J. Parallel Distrib. Comput. 67 (2007) 259 – 270 www.elsevier.com/locate/jpdc SLA based resource allocation policies in autonomic environments Danilo Ardagna a , ∗ , Marco Trubian b , Li Zhang c a Dipartimento di Elettronica e Informazione, Politecnico di Milano, Italy b Dipartimento di Scienze dell’Informazione, Università degli Studi di Milano, Italy c IBM T.J. Watson Research Center, USA Received 20 June 2005; received in revised form 21 October 2006; accepted 28 October 2006 Available online 19 January 2007 Abstract Nowadays, large service centers provide computational capacity to many customers by sharing a pool of IT resources. The service providers and their customers negotiate utility based Service Level Agreement (SLA) to determine the costs and penalties on the base of the achieved performance level. The system is often based on a multi-tier architecture to serve requests and autonomic techniques have been implemented to manage varying workload conditions. The service provider would like to maximize the SLA revenues, while minimizing its operating costs. The system we consider is based on a centralized network dispatcher which controls the allocation of applications to servers, the request volumes at various servers and the scheduling policy at each server. The dispatcher can also decide to turn ON or OFF servers depending on the system load. This paper designs a resource allocation scheduler for such multi-tier autonomic environments so as to maximize the profits associated with multiple class SLAs. The overall problem is NP-hard. We develop heuristic solutions by implementing a local-search algorithm. Experimental results are presented to demonstrate the benefits of our approach. © 2006 Elsevier Inc. All rights reserved. Keywords: Autonomic computing; Resource allocation; Load balancing; Quality of service; SLA optimization 1. Introduction To reduce their management cost, companies often outsource their IT infrastructure to third party service providers. Many companies, from hardware vendors to IT consulting, have set up large service centers to provide services to many customers by sharing the IT resources. This leads to the efficient use of resources and a reduction of the operating costs. The service providers and their customers negotiate utility based Service Level Agreements (SLAs) to determine costs and penalties based on the achieved performance level. The service provider needs to manage its resources to maximize its profits. Utility based optimization approaches are commonly used for providing load balancing and for obtaining the optimal trade- off among request classes for quality of service levels [22]. One main issue of these systems is the high variability of the workload. For example for Internet applications, the ratio ∗ Corresponding author. Fax: +39 02 2399 3411. E-mail addresses: [email protected] (D. Ardagna), [email protected] (M. Trubian), [email protected] (L. Zhang). 0743-7315/$ - see front matter © 2006 Elsevier Inc. All rights reserved. doi:10.1016/j.jpdc.2006.10.006 of the peak to light load is usually in the order of 300% [8]. Due to such large variations in loads, it is difficult to estimate workload requirements in advance, and planning the capacity for the worst-case is either infeasible or extremely inefficient. In order to handle workload variations, many service centers have started employing self-managing autonomic techniques [3,16,18,19]. Autonomic systems maintain and adjust their operations in the face of changing components, demands or external condi- tions and dynamically allocate resources to applications of dif- ferent customers on the base of short-term demand estimates. The goal is to meet the application requirements while adapting IT architecture to workload variations [13]. In such systems, a network dispatcher manages autonomic components (e.g. stor- age systems, physical servers, software elements) and dynami- cally determines the best use of resources on the base of a short term load prediction (see Fig. 1). Usually, heterogeneous clus- ters of servers are considered and many technical solutions, e.g. grid and Web services [13,11], or system virtualization [10], have been proposed to support application migration and re- source management.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

J. Parallel Distrib. Comput. 67 (2007) 259–270www.elsevier.com/locate/jpdc
SLA based resource allocation policies in autonomic environments
Danilo Ardagnaa,∗, Marco Trubianb, Li Zhangc
aDipartimento di Elettronica e Informazione, Politecnico di Milano, ItalybDipartimento di Scienze dell’Informazione, Università degli Studi di Milano, Italy
cIBM T.J. Watson Research Center, USA
Received 20 June 2005; received in revised form 21 October 2006; accepted 28 October 2006Available online 19 January 2007
Abstract
Nowadays, large service centers provide computational capacity to many customers by sharing a pool of IT resources. The service providersand their customers negotiate utility based Service Level Agreement (SLA) to determine the costs and penalties on the base of the achievedperformance level. The system is often based on a multi-tier architecture to serve requests and autonomic techniques have been implementedto manage varying workload conditions. The service provider would like to maximize the SLA revenues, while minimizing its operating costs.The system we consider is based on a centralized network dispatcher which controls the allocation of applications to servers, the requestvolumes at various servers and the scheduling policy at each server. The dispatcher can also decide to turn ON or OFF servers depending onthe system load. This paper designs a resource allocation scheduler for such multi-tier autonomic environments so as to maximize the profitsassociated with multiple class SLAs. The overall problem is NP-hard. We develop heuristic solutions by implementing a local-search algorithm.Experimental results are presented to demonstrate the benefits of our approach.© 2006 Elsevier Inc. All rights reserved.
Keywords: Autonomic computing; Resource allocation; Load balancing; Quality of service; SLA optimization
1. Introduction
To reduce their management cost, companies often outsourcetheir IT infrastructure to third party service providers. Manycompanies, from hardware vendors to IT consulting, have setup large service centers to provide services to many customersby sharing the IT resources. This leads to the efficient use ofresources and a reduction of the operating costs.
The service providers and their customers negotiate utilitybased Service Level Agreements (SLAs) to determine costs andpenalties based on the achieved performance level. The serviceprovider needs to manage its resources to maximize its profits.Utility based optimization approaches are commonly used forproviding load balancing and for obtaining the optimal trade-off among request classes for quality of service levels [22].
One main issue of these systems is the high variability ofthe workload. For example for Internet applications, the ratio
∗ Corresponding author. Fax: +39 02 2399 3411.E-mail addresses: [email protected] (D. Ardagna),
[email protected] (M. Trubian), [email protected] (L. Zhang).
0743-7315/$ - see front matter © 2006 Elsevier Inc. All rights reserved.doi:10.1016/j.jpdc.2006.10.006
of the peak to light load is usually in the order of 300% [8].Due to such large variations in loads, it is difficult to estimateworkload requirements in advance, and planning the capacityfor the worst-case is either infeasible or extremely inefficient.In order to handle workload variations, many service centershave started employing self-managing autonomic techniques[3,16,18,19].
Autonomic systems maintain and adjust their operations inthe face of changing components, demands or external condi-tions and dynamically allocate resources to applications of dif-ferent customers on the base of short-term demand estimates.The goal is to meet the application requirements while adaptingIT architecture to workload variations [13]. In such systems, anetwork dispatcher manages autonomic components (e.g. stor-age systems, physical servers, software elements) and dynami-cally determines the best use of resources on the base of a shortterm load prediction (see Fig. 1). Usually, heterogeneous clus-ters of servers are considered and many technical solutions, e.g.grid and Web services [13,11], or system virtualization [10],have been proposed to support application migration and re-source management.

260 D. Ardagna et al. / J. Parallel Distrib. Comput. 67 (2007) 259–270
Fig. 1. Autonomic system infrastructure.
Independent on the technology used for the implementation,the main components of the network dispatcher [7,20] are amonitor, a predictor and a resource allocator. The system mon-itor measures the workload and performance metrics of eachapplication, identifies requests from different customers andestimates requests service times. The predictor forecasts fu-ture system load conditions from load history and the alloca-tor determines the best system configuration and applicationsto servers assignment. Usually, each request requires the ex-ecution of several applications allocated on multiple physicalservers.
This paper focuses on the design of a resource allocator forautonomic multi-tier environments. The goal is to maximizethe revenue while balancing the cost of using the resources.The cost includes the energy costs [8] and software and hard-ware cost of resources allocated on demand [25,12]. The over-all profit (utility) includes the revenues and penalties incurredwhen quality of service guarantees are satisfied or violated.The resource allocator can establish: (i) the set of servers to beturned ON depending on the system load, (ii) the applicationtiers to servers assignment, (iii) the request volumes at variousservers and (iv) the scheduling policy at each server.
We model the problem as a mixed integer nonlinear program-ming problem and develop heuristic solutions based on a local-search approach. The neighborhood exploration is based on afixed-point iteration (FPI) technique, which iteratively solvesa scheduling and a load balancing problem by implementinga gradient method. Our resource allocator considers two time
scales: optimum load balancing and scheduling are determinedin real-time and applied every few minutes, while applicationallocation and servers status are evaluated with a greater timescale, i.e., every half an hour, in order to reduce system re-configuration overhead.
