Source Coding Efficient Data Representation A.J. Han Vinck

Source Coding Efficient Data Representation A.J. Han Vinck.
Dec 13, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Source Coding
Efficient Data Representation
A.J. Han Vinck
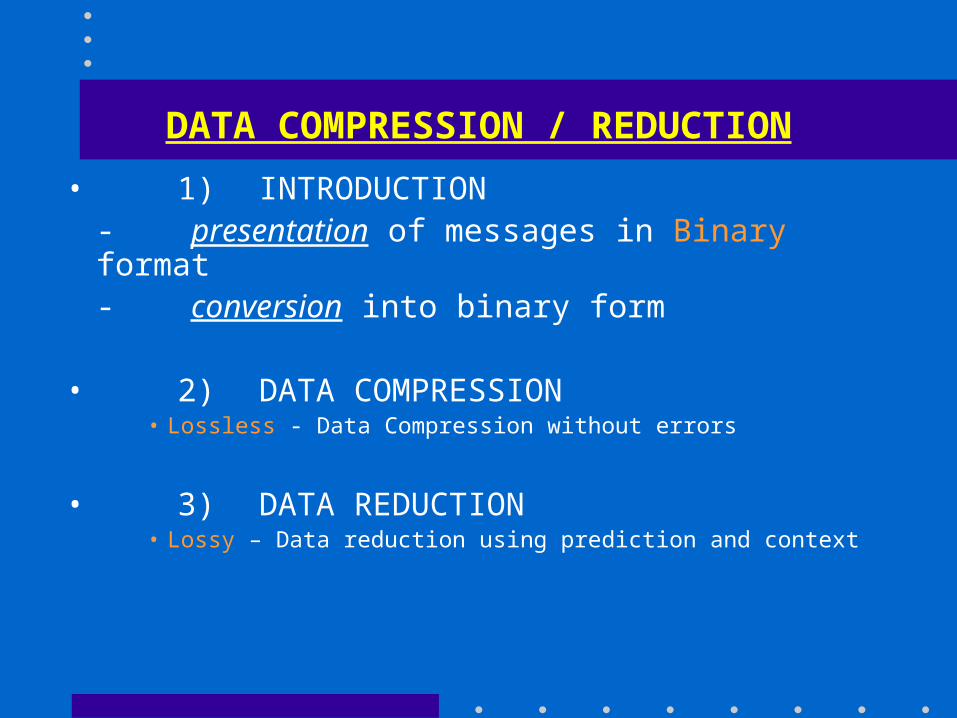
DATA COMPRESSION / REDUCTION
• 1) INTRODUCTION- presentation of messages in Binary format- conversion into binary form
• 2) DATA COMPRESSION• Lossless - Data Compression without errors
• 3) DATA REDUCTION• Lossy – Data reduction using prediction and context
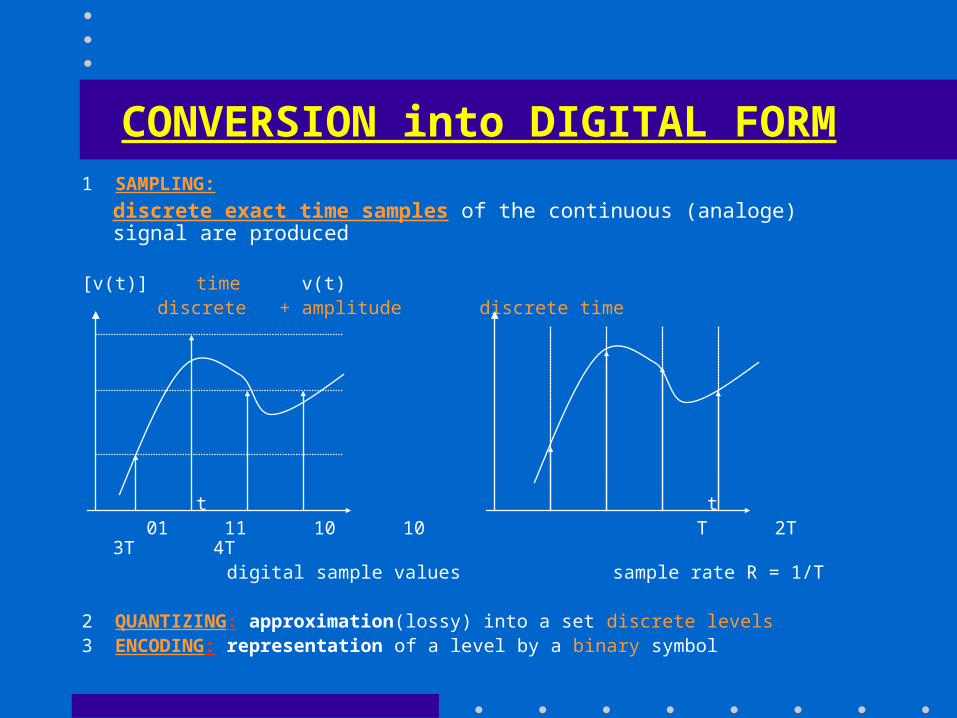
CONVERSION into DIGITAL FORM1 SAMPLING:
discrete exact time samples of the continuous (analoge) signal are produced
[v(t)] time v(t) discrete + amplitude discrete time
t t 01 11 10 10 T 2T 3T 4T
digital sample values sample rate R = 1/T
2 QUANTIZING: approximation(lossy) into a set discrete levels3 ENCODING: representation of a level by a binary symbol
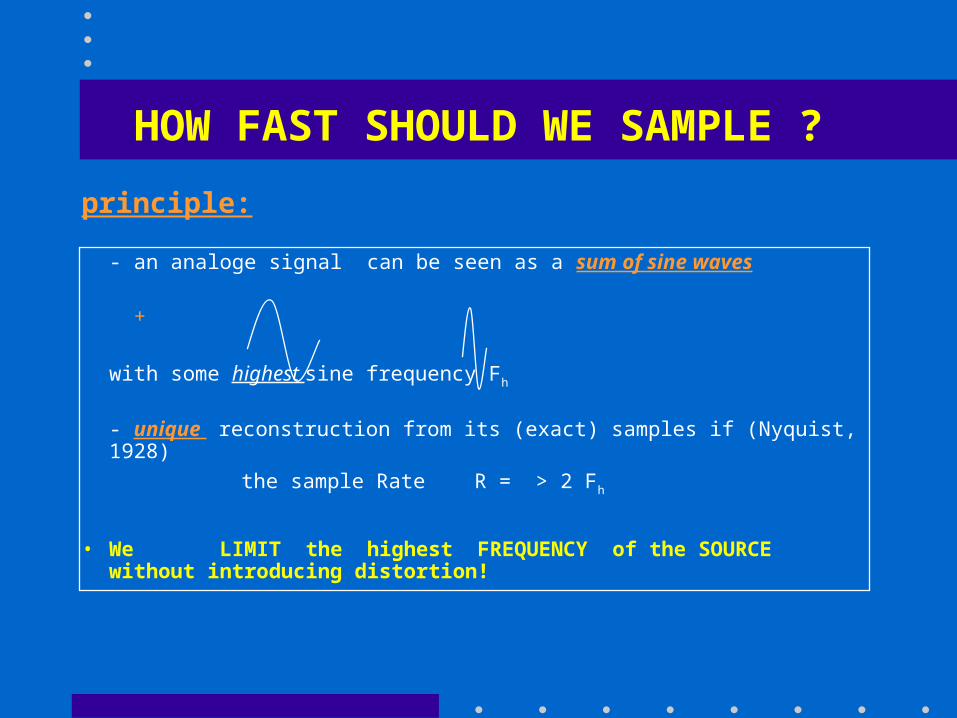
HOW FAST SHOULD WE SAMPLE ?
principle:
- an analoge signal can be seen as a sum of sine waves
+
with some highest sine frequency Fh
- unique reconstruction from its (exact) samples if (Nyquist, 1928)
the sample Rate R = > 2 Fh
• We LIMIT the highest FREQUENCY of the SOURCE without introducing distortion!

