IEMS5730/ IERG4330/ ESTR4316 Spring 2022 Spark SQL Prof. Wing C. Lau Department of Information Engineering [email protected]

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

IEMS5730/ IERG4330/ ESTR4316 Spring 2022
Spark SQLProf. Wing C. Lau
Department of Information [email protected]

Spark Part II 2
Acknowledgementsn These slides are adapted from the following sources:
n Matei Zaharia, “Spark 2.0,” Spark Summit East Keynote, Feb 2016.n Reynold Xin, “The Future of Real-Time in Spark,” Spark Summit East Keynote, Feb 2016.n Michael Armburst, “Structuring Spark: SQL, DataFrames, DataSets, and Streaming,” Spark Summit East Keynote, Feb
2016.n Ankur Dave, “GraphFrames: Graph Queries in Spark SQL,” Spark Summit East, Feb 2016.n Michael Armburst, “Spark DataFrames: Simple and Fast Analytics on Structured Data,” Spark Summit Amsterdam, Oct
2015.n Michael Armburst et al, “Spark SQL: Relational Data Processing in Spark,” SIGMOD 2015.n Michael Armburst, “Spark SQL Deep Dive,” Melbourne Spark Meetup, June 2015.n Reynold Xin, “Spark,” Stanford CS347 Guest Lecture, May 2015.n Joseph K. Bradley, “Apache Spark MLlib’s past trajectory and new directions,” Spark Summit Jun 2017.n Joseph K. Bradley, “Distributed ML in Apache Spark,” NYC Spark MeetUp, June 2016.n Ankur Dave, “GraphFrames: Graph Queries in Apache Spark SQL,” Spark Summit, June 2016.n Joseph K. Bradley, “GraphFrames: DataFrame-based graphs for Apache Spark,” NYC Spark MeetUp, April 2016.n Joseph K. Bradley, “Practical Machine Learning Pipelines with MLlib,” Spark Summit East, March 2015.n Joseph K. Bradley, “Spark DataFrames and ML Pipelines,” MLconf Seattle, May 2015.n Ameet Talwalkar, “MLlib: Spark’s Machine Learning Library,” AMPCamps 5, Nov. 2014. n Shivaram Venkataraman, Zongheng Yang, “SparkR: Enabling Interactive Data Science at Scale,” AMPCamps 5, Nov.
2014. n Tathagata Das, “Spark Streaming: Large-scale near-real-time stream processing,” O’Reilly Strata Conference, 2013. n Joseph Gonzalez et al, “GraphX: Graph Analytics on Spark,” AMPCAMP 3, 2013. n Jules Damji, “Jumpstart on Apache Spark 2.X with Databricks,” Spark Sat. Meetup Workshop, Jul 2017.n Sameer Agarwal, “What’s new in Apache Spark 2.3,” Spark+AI Summit, June 2018.n Reynold Xin, Spark+AI Summit Europe, 2018.n Hyukjin Kwon of Hortonworks, “What’s New in Spark 2.3 and Spark 2.4,” Oct 2018.n Matel Zaharia, “MLflow: Accelerating the End-to-End ML Lifecycle,” Nov. 2018.n Jules Damji, “MLflow: Platform for Complete Machine Learning Lifecycle,” PyData, Jan 2019.
n All copyrights belong to the original authors of the materials.

Spark Part II 3
Major Modules in Spark

Spark Part II 4
Before SQL support was available from Spark
n The Spark Core Engine does not understand the structure of the data in RDDs or the semantics of user functions à limited optimization.
n However, most data is structured, e.g. JSON, CSV, Avro, Parquet, Hive, etc
=> Programming/ Operations via the RDD API inevitably ends up with a lot of tuples ( _1, _2, …)
n Functional Transformations, e.g. Map/Reduce are still not as Intuitive as SQL for a lot of Experienced System/Data Analysts.

