Simulation of Parallel Applications in GridSim Julio L. Alb´ ın, Juan A. Lorenzo, Jos´ e Carlos Cabaleiro, Tom´ as F. Pena and Francisco F. Rivera Departamento de Electr´ onica e Computaci´ on, Universidad de Santiago de Compostela 15782 Santiago de Compostela, SPAIN {xulio,juanangel,caba,tomas,fran}@dec.usc.es, WWW home page: http://www.ac.usc.es Abstract. Grids offer a great opportunity to find solutions to HPC problems. For these architectures, because of their large dimensions and dynamic nature, a simulation tool can be useful ,for example, to de- sign parallel applications for Grids or as a tool for the study of efficient metaschedulers. To optimise the execution of parallel applications on a Grid, an extension of GridSim toolkit to support parallel applications was developed. Several components to model parallel applications were included: as job models for different kinds of applications, models for internal networks and different local parallel schedulers. Also, due to the importance of resource failures in parallel applications on Grids, a frame- work to support checkpointing and failure simulation was also added to this tool. 1 Introduction In the last decade, clusters becomes the principal solution for supercomputing [2– 4]. The main reason for this is that they are more economic than supercomputers, and provide similar computational facilities for a large extent of applications. We presume that Grids could be the next computer infrastructure for this kind of applications. For these architectures, parallel and distributed solutions are the most ad- equate programming models for high performance computing. The develop- ment of these architectures has been one of the factors that makes parallel and distributed programming the main solution for High Performance Computing (HPC). Grid Technologies provide mechanisms for sharing and coordinating the use of diverse resources, enabling the creation of virtual computing systems that are sufficiently integrated to deliver qualities of service [7]. However, Grids are environments of very high complexity; mainly because of the lack of a centralised control, the heterogeneity of resources, and the dynamic nature of its infrastructure. As a consequence, the performance does not only depend on the aggregate computational power of the grid resources, but also on the interconnection networks, the data location, the resource selection and the changes of state of the system. In High Performance Computing, performance is mainly characterised by the execution time, and the Grid offers a great opportunity to find solutions to HPC

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Simulation of Parallel Applications in GridSim
Julio L. Albın, Juan A. Lorenzo, Jose Carlos Cabaleiro, Tomas F. Pena andFrancisco F. Rivera
Departamento de Electronica e Computacion, Universidad de Santiago deCompostela 15782 Santiago de Compostela, SPAIN{xulio,juanangel,caba,tomas,fran}@dec.usc.es,
WWW home page: http://www.ac.usc.es
Abstract. Grids offer a great opportunity to find solutions to HPCproblems. For these architectures, because of their large dimensions anddynamic nature, a simulation tool can be useful ,for example, to de-sign parallel applications for Grids or as a tool for the study of efficientmetaschedulers. To optimise the execution of parallel applications on aGrid, an extension of GridSim toolkit to support parallel applicationswas developed. Several components to model parallel applications wereincluded: as job models for different kinds of applications, models forinternal networks and different local parallel schedulers. Also, due to theimportance of resource failures in parallel applications on Grids, a frame-work to support checkpointing and failure simulation was also added tothis tool.
1 Introduction
In the last decade, clusters becomes the principal solution for supercomputing [2–4]. The main reason for this is that they are more economic than supercomputers,and provide similar computational facilities for a large extent of applications. Wepresume that Grids could be the next computer infrastructure for this kind ofapplications.
For these architectures, parallel and distributed solutions are the most ad-equate programming models for high performance computing. The develop-ment of these architectures has been one of the factors that makes parallel anddistributed programming the main solution for High Performance Computing(HPC). Grid Technologies provide mechanisms for sharing and coordinating theuse of diverse resources, enabling the creation of virtual computing systems thatare sufficiently integrated to deliver qualities of service [7].
However, Grids are environments of very high complexity; mainly because ofthe lack of a centralised control, the heterogeneity of resources, and the dynamicnature of its infrastructure. As a consequence, the performance does not onlydepend on the aggregate computational power of the grid resources, but also onthe interconnection networks, the data location, the resource selection and thechanges of state of the system.
In High Performance Computing, performance is mainly characterised by theexecution time, and the Grid offers a great opportunity to find solutions to HPC

problems. However, the features mentioned before make this goal a challengingissue. To use successfully the grid in High Performance Computing, applicationshave to be adapted in several ways, and scheduling and metascheduling Gridalgorithms have to be developed in order to obtain good performances.