EXAMPLES:text: represent every symbol with 8 bit
storage: 8 * (500 pages) * 1000 symbols = 4 Mbit compression possible to 1 Mbit (1:4)
speech: sampling speed 8000 samples/sec; accuracy 8 bits/sample; needed transmission speed 64 kBit/s compression possible to 4.8 kBit/s (1:10)
CD music: sampling speed 44.1 k samples/sec; accuracy 16 bits/sample needed storage capacity for one hour stereo: 5 Gbit 1250 books compression possible to 4 bits/sample ( 1:4 )
digital pictures: 300 x 400 pixels x 3 colors x 8 bit/sample 2.9 Mbit/picture; for 25 images/second we need 75 Mb/s
2 hour pictures need 540 Gbit 130.000 books compression needed (1:100)
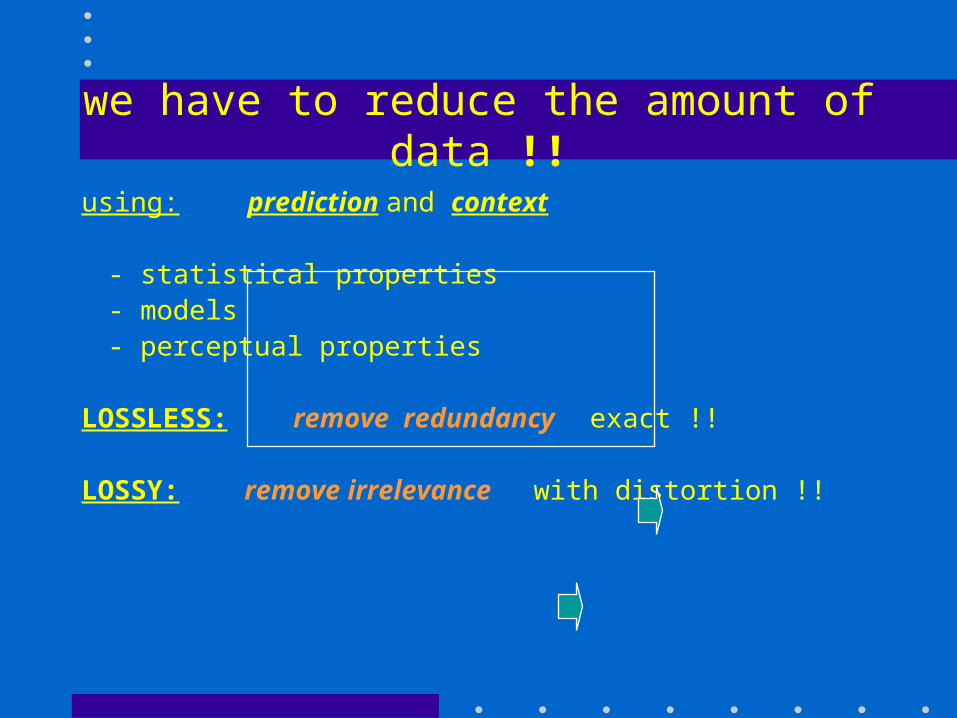
we have to reduce the amount of data !!
using: prediction and context
- statistical properties- models- perceptual properties
LOSSLESS: remove redundancy exact !!
LOSSY: remove irrelevance with distortion !!

