SOCIAL NETWORK ANALYSIS TERHADAP PENGGUNA TWITTER TERKAIT BERITA HOAX DI INDONESIA DENGAN METODE SINGLE CLUSTER MULTI NODE MENGGUNAKAN APACHE HADOOP TERDISTRIBUSI HORTONWORKS TM Skripsi Disusun Oleh: Husain Faiz Karimi 1112091000027 PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA 2018 M/1439 H

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

SOCIAL NETWORK ANALYSIS TERHADAP PENGGUNA TWITTER
TERKAIT BERITA HOAX DI INDONESIA DENGAN METODE
SINGLE CLUSTER MULTI NODE MENGGUNAKAN APACHE
HADOOP TERDISTRIBUSI HORTONWORKSTM
Skripsi
Disusun Oleh:
Husain Faiz Karimi
1112091000027
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH
JAKARTA
2018 M/1439 H

SOCIAL NETWORK ANALYSIS TERHADAP PENGGUNA TWITTER
TERKAIT BERITA HOAX DI INDONESIA DENGAN METODE
SINGLE CLUSTER MULTI NODE MENGGUNAKAN APACHE
HADOOP TERDISTRIBUSI HORTONWORKSTM
Skripsi
Diajukan sebagai salah satu syarat untuk memperoleh gelar Sarjana Strata-1
Disusun Oleh:
Husain Faiz Karimi
1112091000027
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH
JAKARTA
2018 M/1439 H
i

HALAMAN PERSETUJUAN
SOCIAL NETWORK ANALYSIS TERHADAP PENGGUNA TWITTER
TERKAIT BERITA HOAX DI INDONESIA DENGAN METODE
SINGLE CLUSTER MULTI NODE MENGGUNAKAN APACHE
HADOOP TERDISTRIBUSI HORTONWORKSTM
Skripsi
Sebagai Salah Satu Syarat untuk
Memperoleh Gelar Sarjana Komputer (S.Kom)
Oleh:
Husain Faiz Karimi
NIM : 1112091000027
Menyetujui,
Pembimbing I, Pembimbing II,
Siti Ummi Masruroh, M.Sc. Arini, MT.
NIP.19820823 201101 2 013 NIP. 19760131 200901 001
Mengetahui,
Ketua Program Studi Teknik Informatika
Arini, MT.
NIP. 19760131 200901 001
ii

HALAMAN PENGESAHAN
Skripsi yang berjudul “Social Network Analysis Terhadap Pengguna Twitter Terkait Berita
Hoax Di Indonesia Dengan Metode Single Cluster Multi Node Menggunakan Apache Hadoop
Terdistribusi Hortonworkstm” telah diuji dan dinyatakan lulus dalam Sidang Munaqasah Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta pada
Jum’at, 05 Januari 2018. Skripsi telah diterima sebagai salah satu syarat untuk memperoleh
gelar Sarjana Strata 1 (S1) Komputer pada Program Studi Teknik Informatika.
Jakarta, 05 Januari 2018
Tim Penguji,
Penguji I Penguji II
Fitri Mintarsih, M.Kom. Anif Hanifa Setyaningrum, M.Si.
NIP. 19721223 200710 2 004 NIDN. 410116402
Tim Pembimbing, Pembimbing I Pembimbing II
Siti Ummi Masruroh, M.Sc. Arini, M.T.
NIP. 19820823 201101 2 013 NIP. 19760131 200901 2 001
Mengetahui, Dekan Ketua Program Fakultas Sains dan Teknologi Studi Teknik Informatika
Dr. Agus Salim, M.Si. Arini, M.T.
NIP. 19720816 199903 1 003 NIP. 19760131 200901 2 001
iii

PERNYATAAN ORISINALITAS
DENGAN INI SAYA MENYATAKAN BAHWA SKRIPSI INI BENAR-BENAR HASIL
KARYA SAYA SENDIRI YANG BELUM PERNAH DIAJUKAN SEBAGAI SKRIPSI
ATAU KARYA ILMIAH PADA PERGURUAN TINGGI ATAU LEMBAGA MANAPUN.
Jakarta, 05 Januari 2018
Husain Faiz Karimi
NIM 1112091000027
iv

PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI
Sebagai sivitas akademik UIN Syarif Hidayatullah Jakarta, saya yang
bertanda tangan dibawah ini:
Nama : Husain Faiz Karimi
NIM : 1112091000027
Program Studi : Teknik Informatika
Fakultas : Sains dan Teknologi
Jenis Karya : Skripsi
demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada
Universitas Islam Negeri Syarif Hidayatullah Jakarta Hak Bebas Royalti
Noneksklusif (Non-exclusive royalty Free Right) atas karya ilmiah saya yang
berjudul:
Social Network Analysis Terhadap Pengguna Twitter Terkait Berita Hoax Di Indonesia Dengan Metode Single Cluster Multi
Node Menggunakan Apache Hadoop Terdistribusi
Hortonworkstm
beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti
Noneksklusif ini Universitas Islam Negeri Syarif Hidayatullah Jakarta berhak
menyimpan, mengalih media/formatkan, mengelola dalam bentuk pangkalan data
(database), merawat dan mempublikasikan tugas akhir saya selama tetap
mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilih Hak Cipta.
Demikian pernyataan ini saya buat dengan sebenarnya.
Jakarta
05 Januari 2018
Yang Menyatakan
(Husain Faiz Karimi)
v

KATA PENGANTAR
Puji dan syukur penulis lantunkan kehadirat Allah SWT yang telah
memberikan Rahmat dan Hidayah-Nya kepada kita semua, sehingga peneliti dapat
menyelesaikan penulisan skripsi dengan judul “SOCIAL NETWORK ANALYSIS
TERHADAP PENGGUNA TWITTER TERKAIT BERITA HOAX DI
INDONESIA DENGAN METODE SINGLE CLUSTER MULTI NODE
MENGGUNAKAN APACHE HADOOP TERDISTRIBUSI
HORTONWORKSTM”. Pada kesempatan ini, peneliti berterima kasih kepada pihak-pihak yang telah banyak berjasa dan membantu dalam melakukan penulisan penelitian ini. Secara khusus peneliti mengucapkan terima kasih kepada:
1) Prof. Dr. Dede Rosyada, MA selaku rektor Universitas Islam Negeri Syarif
Hidayatullah Jakarta.
2) DR. Agus Salim, M.Si selaku Dekan Fakultas Sains dan Teknologi UIN
Syarif Hidayatullah Jakarta.
3) Ibu Arini, M.T selaku ketua program studi Teknik Informatika UIN Syarif
Hidayatullah Jakarta.
4) Feri Fahrianto, M.Sc selaku Sekretaris Program Studi Teknik Informatika,
Fakultas Sains dan Teknologi, Universitas Islam Negeri Syarif
Hidayatullah Jakarta.
5) Siti Ummi Masruroh M.Sc selaku Dosen Pembimbing I
6) Arini, M.T selaku Dosen Pembimbing II
7) Keluarga terkasih dan tersayang, yang senantiasa memberikan doa, support
dan semangat.
vi

8) Keluarga Besar KOMDA FST, Keluarga Besar LDK Syahid UIN Jakarta dan
FSLDK Banten khususnya KOMISI A. Yang telah memberikan motivasi, doa
dan bantuan dari awal hingga penulisan skripsi.
9) Irvan Faturrahman, Qadavi Muhammad Sofyan, M. Lazuardi Imani, serta
teman-teman Teknik Informatika angkatan 2012 yang selalu memberikan
inspirasi dan motivasi.
10) Senda, Gufron, Tamui, Tyo, Agung, Fahri, Budi, Syauqi, Ka Hari P. Sebagai
sahabat yang selalu mendukung dan memberikan doa terbaik kepada penulis.
Peneliti menyadari bahwa penulisan laporan hasil penelitian ini tidak
sempurna dan tidak luput dari kesalahan. Oleh karena itu, peneliti mengharapkan
kritik dan saran yang membangun dalam proses penyempurnaan laporan ini.
Akhir kata, penulis berharap laporan peneliti ini dapat bermanfaat bagi peneliti
sendiri pada khususnya dan bagi khalayak pada umumnya.
Jakarta, 05 Jakarta 2018
Peneliti
Husain Faiz Karimi
1112091000027
vii

Penulis Program Studi Judul
: Husain Faiz Karimi : Teknik Informatika : Social Network Analysis Terhadap Pengguna Twitter
Terkait Berita Hoax Di Indonesia Dengan Metode Single Cluster Multi Node Menggunakan Apache Hadoop
Terdistribusi Hortonworkstm.
ABSTRAK
Social network analysis meneliti hubungan node dalam graf. Penelitian sebelumnya hanya menggunakan 3 parameter pada SNA, tanpa melakukan manipulasi terhadap variabel bebas dan masih belum menerapkan metode clustering pada Hadoop. Namun penelitian yang melakukan eksperimen menggunakan Hadoop metode clustering (High Performance Cluster) dan 5 parameter SNA (Degree Centrality, Betweenness Centrality, Closeness Centrality, Eigenvector Centrality, dan PageRank) pada topik hoax, dengan melakukan pengubahan iterasi pengecekan dan penetapan t-max pada tools Gephi masih belum dilakukan. Berdasarkan hasil observasi selama 1 bulan, peneliti menemukan 18 hari dimana keyword hoax menjadi trending topic di Twitter. Artinya 58% pengguna lebih sering membicarakan hoax. Eksperimen intact-group comparison diterapkan pada data Twitter yang akan dikelompokan menjadi 2 kelompok (kontrol dan eksperimen). Proses ETL (Extract, Transform and Load) dilakukan menggunakan Apache NiFi. Peneliti mampu mendapatkan data sebanyak 16,400 data selama tahap penarikan data, pada penelitian sebelumnya rata-rata data yang berhasil diambil hanya sebanyak ±2000 data. Pengubahan variabel dilakukan pada kelompok eksperimen. Penambahan iterasi dari 100 menjadi 200 kali, dapat meningkatkan nilai Degree Centrality sebesar 40,79%. Penetapan t-max menjadi 60s meningkatkan 33,33% jumlah cluster yang terbentuk, dengan hasil jumlah cluster dari 3 menjadi 4 cluster. Penelitian ini dapat dikembangkan menggunakan True Experimental Design dan penambahan Sentiment Analysis.
Kata Kunci
Daftar Pustaka
Jumlah Halaman
: Apache Hadoop, SNA, Hoax, Twitter, Hadoop Multi Node,
Eksperimen Intact-Group Comparison, Apache NiFi, High Performance Cluster.
: 44 (Tahun 2001 – 2017) : VI BAB+ xix Halaman+ 196 Halaman+ 114 Gambar+ 41 Tabel
viii

DAFTAR ISI
HALAMAN PERSETUJUAN ...................................................................... ii
HALAMAN PENGESAHAN ........................................................................ iii
PERNYATAAN ORISINALITAS ................................................................ iv
PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI ........................ v
KATA PENGANTAR .................................................................................... vi
ABSTRAK ...................................................................................................... viii
DAFTAR ISI ................................................................................................... ix
DAFTAR GAMBAR ...................................................................................... xiv
DAFTAR TABEL .......................................................................................... xviii
BAB I PENDAHULUAN ............................................................................... 1
1.1 Latar Belakang ..................................................................................... 1
1.2 Rumusan Masalah ................................................................................ 6
1.3 Batasan Masalah ................................................................................... 7
1.4 Tujuan Penelitian .................................................................................. 8
1.5 Manfaat Penelitian ................................................................................ 8
1.6 Metode Penelitian ................................................................................. 9
1.7 Sistematika Penulisan ........................................................................... 9
BAB II LANDASAN TEORI ........................................................................ 11
2.1 Hoax ..................................................................................................... 11
2.2 Metode Cluster ..................................................................................... 11
2.2.1 Jenis-jenis Clustering ......................................................................... 11
2.2.2 Komputer Terdistribusi (Cluster) ....................................................... 13
2.2.3 Apache Hadoop .................................................................................. 14
2.2.4 Keuntungan Hadoop ........................................................................... 14
2.2.5 HDFS .................................................................................................. 15
2.2.6 Arsitektur HDFS ................................................................................. 15
2.2.7 Struktur HDFS .................................................................................... 17
2.2.8 Keuntungan HDFS ............................................................................. 20
2.3 Apache Ambari .................................................................................... 20
ix

2.3.1 Arsitektur Apache Ambari ................................................................. 20
2.4 Apache NiFi ......................................................................................... 21
2.4.1 Tantangan Dataflow ........................................................................... 22
2.4.2 Konsep Apache NiFi .......................................................................... 22
2.4.3 Arsitektur Apache NiFi ...................................................................... 24
2.5 Solr ....................................................................................................... 26
2.5.1 Fitur Solr ............................................................................................. 26
2.5.2 Tahapan Index .................................................................................... 26
2.6 Twitter .................................................................................................. 28
2.6.1 Glosarium Twitter .............................................................................. 28
2.6.2 Streaming API .................................................................................... 29
2.7 Social Network Analysis ....................................................................... 30
2.7.1 Terminologi ........................................................................................ 30
2.7.2 Social Network Data .......................................................................... 33
2.7.3 Pengukuran Parameter SNA ............................................................... 34
2.7.4 Simulasi Perhitungan Manual SNA ................................................... 37
2.8 Graf ....................................................................................................... 47
2.8.1 Tipe-tipe Graf ..................................................................................... 47
2.9 Gephi .................................................................................................... 51
2.10 Metode Eksperimen .............................................................................. 52
2.11.1 Karakteristik Penelitian Eksperimen ................................................ 52
2.11.2 Bentuk Desain Penelitian Eksperimen ............................................. 53
2.11 Observasi .............................................................................................. 57
2.12 Teknik Sampling .................................................................................. 57
2.12.1 Jenis Teknik Sampling...................................................................... 57
2.13 Tahapan Eksperimen Intact-Group Comparison ................................. 59
BAB III METODOLOGI PENELITIAN .................................................... 60
3.1 Metode Pengumpulan Data ..................................................................... 60
3.1.1 Studi Pustaka ...................................................................................... 60
3.1.2 Observasi ............................................................................................ 60
3.1.3 Abstrak Skripsi Terkait ...................................................................... 62
x

3.1.4 Perbedaan Penelitian Peneliti ............................................................. 68
3.2 Metode Eksperimen ................................................................................ 72
3.2.1 Pemilihan Desain ................................................................................ 73
3.2.2 Penentuan Sampel Representatif ........................................................ 73
3.2.3 Instrumentasi ...................................................................................... 74
3.2.4 Pelaksanaan Eksperimen .................................................................... 75
3.2.5 Pengumpulan dan Penganalisisan Data .............................................. 77
3.2.6 Analisis dan Interpretasi Data ............................................................ 78
3.2.7 Kesimpulan Eksperimen ..................................................................... 78
3.3 Kerangka Pemikiran ............................................................................... 79
BAB IV IMPLEMENTASI DAN EKSPERIMEN ...................................... 80
4.1 Pemilihan Desain .................................................................................... 80
4.1.1 Pemilihan Bentuk Desain ................................................................... 80
4.1.2 Mendefinisikan Kelompok Kontrol dan Eksperimen ......................... 80
4.2 Penentuan Sampel Representatif ............................................................ 81
4.3 Instrumentasi ........................................................................................... 81
4.3.1 Pemilihan Hardware .......................................................................... 82
4.3.2 Pemilihan Software............................................................................. 83
4.3.3 Install Hadoop Cluster Multi Node .................................................... 83
4.3.3.1 Persiapan Pembuatan Cluster ................................................... 83
4.3.3.2 Persyaratan Environment Hadoop ............................................ 85
4.3.3.3 Penggunaan Repository Lokal .................................................. 85
4.3.3.4 Proses Install Ambari dan Komponen Hadoop ........................ 85
4.3.3.5 Proses Install Ambari-Server .................................................... 86
4.3.3.6 Pengaturan SSH Login .............................................................. 86
4.3.3.7 Proses Install dan Setup Ambari-Server ................................... 86
4.3.3.8 Proses Menjalankan Ambari-Server ......................................... 87
4.3.3.9 Proses Install Hadoop Pada Cluster ......................................... 87
4.3.3.10 Proses Install Komponen Hadoop ............................................ 88
4.3.3.11 Summary Install Ambari-Server ............................................... 89
4.4 Pelaksanaan Eksperimen ........................................................................ 91
xi

4.4.1 Tahapan Pengumpulan Data ............................................................... 91
4.4.1.1 Tahapan Penarikan Data ........................................................... 91
4.4.1.2 Tahapan Penentuan Konten Data.............................................. 92
4.4.1.3 Tahapan Pembatasan Data ........................................................ 93
4.4.1.4 Tahapan Segmentasi Data......................................................... 94
4.4.1.5 Tahapan Penggabungan Data ................................................... 95
4.4.2 Tahapan Indexing dan Visualisasi Data Realtime .............................. 96
4.4.2.1 Tahapan Input Data................................................................... 97
4.4.2.2 Tahapan Visualisasi Data Realtime .......................................... 97
4.4.3 Tahapan Klasifikasi Data ................................................................... 98
4.4.4 Tahapan Eksperimen Intact-Group Comparison ............................... 100
4.4.5 Tahapan Penerapan Social Network Analysis .................................... 102
4.4.5.1 Input Data dan Visualisasi Gephi ............................................. 102
4.4.5.2 Perhitungan Parameter Social Network Analysis ...................... 103
BAB V HASIL ANALISIS DAN PEMBAHASAN ..................................... 104
5.1 Pengumpulan dan Penganalisisan Data ................................................. 104
5.1.1 Hasil Pengumpulan Data .................................................................... 104
5.1.2 Hasil Visualisasi Data Realtime ......................................................... 104
5.1.3 Hasil Klasifikasi Data ......................................................................... 109
5.1.4 Hasil Eksperimen Intact-Group Comparison ..................................... 110
5.1.5 Penerapan Social Network Analysis ................................................... 111
5.1.5.1 Hasil Visualisasi Graf Kelompok Kontrol ................................ 111
5.1.5.2 Hasil Perhitungan Parameter SNA Kelompok Kontrol ............ 112
5.1.5.3 Hasil Visualisasi Graf Kelompok Eksperimen ......................... 122
5.1.5.4 Hasil Perhitungan Parameter SNA Kelompok Eksperimen ..... 123
5.1.6 Hasil Analisis Kelompok Kontrol ...................................................... 132
5.1.6.1 Cluster No. 1 Dengan Node Utama rockygerung ..................... 135
5.1.6.2 Cluster No. 2 Dengan Node Utama Gusmus ............................ 137
5.1.6.3 Cluster No. 3 Dengan Node Utama maspiyuuu ....................... 140
5.1.6.4 Kompilasi Hasil Kelompok Kontrol ......................................... 142
5.1.6.5 Analisis User Berpengaruh Kelompok Kontrol ....................... 144
xii

5.1.7 Hasil Analisis Kelompok Eksperimen ............................................... 147
5.1.7.1 Cluster A Dengan Node Utama shitlicious ............................... 150
5.1.7.2 Cluster B Dengan Node Utama lawan_teroris.......................... 152
5.1.7.3 Cluster C Dengan Node Utama bangsa_patriot ........................ 155
5.1.7.4 Cluster D Dengan Node Utama Juno_5760.............................. 158
5.1.7.5 Kompilasi Hasil Kelompok Eksperimen .................................. 160
5.1.7.6 Analisis User Berpengaruh Kelompok Eksperimen ................. 162
5.2 Analisis dan Interpretasi Data ................................................................ 167
5.2.1 Perbandingan Kelompok Kontrol dan Kelompok Eksperimen .......... 168
5.2.2 Hasil Analisis Konten Tweet Node Berpengaruh ............................... 173
5.3 Kesimpulan Eksperimen ........................................................................ 178
5.3.1 Hasil Pengaruh PerubahanNilai Iterasi Pengecekan Perhitungan ...... 178
5.3.2 Hasil Pengaruh Penetapan Variabel Waktu ........................................ 179
5.3.3 Hasil Nilai Perhitungan Parameter SNA ............................................ 180
5.3.4 Hasil Penerapan Desain Intact-Group Comparison ........................... 181
BAB VI PENUTUP ........................................................................................ 182
6.1 Kesimpulan ............................................................................................ 182
6.2 Saran ...................................................................................................... 184
DAFTAR PUSTAKA
LAMPIRAN-LAMPIRAN
xiii

DAFTAR GAMBAR
Gambar 2.1 Overview dari High Performance Clustering ...................................... 12
Gambar 2.2 Overview dari Load Balancing Clustering ........................................... 12
Gambar 2.3 Overview dari High Availability Clustering ......................................... 13
Gambar 2.4 Bagian Inti Arsitektur HDFS .................................................................... 16
Gambar 2.5 Interaksi NameNode dan DataNode pada HDFS ................................ 18
Gambar 2.6 Alur Komunikasi Server dan Agent ........................................................ 21
Gambar 2.7 Arsitektur NiFi Pada JVM ......................................................................... 24
Gambar 2.8 Implementasi Apache NiFi dalam Skema Cluster ............................. 25
Gambar 2.9 Aktor-aktor Tanpa Keterangan Hubungan ........................................... 30
Gambar 2.10 Sekumpulan Actor Dalam Skema Un-Directed Edge ..................... 31
Gambar 2.11 Sekumpulan Actor Dalam Skema Directed Edge ............................ 31
Gambar 2.12 Sekumpulan Actor Beserta Relasi ........................................................ 32
Gambar 2.13 Relasi Dengan Bobot Antara Node ...................................................... 32
Gambar 2.14 Edge List ...................................................................................................... 33
Gambar 2.15 Adjacency Matrix ....................................................................................... 34
Gambar 2.16 Sample Un-Directed Ties Graf .............................................................. 37
Gambar 2.17 Directed Graph .......................................................................................... 45
Gambar 2.18 a. Graf Berarah, b. Graf-Ganda Berarah ............................................. 48
Gambar 2.19 Graf Tak Berarah ....................................................................................... 48
Gambar 2.20 Graf Sederhana ........................................................................................... 49
Gambar 2.21 Graf Ganda .................................................................................................. 50
Gambar 2.22 Graf Pseudograph ..................................................................................... 50
Gambar 3.1 Alur Kerangka Pemikiran .......................................................................... 76
Gambar 4.1 Komponen Pembentuk Cluster ................................................................ 84
Gambar 4.2 Apache HTTP Server Berhasil Pada Proses Install ........................... 85
Gambar 4.3 Proses Pemilihan JDK ................................................................................ 87
Gambar 4.4 Antarmuka Install Wizard Cluster Hadoop .......................................... 87
Gambar 4.5 Target Host Master dan Slave .................................................................. 88
xiv

Gambar 4.6 Pembagian Skema Install Komponen Hadoop .................................... 88
Gambar 4.7 Komponen Apache Ambari ....................................................................... 89
Gambar 4.8 Gambar Processor GetTwitter ................................................................. 91
Gambar 4.9 Gambar Pengaturan Processor GetTwitter ........................................... 92
Gambar 4.10 Gambar Processor EvaluateJsonPath ................................................. 93
Gambar 4.11 Gambar Processor RouteOnAttribute .................................................. 93
Gambar 4.12 Gambar Contoh Data Tweet Yang Berhasil Diambil ...................... 94
Gambar 4.13 Gambar Processor ReplaceText ............................................................ 95
Gambar 4.14 Contoh Hasil ReplaceText ....................................................................... 95
Gambar 4.15 Gambar Processor MergeContent ........................................................ 95
Gambar 4.16 Proses Pengumpulan Data ....................................................................... 96
Gambar 4.17 Gambar Processor PutSolrContentStream ........................................ 97
Gambar 4.18 Proses Indexing dan Visualisasi Data .................................................. 98
Gambar 4.19 Gambar Processor UpdateAttribute ..................................................... 99
Gambar 4.20 Proses Klasifikasi Data ............................................................................ 99
Gambar 4.21 Gambar Processor MergeContent ........................................................ 100
Gambar 4.22 Proses Eksperimen Intact-Group Comparison ................................. 100
Gambar 4.23 Gambar Seluruh Alur Processor Pada Apache NiFi ....................... 101
Gambar 4.24 Proses Input Data Gephi Kelompok Kontrol ..................................... 102
Gambar 4.25 Proses Input Data Gephi Kelompok Eksperimen ............................. 102
Gambar 4.26 Proses Perhitungan Degree Centrality ................................................ 103
Gambar 4.27 Proses Perhitungan Betweenness Centrality ...................................... 103
Gambar 4.28 Proses Perhitungan Closeness Centrality ........................................... 103
Gambar 4.29 Proses Perhitungan Eigenvector Centrality ....................................... 103
Gambar 4.30 Proses Perhitungan PageRank ............................................................... 103
Gambar 5.1 Contoh Data Tweet yang Berhasil Terambil ........................................ 104
Gambar 5.2 Contoh Tweet Pasca Pengambilan Data ................................................ 104
Gambar 5.3 Grafik Histogram Data Tweet .................................................................. 106
Gambar 5.4 Grafik Source Data Tweet ......................................................................... 107
Gambar 5.5 Grafik Post User Terbanyak ..................................................................... 108
Gambar 5.6 Grafik Post Dengan Re-Tweet Terbanyak ............................................ 109
xv

Gambar 5.7 Contoh Kelompok Kontrol Hasil Klasifikasi ....................................... 109
Gambar 5.8 Contoh Kelompok Eksperimen Hasil Klasifikasi ............................... 109
Gambar 5.9 Contoh Data Kelompok Kontrol Hasil Merger ................................... 110
Gambar 5.10 Contoh Data Kelompok Eksperimen Hasil Merger ........................ 110
Gambar 5.11 Hasil Visualisasi Graf Kelompok Kontrol ......................................... 111
Gambar 5.12 Grafik Batang Degree Centrality Kelompok Kontrol..................... 113
Gambar 5.13 Grafik Batang Betweenness Centrality Kelompok Kontrol .......... 115
Gambar 5.14 Grafik Batang Closeness Centrality Kelompok Kontrol ............... 117
Gambar 5.15 Grafik Batang Eigenvector Centrality Kelompok Kontrol............ 119
Gambar 5.16 Grafik Batang PageRank Kelompok Kontrol ................................... 121
Gambar 5.17 Hasil Visualisasi Graf Kelompok Eksperimen ................................. 122
Gambar 5.18 Grafik Batang Degree Centrality Kelompok Eksperimen ............. 124
Gambar 5.19 Grafik Batang Betweenness Centrality Kelompok Eksperimen 126
Gambar 5.20 Grafik Batang Closeness Centrality Kelompok Eksperimen........ 128
Gambar 5.21 Grafik Batang Eigenvector Centrality Kelompok Eksperimen .. 130
Gambar 5.22 Grafik Batang PageRank Kelompok Eksperimen............................ 131
Gambar 5.23 Grafik 20 Besar User Kontrol Dengan Nilai DC Tertinggi .......... 134
Gambar 5.24 Cluster Nomor 1 Dengan Node Utama rockygerung ...................... 135
Gambar 5.25 Perbandingan Parameter SNA pada Anggota Cluster 1 ................. 136
Gambar 5.26 Cluster Nomor 2 Dengan Node Utama Gusmus .............................. 137
Gambar 5.27 Perbandingan Parameter SNA pada Anggota Cluster 2 ................. 138
Gambar 5.28 Cluster Nomor 3 Dengan Node Utama maspiyuuu ......................... 140
Gambar 5.29 Perbandingan Parameter SNA pada Anggota Cluster 3 ................. 141
Gambar 5.30 Kompilasi Nilai Parameter SNA Kelompok Kontrol...................... 143
Gambar 5.31 Akun Twitter @rockygerung ................................................................. 143
Gambar 5.32 Akun Twitter @gusmusgusmu .............................................................. 145
Gambar 5.33 Akun Twitter @maspiyuuu .................................................................... 145
Gambar 5.34 Grafik Status User Berpengaruh pada Kelompok Kontrol ............ 146
Gambar 5.35 Grafik Jumlah Node Di Dalam Cluster Kontrol ............................... 147
Gambar 5.36 Grafik 20 Besar User Eksperimen Dengan Nilai DC Tertinggi. 149
Gambar 5.37 Cluster A Dengan Node Utama shitlicious ........................................ 150
xvi

Gambar 5.38 Perbandingan Parameter SNA pada Anggota Cluster A ................ 151
Gambar 5.39 Cluster B Dengan Node Utama lawan_teroris .................................. 152
Gambar 5.40 Perbandingan Parameter SNA pada Anggota Cluster B ................ 153
Gambar 5.41 Cluster C Dengan Node Utama bangsa_patriot ................................ 155
Gambar 5.42 Perbandingan Parameter SNA pada Anggota Cluster C ................ 156
Gambar 5.43 Cluster D Dengan Node Utama Juno_5760 ....................................... 157
Gambar 5.44 Perbandingan Parameter SNA pada Anggota Cluster D ................ 159
Gambar 5.45 Kompilasi Nilai Parameter SNA Kelompok Eksperimen .............. 161
Gambar 5.46 Akun Twitter @shitlicious ...................................................................... 162
Gambar 5.47 Akun Twitter @lawan_teroris ................................................................ 163
Gambar 5.48 Akun Twitter @bangsa_patriot ............................................................. 163
Gambar 5.49 Akun Twitter @GusYaqut ...................................................................... 164
Gambar 5.50 Grafik Status User Berpengaruh pada Kelompok Eksperimen .. 165
Gambar 5.51 Grafik Jumlah Node Di Dalam Cluster Eksperimen ....................... 165
Gambar 5.52 Komparasi Hasil Visualisasi Graf Kelompok Kontrol dan
Eksperimen 167
Gambar 5.53 Grafik Komparasi Rank User Berpengaruh Kelompok
Kontrol dan Eksperimen 169
Gambar 5.54 Komparasi Nilai Degree Centrality Pasca Eksperimen ................. 171
Gambar 5.55 Grafik Jumlah Nilai Degree Centrality Pada Seluruh Cluster ..... 172
Gambar 5.56 Konten Tweet Node rockygerung.......................................................... 173
Gambar 5.57 Tweet Node Kecil Mention Ke Node Gusmus ................................... 174
Gambar 5.58 Konten Tweet Node maspiyuuu ............................................................. 174
Gambar 5.59 Konten Tweet Node shitlicious .............................................................. 175
Gambar 5.60 Konten 1 Tweet Node lawan_teroris .................................................... 175
Gambar 5.61 Konten 2 Tweet Node lawan_teroris .................................................... 176
Gambar 5.62 Konten 3 Tweet Node lawan_teroris .................................................... 176
Gambar 5.63 Konten Tweet Node bangsa_patriot ...................................................... 177
Gambar 5.64 Konten Tweet Node Juno_5760 ............................................................. 177
xvii

DAFTAR TABEL
Tabel 2.1 Hasil Simulasi Perhitungan Degree Centrality ........................................ 38
Tabel 2.2 Hasil Simulasi Perhitungan Betweenness Centrality ............................. 40
Tabel 2.3 Hasil Simulasi Perhitungan Closeness Centrality ................................... 42
Tabel 2.4 Hasil Simulasi Perhitungan Eigenvector Centrality ............................... 44
Tabel 2.5 Hasil Simulasi Perhitungan PageRank ....................................................... 47
Tabel 2.6 Perluasan Jenis Graf ........................................................................................ 51
Tabel 3.1 Daftar Tanggal Trending Topic Twitter ..................................................... 61
Tabel 3.2 Daftar Abstrak Studi Penelitian Sejenis ..................................................... 62
Tabel 3.3 Perbandingan Penelitian Sebelumnya Dengan Penelitian Peneliti .. 68
Tabel 3.4 Perbandingan Metode Eksperimen .............................................................. 72
Tabel 5.1 Jumlah Data Terambil Pada Setiap Loop Pengambilan ........................ 105
Tabel 5.2 Jumlah Sumber Data Pengguna Twitter ..................................................... 106
Tabel 5.3 Tabel 10 Besar User Dengan Post Terbanyak ......................................... 107
Tabel 5.4 Tabel 10 Besar User Paling Banyak di Re-Tweet ................................... 108
Tabel 5.5 User Kontrol Dengan Nilai DC Tertinggi ................................................. 112
Tabel 5.6 User Kontrol Dengan Nilai BC Tertinggi ................................................. 114
Tabel 5.7 User Kontrol Dengan Nilai CC Tertinggi ................................................. 116
Tabel 5.8 User Kontrol Dengan Nilai EC Tertinggi ................................................. 118
Tabel 5.9 User Kontrol Dengan Nilai PageRank Tertinggi .................................... 120
Tabel 5.10 User Eksperimen Dengan Nilai DC Tertinggi ...................................... 123
Tabel 5.11 User Eksperimen Dengan Nilai BC Tertinggi ....................................... 125
Tabel 5.12 User Eksperimen Dengan Nilai CC Tertinggi ....................................... 127
Tabel 5.13 User Eksperimen Dengan Nilai EC Tertinggi ....................................... 129
Tabel 5.14 User Eksperimen Dengan Nilai PageRank Tertinggi ......................... 131
Tabel 5.15 20 Besar User Kontrol Dengan Nilai DC Tertinggi ............................ 133
Tabel 5.16 Perbandingan Parameter SNA pada Anggota Cluster 1 ..................... 136
Tabel 5.17 Perbandingan Parameter SNA pada Anggota Cluster 2 ..................... 138
Tabel 5.18 Perbandingan Parameter SNA pada Anggota Cluster ......................... 141
xviii

Tabel 5.19 Kompilasi Nilai Parameter SNA Kelompok Kontrol .......................... 141
Tabel 5.20 Status User Berpengaruh pada Kelompok Kontrol .............................. 146
Tabel 5.21 Tabel Jumlah Node Di Dalam Cluster Kontrol ..................................... 147
Tabel 5.22 20 Besar User Eksperimen Dengan Nilai DC Tertinggi .................... 148
Tabel 5.23 Perbandingan Parameter SNA pada Anggota Cluster A ..................... 151
Tabel 5.24 Perbandingan Parameter SNA pada Anggota Cluster B ..................... 153
Tabel 5.25 Perbandingan Parameter SNA pada Anggota Cluster C .................... 156
Tabel 5.26 Perbandingan Parameter SNA pada Anggota Cluster D .................... 159
Tabel 5.27 Kompilasi Nilai Parameter SNA Kelompok Eksperimen .................. 160
Tabel 5.28 Status User Berpengaruh pada Kelompok Eksperimen ...................... 164
Tabel 5.29 Tabel Jumlah Node Di Dalam Cluster Eksperimen ............................. 165
Tabel 5.30 Komparasi Rank User Berpengaruh Kelompok Kontrol dan
Eksperimen 168
Tabel 5.31 Komparasi Nilai Degree Centrality Pasca Eksperimen ...................... 170
Tabel 5.32 Tabel Jumlah Nilai Degree Centrality Pada Seluruh Cluster ........... 172
xix

1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Pada 2015 lebih dari 75 juta masyarakat Indonesia telah memiliki akses ke
internet dan hampir semuanya adalah aktif pengguna media sosial. Jumlah
pengguna media sosial ini bertambah hampir 20 persen dari tahun sebelumnya
dengan rata-rata waktu akses 2,4 jam per hari (Republika, 2016).
Data yang berukuran raksasa sudah tidak dapat lagi dikelola secara tradisional,
dibutuhkan suatu teknologi baru untuk mengelola data secara realtime untuk
mempercepat analisis data. Ada beberapa teknologi pengelolaan data yang saat ini
berkembang pesat, salah satunya Apache Hadoop.
Setiap hari, data tercipta sebanyak 2.5 Quintillion bytes, sebanyak 90% dari
data di dunia tercipta dalam kurun waktu 2 tahun. Data ini bermunculan dari
segala sumber, yaitu: Sensor untuk mengumpulkan informasi iklim, informasi dari
media sosial, gambar digital dan video, rekaman transaksi pembelian, dan data
sinyal GPS dari smartphone (IBM, 2016).
Dengan maraknya media penyebaran data, maka muncul satu masalah utama
dalam melakukan verifikasi dan pengecekan kebenaran pada suatu data yang
muncul dan beredar dimasyarakat. Hoax mempunyai definisi untuk mengelabui
menjadi percaya atau menerima sesuatu yang palsu dan sering kali tidak masuk
akal (Merriam-Webster, 2017). Terlebih berita hoax yang dengan mudah tersebar
dan dibagikan tanpa memperhatikan kebenaran dan keaslian data dan berita.
Data yang dipaparkan oleh Kementerian Komunikasi dan Informatika
menyebut ada sebanyak 800 ribu situs di Indonesia yang terindikasi sebagai
penyebar berita palsu dan ujaran kebencian (hate speech). Menteri Kominfo
Rudiantara menjelaskan, angka tersebut merupakan data terbaru yang dimiliki oleh
1
UIN SYARIF HIDAYATULLAH JAKARTA

2
kementeriannya. Sayangnya, data itu tidak dibarengi dengan jumlah pemilik akun
di media sosial yang juga menyebarkan hoax (CNN, 2016).
Berdasarkan hasil penelitian Hunt Allcott and Matthew Gentzkow (2016). Satu
berita palsu (hoax) mempunyai pengaruh yang lebih besar dan bersifat persuasif
dibandingkan dengan satu berita pada media penyiaran berita mainstream.
Dengan adanya media sosial twitter, pengguna menjadi lebih mudah untuk
bertukar informasi atau opini secara cepat keseluruh penjuru dunia. Namun, twitter
belum memiliki teknologi untuk melakukan pengecekan kebenaran dan filtrasi
terhadap data yang beredar, dikarenakan ukuran data yang sudah terlampau besar.
Sesuai dengan data Twitter pada tahun 2016 menyebutkan bahwa Indonesia berada
pada urutan ke 3 sebagai pengguna Twitter paling aktif di dunia, dengan pengguna
asal Indonesia sebanyak 24,34 Juta pengguna (Statista, 2016).
Dengan dasar tersebut, maka diperlukan media analisis data untuk melakukan
pemetaan terhadap seberapa besar pengaruh berita hoax terhadap daya pikir
pengguna sosial media. Data tersebut dapat digunakan sebagai acuan seberapa
besar pengaruh pengguna sosial media dan seberapa jauh pemahaman pengguna
sosial media dalam menyikapi sebuah berita yang beredar.
Dalam al-Qur'an surat al-Hujurat ayat 6 telah disampaikan terkait berita bohong
dan bagaimana cara memperlakukan berita tersebut, sesuai dengan firman Allah.
“Hai orang-orang yang beriman, jika datang kepadamu orang fasik membawa
suatu berita, maka periksalah dengan teliti, agar kamu tidak menimpakan suatu
musibah kepada suatu kaum tanpa mengetahui keadaannya yang menyebabkan
kamu menyesal atas perbuatanmu itu”. (Q. S Al Hujurat ayat 6).
UIN SYARIF HIDAYATULLAH JAKARTA