Differently from the previous literature, our model considersjointly a broader set of control variables and uses mathemati-cal programming based techniques to obtain a solution of theproblem. Experimental results are presented to show the bene-fits of our approach.
The remainder of the paper is organized as follows. Section 2describes other literature approaches. Section 3 introduces theoverall system model. The optimization problem formulation ispresented in Section 4. The local-search approach is presentedin Section 5. The experimental results in Section 6 demonstratethe quality and efficiency of our solutions. Conclusions aredrawn in Section 7.
2. Related work
Recently, the problem of maximization of SLA revenues inshared service center environments implementing autonomicself-managing techniques has attracted vast attention by theresearch community. The SLA maximization problem whichconsiders (i) the set of servers to be turned ON depending on thesystem load, (ii) the application tiers to servers assignment, (iii)the request volumes at various servers and (iv) the schedulingpolicy at each server as joint control variables, as faced in thispaper, however, has not yet been considered.
In [18,19] authors address the problem of handling servicecenters resources in overload conditions while maximizingSLA revenues. Anyway, applications are assigned to dedicatedservers and the load balancing problem is not addressed. Au-thors in [25] consider the optimization of a multi-tier systemwhere the system workload is evenly shared among servers andthe processor sharing (PS) scheduling policy is applied, i.e.,control variables (iii) and (iv) are not taken into account. Fur-thermore, a single class model is considered and the problemis solved by enumeration.
When the scheduling and load balancing are used as controlvariables, the optimization of a single tier is usually addressed,mainly the Web server tier and the servers are always ON, hencedecisions (i) and (ii) are not considered [23,17,6,16]. In partic-ular, in [23] the problem of minimization of system responsetimes and maximization of throughput is analyzed. The workproposes a static algorithm which assigns Web sites to overlap-ping servers executed once a week, on long term predictionsbasis, while a dynamic algorithm implements a real time dis-patcher and assigns incoming requests to servers consideringshort term load forecasts.
In [17] continuous utility functions are introduced, the loadis evenly shared among servers and the problem of maximiza-tion of SLA is formulated as a scheduling problem. The effec-tiveness of the overall approach is verified by simulation. Theauthors in [6] faced the dual problem of minimizing customers’discontent function considering an online estimate of servicetime requirements and their response times. The optimal gener-

D. Ardagna et al. / J. Parallel Distrib. Comput. 67 (2007) 259–270 261
alized processor sharing (GPS) scheduling policy [28] is iden-tified by using Lagrange techniques. In [16], the authors pro-posed an analytical formulation of the problem to maximize themulti-class SLA in heterogeneous Web clusters, consideringthe tail distribution of the request response times. The controlvariables are the scheduling parameters at each cluster and thefrequency of requests assigned to different clusters. The loadbalancing problem is addressed among different clusters butthe load is evenly shared among servers of the same cluster.
Finally, in a previous paper [26], we extended [16] workby considering step-wise utility functions and the number ofservers to be switched ON as a control variable. Anyway thepricing schema considered the response time of each requestat a single tier. In multi-tier system, the flexibility providedby current technology can be exploited to implement the mostconvenient load sharing among multiple machines, if the overallresource allocation problem is addressed.
3. The system model
The system under study is a distributed computer systemconsisting of M heterogeneous physical servers. There are to-tally K classes of request streams. Each class k ∈ K requestcan be served by a set of server applications (application tiersin the following) according to the client/server paradigm. Forsimplicity we assume that each class k request is associatedwith a single customer. The architecture comprises a requestsdispatcher in front of physical servers that establishes the al-location of application tiers to physical servers, the schedulingpolicy, and the load balancing of incoming requests to eachphysical server. The service discipline under consideration isthe GPS class [28]. The controller can also turn OFF and ONphysical server in order to reduce the overall cost.
For each class k ∈ K , a linear utility function is defined tospecify the per request revenue (or penalty) incurred when theaverage end-to-end response time Rk , from multiple applicationtiers, assumes a given value. Fig. 2 shows, as an example, theplot of an utility function. −mk indicates the slope of the utilityfunction (mk = uk/Rk > 0) and Rk is the threshold that iden-tifies the revenue/penalty region (i.e., if Rk > Rk the SLA isviolated and penalties are incurred). Linear utility functions arecurrently proposed in the literature (see for example [5,18,19]),anyway our approach can be extended in order to consider abroad family of utility functions. We only assume that the util-ity function is monotonically non-increasing, continuous anddifferentiable. Monotonic non-increasing utility functions arevery realistic since the better the achieved performance by endusers, the higher are the revenues gained per request by theservice provider.
The overall system is modeled by a queueing network com-posed of a set of multi-class single-server queues and a multi-class infinite-server queue. The first layers of queues representthe collection of physical servers supporting requests execution.The infinite-server queues represent the client-based delays,or think time, between the server completion of one requestand the arrival of the subsequent request within a session (seeFig. 3).
-mk
uk
RkRk
Uk
Fig. 2. Utility function used to evaluate per request revenues in terms ofaverage requests response times Rk .
Dispatcher
λk pk,k’
DBMS servers tier
Application servers tier
Servlet Engine tier
HTTP servers tier
Think time
Fig. 3. Queueing network performance model of the autonomic system.
User sessions begin with a class k request arriving to the ser-vice center from an exogenous source with rate �k . The analy-sis of actual e-commerce site traces (see for example [21]) hasshown that the Internet workload follows a Poisson distribution,hence we assume that the exogenous arrival streams are Pois-son processes. Upon completion the request either returns to thesystem as a class k′ request with probability pk,k′ or it completeswith probability 1 − ∑K
l=1 pk,l . Let �k denote the aggregaterate of arrivals for class k requests, �k = ∑K
k′=1 �k′pk′,k +�k .The service center can be characterized by the following set
of parameters:
K := set of request classes;Nk := number of application tiers involved in the execution
of class k requests;M := number of physical servers at the service center;Ci := capacity of physical server i;ci := time unit cost for physical server i ON;Ai,k,j := 1 if physical server i can support the execution of
application tier j for class k request, 0 otherwise;�k,j := maximum service rate of a capacity 1 physical server
for executing processes at tier j for class k requests.

262 D. Ardagna et al. / J. Parallel Distrib. Comput. 67 (2007) 259–270
Note that, different request classes require different number ofapplication tiers Nk to be executed. For example, a request for astatic Web page is executed by a Web server, while the requestof dynamic Web page involves multiple tiers, from the Webserver to the DBMS tier (see Fig. 3). The routing matrix [Ai,k,j ]is usually obtained as a result of an optimization problem [23]. Itis used to assign private physical servers to different customerse.g. for dedicated e-commerce transaction servers. It can alsolimit the number of different Web sites assigned to physicalservers due to caching issues [23]. Thus, the routing matrix isused to limit the feasible assignments of application tiers tophysical servers. Note that, ci ∝ Ci , if power is the main costassociated with turning ON a physical server.
The decision variables of our model are the followings:
xi := 1 if physical server i is ON, 0 otherwise;zi,k,j := 1 if the application tier j for class k requests is as-
signed to physical server i, 0 otherwise.�i,k,j := rate of execution for class k requests at application tier
j on physical server i;�i,k,j := GPS parameter at physical server i for executing
application tier j for class k requests.
The analysis of multi-class queueing system is notoriously dif-ficult. We use the GPS bounding technique in [28] to approxi-mate the queueing system. Under GPS, the physical server ca-pacity devoted to class k requests for application tier j at time
t (if any) is Ci�i,k,j /∑
k′∈K(t)
∑Nk′j=1 �i,j,k′ , where K(t) is the
set of classes with waiting requests on physical server i at timet . Requests at different application tiers within each class andon every physical server are executed either in a first-comefirst-served (FCFS) or a PS manner. Under FCFS, we assumethat the service time for class k request at physical server i
has an exponential distribution with mean (Ci�k,j )−1, whereas,
under PS, service time of class k requests at physical server i
follows a general distribution with mean (Ci�k,j )−1, including
heavy-tail distributions of Web application. In the approxima-tion, each multi-class single-server queue associated with an ap-plication tier is decomposed into multiple independent single-class single-server queues with capacity greater than or equal toCi�i,k,j . Authors in [28] have shown that if �i,k,j < Ci�i,k,j
and the external arrivals are exponentially bounded processes(and this hypothesis holds for Poisson arrivals [24,9]), in a net-work of arbitrary topology, then the performance metrics canbe evaluated at any node of the queue network independentlyon the requests route. The response times evaluated in the iso-lated per-class queues are upper bounds on the correspondingmeasures in the original system. Under these hypothesis Ri,k,j ,i.e., the average response time for the execution of the processat application tier j of class k requests at physical server i canbe approximated by Ri,k,j = 1
Ci�k,j�i,k,j −�i,k,j.