Shannon source coding theorem
• Assume – independent source outputs – Consider runs of outputs of length L
• we expect a certain “type of runs” and
– Give a code word for an expected run with prefix ‘1’– An unexpected run is transmitted as it appears with prefix ‘0’
• Example: throw dice 600 times, what do you expect?• Example: throw coin 100 times, what do you expect?

We start with a binary source
Assume: binary sequence x of length L
P(0) = 1 – P(1) = 1-p; t is the # of 1‘s
For L , and > 0 and as small as desired
Probability ( |t/L –p| > ) 0
i.e. Probability ( |t/L –p| ≤ ) 1- 1 (1) L(p- ) ≤ t ≤ L(p + ) with high probability

Consequence 1:
Let A be the set of typical sequences i.e. obeying (1)
for these sequences: |t/L –p| ≤
then, P(A) 1 ( as close as wanted, i.e. P(A) 1 - )
or: almost all observed sequences are typical and have about t ones
Note: we use the notation when we asume that L

Consequence 2:
Lh(p)| A | 2
( )( )
2 2 2 2 2( )
log | | log log (2 ) log 2 log 2L p
Lh p
L p
L LA L L
t Lp
The cardinality of the set A is
( )2 2
1 1log 2 log 2 ( )Lh pL h p
L L

Shannon 1
Encode
every vector in A with Nint L(h(p)+)+1 bits
every vector in Ac with L bits–Use a prefix to signal whether we have a typical sequence or not
The average codeword length:
K = (1- )[L(h(p)+) +1] + L + 1 L h(p) bits