3
Berdasarkan ayat al-Qur’an surat al-Hujarat bahwa setiap berita dan informasi
yang diterima haruslah diteliti dan diperiksa terlebih dahulu agar tidak
menyebabkan masalah terkait keaslian dan kebenaran suatu berita dan informasi.
Berdasarkan ayat tersebut peneliti tergerak untuk mengetahui lebih lanjut terkait
berita hoax, khususnya pada pengguna sosial media Twitter di Indonesia.
Menurut João Cunha, Catarina Silva dan Mário Antunes (2015). Analisis data
Twitter yang berjumlah besar dalam suatu dataset dapat memberikan perbaikan
yang signifikan. Dan dapat ditemukan prediksi-prediksi baru terkait kasus yang
diteliti, yang dapat menghilangkan inefficiency. Oleh karena besarnya data yang
bersumber dari Twitter yang bersifat realtime, dapat mempermudah proses analisis
dan penarikan kesimpulan sesuai dengan studi yang diteliti.
Untuk melakukan pemetaan terhadap data yang bersifat dinamis dan berjalan
secara realtime, maka dibutuhkan teknologi khusus untuk melakukan pengambilan
dan pengolahan data dari Twitter secara langsung. Teknologi tersebut ada dalam
sebuah teknologi open source bernama Apache Hadoop.
Apache Hadoop adalah framework yang dapat melakukan pemrosesan dari
sekumpulan data berukuran besar secara terdistribusi dengan menggunakan model
pemrograman sederhana. Hadoop dirancang untuk melakukan pemrosesan
terdistribusi mulai dari skala kecil yaitu single node sampai skala besar yaitu multi
node. Single node dan multi node sama-sama mempunyai kemampuan untuk
melakukan komputasi dan penyimpanan data (Hadoop. Apache, 2017)
Menurut Michael Malak (2014) Keuntungan terbesar dari Hadoop adalah
menggunakan kemampuan data locality pada High Performance Computing.
Memungkinkan HPC untuk mempunyai interkoneksi yang lebih cepat seperti
infinity band dan high-bandwidth storage.
Berdasarkan hasil penelitian Timothy S. Sliwinski dan Song-Lak Kang (2017)
Komputasi parallel (metode clustering) memberikan pelayanan yang lebih baik
UIN SYARIF HIDAYATULLAH JAKARTA

4
untuk melakukan penyelesaian analisis data pada model output yang bersifat
dinamis dan selalu bertambah dalam ukuran data. Metode parallel
memperbolehkan pengguna untuk melakukan pemanfaatan sumber daya yang
tersedia dari lebih dari satu node melebihi dari kapasitas yang diberikan oleh
single computer node. Pengguna dapat melakukan distribusi iterasi pengerjaan
sesuai dengan metode analisis yang digunakan.
Sebelumnya telah dilakukan beberapa penelitian yang dilakukan oleh (Timothy
S., Song-Lak Kang, 2017) mereka melakukan implementasi komputer terdistribusi
dan analisis data, dengan menggunakan spesifikasi cluster 640 komputer, dimana
setiap komputer mempunyai processor ganda Intel Xeon Westmere 2.8 GHz hex-
core, dengan core berjumlah 16. Dan 24 GB RAM pada setiap komputer. Hal
tersebut membuat penelitian menjadi tidak cost-efficient.
Penelitian Anusha Mogallapu (2011) dan penelitian Bentar Pritopradono (2012)
yang melakukan penelitian terkait social network analysis namun hanya
menggunakan 3 parameter perhitungan saja, sehingga hasil yang didapatkan tidak
beragam. Penelitian Feriza Julian Putra (2016) yang melakukan penelitian social
network analysis hanya pada user Telkomsel dan XL Axiata saja, sehingga data
dari user lain tidak terambil dan tidak dapat dianalisis.
Penelitian yang telah dilakukan oleh Aditya Abimanyu (2012) dengan
menggunakan tools Gephi sebagai alat bantu perhitungan dan visualisasi graf,
namun penelitian sebelumnya tidak melakukan pengubahan terhadap variabel
iterasi dan pembatasan waktu pada tools gephi. Penelitian sebelumnya hanya
menggunakan variabel standar yang telah ditetapkan oleh Gephi. Berdasarkan hal
tersebut peneliti ingin melakukan perbedaan dengan penelitian sebelumnya,
dengan melakukan pengubahan iterasi pengecekan perhitungan dari nilai 100
menjadi 200, dan menetapkan waktu maksimal (t-max) menjadi 60 detik, untuk
melihat apakah terjadi perubahan terhadap hasil yang didapat pada penelitian.
UIN SYARIF HIDAYATULLAH JAKARTA

5
Adapun hal yang peneliti usulkan pada penelitian ini sebagai pembeda dengan
penelitian lainnya adalah penggunaan Hadoop cluster multi node untuk proses
pengambilan data. Dan peneliti menggunakan 5 parameter pengukuran pada Social
Network Analysis yaitu pengukuran (Degree Centrality, Betweenness Centrality,
Closeness Centrality, Eigenvector Centrality, dan PageRank) untuk melakukan
pengukuran pada graf yang peneliti teliti.
Menurut Kate Ehrlich dan Inga Carboni (2005), Social network analysis
meneliti struktur hubungan sosial dalam sebuah kelompok untuk menemukan
hubungan informal antara manusia. Hubungan sering diterjemahkan dalam bentuk
komunikasi, kesadaran, kepercayaan, dan pengambilan keputusan. Untuk
melakukan pendekatan terhadap hubungan tersebut dibutuhkan SNA.
Peneliti melakukan observasi terhadap daftar trending topic pada sosial media
Twitter selama 1 bulan dari tanggal 15 Agustus 2017 sampai 14 September 2017,
untuk mengumpulkan data mengenai tingkat partisipasi pengguna Twitter terkait
hoax di Indonesia. Sebanyak 18 hari dari 1 bulan pelaksanaan observasi, peneliti
menemukan beberapa hashtag dan topik pembicaraan yang bersinggungan secara
langsung dengan penelitian peneliti. Munculnya topik dengan nama Saracen,
saracengate, sara, bijakbersosmed, dan topik lainnya. Artinya 58% hari topik hoax
muncul dan menjadi pembicaraan masyarakat di sosial media Twitter. Dengan
munculnya topik terkait hoax pada sosial media, menjadikan dasar peneliti untuk
melakukan penelitian.
Pada penelitian ini peneliti menggunakan parameter pengukuran pada Social
Network Analysis untuk melakukan pengukuran dan pemetaan terhadap ruang
lingkup yang peneliti teliti. Dikarenakan fleksibilitas dan tujuan yang akan dicapai
dari hasil pengolahan dan analisis data tersebut, sesuai dengan karakteristik dari
hubungan manusia itu sendiri yang diterjemahkan ke dalam kata-kata pada sosial
media Twitter. Peneliti menggunakan metode Eksperimen Intact-Group
UIN SYARIF HIDAYATULLAH JAKARTA

6
Comparison yang terdiri dari 7 langkah penelitian yaitu Pemilihan Desain,
Penentuan Sampel Representatif, Instrumentasi, Pelaksanaan Eksperimen,
Pengumpulan dan Penganalisisan Data, Analisis dan Interpretasi Data, dan
Kesimpulan Eksperimen. Ada 2 variabel yang akan peneleti ubah dan amati
perbedaannya pada penelitian ini yaitu, variabel iterasi pengecekan perhitungan
dan variabel waktu maksimal pada gephi.
Pada penelitian sebelumnya tidak dijelaskan secara mendetail mengenai desain
eksperimen apa yang digunakan pada penelitian, oleh karena itu peneliti ingin
melakukan penerapan metode eksperimen dengan desain intact-group comparison
pada penelitian sebagai pembeda dengan penelitian lain.
Peneliti juga menggunakan teknik multi node Hadoop clustering (High
Performance Cluster). Pemilihan teknik cluster dikarenakan secara alamiah jumlah
data yang dapat diambil yang bersumber dari Streaming API Twitter bersifat besar
dan berjalan dalam keadaan dinamis dan dalam rentang waktu realtime.
Berdasarkan pada latar belakang yang telah peneliti bahas, maka peneliti akan
melakukan sosial network analisis terhadap pengguna Twitter terkait berita hoax dan
menjadikannya sebagai bahan kajian yang tertuang dalam bentuk skripsi dengan judul
“Social Network Analysis Terhadap Pengguna Twitter Terkait Berita
Hoax Di Indonesia Dengan Metode Single Cluster Multi Node Menggunakan
Apache Hadoop Terdistribusi HortonworksTM”.
1.2 Rumusan Masalah
Rumusan masalah yang akan peneliti angkat dalam penelitian ini, sesuai
dengan latar belakang yang telah peneliti uraikan sebelumnya adalah:
1. Bagaimana melakukan social network analysis terhadap pengguna Twitter dengan studi data berita hoax dengan metode clustering menggunakan Apache
Hadoop terdistribusi HortonworksTM?
UIN SYARIF HIDAYATULLAH JAKARTA

7
2. Bagaimana pengaruh pengubahan iterasi pengecekan perhitungan pada gephi,
dengan penambahan iterasi, dari iterasi default sebesar 100 kali menjadi 200
kali pengecekan perhitungan?
3. Bagaimana pengaruh pengubahan penetapan waktu maksimal (t-max) pada
tahap visualisasi graf pada gephi, dengan penentuan nilai waktu maksimal (t-
max) pengecekan menjadi 60 detik?
4. Bagaimana melakukan penerapan metode eksperimen dengan desain intact-
group comparison pada penelitian?
1.3 Batasan Masalah
Batasan masalah pada penelitian ini agar tidak menyimpang terhadap topik
pembicaraan lain adalah:
1. Framework Hadoop menggunakan Hadoop yang didistibusikan oleh
HortonworksTM dan berjalan pada mode multi node.
2. Sistem ini akan mengelola data hanya dari sosial media twitter dengan API
yang telah disediakan oleh pihak twitter.
3. Penulisan Skripsi ini ditekankan pada analisis penyebaran data hoax, hubungan
user dengan user lain dalam ruang lingkup objek yang peneliti teliti.
4. Parameter utama dalam penelitian adalah pembatasan data yang hanya
bersinggungan dengan kata kunci hoax.
5. Data pengguna twitter merupakan pengguna media sosial twitter yang berasal
dari Indonesia.
6. Output dari penelitian ini adalah hasil analisis SNA berita hoax dan pengaruh
pengguna media sosial twitter terhadap berita hoax.
7. Peneliti tidak melakukan verifikasi terhadap konten tweet, setiap user yang
melakukan tweet dengan melibatkan keyword hoax, maka dapat dikategorikan
sebagai data penelitian.
8. Peneliti hanya membagi User Twitter menjadi 2 kelompok, pertama kelompok
user original yaitu user yang menuliskan tweet yang berasal dari penulisan
UIN SYARIF HIDAYATULLAH JAKARTA

8
original dari penulis tweet. Kelompok kedua yaitu user re-tweet yaitu user yang
melakukan posting ulang terhadap tweet dari user original.
9. Peneliti tidak melakukan validasi terhadap data, terkait apakah data termasuk
hoax atau bukan hoax. Seluruh tweet yang mengandung kata hoax akan
digunakan sebagai data penelitian.
1.4 Tujuan Penelitian
Tujuan utama dari penelitian ini adalah:
1. Melakukan analisis data twitter menggunakan social network analysis, dengan subjek berupa pengguna media sosial twitter, dengan objek penelitian berita hoax, dan tools yang digunakan adalah Apache Hadoop
terdistribusi HortonworksTM.
2. Mengetahui apakah terjadi perbedaan pada hasil perhitungan parameter
social network analysis, setelah dilakukan penambahan nilai variabel seperti
penambahan iterasi pengecekan perhitungan.
3. Mengetahui apakah terjadi perbedaan pada hasil visualisasi graf pada gephi.
Setelah dilakukan penetapan waktu maksimal (t-max).
4. Melakukan penerapan metode eksperimen dengan desain intact-group
comparison pada penelitian.
1.5 Manfaat Penelitian 1.5.1 Bagi Peneliti
1. Dapat memenuhi salah satu syarat wajib dalam menyelesaikan kurikulum
tingkat akhir Program Studi Teknik Informatika Fakultas Sains dan
Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta.
2. Menambah pengalaman dan pengetahuan dalam mengelola data pada
sistem Hadoop.
1.5.2 Bagi Pengguna
1. Memberikan wawasan baru terkait teknologi pengelolaan data yang
dapat digunakan untuk penelitian selanjutnya.
UIN SYARIF HIDAYATULLAH JAKARTA

9
2. Sebagai rujukan mengenai analisis kinerja Hadoop yang berjalan pada
multi node dan dapat dikembangkan lebih lanjut sesuai dengan
perkembangan teknologi yang ada.
3. Sebagai rujukan mengenai pemetaan penyebaran berita hoax yang
selama ini beredar dalam ruang lingkup media sosial twitter.
1.5.3 Bagi Universitas
1. Mengukur kemampuan dan pemahaman mahasiswa dalam menyerap
materi yang diperoleh selama belajar.
2. Sebagai referensi untuk penelitian selanjutnya.
3. Mengetahui kemampuan mahasiswa dalam mengimplementasikan hasil
pembelajaran selama di Universitas.
1.6 Metode Penelitian
Metode yang digunakan peneliti dalam menyusun Tugas Akhir ini adalah sebagai
berikut:
1.6.1 Metode Pengumpulan Data
1. Studi Pustaka
2. Observasi
1.6.2 Metode Eksperimen
1. Pemilihan Desain
2. Penentuan Sampel Representatif
3. Instrumentasi
4. Pelaksanaan Eksperimen
5. Pengumpulan dan Penganalisisan Data
6. Analisis dan Interpretasi Data
7. Kesimpulan Eksperimen
1.7 Sistematika Penulisan
Untuk memudahkan dalam membaca penelitian skripsi ini, maka peneliti membuat
sistematika penulisan dari penelitian ini adalah sebagai berikut: BAB 1
PENDAHULUAN
UIN SYARIF HIDAYATULLAH JAKARTA

10
Pada bab ini dijelaskan latar belakang, rumusan masalah, batasan masalah,
tujuan penelitian, manfaat penelitian, metodologi penelitian, dan
sistematika penulisan.
BAB II LANDASAN TEORI
Pada bab ini akan dijelaskan terkait teori-teori yang mendukung
eksperimen dan analisis yang dilakukan.
BAB III METODOLOGI PENELITIAN
Pada bab ini menjelaskan metode-metode yang digunakan dalam tahap
eksperimen dan analisis pada penelitian.
BAB IV EKSPERIMEN DAN IMPLEMENTASI
Pada bab ini menjelaskan proses eksperimen dan tahapan-tahapan analisis
yang dilakukan dalam penelitian ini.
BAB V HASIL ANALISIS DAN PEMBAHASAN
Pada bab ini berisi tentang output pada eksperimen yang dilakukan dan
pembahasan sesuai dengan analisis yang dilakukan terhadap data dan
sistem dalam penelitian.
BAB VI PENUTUP
Bab ini berisi tentang kesimpulan yang diperoleh dari hasil penelitian
pada skripsi ini.
UIN SYARIF HIDAYATULLAH JAKARTA

11
BAB II
LANDASAN TEORI
2.1 Hoax
Hoax adalah kegiatan untuk mengelabui menjadi percaya atau menerima sesuatu
yang palsu dan seringkali tidak masuk akal (Merriam-Webster.com, 2017). Menurut
Hunt Allcott dan Matthew Gentzkow (2016) Berita hoax adalah artikel berita atau
informasi yang memuat berita bohong yang sengaja dibuat oleh pembuatnya, untuk
menipu pembaca atau orang banyak. Semua informasi yang secara sengaja dibuat
seperti berita yang dibagikan atau share kepada orang banyak agar orang banyak
percaya dengan konten dari informasi palsu tersebut. Satu berita palsu (hoax)
mempunyai pengaruh yang lebih besar dan bersifat persuasif dibandingkan dengan
satu berita pada media penyiaran berita mainstream.
2.2 Metode Cluster
Komputer cluster adalah sekumpulan dari banyak komputer yang terhubung
dengan baik, dan bekerja bersama sehingga dapat dilihat seperti satu kesatuan
sistem. Komputer cluster mempunyai beberapa node (komputer) untuk
menjalankan tugas yang sama, yang telah dikontrol dan dijadwalkan oleh
perangkat lunak.
Komponen cluster biasanya terhubung antara satu dengan yang lain
menggunakan local area network, dengan setiap node menjalankan sistem
operasi masing-masing. Pada kondisi standar, seluruh node pada cluster
menggunakan perangkat keras yang mirip dan sistem operasi yang sama.
2.2.1 Jenis-jenis Clustering
Dalam metode clustering terdapat berbagai macam jenis cluster yang dapat
diterapkan pada komputer. Jenis-jenis clustering adalah sebagai berikut:
1. High Performance Cluster
Beberapa komputer bekerja bersama untuk menjalankan satu atau lebih
pekerjaan yang membutuhkan banyak sumber daya komputer.
11 UIN SYARIF HIDAYATULLAH JAKARTA
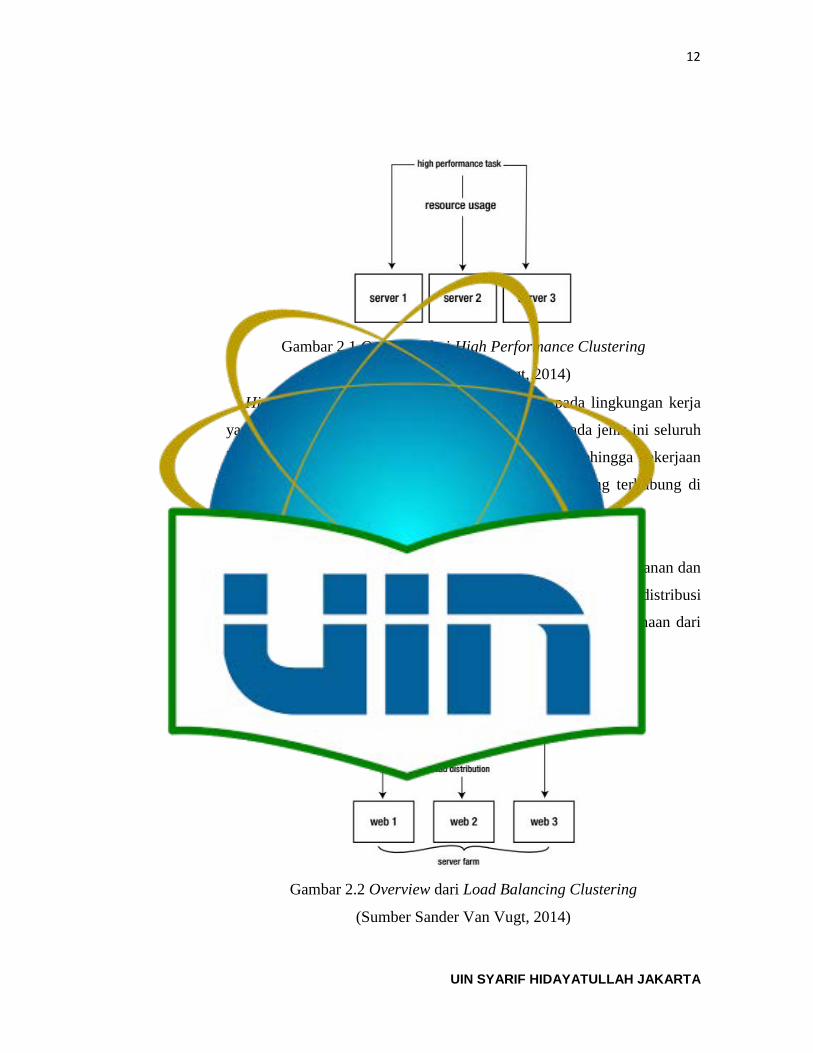
12
Gambar 2.1 Overview dari High Performance Clustering
(Sumber Sander Van Vugt, 2014)
High performance cluster biasanya digunakan pada lingkungan kerja
yang sangat membutuhkan sumber daya komputer. Pada jenis ini seluruh
komputer atau server bekerja sebagai satu kesatuan. Sehingga pekerjaan
yang berat dapat dibagi kepada komputer-komputer yang terhubung di
dalam cluster.
2. Load Balancing Cluster
Sekumpulan load balancer yang digunakan sebagai penyedia layanan dan
menerima permintaan dari user. Jenis cluster ini melakukan distribusi
permintaan pekerjaan kepada server yang berbeda, sesuai kegunaan dari
server yang ada.
Gambar 2.2 Overview dari Load Balancing Clustering
(Sumber Sander Van Vugt, 2014)
UIN SYARIF HIDAYATULLAH JAKARTA

13
Jenis clustering ini biasanya digunakan sebagai sistem pada layanan
website. Dikarenakan sebuah website yang ramai pengunjung
membutuhkan sokongan sumber daya komputer yang memadai untuk
mendukung proses optimalisasi dari website.
3. High Availability Cluster
Beberapa server bekerja bersama untuk memastikan bahwa sumber daya
penting yang ada pada jaringan selalu tersedia dan tidak mengalami
penurunan kecepatan dan penurunan kualitas.
Gambar 2.3 Overview dari High Availability Clustering
(Sumber Sander Van Vugt, 2014)
Tujuan utama dari penggunaan high availability clustering adalah untuk
memastikan ketersediaan sumber daya penting dalam tingkat maksimal.
Perangkat lunak melakukan monitoring terhadap kesediaan dari node di
dalam cluster, sehingga apabila salah satu server mati, maka perangkat lunak
akan melakukan monitoring dan memastikan bahwa pekerjaan tetap berjalan
pada node lain di dalam cluster (Sander Van Vugt, 2014).
2.2.2 Komputer Terdistribusi (Cluster)
Komputasi terdistribusi adalah sekumpulan sistem yang terdiri dari
hardware dan software yang mengandung lebih dari satu elemen pemroses
UIN SYARIF HIDAYATULLAH JAKARTA

14
atau storage, proses-proses yang konkuren, atau sekumpulan program yang
berjalan dalam suatu domain yang dikendalikan secara langsung.
Dalam komputasi terdistribusi, suatu program dipecah ke dalam bagian-
bagian yang berjalan secara simultan (bersamaan) pada banyak komputer
yang berkomunikasi pada satu jaringan. Komputasi terdistribusi merupakan
suatu bentuk dari komputasi paralel, tetapi komputasi paralel digunakan
untuk menggambarkan bagian-bagian program yang berjalan secara simultan
pada banyak prosesor dalam komputer yang sama. Kedua tipe pemrosesan
ini memerlukan pembagian suatu program kedalam bagian-bagian yang
berjalan secara bersamaan, tetapi program terdistribusi sering berhadapan
dengan lingkungan yang heterogen, link jaringan dengan latency bervariasi,
dan kegagalan yang tidak dapat diprediksi, baik di dalam jaringan maupun
computer (Komputasi.lipi, 2010).
2.2.3 Apache Hadoop
Hadoop adalah framework open source untuk menulis dan menjalankan
aplikasi terdistribusi yang memproses sejumlah data. Hadoop berjalan pada
sekumpulan komputer atau server dalam cluster atau layanan cloud computing.
Karena ditujukan untuk berjalan diperangkat keras cluster, Hadoop dirancang
dengan asumsi malfungsi perangkat keras yang sering terjadi. Hadoop mampu
menangani sebagian besar kegagalan tersebut. Hadoop melakukan skala secara
linear menangani data yang besar, dengan menambahkan lebih banyak node
baru ke cluster. Hadoop memungkinkan pengguna untuk menulis dengan cepat
kode paralel yang efisien. Aksesibilitas dan kesederhanaan Hadoop memberikan
keunggulan dalam menulis dan menjalankan program terdistribusi yang besar
(Chuck Lam, 2011).
2.2.4 Keuntungan Hadoop
1. Scalability. Arsitektur Hadoop yang mampu berjalan dalam lingkungan
cluster, menjadikan Hadoop mudah dan ekonomis untuk melakukan
manipulasi dalam hal penambahan jumlah node baru ke dalam cluster
UIN SYARIF HIDAYATULLAH JAKARTA

15
yang sudah terbentuk. Penambahan node mempunyai tujuan apabila
terjadi beban ekstra atau bertambahnya jumlah user di dalam sistem.
2. Fault tolerance, Kemungkinan kegagalan pada saat running system tidak
bisa dikesampingkan. HDFS menawarkan redundansi dan pemulihan
pada saat terjadinya kesalahan. Jika salah satu server berhenti berfungsi,
node lain menyimpan data sebagai hasil replikasi, yang merupakan fitur
penting dari Hadoop. Eksekusi ulang tugas merupakan fitur penting
karena perhitungan akan dialihkan ke node yang berbeda jika terjadi
kegagalan pada node yang lain. Oleh karena itu, tidak ada kehilangan
data, dan ini juga menjamin ketersediaan data kapanpun dibutuhkan.
3. Resource sharing, Hadoop mengikuti konsep komputasi terdistribusi.
Oleh karena itu, sumber daya dan CPU di seluruh cluster digunakan
bersamaan satu sama lain. Perhitungan paralel dapat dicapai dengan
mudah dengan Hadoop (Aravind Shenoy, 2014).
2.2.5 HDFS
Hadoop Distributed File System (HDFS) adalah sistem file terdistribusi
yang dirancang untuk berjalan pada perangkat keras cluster. HDFS memiliki
banyak kesamaan dengan sistem file terdistribusi yang lain. HDFS sangat
toleran terhadap kesalahan dan dirancang untuk digunakan pada perangkat
keras berbiaya rendah. HDFS menyediakan akses throughput yang tinggi ke
data aplikasi dan cocok untuk aplikasi yang memiliki kumpulan data yang
besar. HDFS adalah bagian dari proyek Apache Hadoop Core (Hadoop
Apache, 2017).
2.2.6 Arsitektur HDFS
HDFS memiliki arsitektur master / slave. Sebuah cluster HDFS terdiri
dari satu NameNode tunggal, server yang mengelola namespace system file
dan mengatur akses ke file oleh klien. Biasanya ada satu DataNode per node
di dalam cluster, yang mengelola penyimpanan yang ter-install pada node
yang berjalan. HDFS menampilkan namespace system file dan
UIN SYARIF HIDAYATULLAH JAKARTA

16
memungkinkan data pengguna disimpan di dalam file. Secara internal, file
dipecah menjadi satu atau beberapa blok dan blok ini disimpan dalam satu set
DataNodes. NameNode mengeksekusi operasi namespace system file seperti
membuka, menutup, dan mengganti nama file dan direktori. NameNode juga
menentukan pemetaan blok ke DataNodes. DataNodes bertanggung jawab
untuk melayani permintaan read and write. DataNodes juga melakukan block
creation, deletion, dan replication pada instruksi dari NameNode.
Gambar 2.4 Bagian Inti Arsitektur HDFS
(Sumber Hadoop Apache, 2017)
Gambar 2.4 menjelaskan skema replikasi data pada DataNode, setiap
user melakukan input data atau perintah secara langsung ke NameNode,
NameNode langsung melakukan penyimpanan data pada DataNode yang
tersebar pada server dan melakukan replikasi sesuai dengan konfigurasi
awal HDFS, by default HDFS hanya melakukan 1 kali replikasi blok data.
NamaNode dan DataNode dirancang untuk berjalan pada teknik cluster.
Mesin ini biasanya menjalankan sistem operasi GNU / Linux (OS). HDFS
dibangun dengan menggunakan bahasa JAVA. Setiap mesin yang
UIN SYARIF HIDAYATULLAH JAKARTA

17
mendukung JAVA dapat menjalankan perangkat lunak NameNode atau
DataNode. Penggunaan bahasa JAVA yang sangat fleksibel memungkinkan
HDFS untuk digunakan pada berbagai mesin. Biasanya sebuah NameNode
hanya berada pada satu mesin yang sengaja ditugaskan sebagai server
utama. Masing-masing mesin lainnya di dalam cluster menjalankan satu
DataNode. Keberadaan satu NamaNode tunggal dalam sebuah cluster
membuat sistem arsitektur HDFS menjadi sederhana. NameNode adalah
arbitrator dan repositori untuk semua metadata HDFS. Sistem ini dirancang
sedemikian rupa sehingga data pengguna tidak pernah mengalir melalui
NameNode (Hadoop Apache, 2017).
2.2.7 Struktur HDFS
Hadoop mempunyai struktur yang berisi sekumpulan daemons yang
berjalan berkesinambungan yang tersebar pada nodes yang berbeda dalam
satu jaringan. Daemon adalah program komputer yang berjalan pada
komputer dalam tatanan level background. Daemons mempunyai tugas yang
spesifik sesuai dengan tujuan daemon tersebut. Ada yang hanya ditugaskan
pada satu server saja dan bahkan berjalan pada semua server. Beberapa
daemons yang membentuk struktur Hadoop adalah NameNode, DataNode,
Secondary NameNode, JobTracker, dan TaskTracker.
a. NameNode
Sistem distribusi penyimpanan data pada Hadoop dinamakan Hadoop
file system atau HDFS. NameNode merupakan daemon yang berjalan
pada master di HDFS, NameNode mempunyai tugas untuk melakukan
perintah secara langsung terhadap daemon DataNode yang berjalan pada
slave, untuk melakukan proses input dan output. NameNode menyimpan
data terkait spesifikasi data seperti bagaimana data dipecah menjadi file
blocks, mengetahui node mana yg menyimpan block tersebut dan
mengetahui tingkan kesehatan dari file system untuk melakukan
monitoring terhadap HDFS.
UIN SYARIF HIDAYATULLAH JAKARTA

18
b. DataNode
Setiap komputer yang berfungsi sebagai slave di dalam cluster akan
menjadi node dimana daemon DataNode berjalan, berfungsi untuk proses
read and write blok-blok HDFS yang sudah dipecah untuk disimpan di
dalam storage. Saat proses read and write file HDFS, file dipecah menjadi
blok-blok kemudian NameNode akan memberitahu dimana DataNode
menyimpan setiap blok-blok yang tersimpan. Kemudian user melakukan
komunikasi langsung dengan daemon DataNode untuk melakukan proses
sesuai dengan dimana lokasi file yang akan di proses. DataNode dapat
melakukan komunikasi dengan DataNode lain untuk melakukan replikasi
data untuk proses redundancy data apabila terjadi kesalahan.
Gambar 2.5 Interaksi NameNode dan DataNode pada HDFS
(Sumber Chuck Lam, 2011)
Dari Gambar 2.5, menjelaskan tugas dari NameNode dan DataNode.
Data utama dipecah menjadi beberapa blok-blok dan dilakukan proses
duplikasi blok yang kemudian disimpan di dalam DataNode yang tersebar
pada cluster. Proses duplikasi dan replikasi bertujuan untuk mengurangi
kegagalan dalam cluster, sehingga apabila ada DataNode yg rusak, user
masih bisa mengakses blok lain yang telah diduplikasi. Pada proses
UIN SYARIF HIDAYATULLAH JAKARTA

19
inisiasi, DataNode melaporkan kepada NameNode terkait lokasi blok-
blok yang disimpan.
c. Secondary NameNode
Secondary NameNode (SNN) adalah daemon yang bertugas sebagai
asisten untuk melakukan monitoring terkait kondisi cluster HDFS. Sama
seperti NamneNode, setiap mesin pada cluster mempunyai satu SNN.
SNN mempunyai perbedaan dengan NameNode dimana pada setiap
proses SNN tidak menerima atau melakukan pencatatan terkait
pergantian yang terjadi pada HDFS secara real-time. SNN
berkomunikasi dengan NameNode untuk mengambil gambaran umum
dari metadata HDFS yang telah ditentukan pada konfigurasi awal. SNN
membantu untuk meminimalisir kehilangan data.
d. JobTracker
Daemon JobTracker bertugas sebagai penghubung antara services dan
Hadoop. Pada saat user melakukan input code ke dalam cluster,
JobTracker melakukan penentuan planning eksekusi dengan
menentukan file mana yang akan diproses, menentukan node-node
sesuai dengan tugas yang dibutuhkan, dan melakukan monitoring
terhadap tugas yang berjalan. Apabila ada tugas yang gagal, JobTracker
akan secara otomatis melakukan pengulangan tugas kembali dan bila
memungkinkan dilakukan pemindahan lokasi dimana tugas akan
dilakukan. Hanya ada satu daemon JobTracker pada setiap cluster
Hadoop, dan berjalan pada node yang bertugas sebagai master.
e. TaskTracker
Konsep dalam cluster berjalan berdasarkan fondasi utama pembagian
node kedalam dua arsitektur, yaitu master dan slave. dalam hubungan
antara JobTracker dan TaskTracker juga mengikuti arsitektur tersebut.
JobTracker bertugas sebagai master yang melakukan monitoring tugas-
tugas dan TaskTracker melakukan manajemen eksekusi dari tugas-tugas
UIN SYARIF HIDAYATULLAH JAKARTA

20
individual yang berjalan pada node yang bertugas sebagai slave (Chuck
Lam, 2011).
2.2.8 Keuntungan HDFS
Keuntungan dari HDFS adalah toleransi akan terjadinya kesalahan.
HDFS mampu menyediakan kemampuan untuk menyiapkan data transfer
secara cepat antara nodes yang ada apabila terjadi kesalahan di dalam
cluster Hadoop. Berkat adanya kemampuan tersebut Hadoop mampu
membuat proses yang berjalan pada cluster tetap berjalan seperti semestinya
walaupun terjadi kesalahan atau error pada cluster (Mohd Rehan G., 2015).
2.3 Apache Ambari
Apache Ambari adalah sebuah alat untuk melakukan penyediaan, pengelolaan,
dan pemantauan terhadap Apache Hadoop yang berjalan pada mode cluster multi
node. Ambari berisikan sekumpulan REST (Representational state transfer),
services yang disediakan Apache Ambari sesuai dengan komponen Hadoop yang
akan digunakan dan sesuai dengan kebutuhan. Dan menyediakan manajemen
Hadoop berbasis Browser. Ambari mempermudah user untuk melakukan
penyediaan cluster Hadoop dengan menyediakan urutan dalam melakukan install
services Hadoop yang dapat di pasang pada node yang tersedia, dan Ambari
mampu melakukan konfigurasi services Hadoop pada cluster secara mudah
dikarenakan berbasis browser. Ambari menyediakan dashboard untuk melakukan
monitoring kesehatan dan status dari cluster Hadoop (Ambari Apache, 2017).
2.3.1 Arsitektur Apache Ambari
Ambari menyediakan REST yang melakukan otomatisasi operasi di
dalam cluster Hadoop. Ambari memberikan pelayanan yang konsisten dan
aman untuk melakukan kontrol operasional secara efisien.
UIN SYARIF HIDAYATULLAH JAKARTA

21
Gambar 2.6 Alur Komunikasi Server dan Agent
(Sumber Intellipaat, 2017)
Gambar 2.6 menjelaskan bagaimana proses komunikasi antara Ambari-
Server dan Ambari-Agent. Hanya tersedia satu master pada setiap cluster
Hadoop dan beberap agent pada beberapa slave sesuai dengan spesifikasi
cluster yang dibuat. User melakukan perintah secara langsung pada server.
Arsitektur ambari biasanya mempunyai dua komponen utama yaitu
Ambari-Server dan Ambari-Agent. Server bertugas sebagai proses yang
melakukan komunikasi dengan agent yang berada pada seluruh node di
dalam cluster. Sedangkan Agent bertugas selalu aktif untuk memberikan
informasi mengenai status kesehatan dari seluruh node yang berjalan pada
cluster Hadoop (Intellipaat, 2017).
2.4 Apache Nifi
NiFi adalah sebuah projek yang dibuat oleh National Security Agency (NSA)
Amerika Serikat dan mempunyai nama Niagarafiles. Pada tahun 2014 NSA
melakukan penyebar luasan NiFi dan menjadikannya berbasis Open-Source. NiFi
mampu malakukan otomatisasi data flows dalam lingkup jaringan komputer dalam
cluster, walaupun format data dan protokol yang digunakan berbeda. Code dari NiFi
kemudian dilakukan release ke publik melalui Apache Software Foundation.
UIN SYARIF HIDAYATULLAH JAKARTA

22
NiFi dibuat untuk menciptakan kesadaran situasional yang didapat dari arus
informasi yang datang dari berbagai sumber (Convergedigest, 2014). Dataflow
adalah paradigma software yang dilandaskan pada ide untuk pemutusan aktor
pada komputasi kemudian diubah menjadi tahapan-tahapan yang dapat dieksekusi
secara bersamaan (Jonathan Beard, 2015).
2.4.1 Tantangan Dataflow
1. Systems fail yang meliputi kegagalan jaringan, kegagalan penyimpanan
data, software crashes, kesalahan dari pihak user. Dikarenakan banyak
faktor yang menentukan kegagalan dalam proses dataflow.
2. Akses data mengalami hambatan kapasitas penyimpanan. Data yang
berasal dari sumber data yang tidak terhingga mampu memberikan
kegagalan dalam hal penyimpanan yang melebihi kapasitas
penyimpanan data.
3. Adanya batasan kondisi yang menghalangi proses, Dataflow mungkin
memberikan data yang terlalu besar, terlalu kecil, terlalu cepat, terlalu
lambat, data yang rusak, kesalahan spesifikasi data, dan format data
yang salah.
4. Pengubahan data, Pengubahan data yang cepat yang dimana
memungkinkan pengubahan data noise menjadi data signal dalam
kurun waktu yang cepat, maka dibutuhkan kemampuan untuk
beradaptasi terhadap pengubahan data yang sangat cepat. Sehingga
proses pengambilan data tetap berjalan stabil.
5. Pengubahan sistem yang berbeda-beda. Protokol dan format yang
digunakan dalam sistem dapat berubah kapan saja. Dataflow
digunakan untuk mengkoneksikan apa yang penting dalam komputasi
terdistribusi dan menentukan bagaimana data bekerja.
2.4.2 Konsep Apache NiFi
Apache Nifi mempunyai konsep utama dalam melakukan proses
Dataflow dalam setiap iterasi sebagai berikut:
UIN SYARIF HIDAYATULLAH JAKARTA