Our main objective in this work is to study and characterise parallel applica-tions when they are executed in Grids. In particular we focus on message passingprograms, coded using MPI library. As it is shown in section 2 to achieve thisobjective, simulators are very useful tools. In this work we present a extensiontoolkit integrated in GridSim [12] to simulate parallel applications in a Grid.
This paper is organised as follows. Section 2 presents a brief summary of thestate of the art of grid simulators and the reasons to select GridSim. In Section3, a description of the extensions developed to simulate parallel applications ona Grid is shown, including a description of the different effects simulated. Asimulation example about the influence of local schedulers is shown in Section4. Finally, Section 5 presents the main conclusions and the future research lines.
2 State of the art in simulation of Grids
Simulating or emulating parallel applications is a challenge in Computer Science.This is particularly true in Grid Computing, where simulators are very usefultools to study new scheduling algorithms, and developing new technologies onGrids for example. Several reasons make very interesting the use of this kindof tools. In first place, building a Grid with enough resources to be significa-tive, only for testing purposes, is too expensive. Also, adding new technologiesor new schedulers for testing them could produce an unstable situation for theusers in a production Grid . As well, we have to consider that deploying in ahuge Grid any solution implies a lot of work and collaboration among differententities. Moreover, due to the dynamic nature of a Grid, it is very difficult toreproduce a specific situation in order to compare different experiments. Besides,interconnection networks are usually not dedicated, so it is difficult to perform acontrolled study of their influence. Finally, to design new Grids with special char-acteristics, like an interplanetary Grid [9] or a Grid of really large proportions,currently it is not possible to produce these situations in a real environment.
Due to these requirements and others, different projects have developed toolsto study the design and operation of different grids. For example,
– Microgrid [14] is an emulator that uses a set of local resources to emulatemultiple machines on each local one. This environment allows us to study realapplications in a controlled situation. But this is not suitable for studying amacro situation along the time, because each emulated resource slows downthe others running on the same machine.
– Simgrid [10] is an event based simulator written in C that simulates nondedicated resources and allows the use of traces from real executions forsimulating the resource workload. A reference resource is defined to providethe execution time of any job to simulate. The performance of any resource

is specified with respect to some predefined reference resource, so this ratiois used to scale the submitted jobs.
– GridSim [12] is a Java toolkit based in the SimJava library. It is designed forsimulating heterogeneous resources with several users, applications and localschedulers. It can be adapted to both centralised and decentralised resourcebrokers.
– Gangsim [6] is an event based simulator developed as an extension of themonitoring tool Ganglia [11]. It was designed for studying the impact ofscheduling policies. The user provides the execution time to model jobs.
– Optorsim [5] is based on the EU DataGrid architecture for modelling in-teractions among Data Grid components. This simulator is designed to thestudy of policies for data transference and replication, and it uses a globalmetascheduler for job assignment.
– Hypersim [13] is a simulator motivated from the search of efficiency. Schedul-ing time simulations are allowed in order to be considered them as a step inresource broker algorithms. It consists of two layers structure with a globalcentralised manager and local managers.
As mentioned in the introduction, our objective is to develop a tool to simu-late parallel HPC applications on Grids, and we will illustrate its use to performthe evaluation of different scheduling algorithms for the execution of parallelapplications. We consider GridSim the most appropriate tool for extending it inorder to achieve our goals.
2.1 GridSim
GridSim is a Java-based discrete event Grid simulation toolkit. This toolkitsupports modelling and simulation of heterogeneous Grid resources (both time-and space-shared), users and application models. It provides primitives to createof application tasks, mapping of tasks to resources, and their management.
GridSim implements both local schedulers, that can be easily extended, andmeta-schedulers, not only centralised, but also decentralised ones. This featureoffers more flexibility for the evaluation of different strategies than other sim-ulators that consider only a centralised job assignment. Centralised solutionspresent low scalability, and they cannot be adapted to different users, howeverdecentralised approaches allow the users or groups of users to define particularprofiles for their own resource brokers. Furthermore, GridSim has some usefulfeatures as complex interconnection resources networks and data repositories aswell as a modular Java implementation.
The GridSim toolkit provides facilities for the modelling and simulation ofresources and network connectivity with different capabilities, configurations,and domains. It supports primitives for application composition and informationservices for resource discovery. In particular, it was designed to study scheduleralgorithms in a repetitive and controllable environment.

