SIGIR 2013 Recap September 25, 2013

SIGIR 2013 Recap
Feb 22, 2016
SIGIR 2013 Recap. September 25, 2013. Today’s Paper Summaries. Yu Liu Personalized Ranking Model Adaptation for Web Search Nadia V ase Toward Self-Correcting Search Engines: Using Underperforming Queries to Improve Search Riddick Jiang - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

SIGIR 2013 Recap
September 25, 2013

SIGIR 2013 Recap 2
Today’s Paper Summaries
• Yu Liu– Personalized Ranking Model Adaptation for Web
Search• Nadia Vase– Toward Self-Correcting Search Engines: Using
Underperforming Queries to Improve Search• Riddick Jiang– Fighting Search Engine Amnesia: Reranking
Repeated Results

SIGIR 2013 Recap 3
SIGIR 2013 Reference Material
• Jul 28 – Aug 1, 2013. Dublin, Ireland• Proceedings (ACM Digital library):
http://dl.acm.org/citation.cfm?id=2484028– Available free via the eBay intranet
• Best paper nominations: http://www.bibsonomy.org/user/nattiya/sigir2013
• Papers we liked: SIGIR 2013 Recap Wiki• SIGIR 2014: July 6-11, Queensland, Australia

SIGIR 2013 Recap 4
PERSONALIZED RANKING MODEL ADAPTATION FOR WEB SEARCH
Hongning Wang (University of Illinois at Urbana-Champaign)Xiaodong He (Microsoft Research)
Ming-Wei Chang (Microsoft Research)Yang Song (Microsoft Research)
Ryen W. White (Microsoft Research)Wei Chu (Microsoft Bing)
Paper Review by Yu Liu

Motivations• Searcher’s information needs are diverse • Need personalization for web search• Existing methods for personalization
– Extracting user-centric features [Teevan et al. SIGIR’05]
• Location, gender, click history• Require large volume of user history
– Memory-based personalization [White and Drucker WWW’07, Shen et al. SIGIR’05] • Learn direct association between query and URLs• Limited coverage, poor generalization
• Major considerations– Accuracy
• Maximize the search utility for each single user– Efficiency
• Executable on the scale of all the search engine users• Adapt to the user’s result preferences quickly
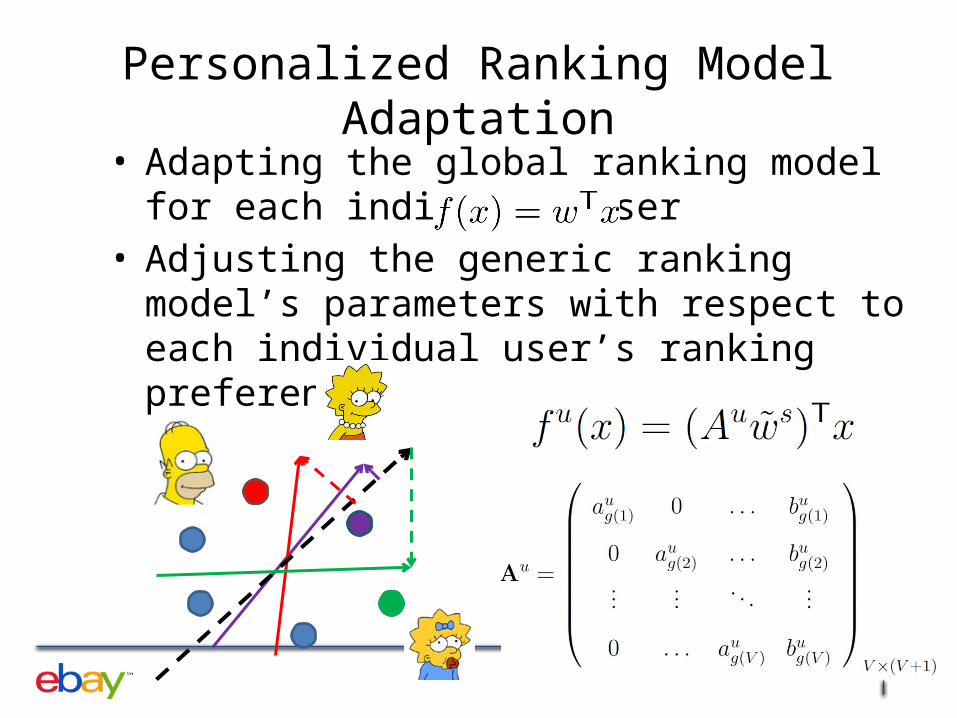
Personalized Ranking Model Adaptation• Adapting the global ranking model for each
individual user• Adjusting the generic ranking model’s parameters
with respect to each individual user’s ranking preferences

SIGIR 2013 @ Dublin Ireland 7
Linear Regression Based Model Adaptation
• Adapting global ranking model for each individual user
Lose function from any linear learning-to-rank algorithm, e.g., RankNet, LambdaRank, RankSVM
Complexity of adaptation