23
1. Flowfile
Flowfile merepresentasikan setiap objek yang berpindah melalui
sistem, dan untuk setiap perpindahan, NiFi melakukan pelacakan
lokasi key/value yang dipasangkan dengan atribut dan kontennya.
2. FlowFile Processor
Prosesor yang melakukan pekerjaan. Prosesor melakukan kombinasi
dari routing data, transformasi data atau mediasi antar sistem. Prosesor
mempunyai akses terhadap atribut dari Flowfile dan konten stream.
Prosesor dapan melakukan operasi terhadap sejumlah FlowFile dalam
kurun waktu dan kerja yang ditentukan.
3. Connection
Connection menyediakan hubungan dalam lingkup pengerjaan antara
FlowFile Processor. Connection berfungsi sebagai queues (antrian)
dan mengizinkan beberapa proses untuk berinteraksi dalam tingkatan
yang berbeda. Queues (antrian) dapat diprioritaskan secara dinamis
sesuai dengan kebutuhan.
4. Flow Controller
Flow Controller melakukan maintenance terhadap bagaimana proses
melakukan koneksi dan mengatur threads dan alokasi tempat yang
dilakukan oleh semua proses. Flow controller berfungsi sebagai broker
yang memfasilitasi pertukaran FlowFiles diantara prosesor.
5. Process Group
Process Group adalah sekumpulan proses-proses termasuk hubungan
dan koneksi tiap proses secara spesifik. Process Group mampu
menerima data melalui port input dan mengirim data melalui port
output. Process group memperbolehkan penciptaan komponen baru
dengan menggunakan komponen-komponen lainnya.
UIN SYARIF HIDAYATULLAH JAKARTA

24
2.4.3 Arsitektur Apache Nifi
Nifi melakukan eksekusi program dalam ruang lingkup JVM (JAVA
Virtual Machine) yang berada pada level sistem operasi. Komponen-
komponen primer pada Apache NiFi adalah:
Gambar 2.7 Arsitektur NiFi Pada JVM
(Sumber NiFi Apache, 2017)
Gambar 2.7 menjelaskan bahwa Apache NiFi menggunakan JVM
untuk melakukan eksekusi program kemudian dihubungkan dengan Host
dimana NiFi di install kemudian dihubungkan menggunakan penyimpanan
baik local storage ataupun penyimpanan di HDFS. Apache NiFi
mengunakan tampilan antarmuka GUI berbasis browser.
1. Web Server. Kegunaan dari web server adalah sebagai wadah berjalannya
perintah dan kontrol NiFi berbasis HTTP.
2. Flow Controller. Adalah otak dari proses operasi. Flow controller
menyediakan thread untuk melakukan ekstensi proses yang berjalan dan
melakukan pengaturan scheduling terkait kapan sebuah ekstensi dapat
menerima data atau kode untuk dieksekusi.
3. Extension. Banyak tipe-tipe ekstensi dalam Nifi yang melakukan operasi
pengerjaan dan eksekusi di dalam lingkup JVM.
UIN SYARIF HIDAYATULLAH JAKARTA

25
4. FlowFile Repository adalah tempat NiFi melacak keadaan dari FlowFile
yang sedang aktif dalam proses Dataflow. Implementasi dari sebuah
repository adalah temporary, artinya dapat digunakan saat dibutuhkan dan
dapat tidak digunakan saat tidak dibutuhkan.
5. Content Repository. Adalah tempat dimana konten utama yang diberikan
dari FlowFile berada. Content repository menyimpan blok-blok data di
dalam file system. Lebih dari satu tempat penyimpanan dapat digunakan
dan dilakukan partisi sesuai kebutuhan untuk mengurangi dampak
kegagalan bila kerusakan data terjadi.
6. Provenance Repository. Semua event dari data disimpan pada provenance
repository. Repository ini dapat digunakan pada lebih dari satu lokasi
penyimpanan. Lokasi dari event data sudah dilakukan proses index dan
dapat dicari secara langsung.
Gambar 2.8 Implementasi Apache NiFi dalam Skema Cluster
(Sumber NiFi Apache, 2017)
Apache NiFi juga bisa diimplementasikan dalam mode clustering.
Dimana setiap host node menjalankan satu service dari NiFi dan kemudian
digabungkan melalui satu penyimpanan data yang besar pada server di
local disk ataupun di HDFS sesuai dengan besar cluster.
UIN SYARIF HIDAYATULLAH JAKARTA

26
Koordinator cluster sangat berpengaruh dan bertanggungjawab untuk
melakukan penyambungan dan pemutusan hubungan antar node. Setiap
cluster mempunyai node primer, yang berfungsi sebagai pusat kendali
(NiFi Apache, 2017).
2.5 Solr
Solr adalah alat untuk melakukan pencarian dalam skala enterprise, dalam
kurun waktu yang cepat dan scalable, yang dibuat menggunakan pondasi Apache
Lucene. Solr telah berkembang sedemikian rupa sehingga mampu menyediakan
seluruh fitur dan teknik untuk melakukan pencarian dan lainnya. Solr mampu
dijalankan berbasis cloud untuk meningkatkan ketahanan, toleransi kesalahan
dan kehandalan.
2.5.1 Fitur Solr
1. Inverted Index
Solr membuat index terbalik dari dokumen yang ditambahkan ke Solr, dan
pada saat melakukan query, Solr mencari index untuk mencocokkan
dokumen. Index invert mirip dengan indek di akhir buku.
2. Vector Space
Secara default, Solr menggunakan VSM (vector space model) berbarengan
dengan model Boolean untuk menentukan kecocokkan dokumen dengan
keyword pencarian yang user masukan.
3. Analysis Chain
Pada saat melakukan query pencarian, dokumen yang sedang melalui proses
index akan melalui beberapa rantai analisis dan pemberian token. Output dari
token terakhir yang dihasilkan menjadi keyword index suatu dokumen.
2.5.2 Tahapan Index
Tahap indexing dapat berjalan secara simpel dan mudah apabila data
mempunyai bentuk terstruktur dan terformat dengan baik. Namun apabila
bentuk data tidak terstruktur dan mempunyai berbagai macam format dan
UIN SYARIF HIDAYATULLAH JAKARTA

27
sumber data yang berbeda, proses indexing akan menjadi lebih sulit. Berikut
ini adalah tahapan pada proses indexing:
1. Text Extraction
Dalam proses ini, Solr mengekstrak teks untuk pengindeksan. Teks dapat
diperoleh, misalnya dengan membaca file, query database, merangkak
halaman web, atau membaca RSS feed. Ekstraksi dapat dilakukan oleh
aplikasi klien Java atau komponen Solr. DataImportHandler adalah modul
contrib yang bisa digunakan untuk membaca data dari databas, misalnya.
Kerangka Solr Cell, dapat langsung mengekstrak data dari file dalam
format Office, Word, dan PDF, serta format proprietary lainnya.
2. Document Preparation
Teks yang diekstraksi harus diubah menjadi dokumen Solr untuk
dikonsumsi. Dokumen yang disiapkan harus mematuhi format asli yang
ditentukan, misalnya untuk XML atau JSON. Jika data langsung dicerna
dengan menggunakan salah satu kerangka kerja Solr yang mendukung
transformasi otomatis, langkah ini mungkin tidak diperlukan.
3. Post and Commit
Selama proses ini, user memposting dokumen ke titik akhir Solr yang
sesuai dengan parameter yang dibutuhkan. Kemampuan ekstraksi yang
disediakan Solr dilakukan berdasarkan titik akhir yang user panggil.
4. Document Preprocesing
User mungkin ingin melakukan pembersihan, pengayaan, atau validasi teks
yang diterima oleh Solr. Solr menyediakan sejumlah besar implementasi
seperti UpdateRequestProcessor untuk melakukan tugas ini. Tugas ini
menguraikan penerapan prosesor untuk tugas umum seperti deteksi
duplikasi ganda dan bahasa, dan memungkinkan user menulis prosesor
khusus.
UIN SYARIF HIDAYATULLAH JAKARTA

28
5. Field Analysis
Analisis lapangan mengubah aliran input menjadi istilah. Langkah ini
mengacu pada rantai analisis penganalisis, tokenizers dan filter token yang
diterapkan pada fieldType definition.
6. Index
Output dari tahap field analysis adalah index terbalik. Istilah index
digunakan untuk melakukan pencocokkan dan ranking pada tahap query.
Proses ini akan dijalankan setelah user melakukan proses post operation.
Tahap preprocessing dan field analysis yang telah didefinisikan pada Solr
akan secara otomatis berjalan. Dan dokumen akan ter-index (Dikshant
Shahi, 2015).
2.6 Twitter
Twitter merupakan sosial media masif yang berubah menjadi situs berbagi
informasi dan berkomunikasi secara cepat. Kecepatan dan kemudahan twitter
dalam hal publikasi, membuat twitter menjadi sebuah medium pilihan bagi
pengguna untuk berkomunikasi setiap hari. Twitter mempunyai peran dan andil
penting dalam pergerakan sosial-politik seperti Arab Spring dan The Occupy Wall
Street movement. Twitter juga dapat digunakan untuk melakukan laporan
kerusakan dan persiapan informasi terkait bencana pada saat bencana alam akan
dan sedang terjadi (Shamath Kumar, 2013).
2.6.1 Glosarium Twitter
Glosarium Twitter berisi kosakata dan istilah yang sering digunakan
untuk membahas fitur dan aspek dari Twitter.
1. @. Simbol @ digunakan untuk memanggil nama pengguna dalam
Tweet: "Halo @twitter!" Orang lain akan menggunakan
@namapengguna Anda untuk menyebut Anda di Tweet dan mengirim
Direct Message atau tautan ke profil Anda.
2. @username. Anda dikenali di Twitter melalui nama pengguna yang selalu
diawali simbol @. Misalnya, Bantuan Twitter adalah @BantuanTwitter.
UIN SYARIF HIDAYATULLAH JAKARTA

29
3. #hashtag. Hashtag adalah kata atau frasa yang diawali langsung dengan
simbol #. Bila Anda melakukan klik atau menyentuh hashtag, Anda
akan melihat Tweet lain yang berisi kata kunci atau topik yang sama.
4. Geolokasi. Dengan menambahkan lokasi pada Tweet (geolokasi atau
geotag), pengguna yang melihat Tweet Anda akan mengetahui lokasi
Anda saat mengirimkan Tweet.
5. Time Stamp. Tanggal dan waktu ketika Tweet dikirim ke Twitter. Cap
waktu Tweet terlihat sebagai tulisan abu-abu di setiap tampilan rincian
Tweet.
6. Following. Berlangganan ke sebuah akun Twitter disebut “mengikuti”.
Untuk mulai mengikuti, klik atau sentuh tombol ikuti di samping nama
akun atau di halaman profil mereka untuk melihat Tweet mereka.
Pengguna di Twitter dapat mengikuti atau berhenti mengikuti pengguna
lain kapan saja, kecuali akun yang diblokir.
7. Follower. Mengikuti dihasilkan dari pengguna yang mengikuti akun
Twitter Anda. Anda dapat mengetahui jumlah mengikuti (atau pengikut)
yang Anda miliki dari profil Twitter Anda.
8. Retweet. Tindakan menyebarkan Tweet akun lain kesemua pengikut
Anda dengan mengeklik atau menyentuh tombol Retweet (Support
Twitter, 2017).
2.6.2 Streaming API
Streaming API merupakan fitur pada twitter yang membantu developer
untuk melakukan akses secara langsung ke dalam stream global Twitter
dengan latency yang rendah, sehingga memudahkan developer untuk
melakukan pengambilan data. Beberapa tipe endpoint dalam Streaming
API adalah:
1. Public Streams. Menyediakan streams yang berasal dari data publik
yang bergabung dengan Twitter. Jenis endpoint ini berguna untuk
mencari user tertentu, mencari topik dan melakukan data mining.
UIN SYARIF HIDAYATULLAH JAKARTA

30
2. User Streams. Single-user streams yang menyediakan seluruh data yang
berkesesuaian dengan seluruh informasi mengenai user pilihan.
3. Site Streams. Adalah streams untuk melakukan pencarian data yang
dikhususkan untuk mecari seluruh informasi pada banyak user.
Endpoint ini mengharuskan developer untuk melakukan koneksi ke
twitter dengan otentikasi banyak user.
2.7 Social Network Analysis
Social Network Analysis adalah sebuah analisis untuk melakukan pemeriksaan
terhadap hubungan dari komunikasi dalam sebuah kumpulan kelompok untuk
mengetahui koneksi non-formal antara manusia. SNA berlandaskan akan asumsi
dari pentingnya relasi antara node yang berinteraksi. Hal tersebut menunjukkan
arah koneksi antar user yang terkoneksi melalui background yang berbeda sampai
pada tingkatan keluarga (Rupam Some, 2013).
2.7.1 Terminologi
1. Aktor juga disebut sebagai node atau simpul. Merujuk kepada seorang
individu yang mempunyai atau tidak mempunyai hubungan dengan
individu lain. Dalam hal ini individu dengan individu, individu dengan
kelompok dan kelompok dengan kelompok.
Gambar 2.9 Aktor-aktor Tanpa Keterangan Hubungan
(Sumber Matthew Denny, 2014)
UIN SYARIF HIDAYATULLAH JAKARTA

31
2. Edge atau relasi. Menjelaskan secara spesifik hubungan antara dua
aktor. Ini dapat merujuk kepada hubungan secara langsung atau tidak
langsung seperti, aktor A menyukai aktor B, aktor B bertukar informasi
dengan aktor C dan aktor C mengikuti aktor D. Edge dapat berupa un-
directed atau tidak secara spesifik digambarkan arah hubungan seperti
aktor A dan aktor B bersekolah di tempat yang sama.
Gambar 2.10 Sekumpulan Actor Dalam Skema Un-Directed Edge
(Sumber Matthew Denny, 2014)
Gambar 2.11 Sekumpulan Actor Dalam Skema Directed Edge.
(Sumber Matthew Denny, 2014)
3. Network (Jaringan) juga bisa disebut graph, menjelaskan mengenai
sekumpulan aktor dan edge atau hubungan diantara mereka.
UIN SYARIF HIDAYATULLAH JAKARTA

32
Gambar 2.12 Sekumpulan Actor Beserta Relasi
(Sumber Matthew Denny, 2014)
4. Weighted Ties. Relasi dengan bobot. Relasi ini menjelaskan secara
spesifik bobot hubungan antar aktor.
Gambar 2.13 Relasi Dengan Bobot Antara Node
(Sumber Matthew Denny, 2014)
UIN SYARIF HIDAYATULLAH JAKARTA

33
2.7.2 Social Network Data
Data jaringan sosial dapat dikategorikan menjadi dua bentuk,
pertama edge list dan sociamatricies. Kedua format memiliki
kelemahan dan kelebihan untuk melakukan analisis data.
1. Edge List
Daftar node adalah bentuk penyimpanan untuk SNA. Bentuk ini
hanya memberikan informasi mengenai hubungan di dalam jaringan
sesuai dengan jumlah aktor. Bentuk format data ini sangat baik untuk
menyimpan informasi mengenai data yang dikoleksi secara langsung,
format ini memiliki efisiensi dalam hal penyimpanan data dan sangat
mudah untuk melakukan pengurangan atau penambahan data. Namun,
format ini diharuskan untuk lebih berhati-hati dalam memberikan
penamaan terhadap node dan selalu melakukan pencatatan terhadap
node yang sama sekali tidak memiliki hubungan sama sekali tetapi
berada di dalam jaringan yang sama.
Gambar 2.14 Edge List
(Sumber Matthew Denny, 2014)
2. Adjacency Matrix
Format ini merepresentasikan directed atau un-directed relasi
antara aktor menggunakan matrix angka. Dalam format ini tersedia
jumlah kolom dan baris sesuai sengan jumlah aktor. Setiap baris
UIN SYARIF HIDAYATULLAH JAKARTA

34
dalam sociomatrix merepresentasikan hubungan antara aktor i ke
aktor j. Keuntungan format ini adalah pada saat penyimpanan data
format ini menyimpan informasi mengenai aktor yang tidak
memiliki hubungan dengan aktor lain. Kekurangan terbesar adalah
sulitnya memanipulasi data baru.
Gambar 2.15 Adjacency Matrix
(Sumber Matthew Denny, 2014)
2.7.3 Pengukuran Parameter SNA
Untuk melakukan analisis jaringan sosial. SNA menyediakan beberapa
tools untuk melakukan pengukuran terhadap node-node dengan
menggunakan:
1. Degree Centrality (DC - Pengaruh).
Centrality ini menjelaskan mengenai pengukuran terhadap jaringan dan
mengetahui jumlah relasi terhadap aktor yang bersangkutan. Untuk skema
un-directed, relasi dihitung berdasarkan jumlah relasi pada setiap aktor.
Pada skema directed, aktor mungkin mempunyai nilai indegree dan
outdegree. Degree centrality mengukur dimana node central atau mana
node yang memiliki koneksi paling baik di dalam jaringan. Pengukuran
UIN SYARIF HIDAYATULLAH JAKARTA

35
ini melambangkan pengaruh, power dan kepentingan dari node yang
dapat memberikan akses kepada informasi.
Rumus perhitungan C (i) = d(i)
D n−1
i = Nomor node CD = Degree Centrality
n = Jumlah node d(i) = Jumlah relasi
2. Betweenness Centrality (BC - Alur Terpendek).
Centrality ini menjelaskan alur terpendek antara jaringan yang
menghubungkan aktor tertentu. Alur terpendek antara aktor dimana
informasi bergerak di dalam jaringan dikalkulasi dengan jarak alur
terpendek antara node. Hal ini mengukur bagaimana informasi dan
koneksi mengalir antara aktor dengan aktor lain dan seberapa besar
pengaruhnya dalam jaringan. Rumus perhitungan C B (i) = ∑ ≠ ≠ ( )
Pjk (i) = jumlah jalur terpendek antara node j dan k yang melewati
i Pjk = jumlah jalur terpendek antara node j dan k
i = Nomor node CB = Betweenness Centrality
3. Closeness Centrality (CC - Kedekatan).
Centrality ini mengukur berapa banyak relasi yang dibutuhkan aktor
untuk melakukan hubungan dengan seluruh aktor di dalam jaringan.
Pengukuran ini dilakukan dengan membagi angka 1 dengan seluruh
jumlah jarak geodesi dari sebuah aktor. Pengukuran ini akan mencapai
titik maksimum ketika aktor terhubung secara langsung dengan aktor
lain dalam jaringan. Dan mencapai titik minimum ketika aktor tidak
terhubung dengan aktor lain. Hal ini merepresentasikan bahwa semakin
pendek alur antara aktor menggambarkan bahwa aktor yang
bersangkutan semakin dekat hubungannya.
UIN SYARIF HIDAYATULLAH JAKARTA

36
Rumus perhitungan C (x) = N−1
C ∑ ( , )
x = Nomor node CC = Closeness Centrality
n = Jumlah node y = node tujuan
d(y, x) = Jarak terpendek antara x ke y
4. Eigenvector Centrality (EC - Relasi).
Centrality ini melakukan perhitungan terhadap aktor yang terhubung
dengan baik dengan aktor lain. Perhitungan ini menampilkan nilai dari
besarnya hubungan dari aktor-aktor yang mempunyai banyak hubungan
atau relasi di dalam jaringan.
Menurut Maksim Tsvetovat dan Alexander Kouznetsov (2011),
Algoritma Eigenvector Centrality adalah sebagai berikut:
a. Mulailah dengan menetapkan nilai sentralitas 1 ke semua nodes
(v_i = 1 untuk semua i dalam jaringan)
b. Menghitung ulang nilai setiap node sebagai jumlah tertimbang dari sentralitas semua node.
Rumus = ∑ , ∗
Vj =
∑ , = Jumlah Edge
ℎ
c. Normalisasikan v dengan membagi setiap nilai dengan nilai terbesar.
d. Ulangi proses b dan c sampai mendapat nilai tetap.
5. Page Rank (PR - Kualitas)
Pengukuran Page Rank digunakan Google untuk menentukan kualitas suatu page. Dapat digunakan untuk jaringan yang berbentuk graph berarah. Prinsip yang digunakan adalah semakin penting sebuah node, maka semakin banyak node tersebut di refer oleh node lain.
Rumus perhitungan
PR = Page Rank
i = node
∑ ( ) PRt+1( ) = (
) PRt = Nilai dari iterasi sebelumnya
C = Jumlah Arah node tujuan
UIN SYARIF HIDAYATULLAH JAKARTA

37
t = waktu
Setiap parameter melambangkan karakteristik dari masing masing
perhitungan. Semakin besar nilai parameter, maka semakin besar pula
karakteristik yang direpresentasikan oleh masing-masing parameter
(Matthew Denny, 2014).
2.7.4 Simulasi Perhitungan Manual SNA
Gambar 2.16 Sample Un-Directed Ties Graf (Data Primer)
Berdasarkan Gambar 2.16 dapat dijabarkan bahwa graf memiliki 6 node
pembentuk graf. Dengan jumlah edge sebanyak 7 edge. Dengan relasi
antara node sebagai berikut:
A. Node 1 mempunyai relasi ke node 2 dan 5.
B. Node 2 mempunyai relasi ke node 1, 3 dan 4.
C. Node 3 mempunyai relasi ke node 2, 4 dan 6.
D. Node 4 mempunyai relasi ke node 2 dan 3.
E. Node 5 mempunyai relasi ke node 1 dan 6.
F. Node 6 mempunyai relasi ke node 3 dan 5.
1. Degree Centrality.
Rumus perhitungan C (i) = d(i)
D n−1
i = Nomor node CD = Degree Centrality
n = Jumlah node d(i) = Jumlah relasi
UIN SYARIF HIDAYATULLAH JAKARTA

38
Node = 1
Rumus perhitungan C (1) = d(1) = 2 = 0,4
D
6−1 5
Node = 2
Rumus perhitungan C (2) = d(2) = 3 = 0,6
D
6−1 5
Node = 3
Rumus perhitungan C (3) = d(3) = 3 = 0,6
D
6−1 5
Node = 4
Rumus perhitungan C (4) = d(4) = 2 = 0,4
D
6−1 5
Node = 5
Rumus perhitungan C (5) = d(5) = 2 = 0,4
D
6−1 5
Node = 6
Rumus perhitungan C (6) = d(6) = 2 = 0,4
D
6−1 5
Tabel 2.1 Hasil Simulasi Perhitungan Degree Centrality
Node Nilai Degree Centrality Desimal
1 2 2/5 0,4
2 3 3/5 0,6
3 3 3/5 0,6
4 2 2/5 0,4
5 2 2/5 0,4
6 2 2/5 0,4
*Nilai adalah jumlah relasi
Dari hasil perhitungan dapat disimpulkan bahwa node 2 dan node 3
mempunyai nilai Degree Centrality sebesar 0,6 jika dibandingkan dengan
nodes lain. Hal ini dikarenakan posisi node 2 dan 3 yang berada diantara
node-node lain dan berfungsi sebagai node central dengan jumlah edge
masing- masing node 2 adalah 3 edge dan node 3 adalah 3 edge.
UIN SYARIF HIDAYATULLAH JAKARTA

39
2. Betweenness Centrality Rumus perhitungan C B (i) = ∑ ≠ ≠ ( )
Pjk (i) = jumlah jalur terpendek antara node j dan k yang melewati
i Pjk = jumlah jalur terpendek antara node j dan k
i = Nomor node CB = Betweenness Centrality Node 1 Rumus perhitungan CB(1) = ∑ ≠ ≠ (1) = 1,5
Alur {23 , 24, 25, 26, 34, 35, 36, 45, 46, 56}
Nilai {0/1, 0/1, 1/1, 0/1, 0/1, 0/1, 0/1, 1/2, 0/1, 0/1}
Betwenness = 3/2 = 1,5
Node 2 Rumus perhitungan C B (2) = ∑ ≠ ≠ (2) = 2,5
Alur {13, 14, 15, 16, 34, 35, 36, 45, 46, 56}
Nilai {1/1, 1/1, 0/1, 0/1, 0/1, 0/1, 0/1, 1/2, 0/1, 0/1}
Betwenness = 5/2 = 2,5
Node 3 Rumus perhitungan C B (3) = ∑ ≠ ≠ (3) = 2,5
Alur {12, 14, 15, 16, 24, 25, 26, 45, 46, 56}
Nilai {0/1, 0/1, 0/1, 0/1, 0/1, 0/1, 1/1, 1/2, 1/1, 0/1}
Betwenness = 5/2 = 2,5
Node 4 Rumus perhitungan C B (4) = ∑ ≠ ≠ (4) = 0,0
Alur {12, 13, 15, 16, 23, 25, 26, 35, 36, 56}
Nilai {0/1, 0/1, 0/1, 0/1, 0/1, 0/1, 0/1, 0/1, 0/1, 0/1}
Betwenness = 0/1 = 0,0
UIN SYARIF HIDAYATULLAH JAKARTA

40
Node 5 Rumus perhitungan C B (5) = ∑ ≠ ≠ (5) = 1,0
Alur {12, 13, 14, 16, 23, 24, 26, 34, 36, 46}
Nilai {0/1, 0/1, 0/1, 1/1, 0/1, 0/1, 0/1, 0/1, 0/1, 0/1}
Betwenness = 1/1 = 1,0
Node 6 Rumus perhitungan C B (6) = ∑ ≠ ≠ (6) = 1,5
Alur {12, 13, 14, 15, 23, 24, 25, 34, 35, 45}
Nilai {0/1, 0/1, 0/1, 0/1, 0/1, 0/1, 0/1, 0/1,0 /1, 1/2}
Betwenness = 3/2 = 1,5
Tabel 2.2 Hasil Simulasi Perhitungan Betweenness Centrality Node Betwenness Desimal
1 3/2 1,5 2 5/2 2,5 3 5/2 2,5 4 0/1 0,0 5 1/1 1,0 6 3/2 1,5
Dari hasil perhitungan dapat ditarik kesimpulan bahwa node 2 dan
node 3 menjadi node perantara di dalam graf. Hal tersebut dikarenakan
posisi node 2 dan node 3 yang terletak diantara node-node lain, dan
berfungsi sebagai perantara atau jembatan antara nodes di dalam graf
untuk berkomunikasi. Dibuktikan dengan nilai node 2 sebesar 2,5 dan
node 3 sebesar 2,5. Hal tersebut berbanding terbalik dengan nilai node 4
sebesar 0,0. Nilai Betwenness Centrality dari node 4 menandakan bahwa
node 4 tidak bertugas sebagai perantara antara node dalam berhubungan.
UIN SYARIF HIDAYATULLAH JAKARTA

41
3. Closeness Centrality
Rumus perhitungan C (x) = N−1
C ∑ ( , )
x = Nomor node CC = Closeness Centrality
n = Jumlah node y = node tujuan
d(y, x) = Jarak terpendek antara x ke y
Node = 1
Rumus perhitungan C (1) = 6−1 = 5 = 0,6250
C ∑ ( ,1) 8
Total Jarak = 12, 13, 14, 15, 16 Nilai ∑ ( , 1) = 1 + 2 + 2 + 1 + 2 = 8 Node = 2
Rumus perhitungan C (2) = 6−1 = 5 = 0,7143
C ∑ ( ,2) 7
Total Jarak = 21, 23, 24, 25, 26 Nilai ∑ ( , 2) = 1 + 1 + 1 + 2 + 2 = 7
Node = 3
Rumus perhitungan C (3) = 6−1 = 5 = 0,7143
C ∑ ( ,3) 7
Total Jarak = 31, 32, 34, 35, 36 Nilai ∑ ( , 3) = 2 + 1 + 1 + 2 + 1 = 7
Node = 4
Rumus perhitungan C (4) = 6−1 = 5 = 0,5556
C ∑ ( ,4) 9
Total Jarak = 41, 42, 43, 45, 46 Nilai ∑ ( , 4) = 2 + 1 + 1 + 3 + 2 = 9
Node = 5
Rumus perhitungan C (5) = 6−1 = 5 = 0,5556
C ∑ ( ,5) 9
Total Jarak = 51, 52, 53, 54, 56 Nilai ∑ ( , 5) = 1 + 2 + 2 + 3 + 1= 9
UIN SYARIF HIDAYATULLAH JAKARTA

42
Node = 6
Rumus perhitungan C (6) = 6−1 = 5 = 0,6250
C ∑ ( ,6) 8
Total Jarak = 61, 62, 63, 64, 65 Nilai ∑ ( , 6) = 2 + 2 + 1 + 2 + 1= 8
Tabel 2.3 Hasil Simulasi Perhitungan Closeness Centrality
Node Nilai Closeness Desimal 1 8 5/8 0,6250 2 7 5/7 0,7143 3 7 5/7 0,7143 4 9 5/9 0,5556 5 9 5/9 0,5556 6 8 5/8 0,6250
Dari perhitungan sebelumnya dapat ditarik kesimpulan bahwa node 2
dan node 3 mempunyai nilai Closeness Centrality paling tinggi dengan
nilai node 2 sebesar 0,7143 dan node 3 sebesar 0,714. Sedangkan node 4
dan node 5 memiliki nilai Closeness Centralitypaling rendah dengan
nilai node 4 sebesar 0,5556 dan node 5 sebesar 0,5556. Posisi node 4
dan node 5 berada pada graf bagian luar sedangkan node 2 dan node 3
berada pada posisi graf bagian dalam.
4. Eigenvector Centrality
Jumlah total edge list adalah 14 titik. Jumlah masing-masing edge
pada setiap node paling banyak adalah node 2 dan node 3 sebanyak 3
edge yaitu node 2 (1, 3, 4) dan node 3 (2, 4, 6).
Node 1 Rumus 1 = ∑ 1, ∗ 0,07142
Jumlah Total Edge List = 14, Nilai sentralitas = 1 Nilai = = 14 1 = 0,07142857142857142857142857142857
UIN SYARIF HIDAYATULLAH JAKARTA

43
Nilai Eigenvector = 1 = ∑ 2 ∗ 0,07142 = 0,14284
Node 2 Rumus 2 = ∑ 2, ∗ 0,07142
Jumlah Total Edge List = 14, Nilai sentralitas = 1
Nilai = = 141 = 0,07142857142857142857142857142857 Nilai Eigenvector = 2 = ∑ 3 ∗ 0,07142 = 0,21426
Node 3 Rumus 3 = ∑ 3, ∗ 0,07142
Jumlah Total Edge List = 14, Nilai sentralitas = 1
Nilai = = 141 = 0,07142857142857142857142857142857 Nilai Eigenvector = 3 = ∑ 3 ∗ 0,07142 = 0,21426
Node 4 Rumus 4 = ∑ 4, ∗ 0,07142
Jumlah Total Edge List = 14, Nilai sentralitas = 1
Nilai = = 141 = 0,07142857142857142857142857142857 Nilai Eigenvector = 4 = ∑ 2 ∗ 0,07142 = 0,14284
Node 5 Rumus 5 = ∑ 5, ∗ 0,07142
Jumlah Total Edge List = 14, Nilai sentralitas = 1
Nilai = = 141 = 0,07142857142857142857142857142857 Nilai Eigenvector = 5 = ∑ 2 ∗ 0,07142 = 0,14284
UIN SYARIF HIDAYATULLAH JAKARTA

44
Node 6 Rumus 6 = ∑ 6, ∗ 0,07142
Jumlah Total Edge List = 14, Nilai sentralitas = 1
Nilai = = 1 = 0,07142857142857142857142857142857
14
Nilai Eigenvector = 6 = ∑ 2 ∗ 0,07142 = 0,14284
Tabel 2.4 Hasil Simulasi Perhitungan Eigenvector Centrality
Node Nilai Edge Eigenvector
1 0,07142 2 0,14284
2 0,07142 3 0,21426
3 0,07142 3 0,21426
4 0,07142 2 0,14284
5 0,07142 2 0,14284
6 0,07142 2 0,14284
Dari perhitungan didapatkan bahwa node 2 dan node 3 memiliki
nilai eigenvector paling tinggi. Dengan nilai node 2 sebesar 0,21426
dan node 3 sebesar 0,21426. Hal ini membuktikan bahwa node 2 dan
node 3 menjadi node paling berpengaruh di dalam jaringan.
5. Page Rank
Rumus perhitungan
PR = Page Rank
i = node
t = waktu
∑ ( ) PRt+1( ) = ( )
PRt = Nilai dari iterasi sebelumnya
C = Jumlah Arah node tujuan
UIN SYARIF HIDAYATULLAH JAKARTA

45
Gambar 2.17 Directed Graph (Data Primer)
Berdasarkan Gambar 2.17 graf memiliki jumlah node sebanyak 4
node. Jumlah edge sebanyak 5 edge. Keterangan masing-masing relasi
pada graf adalah sebagai berikut:
A. Node A mempunyai relasi dengan node B dan C.
B. Node B mempunyai relasi dengan node C dan D.
C. Node C mempunyai relasi dengan node A dan D.
D. Node D mempunyai relasi dengan node B dan C.
Iterasi pertama perhitungan menggunakan nilai default yaitu node awal dibagi jumlah node. PR = 14 untuk seluruh node.
Iterasi 0 PR(A) = ∑ 0( ) = 1
( ) 4 PR(B) = ∑ 0( ) = 1
( ) 4 PR(C) = ∑ 0( ) = 1
( ) 4 PR(D) = ∑ 0( ) = 1
( ) 4
UIN SYARIF HIDAYATULLAH JAKARTA

46
Iterasi 1
• Node A, Hanya node C yang melakukan referral ke node A. Nilai ( ) = Referral dari node C ke node lain berjumlah 3 arah.
1 PR(A) = ∑ 1( ) = 4 = 1
( ) 3 12
• Node B, node A dan node C melakukan referral ke node B.
Nilai ( ) = Referral dari node A ke node lain berjumlah 2 arah. Nilai ( ) = Referral dari node C ke node lain berjumlah 3 arah.
1 ( ) ( ) ( ) 1 1 5
5 2,5
4
4 2
PR(B) = ∑ = 1
+ 1 = + = = =
( ) ( )
( )
12 24 12
2 3
• Node C, node A dan node D melakukan referral ke node C. Nilai ( ) = Referral dari node A ke node lain berjumlah 2 arah. Nilai ( ) = Referral dari node D ke node lain berjumlah 1 arah.
1 ( ) ( ) (
) 1 1 3 9 4.5
4
4
PR(C) = ∑ = 1
+ 1 = + = = =
( ) ( )
( )
8 24 12
2 1
• Node D, node B dan node C melakukan referral ke node D. Nilai ( ) = Referral dari node B ke node lain berjumlah 1 arah. Nilai ( ) = Referral dari node C ke node lain berjumlah 3 arah.
1 ( ) ( ) ( ) 1 1
4
4
4
PR(D) = ∑ = 1
+ 1 = + =
( ) ( )
( )
12
1 3
Iterasi 2
• Node A, Hanya node C yang melakukan referral ke node A. Nilai ( ) = Referral dari node C ke node lain berjumlah 3 arah.
1 ( ) 4.5
4.5
1.5 PR(A) = ∑ = 12 = =
( )
3 36 12
• Node B, node A dan node C melakukan referral ke node B. Nilai ( ) = Referral dari node A ke node lain berjumlah 2 arah. Nilai ( ) = Referral dari node C ke node lain berjumlah 3 arah.
1 ( ) ( ) ( ) 1 4.5
12 2
12
12
PR(B) = ∑ = 1
+ 1 = + = =
( ) ( )
( )
72 12
2 3
UIN SYARIF HIDAYATULLAH JAKARTA

47
• Node C, node A dan node D melakukan referral ke node C. Nilai ( ) = Referral dari node A ke node lain berjumlah 2 arah. Nilai ( ) = Referral dari node D ke node lain berjumlah 1 arah.
1 ( ) ( ) (
) 1 4 9 4.5
12
12
PR(C) = ∑ = 1
+ 1 = + = =
( ) ( )
( )
24 12
2 1
• Node D, node B dan node C melakukan referral ke node D.
Nilai ( ) = Referral dari node B ke node lain berjumlah 1 arah. Nilai ( ) = Referral dari node C ke node lain berjumlah 3 arah. PR(D) = ∑ 1( )
( )
Final Page Rank
2.5 4.5
= 1( ) + 1( ) = 12 + 12 = 12 = 4 ( ) ( )1336 12
Tabel 2.5 Hasil Simulasi Perhitungan PageRank
Node Iterasi ke-0 Iterasi ke-1 Iterasi ke-2 Desimal Final Page Rank A 1/4 1/12 1,5/12 0,125 1 B 1/4 2,5/12 2/12 0,167 2 C 1/4 4,5/12 4,5/12 0,375 4 D 1/4 4/12 4/12 0,333 3
2.8 Graf
Graf adalah sepasang set (V, E), yang mana V adalah set himpunan kosong
yang elemen-nya disebut dengan vertex (simpul) dan E adalah kumpulan dua
elemen subset V yang disebut edge (tepi). Jika G adalah sebuah graf yang terdiri
dari vertexs-vertexs V dan rusuk-rusuk E, maka kita dapat menuliskan G = (V, E).
2.8.1 Tipe-Tipe Graf
Tipe graf dapat dibedakan berdasarkan ada tidaknya gelang atau sisi
ganda pada suatu graf, jumlah simpul, dan orientasi arah pada sisi.
Tipe graf berdasarkan orientasi arah pada sisi, dapat dibedakan menjadi:
1. Graf berarah adalah suatu graf yang setiap sisinya diberikan orientasi
arah. Sebuah graf terarah G, terdiri dari suatu himpunan V yang disebut
vertexs (titik) dan suatu himpunan E yang disebut dengan edge (rusuk)
sedemikian rupa sehingga, tiap rusuk-rusuk e dihubungkan dengan
UIN SYARIF HIDAYATULLAH JAKARTA

