
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


Two Opinions
There exists a group of news sources X such that at least one of thefollowing is true:
“All news come from X and the rest just comments on them”
“A story receives wide public attention only if X reports on them”
1

1 Method: how we did it
2 Results: what we found
2

Remainder of this Talk
1 Method: how we did it
2 Results: what we found
3

The Setting
Given a list of sources, crawl periodically all new articles and find events
Event
“An event is a particular thing that happens at a specific time and place”
We know how to do this since 15+ years (TDT)
A Study on Retrospective and On2Line Event DetectionYiming Yang& Tom Pierce& Jaime CarbonellSchool of Computer ScienceCarnegie Mellon UniversityPittsburgh& PA =>?=@A@BC?& USAwww!cs!cmu!edu()yiming(Abstract This paper investigates the use and exten/sion of text retrieval and clustering techniques for eventdetection5 The task is to automatically detect novelevents from a temporally/ordered stream of news stories:either retrospectively or as the stories arrive5 We appliedhierarchical and non/hierarchical document clustering al/gorithms to a corpus of <=:>?@ stories: focusing on theexploitation of both content and temporal information5We found the resulting cluster hierarchies highly infor/mative for retrospective detection of previously uniden/tiBed events: eCectively supporting both query/free andquery/driven retrieval5 We also found that temporal dis/tribution patterns of document clusters provide usefulinformation for improvement in both retrospective de/tection and on/line detection of novel events5 In anevaluation using manually labelled events to judge thesystem/detected events: we obtained a result of >FG inthe F measure for retrospective detection: and a F value of HFG for on/line detection5' IntroductionThe rapidly/growing amount of electronically availableinformation threatens to overwhelm human attention:raising new challenges for information retrieval technol/ogy5 Although traditional query/driven retrieval is use/ful for content/focused queries: it is deBcient for genericqueries such as JWhat happenedKL or JWhatMs newKL5Browsing without guidance or a conceptual structure ofthe search space is useful only in miniscule informationspaces5Consider a person who returns from an extended va/cation and needs to Bnd out quickly what happened in theworld during her absence5 Reading the entire news col/lection is a daunting task: and generating speciBc queriesabout unknown facts is rather unrealistic5 Thus: intel/ligent assistance from the computer is clearly desirable5Such assistance could take the form of a content summaryof a corpus for a quick review: the temporal evolution ofpast events of interest: or a listing of automatically de/tected new events which demonstrate a signiBcant con/tent shift from any previously known events5 It wouldalso be useful to have structured guidelines for naviga/tion through document clusters5 Table < shows a samplePermission to make digital.hard copy of all or part of this workfor personal or classroom use is granted without fee provided thatcopies are not made or distributed for pro8t or commercial ad9vantage: the copyright notice: the title of the publication and itsdate appear: and notice is given that copying is by permission ofACM: Inc? To copy otherwise: to republish: to post on servers orto redistribute to lists: requires prior speci8c permission and.orfee? SIGIREFG: Melbourne: Australia c HFFG ACM H9IGHHJ9KHI9IG.FG LI?KK?
Table <5 Corpus summary using keywords ofautomatically generated clusters of news storiesSizeS Top/ranking Words TstemmedU??V republ clinton congress hous amendF<W simpson o prosecut trial juryX> israel palestin gaza peac arafatXW japan kobe earthquak quak tokyX? russian chech chechny grozn yeltsin=@ somal u mogadishu iraq marin== Yood rain californ malibu riveH> serb bosnian bosnia croat u?= game leagu play basebal season?? crash airlin Yight airport passengF> clinic sav abort massachuset norfolkFW shuttl spac astronaut mir discovF@ patient drug virus holtz infectFH chin beij deng trad copyright555S Size means the number of documents included5summary of a corpus obtained by applying our hierarchi/cal content/based clustering algorithm to a few thousandnews stories TCNN news and Reuters articles from Jan/uary to February in <XX=U and presenting each clusterusing a few Tstatistically signiBcantU key terms5 As thetable shows: domestic politics reigns supreme as usual:the OJ trial still receives media attention: etc5 How/ever: the table also reveals that disasters struck KobeJapan and Malibu California: and Chechnia has Yared upagain: events which were not present the month before5The key terms provide content information: and the storycounts imply signiBcance: as measured by media atten/tion5 If further detail is desired: the sub/clusters can beexamined via query/driven retrieval: browsing individualdocuments or synthetic summaries across documents aFb5The utility of such computer assistance is evident eventhough some clusters may be imperfect and the currentuser interface is rudimentary5This paper reports our work in event detection: anew research topic initiated by the Topic Detection andTracking TTDTU project 5 The objective is to identifystories in several continuous news streams that pertainto new or previously unidentiBed events5 To be moreprecise: detection consists of two tasksd retrospective de+tection and on+line detection5 The former entails the dis/covery of previously unidentiBed events in an accumu/lated collection: and the latter strives to identify the on/set of new events from live news feeds in real/time5 Both The TDT project is supported by the U?S? Government: con9sisting of segmentation of stories in a continuous news9stream:temporal event tracking and event detection? Our event trackingwork will be reported in a separate paper?
4