3 Simulation of parallel and distributed applications inGridSim
Simulation of parallel and distributed applications is not actually fully consideredin GridSim. Although it is possible to define jobs that require more than oneprocessor, currently their simulation is just obtained by scaling the simulationon one processor. This approach is not appropriate in many cases.
In order to simulate the behaviour of a Grid processing parallel and dis-tributed applications, new structures and functionalities were added to GridSimin this work. Due to the number of types of applications in parallel computing,and the number of paradigms to be used: from loose coupled message passing tofine grained shared memory, as well as the different possibilities for their imple-mentation: as OpenMP, PVM or MPI, a basic and general structure (i.e. a Javaclass), called ParallelGridlet, was defined.
Based on this generic scheme, two different implementations, called Barrier-Based and PTPBased, are considered for message-passing programs; and theirprincipal difference is the communication flexibility. Even so, this scheme canalso be adapted for the simulation of synchronisations in shared memory par-allel applications and distributed ones. Both implementations define a parallelapplication as a group of tasks that interact among them. Each task is charac-terised by a sequence of computations and communications. Each computationchunk is defined by the number of MIPS or FLOPS involved in it, and thecommunications are characterised by the amount of transfered data.
Fig. 1. Parallel Gridlets
The accurated simulation of communications of a parallel application usuallyis a hard problem, and often a computational intensive task. Simple models tocharacterise the communications do not capture the real behaviour, and more

complicated ones require important overheads. To deal with this problem, wepropose to simulate the communications in a exhaustive way. In particular, aswe mentioned before, two different solutions were implemented (see Fig. 1):
BarrierBased Model. In order to simplify the simulation of the communica-tions among tasks, in this model all the communications are assumed tobe global. This is not a so strong assumption as it could sound, becausemany real applications present global communications (broadcasts, reduc-tions, scatters, gathers, etc.) or another kind of global communication struc-ture implemented through point-to-point communications.In this model, communications are supposed to be global, and with implicitbarriers, then all tasks are executed in a synchronised way. The first partof Fig. 1 illustrates this approach. With this model, the complexity of thesimulation, and the memory requirements do not increase noticeably in com-parison with the cost of the sequential simulation itself.
PointToPoint Model. This is a more sophisticated model in which each com-munication is associated to a pair or group of tasks. Each task uses a struc-ture with information about the computation chunks, and a different struc-ture to store the information about the communications between pairs ofcomputing chunks.Each communication is represented by an abstraction, called TaskCommu-nication, with a generic scheme to simulate every kind of communication.Different models (scatter/gather, reduce, reduceAll, master/slave, etc.) couldbe implemented for each one, as it is shown in the Fig. 1.This model can require a big amount of memory, and it increases the over-all simulation complexity when the number of parallel tasks increases. It isnot suitable to massive simulations with a big amount of jobs. Neverthe-less, to minimise this overhead, it is possible to simulate a mixed group ofapplications with both models, in such a way that jobs with complex struc-tures are simulated concurrently with simple ones, each one with differentimplementations.
3.1 Communication Networks
To evaluate accurately parallel applications, it is necessary to take into accountthe features of the network. In fact, in many applications this is the main factor tocharacterise the performance. In our approach, a framework to simulate internalnetworks was included.
Some internal network models has been characterised by attributes like thebandwidth, the latency and the network topology. In the current implementa-tion of our simulator, three network topologies (see Fig. 2) are considered forcharacterising collective communications:
– TreeNet: The collective communications behave as a binary tree.– BroadcastNet: In this network it is possible to broadcast messages from the
source node to all the nodes in a single step.

– PTPNet: In this model, only one communication between two nodes can beestablished in the network at the same time.
Fig. 2. Basic network topologies
For these internal network models, the following expressions can be consid-ered to evaluate the influence of the network:
time = (latency + transferedData/bandwith) ∗ NetFactor
NetFactor =
log2tasksinvolved for the TreeNet model1 for the BroadcastNet modeltasksinvolved for the PTPNet model
3.2 Local scheduling algorithms
The response time of parallel applications is conditioned by the local schedulers.This factor is more relevant in a Grid, where different kinds of schedulers couldoperate at same time.
