Simultaneous feature selection and classification using kernel-penalized support vector machines Sebastián Maldonado, Richard Weber ⇑ , Jayanta Basak 1 Department of Industrial Engineering, University of Chile, República 701, Santiago de Chile, Chile IBM India Research Lab, New Delhi, India article info Article history: Received 17 November 2009 Received in revised form 14 July 2010 Accepted 31 August 2010 Keywords: Feature selection Embedded methods Support vector machines Mathematical programming abstract We introduce an embedded method that simultaneously selects relevant features during classifier construction by penalizing each feature’s use in the dual formulation of support vector machines (SVM). This approach called kernel-penalized SVM (KP-SVM) optimizes the shape of an anisotropic RBF Kernel eliminating features that have low relevance for the classifier. Additionally, KP-SVM employs an explicit stopping condition, avoiding the elimination of features that would negatively affect the classifier’s performance. We per- formed experiments on four real-world benchmark problems comparing our approach with well-known feature selection techniques. KP-SVM outperformed the alternative approaches and determined consistently fewer relevant features. Ó 2010 Elsevier Inc. All rights reserved. 1. Introduction Classification is one of the most important data mining tasks. The performance of the respective models depends on – among other elements – an appropriate selection of the most relevant features which is a combinatorial problem in the num- ber of original features and offers the following advantages [1]: A low-dimensional representation reduces the risk of overfitting [5,10]. Using fewer features decreases the model’s complexity which improves its generalization ability. A low-dimensional representation requires less computational effort. Among existing classification methods, support vector machines (SVMs) provides several advantages such as adequate generalization to new objects, absence of local minima, and representation that depends on only a few parameters [21]. However, this method in standard formulation does not determine the importance of the features used [10] and is therefore not suitable for feature selection. This fact has motivated the development of several approaches for feature selection using SVMs (see e.g. [7]). Those methods generally work as filters selecting features from a high-dimensional feature space prior to designing the subsequent classifier. They provide feature ranking but without considering the combination of variables that optimizes classification performance. In this paper a novel embedded method for feature selection using SVM for classification problems is intro- duced. This method, called kernel-penalized SVM (KP-SVM), determines simultaneously a classifier with high classification 0020-0255/$ - see front matter Ó 2010 Elsevier Inc. All rights reserved. doi:10.1016/j.ins.2010.08.047 ⇑ Corresponding author at: Department of Industrial Engineering, University of Chile, República 701, Santiago de Chile, Chile. Tel.: +56 2 9784072; fax: +56 2 678 7895. E-mail addresses: [email protected] (S. Maldonado), [email protected] (R. Weber), [email protected] (J. Basak). 1 The author is presently affiliated with NetApp Bangalore India, Advanced Technology Group. Information Sciences 181 (2011) 115–128 Contents lists available at ScienceDirect Information Sciences journal homepage: www.elsevier.com/locate/ins

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Information Sciences 181 (2011) 115–128
Contents lists available at ScienceDirect
Information Sciences
journal homepage: www.elsevier .com/locate / ins
Simultaneous feature selection and classification usingkernel-penalized support vector machines
Sebastián Maldonado, Richard Weber ⇑, Jayanta Basak 1
Department of Industrial Engineering, University of Chile, República 701, Santiago de Chile, ChileIBM India Research Lab, New Delhi, India
a r t i c l e i n f o a b s t r a c t
Article history:Received 17 November 2009Received in revised form 14 July 2010Accepted 31 August 2010
Keywords:Feature selectionEmbedded methodsSupport vector machinesMathematical programming
0020-0255/$ - see front matter � 2010 Elsevier Incdoi:10.1016/j.ins.2010.08.047
⇑ Corresponding author at: Department of Industr+56 2 678 7895.
E-mail addresses: [email protected] (S. Ma1 The author is presently affiliated with NetApp Ba
We introduce an embedded method that simultaneously selects relevant features duringclassifier construction by penalizing each feature’s use in the dual formulation of supportvector machines (SVM). This approach called kernel-penalized SVM (KP-SVM) optimizesthe shape of an anisotropic RBF Kernel eliminating features that have low relevance forthe classifier. Additionally, KP-SVM employs an explicit stopping condition, avoiding theelimination of features that would negatively affect the classifier’s performance. We per-formed experiments on four real-world benchmark problems comparing our approachwith well-known feature selection techniques. KP-SVM outperformed the alternativeapproaches and determined consistently fewer relevant features.
� 2010 Elsevier Inc. All rights reserved.
1. Introduction
Classification is one of the most important data mining tasks. The performance of the respective models depends on –among other elements – an appropriate selection of the most relevant features which is a combinatorial problem in the num-ber of original features and offers the following advantages [1]:
� A low-dimensional representation reduces the risk of overfitting [5,10].� Using fewer features decreases the model’s complexity which improves its generalization ability.� A low-dimensional representation requires less computational effort.
Among existing classification methods, support vector machines (SVMs) provides several advantages such as adequategeneralization to new objects, absence of local minima, and representation that depends on only a few parameters [21].However, this method in standard formulation does not determine the importance of the features used [10] and is thereforenot suitable for feature selection.