Note that, this approximation is asymptotically correct forhigh workloads, since at a high load if a requests class have beenassigned to a physical server at least one request will be waitingfor the execution and hence Ci�i,k,j is the capacity devotedfor every request streams execution without any approximation.We adopt analytical models in order to obtain an indication of
system performance and response time as the authors in [16,29].In Section 6, resource allocation results will be validated bysimulations considering also heavy-tail distributions for servicetime.
The average response time for class k requests is thesum of the average response times at each application tiercomputed over all physical servers, and is given by Rk =
1�k
(∑Mi=1
∑Nk
j=1 �i,k,jRi,k,j
).
Our objective is to maximize the difference between revenuesfrom SLAs and the costs associated with physical servers ONin the inter-scheduler time period which can be expressed as∑K
k=1 �k(−mkRk +uk)−∑Mi=1 cixi , which, after substituting
Rk , becomes
K∑k=1
⎛⎝−mk
M∑i=1
Nk∑j=1
�i,k,j
Ci�k,j�i,k,j − �i,k,j
⎞⎠
+K∑
k=1
uk�k −M∑i=1
cixi .
4. Optimization problem
The overall optimization problem can be formulated as:
(P1)
maxxi ,zi,k,j ,�i,k,j ,�i,k,j
f (x, Z, �, �)
=K∑
k=1
⎛⎝−mk
M∑i=1
Nk∑j=1
�i,k,j
Ci�k,j�i,k,j − �i,k,j
⎞⎠
−M∑i=1
cixi
such that
M∑i=1
�i,k,j = �k, ∀k, j, (1)
K∑k=1
Nk∑j=1
�i,k,j �1, ∀i, (2)
∑(k,j)∈Bl
zi,k,j �1, ∀i, l, (3)
zi,k,j �Ai,k,j xi, ∀i, k, j, (4)
�i,k,j ��kzi,k,j , ∀i, k, j, (5)
�i,k,j < Ci�k,j�i,k,j , ∀i, k, j,
�i,k,j , �i,k,j �0, ∀i, k, j,
xi, zi,k,j ∈ {0, 1}, ∀i, k, j. (6)

D. Ardagna et al. / J. Parallel Distrib. Comput. 67 (2007) 259–270 263
In the above objective function we have omitted the term∑Kk=1 uk�k since it does not depend on the decision variables.
Constraint family (1) entails that the traffic assigned to indi-vidual physical servers, and for every application tier, equalsthe overall load predicted for class k requests. Constraint fam-ily (2) expresses the bounds for GPS scheduling parameters.Constraint family (3) is introduced in order to assign distinctphysical servers to subset of applications, where Bl is a subsetof the indexes in Nk ×K . For example, a servlet engine can beexecuted with a Web server or an application server instance,vice versa application and DBMS servers are usually allocatedto individual physical servers (i.e., eventually supporting mul-tiple application or DBMS instances) for management and se-curity reasons. The constraint family (4) allows assigning ap-plication tiers to physical severs according to Ai,k,j and only ifservers are ON. Constraint family (5) allows executing requestk at server i only if the application tier j has been assigned toserver i. Note that, for a given request class k, the overall load�k is the same at every application tier. Finally, constraintsfamily (6) guarantees that resources are not saturated.
Observation 1. Problem (P1) is a mixed integer nonlinear pro-gramming problem. Even if the set of server ON is fixed, i.e.,the value of variables xi and zi,k,j have been determined, thejoint scheduling and load balancing problem is difficult sincethe objective function is neither concave nor convex. In fact,it is possible to prove by diagonalization techniques, that theeigenvalues of the Hessian of the cost function are mixed insigns (see [4]).
Observation 2. Constraint family (3) defines implication con-straints. In a preprocessing phase, implication (or logical)constraints can be strengthened by dedicated constraint pro-gramming tools or by standard integer programming toolsto obtain stronger formulations. E.g., let us suppose that aWeb server (tier 1) can share a machine only with a servletengine instance (tier 2), while the application server (tier3) and the DBMS server (tier 4) are allocated to individualphysical server. The servlet engine instance can share serversalso with the application server. Such a situation can bemodeled by the following set of equations: zi,k,1 + zi,k,3 �1;zi,k,1 + zi,k,4 �1; zi,k,2 + zi,k,4 �1 and zi,k,3 + zi,k,4 �1.Adding the first, second and fourth constraint we obtain theinequality 2zi,k,1 + 2zi,k,3 + 2zi,k,4 �3, which is equivalent tozi,k,1 + zi,k,3 + zi,k,4 �1 since z-s are binary. This last equa-tions entails that only one process among Web, Applicationand DBMS servers can be active on the same machine.
5. Optimization technique
As it will be discussed in the experimental results section,the given problem can be solved by nonlinear commercial toolsonly for small size instances. For all instances of interest, anheuristic approach has to be considered. We resolve the problemin four steps:
(1) we estimate �k,j the value of the service center capacityto be provided to each application tier;
(2) we build a feasible solution which identifies an initial setof servers ON (by setting xi variables), assigns applicationtiers to physical servers (by setting zi,k,j variables), andidentifies an initial scheduling and load balancing for sys-tem requests (by setting �i,k,j and �i,k,j variables). �k,j
are used to initialize the �i,k,j values;(3) a FPI based on the sub-gradient method is then applied in
order to improve �-s and �-s. This technique iterativelyidentifies the optimum value of a set of variables (�-s or�-s), while the value of the other one (alternatively �-s or�-s) is hold fixed;
(4) the obtained solution is finally enhanced with a local-search algorithm which turns on and off servers, modifiesthe assignment of application tiers to physical servers andupdate the scheduling (�-s) and load balancing (�-s).
The optimization problem (P1) (steps (1)–(4)) is solved peri-odically. The time period Tlong is in the order of magnitude ofseveral minutes, e.g. 15–30 min which are mainly due by step(4). The optimum scheduling and load balancing (step (3)) areevaluated in a shorter time scale Tshort>Tlong and are appliedevery few minutes (e.g., 5 min). The two optimization prob-lems (P1 and the joint optimum scheduling and load balancing)are solved by considering the workload prediction for the nextcontrol time interval (Tlong and Tshort, respectively) and theirsolutions are applied only if the variation of the objective func-tion value which can be obtained by applying the new systemconfiguration is greater than a given threshold. As proposed in[2], in this way system re-configuration overhead is reducedand the system will be stable, i.e., the system will not oscillatebetween two equilibrium points if the incoming workload willchange slightly during the time control horizon.
5.1. Application tiers capacity estimation
In order to estimate the value of the service center capacity tobe provided to each application tier, we model the service centeras a single physical server of capacity U . We consider theproblem of minimizing the weighted average of response timesand the cost associated with resource use as a function of �k,j ,the computing capacity assigned to the execution of requestk at application tier j . Because the utility function is linear,the minimization of the weighted average of response times isequivalent to the maximization of SLA revenues. In this waywe consider the trade-off between the SLA revenues and thecosts of use of resources assigned to each application tier.