Actually, an efficient resource selection must choose the adequate resourcestaking into account the local scheduler behaviour for different kind of jobs. Forexample, a resource with a FirstFit scheduler is favourable to jobs that requirea small number of processors. To take this into account, a generic structure toinclude parallel local schedulers has been implemented. Currently, in our tool,some of the most commonly used schedulers [8] were considered:
First Come-First Served (FCFS) is a scheduling policy whereby the jobsare executed in the order in which they arrive, without other biases or pref-erences.
First Fit is a scheduling policy whereby the first available job that is suitablefor the idle resources is executed.

Conservative Backfilling In this policy, the arrival order is used to schedulethe jobs, as in the FCFS. Nevertheless, if some local nodes are empty becausethe next work in the queue is not suitable, the queue is examined to executeanother job. The selection of this job should not delay the execution of therest of the queued jobs. Two ways of selecting the promoted job for thisalgorithm have been included:First Fit The first job that is suitable for execution without delaying a
FCFS order is executed first.Predictive The first job that is suitable for execution that one that does
not delay the best possibility of launching of previous queued jobs.EASYBackfilling is an aggressive backfilling in which only the first element
of the queue is considered. This means that a job is promoted if it does notdelay the execution start of the next one in the queue, and that the rest ofentries in the queue are not taken into account.
An example of the behaviour of these schedulers is shown in Fig. 3. Eachcoloured rectangle represents a job to be executed. The height of each shows thenumber of required processors, and the width is the execution time. In the firstrow of the figure, the jobs are stored in a queue according to the arrival time.The other rows shows the execution of the jobs in a cluster with each of the localschedulers.
Fig. 3. Example of behaviour of different local schedulers policies
3.3 Other features
To increase the precision in the simulations, a framework to support fault man-agement, checkpointing and workflows has been implemented.
Fault Management The large dimensions of a Grid and its dynamic behaviourimply that structural and configurational changes are usual. Some machines and

resources may fall down due to different reasons, including hardware or networkfails. The behaviour and efficiency of a Grid has to be evaluated taking this factinto account. To be able to deal properly with this situation, the gridlets haveto be cancelled or rescheduled and the machines have to be set as available orunavailable through the time.
In order to simulate this situation, a failure source entity has been imple-mented. It generates Grid failures based in a well-defined Grid resource failurescheme. These Grid failures modify the state of availability of the resources.Therefore, a processor can be in one of three states: free, busy or unavailable.New extensions of the local allocation policies have been defined, which cancancel or pause gridlets when a failure event happens. As response to failures,gridlets can be migrated or restarted based in a local scheduler configuration.
The Grid resource failure scheme could be defined totally by the user, buttwo implementations are currently included in our tool:
– SimpleGridResourceFailureScheme. It represents a set of Grid failure eventscharacterised by their launch time and the time needed to recover from thefailure. They can be produced cyclically in user defined intervals.
– MarkovGridResourceFailureScheme. In this scheme, every resource can be inone of the following two states: available or unavailable. And a pair of prob-abilities (pe, pr) are associated to each resource: the failure and recuperationprobabilities. Using a Markov chains model, events are generated to changethe state of the resources.
Checkpointing To avoid the problem of failures, checkpointing strategies areadded to some applications. Then, when the application fails, it could be mi-grated, and its execution is restarted from the last successful checkpoint. To im-prove the accuracy, when fault tolerant applications are simulated, a checkpointsimulation support was added in our tool. A basic extra checkpoint simulationcost is specified by some predefined checkpoint frequency, and by the amount ofcomputations and communications associated with each checkpoint operation.
Workflows A model to simulate dependencies between jobs has been added tosimulate job workflows. This model can be also used to simulate the behaviourof an user who executes a job, interprets the results, and generates a new job.Each job is also characterised by its dependencies, and, after the completion ofthese dependencies, a waiting time before the start of the job.
4 An example of use: the study of the effect of localschedulers
As an example of the functionality of our extensions of GridSim, a study ofthe influence of the local parallel schedulers is presented in this section. In thisexample, we study the effects in a Grid of 3 different schedulers: FCFS, FirstFitand EASYBackfilling.

Fig. 4. Resources of CrossGrid testbed
4.1 The simulated scenario: The CrossGrid Testbed and Workload
Heterogeneity is an usual situation in Grids that makes difficult the use of fairscheduling algorithms. To reflect this fact in our study, we selected the Cross-grid [1], a real testbed, as a case of study. This Grid is composed by a set ofclusters with great variety of resources. The characteristics and location of theseresources are shown in Table 1 and in Fig. 4. In this simulation, a random re-source selection algorithm was used, in such a way that, for each job, a randomresource is selected from a set of suitable resources. The selected resources foreach of the jobs are the same for all local schedulers. Also, a random simulationworkload was generated. This workload consits of 10000 works and it was gen-erated with an uniform distribution with a mean of 90% parallel jobs, each onerequires from 2 to 16 processors selected randomly.
