SIGMOD2009 Overview Web group Li Yukun

SIGMOD2009 Overview Web group Li Yukun. Outline Overview SIGMOD2009 Overview two selected papers Optimizing Complex Extraction Programs over Evolving.
Dec 18, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

SIGMOD2009 Overview
Web group
Li Yukun

Outline
Overview SIGMOD2009 Overview two selected papers
Optimizing Complex Extraction Programs over Evolving Text Data Exploiting Context Analysis for Combining Multiple Entity Resolution
Systems

Section of SIGMOD2009 Research Session 1: Security I Research Session 2: Databases on Modern Hardware Research Session 3: Information Extraction Research Session 4: Security II Research Session 5: Large-Scale Data Analysis Research Session 6: Entity Resolution Research Session 7: Testing and Security Research Session 8: Column Stores Research Session 9: Data on the Web Research Session 10: Probabilistic Databases I Research Session 11: Database Optimization Research Session 12: Probabilistic Databases II Research Session 13: Skyline Query Processing Research Session 14: Understanding Data and Queries Research Session 15: Nearest Neighbor Search Research Session 16: Query Processing on Semi-structured Data Research Session 17: Data Integration Research Session 18: Keyword Search Research Session 19: Semi-structured Data Management Research Session 20: Data Management Pearls Research Session 21: Indexing

SIGMOD keynote talks
Enterprise Applications - OLTP and OLAP - Share One Database ArchitectureHasso Plattner (Hasso-Plattner-Institute for IT Systems Engineering)
Transforming Data Access Through Public VisualizationFernanda B. Viegas (IBM)Martin Wattenberg (IBM)
Web-based visualizations—ranging from political art projects to news stories—have reached audiences of millions. Meanwhile, new initiatives in government, aimed at all citizens, point to an era of increased transparency. a "living laboratory" web site where people may upload their own data, create interactive visualizations, and carry on conversations. Political discussions, citizen activism, religious discussions, game playing, and educational exchanges all happen on the site. To further support these scenarios, and the users they represent, will require continued innovation in data presentation and interaction.

SIGMOD INVITED SESSIONS
Special Invited Session on Human-Computer Interaction with InformationDesign for InteractionDaniel Tunkelang (Endeca)Voyagers and Voyeurs: Supporting Social Data AnalysisJeffrey Heer (Stanford University)Augmented Social CognitionEd H. Chi (PARC)
Special Invited Session on Systems Research and Information ManagementStorage Class Memory: Technology, Systems and ApplicationsRichard F. Freitas (IBM)Distributed Data-Parallel Computing Using a High-Level Programming LanguageMichael Isard (Microsoft Research)Yuan Yu (Microsoft Research)

SIGMOD TUTORIALS
Large-Scale Uncertainty Management Systems: Learning and Exploiting Your Data
FPGA: What's in it for a Database? Keyword Search on Structured and Semi-Structured Data Database Research in Computer Games Anonymized Data: Generation, Models, Usage

Summary
Hot words Probabilistic,Semi-structure, Security, Searc
h&Query, Extraction&resolution User Interaction

DataSpace Framework
Domain
Extraction
QueryBrowsing
Evolution
Entity Association
DB
Integration
用户日志
Kd search
关联数据库
resolution
Association DB
Email Memo Users Documents Web pages
Blogs

Managing Entity and association Entity Identify and Resolution Data extraction and cleaning
Pay-as-you-go integration Uncertain data mapping Update of entity and association
Query&Search in dataspace Keyword search Approximate query Facet-based search in dataspace
Future work on DataSpace

Selected readings Data integration
Top-K Generation of Integrated Schemas Based on Directed and Weighted Correspondences Core Schema Mappings
Entity Resolution Exploiting Context Analysis for Combining Multiple Entity Resolution Systems Entity Resolution with Iterative Blocking A Grammar-based Entity Representation Framework for Data Cleaning
Data on the Web Optimizing Complex Extraction Programs over Evolving Text Data Robust Web Extraction: An Approach Based on a Probabilistic Tree-Edit Model Combining Keyword Search and Forms for Ad Hoc Querying of Databases
Indexing A Revised R*-tree in Comparison with Related Index Structures
Understanding Data and Queries Why Not? Query by Output Detecting and Resolving Unsound Workflow Views for Correct Provenance Analysis
Query processing on Semi-structured data Scalable Join Processing on Very Large RDF Graphs

Outline
Overview SIGMOD2009 Two selected papers
Optimizing Complex Extraction Programs over Evolving Text Data
Exploiting Context Analysis for Combining Multiple Entity Resolution Systems

Paper 1

Introduction
Motivation Traditional IE method: Static Practical conditions: Dynamic corpus
DBlife(10000+URLs,120+MB corpus snapshot.) Enterprise Intranet
Problem How to efficiently extract information based on
Dynamic corpora

