SUPPORTING TOP-K QUERIES IN RELATIONAL DATABASES. PROCEEDINGS OF THE 29TH INTERNATIONAL CONFERENCE ON VERY LARGE DATABASES, MARCH 2004 Sowmya Muniraju Presented By: Proposed By, Ihab F. Ilyas Walid G. Aref Ahmed K. Elmagarmid

Sowmya Muniraju
Feb 25, 2016
Proposed By, Ihab F. Ilyas Walid G. Aref Ahmed K. Elmagarmid. Supporting top-k queries in Relational databases. Proceedings of the 29th international conference on Very large databases, March 2004. Sowmya Muniraju. Presented By:. Outline. Introduction - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

SUPPORTING TOP-K QUERIES IN RELATIONAL DATABASES.
PROCEEDINGS OF THE 29TH INTERNATIONAL CONFERENCE ON VERY LARGE DATABASES, MARCH 2004
Sowmya MunirajuPresented By:
Proposed By, Ihab F. Ilyas
Walid G. Aref Ahmed K. Elmagarmid

2
Outline Introduction
Existing join strategies Contributions
Related Work Introduction to New Rank join algorithm Overview of Ripple Joins New Rank join algorithm Physical Rank Join Operators
HRJN HRJN*
Performance Evaluation Conclusion

3
Introduction Need for support of ranking in Relational
Databases. Attributes in Relational databases spread
across multiple relations, hence need for ranking on join queries.
