Single-Chip Multiprocessor Nirmal Andrews

Single-Chip Multiprocessor
Feb 14, 2016
Single-Chip Multiprocessor. Nirmal Andrews. Case for single chip multiprocessors. Advances in the field of integrated chip processing. - Gate density (More transistors per chip) - Cost of wires - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Single-Chip Multiprocessor
Nirmal Andrews

Case for single chip multiprocessors
Advances in the field of integrated chip processing. - Gate density
(More transistors per chip) - Cost of wires
Many studies done in Stanford University during late 90’s and proved CMP (single-chip multiprocessor) is better than competing technology .

Parallelism
Parallelism becomes a necessity for improving performance.
Parallelism made possible using dynamic scheduling, multiple instruction issue, speculative execution, non-blocking caches etc., (late 90’s)
Parallelism classifications: Instruction level Loop level Thread level - Future trend Process level - Future trend

Loop level parallelism
To increase amount of parallelism – exploit parallelism among iterations of a loop.
ILP that results from data independent loop iterations is LLP.
No circular dependencies. This could be avoided too using loop unrolling (beyond the scope of this lecture).

LLP (Loop Level Parallelism)
15% ILP extracted from a basic block in an integer programs – 7 instructions.
for (i=1; i<=100; i= i+1) {
a[i] = a[i] + b[i]; //s1 b[i+1] = c[i] + d[i]; //s2 }
s1 depends on s2. So to extract LLP rearrange: a[1] = a[1] + b[1];
for (i=1; i<=99; i= i+1) {
b[i+1] = c[i] + d[i]; a[i+1] = a[i+1] + b[i+1]; } b[101] = c[100] + d[100];
No dependencies.

Competing technology - Superscalar
Executing multiple instruction in the same clock cycle.
Dynamic scheduling
Single processor
Redundant functional units on processor
Mixture between a scalar and vector processor

Competing technology - Superscalar

Wide issue superscalar

Fetch Phase
3 phase: Fetch, Issue, Execution
Bottlenecks: Issue and Execution phase.
Fetch phase: Provide large and accurate window of decoded instructions - 3 issues: instruction misalignment, cache miss, mispredicted branch.
- misprediction reduced to under 5% using branch predictor designed by McFarling*. - instruction misalignement reduced to under 3% by dividing cache into banks (Conte). - Roesnblum et al. shows that the 60% of latency by cache miss can be hidden**.
* S. McFarling, “Combining branch predictors,” WRL Technical Note TN-36, Digital Equipment Corporation, 1993.
** M. Rosenblum, E. Bugnion, S. Herrod, E. Witchel, and A. Gupta, “The impact of architectural trends on operating system performance,” Proceedings of 15th ACM
symposium on Operating Systems Principles, Colorado,December, 1995.

Issue phase
Issue phase: Register renaming. 2 techniques for register renaming: - Use a table to map architectural registers and physical registers. Ports
required: operands per instruction* Instruction window size - Use reorder buffer. Comparators required to find which physical register
should provide data to which packet of instruction. Large number of comparators required.
In HP – PA 8000 20% of die space occupied by comparators.
Quadratic increase in instruction queue register with increase in issue width.
Queue register uses broadcast to connect to registers which increases the wires used – increased delay and cost

Execute phase
Execution phase also has similar issues.
Increase in issue width causes increase in renamed registers leading to quadratic increase in register file complexity.
Increase in execution unit causes quadratic increase in the complexity of bypass logic.
Bottleneck: Interconnect delay between execution units.

Architecture - Superscalar

Competing technologies – Simultaneous Multi Threading
Simultaneous Multi threading architecture is similar to that of the superscalar.
SMT processors support wide superscalar processors with hardware, to execute instructions from multiple thread concurrently.
Provides latency tolerance.
Reduces to conventional wide-issue superscalar when no multiple threads possible.