This fact has motivated the development of several approaches for feature selection using SVMs (see e.g. [7]). Thosemethods generally work as filters selecting features from a high-dimensional feature space prior to designing the subsequentclassifier. They provide feature ranking but without considering the combination of variables that optimizes classificationperformance. In this paper a novel embedded method for feature selection using SVM for classification problems is intro-duced. This method, called kernel-penalized SVM (KP-SVM), determines simultaneously a classifier with high classification
. All rights reserved.
ial Engineering, University of Chile, República 701, Santiago de Chile, Chile. Tel.: +56 2 9784072; fax:
ldonado), [email protected] (R. Weber), [email protected] (J. Basak).ngalore India, Advanced Technology Group.

116 S. Maldonado et al. / Information Sciences 181 (2011) 115–128
accuracy and an adequate feature subset by penalizing each feature’s use in the dual formulation of the respectivemathematical model. In numerical experiments using four well-known data sets, KP-SVM outperforms existing approaches.
This paper is structured as follows. Section 2 introduces SVM for classification. Recent developments for feature selectionusing SVMs are reviewed in Section 3. KP-SVM, the proposed embedded method for feature selection based on SVM is pre-sented in Section 4. Section 5 provides experimental results using four real-world data sets. Several important aspects thatarise from this work are discussed in Section 6. A summary of this paper can be found in Section 7 where we provide its mainconclusions and address future developments.
2. Classification with SVM
Vapnik [21] developed SVMs for binary classification. This section introduces the respective approach using the followingterminology. Given training vectors xi 2 Rn, i = 1, . . . ,m and a vector of labels y 2 Rm, yi 2 {�1,+1}, SVM provides the optimalhyperplane f(x) = wT � x + b that aims to separate the training patterns. In the case of linearly separable classes this hyper-plane maximizes the sum of the distances to the closest positive and negative training patterns. This sum is called margin.To construct the maximum margin or optimal separating hyperplane, we need to classify correctly the vectors xi of the train-ing set into two different classes yi, using the smallest norm of coefficients w.
For a non-linear classifier, SVM maps the data points into a higher dimensional space H, where a separating hyperplanewith maximal margin is constructed. The following quadratic optimization problem has to be solved
Minw;b;n
12
wk k2 þ CXm
i¼1
ni; ð1Þ
subject to
yi � wT � /ðxiÞ þ b� �
P 1� ni; i ¼ 1; . . . ;m;
ni P 0; i ¼ 1; . . . ;m;
where training data are mapped to the higher dimensional space H by the function x! /ðxÞ 2 H. A set of slack variables n isintroduced for each training vector and C is a penalty parameter on the training error [21].
Under this mapping the solution of an SVM has the form:
f ðxÞ ¼ signXm
i¼1
yia�i /ðxÞ � /ðxiÞ þ b� !
: ð2Þ
As can be seen it is sufficient to compute the scalar products of the form /(x) � /(y) [18]. A kernel function K(x,y) = /(x) � /(y) which defines an inner product in H performs the respective mapping leading to the following decision function f(x):
f ðxÞ ¼ signXm
i¼1
yia�i Kðx; xiÞ þ b� !
: ð3Þ
The optimal hyperplane is the one with maximal distance (inH) to the closest image /(xi) from the training data. The dualformulation can be stated as follows:
Maxa
Xm
i¼1
ai �12
Xm
i;s¼1
aiasyiysKðxi; xsÞ; ð4Þ
subject to
Xmi¼1
aiyi ¼ 0;
0 6 ai 6 C; i ¼ 1; . . . ;m:
In most applications the polynomial or the radial basis function (Gaussian kernel) are chosen [18]:
1. Polynomial function: K(xi,xs) = (xi � xs+1)d, where d 2 N is the degree of the polynomial.
2. Radial basis function: Kðxi;xsÞ ¼ exp � kxi�xsk22r2
� �, where r > 0 is the parameter controlling the width of the kernel.
Empirically, the Gaussian kernel provided best classification performance in our previous studies [10] and will be used inthe subsequent experiments. In Section 5 we also study the classification performance using different kernel functions onfour benchmark data sets, in order to confirm our hypothesis.
3. Feature selection for SVMs
According to [5,7], there are three main directions for feature selection: filter, wrapper, and embedded methods. In thissection we provide a brief overview of each one of these approaches, and present the methods that have been compared with

S. Maldonado et al. / Information Sciences 181 (2011) 115–128 117
the proposed technique in the present paper. The first direction (filter methods) uses statistical properties of the features inorder to filter out poorly informative ones. This is usually done before applying any classification algorithm.
The Fisher Criterion Score computes the importance of each feature independently of others by comparing the correlationof each variable with the output labels. The score F(j) of feature j is given by:
FðjÞ ¼lþj � l�j
rþj� �2
þ r�j� �2
��������������; ð5Þ
where lþj l�j� �
represents the mean for the jth feature in the positive (negative) class and rþj r�j� �
is the respective standarddeviation.
A wrapper method explores the whole set of variables to score feature subsets according to their predictive power, opti-mizing a performance criterion of the subsequent algorithm that uses the respective subset for classification. These algo-rithms are computationally demanding, but often provide more accurate results than filter methods since they areperformed in combination with the subsequent classification technique [5,10].