Spark Part II 5
SQL support in Spark - Take 1: The Shark Story
n Hive is great, but Hadoop’s execution engine makes even the smallest queries take minutes
n Scala is good for programmers, but many data users only know SQL
n Initial Approach: Make Hive to run on Spark
= Hive on Spark

Spark Part II 6
Original Hive Architecture
Meta store
HDFS
Client
Driver
SQL Parser
Query Optimizer
Physical Plan
Execution
CLI JDBC
MapReduce

Spark Part II 7
Shark Architecture
Meta store
HDFS
Client
Driver
SQL Parser
Physical Plan
Execution
CLI JDBC
Spark
Cache Mgr.
Query Optimizer
[Engle et al, SIGMOD 2012]
Spark Part II 8
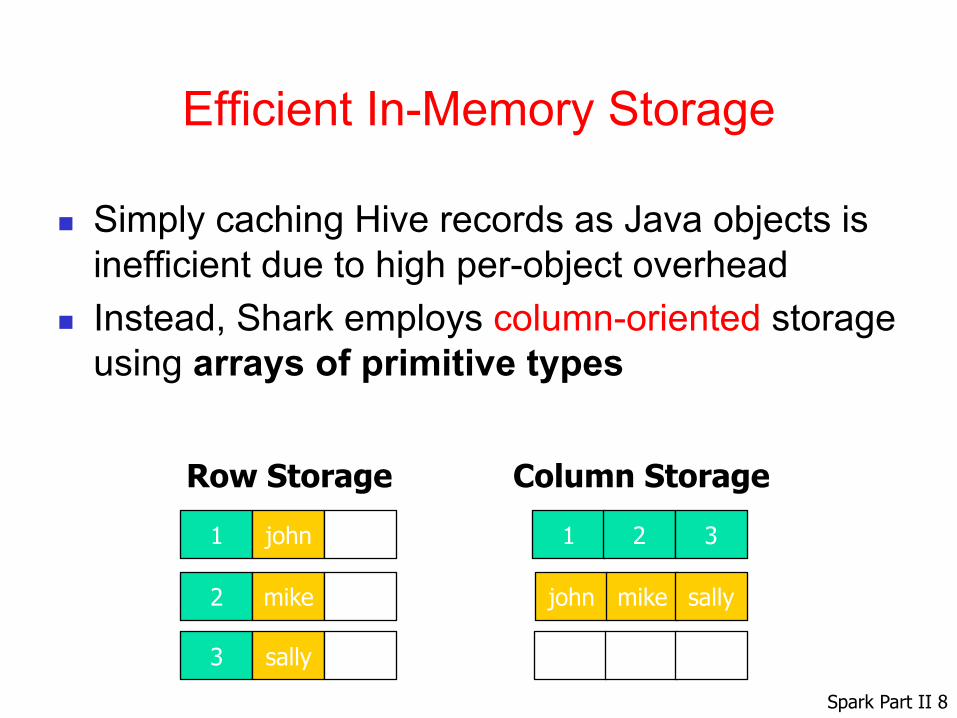
Efficient In-Memory Storage
n Simply caching Hive records as Java objects is inefficient due to high per-object overhead
n Instead, Shark employs column-oriented storage using arrays of primitive types
1
Column Storage2 3
john mike sally
4.1 3.5 6.4
Row Storage1 john 4.1
2 mike 3.5
3 sally 6.4

Spark Part II 9
Efficient In-Memory Storage
n Simply caching Hive records as Java objects is inefficient due to high per-object overhead
n Instead, Shark employs column-oriented storage using arrays of primitive types
1
Column Storage2 3
john mike sally
4.1 3.5 6.4
Row Storage1 john 4.1
2 mike 3.5
3 sally 6.4
Benefit: similarly compact size to serialized data,
but >5x faster to access

Spark Part II 10
But Shark was short-lived (2011-2014)
Limitations of nCan only be used to query external data in Hive catalog àlimited data sourcesnCan only be invoked via SQL string from Spark
à error pronenHive optimizer tailored for MapReduce
à difficult to extend
nAs a result, BDAS Project decided to switch to Spark SQL and stopped development of Shark in 2014
n The Apache Hive community still runs a Hive-over-Spark effort, as well as the Stinger/ Stinger.Next efforts to make Hive/HiveQL to be SQL compatible and low-latency

