Strojno učenje na slikovnih podatkih Janez Brank

Strojno učenje na slikovnih podatkih
Jan 02, 2016
Strojno učenje na slikovnih podatkih. Janez Brank. Motivacija. Imamo zbirko slik, vsaka pripada nekemu razredu Želimo naučiti klasi fi kator, ki bi znal v ustrezen razred razvrščati tudi nove slike. Motivacija. Pri klasi fi kaciji: - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Strojno učenjena slikovnih podatkih
Janez Brank

Motivacija
Imamo zbirko slik,vsaka pripada nekemu razredu
Želimo naučiti klasifikator, ki biznal v ustrezen razred razvrščatitudi nove slike

Motivacija
Pri klasifikaciji: Podana je ena slika, ugotoviti moramo, v
katerem razredu so ji slike najbolj podobne Pregledovanje podatkovnih zbirk
(image retrieval) Uporabnik poda poizvedovalno sliko,
program naj v bazi poišče nekaj najboljpodobnih
Ugotavljanje podobnosti:• Na podlagi besedila (ključne besede, opisi, itd.)• Na podlagi semantike (okviri, predikati, itd.)• Na podlagi videza oz. vsebine

Motivacija
Odgovoriti moramo na dve vprašanji: Algoritmi strojnega učenja ne znajo kar
delati s slikami
slike moramo opisati z nekimi strukturami, ki jih bodo ti algoritmi lahko uporabljali
Katere algoritme strojnega učenjanaj bi uporabili?

Novi primerek uvrstimo v razred, ki mupripadajo tudi najpodobnejši učni primerki.
Lahko uporabimo poljubno mero podobnosti Možne so različne izboljšave:
Ne zapomnimo si vseh učnih primerkov, ampakle tiste, ki dobro klasificirajo (glasujejo za pravega)
Upoštevamo več najbližjih sosedov, njihov vpliv različno obtežimo glede na podobnost zopazovanim primerkom.
Metoda najbližjih sosedov (NN)

Primerki, s katerimi delamo, morajo biti vektorji Predstavnike dveh razredov skušamo ločiti z
ravnino Vektorje lahko nelinearno preslikamo v kak
visokodimenzionalen prostor in dobimo nelinearnorazmejitveno ploskev. Te preslikave ni potrebnoračunati eksplicitno.
Več razredov: ločimo enega od ostalih; ali pa:vsak par razredov med sabo
Metoda podpornih vektorjev (SVM)

Tehnike opisovanja slik

Histogrami
Barvni prostor razbijemo na nekaj(npr. C) disjunktnih področij (kvantizacija) Lahko si mislimo, da smo sliko naslikali
s paleto C barv Za vsako področje pogledamo, koliko
pikslov iz tega področja je na sliki(ali pa: kolikšen delež slike pokrivajo)
Te vrednosti združimo v vektor sC komponentami — histogram

Primerjanje histogramov
Hi = (hi1, hi2, . . . , hiC), i =1, 2
Manhattanska razdalja (»L1-norma«):
||H1–H2||1 = c1..C |h1c–h2c|
Evklidska razdalja (»L2-norma«):
||H1–H2||22 = c1..C (h1c–h2c)2
Presek histogramov (Swain in Ballard, 1991):
pod(H1, H2) = c1..C min{h1c, h2c}

Primerjanje histogramov
Poskus, da bi upoštevali podobnost medbarvami: (QBIC, 1994)
||H1–H2||A2 = c,k1..C (h1c–h2c) ack (h1k–h2k) A = (ack); ack je podobnost med
barvama c in k To mero si lahko predstavljamo kot vektorsko
normo, v kateri posamezne komponente nisoneodvisne (kot da koordinatne osi ne bibile pravokotne).
To mero je dražje računati; pri poizvedbahpostavimo prednjo še kak preprostejši filter.

Vektorji barvnih koherenc
Histogram ne pove ničesar orazporeditvi barv po sliki
Piksli, ki so del kakšnega večjega področja(lise) iste barve, so »koherentni« Pri vsaki barvi štejmo koherentne piksle
posebej in ostale posebej Dobimo 2C-dimenzionalni »koherenčni vektor«
Primerjamo z L1- ali L2-normo
(Pass in Zabih, 1996)

Razčlenjevanje histogramov
Piksle iste barve ločimo še po kakšnem drugem kriteriju (histogram refinement): Koherentni ali nekoherentni V osrednjem delu slike ali pri strani Blizu roba ali ne Na področju s teksturo ali ne
Tako razčlenjenemu histogramu pravitajoint histogram
(Pass in Zabih, 1996, 1999)