The optimization problem can be formalized as:
(P2)
min�k,j
1
�′K∑
k=1
Nk∑j=1
mk�k
�k,j − �k
+ CK∑
k=1
Nk∑j=1
�k,j
such that
K∑k=1
Nk∑j=1
�k,j �U, �k < �k,j , ∀k, j. (7)

264 D. Ardagna et al. / J. Parallel Distrib. Comput. 67 (2007) 259–270
The decision variables are �k,j . C = 1M
∑Mi=1
ci
Ciis the mean
cost per unit resource use, U is the overall capacity of the
service center which is estimated as U =∑M
i=1 Ci
∑Kk=1 �kNk∑K
k=1 �k(∑Nk
j=1 1/�k,j )
by applying a single class model as proposed in [14], and �′ =∑Kk=1 �k is the overall service center workload.Eq. (7) entails that the capacity assigned to application tiers
is lower than the overall capacity of the service center. Sincethe cost function is continuous and convex (the Hessian is adiagonal matrix with elements 2mk�k
(�k,j −�k)3 > 0) the global opti-
mum can be found in polynomial time. In [4], we have deter-mined closed formulas to evaluate �k,j by applying Karush–Kuhn–Tucker conditions, and we have obtained an interestinginequality that relates the overall load and the cost of physi-cal servers to the overall capacity of the service center: C >
1�′
(∑Kk=1 Nk
√mk�k
U−∑Kk=1 Nk�k
)2
. If this inequalities holds, then SLA prof-
its cannot counter balance the cost of use of service center re-sources and some physical servers should be turned OFF. Withthis technique �k,j can be computed by performing O(K) op-erations, for further details see [4].
5.2. Application tiers to servers assignment
We now consider the problem of the assignment of applica-tion tiers to physical servers. The problem is NP-hard. This canbe proved by a reduction from the capacitated facility locationproblem (see [4]). We have implemented a greedy algorithm forobtaining an initial solution which will be eventually enhancedby the local-search algorithm in the final step.
We first sort the physical servers according to the non-decreasing cost-over-capacity ratio and the application tiersaccording to the non-increasing number of different sets Bl
they belong to. Then, each application tier is assigned to phys-ical servers in the given order until the corresponding capacityrequirement �k,j is satisfied, while respecting the constraintsfamily (3) in problem (P1). When a single physical servercannot satisfy an application tier’s demand, then the applica-tion tier is split into multiple physical servers. Let us denotewith yi,k,j the values returned by the algorithm. They define,for each combination of the i, j and k indices, the capacity ofphysical server i devoted to the execution of application tierj of request class k. yi,k,j > 0 implies zi,k,j = 1, xi = 1, i.e.server i is turned ON, and
∑i yi,k,j = �k,j . The CFLP prob-
lem is depicted in Fig. 4 where application tiers and serversare modeled as a bipartite graph. The overall complexity isO(ML + L log L + M log M), where L = ∑K
k=1 Nk , underthe worst case hypothesis that at each iteration for every appli-cation tier the last physical server of the set has to be turnedON and physical servers are never saturated (which alwaysrequires to consider physical server compatibility with thecurrent application tier �k,j to be allocated).
5.3. The load balancing and scheduling problems
Once the application tiers are assigned to physical servers, thescheduling policy at each physical server and the load balancing
Γk,j
ΓK,Nk
1
yi,k,j
Γ1,N1
i
M
2
y2,1,1
y2,1,N1
Application tiers Physical Servers
y1,1,1Γ1,1
Fig. 4. CFLP formalization of the application tiers to physical servers alloca-tion problem. Nodes on the left represent the application tiers capacity thathave to be provided by the servers represented as nodes on the right.
policy have to be identified. Let I = {i|xi = 1} denote theset of physical servers ON and let zi,k,j = 1 if yi,k,j > 0, asdetermined by the solution of the previous sub-problems. Thejoint scheduling and load balancing problem can be modeledas follows:
(P3)
min�i,k,j ,�i,k,j
K∑k=1
mk
∑i∈I
Nk∑j=1
�i,k,j
Ci�k,j�i,k,j − �i,k,j
such that
∑i∈I
�i,k,j = �k, ∀k, j,
K∑k=1
Nk∑j=1
�i,k,j �1, ∀i ∈ I,
�i,k,j ��kzi,k,j , ∀i ∈ I, ∀k, j,
�i,k,j < Ci�k,j�i,k,j , ∀i ∈ I, ∀k, j,
�i,k,j , �i,k,j �0, ∀i ∈ I, ∀k, j,
where the decision variables are �i,k,j and �i,k,j . Note thatthe goal is to minimize the weighted average response timeof request classes. As discussed in Section 5, (P3) is solvedperiodically with time period Tshort. We applied a FPI techniqueto obtain a solution. This approach iteratively identifies theoptimum value of a set of variables (�-s or �-s), while the valueof the other one (alternatively �-s or �-s) is hold fixed.
If the scheduling policy at every physical server is fixed, i.e.the �i,k,j variables are fixed to the values �i,k,j , then the prob-

D. Ardagna et al. / J. Parallel Distrib. Comput. 67 (2007) 259–270 265
lem is separable and∑K
k=1 Nk load balancing sub-problems(one for every application tier of every request class) can besolved independently. As the objective function is convex (the
Hessian is given by Diag
(2mkCi�k,j�i,k,j
(Ci�k,j�i,k,j −�i,k,j )3
)and eigenval-
ues are positives), the optimal solution of each sub-problemcan be identified. An initial solution for �-s parameters can beobtained from the solution of the problem in Section 5.2 bysetting �i,k,j = yi,k,j
Ci�k,j.
Vice versa, if the load balancing is fixed, i.e. �i,k,j variablesare fixed to the values �i,k,j , then the problem is separableand M scheduling sub-problems (one for each physical server)can be solved independently. Again, the objective function is
convex (the Hessian is given by Diag
(2mkC
2i �
k,j2�i,k,j
(Ci�k,j�i,k,j −�i,k,j )3
)
and eigenvalues are positives), the optimal solution of each sub-problem can be identified.
The FPI iteratively solve the load balancing and schedulingproblems. Although we cannot guarantee that the procedureconverges to a global optimum, we can state that the procedurewill always converge. In fact, since the optimal solutions ofeach sub-problem can be identified, at each step, the current �-s and �-s assignment is improved and the algorithm will finda local optimal solution.
The optimal solution of each of the two sub-problems canbe obtained by applying KKT conditions (see [4]). Here, wepresent a faster iterative solution based on the gradient method.
The solution of the load balancing problem (where a requestof class k and its corresponding application tier j are fixed)is obtained by starting from a feasible solution s and perform-ing the optimal re-allocation of request load between only twophysical servers, say l and m, according to the gradient g of
the objective function f1(�l,k,j , �m,k,j ) = �l,k,j
Cl�k,j�l,k,j −�l,k,j
+�m,k,j
Cm�k,j�m,k,j −�m,k,j
. Since we consider the minimization of the
weighted average response times, we can improve the objec-tive function value of the solution s by optimally balancing theload between the two physical servers with the maximum andminimum component in g, respectively. Note that, the optimalsolution of this balancing problem can be found by expressingthe load at the two physical servers as a function of a singlevariable and by solving a second degree equation. In more de-tail, if � = �l,k,j +�m,k,j indicates the current load assignmentto physical server m and l, the new assignment is obtained bysolving the following problem:
(P4)
min�l,k,j ,�m,k,j
�l,k,j
Cl�k,j�l,k,j−�l,k,j
+ �m,k,j
Cm�k,j�m,k,j−�m,k,j
,
0��l < Cl�k,j�l,k,j , (8)
0��m < Cm�k,j�m,k,j , (9)
�l,k,j + �m,k,j = �. (10)
Problem (P4) can be solved by minimizing the convex functionof a single variable f1(�l,k,j , � − �l,k,j ), i.e., by solving thesecond degree equation df1
d�l,k,j= 0. Note that, if the solution
of the first order derivative is not feasible, then the optimalsolution is either �l,k,j = � and �m,k,j = 0, or �l,k,j = 0 and�m,k,j = �.
The algorithm stops when the improvement in the objec-tive function value is less than 1% in two consecutive itera-tions. Using ad hoc data structure the algorithm can run withO(M +Ng ln M) complexity, where Ng denotes the number ofiterations of the FPI algorithm (see [4]).
Likewise, the solution of the scheduling problem at a phys-ical server i is obtained by starting from a feasible solutions and evaluating the request scheduling parameters only forthe classes which corresponds to the maximum (k1, j1) and tothe minimum (k2, j2) of the gradient of the objective function∑K
k=1∑Nk
j=1 mk�i,k,j
Ci�k,j�i,k,j −�i,k,j
.
Again, the optimal solution can be found by minimizing aconvex function of a single variable. The algorithm can runwith O(
∑Kk=1 Nk + Ng ln
∑Kk=1 Nk) complexity (see [4]).
