THE UNIVERSITY OF TEXAS AT DALLAS Erik Jonsson School of Engineering and Computer Science c C. D. Cantrell (05/1999) PARALLEL PROCESSING • Numerical problems and algorithms • Impact of Amdahl’s law • Parallel computer architectures . Memory architectures . Interconnection networks • Flynn’s taxonomy (SIMD, MIMD, etc.) • Shared-memory multiprocessors • Distributed-memory, message-passing multicomputers

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

THE UNIVERSITY OF TEXAS AT DALLAS Erik Jonsson School of Engineeringand Computer Science
c© C. D. Cantrell (05/1999)
PARALLEL PROCESSING
• Numerical problems and algorithms
• Impact of Amdahl’s law
• Parallel computer architectures
. Memory architectures
. Interconnection networks
• Flynn’s taxonomy (SIMD, MIMD, etc.)
• Shared-memory multiprocessors
• Distributed-memory, message-passing multicomputers

THE UNIVERSITY OF TEXAS AT DALLAS Erik Jonsson School of Engineeringand Computer Science
c© C. D. Cantrell (05/1999)
COMPUTATIONAL PROBLEMS
• Numerical simulation has become as important as experimentation
. Permits exploration of a much larger region in parameter space
. All-numerical designs
• The most CPU-intensive application areas include:
. Computational fluid dynamics
. Computational electromagnetics
. Molecular modeling
• Typical problem sizes (in double-precision floating-point operations)and execution times (in CPU-days @ 109 FLOPS):
Problem size Execution time (CPU-days)1014 1.161015 11.571016 115.71017 1157

THE UNIVERSITY OF TEXAS AT DALLAS Erik Jonsson School of Engineeringand Computer Science
c© C. D. Cantrell (05/1999)
NUMERICAL ALGORITHMS
•Most of the important CPU-intensive applications involve the solutionof a system of coupled partial differential equations
• Initial-value problems
. Time-dependent wave propagation (electromagnetics, geophysics,optical networking)
. Time-dependent dynamics (fluid flow, mechanical engineering)
• Boundary-value problems
. Typically require solution of very large systems of linear equations
. Quasi-static electromagnetic problems
. Static mechanical engineering (finite element analysis)
. Eigenvalue problems (molecular energy surfaces)

THE UNIVERSITY OF TEXAS AT DALLAS Erik Jonsson School of Engineeringand Computer Science
c© C. D. Cantrell (05/1999)
PROPAGATION EQUATIONS FOR 4-WAVE MIXING
• Paraxial wave equation: ∂∂z′
+iβ2
2∂2
∂t′2− β3
6∂3
∂t′3
Fn
= −α2Fn+i
16π2ωnχ(3)
n20,nc
2AeµnklmD|k|,|l|,|m|
× FkF lFmei(∆βnklm)z′
• Two regimes to study:
. Three strong waves (Fk, Fl, Fm) generate nine weak waves (Fn)◦ Useful for estimating crosstalk among channels
. Parametric coupling of three strong waves◦ Leads to coherent amplification of some channels and de-amplification
of others

THE UNIVERSITY OF TEXAS AT DALLAS Erik Jonsson School of Engineeringand Computer Science
c© D. M. Hollenbeck and C. D. Cantrell (05/1999)
PULSE PROPAGATION IN AN OPTICAL FIBER (1)
0
20
40
Propagation distance (km)
–0.3
–0.1
0.1
0.3
Frequency
0
1
2
Power (mW)