Spark Part II 11
Take 2: Spark SQL Overviewn Part of the core distribution since Spark 1.0 (April 2014)
n Optionally alongside or replacing existing Hive deploymentsn Run SQL/ HiveQL queries including UDFs, UDAFs and
SerDes, e.g.
n Connect existing Business Intelligence (BI) tools to Spark through JDBC
n Bindings in Python, Scala and Java

Spark Part II 12
The Approach of Spark SQLn Introduce a Tightly Integrated way to work with a new abstraction
of Structured Data called SchemaRDD, which is a Distributed Collection of Rows (i.e. a Table) with Named Columnsn SchemaRDD was renamed to DataFrame in Spark 1.3
n Support the Transformation of RDDs using SQL: In particular, DataFrames (aka SchemaRDDs) is an abstraction which supports:n Selecting, Filtering, Aggregating and Plotting Structured data
(cf. R or Python-based Pandas)n Evaluated lazily à unmaterialized logical plan
n Data source integration Support for: Hive, Parquet, JSON and …

Spark Part II 13
Relationship between Spark SQL and Sharkn Shark modified the Hive backend to run over Spark but had
two challenges:n Limited integration with Spark programsn Hive Optimizer not designed for Spark
n Spark SQL reuses some parts of Shark byBorrowing:
n Hive Data Loadingn In-memory Column-store
while Adding:n RDD-aware Optimizern Richer Language Interfaces

Spark Part II 14
What is an RDD ?
n Dependenciesn Partitions (with optional locality information)n Compute Function: Partition=>Iterator[T]

Spark Part II 15
What is an RDD ?
n Dependenciesn Partitions (with optional locality information)n Compute Function: Partition=>Iterator[T]

Spark Part II 16
Why Structure ?
n What do we mean by “Structure” [verb] ?:n Construct or Arrange according to a plan ; Give a pattern
or organization to.n By definition, structure will LIMIT what can be
expressed.n In practice, it is still possible to accommodate a vast
majority of computationsBUTn By Limiting the space of what can be expressed
ENABLES Optimization

Spark Part II 17
Adding Schema to RDDs
Spark + RDDsn Functional transformations
on Partitioned Collections of Opaque Objects
SQL + DataFrames (aka SchemaRDDs)n Declarative transformations
on Partitioned Collections of Tuples

Spark Part II 18
Comparing the Approaches ofRDD vs. DataFrame

Spark Part II 19
Data Model for DataFrame
n Nested data modeln Supports both primitive SQL types
(boolean, integer, double, decimal, string, data, timestamp) and complex types (structs, arrays, maps, and unions); alsouser defined types.
n First class support for complex data types

Spark Part II 20
DataFrame Operations
n Relational operations (select, where, join, groupBy) via a DSL
n Operators take expression objectsn Operators build up an abstract syntax tree
(AST), which is then optimized by Catalyst.
n Alternatively, register as temp SQL table and perform traditional SQL query strings

Spark Part II 21
Programming Interface for Spark SQL

Spark Part II 22
Spark SQL Components

Spark Part II 23
Getting Started: Spark SQLn SQLContext/ HiveContext
n Entry point for all SQL functionalityn Wraps/Extend existing Spark Context
OR

Spark Part II 24
SparkContext subsumed by SparkSessionsince Spark v2.0 !
n Starting v2.0, SparkSession becomes the unified entry point, i.e. a Conduit, to Sparkn Create Datasets/ DataFramesn Read/Write Data,n Access services of all Spark modules like SparkSQL, Streaming, …n Work with metadatan Set/Get Spark Configuration ; Driver uses for Cluster Resource Management

Spark Part II 25
Sample Input Data
n A text file filled with people’s names and ages:

Spark Part II 26
RDDs as Relations (Scala)

Spark Part II 27
RDDs as Relations (Python)

Spark Part II 28
RDDs as Relations (Java)

Spark Part II 29
Querying using Spark SQL (Python)

Spark Part II 30
Support of Existing Tools, and New Data Sources
n SparkSQL includes a server that exposes its data using JDBC/ODBCn Query data from HDFS/S3n Including formats like Hive/Parquet/JSONn Support for caching data IN-MEMORY