Shannon 1: converse
source output words XL encoder Yk: k output bits/L input of length L symbols
H(X) =h(p); H(XL ) =Lh(p) k = L[h(p)-] > 0
encoder: assignment of 2L[h(p)-] –1 code words 0
or all zero code word
Pe = prob (all zero code word assigned) =Prob(error)
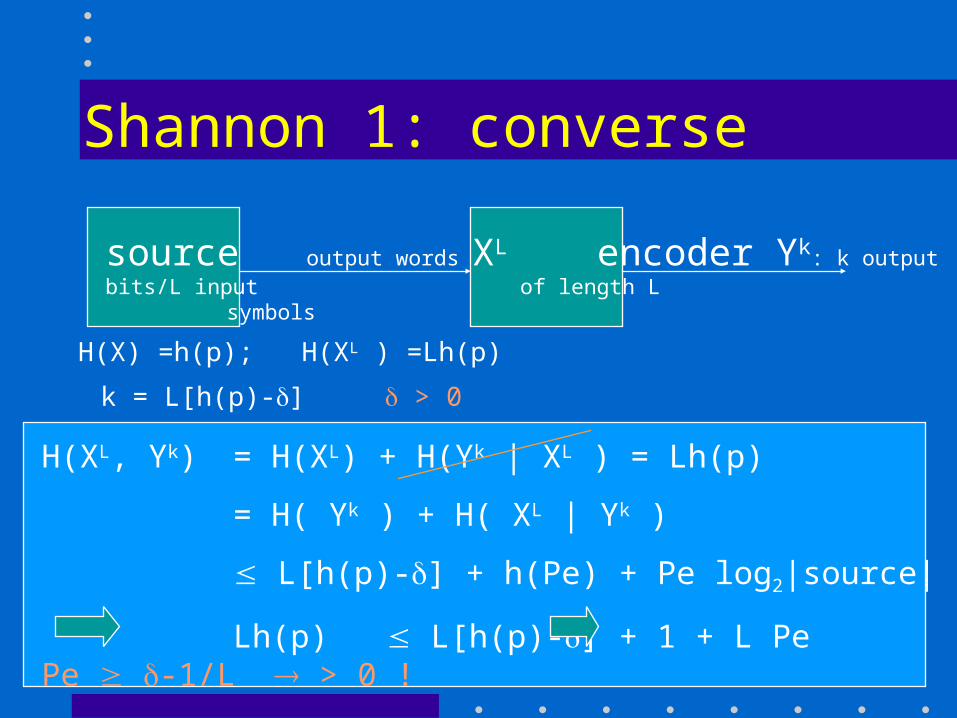
Shannon 1: converse
source output words XL encoder Yk: k output bits/L input of length L symbols
H(XL, Yk) = H(XL) + H(Yk | XL ) = Lh(p)
= H( Yk ) + H( XL | Yk )
L[h(p)-] + h(Pe) + Pe log2|source|
Lh(p) L[h(p)-] + 1 + L Pe Pe -1/L > 0 !
H(X) =h(p); H(XL ) =Lh(p) k = L[h(p)-] > 0

typicality
Homework:
Calculate for = 0.04 and p = 0.3
h(p), |A|, P(A), (1- )2L(h(p)-) , 2L(h(p)+)
as a function of L
Homework:
Repeat the same arguments for a more general source with entropy H(X)

Sources with independent outputs
• Let U be a source with independent outputs: U1 U2 UL subscript = time
The set of typical sequences can be defined as
Then:
for large L
2 22 2
22
log ( ) var ( log ( ))Pr | ( ) | }
var ( log ( ))0
L LP U iance P Uob H U
L Liance P U
L
2log ( ){ | ( ) | }
LL P U
A U H UL

Sources with independent outputs cont’d
To see how it works, we can write
|U||U|2211
|U|2|U|222121
iL
1i2L
2
PlogPPlogPPlogPL
PlogN
L
PlogN
L
PlogN
L
))U(Plog(
L
)U(Plog
|U||U|2211
|U|2|U|222121
iL
1i2L
2
PlogPPlogPPlogPL
PlogN
L
PlogN
L
PlogN
L
))U(Plog(
L
)U(Plog
where |U| is the size of the alphabet, Pi the probability that symbol i occurs, Ni the fraction of occurances of symbol i

