3)
free acid + amide oligonucletide
Wang (TFA then conc. NH3) free acid + amide oligonucletide
Tentagel (conc. NH3) free acid + amide oligonucletide
Mmt/Acyl hydroxyhexyl-CPG (conc. NH3)
N-Mmt-protected amide oligonucletide
Boc/Acyl PAM-CPG (conc. NH3) free amide oligonucletide
PAM-MBHA (conc. NH3) free amide oligonucletide
Recently, a new type of building blocks, benzothiazole-2-sulfonyl (Bts)-protected
cyclic monomers,48 were shown to be useful in the construction of PNA oligomers,
opening new ways of PNA synthesis on large scale (Figure I.9).
Figure I.9. Deprotection/Coupling steps in PNA synthesis by cyclic Bts monomers
S
NN
B
O
O NH
S
O
O
S
N
NS
O
O
N
B
O
O
N
B
O
O NH
S
NN
B
O
O NH
S
O
O1. MeOPhSH/DIEA
2.

Introduction
20
In these PNA monomers the Bts group plays an important role not only as a protecting
group of the PNA backbone but also as an activating group for the coupling reaction.
This group can be easily removed during synthesis using 4-metoxybenzenethiol/DIEA.
I.6. Chemical modification of the PNA backbone
As mentioned above, the PNA scaffold has served as a model for the design of new
compounds able to perform DNA recognition. Since their discovery, many
modifications of the basic PNA structure have been proposed in order to improve their
performances in term of affinity and specificity towards complementary
oligonucleotide sequences. A modification introduced in the PNA structure can
improve its properties generally in three different ways: i) improving DNA binding
affinity; ii) improving sequence specificity, in particular for directional preference
(antiparallel vs parallel) and mismatch recognition; iii) improving bioavailability (cell
internalization, pharmacokinetics, etc.). Several reviews have covered the literature
concerning new chemically modified PNAs.49 Structure activity relationships showed
that the original design containing a 6-atom repeating unit and a 2-atom spacer
between backbone and the nucleobase was optimal for DNA recognition. Introduction
of different functional groups with different charges/polarity/flexibility have been
described and are extensively reviewed in several papers.50,51,52 These studies showed
that a “constrained flexibility” was necessary to have good DNA binding. On the basis
of these studies, modified PNAs have been constantly improved during the years,
using the concept of “preorganization”, i.e. the ability to adopt a conformation which
is most suitable for DNA binding, thus minimizing the entropy loss of the binding
process.
The main strategies which have been used for achieving this goal are summarized in
Figure I.10.

Introduction
21
Figure I.10. Strategies for inducing preorganization in the PNA monomers53
Preorganization was achieved either by cyclization of the PNA backbone (in the
aminoethyl side or in the glycine side), by adding substituents in the C2 or C5 carbon
of the monomer or by inserting the aminoethyl group into cyclic structures. The
addition of substituents at C2 or C5 carbon of the monomers can also in principle
preorganize the PNA strand, but mainly it has the effect of shifting the PNA
preference towards a right-handed or left-handed helical conformation, according to
the configuration of the new stereogenic centers, in turn affecting the stability of the
PNA-DNA duplex through a control of the helix handedness.
Many of these modifications included the presence of one or more stereogenic
centers, allowing to study the effect of chirality on DNA recognition.52 From this point
of view, PNAs are very appealing as models since, unlike DNA, the binding properties
of chiral PNAs may be compared with those of achiral PNAs, thus outlining the
effects due to the presence of chirality. These effects in acyclic PNAs will be
discussed in details in the following paragraphs.

Introduction
22
I.7. Chiral acyclic PNAs and the influence of chirality
Using the linear N-2-aminoethylglycine as a starting point, several PNA derivatives
were obtained by insertion of side chains either at the C2 (α) or C5 (γ) carbon atoms
(Figure I.11).
Figure I.11. Schematic representation of acyclic chiral PNAs
These modifications have an effect of introducing new constraints in the PNA
structure. If the constraint is appropriate for the conformation required for DNA
binding, this can actually results in improved DNA binding properties, whereas if not,
a detrimental effect is obtained. Nielsen and co-workers carried out the synthesis of 2-
substituted chiral PNAs starting from L-amino acid synthons.54 Only one chiral
monomer was inserted in the middle of a decameric PNA strand, and the results
indicated that the insertion of an amino acid-derived side chain slightly destabilized
antiparallel PNA-DNA duplexes, when compared to the achiral PNA with the same
sequence. Chiral PNAs derived from alanine or from arginine and lysine side chains
showed the best affinity for DNA, on account, respectively, of the small steric
hindrance and of the electrostatic interaction with the negatively charged DNA strand.
The worst affinity for DNA was displayed by PNAs bearing side chains derived from
bulky apolar amino acids, such as valine, tryptophan or phenylalanine. Thus steric
hindrance was clearly responsible for the destabilization of these PNA-DNA duplexes.

Introduction
23
However, when the binding affinity of chiral PNAs including L and D-alanine, L- and
D-lysine, L- and D-serine, D-glutamic acid, L-aspartic acid, L- and D-leucine was
considered,51,55 the PNA:DNA duplex stability was found to be dependent on
stereochemistry: PNAs carrying the D-amino acid derived monomers bound
complementary antiparallel DNA strands with higher affinity than the corresponding
L-monomers. Therefore, the affinity of chiral PNAs for complementary DNA emerged
to be a contribution of different factors: electrostatic interactions, steric hindrance and,
most interestingly, enantioselectivity, with a preference for the D-configuration.
One clue for understanding this behaviour was obtained by studying PNA-PNA
double helices. In fact, not only PNA:DNA, but also PNA:PNA duplexes are in the
form of helices.35 In absence of any stereogenic centers, two achiral complementary
PNAs will form an equimolar mixture of left-handed and right-handed helices. The
insertion of stereogenic centers in one of the PNA strands results in a predominant
helix handedness51; from CD spectroscopy it could be demonstrated that PNAs
containing D-monomers with the stereogenic center in position 2 induced a preference
for a right-handed conformation in PNA-PNA duplexes, whereas PNAs containing L-
monomers with the stereogenic center in the same position induced an opposite
preference for a left-handed double helix.56 Thus it was reasonable to propose that
PNAs preferring a right-handed helical conformation would have higher DNA binding
affinity than their mirror images. Inspection of known PNA:DNA structures led us to
propose a model based on intra-strand interaction of the PNA residues.52 Using
synthetic approaches aimed at preserving optical purity,57 chiral peptide nucleic acids
based on D-lys monomers were synthesized by our group.58 Thus, the first crystal
structure of a PNA:DNA duplex, in which three adjacent chiral monomers based on D-
lysine (“chiral box”, Figure I.12a) were present in the middle of the PNA strand was
obtained by X-ray diffraction, and fully confirmed the proposed model.36 As shown in
Figure I.12b), the D-configuration allows the lysine side chains to be placed in an
optimal position to fit in the right-handed helix, whereas the L-lysine side chains
would have given strong intra-strand steric clashes.

Introduction
24
Figure I.12. a) Crystal structure of the “chiral box” PNA:DNA duplex. b) Stereochemical model obtained from a monomer in the crystal structure, showing the effect of substituents derived from D- or L-amino acids either on the C2 or on the C5 carbon of the monomers.
The structural data reported for the PNA:DNA duplexes and the model reported above
was used as a reference in order to predict the behaviour of substituents on the 5-
position. In fact, in this case the preferred stereochemistry would be that derived from
L-amino acids, since it allows the functional group to be placed in a less hindered
region. Using this design, Seitz et al. synthesized a PNA bearing at the N-terminus a
monomer with L-cysteine side chain at position 5 a allowing, in combination with
another PNA strand modified at the C-terminus as thioester, for PNA synthesis via
chemical ligation.59 Appella et al. synthesized a PNA bearing a fluorophore linked to a
L-lysine side chain in the same position.60 A more detailed study was performed by
our group by comparing chiral PNAs substituted with L- or D-lysine at either 2 or 5
position or at both position simultaneously, and it actually confirmed that, when
inserting a stereogenic center in position 5, the L-enantiomer gave rise to a PNA able
to bind to the complementary antiparallel DNA with increased stability.61 Recently, Ly
and co-workers have reported a detailed study on the effect of 5-substituted PNAs
bearing small side chains derived from alanine and serine on PNA helicity and on
DNA binding properties.62 Using NMR studies they could show that a single stranded
PNA dimer of this type derived from L-Ala have a right handed helical conformation,
similar to the PNA conformation in the PNA:DNA crystal structure reported in figure
I.12. Accordingly, PNAs made of 5-substituted monomers derived from L-Ser showed

Introduction
25
a very high degree of preorganization and hence very high DNA binding affinities,
with an increase of up to 19 °C of the melting temperature if compared to unmodified
PNAs. Also in this case, the proper use of chirality turned out to be a very powerful
tool for making this type of derivatives promising tools for drug development.
Furthermore, the comparison on the effect of substitution on 2 or 5 carbon of PNA
revealed that the latter is much more effective in determining both the helical
preference and the DNA binding ability.63
I.8. Applications of PNA in molecular biology and medicine The ability of PNAs to bind to specific RNA and DNA targets has provided new tools
to molecular biologists for studying nucleic acid recognition. Like antisense
oligonucleotides, PNAs have been used to block translation of mRNA into proteins.
PNA are much more selective than DNA oligonucleotides for point mutations
discrimination.64 Unlike oligonucleotides, PNAs have the ability of invading dsDNA,
thus allowing to interfere with gene expression at the DNA level.65 One example of
how powerful this strategy can be is illustrated in Figure I.13. The formation of a
triplex between T10 PNA and an A10 termination site has been used as a "roadblock"
for arresting the transcription by RNA polymerase III, which produces, among others,
tRNAs.66 This process allowed to isolate a truncated RNA transcript lacking ~25
bases, thus indicating the distance between the catalytic site and the front end of the
enzyme, an information which could be obtained in other experiments only by a much
more elaborated scheme.
Triplex forming PNAs have been used as "DNA openers". The efficiency of these
methods is higher when using "hairpin" PNAs in which two strands composed of
thymine and cytosine (in the Watson-Crick strand) and pseudoisocytosine (in the
Hoogsteen strand) are linked through an appropriate spacer. Labelling of plasmids by
triplex forming PNAs have also been described.67
Figure I.13. Triplex forming PNAs as “roadblocks” for RNA polymerase III. From ref. 66
AAAAAAAAAA
TTTTTTTTTT
TTTTTTTTTT
TTTTTTTTTT~ 25 bp
Pol IIIDNA
PNA
tRNA

Introduction
26
The availability of non self-complementary PNAs, containing the modified bases
thiouracyl and diaminopurine has allowed to target dsDNA in a more general way, not
restricted to polypyrimidine sequences, through double duplex invasion. The use of
PNA-DNA chimeras allowed new applications to be developed, in which the PNA
acts as a recognition element and the DNA part acts as a substrate for proteins
naturally interacting with DNA (nucleases, transcription factors).68,69
Due to their high specificity, chemical stability and resistance to nucleases and
peptidases26, PNA are also tested as drug candidates in antisense or antigene strategies
(Figure I.14)70 While sound evidence of antisense and antigene effects of PNAs has
been achieved in cell-free systems, the potential of these molecules as gene therapeutic
drugs have been hampered by the poor intrinsic uptake of PNAs by living cells.71
However, a variety of cellular delivery systems using either unmodified or modified
PNAs have been developed during the last few years. Although these systems have not
yet affored a general and easy-to –perform method for cellular delivery of PNAs, they
certainly provide clues for the eventual future of PNA drugs.72
A recent study has demonstrated that PNAs containing a lysine backbone are
internalized more than achiral PNAs.73
PNAs have recently been used for the inhibition of gene expression in vivo; these
results have been obtained in prokaryotes by direct permeation,74 indicating a possible
use of PNAs as antibiotics.75 Delivery of PNAs directed against galanine receptor
genes in eukaryotic cells was obtained by conjugation with “cargo” peptides, which
allowed the inhibition of gene expression in mice.76
Figure I.14. Antisense (a) and anti-gene (b) strategies.

Introduction
27
Antisense PNAs directed against the retinoic acid receptor (RAR) gene and bearing an
adamantyl group were used in combination with cationic liposomes. This strategy
allowed to increase the cellular uptake (5 fold) by promyelocytic leukemia cells,
leading to a 90% reduction of the expression of the targeted gene.77
Thanks to these promising examples, the use of PNAs as antisense agents has been
recently extended to other pathologies, such as the Alzheimer’s desease,78 with
positive results.
The interaction between the HIV trans-activating protein-TAT and its TAR RNA
target was recently inhibited by specific PNAs, leading to a 99% decrease of virus
production.79
An antisense PNA targeted against a unique sequence in terminus of the 5’-UTR of
oncogene MYCN mRNA, designed for selective inhibition of MYCN in
neuroblastoma cells has also been described. The probe, which determined MYCN-
translation inhibition , was tested in two human neuroblastoma cell lines.80
The ability of some PNAs to bind to dsDNA has also promoted attempts to use them
in an antigene approach (Figure I.14) in order to block transcription from DNA to
mRNA. Using a nuclear localization signal (NLS) peptide, a PNA directed against the
c-myc oncogene was delivered to the nucleus, and an antigene effect was shown to
occur, a mechanism rarely observed for other modified oligonucleotides.81 Coupling
with compounds able to interact with specific cellular receptors, such as
dihydrotestosterone, was shown to be an efficient method for cellular/nuclear delivery
for an antigene PNA, which was specifically targeted to prostatic carcinoma cells.82
After these seminal studies, other applications of the anti-gene strategy, for example
for the treatment of hypertension in vivo, have been described.83 A very effective
example has been described in the treatment of neuroblastoma cell lines with anti-gene
PNA targeted against the MYCN DNA.84
Previous interesting applications of PNAs in gene therapy have been reported:
hormone-PNAs conjugates have been used as non-covalent carriers for plasmid
vectors85 and PNA-DNA chimeras have been used for the reparing of mutated genes.86
The photochemical internalization of PNAs targeting the catalytic subunit of human
telomerase into the cytoplasm of DU145 prostate cancer cells has also been reported.87
After light exposure, cancer cells ,treated with the PNA probe and the photosensitizer

Introduction
28
TPPS2a, showed a marked inhibition of the telomerase activity and a reduced cell
survival, which was not observed after treatment with the PNA alone.
A PNA-based RNA-triggered drug-releasing system88, consisting of a PNA linked to a
coumarin ester (the prodrug component) and a PNA linked to a hystidine (the catalytic
component) complementary to the C loop of E.Coli 5S rRNA ( the triggering
component) has been reported. Upon binding the catalytic component to the RNA, a
prodrug-metabolizing enzyme is created which catalyzes a 60000 fold acceleration in
the rate of coumarin release from the prodrug.
I.9. PNA as tool for molecular devices and nanobiotechnology
I.9.1. PNA-based biosensors PNAs have been used for detecting specific gene sequences in connection with many
advanced diagnostic methods,89 such as PCR clamping,90 Real-time PCR,91 capillary
electrophoresis92, MALDI-TOF mass spectrometry,93 electrochemical biosensors,94,95
quartz crystal microbalance (QCM).96 Single-molecule detection of transgenic DNA
has also been performed by means of PNA probes and double wavelength
fluorescence analysis.97 Ultra fast detection and identification of microbial
contamination98 as well as measurements of the length of telomeres, the terminal part
of chromosomes, have been achieved by in situ hybridization techniques based on
fluorescence (FISH).99, 100
Recently, an analytical method based on ion-exchange HPLC for the detection of
PNA:DNA hybrids has been developed.101 The method was applied to DNA analysis
in food (in particular genetically modified organisms), allowing this type of analysis to
be performed on simple and widely available instrumentation within chemical
laboratories.
Surface-plasmon resonance (BIAcore) biosensors have been used for studying the
hybridization kinetics of PNA:DNA duplexes 102 and have been proposed as analytical
tools for the analysis of PCR products.103 PNA probes have also been used, for the
detection of a cystic fibrosis (W1282X) point mutation using BIAcore biosensors.104
More recently, a chiral PNA based on D-Lysine, containing a “chiral box” centered on
the mismatched base, was found to be much more selective when compared to achiral

Introduction
29
PNAs, allowing a better discrimination between homozygous and heterozygous
cases.105
Single nucleotide polymorphism of ssDNA has also been detected in solution by using
PNA probes in the presence of cyanine dyes, which change their colour at the
formation of a PNA:DNA duplexes51,106 and in PCR products with the combination of
single strand DNA nuclease and the dye.107
Electrochemical hybridization based on PNA probes has also been described. The
detection of PNA:DNA hybridization was accomplished on account of the oxidation
signal of guanine. Also with this technique it was possible to detect point mutations
containing DNA target sequences by the difference of the oxidation signals of the
guanine bases.108
Sequence-specific nucleic acid detection is critical for many medicinal and diagnostic
applications. In this area, molecular beacons (MBs) are popular tools for nucleic acids
detection. In these systems, a nucleic acid exhibits a fluorescent signal only in the
presence of the target oligonucleotide. Molecular beacons usually consist of a
fluorophore and a fluorescence-quencher attached at the termini of a nucleic acid
oligomer. When the termini are closed to one another, the fluorescence is quenched.
upon binding to the target oligonucleotide, separation of the termini is accompanied by
an increase in fluorescence. Previously, quencher-free molecular beacons have been
synthesized from DNA that utilize fluorophores quenched by nucleobases. With the
inception and continued study of PNA, molecular beacon strategies incorporating this
non natural oligoncleotide analogs have become increasingly popular.
The original design of DNA beacons placed the fluorophore and quencher on the ends
of hairpin-shaped molecules featuring a stem-loop structure. Stemless DNA beacons
in which the two ends of the sequence are non-complementary likely adopt extended
conformations at low salt concentration due to the polyanionic nature of the
backbone109. This reduces the amount of quenching in the unhybridized state, leading
to lower sensitivity for detection of DNA. In the case of PNA beacons, it was found
that a hairpin structure is not necessary. The lack of backbone charges allows single-
stranded PNA to collapse into a folded structure, most likely stabilized by a
combination of favorable intramolecular contacts as well as the hydrophobic effect.110
Moreover, PNAs are more likely to aggregate in solution. Due to this inter or

Introduction
30
intramolecular association, fluorophore and quencher groups attached to the PNA
probe are in sufficiently close proximity to reduce the fluorescence even without the
stem-loop construct, but hybridization has the desired effect of increasing the distance
and enhancing fluorescence.111,112,113
Figure I.15. Mechanism of detection by PNA beacons.
Applications of PNA beacons can be in part split into reactions that occur either in
homogeneous solution or with one interacting partner being attached to a solid
support. in this second system, PNA or the complementary nucleic acid is immobilized
on a solid support. Microarrays made of PNA beacons could be typical examples of
this approach.
I.9.2. Conjugation of PNA with micro- and nanofabricated systems
PNA have been used in the fabrication of many micro and nano-devices as DNA
substitutes, showing advantages in their chemistry and in performances.
PNA microarrays have been described and are very promising devices for the
simultaneous detection of many DNA sequences, in particular for the detection of
single nucleotide polymophisms.114 Using dedicated PNA microarrays different
problems were addressed, both in biomedical114 and in the food chemistry fields.115
PNA can also be used as encoding entitites in combination with microarray
technologies for the construction of chemical libraries116 or molecular computers.117

Introduction
31
Coupling of PNA with nanomaterials allows to produce very specific tools for
biomedical applications. Gold nanocrystal sensors modified with PNAs have been
prepared and applied to self-assembly and DNA sensing. In particular it was found
that base pair mismatch selectivity of PNAs is further enhanced on nanocrystals.118
PNAs have been combined with silicon nanowires for label-free detection of DNA.119
In these studies, highly sensitive, sequence-specific and label-free DNA sensors have
been developed by monitoring the electronic conductance of silicon nanowires
(SiNWs) with chemically bonded PNA probe molecules.
PNA have also been conjugated with single wall carbon nanotubes and with fullerene
to generate hybrid materials with special optical and electronic properties as
components of nanosystems.120
I.9.3. PNA:PNA duplexes as tunable nanomaterials: sergeant and soldiers behaviour. The helix is a very important conformational state, which exists widely in nature, be it
biological molecules like peptides, DNA, RNA, viruses or synthetic molecules like
polyisocyanates. Many internal and external factors have an effect on handedness of
the helix and are an interesting topic for scientists to study the origin of chirality and
evolution of biological molecules. Most biological polymers adopt a helical
conformation. This is clearly seen in the polynucleotide duplexes, the α- helix formed
by peptides and parts of protein structures. The presence of stabilizing soft interactions
in such biological systems gives rise to a barrier for inversion of helix handedness. In
the case of DNA (with certain base sequences), the B-form can invert to Z-form only
under drastic conditions of low humidity, high salt concentrations and certain base
sequences.
As mentioned earlier, two complementary PNA strands are able to form stable
PNA/PNA duplexes,31 both in parallel and in an antiparallel orientation. These
duplexes have no biological application, but can be considered as stable, highly
specific, programmable nanostructures, with higher chemical and biological stability
than DNA-based objects. One major difference among DNA- and PNA-based
duplexes is the possibility to control chirality and, through this, fine tuning helical
handedness and thus optical activity. The full control of these properties requires,

Introduction
32
however, the knowledge of factors able to induce and to propagate helicity in these
DNA-like structures, and the theoretical background in this field is still not complete.
Sound and experimentally proved models about helical propagation have been
developed in the polymer science. Based on the possibility of helix inversion, helical
polymers can be divided into two categories, helical polymers having high helix
inversion barriers and those with low helix inversion barriers. The polymers having
high helix inversion barriers can not easily be inverted from one helical sense to
another, as in case of the biological molecules. In recent years research has focused on
helical polymers with low helical inversion barriers. In these molecules the helical
domains with opposite handedness coexist and are interconvertible with reasonable
timescales. This makes it possible to use milder internal and external stimuli to
influence the helical conformation of the backbone.
Polyisocyanates fall in the second category of the helical polymers described above.
They are interesting in showing cooperative phenomenon in different situations and
give rise to chiral amplification121. The polymer backbone is found to be stiff and
helical due to the steric strain between the carbonyl oxygen and the nitrogen
substituent. The X-ray crystal structure of poly (butyl isocyanate) revealed a 8/3 -
helix. The backbones of achiral polyisocyanates composed of equal amounts of left
and right handed helices throughout the polymer chain, which are mirror images of
each other and dynamically interconvertible (similar to achiral PNAs), however with
small chiral perturbations in side groups, solvents or even circularly polarized light,
lead to the excess of one helical sense.
In case of short chain polyisocyanates, the whole chain can be composed of one single
helical sense consists of left or right handed. Thus the solution of short chain
polyisocyanates is a racemic mixture of the two helical senses. It was found that with
an increase of chain length, the single polymer chain is no longer composed of one
helical domain, but has multiple helical domains which are connected by helical
reversals. The free energy for a helical reversal in case of poly (n-hexyl isocyanate) in
hexane is about 3900cal/mol and varies somewhat with solvent. This energy
determines the length of the chain with a single helical sense. The 3900cal/mol free
energy corresponds to about 800 units at an ambient temperature, which is far larger
than the number of units in the persistence length. This is the source of cooperativity

Introduction
33
and the consequent effect of chiral amplification. This study was followed by the
synthesis of polyisocyanate copolymers consisting of varying ratios of chiral and
achiral monomers. The chiral residues impart preferential handedness to the helix
which tends to continue by the following achiral residues. The situation is similar to
soldiers following a sergeant and keeping in step with him. When small amounts of
chiral monomers (sergeant units) are introduced into polyisocyanates, which consist
predominately of achiral monomers (soldiers), it was found that the resulting
copolymer show high optical properties measured from the molar ellipticity values
obtained from CD at 254nm. The varying ratios of the chiral and achiral monomeric
units in the polymeric chains showed that a large CD signal appears even with the
incorporation of minute amounts of the chiral pendant group.122 The ellipticity
increased quickly and reached a saturation point with a proportion of only 2% of the
chiral monomer residue. It was evident that the preferential handedness in the helix
was controlled by very small portions of the chiral groups.
On the basis of the sergeant and soldiers experiment, it is reasonable to explore if this
kind of experiment could be applied to synthetic biopolymers such as PNA.
For example, the duplex formed by the PNA decamer H-G TAG ATC ACT- (L-Lys)-
NH2 and the complementary antiparallel sequence H- A GTG ATC TAC-(L-Lys)-NH2
melts at 67ºC. The corresponding antiparallel DNA-PNA duplex melts at 51ºC and the
DNA-DNA duplex melts at 33.5ºC. The antiparallel orientation is characteristically
more stable than the parallel duplex (45.5 ºC). It has been shown that, when achiral
strands of PNA are used for the formation of the duplex, no preferential helical sense
prevails. However attaching an amino acid at the carboxy terminus of one of the PNA
stands induces the formation of helices with preferential handedness (Figure I.16). The
kinetics of such a PNA-PNA duplex formation has been investigated by UV and CD
spectroscopy.31,123 The formation of a racemic mixture of the PNA/PNA duplex, as
estimated by UV measurements is a fast step followed by a relative slow conversion of
the double helix to one preferred helical sense as governed by the C-terminal amino
acid

Introduction
34
Figure I.16. Preferential helix handedness induced by C-terminal lysine in PNA/PNA duplexes
X-ray crystal structure analysis of a self-complementary PNA/PNA duplex (H-CGT
ACG-NH2), without the incorporation of chiral information, has been elucidiated.36,38
The duplex exists as both right-and left-handed helices, which are stacked alternately
in the crystal. As expected the base pairing is of Watson-Crick type and the bases lie
almost perpendicular to the helix axis with a propeller twist of about 5-9º. The helix
pitch was found to be 5.8nm and the rise per turn was equal to 32 Å. The base pairs
are displaced by 8.3Å relative to the helix axis, which gives a wide helix (28 Å) with
18 base pairs per turn. The helix has a very wide and deep major groove and a narrow
and shallow minor groove. The amide groups of the backbone are in the trans
conformation and carbonyl groups of the linkers point towards the C-terminus. This
type of helix is consistent with the P-form mentioned above. In DNA, the strong
circular dichroism arises from the helical stacking of the bases. The exciton coupling
between the transitions in nucleobases and the chiral deoxyribose backbone generates
strong chirality in duplexes and a strong CD spectrum. However, in case of PNAs the
backbone is completely achiral. Any electronic transitions between the majority of the
bases and the chiral C-terminal amino acid would be small. Thus any CD will arise
because of the chiral orientation of the base pairs relative to each other. As expected
the helices induced by D- and L- lysine were found to be of opposite helical sense.
NH
O
NH3+
NH2
ONH2H
3N+
NH3+
Achiral antiparallel
PNA duplex
Teminal AAL-Lys
Left-HandedRight-Handed
D-Lys
NH
O
NH3+
NH2
ONH2 NH
3+
H3N+

Introduction
35
I.10. PNA as models for prebiotic chemistry Due to their simple and chemically robust structure, PNA has also been considered as
a possible model for prebiotic chemistry. Many theories have been put forward which
lead to the current thinking that RNA may have been the first genetic material.
However the instability of the ribose and other sugars and the great difficulty of
prebiotic synthesis of the glycosidic bonds of nucleotides raised serious questions
about whether RNA could have been the first genetic material. In 1987, four years
before the discovery of PNA, Westheimer predicted that the backbone of the first
genetic material would be different from the ribose sugar backbone and N-(2-
aminoethylglycine) [AEG] could be one of the possibilities for the backbone of
prebiotic material. PNA thus seems to be one of the candidates for such a suggested
prebiotic material. It has been demonstrated124 that AEG and ethylenediamine are
produced directly in electric discharge from CH4, N2, H2 and H2O. Ethylenediamine is
also produced from NH4CN polymerization. The NH4CN polymerization in the
presence of glycine leads to adenine, cytosine and guanine-N9-acetic acid. Preliminary
experiments suggest that AEG may rapidly polymerize at 100ºC to give the
polypeptide backbone of PNA. The ease of synthesis of the components of PNA and
the possibility of polymerization of AEG reinforces that possibility that PNA may
have been the first genetic material.
An important number of theoretical and experimental studies has been performed in
order to support this hypothesis and gain further insight into the chemical evolution
and origin of life, in particular, of the RNA.
The origin of the RNA world is not easily understood, as effective prebiotic syntheses
of the components of RNA, the β-ribofuranoside-5’-phosphates are hard to envisage.
Recognition of this difficulty has led to the proposals that other genetic systems, the
components of which are more easily formed, may have preceded RNA. Among these,
PNA, which resembles RNA in its ability to form doubled-helices stabilized by
Watson-Crick H-bonding and bases stacking, has been investigated as model of a
potential genetic material that is free of phosphate. Based on these considerations,
several papers reported the use of PNA as possible precursor of RNA through
template-directed synthesis125, 126. For example, BÖhler et al126 suggested a new kind of
mechanism for genetic takeover, which demonstrates that PNA oligomers can act as a

Introduction
36
template for the regioselective oligomerization of RNA and vice versa. This means
that a transition between genetic systems can occur without loss of information.
However, a continuous transitions from one genetic system to another would be
possible if mixed molecules containing building block of both systems could be
formed. Koppitz et al.127 used PNA as template to form PNA/RNA (or DNA) chimeras
and investigated the role of the latter in a transition of information from PNA to RNA
or to DNA. They results provided evidence that a transition from PNA-like genetic
world to an DNA world is possible through multi-step process involving PNA-directed
PNA-DNA ligation. However, in the case of RNA transition, the information stored in
PNA could not necessary be utilized by RNA. Then, a sequence, that is, for example,
catalytically as PNA is unlikely to be active as RNA. Chimera formation, therefore
could not transfer useful information from PNA to RNA, but, could allow a transition
to a superior information-storing polymer. Therefore, RNA could first has evolved to
serve as a template to PNA synthesis, and only later evolved in sequences showing
independent catalytic function.
Although the RNA-world hypothesis which states that our biological life was preceded
by a prebiotic system in which RNA functioned both as genetic material and as
enzyme-like catalyst is widely accepted, this emphasizes the difficulty of forming and
replicating a homochiral nucleic acid in a solution of racemic nucleotides.128,129
Furthermore, prebiotic syntheses of chiral monomers always yield racemic mixtures.
Living systems use L-amino acids and D-nucleotide in their biopolymers. The
generation of optical asymmetry by selection and amplification in an autocatalytic
process is therefore an important element in many theory of the origin of the life.
Replication of polynucleotides in template-directed syntheses, is an obvious candidate
for such an amplification step for pre-“RNA world”130 A serious objection for this
suggestion is the observation that the efficiency of template-directed syntheses of
RNA is limited by enantiomeric cross-inhibition.131 PNA as model for a hypothetical,
nonachiral precursor of RNA in experiments re-examining enantiomeric cross-
inhibition has also been investigated and it was found that enantiomeric cross-
inhibition is as serious in the polymerization of nucleotides on PNA templates as it is
on a conventional RNA or DNA template.132 Since the influence of chiral substituents
such as amino acids on the distribution of left- and right-handed helices PNA has been

Introduction
37
investigated51,123 , one possible solution of this problem has been proposed by Kozlov
et al133, by using achiral PNA or PNA/RNA chimera as template through which a
chiral information induced by a terminal chiral unit can be propagated and amplified.
Their results especially suggested that the chirality induced by two nucleotides in a
template strand could be transmitted through normally achiral PNA and result in a
chirally selective template-directed remote elongation of a primer strand. This means
that the introduction of a short homochiral segment of DNA into a PNA helix could
have guaranteed that the next short segment of DNA to be incorporated would have
the same handedness. Once two segments of DNA were present, the probability that a
third segment would have the same handedness would increase and so on. This
scenario would allow the formation of a chiral oligonucleotide by processes that are
largely resistant to enantiomeric cross-inhibition.