48
pasangan vertexs tak terurut. Kemudian jika terdapat rusuk e1 yang
menghubungkan dua buah vertexs v1 dan v2, maka kita dapat
menuliskan e1 = (v1, v2).
Gambar 2.18 a. Graf Berarah, b. Graf-Ganda Berarah
(Sumber Anita Kurniawati, 2010)
2. Graf tak berarah adalah graf yang kedua sisinya tidak mempunyai
orientasi arah. Sebuah graf (tak terarah) G, terdiri dari suatu himpunan
V yang disebut vertexs (titik) dan suatu himpunan E yang disebut
dengan edge (rusuk) sedemikian rupa sehingga, tiap rusuk-rusuk e
dihubungkan dengan pasangan vertexs tak terurut. Kemudian jika
terdapat rusuk e1 yang menghubungkan dua buah vertexs v1 dan v2,
maka kita dapat menuliskan e1 = (v1, v2) atau e1 = (v2, v1).
Gambar 2.19 Graf Tak Berarah
(Sumber Anita Kurniawati, 2010)
Tipe graf berdasarkan ada tidaknya gelang atau sisi ganda ada sebuah graf,
dapat dibedakan menjadi:
UIN SYARIF HIDAYATULLAH JAKARTA

49
1. Graf Sederhana
Simple graph G = (V, E) terdiri dari V, yaitu set dari vertex, dan E adalah set
dari pasangan element V yang disebut edge. Sebuah edge menghubungkan 2
vertexs yang berbeda, dan tidak terdapat edge lain yang menghubungkan 2
vertexs yang telah terhubung tersebut. Atau dengan kata lain graf sederhana
ini tidak mengandung gelang maupun sisi ganda.
Gambar 2.20 Graf Sederhana
(Sumber Anita Kurniawati, 2010)
2. Graf tak Sederhana
Graf tak sederhana adalah graf yang mengandung sisi ganda atau gelang.
Graf tak sederhana dapat dibedakan menjadi 2, yaitu graf ganda
(multigraph) dan graf semu (psedograph).
a. Graf Ganda. Jika sebuah vertex terhubung dengan vertex lain hanya
melalui sebuah edge. Sehingga, tiap rusuk-rusuk e dihubungkan
dengan pasangan vertexs tak terurut. Kemudian jika terdapat rusuk e1
yang menghubungkan dua buah vertexs v1 dan v2, maka kita dapat
menuliskan e1 = (v1, v2).
UIN SYARIF HIDAYATULLAH JAKARTA

50
Gambar 2.21 Graf Ganda
(Sumber Anita Kurniawati, 2010)
b. Graf Semu
Pseudograph adalah jenis paling umum dari grafik berarah yang bisa
mengandung loop dan beberapa edge.
Gambar 2.22 Graf Pseudograph
(Sumber Anita Kurniawati, 2010)
Definisi graf dapat diperluas sehingga mencakup graf berarah ganda.
Pada graf berarah ganda, gelang dan sisi ganda diperbolehkan ada.
Sehingga perluasan definisi graf dapat dirangkum seperti:
UIN SYARIF HIDAYATULLAH JAKARTA

51
Tabel 2.6 Perluasan Jenis Graf
(Sumber Anita Kurniawati, 2010)
2.9 Gephi
Gephi adalah perangkat lunak open-source untuk visualisasi dan analisis
jaringan. Gephi membantu analis data untuk secara intuitif mengungkapkan pola
dan trend, menyoroti outliers dan bercerita tentang data. Menggunakan mesin
render 3D untuk menampilkan grafik besar secara realtime dan untuk
mempercepat eksplorasi.
Gephi menggabungkan fungsi built-in dan arsitektur yang fleksibel untuk melakukan
proses sebagai berikut:
1. Explore
2. Analyze
3. Spatialize
4. Filter
5. Cluster
6. Manipulate
7. Export
Gephi didasarkan pada paradigma visualisasi dan manipulasi yang
memungkinkan pengguna menemukan jaringan dan properti data yang
dibutuhkan dalam proses analisis data.
Berdasarkan tools gephi, gephi menentukan jumlah iterasi pengecekan
perhitungan standar sebanyak 100 kali pengecekan perhitungan dan gephi tidak
UIN SYARIF HIDAYATULLAH JAKARTA

52
melakukan pembatasan waktu maksimal pada tahap visualisasi graf. Hasil visualisasi
akan muncul ketika graf telah berhasil dimunculkan (Gephi.org, 2017).
2.10 Metode Eksperimen
Menurut Solso dan MacLin (2005), penelitian eksperimen adalah suatu
penelitian yang di dalamnya ditemukan minimal satu variabel yang dimanipulasi
untuk mempelajari hubungan sebab-akibat. Oleh karena itu, penelitian
eksperimen erat kaitanya dalam menguji suatu hipotesis dalam rangka mencari
pengaruh, hubungan, maupun perbedaan pengubahan terhadap kelompok yang
dikenakan perlakuan.
2.11.1 Karakteristik Penelitian Eksperimen
1. Variabel-veriabel penelitian dan kondisi eksperimen diatur secara
tertib ketat (rigorous management), baik dengan menetapkan kontrol,
memanipulasi langsung, maupun random (acak).
2. Adanya kelompok kontrol sebagai data dasar (base line) untuk
dibandingkan dengan kelompok eksperimen.
3. Penelitian ini memusatkan diri pada pengontrolan variansi, untuk
memaksimalkan variansi variabel yang berkaitan dengan hipotesis
penelitian, meminimalkan variansi variabel pengganggu yang mungkin
mempengaruhi hasil eksperimen, tetapi tidak menjadi tujuan
penelitian. Di samping itu, penelitian ini meminimalkan variansi
kekeliruan, termasuk kekeliruan pengukuran. Untuk itu, sebaiknya
pemilihan dan penentuan subjek, serta penempatan subjek dalarn
kelompok-kelompok dilakukan secara acak.
4. Validitas internal (internal validity) mutlak diperlukan pada rancangan
penelitian eksperimen, untuk mengetahui apakah manipulasi
eksperimen yang dilakukan pada saat studi ini memang benar-benar
menimbulkan perbedaan.
UIN SYARIF HIDAYATULLAH JAKARTA

53
5. Validitas eksternalnya (external validity) berkaitan dengan bagaimana
kerepresentatifan penemuan penelitian dan berkaitan pula dengan
menggeneralisasikan pada kondisi yang sama.
6. Semua variabel penting diusahakan konstan, kecuali variabel
perlakuan yang secara sengaja dimanipulasikan atau dibiarkan
bervariasi (Sudarwan Danim, 2002).
2.11.2 Bentuk Desain Penelitian Eksperimen
1. Pre-experimental Design
Desain ini dikatakan sebagai pre-experimental design karena
belum merupakan eksperimen sungguh-sungguh karena masih
terdapat variabel luar yang ikut berpengaruh terhadap
terbentuknya variabel dependen. Rancangan ini berguna untuk
mendapatkan informasi awal terhadap pertanyaan yang ada dalam
penelitian. Bentuk Pre-Experimental Design ini ada beberapa
macam antara lain:
a. One – Shoot Case Study
Dimana dalam desain penelitian ini terdapat suatu kelompok
diberi treatment (perlakuan) dan selanjutnya diobservasi hasilnya
(treatment adalah sebagai variabel independen dan hasil adalah
sebagai variabel dependen). Dalam eksperimen ini subjek
disajikan dengan beberapa jenis perlakuan lalu diukur hasilnya.
b. One – Group Pretest-Posttest Design
Kalau pada desain “a” tidak ada pre-test, maka pada desain ini
terdapat pre-test sebelum diberi perlakuan. Dengan demikian hasil
perlakuan dapat diketahui lebih akurat, karena dapat
membandingkan dengan keadaan sebelum diberi perlakuan.
c. Intact-Group Comparison
Pada desain ini terdapat satu kelompok yang digunakan untuk
penelitian, tetapi dibagi dua yaitu; setengah kelompok untuk
UIN SYARIF HIDAYATULLAH JAKARTA

54
eksperimen (yang diberi perlakuan) dan setengah untuk
kelompok kontrol (yang tidak diberi perlakuan).
2. True Experimental Design
Dikatakan true experimental (eksperimen yang
sebenarnya/betul-betul) karena dalam desain ini peneliti dapat
mengontrol semua variabel luar yang mempengaruhi jalannya
eksperimen. Dengan demikian validitas internal (kualitas
pelaksanaan rancangan penelitian) dapat menjadi tinggi. Ciri utama
dari true experimental adalah bahwa, sampel yang digunakan untuk
eksperimen maupun sebagai kelompok kontrol diambil secara
random (acak) dari populasi tertentu. Jadi cirinya adalah adanya
kelompok kontrol dan sampel yang dipilih secara random. Desain
true experimental terbagi atas:
a. Posttest-Only Control Design
Dalam desain ini terdapat dua kelompok yang masing-masing
dipilih secara random (R). Kelompok pertama diberi perlakuan
(X) dan kelompok lain tidak. Kelompok yang diberi perlakuan
disebut kelompok eksperimen dan kelompok yang tidak diberi
perlakuan disebut kelompok kontrol.
b. Pretest-Posttest Control Group Design
Dalam desain ini terdapat dua kelompok yang dipilih secara
acak/random, kemudian diberi pretest untuk mengetahui
keadaan awal adakah perbedaan antara kelompok eksperimen
dan kelompok kontrol.
c. The Solomon Four-Group Design
Dalam desain ini, dimana salah satu dari empat kelompok
dipilih secara random. Dua kelompok diberi pratest dan dua
kelompok tidak. Kemudian satu dari kelompok pratest dan satu
UIN SYARIF HIDAYATULLAH JAKARTA

55
dari kelompok nonpratest diberi perlakuan eksperimen, setelah
itu keempat kelompok ini diberi posttest.
3. Quasi Experimental Design
Bentuk desain eksperimen ini merupakan pengembangan dari
true experimental design, yang sulit dilaksanakan. Desain ini
mempunyai kelompok kontrol, tetapi tidak dapat berfungsi
sepenuhnya untuk mengontrol variabel-variabel luar yang
mempengaruhi pelaksanaan eksperimen. Walaupun demikian,
desain ini lebih baik dari pre-experimental design. Quasi
Experimental Design digunakan karena pada kenyataannya sulit
medapatkan kelompok kontrol yang digunakan untuk penelitian.
Dalam suatu kegiatan administrasi atau manajemen misalnya,
sering tidak mungkin menggunakan sebagian para karyawannya
untuk eksperimen dan sebagian tidak. Sebagian menggunakan
prosedur kerja baru yang lain tidak. Oleh karena itu, untuk
mengatasi kesulitan dalam menentukan kelompok kontrol dalam
penelitian, maka dikembangkan desain Quasi Experimental.
Desain eksperimen model ini diantarnya sebagai berikut:
a. Time Series Design
Dalam desain ini kelompok yang digunakan untuk penelitian
tidak dapat dipilih secara random. Sebelum diberi perlakuan,
kelompok diberi pretest sampai empat kali dengan maksud
untuk mengetahui kestabilan dan kejelasan keadaan kelompok
sebelum diberi perlakuan. Bila hasil pretest selama empat kali
ternyata nilainya berbeda-beda, berarti kelompok tersebut
keadaannya labil, tidak menentu, dan tidak konsisten. Setelah
kestabilan keadaan kelompok dapat diketahui dengan jelas,
maka baru diberi treatment/perlakuan. Desain penelitian ini
UIN SYARIF HIDAYATULLAH JAKARTA

56
hanya menggunakan satu kelompok saja, sehingga tidak
memerlukan kelompok kontrol.
b. Nonequivalent Control Group Design
Desain ini hampir sama dengan pretest-posttest control
group design, hanya pada desain ini kelompok eksperimen
maupun kelompok kontrol tidak dipilih secara random. Dalam
desain ini, baik kelompok eksperimental maupun kelompok
kontrol dibandingkan, kendati kelompok tersebut dipilih dan
ditempatkan tanpa melalui random. Dua kelompok yang ada
diberi pretest, kemudian diberikan perlakuan, dan terakhir
diberikan postest.
c. Conterbalanced Design
Desain ini semua kelompok menerima semua perlakuan,
hanya dalam urutan perlakuan yang berbeda-beda, dan
dilakukan secara random.
4. Factorial Design
Desain Faktorial selalu melibatkan dua atau lebih variabel bebas
(sekurang-kurangnya satu yang dimanipulasi). Desain faktorial
secara mendasar menghasilkan ketelitian desain true-
eksperimental dan membolehkan penyelidikan terhadap dua atau
lebih variabel, secara individual dan dalam interaksi satu sama
lain. Tujuan dari desain ini adalah untuk menentukan apakah efek
suatu variabel eksperimental dapat digeneralisasikan lewat semua
level dari suatu variabel kontrol atau apakah efek suatu variabel
eksperimen tersebut khusus untuk level khusus dari variabel
kontrol, selain itu juga dapat digunakan untuk menunjukkan
hubungan yang tidak dapat dilakukan oleh desain eksperimental
variabel tunggal (Sugiyono, 2010).
UIN SYARIF HIDAYATULLAH JAKARTA

57
2.11 Observasi
Menurut Nana Syaodih Sukmadinata (2012) Observasi merupakan suatu
teknik atau cara mengumpulkan data dengan jalan mengadakan pengamatan
terhadap kegiatan yang sedang berlangsung, kegiatan tersebut bisa berkenaan
dengan cara guru mengajar, siswa belajar, kepala sekolah yang sedang
memberikan pengarahan. Teknik observasi merupakan salah satu teknik
pengumpulan data yang digunakan peneliti untuk mengadakan pengamatan dan
pencatatan secara sistematis terhadap objek yang diteliti, baik dalam situasi
buatan yang secara khusus diadakan (laboratorium) maupun situasi alamiah
yang sebenarnya (lapangan).
2.12 Teknik Sampling
Menurut Sugiyono (2001) sampel adalah sebagian dari jumlah dan
karakteristik yang dimiliki oleh populasi. Bila populasi besar, dan peneliti tidak
mungkin mempelajari semua yang ada pada populasi, misalnya karena
keterbatasan dana, tenaga dan waktu, maka peneliti dapat menggunakan sampel
yang diambil dari populasi itu. Apa yang dipelajari dari sampel itu,
kesimpulannya akan diberlakukan untuk populasi. Untuk itu sampel yang
diambil dari populasi harus betul-betul representatif.
2.13.1 Jenis Teknik Sampling
1. Probability Sampling
Probability sampling adalah teknik sampling yang memberikan peluang
yang sama bagi setiap unsur (anggota) populasi untuk dipilih menjadi
anggota sampel. Teknik probability sampling adalah sebagai berikut:
A. Simple Random Sampling
Simple Random Sampling dinyatakan simple (sederhana) karena
pengambilan sampel anggota populasi dilakukan secara acak tanpa
memperhatikan strata yang ada dalam populasi itu.
B. Proportionate Stratified Random Sampling
UIN SYARIF HIDAYATULLAH JAKARTA

58
Proportionate Stratified Random Sampling biasa digunakan pada
populasi yang mempunyai susunan bertingkat atau berlapis-lapis.
Teknik ini digunakan bila populasi mempunyai anggota/unsur yang
tidak homogen dan berstrata secara proporsional.
C. Disproportionate Stratified Random Sampling
Disproportionate Stratified Random Sampling digunakan untuk
menentukan jumlah sampel bila populasinya berstrata tetapi kurang
proporsional.
D. Cluster Sampling (Area Sampling)
Cluster Sampling (Area Sampling) juga cluster random sampling.
Teknik ini digunakan bilamana populasi tidak terdiri dari individu-
individu, melainkan terdiri dari kelompok-kelompok individu atau
cluster. Teknik sampling daerah digunakan untuk menentukan
sampel bila objek yang akan diteliti atau sumber data sangat luas.
2. Nonprobability Sampling
Nonprobability sampling adalah teknik yang tidak memberi
peluang/kesempatan yang sama bagi setiap unsur atau anggota
populasi untuk dipilih menjadi sampel. Teknik nonprobabilty sampling
adalah sebagai berikut:
A. Sampling Sistematis
Sampling sistematis adalah teknik penentuan sampel berdasarkan
urutan dari anggota populasi yang telah diberi nomor urut.
B. Sampling Kuota
Sampling kuota adalah teknik untuk menentukan sampel dari
populasi yang mempunyai ciri-ciri tertentu sampai jumlah (kuota)
yang diinginkan. Pengumpulan data dilakukan langsung pada unit
sampling. Setelah jatah terpenuhi, maka pengumpulan data
dihentikan.
C. Sampling Aksidental
UIN SYARIF HIDAYATULLAH JAKARTA

59
Sampling aksidental adalah teknik penentuan sampel berdasarkan
kebetulan, yaitu siapa saja yang secara kebetulan bertemu dengan
peneliti dapat digunakan sebagai sampel, bila dipandang orang yang
kebetulan ditemui itu sesuai sebagai sumber data.
D. Snowball Sampling
Snowball sampling adalah teknik penentuan sampel yang awal mula
jumlahnya kecil, kemudian sampel ini disuruh memilih teman-
temannya untuk dijadikan sampel. Dan begitu seterusnya, sehingga
jumlah sampel makin lama makin banyak. Ibaratkan sebuah bola
salju yang menggelinding, makin lama semakin besar (Sugiyono,
2001).
2.13 Tahapan Eksperimen Intact-Group Comparison
Pada desain ini terdapat satu kelompok yang digunakan untuk penelitian,
tetapi dibagi dua yaitu setengah kelompok untuk eksperimen dan setengah
untuk kelompok kontrol
Menurut Sugiyono (2010), Tahap-tahap untuk menyelesaikan tahapan
eksperimen adalah sebagai berikut:
1. Pemilihan Desain
2. Penentuan Sampel Representatif
3. Instrumentasi
4. Pelaksanaan Eksperimen
5. Pengumpulan dan Penganalisisan Data
6. Analisis dan Interpretasi Data
7. Kesimpulan Eksperimen
UIN SYARIF HIDAYATULLAH JAKARTA

60
BAB III
METODOLOGI PENELITIAN
3.1 Metode Pengumpulan Data
Dalam melakukan penelitian, peneliti melakukan pengumpulan data-data
pendukung penelitian dengan metode sebagai berikut:
3.1.1 Studi Pustaka
Pada metode studi pustaka, peneliti melakukan riset, mengumpulkan
buku, jurnal, dan skripsi. Serta mempelajari teori yang berkaitan dengan
permasalahan yang akan diteliti pada penelitian ini. Peneliti juga melakukan
perbandingan dengan penelitian lain yang sudah dilakukan terlebih dahulu
oleh peneliti sebelumnya, sebagai acuan dalam melakukan penelitian dan
mengembangkan teknologi dan metode yang belum diterapkan pada
penelitian sebelumnya. Daftar referensi berupa buku, jurnal, skripsi, dan
website, peneliti jabarkan pada bagian Daftar Pustaka.
3.1.2 Observasi
Peneliti melakukan observasi pada situs sosial media Twitter selama 1
bulan dari tanggal dari tanggal 15 Agustus 2017 sampai 14 September 2017.
Peneliti melakukan pengamatan dan pencatatan selama satu bulan pada
kolom Trending Topic pada sosial media Twitter, untuk melihat apakah topik
yang berkaitan dengan keyword hoax yang peneliti angkat muncul dan
menjadi bahan pembicaraan pada masyarakat di Indonesia.
Berdasarkan observasi yang peneliti lakukan, maka peneliti mendapatkan
tabel hasil pengamatan pada sosial media Twitter sebagai berikut:
60 UIN SYARIF HIDAYATULLAH JAKARTA

61
Tabel 3.1 Daftar Tanggal Trending Topic Twitter
No Tanggal Lokasi Topik
1 25 Agustus 2017 Jakarta Saracen 2 25 Agustus 2017 Jakarta SaracenGate
3 25 Agustus 2017 Indonesia Saracen 4 25 Agustus 2017 Indonesia SaracenGate
5 26 Agustus 2017 Jakarta BijakBersosmed 6 26 Agustus 2017 Indonesia BijakBersosmed
7 28 Agustus 2017 Jakarta Saracen 8 28 Agustus 2017 Indonesia Saracen
9 29 Agustus 2017 Jakarta Jonru 10 29 Agustus 2017 Indonesia Jonru
11 30 Agustus 2017 Jakarta ILCSaracen 12 30 Agustus 2017 Jakarta TaunyaHoax
13 30 Agustus 2017 Indonesia ILCSaracen 14 30 Agustus 2017 Indonesia TaunyaHoax
15 31 Agustus 2017 Jakarta PolemikTVSaracen 16 31 Agustus 2017 Jakarta GebukHoaxJokowi 17 31 Agustus 2017 Indonesia PolemikTVSaracen 18 31 Agustus 2017 Indonesia GebukHoaxJokowi
Berdasarkan Tabel 3.1 peneliti menemukan 18 hari dimana topik yang
berkaitan dengan topik penelitian yaitu Hoax, muncul dan menjadi
perbincangan pengguna sosial media Twitter. Kemunculan topik
perbincangan yang berkaitan dengan hoax muncul sebesar 58% dari total
keseluruhan waktu pada saat observasi. Hal ini membuktikan bahwa topik
perbincangan hoax menjadi topik perbincangan yang paling sering
dibicarakan 8% lebih banyak dibandingkan topik lain. Sedangkan pada 12
hari pada masa observasi peneliti tidak menemukan munculnya keyword
yang berhubungan dengan hoax pada sosial media Twitter.
UIN SYARIF HIDAYATULLAH JAKARTA

60
3.1.3 Abstak Skripsi Terkait
Tabel 3.2 Daftar Abstrak Studi Penelitian Sejenis
No Nama Tahun Judul Abstrak 1 Hunt Allcott and 2016 SOCIAL MEDIA AND Demokrasi Amerika telah berulang kali diliputi oleh perubahan dalam teknologi
Matthew Gentzkow FAKE NEWS IN THE 2016 media. Pada abad ke-19, kertas koran murah dan penekanan yang lebih baik ELECTION memungkinkan koran partisan untuk memperluas jangkauan mereka secara dramatis. Banyak yang berpendapat bahwa efektivitas pers sebagai cek kekuasaan secara signifikan dikompromikan sebagai hasilnya (misalnya, Kaplan 2002). Pada abad ke-20, saat radio dan kemudian televisi menjadi dominan, para pengamat khawatir bahwa platform baru ini akan mengurangi perdebatan kebijakan substantif terhadap gigitan suara, hak istimewa karismatik atau "telegenic" terhadap mereka yang mungkin memiliki kemampuan lebih untuk memimpin namun kurang dipoles, dan berkonsentrasi di tangan beberapa perusahaan besar (Lang dan Lang 2002; Bagdikian 1983). Pada awal tahun 2000an, pertumbuhan berita online memicu kekhawatiran baru, di antaranya bahwa kelebihan keragaman sudut pandang akan memudahkan warga yang berpikiran serupa untuk membentuk "ruang gema" atau "gelembung filter" di mana mereka akan terisolasi dari perspektif yang berlawanan (Sunstein 2001a, b, 2007; Pariser 2011). Baru-baru ini, fokus perhatian telah beralih ke media sosial. Platform media sosial seperti Facebook memiliki struktur yang sangat berbeda dari teknologi media sebelumnya. Konten dapat disampaikan di antara pengguna tanpa penyaringan pihak ketiga, pengecekan fakta, atau keputusan editorial yang signifikan. Pengguna individual yang tidak memiliki rekam jejak atau reputasi dapat dalam beberapa kasus menjangkau sebanyak mungkin pembaca seperti Fox News, CNN, atau New York Times.
62 UIN SYARIF HIDAYATULLAH JAKARTA

61
2 João Cunha, 2015 HEALTH TWITTER BIG Kemajuan media sosial dan peningkatan volume dan kompleksitas data yang Catarina Silva, DATA MANAGEMENT dihasilkan oleh layanan Internet menjadi tantangan tidak hanya secara teknologi, Mário Antunes WITH HADOOP namun juga dalam hal area aplikasi. Kinerja dan ketersediaan pengolahan data FRAMEWORK merupakan faktor penting yang perlu dievaluasi karena mekanisme pengolahan data konvensional mungkin tidak memberikan dukungan yang memadai. Apache Hadoop dengan Mahout adalah kerangka kerja untuk penyimpanan dan mengolah data pada skala besar, termasuk alat yang berbeda untuk mendistribusikan pengolahan. Ini telah dianggap sebagai alat efektif yang saat ini digunakan oleh perusahaan kecil dan besar dan perusahaan, seperti Google dan Facebook, namun juga institusi kesehatan publik dan swasta. Mengingat kemunculannya yang baru- baru ini dan meningkatnya kompleksitas masalah teknologi terkait, berbagai solusi kerangka holistik telah diajukan untuk setiap aplikasi spesifik. Dalam karya ini, kami mengusulkan sebuah arsitektur fungsional generik dengan kerangka Apache Hadoop dan Mahout untuk menangani, menyimpan dan menganalisis data besar yang dapat digunakan dalam skenario yang berbeda. Untuk menunjukkan nilainya, kami akan menunjukkan fitur, kelebihan dan aplikasinya pada data Twitter kesehatan. Kami menunjukkan bahwa data sosial kesehatan yang besar dapat menghasilkan informasi penting, bermanfaat bagi pengguna umum dan praktisi. Hasil awal analisis data data kesehatan Twitter menggunakan Apache Hadoop menunjukkan potensi kombinasi dari teknologi tersebut.
63 UIN SYARIF HIDAYATULLAH JAKARTA

62
3 Timothy S., Song- 2017 APPLYING PARALLEL Dalam ilmu atmosfir, ukuran output simulasi terus bertambah seiring dengan Lak Kang COMPUTING sumber komputasi yang mampu menangani simulasi dengan resolusi spasial dan TECHNIQUES TO temporal skala halus menjadi lebih mudah diakses. Seiring bertambahnya ukuran ANALYZE TERABYTE output, metode analisis data serial menjadi kewalahan, mengakibatkan penundaan ATMOSPHERIC yang lama selama pemrosesan atau kegagalan total karena kendala memori. Metode BOUNDARY LAYER analisis data paralel dapat meringankan masalah ini, namun ilmuwan atmosfer MODEL OUTPUTS. seringkali tidak mengetahui bagaimana cara mencapai hal ini. Oleh karena itu, diperlukan metode contoh untuk membantu memandu penggunaan pengolahan paralel dalam analisis Big Data dari simulasi atmosfer. Dalam karya ini, metode praktis dipresentasikan dimana analisis dapat dilakukan secara paralel dengan menggunakan Message Passing Interface (MPI) dan Python. Metode ini pertama- tama mempertimbangkan dependensi spasial inheren dari proses analisis data tertentu. Dengan mengidentifikasi dependensi ini, distribusi horisontal atau vertikal dari dataset antar proses dapat dilakukan dengan proses interkomunikasi minimal. Selain itu, metode analisis diklasifikasikan sebagai data-transfer-limited atau computational-limited. Dalam masalah transfer data terbatas, waktu transfer data melebihi waktu pemrosesan. Dalam masalah komputasi yang terbatas, waktu pemrosesan melebihi waktu transfer data. Hasilnya menunjukkan bahwa dengan meningkatkan jumlah prosesor, waktu eksekusi masalah terbatas komputasi menunjukkan perbaikan. Untuk masalah transfer data-terbatas, peningkatan jumlah node menawarkan peningkatan terbesar. Untuk lebih meningkatkan kinerja dari masalah komputasi yang terbatas, kerangka kerja Graphics Processing Unit (GPU) dan Compute Unified Device Architecture (CUDA) digunakan. Hal ini menunjukkan bahwa implementasi GPU ini menawarkan perbaikan lebih lanjut atas versi MPI metode analisis yang diuji.
64
UIN SYARIF HIDAYATULLAH JAKARTA

63
4 Feriza Julian Putra, 2016 ANALISIS JARINGAN Peningkatan penggunaan internet saat ini tidak dapat dipisahkan dari peningkatan Skripsi, Universitas TEKS BERDASARKAN teknologi telekomunikasi dalam segi kecepatan dan kualitas aksesnya karena Telkom SOCIAL NETWORK adanya layanan operator telekomunikasi nasional terutama yang terbesar seperti ANALYSIS DAN TEXT Telkomsel, Indosat, XL Axiata. Dalam perkembangannya, media sosial, dalam hal MINING UNTUK ini Twitter, menjadi salah satu situs media sosial utama masyarakat Indonesia untuk BUSINESS penyampaian ekspresi secara terbuka, yang berguna untuk kepentingan individu dan INTELLIGENCE perusahaan dalam mengetahui persepsi tentang kualitas merek. Metode social MENGGUNAKAN network analysis dan text mining diterapkan untuk mengetahui persepsi kualitas ASSOCIATION RULES merek, masalah dominan yang muncul, kelompok kata, dan asosiasi kata-kata yang (STUDI KASUS muncul melalui percakapan menjadi fokus utama dalam penelitian ini. Proses yang PERCAKAPAN TWITTER dilakukan adalah meringkas data percakapan di media sosial menjadi klasifikasi PT. TELKOMSEL DAN PT. kata dominan yang telah ditentukan untuk selanjutnya diproses visualisasi XL AXIATA TBK.) jaringannya. Metode association rules dan community detection digunakan untuk menemukan asosiasi kata-kata dan kelompok kata untuk dianalisis agar mendapatkan persepsi kualitas masing-masing Merek. Hasil analisis berupa persepsi kualitas, ditunjukan dari hubungan kata-kata dominan dalam graph sesuaidengan Branding Mention Merek “Indosat” dan “Telkomsel” menunjukan proses Penelitian ini dapat diandalkan untuk pengolahan ekspresi dari media sosial kedalam asosiasi antar kata representasi untuk menghasilkan Brand Perceived Quality dan kedepannya dapat dikembangkan analisa terkait.
65 UIN SYARIF HIDAYATULLAH JAKARTA

64
5 Anusha Mogallapu, 2011 SOCIAL NETWORK Penelitian ini mempelajari struktur jejaring sosial komunitas blogger video di Master Theses, ANALYSIS OF THE YouTube. Ini menganalisis struktur jaringan sosial teman dan pelanggan dari 187 Missouri University VIDEO blogger video di YouTube dan menghitung ukuran jaringan sosial. Tesis ini of Science and BLOGGERS'COMMUNITY membandingkan hasil dengan struktur yang dijelaskan oleh Warmbrodt et al. pada Technology. IN YOUTUBE tahun 2007 dan menjelaskan alasan pembedaan. Jumlah blogger video telah meningkat pesat, dan bentuk interaksi mereka telah berubah. Akibatnya, jaringan sosial video blogger telah berevolusi dari struktur inti / pinggiran ke satu yang terpusat. Ini menunjukkan bahwa komunitas blogger video di YouTube saat ini berkisar beberapa orang pusat di jaringan.
6 Bentar 2012 SPATIAL SOCIAL Saat ini, implementasi Program Pengembangan Agribisnis Pedesaan (RADP)
Priyopradono, NETWORK ANALYSIS: khususnya di Rejang Lebong, Bengkulu berkembang. Dimulai dengan dana Master Thesis, PROGRAM Bantuan Langsung Masyarakat (di Indonesia berarti bantuan langsung masyarakat: Universitas Kristen PENGEMBANGAN BLM) kepada Gapoktan atau di Indonesia berarti bahwa Gabungan kelompok tani Satya Wacana. USAHA AGRIBISNIS (Asosiasi Petani) yang digunakan untuk penguatan modal finansial (1) budidaya PERDESAAN (PUAP) pangan tanaman pangan, hortikultura, ternak, dan perkebunan. (2) Non-pertanian DALAM MENDUKUNG industri termasuk industri rumahan pertanian, pemasaran skala kecil dan pertanian REVITALISASI berbasis usaha lainnya, analisis lain dari peran semua pemangku kepentingan aktor PENINGKATAN PANGAN RADP menjadi langkah yang relevan, untuk menemukan strategi untuk DAERAH KABUPATEN meningkatkan kinerja di RADP, dengan Tujuan memahami keterhubungan atau REJANG LEBONG Konektivitas dari para pelaku dalam jaringan. Selain itu, Untuk mengembangkan PROVINSI BENGKULU strategi, tentukan strategi dan perencanaan yang tepat dalam pelaksanaan program kerja untuk keberlanjutan program RADP untuk masa depan. Penelitian ini menggunakan Social Network Analysis (SNA) dan mencoba menggabungkan analisis spasial untuk melihat bagaimana posisi seorang aktor di wilayah geografis seperti jarak, lokasi, kedekatan, lingkungan, dan daerah dekat analisis posisi mereka di jaringan sosial.
66 UIN SYARIF HIDAYATULLAH JAKARTA

65
7 Aditya Abimanyu, 2012 ANALISA MEDIA SOSIAL Pesatnya perkembangan teknologi disertai dengan tingkat penggunaannya Skripsi, Universitas TWITTER DENGAN membawa dampak posifit di berbagai bidang kehidupan manusia, namun juga dapat Indonesia PERHITUNGAN GRAPH membawa dampak negatif jika tidak didukung dengan tanggung jawab pengguna EDIT DISTANCE UNTUK teknologi itu sendiri. Bidang telekomunikasi adalah salah satu bidang yang MENDETEKSI RUMOR perkembangannya sangat dirasakan oleh manusia. Salah satu dari perkembangan PADA TRENDING TOPIC telekomunikasi adalah lahirnya media sosial. Manusia menggunakan media sosial SIAK-NG untuk berbagi informasi apapun kepada siapapun. Namun yang menjadi masalah kemudian adalah apakah informasi yang tersebar merupakan informasi yang nilai kebenarannya telah teruji atau hanya sebuah rumor. Rumor dapat saja mengakibatkan tersebarnya informasi yang salah di suatu golongan atau komunitas manusia. Adapun topik yang terkait pada tugas akhir ini adalah siak-ng yang menjadi trending topic di media sosial twitter. 1. Mengidentifikasi rumor pada media sosial online sangat krusial nilainya karena mudahnya informasi yang disebar oleh sumber yang tidak jelas. Pada tugas akhir ini akan ditunjukkan salah satu cara pengidentifikasian rumor dengan menggunakan kalkulasi gephi edit distance. Graph edit distance merupakan salah satu langkah yang paling cocok untuk menentukan persamaan antar grafik dan pengenalan pola jaringan kompleks. Untuk mencapai tujuan akhir, langkah-langkah yang dilakukan adalah pengambilan data, konversi data, pengolahan data, dan visualisasi. Dengan pengolahan data didapat Sembilan padanan kata antara Parent Node dan Child Node serta 3 kategori edge label. Pada akhirnya ditemukan bahwa rumor sistem siak-ng sedang mengalami load tinggi merupakan rumor yang nilai kebenarannya tinggi.
67 UIN SYARIF HIDAYATULLAH JAKARTA

66
3.1.4 Perbedaan Penelitian Peneliti
Tabel 3.3 Perbandingan Penelitian Sebelumnya Dengan Penelitian Peneliti
No. Penulis Tahun Judul Perbedaan
Penelitian Sebelumnya Penelitian Penulis
1 Hunt Allcott and 2016 SOCIAL MEDIA AND Peneliti menggunakan data historis (1975- Peneliti menggunakan data yang bersifat Matthew FAKE NEWS IN THE 2016 2010). Menyediakan data online dan offline. real-time sebagai data trend dan melihat Gentzkow ELECTION Tidak menggunakan SNA sebagai alat ukur, secara langsung apa yang sedang terjadi namun lebih kepada observasi sekitar. pada subjek penelitian. Menggunakan 5 Points pengukuran SNA.
2 João Cunha, 2015 HEALTH TWITTER BIG Menggunakan alat Twitter4J API sebagai Menggunakan kombilasi Apache NiFi Catarina Silva, DATA MANAGEMENT perantara penarikan data dari Twitter. danSolrsebagaialatutama Mário Antunes WITH HADOOP MenggunakanHDFShanyasebagai pengambilan data dari twitter, sehingga FRAMEWORK perantara penyimpanan Data. data yang terambil mempunyai format data JSON yang mudah untuk dilakukan percobaan secara langsung. Menggunakan komponen utama dalam hadoop seperti HDFS, NiFi, Solr, dan Zookeeper.
3 Timothy S., Song- 2017 APPLYING PARALLEL Menggunakan 640 node, 24 GB RAM, 2 x Menggunakan cluster dengan cost yang Lak Kang COMPUTING 2.8 GHz hex-core. Tergolong eksperimen tergolong murah dan mudah untuk TECHNIQUES TO yang tidak murah. Peneliti menggunakan diterapkan sehingga mempermudah ANALYZE TERABYTE metode clustering untuk melakukan analisis proses penelitian. Menggunakan seluruh ATMOSPHERIC data berjumlah terabyte. komponen yang tersedia dan berjalan BOUNDARY LAYER pada server lokal. MODEL OUTPUTS.
68
UIN SYARIF HIDAYATULLAH JAKARTA

67
4 Feriza Julian Putra, 2016 ANALISIS JARINGAN Subjek penelitian terbatas oleh user twitter Subjek penelitian berada pada ruang Skripsi, Universitas TEKS BERDASARKAN dari PT. Telkomsel dan PT. XL Axiata. lingkup lokasi di Indonesia dengan Telkom SOCIAL NETWORK Penyebaran data sempit dikarenakan user variabel penyaringan data hoax. Setiap ANALYSIS DAN TEXT diluar subjek yang bersinggungan langsung user yang bersinggungan secara MINING UNTUK tidak ter capture pada saat data mining. langsung dan tidak langsung dapat di BUSINESS capture pada saat penarikan data. INTELLIGENCE MENGGUNAKAN ASSOCIATION RULES (STUDI KASUS PERCAKAPAN TWITTER PT. TELKOMSEL DAN PT. XL AXIATA TBK.)
5 Anusha Mogallapu, 2011 SOCIAL NETWORK Menggunakan Youtube sebagai basis Menggunakan Twitter sebagai basis Master Theses, ANALYSIS OF THE penarikan data. Hanya menggunakan penarikan data. Menggunakan5 Missouri VIDEO parameter pengukuran SNA menggunakan parameter pengukuran SNA (Degree University of BLOGGERS'COMMUNITY centrality(degree,betweennessdan centrality, betweenness centrality, Science and IN YOUTUBE closeness). Menggunakan metode closeness centrality, eigenvector Technology. eksperimen saja. centrality, dan page rank). Peneliti menjelaskan lebih detail penggunaan metode eksperimen dengan desain intact-group comparison.
69 UIN SYARIF HIDAYATULLAH JAKARTA