One of the most popular wrapper methods for SVMs was proposed by Guyon et al. [6] and is known as Recursive FeatureElimination (SVM-RFE). In this work we consider a version of SVMs that includes kernel functions as described in [7,14] andin [17] for multi-class classification [24]. The goal of this approach is to find a subset of size r among n variables (r < n) whichmaximizes the performance of the classifier. The method, given that one wishes to employ only r < n input variables in thefinal decision rule, attempts to find the best subset of r features, i.e. the r features which lead to the largest margin of classseparation. This problem is based on a sequential backward selection, removing one feature at a time until r features remain.The feature to be removed at each iteration is the one whose removal minimizes the variation of W2(a):
W2ðaÞ ¼Xm
i;s¼1
aiasyiysKðxi;xsÞ: ð6Þ
The vector W2(a) is a measure of the model’s predictive ability and is inversely proportional to the margin. The elimination offeatures is done applying the following procedure:
1. Given a solution a, for each feature p calculate:
W2ð�pÞðaÞ ¼
Xm
i;s¼1
aiasyiysK xð�pÞi ; xð�pÞ
s
� �; ð7Þ
where xð�pÞi represents the training object i with feature p removed.
2. Eliminate the feature with smallest value of W2ðaÞ �W2ð�pÞðaÞ
��� ���.The last approach (embedded methods) performs feature selection in the process of model construction. For example, the
methods presented in [12,13] add an extra term that penalizes the cardinality of the selected feature subset to the standardcost function of SVM. By optimizing this modified cost function features are selected simultaneously to model construction.
Another embedded approach is the Feature Selection ConcaVe (FSV) [1], based on the minimization of the ‘‘zero norm”:kwk0 ¼ jfi : wi–0gj. Note that k � k0 is not a norm because the triangle inequality does not hold [1], unlike lp-norms with p > 0.Since l0-‘‘norm” is non-smooth, it was approximated by a concave function:
wk k0 � eTðe� expð�bjwjÞÞ ð8Þ
with an approximation parameter b 2 Rþ and e = (1, . . . ,1)T. The formulation for FSV follows:
Minw;v;b;n
Xn
j¼1
½1� expð�bv jÞ� þ CXm
i¼1
ni; ð9Þ
subject to
yi � wT � xi þ b� �
P 1� ni; i ¼ 1; . . . ;m;
� v j 6 wj 6 v j; j ¼ 1; . . . ;n;
ni P 0; i ¼ 1; . . . ;m:
The problem (9) can be solved using an iterative method called Successive Linearization Algorithm (SLA) for FSV [2].
4. The proposed method for feature selection
An embedded method for feature selection using SVMs is proposed in this section. The reasoning behind this approach isthat we can improve classification performance by eliminating the features that affect on the generalization of the classifierby optimizing the kernel function. The main idea is to penalize the use of features in the dual formulation of SVMs using a

118 S. Maldonado et al. / Information Sciences 181 (2011) 115–128
gradient descent approximation for kernel optimization and feature elimination. The proposed method attempts to find thebest suitable RBF-type kernel function for each problem with a minimal dimension by combining the parameters of gener-alization (using the 2-norm), goodness of fit and feature selection (using a 0-‘‘norm” approximation).
4.1. Notation and preliminaries
For this approach we use the anisotropic Gaussian kernel: !
Kðxi;xsÞ ¼ exp �Xn
j¼1
ðxij � xsjÞ2
2r2j
; ð10Þ
in which the kernel shape is given by r = [r1,r2, . . . ,rn], n being the number of variables. Considering different widths in dif-ferent dimensions, the importance of feature j is determined by (rj). For example, if rj is very large, the particular variable jloses its importance since its contribution to the kernel function’s exponent will be close to zero. On the other hand, if rj isvery small then the contribution of the variable j to the exponent will be large thus increasing its importance.
We propose the following change of variables for (10), in order to convert the feature selection process into a minimiza-tion problem: m ¼ 1
r1; 1r2; . . . ; 1
rn
h i, which leads to:
Kðxi;xs; mÞ ¼ exp � jjm � xi � m � xsjj2
2
!; ð11Þ
where � denotes the componentwise vector product operator, which is defined as a�b = (a1b1, . . . ,anbn).
4.2. KP-SVM algorithm
The proposed approach (kernel-penalized SVM) incorporates feature selection in the dual formulation of SVMs. The for-mulation includes a penalization function f(m) based on the 0-‘‘norm” approximation (8) described in Section 3 and modify-ing the Gaussian kernel using an (anisotropic) width vector m as a decision variable. The feature penalization should benegative since the dual SVM is a maximization problem. The following embedded formulation of SVMs for feature selectionis initially proposed:
Maxa;m
Xm
i¼1
ai �12
Xm
i;s¼1
aiasyiysKðxi; xs; mÞ � C2f ðmÞ; ð12Þ
subject to
Xm
i¼1
aiyi ¼ 0;
0 6 ai 6 C; i ¼ 1; . . . ;m;
mj P 0; j ¼ 1; . . . ;n:
Notice that the values of m are always considered to be positive, in contrast to the weight vector w in formulation (9),since it is desirable that the kernel widths be positive values. Considering the 0-‘‘norm”approximation described in (8),kmk0 � eTðe� expð�bjmjÞÞ, and since jmjj = mj "j, it is not necessary to use the 1-norm in the approximation.