5.4. The local search algorithm
The solution returned by the FPI technique is (possibly) im-proved by applying a local search algorithm, i.e., the FPI solu-tion is the starting point of our local search.
Let S denote the set of the feasible solutions of our prob-lem. To each s ∈ S we associate a subset N(s) of S, calledneighborhood of s which contains all those solutions that canbe obtained by applying four different kind of moves: turningON a physical server, turning OFF a physical server, physi-cal servers swapping, and re-allocation of application tiers tophysical servers.
The above moves directly modify either the values of the x
or the z variables. For each modification new optimal (or sub-optimal) �-s and �-s values have to be computed. If the FPIwere performed at each move, then only local optimal states forthe overall system would be obtained. Unfortunately, we cannotrun the fixed point procedure for every neighborhood candidatesolution s′ ∈ N(s), because it is too time consuming evenwith the gradient implementation. To overcome this difficulty,we overestimate the value of the each candidate solution s′by updating the values of a restricted subset of the variables� and �. In fact, after the first execution of the FPI from theinitial state obtained by the solution of problem in Section 5.2,we can reasonably assume that the optimal load balancing andscheduling solutions are only perturbed by switching ON orOFF one physical server or by re-allocating applications. Thishypothesis has been confirmed by computational experimentsunder low or medium load. When the local-search stops at alocal optimum, we execute a full run of the FPI. In this way wetry to escape from the local minimum by optimal updating allthe � and � variables, instead of considering only a subset ofthem, as usually done in the neighborhood exploration. If thisstep modifies the � or � variables we restart the local searchfrom the last FPI solution.

266 D. Ardagna et al. / J. Parallel Distrib. Comput. 67 (2007) 259–270
Note that, the local-search is not effective for high load. Aswe can expect a priori the optimal solution uses all the physicalservers available when the average utilization of the data centeris greater than 50–60% [8,26]. Under high load conditions, onlythe optimal scheduling and load balancing policies have to beidentified.
5.4.1. Turning OFF serversAll physical servers with average utilization Ui in [min Ui, P ·
min Ui] are candidates to be turned OFF. Here P is a con-stant experimentally set between 1.1 and 1.2. The load of thephysical server, say i, to be switched off is allocated on the re-maining physical servers proportionally to their spare capacity.The spare capacity for the application tier j of class k requestat physical server i is Si,k,j = Ci�k,j�i,k,j − �i,k,j . Let beSk,j = ∑
i∈I−{i} Si,k,j the overall spare capacity available atremaining physical servers ON for application tier j of class k.The load at physical server i is assigned to remaining physicalservers according to the equation �i,k,j = �i,k,j +�
i,k,j· Si,k,j
Sk,j.
The spare capacity is zero for all physical servers that cannotsupport application tier j for class k for constraints (3)–(5) ofproblem (P1). The neighborhood exploration has complexityO(M · ∑K
k=1 Nk).
5.4.2. Turning ON serversTo alleviate the load at a bottleneck physical server, a phys-
ical server in OFF status is turned ON. All physical serverwhose utilization Ui is in [P · max Ui, max Ui], where P is aconstant experimentally set between 0.9 and 0.95, are consid-ered as bottleneck physical servers. The physical server turnedON applies the same scheduling policy adopted at the bottle-neck physical server. For each bottleneck physical server theset of compatible physical servers in status OFF is identified. Aphysical server machine is compatible to a bottleneck physicalserver, if they are characterized by the same value of param-eters Ai,k,j limited to the set of application tiers and requestclasses currently executed at the bottleneck. The optimal loadbalancing among the two physical servers is identified by solv-ing an instance of problem (P4). The neighborhood explorationhas complexity O(M2 · ∑K
k=1 Nk).
5.4.3. Servers swapThis move looks for a physical server i1 in status ON and one
i2 in status OFF which are compatible and such that the physicalserver OFF has greater capacity or lower cost than the physicalserver ON. The load is moved from physical server i1 to i2, andat i2 the same scheduling policy applied at i1 is used, i.e., � and� variables are unchanged. Note that this move cannot alwaysbe substituted by a sequence of switching ON and switchingOFF moves. For example, if a single physical server i1 is theonly one supporting a class of requests k1, then it will neverbe turned OFF. Furthermore, turning ON a physical server i2,which can support k1, could worsen the objective function valuesince the enhancement of the system performance could notcounterbalance the cost of i2. Vice versa, the swap of i1 and i2can be performed and the variation of the cost function can beevaluated accordingly.
Note that, since the set of swaps which are not consideredmust satisfy the following conditions: Ci2 �Ci1 and ci2 �ci1 ,only worsening moves are excluded. The neighborhood explo-ration has complexity O(M2 · ∑K
k=1 Nk).
5.4.4. Re-allocation of application tiers to serversThe aim of this move is to allow modifying the value of the z
variables. We look for application tiers which can be allocatedon a different set of physical servers with respect to those whichthey are currently assigned to. In fact, if the FPI sets the valueof one � to be 0, that � will never change to a different value.Furthermore, in the next iteration, the corresponding � is set to 0and it will stay at 0 forever. Hence, the FPI can only de-allocatesapplication tiers from physical servers. If an application tier isde-allocated from a physical server i, then the corresponding z
variable is set to zero, and for constraints family (3) and (5), atier which was not allowed to be executed on physical server i
could now be allocated on it.Before allocating an application tier to a physical server,
we need to create spare capacity on that physical server. Thisis because for the optimal solution of problem (P4) the sumof � variables on each physical server equals to 1 (this canbe verified by KKT conditions [4]). We consider the physicalservers whose utilization Ui is lower than a constant U ascandidate physical servers for hosting a new application tier.U is experimentally set to 0.6, since it is not easy to allocateanother application tier on over-utilized physical servers andgenerate more profits.
Only one new application tier is allocated on a candidatephysical server i. And the set of application tiers which canbe possibly hosted on each candidate physical server is de-termined by an exhaustive search because only a small num-ber of alternatives need to be evaluated. The spare capacity
is created by setting Ui
= U , that is by setting �′i,k,j
�i,k,j
Ci�k,j U
for all application tiers currently executed on physical serveri. The value C
i�
k,j�
i,k,jis the capacity available at physical
server i for the candidate application tier (k, j ), where �i,k,j
=1−∑
k∈Ki
∑Nk
j=1 �′i,k,j
and Ki
is the set of request classes cur-
rently executed at physical server i. The candidate applicationtier will reduce the load of a bottleneck physical server i (i.e.,such that U
i> U ). The optimal load balancing among physical
servers i and i is computed by solving problem (P4). Neigh-borhood exploration complexity is O(M2 · (
∑Kk=1 Nk)
2).