Introduction
38
I.11. References 1 a) Martìnnez-Mànez , R.; Sancenòn, F., Chem. Rev. 2003, 103, 4419–4476.
b) Callan, J. F.; de Silva; A. P.; Magri, D. C.,Tetrahedron, 2005, 61, 8551 – 8588 2 a) Dale, T.J.; Rebek Jr., J., J. Am. Chem. Soc., 2006, 128 4500.
b) Balzani, V.; Venturi, M.; Credi, A., Molecular Devices and Machines, 2003.
Wiley–VCH, Weinheim.
c) Stojanovic, M.N.; Mitchell, T.E.; Stefanovic, D., J. Am. Chem. Soc., 2002, 124
3555. 3 Bath, J.; Turberfield, A., Nature nanotechnology, 2007, 2, 275-284. 4 Descalzo, A.B.; Martìnnez-Mànez, R.; Sancenòn, R.; Hoffman, K.; Rurack, K.,
Angew. Chem. Int. Ed, 2006, 45, 5924–5948. 5 Watson, J.D. and Crick, F.H.C., Nature, 1953, 171, 737-738. 6 Watson, J.D, Hopkins, N.H., Roberts, J.W., Steitz, J.A., and Weiner, A.M.,
Molecular Biology of the Gene, 1987, 4th ed. Benjamin/Cummings, Menlo park, CA. 7 Ptashne, M., Genetic Switch, 1987, Blackwell Scientific Publications, Palo Alto, CA. 8 Steitz, T.A., Q. Rev. Biophys., 1990, 23, 205-280. 9 Nielsen, P.E., Bioconjugate Chem., 1991, 2, 1-12. 10 Pyle, A.M. & Barton, J.K., Prog. Inorg. Chem., 1990, 38, 413-475. 11 b) Niemeyer, C. M.; Angew. Chem., 1997, 109, 603-606. 12 Seeman, N. C., Acc. Chem. Res., 1997, 30, 357-363. 13 a) Chen, J.; Seeman, N. C., Nature, 1991, 350, 631-633.
b) Brucale, M.; Zuccheri, G.; Samorì, B.; Trends Biotech., 2006, 24, 235-243. 14 Rothermund, P. W. K., Nature, 2006, 440, 297-302. 15 De Clerq E., Eckstein F., Sternbach H., Merigan T.C.; Virology, 1970, 42, 421. 16 Miller, P.S; Oligodeoxynucleotides. Antisense inhibitors of gene expression; 1989,
Macmillian Press, 79. 17 Manoharan M., Biochim. Biophys. Acta, 1999, 1489, 117. 18 Gryaznov, S. M., Biochim. Biophys. Acta 1999, 1489, 131. 19 Summerton, J., E., Biochim. Biophys. Acta 1999, 1489, 141. 20 Wengel, J., Acc. Chem. Res. 1999, 32, 301. 21 Nielsen P. E., Egholm M., Berg R. H., Buchardt O., Science, 1991, 1497.

Introduction
39
22 Egholm M., Buchardt O., Christensen R., Behrens C., Freier S. M., Driver D. A.,
Berg R. H., Kim S. K., Norden B., Nielsen P.E., Nature, 1993, 365, 566. 23 Buchardt O., Egholm M., Berg R. H., Nielsen P. E., Trends Biotechnol. 1993, 11,
384. 24 Nielsen P. E., Egholm M., Berg R. H., Buchardt O., Anti-Cancer Drug Des. 1993, 8,
53. 25 Koch, T.; Hansen, H.F., Andersen, P., Larsen, T.; Batz, H.G.; Otteson, K., Orum, H.
J. Pept. Res., 1997, 49, 80. 26 Demidov V.A., Potaman V.N., Frank-Kamenetskii M. D., Egholm M., Buchardt O.,
Sonnichsen S. H., Nielsen P.E., Biochem. Pharmscol. 1994, 48, 1310. 27 Giesen, U.; Kleider, W.; Berding, C.; Geiger, A.; Ørum, H.; Nielsen, P.E. Nucleic
Acid Res. 1998, 26, 5004. 28 Egholm M., Buchardt O., Nielsen P.E., Berg R.H., J. Am. Chem. Soc., 1992, 114,
1895. 29 Wittung P., Nielsen P. E., Buchardt O., J. Am. Chem. Soc., 1996, 118, 7049 30 Bentin T., Larsen H. J., Nielsen P.E.; Biochemistry, 2003, 42, 13987. 31 Wittung P., Nielsen P. E., Buchardt O., Egholm M., Norden B., Nature, 1994, 368,
561. 32 Brown S.C., Thomson S.A., Veal J.M., Davis D.G., Science, 1994, 265, 777 33 Erikson M., Nielsen P.E., Nature Struct. Biol., 1996, 3, 410 34 Betts L., Josey J.A., Veal J.M., Jordan S.R., Science, 1995, 270, 1838 35 Rasmussen H., Kastrup J.S., Nielsen J.S., Nielsen J.M., Nielsen P.E., Nature Struct.
Biol., 1997, 4, 98 36 Menchise, V.; De Simone, G.; Corradini, R. ; Sforza, S. ; Marchelli, R.; Sorrentino,
N.; Romanelli, A.; Saviano, M.; Pedone, Proc. Nat. Acad. Sci. USA, 2003, 100(21)
12021-12026 37 Haiama, G; Rasmussen, H.; Schmidt, G.; Jensen, D. K.; Kastrup, J. S.; Stafshede, P.
W.; Nordén, B.; Buchardt, O.; Nielsen, P. E., New. J. Chem., 1999, 23, 833-840. 38 Bloomfield, V.A., Crothers, D.M., Tinoco, I., Jr. eds. 2000, Nucleic Acids
Structures, properties, and functions, eds. University Science Books (Sausalito,
California), pp 88-91.

Introduction
40
39 Nahm, S.; Weinreb, S.W., Tetrahedron Lett., 1981, 22, 3815 40 Dueholm, K.L.; Egholm, M.; Buchardt, O. Org. Prep. Proc. Int. 1993, 25, 457 41 Matysiak, S; Reuthner, F.; Hoehisel, J.D. Biotechniques, 2001, 31, 896 42 Thomson, S.A.; Josey, J.A.; Cadilla R.; Gaul M.D.; Hassman C.F., Luzzio M.J.;
Pipe A.J.; Reed K.L.; Ricca D.J.; Wiethe R.W.; Noble S.A. Tetrahedron, 1995, 51,
6179 43 Breipohl, G.; Knolle, J.; Langner, D.; O’Malley, G.; Uhlmann, E. Bioorg. Med.
Chem. Lett., 1996, 6, 665. 44 Bergmann, F.; Bannwarth, W.; Tam S. Tertahedron Lett., 1995, 36, 6823 45 Casale R., Paul C.H., Jensen I.S., Moyer M.L, Kates S. A., Egholm M., in
Innovation in Solid Phase Synthesis and Combinatorial Libraries, Mayflower Science,
1998, 31, 139 46 Kovacs, G.; Timar, Z.; Kupihar, Z.; Kele, Z.; Kovacs, L. J. Chem. Soc.Perkin Trans.
1, 2002, 1266-1270. 47 Tedeschi, T.; Ph.D Thesis, University of Parma 2001-2003, pp 18 48 Hyunil, L.; Jae Hoon, J.; Jong Chan L.; Hoon C.; Yeohong Y.; Sung Kee, K., Org.
Lett., 2007, 9 (17), 3291-3293. 49 Ganesh, K. N.; Nielsen, P. E, Curr. Org. Chem., 2000, 4, 931-943. 50 a) Kumar, V. A., Eur. J. Org. Chem., 2002, 2021-2032.
b)Corradini R.; Sforza S.; Tedeschi T.; Marchelli R.; Seminar in Organic Synthesis,
Società Chimica Italiana, 2003, pp 41-70. 51 Sforza, S.; Haaima, G.; Marchelli, R.; Nielsen, P.E.. Eur. J. Org. Chem. 1999, 197-
204. 52 Sforza, S.; Galaverna, G.; Dossena, A.; Corradini, R.; Marchelli, R. Chirality, 2002,
14, 591-598. 53 Corradini, R.; Sforza, S.; Tedeschi, T.; Totsingan, F.; Marchelli, R., Current Topics
in Medicinal Chemistry, 2007, 7, 681-694. 54 Puschl, A.; Sforza, S.; Haaima, G.; Dahl, O.; Nielsen, P. E., Tetrahedron Lett.,
1998, 39, 711-714. 55 Haaima, G.; Lohse, A.; Buchardt, O.; Nielsen; P.E., Angew. Chem. Int. Ed. Engl.
1996, 35, 1939-1942.

Introduction
41
56 Tedeschi T.; Sforza S.; Corradini R.; Dossena, A.; Marchelli R.; Chirality, 2005, S1,
S196-S204. 57 Sforza, S.; Tedeschi, T.; Corradini, R Ciavardelli, D.; Dossena, A.;.Marchelli, R.
Eur. J. Org. Chem., 2003, 1056-1063. 58 Sforza, S.; Corradini, R.; Ghirardi, S.; Dossena, A.; Marchelli, R. Eur J. Org. Chem.
2000, 2905-2913. 59 Ficht, S.; Dose, C.; Seitz, O., Chem. Bio. Chem., 2005, 6, 2098-2103. 60 Englund, E. A.; Appella, D. H., Org. Lett., 2005, 7, 3465-3467. 61 Tedeschi T.; Sforza S.; Corradini R.; Marchelli R.; Tetrahedron Lett., 2005, 46,
8395-8399 62 Dragulescu-Andrasi, A.; Rapireddy, S.; Frezza, B. M.; Gayathri, C.; Gil, R. R.; Ly,
D. H., J. Am. Chem. Soc., 2006, 128, 10258-10267. 63 Sforza, S.; Tedeschi, T.; Corradini, R.; Marchelli, R., Eur. J. Org. Chem., 2007, 5879–5885. 64 Jensen K.K.; Orum, H.; Nielsen P.E.; Nordén, B. Biochemistry 1997, 36, 5072. 65 Nielsen P.E.; Egholm, M.; Buchardt, O. Gene 1994, 149, 139. 66 Dieci, G.; Corradini, R.; Sforza, S.; Marchelli, R.; Ottonello, S. J. Biol. Chem.
2001, 276, 5720 67 Zelphati, O.; Liang, X.W.; Hobart, P.; Felgner, P.L. Human Gene Ther.1999, 10, 15. 68 Romanelli, A.; Pedone,C.; Saviano, M., Bianchi, N.; Borgatti, M.; Mischiati, C.;
Gambari, R. Eur. J. Biochem. 2001; 268, 6066 69 Uhlmann, E. Biol. Chem. 1998, 379, 1045. 70 a) Braasch, D. A.; Corey, D. R, Biochemistry, 2002, 41, 4503-4510.
b) Xodo, L. E.; Cogoi, S.; Rapozzi, V., Curr. Pharm. Design, 2004, 10, 805-819. 71 Wittung P., Kajanus K., Edwards G., Haaima G., Nielsen P.E., Norden B.,
Malmstrom B.G., FEBS Lett., 1995, 375, 27 72 Koppelhus U., Nielsen P.E., Advanced Drug Delivery Reviews, 2003, 55, 267 73 Koppelhus, U.; Awasthi, S. K.; Holst, H. U.; Hebbesen, P.; Nielsen, P. E., Antisense
and Nucleic Acid Drug Develop, 2002, 12, 51. 74 Good, L.; Nielsen, P.E. Nature Biotech 1998, 16, 355. 75 Dryselius R., Nekhotiaeva N., Nielsen P.E., Good L.; BioTechniques, 2003, 35,
1060.

Introduction
42
76 Pooga, H.; Soomets, U.; Hallbrink, M.;, Valkna, A.; Saar, K.; Rezaei, K.; Kahl, U.;
Hao, J-X.; Xu, X-J.; Wiensenfeld-Hallin, Z.; Hockfelt, T.; Bartfai, T.; Langelm, U.
Nature Biotechnol. 1998, 16, 857. 77 Mologni, L.; Marchesi, E.; Nielsen, P.E. Gambacorti-Passerini, C. Cancer Res.
2001, 61, 5468. 78 Adlerz, L.; Soomets, U.; Holmlund, L.; Viirlaid, S.; Langel, U.; Iverfeldt, K.
Neurosci. Lett .2003, 336, 55. 79 Kaushik, N.; Basu, A.; Pandey, V.N. Antiviral Res. 2002, 56, 13. 80 Pession A., Tonelli R., Fronza R., Sciamanna E., Corradini R., Sforza S., Tedeschi
T., Marchelli R., Montanaro L., Camerin C., Franzoni M., Paolucci G., Int. J.
Oncology, 2004, 24, 265. 81 Cutrona, G.; Carpaneto, E.M.; Ulivi, M.; Rondella, S.; Landt, O.; Ferrarini, M.;
Boffa, L.C. Nature Biotech. 2000, 18, 300. 82 Boffa, L.C.; Scarfi, S.; Mariani, M.R.; Da monte, G.; Allfrey, V.G.; Benfatti, U.;
Morris, P.L. Cancer Res. 2000, 60, 2258 83 Mc Mahon, B.H., Stewart, J.A.; Bitter, M.D.; Fauq, A.; McCormick, D.J.;
Richelson, E. Life Sci. 2002, 71, 325. 84 Tonelli R., Purgato, S.; Camerin C., Fronza R., Bologna, F.; Alboresi, S.; Franzoni,
M.; Corradini R.; Sforza S., Faccini, A.; Shohet, J. M.; Marchelli R., Pession A., Mol.
Cancer Ther., 2005, 4(5), 779-786. 85 Rebuffat, A.G.; Nawrocki, A.R.; Nielsen, P.E.; Bernasconi, A.; Bernal-Mendez, E.;
Frey, B.M.; Frey, F. FASEB J. 2002, 16. 364 86 Rogers, F.A.; Vasquez, K.-M.; Egholm, M.,Glazer, P.M. . Proc. Nat. Acad. Sci
2002, 99, 16695. 87 Follini M., Berg K., Millo E., Villa R., Prasmickaite L., Dandone M., Benatti U.,
Zaffarono N.; Cancer Res., 2003, 63, 3490. 88 Ma Z.C., Taylor J.S.; Bioconjugate Chem., 2003, 14, 679 89 Nielsen, P.E. Current Opinion in Biotechnology, 2001, 12, 16 90 Ørum, H.; Nielsen, P.E.; Egholm, M.; Berg, R.H.; Buchardt, O.; Stanley, C. Nucleic
Acid Res. 1993, 21, 5332. 91 Kyger, E.M.; Krevolin, M.D.; Powell, M..J. Anal. Biochem. 1998, 260, 142

Introduction
43
92 Igloi, G.L. Biotechniques 1999, 27, 798 93 Griffin, T.J.; Tang, W.; Smith, L.M. Nature Biotech. 1997, 15, 1368. 94 Wang, J.; Rivas, G.; Cai, X.; Chicharro, M.; Parrado, C.; Dontha, N.; Begleiter, A.;
Mowat, M.; Palecek, E.; Nielsen, P.E. Anal. Chim. Acta 1997, 344, 111. 95 Wang, J. Biosensors & Bioelectron 1998, 13, 757. 96 Wang, J.; Nielsen, P.E.; Jiang, M.; Cai, X.; Fernandes, J.R.; Grant, D.H.; Ozsoz,
M.; Beglieter A.; Mowat, M. Anal. Chem. 1997, 69, 5200. 97 Castro, A.; Williams, J.G.K. Anal. Chem 1997, 69, 3915 98 Stender. H.; Fiandaca, M.; Hyldig-Nielsen, J.J.; Coull, J. J. Microbiol. Meth. 2002,
48, 1. 99 Hultdin M., Gronlund E., Norrback K.-F., Eriksson-Lindstrom E., Just T., Roos G.,
Nucl. Acid Res., 1998, 26, 3651 100 Stender, H.; Expert Rev.of Mol.Diagnostics, 2003, 3, 649. 101 Lesignoli, F.; Germini, A.; Corradini, R.; Sforza, S.; Galaverna, G.; Dossena, A.;
Marchelli, R. J. Chromatogr. A 2001, 922, 177. 102 Bigey, P.; Sonnivhsen, S. H.; Meunier, B.; Nielsen, P. E.; Bioconjugate Chem.,
2000, 11, 741. 103 Sawata, S.; Kai , E.; Ikebukuro, K.; Iida, T.; Honda, T.; Karube, I. Biosensors &
Bioelectronics 1999, 14, 397. 104 Feriotto,G.; Corradini, R.; Sforza, S.; Mischiati, C.; Marchelli, R.; Gambari, R.
Lab. Invest. 2001, 81, 1415. 105 Corradini, R.; Feriotto, G.; Sforza, S.; Marchelli, R.; Gambari, R. J. Mol. Rec.
2004, 17, 76-84. 106 Wilhelmsson L.M., Norden B., Murkherjee K., Dulay M. T., Zare R., N.; Nucleic
Acids Res., 2002, 30, 1. 107 Komiyama M., Ye S., Liang X., Yamamoto Y., Tomita T., Zhou J., Aburatani H.,
J. Am. Chem. Soc, 2003, 125, 3758 108 Kerman K., Ozkan D., Kara P., Erdem A., Meric B., Nielsen P.E., Ozsoz M.,
Electroanalysis, 2003, 15, 667. 109 Tinland, B., Pluen, A., Sturm, J., Weill, G., Macromolecules 1997, 30, 5763-5765 110 Ratilainen, T., Holmén, A., Tuite, E., Haaima, G., Christensen, L., Nielsen, P.E.,
Nordén, B., Biochemistry, 1998, 37, 12331-12342

Introduction
44
111 Seitz, O., Angew. Chem. Int. Ed. 2000, 39, 3249-3252 112 Kuhn, H., Demidov, V.V., Coull, J.M., Fiandaca, M.J., Gildea, B.D., Frank-
Kamenetskii, M.D., J. Am. Chem. Soc., 2002, 124, 1097-1103 113 Kuhn, H., Demidov, V.V., Gildea, B.D., Fiandaca, M.J., Coull, J.M., Frank-
Kamenetskii, M.D., Antisense Nucleic Acids Drug Devel. 2001, 11, 265-270 114 Weiler, J.; Gausepohl, H.; Hauser, N.; Jensen, O.N.; Hoeisel, J.D. Nucleic Acids
Res. 1997, 25, 2792. 115 a) Germini A, Mezzelani A, Lesignoli F, Corradini R, Marchelli R, Bordoni R,
Consolandi C, De Bellis G, J Agric Food Chem, 2004, 52(14), 4535–4540.
b) Germini A., Rossi S., Zanetti A., Corradini R., Fogher C., Marchelli R., J Agric
Food Chem, 2005, 53, 3958–3962. 116 Winssinger, N.; Harris, J.L.; Backes, B.J.; Schultz, P.G. Angew. Chem. Int. Ed.
Engl. 2001, 40, 3152. 117 Wang, L.; Liu, Q.; Corn, R.M.; Condon, A.E.; Smith, L.M. J. Am. Chem. Soc.
2000, 122, 7435. 118 Chakrabarti R., Klibanov M.; J. Am. Chem. Soc. 2003, 125, 12531. 119 a) Gao, Z.; Agarwal, A.; Trigg, A. D.; Singh, N.; Fang, C., Tung, C-H.; Fang, Y.;
Buddharaju, K. D.; Kong, J., Anal, Chem., 2007, 79, 3291-3297.
b) Li, Z.; Rajendran, B.; Kamins, T. I.; Li, X.; Cheng, Y.; Stanley Williams, R., Appl.
Phys. A., 2005, 80, 1257-1263. 120 Singh, K. V.; Panday, R. R.; Wang, X.; Lake, R.; Ozkan, C. S.; Wang, K.; Ozkan,
M., Carbon, 2006, 44, 1730-1739. 121 a) Green, M. M.; Park, J.-W.; Sato, T.; Teramoto, A.; Lifson, S.; Selinger, R. L. B.;
Selinger, J. V., Angew. Chem. Int. Ed. 1999, 38, 3138;
b) Green, M. M.; Cheon, K. S.; Yang, S. Y.; Park, J. W.; Swansburg, S.; Liu, W., Acc.
Chem. Res. 2001, 34, 672. 122 Jha, S.K.; Cheon, K. S.; Green M.M.; Selinger, J.V., J. Am. Chem. Soc. 1999,
121,1665. 123 Wittung, P.; Eriksson, M.; Reidar, L.; Nielsen P. E.; Nordén, B., J. Am, Chem.
Soc.1995, 117, (41), 10167. 124 Nelson, K.E.; Levy, M.; Miller, S.L., Proc. Nat. Acad. Sci. USA, 2000, 97, 3868.

Introduction
45
125 Miller, S. L. Nat. Struct. Biol., 1997, 4, 167-169. 126 Bohler, C.; Nielsen, P. E.; Orgel, L. E., Nature, 1995, 376, 578-581. 127 Koppitz, M.; Nielsen, P. E.; Orgel, L. E., J. Am. Chem. Soc., 1998, 120, 4563-4569. 128 Bolli, M.; Micura, R.; Eschenmoser, A, Chem. Biol., 1997, 4, 309-320. 129 Schwartz, A. W., Curr. Biol., 1997, 7, R477-R479. 130 Gestland, R.; Atkins, J. F., Eds; Cold Spring Habor Laboratory Press: Cold Spring
Habor, NY, 1993, Vol, Monograph 24. 131 Joyce, G. F.; Visser, G. M.; Van Boeckel, C. A. A.; Van Boom, J. H.; Orgel, L. E.;
Van Westrenen, J., Nature, 1984, 310, 602-604. 132 Schmidt, J. G.; Nielsen, P. E.; Orgel, L. E., J. Am. Chem. Soc, 1997, 119, 1494-
1495. 133 Kozlov, I. A.; Orgel, L. E.; Nielsen, P. E., Angew. Chem. Int. Ed., 2000, 39 (23),
4292-4295.