Along the lines of formula (8) the following feature penalization function is proposed, where the approximation param-eter b is also considered. In [2], the authors suggest setting b to 5. We also try different values for this parameter to study theinfluence of b in the final solution (see Section 6)
f ðmÞ ¼ eTðe� expð�bmÞÞ ¼Xn
j¼1
1� exp �bmj� �� �
: ð13Þ
Since the formulation (12) is non-convex, we develop an iterative algorithm as an approximation for this formulation.We propose a 2-step methodology: first the traditional dual formulation of SVM for a fixed (isotropic) kernel width m issolved:
Maxa
Xm
i¼1
ai �12
Xm
i;s¼1
aiasyiysKðxi; xs; mÞ; ð14Þ
subject to
Xm
i¼1
aiyi ¼ 0;
0 6 ai 6 C; i ¼ 1; . . . ;m:

S. Maldonado et al. / Information Sciences 181 (2011) 115–128 119
In the second step the algorithm solves, for a given solution a, the following non-linear formulation:
Minm
FðmÞ ¼Xm
i;s¼1
aiasyiysKðxi;xs; mÞ þ C2f ðmÞ; ð15Þ
subject to
mj P 0; j ¼ 1; . . . ; n:
The goal of formulation (14) is to find a sparse solution, making zero as many components of m as possible. We propose aniterative algorithm that updates the anisotropic kernel variable m, using the gradient of the objective function, and eliminatesthe features that are close to zero (below a given threshold �). The algorithm kernel width updating and feature eliminationfollows:
Algorithm 1. Kernel width updating and feature elimination
1. Start with m = m0e;2. cont = true; t = 0;3. while(cont==true) do4. train SVM (step 1) for a given m;5. mt+1 = mt � cDF(mt);
6. for all mtþ1j < �
� �do
7. mtþ1j ¼ 0;
8. end for9. if (mt+1 == mt) then10. cont = false;11. end if12. t = t + 1;13. end while;
In the fourth line the algorithm adjusts the kernel variables by using the gradient descent procedure, incorporating aparameter c, which has to be sufficiently small to avoid negative widths, especially at the first iterations. In this step the
algorithm computes the gradient of the objective function in formulation (15) for a given solution of SVMs a, obtained bytraining an SVM classifier using formulation (14). For a given feature j, the gradient of formulation (15) is:DjFðmÞ ¼Xm
i;s¼1
mjðxi;j � xs;jÞ2aiasyiysKðxi;xs; mÞ þ C2b expð�bmjÞ: ð16Þ
The lines 6, 7, and 8 of the algorithm represent the feature elimination step. When a kernel variable mj in iteration t + 1 isbelow a threshold �, we consider this feature irrelevant because of the argument given in sub Section 4.1 and we eliminatethis feature by setting mj = 0. This variable will not be included in further iterations of the algorithm. The threshold � has to besufficiently small to avoid the elimination of relevant variables in the first iterations of the algorithm.
The lines 9, 10, and 11 of the algorithm represent the stopping criterion, which is reached when mt+1 � mt. It is also possibleto monitor the convergence by considering the measure kmt+1 � mtk1, which represents the variation of the kernel width be-tween two consecutive iterations t and t + 1, as will be shown in Section 6.
Notice that the 1-norm penalty (LASSO penalty) can also be used instead of the 0-norm approximation. According to [2,13],the 1-norm by itself can lead to good feature selection and classification results, without considering the 2-norm for robust-ness. In order to improve feature selection, both papers consider the 0-norm penalization when the main objective is to findsparse solutions. Following this argument, we suggest using the proposed methodology with the zero norm approximation.
4.3. Feature ranking using KP-SVM
The approach KP-SVM presented in Sub Section 4.2 attempts to find an optimal subset of features for classification. Otherfeature selection methods for SVMs such as [5,7,14] find a subset of size r among the n features which maximizes the clas-sifier’s performance and use different validation methods in order to answer the question of how many ranked features mustbe provided to the classifier.
If the goal of feature selection is to find a subset of r features, KP-SVM can be modified in order to accomplish this goal aswell. The main idea is to keep iterating until fewer than r features are selected. Considering k the number of features selectedin iteration t + 1, k 6 r, we sort the eliminated features in the (t + 1)th iteration according to their respective value of m in thetth iteration. We replace the r � k most relevant removed features (greater m) and include them in the solution of the (t + 1)thsolution. The modified algorithm follows:

120 S. Maldonado et al. / Information Sciences 181 (2011) 115–128
Algorithm 2. KP-SVM algorithm for feature ranking
1. Start with m = m0e;2. cont = true; t = 0;3. while(cont==true) do4. train SVM (step 1) for a given m;5. mt+1 = mt � cDF(mt);
6. for all mtþ1j < �
� �do
7. mtþ1j ¼ 0;
8. end for
9. if jfj : mtþ1j –0gj 6 r
� �then
10. jfj : mtþ1j –0gj ¼ k
� �;
11. Sort(mt, desc);
12. if mtj > 0 and mtþ1
j ¼ 0; 8j 6 r � k� �
then
13. mtþ1j ¼ mt
j
14. end if15. cont = false;16. end if17. t = t + 1;18: end while;
Notice that this approach is only valid when r is greater than the number of selected features given by the method’s stop-ping criterion.
In this variation of the algorithm we modify its stopping criterion (line 9). Instead of reaching convergence, the algorithmstops when the number of available features, k, at this iteration is smaller or equal to the desired number of attributes, r.Then we recover the r � k most relevant features removed in the past iteration and update m.