The Setting
Given a list of sources, crawl periodically all new articles and find events
Event
“An event is a particular thing that happens at a specific time and place”
We know how to do this since 15+ years (TDT)
A Study on Retrospective and On2Line Event DetectionYiming Yang& Tom Pierce& Jaime CarbonellSchool of Computer ScienceCarnegie Mellon UniversityPittsburgh& PA =>?=@A@BC?& USAwww!cs!cmu!edu()yiming(Abstract This paper investigates the use and exten/sion of text retrieval and clustering techniques for eventdetection5 The task is to automatically detect novelevents from a temporally/ordered stream of news stories:either retrospectively or as the stories arrive5 We appliedhierarchical and non/hierarchical document clustering al/gorithms to a corpus of <=:>?@ stories: focusing on theexploitation of both content and temporal information5We found the resulting cluster hierarchies highly infor/mative for retrospective detection of previously uniden/tiBed events: eCectively supporting both query/free andquery/driven retrieval5 We also found that temporal dis/tribution patterns of document clusters provide usefulinformation for improvement in both retrospective de/tection and on/line detection of novel events5 In anevaluation using manually labelled events to judge thesystem/detected events: we obtained a result of >FG inthe F measure for retrospective detection: and a F value of HFG for on/line detection5' IntroductionThe rapidly/growing amount of electronically availableinformation threatens to overwhelm human attention:raising new challenges for information retrieval technol/ogy5 Although traditional query/driven retrieval is use/ful for content/focused queries: it is deBcient for genericqueries such as JWhat happenedKL or JWhatMs newKL5Browsing without guidance or a conceptual structure ofthe search space is useful only in miniscule informationspaces5Consider a person who returns from an extended va/cation and needs to Bnd out quickly what happened in theworld during her absence5 Reading the entire news col/lection is a daunting task: and generating speciBc queriesabout unknown facts is rather unrealistic5 Thus: intel/ligent assistance from the computer is clearly desirable5Such assistance could take the form of a content summaryof a corpus for a quick review: the temporal evolution ofpast events of interest: or a listing of automatically de/tected new events which demonstrate a signiBcant con/tent shift from any previously known events5 It wouldalso be useful to have structured guidelines for naviga/tion through document clusters5 Table < shows a samplePermission to make digital.hard copy of all or part of this workfor personal or classroom use is granted without fee provided thatcopies are not made or distributed for pro8t or commercial ad9vantage: the copyright notice: the title of the publication and itsdate appear: and notice is given that copying is by permission ofACM: Inc? To copy otherwise: to republish: to post on servers orto redistribute to lists: requires prior speci8c permission and.orfee? SIGIREFG: Melbourne: Australia c HFFG ACM H9IGHHJ9KHI9IG.FG LI?KK?
Table <5 Corpus summary using keywords ofautomatically generated clusters of news storiesSizeS Top/ranking Words TstemmedU??V republ clinton congress hous amendF<W simpson o prosecut trial juryX> israel palestin gaza peac arafatXW japan kobe earthquak quak tokyX? russian chech chechny grozn yeltsin=@ somal u mogadishu iraq marin== Yood rain californ malibu riveH> serb bosnian bosnia croat u?= game leagu play basebal season?? crash airlin Yight airport passengF> clinic sav abort massachuset norfolkFW shuttl spac astronaut mir discovF@ patient drug virus holtz infectFH chin beij deng trad copyright555S Size means the number of documents included5summary of a corpus obtained by applying our hierarchi/cal content/based clustering algorithm to a few thousandnews stories TCNN news and Reuters articles from Jan/uary to February in <XX=U and presenting each clusterusing a few Tstatistically signiBcantU key terms5 As thetable shows: domestic politics reigns supreme as usual:the OJ trial still receives media attention: etc5 How/ever: the table also reveals that disasters struck KobeJapan and Malibu California: and Chechnia has Yared upagain: events which were not present the month before5The key terms provide content information: and the storycounts imply signiBcance: as measured by media atten/tion5 If further detail is desired: the sub/clusters can beexamined via query/driven retrieval: browsing individualdocuments or synthetic summaries across documents aFb5The utility of such computer assistance is evident eventhough some clusters may be imperfect and the currentuser interface is rudimentary5This paper reports our work in event detection: anew research topic initiated by the Topic Detection andTracking TTDTU project 5 The objective is to identifystories in several continuous news streams that pertainto new or previously unidentiBed events5 To be moreprecise: detection consists of two tasksd retrospective de+tection and on+line detection5 The former entails the dis/covery of previously unidentiBed events in an accumu/lated collection: and the latter strives to identify the on/set of new events from live news feeds in real/time5 Both The TDT project is supported by the U?S? Government: con9sisting of segmentation of stories in a continuous news9stream:temporal event tracking and event detection? Our event trackingwork will be reported in a separate paper?
4