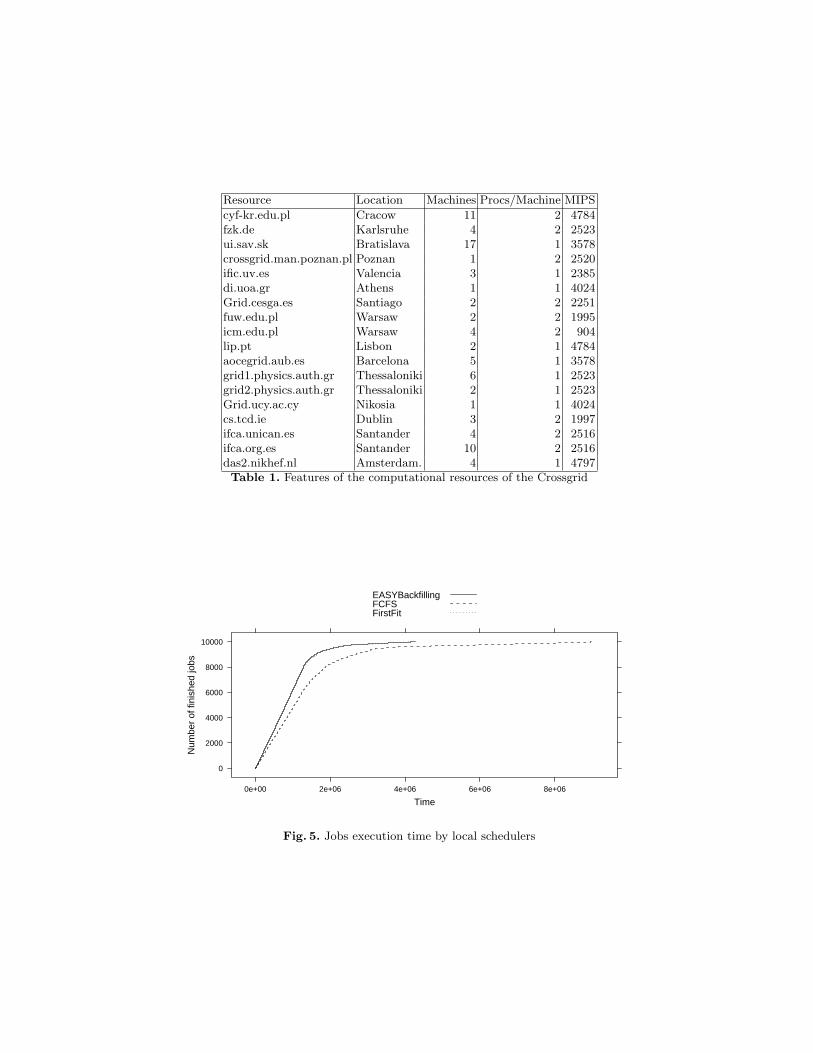
After running the simulation, we obtain a number of state changes in eachnode where the application was submitted as well as a trace of their execution.The time required to complete all the workload is shown in Fig. 5. The figureshows the completion times of the workload along the simulated time for eachlocal scheduler. Note that a FCFS scheduling produces the worst performance,as it should be expected, because the FCFS does not take advantage of emptyresources.