Spark Part II 31
Caching Tables In-Memory
n SparkSQL can cache tables using an in-memory columnar format:n Scan only required columnsn Fewer allocated objects (less Garbage Collection)n Automatically selects best compressione.g.
cacheTable(“people”) or dataframe.cache( )

Spark Part II 32
Caching Comparison

Spark Part II 33
Language Integrated UDFs

Spark Part II 34
Reading Data stored in Hive

Spark Part II 35
Parquet Compatibility
n Native support for reading data in Parquetn Columnar storage avoids reading unneeded datan RDDs can be written to Parquet files, preserving the
scheman Convert other slower formats into Parquet for
repeated querying

Spark Part II 36
Using Parquet

Spark Part II 37
JSON Support
n Use jsonFile or jsonRDD to convert a collection of JSON objects into a DataFrame
n Infer and Union the schema of each recordn Maintain nested structures and arrays

Spark Part II 38
JSON Example

Spark Part II 39
Data Sources API
n Allow easy integration with new sources of structured data:

Spark Part II 40
Much More than SQL: DataFrames as A Unified Interface for the Processing of
Structured Data
DataFrames(aka SchemaRDDs)

Spark Part II 41
Much More than SQL: Simplifying Inputs and Outptuts

Spark Part II 42
Unified and Simplified Interface to Read/ Write Data in Many different Formats

Spark Part II 43
Unified and Simplified Interface to Read/ Write Data in Many different Formats

Spark Part II 44
Unified and Simplified Interface to Read/ Write Data in Many different Formats

Spark Part II 45
ETL using Custom Data Sources

Spark Part II 46
Write Less Codes with DataFramesn Common operations can be expressed concisely as higher
level operation calls to the DataFrame API:n Selecting required Columnsn Joining Different Data Sourcesn Aggregation (Count, Sum, Average, etc)n Filtering

Spark Part II 47
Write Less Codes: An Example of Computing Average
private IntWritable one =new IntWritable(1)
private IntWritable output =new IntWritable()
proctected void map(LongWritable key,Text value,Context context) {
String[] fields = value.split("\t")output.set(Integer.parseInt(fields[1]))context.write(one, output)
}
IntWritable one = new IntWritable(1)DoubleWritable average = new DoubleWritable()
protected void reduce(IntWritable key,Iterable<IntWritable> values,Context context) {
int sum = 0int count = 0for(IntWritable value : values) {
sum += value.get()count++}
average.set(sum / (double) count)context.Write(key, average)
}
data = sc.textFile(...).split("\t")data.map(lambda x: (x[0], [x.[1], 1])) \
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] +y[1]]) \
.map(lambda x: [x[0], x[1][0] / x[1][1]]) \
.collect()

Spark Part II 48
Write Less Code: Example of Computing Average
n Using RDDsn data = sc.textFile(...).split("\t")n data.map(lambda x: (x[0], [int(x[1]), 1])) \n .reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]]) \n .map(lambda x: [x[0], x[1][0] / x[1][1]]) \n .collect()
Using DataFramessqlCtx.table("people") \
.groupBy("name") \
.agg("name", avg("age")) \
.collect()
Using SQLSELECT name, avg(age)FROM peopleGROUP BY name
Using PigP = load '/people' as (name, name);G = group P by name;R = foreach G generate … AVG(G.age);

Spark Part II 49
Read Less Data with DataFrames & SparkSQL“The fastest way to process big data is to never read it.”
nSparkSQL can help the program to read less data automatically by performing BEYOND naïve scanning:
n Using Columnar formats (e.g. Parquet) and prune irrelevant Columns and Blocks of data
n Push filters to the sourcen Converting to more efficient formats, e.g. turning string
comparisons into integer comparisons for dictionary encoded data
n Using Partitioning (i.e., /year=2-14/month=02/.. )n Skipping data using statistics (i.e. min, max)n Pushing predicates into storage systems (i.e. JDBC)

Spark Part II 50
Intermix DataFrame Operations withCustom Codes (Python, Java, R, Scala)
Takes and returns a
DataFrame