Korelogrami
(d )ck = verjetnost, da je, če na razdalji d od naključno
izbranega piksla barve c naključno izberemo še nek piksel, slednji barve k
Preveliki in preokorni obdržimo lediagonalne elemente (avtokorelogram):
(d )c = (d )
cc
Te verjetnosti izračunamo za nekaj razdalj,npr. d = 1, 3, 5, 7 avtokorelogramiso 4C-razsežni vektorji
(Huang et. al., 1997)

Zgoščeni avtokorelogrami
V avtokorelogramu seštejmo elementeza različne d zgoščeni akg (banded autocorrelogram)
c = d (d )c
Veliki so le še toliko kot histogrami, torejprecej obvladljivi
(Huang et. al., 1998)

Lokalni histogrami
Sliko razdelimo na več celic, za vsako od njih shranimo histogram Npr. osrednja in štiri robne celice Cela slika, 3 3 celice, 5 5 celic
Lahko prihranimo kaj prostora, če sinamesto tega za vsako barvo zapomnimo,koliko je je v posamezni celici(color shape histograms) (Stehling et al., 2000) Prihranimo, če kakšne barve na sliki sploh ni.
Barvni prostori

RGB, HSV
RGB Barvo opišemo kot vsoto rdeče,
zelene in modre komponente, vsakaje recimo z intervala [0, 1]
Barve torej tvorijo enotsko kocko HSV
Barvo opišemo s temeljnim odtenkom(hue), zasičenostjo (saturation) insvetlostjo (brightness ali “value”)
Ta prostor si lahko predstavljamo kotvalj, stožec ali šeststrano piramido

XYZ
RGB ne more opisati vseh barv, ki jih človek lahko vidi, zato so pri CIE za potrebe standardizacije (1931) vzeli drugačne temeljne barve X, Y, Z (tristimulus values) Kot če bi v prostor RGB vpeljali nove
koordinatne osi
Y je svetlost, barvo pogosto izrazijo zx = X/(X+Y+Z), y = Y/(X+Y+Z) (chromaticity coordinates)

Perceptualna uniformnost
Lepo bi bilo, če bi lahko razdalje gledali karkot 3-d vektorje (r, g, b) ali (h, s, v) in merili razdaljo oz. različnost z evklidsko razdaljo Ljudje modre odtenke razločijo slabše Vse (h, s, 0) so črna barva, vse (h, 0, v0)
nek odtenek sive. Definirali so še druge barvne prostore,
ki naj bi bili v tem pogledu primernejši Lab, Luv, YCC, Munsellov prostor, . . .
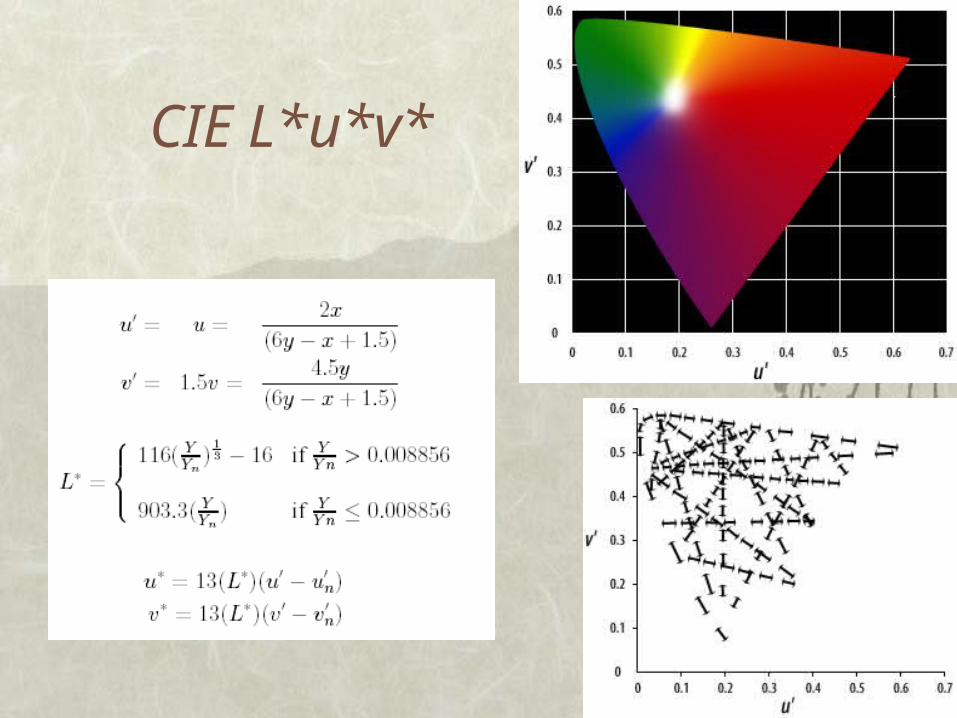
CIE L*u*v*
Segmentacija