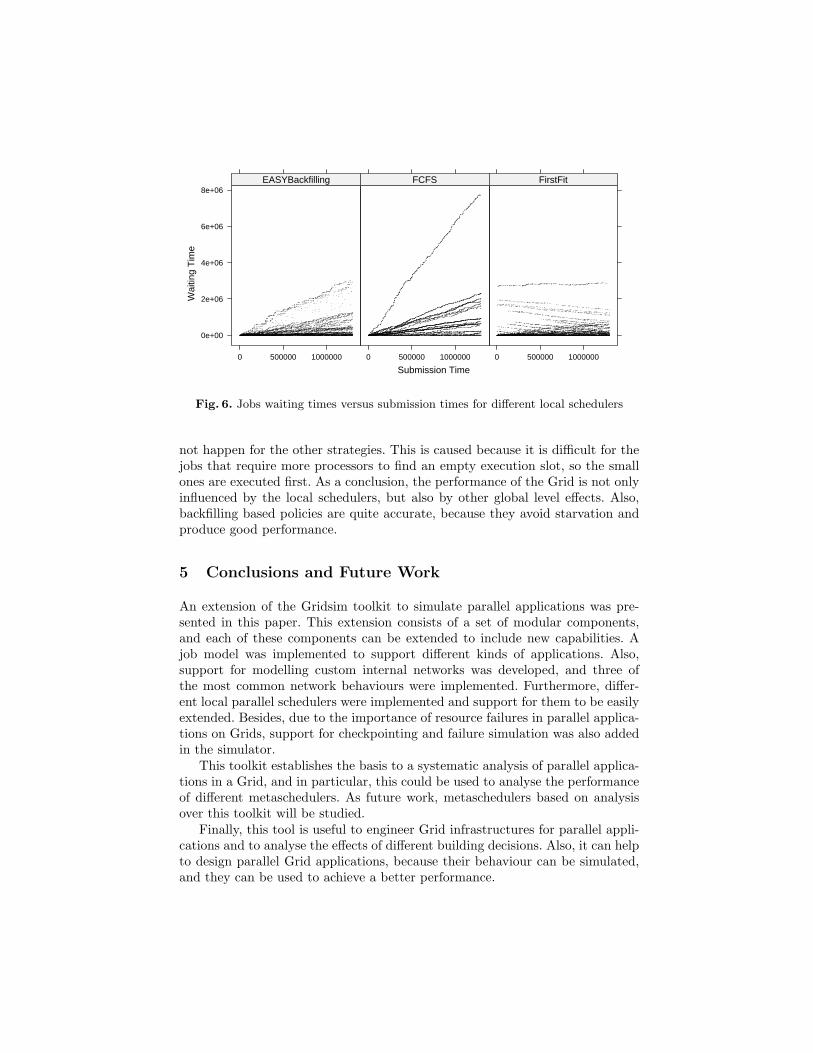
Although First Fit and EASYBackfilling simulations spend almost the sametime in the workload, the response time to the user is quite different. Fig. 6 showsthe waiting time for all considered jobs versus its submission time for each localscheduler. Note that First Fit presents a very unfair behaviour, and some jobssubmitted at the beginning are delayed in their execution. For example, somejobs submitted early (near 0 s) are delayed more than 2 · 106 seconds, that does
Resource Location Machines Procs/Machine MIPS
cyf-kr.edu.pl Cracow 11 2 4784fzk.de Karlsruhe 4 2 2523ui.sav.sk Bratislava 17 1 3578crossgrid.man.poznan.pl Poznan 1 2 2520ific.uv.es Valencia 3 1 2385di.uoa.gr Athens 1 1 4024Grid.cesga.es Santiago 2 2 2251fuw.edu.pl Warsaw 2 2 1995icm.edu.pl Warsaw 4 2 904lip.pt Lisbon 2 1 4784aocegrid.aub.es Barcelona 5 1 3578grid1.physics.auth.gr Thessaloniki 6 1 2523grid2.physics.auth.gr Thessaloniki 2 1 2523Grid.ucy.ac.cy Nikosia 1 1 4024cs.tcd.ie Dublin 3 2 1997ifca.unican.es Santander 4 2 2516ifca.org.es Santander 10 2 2516das2.nikhef.nl Amsterdam. 4 1 4797Table 1. Features of the computational resources of the Crossgrid
Time
Num
ber
of fi
nish
ed jo
bs
0
2000
4000
6000
8000
10000
0e+00 2e+06 4e+06 6e+06 8e+06
EASYBackfillingFCFSFirstFit
Fig. 5. Jobs execution time by local schedulers
Submission Time
Wai
ting
Tim
e
0e+00
2e+06
4e+06
6e+06
8e+06
0 500000 1000000
EASYBackfilling
0 500000 1000000
FCFS
0 500000 1000000
FirstFit
Fig. 6. Jobs waiting times versus submission times for different local schedulers
not happen for the other strategies. This is caused because it is difficult for thejobs that require more processors to find an empty execution slot, so the smallones are executed first. As a conclusion, the performance of the Grid is not onlyinfluenced by the local schedulers, but also by other global level effects. Also,backfilling based policies are quite accurate, because they avoid starvation andproduce good performance.