68
6 Bentar 2012 SPATIAL SOCIAL Menggunakan studi kasus dan data sampel. Menggunakan Twitter sebagai basis Priyopradono, NETWORK ANALYSIS: Hanya menggunakan 4 pengukuran SNA penarikan data. Menggunakan parameter Master Thesis, PROGRAM (ego network, density, degree, betweenness). pengukuran SNA (Degree centrality, Universitas Kristen PENGEMBANGAN Tidak menerapkan metode clustering. betweenness centrality, closeness Satya Wacana. USAHA AGRIBISNIS centrality, eigenvector centrality, dan PERDESAAN (PUAP) page rank). Menerapkan teknologi DALAM MENDUKUNG hadoop. Peneliti menggunakan metode REVITALISASI clustering untuk mempermudah dalam PENINGKATAN PANGAN tahapan penarikan data. DAERAH KABUPATEN REJANG LEBONG PROVINSI BENGKULU
7 Aditya Abimanyu, 2012 ANALISA MEDIA SOSIAL Tidak melakukan pengubahan terhadap Peneliti melakukan pengubahan Skripsi, Universitas TWITTER DENGAN variabel pada gephi, peneliti hanya terhadap variabel iterasi pengecekan Indonesia PERHITUNGAN GRAPH menggunakan pengaturan standar yang telah perhitungan, dari nilai standar 100 EDIT DISTANCE UNTUK disediakan oleh gephi. menjadi 200. dan menetapkan waktu MENDETEKSI RUMOR maksimal (t-max) dari tidak ada PADA TRENDING TOPIC penetapan waktu menjadi 60 detik. SIAK-NG
Peneliti hanya berfokus kepada hasil social network analysis dengan sumber data yang bersumber dari Twitter,
dengan bantuan framework Apache Hadoop single cluster multi node untuk melihat bagaimana hasil analisis dari
pengukuran parameter SNA. Berbeda dengan apa yang penelitian sebelumnya lakukan tanpa melibatkan framework
Hadoop. Peneliti menggunakan data twitter dengan batasan keyword hoax pada pengguna sosial media Twitter di
Indonesia.
70 UIN SYARIF HIDAYATULLAH JAKARTA

69
Pada penelitian ini peneliti melakukan beberapa perbedaan penting dibandingkan dengan penelitian sebelumnya.
Perbedaan tersebut adalah sebagai berikut:
1. Peneliti melakukan penerapan metode clustering High Performance Cluster (metode komputer terdistribusi),
dikarenakan metode ini mempermudah penelitian pada tahap penarikan data, jumlah data yang dapat diambil
dibatasi sebesar jumlah penyimpanan yang tersedia. Jika dibandingkan dengan metode non clustering, metode non
clustering hanya menggunakan kapasitas satu node, sehingga seluruh kegiatan dibebankan kepada satu node
sehingga tidak efisien. Menjalankan Hadoop tanpa metode clustering memiliki arti bahwa, seluruh kapasitas dan
keutamaan Hadoop tidak dapat digunakan pada tingkatan maksimal.
2. Peneliti melakukan perbandingan hasil terhadap pengubahan yang terjadi terhadap variabel yang berkaitan dengan
penelitian. Peneliti melakukan penambahan jumlah iterasi pengecekan perhitungan yang disediakan oleh Gephi
dari nilai standar sebesar 100 kali pengecekan perhitungan menjadi 200 kali pengecekan perhitungan.
3. Peneliti melakukan perbandingan hasil visualisasi graf pada Gephi untuk melihat apakah ada pengaruh terhadap
pengubahan variabel, dengan melakukan penetapan nilai waktu maksimal (t-max) menjadi 60 detik pada
kelompok eksperimen.
4. Peneliti menggunakan pre-eksperimental design dengan jenis intact-group comparison, dikarenakan peneliti ingin
mengetahui apakah terjadi perubahan terhadap hasil penelitian, apabila dilakukan pengubahan terhadap variabel-
variabel yang mempengaruhi kelompok eksperimen.
71 UIN SYARIF HIDAYATULLAH JAKARTA

72
3.2 Metode Eksperimen
Metode penelitian yang peneliti gunakan untuk melakukan social network
analysis pada data Twitter yaitu menggunakan metode eksperimen. Peneliti
menggunakan metode eksperimen dikarenakan, sesuai dengan pengertian metode
eksperimen yang telah peneliti jelaskan pada BAB II, dikarenakan dalam rangka
untuk mencari pengaruh, hubungan, maupun perbedaan terhadap kelompok yang
dikenakan perlakuan. Kegunaan utama dari metode eksperimen adalah untuk
mencari tahu apakah dengan diadakannya pengubahan variabel bebas terhadap
kelompok yang akan diuji, memberikan hasil terhadap kelompok tersebut. Peneliti
menggunakan metode Pre-Experimental Design Intact-Group Comparison.
Berikut ini adalah tabel perbandingan dari metode eksperimen:
Tabel 3.4 Perbandingan Metode Eksperimen
No Metode Pengertian Kegunaan
1 Pre-Experimental Design Desain ini belum Untuk mendapatkan merupakan eksperimen informasi awal terhadap sungguh-sungguh karena pertanyaan yangada masih terdapat variabel dalam penelitian. luar yang ikut berpengaruh terhadap terbentuknya varuabel dependen.
2 True Experimental Design Pada desain ini, peneliti Validitas internal
dapat mengontrol semua (kualitas pelaksanaan variabel luar yang rancangan penelitian) mempengaruhi jalannya dapat menjadi tinggi. eksperimen.
3 Quasi Experimental Design Merupakan Untuk mengontrol pengembangan dari True variabel-variabel luar Experimental Design yang yang berpengaruh sulit dilaksanakan. terhadap penelitian.
4 Factorial Design Melibatkan dua atau lebih Menghasilkan ketelitian variabel bebas yang dan memperbolehkan dimanipulasi. penyelidikan terhadap dua atau lebih variabel.
UIN SYARIF HIDAYATULLAH JAKARTA

73
3.2.1 Pemilihan Desain
Pada tahap pertama, yang harus dilakukan dalam melakukan penelitian
dengan metode eksperimen adalah pemilihan desain eksperimen. Pemilihan
desain eksperimen harus sesuai dengan kebutuhan penelitian. Jenis-jenis
penelitian eksperimen telah peneliti uraikan pada BAB sebelumnya.
Berdasarkan keterangan pada Tabel 3.4, peneliti menggunakan metode
eksperimen dengan desain Pre-Experimental dikarenakan peneliti akan
melakukan pengubahan terhadap variabel-variabel untuk mengetahui apakah
ada perubahan yang terjadi setelah dilakukan hal tersebut. Dan untuk
mengetahui informasi awal terhadap pertanyaan yang ada dalam penelitian
Pada tahapan pemilihan desain, peneliti melakukan tahapan, yaitu:
1. Pemilihan Bentuk Desain
Pada tahap ini peneliti melakukan pemilihan desain eksperimen sesuai
dengan kebutuhan penelitian. Seperti dalam penelitian, peneliti akan
membagi seluruh data menjadi dua kelompok, kemudian kelompok
tersebut akan dilakukan perbandingan hasil.
2. Mendefinisikan Kelompok Kontrol dan Eksperimen
Pada tahap ini peneliti menentukan mana data yang akan dikelompokkan
menjadi kelompok kontrol dan kelompok eksperimen.
3.2.2 Penentuan Sampel Representatif
Setelah desain eksperimen ditentukan, kemudian peneliti menentukan
teknik pengumpulan sampel yang sesuai dengan penelitian. Kemudian
peneliti menentukan variabel-variabel dalam penelitian. Penentuan Variabel
dalam penelitian ini adalah:
1. Variabel Bebas (Independen)
Variabel yang mempengaruhi atau yang menyebabkan terjadinya
perubahan. Peneliti melakukan penambahan terhadap variabel iterasi
pengecekan perhitungan dari nilai standar sebesar 100 kali pengecekan
perhitungan menjadi 200 kali pengecekan perhitungan. Dan peneliti juga
UIN SYARIF HIDAYATULLAH JAKARTA

74
melakukan penetapan waktu maksimal (t-max) sebesar 60 detik, untuk
melihat apakah ada pengaruh pembatasan waktu terhadap hasil visualisasi
graf pada Gephi.
2. Variabel Terikat (Dependen)
Variabel terikat merupakan faktor-faktor yang diamati pada saat proses
eksperimen dan diukur dalam sebuah penelitian. Sebagai penentu ada
tidaknya pengaruh variabel bebas.
3. Variabel Kontrol
Variabel inilah yang menyebabkan hubungan di antara variabel bebas dan
juga variabel terikat bisa tetap konstan.
3.2.3 Instrumentasi
Untuk melakukan proses eksperimen diperlukan adanya sekumpulan
perangkat pendukung dalam metode eksperimen yang peneliti teliti.
Instrumen penelitian ini diantaranya:
1. Pemilihan Hardware
Pada tahap ini peneliti menentukan mana perangkat keras yang
dibutuhkan oleh penelitian sesuai dengan batasan penelitian yang telah
ditentukan. Peneliti menggunakan 2 buah laptop dengan klasifikasi yang
sesuai dengan rekomendasi penggunaan Hadoop, yaitu RAM sebesar
4GB, Penyimpanan Hard Disk 250GB dan Jumlah Core Processor
sebanyak 4 core.
2. Pemilihan Software
Pada tahap ini peneliti menentukan dan melakukan install perangkat
lunak yang mendukung penelitian. Software yang peneliti gunakan adalah
Apache Ambari, Apache Solr, Apache NiFi, Dashboard Banana, dan
Gephi.
3. Penerapan Metode Single Cluster Multi Node
Pada tahap ini peneliti melakukan proses penerapan metode single cluster
multi node pada framework Hadoop. Peneliti memilih metode high
UIN SYARIF HIDAYATULLAH JAKARTA

75
performance clustering karena metode ini mempermudah proses
penarikan data dan mempermudah kinerja masing-masing node pada
cluster. Sesuai dengan penelitian Timothy S. dan Song-Lak Kang (2017)
bahwa penggunaan komputasi terdistribusi sangat membantu dalam
melakukan analisis data yang berjumlah besar (dalam penelitian Timothy
S. dan Song-Lak Kang jumlah data mencapai terabyte). Dengan alasan
tersebut peneliti ingin menerapkan metode clustering pada penelitian ini.
Proses pembuatan cluster dilakukan pada tahap instrumentasi dengan
menggabungkan kedua laptop kedalam satu cluster. Tahapan pembuatan
cluster adalah sebagai berikut:
A. Persiapan Pembuatan Cluster
B. Persyaratan Environment Hadoop
C. Penggunaan Repository Lokal
D. Proses Install Ambari dan Komponen Hadoop
E. Proses Install Ambari-Server
F. Pangaturan SSH Login
G. Proses Install dan Setup Ambari-Server
H. Proses Menjalankan Ambari-Server
I. Proses Install Hadoop Pada Cluster
J. Proses Install Komponen Hadoop
K. Summary Install Ambari-Server
3.2.4 Pelaksanaan Eksperimen
Setelah tahap instrumentasi selesai, peneliti melakukan tahap pelaksanaan
eksperimen. Pada tahap ini peneliti melakukan 5 tahapan, yaitu:
1. Tahapan Pengumpulan Data
Pada tahap ini peneliti melakukan pengumpulan data yang digunakan
pada penelitian ini. Tahapan pengumpulan data adalah sebagai berikut:
A. Tahapan Penarikan Data
B. Tahapan Penentuan Konten Data
UIN SYARIF HIDAYATULLAH JAKARTA

76
C. Tahapan Pembatasan Data
D. Tahapan Segmentasi Data
E. Tahapan Penggabungan Data
2. Tahapan Indexing dan Visualisasi Data Realtime
Pada tahap ini peneliti melakukan proses penomoran terhadap seluruh
data yang berhasil dikumpulkan, dan visualisasi realtime yaitu melakukan
proses penggambaran secara cepat terhadap keadaan data yang berhasil
dilakukan pada tahap penomoran. Tahapan Indexing dan Visualisasi data
adalah sebagai berikut:
A. Tahapan Input Data
Pada tahapan ini seluruh data akn dilakukan penomoran menggunakan
solr.
B. Tahapan Visualisasi Data Realtime
Data yang berhasil dilakukan penomoran akan muncul secara otomatis
dalam bentuk visualisasi data realtime.
3. Tahapan Klasifikasi Data
Pada tahapan ini dilakukan klasifikasi data terhadap seluruh data yang
telah melalui proses sebelumnya, kemudian akan dikategorikan menjadi
dua kelompok sesuai dengan desain eksperimen yang dipilih.
4. Tahapan Eksperimen Intact-Group Comparison
Pada tahapan ini peneliti melakukan pembagian data ke dalam kelompok-
kelompok yang telah ditentukan. Pada penelitian ini peneliti mengubah
jumlah iterasi pengecekan perhitungan dan menetapkan waktu maksimal
pada visualisasi graf. Peneliti melakukan pengubahan variabel iterasi
pengecekan perhitungan dan penetapan waktu maksimal (t-max)
dikarenakan, pada penelitian sebelumnya tidak dikakukan pengubahan
terhadap variabel, sehingga peneliti ingin melihat apakah terjadi
perubahan terhadap hasil pada penelitian setelah dilakukan pengubahan
variabel iterasi dan waktu maksimal.
UIN SYARIF HIDAYATULLAH JAKARTA

77
5. Tahapan Penerapan Social Network Analysis
Pada tahapan ini peneliti menerapkan perhitungan parameter yang
tersedia pada social network analysis. Perhitungan parameter social
network analysis diterapkan kepada seluruh kelompok yang ada.
Penerapan social network analysis berisikan 2 tahap, yaitu:
A. Input Data dan Visualisasi Gephi
Pada tahap ini peneliti melakukan input data ke aplikasi Gephi untuk
melakukan visualisasi graf, sesuai dengan masing-masing kelompok.
B. Perhitungan Parameter Social Network Analysis
Pada tahap ini peneliti melakukan perhitungan sesuai dengan
parameter yang tersedia pada social network analysis.
3.2.5 Pengumpulan dan Penganalisisan Data
Pada tahap ini peneliti melakukan pengumpulan data setelah dilakukan
pengukuran parameter social network analysis. Kemudian dilakukan analisis
data dari kedua kelompok yaitu kelompok eksperimen dan kelompok
kontrol,
Tahapan yang akan dilakukan adalah sebagai berikut:
1. Hasil Pengumpulan Data
2. Hasil Visualisasi Data Realtime
3. Hasil Klasifikasi Data
4. Hasil Eksperimen Intact-Group Comparison
5. Hasil Penerapan Social Network Analysis
A. Hasil Visualisasi Graf Kelompok Kontrol
B. Hasil Perhitungan Parameter SNA Kelompok Kontrol
C. Hasil Visualisasi Graf Kelompok Eksperimen
D. Hasil Perhitungan Parameter SNA Kelompok Eksperimen
6. Hasil Analisis Kelompok Kontrol
A. Cluster Nomor 1
B. Cluster Nomor 2
UIN SYARIF HIDAYATULLAH JAKARTA

78
C. Cluster Nomor 3
D. Kompilasi Hasil Kelompok Kontrol
E. Analisis User Berpengaruh Kelompok Kontrol
7. Hasil Analisis Kelompok Eksperimen
A. Cluster A
B. Cluster B
C. Cluster C
D. Cluster D
E. Kompilasi Hasil Kelompok Eksperimen
F. Analisis User Berpengaruh Kelompok Eksperimen
3.2.6 Analisis dan Interpretasi Data
Pada tahap ini peneliti melakukan tahapan analisis dan interpretasi data
dari tahap pengumpulan dan penganalisisan data. Peneliti melakukan
perbandingan data antara kedua kelompok yang telah didapatkan pada tahap
sebelumnya. Tahapan yang akan dilakukan adalah sebagai berikut:
1. Perbandingan Kelompok Kontrol dan Kelompok Eksperimen
2. Hasil Analisis Konten Tweet Node Berpengaruh
3.2.7 Kesimpulan Eksperimen
Pada tahapan ini peneliti melakukan tahapan penarikan kesimpulan, dari
seluruh proses yang dilakukan pada metode eksperimen ini. Tahapan yang
akan dilakukan adalah sebagai berikut:
1. Hasil Pengaruh Pengubahan Nilai Iterasi Pengecekan Perhitungan
2. Hasil Pengaruh Penetapan Variabel Waktu
3. Hasil Nilai Perhitungan Parameter SNA
UIN SYARIF HIDAYATULLAH JAKARTA

79
3.3 Kerangka Pemikiran
Peneliti menuangkan hasil dari metode yang peneliti pilih untuk digunakan
dalam penelitian ini kedalam sebuah kerangka pemikiran seperti berikut:
Rumusan Masalah
Keterangan *Hasil Pengumpulan Data
*Hasil Visualisasi Data Realtime *Hasil Klasifikasi Data
*Hasil Eksperimen Intact-Group Comparison
*Hasil Penerapan Social Network Analysis *Hasil Analisis Kelompok Kontrol
*Hasil Analisis Kelompok Eksperimen
Keterangan
*Hasil Pengaruh Perubahan Nilai Iterasi Pengecekan Perhitungan
*Hasil Pengaruh Penetapan Variabel Waktu *Hasil Nilai Perhitungan Parameter SNA *Hasil Penerapan Desain Intact-Group
Comparison
Gambar 3.1 Alur Kerangka Pemikiran
UIN SYARIF HIDAYATULLAH JAKARTA

80
BAB IV
IMPLEMENTASI DAN EKSPERIMEN
4.1 Pemilihan Desain
4.1.1 Pemilihan Bentuk Desain
Peneliti memilih desain pre-eksperimen menggunakan rancangan Intact-
Group Comparison. Pada desain ini, terdapat satu kelompok yang digunakan
untuk penelitian, kemudian seluruh data akan dibagi dua yaitu: setengah
kelompok untuk eksperimen (yang diberi perlakuan) dan setengah untuk
kelompok kontrol (yang tidak diberi perlakuan). Peneliti menggunakan desain
eksperimen Intact-Group Comparison dikarenakan jenis ekperimen yang
peneliti gunakan sesuai dengan kaidah ekperimen rancangan Intact-Group
Comparison. Dimana peneliti akan membagi sampel menjadi dua kelompok,
yaitu kelompok dengan tweet original dan kelompok dengan tweet hasil re-
tweet user lain. Peneliti juga akan melakukan pengubahan terhadap variabel
bebas terhadap kelompok eksperimen untuk mengetahui apakan ada pengaruh
terhadap pengubahan tersebut.
4.1.2 Mendefinisikan Kelompok Kontrol dan Eksperimen
Berdasarkan desain Intact-Group Comparison, seluruh data akan dibagi
menjadi dua kelompok yaitu kelompok kontrol dan kelompok eksperimen,
pembagian data menjadi masing-masing kelompok ditentukan dengan kaidah
sebagai berikut:
1. Kelompok Kontrol
Kelompok kontrol adalah seluruh data yang merupakan tweet yang
termasuk ke dalam golongan post original. Post original adalah tweet
yang merupakan hasil tulisan pribadi dari pengguna sosial media Twitter.
2. Kelompok Eksperimen
Kelompok eksperimen adalah seluruh data yang merupakan tweet yang
termasuk ke dalam golongan post re-tweet. Post re-tweet adalah tweet yang
80 UIN SYARIF HIDAYATULLAH JAKARTA

81
merupakan tulisan orang lain, pengguna sosial media Twitter hanya
melakukan penulisan kembali atau share tulisan orang lain.
4.2 Penentuan Sampel Representatif
Data twitter bersifat realtime, sehingga setiap data yang tidak terambil dan
sudah lewat masa kadar waktunya tidak dapat digunakan. Hanya data yang
terambil dan bersifat realtime yang dapat digunakan. Berdasarkan hal tersebut
peneliti menggunakan metode nonprobability sampling yaitu teknik sampling
aksidental. Sesuai dengan penjabaran mengenai sampling aksidental pada BAB II,
dimana peneliti menggunakan data yang dijumpai pada saat tahapan penarikan
data saja, setiap data yang tertarik akan masuk menjadi sampel data, dan data yang
tidak tertarik atau tidak ditemukan, tidak masuk menjadi sampel data.
Peneliti menggunakan seluruh data yang sesuai dengan karakteristik penelitian
yang bersumber dari Twitter, maka setiap data tweet yang cocok dengan
karakteristik variabel kontrol yaitu keyword hoax, akan dimasukan ke dalam
database sebagai sampel representative. Dan setiap tweet menggunakan Bahasa
Indonesia dimaksudkan untuk melakukan filtering terhadap data. Variabel-variabel
dalam penelitian ini adalah:
1. Variabel Bebas (Independen)
Pada penelitian ini Variable Bebas adalah penetapan waktu maksimal dan
iterasi pengecekan perhitungan.
2. Variabel Terikat (Dependen)
Pada penelitian ini Variable Terikat adalah jumlah cluster pembentuk graf dan
hasil perhitungan parameter social network analysis.
3. Variabel Kontrol
Pada penelitian ini Variabel Kontrol adalah Keyword Hoax.
4.3 Instrumentasi
Pada tahap instrumentasi peneliti menggunakan metode multi node pada
rancangan komputer terdistribusi. Alasan peneliti memilih metode multi node
dikarenakan salah satu syarat utama agar Apache NiFi dapat berjalan pada
UIN SYARIF HIDAYATULLAH JAKARTA

82
environtment Hadoop adalah pada rancangan komputer terdistribusi minimal 2
node dan satu cluster yang berjalan.
Penggunaan metode multi node juga untuk mempermudah kinerja dari Hadoop
itu sendiri, dikarenakan proses pengerjaan dapat diatur dan dibagi secara rata
kepada node yang terlibat.
4.3.1 Pemilihan Hardware
Spesifikasi hardware yang peneliti gunakan pada proses eksperimen ini
adalah:
1. Nama Perangkat : Router Huawei
Pengaturan IP : Statis
Manufacture Info : 2150082766EGFA016288.C402
2. Nama Perangkat : Laptop 1
Hostname : master
Domain : skripsi.com
FQDN : master.skripsi.com
CPU : Intel Core i5 Quad-Core
RAM : 8 GB
Connection : WLAN Internet
HDD : 500 GB
IP Static : 192.168.100.51
3. Nama Perangkat : Laptop 2
Hostname : slave
Domain : skripsi.com
FQDN : slave.skripsi.com
CPU : Intel Celeron Dual-Core
RAM : 2 GB
Connection : WLAN Internet
HDD : 500 GB
IP Static : 192.168.100.52
UIN SYARIF HIDAYATULLAH JAKARTA

83
Tipe IP : IPv4
4.3.2 Pemilihan Software
Spesifikasi software yang peneliti gunakan pada proses eksperimen ini
adalah:
1. Sistem Operasi : CentOS
Arsitektur : 64 Bit
GUI : Classic Gnome
2. Web-Browser : Mozilla Firefox
3. Web-Hosting : Apache HTTPD (Local Repo)
4. Editor : Nano, Gedit
5. Hadoop : Hortonworks
6. Visualisasi : Banana dan Gephi
7. Pencarian Data : Apache NiFi
8. Real-time Searching: Apache Solr dan Banana Dashboard
4.3.3 Penerapan Metode Single Cluster Multi Node
4.3.3.1 Persiapan Pembuatan Cluster
Peneliti mempersiapkan kedua laptop yang akan digunakan sebagai
node pada cluster dalam penelitian. Pengaturan IP dan Hostname dengan
aturan sebagai berikut:
A. Node Master. Pengaturan IP Static pada master dengan mengganti IP
DHCP menjadi IP Manual. Pada kolom IPv4 masukan pengaturan IP
Static pada kolom addresses menjadi:
Address : 192.168.100.51
Netmask : 255.255.255.0
Gateway : 192.168.100.1
DNS Server : 192.168.100.1
UIN SYARIF HIDAYATULLAH JAKARTA

84
Kemudian matikan fitur IPv6 dikarenakan router belum mempunyai IP
Public versi IPv6.
B. Node Slave. Pengaturan Ip Static pada slave dengan mengganti IP
DHCP menjadi IP Manual. Pada kolom IPv4 masukan pengaturan IP
Static pada kolom addresses menjadi:
Address : 192.168.100.52
Netmask : 255.255.255.0
Gateway : 192.168.100.1
DNS Server : 192.168.100.1
C. Atur hostname pada master dan slave dengan aturan hostname dan
domain sesuai aturan FQDN. Input perintah Kode #nano
/etc/hosts pada master dan slave.
192.168.100.51 master.skripsi.com master
192.168.100.52 slave.skripsi.com slave
Line nomor 1 dan 2 bermaksud agar master dan slave dapat
melakukan koneksi secara langsung dengan memanggil instance
hostname dari node yg akan dihubungkan.
D. Kemudian cek apakah masing-masing node (master dan slave) dapat
melakukan pengecekan latency antar node.
Gambar 4.1 Komponen Pembentuk Cluster
UIN SYARIF HIDAYATULLAH JAKARTA

85
Gambar 4.1 merupakan gambar rancangan cluster pada penelitian.
Peneliti menggunakan single cluster, dengan jumlah node 2 laptop.
Software pengendali cluster adalah Apache Hadoop yang dilakukan
proses install menggunakan metode High Performance Clustering.
4.3.3.2 Persyaratan Environtment Hadoop
Ubah pengaturan pada file SELinux pada directory
/etc/sysconfig/SELinux, ubah konfigurasi SELinux menjadi disabled.
SELinux adalah Security Enhanced Linux, Hadoop merekomendasikan
untuk mematikan selinux dikarenakan fitur http dan ftp pada Hadoop
harus dibuka tanpa pengaturan security tambahan. Kemudian ubah
pengaturan SELINUX=enforcing menjadi SELINUX=disabled.
4.3.3.3 Penggunaan Repository Lokal
Peneliti melakukan install Apache http server pada node master saja.
Apache http merupakan web hosting untuk melakukan hosting file baik
pada mode local ataupun online. Peneliti menggunakan mode local
sebagai tempat untuk melakukan hosting repository data Hadoop untuk
digunakan saat proses install. Kode untuk install adalah: Kode #yum –y install httpd.
Gambar 4.2 Apache HTTP Server berhasil Pada Proses
Install 4.3.3.4 Proses Install Ambari dan Komponen Hadoop
Salin semua berkas Ambari, Hadoop, HDP dan HDF ke directory
APACHE HTTP Server. Buat folder dengan nama repo pada direktori
/var/www/html/repo. Kemudian salin semua berkas ke dalam direktori
repo. Untuk pengaturan dan kode repository terlampir pada lampiran 4.1.
UIN SYARIF HIDAYATULLAH JAKARTA

86
4.3.3.5 Proses Install Ambari-Server
Kemudian install Ambari Server hanya pada node master. By default
ambari menggunakan database postgresql versi 9.2 sebagai default
database.
4.3.3.6 Pengaturan SSH Login
Pengaturan SSH antara master dan server untuk melakukan remote login
pada proses install komponen Hadoop antara master dan slave. Pada master
dan slave lakukan perintah yang sama tanpa perbedaan sama sekali.
Kode #ssh-keygen –t rsa –P “”
Ssh-keygen adalah perintah untuk melakukan regenerate kunci login
dengan atribut passwordless agar memudahkan koneksi antara master dan
slave. Kode key SSH terlampir pada lampiran 4.2.
Salin id_rsa ke node master dan node slave sehingga master dan slave
mampu melakukan remote login secara otomatis.
Kode #ssh-copy-id -i ~/.ssh/id_rsa.pub root@master
Kode #ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave
Kemudian ubah ownership dan tambahkan path ssh
Kode #chmod 0600 ~/.ssh/id_rsa
Kode #ssh-add
Identity added: /root/.ssh/id_rsa
(/root/.ssh/id_rsa).
4.3.3.7 Proses Install dan Setup Ambari-Server
Untuk melakukan proses install maka masukan kode sebagai berikut:
Kode #ambari-server setup. Secara default ambari juga
melakukan install oracle jdk versi 1.8.0 sebagai environtment
complimentary pendukung berjalannya Hadoop. Proses pengaturan
database pada ambari terlampir pada lampiran 4.3.
UIN SYARIF HIDAYATULLAH JAKARTA

87
Gambar 4.3 Proses Pemilihan JDK
4.3.3.8 Proses Menjalankan Ambari-Server
Menjalankan ambari-server pada node master. Saat ambari-server
berjalan, ambari-agent pada setiap node di master dan slave otomatis juga
akan berjalan. Proses menjalankan server terlampir pada lampiran 4.4.
Kemudian kunjungi web browser dan arahkan ke
http://master.skripsi.com:8080/ untuk kemudian melakukan proses install
cluster.
4.3.3.9 Proses Install Hadoop Pada Cluster
Gambar 4.4 Antarmuka Install Wizard Cluster Hadoop
Kemudian kunjungi web server ambari kemudian klik launch install
wizard untuk melakukan proses pembuatan cluster Hadoop. Berikan
nama pada cluster. Pada penelitian ini peneliti memberika nama cluster
FAIZ_Skripsi_UIN.
UIN SYARIF HIDAYATULLAH JAKARTA

88
Gambar 4.5 Target Host Master dan Slave
Tuliskan secara lengkap FQDN dari master dan slave sebagai penentu
node yang akan dilakukan proses. Print key SSH untuk melakukan
otentifikasi ssh root@master dan root@slave. Kode key SSH yang telah
berhasil dicetak terlampir pada lampiran 4.5.
4.3.3.10 Proses Install Komponen Hadoop
Proses selanjutnya adalah pembagian komponen Hadoop pada node-
node master dan slave sesuai dengan spesifikasi pada setiap node.
Gambar 4.6 Pembagian Skema Install Komponen Hadoop
NameNode berada pada node master dan secondary NameNode pada
node slave. Dikarenakan NameNode utama berada pada pusat server
yaitu pada node master. Setiap client dari service Hadoop, peneliti
posisikan pada node master dikarenakan node master mempunyai
resource 2 kali lipat dari node slave.
DataNode diposisikan pada kedua node master dan slave, digunakan
sebagai tempat penyimpanan data dengan mengkombinasikan resource
dari masing-masing node menjadi satu penyimpanan tunggal yang besar.
UIN SYARIF HIDAYATULLAH JAKARTA

89
Lokasi Directory NameNode /Hadoop/hdfs/namenode. Lokasi Directory
DataNode /Hadoop/hdfs/data.
4.3.3.11 Summary Install Ambari-Server
Tahapan pemasangan ambari telah berhasil dilakukan dengan node
dua buah laptop yaitu master dan slave, dimana master sebagai pusat
kendali pada cluster, dan slave sebagai client pada cluster sebagai node
monitoring. Berikut ini adalah keterangan hasil proses install pada
tahapan pembuatan cluster dan install Ambari-Server:
Admin Name: admin
Cluster Name: FAIZ_Skripsi_UIN
Total Hosts: 2 (2 new)
Repositories:
• redhat7/centos7 (HDP-2.6):
http://master.skripsi.com/repo/hdp/HDP/centos7/2.x/updates/2.6.1.0
• redhat7/centos7 (HDP-UTILS-1.1.0.21):
http://master.skripsi.com/repo/hdp/HDP-UTILS-1.1.0.21/repos/centos7
HDFS DataNode: 2 hosts
NameNode: master.skripsi.com NFSGateway: 0 host
SNameNode: slave.skripsi.com YARN + MapReduce2
App Timeline Server: slave.skripsi.com NodeManager: 1 host
ResourceManager: slave.skripsi.com Tez
Clients: 1 host ZooKeeper
Server: master.skripsi.com
Ambari Metrics
Metrics Collector: master.skripsi.com Grafana: master.skripsi.com
SmartSense Activity Analyzer: master.skripsi.com Activity Explorer: master.skripsi.com HST Server: master.skripsi.com
Zeppelin Notebook Apache NiFi
Apache Solr with Banana Dashboard Notebook: master.skripsi.com
Slider Clients: 1 host (Master)
Gambar 4.7 Komponen Apache Ambari
UIN SYARIF HIDAYATULLAH JAKARTA

90
Berikut ini adalah seluruh list dari services yang berhasil di install pada cluster.
Services: HDFS DataNode: 2 hosts NameNode: master.skripsi.com NFSGateway: 0 host SNameNode: slave.skripsi.com YARN + MapReduce2 App Timeline Server: slave.skripsi.com NodeManager: 1 host ResourceManager: slave.skripsi.com Tez Clients: 1 host ZooKeeper Server: master.skripsi.com Ambari Metrics Metrics Collector: master.skripsi.com Grafana: master.skripsi.com SmartSense Activity Analyzer: master.skripsi.com Activity Explorer: master.skripsi.com HST Server: master.skripsi.com Zeppelin Notebook Apache NiFi Apache Solr with Banana Dashboard Notebook: master.skripsi.com Slider Clients: 1 host (Master)
UIN SYARIF HIDAYATULLAH JAKARTA

91
4.4 Pelaksanaan Eksperimen
4.4.1 Tahapan Pengumpulan Data
Peneliti melakukan tahap pengumpulan data selama 15 hari dari tanggal
16 November 2017 sampai 30 November 2017. Seluruh data yang peneliti
gunakan pada penelitian ini adalah data yang bersumber dari sosial media
Twitter, dangan user yang berada pada ruang lingkup negara Indonesia dan
user menggunakan Bahasa Indonesia. Pada twitter, Bahasa Indonesia dapat
dikategorikan sebagai parameter dengan nilai ID atau IN. Dalam melakukan
penarikan data, peneliti menggunakan pembatasan pada keyword hoax, jadi
setiap user yang melakukan penulisan tweet yang melibatkan penulisan kata
hoax akan terambil sebagai data penelitian.
4.4.1.1 Tahapan Penarikan Data
Peneliti menggunakan Apache NiFi untuk melakukan penarikan
data melalui Twitter dengan menggunakan bantuan Processor
GetTwitter dengan nama TarikDataTwitter.
Gambar 4.8 Gambar Processor GetTwitter
Kemudian peneliti melakukan pengaturan terhadap processor untuk
melakukan proses penghubungan antara Apache NiFi dengan API
Twitter. Peneliti menggunakan kode akses pribadi untuk melakukan
UIN SYARIF HIDAYATULLAH JAKARTA

92
hubungan antara Apache NiFi dan API Twitter. Dengan melakukan
klasifikasi data Twitter menggunakan kata kunci hoax pada pengaturan
processor GetTwitter.
Gambar 4.9 Gambar Pengaturan Processor GetTwitter
Berdasarkan Gambar 4.9 peneliti menggunakan fitur yang
disediakan oleh Twitter untuk melakukan penarikan data secara gratis,
namun hanya data yang bersifat realtime, yang dapat diambil.
Batasan yang digunakan adalah batasan Bahasa yaitu Bahasa
Indonesia dengan parameter ln dan input batasan keyword yaitu hoax.
Hal tersebut dimaksudkan supaya hanya tweet yang menggunakan
Bahasa Indonesia dan mengandung keyword hoax saja yang dapat
terambil sebagai data pada penelitian.
4.4.1.2 Tahapan Penentuan Konten Data
Setelah berhasil terhubung dengan API Twitter, peneliti melakukan
penambahan parameter data dengan melakukan penentuan konten data
dengan bantuan Processor EvaluateJsonPath dengan nama
ParameterPenarikanData. Dengan penentuan bahwa seluruh data harus
UIN SYARIF HIDAYATULLAH JAKARTA

93
memenuhi persyaratan klasifikasi yang telah ditentukan Twitter secara
default.
Gambar 4.10 Gambar Processor
EvaluateJsonPath 4.4.1.3 Tahapan Pembatasan Data
Pada tahap selanjutnya peneliti melakukan pembatasan pada data
Twitter yang akan ditarik melalui API Twitter dengan bantuan
Processor RouteOnAttribute dengan nama ParameterBatasanData.
Dengan pengaturan hanya data tweet yang mempunyai pesan pada
tweet body yang dapat ditarik ke dalam database data.
Gambar 4.11 Gambar Processor RouteOnAttribute
Berikut ini adalah contoh data tweet yang berhasil diambil dengan
menggunakan Apache NiFi:
UIN SYARIF HIDAYATULLAH JAKARTA

94
Gambar 4.12 Gambar Contoh Data Tweet Yang Berhasil
Diambil 4.4.1.4 Tahapan Segmentasi Data
Setelah data twitter dengan batasan kata kunci hoax berhasil
diambil, peneliti melakukan tahap melakukan pengambilan segmentasi
penting dari tweet. Segmentasi yang peneliti ambil hanya berisikan 6
konten yaitu:
A. ${twitter.original} = Segmentasi ini merupakan nama user original
yang merupakan user yang menuliskan tweet yang berasal dari
pemikiran pribadi.
B. ${twitter.overified} = Segmentasi ini merupakan status user,
apakah user original merupakan akun yang telah berhasil
diverifikasi oleh twitter atau belum diverifikasi.
C. ${twitter.handle} = Segmentasi ini merupakan nama user yang
melakukan re-tweet atau melakukan kegiatan posting ulang tweet
user original.
D. ${twitter.uverified} = Segmentasi ini merupakan status user,
apakah user re-tweet merupakan akun yang telah berhasil
diverifikasi oleh twitter atau belum diverifikasi.
E. ${twitter.ofollower} = Segmentasi ini merupakan jumlah pengikut
dari user original.
UIN SYARIF HIDAYATULLAH JAKARTA