User mostly interested in top few results. Resultset should be ordered based on
certain conditions (scoring functions).

4
Existing Join strategies Sort-Merge join
Relations sorted on join columns. Nested loop join
Tuples of outer relation are joined with tuples of the inner relation.
Hash join 2 phases: Build, Probe Build hash table for smaller of the two
relations. Probe this hash table with hash value for each
tuple in the other relation.
5
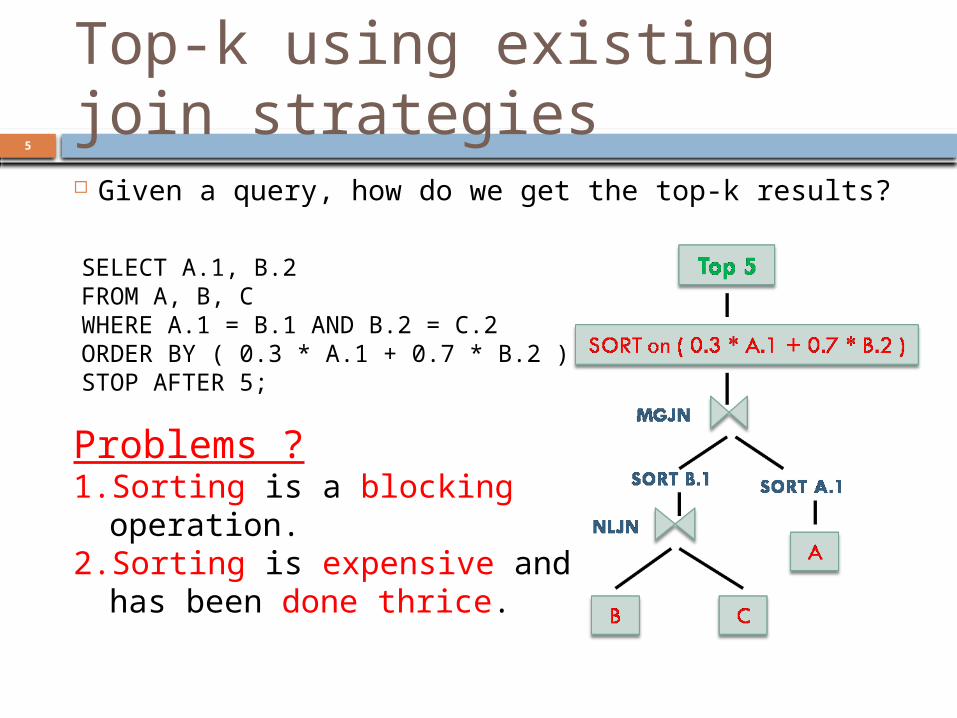
Top-k using existing join strategies Given a query, how do we get the top-k results?
SELECT A.1, B.2 FROM A, B, CWHERE A.1 = B.1 AND B.2 = C.2ORDER BY ( 0.3 * A.1 + 0.7 * B.2 )STOP AFTER 5;
Problems ?1. Sorting is a blocking
operation. 2. Sorting is expensive and has
been done thrice.
6
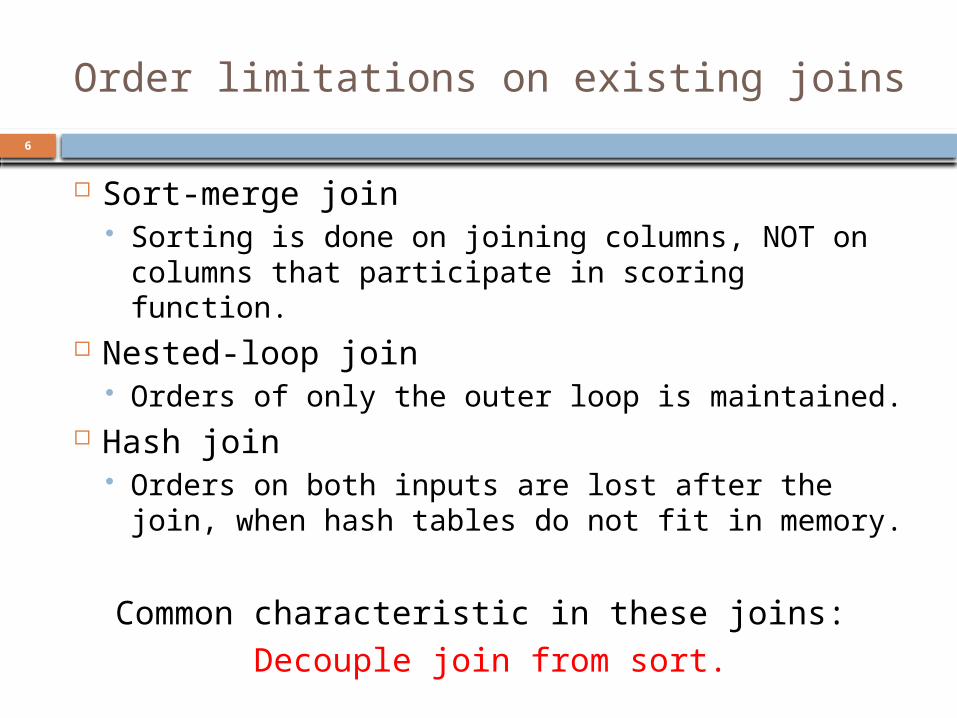
Order limitations on existing joins
Sort-merge join Sorting is done on joining columns, NOT on
columns that participate in scoring function. Nested-loop join
Orders of only the outer loop is maintained. Hash join
Orders on both inputs are lost after the join, when hash tables do not fit in memory.
Common characteristic in these joins: Decouple join from sort.