5 Conclusions and Future Work
An extension of the Gridsim toolkit to simulate parallel applications was pre-sented in this paper. This extension consists of a set of modular components,and each of these components can be extended to include new capabilities. Ajob model was implemented to support different kinds of applications. Also,support for modelling custom internal networks was developed, and three ofthe most common network behaviours were implemented. Furthermore, differ-ent local parallel schedulers were implemented and support for them to be easilyextended. Besides, due to the importance of resource failures in parallel applica-tions on Grids, support for checkpointing and failure simulation was also addedin the simulator.
This toolkit establishes the basis to a systematic analysis of parallel applica-tions in a Grid, and in particular, this could be used to analyse the performanceof different metaschedulers. As future work, metaschedulers based on analysisover this toolkit will be studied.
Finally, this tool is useful to engineer Grid infrastructures for parallel appli-cations and to analyse the effects of different building decisions. Also, it can helpto design parallel Grid applications, because their behaviour can be simulated,and they can be used to achieve a better performance.

Acknowledgement
This work was supported by the Spanish Government (MCYT) under the projectTIN2004-07797-C02. We are particular grateful to CESGA and Grid Computingand Distributed Systems (GRIDS) Laboratory, specially to Dr. Rajkumar Buyyaand Mr. Anthony Sulistio, for their support and for providing access to theirsystems. We also thank the Ministerio de Educacion y Ciencia of Spain forfellowship awarded (FPU) and PGIDIT program.
References
1. Crossgrid project. http://www.crossgrid.org.2. Top500 supercomputer sites. http://www.top500.org.3. Mark Baker. Cluster computing white paper, 2000.4. Gordon Bell and Jim Gray. What’s next in high-performance computing? Com-
mun. ACM, 45(2):91–95, 2002.5. William H. Bell, David G. Cameron, Luigi Capozza, A. Paul Millar, Kurt
Stockinger, and Floriano Zini. Optorsim - a grid simulator for studying dynamicdata replication strategies. International Journal of High Performance ComputingApplications, 17(4), 2003.
6. C.L. Dumitrescu and I. Foster. Gangsim: a simulator for grid scheduling stud-ies. In Cluster Computing and the Grid, 2005. CCGrid 2005. IEEE InternationalSymposium on, volume 2, pages 1151–1158Vol.2, 9-12 May 2005.
7. Ian Foster and Carl Kesselman, editors. The Grid: Blueprint for a New ComputingInfrastructure. Morgan Kaufmann, 2004.
8. Jochen Krallmann, Uwe Schwiegelshohn, and Ramin Yahyapour. On the design andevaluation of job scheduling algorithms. In Dror G. Feitelson and Larry Rudolph,editors, Job Scheduling Strategies for Parallel Processing, pages 17–42. SpringerVerlag, 1999.
9. Laurent Lefevre and Jean-Patrick Gelas. Towards interplanetary grids. In Work-shop on ”Next Generation Communication Infrastructure for Deep-Space Commu-nications”, Pasadena, California, July 2006.
10. A. Legrand, L. Marchal, and H. Casanova. Scheduling distributed applications:the simgrid simulation framework. In Cluster Computing and the Grid, 2003.Proceedings. CCGrid 2003. 3rd IEEE/ACM International Symposium on, pages138–145, 12-15 May 2003.
11. Matthew L. Massie, Brent N. Chun, and David E. Culler. The ganglia distributedmonitoring system: design, implementation, and experience. Parallel Computing,30(7):817–840, July 2004.
12. Manzur Murshed, Rajkumar Buyya, and David Abramson. Gridsim: A toolkit forthe modeling and simulation of distributed resource management and schedulingfor grid computing. The Journal of Concurrency and Computation: Practice andExperience (CCPE), Wiley Press, 2002.
13. S. Phatanapherom, P. Uthayopas, and V. Kachitvichyanukul. Fast simulationmodel for grid scheduling using hypersim. In Simulation Conference, 2003. Pro-ceedings of the 2003 Winter, volume 2, pages 1494–1500vol.2, 7-10 Dec. 2003.
14. H.J. Song, X. Liu, D. Jakobsen, R. Bhagwan, X. Zhang, K. Taura, and A. Chien.The microgrid: a scientific tool for modeling computational grids. In Supercomput-ing, ACM/IEEE 2000 Conference, pages 53–53, 04-10 Nov. 2000.
Related Documents