4.4. Relation to other feature selection methods for SVMs
Different approaches for SVM-based feature selection are already available. SVM-RFE and other wrapper methods pre-sented in [14] differ regarding the feature selection methodology and the stopping criterion. The proposed method directlyobtains a variable subset that simultaneously attempts to improve classification performance with minimal dimension, anddoes not rank variables based on different criteria, such as a weight vector w [6] or a gradient-based measure [14,23]. Addi-tionally, KP-SVM presents an explicit stopping criterion, unlike other wrapper methods cited.
In contrast to the proposed approach, many embedded methods penalize the weight vector of SVMs and therefore arelimited to linear [2,12,13] or polynomial kernels [23]. The method proposed by Weston et al. [22] differs from ours in theobjective function since it minimizes the R2W2 bound on the leave-one-out error LOO of a trained hard-margin SVM classifierinstead of the dual formulation of SVM.
The embedded formulation proposed in [4] performs feature selection via adaptive scaling, which is similar to consideringdifferent kernel widths. However, this method differs from KP-SVM in the formulation of the optimization problem: insteadof penalizing the features, the cited method restricts the number of features in order to perform feature selection. Theauthors also proposed an optimization scheme that differs from our gradient-based algorithm. Another approach, proposedin [3] performs feature selection by removing small scaling factors in a principal components space, where each principalcomponent is scaled by a scaling factor. The differences from our approach are mainly the same: the feature selection processvia kernel penalization and the algorithm for kernel updating.
5. Experimental results
We applied the proposed approach for feature selection on four well-known benchmark data sets: Two real-world datasets from the UCI repository [8], and two DNA microarray data sets. These data sets have already been used to compare fea-ture selection algorithms (see, for example, [15,22]).
For model selection we follow the procedure presented in [16]: training and test subsets are obtained from the originaldata set by dividing it randomly, preserving the proportions of the different classes. For model and feature selection pur-poses, the training set is then further divided using 10-fold cross-validation in order to estimate prediction accuracy. Aftermodel selection, a model comparison is performed on the test subset following the procedure proposed in [14,15]: we splitthe test subset into two subsets of approximately 60% of the observations for training the final models and the remaining 40%

S. Maldonado et al. / Information Sciences 181 (2011) 115–128 121
for the testing, while ensuring that the proportions of positive and negative classes are similar in both sets. A mean test erroris finally obtained by averaging the results over 100 different splits of the test subset.
5.1. Description of data sets
In this subsection we briefly describe the different data sets mentioned above.
5.1.1. Diabetes data set (DIA)The Pima Indians Diabetes (DIA) data set presents 8 features and 768 instances (500 tested negative for diabetes and 268
tested positive).
5.1.2. Wisconsin Breast Cancer (WBC)This data set contains 569 observations (212 malignant and 357 benign tumors) described by 30 continuous features that
are computed from a digitized image of a Fine Needle Aspirate (FNA) of a breast mass. They describe characteristics of thecell nuclei present in the image. As a preprocessing step the features were scaled between 0 and 1.
5.1.3. Colorectal Microarray data set (CMA)This data set contains the expression of the 2000 genes with highest minimal intensity across 62 tissues (40 tumor and 22
normal). The genes are placed in order of descending minimal intensity. In contrast to our proposed method, which automat-ically determines a subset of features for classification, other filter and wrapper methods generate a feature ranking. In thesecases we use the number of ranked variables as mentioned in [14]: 20, 50, 100, 250, 500, 1000 and 2000 (i.e. no variablesremoved).
5.1.4. Lymphoma Microarray data set (LMA)The lymphoma problem contains the gene expression of 96 samples (61 malignant and 35 normal) described by 4026
features. We compare our results using the number of variables as mentioned in [14]: 20, 50, 100, 250, 1000, 2000 and4026 (i.e. no variables removed).
Table 1 summarizes the relevant information for each benchmark data set:
5.2. Results using kernel-penalized feature selection
The first step of the experimentation is model selection. We compare the results of the best model found using a standardmodel selection procedure for three different kernel functions (linear, polynomial and Gaussian) without feature selection.The best combination of parameters will be used as input for KP-SVM (initial kernel parameter m0 and C).
Table 2 presents the mean and standard deviation of the test error for the training subset using 10-fold cross-validation.The following set of values for the parameters (penalty parameter C, degree of the polynomial function d, and Gaussian ker-nel width r) were used:
Table 2Numbekernel f
DIAWBCCMALMA
C 2 f0:1;0:5;1;10;20;30;40;50;60;70;80;90;100;200;300;400;500;1000g;d 2 f2;3;4;5;6;7;8;9g;r 2 f0:1;0:5;1;2;3;4;5;6;7;8;9;10;20;100g:
Table 1Number of variables, number of examples, and proportion of examples in the predominant classfor all four data sets.
Variables Examples Predominant class proportion
DIA 8 768 0.65WBC 30 569 0.63CMA 2000 62 0.65LMA 4026 96 0.64
r of original features N, mean and standard deviation of effectiveness in percentage terms on four data sets using three different SVM with differentunctions.