Aim of the work
46
Aim of the work
The objective of this research, would be to gain new insights into the use of PNA as
powerful tools for nanobiotechnological applications (Figure A.1). In particular, we
would investigate the use of PNA as:
1. Potential biosensors: By combining PNA beacon with other analytic
techniques, such as HPLC, we should be able to develop a new technique for
selective label-free detection of DNA. Furthermore, by introducing a chiral
monomer into PNA beacon, its fluorescent and binding properties would be
increased. The possibility to use beacon on Lab-On-Chip would be investigated.
2. Model for tunable nanomaterials: The possibility of inducing and
amplifying chirality through covalent or self-assembled PNA:PNA duplexes would
be discussed.
3. Tool for molecular computers: The use of genetic code as computing
would also be evaluated taking advantages of the high stability and sequence-
selectivity of PNA:PNA duplex if compared to DNA:DNA.
Figure A.1. PNA as tools for nanotechnology

Chapter 1
47
PNA Beacons in Label-Free Selective Detection of DNA by
Fluorimetry and by Ion Exchange HPLC.
1.1. Introduction
Genome-based technologies rely on the possibility to selectively recognize DNA
sequences of applicative interest. The quest of new and selective methods and
technologies for the detection of specific DNA tracts is gaining more and more
importance in diagnostics, from biomedical to more large scale items such as food and
feed1,2
One very important class of probes is represented by molecular beacons (MB), which
are composed of a sequence specific oligonucleotide coupled with a fluorophore and a
quencher (or a quenching surface) at each end, held together by a zipper DNA
sequence made of complementary antiparallel tracts; this structure allows to produce a
”switch-on” of fluorescence upon interaction with the target DNA sequence3,4. A
variety of applications to DNA or RNA detection have been proposed using MB
probes5,6; detection of single point mutations can be achieved by MB through careful
design of the sequence and selection of the detection temperature7,8. Combined
approaches using molecular beacons are also effective in mismatch detection9.
Peptide nucleic acids (PNAs) are efficient tools in diagnostics, since they can bind
DNA with high affinity and selectivity and are superior to oligonucleotide probes in
the recognition of single base mutations10,11. PNA-beacons12,13,14 and the related “light
up probes”15,16 have been recently described, displaying the advantages of higher
selectivity and simpler design, since their flexibility allows the fluorophore-quencher
interaction to occur even in the absence of a “zipper” sequence, thus allowing to
introduce possible interferences, and they are less sensitive to ionic strength changes17.
One of the major limitations in the use of PNA and other Molecular Beacons in
diagnostics is represented by the fluorescence background of the free (uncomplexed)
probe, which can be interfering with the signal obtained by the analyte sequence when
it is in low concentrations, especially for DNA amplified by complex biological
samples.
Chromatographic analysis has been performed on PCR products18. This type of
chromatography is simple and uses water solution at increasing ionic strength as

Chapter 1
48
eluents19, thus allowing the analysis to be performed under non-denaturing conditions;
however, the presence of a high number of interfering components, such as primers,
mononucleotide, or enzymes used in the PCR reaction, which are revealed by UV and
other type of detectors, makes the interpretation of data more difficult in real samples.
Furthermore, detection of small sequence differences such as single nucleotide
polymorphisms (SNPs) are very difficult using this approach. In previous works
carried out in our group it was demonstrated that ion-exchange (IE) HPLC can be used
for directly visualize the PNA:DNA interaction, since the latter shows retention times
different from those of PNA and DNA20,21. When the DNA to be analyzed is labelled
with fluorescent groups, the chromatographic profile is simpler, but interfering peaks
of primers and of unspecific amplified DNA can be present.
In the present work, we report the combined use of PNA-beacon and IE-HPLC
analysis for the label-free detection of DNA, taking advantage on one side from the
separation of the free probe from the complex, and on the other side from the very
specific signal generated by the PNA beacon, which allows to avoid unspecific peaks.
Furthermore, unlabelled PCR products can be detected with this method.
The PNA beacons and DNA sequences used are listed in Figure 1.1.
X = A; C; G; T
Figure 1.1. PNA beacons design. In the unhybridized state, the termini are close to one another, the
fluorescence is quenched. Upon binding to the target oligonucleotide, separation of the termini is
accompanied by an increase in fluorescence (switch-on).
Dabcyl was used as quencher, linked to the ε-amino group of lysine at the C-terminal
part and carboxyfluorescein was used as fluorophore, linked to the N-terminus of the
PNA molecule; two additional charges (a positive lysine side chain and a negative
glutamate unit) were inserted just before and after the PNA segment, following the
design described by Frank-Kamenetskii and co-workers.17
PNA
PNA 1 : GATTTCAATGC
PNA 2 : AGAGTCAGCTT
DNA 3-X 5’GCATTXAAATC3’
DNA 4-X 5’AAGCTGXCTCT3’
Glu -Lys-Lys-CONH2
Fluo DabcylN-terminal group N-Hε-amino group
H-N

Chapter 1
49
1.2. Results and Discussion
The beacon 1 was synthesized in a previous work and has a sequence for which a
relatively low melting temperature of the PNA:DNA duplex was observed (Table 2.1)
while the beacon 2 has the same sequence of a PNA previously utilized as a probe for
the detection of Roundup Ready soybean in HPLC, with higher PNA:DNA melting
temperature21.
Both PNA beacons were synthesized using solid phase synthesis on an automatic ABI
433A Synthesizer, according to the scheme reported in the introduction of this thesis.
Fmoc strategy was used with HBTU/DIEA as coupling agent. The fluorophore
(Carboxyfluorescein) and quencher (Dabcyl) were attached manually. The crude
products were purified by RP-HPLC and characterized with HPLC-MS. The
chromatogram profiles and ESI-MS spectra of the pure products are reported in
Figures 1.2 and 1.3.
Figure 1.2. Chromatogram profile and ESI-MS reconstructed spectra of PNA 1.
5.00 10.00 15.00 20.00 25.00 30.00 35.00 40.00 45.00Time0
100
%
bnoc2 2: Diode Array 260
5.34e521.48
1600 1800 2000 2200 2400 2600 2800 3000 3200 3400 3600 3800 4000 4200 4400 4600 4800mass0
100
%
bnoc2 427 (22.089) M1 [Ev-43595,It15] (Gs,0.500,150:1500,1.00,L33,R33); Cm (411:446) 1: Scan ES+ 2.15e63988.0

Chapter 1
50
Figure 1.3. Chromatogram profile and ESI-MS reconstructed spectra of PNA 2.
Fluorimetric detection of DNA. Hybridization of the two beacons with fully
complementary or single mismatched oligonucleotides gave rise to a switch-on of the
beacon fluorescence, which was sequence-selective and depended on the beacon
affinity for the DNA.
Figure 1.4. Fluorescence spectra of PNA 1 alone and in the presence of fullmatched DNA (3-G) and a mismatched DNA (3-C). All spectra were recorded at T = 25°C in Tris buffer (0.25 mM
MgCl2. H2O, 10 mM Tris, pH = 8.0) using 1µΜ concentration. λex = 497 nm; λex = 520 nm.
0
1
2
3
4
5
6
7
8
9
400 450 500 550 600
Wavelength (nm)Wavelength (nm)Wavelength (nm)Wavelength (nm)
F/F0
F/F0
F/F0
F/F0
PNA 1:DNA 3-G
(F/F0)max = 8.6
PNA 1: 3-C
(F/F0)max = 1.3PNA 1
(F/F0)max = 1
5.00 10.00 15.00 20.00 25.00 30.00 35.00 40.00 45.00Time0
100
%
bsoia 2: Diode Array 260
2.24e521.74
13.44
1600 1800 2000 2200 2400 2600 2800 3000 3200 3400 3600 3800 4000 4200 4400 4600 4800mass0
100
%
bsoia 432 (22.347) M1 [Ev-42909,It18] (Gs,0.500,150:1500,1.00,L33,R33); Cm (419:444) 1: Scan ES+ 1.39e64013.0
1780.0 2752.03346.0 3866.0
4029.0

Chapter 1
51
Using fluorimetric measurements, it was possible to discriminate between full match
and mismatched DNA at 1 µΜ concentration of 1 and 0.1 µΜ for 2 , but with only
partial mismatch recognition (Table 1.1).
Addition of complementary parallel DNA sequences (DNA 5 for PNA 1 and DNA
6 for PNA 2 ) induced only very low or no fluorescence increase, with only a 1.4
increase at 25°C for the PNA 2 : DNA 6 case, which was reduced to 1.1 by increasing
the temperature to 35°C.
Therefore, using fluorimetric measurements it was possible to discriminate between
full match and mismatched DNA at 1 µΜ concentration of 1 and 0.1 µΜ for 2, but
with only partial mismatch recognition; the possibility of detection of a single
mismatch with high selectivity strongly depends on the sequence used and on the
measuring conditions.
Table 1.1. Comparison between the fluorescence response and peak area for beacon 1 and 2 with oligonucleotides in the presence of different DNA oligonucleotides. Standard deviation are in parenthesis.
a PNA:DNA melting temperature c = 5 µM of each strand. b Concentration of the beacon and of DNA used in the measurement (in strand) cFlorescence intensity normalized to the value of the free beacon. d Area of the PNA:DNA peak normalized to that of the full matched, measured at 25 °C for PNA 1, and
at 35°C for PNA 2.
PNA DNA Tm (°C)a
c
(µM)b Fluorimetric
F/F0c (520 nm)
HPLC Aread
25°C 35°C 1 none - 1 1.0 (0.1) 1.0 (0.1) 1.7 (0.6) 1 3-G 48 0.1 1.8 (0.1) 1.5 (0.1) 7.2 (1.5) 1 3-G 48 1 8.6 (0.3) 5.5 (0.1) 100.0 (7.7) 1 3-C 32 1 1.3 (0.1) 1.2 (0.1) 1.7 (0.4) 1 3-A 30 1 1.5 (0.1) 1.4 (0.1) 2.6 (1.1) 1 3-T 31 1 1.2 (0.1) 1.2 (0.1) 2.0 (0.4) 1 5 1 1.0 (0.1) 1.0 (0.1) 1.3 (0.8) 2 None - 0.1 1.0 (0.1) 1.0 (0.1) 1.6 (0.4) 2 4-A 65 0.1 7.2 (0.5) 7.0 (0.2) 100.0 (4.4) 2 4-C 54 0.1 5.2 (0.4) 4.2 (0.1) 1.0 (0.4) 2 4-T 53 0.1 5.0 (0.4) 3.9 (0.1) 1.1 (0.3) 2 4-G 55 0.1 6.4 (0.6) 5.1 (0.3) 1.1 (0.8) 2 6 0.1 1.4 (0.1) 1.1 (0.1) 1.6 (0.4) 2 79-A - 0.1 6.9 (0.5) 6.5 (0.2) 82.6 (8.3) 2 79-T - 0.1 1.8 (0.1) 1.5 (0.1) 2.1 (0.2)

Chapter 1
52
IE-HPLC Detection of Oligoncleotides. Using IE-HPLC analysis with fluorescence
detection allowed to detect the PNA:DNA in a very selective way (Figure 1.5). In the
fluorescence detection mode, only the residual beacon (broad peak at lower retention
time, visible in Figure 1.5 (left panel) and the PNA:DNA complex were observed, the
latter being enhanced by the “switch on” of the fluorescence due to complexation.
Therefore, an excess of beacon can be used to reveal the DNA without overlap of the
corresponding peak with that of the complex.
Figure 1.5. IE HPLC profiles obtained using the Beacons 1 (1 µM, left panel) and 2 (0.1 µM, right
panel) with 1:1 complementary oligonucleotides (upper traces) or with a single mismatched
oligonucleotide (lower traces). Column: TSK-gel DNA NPR (4.6mm ID x 7.5cm); eluents: A = TRIS
0.02M, pH = 9.0, B = NaCl 1M in eluent A. Linear gradient: from 100%A to 100% B in 20 min; flow
rate: 0.5 mL/min. T = 25°C for left panel and 35°C for right panel. Fluorescence detector λex = 497 nm,
λ em = 520 nm.
At 25°C a linear increase of the fluorescence response was observed in the range 1-100
nM, with detection limit of 2 nM (i.e of 20 fmole of injected DNA). Furthermore, the
chromatographic system has a significant denaturing effect for the mismatched
PNA:DNA duplexes, allowing to detect the full matched DNA with complete
selectivity (Figure 1.5 and Table 1.1). Best results in terms of single-mismatch
G
C-50
0
50
100
150
200
250
300
350
400
450
0 5 10 15 20t /min
F /
mV
0
5
10
15
20
25
30
35
40
0 5 10 15 20
t/min
F/m
V
A
TG
C
- +- +
PNA
PNA:DNA
3-
3-
4-
4-4-
4-
-+
-+

Chapter 1
53
recognition were observed at 25°C for beacon 1 and at 35°C for beacon 2, according to
the different melting temperatures of the PNA:DNA duplexes. Upon injection of a
mixture of beacon 2 and of a 79mer synthetic oligonucleotide (DNA 79-A), which
contains the target sequence and is identical to a PCR fragment previously tested for
Roundup Ready soybean21, a peak with increased retention time was observed (Figure
1.6, left). In the presence of a single nucleotide mismatch (T instead of A, DNA 79-T)
no peak was observed in the fluorescence channel (while the corresponding peak was
detected by UV, figure 1.6, right). Although this mismatch has no biological
significance, the present results suggest that selectivity can be very high also in the case
of PCR products.
Figure 1.6. IE HPLC profiles obtained by fluorescence (left panel) and by UV (right panel) using the
Beacon 2; a) beacon 2 (0.1 µM) + full match synthetic 79-mer (79-A); b) beacon 2 (0.1 µM) +
synthetic 79-T. T = 25°C. All other conditions were as reported in Figure 1.5.
The beacon 2 was subsequently tested against the same 79-A DNA obtained as PCR
product from RR soybean flour and with a 201bp PCR product not containing the
sequence (tract of peanut DNA). In both cases, unbalanced PCR with an excess of one
primer was carried out, in order to obtain the single-stranded target strand.
0
10
20
30
40
50
60
70
0 5 10 15 20
t/min
F/m
V
a)
b) a)
b)
0
0.01
0.02
0.03
0 5 10 15 20t/min
A2
60
/mV

Chapter 1
54
Using fluorimetric detection, only an increase to F/F0 = 3.8 was observed for the target
PCR amplicon, while the non-specific PCR sample gave rise to an increase to F/F0 =
1.2. An increase in the fluorescence of the beacon was also observed only in a blank
sample (i.e. containing all PCR components except DNA). Therefore, also taking into
account the signal increase in the blank, it is in principle not possible to distinguish
between aspecific and specific effects obtained by a lower GMO content. The use of
more elaborated measurements such as fluorescence anisotropy or time-resolved
fluorescence did not allow to substantially increase the signal selectivity.
In contrast, in the HPLC system, two peaks were observed by injecting the mixture of
beacon 2 and the PCR product (obtained from RR soy): one corresponding to the
retention time of the PNA:DNA duplex obtained with the synthetic 79-A DNA and the
other corresponding to the beacon (results not shown). Most interestingly, no
interfering peak was observed upon addition of either a blank sample or the 201 nt
unspecific PCR product, although an enhancement of the intensity of the broad beacon
peak was observed, due to unspecific interaction with the components of the PCR
reaction . These results are reported in a recent paper.22
We have also investigated the possibility to use our approach to discriminate
between antiparallel and parallel PNA:DNA duplexes. It is well-known that the
difference in melting temperatures between full-match and mismatched PNA:DNA
duplexes is comparable with or smaller than that between antiparallel and parallel
duplexes23. Therefore, if the system is able to discriminate almost perfectly the
mismatched DNA, it can be expected to be even more effective in the discrimination
between antiparallel and parallel DNA. In order to verify this hypothesis, we have
performed measurements with parallel DNA (DNA 5 and DNA 6) on both beacons,
and the results obtained are reported (Table 1.1 and Figure 1.7).

Chapter 1
55
Figure 1.7. IE-HPLC profiles obtained using the Beacons 1 (left panel, 1 µM) 2 (right panel, 0.1
µM,) with 1:1 of: a) antiparallel complementary or , b) complementary parallel oligonucleotide.
Column: TSK-gel DNA NPR (4.6mm ID x 7.5cm); eluents: A = TRIS 0.02M, pH = 9.0, B = NaCl 1M
in eluent A. Linear gradient: from 100%A to 100% B in 20 min; flow rate: 0.5 mL/min. T = 25°C for 1
and 35°C for 2. Fluorescence detector λex = 497 nm, λ em = 520 nm.
The results fully confirm our previous conclusions both in the HPLC and in
fluorimetric measurements. Both cases (mismatch recognition and directional control)
are examples of increased sequence selectivity of the PNA beacon in the HPLC
system, though the former is more important in diagnostic cases, e.g. in the detection
of point mutations related to diseases such as cystic fibrosis, Alzheimer disease, and
cancer, or to discriminate between individuals bearing single nucleotide
polymorphisms (SNPs).
1.3. Conclusions
The present results allow to propose a sensitive and very selective method for the
detection of specific DNA tracts by means of a simple, widely diffused technique such
as HPLC with fluorescence detector, using simple aqueous eluents and ionic strength
gradient. Both single mismatch recognition and directional control have been intensely
-20
80
180
280
380
480
0 5 10 15 20
t (min)
F (
A.U
)
(a)
(b)
-200
0
200
400
600
800
0 5 10 15 20
t (min)
F (
A.U
.)
(a)
(b)

Chapter 1
56
investigated. As an example of application, we choose the detection of GMO soy,
however, data on the single mismatch recognition are encouraging also for other
important applications such as detection of single point mutation of clinical interest or
SNPs identification for the study of vegetal varieties or animal breeds. Even more
selective responses could be obtained using this strategy in combination with modified
PNA backbones which allow to increase sequence selectivity24,25,26.
1.4. Experimental Section
PNA Beacons Synthesis. The synthesis was performed on an ABI 433A peptide
synthesizer with software modified to run the PNA synthetic steps (scale: 5 µmol),
using Fmoc chemistry and standard protocols as described in the introductive part,
with HBTU/DIEA coupling. Rink amide resin was used and downloaded manually by
Fmoc-Lys-(Dabcyl)-OH (Quencher unit). Upon completion of PNA oligomer
synthesis, the attachment of carboxyfluorescein (Fluorophore unit) was done manually
using DIC/DHBTOH as coupling reagent. The crude PNA beacons were purified by
RP- HPLC with UV detection at 260 nm. Semi-prep column C18 (5 microns, 250 x
10mm, Jupiter Phenomenex, 300 A ) was utilized, eluting with water + 0.01% TFA (
eluent A) and the mixture 60: 40 of water / acetonitrile + 0.01% TFA (eluent B);
elution gradient: from 100% A to 100% B in 65 min, flow: 4 ml/min. The resulting
pure PNA oligomers were characterized by MS-ESI with gave positive ions consistent
with the final products.
PNA Beacon 1. yield (after purification): 5.8 %; calculated MW: 3989.0.
ESI-MS: m/z = found 798.6 (calc 798.8; MH55+), found 665.7 (calc 665.8; MH6
6+),
found 570.8 (calc 570.9; MH77+).
PNA Beacon 2. yield (after purification): 6.1 %; calculated MW 4014.0.
ESI-MS: m/z = found 803.6 (calc 803.8 (MH55+), found 669.9 (calc 670.0;MH6
6+),
found 574.3 (calc 574.4; MH77+).
UV Melting Analysis. The PNA beacons were dissolved in water and their
concentrations were determined by UV absorption at 260 nm on an UV/Vis Lambda
Bio 20 Spectrometer ( Perkin Elmer).

Chapter 1
57
For thermal melting measurements, solutions of 1:1 DNA/PNA were prepared in pH =
7.0 Buffer consisting of 100 mM NaCl, 10 mM NaH2PO4.H2O, 0.1 mM EDTA. Strand
concentrations were 5 µM in each component. Thermal denaturation profiles (Abs vs
T) of the hybrids were measured at 260 nm with an UV/Vis Lambda Bio 20
Spetrometer equipped with a Peltier Temperature Programmer PTP6 which is
interfaced to a personal computer. For the temperature range 95°C to 20°C, UV
absorbance was recorded at 260 nm every 0.5°C. A melting curve was recorded for
each duplex. The melting temperature (Tm) was determined from the maximum of the
first derivative of the melting curves.
Fluorescence Studies. Fluorescence measurements were performed on Luminescence
Spectrometer LS 55. All solutions were prepared in Tris buffer consisting of 0.25 mM
MgCl2. H2O, 10 mM Tris, pH = 8.0. Strand concentrations were 0.1 or 1 µM in each
component. All samples were excited at 497 nm and the emission was monitored at
520 nm. All samples were run in triplicate and gave consistent results.
IE-HPLC Experiments. All experiments were carried out using an Alliance 2690
Separation Module HPLC system (Waters), equipped with temperature Controller,
Dual λ Absorbance Detector 2487(Waters) and Scanning Fluorescent Detector 474
(Waters). Separation was performed using a Column: TSK-gel DNA NPR (4.6mm ID
x 7.5cm); eluents: A = TRIS 0.02M, pH = 9.0, B = NaCl 1M in eluent A. Linear
gradient: from 100%A to 100% B in 20 min; flow rate: 0.5 mL/min. T = 25°C for
beacon 1 and 35°C for beacon 2. Fluorescence detector was monitored at λex = 497
nm and λ em = 520 nm. The PCR amplicons were obtained as single-stranded DNA as
described in ref 21.

Chapter 1
58
1.5. References
1 Ranasinghe, R.T.; Brown, T., Chem. Commun., 2005, 5487
2 Kubista, M.; Andrade, J.M.; Bengtsson, M.; Forootan, A.; Jonák, J.; Lind, K.;
Sindelka, R.; Sjöback, R.; Sjögreen, B.; Strömbom, L.; Ståhlberg, A.; Zoric, N.,
Molecular Aspects of Medicine 2006, 27, 95.
3 Tyagi, S.; Kramer, F.R., Nat. Biotechnol. 1996, 14, 303
4 a) Stoermer, R.L.; Cederquist, K.B.; McFarland, S.K.; Sha, M.Y.; Penn, S.G.;
Keating, C.D., J. Am. Chem. Soc. 2006, 128, 16892.
b) Cady, N.C.; Strickland, A.D.; Batt,. C.A, Mol. Cell Probe, 2007, 21, 116.
5 Nitin, N.; Santangelo, P.J.; Kim, G.; Nie, S.; Bao, G., Nucleic Acids Res., 2004, 32,
58.
6 BØydler Andersen C.; Holst-Jensen A.; Berdal K.G.; Thorstensen T.; Tengs, T.; J.
Agric. Food Chem., 2006, 54, 9658-9663
7 Bonnet, G.; Tyagi, S.; Libchaber, A.; Kramer, F.R., Proc. Nat. Acad. Sci. U.S.A.
1999, 96, 6171.
8 Li, X.; Huang, Y.; Guan, Y.; Zhao, M.; Li, Y., Anal. Chim. Acta, 2007, 58, 12.
9 Kolpashchikov, D.M., J. Am. Chem. Soc. 2006, 28, 10625.
10 a) Nielsen, P.E., Curr. Opin. Biotech. 2001, 12, 16.
b) Stender, H.; Fiandaca, M.; Hyldig-Nielsen, J. J.; Coull, J., J. Microbiol. Meth.
2002, 48, 1
11 a) Demidov, V.V., Trends in Biotech. 2003, 21, 4.
b) Sawata, S.; Kai, E.; Ikebukuro, K.; Iida, T.; Honda, T.; Karube, I., Biosens.
Bioelectron. 1999, 14, 397.
12 Smolina, I.V.; Demidov, V.V.; Soldatenkov, V.A.; Chasovskikh, S.G.; Frank-
Kamenetskii, M.D., Nucleic Acids Res. 2005, 33, e146/1
13 Seitz, O., Angew. Chem. Int. Ed. 2000, 39, 3249.
14 Petersen, K.; Vogel, U.; Rockenbauer, E.; Vang Nielsen, K.; Kolvraa, S.; Bolund,
L.; Nexo, B., Mol. Cell. Probes, 2004, 18, 117.
15 Leijon, M.; Mousavi-Jazi, M.; Kubista, M., Molecular Aspects of Medicine, 2006,
27, 160.

Chapter 1
59
16 Svanvik, N.; Nygren, J.; Westman, G.; Kubista, M., J. Am. Chem. Soc. 2001, 123,
803.
17 Kuhn, H. ; Demidov, V.V.; Coull, J.M.; Fiandaca, M.J.; Gildea, B.D.; Frank-
Kamenetskii, M.D., J. Am. Chem. Soc. 2002, 124, 1097.
18 Hulier, E. ; Petour, P. ; Marussig, M. ; Nivez, M.P. ; Mazier, D. ; Renia, L., J.
Viriol. Methods, 1996, 60, 109-117.
19 Huber, C.G., J. Chromatogr. A., 1998, 806, 3-30
20 Lesignoli, F.; Germini, A.; Corradini, R.; Sforza, S.; Galaverna, G.; Dossena, A.;
Marchelli, R., J. Chromatogr. A 2001, 922, 177.
21 Rossi, S.; Lesignoli, F.; Germini, A;. Faccini, A.; Sforza, S.; Corradini, R.;
Marchelli, R., J. Agric. Food Chem., 2007, 55, 2509.
22 Totsingan, F.; Rossi, S.; Corradini, R.; Tedeschi, T.; Sforza, S.; Juris, A.; Scaravelli,
E.; Marchelli, R., Org. Biomol. Chem., 2008, DOI: 10. 1039/B718772F.
23 Egholm M., Buchardt O., Christensen R., Behrens C., Freier S. M., Driver D. A.,
Berg R. H., Kim S. K., Norden B., Nielsen P.E., Nature, 1993, 365, 566-568.
24 Corradini, R.; Sforza, S.; Tedeschi, T.; Totsingan, F.; Marchelli, R., Cur. Topics
Med. Chem. 2007, 7, 681.
25 Kumar, V.A.; Ganesh, K.N., Acc Chem Res., 2005, 38, 404
26 ) Sforza, S.; Tedeschi, T.; Corradini, R.; Dossena, A.; Marchelli, R. Chem. Commun.
2003, 1102.