Problem Definition
Concepts Data pages, Extractors, Mentions
An extractor E:p→R(a1,a2,…,an) extracts mentions of relation R from page p. A mention of R is a tuple(m1,m2,…,mn,)such that mi is either a mention of attribute ai or nil.
Examples
Assumptions Extract mentions from each single data pages

Methods Concepts
Extractor scope Let s.start and s.end be the start and end character positions of a string s in a
page p. We say an extractor E has scope α iff for any mention m = (m1, . . . ,mn) produced by E, (maxi mi.end − mini mi.start) < α, where mi.start and mi.end are the start and end character positions of attribute mention mi in page p.
Extractor Context The β-context of mention m in page p is the string p[(m.start−β)..(m.e
nd+ β)], i.e., the string of m being extended on both sides by β characters. We say extractor E has context β iff for any m and p′ obtained by perturbing the text of p outside the β- context of m, applying E to p′ still produces m as a mention.
Clallenges Matchers (Find overlaping)

Solutions CAPTURING IE RESULTS
Level of Reuse: IE Results to Capture: Storing Captured IE Results:
REUSING CAPTURED IE RESULTS Scope of Mention Reuse Overall Processing Algorithm Identifying Reuse with Matchers
SELECTING A GOOD IE PLAN Searching for Good Plans Cost Model

Evaluation(DataSet)
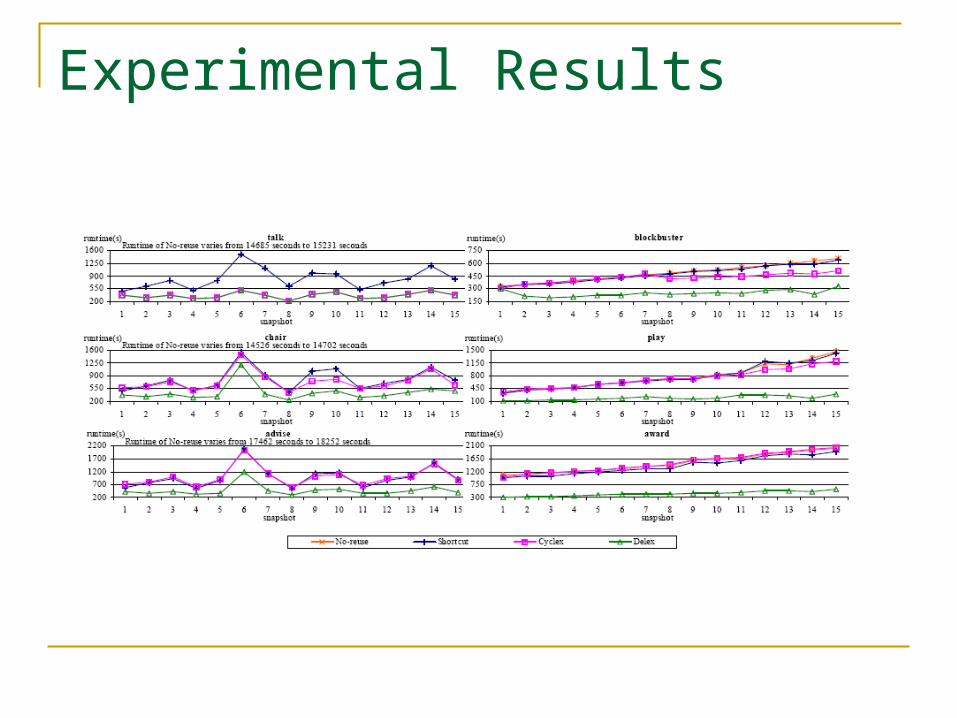
Experimental Results

Paper 2

Introduction
What is entity resolution to identify and group references that co-refer, that
is, refer to the same entity. Motivation
New data characters: Examples
The output a clustering of references, where each cluster is
supposed to represent one distinct entity.
Jone SmithJ. Smith
John.SmithJ.Smith

Problem definition
Entity Resolution ER problem has been studied in several research areas under ma
ny names such as coreference resolution, deduplication, object uncertainty,record linkage, reference reconciliation, etc. In the past, a wide variety of techniques have been developed for ER problem.
Methods Similarity (metrics, textual, attributes, and etc.) Blocking Voting
Problem Pay little attention to context feature

Problem Definition
To identify co-offer relationship between two mentions

Context-based framework
Context features Effectiveness Generality Number of clusters
Overview of the approaches Meta-level Classification
Context-extended classification Context-weighted Classification
Creating final clusters

Experiments
Web domain Data set by WWW05[Bekkerman, and etc.]
Contain web pages of 12 different persons Created by searching web using Google
RealPub domain 11682 publications 14590 authors 3084 departments 1494 organizations

Experimental results on Web domain

Summary
How to manage uncertainty data, and unstructured data are becoming a hot topic
It is also important problem of DataSpace Based on it, to select promising topics.

Thanks
Related Documents