95
F. ${twitter.ufollower} = Segmentasi ini merupakan jumlah pengikut
dari user re-tweet.
Peneliti menggunakan Processor ReplaceText dengan nama
SegmentasiData untuk melakukan penarikan segmentasi data yang
akan peneliti gunakan pada tahapan SNA.
Gambar 4.13 Gambar Processor ReplaceText
Gambar 4.14 Contoh Hasil
ReplaceText 4.4.1.5 Tahapan Penggabungan Data
Pada tahap ini seluruh data akan dilakukan proses penggabungan
data menjadi satu data utuh dengan format file extention .csv. Tahapan
penggabungan data menggunakan Processor MergeContent dengan
nama GabungData.
Gambar 4.15 Gambar Processor MergeContent
UIN SYARIF HIDAYATULLAH JAKARTA

96
Gambar 4.16 Proses Pengumpulan Data
Gambar 4.16 adalah proses alur pada tahap pengumpulan data,
dimana input merupakan key otentifikasi Twitter yang digunakan untuk
melakukan komunikasi langsung dengan Twitter Streaming Interface,
sehingga Processor pada Apache NiFi dapat melakukan penarikan data
dari Twitter database. Setiap simbol proses, melambangkan satu
Processor pada Apache NiFi yang digunakan pada penelitian.
4.4.2 Tahapan Indexing dan Visualisasi Data Realtime
Pada tahapan indexing dan visualisasi data, peneliti melakukan tahapan
untuk melakukan proses input dari seluruh data yang berhasil terambil pada
tahapan pengambilan data. Proses input menggunakan Apache NiFi dengan
UIN SYARIF HIDAYATULLAH JAKARTA

97
menggunakan Processor PutSolrContentStream dengan nama
IndexSolrVisualisasiBanana.
4.4.2.1 Tahapan Input Data
Pada tahapan pemindahan data menggunakan Processor
PutSolrContentStream, dengan konfigurasi tipe Solr yaitu berbasis
cloud dengan lokasi master.skripsi.com:2181/solr dan container
penyimpanan data dengan nama tweets. Berikut ini adalah gambar
Processor PutSolrContentStream:
Gambar 4.17 Gambar Processor PutSolrContentStream
Dengan bantuan Processor PutSolrContentStream proses indexing
secara otomatis dilakukan antara Apache NiFi dan Solr yang akan
melakukan penomoran pada setiap data tweet yang masuk kedalam
container tweets. Setiap data yang telah berhasil diberikan nomor oleh
solr kemudian dapat dilakukan visualisasi menggunakan banana.
4.4.2.2 Tahapan Visualisasi Data Realtime
Pada tahapan ini peneliti melakukan input data dari seluruh data
tweet yang berhasil dikumpulkan dan dilakukan penomoran pada tahap
indexing. Alur tahapan indexing dan visualisasi data adalah sebagai
berikut:
UIN SYARIF HIDAYATULLAH JAKARTA

98
Gambar 4.18 Proses Indexing dan Visualisasi Data
Solr digunakan hanya sebagai alat untuk melakukan penomoran
sehingga seluruh data yang telah terkumpul, dapat langsung dilakukan
proses visualisasi secara cepat. Berdasarkan Gambar 4.18 seluruh data
yang berhasil terambil akan disimpan sementara pada penyimpanan
database, kemudian seluruh data akan dilakukan proses indexing
dengan menggunakan Solr. Kemudian setelah berhasil dilakukan
penomoran, hasil visualisasi secara realtime akan muncul secara
otomatis.
4.4.3 Tahapan Klasifikasi Data
Peneliti melakukan pembagian seluruh data yang berhasil terambil pada
tahapan pengambilan data. Peneliti akan membagai menjadi dua kelompok,
yaitu kelompok kontrol dan kelompok eksperimen sesuai dengan desain
eksperimen yang peneliti pilih yaitu rancangan Intact-Group Comparison.
UIN SYARIF HIDAYATULLAH JAKARTA

99
Peneliti menggunakan Apache NiFi dengan bantuan Processor
UpdateAttribute dengan nama KlasifikasiData untuk melakukan pembagian
data, dimana seluruh data yang bersumber dari user original akan masuk ke
dalam kelompok kontrol, sedangkan data yang bersumber dari user re-tweet
akan masuk kedalam kelompok eksperimen.
Gambar 4.19 Gambar Processor UpdateAttribute
Gambar 4.20 Proses Klasifikasi Data
Gambar 4.20 merupakan alur perpindahan data yang berasal dari
proses pengumpulan data. Kemudian seluruh data tweet yang berhasil
terkumpul pada tahapan sebelumnya, akan melalui proses klasifikasi
UIN SYARIF HIDAYATULLAH JAKARTA

100
data, dan dilakukan pembagian sesuai dengan kelompok dari data yang
telah didefinisikan pada tahap penentuan desain penelitian.
4.4.4 Tahapan Eksperimen Intact-Group Comparison
Pada tahap ini peneliti menggunakan Apache NiFi dengan bantuan
Processor MergeContent dengan nama GabungData. Processor ini
digunakan untuk menggabungkan seluruh data menjadi satu file dengan
ekstensi .csv, ekstensi .csv digunakan sebagai medium untuk penyimpanan
data sebelum dilakukan penerapan SNA.
Gambar 4.21 Gambar Processor MergeContent
Gambar 4.22 Proses Eksperimen Intact-Group Comparison
UIN SYARIF HIDAYATULLAH JAKARTA

87
Gambar 4.22 merupakan alur penggabungan data menjadi satu data utuh dengan format file .csv, proses penggabungan
dilakukan pada kedua kelompok. Penggabungan data dimaksudkan agar pada tahap selanjutnya penerapan social network
analysis pada gephi dapat dilakukan. Berikut ini adalah gambaran seluruh Processor yang digunakan pada proses
penarikan data sampai proses pembentukan dua kelompok eksperimen.
Gambar 4.23 Gambar Seluruh Alur Processor Pada Apache NiFi
101
UIN SYARIF HIDAYATULLAH JAKARTA

102
4.4.5 Tahapan Penerapan Social Network Analysis
4.4.5.1 Input Data dan Visualisasi Gephi
Peneliti melakukan input data ke dalam gephi untuk melakukan
proses perhitungan parameter social network analysis. Setiap
kelompok dilakukan proses visualisasi untuk mengetahui bentuk graf
dari tiap-tiap kelompok. Penetapan variabel waktu maksimal (t-max)
ditetapkan pada tahapan ini.
1. Kelompok Kontrol
Gambar 4.24 Proses Input Data Gephi Kelompok
Kontrol 2. Kelompok Eksperimen
Gambar 4.25 Proses Input Data Gephi Kelompok
Eksperimen Berdasarkan Gambar 4.24 dan Gambar
4.25, tiap data pada masing-masing kelompok akan di
input kedalam Gephi dalam bentuk format .csv.
untuk kemudian dilakukan visualisasi graf secara
UIN SYARIF HIDAYATULLAH JAKARTA

103
otomatis, pada kelompok kontrol peneliti tidak melakukan
pembatasan waktu terhadap proses visualisasi graf, sedangkan pada
kelompok eksperimen peneliti menerapkan penetapan variabel waktu
maksimal terhadap proses visualisasi graf sebesar 60 detik.
4.4.5.2 Perhitungan Parameter Social Network Analysis
Proses selanjutnya adalah melakukan perhitungan parameter social
network analysis pada masing-masing kelompok dengan menggunakan
bantuan perhitungan pada Gephi. Secara default, gephi hanya
menampilkan 20 node dengan nilai perhitungan paling besar.
Parameter perhitungan adalah sebagai berikut:
1. Perhitungan Degree Centrality
Gambar 4.26 Proses Perhitungan Degree Centrality
2. Perhitungan Betweenness Centrality
Gambar 4.27 Proses Perhitungan Betweenness Centrality
3. Perhitungan Closeness Centrality
Gambar 4.28 Proses Perhitungan Closeness Centrality
4. Perhitungan Eigenvector Centrality
Gambar 4.29 Proses Perhitungan Eigenvector Centrality
5. Perhitungan PageRank
Gambar 4.30 Proses Perhitungan PageRank
UIN SYARIF HIDAYATULLAH JAKARTA

104
BAB V
HASIL ANALISIS DAN PEMBAHASAN
5.1 Pengumpulan dan Penganalisisan Data
Pengumpulan dan penganalisisan data dilakukan dengan mengumpulkan data
dari masing-masing kelompok, untuk kemudian dilakukan analisis sesuai dengan
hasil yang didapat pada tahap pelaksanaan eksperimen.
5.1.1 Hasil Pengumpulan Data
Pada tahap pengumpulan data, peneliti berhasil menarik data tweet dari
Twitter, dengan jumlah data sebanyak 16,400 data. Data tersebut berisikan
seluruh post dari user yang menggunakan Bahasa Indonesia dan mengandung
keyword hoax.
Berikut ini adalah salah satu contoh data yang berhasil diambil pada tahap
pengumpulan data:
Gambar 5.1 Contoh Data Tweet yang Berhasil Terambil
Berikut ini adalah salah satu contoh data yang behasil melalui proses
penarikan data, penentuan konten data, pembatasan data, dan segmentasi data.
Gambar 5.2 Contoh Tweet Pasca Pengambilan
Data 5.1.2 Hasil Visualisasi Data Realtime
Pada tahapan ini peneliti berhasil mekakukan proses indexing sebanyak 8,240
jumlah data dari total 16,400 data. Pada tahap visualisasi dapat dilakukan
104 UIN SYARIF HIDAYATULLAH JAKARTA

105
penggambaran umum secara singkat terhadap kondisi data yang terambil.
Berikut ini adalah hasil visualisasi data realtime pada 8,240 data tweet.
1. Jumlah Data Tweet Original
Tabel 5.1 Jumlah Data Terambil Pada Setiap Loop Pengambilan
UIN SYARIF HIDAYATULLAH JAKARTA

106
Gambar 5.3 Grafik Histogram Data Tweet
Gambar 5.3 menjelaskan grafik histogram tahapan pengambilan data
pada interval 4 jam dengan jeda 30 menit pada setiap bar. Berdasarkan
Tabel 5.1 dan Gambar 5.3 data terbanyak yang dapat diambil pada tahapan
pengambilan data adalah pada loop nomor 38 yaitu sebanyak 215 data.
Data paling sedikit adalah data pada loop 1 yaitu sebanyak 11 data dengan
rata-rata 126 data.
2. Source Data
Tabel 5.2 Jumlah Sumber Data Pengguna Twitter No Source Jumlah 1 Android 6095 2 iPhone 1142 3 Lite 507 4 Web 274 5 Mobile Web 46 6 Deck 35 7 iPad 34 8 Caster 21 9 Plume 11
10 Echofon 10 11 Lain-lain 65 Total 8240
UIN SYARIF HIDAYATULLAH JAKARTA

107
Gambar 5.4 Grafik Source Data Tweet
Berdasarkan Tabel 5.2 dan Gambar 5.4 sebanyak 6,095 data berasal dari
Twitter versi Android, 1,142 data dari Twitter versi iPhone, 507 data dari
Twitter versi Lite, 274 data dari Twitter versi Web, 46 data dari Twitter
versi Mobile Web, 35 data dari Twitter versi Deck, 34 data dari Twitter
versi iPad, 21 data dari Twitter Caster, 11 data dari Twitter Plume, 10 data
dari Twitter Echofon, dan 65 data dari sumber lain yang merupakan
kompilasi berbagai sumber.
3. Jumlah Post User Terbanyak
Tabel 5.3 Tabel 10 Besar User Dengan Post Terbanyak Peringkat Nama User Jumlah Post
1 nogoshop 14 2 FPurwatmo 14 3 aulia2199 12 4 LadyTomato2 12 5 dagadgetboi 11 6 SajaPaulus 11 7 triwul82 10 8 jimmyherdyansy2 10 9 inu_ratih 10
10 AyuGalax 9
UIN SYARIF HIDAYATULLAH JAKARTA

108
Gambar 5.5 Grafik Post User Terbanyak
Berdasarkan Tabel 5.3 dan Gambar 5.5 dapat ditarik kesimpulan bahwa
user nogoshop adalah user dengan jumlah post terbanyak sebesar 14 post.
Sesuai dengan pengaturan default pada dashboard banana, yaitu hanya
user yang masuk kedalam 10 besar data yang akan ditampilkan pada tahap
visualisasi.
4. Post Paling Banyak di Re-Tweet
Tabel 5.4 Tabel 10 Besar User Paling Banyak di Re-Tweet Peringkat Nama User Jumlah Re-Tweet
1 shitlicious 2572 2 lawan_teroris 1570 3 bangsa_patriot 346 4 ZAEffendy 202 5 GusYaqut 201 6 Takviri 187 7 Juno_5760 179 8 tvOneNews 109 9 amiraayuadisty 104
10 henao_212 103
UIN SYARIF HIDAYATULLAH JAKARTA

109
Gambar 5.6 Grafik Post Dengan Re-Tweet Terbanyak
Berdasarkan Tabel 5.4 dan Grafik 5.6 user yang mempunyai jumlah post
yang paling sering di re-tweet adalah user shitlicious dengan jumlah count
sebanyak 2,572 kali.
5.1.3 Hasil Klasifikasi Data
Pada tahap klasifikasi data, dari total data berjumlah 16,400, peneliti berhasil
membagi data tersebut menjadi dua kelompok penelitian, yaitu 8,200 data
termasuk ke dalam kelompok kontrol, dan 8,200 data termasuk ke dalam
kelompok eksperimen. Berikut ini adalah contoh data yang telah berhasil dibagi
menjadi dua kelompok yaitu kelompok kontrol dan kelompok eksperimen.
Gambar 5.7 Contoh Kelompok Kontrol Hasil Klasifikasi
Gambar 5.8 Contoh Kelompok Eksperimen Hasil Klasifikasi
Gambar 5.7 dan Gambar 5.8 merupakan contoh sampel data yang telah
dilakukan pembagian klasifikasi berdasarkan kelompok dari masing-masing
data.
UIN SYARIF HIDAYATULLAH JAKARTA

110
5.1.4 Hasil Eksperimen Intact-Group Comparison
Seluruh data yang telah termasuk ke dalam kelompok penelitian akan
digabungkan menjadi satu kesatuan. Berikut ini adalah hasil dari proses
penggabungan seluruh data menjadi satu data utuh. Yaitu:
Gambar 5.9 Contoh Data Kelompok Kontrol Hasil Merger
Gambar 5.10 Contoh Data Kelompok Eksperimen Hasil Merger
UIN SYARIF HIDAYATULLAH JAKARTA

111
5.1.5 Hasil Penerapan Social Network Analysis
5.1.5.1 Hasil Visualisasi Graf Kelompok Kontrol
Berikut ini adalah hasil visualisasi graf pada tahap visualisasi data
menggunakan gephi dari kelompok kontrol.
Gambar 5.11 Hasil Visualisasi Graf Kelompok Kontrol
Gambar 5.11 merupakan hasil visualisasi yang dilakukan pada kelompok
kontrol, didapat gambar dengan tingkat perbedaan warna gradasi biru muda
menggambarkan nilai rendah, biru gelap menggambarkan nilai
UIN SYARIF HIDAYATULLAH JAKARTA

112
menengah dan warna ungu menggambarkan nilai tinggi. Setiap garis
(edge) melambangkan hubungan antar node.
5.1.5.2 Hasil Perhitungan Parameter SNA Kelompok Kontrol
Pada kelompok kontrol didapatkan karakteristik graf dengan jumlah
node sebanyak 5,234 node dan jumlah edge sebanyak 6,897 edge,
berdasarkan dari data yang berhasil terambil pada tahap pengambilan
data. Dengan total data sebanyak 8,200 data tweet yang termasuk kedalam
kelompok kontrol dalam penelitian.
1. Perhitungan Degree Centrality Kelompok Kontrol
Berdasarkan perhitungan Degree Centrality menggunakan gephi
dengan parameter maksimal iterasi 100 kali pengecekan perhitungan,
maka didapatkan hasil pembagian distribusi degree dengan hasil 20
user dengan nilai Degree Centrality paling besar. Dengan rincian 20
user dengan nilai terbesar sebagai berikut:
Tabel 5.5 User Kontrol Dengan Nilai DC Tertinggi
No User Degree Centrality
1 rockygerung 775
2 Gusmus 653
3 maspiyuuu 557
4 OomNanang 291
5 wahhabicc_jabar 244
6 GunRomli 228
7 wartapolitik 220
8 bangsa_patriot 214 9 shitlicious 131
10 Husen_jafar 113
11 RustamIbrahim 102
12 muannas_alaidid 97
13 SiPinokio_ 89
14 _adityaiskandar 85
15 roninpribumi 78
UIN SYARIF HIDAYATULLAH JAKARTA

113
16 KompasTV 73
17 GKRHayu 71
18 kompascom 65
19 Muhamma37029013 62
20 digembok 61
Gambar 5.12 Grafik Batang Degree Centrality Kelompok Kontrol
Berdasarkan Tabel 5.5 dan Gambar 5.12 dapat ditarik kesimpulan
bahwa Degree Centrality paling tinggi yaitu node rockygerung dengan
nilai 775. Nilai Degree Centrality paling rendah yaitu node digembok
dengan nilai 61. Dengan nilai rata-rata sebesar 210.45 dan jumlah total
nilai sebesar 4209.
2. Perhitungan Betweenness Centrality Kelompok Kontrol Berdasarkan perhitungan Betweenness Centrality menggunakan
gephi dengan parameter maksimal iterasi 100 kali pengecekan
perhitungan, maka didapatkan hasil pembagian distribusi Betweenness
Centrality dengan hasil 20 user dengan nilai Betweenness Centrality
UIN SYARIF HIDAYATULLAH JAKARTA

114
paling besar. Dengan rincian 20 user dengan nilai terbesar sebagai
berikut:
Tabel 5.6 User Kontrol Dengan Nilai BC Tertinggi
No User Betweenness Centrality
1 Gusmus 0.290114
2 rockygerung 0.240371
3 maspiyuuu 0.156906
4 wahhabicc_jabar 0.098745
5 JamalHabsy 0.081072
6 OomNanang 0.074948
7 GunRomli 0.064041
8 rahmaniboy1 0.062650
9 muannas_alaidid 0.056084
10 Husen_jafar 0.050016
11 shitlicious 0.045344
12 Jimlove78A 0.042474
13 wartapolitik 0.039603
14 bangsa_patriot 0.038554
15 kuyabatok 0.032929
16 Rustamibrahim 0.027254
17 KompasTV 0.026352
18 buyaben 0.025663
19 mukejul 0.024875
20 digembok 0.023699
UIN SYARIF HIDAYATULLAH JAKARTA

115
Gambar 5.13 Grafik Batang Betweenness Centrality Kelompok
Kontrol
Berdasarkan Tabel 5.6 dan Gambar 5.13 dapat ditarik kesimpulan
bahwa Betweenness Centrality paling tinggi yaitu node Gusmus
dengan nilai 0.290114. Nilai Betweenness Centrality paling rendah
yaitu node digembok dengan nilai 0.023699. Dengan nilai rata-rata
sebesar 0.0750847 dan jumlah total nilai sebesar 1.501694.
3. Perhitungan Closeness Centrality Kelompok Kontrol
Berdasarkan perhitungan Closeness Centrality menggunakan gephi
dengan parameter maksimal iterasi 100 kali pengecekan perhitungan,
maka didapatkan hasil pembagian distribusi Closeness Centrality
dengan hasil 20 user dengan nilai Closeness Centrality paling besar.
Dengan rincian 20 user dengan nilai terbesar sebagai berikut:
UIN SYARIF HIDAYATULLAH JAKARTA

116
Tabel 5.7 User Kontrol Dengan Nilai CC Tertinggi
No User Closeness Centrality 1 Gusmus 0.336759
2 rockygerung 0.323765
3 maspiyuuu 0.320941
4 JamalHabsy 0.307466
5 rahmaniboy1 0.307108
6 OomNanang 0.306709
7 muannas_alaidid 0.303619
8 Jimlove78A 0.300912
9 wahhabicc_jabar 0.295777
10 buyaben 0.292729
11 kuyabatok 0.287959
12 bangsa_patriot 0.273469
13 KompasTV 0.273220
14 Rustamibrahim 0.270536
15 mukejul 0.268706
16 Husen_jafar 0.268128
17 wartapolitik 0.267250
18 GunRomli 0.260579
19 digembok 0.232663
20 shitlicious 0.228123
UIN SYARIF HIDAYATULLAH JAKARTA

117
Gambar 5.14 Grafik Batang Closeness Centrality
Kelompok Kontrol
Berdasarkan Tabel 5.7 dan Gambar 5.14 dapat ditarik kesimpulan
bahwa Closeness Centrality paling tinggi yaitu node Gusmus dengan
nilai 0.336759. Nilai Closeness Centrality paling rendah yaitu node
shitlicious dengan nilai 0.228123. Dengan nilai rata-rata sebesar
0.2863209 dan jumlah total nilai sebesar 5.726418.
4. Perhitungan Eigenvector Centrality Kelompok Kontrol Berdasarkan
perhitungan Eigenvector Centrality menggunakan
gephi dengan parameter maksimal iterasi 100 kali pengecekan
perhitungan, maka didapatkan hasil pembagian distribusi Eigenvector
Centrality dengan hasil 20 user dengan nilai Eigenvector Centrality
paling besar. Dengan rincian 20 user dengan nilai terbesar sebagai
berikut:
UIN SYARIF HIDAYATULLAH JAKARTA

118
Tabel 5.8 User Kontrol Dengan Nilai EC Tertinggi
No User Eigenvector Centrality 1 rockygerung 1.000000
2 maspiyuuu 0.737111
3 Gusmus 0.619538
4 OomNanang 0.348490
5 bangsa_patriot 0.257696
6 wartapolitik 0.240930
7 wahabicc_jabar 0.177192
8 GunRomli 0.164676
9 roninpribumi 0.153998
10 SiPinokio_ 0.135534
11 Muhamma37029013 0.107585
12 muannas_alaidid 0.097152
13 arman_effendi 0.092594
14 pejoeanglaskar 0.091002
15 badakberacun 0.090621
16 AdeKeren 0.090210
17 youdi40 0.089159
18 1MenujuDamai 0.088035
19 duta_kurniawan 0.087521
20 sakabato9 0.085746
UIN SYARIF HIDAYATULLAH JAKARTA

119
Gambar 5.15 Grafik Batang Eigenvector Centrality
Kelompok Kontrol
Berdasarkan Tabel 5.8 dan Gambar 5.15 dapat ditarik kesimpulan
bahwa Eigenvector Centrality paling tinggi yaitu node rockygerung
dengan nilai 1.00000. Nilai Eigenvector Centrality paling rendah yaitu
node sakabato9 dengan nilai 0.085746. Dengan nilai rata-rata sebesar
0.2377395 dan jumlah total nilai sebesar 4.754790.
5. Perhitungan PageRank Kelompok Kontrol
Berdasarkan perhitungan PageRank menggunakan gephi dengan
parameter maksimal iterasi 100 kali pengecekan perhitungan, maka
didapatkan hasil pembagian distribusi PageRank dengan hasil 20 user
dengan nilai PageRank paling besar. Dengan rincian 20 user dengan
nilai terbesar sebagai berikut:
UIN SYARIF HIDAYATULLAH JAKARTA

120
Tabel 5.9 User Kontrol Dengan Nilai PageRank Tertinggi
No User PageRank 1 rockygerung 0.048477
2 Gusmus 0.044111
3 maspiyuu 0.029835
4 OomNanang 0.016359
5 wahhabicc_jabar 0.014880
6 GunRomli 0.013886
7 wartapolitik 0.011496
8 bangsa_patriot 0.011382
9 shitlicious 0.010989
10 Husen_Jafar 0.008725
11 Rustamibrahim 0.006401
12 GKRHayu 0.006088
13 muannas_alaidid 0.005589
14 mnajibzain 0.005209
15 SuperToleran 0.004842
16 KompasTV 0.004840
17 _adityaiskandar 0.004706
18 SiPinokio_ 0.004342
19 KontraS 0.004127
20 kompascom 0.004117
UIN SYARIF HIDAYATULLAH JAKARTA

121
Gambar 5.16 Grafik Batang PageRank Kelompok Kontrol
Berdasarkan Tabel 5.9 dan Gambar 5.16 dapat ditarik kesimpulan
bahwa PageRank paling tinggi yaitu node rockygerung dengan nilai
0.048477. Nilai PageRank paling rendah yaitu node kompascom
dengan nilai 0.004117. Dengan nilai rata-rata sebesar 0.0130201 dan
jumlah total nilai sebesar 0.260401.
UIN SYARIF HIDAYATULLAH JAKARTA

122
5.1.5.3 Hasil Visualisasi Graf Kelompok Eksperimen
Berikut ini adalah hasil visualisasi graf pada tahap visualisasi data
menggunakan gephi dari kelompok eksperimen.
Gambar 5.17 Hasil Visualisasi Graf Kelompok Eksperimen
Gambar 5.17 merupakan hasil visualisasi yang dilakukan pada
kelompok eksperimen, didapat gambar dengan tingkat perbedaan
warna gradasi biru muda menggambarkan nilai rendah, biru gelap
UIN SYARIF HIDAYATULLAH JAKARTA

123
menggambarkan nilai menengah dan warna ungu menggambarkan
nilai tinggi. Setiap garis (edge) melambangkan hubungan antar node.
5.1.5.4 Hasil Perhitungan Parameter SNA Kelompok Eksperimen
Pada kelompok eksperimen didapatkan karakteristik graf dengan
jumlah node sebanyak 6741 node dan jumlah edge sebanyak 7792 edge,
berdasarkan data yang berhasil terambil pada tahap pengambilan data dari
total 8200 data tweet yang termasuk ke dalam kelompok eksperimen
dalam penelitian.
1. Perhitungan Degree Centrality Kelompok Eksperimen
Berdasarkan perhitungan Degree Centrality menggunakan gephi
dengan parameter maksimal iterasi i = 200 dan t max 60 detik. Maka
didapatkan hasil pembagian distribusi degree dengan hasil 20 user
dengan nilai Degree Centrality paling besar. Dengan rincian 20 user
dengan nilai terbesar sebagai berikut:
Tabel 5.10 User Eksperimen Dengan Nilai DC Tertinggi
No User Degree Centrality
1 shitlicious 2317
2 lawan_teroris 1399
3 bangsa_patriot 286
4 GusYaqut 202
5 ZAEffendy 198
6 Takviri 189
7 Juno_5760 174
8 tvOneNews 106
9 amiraayuadisty 104
10 Stakof 90
11 henao_212 87
12 Doy63014161 84
13 RestyCayah 79
14 muannas_alaidid 73
UIN SYARIF HIDAYATULLAH JAKARTA

124
15 Gun4w4nAhokers 68
16 roninkhalid 66
17 RinjaniJB 60
18 pekaklonto 49
19 IreneViena 44
20 Kimochiii_ 42
Gambar 5.18 Grafik Batang Degree Centrality Kelompok
Eksperimen
Berdasarkan Tabel 5.10 dan Gambar 5.18 dapat ditarik kesimpulan
bahwa Degree Centrality paling tinggi yaitu node shitlicious dengan
nilai 2317. Nilai Degree Centrality paling rendah yaitu node
Kimochiii_dengan nilai 42. Dengan nilai rata-rata sebesar 285.85 dan
jumlah total nilai sebesar 5717.
2. Perhitungan Betweenness Centrality Kelompok Eksperimen Berdasarkan perhitungan Betweenness Centrality menggunakan
gephi dengan parameter maksimal iterasi i = 200 dan t max 60 detik.
Maka didapatkan hasil pembagian distribusi Betweenness Centrality
UIN SYARIF HIDAYATULLAH JAKARTA

125
dengan hasil 20 user dengan nilai Betweenness Centrality paling besar.
Dengan rincian 20 user dengan nilai terbesar sebagai berikut:
Tabel 5.11 User Eksperimen Dengan Nilai BC Tertinggi
No User Betweenness Centrality
1 shitlicious 0.580361
2 lawan_teroris 0.402424
3 bangsa_patriot 0.119399
4 Juno_5760 0.084264
5 ZAEffendy 0.054459
6 GusYaqut 0.049539
7 Doy63014161 0.037279
8 Takviri 0.033183
9 amiraayuadisty 0.025649
10 tvOneNews 0.022902
11 roninkhalid 0.019569
12 muannas_alaidid 0.018712
13 henao_212 0.018283
14 Stakof 0.014532
15 IreneViena 0.012900
16 RestyCayah 0.012092
17 Gun4w4nAhokers 0.009945
18 Kimochiii_ 0.008210
19 RinjaniJB 0.007002
20 pekaklonto 0.005203
UIN SYARIF HIDAYATULLAH JAKARTA

126
Gambar 5.19 Grafik Batang Betweenness Centrality Kelompok
Eksperimen
Berdasarkan Tabel 5.11 dan Gambar 5.19 dapat ditarik kesimpulan
bahwa Betweenness Centrality paling tinggi yaitu node shitlicious
dengan nilai 0.580361. Nilai Betweenness Centrality paling rendah
yaitu node pekaklonto dengan nilai 0.005203. Dengan nilai rata-rata
sebesar 0.0767954 dan jumlah total nilai sebesar 1.535907.
3. Perhitungan Closeness Centrality Kelompok Eksperimen Berdasarkan perhitungan Closeness Centrality menggunakan gephi
dengan parameter maksimal iterasi i = 200 dan t max 60 detik. Maka
didapatkan hasil pembagian distribusi Closeness Centrality dengan
hasil 20 user dengan nilai Closeness Centrality paling besar. Dengan
rincian 20 user dengan nilai terbesar sebagai berikut:
UIN SYARIF HIDAYATULLAH JAKARTA

127
Tabel 5.12 User Eksperimen Dengan Nilai CC Tertinggi
No User Closeness Centrality
1 shitlicious 0.386739
2 lawan_teroris 0.344720
3 GusYaqut 0.315169
4 muannas_alaidid 0.310828
5 Kimochiii_ 0.310238
6 bangsa_patriot 0.287968
7 Takviri 0.278433
8 pekaklonto 0.267916
9 Gun4w4nAhokers 0.264976
10 RinjaniJB 0.264840
11 Stakof 0.264321
12 RestyCayah 0.249357
13 Juno_5760 0.235415
14 Doy63014161 0.234180
15 ZAEffendy 0.228296
16 tvOneNews 0.223922
17 roninkhalid 0.223037
18 IreneViena 0.221516
19 henao_212 0.206543
20 amiraayuadisty 0.163153
UIN SYARIF HIDAYATULLAH JAKARTA

128
Gambar 5.20 Grafik Batang Closeness Centrality
Kelompok Eksperimen
Berdasarkan Tabel 5.12 dan Gambar 5.20 dapat ditarik kesimpulan
bahwa Closeness Centrality paling tinggi yaitu node shitlicious dengan
nilai 0.386739. Nilai Closeness Centrality paling rendah yaitu node
amiraayuadisty dengan nilai 0.163153. Dengan nilai rata-rata sebesar
0.2640784 dan jumlah total nilai sebesar 5.281567.
4. Perhitungan Eigenvector Centrality Kelompok Eksperimen Berdasarkan perhitungan Eigenvector Centrality menggunakan
gephi dengan parameter maksimal iterasi i = 200 dan t max 60 detik.
Maka didapatkan hasil pembagian distribusi Eigenvector Centrality
dengan hasil 20 user dengan nilai Eigenvector Centrality paling besar.
Dengan rincian 20 user dengan nilai terbesar sebagai berikut:
UIN SYARIF HIDAYATULLAH JAKARTA

129
Tabel 5.13 User Eksperimen Dengan Nilai EC Tertinggi
No User Eigenvector Centrality
1 Shitlicious 1.000000
2 lawan_teroris 0.487932
3 GusYaqut 0.070136
4 bangsa_patriot 0.066337
5 Takviri 0.057198
6 ZAEffendy 0.043862
7 muannas_alaidid 0.038465
8 Juno_5760 0.036673
9 Kimochiii_ 0.030504
10 Stakof 0.025003
11 tvOneNews 0.023579
12 amiraayuadisty 0.020926
13 RestyCayah 0.019920
14 henao_212 0.019071
15 Gun4w4nAhokers 0.018535
16 Doy63014161 0.018336
17 RinjaniJB 0.017585
18 Roninkhalid 0.014724
19 Pekaklonto 0.013609
20 IreneViena 0.009738
UIN SYARIF HIDAYATULLAH JAKARTA

130
Gambar 5.21 Grafik Batang Eigenvector Centrality
Kelompok Eksperimen
Berdasarkan Tabel 5.13 dan Gambar 5.21 dapat ditarik kesimpulan
bahwa Eigenvector Centrality paling tinggi yaitu node
shitliciousdengan nilai 1.00000. Nilai Eigenvector Centrality paling
rendah yaitu node IreneViena dengan nilai 0.009738. Dengan nilai
rata-rata sebesar 0.1016067 dan jumlah total nilai sebesar 2.032133.
5. Perhitungan PageRank Kelompok Eksperimen
Berdasarkan perhitungan PageRank menggunakan gephi dengan
parameter maksimal iterasi i = 200 dan t max 60 detik. Maka
didapatkan hasil pembagian distribusi PageRank dengan hasil 20 user
dengan nilai PageRank paling besar. Dengan rincian 20 user dengan
nilai terbesar sebagai berikut:
UIN SYARIF HIDAYATULLAH JAKARTA

131
Tabel 5.14 User Eksperimen Dengan Nilai PageRank Tertinggi
No User PageRank
1 shitlicious 0.145157
2 lawan_teroris 0.080633
3 bangsa_patriot 0.014430
4 GusYaqut 0.011088
5 Juno_5760 0.010764
6 ZAEffendy 0.010421
7 Takviri 0.008935
8 amiraayuadisty 0.006381
9 tvOneNews 0.005145
10 Doy63014161 0.004863
11 Stakof 0.004630
12 henao_212 0.004286
13 muannas_alaidid 0.003573
14 RestyCayah 0.003561
15 Gun4w4nAhokers 0.003317
16 roninkhalid 0.003269
17 RinjaniJB 0.002721
18 pekaklonto 0.002103
19 Kimochiii_ 0.001966
20 IreneViena 0.001938
UIN SYARIF HIDAYATULLAH JAKARTA

132
Gambar 5.22 Grafik Batang PageRank Kelompok Eksperimen
Berdasarkan Tabel 5.14 dan Gambar 5.22 dapat ditarik kesimpulan
bahwa PageRank paling tinggi yaitu node shitlicious dengan nilai
0.145157. Nilai PageRank paling rendah yaitu node IreneViena
dengan nilai 0.001938. Dengan nilai rata-rata sebesar 0.0164591
dan jumlah total nilai sebesar 0.329181.
5.1.6 Hasil Analisis Kelompok Kontrol
Kelompok kontrol mempunyai karakteristik graf dengan jumlah node
sebanyak 5,234 node dan jumlah edge sebanyak 6,897 edge. Berdasarkan
hasil visualisasi kelompok kontrol Gambar 5.11 terdapat 3 cluster raksasa
yang tercipta berdasarkan nilai Degree Centrality. Pemilihan Degree
Centrality dikarenakan peneliti ingin melihat dan memunculkan seberapa
besar pengaruh node di dalam jaringan.
UIN SYARIF HIDAYATULLAH JAKARTA

133
Tabel 5.15 20 Besar User Kontrol Dengan Nilai DC Tertinggi
Rank Id User Degree Centrality
1 122 rockygerung 775
2 58 Gusmus 653
3 62 maspiyuuu 557
4 416 OomNanang 291
5 432 wahhabicc_jabar 244
6 319 GunRomli 228
7 321 wartapolitik 220
8 10 bangsa_patriot 214
9 1 shitlicious 131
10 57 Husen_jafar 113
11 11 RustamIbrahim 102
12 54 muannas_alaidid 97
13 310 SiPinokio_ 89
14 401 _adityaiskandar 85
15 376 roninpribumi 78
16 282 KompasTV 73
17 407 GKRHayu 71
18 281 kompascom 65
19 240 Muhamma37029013 62
20 162 digembok 61
UIN SYARIF HIDAYATULLAH JAKARTA

134
Gambar 5.23 Grafik 20 Besar User Kontrol Dengan Nilai DC
Tertinggi
Berdasarkan Tabel 5.15 dan Gambar 5.23 node utama adalah user dengan
nama rockygerung dengan nilai Degree Centrality sebesar 775 poin, Gusmus
dengan nilai 653 poin dan maspiyuuu dengan nilai 557 poin. Dengan nilai
tersebut graf dapat dibagi menjadi 3 cluster utama.
UIN SYARIF HIDAYATULLAH JAKARTA

135
5.1.6.1 Cluster Nomor 1 Dengan Node Utama rockygerung.
Gambar 5.24 Cluster Nomor 1 Dengan Node Utama rockygerung
Berdasarkan Gambar 5.24 dapat ditarik kesimpulan bahwa ada 2 node besar
yaitu node bangsa_patriot dengan nilai Degree Centrality sebesar 214 dan
node OomNanang dengan nilai sebesar 291. Artinya node rockygerung adalah
node yang mempunyai pengaruh utama pada cluster nomor 1 dengan berhasil
menarik 2 node besar lain kedalam ruang lingkup pertukaran informasi pada
cluster di dalam graf.
UIN SYARIF HIDAYATULLAH JAKARTA