6. Experimental results
The effectiveness of our approach has been tested on a wideset of randomly generated instances. All tests have been per-formed on a 3 GHz Intel Pentium IV workstation. The numberof physical servers has been varied between 40 and 400 (withsteps of 40). Service centers up to 200 request classes havebeen considered and the number of application tiers has beenvaried between 2 and 4. Ai,k,j values were randomly gener-ated, and every physical server was shared by at most five cus-tomers (see Section 3). Service times were randomly generated
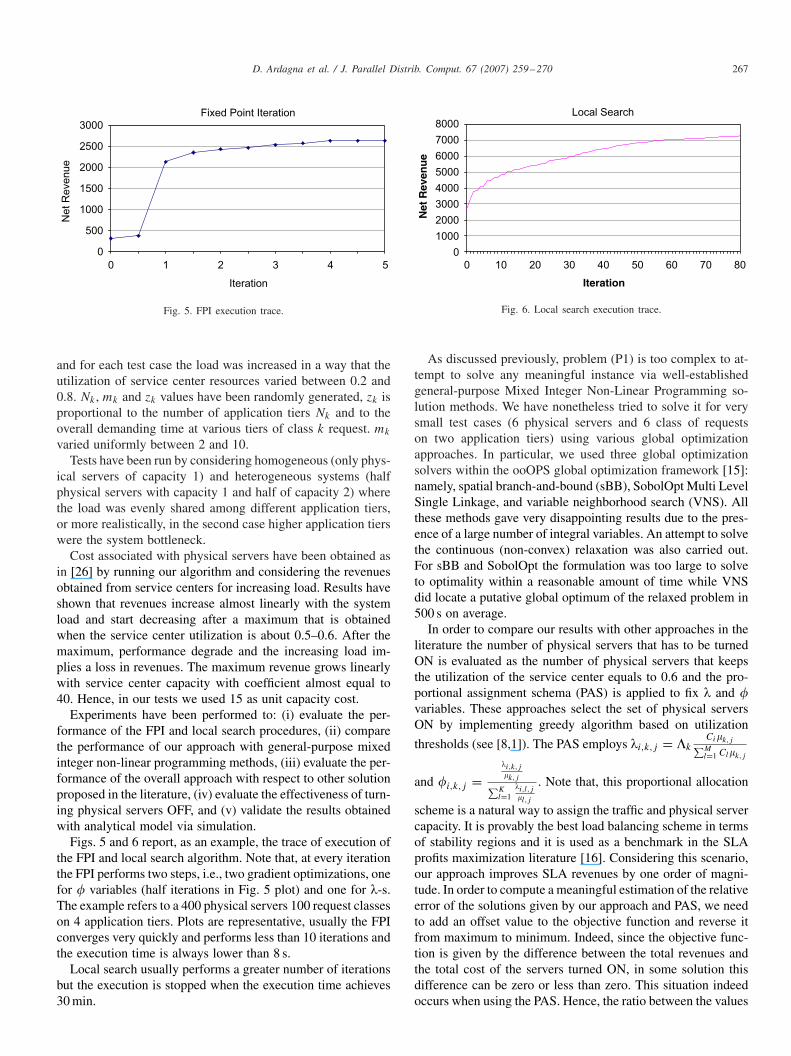
D. Ardagna et al. / J. Parallel Distrib. Comput. 67 (2007) 259–270 267
0
500
1000
1500
2000
2500
3000
0 3
Net R
evenue
Fixed Point Iteration
Iteration
4 51 2
Fig. 5. FPI execution trace.
and for each test case the load was increased in a way that theutilization of service center resources varied between 0.2 and0.8. Nk , mk and zk values have been randomly generated, zk isproportional to the number of application tiers Nk and to theoverall demanding time at various tiers of class k request. mk
varied uniformly between 2 and 10.Tests have been run by considering homogeneous (only phys-
ical servers of capacity 1) and heterogeneous systems (halfphysical servers with capacity 1 and half of capacity 2) wherethe load was evenly shared among different application tiers,or more realistically, in the second case higher application tierswere the system bottleneck.
Cost associated with physical servers have been obtained asin [26] by running our algorithm and considering the revenuesobtained from service centers for increasing load. Results haveshown that revenues increase almost linearly with the systemload and start decreasing after a maximum that is obtainedwhen the service center utilization is about 0.5–0.6. After themaximum, performance degrade and the increasing load im-plies a loss in revenues. The maximum revenue grows linearlywith service center capacity with coefficient almost equal to40. Hence, in our tests we used 15 as unit capacity cost.
Experiments have been performed to: (i) evaluate the per-formance of the FPI and local search procedures, (ii) comparethe performance of our approach with general-purpose mixedinteger non-linear programming methods, (iii) evaluate the per-formance of the overall approach with respect to other solutionproposed in the literature, (iv) evaluate the effectiveness of turn-ing physical servers OFF, and (v) validate the results obtainedwith analytical model via simulation.
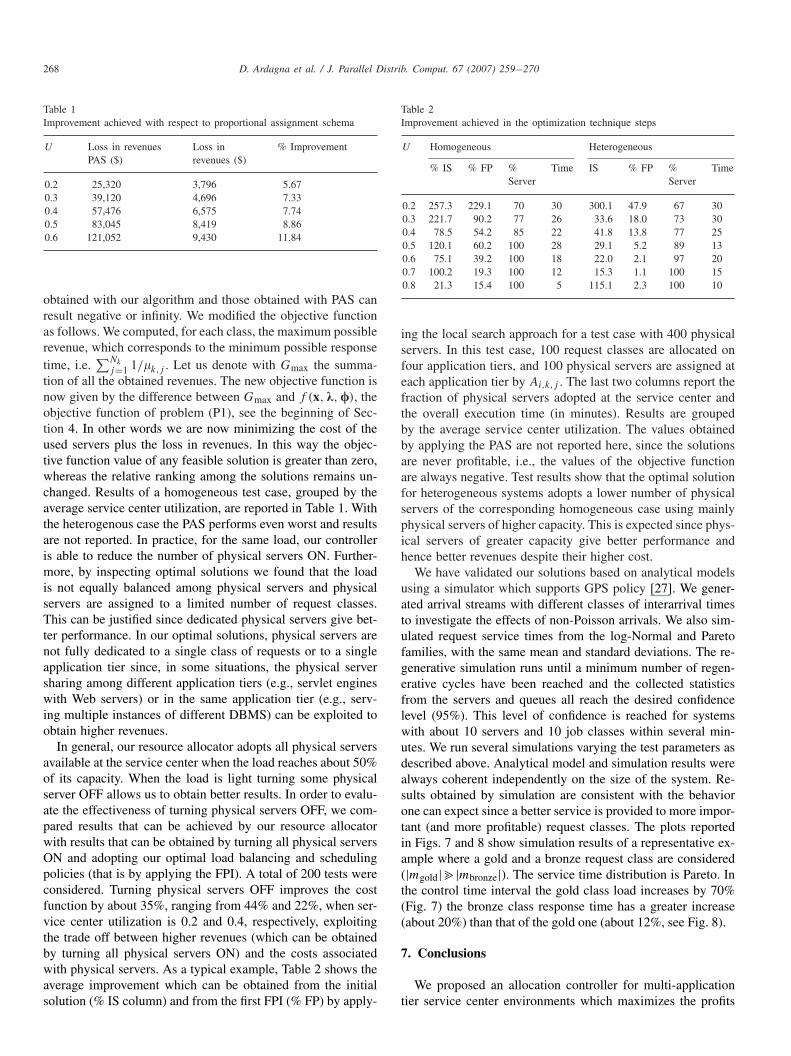
Figs. 5 and 6 report, as an example, the trace of execution ofthe FPI and local search algorithm. Note that, at every iterationthe FPI performs two steps, i.e., two gradient optimizations, onefor � variables (half iterations in Fig. 5 plot) and one for �-s.The example refers to a 400 physical servers 100 request classeson 4 application tiers. Plots are representative, usually the FPIconverges very quickly and performs less than 10 iterations andthe execution time is always lower than 8 s.
Local search usually performs a greater number of iterationsbut the execution is stopped when the execution time achieves30 min.
0
1000
2000
3000
4000
5000
6000
7000
8000
0 20 30 40 50 60 70 80
Net
Rev
enu
e
Local Search
Iteration
10
Fig. 6. Local search execution trace.
As discussed previously, problem (P1) is too complex to at-tempt to solve any meaningful instance via well-establishedgeneral-purpose Mixed Integer Non-Linear Programming so-lution methods. We have nonetheless tried to solve it for verysmall test cases (6 physical servers and 6 class of requestson two application tiers) using various global optimizationapproaches. In particular, we used three global optimizationsolvers within the ooOPS global optimization framework [15]:namely, spatial branch-and-bound (sBB), SobolOpt Multi LevelSingle Linkage, and variable neighborhood search (VNS). Allthese methods gave very disappointing results due to the pres-ence of a large number of integral variables. An attempt to solvethe continuous (non-convex) relaxation was also carried out.For sBB and SobolOpt the formulation was too large to solveto optimality within a reasonable amount of time while VNSdid locate a putative global optimum of the relaxed problem in500 s on average.