Segmentacija
Sliko bi radi razdelili na več področij (regij),tako da bi bila barva ali tekstura znotrajvsakega področja približno enotna
Potem lahko opišemo vsako regijo posebejin tudi merimo podobnost medposameznimi regijami Kako pa iz tega določiti podobnost med
celimi slikami?

Segmentacija z digitalnimi filtri
Lahko poskusimo poiskati robove; kjer so ti dovolj močni, naj bi bile meje med regijami
Tekstura kot vzorec, ki se periodično ponavlja lahko jo poskusimo prepoznati s filtrom,ki se odziva le na določen frekvenčni pas(npr. Gaborjevi filtri)

Segmentacija kot clustering
Če nam gre le za primerjanje slik popodobnosti, smo zadovoljni že s preprostejšoin z bolj grobo segmentacijo Razrežimo sliko na majhna okna. Vsako od njih opišimo z nekim vektorjem. Te vektorje združimo v skupine. Vsaka skupina določa eno regijo (unijo vseh
oken v skupini), njen opis je centroid vsehvektorjev v skupini.

Segmentacija pri WALRUSu
Sliko razrežejo na okna velikosti 2n 2n, lahkoza različne n, okna se lahko tudi prekrivajo,na vsakem oknu izvedejo valčno transformacijo, zapomnijo si glavne štiri koeficiente
(Natsev et. al., 1998, 1999)
x
y
1
2
A
DWT
B
C D

Segmentacija pri SIMPLIcity
Sliko razrežejo na okna velikosti 4 4,na vsakem oknu izvedejo valčno transformacijo, zapomnijo si povprečje okna in tri podatke oenergiji v višjih frekvenčnih pasovih
(Wang et. al., 1999, 2000)
x
y
1
2
EHH
EHL
ELH
A
DWT

Mere podobnosti pri segmentiranih slikah
WALRUS: Naj bodo (Ri, xi) regije prve slike I1 in njihovi opisi,
(Sj, yj) pa regije druge slike I2 in njihovi opisi Izberemo si nek . Poiščemo pare podobnih
regij: P := { (i, j) : ||xi – yj|| < }. Izračunamo delež površine, ki jo pokrivajo te
regije: R := (i, j)P Ri, S := (i, j)P Sj,pod(I1, I2) := [|R| + |S|] / [|I1| + |I2|].

Mere podobnosti pri segmentiranih slikah
IRM (Integrated Region Matching): (Li et al., 2000)
Naj bo dij razdalja med i-to regijo prve inj-to regijo druge slike, npr. ||xi – yj||2.
Razdalja med celima slikama naj bo i,j sij dij.
Uteži sij si izberemo tako, da vsaki regijipripišemo neko pomembnost pi ali qj. Vse sij postavimo na 0 in gremo po vseh (i, j) (ponaraščajoči dij). Trenutno sij povečamo za toliko, kolikor se da, ne da bi j sij presegla pi alii sij presegla qj.
Poskusi

Uporabljena zbirka slik Iz zbirke misc sem izbral 1172 slik in
jih ročno razvrstil v 14 razredov



Poskusi z globalnimi opisi
Celo sliko opišemo z enim samim vektorjem: Histogrami, koherenčni vektorji, avtokorelogrami,
zgoščeni avtokorelogrami Različne kvantizacije barvnega prostora:
• RGB-64 (444), RGB-216 (666),RGB-332 (884), HSV-422 (1684)
Metoda najbližjih sosedov Metoda podpornih vektorjev (linearna,
kubična, radialna jedra)

Poskusi z globalnimi opisi Avtokorelogrami boljši od histogramov,
zgoščeni AKG enako dobri kot navadni Kvantizacija barvnega prostora ne sme biti pregroba