THE UNIVERSITY OF TEXAS AT DALLAS Erik Jonsson School of Engineeringand Computer Science
c© D. M. Hollenbeck and C. D. Cantrell (05/1999)
PULSE PROPAGATION IN AN OPTICAL FIBER (2)
-3.4
-1.7
0.0
1.7
3.4
Time (ps) 0.0
5.0
10.0
15.0
20.0
20.0
40.0
60.0
Power (mW)
Propagation distance (km)
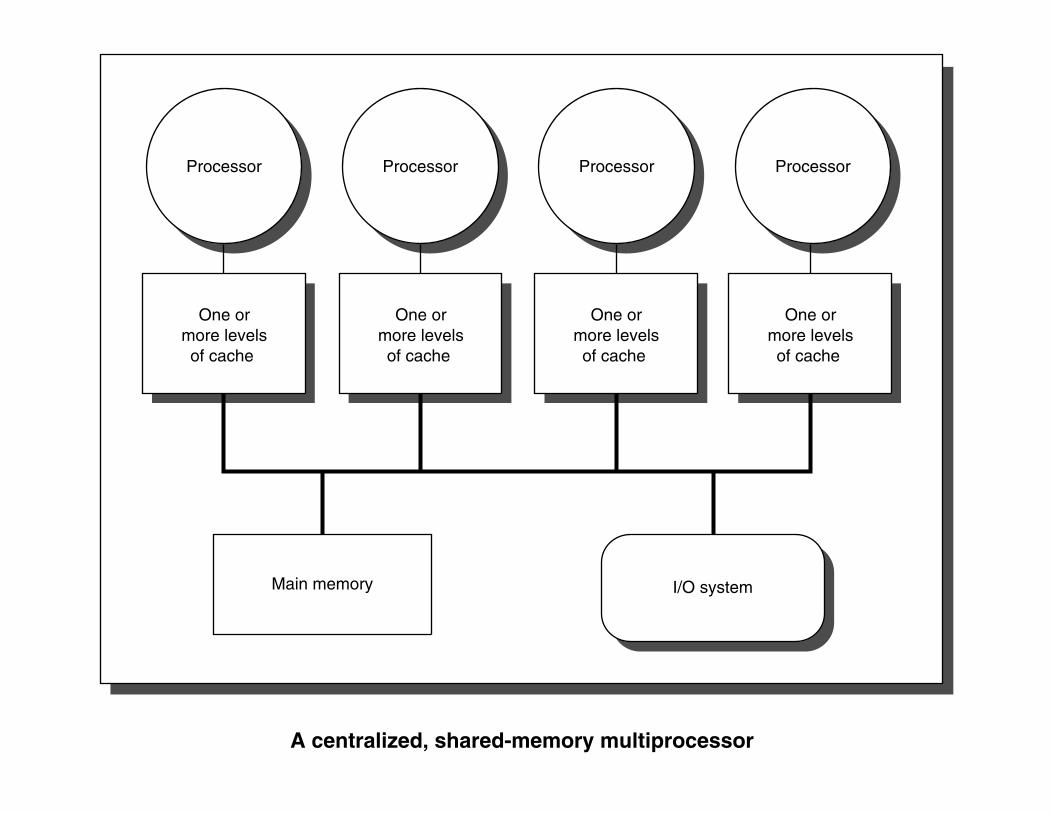
Processor
One ormore levelsof cache
ProcessorProcessor Processor
Main memory I/O system
One ormore levelsof cache
One ormore levelsof cache
One ormore levelsof cache
A centralized, shared-memory multiprocessor

Machine 1 Machine 2
Languagerun-timesystem
Operatingsystem
Shared memory
Application
Hardware
Languagerun-timesystem
Operatingsystem
Application
Hardware
Machine 1 Machine 2
Languagerun-timesystem
Operatingsystem
Shared memory
Application
Hardware
Languagerun-timesystem
Operatingsystem
Application
Hardware
Machine 1 Machine 2
Languagerun-timesystem
Operatingsystem
Shared memory
Application
Hardware
Languagerun-timesystem
Operatingsystem
Application
Hardware
Layers where shared memory can be implemented

Memory I/O
Interconnection network
Memory I/O Memory I/O
Processor+ cache
Processor+ cache
Processor+ cache
Processor+ cache
Memory I/O
Memory I/O Memory I/O Memory I/O Memory I/O
Processor+ cache
Processor+ cache
Processor+ cache
Processor+ cache
A distributed-memory multicomputer

star full interconnection
Interconnection topologies
tree ring
grid double torus
cube 4-D hypercube

C D
CPU 1
Endof
packet
Middleof
packet
A
Input port
Output port
Front of packet
Four-port switch
B
CPU 2
Interconnection network consisting of a 4-switch square grid