N SVM linear SVM poly SVM RBF
8 76.95 ± 1.4 77.08 ± 1.7 77.34 ± 1.530 94.55 ± 2.4 96.49 ± 2.2 98.25 ± 2.02000 80.30 ± 6.4 80.30 ± 6.4 85.70 ± 5.64026 94.89 ± 2.3 94.89 ± 2.3 95.89 ± 2.2

122 S. Maldonado et al. / Information Sciences 181 (2011) 115–128
Best results were obtained for all four data sets mentioned above using the Gaussian kernel. It is also possible to modifyfunction (11) in order to adjust the kernel function by incorporating the componentwise product to any suitable kernel if thebest kernel is not the Gaussian.
In order to study the classification performance of KP-SVM we compared the results for a given number of features (deter-mined by the stopping criterion of our approach) with different feature selection algorithms for SVMs presented before inthis paper (SVM-RFE, FSV). Furthermore, we applied the filter technique Fisher Criterion Score (Fisher). The results of themean test error over 100 realizations using the test subset are shown in Table 3, where n is the number of features deter-mined by KP-SVM.
The proposed method outperforms all other approaches in terms of classification error for a given number of features, ascan be concluded from Table 3. The gain in terms of effectiveness is significant in the microarray data sets. For these data setsother methods fail at finding a small subset of features with good classification performance.
Then we compared the classification performance of the different ranking criteria for feature selection by plotting themean test error for an increasing number of ranked features used for learning. Figs. 1–4 show the results for each data
Fig. 1. Mean of test error for DIA vs. the number of ranked variables used for training.
Fig. 2. Mean of test error for WBC vs. the number of ranked variables used for training.
Table 3Number of selected features n, mean and standard deviation of effectiveness (in percentage) using four different feature selection methods on four data sets. Weoutline the best model performance in bold.
n Fisher + SVM FSV RFE-SVM KP-SVM
DIA 5 76.42 ± 1.9 76.58 ± 1.7 76.56 ± 1.9 76.74 ± 1.9WBC 15 94.70 ± 1.3 95.23 ± 1.1 95.25 ± 1.0 97.55 ± 0.9CMA 20 87.46 ± 7.9 92.03 ± 7.7 92.52 ± 7.2 96.57 ± 5.6LMA 8 75.23 ± 11.7 63.06 ± 6.0 63.04 ± 5.9 99.73 ± 1.0

Fig. 3. Mean of test error for CMA vs. the number of ranked variables used for training.
Fig. 4. Mean of test error for LMA vs. the number of ranked variables used for training.
Fig. 5. Mean of test error for CMA vs. the number of ranked variables used for training.
S. Maldonado et al. / Information Sciences 181 (2011) 115–128 123
set respectively. The proposed KP-SVM approach is represented by one single point: the mean test error obtained by its stop-ping criterion.
These experiments underline that the proposed approach, KP-SVM, outperforms other feature selection methods in termsof classification performance for a small number of features in all four data sets used.

124 S. Maldonado et al. / Information Sciences 181 (2011) 115–128
5.3. Results obtained using KP-SVM as feature ranking algorithm
In order to study the performance of the modification presented in Section 4.3, we ran the algorithm for the ColorectalMicroarray data set using r 2 {20,50,100,250,500,1000} and comparing the results with other feature selection methods.Fig. 5 shows these results, illustrating that our ranking outperforms other feature selection methods for almost all the num-bers of features, r. SVM-RFE performs better two out of six times but the difference is not significant. We can conclude thatthis modification represents a very good alternative for obtaining good classification performance for a desired number offeatures, even if the algorithm is designed to achieve best classification performance with few variables.
6. Discussions
The main advantage of KP-SVM in terms of computational effort is that it automatically obtains an optimal feature subset,avoiding a validation step to determine how many ranked features will be used for classification. However, several param-eters should be tuned in order to obtain the final solution. In this section we study the method’s performance by varying oneparameter at a time, obtaining its influence on the final solution.
For the different data sets we vary the parameters C2, b, c, �, and m0. In order to illustrate their influence on the classifier,the following graphs (Figs. 6–10) display the performance in terms of classification error (using 10-fold cross-validation) andnumber of selected features for the data set Colorectal Microarray dataset.
Fig. 6. Classification performance for CMA by varying parameter C2.
Fig. 7. Classification performance for CMA by varying parameter c.