7
Contributions Proposed a new rank join algorithm. Implemented this algorithm in practical
pipelined rank-join operators based on ripple join.
Proposed a scoring guide function that reduces the number of tuples to be evaluated to get the desired resutls.

8
Desired Result
SELECT A.1, B.2 FROM A, B, C WHERE A.1 = B.1 AND B.2 = C.2ORDER BY ( 0.3 * A.1 + 0.7 * B.2 ) STOP AFTER 5;
Using existing join strategies
DESIRED: Using rank join

9
Related Work This problem is closely related to top-k
selection queries. Here, scoring function is applied on
multiple attributes m of the same relation.
Related algorithms: Threshold Algorithm(TA),
No-Random Access Algorithm(NRA), J*, A*

10
Introduction: New Rank Join Algorithm
Tuples are retrieved in order to preserve ranking.
Produces first ranked join results as quickly as possible.
Uses a monotonic ranking function. Based on the idea of ripple join. Integration with existing physical query
engines. Variations: HRJN, HRJN*

11
Overview of Ripple Joins Previously unseen random tuple from
one relation is joined with previously seen tuples from another relation.
Variations of Ripple Joins Block Hash

12
Rank Join Algorithm

13
1010
10
ExampleId A B1 1 52 2 43 2 34 3 2
Id A B1 3 52 1 43 2 34 2 2
L R
L.A = R.A
Threshold (T):
L_top
L_bottom
R_top
R_bottom
LI, RI not a valid join
Right_threshold =f( R_top, L_bottom )
Left_threshold = f( L_top, R_bottom )
T = Max(Left_threshold, Right_threshold )
99
9
109
L1, R2 is a valid join.
88
8
8
L3, R3 | L2, R3 are valid joins
[ (1,1,5) (2,1,4) ] = 9 [ (2,2,4) (3,2,3) ] = 7
77
7
7
[ (3,2,3) (3,2,3) ] = 6
L4,R1 | L2,R4 | L3,R4 are valid joins
[ (4,3,2) (1,3,5) ] = 7[ (2,2,4) (4,2,2) ] = 6[ (3,2,3) (4,2,2) ] = 5
Scoring Function:L.B+ R.B
K = 2
K = 0K = 1K = 2

14
Hash Rank Join Operator (HRJN) Variant of Symmetrical hash join algorithm. Data Structures
Hash table for each input. Priority Queue - holds valid join combinations along
with their scores. Methods implemented
Open: initializes its operator and prepares its internal state.
Get Next: returns next ranked join result upon each call. Close: terminates the operator and performs the
necessary clean up.

15
Open(L, R, C, f)L = Left InputR = Right Input C = Join conditionf = Monotonic scoring function

16
GetNext()Output: Next ranked join result

17
Local Ranking Problem
Unbalance retrieval rate of left and right inputs.
Use concept of Block Ripple Join.
Solving
18
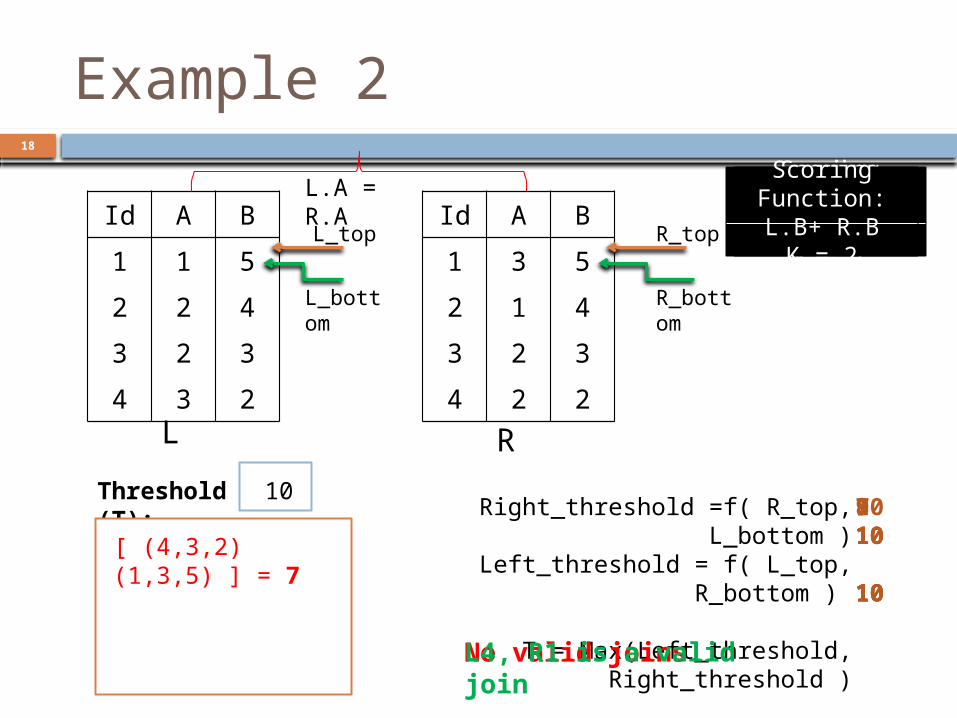
Example 2Id A B1 1 52 2 43 2 34 3 2
Id A B1 3 52 1 43 2 34 2 2
L.A = R.AL_top
L_bottom
R_top
R_bottom
Threshold (T): Right_threshold =f( R_top,
L_bottom )Left_threshold = f( L_top,
R_bottom )
T = Max(Left_threshold, Right_threshold )
1010
10
10
Scoring Function:L.B+ R.B
K = 2
Scoring Function:L.B+ R.B
K = 2
910
10No valid joins.
810
10
710
10L4, R1 is a valid join
[ (4,3,2) (1,3,5) ] = 7
L R

19
HRJN*: Score-Guided Join Strategy
Retrieve tuple from input
T1 = f( L_top, R_bottom)T2 = f( R_top, L_bottom)
IfT1 > T2
Input = R Input = L
Yes
No

20
Exploiting available indexes Generalize Rank-join to use random
access if available. Two cases:
An index on join attribute(s) of one input.
An index on join attribute(s) for each input.
Problem: Duplicates can be produced as indexes will contain all data seen and not yet seen.