Chapter 2
60
Design and Synthesis of a PNA Beacon Modified with a
Chiral Monomer Linker 2.1. Introduction
Methods for the detection of nucleic acids are highly significant in identifying specific
target and in understanding their basic function. Hybridization probe technologies
continue to be one of the most essential elements in the study of gene-related
biomolecules1,2. They are useful for a variety of commercial and scientific
applications, including the identification of genetic mutations or single-nucleotide
polymorphisms (SNPs), medical diagnostics, gene delivery, assessment of gene
expression, and drug discovery3,4. Heterogeneous formats for performing such
hybridization probe assays have become increasingly common and powerful with the
advancement of gene chip and DNA microarray technologies5,6.
Microarray-based hybridization analyses have emerged in recent years as powerful
tools in biological and biomedical research allowing for the simultaneous
identification of several nucleic acid sequences, thus offering the possibility of rapid
and cost effective screening analyses. Oligonucleotide-based microarrays have been
developed to be used in genetic analysis7, drug discovery8, diagnostics9 and can also be
used, often in combination with multiplex PCRs, for the specific detection of DNA
tracts in food matrices10,11. Because of the special features of PNA:DNA interaction,
the use of PNA oligomers as chip-bound receptors could be advantageous for some
applications. In fact, PNA microarrays are very promising devices for the simultaneous
detection of many DNA sequences, in particular for detection of single nucleotide
polymorphisms (SNPs)12; they can also be useful tools in nanotechnologies for the
detection of GMOs in food13,14.
One most important class of PNA probes is represented by PNA beacons. Several
applications have been reported15,16, displaying the advantages of higher selectivity
and simpler design, since their flexibility allows the fluorophore-quencher interaction
to occur in the absence of a the complementary target. One of the major limitations in
the use of PNA Beacons in diagnostics is represented by the fluorescence background
of the free (uncomplexed) probe, which can be interfering with the signal obtained by
the analyte sequence when it is in low concentrations, especially for DNA amplified

Chapter 2
61
by complex biological samples. A way to overcome this limitation was discussed in
the previous chapter, in which we reported the combined use of PNA beacons and IE-
HPLC for the selective label-free detection of DNA, taking advantage on one side
from the separation of the free probe from the complex, and on the other side from the
very specific signal generated by the PNA beacon, which allows to avoid unspecific
peaks. Another limitation to be considered is the difficulty to perform parallel analysis
in homogenous solution.
In this work, we investigate the possibility to modify the PNA beacon design for
linking to a solid surface in microarrays or Lab-On-Chip devices.
The chiral PNA beacon and DNA sequences used are reported in Figure 2.1
Figure 2.1. Chiral PNA beacon design
+-
PNA BEACON CONTAINING A MODIFIED CHIRAL MONOMER
Chiral PNA beacon (RR-Soy) Synthesis by Fmoc chemistry
Higher fluorescence responseHigher sequence selectivity
NN
H
H
T
O
OH
O
fmoc
NH
O
O
O
NH
boc
Chiral PNA monomer(from L-Lys)
Synthesis: 7-steps
cPNA: Fluo-Glu-AGAGT*CAGCTT-Arg-Lys-DabcylaPNA: Fluo-Glu-AGAGTCAGCTT-Lys-Lys-DabcylfDNA: 5’-AAGCTGACTCT-3’mDNA: 5’-AAGCTGTCTCT-3’T* = chiral monomer

Chapter 2
62
2.2. Results and Discussion
Beacon design and chiral monomer synthesis. The PNA beacon sequence and
design was the same used in the previous chapter for RR-soy bean detection (PNA2),
however, the thymine monomer close to the middle of the sequence was replaced by a
chiral unit based on a monomer derived from L-lysine.
Recent studies carried out in our laboratory have shown that substitution of the achiral
N-(2-aminoethyl)amino acid backbone with chiral units derived from amino acid can
affect the DNA binding ability depending on the position and the stereochemistry of
the stereogenic centers introduced (see Introduction). Mono-substitution at the 5-
carbon of the backbone turned out to induce strong preference for helical structures
and the S-configuration induces strong DNA binding, while the R-one gives
unfavourable intra-strand interactions which hamper hybridization, as shown in Figure
2.2.
Figure 2.2. a) Chiral 5-substituted monomer; b) effect of C-5 Lys monomers on PNA:PNA helicity
and on PNA:DNA duplex stability; c) and d) molecular details of the effect of substituent derived from
L-or D-AA on PNA conformation: c) side view; d) top view.
NH
NPGOR
OO
Base
R(5)
L-AA D-AA
C5
C4
D-AA
L-AA
C5
(5L) Right-handed 56
(5D) Left-handed 32
Achiral - 50
GTAGAT5-LysCACT
Stereochemistry PNA:PNA Tm (PNA:DNA)
a) b)
c) d)

Chapter 2
63
Furthermore, the use of a 5-substituted PNA monomer prevents the epimerization
problem which was shown to occurr for the 2-substituted PNA monomers during
solid-phase synthesis17.
Therefore we designed a 5-substituted Fmoc-PNA-Thymine monomer with a Boc-
protected AEEA-lysine-derived side chain at the amino group of the spacer to serve as
the attachment point (Figure 2.1). A similar design was recently reported by the group
of Danith Ly for obtaining high affinity PNA18 and by Appella and coworkers for
conjugation with fluorophores through the backbone.19 The scheme of the modified
chiral monomer (Fmoc-T*-OH) is chosen in Figure 2.3.
Figure 2.3. Scheme of the chiral PNA monomer synthesis: a) (MeO)(Me)NH.HCl, HBTU, DIEA in
DMF; 99% b) LiAlH4 in THF; 90% c) HCl.H2NCH2CO2Me, NaBH3CN, CH3COOH in MeOH; 45% d)
T-CH2COOH, DCC/DHBTOH in DMF; 86% e) TFA/CH2Cl2 = 1 : 1; quantitative yield f) Boc-
AEEA.ODCHA, HBTU, DIEA in DMF; 95% g) Ba(OH)2 in THF/H2O = 1: 1; 85%.
NH
OH
O
NH
NH
NH
COOCH3
NH
NH
N
O
NH
Me
OMe
NH
H
O
NH
NH
NH
N
N
NH
O
O
COOCH3
O
NH
N
N
NH
O
O
COOCH3
O
NH
O
O
ONH
NH
N
N
NH
O
O
O
NH
O
O
ONH
COOH
NH2
NH
N
N
NH
O
O
COOCH3
O
Fmoc
Boc
Fmoc
Boc
Fmoc
Boc
Fmoc
Boc
Fmoc
Fmoc
Boc
Fmoc
Boc
Boc
Chiral Monomer
a b
c d Fmoce
fg
2
34
5
6
1
7

Chapter 2
64
The synthesis of the chiral monomer was performed in 7 steps (Figure 2.3). Starting
from the commercially available Fmoc-L-Lys(Boc)-OH, the insertion of the N-methyl-
N-methoxy group was made simply by treatment with N-methoxymethylamine
hydrochloride in DMF using HBTU as activating agent and DIEA as base. In this way
the Fmoc-L-Lys(Boc) N-methoxy-N-methyl amide 1 was obtained. This was followed
by reduction to the corresponding aldehyde 2 with LiAlH4 in THF. After standard
reductive amination to obtain the methyl ester backbone 3, coupling with
carboxymethylthymine was performed in DMF using DCC/DHBtOH as activating
agent, then obtaining the monomer methyl ester 4. After deprotection of the Boc
protecting group with TFA/CH2Cl2 mixture, affording 5 in quantitative yield, the Boc-
aminoethoxyethoxyacetyl group was subsequently inserted into the lysine side chain
forming the product 6. Hydrolysis of 6 by 1M Ba(OH)2 in THF/H2O solution yielded
the chiral monomer 7.
The chiral PNA beacon was synthesized using solid phase synthesis on an automatic
ABI 433A Synthesizer, according to the scheme reported in the introduction of this
thesis. Fmoc strategy was used with HBTU/DIEA as coupling agent and
piperidine/NMP as deprotecting solution. Dabcyl was used as quencher, linked to the
ε-amino group of lysine at the C-terminal part and carboxyfluorescein was used as
fluorophore, linked to the N-terminus of the PNA molecule; two additional charges (a
positive arginine side chain and a negative glutamate unit) were inserted just before
and after the PNA segment, following the design described by Frank-Kamenetskii and
co-workers. The arginine moiety was used instead of lysine as originally proposed by
Frank-Kamenetskii to avoid any possible competition with the side chain amino group
of the chiral monomer during attachment on solid support.
The fluorophore and quencher were attached manually. Upon completion of the
synthesis, the crude product was purified by RP-HPLC and characterized with HPLC-
MS. The chromatogram profile and ESI-MS spectra is reported in Figure 2.4.

Chapter 2
65
eluenti con lo 0.1% di ac formico
Time22.00 24.00 26.00 28.00 30.00
AU
0.0
2.0e-3
4.0e-3
6.0e-3
8.0e-3
1.0e-2
1.2e-2
1.4e-2
filbert 2: Diode Array 260
Range: 1.746e-227.11
27.89
2600 2800 3000 3200 3400 3600 3800 4000 4200 4400 4600 4800mass0
100
%
beacons 404 (24.230) M1 [Ev0,It22] (Gs,1.000,242:1498,1.00,L33,R33); Sm (SG, 1x1.00); Cm (389:411) 1: Scan ES+ 6.85e54258.0
3650.03042.0
2739.02521.0 2832.03615.0
3424.03123.0 3340.0
4110.0
4037.03851.0
4968.04867.0
4274.04378.0 4555.0
4682.04979.0
Figure 2.4. Chromatogram profile (left) and reconstructed mass spectrum of chiral beacon. Two
isomers are present.
Comparative study of the performance of chiral and achiral PNA beacons. Since
achiral PNA beacon has been successfully used in many applications and has shown to
strongly discriminate between full-matched and single mismatched DNA sequence, it
was interesting to verify if the selectivity of PNA beacon/DNA hybridization in
recognizing single-point mutations could be further improved by the presence of the
stereogenic center and the positive charge of lysine-spacer side-chain. Hybridization
properties of chiral PNA beacon were examined using UV melting temperatures and
compared to unmodified beacon (Table 2.1). The thermal denaturation studies showed
that chiral PNA beacon (cPNA):DNA duplex melts at a higher temperature (Tm) than
the corresponding unmodified oligomer (aPNA) with the fully complementary
oligonucleotide (fDNA). Discrimination of single-base mismatch (mDNA) was also
higher than that of the corresponding achiral beacon.

Chapter 2
66
Table 2.1. Comparison between the melting temperature and the fluorescence response for chiral
beacon (cPNA) and achiral beacon (aPNA) in the presence of fully complementary and single
mismatched DNA (fDNA: 5’-AAGCTGACTCT-3’; mDNA: 5’-AAGCTGTCTCT-3’)
PNA DNA Tm
(°C)a
C(µµµµM) Fluorescence
F/F0b(520nm)
cPNA None - 1/0.1 1.0 (0.1) cPNA fDNA 73 1 18.3 (0.2) cPNA mDNA 59 1 14.7 (0.2) cPNA fDNA 73 0.1 8.2 (0.3) cPNA mDNA 59 0.1 3.6 (0.2) aPNA None - 1/0.1 1.0 (0.1) aPNA fDNA 65 1 10.4 (0.1) aPNA mDNA 53 1 9.4 (0.2) aPNA fDNA 65 0.1 7.2 (0.5) aPNA mDNA 53 0.1 5.0 (0.4)
a PNA:DNA melting temperature c = 5 µM of each strand. b Fluorescence intensity normalized to the value of the free beacon.
We also investigated the fluorescence intensity changes of the PNA beacons when
bound to fully complementary and single mismatched DNA. Two different beacon
concentrations: 0.1 µΜ and 1 µΜ were chosen for our investigation. On the basis of
our results (Table 2.1, Figure 2.5), both PNA beacons were weakly fluorescent in the
absence of DNA. At the higher concentration:1 µΜ, in the presence of complementary
oligonucleotide (1 µΜ), the fluorescence intensity increased 18.3-fold over that of the
unbound beacon which is considerably higher than that exhibited by the achiral beacon
with fullmatched DNA (10.4-fold) at the same duplex concentration. When combined
with a single-mismatched DNA, the chiral and achiral beacons gave 14.7-fold and 9.4-
fold increase in fluorescence intensity, respectively. At lower duplex concentration
(0.1.µΜ ), the same trend was observed (Table 2.1). Another interesting observation
that can be drawn out from our data is the higher selectivity of chiral beacon if
compared to that of the achiral probe. The Figure 2.6. reports the fluorescence
intensity ratio fullmatch/mismatch at two different concentrations. Although the higher
fluorescence signal was exhibited at higher concentration (1.µΜ), the best sequence-
selectivity was obtained at lower concentration (0.1 µΜ).
According to UV melting and fluorescence data, it is clear that the incorporation of a
chiral monomer into PNA beacon can strongly increase either the duplex stablitity, the

Chapter 2
67
sequence-selectivity or the fluorescent properties, allowing the use of chiral PNA
beacon as powerful biosensors for DNA detection and mismatch recognition.
Figure 2.5. Fluorescence spectra recorded at 25°C of chiral PNA beacon (cPNA) and achiral beacon
(aPNA) bound to a fully complementary DNA (fDNA) and a single-mismatched DNA (mDNA).
Excitation was monitored at 497 nm and Emission was measured at 520 nm. Strand concentration was
1µM in each component (PNA/DNA = 1:1).
1
1.2
1.4
1.6
1.8
2
2.2
2.4
Fullmatch/Mismatch
0.1 1
Concentration (uM)
Chiral
Achiral
Figure 2.6. Fluorescence intensity ratio between fullmatched and mismatched DNA hybridized with
chiral PNA beacon (Blu) and achiral beacon (Red) at two differents concentrations: 0.1.µΜ and 1.µΜ
0
2
4
6
8
10
12
14
16
18
20
400 450 500 550 600
Wavelength (nm)
F/F0
cPNA:fDNA
cPNA:mDNA
aPNA:mDNA
aPNA:fDNA
aPNA; cPNA

Chapter 2
68
Preliminary microarray studies. On the basis of the results obtained in solution, we
sought to determine if the higher performance of the chiral beacon, both in sequence-
selectivity and fluorescence properties can be further increased by attachment on a
solid support. Both PNA beacons were immobilized on the N-hydroxysuccinimide
(NHS) activated glass slide using microarray techniques protocols. The resulting spots
were hybridized with fully complementary DNA (fDNA) and a single-mismatched
DNA (mDNA). Despite a fluorescence signal was observed in the presence of the fully
complementary target sequence, no significant difference either in fluorescence
intensity or in sequence-selectivity was revealed between the two beacons (data not
shown). Then, the advantage of using a PNA containing the chiral monomer was not
as evident as in the solution study. Furthermore, the selectivities towards mismatch
were depending on the deposition conditions.
The major problem revealed in these experiments was the background fluorescence of
the beacon which was dependent on the hybridization conditions. This problem was
particularly severe when PCR products were directly hybridized on the microarray
(data not shown). In order to overcome this limitation, in collaboration with G. De
Bellis of the CNR (Milan), we performed a test using a new and powerful technology,
named “Lab-on-chip” (Figure 2.7) using the chiral beacon. This tool is a miniaturized
device (25x75.5 mm2) containing a thermostated chamber for PCR thermal cycles,
capillary electrophoresis unit and a microarray part, all arranged in sequence. The pre-
hybridization (PCR area) consists in PCR reaction step followed by separation of PCR
products; whereas, the chiral PNA beacon was immobilized in the hybridization area.
Although the study is still preliminary, it provides some important observations : The
presence of a fluorescence signal only in the case of specific PCR product suggesting
that this device could be use as a selective technology for detecting DNA tracts.
Futhermore, the time of analysis (45 min) is drastically reduced if compared to that of
traditional PNA microarray techniques. However, deposition conditions and
microarray set up has still to be improved. The advantage of this approach should be
the use of label-free DNA samples on a fully automated and miniaturized device.

Chapter 2
69
Figure 2.7. a) Lab-on-Chip device: showing the electrical contacts (left side) for interfacing with the TCS (temperature control system) instrument; the silicon chip (right side), showing four inlet holes, PCR area (center), and post-PCR analysis area. b) Results of detection by chiral PNA beacon of specific PCR product amplified on Lab-on-chip.device. PCR thermal cycling program: 40 cycles, 15s at 94 °C; 15s at 60 °C and 15s at 72 °C.The fluorescence signal deriving from the hybridization was acquired at λex = 497 nm and λex = 520 nm.
2.3. Conclusions
In this study, we developed a method to modify PNA backbone with side chain that
can be covalently attached to a solid support. Our modification shows an increase (in
solution) either in duplex stability and selectivity in mismatch recognition or in
fluorescence properties. Although the results obtained on microarray were not
satisfactory, the preliminary study performed on Lab-on-chip opens the possibility to
use the latter as a more selective and fast technology for DNA detection.
2.4. Experimental Section
General Information. Reagents were purchased from Sigma –Aldrich, Fluka, Applied
Biosystems, NovaBiochem and used without purification. DMF was dried over 4 Å
molecular sieves. THF was dried by distillation. TLC was run on Merck 5554 silica 60
aluminium sheets. Column chromatography was performed as flash chromatography
on Merck 9385 silica 60 ( 0.040- 0.063 mm). Reactions were carried out under
nitrogen.
NMR spectra were obtained on a Brucker 300 or Varian 600 MHZ spectrometer.
−δ values are in ppm relative to CDCl3 (7.29 ppm for proton and 76.9 for carbon) or
DMSO-d6 (2.50 ppm for proton and 39.5 for carbon).
b) Resultsa) Lab-On-Chip Device
PCR area Hybridization and
Detection areaElectric contacts
Inlet holesSpecific PCR
productAspecific products
And others
b) Resultsa) Lab-On-Chip Device
PCR area Hybridization and
Detection areaElectric contacts
Inlet holes
b) Resultsa) Lab-On-Chip Device
PCR area Hybridization and
Detection areaElectric contacts
b) Resultsa) Lab-On-Chip Device
PCR area Hybridization and
Detection areaElectric contacts
Inlet holesSpecific PCR
productAspecific products
And others

Chapter 2
70
Fmoc-Lys(Boc)–N(Me)OMe (1). Fmoc-Lys(Boc)-OH (2.01 g, 4.3 mmol) was
dissolved in dry DMF (20 ml) and HBTU ( 1.58 g, 4.13 mmol) was added to the
solution. the reaction mixture was then cooled to 0°C with an ice batch. after 15
minutes of stirring, DIEA (1.5 ml, 8.6 mmol) and N-methoxy-N-methylamine
hydrochloride salt (0.42 g, 4.3 mmol) were added slowly to the stirring solution. The
solution was allowed to stir for ten minutes at 0° C and the ice batch was removed.
The reaction mixture kept for 17 hours at room temperature and the DMF was then
evaporated. The residue was dissolved in EtOAc and washed with saturated potassium
hydrogen sulfate (2 times) and saturated sodium hydrogen carbonate (2 times). The
organic layer was dried over sodium sulfate, filtered and evaporated to afford 2.20 g
(99% yield) of the product as a colorless foam. 1H NMR (300 MHz, CDCl3): δ = 7.76 (d, 2H, J = 7.3 Hz, CH aromatic Fmoc), 7.60
(m, 2H, CH aromatic Fmoc), 7.40 (t, 2H, J = 7.1 Hz, CH aromatic Fmoc), 7.31 (m, 2H,
CH aromatic Fmoc), 5.52 (d, 1H, J = 8.4 Hz, NH-Fmoc), 4.75 (s, br, 1H, NH-Boc),
4.55 (s, br, 1H, α - H), 4.37 (d, 2H, J = 7.2 Hz, CH2 Fmoc), 4.21 (t, 1H, J =7.2 Hz, CH
Fmoc), 3.77 (s, 3H, OCH3), 3.22 (s, 3H, N-CH3), 3.11 (s, br 2H, CH2-NH lysine side
chain), 1.43 (s, 9H, (CH3)3 Boc), 1.21-1.78 (m, 6H, CH2CH2CH2 Lysine side chain). 13
C NMR ( 75.4 MHz, CDCl3): δ = 172.5, 156.1, 155.9, 143.9, 143.7, 141.2, 127.6,
127.00, 125.09, 119.89, 66.93, 61.56, 50.65, 47.11, 40.10, 32.41, 32.00, 29.49, 28.34,
22.37.
Fmoc-Lys(Boc)-H (2). Fmoc-Lys(Boc)-N(Me)OMe (2.20 g, 4.3 mmol) was dissolved
in a minimal amount of dry THF (30 ml) and lithium aluminum hydride solution 1M
in THF (4.9 ml, 4.9 mmol) was added slowly to the stirring solution. the mixture was
then cooled to 0° C with an ice bath for 15 minutes. The ice bath was removed and the
reaction mixture was allowed to stir for 45 minutes at room temperature. The reaction
was monitored via TLC ( CH2CL2/MeOH = 9 : 1, Rf = 0.6). After 1 hour, the mixture
was quenched with EtOAc (30 ml) and the solvent was evaporated. The residue was
dissolved in CH2Cl2 and transferred to a separatory funnel and washed twice with
saturated potassium hydrogen sulfate and saturated sodium hydrogen carbonate (2
times). The organic phase was dried over Na2SO4, filtered and evaporated under
reduced pressure to afford 1.64 g (90% yield) of the product as a colorless foam.

Chapter 2
71
1H NMR (300 MHz, DMSO-d6): δ = 9.42 (s, 1H, CHO), 7.89 (d, 2H, J = 7.2 Hz, CH
aromatic Fmoc), 7.71 (d, 2H, J = 7.2 Hz, CH aromatic Fmoc), 7.58 (d, 2H, J = 7.2 Hz,
NH-Fmoc), 7.32-7.48 (m, 4H, CH aromatic Fmoc), 6.78 (t, br, NH-Boc), 4.35 (d, 2H,
J = 6.9 Hz, CH2 Fmoc), 4.25 (m, 1H, CH Fmoc),3.80-4.00 (m, 1H, α - H), 2.88 (m,
2H, CH2-NH lysine side chain), 1.36 (s, 9H, (CH3)3 Boc), 1.46-1.14 (m, 6H,
CH2CH2CH2 Lysine side chain).
Fmoc-Lys(Boc)-PNA backbone (3). Fmoc-Lys(Boc)-H (1.60 g, 3.55 mmol) and Gly-
OMe.HCl (0.45 g, 3.55mmol) were dissolved in MeOH (35 ml). The reaction mixture
was cooled to 0° C with an ice bath and NaBH3CN (0.23 g, 3.55 mmol), CH3COOH
(0.21 g, 3.55 mmol) were added to the stirring solution. The reaction was allowed to
stir for 3 hours and was monitored via TLC. The solvent was evaporated and the
residue was taken up in EtOAc and washed with saturated KHSO4 (2 times) and
saturated NaHCO3 (2 times). The organic layer was dried over Na2SO4, filtered and
evaporated to afford an oil. The oil was purified via column chromatography
(EtOAc/Hexane = 9 : 1, rf = 0.2) to afford 0.85 g (45% yield) of the desired product as
a colorless foam. 1H NMR (600 MHz, CDCl3): δ = 7.78 (d, 2H, J = 7.8 Hz, CH aromatic Fmoc), 7.65
(d, 2H, J = 7.2 Hz, CH aromatic Fmoc), 7.42 (t, 2H, J = 7.8 Hz, CH aromatic Fmoc),
7.34 (t, 2H, J = 7.2 Hz, CH aromatic Fmoc), 5.17 (d, br, J = 7.2 Hz, 1H, NH-Fmoc),
4.68 (s, br, 1H, NH-Boc), 4.42 (d, 2H, J = 6.6 Hz, CH2 Fmoc), 4.25 (t, 1H, J = 6.6 Hz,
CH Fmoc), 3.75 (s, 3H, OCH3), 3.70-3.78 (m, br, 1H, CH Lys), 3.49 (d, 1H, J = 16.8
Hz, CH Gly), 3.41 (d, 2H, J = 16.8 Hz, CH Gly), 3.08-3.18 (m, 2H, CH2 backbone),
2.64-2.78 (m, 2H, CH2-NH Lys side chain), 1.42 (s, 9H, (CH3)3 Boc), 1.15-1.60 (m,
6H, CH2CH2CH2 Lys side chain). 13
C NMR (75.4 MHz, CDCl3): δ = 172.72, 156.36, 156.01, 143.91, 141.26, 127.56,
126.95, 125.02, 119.86, 77.40, 66.38, 60.32, 52.73, 51.75, 50.54, 47.26, 40.10, 32.5,
29.72, 28.34, 22.88..
Fmoc-Lys(Boc)-PNA-Thymine–OMe monomer (4). CMT (0.59 g, 3.2 mmol) was
dissolved in DMF (15 ml) at 0° C, together with DHBtOH (0.52 g, 3.2 mmol) and
DCC (0.66 g, 3.2 mmol). The solution was stirred for 1.5 hours at 0° C, then for 30

Chapter 2
72
minutes at room temperature. The DCU was then filtered and the Fmoc-protected
lysine backbone ( 0.84 g, 1.6 mmol) dissolved in DMF (15 ml) was added to the
mixture solution. the solution was stirred overnight and the DMF was then evaporated.
the residue was dissolved in CH2Cl2 and washed with saturated KHSO4 (2 times) and
saturated NaHCO3 (2 times). the organic layer was dried over Na2SO4 and filtered;
solvent was removed and the residue was purified via flash chromatography (
CH2Cl2/MeOH = 95 : 5, rf = 0.4) to afford 0.95 g (86% yield) of the product as a clear
colorless solid. 1H NMR (300 MHz, DMSO-d6 ): δ = 10.66 (s, 1H, NH Thymine), 7.89 (d, 2H, J = 7.5
Hz, CH aromatic Fmoc), 7.79 (m, 2H, CH aromatic Fmoc), 7.41 (t, 2H, J = 7.5 Hz, CH
aromatic Fmoc), 7.33 (d, 1H, J = 7.2 Hz, NH-Fmoc), 7.32 (m, 2H, CH aromatic
Fmoc), 7.20 (s, 1H, CH Thymine), 6.55 (s, br, NH-Boc), 4.76 (d, 1H, J = 16.8 Hz, CO-
CH-Thymine), 4.63 (d, 1H, J = 16.8 Hz, CO-CH-Thymine), 4.21-4.46 (m, 3H, CH2-
CH Fmoc), 4.09 (d, 2H, J = 17.1 Hz, CH Gly), 3.98 (d, 2H, J = 17.1 Hz, CH Gly), 3.70
(s,1H, Fmoc-NH-CH-(CH2)2), 3.62 (s, 3H, OCH3), 3.25-3.40 (m, 2H, Fmoc-NH-CH-
CH2-N), 2.89 (s, 2H, CH2-NH lysine side chain), 1.69 (s, 3H, CH3 Thymine), 1.36 (s,
9H, (CH3)3 Boc), 1.15-1.48 (m, 6H, CH2CH2CH2 Lysine side chain). 13
C NMR (75.4 MHz, DMSO-d6): δ = 169.13, 164.20, 162.14, 155.94, 155.42,
150.78, 143.71, 141.77, 140.60, 127.45, 126.89, 125.00, 124.94, 119.95, 107.99,
77.17, 65.16, 55.88, 52.07, 51.56, 51.39, 50.71, 46.68, 35.62, 33.19, 29.13, 28.10,
22.67.
Minor isomers were also present
Fmoc-Lys-PNA-Thymine –OMe monomer –Boc-deprotection (5). Fmoc-Lys(Boc)-
PNA-Thymine-OMe 4 (0.43 g, 0.62 mmol) was dissolved in a mixture TFA/CH2Cl2 =
1 : 1 (4 ml) at 0° C. the solution was allowed to stir for 30 minutes at room
temperature. the reaction was monitored via TLC. After evaporation of the solvent, the
residue was washed many times with dichloromethane to remove trace of TFA. The
product was obtained as a solid: 0.44 g (quantitative yield). 1H NMR (300 MHz, DMSO-d6 ): δ = 10.66 (s, 1H, NH Thymine), 7.89 (d, 2H, J = 7.5
Hz, CH aromatic Fmoc), 7.66-7.74 (m, 3H, CH aromatic Fmoc + NH-Fmoc), 7.21-
7.46 (m, 3H, CH aromatic Fmoc + NH-Boc), 7.32 (t, 2H, CH aromatic Fmoc), 7.21 (s,

Chapter 2
73
1H, CH Thymine), 4.74 ( d, 1H, J = 16.6 Hz, CO-CH-Thymine), 4.63 ( d, 1H, J = 16.6
Hz, CO-CH-Thymine), 4.22-4.46 (m, 3H, CH-CH2 Fmoc), 4.09 (d, 2H, J = 17.1 Hz,
CH Gly), 3.97 (d, 2H, J = 17.1 Hz, CH Gly), 3.70 (s,1H, Fmoc-NH-CH Lys), 3.62 (s,
3H, OCH3), 3.20-3.40 (m, 2H, Fmoc-NH-CH-CH2-N), 2.60-2.80 (s, 2H, CH2-NH
lysine side chain), 1.69 (s, 3H, CH3 Thymine, Rotomer), 1.23-1.50 (m, 6H,
CH2CH2CH2 Lysine side chain).
Minor isomers were also present
Fmoc-Lys(AEEA-Boc)-PNA-Thymine –OMe monomer (6). Fmoc-Lys-PNA-
Thymine-OMe monomer (0.44 g, 0.62 mmol) was dissolved in DMF (5ml) and DIEA
(88.3 mg, 0.68 mmol) was added at room temperature. The solution was stirred for 30
minutes. Separately, Boc-AEEA-ODCHA (0.34 g, 0.76 mmol) was dissolved in DMF
(5 ml) together with HBTU (0.29 g, 0.76 mmol) at 0° C and the solution was stirred
for about 10 minutes. The two solutions were mixed and another portion of DIEA
(192.6 mg, 1.49 mmol) was added to the mixture. The reaction mixture was allowed to
stir overnight at room temperature and the DMF was then evaporated. The residue was
dissolved in EtOAc and washed with saturated potassium hydrogen sulfate (2 times)
and saturated sodium hydrogen carbonate (2 times). The organic layer was dried over
sodium sulfate, filtered and evaporated to obtain an oil. The oil was purified by flash
chromatography (CH2Cl2/MeOH = 95 : 5, rf = 0.4) to afford 0.49 g (95% yield) of the
product as a white foam. 1H NMR (300 MHz, CDCl3): δ = 8.91 (br d, 1H, NH Thymine), 7.75 (d, 2H, J = 7.5
Hz, CH aromatic Fmoc), 7.59 (m, br, 2H, CH aromatic Fmoc), 7.39 (t, 2H, CH
aromatic Fmoc), 7.30 (t, 2H, CH aromatic Fmoc), 7.26 (s, 1H, CH Thymine), 7.12 (br
s, 1H, NH Fmoc), 6.99 (br s, 1H, NH Boc), 4.20-4.70 ( m, 3H, CO-CH2-Thymine +
CH Fmoc), 4.18 (s, 2H, CH2 Fmoc), 3.95 (br s, 2H, α -CH2 Gly), 3.77 (s, 2H, CH2-CO
spacer), 3.70 (s, 3H, OCH3), 3.60 (m, 4H, O-CH2CH2-O spacer), 3.52 (s, 3H, Fmoc-
NH-CH-CH2-N), 3.28 (s, 4H, O-CH2CH2-NH spacer), 3.10 (s, 2H, CH2-NH lysine
side chain), 1.87 (s, 3H, CH3 Thymine), 1.43 (s, 9H, (CH3)3 Boc), 1.20-1.68 (m, 6H,
CH2CH2CH2 Lysine side chain).