Spark Part II 51
Integration with RDDsn Internally, DataFrame execution is done with Spark RDDs=> Easy Interoperation with outside sources and custom
algorithms
External Inputdef buildScan(
requiredColumns: Array[String],filters: Array[Filter]): RDD[Row]
Custom ProcessingqueryResult.rdd.mapPartitions { iter =>
… Your code here …
}

Spark Part II 52
DataFrame & SparkSQL DemoDemo: nUsing Spark SQL to read, write, and transform data in a variety of formats:
http://people.apache.org/~marmbrus/talks/dataframe.demo.pdf

Spark Part II 53
Plan Optimization and Execution for the entire Pipelines
n Optimization happens as late as possible=> Spark SQL can optimize even across different functions !

Spark Part II 54
Optimization Example

Spark Part II 55
Optimization Example

Spark Part II 56
Optimization Example
Only joinrelevant users

Spark Part II 57
Optimization Example

Spark Part II 58
Named Columns (vs. Opaque Objects in RDDs) Enable Performance Optimization

Spark Part II 59
More Performance Comparison

Spark Part II 60
Datasets: Another Structured Data Abstraction and its API in Spark
More info at: https://techvidvan.com/tutorials/apache-spark-dataframe-vs-datasets/

Spark Part II 61
Datasets vs. DataFramesn DataFrames are collections of rows with a scheman Datasets add static types, e.g. Dataset[Person]n Spark 2.0 has merged these APIs:
Dataframe = Dataset[Row]Benefits of Mergingn Simpler to understand
n Only kept Dataset separate to keep binary compatibility in Spark 1.x
n Libraries can take data of both formsn With Streaming, same API will also work on streams

Spark Part II 62
Datasets vs. DataFramesSource: Chapter 4, p.g. 50 of “Spark - The Definitie Guide” by Bill Chambers & Matei Zaharia
“In essence, within the Structured APIs, there are two more APIs, the “untyped”DataFrames and the “typed” Datasets. To say that DataFrames are untyped is aslightly inaccurate; they have types, but Spark maintains them completely and only checks whether those types line up to those specified in the schema at runtime. Datasets, on the other hand, check whether types conform to the specification at compile time.
Datasets are only available to Java Virtual Machine (JVM)–based languages (Scala and Java) and we specify types with case classes or Java beans. For the most part, you’re likely to work with DataFrames. To Spark (in Scala), Data‐Frames are simply Datasets of Type Row. The “Row” type is Spark’s internal representation of its optimized in-memory format for computation. This format makes for highly specialized and efficient computation because rather than using JVM types, which can cause high garbage-collection and object instantiation costs, Spark can operate on its own internal format without incurring any of those costs. To Spark (in Python or R), there is no such thing as a Dataset: everything is a DataFrame and therefore we always operate on that optimized format.”

Spark Part II 63
Example for Datasets and DataFrames

Spark Part II 64
Datasets APIn Type-safe: Operate on domain objects with compiled lambda
functions

Spark Part II 65
Long-Term Direction
n RDD will remain the low-level API in Sparkn Datasets and DataFrames give richer semantics and
optimizationsn New libraries will increasingly use these as interchange format,
e.g. Structured Streaming, MLlib and GraphFrames

Spark Part II 66
Shared Optimization and Execution

Spark Part II 67
Towards to the Support of SQL 2003
n Since 2017, Spark can run all 99 TPC-DS queriesn Have a standard compliant parsern Subqueries (correlated & uncorrelated)n Approximate Aggregate Stats
n https://databricks.com/blog/2016/06/17/sql-subqueries-in-apache-spark-2-0.html

Spark Part II 68
Lessons Learnt from Spark SQLn SQL is wildly popular and important for real-world
customersn Schema is very useful
n In most data pipelines, even the ones that start with unstructured data end up having some implicit structure
n Key-value abstraction (under RDD) is too limitedn Nevertheless, Support for Semi/Un-structured data is critical !
n Separation of Logical vs. Physical Plan is important for Performance Optimizations, e.g. join selection.
Related Documents