136
Tabel 5.16 Perbandingan Parameter SNA pada Anggota Cluster 1 Rank Id User Degree C Betweenness C Closeness C Eigenvector C PageRank
1 122 rockygerung 775 0.240371 0.323765 1.000000 0.048477 4 416 OomNanang 291 0.074948 0.306709 0.348490 0.016359 8 10 bangsa_patriot 214 0.038554 0.273469 0.257696 0.011382
Gambar 5.25 Perbandingan Parameter SNA pada Anggota Cluster 1
Tabel 5.16 dan Gambar 5.25 merupakan perbandingan nilai hasil
pengukuran SNA terhadap anggota cluster nomor 1 dengan jumlah anggota
utama 3 node yang termasuk ke dalam 20 besar node paling berpengaruh
dalam graf. Berdasarkan Tabel 5.16 dan Gambar 5.25 node rockygerung
menempati posisi paling tinggi pada cluster nomor 1, sesuai dengan nilai dari
parameter lain yaitu:
1. Nilai Degree Centrality
Node rockygerung dengan nilai 775 sebagai node paling berpengaruh di
dalam cluster.
2. Nilai Betweenneess Centrality
Node rockygerung dengan nilai 0.240371 sebagai node dengan alur jarak
terpendek dalam penyebaran informasi di dalam cluster.
3. Nilai Closeness Centrality
Node rockygerung dengan nilai 0.323765 sebagai node dengan jumlah
relasi paling banyak di dalam cluster.
UIN SYARIF HIDAYATULLAH JAKARTA

137
4. Nilai Eigenvector Centrality
Node rockygerung dengan nilai 1.000000 sebagai node yang mempunyai
hubungan dengan node lain paling tinggi dari sisi relasi.
5. Nilai PageRank
Node rockygerung dengan nilai 0.048477 sebagai node yang paling banyak
diberikan referensi oleh node lain di dalam cluster.
5.1.6.2 Cluster Nomor 2 Dengan Node Utama Gusmus.
Gambar 5.26 Cluster Nomor 2 Dengan Node Utama Gusmus
UIN SYARIF HIDAYATULLAH JAKARTA

138
Berdasarkan Gambar 5.26 dapat ditarik kesimpulan bahwa ada 4 node
besar yaitu node wahhabicc_jabar dengan nilai Degree Centrality sebesar 244,
node RustamIbrahim dengan nilai sebesar 102, node GunRomli dengan nilai
sebesar 228, dan node KompasTV dengan nilai sebesar 73. Artinya node
Gusmus adalah node yang mempunyai pengaruh utama pada cluster nomor 2
dengan berhasil menarik 4 node besar lain menuju ruang lingkup pertukaran
informasi pada cluster di dalam graf.
Tabel 5.17 Perbandingan Parameter SNA pada Anggota Cluster 2 Rank Id User Degree C Betweenness C Closeness C Eigenvector C PageRank
2 58 Gusmus 653 0.290114 0.336759 0.619538 0.044111 5 432 wahhabicc_jabar 244 0.098745 0.295777 0.177192 0.014880 6 319 GunRomli 228 0.064041 0.260579 0.164676 0.013886
11 11 RustamIbrahim 102 0.027254 0.270536 0.083879 0.006401 16 282 KompasTV 73 0.026352 0.273220 0.037895 0.004840
Gambar 5.27 Perbandingan Parameter SNA pada Anggota Cluster 2
Tabel 5.17 dan Gambar 5.27 merupakan perbandingan nilai hasil
pengukuran SNA terhadap anggota cluster nomor 2 dengan jumlah anggota
utama 5 node yang termasuk ke dalam 20 besar node paling berpengaruh dalam
graf. Berdasarkan Tabel 5.17 dan Gambar 5.27 node Gusmus menempati posisi
paling tinggi pada cluster nomor 2, sesuai dengan nilai dari parameter lain yaitu:
UIN SYARIF HIDAYATULLAH JAKARTA

139
1. Nilai Degree Centrality
Node Gusmus dengan nilai 653 sebagai node paling berpengaruh di dalam
cluster.
2. Nilai Betweenneess Centrality
Node Gusmus dengan nilai 0.290114 sebagai node dengan alur jarak
terpendek dalam penyebaran informasi di dalam cluster.
3. Nilai Closeness Centrality
Node Gusmus dengan nilai 0.336759 sebagai node dengan jumlah relasi
paling banyak di dalam cluster.
4. Nilai Eigenvector Centrality
Node Gusmus dengan nilai 0.619538 sebagai node yang mempunyai
hubungan dengan node lain paling tinggi dari sisi relasi.
5. Nilai PageRank
Node Gusmus dengan nilai 0.044111 sebagai node yang paling banyak
diberikan referensi oleh node lain di dalam cluster.
UIN SYARIF HIDAYATULLAH JAKARTA

140
5.1.6.3 Cluster Nomor 3 Dengan Node Utama maspiyuuu
Gambar 5.28 Cluster Nomor 3 Dengan Node Utama maspiyuuu
Berdasarkan Gambar 5.28 dapat ditarik kesimpulan bahwa ada 3 node besar
yaitu node wartapolitik dengan nilai Degree Centrality sebesar 220, node
Husen_Jafar dengan nilai sebesar 113, dan node shitlicious dengan nilai sebesar
131. Artinya node maspiyuuu adalah node yang mempunyai pengaruh utama
pada cluster nomor 3 dengan berhasil menarik 3 node besar lain menuju ruang
lingkup pertukaran informasi pada cluster di dalam graf.
UIN SYARIF HIDAYATULLAH JAKARTA

141
Tabel 5.18 Perbandingan Parameter SNA pada Anggota Cluster 3 Rank Id User Degree C Betweenness C Closeness C Eigenvector C PageRank
3 62 maspiyuuu 557 0.156906 0.320941 0.737111 0.029835 7 319 wartapolitik 220 0.039603 0.267250 0.240930 0.011496 9 282 shitlicious 131 0.045344 0.228123 0.056066 0.010989 10 11 Husen_Jafar 113 0.050016 0.268128 0.052812 0.008725
Gambar 5.29 Perbandingan Parameter SNA pada Anggota Cluster 3
Tabel 5.18 dan Gambar 5.29 merupakan perbandingan nilai hasil
pengukuran SNA terhadap anggota cluster nomor 3 dengan jumlah anggota
utama 4 node yang termasuk ke dalam 20 besar node paling berpengaruh
dalam graf. Berdasarkan Tabel 5.18 dan Gambar 5.29 node maspiyuuu
menempati posisi paling tinggi pada cluster nomor 3, sesuai dengan nilai dari
parameter lain yaitu:
1. Nilai Degree Centrality.
Node maspiyuuu dengan nilai 557 sebagai node paling berpengaruh di
dalam cluster.
2. Nilai Betweenneess Centrality.
Node maspiyuuu dengan nilai 0.156906 sebagai node dengan alur jarak
terpendek dalam penyebaran informasi di dalam cluster.
UIN SYARIF HIDAYATULLAH JAKARTA

142
3. Nilai Closeness Centrality.
Node maspiyuuu dengan nilai 0.320941 sebagai node dengan jumlah relasi
paling banyak di dalam cluster.
4. Nilai Eigenvector Centrality.
Node maspiyuuu dengan nilai 0.737111 sebagai node yang mempunyai
hubungan dengan node lain paling tinggi dari sisi relasi.
5. Nilai PageRank.
Node maspiyuuu dengan nilai 0.029835 sebagai node yang paling banyak
diberikan referensi oleh node lain di dalam cluster.
5.1.6.4 Kompilasi Hasil Kelompok Kontrol
Tabel 5.19 Kompilasi Nilai Parameter SNA Kelompok Kontrol
Rank Id User Degree C Betweenness C Closeness C Eigenvector C PageRank
1 122 rockygerung 775 0.240371 0.323765 1.000000 0.048477
2 58 Gusmus 653 0.290114 0.336759 0.619538 0.044111
3 62 maspiyuuu 557 0.156906 0.320941 0.737111 0.029835
4 416 OomNanang 291 0.074948 0.306709 0.348490 0.016359
5 432 wahhabicc_jabar 244 0.098745 0.295777 0.177192 0.014880
6 319 GunRomli 228 0.064041 0.260579 0.164676 0.013886
7 321 wartapolitik 220 0.039603 0.267250 0.240930 0.011496
8 10 bangsa_patriot 214 0.038554 0.273469 0.257696 0.011382
9 1 shitlicious 131 0.045344 0.228123 0.056066 0.010989
10 57 Husen_jafar 113 0.050016 0.268128 0.052812 0.008725
11 11 RustamIbrahim 102 0.027254 0.270536 0.083879 0.006401
12 54 muannas_alaidid 97 0.056084 0.303619 0.097152 0.005589
13 310 SiPinokio_ 89 0.019186 0.280212 0.135534 0.004342
14 401 _adityaiskandar 85 0.020405 0.272971 0.072436 0.004706
15 376 roninpribumi 78 0.017471 0.279845 0.153998 0.003742
16 282 KompasTV 73 0.026352 0.273220 0.037895 0.004840
17 407 GKRHayu 71 0.022482 0.169371 0.026816 0.006088
18 281 kompascom 65 0.015117 0.232506 0.034658 0.004117
19 240 Muhamma37029013 62 0.007432 0.255492 0.107585 0.002964
20 162 digembok 61 0.023699 0.232663 0.042175 0.003443
UIN SYARIF HIDAYATULLAH JAKARTA

143
Gambar 5.30 Kompilasi Nilai Parameter SNA Kelompok Kontrol
Tabel 5.19 dan Gambar 5.30 menjabarkan bahwa node rockygerung
dan node Gusmus bertindak sebagai node yang paling berpengaruh pada
kelompok kontrol. Hal tersebut menyebabkan polarisasi sesuai dengan
hasil visualisasi graf kelompok kontrol pada Gambar 5.11.
Pada Gambar 5.30 peneliti melakukan normalisasi nilai Degree
Centrality dengan melakukan perhitungan pembagian dengan jumlah
seluruh data pada kelompok kontrol, hal tersebut peneliti lakukan agar
seluruh nilai pada perhitungan parameter social network analysis dapat
dilakukan perbandingan dan visualisasi.
Berdasarkan perhitungan pada cluster nomor 1, cluster nomor 2 dan
cluster nomor 3 dapat ditarik kesimpulan bahwa pada tiap cluster
mempunyai 1 node yang bertugas sebagai node paling berpengaruh di
dalam graf. Dalam penelitian terkait berita hoax dapat disimpulkan
bahwa 3 node pada cluster adalah node yg secara langsung berperan
dalam lingkup tweet dengan batasan keyword hoax.
UIN SYARIF HIDAYATULLAH JAKARTA

144
5.1.6.5 Analisis User Berpengaruh Kelompok Kontrol
Berdasarkan hasil visualisasi graf kelompok kontrol pada gambar
5.11 dan hasil perhitungan parameter SNA pada Tabel 5.19 dapat ditarik
kesimpulan bahwa ada 3 node yang paling berpengaruh di dalam graf.
Berikut ini adalah analisis user paling berpengaruh di graf kelompok
kontrol:
1. User rockygerung
Gambar 5.31 Akun Twitter @rockygerung
Berdasarkan informasi dari gambar 5.31 dan akun Twitter
@rockygerung dapat diambil informasi bahwa akun @rockygerung
mempunyai Followers atau pengikut sebanyak 77,800 orang. Dengan
jumlah Posting Tweets sebanyak 24,300 post. Status akun belum
diakui secara resmi oleh Twitter.
UIN SYARIF HIDAYATULLAH JAKARTA

145
2. User Gusmus
Gambar 5.32 Akun Twitter @gusmusgusmu
Berdasarkan informasi dari gambar 5.32 dan akun Twitter
@gusmusgusmu dapat diambil informasi bahwa akun
@gusmusgusmu mempunyai Followers atau pengikut sebanyak
1,540,000 orang. Dengan jumlah Posting Tweets sebanyak 13,800
post. Status akun sudah diakui secara resmi oleh Twitter.
3. User maspiyuuu
Gambar 5.33 Akun Twitter @maspiyuuu
Berdasarkan informasi dari gambar 5.33 dan akun Twitter
@maspiyuuu dapat diambil informasi bahwa akun @maspiyuuu
mempunyai Followers atau pengikut sebanyak 164,000 orang. Dengan
UIN SYARIF HIDAYATULLAH JAKARTA

146
jumlah Posting Tweets sebanyak 394,000 post. Status akun belum
diakui secara resmi oleh Twitter.
Tabel 5.20 Status User Berpengaruh pada Kelompok Kontrol Rank Id User Follower Post Status
1 122 rockygerung 77800 24300 Non-Verified 2 58 Gusmus 1540000 13800 Verified
3 62 maspiyuuu 164000 394000 Non-Verified
Gambar 5.34 Grafik Status User Berpengaruh pada Kelompok
Kontrol
Berdasarkan Tabel 5.20 dan Gambar 5.34 maka node gusmus
adalah node yang mempunyai jumlah pengikut paling banyak, namun
jika dilihat dari jumlah post, node maspiyuu adalah node yang
mempunyai jumlah post paling banyak. Node gusmus menempati
posisi ke 2 dikarenakan jumlah post tidak sebanyak jumlah post dari
node lain. Dan salah satu penunjang pengaruh akun gusmus adalah
status akun Twitter gusmus sudah diakui oleh Twitter. Dan sesuai
dengan hasil visualisasi graf kelompok kontrol pada Gambar 5.11
menggambarkan bahwa kedekatan node rockygerung dan maspiyuuu
lebih erat jika dibandingkan dengan node gusmus.
UIN SYARIF HIDAYATULLAH JAKARTA

147
Tabel 5.21 Tabel Jumlah Node Di Dalam Cluster Kontrol Rank Id User Node Total Nilai Degree Centrality
1 122 rockygerung 3 1280 2 58 Gusmus 5 1300 3 62 maspiyuuu 4 1021
Gambar 5.35 Grafik Jumlah Node Di Dalam Cluster Kontrol
Berdasarkan Tabel 5.21 dan Gambar 5.23 dan hasil visualisasi graf
kelompok kontrol gambar 5.11 bahwa node rockygerung mempunyai
relasi dan jalur terpendek yang dekat dengan node maspiyuuu, maka
dapat ditarik kesimpulan bahwa node rockygerung dan maspiyuuu
mempunyai jumlah node anggota cluster sebanyak 7 node besar,
sedangkan node Gusmus hanya mempunyai anggota cluster sebanyak 5
node besar. Dengan total nilai Degree Centrality cluster rockygerung
dan maspiyuu sebesar 1280 + 1021 = 2301. Sedangkan cluster gusmus
hanya mempunyai nilai 1300. Dengan Total Nilai sebesar 3601.
5.1.7 Hasil Analisis Kelompok Eksperimen
Kelompok eksperimen mempunyai karakteristik graf dengan jumlah node
sebanyak 6,741 node dan jumlah edge sebanyak 7,792 edge. Berdasarkan hasil
visualisasi graf kelompok eksperimen Gambar 5.17 terdapat 4 cluster raksasa
UIN SYARIF HIDAYATULLAH JAKARTA

148
yang tercipta berdasarkan nilai Degree Centrality. Pemilihan Degree
Centrality dikarenakan peneliti ingin melihat dan memunculkan seberapa
besar pengaruh node di dalam jaringan.
Tabel 5.22 20 Besar User Eksperimen Dengan Nilai DC Tertinggi
Rank Id User Degree Centrality
1 4 shitlicious 2317
2 2 lawan_teroris 1399
3 340 bangsa_patriot 286
4 230 GusYaqut 202
5 16 ZAEffendy 198
6 43 Takviri 189
7 6 Juno_5760 174
8 277 tvOneNews 106
9 352 amiraayuadisty 104
10 3 Stakof 90
11 194 henao_212 87
12 262 Doy63014161 84
13 342 RestyCayah 79
14 26 muannas_alaidid 73
15 14 Gun4w4nAhokers 68
16 399 roninkhalid 66
17 25 RinjaniJB 60
18 182 pekaklonto 49
19 306 IreneViena 44
20 41 Kimochiii_ 42
UIN SYARIF HIDAYATULLAH JAKARTA

149
Gambar 5.36 Grafik 20 Besar User Eksperimen Dengan Nilai DC Tertinggi
Berdasarkan Tabel 5.22 dan Gambar 5.36, 4 node utama adalah user
dengan nama shitlicious dengan nilai Degree Centrality sebesar 2317 poin,
lawan_teroris dengan nilai 1399 poin, bangsa_patriot dengan nilai 286, dan
GusYaqut dengan nilai 202 poin. Dengan nilai tersebut graf dapat dibagi
menjadi 4 cluster utama.
UIN SYARIF HIDAYATULLAH JAKARTA

150
5.1.7.1 Cluster A Dengan Node Utama shitlicious.
Gambar 5.37 Cluster A Dengan Node Utama shitlicious
Berdasarkan Gambar 5.37 dapat ditarik kesimpulan bahwa ada 2 node kecil
yaitu node Asadi1933 dengan nilai Degree Centrality sebesar 2 dan node
ItsRahSya dengan nilai sebesar 3. Artinya node shitlicious adalah node yang
mempunyai pengaruh utama kepada node dengan ukuran node kecil, node
kecil adalah node yang mempunyai perbandingan nilai Degree Centrality
berbanding jauh dengan node utama dengan nilai 2317:2. Node kecil bertugas
sebagai node representatif terhadap node kecil lainnya.
UIN SYARIF HIDAYATULLAH JAKARTA

151
Tabel 5.23 Perbandingan Parameter SNA pada Anggota Cluster A Rank Id User Degree C Betweenness C Closeness C Eigenvector C PageRank
1 4 shitlicious 2317 0.580361 0.386739 1.000000 0.145157 352 3636 ItsRahSya 3 0.115802 0.293289 0.020346 0.000177 1001 2706 Asadi1933 2 0.038601 0.306560 0.020379 0.000118
Gambar 5.38 Perbandingan Parameter SNA pada Anggota Cluster A
Tabel 5.23 dan Gambar 5.38 merupakan perbandingan nilai hasil
pengukuran SNA terhadap anggota cluster A dengan jumlah anggota utama 1
node yang termasuk ke dalam 20 besar node paling berpengaruh dalam graf.
Berdasarkan Tabel 5.23 dan Gambar 5.38 node shitlicious menempati posisi
paling tinggi pada cluster A, sesuai dengan nilai dari parameter lain yaitu:
1. Nilai Degree Centrality
Node shitlicious dengan nilai 2317 sebagai node paling berpengaruh di
dalam cluster.
2. Nilai Betweenneess Centrality
Node shitlicious dengan nilai 0.580361 sebagai node dengan alur jarak
terpendek dalam penyebaran informasi di dalam cluster.
3. Nilai Closeness Centrality
Node shitlicious dengan nilai 0.386739 sebagai node dengan jumlah relasi
paling banyak di dalam cluster.
UIN SYARIF HIDAYATULLAH JAKARTA

152
4. Nilai Eigenvector Centrality
Node shitlicious dengan nilai 1.000000 sebagai node yang mempunyai
hubungan dengan node lain paling tinggi dari sisi relasi.
5. Nilai PageRank
Node shitlicious dengan nilai 0.145157 sebagai node yang paling banyak
diberikan referensi oleh node lain di dalam cluster.
5.1.7.2 Cluster B Dengan Node Utama lawan_teroris.
Gambar 5.39 Cluster B Dengan Node Utama lawan_teroris
UIN SYARIF HIDAYATULLAH JAKARTA

153
Berdasarkan Gambar 5.39 dapat ditarik kesimpulan bahwa ada 2 node
besar yaitu node Takviri dengan nilai Degree Centrality sebesar 189 dan node
Stakof dengan nilai sebesar 90. Artinya node lawan_teroris adalah node yang
mempunyai pengaruh utama pada cluster B dengan berhasil menarik 2 node
besar lain menuju ruang lingkup pertukaran informasi pada cluster di dalam
graf. Dapat dilihat bahwa node lawan_teroris juga menarik 5 node kecil
disekelilingnya yaitu node (PartaiSocmed, WartaNU, nu_online,
republikaonline, dan DivHumasPolri).
Tabel 5.24 Perbandingan Parameter SNA pada Anggota Cluster B Rank Id User Degree C Betweenness C Closeness C Eigenvector C PageRank
1 2 lawan_teroris 1399 0.402424 0.344720 0.487932 0.080633 6 43 Takviri 189 0.033183 0.278433 0.057198 0.008935
10 3 Stakof 90 0.014532 0.264321 0.025003 0.004630
Gamber 5.40 Perbandingan Parameter SNA pada Anggota Cluster B
Tabel 5.24 dan Gambar 5.40 merupakan perbandingan nilai hasil
pengukuran SNA terhadap anggota cluster B dengan jumlah anggota utama 3
node yang termasuk ke dalam 20 besar node paling berpengaruh dalam graf.
Berdasarkan Tabel 5.24 dan Gambar 5.40 node lawan_teroris menempati
posisi paling tinggi pada cluster B, sesuai dengan nilai dari parameter lain yaitu:
UIN SYARIF HIDAYATULLAH JAKARTA

154
1. Nilai Degree Centrality
Node lawan_teroris dengan nilai 1399 sebagai node paling berpengaruh di
dalam cluster.
2. Nilai Betweenneess Centrality
Node lawan_teroris dengan nilai 0.402424 sebagai node dengan alur jarak
terpendek dalam penyebaran informasi di dalam cluster.
3. Nilai Closeness Centrality
Node lawan_teroris dengan nilai 0.344720 sebagai node dengan jumlah
relasi paling banyak di dalam cluster.
4. Nilai Eigenvector Centrality
Node lawan_teroris dengan nilai 0.487932 sebagai node yang mempunyai
hubungan dengan node lain paling tinggi dari sisi relasi.
5. Nilai PageRank
Node lawan_teroris dengan nilai 0.080633 sebagai node yang paling
banyak diberikan referensi oleh node lain di dalam cluster.
UIN SYARIF HIDAYATULLAH JAKARTA

155
5.1.7.3 Cluster C Dengan Node Utama bangsa_patriot.
Gambar 5.41 Cluster C Dengan Node Utama bangsa_patriot Berdasarkan
Gambar 5.41 dapat ditarik kesimpulan bahwa ada 3 node besar
yaitu node ZAEffendy dengan nilai Degree Centrality sebesar 198, node
GusYaqut dengan nilai sebesar 202, dan node tvOneNews dengan nilai sebesar
106. Artinya node bangsa_patriot adalah node yang mempunyai pengaruh
utama pada cluster C dengan berhasil menarik 3 node besar lain menuju ruang
lingkup pertukaran informasi pada cluster di dalam graf. Pada cluster ini dapat
UIN SYARIF HIDAYATULLAH JAKARTA

156
dilihat bahwa node bangsa_patriot dan GusYaqut menjadi node 4 besar
pembentukan cluster, namun bangsa_patriot menjadi node utama dalam
cluster. Dikarenakan nilai Betweenness Centrality node bangsa_patriot lebih
besar dari node GusYaqut.
Tabel 5.25 Perbandingan Parameter SNA pada Anggota Cluster C Rank Id User Degree C Betweenness C Closeness C Eigenvector C PageRank
3 340 bangsa_patriot 286 0.119399 0.287968 0.066337 0.014430 4 230 GusYaqut 202 0.049539 0.315169 0.070136 0.011088 5 16 ZAEffendy 198 0.054459 0.228296 0.043862 0.010421 8 277 tvOneNews 106 0.022902 0.223922 0.023579 0.005145
Gambar 5.42 Perbandingan Parameter SNA pada Anggota Cluster C
Tabel 5.25 dan Gambar 5.42 merupakan perbandingan nilai hasil pengukuran
SNA terhadap anggota cluster C dengan jumlah anggota utama 4 node yang
termasuk ke dalam 20 besar node paling berpengaruh dalam graf. Berdasarkan
Tabel 5.25 dan Gambar 5.42 node bangsa_patriot menempati posisi paling tinggi
pada cluster C, sesuai dengan nilai dari parameter lain yaitu:
1. Nilai Degree Centrality.
Node bangsa_patriot dengan nilai 286 sebagai node paling berpengaruh di
dalam cluster.
UIN SYARIF HIDAYATULLAH JAKARTA

157
2. Nilai Betweenneess Centrality.
Node bangsa_patriot dengan nilai 0.119399 sebagai node dengan alur jarak
terpendek dalam penyebaran informasi di dalam cluster.
3. Nilai Closeness Centrality.
Node GusYaqut dengan nilai 0.315169 sebagai node dengan jumlah relasi
paling banyak di dalam cluster.
4. Nilai Eigenvector Centrality.
Node GusYaqut dengan nilai 0.070136 sebagai node yang mempunyai
hubungan dengan node lain paling tinggi dari sisi relasi.
5. Nilai PageRank.
Node bangsa_patriot dengan nilai 0.014430 sebagai node yang paling
banyak diberikan referensi oleh node lain di dalam cluster.
UIN SYARIF HIDAYATULLAH JAKARTA

158
5.1.7.4 Cluster D Dengan Node Utama Juno_5760.
Gambar 5.43 Cluster D Dengan Node Utama Juno_5760 Berdasarkan
Gambar 5.43 dapat ditarik kesimpulan bahwa ada 1 node besar
yaitu node amiraayuadisty dengan nilai Degree Centrality sebesar 104.
Artinya node Juno_5760 adalah node yang mempunyai pengaruh utama pada
cluster D dengan berhasil menarik 1 node besar lain menuju ruang lingkup
pertukaran informasi pada cluster di dalam graf.
UIN SYARIF HIDAYATULLAH JAKARTA

159
Tabel 5.26 Perbandingan Parameter SNA pada Anggota Cluster D Rank Id User Degree C Betweenness C Closeness C Eigenvector C PageRank
7 6 Juno_5760 174 0.084264 0.235415 0.036673 0.010764 9 352 amiraayuadisty 104 0.025649 0.163153 0.020926 0.006381
Gambar 5.44 Perbandingan Parameter SNA pada Anggota Cluster D
Tabel 5.26 dan Gambar 5.44 merupakan perbandingan nilai hasil
pengukuran SNA terhadap anggota cluster D dengan jumlah anggota utama 2
node yang termasuk ke dalam 20 besar node paling berpengaruh dalam graf.
Berdasarkan Tabel 5.26 dan Gambar 5.44 node Juno_5760 menempati posisi
paling tinggi pada cluster D, sesuai dengan nilai dari parameter lain yaitu:
1. Nilai Degree Centrality.
Node Juno_5760 dengan nilai 174 sebagai node paling berpengaruh di
dalam cluster.
2. Nilai Betweenneess Centrality.
Node Juno_5760 dengan nilai 0.084264 sebagai node dengan alur jarak
terpendek dalam penyebaran informasi di dalam cluster.
3. Nilai Closeness Centrality.
Node Juno_5760 dengan nilai 0.235415 sebagai node dengan jumlah relasi
paling banyak di dalam cluster.
UIN SYARIF HIDAYATULLAH JAKARTA

160
4. Nilai Eigenvector Centrality.
Node Juno_5760 dengan nilai 0.036673 sebagai node yang mempunyai
hubungan dengan node lain paling tinggi dari sisi relasi.
5. Nilai PageRank.
Node Juno_5760 dengan nilai 0.010764 sebagai node yang paling banyak
diberikan referensi oleh node lain di dalam cluster.
5.1.7.5 Kompilasi Hasil Kelompok Eksperimen
Tabel 5.27 Kompilasi Nilai Parameter SNA Kelompok Eksperimen
Rank Id User Degree C Betweenness C Closeness C Eigenvector C PageRank
1 4 shitlicious 2317 0.580361 0.386739 1.000000 0.145157
2 2 lawan_teroris 1399 0.402424 0.344720 0.487932 0.080633
3 340 bangsa_patriot 286 0.119399 0.287968 0.066337 0.014430
4 230 GusYaqut 202 0.049539 0.315169 0.070136 0.011088
5 16 ZAEffendy 198 0.054459 0.228296 0.043862 0.010421
6 43 Takviri 189 0.033183 0.278433 0.057198 0.008935
7 6 Juno_5760 174 0.084264 0.235415 0.036673 0.010764
8 277 tvOneNews 106 0.022902 0.223922 0.023579 0.005145
9 352 amiraayuadisty 104 0.025649 0.163153 0.020926 0.006381
10 3 Stakof 90 0.014532 0.264321 0.025003 0.004630
11 194 henao_212 87 0.018283 0.206543 0.019071 0.004286
12 262 Doy63014161 84 0.037279 0.234180 0.018336 0.004863
13 342 RestyCayah 79 0.012092 0.249357 0.019920 0.003561
14 26 muannas_alaidid 73 0.018712 0.310828 0.038465 0.003573
15 14 Gun4w4nAhokers 68 0.009945 0.264976 0.018535 0.003317
16 399 roninkhalid 66 0.019569 0.223037 0.014724 0.003269
17 25 RinjaniJB 60 0.007002 0.264840 0.017585 0.002721
18 182 pekaklonto 49 0.005203 0.267916 0.013609 0.002103
19 306 IreneViena 44 0.012900 0.221516 0.009738 0.001938
20 41 Kimochiii_ 42 0.008210 0.310238 0.030504 0.001966
UIN SYARIF HIDAYATULLAH JAKARTA

161
Gambar 5.45 Kompilasi Nilai Parameter SNA Kelompok Eksperimen
Tabel 5.27 dan Gambar 5.45 menjabarkan bahwa node shitlicious,
node lawan_teroris, node bangsa_patriot, dan node GusYaqut. Bertindak
sebagai node yang paling berpengaruh pada kelompok eksperimen. Hal
tersebut menyebabkan polarisasi sesuai dengan hasil visualisasi graf
kelompok eksperimen pada Gambar 5.17.
Pada Gambar 5.45 peneliti melakukan normalisasi nilai Degree
Centrality dengan melakukan perhitungan pembagian dengan jumlah
seluruh data pada kelompok kontrol, hal tersebut peneliti lakukan agar
seluruh nilai pada perhitungan parameter social network analysis dapat
dilakukan perbandingan dan visualisasi.
Berdasarkan perhitungan pada cluster A, cluster B, cluster C, dan
cluster D. Dapat ditarik kesimpulan bahwa pada tiap cluster mempunyai
1 node yang bertugas sebagai node paling berpengaruh di dalam graf.
Dalam penelitian terkait berita hoax dapat disimpulkan bahwa 4 node
pada cluster adalah node yg secara langsung berperan dalam lingkup
tweet dengan batasan keyword hoax.
UIN SYARIF HIDAYATULLAH JAKARTA

162
5.1.7.6 Analisis User Berpengaruh Kelompok Eksperimen
Berdasarkan hasil visualisasi graf pada gambar 5.17 dan hasil
perhitungan parameter SNA pada Tabel 5.27 dapat ditarik kesimpulan
bahwa ada 4 node yang paling berpengaruh di dalam graf. Berikut ini
adalah analisis user paling berpengaruh di graf kelompok eksperimen:
1. User shitlicious
Gambar 5.46 Akun Twitter @shitlicious
Berdasarkan informasi dari gambar 5.46 dan akun Twitter
@shitlicious, dapat diambil informasi bahwa akun @shitlicious
mempunyai Followers atau pengikut sebanyak 739,000 orang.
Dengan jumlah Posting Tweets sebanyak 116,000 post. Status akun
sudah diakui secara resmi oleh Twitter.
UIN SYARIF HIDAYATULLAH JAKARTA

163
2. User lawan_teroris
Gambar 5.47Akun Twitter @lawan_teroris
Berdasarkan informasi dari gambar 5.47 dan akun Twitter
@lawan_teroris, dapat diambil informasi bahwa akun
@lawan_teroris mempunyai Followers atau pengikut sebanyak 4,989
orang. Dengan jumlah Posting Tweets sebanyak 20,600 post. Status
akun belum diakui secara resmi oleh Twitter.
3. User bangsa_patriot
Gambar 5.48 Akun Twitter @bangsa_patriot
Berdasarkan informasi dari gambar 5.48 dan akun Twitter
@bangsa_patriot, dapat diambil informasi bahwa akun @bangsa_patriot
mempunyai Followers atau pengikut sebanyak 8,298
UIN SYARIF HIDAYATULLAH JAKARTA

164
orang. Dengan jumlah Posting Tweets sebanyak 24,100 post. Status
akun belum diakui secara resmi oleh Twitter.
4. User GusYaqut
Gambar 5.49 Akun Twitter @GusYaqut
Berdasarkan informasi dari gambar 5.49 dan akun Twitter
@GusYaqut, dapat diambil informasi bahwa akun @GusYaqut
mempunyai Followers atau pengikut sebanyak 24,700 orang. Dengan
jumlah Posting Tweets sebanyak 9,518 post. Status akun belum
diakui secara resmi oleh Twitter.
Tabel 5.28 Status User Berpengaruh pada Kelompok Eksperimen Rank Id User Follower Post Status
1 4 shitlicious 739000 116000 Verified 2 2 lawan_teroris 4989 20600 Non-Verified 3 340 bangsa_patriot 8298 24100 Non-Verified 4 230 GusYaqut 24700 9518 Non-Verified
UIN SYARIF HIDAYATULLAH JAKARTA

165
Gambar 5.50 Grafik Status User Berpengaruh pada Kelompok
Eksperimen
Berdasarkan Tabel 5.28 dan Gambar 5.50 node shitlicious adalah
node yang mempunyai jumlah pengikut paling banyak dan post
paling banyak di dalam garf. Dan node shitlicious sudah diakui
secara resmi oleh Twitter.
Tabel 5.29 Tabel Jumlah Node Di Dalam Cluster Eksperimen Rank Id User Node Total Nilai Degree Centrality
1 4 shitlicious 3 2322 2 2 lawan_teroris 3 1678 3 340 bangsa_patriot 4 792 7 6 Juno_5760 2 278
Gambar 5.51 Grafik Jumlah Node Di Dalam Cluster Eksperimen
UIN SYARIF HIDAYATULLAH JAKARTA

166
Berdasarkan Tabel 5.29 dan Gambar 5.51, dan hasil visualisasi graf
kelompok eksperimen gambar 5.17 bahwa node shitlicious dan node
lawan_teroris mengalami pembenturan yang sangat besar, jika dilihat
dari nilai Degree Centrality masing-masing node yaitu node shitlicious
dengan nilai 2317 dan node lawan_teroris dengan nilai 1678. Dengan
Total Nilai sebesar 5070. Maka perbadaan yang sangat terlihat jelas
sesuai dengan hasil visualisasi graf kelompok eksperimen pada Gambar
5.17 terlihat bahwa node lawan_teroris mempunyai relasi dan hubungan
yang lebih dekat dengan node bangsa_patriot dan node Juno_5760. Node
bangsa_patriot juga mempunyai hubungan dengan node GusYaqut
ditandai dengan ketertarikan node GusYaqut ke node bangsa_patriot.
Sedangkat node shitlicious tidak memiliki kedekatan secara langsung
dengan 3 node besar lainnya.
UIN SYARIF HIDAYATULLAH JAKARTA

153
5.2 Analisis dan Interpretasi Data
Gambar 5.52 Komparasi Hasil Visualisasi Graf Kelompok Kontrol dan Eksperimen
167
UIN SYARIF HIDAYATULLAH JAKARTA

168
Gambar 5.52 adalah gambar komparasi hasil visualisasi graf pada tahap
visualisasi kelompok kontrol dan kelompok eksperimen. Kelompok kontrol adalah
kelompok yang berisikan user Twitter yang merupakan user dengan post original.
Kelompok eksperimen adalah kelompok yang berisikan user Twitter yang
merupakan user dengan post hasil re-tweet dari user original.
Berdasarkan Gambar 5.52 terlihat bahwa kelompok kontrol mempunyai 3
cluster utama, setelah diterapkan penerapan waktu maksimal menjadi 60 detik,
cluster pembentuk graf pada kelompok eksperimen menjadi 4 cluster utama.
5.2.1 Perbandingan Kelompok Kontrol dan Kelompok Eksperimen
Tabel 5.30 Komparasi Rank User Berpengaruh Kelompok Kontrol dan
Eksperimen Rank Rank
Id User Follower Post Status
Kontrol Eksperimen
2 >20 58 Gusmus 1540000 13800 Verified
9 1 4 shitlicious 739000 116000 Verified
3 >20 62 maspiyuuu 164000 394000 Non-Verified
1 >20 122 rockygerung 77800 24300 Non-Verified
>20 4 230 GusYaqut 24700 9518 Non-Verified
8 3 340 bangsa_patriot 8298 24100 Non-Verified
>20 2 2 lawan_teroris 4989 20600 Non-Verified
UIN SYARIF HIDAYATULLAH JAKARTA

169
Gambar 5.53 Grafik Komparasi Rank User Berpengaruh Kelompok Kontrol
dan Eksperimen
Berdasarkan Tabel 5.30 dan Gambar 5.53 hanya ada 2 node besar yang
mampu bertahan pada posisi 20 besar node pengaruh setelah dilakukan proses
eksperimen dengan melakukan penambahan iterasi i = 200 dan t max = 60
detik. Node tersebut adalah node shitlicious dan node bangsa_patriot. Dan ada
dua node yang pada kelompok kontrol tidak berada pada 20 besar node
pengaruh, mengalami peningkatan menjadi node berpengaruh setelah
eksperimen. Node tersebut adalah node GusYaqut dan node lawan_teroris.
Catatan pada Gambar 5.53, rank 21 merupakan simbol pengganti bahwa
node tersebut tidak masuk kedalam peringkat 20 besar node berpengaruh.
UIN SYARIF HIDAYATULLAH JAKARTA

170
Tabel 5.31 Komparasi Nilai Degree Centrality Pasca Eksperimen
Id User DC Kelompok DC Eksperimen
122 rockygerung 775 4
58 Gusmus 653 4
62 maspiyuuu 557 33
416 OomNanang 291 35
432 wahhabicc_jabar 244 16
319 GunRomli 228 11
321 wartapolitik 220 4
10 bangsa_patriot 214 286
1 shitlicious 131 2317
57 Husen_jafar 113 2
11 RustamIbrahim 102 21
54 muannas_alaidid 97 73
310 SiPinokio_ 89 5
401 _adityaiskandar 85 5
376 roninpribumi 78 2
282 KompasTV 73 2
407 GKRHayu 71 4
281 kompascom 65 1
240 Muhamma37029013 62 1
162 digembok 61 1
UIN SYARIF HIDAYATULLAH JAKARTA