Chapter 2
74
13C NMR ( 75.4 MHz, CDCl3): Some characteristic signals δ = 127.69, 127.05,
124.96, 119.95, 70.84, 70.21, 69.76, 66.47, 52.80, 52.32, 50.12, 47.64, 47.16, 38.06,
31.39, 29.17, 28.33, 24.46, 22.59.
Minor isomers were also present
Fmoc-Lys(AEEA-Boc)-PNA-Thymine –OH monomer (7). To a suspension of the
methyl ester 6 (0.37 g, 0.44 mmol) in 28.8 ml THF/H2O mixture (1:1) was added
Ba(OH)2.8H2O (0.22 g, 0.68 mmol). After 30 minutes the reaction was complete as
monitored by TLC (silica gel; eluent: CH2Cl2/MeOH = 9 : 1). The pH was adjusted to
2.5 with KHSO4, the solvent was evaporated off, and the residue was dissolved in the
minimum amount of DMF and precipitated with water. the solid was filtered off, dried
under vacuum to afford 0.31 g (85% yield) of the desired product as a white solid. 1H NMR (300 MHz, DMSO-d6): δ = 10.66 (s, br, 1H, NH Thymine), 7.88 (d, 2H, CH
aromatic Fmoc), 7.55-7.70 (m, 3H, CH aromatic Fmoc + NH-Fmoc), 7.20-7.50 (m,
4H, CH aromatic Fmoc), 7.18 (s, br, 1H, NH Thymine), 6.76 (s, br, 1H, NH-Boc),
4.50-4.70 (m, 2H, CO-CH2-Thymine), 4.10-4.50 (m, 5H, CH-CH2 Fmoc + CO-CH2
spacer), 3.83 (s, br, 2H, α -CH2 Gly), 3.40-3.60 (m, 5H, O-CH2CH2-O spacer + CH
Lys), 3.20-3.40 (m, br, 4H, O-CH2CH2-NH spacer), 3.00-3.20 (m, 4H, CH2 backbone
+ CH2-NH lysine side chain), 1.69 (s, 3H, CH3 Thymine), 1.36 (s, 9H, (CH3)3 Boc),
1.00-1.50 (m, 6H, CH2CH2CH2 Lysine side chain). 13
C NMR (75.4 MHz, DMSO-d6): δ = 171.00, 168.79, 164.23, 155.93, 155.45,
150.83, 143.71, 141.83, 140.57, 127.46, 126.91, 125.08, 119.96, 107.86, 77.44, 70.02,
69.82, 69.06, 65.15, 50.99, 47.57, 46.64, 40.17, 37.85, 28.88, 28.06, 22.82.
PNA Oligomer Synthesis. The synthesis was performed on an ABI 433A peptide
synthesizer with software modified to run the PNA synthetic steps (scale: 5 µmol),
using Fmoc chemistry and standard protocols as described in the introductive part,
with HBTU/DIEA coupling. Rink amide resin was used and downloaded manually by
Fmoc-Lys-(Dabcyl)-OH (Quencher unit). Upon completion of PNA oligomer
synthesis, the attachment of carboxyfluorescein (Fluorophore unit) was done manually
using DIC/DHBTOH as coupling reagent. The crude PNA beacons were purified by
RP- HPLC with UV detection at 260 nm. Semi-prep column C18 (5 microns, 250 x

Chapter 2
75
10mm, Jupiter Phenomenex, 300 A ) was utilized, eluting with water + 0.01% TFA (
eluent A) and the mixture 60: 40 of water / acetonitrile + 0.01% TFA (eluent B);
elution gradient: from 100% A to 100% B in 65 min, flow: 4 ml/min. The resulting
pure PNA oligomer was characterized by MS-ESI with gave positive ions consistent
with the final products.
cPNA (chiral Beacon). yield (after purification): 2 %; calculated MW: 4257.0
ESI-MS: m/z = found 1065.4 (calc 1065.3, MH44+); found 852.5 (calc 852.4; MH5
5+),
found 710.6 (calc 710.5; MH66+), found 609.2 (calc 609.1; MH7
7+); found 533.3 (calc
533.1; MH88+).
UV Melting Analysis. Solutions of 1:1 DNA/PNA were prepared in pH = 7.0 Buffer
consisting of 100 mM NaCl, 10 mM NaH2PO4.H2O, 0.1 mM EDTA. Strand
concentrations were 5 µM in each component. Thermal denaturation profiles (Abs vs
T) of the hybrids were measured at 260 nm with an UV/Vis Lambda Bio 20
Spetrometer equipped with a Peltier Temperature Programmer PTP6 which is
interfaced to a personal computer. For the temperature range 95°C to 20°C, UV
absorbance was recorded at 260 nm every 0.5°C. A melting curve was recorded for
each duplex. The melting temperature (Tm) was determined from the maximum of the
first derivative of the melting curves.
Fluorescence Studies. Fluorescence measurements were performed on Luminescence
Spectrometer LS 55. All solutions were prepared in Tris Buffer consisting of 0.25 mM
MgCl2. H2O, 10 mM Tris, pH = 8.0. Strand concentration was 1 µM in each
component. All samples were excited at 497 nm and the emission was monitored at
520 nm. All samples were run in triplicate and gave consistent results.
Array Preparation, Hybridization and Scanning. Activated Slides were used as
solid supports to which the amino-terminal group of the PNA probes were covalently
linked. The deposition of the probes was carried out using a GMS 417 Arrayer
(Genetic Microsystem) with a pin-and-ring deposition system. The manufacturer's
instructions for the deposition protocol were slightly changed in order to comply with
the special requirement of the chemical structures of PNAs: in particular a 100mM

Chapter 2
76
carbonate buffer (pH 9.0) containing 10% acetonitrile and 0.001% sodium dodecyl
sulphate (SDS) was used as deposition buffer. Moreover, after every deposition, the
pin-and-ring system was purged with water for 10s and further washed with
acetonitrile/water (1:1), in order to avoid dragging of the probes in subsequent
depositions. The probes were coupled to the surface and the remaining reactive sites
were blocked by leaving the slides in a humid chamber (relative humidity 75%) at
room temperature for 12h, followed by immersion in a glass rack containing a 50mM
solution of ethanolamine, 0.1M TRIS, pH 9, prewarmed at 50°C, for 30min. The slides
were washed twice with bidistilled water at room temperature and then slowly shaken
for 30min in plastic tubes containing a 4× saline/sodium citrate (SSC) solution and a
0.1% SDS buffer prewarmed at 50°C. Each slide was then washed with bidistilled
water at room temperature and centrifuged in a plastic tube at 800rpm for 3min. Slides
were then ready to undergo the hybridization protocol.
DNA samples (1µM strand concentration) to be tested were prepared by diluting stock
solutions to a final volume of 65µl and a final concentration of 4× SSC and 0.1% SDS
buffer. Hybridization was performed by loading the samples to “in situ frame”
chambers and leaving the slides under slow shaking for 2h at 40°C. After the
hybridization step all the slides were treated individually to prevent cross
contamination. The slides were washed under slow shaking for 5min at 40°C with a 2×
SSC, 0.1% SDS buffer prewarmed at 40°C, followed by treatment for 1min with 0.2×
SSC and for 1min with 0.1× SSC at room temperature. The slides were then spin-dried
at 1000 rpm for 5min.
The fluorescent signal deriving from the hybridization was acquired using a GMS 418
Array Scanner (Genetic Microsystem) at λ ex=497nm and λ em=520nm.
PCR amplification and detection on Lab-On-Chip. The biochip was used to
amplify a long target DNA specific for Round Ready soy bean. The PCR
amplification was performed according to a protocol reported in a recent study.20 Then
the PCR products were transferred in the detection area where the chiral PNA beacon
was covalently linked. The fluorescence signal derived from hybridization was acquire
at λ ex=497nm and λ em=520nm.

Chapter 2
77
2.5. References 1Lipshutz, R. J., Fodor, S. P. A., Gingeras, T. R. & Lockart, D. J., Nat.Genet., 1999,
21, 20–24. 2 Wolcott, M. J., Clin. Microbiol., 1992, Rev. 5, 370–386. 3 Piatek, A. S., Tyagi, S., Pol, A. C., Telenti, A., Miller, L. P., Kramer, F. R. &Alland,
D., Nat. Biotechnol.,1998, 16, 359–363. 4 a) Ranade, K., Chang, M. S., Ting, C. T., Pei, D., Hsiao, C. F., Olivier, M., Pesich,
R., Hebert, J., Chen, Y. D., Dzau, V. J., Genome Res.,2001, 11, 1262–1268.
b) Wang, J., Nucleic Acids Res.,2000, 28, 3011–3016. 5 a) Service, R. F., Science, 1998, 282, 396–399.
b) Southern, E. M., Trends Genet, 1996, 12, 110–115. 6 Epstein, C. B. & Butow, R. A., Curr. Opin. Biotechnol., 2000, 11, 36–41. 7 Kozian, D.H.; Kirschbaum, B.J., Trends Biotechnol., 1999, 17, 73-78. 8 Debouck, C.; Goodfellow, P.N., Nat Genet., 1999, 21, 48-50. 9 Whitcombe, D.; Newton, C.R.; Little, S., Curr, Opin. Biotechnol., 1998, 9, 602-608. 10 Blais, B. W.; Phillippe L. M.; Vary, N., Biotechnol. Lett.,. 2002, 24 (17), 1407-1411. 11 Rudi, K.; Rud, I.; Holck, A., Nucleic Acid Res. 2003, 31 (11), e62/1-e62/8. 12 Weiler, J.; Gausepohl, H.; Hauser, N.; Jensen, O. N.; Hoeisel, J. D., Nucleic Acids
Res., 1997, 25, 2792. 13 Germini A, Mezzelani A, Lesignoli F, Corradini R, Marchelli R, Bordoni R,
Consolandi C, De Bellis G, J Agric Food Chem, 2004, 52(14), 4535–4540. 14 Germini A., Rossi S., Zanetti A., Corradini R., Fogher C., Marchelli R., J Agric
Food Chem, 2005, 53, 3958–3962. 15 Smolina, I.V.; Demidov, V.V.; Soldatenkov, V.A.; Chasovskikh, S.G.; Frank-
Kamenetskii, M.D., Nucleic Acids Res. 2005, 33, e146/1 16 Petersen, K.; Vogel, U.; Rockenbauer, E.; Vang Nielsen, K.; Kolvraa, S; Bolund, L.;
Nexo, B., Mol. Cell. Probes, 2004, 18, 117. 17 a) Corradini, R.; Sforza, S.; Dossena, A.; Palla, G.; Rocchi, R.; Filira, F; Nastri, F.;
Marchelli, R, J Chem. Soc. Perkin Trans. 1, 2001, 2690-2696.
b) Corradini, R.; Di Silvestro, G.; Sforza, S.; Palla, G.; Dossena, A.; Nielsen, P.E.;
Marchelli R., Tetrahedron Asymm., 1999, 10, 2063.

Chapter 2
78
18 Dragulescu-Andrasi, A.; Rapireddy, S.; Frezza, B.M.; Gayathri, C.; Gil, R.R.; Ly,
D.H. J. Am. Chem. Soc. 2006, 128, 10258-10267. 19 Englund E. A., Appella D. H., Org Lett 2005; 7: 3465-3467. 20 Consolandi, C.; Severgini, M.; Frosini, A; Caramenti, G.; De Fazio, M.; Ferrara, F.;
Zocco, A.; Fischetti, A.; Calmieri, M.; De Bellis, G.; Anal. Biochem, 2006, 353, 191-
197.

Chapter 3
79
Insights into the Propagation of Helicity in PNA:PNA
Duplexes as a Model for Nucleic Acid Cooperativity
3.1. Introduction
In recent years, the DNA molecule has been considered not only for its central role in
biological systems, but also as a special nanostructured programmable material which
allows fabrication of special structures through a self assembly process1.
The characteristics of DNA are well explored including the sense of the double helix
of the varying forms of DNA. The helical sense of a DNA duplex, as for example the
right handed conformation of B-DNA, is determined by the absolute configuration of
the D-deoxyribose sugar that attends every unit on each strand of the duplex. This
chiral influence is certainly over-determined considering that the structure of DNA is
highly cooperative.
In synthetic helical polymers the highly cooperative effect of monomers was shown
both theoretically and experimentally to allow far less chiral input than is found in
DNA to be capable of controlling helical sense2. For example, a helical polymer
constructed of very few chiral non-racemic chiral units disbursed among many achiral
units is adequate in a highly cooperative system to control the helical sense of large
portions of the chain (sergeant and soldiers experiment)3. In another approach, a
helical polymer constructed of a mixture of nearly racemic chiral units randomly
dispersed along the chain will take a helical sense of the units in the majority (majority
rule experiment)4. These studies have demonstrated that the higher the level of
cooperativity, the smaller is the chiral influence necessary to control helical sense. For
this reason these kinds of experiments yield a means to test the cooperative nature of a
polymer. However, this approach is not possible in DNA or for that matter in other
biological helical polymers because the chiral input is invariable and overwhelming in
enforcing one helical sense.
Peptide nucleic acids (PNA)5 and deoxyribonucleic acids (DNA)6 are similar to each
other in forming double stranded duplexes, which are maintained via base stacking and
Watson-Crick hydrogen bonding but differ from each other in the absence of charge
and in the absence of chiral information enforcing a preferred helical sense in the
duplex of PNA. These similarities and differences offer an opportunity to carry out

Chapter 3
80
experiments on PNA, which although relevant to the structure of DNA could not be
carried out directly on DNA.
PNA oligomers are controlled by parameters of fundamental biological interest5 while
yielding the possibility of addressing the question of cooperativity using the effect of
variable chiral input on helical sense excess .
Although unmodified PNAs are achiral molecules, they can form PNA:PNA duplex
showing helical structures in the solid state,7 with a peculiar structure called “P-helix”,
characterized by a rise in the base pair stacking similar to B-DNA (3.2 Å vs 3.4 Å of
B-DNA), but a much less pronounced twist angle (19.8° vs 36° of B-DNA), which
leads to a longer helix pitch (18 bp vs 10bp of B-DNA). In the structure of achiral
PNA:PNA duplexes, both helical handedness are observed in equal amounts with left-
and right-handed helices coaxially stacked. However, the presence of helical stuctures
indicates that the PNA naturally tend to adopt a chiral conformation in order to
maximize stabilizing interactions, in particular base stacking. It is also interesting to
note that in a PNA:DNA duplex described by our group,8 the conformation of the PNA
strand was conserved, and was similar to that of P-helix, while the structure of DNA
was distorted, being partly in A-type and partly in B-type conformations. This
suggests that the conformation assumed by the PNA is the more stabilized than that of
B-DNA.
The inventors of PNA, early understood the importance of chirality as a parameter
with a likely strong effect on the complexation of PNA with complementary sequences
of nucleic acids. The earliest experiments9 showed that terminal amino acids had a
significant effect on the helical sense character of PNA-PNA duplexes but with
restrictions of several factors including the amino acid used, the terminus of the PNA
strand holding the amino acid and the manner in which the two PNA strands were
associated with each other. They explored how the terminal chiral influence extended
through a series of oligomers from 8 to 12 units long. The result was reasonably
interpreted as arising from loss of influence on the helical sense of the PNA-PNA
duplex by the terminal amino acid after the 10-mer.
In a more recent paper10, the crystal strucutre of a PNA:PNA duplex bearing a C-
terminal lysine was described. Surprisingly, both right handed and left handed helices
were present again in equal amounts, while in solution an excess of one of the two was

Chapter 3
81
observed by the occurrence of a circular dichroism signal. It is interesting that a
similar difference between the solid crystal state and the solution state had been
observed in earlier studies by Pino and co-workers11 in Pisa on isotactic vinyl
polymers with pendant chiral side chains. That result was attributed to the crystal
forces favouring heterochiral packing of the helices, which then overwhelmed the
favouring of one helical sense by the side chain. In the PNA duplexes, through
molecular modelling, it was calculated that an excess of 96 to 4% left-handed to right-
handed helices should be present due to the differences in free energy, a result in line
with the observation of significant circular dichroism signals in the dissolved state.
Here we report on the properties of a series of oligomeric PNAs of closely related base
sequence to those studied previously9 but extended here from 6 to 19 bp, the latter
being the upper limit to what can be efficiently synthesized in fairly large quantitites.
This allowed us to have new insights in the propagation of helical structure far beyond
the previously reported limit. In an additional and related experiment, we have
evaluated the effect of helix propagation through self assembly of achiral PNA
segments using only one amino acid as inductor.The work reported here demonstrates
the complex cooperative issues involved in how chirality can be propagated in the
PNA duplexes.
This part of the work was carried out under the supervision of Prof. M. Green and in
collaboration with V. Jain at the Polytechnic University of New York.
3.2. Results
PNA Sequences Design. In 1995, Nielsen, Nordén and co-workers reported that an
increase in the CD signal was observed in a PNA duplex with terminal L-lysine
moiety in going from an 8mer to a 10 bp duplex after which the CD is unchanged as
the chain length is increased to a 12 bp duplex. These data, which were taken at
constant molarity of the oligomer so that the number of base pairs increased as the
oligomer length increased, seemed to indicate that L-lysine extends its effect until a
maximum of 10 base pairs after which it looses its influence. As a consequence, the
energy barrier for helix inversion was calculated to be included between 5 to 6kJ/mol
per base pair.

Chapter 3
82
To verify if this hypothesis can still be valid beyond the 12mer limit, a complete set of
PNA oligomers bearing an L-Lys or L-His residue at the C-terminus (Table 3.1) was
synthesized with the shorter ones having the same sequences as those described
previously and the longer one designed in order to have a balanced presence of
nucleobases. The PNAs containing L-lysine as terminal residues were synthesized in a
previous PhD thesis12 by V. Jain at the Polytechnic University in New York. All other
PNAs were synthesized in this work.
Table 3.1. Various PNA sequences utilized in the present work.
Length Chiral PNAa Complementary sequence
6 1-aa:H-ATCTAC-aa-NH2 C-1:H-GTAGAT-NH2
8 2-aa:H-TGATCTAC-aa-NH2 C-2:H-GTAGATCA-NH2
10 3-aa:H-AGTGATCTAC-aa-NH2 C-3:H-GTAGATCACT-NH2
12 4-aa: H-ACAGTGATCTAC-aa-NH2 C-4:H-GTAGATCACTGT-NH2
15 5-aa:H-GTGACAGTGATCTAC-aa-NH2 C-5:H-GTAGATCACTGTCAC-NH2
17 6-aa:H-CTGTGACAGTGATCTAC-aa-NH2 C-6:H-GTAGATCACTGTCACAG-NH2
19 7-aa:H-ATCTGTGACAGTGATCTAC-aa-NH2 C-7:H-GTAGATCACTGTCACAGAT-NH2
a aa = C-terminal amino acid ( L-Lys, L-His, L-Arg or L-Ac-lys)
Effects of the length and terminal amino acid. For this study, we used two different
amino acids: L-lysine and L-histidine, since they have different charges at pH = 7.0.
As lysine is frequently used as a solubility-enhancing group for PNA probes, we chose
the PNA-lysine system as benchmark sequence for our investigation. Considering the
importance of a conformational motion that has certain comparable elements to DNA
and the interest in helical reversals as limits to cooperativity in synthetic polymers3,4
we decided to investigate the effect of terminal amino acids on optical and other
properties over a wider range of PNA duplex oligomers. Therefore, a systematic study
was done by varying duplex length, amino acid side chain (L-Lys or L-His). The
Figure 3.1 shows the CD spectra at various lengths.

Chapter 3
83
Figure 3.1. CD spectra of various PNA:PNA duplexes (6-19 bp) bearing a C-terminal L-Lysine (a)
and L-Histidine (b). All spectra were recorded in water (pH = 6.9) at T = 22°C. 5µM strand
concentration was used.
In order to compare the CD signal induced by each of these duplexes, the CD
intensities were calculated on the basis of peak to peak values at the maxima (272nm)
and the minima (255nm). By accurately preparing the solutions used, comparison of
CD/µmol duplex can be precisely made as shown in Figure 3.2.
Figure 3.2. CD amplitude (A) in mdeg/uMol vs duplex length (6-19 mer). The data reported were
obtained from Figure 3.1. and normalised by duplex concentration.
-6
-5
-4
-3
-2
-1
0
1
2
3
220 240 260 280 300 320
Wavelength (nm)
CD
(m
deg
)
1-lys:C-1
2-lys:C-2
3-lys:C-3
4-lys:C-4
5-lys:C-5
6-lys:C-6
7-lys:C-7
A(amplitude)
-4
-3
-2
-1
0
1
2
3
220 240 260 280 300 320
Wavelength (nm)
CD
(m
de
g)
1-His:C-1
2-His:C-2
3-His:C-3
4-His:C-4
5-His:C-5
6-His:C-6
7-His:C-7
a) b)
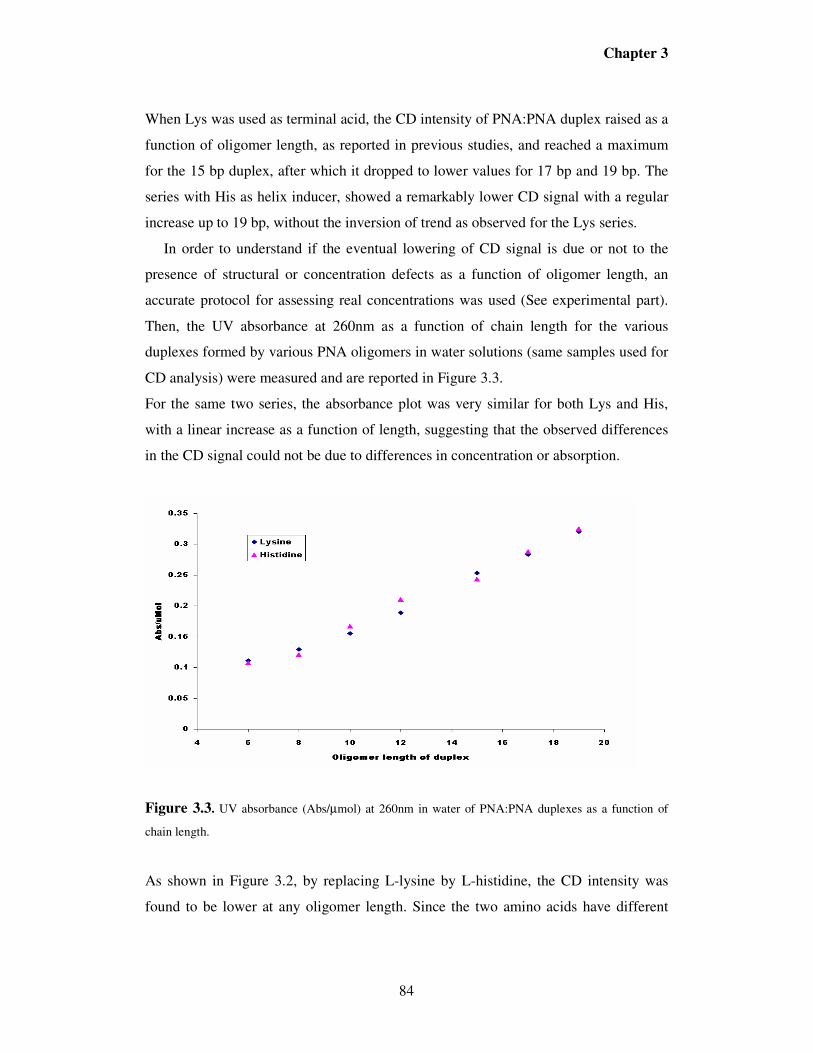
Chapter 3
84
When Lys was used as terminal acid, the CD intensity of PNA:PNA duplex raised as a
function of oligomer length, as reported in previous studies, and reached a maximum
for the 15 bp duplex, after which it dropped to lower values for 17 bp and 19 bp. The
series with His as helix inducer, showed a remarkably lower CD signal with a regular
increase up to 19 bp, without the inversion of trend as observed for the Lys series.
In order to understand if the eventual lowering of CD signal is due or not to the
presence of structural or concentration defects as a function of oligomer length, an
accurate protocol for assessing real concentrations was used (See experimental part).
Then, the UV absorbance at 260nm as a function of chain length for the various
duplexes formed by various PNA oligomers in water solutions (same samples used for
CD analysis) were measured and are reported in Figure 3.3.
For the same two series, the absorbance plot was very similar for both Lys and His,
with a linear increase as a function of length, suggesting that the observed differences
in the CD signal could not be due to differences in concentration or absorption.
Figure 3.3. UV absorbance (Abs/µmol) at 260nm in water of PNA:PNA duplexes as a function of
chain length.
As shown in Figure 3.2, by replacing L-lysine by L-histidine, the CD intensity was
found to be lower at any oligomer length. Since the two amino acids have different

Chapter 3
85
charges at pH = 7.0, These results suggest that the charge could play a fundamental
role.
In order to understand whether the electric charge could be of great importance in
increasing the CD intensity, we report in Figure 3.4, the CD amplitude normalized
with duplex concentration of His-PNA system at two different pH (7.0 and 5.0).
Although the study reported above was performed in pure water, this experiment on
the influence of the pH was carried out in sodium phosphate buffer in order to avoid
significant pH changes. However, the data obtained at pH = 7.0 were consistent with
those obtained in pure water.
0
0,2
0,4
0,6
0,8
1
8 10 12 14 16 18
Oligomer length of duplex
CD amplitude (A) mdeg/uMol
L-His at pH = 7
L-His at pH = 5
Figure 3.4. CD amplitude (A) in mdeg/uMol vs duplex length (10, 12, 15, 17 bp) of L-His-PNA:
PNA duplexes in 10 mM Phosphate buffer at pH = 7 and pH = 5. 5µM duplex concentration were used.
The CD signal was found to be dependent on the pH used. At pH = 7.0, at which His
side chain is deprotonated, the CD signal was lower than that at pH = 5.0 (side chain
protonated), and the difference between data at the two pHs increased as a function of
oligomer length, suggesting a cooperative effect able to amplify the initial small CD
difference.
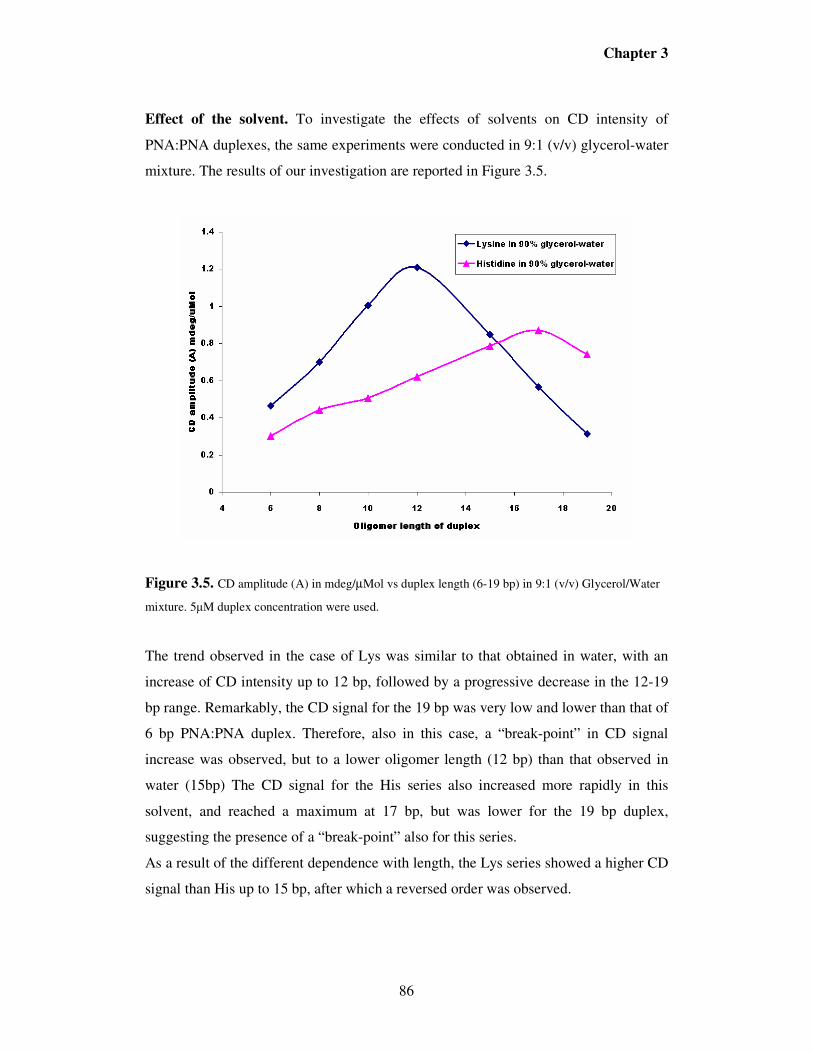
Chapter 3
86
Effect of the solvent. To investigate the effects of solvents on CD intensity of
PNA:PNA duplexes, the same experiments were conducted in 9:1 (v/v) glycerol-water
mixture. The results of our investigation are reported in Figure 3.5.
Figure 3.5. CD amplitude (A) in mdeg/µMol vs duplex length (6-19 bp) in 9:1 (v/v) Glycerol/Water
mixture. 5µM duplex concentration were used.
The trend observed in the case of Lys was similar to that obtained in water, with an
increase of CD intensity up to 12 bp, followed by a progressive decrease in the 12-19
bp range. Remarkably, the CD signal for the 19 bp was very low and lower than that of
6 bp PNA:PNA duplex. Therefore, also in this case, a “break-point” in CD signal
increase was observed, but to a lower oligomer length (12 bp) than that observed in
water (15bp) The CD signal for the His series also increased more rapidly in this
solvent, and reached a maximum at 17 bp, but was lower for the 19 bp duplex,
suggesting the presence of a “break-point” also for this series.
As a result of the different dependence with length, the Lys series showed a higher CD
signal than His up to 15 bp, after which a reversed order was observed.