The Setting
Given a list of sources, crawl periodically all new articles and find events
Event
“An event is a particular thing that happens at a specific time and place”
We know how to do this since 15+ years (TDT)
A Study on Retrospective and On2Line Event DetectionYiming Yang& Tom Pierce& Jaime CarbonellSchool of Computer ScienceCarnegie Mellon UniversityPittsburgh& PA =>?=@A@BC?& USAwww!cs!cmu!edu()yiming(Abstract This paper investigates the use and exten/sion of text retrieval and clustering techniques for eventdetection5 The task is to automatically detect novelevents from a temporally/ordered stream of news stories:either retrospectively or as the stories arrive5 We appliedhierarchical and non/hierarchical document clustering al/gorithms to a corpus of <=:>?@ stories: focusing on theexploitation of both content and temporal information5We found the resulting cluster hierarchies highly infor/mative for retrospective detection of previously uniden/tiBed events: eCectively supporting both query/free andquery/driven retrieval5 We also found that temporal dis/tribution patterns of document clusters provide usefulinformation for improvement in both retrospective de/tection and on/line detection of novel events5 In anevaluation using manually labelled events to judge thesystem/detected events: we obtained a result of >FG inthe F measure for retrospective detection: and a F value of HFG for on/line detection5' IntroductionThe rapidly/growing amount of electronically availableinformation threatens to overwhelm human attention:raising new challenges for information retrieval technol/ogy5 Although traditional query/driven retrieval is use/ful for content/focused queries: it is deBcient for genericqueries such as JWhat happenedKL or JWhatMs newKL5Browsing without guidance or a conceptual structure ofthe search space is useful only in miniscule informationspaces5Consider a person who returns from an extended va/cation and needs to Bnd out quickly what happened in theworld during her absence5 Reading the entire news col/lection is a daunting task: and generating speciBc queriesabout unknown facts is rather unrealistic5 Thus: intel/ligent assistance from the computer is clearly desirable5Such assistance could take the form of a content summaryof a corpus for a quick review: the temporal evolution ofpast events of interest: or a listing of automatically de/tected new events which demonstrate a signiBcant con/tent shift from any previously known events5 It wouldalso be useful to have structured guidelines for naviga/tion through document clusters5 Table < shows a samplePermission to make digital.hard copy of all or part of this workfor personal or classroom use is granted without fee provided thatcopies are not made or distributed for pro8t or commercial ad9vantage: the copyright notice: the title of the publication and itsdate appear: and notice is given that copying is by permission ofACM: Inc? To copy otherwise: to republish: to post on servers orto redistribute to lists: requires prior speci8c permission and.orfee? SIGIREFG: Melbourne: Australia c HFFG ACM H9IGHHJ9KHI9IG.FG LI?KK?
Table <5 Corpus summary using keywords ofautomatically generated clusters of news storiesSizeS Top/ranking Words TstemmedU??V republ clinton congress hous amendF<W simpson o prosecut trial juryX> israel palestin gaza peac arafatXW japan kobe earthquak quak tokyX? russian chech chechny grozn yeltsin=@ somal u mogadishu iraq marin== Yood rain californ malibu riveH> serb bosnian bosnia croat u?= game leagu play basebal season?? crash airlin Yight airport passengF> clinic sav abort massachuset norfolkFW shuttl spac astronaut mir discovF@ patient drug virus holtz infectFH chin beij deng trad copyright555S Size means the number of documents included5summary of a corpus obtained by applying our hierarchi/cal content/based clustering algorithm to a few thousandnews stories TCNN news and Reuters articles from Jan/uary to February in <XX=U and presenting each clusterusing a few Tstatistically signiBcantU key terms5 As thetable shows: domestic politics reigns supreme as usual:the OJ trial still receives media attention: etc5 How/ever: the table also reveals that disasters struck KobeJapan and Malibu California: and Chechnia has Yared upagain: events which were not present the month before5The key terms provide content information: and the storycounts imply signiBcance: as measured by media atten/tion5 If further detail is desired: the sub/clusters can beexamined via query/driven retrieval: browsing individualdocuments or synthetic summaries across documents aFb5The utility of such computer assistance is evident eventhough some clusters may be imperfect and the currentuser interface is rudimentary5This paper reports our work in event detection: anew research topic initiated by the Topic Detection andTracking TTDTU project 5 The objective is to identifystories in several continuous news streams that pertainto new or previously unidentiBed events5 To be moreprecise: detection consists of two tasksd retrospective de+tection and on+line detection5 The former entails the dis/covery of previously unidentiBed events in an accumu/lated collection: and the latter strives to identify the on/set of new events from live news feeds in real/time5 Both The TDT project is supported by the U?S? Government: con9sisting of segmentation of stories in a continuous news9stream:temporal event tracking and event detection? Our event trackingwork will be reported in a separate paper?
4

