[course site] Day 4 Lecture 3 Speech Synthesis: WaveNet Antonio Bonafonte

Speech Synthesis: WaveNet (D4L3 Deep Learning for Speech and Language UPC 2017)
Feb 07, 2017
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

[course site]
Day 4 Lecture 3
Speech Synthesis:WaveNetAntonio Bonafonte

2
deepmind.com/blog/wavenet-generative-model-raw-audio/
September 2016
3
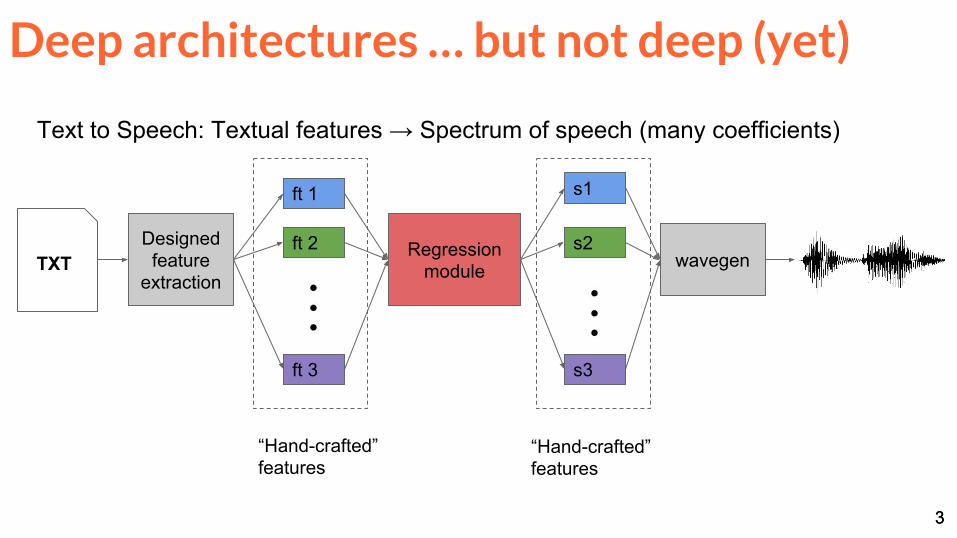
Deep architectures … but not deep (yet)
3
Text to Speech: Textual features → Spectrum of speech (many coefficients)
TXTDesigned
feature extraction
ft 1
ft 2
ft 3
Regression module
s1
s2
s3
wavegen
“Hand-crafted” features
“Hand-crafted” features

4
Text-to-Speech using WaveNet
4
TXTDesigned
feature extraction
ft 1
ft 2
ft 3
W
“Hand-crafted” features

5
Introduction
● Based on PixelCNN● Generative model operating directly on audio samples● Objective: factorised joint probability
● Stack of convolutional networks● Output: categorical distribution → softmax● Hyperparameters & overfitting controlled on validation set

6
High resolution signal and long term dependencies

7
Autoregressive model
DPCM decoder: next sample is (almost) reconstructed from linear causal convolution of past samples

8
Dilated causal convolutions
Stacked dilated convolutions:Eg: 1, 2, 4, . . . , 512, 1, 2, 4, . . . , 512, 1, 2, 4, . . . , 512
Receptive field: 1024 x 3 → 192 ms (at 16kHz)

9
Dilated causal convolutions
In training: all convolutions can be done in parallel

10
Dilated causal convolutions
Generating: predictions are sequential (~ 2min. per second)

11
Modeling pdf
● Not MSE● Not Mixture Density Networks (MDN)● But categorical distribution, softmax (classification
problem)

12
Modeling pdf
A softmax distribution tends to work better, even when the data is implicitly continuous (as is the case for image pixel intensities or audio sample values)Van den Oord et al. 2016
Signal represented using mu law: 16 bits → 8 bits (256 categories)

13
Gated Activation Units
Residual Learning

14
Architecture

15
Conditional WaveNet
They show results with h:● Speaker ID● Music genre, instrument● TTS: Linguistic Features +F0. (duration model needed to
switch condition phoneme to phoneme.

16
Results

17
Results
Listen yourself!

Discussion
18
● Wavenet: deep generative model of audio samples● Convolutional nets: faster than RNN● Outperforms best TTS systems● Autoregressive model: sequential model in generation
GANs were designed to be able to generate all of x in parallel, yielding greater generation speed
Ian GoodfellowNIPS 2016 Tutorial: Generative Adversarial Networks

19
deepmind.com/blog/wavenet-generative-model-raw-audio/
September 2016
Related Documents








![Natural TTS Synthesis by Conditioning WaveNet on Mel ... · [2] Oord, Aaron van den, et al. "Parallel WaveNet: Fast High-Fidelity Speech Synthesis.", Section 2.1 J. Shen, et al. |](https://static.cupdf.com/doc/110x72/602941018898c21bd672b6d3/natural-tts-synthesis-by-conditioning-wavenet-on-mel-2-oord-aaron-van-den.jpg)