Chapter 3
87
Therefore, the effect of the glycerol: water mixture was for both systems to produce
faster increase of the CD signal as a function of length, and to shift the “break-point”
to lower lengths.
Effects of the temperature on duplex and helix stability. To gain further insight into
the stability and conformation of induced helix in PNA/PNA duplexes, we performed
temperature-dependent CD and UV spectroscopy measurements on PNA:PNA
duplexes with different lengths (6-19 bp). In particular, the T1/2(CD) temperature, at
which half of the optical activity is lost and the UV melting temperature, at which 50%
of the duplex is dissociated were determined. T1/2(CD) was chosen as a parameter for
half-racemization since the complete racemization in most cases was overlapped with
melting process. The Figure 3.6 shows an example of UV (left) and CD (right) melting
curves obtained with 15 bp Lys-PNA:PNA duplex.
Figure 3.6.Examples of UV melting (Left) and CD melting (Right) of PNA: PNA duplex 5-Lys: C-5
(15 bp with Lysine).
It is worth noticing that the CD signal was completely lost before the complete melting
of the PNA:PNA duplex, suggesting that in this state, equal amounts of left- and right-
handed helices are formed, and thus that the helix “racemization” is a process distinct
from melting.

Chapter 3
88
For shorter duplexes, the two processes were not completely separated as in this case,
then we chose the T1/2(CD) (temperature at wich half of the initial CD signal is lost) to
evaluate the difference obtained for the two processes. The results for the Lys and His
oligomers are reported in Table 3.2.
Table 3.2. UV and CD data in water and 9:1 (v/v) glycerol-water. The UV melting temperature (Tm)
corresponds to half denaturation of the PNA duplexes. T1/2(CD) corresponds to 50% loss of optical
activity.
PNA duplexes in Water PNA duplexes in 90% Glycerol Oligomer
length Lysine Histidine Lysine Histidine
Tm(UV) T1/2(CD) Tm(UV) T1/2(CD) Tm(UV) T1/2(CD) Tm(UV) T1/2(CD)
6 31 27 26 25 30 <20°C 26 25
8 55 55 53 50 52 47 52 50
10 69 65 62 55 65 55 62 55
12 75 70 72 58 71 70 63 60
15 84 75 77 60 81 68 72 65
17 88 80 84 65 87 70 78 75
19 91 78 85 70 91 n.d. 81 70
The T1/2(CD) values were found to be always lower than the UV melting temperatures
(Tm), with the difference increasing as the oligomer length increase. The melting
temperature were not dramatically affected by solvent change, with a small
destabilizing effect.
The T1/2(CD) values were found to be lower in glycerol: water than in water for the
Lys series and higher or similar for the His series, but the latter effect can be ascribed
to the superposition of the “racemization” and melting processes.
Effects of the amino acid side-chain charge. According to the results reported above,
we decided to gain further insights into the contribution of the lysine side-chain
positive charge on PNA:PNA duplexes and helix stability. For our study, we
synthesized a set of PNA oligomers (8, 10, 17 bp) by replacing L-lysine with an Nε-

Chapter 3
89
acetylated-lysine moiety at the C-terminus; maintaining the PNA sequences invariable.
CD experiments and UV melting analysis were carried out using 5 µM strand
concentration in water. The results were compared to those obtained with positively
charged L-lysine-PNA system at the same chain length. CD spectra and UV melting
profiles for 8 bp and 10 bp Lys-PNA:PNA duplexes are given in Figures 3.7 and 3.8,
respectively.
Figure 3.7. Effects of the charge on CD spectra of PNA/PNA duplexes: comparison between
acetylated-lysine and lysine-PNA systems (8 bp, left)and (10 bp, right). All spectra were recorded in
water (pH = 6.9) at T = 22°C.
Figure 3.8. UV melting temperatures profiles of PNA/PNA duplexes: comparison between
acetylated-lysine and lysine-PNA systems (8 bp, left)and (10 bp, right). All spectra were recorded in
water (pH = 6.9).
The data clearly showed a significant drop in CD signal and a less steep melting
profile of acetyl-lysine suggesting that the positive charge has a large influence either
0.8
0.85
0.9
0.95
1
20 25 30 35 40 45 50 55 60 65 70 75 80 85
Temperature (°C)
No
rm.
Ab
s
Lys10mer
Ac- Lys10mer
0.8
0.85
0.9
0.95
1
20 25 30 35 40 45 50 55 60 65 70 75 80 85
Temperature (°C)
No
rm.
Ab
s
Lys8mer
Ac- Lys8mer

Chapter 3
90
on CD intensity or on the dissociation process.
Since acetylated lysine is able to be involved in hydrogen bonding, the present results
strongly suggest an involvement of specific interactions of the cationic amonium
group. This observation could support the presence of a specific cation-π interaction
between the positively charged amino group of lysine side-chain and the first base
pairs (G:::C) of the PNA/PNA duplex, as suggested, by Rasmussen et al10. This feature
was further evaluated by replacing L-lysine with L-arginine. The latter was chosen
because of its ability to give stronger cation-π interactions with nucleobases. In fact,
statistical studies13 have demonstrated that more than 54% of the cation-π interactions
in DNA-Proteins interactions involve an Arg and most of the Arg residues involved,
simultaneously make H-bonds with a contiguous nucleobase.
We therefore synthesized a set of PNA oligomers with different length (8, 10, 17 bp)
bearing an arginine unit at the C-terminus. Then, the CD spectra of the corresponding
PNA:PNA duplexes were recorded and the results of our investigation are summarized
in Figures 3.9a, 3.9b, 3.9c.
-12
-10
-8
-6
-4
-2
0
2
4
220 240 260 280 300 320
Wavelength (nm)
CD (m
deg)
3-Arg : C-3
3-Lys : C-3
3-His : C-3
b)-7
-6
-5
-4
-3
-2
-1
0
1
2
3
220 240 260 280 300 320
Wavelength (nm)
CD (mdeg)
2-Arg : C-2
2-Lys : C-2
2-His : C-2
a)

Chapter 3
91
Figure 3.9. Effects of the charge on CD spectra of PNA/PNA duplexes: comparison between
Arginine, Lysine and Histidine PNA systems at different lengths. 8 bp (a); 10 bp (b); 17 bp (c). All
spectra were recorded in water (pH = 6.9) at T = 22°C.
An important observation can be drawn out from the CD spectra reported above.
Indeed, contrary to what happened in the replacement of Lys with Ac-Lys, the
introduction of an arginine residue strongly enhanced the CD signal for all the
oligomers studied. This supports the idea of a specific cation-π interaction between the
arginine side-chain and the first base pair.
We also sought to determine the effect of the terminal amino acid on duplex
stability by comparing the UV melting temperatures of various PNA duplexes with
lysine, arginine, acetyl-lysine and histidine at three different lengths (8, 10, 17 bp).
The data are reported in Table 3.3 below.
Table 3.3. UV melting temperatures of Lys-, Ac-lys-, His- and Arg-PNA systems in water
UV Melting Temperature (Tm); °C Oligomer
Length Lys Ac-Lys His Arg
8 55 53 53 53
10 69 64 62 63
17 88 84 84 83
The Tm values for positively charged Lys were found to be always higher than those
obtained for both uncharged Ac-lys and His (almost similar). In the case of the
c)
-10
-8
-6
-4
-2
0
2
4
6
220 240 260 280 300 320
Wavelength (nm)
CD (mdeg)
6-Arg : C-6
6-Lys : C-6
6-His : C-6

Chapter 3
92
arginine system, although a higher CD signal was observed, as shown previously, the
Tm values were very close to those of Ac-Lys and His. This apparent paradox would
be clarified by thermodynamic analysis of melting curves.
Thermodynamic data. By comparing the UV melting profiles, we realized that the
shape was strongly dependent on the nature of the amino acid side chain as shown in
Figure 3.10. Therefore, we also performed a thermodynamic study of UV melting
curves in order to determine the thermodynamic parameters (∆Η° and ∆S°) of
PNA:PNA duplexes. From the temperature dependence of some equilibrium
properties, such as α, which is the fraction of single strands in the duplex state, we
have calculated the transition enthalpy (using van’t Hoff equation with the assumption
of constant enthalpy) and the transition entropy by assuming the “two-state model” for
the transition process, according to the model of Marky and Breslauer.14 An example
of Tm curve fitting is reported in Figure 3.11.
0,8
0,85
0,9
0,95
1
20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95
Temperature (°C)
Norm. Abs
3-Lys: C-3
3-His: C-3
Figure 3.10. Normalized melting curves of 10 bp Lys-PNA:PNA duplex (3-Lys: C-3) and 10 bp His-
PNA:PNA duplex (3-His: C-3).
6
8
10
12
14
16
18
20
0.0028 0.00285 0.0029 0.00295 0.003 0.00305 0.0031
1/T
Log K
0.15
0.155
0.16
0.165
0.17
0.175
0.18
0.185
0.19
0.195
0 20 40 60 80 100
Temperature (°C)
Norm. Abs
measured
calculated

Chapter 3
93
Figure 3.11. Plot of measured absorbance and calculated absorbance vs the temperature (Left panel ).
Plot of the natural logarithm of the equilibrium constant (Log K) vs the reciprocal temperature (1/T)
(right panel) for 10 bp Lys-PNA:PNA duplex (3-Lys:C-3). 5 µM duplex concentration was used.
The plot of the natural logarithm of the equilibrium constant (right panel, Figure 3.11)
shows a linear dependence of Log K with 1/T. From these data, values of ∆H° and ∆S°
could be obtained. The overall results of this study are summarized in Tables 3.4 and
3.5.
Table 3.4. Thermodynamic data for Lys-PNA:PNA (8-19 bp); Ac-Lys-PNA:PNA (17 bp) and Arg-
PNA:PNA (17 bp) duplexes
Table 3.5. Thermodynamic data of His-PNA:PNA duplexes (8-19 bp)
Duplex length ∆Η°∆Η°∆Η°∆Η°
(Κ(Κ(Κ(Κcal/mol)
∆∆∆∆S°°°°
((((Cal/mol.K)
∆∆∆∆G°298Κ°298Κ°298Κ°298Κ
(Κ(Κ(Κ(Κcal/mol)
8 -60.9 -160.6 -13.1
10 -89.1 -236.4 -18.7
12 -97.1 -253.8 -21.4
15 -117.1 -304.3 -26.4
17 -120.2 -307.1 -28.7
19 -122.8 -290.2 -36.3
17 (Ac-Lys) -93.5 -236.6 -22.9
17 (Arg) -122.6 -319.6 -27.3
Duplex length ∆Η°∆Η°∆Η°∆Η°
(Κ(Κ(Κ(Κcal/mol)
∆∆∆∆S°°°°
((((Cal/mol.K)
∆∆∆∆G°298Κ°298Κ°298Κ°298Κ
(Κ(Κ(Κ(Κcal/mol)
8 -40.0 -100.6 -10.0
10 -50.2 -124.3 -13.2
12 -83.9 -218.0 -18.9
15 -87.2 -228.0 -19.3
17 -93.9 -237.1 -23.2
19 -103.5 -267.7 -23.7

Chapter 3
94
As expected, the PNA:PNA duplex formation was characterized by negative ∆H° and
negative ∆S° contributions. A difference in the enthalpic contribution varied according
to the terminal amino acid and to its charge. The ∆H° varied in the order:
Arg > Lys > His ≈ Ac-Lys for 17 bp duplex, suggesting a dependence on amino side
chain and structure. The ∆S° varied in the same order, showing enthalpy-entropy
compensation.
Propagation of Helicity through Self-assembly. We were further interested to the
extension of chiral information induced by the terminal L-lysine over 19 mer chain
length. However, there are limitations in the synthesis to go to high molecular weight
PNAs and therefore, we have designed a new type of structure based on self assembly
of PNA segments, named “Brick type aggregate”. The main advantage of this model is
the possibility to extend the helicity through longer PNA/PNA duplexes via self-
assembly. A schematic representation of this model is given in Figure 3.12.
Figure 3.12. Brick type model:
The PNA sequences used for this study are reported below:
2-lys: H-TGATCTAC-(L-Lys)-NH2 (A) C-6b: H-TGATCTACCTGTGACAG-NH2 (BA)
C-6: H-GTAGATCACTGTCACAG-NH2) (A’B’) C-2: H-GTAGATCA-NH2 (A’)

Chapter 3
95
According to this model, a pre-organized left-handed helix can be formed by adding
the achiral 17mer (A’B’) to the chiral 8mer. The resulting CD signal is similar to that
obtained previously with 8mer PNA duplex. A further increase in CD signal was
observed by adding a new 17mer (BA) in which B is complementary to B’. The
resulting CD spectra are reported in Figure 3.13.
Figure 3.13. CD spectra of 8, 17, 25 base pairs PNA/PNA duplexes obtained through self-assembly.
All spectra were recorded in water (pH = 6.9) at T = 22°C using 5 µM strand concentration.
The CD intensity measured as the difference between the maximum at 272 nm and the
minimum at 253 nm is reported as a function of duplex length in Figure 3.14, and
compared with the data for the Lys series in the same solvent.
Figure 3.14. Comparison between self-assembled PNA duplexes and covalent PNA double-stranded
25mer
17mer
8mer

Chapter 3
96
The CD signal of the self-assembled systems increased with length more slowly than
that of the covalent duplexes, and no “break-point” was evident. Although the present
design did not allow to the bases pairs continuously, the progressive increase seems to
be regular. Furthermore, the CD intensity increased upon addition of achiral
components (A’B’, BA, and A’), suggesting a propagation of induced helicity through
non-covalent interactions far beyond the previously stated limit.
3.3. Discussion
Helicity induced by C-terminal Lys in long PNA:PNA duplexes is limited.
Since PNA backbone is achiral, PNA duplexes can be expected to form as a racemic
mixture of right and left handed helices15. Initially, it was thought that the presence of
a terminal lysine at the carboxy terminus of both PNA strands would be important in
establishing a preferred helical sense. Later studies however showed that only one of
the carboxyl terminal lysines is necessary and sufficient to generate preferred chirality
(equivalent to “sergeant and soldiers” behaviour). Since from previous work by
Nielsen’s group9 it was found that stabilization of a preferred helical sense is obtained
if the base next to lysine is either G or C, the same base pair was used as the first PNA
monomer in this study.
Based on Nielsen’s study, if the duplex helical conformation were maintained
throughout the longest oligomer studied (12 bp), loss of chiral influence of the
terminal amino acid would have to arise from the intervention of a helical reversal,
which suggests that a reduction in CD intensity would be observed rather than a
leveling off. In addition the results pointed to a structural characteristic of the PNA
that seems surprising in the light of the breaking of hydrogen bonds and twisting
motions necessary. A far higher level of cooperativity seems more reasonable.
Although not directly comparable, the reversal in helical sense in the change from B to
Z-DNA is attended by a barrier in the range of nearly 16.8 kJ/mole per base pair,
which would lead to far less frequent reversals than 1 in 10 as in the case of PNA.
Our results on the PNA-lysine duplex system indicate, using higher oligomers than
those reported by Nielsen and Nordén9, that lysine extends its control until 15 base
pairs after which it probably loses its influence as observed from the drop in CD signal
(Figure 3.2). This result is consistent with observations on other helical polymers. In

Chapter 3
97
fact, previous studies on model helical polymers with a terminal chiral group show one
preferred handedness until a helical reversal occurs within the same chain as the
degree of polymerization increases. This causes then not a limit in the CD signal but
rather a decrease as the other helical sense is populated.
As we can see, the UV data (Figure 3.3) show a regular linear increase of the UV
absorbance at 260 nm as the oligomer length of duplex increases demonstrating that
the contribution of each base pair to the overall absorbance of the duplex is almost the
same. On the other hand, the values of absorbance measured at room temperature in
both systems (lysine and histidine) are almost similar. Both of these observations
clearly demonstrate that the differences in CD signals are not due to a defect in duplex
concentration.
One may conclude therefore that the loss in the CD signal could be attributed either to
a helix inversion occurring within a single duplex or the presence of different duplexes
with helical senses opposite with the majority of duplexes following the helical
preference of the L-lysine. These possible mechanisms able to explain the drop of CD
signal with increase of the chain length are reported in Figure 3.15.
L e f t - h a n d e d ( L - H )
R ig h t - h a n d e d ( R - H )
H e l ix in v e r s io n
L - L y s
L - L y s L - L y sL - L y s L - L y s
R - H L - HR - H L - H
A
B
Figure 3.15. Possible mechanisms for the lowering of CD signal with increasing chain length: Helix
inversion (A); shift of the equilibrium between left-handed (L-H) and right-handed (R-H) helices (B).
In these simplified models, if a helical reversal occurs (Figure 3.15.A) when the chain
length exceeds 15, it would mean that the helical PNA:PNA structure is stable up to a

Chapter 3
98
definite length, after which steric constraints prevent the following monomers from
adopting the proper conformation needed for the formation of a left-handed helix.
Indeed a transition from right- to left-handedness has been observed for a PNA in the
solid state, though in a completely different case16. If this interpretation is true, the
longer PNA:PNA duplexes might serve as a simplified model of the transition from
right handed B-DNA and left handed Z-DNA.
In the second hypothesis the equilibrium between the two diastereomeric complexes
(Right- and Left-handed helices) of the PNA:PNA duplex could be shifted more
towards right-handed helices (R-H) as the length of the chain is increased (Figure
3.14.B). It interesting to note however that a levelling effect (which could be expected
from previous interpretations) is not observed. In molecular terms, it could be due to
the fact that an helical structure of sufficiently high stability could be formed in these
PNAs in the other helical sense without involving the lysine residue, or with the effect
of the “seeding” L-Lys chiral center becoming more and more negligible in the overall
stability as the chain length increases, so that differences in the free energy of the two
diasteromers could be relatively less important.
These results reported have two major consequences: the first is that the effect of a
single chiral center (L-lysine) on the overall helicity is limited in space and has its
threshold at 15 base pairs in water. The second is that if PNA is considered as a
precursor of nucleic acids, a prebiotic “seeding” of chirality is most likely to have
occurred in short oligomers, while for longer ones, new stereogenic centers should
have be inserted further down in the chain (for example with monomers derived from
chiral amino acids).
Solvent effects
It has been reported that glycerol tends to weaken a DNA:DNA duplex17,18,19,20.
Glycerol is a solvent with a lower dielectric constant (46.5) than water (80) and thus
causes an increased repulsion in the phosphate backbone of DNA. In the case of
PNA:PNA duplexes, due to the absence of negative charges on the backbone this
effect is absent. We have investigated the solvent effect of glycerol in the PNA:PNA
duplex to explore the consequence of the absence of charge along the backbone of the
helix.

Chapter 3
99
It is also well-known that polyols stabilize the native structure of some proteins21, 22,
which is relevant for PNAs with their pseudo-peptide backbone. The polyols do not
seem to interact directly with the native structures of proteins. The stabilization of
proteins23, 24 may be understood in terms of the formation of water-glycerol structures
around the protein molecule and the lessened capacity of glycerol compared to water
to form hydrogen bonds with the various amino acids present in the protein, leading to
a decrease in the hydrogen-bond rupturing nature of the medium. However, the main
emphasis had been laid on the solvation layer of the water glycerol mixtures on
proteins25. Results in the literature indicate that glycerol reduces the solubility of the
hydrophobic parts of the protein thereby increasing the hydrophobicity of the protein.
The experimental data obtained in glycerol:water mixture for shorter duplexes show
that the CD intensity is still lower in the case of histidine if compared to that obtained
with lysine. In glycerol, the induced helicity in PNA:PNA duplex is extended only
until 12 base pairs for L-lysine and 17 base pairs in the case of PNA-histidine system.
One important observation that can be drawn from lysine data in glycerol is the high
rate of decrease of the CD intensity from 12 bp to 19 bp for which the CD signal is
almost lost. It seems that the stronger is the helical induction, the shorter is the “break
point” length. The same holds true in the comparison between the water and glycerol
data (Figure 3.2 and 3.5). CD intensities are higher in glycerol if compared to that in
water and correspondingly, the “break point” is at shorter oligomer length. This can be
due to the lower dielectric constant of glycerol, which makes the interaction at C-
terminus more intense if it is of electrostatic nature.
An interesting comparison that could be made between the two solvents is the different
abiltity of the PNA:PNA duplexes to keep their preferential helicity with the increase
of the temperature. This aspect will be discussed below.
C-terminal amino acid influence: charge effects and ππππ-cation interactions
The comparison of the data obtained using either Lys or His for seeding of chirality
clearly show a dependence of both helicity and stability on the amino acid side chain
for all the oligomers studied.
According to the results shown in Figure 3.4, at acidic pH (pH = 5.0), the state in
which L-histidine is positively charged, the CD intensity is higher than that obtained at

Chapter 3
100
neutral pH (uncharged state) but is still lower if compared to positively charged L-
Lysine (Figure 3.2 vs Figure 3.4). Therefore, there should be a specific interaction (i.e.
hydrogen bond, dipole-dipole, cation-π,…) between the lysine side chain and the PNA
sequence which imposed a preorganization to the system higher than that obtained
with histidine. Correspondingly, and maybe as a consequence of the lower
preorganization of PNA-histidine system, there is a more regular dependence of the
CD spectrum as a function of length (see Figure 3.2).
These data, together with solvent dependent behaviour, strongly support the
hypothesis of the electrostatic nature of the “seeding” interaction.
Many fundamental cellular processes, such as control of gene expression, cell division
and growth, are managed by proteins that bind DNA. A prerequisite for
comprehending these processes in their immense complexity involves a thorough
understanding of the nature of the interactions between amino acids and DNA
nucleobases. The well-described electrostatic and hydrogen bond intermolecular forces
are clearly essential in conferring stability and specificity to protein-DNA complexes,
but other non-covalent interactions, in particular those involving aromatic moieties,
appear also to yield non-negligible contributions.
A growing number of experimental and theoretical studies has been reported26,27 and
have emphasized the existence of favourable interactions between positively charged
groups and π-aromatic systems. This type of non-covalent binding force, named
cation-π interaction has been assumed to play an important role in protein structure28
as well as in biomolecular association processes such as ligand-antibody binding29 and
receptor-ligand interaction30. In DNA-binding proteins, cation-π interactions between
aromatic rings of nucleobases and positively charged amino acid side-chains such as
lysine or arginine (Figure 3.16) have recently been shown to be quite common at the
protein-DNA interface.31,32 These interactions involve preferentially G bases, which
yield the most favorable energy according to quantum mechanics calculations13. The
stabilization energy of the different H-bonded Arg-DNA base systems was evaluated.
Arg-G system has revealed to be the most stable ones with energies average value of -
29.5 kcal/mol. Hence, the energy of cation-π interaction between arginine and guanine
has been estimated to be about 1/3 to1/4 of that of the accompanying H-bond.

Chapter 3
101
Figure 3.16. Cation–π interaction between CZ of Arg546 and 5-member ring of G23 in the protein–
DNA complex
Furthermore, in an earlier study, Rasmussen et al10 have investigated the influence of a
chiral amino acid on the helical handedness of PNA in solution and in crystals. Their
results shown that, although in the crystal structures there were no significant
interactions between the lysine residue and the remaining PNA molecule (an equal
amount of left- and right-handed helices was obtained), in solution, the lysine side
chain displays a coiled conformation with the positively charged amino group
interacting with the nucleobase (guanine) closest at C-terminus of PNA, via a contact
cation-π interaction. From molecular mechanic calculations data, the most obvious
explanations for chiral induction by L-lysine in solution were interaction with either (i)
the backbone carbonyl oxygen atom of the second last C-terminal PNA-unit, (ii) with
the linker carbonyl oxygen atom, or (iii) with the nucleobase of the C-terminal PNA-
unit.
Therefore we have further investigated the influence of the amino acid side chain
charge using a lysine residue deprived of its charge and an arginine residue.
The data reported in Figures 3.7 and 3.8, indicate that the contribution of the
electrostatic force is non-negligible and can affect either the CD intensity (Figure 3.7)
or the melting curve shape and duplex stability. The Lys-PNA/PNA has a sharper
melting profile (Figure 3.8), while those of both His-PNA/PNA (Figure 3.10) and
AcLys-PNA/PNA (Figure 3.8) are broader, suggesting again different enthalpy-
entropy contribution as observed for the His oligomers (vede infra).

