Spark Streaming Preview Fault-Tolerant Stream Processing at Scale Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY

Spark Streaming Preview
Feb 24, 2016
Spark Streaming Preview. Fault-Tolerant Stream Processing at Scale. Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker , Ion Stoica. UC BERKELEY. Motivation. Many important applications need to process large data streams arriving in real time - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Spark Streaming PreviewFault-Tolerant Stream Processing
at Scale
Matei Zaharia, Tathagata Das,Haoyuan Li, Scott Shenker, Ion
Stoica UC BERKELEY

Motivation• Many important applications need to process
large data streams arriving in real time– User activity statistics (e.g. Facebook’s Puma)– Spam detection– Traffic estimation– Network intrusion detection
• Our target: large-scale apps that need to run on tens-hundreds of nodes with O(1 sec) latency

System Goals• Simple programming interface• Automatic fault recovery (including
state)• Automatic straggler recovery• Integration with batch & ad-hoc
queries(want one API for all your data analysis)
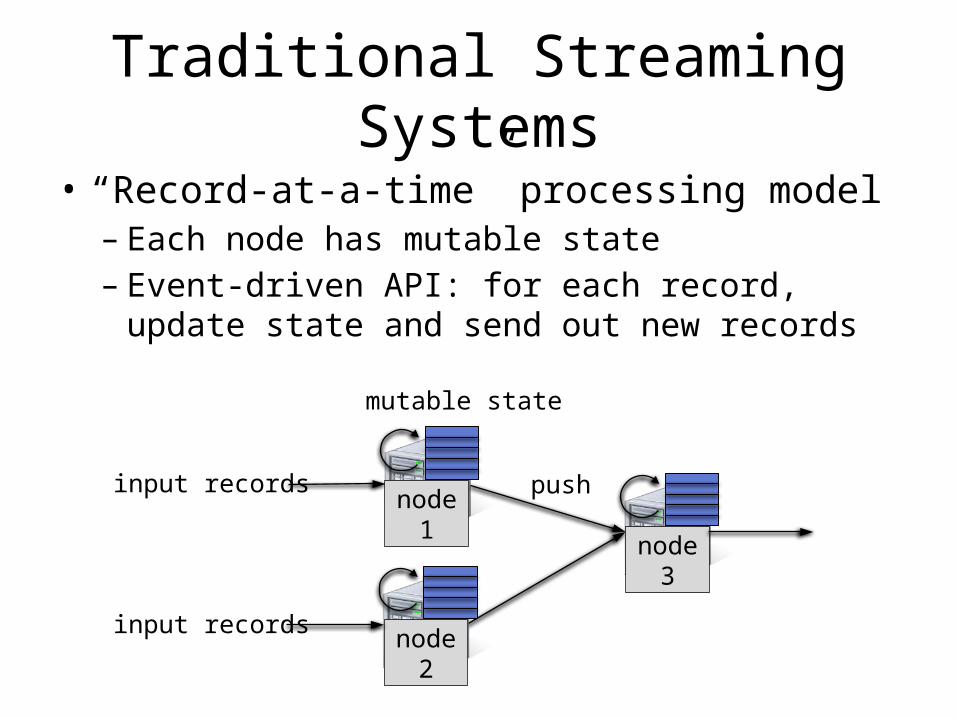
Traditional Streaming Systems
• “Record-at-a-time” processing model– Each node has mutable state– Event-driven API: for each record, update
state and send out new recordsmutable state
node 1 node
3
input records push
node 2
input records

Challenges with Traditional Systems
• Fault tolerance– Either replicate the whole system (costly)
or use upstream backup (slow to recover)
• Stragglers (typically not handled)
• Consistency (few guarantees across nodes)
• Hard to unify with batch processing

Our Model: “Discretized Streams”
• Run each streaming computation as a series of very small, deterministic batch jobs– E.g. a MapReduce every second to count tweets
• Keep state in memory across jobs– New Spark operators allow “stateful” processing
• Recover from faults/stragglers in same way as MapReduce (by rerunning tasks in parallel)