Sources with independent outputs cont’d
• the cardinality of the set A 2LH(U)
• Proof:
( ( ) )2
( ( ) )
( ( ) )
log ( )| ( ) | } ( ) 2
1 ( ) | |2
| | 2
LL L H U
L L H U
A
L H U
P UH U P U
Land
p U A
hence
A

encoding
Encode
every vector in A with L(H(U)+)+1 bits
every vector in Ac with L bits
– Use a prefix to signal whether we have a typical sequence or not
The average codeword length:
K = (1- )[L(H(U)+) +1] + L +1 L H(U) +1 bits

converse
• For converse, see binary source

Sources with memoryLet U be a source with memory
Output: U1 U2 UL subscript = time
states: S {1,2, , |S|}
The entropy or minimum description length
H(U) = H(U1 U2 UL) (use the chain rule)
= H(U1)+ H(U2|U1 ) + + H( UL | UL-1 U2U1 )
H(U1)+ H(U2) + + H( UL) ( use H(X) H(X|Y)
)
How to calculate?
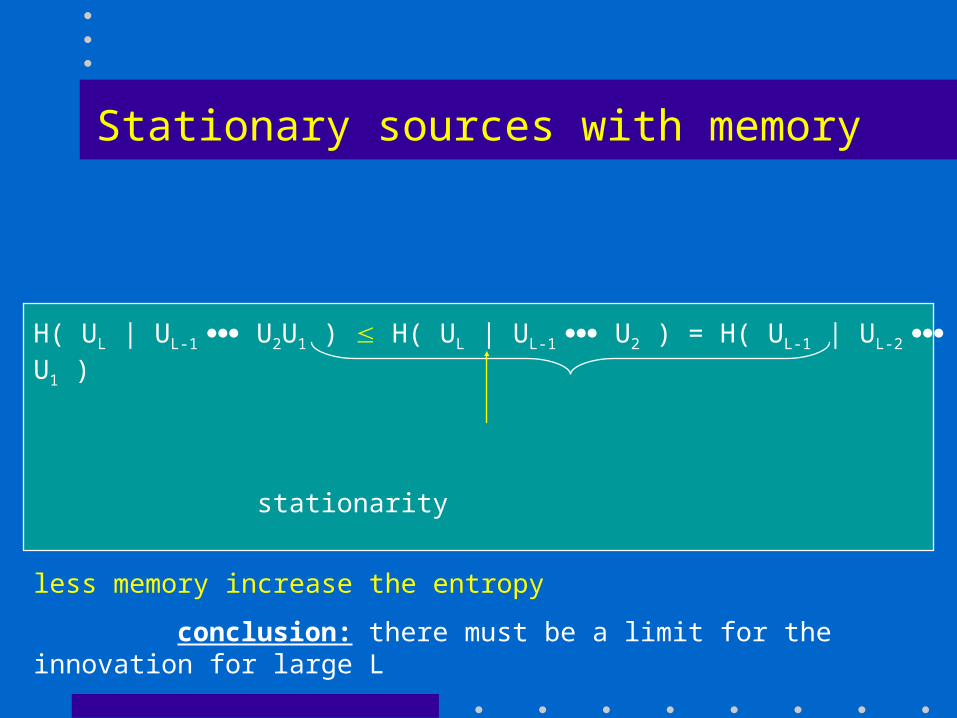
Stationary sources with memory