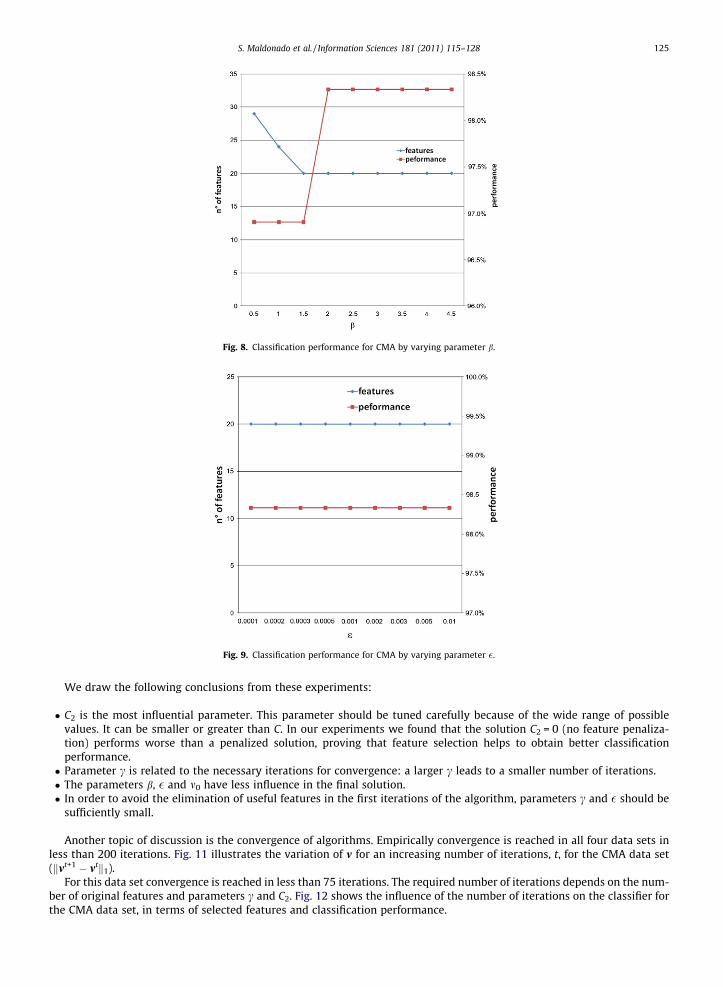
Fig. 8. Classification performance for CMA by varying parameter b.
Fig. 9. Classification performance for CMA by varying parameter �.
S. Maldonado et al. / Information Sciences 181 (2011) 115–128 125
We draw the following conclusions from these experiments:
� C2 is the most influential parameter. This parameter should be tuned carefully because of the wide range of possiblevalues. It can be smaller or greater than C. In our experiments we found that the solution C2 = 0 (no feature penaliza-tion) performs worse than a penalized solution, proving that feature selection helps to obtain better classificationperformance.� Parameter c is related to the necessary iterations for convergence: a larger c leads to a smaller number of iterations.� The parameters b, � and m0 have less influence in the final solution.� In order to avoid the elimination of useful features in the first iterations of the algorithm, parameters c and � should be
sufficiently small.
Another topic of discussion is the convergence of algorithms. Empirically convergence is reached in all four data sets inless than 200 iterations. Fig. 11 illustrates the variation of m for an increasing number of iterations, t, for the CMA data set(kmt+1 � mtk1).
For this data set convergence is reached in less than 75 iterations. The required number of iterations depends on the num-ber of original features and parameters c and C2. Fig. 12 shows the influence of the number of iterations on the classifier forthe CMA data set, in terms of selected features and classification performance.

Fig. 10. Classification performance for CMA by varying parameter r ¼ 1m0
.
Fig. 11. kmt+1 � mtk1 for CMA by increasing the number of iterations t.
126 S. Maldonado et al. / Information Sciences 181 (2011) 115–128
From this graph we observe that the classification performance decreases after 26 iterations, and the features selecteddecrease smoothly after 13 iterations.
Empirically we observe that some kernel variables m may grow unboundedly, affecting the classification performance.Therefore it is important to monitor the process and select the model by maximizing classification performance. Upperbounding the vector m is also recommended.
We propose the following suggestions for model selection:
� Perform model selection by finding the best model for the isotropic Gaussian kernel, in order to obtain the best solution aand parameters C and r.� Set the parameters C and m0 according to the first model selection step.� The value for � should be sufficiently small, for example � = m0/4. Other good initial values are c = 0.25 and b = 5, as sug-
gested in the literature [2].� Vary C2 studying the classification performance and number of selected features using cross-validation for an increasing
number of iterations, t.

Fig. 12. classification performance for CMA by increasing the number of iterations t.
S. Maldonado et al. / Information Sciences 181 (2011) 115–128 127
� Try different values of c and b in order to improve the classification performance.
7. Conclusions
In this paper we present a novel embedded method for feature selection using SVMs. A comparison with other featureselection techniques shows the advantages of our approach:
� Empirically, KP-SVM outperforms other filter and wrapper techniques, based on its ability to adjust better to the data byoptimizing the kernel function and simultaneously selecting an optimal feature subset for classification.� Unlike most feature selection methods, it is not necessary to set the feature number to be selected a priori: KP-SVM deter-
mines the optimal number of features according to the regularization parameter, C2.� Any suitable kernel function can be used instead of the Gaussian.� It can easily be generalized to variations of SVM, such as SV Regression and Multi-class SVM.
Even if several parameters should be tuned to obtain the final solution, the computational effort can be reduced since thefeature subset is obtained automatically, reducing computational time by avoiding a further validation step in order to findthe adequate number of ranked features. The proposed model selection methodology also reduces computational effort forfinding the parameters.
KP-SVM attempts to find an optimal subset of features for classification. If, however, the goal of feature selection is to find asubset of a fixed size r among all n features, KP-SVM can be modified to accomplish this goal as well. The main idea is to con-struct a feature ranking with the removed features. Earlier removed variables have a lower rank than later removed variables.For features that have been eliminated as a batch in the same iteration, the ones with higher last value of mj have a better rank.
Our algorithm relies on a non-linear optimization problem, which is computationally treatable but expensive if the num-ber of input features is large. We could improve its performance by applying filter methods for feature selection before run-ning KP-SVM [9,19] or by developing hybrid models [20]. This way we can identify and remove irrelevant features at lowcost. In several Credit Scoring projects we have performed for Chilean financial institutions we used univariate analysis(Chi-Square Test for categorical features and the Kolmogorov–Smirnov Test for continuous ones) as a first filter for featuresselection with excellent results [10].