Discretized Streams in Action
t = 1:
t = 2:
stream 1 stream 2
batch operationinput
… …
input
immutable dataset
(stored reliably)
immutable dataset
(output or state);
stored in memory
as Spark RDD
…

Example: View Count• Keep a running count of views to each
webpage
views = readStream("http:...", "1s")
ones = views.map(ev => (ev.url, 1))
counts = ones.runningReduce(_ + _)
t = 1:
t = 2:
views ones counts
map reduce
. . .
= dataset = partition

Fault Recovery• Checkpoint state datasets periodically• If a node fails/straggles, build its data in
parallel on other nodes using dependency graphmap
input dataset
Fast recovery without the cost of full replication
output dataset

How Fast Can It Go?• Currently handles 4 GB/s of data (42
million records/s) on 100 nodes at sub-second latency
• Recovers from failures/stragglers within 1 sec

Outline• Introduction• Programming interface• Implementation• Early results• Future development

D-Streams• A discretized stream is a sequence of
immutable, partitioned datasets– Specifically, each dataset is an RDD
(resilient distributed dataset), the storage abstraction in Spark
– Each RDD remembers how it was created, and can recover if any part of the data is lost

D-Streams• D-Streams can be created… – either from live streaming data – or by transforming other D-streams
• Programming with D-Streams is very similar to programming with RDDs in Spark

D-Stream Operators • Transformations– Build new streams from existing streams– Include existing Spark operators, which
act on each interval in isolation, plus new “stateful” operators
• Output operators– Send data to outside world (save results
to external storage, print to screen, etc)

Example 1Count the words received every second
words = readStream("http://...", Seconds(1))
counts = words.count()D-
Streamstransformati
on
time = 0 - 1:
time = 1 - 2:
time = 2 - 3:
words counts
count
count
count
= RDD

Demo• Setup– 10 EC2 m1.xlarge instances– Each instance receiving a stream of
sentences at rate of 1 MB/s, total 10 MB/s
• Spark Streaming receives the sentences and processes them

Example 2Count frequency of words received
every secondwords = readStream("http://...", Seconds(1))
ones = words.map(w => (w, 1))
freqs = ones.reduceByKey(_ + _)Scala function literal
time = 0 - 1:
time = 1 - 2:
time = 2 - 3:
words ones freqs
map reduce

Demo

Example 3Count frequency of words received in
last minuteones = words.map(w => (w, 1))
freqs = ones.reduceByKey(_ + _)
freqs_60s = freqs.window(Seconds(60), Second(1)) .reduceByKey(_ + _)
window length window movement
sliding window operator
freqstime = 0 - 1:
time = 1 - 2:
time = 2 - 3:
words ones
map reduce freqs_60swindow reduce

freqs = ones.reduceByKey(_ + _)
freqs_60s = freqs.window(Seconds(60), Second(1)) .reduceByKey(_ + _)
freqs = ones.reduceByKeyAndWindow(_ + _, Seconds(60), Seconds(1))
Simpler running reduce

Demo

“Incremental” window operators
words freqs freqs_60st-1t
t+1t+2t+3t+4
+
Aggregation function
words freqs freqs_60st-1t
t+1t+2t+3t+4 +
+
–
Invertible aggregation function

freqs = ones.reduceByKey(_ + _)
freqs_60s = freqs.window(Seconds(60), Second(1)) .reduceByKey(_ + _)
freqs = ones.reduceByKeyAndWindow(_ + _, Seconds(60), Seconds(1))
freqs = ones.reduceByKeyAndWindow(_ + _, _ - _, Seconds(60), Seconds(1))
Smarter running reduce

Output Operators• save: write results to any Hadoop-
compatible storage system (e.g. HDFS, HBase)
• foreachRDD: run a Spark function on each RDD
freqs.save(“hdfs://...”)
words.foreachRDD(wordsRDD => {// any Spark/scala processing, maybe save to database
})

