Apache Spark Concepts - Spark SQL, GraphX, Streaming Petr Zapletal Cake Solutions

Spark Concepts - Spark SQL, Graphx, Streaming
Jul 15, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Apache Spark
Concepts - Spark SQL, GraphX, Streaming
Petr Zapletal Cake Solutions

Apache Spark and Big Data
1) History and market overview
2) Installation
3) MLlib and Machine Learning on Spark
4) Porting R code to Scala and Spark
5) Concepts - Spark SQL, GraphX, Streaming
6) Spark’s distributed programming model
7) Deployment

Table of contents
● Resilient Distributed Datasets
● Spark SQL
● GraphX
● Spark Streaming
● Q & A

Spark Modules

Resilient Distributed Datasets
● Immutable, distributed collection of records
● Lazy evaluation, caching option, can be persisted
● Number of operations & transformations
● Can be created from data storage or different RDD

Spark SQL
● Spark’s interface to work with structured or semistructured data
● Structured data
o known set of fields for each record - schema
● Main capabilities
o load data from variety of structured sources
o query the data with SQL
o integration between Spark (Java, Scala and Python API) and SQL
(joining RDDs and SQL tables, using SQL functionality)
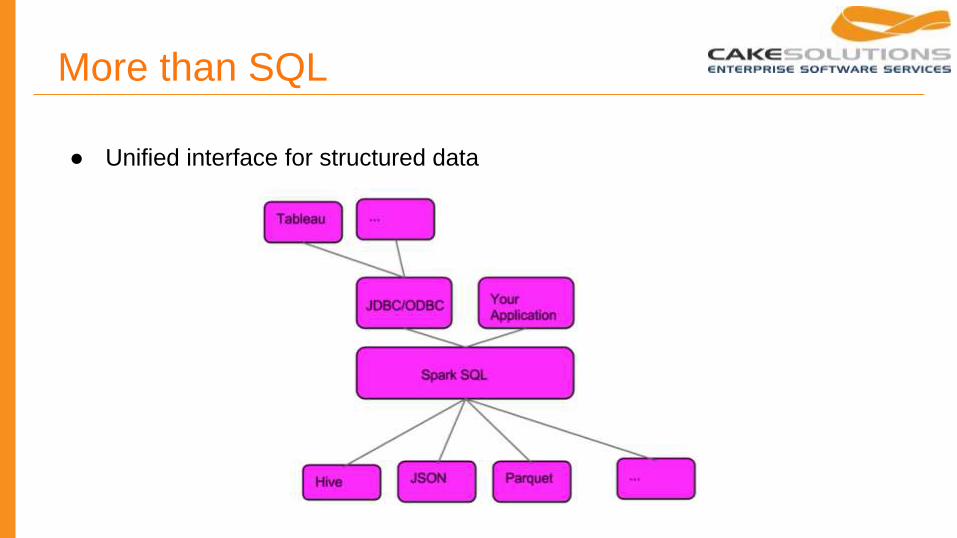
More than SQL
● Unified interface for structured data

SchemaRDD
● RDD of row objects, each representing a record
● Known schema (i.e. data fields) of its rows
● Behaves like regular RDD, stored in more efficient manner
● Adds new operations, especially running SQL queries
● Can be created from
o external data sources
o results of queries
o regular RDD
● Used in ML Pipeline API

SchemaRDD

Getting Started
● Entry points:
o HiveContext
superset functionality, Hive related
o SQLContext

● Loads input JSON file into SchemaRDD
● Uses context to execute query
Query Example

Loading and Saving Data
● Supports number of structured data sources
o Apache Hive
data warehouse infrastructure on top of Hadoop
summarization, querying (SQL-like interface) and analysis
o Parquet
column-oriented storage format in Hadoop ecosystem
efficient storage of records with nested fields
o JSON
o RDDs
o JDBC/ODBC Server
connecting Business Intelligence tools
remote access to Spark cluster

GraphX
● New Spark API for graphs and graph-parallel computation
● Resilient Distributed Property Graph (RDPG, extends RDD)
o directed multigraph ( -> parallel edges)
o properties attached to each vertex and edge
● Common graph operations (subgraph computation, joining vertices, ...)
● Growing collection of graph algorithms

Motivation● Growing scale and importance of graph data
● Application of data-parallel algorithms to graph computation is inefficient
● Graph-parallel systems (Pregel, PowerGraph, ...) designed for efficient
execution of graph algorithms
o do not address graph construction & transformation
o limited fault tolerance & data mining support