In order to compare our results with other approaches in theliterature the number of physical servers that has to be turnedON is evaluated as the number of physical servers that keepsthe utilization of the service center equals to 0.6 and the pro-portional assignment schema (PAS) is applied to fix � and �variables. These approaches select the set of physical serversON by implementing greedy algorithm based on utilization
thresholds (see [8,1]). The PAS employs �i,k,j = �kCi�k,j∑Ml=1 Cl�k,j
and �i,k,j =�i,k,j�k,j∑K
l=1�i,l,j�l,j
. Note that, this proportional allocation
scheme is a natural way to assign the traffic and physical servercapacity. It is provably the best load balancing scheme in termsof stability regions and it is used as a benchmark in the SLAprofits maximization literature [16]. Considering this scenario,our approach improves SLA revenues by one order of magni-tude. In order to compute a meaningful estimation of the relativeerror of the solutions given by our approach and PAS, we needto add an offset value to the objective function and reverse itfrom maximum to minimum. Indeed, since the objective func-tion is given by the difference between the total revenues andthe total cost of the servers turned ON, in some solution thisdifference can be zero or less than zero. This situation indeedoccurs when using the PAS. Hence, the ratio between the values
268 D. Ardagna et al. / J. Parallel Distrib. Comput. 67 (2007) 259–270
Table 1Improvement achieved with respect to proportional assignment schema
U Loss in revenues Loss in % ImprovementPAS ($) revenues ($)
0.2 25,320 3,796 5.670.3 39,120 4,696 7.330.4 57,476 6,575 7.740.5 83,045 8,419 8.860.6 121,052 9,430 11.84
obtained with our algorithm and those obtained with PAS canresult negative or infinity. We modified the objective functionas follows. We computed, for each class, the maximum possiblerevenue, which corresponds to the minimum possible responsetime, i.e.
∑Nk
j=1 1/�k,j . Let us denote with Gmax the summa-tion of all the obtained revenues. The new objective function isnow given by the difference between Gmax and f (x, �, �), theobjective function of problem (P1), see the beginning of Sec-tion 4. In other words we are now minimizing the cost of theused servers plus the loss in revenues. In this way the objec-tive function value of any feasible solution is greater than zero,whereas the relative ranking among the solutions remains un-changed. Results of a homogeneous test case, grouped by theaverage service center utilization, are reported in Table 1. Withthe heterogenous case the PAS performs even worst and resultsare not reported. In practice, for the same load, our controlleris able to reduce the number of physical servers ON. Further-more, by inspecting optimal solutions we found that the loadis not equally balanced among physical servers and physicalservers are assigned to a limited number of request classes.This can be justified since dedicated physical servers give bet-ter performance. In our optimal solutions, physical servers arenot fully dedicated to a single class of requests or to a singleapplication tier since, in some situations, the physical serversharing among different application tiers (e.g., servlet engineswith Web servers) or in the same application tier (e.g., serv-ing multiple instances of different DBMS) can be exploited toobtain higher revenues.
In general, our resource allocator adopts all physical serversavailable at the service center when the load reaches about 50%of its capacity. When the load is light turning some physicalserver OFF allows us to obtain better results. In order to evalu-ate the effectiveness of turning physical servers OFF, we com-pared results that can be achieved by our resource allocatorwith results that can be obtained by turning all physical serversON and adopting our optimal load balancing and schedulingpolicies (that is by applying the FPI). A total of 200 tests wereconsidered. Turning physical servers OFF improves the costfunction by about 35%, ranging from 44% and 22%, when ser-vice center utilization is 0.2 and 0.4, respectively, exploitingthe trade off between higher revenues (which can be obtainedby turning all physical servers ON) and the costs associatedwith physical servers. As a typical example, Table 2 shows theaverage improvement which can be obtained from the initialsolution (% IS column) and from the first FPI (% FP) by apply-
Table 2Improvement achieved in the optimization technique steps
U Homogeneous Heterogeneous
% IS % FP % Time IS % FP % TimeServer Server
0.2 257.3 229.1 70 30 300.1 47.9 67 300.3 221.7 90.2 77 26 33.6 18.0 73 300.4 78.5 54.2 85 22 41.8 13.8 77 250.5 120.1 60.2 100 28 29.1 5.2 89 130.6 75.1 39.2 100 18 22.0 2.1 97 200.7 100.2 19.3 100 12 15.3 1.1 100 150.8 21.3 15.4 100 5 115.1 2.3 100 10
ing the local search approach for a test case with 400 physicalservers. In this test case, 100 request classes are allocated onfour application tiers, and 100 physical servers are assigned ateach application tier by Ai,k,j . The last two columns report thefraction of physical servers adopted at the service center andthe overall execution time (in minutes). Results are groupedby the average service center utilization. The values obtainedby applying the PAS are not reported here, since the solutionsare never profitable, i.e., the values of the objective functionare always negative. Test results show that the optimal solutionfor heterogeneous systems adopts a lower number of physicalservers of the corresponding homogeneous case using mainlyphysical servers of higher capacity. This is expected since phys-ical servers of greater capacity give better performance andhence better revenues despite their higher cost.
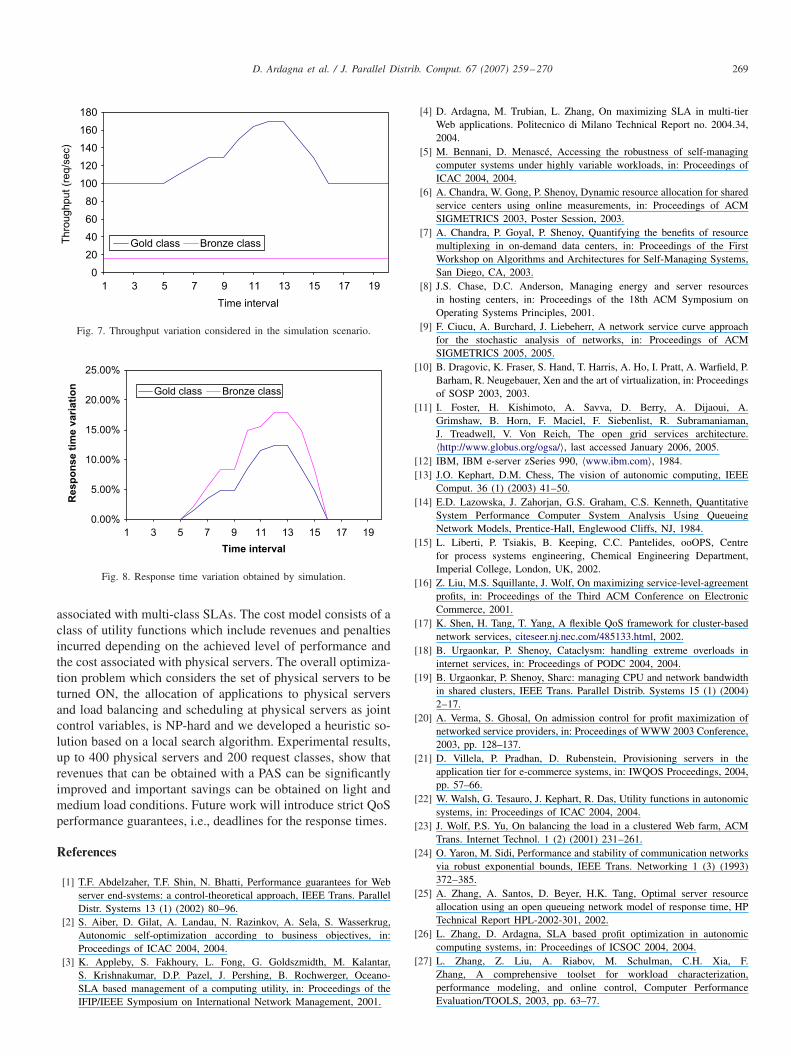
We have validated our solutions based on analytical modelsusing a simulator which supports GPS policy [27]. We gener-ated arrival streams with different classes of interarrival timesto investigate the effects of non-Poisson arrivals. We also sim-ulated request service times from the log-Normal and Paretofamilies, with the same mean and standard deviations. The re-generative simulation runs until a minimum number of regen-erative cycles have been reached and the collected statisticsfrom the servers and queues all reach the desired confidencelevel (95%). This level of confidence is reached for systemswith about 10 servers and 10 job classes within several min-utes. We run several simulations varying the test parameters asdescribed above. Analytical model and simulation results werealways coherent independently on the size of the system. Re-sults obtained by simulation are consistent with the behaviorone can expect since a better service is provided to more impor-tant (and more profitable) request classes. The plots reportedin Figs. 7 and 8 show simulation results of a representative ex-ample where a gold and a bronze request class are considered(|mgold|?|mbronze|). The service time distribution is Pareto. Inthe control time interval the gold class load increases by 70%(Fig. 7) the bronze class response time has a greater increase(about 20%) than that of the gold one (about 12%, see Fig. 8).
7. Conclusions
We proposed an allocation controller for multi-applicationtier service center environments which maximizes the profits
D. Ardagna et al. / J. Parallel Distrib. Comput. 67 (2007) 259–270 269
0
20
40
60
80
100
120
140
160
180
1 13 15 17 19
Thro
ughput (r
eq/s
ec)
Gold class Bronze class
3 5 7 9
Time interval
11
Fig. 7. Throughput variation considered in the simulation scenario.