Competing technologies - Simultaneous Multi Threading
SMT (Simultaneous Multi-threading)

Centralized architecture
Disadvantages of centralized architectures such as SMT and Superscalars are:
- Area increases quadratically with core’s complexity. - Increase in cycle time – interconnect delays. Delay with wires
dominate delay of critical path of CPU. Possible to make simpler clusters, but results in deeper pipeline and increase in branch misprediction penalty.
- Design verification cost high, due to complexity and single processor
- Large demand on memory system.

Single Chip multiprocessor
Motivation for a decentralized architecture due to the disadvantages of competing technologies.
Simple individual processors and high clock rate.
Low interconnect latency Exploits thread level and processor level
parallelism.
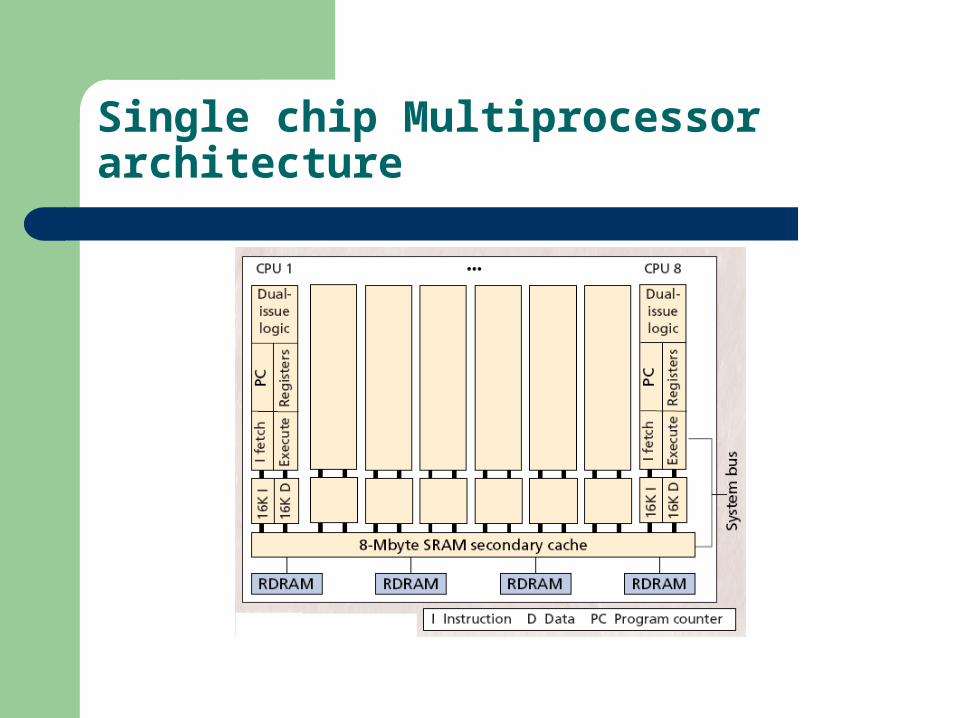
Single chip Multiprocessor architecture

Performance comparison
Example: 8 core Cell processor in the PS3 and the 3 core Xenon processor in the Xbox 360)
Performance chart Run for different
benchmark programs.

Summary (CMP)
CMP (Chip level multiprocessor) provides superior performance with simpler hardware.
No parallelism – Superscalar performance is 30% better than CMP
Fine grained thread-level parallelism – Superscalar is 10% better in performance
Coarse grained thread-level parallelism – CMP is 50-100% better than superscalar.
Disadvantage – Slow when no multithreading, equal development of software required.

Reference
K Olukotun, BA Nayfeh, L Hammond, K Wilson, K, “The case for a single-chip multiprocessor,”ACM SIGPLAN Notices, 1996.
L Hammond, BA Nayfeh, K Olukotun, “A Single-Chip Multiprocessor,” IEEE, Sept 1997.
Wikipedia, “Superscalar,” April 2008. http://en.wikipedia.org/wiki/Superscalar.
Wikipedia, “Multi-core,” April 2008. http://en.wikipedia.org/wiki/Multi-core_computing.
Related Documents