The Particularities
We wanted to be global:
ABC News US EHealthNews Europe North Africa Journal North AfricaAl Jazeera Arabic World EUbusiness Europe Novaya Gazeta RussiaAll Africa Africa EUobserver Europe Novinite BulgariaANSA Italy EurActiv Europe NPR USAntara News Indonesia Euronews Europe NY Post USAOL news Global EuropeanAgenda Europe NY Times USAP Global EuroTopics Europe Reuters GlobalBBC UK Fox News US RFERL Asia, M EastBoston Globe US France24 France RIAN RussiaBudapeast Business J Hungary FT Global The Australian AustraliaBusinessweek Global Helsinki Times Finland The Globe and Mail CanadaCBS News US Kyodo News Japan The Guardian UKChina News Service China The WSJ US The Herald (Glasgow) ScotlandChosun South Korea Irish Examiner Ireland The Star MalaysiaCNN US Le Monde dipl France The Sun UKCyprus Mail Cyprus Mercopress Latin America The Telegraph UKDaily Mail UK Moscov News Russia Times of India IndiaDaily Mirror UK MSNBC Global Times of Malta MaltaDer Spiegel Germany New Europe Europe Voice of America USDW-World Germany New Scientist Global
5

The Particularities
Danger of falling into one of two extremes:
-�get drown consider onlyby local events most salient events
6

Our Solution
Two-stage approach:
1 Scaffold given by main-segments of primary sources
2 Fill in all the remaining articles
7

Our Solution
Two-stage approach:
1 Scaffold given by main-segments of primary sources
2 Fill in all the remaining articles
Main-segment
Sentences containing the first 100 words
7

The Particularities
Primary Sources:
ABC News US EHealthNews Europe North Africa Journal North AfricaAl Jazeera Arabic World EUbusiness Europe Novaya Gazeta RussiaAll Africa Africa EUobserver Europe Novinite BulgariaANSA Italy EurActiv Europe NPR USAntara News Indonesia Euronews Europe NY Post USAOL news Global EuropeanAgenda Europe NY Times USAP Global EuroTopics Europe Reuters GlobalBBC UK Fox News US RFERL Asia, M EastBoston Globe US France24 France RIAN RussiaBudapeast Business J Hungary FT Global The Australian AustraliaBusinessweek Global Helsinki Times Finland The Globe and Mail CanadaCBS News US Kyodo News Japan The Guardian UKChina News Service China The WSJ US The Herald (Glasgow) ScotlandChosun South Korea Irish Examiner Ireland The Star MalaysiaCNN US Le Monde dipl France The Sun UKCyprus Mail Cyprus Mercopress Latin America The Telegraph UKDaily Mail UK Moscov News Russia Times of India IndiaDaily Mirror UK MSNBC Global Times of Malta MaltaDer Spiegel Germany New Europe Europe Voice of America USDW-World Germany New Scientist Global
8