1 5 9 11 13 15 17 19
Gold class Bronze class
Time interval
Re
sp
on
se
tim
e v
ari
ati
on
25.00%
20.00%
15.00%
10.00%
5.00%
0.00%
3 7
Fig. 8. Response time variation obtained by simulation.
associated with multi-class SLAs. The cost model consists of aclass of utility functions which include revenues and penaltiesincurred depending on the achieved level of performance andthe cost associated with physical servers. The overall optimiza-tion problem which considers the set of physical servers to beturned ON, the allocation of applications to physical serversand load balancing and scheduling at physical servers as jointcontrol variables, is NP-hard and we developed a heuristic so-lution based on a local search algorithm. Experimental results,up to 400 physical servers and 200 request classes, show thatrevenues that can be obtained with a PAS can be significantlyimproved and important savings can be obtained on light andmedium load conditions. Future work will introduce strict QoSperformance guarantees, i.e., deadlines for the response times.
References
[1] T.F. Abdelzaher, T.F. Shin, N. Bhatti, Performance guarantees for Webserver end-systems: a control-theoretical approach, IEEE Trans. ParallelDistr. Systems 13 (1) (2002) 80–96.
[2] S. Aiber, D. Gilat, A. Landau, N. Razinkov, A. Sela, S. Wasserkrug,Autonomic self-optimization according to business objectives, in:Proceedings of ICAC 2004, 2004.
[3] K. Appleby, S. Fakhoury, L. Fong, G. Goldszmidth, M. Kalantar,S. Krishnakumar, D.P. Pazel, J. Pershing, B. Rochwerger, Oceano-SLA based management of a computing utility, in: Proceedings of theIFIP/IEEE Symposium on International Network Management, 2001.
[4] D. Ardagna, M. Trubian, L. Zhang, On maximizing SLA in multi-tierWeb applications. Politecnico di Milano Technical Report no. 2004.34,2004.
[5] M. Bennani, D. Menascé, Accessing the robustness of self-managingcomputer systems under highly variable workloads, in: Proceedings ofICAC 2004, 2004.
[6] A. Chandra, W. Gong, P. Shenoy, Dynamic resource allocation for sharedservice centers using online measurements, in: Proceedings of ACMSIGMETRICS 2003, Poster Session, 2003.
[7] A. Chandra, P. Goyal, P. Shenoy, Quantifying the benefits of resourcemultiplexing in on-demand data centers, in: Proceedings of the FirstWorkshop on Algorithms and Architectures for Self-Managing Systems,San Diego, CA, 2003.
[8] J.S. Chase, D.C. Anderson, Managing energy and server resourcesin hosting centers, in: Proceedings of the 18th ACM Symposium onOperating Systems Principles, 2001.
[9] F. Ciucu, A. Burchard, J. Liebeherr, A network service curve approachfor the stochastic analysis of networks, in: Proceedings of ACMSIGMETRICS 2005, 2005.
[10] B. Dragovic, K. Fraser, S. Hand, T. Harris, A. Ho, I. Pratt, A. Warfield, P.Barham, R. Neugebauer, Xen and the art of virtualization, in: Proceedingsof SOSP 2003, 2003.
[11] I. Foster, H. Kishimoto, A. Savva, D. Berry, A. Dijaoui, A.Grimshaw, B. Horn, F. Maciel, F. Siebenlist, R. Subramaniaman,J. Treadwell, V. Von Reich, The open grid services architecture.〈http://www.globus.org/ogsa/〉, last accessed January 2006, 2005.
[12] IBM, IBM e-server zSeries 990, 〈www.ibm.com〉, 1984.[13] J.O. Kephart, D.M. Chess, The vision of autonomic computing, IEEE
Comput. 36 (1) (2003) 41–50.[14] E.D. Lazowska, J. Zahorjan, G.S. Graham, C.S. Kenneth, Quantitative
System Performance Computer System Analysis Using QueueingNetwork Models, Prentice-Hall, Englewood Cliffs, NJ, 1984.
[15] L. Liberti, P. Tsiakis, B. Keeping, C.C. Pantelides, ooOPS, Centrefor process systems engineering, Chemical Engineering Department,Imperial College, London, UK, 2002.
[16] Z. Liu, M.S. Squillante, J. Wolf, On maximizing service-level-agreementprofits, in: Proceedings of the Third ACM Conference on ElectronicCommerce, 2001.
[17] K. Shen, H. Tang, T. Yang, A flexible QoS framework for cluster-basednetwork services, citeseer.nj.nec.com/485133.html, 2002.
[18] B. Urgaonkar, P. Shenoy, Cataclysm: handling extreme overloads ininternet services, in: Proceedings of PODC 2004, 2004.
[19] B. Urgaonkar, P. Shenoy, Sharc: managing CPU and network bandwidthin shared clusters, IEEE Trans. Parallel Distrib. Systems 15 (1) (2004)2–17.
[20] A. Verma, S. Ghosal, On admission control for profit maximization ofnetworked service providers, in: Proceedings of WWW 2003 Conference,2003, pp. 128–137.
[21] D. Villela, P. Pradhan, D. Rubenstein, Provisioning servers in theapplication tier for e-commerce systems, in: IWQOS Proceedings, 2004,pp. 57–66.
[22] W. Walsh, G. Tesauro, J. Kephart, R. Das, Utility functions in autonomicsystems, in: Proceedings of ICAC 2004, 2004.
[23] J. Wolf, P.S. Yu, On balancing the load in a clustered Web farm, ACMTrans. Internet Technol. 1 (2) (2001) 231–261.
[24] O. Yaron, M. Sidi, Performance and stability of communication networksvia robust exponential bounds, IEEE Trans. Networking 1 (3) (1993)372–385.
[25] A. Zhang, A. Santos, D. Beyer, H.K. Tang, Optimal server resourceallocation using an open queueing network model of response time, HPTechnical Report HPL-2002-301, 2002.
[26] L. Zhang, D. Ardagna, SLA based profit optimization in autonomiccomputing systems, in: Proceedings of ICSOC 2004, 2004.
[27] L. Zhang, Z. Liu, A. Riabov, M. Schulman, C.H. Xia, F.Zhang, A comprehensive toolset for workload characterization,performance modeling, and online control, Computer PerformanceEvaluation/TOOLS, 2003, pp. 63–77.

270 D. Ardagna et al. / J. Parallel Distrib. Comput. 67 (2007) 259–270
[28] Z.L. Zhang, D. Towsley, J. Kurose, Statistical analysis of the generalizedprocessor sharing scheduling discipline, IEEE J. Selected Areas Comm.13 (6) (1995) 1071–1080.
[29] X. Zhou, Y. Cai, G.K. Godavari, C.E. Chow, An adaptive processallocation strategy for proportional responsiveness differentiation on Webservers, in: Proceedings of ICWS 2004, 2004.
Danilo Ardagna received his PhD in Computer Engineering in 2004 fromPolitecnico di Milano, Italy, where he also graduated in December 2000. Nowhe is an Assistant Professor of Information Systems at the Department ofElectronics and Information at Politecnico di Milano. His research interestsinclude autonomic computing, computer system costs minimization, Webservices composition and quality of service.
Marco Trubian received the Computer Science degree from the Universita’degli Studi di Milano, Italy, in 1987 and the Ph.D. degree in electronicengineering from the Politecnico of Milano, Italy, in 1992. Since December
2002 he is an Associate Professor of Operational Research at the ComputerScience Department of Universita’ degli Studi di Milano, Italy. His researchinterests include the development of heuristic and exact algorithms for com-binatorial optimization problems. He has published several papers on interna-tional journals as Networks, Discrete Applied Mathematics, Informs Journalon Computing, European Journal of Operational Research and others.
Li Zhang is a Research Staff Member at IBM T.J. Watson Research Center.His research interests include control and performance analysis of computersystems, statistical techniques for traffic modeling and prediction, schedulingand resource allocation in parallel and distributed systems. He also worked onmeasurement based clock synchronization algorithms. A math major at BeijingUniversity, he received his M.S. in Mathematics from Purdue University andhis Ph.D. in Operations Research from Columbia University.
Related Documents