Ranking feature grouping • Organize the ranking features so that shared transformation is
performed on the parameters of features in the same group • Maps V original ranking features to K different groups
– Grouping features by name - Name• Exploring informative naming scheme
– BM25_Body, BM25_Title• Clustering by manually crafted patterns
– Co-clustering of documents and features – SVD [Dhillon KDD’01]
• SVD on document-feature matrix• k-Means clustering to group features
– Clustering features by importance - Cross• Estimate linear ranking model on different splits of data• k-Means clustering by feature weights in different splits

Discussion• A general framework for ranking model
adaptation– Applicable to a majority of existing learning-to-
rank algorithms – Model-based adaptation, no need to operate on
the numerous data from the source domain – Within the same optimization complexity as the
original ranking model– Adaptation sharing across features to reduce the
requirement of adaptation data

SIGIR 2013 @ Dublin Ireland 10
Experimental Setup• Dataset– Bing.com query log: May 27, 2012 – May 31, 2012– Manual relevance annotation• 5-grade relevance score
– 1830 ranking features• BM25, PageRank, tf*idf and etc.

SIGIR 2013 @ Dublin Ireland 11
Improvement analysis
• User-level improvement– Against global model

SIGIR 2013 @ Dublin Ireland 12
Conclusions
• Efficient ranking model adaption framework for personalized search– Linear transformation for model-based adaptation– Transformation sharing within a group-wise manner
• Future work– Joint estimation of feature grouping and model
transformation– Incorporate user-specific features and profiles– Extend to non-linear models

SIGIR 2013 Recap 13
TOWARD SELF-CORRECTING SEARCH ENGINES:USING UNDERPERFORMING QUERIES TO
IMPROVE SEARCH
Ahmed Hassan (Microsoft)Ryen W. White (Microsoft Research)Yi-Min Wang (Microsoft Research)
Paper Review by Nadia Vase

SIGIR 2013 Recap 14
Overview
• What to do with a dissatisfying query?– Why is it bad? New features to fix it?– If the same problem recurs, can find a pattern
• Identify dissatisfying (DSAT) queries• Cluster them• Train specialized rankers+general ranker

SIGIR 2013 Recap 15
Identifying dissatisfying queries
• Use toolbar data• Based on search engine switching events– 60% of switching events: DSAT search
• Trained classifier to predict switch cause– Logistic regression, 562 labeled, 107 users– Binary classifier

SIGIR 2013 Recap 16
Features for dissatisfying switches

SIGIR 2013 Recap 17
Clustering DSAT Queries
• What to do with DSAT queries• DSAT instance has 140 binary features– Query: length, language, “phrase (NP, VP) type”, ODP
category– SERP: direct answer/feature, query suggestion shown,
spell correction, etc– Search instance: market (US, UK, etc), query vertical
(Web, News, etc), search engine, temporal attributes• Use Weka’s implementation of FP-Growth to cluster

SIGIR 2013 Recap 18
Clustering: FP-Growth• filter and order features &create the FP-tree• bottom-up algorithm to find attribute clusters

SIGIR 2013 Recap 19
Example of attribute sets

SIGIR 2013 Recap 20
Building Modified Rankers• 2nd round ranker per each DSAT group– Trained DSAT data, general ranker’s output score

SIGIR 2013 Recap 21
Experiment results

SIGIR 2013 Recap 22
FIGHTING SEARCH ENGINE AMNESIA: RERANKING REPEATED RESULTS
Milad Shokouhi (Microsoft)Ryen W. White (Microsoft Research)Paul Bennett (Microsoft Research)
Filip Radlinski (Microsoft)
Paper Review by Riddick Jiang

SIGIR 2013 Recap 23
Repetition
• 40%-60% sessions have two queries or more • 16- 44% of sessions (depending on the search
engine) with two queries have at least one repeated result
• Repetition increases to almost all sessions with ten or more queries

SIGIR 2013 Recap 24
Intuition
• Promote new results (previously missed or new)• Demote previously skipped results• Demote previously clicked results– Promote previously clicked results if clicked >= 2 (personal
nav)

SIGIR 2013 Recap 25

SIGIR 2013 Recap 26
CTR for skipped results

SIGIR 2013 Recap 27
CTR for clicked results

SIGIR 2013 Recap 28
Ranking features

SIGIR 2013 Recap 29
Evaluation
Personal Nav: Score, Position, and a Personal Navigation feature - counts the number of times a particular result has been clicked for the same query previously in the session ClickHistory: Score, Position, and Click-history - click counts for each result on a per query basis

SIGIR 2013 Recap 30
A/B testing• Interleave results from R-cube and control• randomly allocating each result position to R-cube or the
baseline • Credit click to the corresponding ranker• Five days in June, 2012• 370,000 queries• R-cube ranker was preferred for 53.8% of queries • statistically significant
Related Documents