Our Solution
1 Get new articles2 Scaffold:
1 S = main-segments from primary sources2 Update existing clusters with S3 Consider as event those that have ≥ 3 articles from ≥ 2 sources
3 Fill-in:1 Consider all articles of the last 48 hours and try to match them to one
of the existing events
4 Archive old events (average time ≥ 3 days)
9

Algorithms used
Scaffolding: Star-EM1
Results are a bit better than traditional TDT results (> 0.8 micro F1measure).
Fill-in: tried several alternatives, used one that dynamically classifies& segments:
Scoring function
Given articles d = s1 . . . sn, find (meta-)segments T1, . . . ,Tk , such thatd = T1 . . .Tk , Ti = sj . . . sj+` for some j and ` > 0 and
1
k
(k∑
i=1
maxe∈E∪{u}
sim(Ti , e)
)− β × k
is maximised.
1M Galle & JM Renders. “Full and mini-batch clustering of news articles withStar-EM” ECIR 2012
10

Algorithms used
Scaffolding: Star-EM1
Results are a bit better than traditional TDT results (> 0.8 micro F1measure).
Fill-in: tried several alternatives, used one that dynamically classifies& segments:
Scoring function
Given articles d = s1 . . . sn, find (meta-)segments T1, . . . ,Tk , such thatd = T1 . . .Tk , Ti = sj . . . sj+` for some j and ` > 0 and
1
k
(k∑
i=1
maxe∈E∪{u}
sim(Ti , e)
)− β × k
is maximised.
1M Galle & JM Renders. “Full and mini-batch clustering of news articles withStar-EM” ECIR 2012
10

Some numbers
62 ≈ 1y 1 hssources time batch size
≈ 820 000 541 546 10 752articles crawled assigned to events events
11

Remainder of this Talk
1 Method: how we did it
2 Results: what we found
12

Two Opinions
There exists a group of news sources X such that at least one of thefollowing is true:
“All news come from X and the rest just comments on them”
“A story receives wide public attention only if X reports on them”
13

First reports
Percentage of total events source x reported first on:
source percentageReuters 12.96%All Africa 11.68%France24 10.41%The Globe and Mail 5.47%BBC 4.91%CNN 4.89%Businessweek 3.01%RIAN 2.67%Daily Mirror 2.59%CBS News 2.32%Daily Mail 2.21%The Telegraph 2.21%NY Post 2.19%Kyodo 2.07%NY Times 2.06%Fox News 1.78%
14
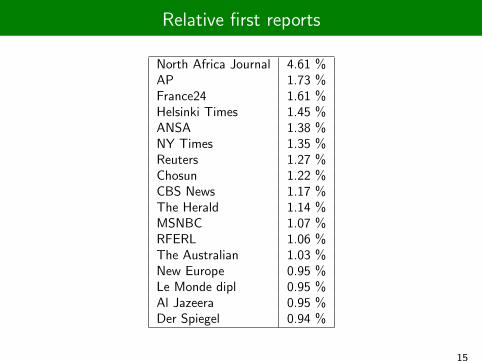
Relative first reports
North Africa Journal 4.61 %AP 1.73 %France24 1.61 %Helsinki Times 1.45 %ANSA 1.38 %NY Times 1.35 %Reuters 1.27 %Chosun 1.22 %CBS News 1.17 %The Herald 1.14 %MSNBC 1.07 %RFERL 1.06 %The Australian 1.03 %New Europe 0.95 %Le Monde dipl 0.95 %Al Jazeera 0.95 %Der Spiegel 0.94 %
15

Two Opinions
There exists a group of news sources X such that at least one of thefollowing is true:
“All news come from X and the rest just comments on them”
“A story receives wide public attention only if X reports on them”
16