Chapter 3
102
According to the hypothesis on cation- π interaction, the spectra reported in Figure 3.9
show that the CD intensity is always higher in the case of arginine if compared to
those exhibited by both lysine and histidine. This further suggests that, among other
interactions, cation-π interaction seems to be important in enhancing the strength of
the helix induced by the terminal amino acid. Therefore, not only the presence of a
positive charge, but also the type of group involved is strongly affecting the interaction
generating helicity in PNA:PNA duplexes, and the order observed is in line with what
expected from π-cation interactions.
PNA:PNA melting and “racemization “ processes.
It was expected that the incorporation of amino acids at the C-terminus of PNA would
have no significant effect on duplex stability. Surprisingly, we observed that the UV
melting temperatures is always higher in the case of lysine if compared to the PNA-
histidine system.
The temperature dependence of the CD intensity and UV absorbance has also been
investigated by measuring the temperature at which half of duplex is lost and the UV
melting temperature (Table 3.2). It is important to note that T1/2(CD) is always similar
or lower than the UV melting temperature and becomes significantly lower for the
higher oligomers. The example reported in Figure 3.6 (for 15 bp) is indicative of this
behaviour. In fact, in the UV measurements a typical melting curve is observed with
Tm of 84°C at which half of the PNA:PNA duplex is dissociated to single strands.
However, at the same temperature, the CD signal is lost. This cannot be due to the
dissociation of the duplex (which would lead to 50% of the CD signal, T1/2(CD) =
75°C), but rather to the “racemization” of the helix which occurs before melting as
depicted in Figure 3.17.
Figure 3.17. Equilibra involved in the racemization / melting processes.
aaPNA:PNA (L-H)
aaPNA:PNA (R-H)
aaPNA + PNA

Chapter 3
103
This behaviour has been observed for longer PNA duplexes, while for short oligomers
the racemization process is overlapped to the duplex dissociation and cannot be
observed separately. Another observation from the data reported in table 3.2 concerns
the values of T1/2(CD) for longer oligomers of Lys-PNA:PNA duplexes. Since 17, 19
bp in water and 15, 17, 19 bp in water-glycerol show the reduced CD intensity at room
temperature, if this was due to the labilization of the helix induced by the
unconstrainted terminal part (Hypothesis B, Figure 3.15), a racemization at lower
temperature will be expected. On the contrary, except for the 19 bp lysine in glycerol,
for which the CD signal is almost lost at room temperature, the T1/2(CD) is higher or
similar; therefore, the helix is not destabilized in this case. This strongly supports the
hypothesis (Hypothesis A, Figure 3.15) for which the helix inversion occurs for longer
oligomers.
Furthermore, the T1/2(CD) is always lower in the case of histidine. This means that
there is a specific interaction between the lysine residue and the PNA duplex, which
can strongly affect both the stability of the duplex and the stability of the helix.
Some comments can be made about the solvent effect on the melting temperatures. A
recent study33 reported that the presence of a large amount of an aprotic non-polar
organic solvent doesn’t dramatically destabilize the PNA:PNA duplexes. The same
effect is now observed in this study for the first time in the case of a protic polar
organic solvent such as glycerol, which has no destabilizing effect in Lys-PNA
duplexes and only a small destabilizing effect in the case of His-PNA:PNA duplexes.
A different behaviour is observed for T1/2(CD) which is significantly lower for lysine
and similar or higher for histidine in the organic solvent (for longer oligomers).
As mentioned above, an important comparison between the two solvents is the
different ability of the PNA:PNA duplexes to keep their preferential helicity with the
increase of the temperature, a property which could be important in view of the use of
PNAs as optically active materials. Since PNAs are relatively flexible molecules, this
effect could be a combination of both differential solvation and of different
conformations of the PNA:PNA duplexes.
Further confirmation of the effect of the charge is given by melting data concerning
the comparison of Arg, Lys, His and AcLys PNA in Table 3.3. From these data, the
UV melting temperatures were found to be higher in the case of lysine system if

Chapter 3
104
compared to N-acetyl-lysine and histidine; demonstrating that the presence of the
charge also increases the stability of the PNA:PNA duplex. We expected this
stabilizing effect to be stronger in the case of arginine; surprisingly, the melting
temperature values were very close to those obtained in the case of histidine and
acetyl-lysine suggesting probably an unusual behaviour for the lysine system. This
anomalous behaviour could be explained by analysing the thermodynamic
contributions to the melting process.
Thermodynamic data analysis
Analysis of the UV melting curves according to the literature method of Marky and
Breslauer14 (Tables 3 4 and 3.5) indicated that the formation of PNA:PNA duplexes, as
expected, is caracterized by a large favorable (negative) ∆H° and a large unfavorable
(negative) ∆S°, both increase with the increase of the duplex length. The His-
PNA:PNA duplexes have a lower favorable enthalpic term and a lower unfavorable
entropic term than those observed for Lys-duplexes. This is clearly visible in the
different shape of the melting curves (as an example, the melting curves of 10 bp His
and 10 bp Lys are reported in Figure 3.10). This enthalpy-entropy compensation
indicates that a specific (thus ordering) interaction is most likely to occurr in the case
of Lys.
The apparent paradox of lower Tm observed for Arg-PNA compared to that of Lys-
PNA, in spite of the higher helical induction of the former can also be explained if we
analyze the UV melting profiles by means of the thermodynamic model.14 In fact, by
this method it was calculated that the ∆H° for the duplex becomes more negative in the
series: Ac-Lys ≤ His < Lys < Arg; and ∆S° becomes more negative in the same order.
For example, for the 17 mer duplex the ∆H° values were -93.4 Kcal/mol for Ac-Lys, -
93.9 kcal/mol for His, -120.2 kcal/mol for Lys and -122.6 kcal/mole for Arg.
However, the large negative term observed for arginine is compensated by a more
negative ∆S° value, thus producing melting temperature similar to histidine. These
results are in agreement with the occurence of the interactions between the amino acid
side-chain and the terminal nucleobase which imposes a more tight conformation with
more intense stacking interactions and a higher degree of order.

Chapter 3
105
Analysis of the thermodynamic contributions of CD melting curves allows to
separately evaluate the equilibrium between the two diatereomeric form L-H and R-H.
The CD vs temperature profiles suggest that, assuming a two state model for the
equilibrium between the helices R-H and L-H, the latter is enthalpically favoured,
since the rise in temperature shifts the equilibrium towards the R-H form, as observed
for the 15, 17, 19mer series for lysine system. Although it is not possible to exactly
infer the ∆H of this process, since it is not possible to establish the enantiomeric
excess (ee) of L-H helix at room temperature, it is possible to establish that similar
values would be obtained for 15-19mer, given any guess value of ee. Therefore, this
suggests that a labilization of the helical preference in the terminal part is not
observed, then supporting the hypothesis A (Figure 3.15). This enthalpic contribution
is higher for lysine than for histidine, and is accompanied by an unfavorable (negative)
∆S° for the transition from R-H to L-H. Therefore, under these conditions, an
inversion of helicity should be observed by raising the temperature, although in the
present case, the observation of this phenomenon is prevented by the subsequent
melting process.
Long- range propagation of helicity in self-assembled duplexes.
Based on the self-assembly experiment (Figures 3.12, 3.13 and 3.14), it is clear that
the CD intensity increases as a function of the chain length suggesting that the helicity
can propagate through gaps in a duplex composed of various segments.
Several points can be inferred from this experiment: First of all it is worth noticing that
the addition of an achiral PNA (BA) to a preformed duplex (PNA A-PNA A’B’)
increases the CD signal (Figure 3.14), suggesting that the preferential handedness is
retained also through non-covalent assembly. Therefore, the “seeding of chirality” can
be propagated also by means of achiral parts to the helix.
Secondly, the behavior of this model helps to clarify the duplex models described in
the previous paragraphs. In fact, if a labilization of the helicity in the terminal part
would have been produced (model B in Figure 3.15), or a loss in the chiral influence
would have occurred, as previously stated, the addition of achiral components would
not be able to propagate helicity. However, in the self-assembled model, going from
the duplex with 8 base pairs (PNA A –PNA A’B’) to the 25-base pair (containing all

Chapter 3
106
four components) there is a significant increase in the CD signal. Therefore this
evidence supports the idea that propagation of chirality can be obtained for PNA with
a C-terminal lysine residue far beyond the previoulsy assessed limit, and that the
inverted trend observed for the lysine-contaning duplexes is not due to labilization or
loss of chiral influence, but rather to constraint within the PNA duplex which impose a
helix inversion.
Furthermore, the increase of the CD signal as a function of length is lower in the non-
covalent duplex (brick type) than in the covalent case; since there is no base gap in the
former, this result suggests that a relaxation through the backbone gaps can occurr and
this is also responsible for the lack of an inverted trend in helicity. Therefore a “break
point” has not been detected.
Finally, this model can help to study the propagation of chirality in self-assembled
PNA structures which can be considered as nanotechnological objects of
programmable length and shape. Further studies are currently in progress to further
extend this model to very long self-assembled PNA:PNA duplexes.
3.4. Conclusions
In the present systematic study, we have extended the view of PNA/PNA duplexes as
models for interactions occurring in the natural nucleic acids, in particular as far as
their helical shape is concerned. Our results indicate that the side-chain of a terminal
amino acid affects the helical conformation, depending on both size and charge in
agreement with a previously proposed cation-π interaction10. The data obtained
showed unexpectedly that the CD intensity in water increases until 15 base pairs after
which an inverted trend is observed, while in the case of histidine, although the CD
intensity was lower than that obtained for lysine system, no inversion of trend was
observed in the range 6-19 base pairs. The melting data indicate that T1/2(CD) is
always similar or lower than the UV melting temperature. This differences becomes
more significant for the higher oligomers, due to the racemization of the helix which
occurs before melting temperature. This behaviour has clearly been observed for
longer PNA duplexes, while for short oligomers the racemization process is
overlapped to the duplex dissociation and cannot be observed separately, therefore
could not be evaluated in previous studies. Furthermore, T1/2(CD) is always higher or

Chapter 3
107
similar as the length increases from 15 to 19 base pairs, demonstrating that the helix is
not destabilized. This strongly supports our hypothesis on helix inversion which
occurs for longer oligomers.
The solvent influences the CD intensity, producing higher signals for the lower
dielectric constant glycerol/water system due to the higher degree of organisation of
the duplex. A higher CD intensity is associated with a “break point” after which the
helicity decreases. This is particularly pronounced in the case of Lys-PNA:PNA in
glycerol/water 9:1 (v/v), for which the 19 bp has a very weak CD (Figure 3.5). Most
interestingly, the solvent has an effect also on the helix racemization temperature. This
in turn suggest a definite role of the solvent in determining the helical shape of these
duplexes.
Furthermore, the data show that the thermal stability (measured by melting
temperature) of the PNA:PNA duplex is not always higher if the terminal amino acid
is a stronger helical inducer (arginine vs. lysine) but a careful analysis of the
thermodynamic parameters shows that a more favorable enthalpic contribution is
accompanied by a more unfavorable entropic contribution, according to the more
favorable cation-π interaction proposed.
We have also demonstrated that helicity can propagate through achiral segments in
self-assembled PNA duplexes. However, the increase of the CD signal as a function of
length is lower than in the covalent case, suggesting a relaxation through the backbone
gaps. This propagation was achieved up to 25 base pairs, suggesting that the limitation
of the propagation of helicity previously proposed has to revised. The limitation is
probably due to the inversion of helicity induced by the constraints in the covalent
bonds of the PNA backbone which are not present in the self-assembled duplexes.
Finally, at least with these simple models, one of the characteristics needed for the
amplification of chirality in macromolecular prebiotic systems, that is helical stability,
has been fully investigated, pointing out some constraint and effects that should be
considered when proposing theories based on PNA or PNA-like molecules as potential
primordial precursors of genetic systems, in particular how a single stereogenic center
can induce chiral double helical structures.
3.5. Experimental section

Chapter 3
108
General information. Reagents and solvents were purchased from ASM Research
Chemicals, Sigma-Aldrich, Fluka, Applied Biosystems and used without purification.
DMF was dried over 4 Ǻ molecular sieves. TLC was run on Merck 5554 silica 60
aluminium sheets. Reactions were carried out under nitrogen. NMR spectra were
obtained on a Brucker 300 MHZ spectrometer. δ-values are in ppm relative to DMSO-
d6 (2.50 ppm for proton and 39.5 ppm for carbon).
Synthesis of Boc-Lys(ac)-OH. Boc-Lys-OH (100 mg, 0.41 mmol) was dissolved in
acetic anhydride (2 ml, 21.2 mmol) and the reaction mixture was allowed to stir for 1
hour at room temperature. The reaction was monitored via TLC. After 1 hour, the
excess of acetic anhydride was evaporated. The residue was dissolved in CH2Cl2 and
transferred to a separatory funnel and washed twice with saturated potassium hydrogen
sulfate and saturated sodium hydrogen carbonate (2 times). The organic phase was
dried over Na2SO4, filtered and evaporated under reduced pressure to afford 80 mg
(68% yield) of the product as a colorless foam.
1H NMR ( 300 MHz, DMSO-d6 ): δ = 11.75 (s, br, 1H, COOH), 7.79 (s, br, NH-
Boc), 4.26-4.30 (m, 1H, α -H), 2.97-3.02 (m, 2H, CH2-NH lysine side chain), 1.91 (d,
2H, CH-CH2- lysine side chain), 1.77 (s, 3H, CH3 acetyl group), 1.30-1.50 (m, 4H,
CH2CH2 Lysine side chain), 1.37 (s, 9H, (CH3)3 Boc). 13
C NMR ( 75.4 MHz, DMSO-d6): δ = 174.10, 171.88, 155.45, 83.21, 54.88, 38.10,
30.27, 28.86, 28.06, 23.13, 22.40.
PNA Oligomers Synthesis. Boc-protected PNA monomers were purchased from
Applied Biosystems. PNA oligomers were synthesized by standard Boc and Fmoc (in
the case of histidine) solid-phase synthesis protocols using MBHA and Rink amide
resin, respectively. The synthesis was performed on an ABI 433A Peptide Synthesizer
(Applied Biosystems). Chiral PNA oligomers were synthesized by incorporating
manually an L-amino acid ( L-lysine, L-histidine, L-Nε-acetyllysine or L-arginine) at
the C-terminus of each oligomer. Upon completion of the last monomer coupling,
PNA oligomers were manually cleaved from the resin using TFA/TFMSA/m-cresol/
thianisole mixture (6:2:1:1) and precipitated with ether. The crude PNAs were purified
by RP- HPLC with UV detection at 260 nm. Semi-prep column C18 (5 microns, 250 x

Chapter 3
109
10mm, Jupiter Phenomenex, 300 A ) was utilized, eluting with water + 0.01% TFA (
eluent A) and the mixture 60: 40 of water / acetonitrile + 0.01% TFA (eluent B);
elution gradient: from 100% A to 100% B in 50 min, flow: 4 ml/min. The resulting
pure PNA oligomers were characterized by MS-ESI with gave positive ions consistent
with the final products.
2-Ac-Lys: MW = 2330.0
m/z = found 1166.2 (calc 1166.0; MH22+); found 778.0 (calc 777.7; MH3
3+); found
583.7 (calc 583.5; MH44+).
3-Ac-Lys: MW = 2897.0
m/z = found 967.8 (calc 966.7; MH33+); found 725.4 (calc 725.3; MH4
4+); found 580.6
(calc 580.4; MH55+).
6-Ac-Lys: MW = 4790
m/z = found 1198.4 (calc 1198.5; MH44+); found 959.0 (calc 959.0; MH5
5+); found
799.3 (calc 799.3; MH66+); found 685.2 (calc 685.3; MH7
7+).
1-His: MW = 1739.7
m/z = found 871.0 (calc 870.9; MH22+), found 581.2 (calc 580.9MH3
3+); found 431.8 (
calc 435.9; MH44+).
2-His: MW = 2297.0
m/z = found 1150.0 (calc 1149.5; MH22+); found 767.0 (calc 766.7; MH3
3+); found
575.5 (calc 575.3; MH44+); found 460.7 (calc 460.4; MH5
5+).
3-His: MW = 2864.0
m/z = found 955.5 (calc 955.7; MH33+); found 716.9 (calc 717.0; MH4
4+); found 573.9
(calc 573.8; MH55+).
4-His: MW = 3392.0
m/z = found 1131.1 (calc 1131.6; MH33+); found 848.8 (calc 849.0; MH4
4+); found
679.2 (calc 679.4; MH55+); found 566.0 (calc 566.3; MH6
6+).

Chapter 3
110
5-His: MW = 4240
m/z = found 1060.9 (calc 1061.0; MH44+); found 848.8 (calc 849.0; MH5
5+); found
707.7 (calc 707.7; MH66+); found 606.9 (calc 606.7; MH7
7+).
6-His: MW = 4758.0
m/z = found 1190.2 (calc 1190.5; MH44+); found 952.3 (calc 952.6; MH5
5+); found
793.8 (calc 794.0; MH66+); found 680.6 (calc 680.7; MH7
7+).
7-His: MW = 5299.0
m/z = found 1326.0 (calc 1325.8; MH44+); found 1061.0 (calc 1060.8; MH5
5+); found
884.3 (calc 884.2; MH66+); found 758.1 (calc 758.0; MH7
7+); found 663.5 (calc 663.4;
MH88+).
2-Arg: MW = 2316.0
m/z = found 773.2 (calc 773.0; MH33+); found 580.1 (calc 580.0; MH4
4+); found 464.3
(calc 464.2; MH55+); found 387.0 (calc 387.0; MH6
6+).
3-Arg: MW = 2883.0
m/z = found 962.0 (calc 962.0; MH33+); found 721.7 (calc 721.7; MH4
4+); found 577.7
(calc 577.6; MH55+); found 481.5 (calc 481.5; MH6
6+).
6-Arg: MW = 4777.0
m/z = found 956.2 (calc 956.4; MH55+); found 797.2 (calc 797.2; MH6
6+); found 683.4
(calc 683.4; MH77+); found 598.1 (calc 598.1; MH8
8+); found 531.6 (calc 531.8;
MH99+).
C-1: MW = 1682.5
m/z = found 842.0 (calc 842.2; MH22+); found 561.8 (calc 561.8; MH3
3+); found 421.6
( calc 421.6; MH44+).

Chapter 3
111
C-2: MW = 2209.0
m/z = found 1105.5 (calc 1105.5; MH22+); found 737.1 (calc 737.3; MH3
3+); found
553.4 (calc 553.3; MH44+); found 443 (calc 442.8; MH5
5+).
C-3: MW = 2726.6
m/z = found 1364.2 (calc 1364.3; MH22+); found 909.9 (calc 909.9; MH3
3+); found
682.7 (calc 682.7; MH44+); found 546.4 (calc 546.3; MH5
5+); found 455.4 (calc 455.4;
MH66+).
C-4: MW = 3286.0
m/z = found 1096.1 (calc 1096.3; MH33+); found 822.5 (calc 822.5; MH4
4+); found
658.4 (calc 658.2; MH55+); found 549.0 (calc 548.7; MH6
6+); found 484.7 (calc 484.0;
MH77+).
C-5: MW = 4063.5
m/z = found 1355.4 (calc 1355.8; MH33+); found 1016.8 (calc 1017.1; MH4
4+); found
813.9 (calc 813.9; MH55+); found 678.6 (calc 678.4; MH6
6+); found 581.9 (calc 581.6;
MH77+).
C-6: MW = 4632.5
m/z = found 1158.4 (calc 1159.1; MH44+); found 925.0 (calc 927.5; MH5
5+); found
772.9 (calc 773.1; MH66+); found 662.8 (calc 662.8; MH7
7+).
C-6b: MW = 4620.0
m/z = found 1155.8 (calc 1155.5; MH44+); found 924.8 (calc 925.0; MH5
5+); found
771.0 (calc 771.0; MH66+); found 660.9 (calc 661.0; MH7
7+).
C-7: MW = 5172.5
m/z = found 1293.7 (calc 1294.1; MH44+); found 1035.3 (calc 1035.5; MH5
5+); found
863.2 (calc 863.1; MH66+); found 740.1 (calc 739.9; MH7
7+); found 647.8 (calc 647.6;
MH88+).

Chapter 3
112
.Measurement of PNAs Concentration. The concentrations of the stock PNA
solutions were measured using a Cary-50 UV-VIS spectrophotometer from Varian Inc.
10 mg of each stock solution were diluted with Methanol/water mixture (25:75) and
the corresponding weight was noted. The exact dilution factors were calculated on the
basis of density at room temperature.
The concentrations were determined by UV absorbance at 260 nm (60°C) using the
following extinction coefficients: A = 13700; C = 6600; G = 11700; T = 8600 M-1cm-1.
Samples preparation for UV and CD studies Once the concentrations of the stock
solutions were known, the volume of the stock solutions required to make a 5µM
solution in 1 ml of the solvent has be calculated. All the solutions were prepared by
weighing the required volumes of PNA solutions and the solvents used. The samples
were then incubated at 90ºC for 5 minutes and then slowly allowed to cool to room
temperature. Care was taken when making highly viscous solutions with glycerol.
They were incubated as mentioned above and then vortexed and left for overnight
before subjecting to UV or CD measurements. From the density data (for water or
glycerol) at room temperature, the actual volumes and concentration of each PNA
strand in the sample were then calculated. Since the concentrations of both PNA
strands used to form the duplex were not exactly equal. The exact concentration of the
duplex was assumed to be equal to the concentration of the PNA single strand present
at the lower concentration.
UV Melting Temperature Measurement. All UV melting analysis were performed
in water (pH = 6.8) or in water/glycerol mixture (90:10). An equal amount of each
chiral PNA strand and its complementary achiral PNA strand was dissolved in the
required solvent. Strand concentrations were 5 µM in each component. Thermal
denaturation profiles (Abs vs T) of the PNA-PNA duplexes were measured at 260 nm
with an UV/Vis Lambda Bio 20 Spectrophotometer equipped with a Peltier
Temperature Programmer PTP6 which is interfaced to a personal computer. For the
temperature range 15°C to 95°C, UV absorbance was recorded at 260 nm every 0.5°C.
A melting curve was recorded for each duplex. The melting temperature (Tm) was
determined from the maximum of the first derivative of the melting curves.

Chapter 3
113
Circular Dichroism Analysis. CD measurements were performed in water (pH = 6.9)
or in water/glycerol mixture (10:90) using Spectropolarimeters JASCO J710 and J715
with temperature control. 1 mL PNA-PNA duplex solutions were prepared from the
stock solutions by diluting them with the required solvent. In order to get the exact
duplex concentration, all the solutions were prepared in a 2 mL eppendorf tube by
weighing the required amounts of PNA stock solutions and the solvents. The total
volume and hence the precise concentration of the duplex was then calculated. The
resulting samples were incubated at 90°C for 5 min and then slowly cooled to room
temperature. CD spectra were recorded in triplicate from 320 nm to 220 nm. Each
spectrum was zeroed, smoothed and treated with a noise reduction software.
Self-assembled duplexes. An aliquot of Lys-PNA 8mer was diluted with water in
order to obtain 5 µM concentration. The complementary achiral 17 mer (5 µM) was
added and the resulting mixture was incubated at 90°C for 5 min. The CD spectrum
was recorded at 22°C. Then, the second achiral 17 mer (5 µM) was added and the
measurement was immediately done without incubation. Further achiral 8 mer (5 µM)
was added and the process was repeated.
Thermodynamic analysis. The thermodynamic study was done using the two-state
model. The absorbance at 260nm, plotted versus temperature, was fitted with six-
parameter function to a two-state model of the hybridization. This model assumes that
single strands are in equilibrium with only one base-paired duplex structure; i.e., there
are no partially base-paired structures in the melting process. Furthermore, the
thermodynamic parameters ∆H° and ∆S° are assumed to be temperature-independent,
and the change in heat capacity (∆Cp) between the two states is assumed to be zero.
For non-self-complementary sequences forming n-mer structures, the general
equilibrium constant at a particular temperature can be expressed as:
( )( ) ( ) 11
−
−=
nn
nCts
TK
α
α (1)
where”αααα”represents the fraction of strands in duplex form; “Cts” is the total
concentration of strands and “n” is the molecularity of the complex.
Assuming a two-state model (n = 2), Equation 1 reduces to:

Chapter 3
114
( )( ) Cts
TK21
2
α
α
−= (2)
αααα can be expressed as:
AdAs
AAs
−
−=α (3)
where, “As” is the absorbance of the single strands in fully denatured condition, “Ad”
is the absorbance of the duplex in fully hybridized condition and “A” is the absorbance
at a particular point on the UV melting curve at temperature T.
“As” and “Ad” are allowed to vary with temperature according to a linear
approximation: ss bTmAs += (4)
dd bTmAd += (5)
The deviations of ms and md from zero can be regarded as a consideration of the
temperature dependence of nucleobase stacking dynamics.
The vant’t Hoff plot “lnK” vs 1/T is a straight line represented by:
∆+
∆−=
R
S
TR
HK
00 1ln (6)
From Equations 4-6, the model can be simply described by a total of six fitting
parameters: ms, bs, md, bd, ∆Η°, ∆∆Η°, ∆∆Η°, ∆∆Η°, ∆S°°°°....
∆∆∆∆G°°°° at a particular temperature can be calculated from:
000STHG ∆−∆=∆ (7)

Chapter 3
115
3.6. References
1 a) Mao, C.; Sun, W.; Seeman, N. C., J. Am. Chem. Soc, 1999, 121, 5437-5443.
b) Rothermond, P. W. K.; Nature, 2006, 440, 297-302.
c) Brucale, M.; Zuccheri, G.; Samorì, B.; Trends Biotech., 2006, 24, 235-243. 2 a) M.M. Green, N. C. Peterson, T. Sato, A. Teromoto, R. Cook and S. Lifson,
Science, 1995, 268, 1860.
b) Green, M.M.; Park, J. W.; Sato, T., Teromoto, A.; Lifson, S.; Selinger, L.B.R.;
Selinger, J.V, Angew. Chem. Int. ed. 1999, 38, 3138. 3 Jha, S.K.; Cheon, K. S.; Green, M.M.; Selinger, J.V., J. Am. Chem. Soc. 1999, 121,
1665. 4 Green, M.M.; Garetz, B. A; Munoz, B.; Chang, H.; Hoke, S.; Cook, R. G., J. Am.
Chem. Soc. 1995, 117, 4181. 5 Nielsen P. E., Egholm M., Berg R. H., Buchardt O., Science, 1991, 1497. 6 Watson, J.D. and Crick, F.H.C., Nature, 1953, 171, 737-738. 7 a) Rasmussen, H.; Kastrup, J. S.; Nielsen, J. E.; Nielsen, J. M.; Nielsen, P. E., Nat.
Struct. Biol., 1997, 4, 98-101.
b) Haaiama, G.; Rasmussen, H.; Schmidt, G.; Jensen, D. K.; Kastrup, J. S.; Wittung
Stafshede, P.; Nordén, B.; Buchardt, O.; Nielsen, P. E.; New J. Chem., 1999, 23, 833-
840. 8 a) Mendise, V.; De Simone, G.; Tedeschi, T.; Corradini, R.; Sforza, S.; Marchelli R.;
Papasso, D.; Saviano, M.; Pedone, C., Proc. Nat. Acad. Sci. USA., 2003, 21, 12021-
12026.
b) Mendise, V.; De Simone, G.; Corradini, R.; Sforza, S.; Sorrentino, N.; Romanelli,
A.; Saviano, M.; Pedone, C., Acta Cryst., 2002, D58, 553. 9 P. Wittung, M. Eriksson, L. Reidar, P. E. Nielsen and B. Nordén, J. Am, Chem.
Soc.1995, 117, (41), 10167. 10 Rasmussen, H.; Liljefors, T.; Peterson, B.; Nielsen, P. E.; Kastrup, J. S., Journal of
Biomolecular Structures & Dynamics, 2004, 21(4), 495-502 11 Pino, P.; Lorenzi, G. P., J. Am. Chem. Soc., 1960, 82, 4745-4747 12 Jain, V., Helical sense preference in peptide nucleic acids duplexes, Ph.D Thesis in
materials Chemistry, Polytechnic University of Brooklyn, NY, 2006.

Chapter 3
116
13 Wintjens, R.; Liévin, J.; Rooman, M.; Buisine, E.; J. Mol. Biol., 2000, 302, 395-410 14 a) Marky, L. A.; Breslauer, K. J., Biopolymers, 1987, 26, 1601-1620.
b) Applequist, J.; Damle, V., J. Am. Chem. Soc., 1965, 87, 1450-1458. 15 Wittung, P.; Nielsen, P.E; Buchardt, O; Egholm, M.; Nordén, B.; Nature, 1994, 368,
561-563. 16 Petersson, B.; Bryde Nielsen, B; Rasmussen, H.; Kjøller Larsen, H.; Gajhede, M.;
Nielsen, P. E.; Sandholm Kastrup, J., J. Am. Chem. Soc. 2005, 127, 1424-1430. 17 Vecchio, P. D.; Esposito, D.; Ricchi, L.; Barone, G., Int. J. Bio. Macro. 1999, 24,
361 18 Herrada, G.A., Rabié, A;, Wintersteiger, R.; Brugidou, J., J. Peptide Sci. 1998, 4,
266-281. 19 Bonner, G., Klibanov, A. M., Biotechnology and Bioengineering, 2000, 68, 339. 20 Sorokin, V.A., Gladchenko, G. O.; Valeev, V.A.; Sysa, I.V.; Petrova, L.G.; Blagoi,
Y.P., J. Mol. Str. 1997, 408/409, 237. 21 Xie, G. ; Timasheff, S. N., Protien Science, 1997, 6, 211. 22 Arakawa, T.; Timasheff, S. N., Biophysics J. 1985, 47, 411. 23 Gerlsma, S. Y. J. Biol. Chem, 1968, 243, 9 24 J. Jarabak, A. E. Seeds and P. Talalay, Biochemistry, 1966, 5, 1269. 25 Gekko, K., Timasheff, S. N., Biochemistry ,1981, 20, 4667. 26 Pletneva, E.V.; Laederach, A.T.; Fulton, D.B.; Kostic, N.M.; J. Am. Chem. Soc.,
2001, 123, 6232-6245 27 Ma, J.C.; Dougherty, D.A.; Chem. Rev., 1997, 1303-1324 28 Gallivan, J.P.; Dougherty, D.A.;.J. Am. Chem. Soc., 2000, 122, 870-874
29 Pellequer, J.L.; Zhao, B.; Kao, H.I.; Bell, C.W.; Li, K.; Li, Q.X.; J. Mol. Biol., 2000,
302, 691-699 30 Kumpf, R.A.; Dougherty, D.A.; Science, 1993, 261, 1708-1710 31Rooman, M.; Liévin, J.; Buisine, E.; Wintjens, R.; J. Mol. Biol., 2002, 309, 67-76 32 Gromiha, M.; Santhosh, C.; Ahmad, S.; Int. J. Biol. Macromol., 2004, 34(3), 203-
211. 33 Sen, A.; Nielsen, P. E., Nucleic Acids Res., 2007, 35, 3367-3374.