H( UL | UL-1 U2U1 ) H( UL | UL-1 U2 ) = H( UL-1 | UL-2 U1 )
stationarity
less memory increase the entropy
conclusion: there must be a limit for the innovation for large L
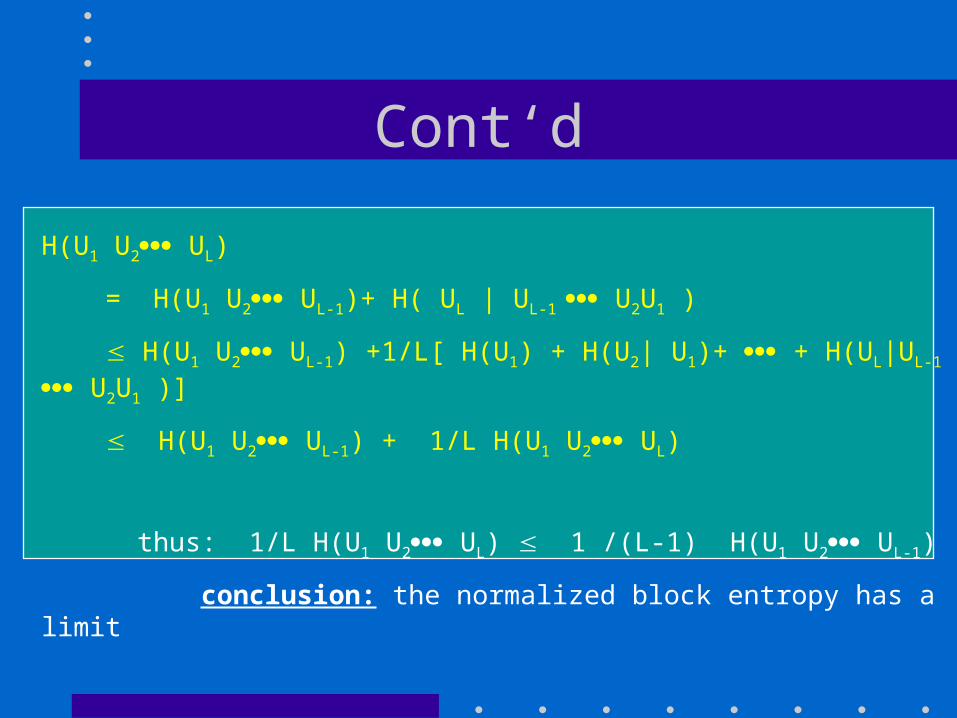
Cont‘d
H(U1 U2 UL)
= H(U1 U2 UL-1)+ H( UL | UL-1 U2U1 )
H(U1 U2 UL-1) +1/L[ H(U1) + H(U2| U1)+ + H(UL|UL-1 U2U1 )]
H(U1 U2 UL-1) + 1/L H(U1 U2 UL)
thus: 1/L H(U1 U2 UL) 1 /(L-1) H(U1 U2 UL-1)
conclusion: the normalized block entropy has a limit
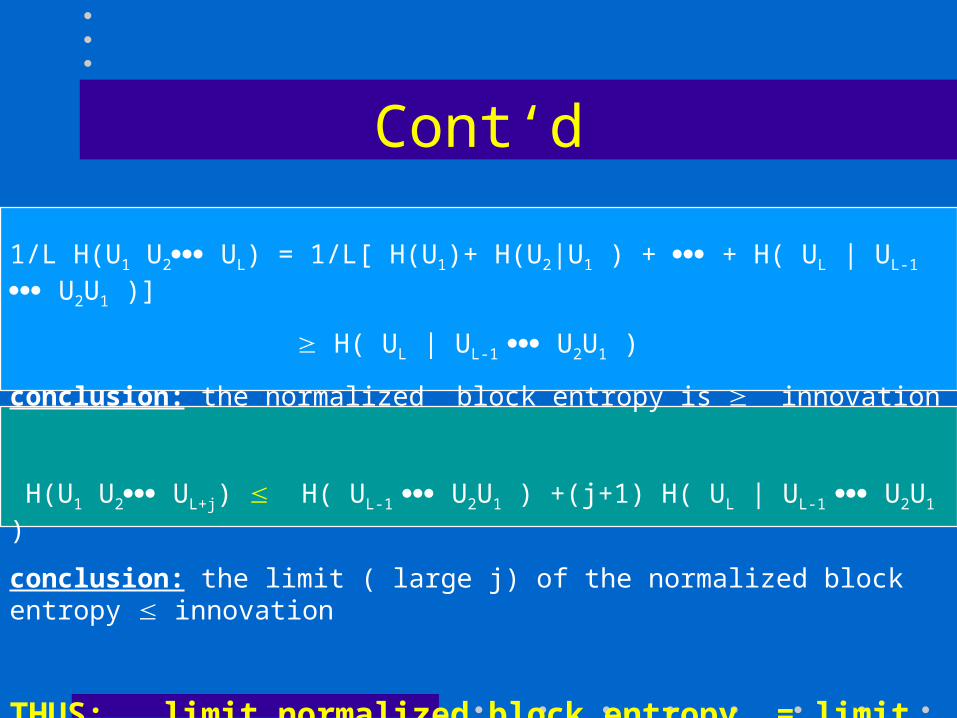
Cont‘d
1/L H(U1 U2 UL) = 1/L[ H(U1)+ H(U2|U1 ) + + H( UL | UL-1 U2U1 )]
H( UL | UL-1 U2U1 )
conclusion: the normalized block entropy is innovation
H(U1 U2 UL+j) H( UL-1 U2U1 ) +(j+1) H( UL | UL-1 U2U1 )
conclusion: the limit ( large j) of the normalized block entropy innovation
THUS: limit normalized block entropy = limit innovation

