Spark Magic Building and Deploying a High Scale Product in 4 Months

Spark Magic Building and Deploying a High Scale Product in 4 Months
Aug 08, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Spark MagicBuilding and Deploying a High Scale Product in 4 Months


Collaborative FilteringBucketed Consumption Groups
GeoRegion-based
Recommendations
ContextMetadata
SocialFacebook/Twitter API
User BehaviorCookie Data
Engine Focused on Maximizing CTR & Post Click Engagement

Largest Content Discovery and Monetization Network
500MMonthly
Unique Users
220BMonthly
Recommendations
10B+Daily User Events
5TB+Incoming Daily
Data

What Does it Mean?
• Using Spark since 1983 (not really, but since 0.7)• 6 Data Centers across the globe• Dedicated Spark & Cassandra (for spark) cluster consists of
– 2,700 cores with 18.5TB of RAM memory and 576TB of SSD local storage, across 2 Data Centers.
• Data must be processed and analyzed in real time, for example:– Real-time, per user content recommendations– Real-time expenditure reports– Automated campaign management– Automated recommendation algorithms calibration– Real-time analytics

About “Newsroom”• Newsroom is a real time analytics product for
editors of news and content sites• MVP Requirements:
– Clicks & Impressions, per position & whole page– Performance against live baseline– AB testing of multiple titles and thumbnails
• The mission - design, develop and deploy a full blown production system in 4 months after an alpha


Spark WHAAAT??!• Assembled an ad-hoc task force to design, develop & deploy
• We already had a very good experience with Spark at that point, so we decided to build the new product around Spark
• We now have many live production publishers using Newsroom exclusively (weather.com, theblaze, tribune, college humor and many others) and usage is growing
• Newsroom is mission critical– Clients are calling immediately if there’s any down time– “Flying blind”

Newsroom Dashboard
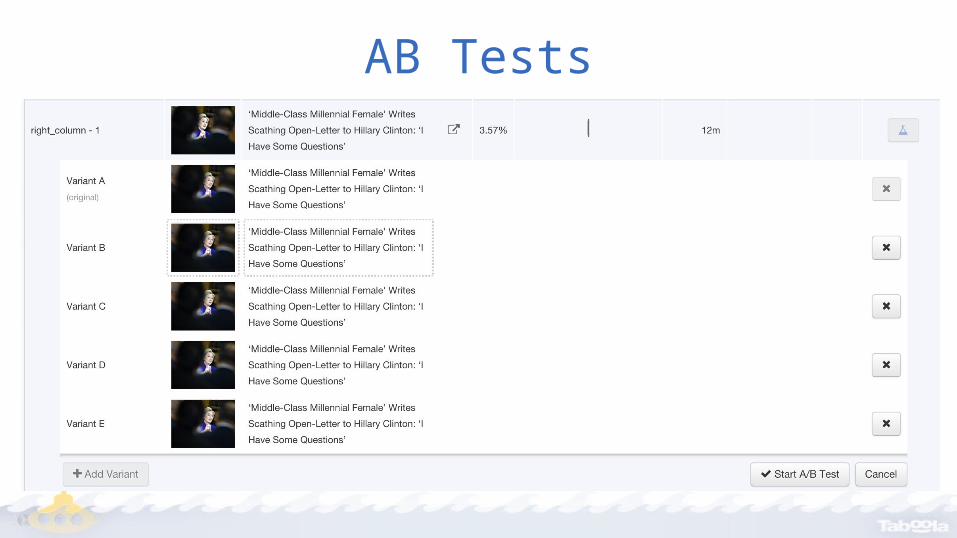
AB Tests

AB Tests

Under the Hood

System Architecture & Data Flow
Driver + Consumers
Spark Cluster
C* Cluster
FE ServersBackstage

Design Concepts• Requirements:
– Semi real time (a few seconds latency)– Idempotent processing / exactly once counting– Support late and out of order data
• Implementation:– Guid per data packet / time based– 1 Minute batches in C* (latest batch is partial)– Re-process time unit over and over and over– Run over data in cassandra – without counters– Data aggregation: Events Minute hour baseline
• Spark Streaming – was an alpha, too early to use (January 2014)

Spark Consumers
Multiple spark jobs using algorithmic and statistical analysis in real time:• Clicks and Impressions Aggregator• Performance Analyzer• AB Tests Manager• Baseline Calculator• Homepage Crawler• More

Diving into the דג
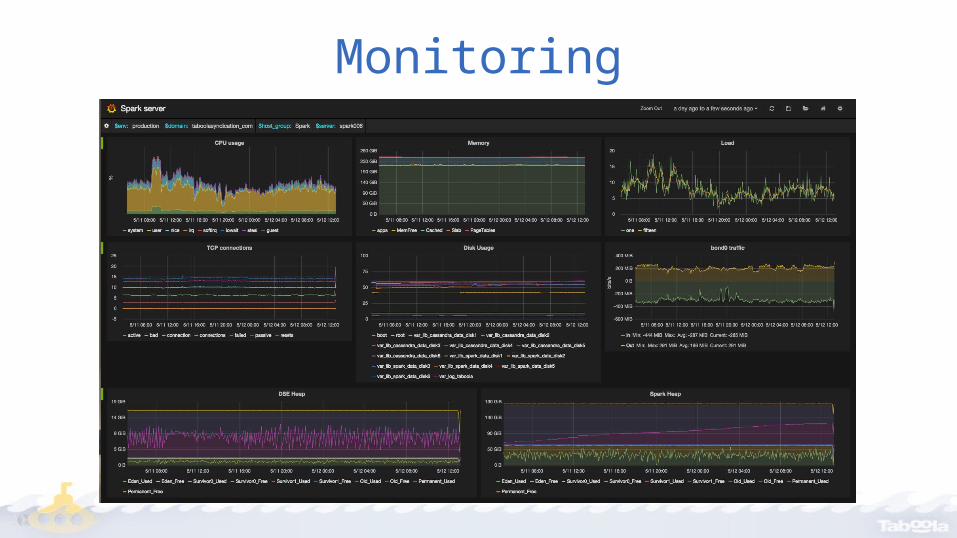
Monitoring

Challenges• Performance Optimizations
– DAG profiling• Using .count() to cancel lazy DAG execution (turned on/off
using a live configuration)
– Code Profiling• Yourkit, etc
• Debugging Errors in Production– Local debugging on small datasets– Remote debugging– Extensive usage of logfiles (ELK)

Hash code pitfall• JavaPairRDD<Key, Value>• The Spark partitioner was hash partitioner• The Key was an object with an enum as a member• enum .hashCode() is final and is the memory position of the
object JVM Dependent The Key hash was JVM dependent• Objects with the same key ended up in multiple partitions
reduceByKey() produced inconsistent results.
• Solution either avoid using enums in keys, or manually change the hashCode method of the key object to use the numeric or string value of the enum

Spark Usages @ Taboola
• Newsroom• Automatic campaigns stopper / reviver• Legacy Spark • Spark SQL for reporting• Algo team research
– MLLIB

Related Documents

![[Spark meetup] Spark Streaming Overview](https://static.cupdf.com/doc/110x72/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)