Performance Comparison
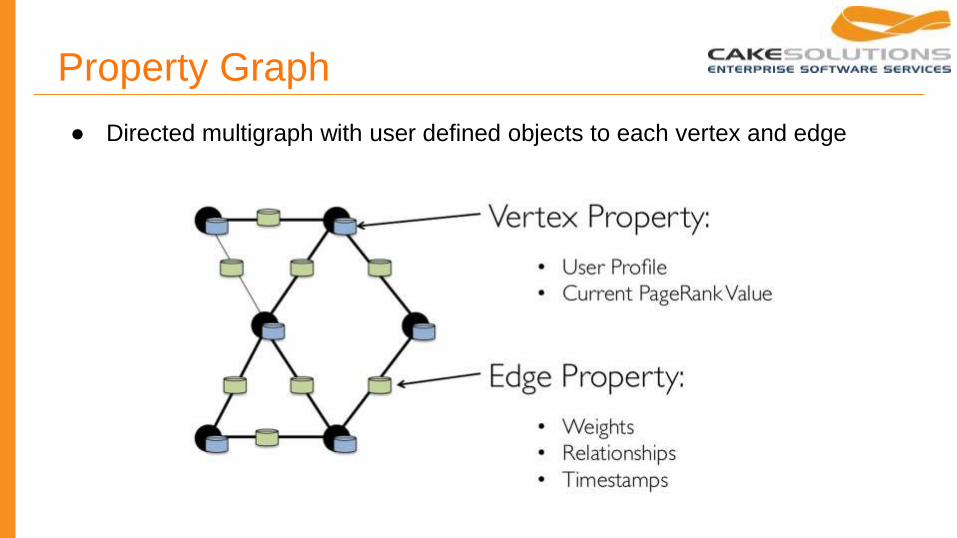
Property Graph
● Directed multigraph with user defined objects to each vertex and edge

Property Graph

Triplet View
● Logical join of vertex and edge properties

Graph Operations
● Basic information (numEdges, numVertices, inDegrees, ...)
● Views (vertices, edges, triplets)
● Caching (persist, cache, ...)
● Transformation (mapVertices, mapEdges, ...)
● Structure modification (reverse, subgraph, ...)
● Neighbour aggregation (collectNeighbours, aggregations, ...)
● Pregel API
● Graph builders (various I/O operations)
● ...

Graph Algorithms
● Built-in algorithms
o PageRank, Connected Components, Triangle Count, ...

Demo
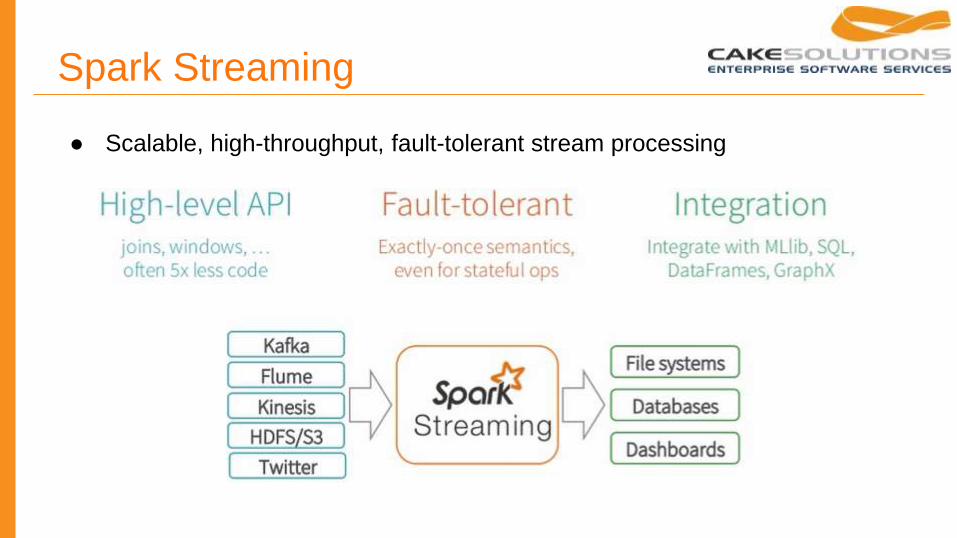
Spark Streaming
● Scalable, high-throughput, fault-tolerant stream processing

Architecture
● Streams are chopped up into batches
● Each batch is processed in Spark
● Results pushed out in batches

Streaming Word Count

Streaming Word Count

StreamingContext
● Entry point for all streaming functionality
o define input sources
o stream transformations
o output operations to DStreams
o starts & stops streaming process
● Limitations
o once started, computations cannot be added
o cannot be restarted
o one active per JVM

Discretized Streams
● Basic abstraction, represents a continuous stream of data
● DStreams
● Implemented as series of RDDs

Stateless Transformations
● Processing of each batch does not depend on previous batches
● Transformation is separately applied to every batch
o Map, flatMap, filter, reduce, groupBy, …
● Combining data from multiple DStreams
o Join, cogroup, union, ...

Stateful Transformations
● Use data or intermediate results from previous batches to compute the
result of the current batch
● Windowed operations
o act over a sliding window of time periods
● UpdateStateByKey
o maintain state while continuously updating it with new information
● Require checkpointing

Output Operations
● Specify what needs to be done with the final transformed data
● Pushing to external DB, printing, …
● If not performed, DStream is not evaluated

Input Sources
● Built-in support for a number of different data sources
● Often in additional libraries (i.e. spark-streaming-kafka)
● HDFS
● Akka Actor Stream
● Apache Kafka
● Apache Flume
● Twitter Stream
● Kinesis
● Custom Sources
● ...

Demo

Conclusion
● RDD repetition
● Spark Modules Overview
o Spark SQL
o GraphX
o Spark Streaming

Questions
Related Documents