Sources with memory: exampleNote: H(U) = minimum representation length
H(U) average length of a practical scheme
English Text: First approach consider words as symbols
Scheme: 1. count word frequencies
2. Binary encode words
3. Calculate average representation length
Conclusion: we need 12 bits/word; average wordlength 4.5 letter
H(english) 2.6 bit/letter
Homework: estimate the entropy of your favorite programming language

Example: Zipf‘s law
Procedure:
order the English words according to frequency of occurence
Zipf‘s law: frequency of the word at position n is Fn = A/n
for English A = 0.1 word frequency
word order
1 10 100 1000
1
0.1
0.01
0.001
Result: H(English) = 2.16 bits/letterIn General: Fn = a n-b where a and b are constants
Application: web-access, complexity of languages

Sources with memory: example
Another approach: H(U)= H(U1)+ H(U2|U1 ) + + H( UL | UL-1 U2U1 )
Consider text as stationary, i.e. the statistical properties are fixed
Measure: P(a), P(b), etc H(U1) 4.1
P(a|a), P(b|a), ... H(U2|U1 ) 3.6
P(a|aa), P(b|aa), ... H(U3| U2 U1 ) 3.3
...
Note: More given letters reduce the entropy.
Shannons experiments give as result that 0.6 H(english) 1.3

Example: Markov model
A Markov model has states: S { 1, , S }
State probabilities Pt (S=i)
Transitions t t+1 with probability P (st+1 =j| st =i)
Every transition determines a specific output, see example
i
k
jP (st+1 =j| st =i)
P (st+1 =k| st =i)
0
1
0 1
0
0
11

Markov Sources
Instead H(U)= H(U1 U2 UL), we consider
H(U‘)= H(U1 U2 UL,S1 )
= H(S1 )+H(U1 |S1 ) + H(U2 |U1 S1 ) + + H(UL |UL-1 U1 S1 )
= H(U) + H(S1 |ULUL-1 U1 )
Markov property: output Ut depends on St only
St and Ut determine St+1
H(U‘)= H(S1) + H(U1 |S1 ) + H(U2 |S2 ) + + H(UL |SL )

Markov Sources: further reduction
assume: stationarity, i.e. P(St=i) = P (S=i) for all t > 0 and all i
then: H(U1|S1 ) = H(Ui|Si ) i = 2, 3, , L
H(U1|S1 ) = P(S1=1)H(U1|S1=1) +P(S1=2)H(U1|S1=2) + +P(S1=|S|) H(U1|S1=|S|)
and H(U‘)= H(S1) + LH(U1 |S1 )
H(U) = H(U‘) - H(S1 |U1 U2 UL)
Per symbol: 1/L H(U) H(U1 |S1 ) +1/L[H(S1) - H(S1 |U1 U2 UL)]
0

example
Pt(A)= ½
Pt (B)= ¼
Pt (C)= ¼
½ 0
¼ 1
¼ 2
A
B
C
A
B
C
P(A|B)=P(A|C)= ½
0
1
0
1
The entropy for this example = 1¼
Homework: check!
Homework: construct another example that is stationary and calculate H

Appendix to show (1)
For a binary sequence X of length n with P(Xi =1)=p
)x()p1(pp])x[(E:Use).p1(pn
1
])np()x(E[n
1p)x
n
1(E)y(E
then;pxn
1ylet
i222
i
2
n,1i
2i2
2
n,1i
2i
2
n,1ii
Because the Xi are independent, the variance of the sum = sum of the variances
2 2
2 22 2
2 2
( )Pr(| | ) Pr( ) Pr( )
| | | |
y
y E yy y y
ty p
n
Related Documents