Future work can be done in several directions. First, it would be interesting to use the proposed method in combinationwith variations of SVM, such as Regression [11] or Multi-class. Also interesting would be the application of this approachwith other kernel functions like polynomial kernel or with weighted support vector machines to compensate for the unde-sirable effects caused by unbalanced data sets in model construction; an issue which occurs for example in the domains ofcredit scoring and fraud detection.
Acknowledgements
Support from the Chilean Instituto Sistemas Complejos de Ingeniera (ICM: P-05-004-F, CONICYT: FBO16) is greatlyacknowledged (www.sistemasdeingenieria.cl). The first author also acknowledges a grant provided by CONICYT for hisPh.D. studies in Engineering Systems at Universidad de Chile.

128 S. Maldonado et al. / Information Sciences 181 (2011) 115–128
References
[1] A.P. Blum, P. Langley, Selection of relevant features and examples in machine learning, Artificial Intelligence 97 (1997) 245–271.[2] P. Bradley, O. Mangasarian, Feature selection vía concave minimization and SVMs, in: Machine Learning Proceedings of the Fifteenth International
Conference, Morgan Kaufmann, San Francisco, 1998, pp. 82–90.[3] S. Canu, Y. Grandvalet, Adaptive scaling for feature selection in SVMs, Advances in Neural Information Processing Systems, vol. 15, MIT Press,
Cambridge, MA, USA, 2002. pp. 553–560.[4] O. Chapelle, V. Vapnik, O. Bousquet, S. Mukherjee, Choosing multiple parameters for support vector machines, Machine Learning 46 (1) (2002) 131–
159.[5] I. Guyon, A. Elisseeff, An introduction to variable and feature selection, Journal of Machine Learning Research 3 (2003) 1157–1182.[6] I. Guyon, S. Gunn, M. Nikravesh, L.A. Zadeh, Feature Extraction, Foundations and Applications, Springer, Berlin, 2006.[7] I. Guyon, J. Weston, S. Barnhill, V. Vapnik, Gene selection for cancer classification using support vector machines, Machine Learning 46 (1–3) (2002)
389–422.[8] S. Hettich, S.D. Bay, The UCI KDD Archive, University of California, Department of Information and Computer Science, Irvine, CA, 1999. <http://
kdd.ics.uci.edu>.[9] Y. Liu, Y.F. Zheng, FS-SFS: A novel feature selection method for support vector machines, Pattern Recognition 39 (2006) 1333–1345.
[10] S. Maldonado, R. Weber, A wrapper method for feature selection using support vector machines, Information Sciences 179 (13) (2009) 2208–2217.[11] S. Maldonado, R. Weber, Feature selection for support vector regression via kernel penalization, in: Proceedings of the 2010 International Joint
Conference on Neural Networks, Barcelona, Spain, 2010, pp. 1973–1979.[12] J. Miranda, R. Montoya, R. Weber, Linear penalization support vector machines for feature selection, in: S.K. Pal et al. (Eds.), PReMI 2005, LNCS, vol.
3776, Springer-Verlag, Berlin, Heidelberg, 2005, pp. 188–192.[13] J. Neumann, C. Schnörr, G. Steidl, Combined SVM-based feature selection and classification, Machine Learning 61 (1–3) (2005) 129–150.[14] A. Rakotomamonjy, Variable selection using SVM-based criteria, Journal of Machine Learning Research 3 (2003) 1357–1370.[15] G. Rätsch, T. Onoda, K-R Müller, Soft margins for AdaBoost, Machine Learning 42 (3) (2001) 287–320.[16] J. Reunanen, I. Guyon, A. Elisseeff, Overfitting in making comparisons between variable selection methods, Journal of Machine Learning Research 3
(2003) 1371–1382.[17] B. Schölkopf, A.J. Smola, Learning with Kernels, MIT Press, Cambridge, MA, USA, 2002.[18] M.-D. Shieh, C.-C. Yang, Multiclass SVM-RFE for product form feature selection, Expert Systems with Applications 35 (1–2) (2008) 531–541.[19] Ö. Uncu, I.B. Türksen, A novel feature selection approach: combining feature wrappers and filters, Information Sciences 177 (2007) 449–466.[20] A. Unler, A. Murat, R.B. Chinnam, mr2PSO: A maximum relevance minimum redundancy feature selection method based on swarm intelligence for
support vector machine classification, Information Sciences, in press, doi:10.1016/j.ins.2010.05.037.[21] V. Vapnik, Statistical Learning Theory, John Wiley and Sons, New York, 1998.[22] J. Weston, S. Mukherjee, O. Chapelle, M. Ponntil, T. Poggio, V. Vapnik, Feature selection for SVMs, Advances in Neural Information Processing Systems,
vol. 13, MIT Press, Cambridge, MA, 2001.[23] J. Weston, A. Elisseeff, B. Schölkopf, M. Tipping, The use of zero-norm with linear models and kernel methods, Journal of Machine Learning Research 3
(2003) 1439–1461.[24] M.L. Zhang, J.M. Pena, V. Robles, Feature selection for multi-label naive Bayes classification, Information Sciences 179 (19) (2009) 3218–3229.
Related Documents