171
Gambar 5.54 Komparasi Nilai Degree Centrality Pasca Eksperimen
Berdasarkan Tabel 5.31 dan Gambar 5.54 hanya ada 2 node yang mengalami
peningkatan nilai Degree Centrality yaitu node shitlicious dengan peningkatan
dari nilai 131 menjadi nilai 2317, dan node bangsa_partiot dari nilai 214 menjadi
nilai 286. Node shitlicious mengalami peningkatan 17.6 kali lebih signifikan, jika
dilihat dari segi jumlah pengikut node shitlicious sebanyak 739,000 hal ini
menandakan bahwa pengikut node shitlicious secara stabil melakukan re-tweet
terhadap setiap post yang ditulis oleh node shitlicious. Artinya node shitlicious
memiliki sokongan pengikut yang paling besar.
UIN SYARIF HIDAYATULLAH JAKARTA

172
Node bangsa_patriot mempunyai peningkatan nilai 1.3 kali lebih banyak
setelah pasca eksperimen. Walaupun jumlah pengikut node bangsa_patriot
hanya sebesar 8298 namun, jika dilihat dari hasil visualisasi graf pada Gambar
4.26, node bangsa_patriot memiliki relasi dengan seluruh node besar pada
graf. Jumlah relasi dengan node besar menjadi penyebab node bangsa_patriot
tetap menempati 20 besar posisi node berpengaruh pada pasca eksperimen.
Tabel 5.32 Tabel Jumlah Nilai Degree Centrality Pada Seluruh Cluster Id User Node Total Nilai Degree Centrality Kelompok 122 rockygerung 3 1280 Kontrol 58 Gusmus 5 1300 Kontrol 62 maspiyuuu 4 1021 Kontrol 4 shitlicious 3 2322 Eksperimen 2 lawan_teroris 3 1678 Eksperimen
340 bangsa_patriot 4 792 Eksperimen 6 Juno_5760 2 278 Eksperimen
Gambar 5.55 Grafik Jumlah Nilai Degree Centrality Pada Seluruh Cluster
UIN SYARIF HIDAYATULLAH JAKARTA

173
Berdasarkan Tabel 5.32 dan Gambar 5.55, bahwa pada kelompok kontrol
mempunyai 3 node paling berpengaruh pada graf dan pada kelompok
eksperimen mempunyai 4 node paling berpengaruh pada graf. Node pada
setiap kelompok merupakan representasi dari setiap cluster pembentuk graf
pada setiap kelompok.
5.2.2 Hasil Analisis Konten Tweet Node Berpengaruh
Peneliti melakukan pengecekan secara langsung ke akun node
berpengaruh, untuk mengatahui tulisan apakah yang menjadikan node tersebut
sebagai akun yang bersinggungan dengan keyword hoax.
1. rockygerung
Gambar 5.56 Konten Tweet Node rockygerung
Node rockygerung melakukan re-tweet dengan menyisipkan tulisan
“Semoga pernyataan dungu ini adalah hoax” terhadap tulisan @setkabgoid,
dengan konten tulisan @setkabgoid yaitu "Kita sudah minta kepada jajaran
NU agar tegas pada aliran radikal & intoleran, apapun organisasinya -
Presiden @jokowi,". Post pada akun @setkabgoid sudah dihapus karena
ada klarifikasi resmi dari pihak @setkabgoid.
Berdasarkan Gambar 5.56 dapat dilihat bahwa tulisan dan re-tweet node
rockygerung mendapatkan komentar sebanyak 176, di re-tweet akun lain
sebanyak 863 dan disukai 771 akun.
Post tersebut mengandung kata hoax sehingga post tersebut
dikategorikan sebagai data penelitian.
UIN SYARIF HIDAYATULLAH JAKARTA

174
2. Gusmus
Peneliti tidak menemukan secara langsung tweet dari node Gusmus yang
bersinggungan langsung dengan keyword hoax. Jumlah pengikut node
Gusmus yang merupakan node dengan jumlah pengikut terbanyak di dalam
cluster, menjadi penyebab node Gusmus masuk sebagai data penelitian.
Ada beberapa node kecil yang melakukan mention atau penyebutan akun
gusmus kedalam post tweet mereka.
Gambar 5.57 Tweet Node Kecil Mention Ke Node Gusmus
3. maspiyuuu
Gambar 5.58 Konten Tweet Node maspiyuuu
UIN SYARIF HIDAYATULLAH JAKARTA

175
Berdasarkan Gambar 5.58 dapat dilihat bahwa tulisan dan re-tweet node
maspiyuuu mendapatkan komentar sebanyak 34, di re-tweet akun lain
sebanyak 441 dan disukai 411 akun. Akun maspiyuuu melakukan re-tweet
dengan node rockygerung.
Post tersebut mengandung kata hoax sehingga post tersebut
dikategorikan sebagai data penelitian.
4. shitlicious
Gambar 5.59 Konten Tweet Node shitlicious
Berdasarkan Gambar 5.59 dapat dilihat bahwa tulisan dan re-tweet node
shitlicious mendapatkan komentar sebanyak 86, di re-tweet akun lain
sebanyak 3,600 dan disukai 1,100 akun. Post dari node shitlicious merupakan
tweet bersifat original, dan dikarenakan jumlah re-tweet mencapai 3,600 kali,
node shitlicious juga tetap bertahan menjadi node 20 besar paling berpengaruh
pada kelompok kontrol dan kelompok eksperimen.
Post tersebut mengandung kata hoax sehingga post tersebut
dikategorikan sebagai data penelitian.
5. lawan_teroris
Gambar 5.60 Konten 1 Tweet Node lawan_teroris
UIN SYARIF HIDAYATULLAH JAKARTA

176
Gambar 5.61 Konten 2 Tweet Node lawan_teroris
Gambar 5.62 Konten 3 Tweet Node lawan_teroris
Berdasarkan Gambar 5.60 dapat dilihat bahwa tulisan dan re-tweet node
lawan_teroris mendapatkan komentar sebanyak 80, di re-tweet akun lain
sebanyak 630 dan disukai 175 akun. Gambar 5.61 dapat dilihat bahwa
tulisan dan re-tweet node lawan_teroris mendapatkan komentar sebanyak
99, di re-tweet akun lain sebanyak 2,200 dan disukai 657 akun. Dan
Gambar 5.62 yang merupakan tweet yang bersinggungan dengan salah satu
node besar yaitu node wahhabicc_jabar.
Post tersebut mengandung kata hoax sehingga post tersebut
dikategorikan sebagai data penelitian.
UIN SYARIF HIDAYATULLAH JAKARTA

177
6. bangsa_patriot
Gambar 5.63 Konten Tweet Node bangsa_patriot
Berdasarkan Gambar 5.63 dapat dilihat bahwa node bangsa_patriot
melakukan re-tweet terhadap post dari node rockygerung. Post tersebut
mengandung kata hoax sehingga post tersebut dikategorikan sebagai data
penelitian.
7. Juno_5760
Gambar 5.64 Konten Tweet Node Juno_5760
Berdasarkan Gambar 5.64 dapat dilihat bahwa tulisan node Juno_5760
mendapatkan komentar sebanyak 0, di re-tweet akun lain sebanyak 450 dan
disukai 19 akun. Post tersebut mengandung kata hoax sehingga post
tersebut dikategorikan sebagai data penelitian. Berdasarkan hasil visualisasi
graf kelompok eksperimen pada Gambar 5.17 node Juno_5760 merupakan
node utama pembentuk cluster, namun posisi cluster berada pada posisi
menjauhi cluster lainnya. Sesuai dengan konten dari node Juno_5760 yang
membahas Miss Universe.
UIN SYARIF HIDAYATULLAH JAKARTA

178
5.3 Kesimpulan Eksperimen
Setelah melakukan tahapan perbandingan kelompok kontrol dan kelompok
eksperimen. Dan berdasarkan hasil analisis konten tweet node berpengaruh dan
hasil analisis dan interpretasi data. Dapat ditarik kesimpulan sebagai berikut:
5.3.1 Hasil Pengaruh Perubahan Nilai Iterasi Pengecekan Perhitungan
Setelah melakukan perubahan variabel iterasi pengecekan perhitungan
dari nilai default sebesar 100 kali menjadi 200 kali, dan Berdasarkan Tabel
Komparasi rank user berpengaruh kelompok kontrol dan eksperimen pada
Tabel 5.30, menjelaskan bahwa:
1. Node Gusmus mengalami penurunan rank, dimana pada kelompok kontrol
menempati posisi rank ke 2, setelah dilakukan perubahan variabel, rank
turun menjadi rank lebih dari 20 pada kelompok eksperimen.
2. Node shitlicious mengalami peningkatan rank, dimana pada kelompok
kontrol menempati posisi rank ke 9, setelah dilakukan perubahan
variabel, rank naik menjadi rank ke 1 pada kelompok eksperimen.
3. Node maspiyuuu mengalami penurunan rank, dimana pada kelompok kontrol
menempati posisi rank ke 3, setelah dilakukan perubahan variabel, rank
turun menjadi rank lebih dari 20 pada kelompok eksperimen.
4. Node rockygerung mengalami penurunan rank, dimana pada kelompok
kontrol menempati posisi rank ke 1, setelah dilakukan perubahan variabel,
rank turun menjadi rank lebih dari 20 pada kelompok eksperimen.
5. Node GusYaqut mengalami peningkatan rank, dimana pada kelompok
kontrol menempati posisi rank lebih dari 20, setelah dilakukan perubahan
variabel, rank naik menjadi rank ke 4 pada kelompok eksperimen.
6. Node bangsa_patriot mengalami peningkatan rank, dimana pada kelompok
kontrol menempati posisi rank lebih dari 8, setelah dilakukan perubahan
variabel, rank naik menjadi rank ke 3 pada kelompok eksperimen.
UIN SYARIF HIDAYATULLAH JAKARTA

179
7. Node lawan_teroris mengalami peningkatan rank, dimana pada kelompok
kontrol menempati posisi rank lebih dari 20, setelah dilakukan perubahan
variabel, rank naik menjadi rank ke 2 pada kelompok eksperimen.
5.3.2 Hasil Pengaruh Penetapan Variabel Waktu
Setelah melakukan penetapan waktu maksimal (t-max) menjadi 60 detik,
dan berdasarkan Gambar Komparasi hasil visualisasi graf kelompok kontrol
dan kelompok eksperimen pada Gambar 5.52, dan Tabel Jumlah nilai
Degree Centrality pada seluruh cluster pada Tabel 5.32, menjelaskan bahwa:
1. Kelompok kontrol terbentuk dari 3 cluster utama, yaitu:
A. Cluster Nomor 1 dengan node utama rockygerung, dengan jumlah
node pembentuk cluster 3 node utama dengan total nilai Degree
Centrality 1280.
B. Cluster Nomor 2 dengan node utama Gusmus, dengan jumlah node
pembentuk cluster 5 node utama dengan total nilai Degree Centrality
1300.
C. Cluster Nomor 3 dengan node utama maspiyuuu, dengan jumlah node
pembentuk cluster 4 node utama dengan total nilai Degree Centrality
1021.
2. Kelompok eksperimen terbentuk dari 4 cluster utama, yaitu:
A. Cluster A dengan node utama shitlicious, dengan jumlah node
pembentuk cluster 3 node utama dengan total nilai Degree Centrality
2322.
B. Cluster B dengan node utama lawan_teroris, dengan jumlah node
pembentuk cluster 3 node utama dengan total nilai Degree Centrality
1678.
C. Cluster C dengan node utama bangsa_patriot, dengan jumlah node
pembentuk cluster 4 node utama dengan total nilai Degree Centrality
792.
UIN SYARIF HIDAYATULLAH JAKARTA

180
D. Cluster D dengan node utama Juno_5760, dengan jumlah node
pembentuk cluster 2 node utama dengan total nilai Degree Centrality
278.
5.3.3 Hasil Nilai Perhitungan Parameter SNA
Berdasarkan kompilasi nilai parameter SNA kelompok kontrol pada Tabel
5.19 menjelaskan bahwa:
1. Node rockygerung dengan nilai Degree Centrality sebesar 775, menjadi
node paling berpengaruh pada kelompok kontrol.
2. Node Gusmus dengan nilai Betweenness Centrality sebesar 0.290114,
menjadi node yang mempunyai alur paling pendek untuk menyebarkan
informasi pada kelompok kontrol.
3. Node Gusmus dengan nilai Closeness Centrality sebesar 0.323765,
menjadi node yang mempunyai kedekatan hubungan dengan node lain
paling tinggi pada kelompok kontrol.
4. Node rockygerung dengan nilai Eigenvector Centrality sebesar 1.000000,
menjadi node yang mempunyai relasi paling banyak pada kelompok
kontrol.
5. Node Gusmus dengan nilai PageRank sebesar 0.048477, menjadi node
yang merupakan node yang paling banyak menerima referral
(rekomendasi) dari node lain, sehingga node Gusmus merupakan node
yang mempunyai kualitas paling tinggi pada kelompok kontrol.
Berdasarkan kompilasi nilai parameter SNA kelompok eksperimen pada
Tabel 5.27 menjelaskan bahwa:
1. Node shitlicious dengan nilai Degree Centrality sebesar 2317, menjadi
node paling berpengaruh pada kelompok eksperimen.
2. Node shitlicious dengan nilai Betweenness Centrality sebesar 0.580361,
menjadi node yang mempunyai alur paling pendek untuk menyebarkan
informasi pada kelompok eksperimen.
UIN SYARIF HIDAYATULLAH JAKARTA

181
3. Node shitlicious dengan nilai Closeness Centrality sebesar 0.386739,
menjadi node yang mempunyai kedekatan hubungan dengan node lain
paling tinggi pada kelompok eksperimen.
4. Node shitlicious dengan nilai Eigenvector Centrality sebesar 1.000000,
menjadi node yang mempunyai relasi paling banyak pada kelompok
eksperimen.
5. Node shitlicious dengan nilai PageRank sebesar 0.145157, menjadi node
yang merupakan node yang paling banyak menerima referral
(rekomendasi) dari node lain, sehingga node Gusmus merupakan node
yang mempunyai kualitas paling tinggi pada kelompok eksperimen.
5.3.4 Hasil Penerapan Desain Intact-Group Comparison
Penerapan metode penelitian eksperimen dengan desain intact-group
comparison menghasilkan dua kelompok yang dapat dilakukan
perbandingan secara langsung. Kelompok eksperimen yang telah dilakukan
proses pengubahan variabel-variabel bebas yaitu variabel iterasi pengecekan
perhitungan dan penetapan variabel waktu maksimal (t-max). Setelah
dilakukan perbandingan dengan kelompok kontrol maka didapatkan bahwa
pengubahan terhadap variabel bebas berpengaruh terhadap nilai dan hasil
yang ditunjukan pada adanya perubahan nilai Degree Centrality yang
signifikan pada Tabel 5.31 Komparasi Nilai Degree Centrality Pasca
Eksperimen hanya ada 2 node yang mengalami peningkatan nilai Degree
Centrality yaitu node shitlicious dengan peningkatan dari nilai 131 menjadi
nilai 2317, dan node bangsa_partiot dari nilai 214 menjadi nilai 286.
UIN SYARIF HIDAYATULLAH JAKARTA

182
BAB VI
PENUTUP
6.1 Kesimpulan
Berdasarkan rumusan masalah yang telah peneliti uraikan dan penjelasan
mengenai analisis dan hasil dari penelitian pada bab sebelumnya, maka peneliti
membuat kesimpulan sebagai berikut:
1. Social network analysis dapat diterapkan pada data pengguna sosial media
Twitter dengan bantuan Apache Hadoop Single Cluster Multi Node. Sesuai
dengan nilai perhitungan dari parameter Social network analysis yaitu degree
centrality, betweenness centrality, closeness centrality, eigenvector centrality,
dan pagerank. Bahwa akun yang mempunyai nilai parameter SNA lebih tinggi
dapat dijadikan sebagai akun utama dan akun berpengaruh dalam penyebaran
atau antisipasi hoax. Berdasarkan Gambar 5.52 bahwa node kecil memiliki
kecendrungan untuk menarik diri mendekati node dengan nilai parameter SNA
yang lebih besar dikarenakan salah satu parameter SNA yaitu degree centrality,
dimana semakin tinggi nilai degree centrality, maka semakin tinggi pula
pengaruh node di dalam graf (subbab 5.2). Berdasarkan hasil perhitungan
parameter SNA, maka didapatkan node rockygerung sebagai node paling
berpengaruh pada kelompok kontrol, dan node shitlicious sebagai node paling
berpengaruh pada kelompok eksperimen (subsubbab 5.3.3).
2. Perhitungan parameter SNA dengan metode eksperimen Intact-Group Comparison
dengan dua kelompok yaitu kelompok kontrol dan kelompok eksperimen,
berdasarkan keterangan dari Tabel 5.19 dan Tabel 5.27 dapat ditarik kesimpulan
bahwa, pada kelompok kontrol dengan iterasi sebanyak 100 kali pengecekan
perhitungan, muncul dualisme kepemimpinan pada node di dalam graf. Hal
tersebut dibuktikan dengan munculnya node rockygerung dan node
182 UIN SYARIF HIDAYATULLAH JAKARTA

183
Gusmus, yang menjadi node dengan nilai paling tinggi pada perhitungan
parameter SNA. Sedangkan pada kelompok eksperimen dengan penambahan
jumlah iterasi pengecekan perhitungan dari nilai 100 menjadi 200 kali, tidak
muncul dualisme kepemimpinan pada node di dalam graf. Dengan total nilai
Degree Centrality cluster utama pembentuk graf kelompok kontrol sebesar
3601. Dan total nilai Degree Centrality cluster utama pembentuk graf
kelompok eksperimen sebesar 5070. Artinya ada peningkatan nilai Degree
Centrality sebanyak 1469 poin atau 40,79% lebih tinggi pasca penerapan
eksperimen pada penelitian (subbab 5.3).
3. Berdasarkan Gambar Komparasi hasil visualisasi graf kelompok kontrol dan
kelompok eksperimen pada Gambar 5.52 dan Tabel Jumlah nilai Degree
Centrality pada seluruh cluster pada Tabel 5.32, dengan penetapan waktu
maksimal (t-max) sebesar 60 detik. Bahwa terjadi perubahan jumlah cluster
utama pendukung graf dari total 3 cluster utama pembentuk graf pada
kelompok kontrol, menjadi 4 cluster utama pembentuk graf pada kelompok
eksperimen, artinya terjadi peningkatan sebesar 33,33% pada pasca eksperimen
(subsubbab 5.3.2). Berdasarkan komparasi hasil visualisasi pada gambar 5.52
menggambarkan bahwa node yang mempunyai pengaruh besar memiliki
kecendrungan untuk menarik node lain menuju ruang lingkup pembicaraan,
sehingga post yang berkaitan dengan hoax menjadi lebih mudah tersebar dan
viral. Sebuah berita tidak akan menjadi hoax apabila tidak ada klarifikasi
terhadap berita tersebut terkait kebenarannya. Dan yang paling penting hoax
tidak akan menjadi viral, apabila tidak ada orang yang menyebarluaskannya.
4. Berdasarkan Tabel 5.31 Komparasi Nilai Degree Centrality Pasca Eksperimen,
bahwa ditemukan ada perubahan nilai Degree Centrality pada kelompok
eksperimen setelah dilakukan pengubahan terhadap variabel-variabel bebas
pada penelitian (subsubbab 5.3.4). Hal ini membuktikan bahwa pengubahan
variabel bebas berpengaruh terhadap hasil penelitian. Sesuai dengan tujuan dari
dilakukannya penelitian dengan metode eksperimen, bahwa penelitian
UIN SYARIF HIDAYATULLAH JAKARTA

184
dimaksudkan dalam rangka mencari pengaruh, hubungan, maupun perbedaan
pengubahan terhadap kelompok yang dikenakan perlakuan.
6.2 Saran
Peneliti menyadari bahwa masih banyak terdapat keterbatasan dan kekurangan
pada penelitian yang telah dilakukan oleh peneliti. Dikarenakan banyak faktor-faktor
lain yang masih belum peneliti terapkan pada penelitian ini. Oleh karena itu, peneliti
menyarankan kepada peneliti selanjutnya untuk mengembangkan penelitian ini agar
menjadi jauh lebih baik dengan beberapa poin saran sebagai berikut:
1. Diharapkan pada tahap pengumpulan data bersifat studi kasus sesuai dengan
topik terkait hoax apa yang sedang dibicarakan oleh publik, sehingga siapa
pelaku utama penyebar dan penghadang dapat terlihat secara langsung.
2. Diharapkan peneliti selanjutnya menggunakan metode eksperimen jenis lain
seperti metode eksperimen sebenarnya sehingga didapatkan hasil data yang
lebih beragam.
3. Diharapkan peneliti selanjutnya melakukan perbandingan data apabila
dilakukan dengan menggunakan metode non-clustering. Sehingga dapat dikaji
lebih menjalam terkait seberapa besar tingkat keberhasilan metode clustering
dan non clustering. Pada penelitian non-clustering bisa diterapkan
menggunakan tools seperti menggunakan bantuan python dan R.
4. Diharapkan penelitian selanjutnya melakukan eksplorasi lebih mendalam terkait
tools gephi, dengan melakukan pengubahan variabel-variabel yang akan
mempengaruhi output dari gephi.
5. Diharapkan penelitian selanjutnya melakukan pembandingan metode analisis
lain selain social network analysis, seperti penerapan machine learning dalam
melakukan tahap analisis data dan menetapkan sentiment analysis untuk
mengetahui sentimen user terkait konten tweet.
UIN SYARIF HIDAYATULLAH JAKARTA

DAFTAR PUSTAKA
Abimanyu, Aditya, 2012. Analisa Media Sosial Twitter Dengan Perhitungan Graph
Edit Distance Untuk Mendeteksi Rumor Pada Trending Topic SIAK-NG.
Universitas Indonesia. Depok.
Allcott Hunt, Matthew Gentzkow, 2016. Social Media and Fake News in the 2016
Election. Journal of Economic Perspectives, Vol. 31, No, 2—Spring 2017,
Pages 211–236.
Apache, Ambari, 2017. Apache Ambari Introduction (https://ambari.apache.org/)
(diakses tanggal 9 September 2017).
Apache, NiFi, 2017. Apache NiFi Overview (https://nifi.apache.org/docs.html)
(siakses tanggal 9 September 2017).
Apache, Hadoop, 2017. HDFS Architecture
(https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-
hdfs/HdfsDesign.html) (diakses tanggal 8 September 2017).
Amazon, AWS, 2017. What is Elasticsearch? (https://aws.amazon.com/elasticsearch-
service/what-is-elasticsearch/) (diakses tanggal 9 September 2017).
Burnap, Pete, dkk, 2014. Tweeting the terror: modelling the social media reaction to
the Woolwich terrorist attack. Soc. Netw. Anal. Min. (2014) 4:206. DOI
10.1007/s13278-014-0206-4.
Beard, Jonathan, 2015. A SHORT INTRO TO STREAM PROCESSING
(http://www.jonathanbeard.io/blog/2015/09/19/streaming-and-dataflow.html)
(diakses tanggal 9 September 2017).
UIN SYARIF HIDAYATULLAH JAKARTA

CNN, 2016. Ada 800 Ribu Situs Penyebar Hoax di Indonesia
(https://www.cnnindonesia.com/teknologi/20161229170130-185-182956/ada-800-
ribu-situs-penyebar-hoax-di-indonesia/) (diakses tanggal 01 Agustus 2017).
Convergedigest, 2014. NSA Releases Niagara files Flow Analysis Tool as Open
Source (http://www.convergedigest.com/2014/11/nsa-releases-niagarafiles-
flow-analysis.html) (diakses tanggal 9 September 2017).
C. João Catarina Silva dan Mário Antunesa, 2015. Health Twitter Big Data
Management with Hadoop Framework. Journal Elsevier: Procedia Computer
Science 64, No, 425 – 431.
Danim, Sudarwan, 2002. Menjadi Peneliti Kualitatif. Bandung: Pustaka Setia.
Denny, Matthew, 2014. Social Network Analysis. Massachusetts: University of
Massachusetts.
Sugiyono, 2010. Metode penelitian Kuantitatif Kualitatif dan R&D. Bandung:
Alfabeta.
Sugiyono, 2001. Statistika untuk Penelitain. Bandung: Alfabeta.
E. Kate and Inga C., 2005. Inside Social Network Analysis.
G. Mohd Rehan, Durgaprasad Gangodkar, 2015. Hadoop, MapReduce and HDFS: A
Developers Perspective. India. Journal Elsevier: Procedia Computer Science
48, No, 45 – 50.
Gephi, 2017. About Gephi (https://gephi.org/about/) (diakses tanggal 10 September
2017)
IBM, 2016. What is big data? (http://www-01.ibm.com/software/data/bigdata/what-
is-big-data.html) (diakses tanggal 16 November 2016).
UIN SYARIF HIDAYATULLAH JAKARTA

Intellipaat, 2017. What is Apache Ambari? (https://intellipaat.com/blog/what-is-
apache-ambari/) (diakses tanggal 9 September 2017).
Jogiyanto, 2008. Metodologi Penelitian. Yogyakarta: ANDI.
Komputasi Lipi, 2010. Komputasi Terdistribusi.
(http://www.komputasi.lipi.go.id/utama.cgi?cetakartikel&1271412582)
(diakses tanggal 8 September 2017).
Kumar Shamath, Fred Morstatter, Huan Liu, 2013. Twitter Data Analytic. Springer.
Kurniawati, Anita, 2010. Matematika Diskrit. Surabaya.
Lam, Chuck, 2011. Hadoop In Action. Stamford: Mainning Publications Co.
Malak, Michael, 2014. Data Locality: HPC vs. Hadoop vs. Spark. IBM. No.
228397102.
Merriam Webster, 2017. Definition of Hoax, (https://www.merriam-
webster.com/dictionary/hoax) (diakses tanggal 10 September 2017).
Mogallapu, Anusha, 2011. Social network analysis of the video bloggers'community
in YouTube. Missouri University of Science and Technology. Missouri US.
News VIVA, 2015. 22.574 GB Data Dipertukarkan di Internet Tiap Detik,
(http://teknologi.news.viva.co.id/news/read/700572-22-574-gb-data-
dipertukarkan-di-internet-tiap-detik) (diakses tanggal 15 November 2016).
Priyopradono, Bentar, 2012. Spatial Social Network Analysis: Program
Pengembangan Usaha Agribisnis Perdesaan (PUAP) dalam Mendukung
Revitalisasi Peningkatan Pangan Daerah Kabupaten Rejang Lebong Provinsi
Bengkulu. Universitas Kristen Satya Wacana. Salatiga Indonesia.
Putra, Feriza Julian, 2016. ANALISIS JARINGAN TEKS BERDASARKAN SOCIAL
NETWORK ANALYSIS DAN TEXT MINING UNTUK BUSINESS
UIN SYARIF HIDAYATULLAH JAKARTA

INTELLIGENCE MENGGUNAKAN ASSOCIATION RULES (Studi Kasus
Percakapan Twitter PT.Telkomsel dan PT. XL Axiata Tbk.). Universitas
Telkom. Bandung Indonesia.
Republika, 2016. Budaya Digital Indonesia,
(http://www.republika.co.id/berita/koran/opini-koran/16/04/19/o5va0622-
budaya-digital-indonesia) (diakses tanggal 15 November 2016).
S. Timothy, Song-Lak Kang, 2017. Applying Parallel Computing Techniques to
Analyze Terabyte Atmospheric Boundary Layer Model Outputs. USA. Journal
Elsevier: Big Data Research 7, No. 31–41.
Shahi , Dikshant, 2015. Apache Solr: A Practical Approach to Enterprise Search. New
York: Apress.
Shenoy, Aravind, 2014. Hadoop Explained. Birmingham: Packt Publishing.
Solso, Robert L., Otto H. Maclin, M. Kimberly Maclin, 2005. Cognitive Psychology.
New York. Pearson.
Some, Rupam, 2013. A Survey on Social Network Analysis and its Future Trends.
International Journal of Advanced Research in Computer and Communication
Engineering Vol. 2, Issue 6, June 2013.
Statista, 2016. Number of active Twitter users in leading markets as of May 2016,
(https://www.statista.com/statistics/242606/number-of-active-twitter-users-in-
selected-countries/) (diakses tanggal 10 September 2017).
Sukmadinata, Nana Syaodih, 2012. Metode Penelitian Pendidikan. Bandung: Remaja
Rosdakarya.
Support, Twitter, 2017. Glosarium Twitter.
UIN SYARIF HIDAYATULLAH JAKARTA

(https://support.twitter.com/articles/20169356) (diakses tanggal 10 September
2017).
Tan, Kelvin, 2017. Basic Elasticsearch Concepts.
(http://www.elasticsearchtutorial.com/basic-elasticsearch-concepts.html)
(diakses tanggal 10 September 2017).
Tsvetovat Maksim, Alexander Kouznetsov, 2011. Social Network Analysis for Startups. Sebastopol, CA: O'Reilly Media.
Vanderzyden, John, 2015. What is Elasticsearch, and How Can I Use It?
(https://qbox.io/blog/what-is-elasticsearch) (diakses tanggal 9 September 2017).
Vugt, Sander, 2014. Pro Linux High Availability Clustering. New York: Apress.
UIN SYARIF HIDAYATULLAH JAKARTA

LAMPIRAN
1. Lampiran 4.1
Berikut ini adalah pengaturan repository pada cluster ambari dengan
pengaturan sebagai berikut:
• Setting Ambari = ambari.repo #VERSION_NUMBER=2.5.1.0-159
[ambari-2.5.1.0]
name=ambari Version - ambari-2.5.1.0
baseurl=http://master.skripsi.com/repo/ambari-
2.5.1.0/centos7
gpgcheck=1
gpgkey=http://master.skripsi.com/repo/ambari
-
2.5.1.0/centos7/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
• Setting HDP = hdp.repo #VERSION_NUMBER=2.6.1.0-129
[HDP-2.6.1.0]
name=HDP Version - HDP-2.6.1.0
baseurl=http://master.skripsi.com/repo/hdp/HDP/ce
n tos7/2.x/updates/2.6.1.0
gpgcheck=1
gpgkey=http://master.skripsi.com/repo/hdp/HDP/cen
t os7/2.x/updates/2.6.1.0/RPM-GPG-KEY/RPM-GPG-
KEY-Jenkins
enabled=1
UIN SYARIF HIDAYATULLAH JAKARTA

priority=1
[HDP-UTILS-1.1.0.21]
name=HDP-UTILS Version - HDP-UTILS-1.1.0.21
baseurl=http://master.skripsi.com/repo/hdp/HDP-
UTILS-1.1.0.21/repos/centos7
gpgcheck=1
gpgkey=http://master.skripsi.com/repo/hdp/HDP-
UTILS-1.1.0.21/repos/centos7/RPM-GPG-KEY/RPM-GPG-
KEY-Jenkins
enabled=1
priority=1
• Setting HDF = hdf.repo #VERSION_NUMBER=3.0.1.1-
5 [HDF-3.0.1.1]
name=HDF Version - HDF-3.0.1.1
baseurl=http://master.skripsi.com/repo/hdf/HDF/ce
n tos7/3.x/updates/3.0.1.1
gpgcheck=1
gpgkey=http://master.skripsi.com/repo/hdf/HDF/cen
t os7/3.x/updates/3.0.1.1/RPM-GPG-KEY/RPM-GPG-
KEY-Jenkins
enabled=1
priority=1
[HDP-UTILS-1.1.0.21]
name=HDP-UTILS Version - HDP-UTILS-1.1.0.21
UIN SYARIF HIDAYATULLAH JAKARTA

baseurl=http://master.skripsi.com/repo/hdp/HDP-
UTILS-1.1.0.21/repos/centos7 gpgcheck=1
gpgkey=http://master.skripsi.com/repo/hdp/HDP-
UTILS-1.1.0.21/repos/centos7/RPM-GPG-KEY/RPM-GPG-
KEY-Jenkins
enabled=1
priority=1
2. Lampiran 4.2 Kode
Keygen SSH.
Generating public/private rsa key pair.
Enter file in which to save the key
(/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Your identification has been saved in
/root/.ssh/id_rsa.
Your public key has been saved in
/root/.ssh/id_rsa.pub.
The key fingerprint is:
ca:af:1d:dd:66:52:94:02:54:d3:d9:5e:5c:05:b9:c6
root@master
The key's randomart image is:
+-- [ RSA 2048]---- +
| .o.o. o.+=|
| . .o.o o|
| . oo o |
| o E |
| S .. |
| . . . o |
UIN SYARIF HIDAYATULLAH JAKARTA

| o . o + |
| o . + |
| ..o |
+ ----------------- +
3. Lampiran 4.3
Proses pengaturan database pada ambari.
Database admin user (postgres) : postgres
Database name (ambari) : ambari
Postgres schema (ambari) : ambari
Username (ambari) : ambari
Enter Database Passwd (bigdata): bigdata
Default properties detected. Using built-in database.
Configuring ambari database...
Checking PostgreSQL...
Running initdb: This may take up to a minute.
Initializing database ... OK
Tahap selanjutnya proses verifikasi bahwa ambari server berhasil
terkonfigurasi pada server master.
About to start PostgreSQL
Configuring local database...
Configuring PostgreSQL...
Restarting PostgreSQL
Creating schema and user...
done.
Creating tables...
UIN SYARIF HIDAYATULLAH JAKARTA

done.
Extracting system views...
ambari-admin-2.5.1.0.159.jar
...........
Adjusting ambari-server permissions and ownership...
Ambari Server 'setup' completed successfully.
4. Lampiran 4.4
Proses memulai server.
[root@master ~]# ambari-server
start Using python /usr/bin/python
Starting ambari-server
Ambari Server running with administrator privileges.
Organizing resource files at /var/lib/ambari-
server/resources...
Ambari database consistency check started...
Server PID at: /var/run/ambari-server/ambari-
server.pid
Server out at: /var/log/ambari-server/ambari-
server.out
Server log at: /var/log/ambari-server/ambari-
server.log
Waiting for server
start....................................
Server started listening on 8080
DB configs consistency check: no errors and warnings
were found.
Ambari Server 'start' completed successfully.
UIN SYARIF HIDAYATULLAH JAKARTA

5. Lampiran 4.5
Kode Key SSH.
Kode #cat ~/.ssh/id_rsa
-----BEGIN RSA PRIVATE KEY-----
MIIEpgIBAAKCAQEAuzNqO99jblJNz+tpk2jN/eh0WW7bY+Tn4O16
ioHP2NG05i/T
NB1fv/tYy1KfMMMlR4QIKrd8Y77k2aWpJ4D80WS8DsjcCHaXHwqC
ubn1oUtGBntO
pLRnTpKtQ6V9TxX7K22T7/8gLweM665uy/nlRUWHFHOCarNflQsx
1+aMf1wK7xKh
sa2tmKACGb2e4rvx6n6Nc4Iud+0gVfYP25ZxPDnWKe6mHZmkIgk0
FwvCPYPe4pXO
iq1nXw0cGQ0COrygKtlPenvAoNKCVQPF+fqfQYqb9OYF0ibW8KE9
QrRi9wdDe9K7
Pj50A+d9zRz8+lfeLQMEHmA6cA3jlx9QvtufUQIDAQABAoIBAQCJ
X6Cc0UCpK7K4
Wrv+FdHceyIuowBSXR+gWwUq8TnylWmX5g6qVsf2HV+6zSXO5dXM
lmJb3oxksihE
Y6IvQCPHEZJDkziM6WHawJ7P5lwPgiqgBQrgKRcKfO6zDpVXXP0V
kHMYknMur+7E
4Rujif2qiOwooN9ap8kDmdR46FG//yypZL0Eu15l1UF7Lyk5Gtb3
TC8u/u4MOWb6
JubVUat3LLKEFrWLB1NY1DkbGWR1oVlIywRv7zQJUUdF/mqn5P2D
Zf8Qs7AjxoE6
TsdhoI4N17Mf8DoflsawXVZ/Ffh1MpuO4vA53Bwh4fgj04OF736w
vPJcM1EqzZ1D
TW3z2TpBAoGBAOdaVVGt5Hq3gTClebFyMInLUlf5OG5jnR8vMpFl
8U1iYu8VOa3+
UIN SYARIF HIDAYATULLAH JAKARTA

Q2eYSJ2xCEHE0KJccjoVBGdVVrgmBRvHsnmekv/vJkcZqQ0noSIe
M9xfiWqevt9k
+hXvrHioC0Te3dnIXxEXI36Dz1f1ceJkgUf+ojDdDg+ZGsBBmF9v
EqsZAoGBAM8k
7WYF4ZJ5c3qo9Fn8OGN2oQ1Mb1tyY6EgYycY0yy274CB5vLzKBAG
s6s7J8fTkggp
IjHYeSmOAlYMqw14hNgRj3OttLhpYwlspOBFyj6EvGti0ISDBr7/
B2/CHiAS2rf6
ix4Ge+r3VbKh0TWhEdgw0W7k54eB6QzwymUC51T5AoGBALqHC3kC
Uc9bOm7lS5t0
rIu8gVRqnEPsTpcA761o2seAhrGqlEmjUecpUYrKXBTiwS/Wh0Yr
AdTqajOoe7/t
HwmNf4mX4G28057Gj9S5Myj/YgSznsLwX+3lwlG5cvSBF69qLLPT
ywtK7JZHTx2v
2MgaFdx9rcOHtpjBij+PhyapAoGBAJk9xU5bfXPh21db1GEZoRGb
+isfZ6YsKp5R
mmibCeajcu0LrLIAxpuMibBcM+K1luvomj5r2b6vKvVDq+tsREKg
QxKd5/shI74e
HJ85ohO8GLQMxxuw3vW/L14zKhwqNpoyhGZy/4tk7IYZBe95t/zK
qLU0LEBoD+Od
4uz1R/PpAoGBALrS3j11GhuUSzwIOO4WS3FgFLEtX87hygEBvhcA
UiBsEUDU8qMl
6UiApbNSfeDtuymbn3ShI2cDVdheNtc4/2adCB8yvj1Ywe4sVmF9
oNDdeooEpl+J
jaDjS9nUrclqu4aggCWn6pv+MnABANN7rfEG++yyPf0O0XSDsagX
C4UP
-----END RSA PRIVATE KEY-----
UIN SYARIF HIDAYATULLAH JAKARTA
Related Documents