Bursty events
17

How to detect bursts
“detect features that occur with high density over a limited time period”
Bursty and Hierarchical Structure in Streams ∗
Jon Kleinberg †
Abstract
A fundamental problem in text data mining is to extract meaningful structure
from document streams that arrive continuously over time. E-mail and news articles
are two natural examples of such streams, each characterized by topics that appear,
grow in intensity for a period of time, and then fade away. The published literature
in a particular research field can be seen to exhibit similar phenomena over a much
longer time scale. Underlying much of the text mining work in this area is the following
intuitive premise — that the appearance of a topic in a document stream is signaled
by a “burst of activity,” with certain features rising sharply in frequency as the topic
emerges.
The goal of the present work is to develop a formal approach for modeling such
“bursts,” in such a way that they can be robustly and efficiently identified, and can
provide an organizational framework for analyzing the underlying content. The ap-
proach is based on modeling the stream using an infinite-state automaton, in which
bursts appear naturally as state transitions; it can be viewed as drawing an analogy
with models from queueing theory for bursty network traffic. The resulting algorithms
are highly efficient, and yield a nested representation of the set of bursts that imposes
a hierarchical structure on the overall stream. Experiments with e-mail and research
paper archives suggest that the resulting structures have a natural meaning in terms
of the content that gave rise to them.
∗This work appears in the Proceedings of the 8th ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining, 2002.†Department of Computer Science, Cornell University, Ithaca NY 14853. Email: [email protected].
Supported in part by a David and Lucile Packard Foundation Fellowship, an ONR Young Investigator Award,
NSF ITR/IM Grant IIS-0081334, and NSF Faculty Early Career Development Award CCR-9701399.
1
18

How to detect bursts
“detect features that occur with high density over a limited time period”
Black box: input an arrival series (with timestamps), and get for eachevent zero or more periods where it was bursty (plus a score)
A bit more technical: model this with HMM of 2 nodes: normal &bursty emissions
18

Bursty sources
1 Compute burst(s) for each event
2 Take for each burst the first article
3 Add the burst’s score to this source total score
19

Bursty sources
source total burst scoreReuters 100.0The Globe and Mail 83.9CNN 72.7Al Jazeera 58.0France24 53.1RIAN 47.0The Star 45.6CBS News 43.8MSNBC 42.4NPR 38.6The Sun 37.5DW 34.7The Guardian 32.1BBC 30.9Businessweek 26.8All Africa 22.1AP 21.6
19

Bursty sources: explanations
1 News agencies: its their job
2 Regional news sources which are trusted (RIAN, AlJazeera)
3 Good “journalistic nose”
20

Lag to report
1 Consider for all sources those events it reported on, but not first
2 Take the time delta with the first article
21

Lag to report
source hours (median)France24 20.85Reuters 20.87BBC 21.41Antara News 21.78All Africa 22.69Kyodo 23.47Fox News 24.74Al Jazeera 24.86ANSA 24.95CNN 24.96RIAN 25.38RFERL 26.29The Telegraph 26.53Daily Mirror 26.70Euronews 27.40The Globe and Mail 27.45NPR 27.94
21

Lag to report: Explanations
Online first policy: you can’t argue (in most cases) that this is due tonighttime
intrinsic delay waiting for confirmation, and assessing news (?)
lingering conservatism (?)
Everybody chooses his priorities
22

Differences in reporting time
23

Differences in reporting time
23

Differences in reporting time
23

Conclusions
Data-driven analysis to study which news outlets break news
Some important fine-tuning deviations from classical TDT to scale up& capture many global events
(In our data) It is not true that only Big Agencies break news
Regarding hotness, many trusted regional outlets rank at the top
Lag to report remains big, but may hide in-house priorities /strategies.
24

Conclusions
Data-driven analysis to study which news outlets break news
Some important fine-tuning deviations from classical TDT to scale up& capture many global events
(In our data) It is not true that only Big Agencies break news
Regarding hotness, many trusted regional outlets rank at the top
Lag to report remains big, but may hide in-house priorities /strategies.
24

Conclusions
Data-driven analysis to study which news outlets break news
Some important fine-tuning deviations from classical TDT to scale up& capture many global events
(In our data) It is not true that only Big Agencies break news
Regarding hotness, many trusted regional outlets rank at the top
Lag to report remains big, but may hide in-house priorities /strategies.
24