Live + Batch + Interactive• Combining D-streams with historical
datasets pageViews.join(historicCounts).map(...)
• Interactive queries on stream state from the Spark interpreter
pageViews.slice(“21:00”, “21:05”).topK(10)

Outline• Introduction• Programming interface• Implementation• Early results• Future development

System ArchitectureBuilt on an optimized version of Spark
Worker
MasterD-streamlineage
Task scheduler
Block tracker
Task executionBlock manager
Input receiver
Worker
Task executionBlock manager
Input receiver
Replication of input & checkpoint RDDs
Client
Client
Client

ImplementationOptimizations on current Spark:– New block store
• APIs: Put(key, value, storage level), Get(key)
– Optimized scheduling for <100ms tasks• Bypass Mesos cluster scheduler (tens of ms)
– Fast NIO communication library– Pipelining of jobs from different time
intervals

Evaluation• Ran on up to 100 “m1.xlarge”
machines on EC2– 4 cores, 15 GB RAM each
• Three applications:– Grep: count lines matching a pattern– Sliding word count– Sliding top K words

Scalability
0 50 1000
1
2
3
4
5TopKWords
0 50 1000
1
2
3
4
5WordCount
# Nodes in Cluster
0 20 40 60 80 1000
1
2
3
4
5Grep
1 sec 2 sec
Clus
ter
Thro
ughp
ut
(GB/
s)
Maximum throughput possible with 1s or 2s latency100-byte records (100K-500K records/s/node)

Performance vs Storm and S4
• Storm limited to 10,000 records/s/node• Also tried S4: 7000 records/s/node• Commercial systems report 100K aggregated
100 1000 100000
20
40
60Spark Storm
Record Size (bytes)
Gre
p Th
roug
h-pu
t (M
B/s/
node
)
100 1000 100000
10
20
30Spark Storm
Record Size (bytes)
TopK
Thr
ough
-pu
t (M
B/s/
node
)

Fault Recovery• Recovers from failures within 1
second
Sliding WordCount on 10 nodes with 30s checkpoint interval

Fault Recovery
0.00.51.01.52.02.53.0
1.47 1.66 1.75
2.31 2.642.03 Before Failure
At Time of Failure
Inte
rval
Pro-
cess
ing
TIm
e (s
)
WordCount Grep0.0
0.4
0.8
1.20.79 0.66
1.09 1.08No stragglerStraggler, with specu-lation
Inte
rval
Pro
-ce
ssin
g Ti
me
(s)
Failures:
Stragglers:

Interactive Ad-Hoc Queries

Outline• Introduction• Programming interface• Implementation• Early results• Future development

Future Development• An alpha of discretized streams will go
into Spark by the end of the summer• Engine improvements from Spark
Streaming project are already there (“dev” branch)
• Together, make Spark to a powerful platform for both batch and near-real-time analytics

Future Development• Other things we’re working on/thinking
of:– Easier deployment options (standalone &
YARN)– Hadoop-based deployment (run as Hadoop
job)?– Run Hadoop mappers/reducers on Spark?– Java API?
• Need your feedback to prioritize these!

More Details• You can find more about Spark
Streaming in our paper: http://tinyurl.com/dstreams

Related Work• Bulk incremental processing (CBP, Comet)
– Periodic (~5 min) batch jobs on Hadoop/Dryad– On-disk, replicated FS for storage instead of RDDs
• Hadoop Online– Does not recover stateful ops or allow multi-stage jobs
• Streaming databases– Record-at-a-time processing, generally replication for FT
• Approximate query processing, load shedding– Do not support the loss of arbitrary nodes– Different math because drop rate is known exactly
• Parallel recovery (MapReduce, GFS, RAMCloud, etc)

Timing Considerations• D-streams group input into intervals based
on when records arrive at the system• For apps that need to group by an
“external” time and tolerate network delays, support:– Slack time: delay starting a batch for a short
fixed time to give records a chance to arrive– Application-level correction: e.g. give a
result for time t at time t+1, then use later records to update incrementally at time t+5
Related Documents