21
Exploiting Indexes: On-the-fly duplicate elimination
Id A B1 1 10
02 2 503 2 254 3 10
Id A B1 3 102 1 93 2 84 2 5
L R
Scoring Function:L.B+ R.B
Index available on R
[ (1,1,100) (2,1,9) ] = 109[ (2,2,5) (3,2,8) ] = 58[ (2,2,50) (4,2,5) ] = 55
Any join result, not yet produced, cannot have a combined score greater than f( L_bottom, R_bottom)
f( L_bottom, R_bottom) = 59
22
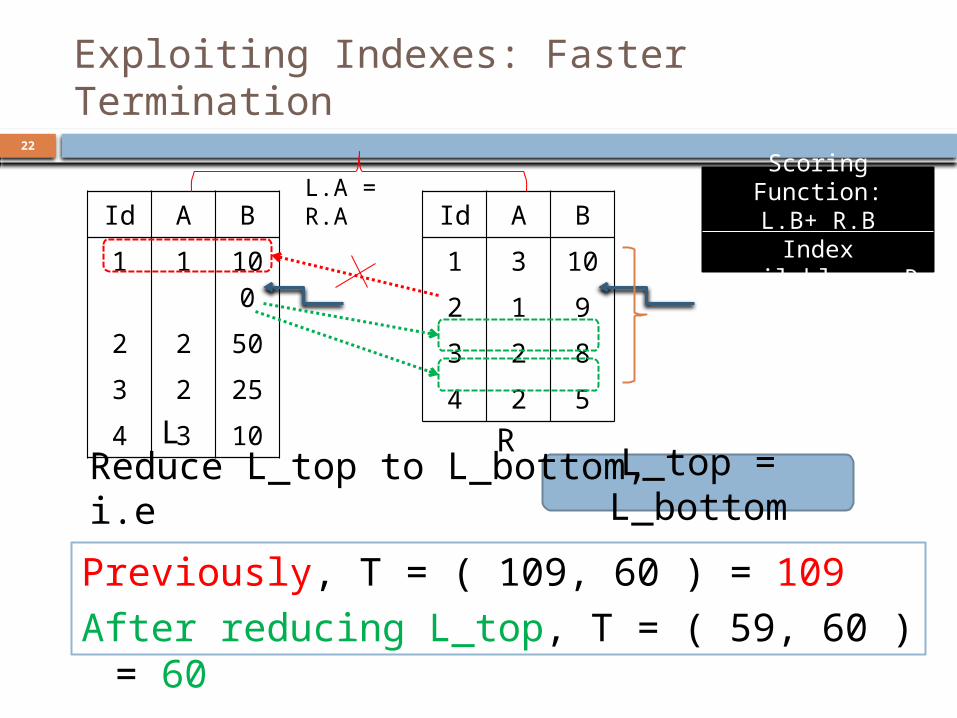
Exploiting Indexes: Faster Termination
Previously, T = ( 109, 60 ) = 109After reducing L_top, T = ( 59, 60 ) = 60
Id A B1 1 10
02 2 503 2 254 3 10
Id A B1 3 102 1 93 2 84 2 5
L R
L.A = R.A
Scoring Function:L.B+ R.B
Index available on R
L_top = L_bottomReduce L_top to L_bottom, i.e

23
Performance Evaluation Top-k join operators
M = 4 Selectivity = 0.2%

24
Effect of selectivityM = 4 K = 50

25
Effect of pipeliningSelectivity = 0.2%K = 50

26
Conclusion Supported top-k join queries using the new rank
join algorithm. Algorithm uses ranking on the input relations to
produce ranked join results on a combined score. The ranking is performed progressively during
the join operation. HRJN, HRJN* operators implement the new
algorithm. Generalization of this algorithm utilized available
indexes for faster termination.

27

28
References “Supporting Top-k Join Queries in
Relational Databases.”, Ihab F. Ilyas, Walid G. Aref, Ahmed K. Elmagarmid, March 2004
Jing Chen: DIBR Spring 2005, CSE - UT Arlington

THANK
YOU
Related Documents