Metoda podpornih vektorjev daje boljše klasifikatorjeod metode najbližjih sosedov
Kubična in radialna jedra so boljša od linearnih
Poskusi z globalnimi opisi
Poskusi s segmentacijo
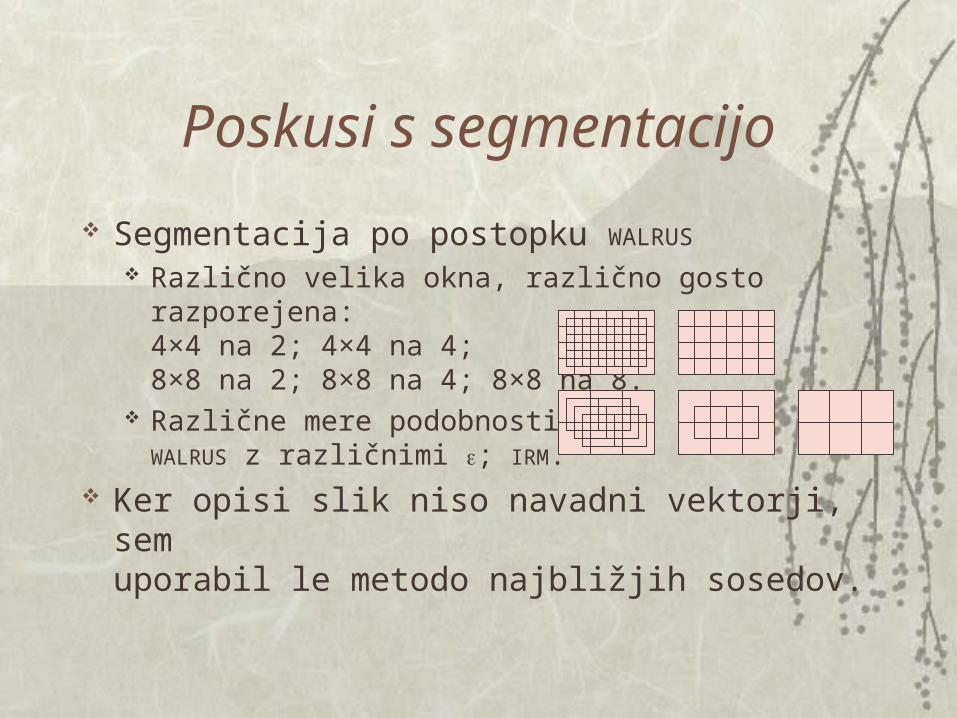
Segmentacija po postopku WALRUS
Različno velika okna, različno gosto razporejena:4×4 na 2; 4×4 na 4;8×8 na 2; 8×8 na 4; 8×8 na 8.
Različne mere podobnosti:WALRUS z različnimi ; IRM.
Ker opisi slik niso navadni vektorji, semuporabil le metodo najbližjih sosedov.

Parametri segmentacije so pomembni IRM boljši od WALRUSove mere podobnosti Segmentacija ni nič boljša od globalnih opisov
Poskusi s segmentacijo

Vpliv števila najbližjih sosedov
Če gledamo več kot enega najbližjega soseda, se rezultati le poslabšujejo
Očitno je prostor, v katerem se gibljemo, zelo kaotičen

Odločitvena drevesa nad slikami

Odločitvena drevesa nad slikami
Slike so opisali z zgoščenimi avtokorelogrami Drevo za slike, katerih razred pripada množici C:
Nad njihovimi korelogrami izvedemo SVD. (Po večkrat, da ugotovimo, koliko singularnih vrednosti vzeti.)
Za i, j C: naj bo mij št. primerkov razreda i, ki bijih po metodi najbližjega soseda uvrstili v razred j.
Naj bo r (C', C") := iC' jC" mij.Minimizirajmo pa r (C', C") [1/r (C', C) + 1/r (C", C)]
Potem zgradijo eno poddrevo za slike, ki pripadajokakšnemu razredu iz C' in bi jih tudi uvrstili v kakšnegaod teh razredov; in podobno še eno poddrevo za C".
(Huang et. al., 1998)

Odločitvena drevesa nad slikami
90 slik, 11 razredov; kvantizacija: RGB, 8×8×8 Izvedli so trikratno prečno preverjanje in primerjali
svoje drevo z navadno metodo najbližjih sosedovter poleg zgošč. akg preizkusili še histograme
(Huang et. al., 1998)

Možnosti nadaljnjega dela
Razumeti nepričakovane rezultate Slabi uspeh klasifikatorjev na podlagi segmentacije Zakaj je metoda k najbližjih sosedov
najuspešnejša pri k = 1? Primerjati z drugimi tehnikami
Druge vrste segmentacije Drugi barvni prostori
Iskati druge načine predstavitve slikin druge mere podobnosti
Related Documents