Deadlock in a circuit-switched interconnection network
CPU 1
CPU 2
CPU 3
A
C
B
D
Input port
Output buffer
Four-port switch
CPU 4

Two-Hypernode Convex Exemplar System
FunctionalBlocks
InterfaceI/O
InterfaceI/O
hypernode 0
hypernode 1
CTI Ring

MachineCommunication
mechanismInterconnection
networkProcessor
countTypical remote
memory access time
SPARCCenter Shared memory Bus ≤ 20 1 µs
SGI Challenge Shared memory Bus ≤ 36 1 µs
Cray T3D Shared memory 3D torus 32–2048 1 µs
Convex Exemplar Shared memory Crossbar + ring 8–64 2 µs
KSR-1 Shared memory Hierarchical ring 32–256 2–6 µs
CM-5 Message passing Fat tree 32–1024 10 µs
Intel Paragon Message passing 2D mesh 32–2048 10–30 µs
IBM SP-2 Message passing Multistage switch 2–512 30–100 µs
Typical access times to retrieve a word from a remote memory

ApplicationScaling of
computation Scaling of
communicationScaling of computation-
to-communication
FFT
LU
BarnesApproximately Approximately
Ocean
Scaling of computation, of communication, and of the ratio are critical factors indetermining performance on parallel machines
n nlogp
-------------- np--- nlog
np--- n
p------- n
p-------
n nlogp
-------------- n nlog( )p
------------------------- n
p-------
np--- n
p------- n
p-------

CPU
Bus
Scalable vs. non-scalable systems

n CPUs active
1 CPUactive
1 – ff
T
Inherentlysequential
part
1 – ff
Potentiallyparallelizable
part
…
fT(1 – f)T/n
AmdahlÕs law for parallel processing

log2n(n = number
of processors)
02
46
810 0
0.2
0.4
0.6
0.8
10.5
1.0
f = parallelizable fraction
efficiency
AMDAHL’S LAW FOR PARALLEL COMPUTING

THE UNIVERSITY OF TEXAS AT DALLAS Erik Jonsson School of Engineeringand Computer Science
c© C. D. Cantrell (05/1999)
THREADS
• Threads are the software equivalent of hardware functional units
• Properties of threads:
. Exist in user process space or kernel space◦ User threads are faster to launch than processes
. Mappings required for execution:user thread → lightweight process → kernel thread → CPU
• Reference: Bil Lewis and Daniel J. Berg, Threads Primer(SunSoft/Prentice Hall, 1996)
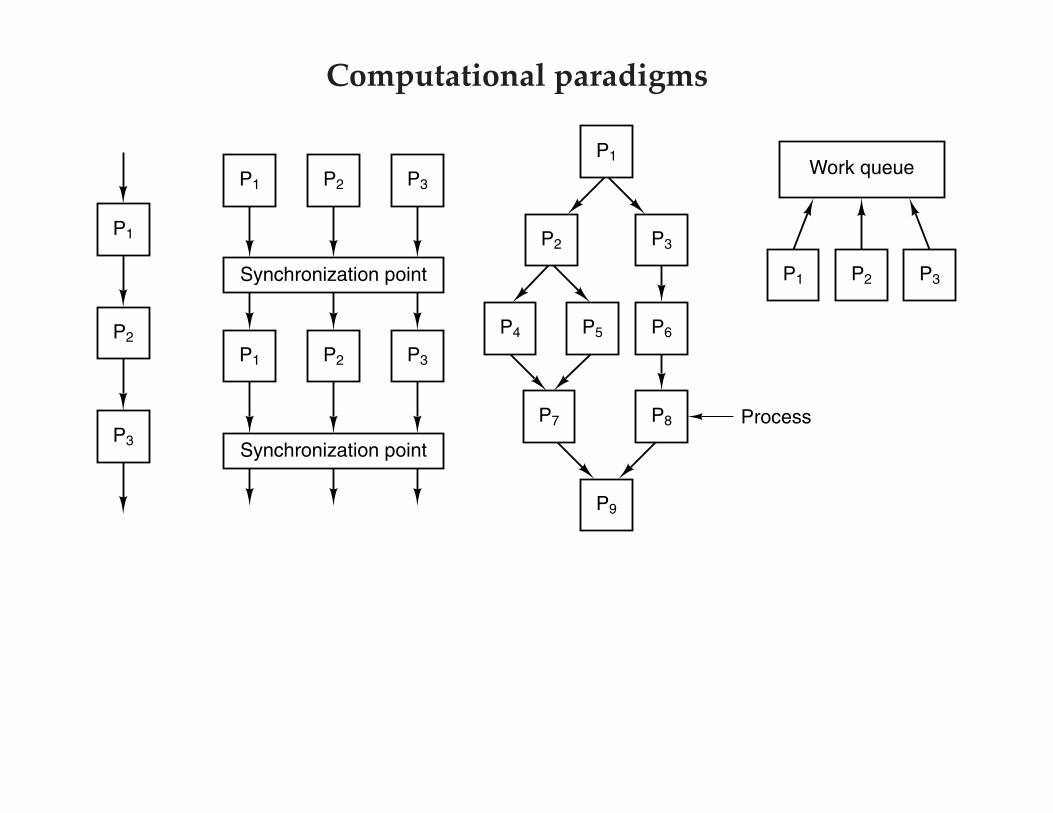
Process
P1
P2
P5 P6
P3
P2P1 P3
P8P7
P1
P9
P1
P2
P3
P2 P3
Synchronization point
P1 P2 P3
Synchronization point
P4
Work queue
Computational paradigms