Chapter 4
117
PNA as tools for molecular computers
4.1. Introduction
The continuous and fast increase of the technology has strongly influenced our daily life.
For many years, humans have used manufactured devices to enhance their computational
abilities. The development of mechanical devices such as the adding machine and the
tabulating machine was an important advance that has further increased our computational
performance. Yet it was only with the advent of electronic devices and, in particular, the
electronic computer more than 60 years ago that a qualitative threshold seems to have
been passed and problem of considerable difficulty could be solved. The increasing role
that electronic devices play in our daily lives, as well as our constant need to pursue
superior technologies, have raised a wide interest in the development of molecular
systems mimicking the operation of electronic logic gates and circuits1,2,3
. Besides their
integration in the heart of digital computers, electronic logic circuits control the operation
of a variety of devices around us from calculators and store automation to video games
and music equipment.
One interesting possibility for improving computing devices is to use molecular
interactions, such as those occurring in the genetic code, for solving mathematical
problems. The pioneer of this idea was Adleman, who first solved a non-determinstic
problem using DNA molecules, in a study that can be considered as the first considerable
achievement of molecular-recognition based computing strategies.
Furthermore, many studies have reviewed the possibility to use supramolecular concepts
for building electronic gates at the molecular level. For example, more recently, an
interesting study4 has reported the development of an important electronic devices
mimicked at the molecular level, named “keypad lock” which differs from a simple logic
gate by the fact that its output signals are dependent not only on the proper combination of
inputs but also on the correct order by which these inputs are introduced. In other words,
one needs to know the exact password that opens this lock. This device could be used for
numerous applications in which access to an object or data is to be restricted to a limited

Chapter 4
118
number of persons; then represents a new approach for protecting information at the
molecular level.
In the few past years, considerable efforts have been focused on developing new
generation of molecular logic gates and molecular computers, based on DNA5,6,7,8,9
; a
biomolecule possessing well-regulated structures and the ability to store genetic
information. DNA computer has been intensively used for solving a class of intractable
computational problems7,10, such as 3-satisfiability (3-SAT) problems, in which the
computing time can grow exponentially with problem size.
The basis for the use of DNA:DNA duplex formation as computing tool is illustrated in
Figure 4.1. A set of DNA sequences can be used as variables and another set as possible
solutions, so that each solution forms a duplex only if it is a solution of a particular clause
containing the corresponding variable. Combining a set of molecular events of this type is
equivalent to performing parallel computing in normal calculators.
The most attractive advantage of DNA computation is its massive parallelism
computation power and huge memories. Up to now, many accomplishments have been
achieved to improve its performance and increase its reliability, 8,11
though improvement
in specificity of interaction and chemical stability are likely to be necessary to make these
devices robust enough.
Compared to DNA probes, PNAs12
have shown to be efficient tools in numerous
applications, since they can form duplexes more stable than double-stranded DNA and are
superior to oligonucleotide probes in the recognition of single base mutations13,14,15
. An
other interesting property of PNAs , which is useful in biological applications, is their
stability to both nucleases and peptidases, since their “unnatural” skeleton prevents
recognition by natural enzymes, making them more persistent in biological fluids16
.
In the present study, we investigated the possibility to use PNA:PNA interactions on a
PNA-based microarray system as a possible way for performing computational
experiments at the molecular level.
The advantages of using PNA:PNA interactions are: i) possibility to use the same scheme
as DNA computers; ii) higher stability of the duplex formed, which allows to use less base

Chapter 4
119
pairs (atom economy); iii) higher specifity of interaction, which increases the precision of
calculation iv) higher chemical and enzymatic stability of the components.
PNA probes (possible solutions) were immobilized on the surface and hybridized with
fluorescence labelling PNA targets (variables). Ideally, we expected that full signal (True)
would observed from all perfectly matched hybrids and no signal (False) from hybrids
including even single base mismatches. The basic principle is reported in Figure 4.1.
This work was intended to be a proof of principle for the use of PNA:PNA interaction in
molecular computing.
Figure 4.1. From Genetic code to computing code: basic principle of the DNA computation.
4.2. Results and Discussion
Sequence design. Using an approach similar to that described by Pirrung and coworkers17
for DNA computing, we used as a model the two-variable SAT problem:
)()( YXYXF ∨∧∨= (1)
where the variables are Boolean and can assume values of 1 (true) and 0 (false); ∨ is the
logical “OR” operation, ∧ is the logical “AND” operation; Y is the negation of Y.
A
A
G
G
C
T
T
C
C
G
A
A
G
G
C
T
T
C
C
G
A
A
G
G
C
T
T
C
C
G
A
A
G
G
C
T
T
C
C
G
True = 1
A
A
G
G
C
G
G
T
A
T
A
A
G
G
C
G
G
T
A
T
Variable Possible solution
No Duplex
Correct Solution
False = 0

Chapter 4
120
The library for a 2-variable SAT problem (possible assignments X = 1; 0 and Y = 1; 0)
was encoded by 4 different PNAs of 8 bp each. The length of the PNA was chosen in
order to use a minimal length which allows sufficiently high stability of the duplexes. All
probes, representing solutions of the problem, and fluorescent targets, representing all
variables, have two distinct regions: a common fixed region designed to maximize the
affinity of probe to its complementary target and a variable (coding) region that codes
the data contained in each strand. Two units of the spacer (2-(2-aminoetoxy)etoxy acetic
acid) were used for the PNA encoding the solutions, in order to avoid possible
interactions of the probes with the surface. 5(6)-Carboxytetramethylrhodamine (TAMRA;
λex=545nm and λem=570nm) was used as fluorescent reporter group for the PNA encoding
the variables. The general structures of various PNA oligomers are reported in Figure 4.2
and PNA sequences are shown in Table 4.1.
Table 4.1. PNA Library encoding possible solutions Figure 4.2. General Structures of PNA (1-4) and variables (5-8). strands with the coding region (XYZW).
Solutions:
H2N-CA-XYZW-CT-OO-H
Variables:
H2N-AG-X
cY
cZ
cW
c-TG-Lys-TAMRA-H
a
O =aminoetoxyetoxyacetyl-spacer
b TAMRA = 5(6)-Carboxytetramethylrhodamine
The corresponding PNA oligomers were synthesized using solid phase synthesis on an
automatic ABI 433A Synthesizer, according to the scheme reported in the introduction of
this thesis. Boc strategy was used with HBTU/DIEA as coupling agent and TFA/m-cresol
Probes Solutionsa
PNA 1 H-OO-TCATCTAC-NH2 (X =1)
PNA 2 H-OO-TCTCATAC-NH2 (Y =1)
PNA 3 H-OO-TCAGTTAC-NH2 (X =0)
PNA 4 H-OO-TCAAATAC-NH2 (Y =0)
Targets Variablesb
PNA 5 TAMRA-Lys-GTAGATGA-NH2 (X)
PNA 6 TAMRA-Lys-GTATGAGA-NH2 (Y)
PNA 7 TAMRA-Lys-GTAACTGA-NH2 ( X )
PNA 8 TAMRA-Lys-GTATTTGA-NH2 (Y )
PNA comp
Spacers PNA

Chapter 4
121
as deprotecting solution. The fluorophore (TAMRA) was attached manually. The crude
products were purified by RP-HPLC and characterized with HPLC-MS.
UV Melting Temperatures. The thermal stability of various duplexes and the sequence-
selectivity were initially evaluated by determining the melting temperatures (Tm) at 260
nm of full-matched and mismatched duplexes, in order to verify if the hybridization was
sufficiently strong and if aspecific binding of mismatched sequences could interfere with
the computing process. The Tm data are summarized in Table 4.2. The results show
almost the same melting temperatures for all perfectly matched duplexes (52.0-55.0 °C).
When two or three Watson-Crick base-pair mismatches were introduced at any position
in the code region (middle of the sequence), a large decrease in Tm (> 30°C) was
observed , thereby providing compelling evidence that the PNA:PNA interaction is highly
specific. According to these results, the subsequent computational study was performed at
T = 40 °C in order to avoid non-specific interactions.
Table 4.2. Melting temperatures Tm (°C) for various fullmatched and mismatched PNA:PNA duplexes.
Duplexes Number
of Mismatches
Tm
(°C)
PNA1:PNA5 0 55.0
PNA2:PNA6 0 54.0
PNA3:PNA7 0 54.0
PNA4:PNA8 0 52.0
PNA1:PNA8 2 25.0
PNA1:PNA7 2 < 20a
PNA2:PNA8 3 < 20a
a No melting transition was observed in the range 20-95°C
PNA Computing using microarray technology. PNA strands (1-4) representing possible
assignments were combinatorially deposited onto the surface (Figure 4.3) so that all
possible solutions were represented (For n variables, there are 2n possible solutions). Each

Chapter 4
122
spot contains two PNA strands, each strand representing the value of a different
variable:PNA1/PNA2 for 1/1, (i.e. x= 1 and y= 1); PNA1/PNA4 for 1/0 (x= 0, y= 0);
PNA3/PNA2 for 0/1 (x= 0, y = 1) and PNA3/PNA4 for 0/0 (x= 0, y =0). The array/PNA
probes were the same for all problems of n or fewer variables; equivalent to computing
hardware.
Moreover, the complementary fluorescent targets used depend of the logic expression to
be verified, for example PNA5/PNA6 for “ YORX ” or PNA5/PNA8 for “ YORX ”, and
were equivalent to software. The fluorescence signals indicate the zones containing
probes complementary to the targets used, and potentially encoding the solution of the
problem.
Figure 4.3.Computation protocol. (a) deposition: 30 µM PNA probes (1-4) representing all possible
solutions were spotted in quadruplicate on the microarray. Each spot contains two different PNA strands. (b)
Hybridization with fluorescent targets (i.e. PNA5 + PNA6; 1 µM strand concentration). The solutions of the
problem were read out using a scanner.
X/Y 1/1 1/0 0/1 0/0
X/Y 1/1 1/0 0/1 0/0
Microarray (Activated Slides)
(Possible Solutions)
Microarray/PNAs (Hardware)
(a)
X/Y 1/1 1/0 0/1 0/0
Microarray/PNAs (Hardware)
X/Y 1/1 1/0 0/1 0/0
Correct Solutions: 1/1; 1/0; 0/1.
Hybridization with
PNA5 (X) + PNA6 (Y)
(Software)
(b)
Deposition

Chapter 4
123
Logic Operation “X OR Y”. Using the protocol described above, we constructed a 2-
input logic gate “OR” that performs Boolean calculations; and a single-input gate
“Report” that releases a fluorescent output signal in response to specific single-stranded
PNA input sequences. The experimental study of this 2-variable problem used the above
described array, on which all possible solutions ( X/Y = 1/1; 1/0; 0/1; 0/0) were
immobilized; followed by hybridization with fluorescent PNA (PNA5 + PNA6)
representing variables X and Y, respectively. The output of the computation is reported in
Figure 4.4.
Figure 4.4. Diagrammatic representation of logic gate “X OR Y” wired to a fluorescent reporter (top).
Observed fluorescent output from execution of the calculation (bottom).
According to Watson-Crick base pairing interactions, upon hybridization with PNA5 +
PNA6, one set of spots (1/1) should contain two perfectly matched duplexes; two sets of
spots (1/0; 0/1) should contain one perfectly matched duplex each and the last set (0/0)
should contain no duplex. Then, after hybridization, only spots 1/1; 1/0; 0/1 should be
1/1 1/0 0/1 0/0
X/Y
Hybridization with PNA strands (X,Y)
0
10
20
30
40
50
60
70
80
90
100
Intensity
hעX
Y(X or Y)OR Report
hעX
Y(X or Y)OR Report
X
Y(X or Y)OR Report
1/11/0
0/1
0/0
X 1 1 0 0
Y 1 0 1 0
X or Y 1 1 1 0

Chapter 4
124
fluorescent. The results obtained are fully consistent with mathematical predictions and
provide solutions to the problem (X OR Y = 1) of (X,Y) = (1,1); (1,0); (0,1).
Logic Operation “X OR Y”. Analogously, when hybridization was performed using
PNA5 + PNA8 representing the variables X and (Not Y), respectively, two sets of spots
(1/1 and 0/0) should contain one fully matched duplex each; one set (1/0) should contain
two matched duplexes and the last one (0/1) should contain no duplex. Therefore, one
must expect only spots 1/1; 1/0; 0/0 containing PNA probes complementary to the targets
X and (Not Y) to be fluorescent. The experimental data reported in Figure 4.5 are fully
consistent to theoretical predictions, providing (X,Y) = (1,1); (1,0); (0,0) as solutions of
the problem.
Figure 4.5. Diagrammatic representation of logic gate “X OR NotY” wired to a fluorescent reporter
(top). Observed fluorescent output from execution of the calculation (bottom).
1/1 1/0 0/1 0/0
X/Y
Hybridization with PNA strands (X,Y)
0
10
20
30
40
50
60
70
80
90
100
Inte
nsity
1/1 1/0
0/1
0/0
X 1 1 0 0
Y 1 0 1 0
Y 0 1 0 1
X or Y 1 1 0 1
X
YX or (Not Y)OR
NOT
hעReport
X
YX or (Not Y)OR
NOT
hעReport
hעReport

Chapter 4
125
Combined Operation “(X OR Y) AND (X OR Y)”. Using the results obtained with the
two independent clauses, the combined “OR-AND-OR” gate was designed such that
outputs from single “OR” gates can serve as input for the further “AND” gate. In this
case, the reported fluorescence intensity (Figure 5.6.) is the product of the intensities of
signal exhibited by single gates in correspondence to the same set of spots (i.e. F(1/1) =
F1(1/1) x F2(1/1)). According to the data reported in Figure 4.6, the equation is true only if
(x,y) = (1,1); (1,0).
Figure 4.6. Diagrammatic representation of combined logic gate “(X OR Y)AND (X OR NotY)” (top).
Observed fluorescent output from execution of the calculation (bottom-right).
Although in this example, we performed a very simple calculation, the number of
calculation needed (two hybridization steps and product of intensities) is less than that of
the systematic test of all possible solutions, which is 2n
, in this case 4. This advantage is
X
Y(X or Y)OR
X
YX or (Not Y)OR
NOT
(X or Y) and (X or Not Y)AND Reporthע
1/1 1/0 0/1 0/0 1/1 1/0 0/1 0/0
X 0
10
20
30
40
50
60
70
80
90
100
Inte
nsity
1/1 1/0
0/10/0
X or Y 1 1 1 0
X or Y 1 1 0 1
F1 and F2 1 1 0 0
F1F2

Chapter 4
126
crucial when performing the same type of operations with a very high number of
variables.
4.3. Conclusions
The three examples described above demonstrate that our approach to Boolean control
based on PNA:PNA interactions is likely general, and that PNAs could be potential
candidates for integration into molecular circuits and computers. Although the prototype
of PNA computer constructed here can so far process a limited number of operations, it
inspires the imagination toward a new generation of processing devices based on PNA,
able to solve in short time, more complicated non deterministic problems. DNA-based
devices (computers and logic gates) have been intensively studied. Compared to DNA
probes, PNA form more stable duplexes and with higher specifity, and are more resistant
to enzymes and chemical agents. The current study, although still not suitable for practical
applications, demonstrate that it should be possible to employ PNA molecules in a broad
spectrum of nanobiotechnological applications, such as computers and logic gates.
For DNA computing, extension of simple technologies such as those described in the
present chapter has already led to the solution of a 20-variable SAT problem, which is a
computing challenge hardly addressable with normal computers. Therefore extension of
this protocol can be easily foreseen.
PNAs have also been successfully used as therapeutic drugs and it is generally believed
that the power of Boolean computing would find application in molecular agents able of
diagnosing biological disorders and produce the right signaling or even therapeutic
outputs18. Then, molecular devices based on biomolecules such as PNA capable of highly
discriminating between fullmatched and mismatched sequences, might have considerable
advantages over simple molecular logic gates.
4.4. Experimental Section
PNA Oligomer Synthesis. The synthesis was performed on an ABI 433A peptide
synthesizer with software modified to run the PNA synthetic steps (scale: 5 µmol), using

Chapter 4
127
Boc chemistry and standard protocols as described in the introductive part, with
HBTU/DIEA coupling. MBHA resin was used and downloaded manually by the first
monomer. In the case of PNA encoding the variables, upon completion of PNA oligomer
synthesis, the attachment of 5(6)-Carboxytetramethylrhodamine (Fluorophore unit) was
done manually using DIC/DHBTOH as coupling reagent. The crude PNA were purified
by RP- HPLC with UV detection at 260 nm. Semi-prep column C18 (5 microns, 250 x
10mm, Jupiter Phenomenex, 300 A ) was utilized, eluting with water + 0.01% TFA (
eluent A) and the mixture 60: 40 of water / acetonitrile + 0.01% TFA (eluent B); elution
gradient: from 100% A to 100% B in 50 min, flow: 4 ml/min. The resulting pure PNA
oligomer was characterized by MS-ESI with gave positive ions consistent
with the final products.
PNA 1. Calculated MW: 2410.4
ESI-MS: m/z = found 804.2 (calc 804.4; MH33+
), found 603.4 (calc 603.6; MH44+
), found
483.1 (calc 483.1; MH55+
).
PNA 2. Calculated MW: 2410.4
ESI-MS: m/z = found 804.4 (calc 804.4; MH33+
), found 603.9 (calc 603.6; MH44+
), found
483.2 (calc 483.1; MH55+
).
PNA 3. Calculated MW: 2450.4
ESI-MS: m/z = found 817.8 (calc 817.8; MH33+), found 613.3 (calc 613.6; MH4
4+), found
491.1 (calc 491.1; MH55+
).
PNA 4. Calculated MW: 2443.4
ESI-MS: m/z = found 815.4 (calc 815.5; MH33+), found 611.6 (calc 611.8; MH4
4+), found
489.7 (calc 489.7; MH55+
).
PNA 5. Calculated MW: 2790.0

Chapter 4
128
ESI-MS: m/z = found 930.5 (calc 931.0; MH33+
), found 698.4 (calc 698.5; MH44+
), found
559.0 (calc 559.0; MH55+), 466.0 (calc 466.0; MH6
6+).
PNA 6. Calculated MW: 2790.0
ESI-MS: m/z = found 930.5 (calc 931.0; MH33+
), found 698.5 (calc 698.5; MH44+
), found
559.0 (calc 559.0; MH55+
), 466.0 (calc 466.0; MH66+
).
PNA 7. Calculated MW: 2750.0
ESI-MS: m/z = found 917.4 (calc 917.6; MH33+
), found 688.4 (calc 688.5; MH44+
), found
550.8 (calc 551.0; MH55+
).
PNA 8. Calculated MW: 2756.0
ESI-MS: m/z = found 919.5 (calc 919.7; MH33+
), found 690.0 (calc 690.0; MH44+
), found
552.2 (calc 552.2; MH55+
).
UV Melting Analysis. Solutions of 1:1 PNA/PNA were prepared in pH = 7.0 Buffer
consisting of 100 mM NaCl, 10 mM NaH2PO4.H2O, 0.1 mM EDTA. Strand
concentrations were 5 µM in each component. Thermal denaturation profiles (Abs vs T)
of the hybrids were measured at 260 nm with an UV/Vis Lambda Bio 20 Spetrometer
equipped with a Peltier Temperature Programmer PTP6 which is interfaced to a personal
computer. For the temperature range 95°C to 20°C, UV absorbance was recorded at 260
nm every 0.5°C. A melting curve was recorded for each duplex. The melting temperature
(Tm) was determined from the maximum of the first derivative of the melting curves.
Array Preparation. Activated Slides were used as solid supports to which the amino-
terminal group of the PNA probes encoding all possible solutions were covalently linked.
The deposition of the probes was carried out using a SpotArrayTM24 (PerkinElmer) with a
pin-and-ring deposition system. The manufacturer's instructions for the deposition
protocol were slightly changed in order to comply with the special requirement of the
chemical structures of PNAs: in particular a 100mM carbonate buffer (pH 9.0) containing

Chapter 4
129
10% acetonitrile and 0.001% sodium dodecyl sulphate (SDS) was used as deposition
buffer. Moreover, after every deposition, the pin-and-ring system was purged with water
for 10s and further washed with acetonitrile/water (1:1), in order to avoid dragging of the
probes in subsequent depositions. The probes were coupled to the surface and the
remaining reactive sites were blocked by leaving the slides in a humid chamber (relative
humidity 75%) at room temperature for 12h, followed by immersion in a glass rack
containing a 50mM solution of ethanolamine, 0.1M TRIS, pH 9, prewarmed at 50°C, for
30min. The slides were washed twice with bidistilled water at room temperature and then
slowly shaken for 30min in plastic tubes containing a 4× saline/sodium citrate (SSC)
solution and a 0.1% SDS buffer prewarmed at 50°C. Each slide was then washed with
bidistilled water at room temperature and centrifuged in a plastic tube at 800rpm for 3min.
Slides were then ready to undergo the hybridization protocol.
Hybridization and Scanning Labeled PNA samples (1µM strand concentration)
encoding two variables were prepared by diluting stock solutions to a final volume of
65µl and a final concentration of 4× SSC and 0.1% SDS buffer. Hybridization was
performed by loading the samples to “in situ frame” chambers and leaving the slides
under slow shaking for 1h at 40°C. After the hybridization step, all the slides were treated
individually to prevent cross contamination. The slides were washed under slow shaking
for 5min at 40°C with a 2× SSC, 0.1% SDS buffer prewarmed at 40°C, followed by
treatment for 1min with 0.2× SSC and for 1min with 0.1× SSC at room temperature. The
slides were then spin-dried at 1000 rpm for 5min.
The fluorescent signal deriving from the hybridization was acquired using a ScanArray
Express (PerkinElmer) at λ ex=545nm and λ em=570nm.
Computational Protocol. The computational protocol was as follows:
Step 1: Prepare a microarray slide containing covalently bound unlabeled PNA library
strands encoding all possible solutions (x/y = 1/1; 1/0; 0/1; 0/0, for two-variable problem).
Four mixtures containing, each, two PNA strands represented possible values of x and y,
were deposited in quadruplicate.

Chapter 4
130
Step 2: For each clause, hybridize with a mixture containing two fluorescent-labeled
PNA strands which represent all variables in the clause. Only library strands encoding
truth assignments satifying the clause form duplexes, then give a fluorescence signal.
Step 3: Read the answer by scanning the microarray slide and assign truth values to
the variables x and y.

Chapter 4
131
4.5. References 1 a) Magri, D. C.; Brown, G. J.; McClean, G. D.; de Silva, A. P.; J. Am. Chem. Soc, 2006,
128, 4950-4951
b) Callan, J. F.; de Silva, A. P.; Magri, D. C.; Tetrahedron, 2005, 61, 8551-8588.
2 Balzani, V.; Credi, A; Venturi, M; ChemPhysChem, 2003, 3, 49-59.
3 Shirashi, Y.; Tokitoh, Y.; Hirai, T.; Chem. Commun, 2005, 42, 5316-5318.
4 Margulies, D.; Felder, C. E.; Melman, G.; Shanzer, A.; J. Am. Chem. Soc,; 2007, 129,
347-354.
5 Okamoto, A.; Tanaka, K.; Saito, I.; J. Am. Chem. Soc.; 2004, 126, 9458-9463
6 Miyoshi, D.; Inoue, M.; Sugimoto, N.; Angew. Chem. Int. Ed.,2006, 45, 7716-7719.
7 Braich, R. S.; Chelyapov, N.; Johson, C.; Rothermund, P. W. K.; Adleman, L.; Science,
2002, 296, 499-502.
8 Lin, C. H.; Cheng, H. P.; Yang, C. B.; Yang, C. N.; Biosystems, 2007, 90, 242-252.
9 Adleman, L.; Science, 1994, 266 (5187), 1021-1024.
10 a) Lipton, R.J., Science, 1995, 268, 542–545.
b) Liu, Q.H., et al., Nature, 2000, 403, 175–179.
11 Wu, H.; Biosystems, 2001, 59, 1-5.
12 Nielsen P. E., Egholm M., Berg R. H., Buchardt O., Science, 1991, 1497.
13 Wittung, P.; Nielsen, P. E.; Buchardt, O.; Egholm, M.; Norden, B., Nature, 1994, 368,
561-563.
14 Egholm, M.; Buchardt, O.; Christensen, L.; Behrens, C.; Freier, S. M.; Driver, D. A.;
Berg, H.; Kim, S. K.; Norden, B.; Nielsen, P. E., Nature, 1993, 365, 566-568.
15 a)Demidov, V. V., Trends in Biotech. 2003, 21, 4.
b) Sawata, S.; Kai, E.; Ikebukuro, K.; Iida, T.; Honda, T.; Karube, I., Biosens.
Bioelectron. 1999, 14, 397.
16 Demidov V.A., Potaman V.N., Frank-Kamenetskii M. D., Egholm M., Buchardt O.,
Sonnichsen S. H., Nielsen P.E., Biochem. Pharmscol. 1994, 48, 1310.
17 Pirrung, J. Am. Chem. Soc, 2000, 122, 1873-1882

Chapter 4
132
18
Margolin, A. A.; Stojanovic, M. N.; Nat. Biotechnol., 2005, 23, 1374-1376.

Acknowledgements
Acknowledgements
I am greatly thankful to Prof. Rosangela Marchelli and Prof. Roberto Corradini, who
introduced me to the fascinating world of Peptide Nucleic Acids (PNAs). It has been a
wonderful experience to work under their supervision and learn the importance of self
determination, perseverance, enthusiasm and patience throughout the course of study even
when the excitement and challenges of research were not so great. Their great skills as
researchers and advisors had an immeasurable effect on my development as a chemist.
Without their help, the completion of this thesis would not have been possible.
Few graduate students get a chance to travel and work with many collaborators over the
world. Part of my research work involved the study of propagation of helicity through
PNA:PNA duplexes was carried out at Polytechnic University of New York. Then, I am
also thankful to Prof. Mark M. Green, who led me to exciting field of amplification of
chirality. It has been a nice experience to gain in-depth knowledge about the way that
chirality.can be amplified through biopolymers, such as PNA. I learnt too much during the
course of my stay in his laboratory.
I would also like to express my gratitude to Dr Gianluca De Bellis for his contribution to
the preliminary studies performed on Lab-On-Chip device.
I am thankful to Dr. Tullia Tedeschi, Prof. Stefano Sforza and Prof. Arnando Dossena, for
their continuous support and advices during scientific discussions. I am also grateful to Dr
Andrea Faccini, for his important contribution concerning the ESI-MS experiments.
I extend special thanks to my co-workers and lab members Alessandro Accetta,
Alessandro Calabretta, Roberto Pela, Dr Stefano Rossi, Elena Scaravelli who have been
very supportive during the course of this project.
I am grateful to the CIM (Centro Interfacoltà Misure) for the contribution concerning
NMR and CD experiments.
I would also like to thank my family, especially, my brother, Dr. Emmanuel Mbobda, for
his supportive nature and healthy discussion and criticism as in-house scientific
consultant, which were useful during the course of this thesis.
Finally, special thanks to Annie Isabelle Djatsa and Aurelien Pitchou for their friendship
and continuous support.
Related Documents