Cache tagand data
Processor
Single bus
Memory I/O
Snooptag
Cache tagand data
Processor
Snooptag
Cache tagand data
Processor
Snooptag

Invalid(not valid
cache block)
Read/Write(dirty)
Read Only(clean)
)tihfietadilavnidneS(
(Write
back
dirty
block
tomem
ory)
Processor read miss
Processor write
Processor write miss
Processorread miss
Processor write(hit or miss)
Cache state transitions using signals from the processor
Invalid(not valid
cache block)
Read/Write(dirty)
Read Only(clean)Invalidate or
another processorhas a write miss
for this block(seen on bus)
Another processor has a readmiss or a write miss forthis block (seen on bus);
write back old block
a.
Cache state transitions using signals from the busb.

(a)
(b)
(c)
(d)
(e)
(f)
Exclusive
Cache Bus
Bus
Bus
Bus
Bus
Bus
Shared Shared
Shared Shared
Modified
Modified
Modified
CPU 1 reads block A
CPU 2 reads block A
CPU 2 writes block A
CPU 3 reads block A
CPU 2 writes block A
CPU 1 writes block A
CPU 1 CPU 2 CPU 3Memory
CPU 1 CPU 2 CPU 3Memory
CPU 1 CPU 2 CPU 3Memory
CPU 1 CPU 2 CPU 3Memory
CPU 1 CPU 2 CPU 3Memory
CPU 1 CPU 2 CPU 3Memory
A
A
A
A
A
A
A
The MESI cache coherence protocol

Succeed?(= 0?)
Unlocked?(= 0?)
Load lockvariable
No
Yes
No
Try to lock variable using swap:read lock variable and then set
variable to locked value (1)
Begin updateof shared data
Finish updateof shared data
Unlock:set lock variable to 0
Yes

Instructionstreams
Datastreams Name Examples
1 1 SISD Classical Von Neumann machine
1 Multiple SIMD Vector supercomputer, array processor
Multiple 1 MISD Arguably none
Multiple Multiple MIMD Multiprocessor, multicomputer
FlynnÕs taxonomy of parallel computers

SISD
(Von Neumann)
SIMD
Parallel computer architectures
MISD
?
MIMD
Vectorprocessor
Arrayprocessor
Multi-processors
Multi-computers
UMA COMA NUMA MPP COW
Bus Switched CC-NUMA NC-NUMA GridHyper-cube
Shared memory Message passing
A taxonomy of parallel computers
Related Documents











