SGeMS User’s Guide Nicolas Remy, Alexandre Boucher & Jianbing Wu April 13, 2006

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

SGeMS User’s Guide
Nicolas Remy, Alexandre Boucher & Jianbing Wu
April 13, 2006

Chapter 1
General Overview
Section?? indicated how GsTL can be integrated into an already existing software. SGeMS,
the Geostatistical Earth Modeling Software, is an example of software built from scratch
using the GsTL. The source code of SGeMS serves as an example of how to use GsTL
facilities.
SGeMS was designed with two aims in mind. The first one, geared toward the end-
user, is to provide a user-friendly software which offers a large range of geostatistics
tools: the most common geostatistics algorithms are implemented, in addition to more
recent developments such as multiple-point statistics simulation. The user-friendliness
of SGeMS comes mainly from its non-obtrusive graphical user interface, and the pos-
sibility to directly visualize data sets and results in a full 3-D interactive environment.
The second objective was to design a software whose functionalities could conveniently
be augmented. New features can be added into SGeMS through a system of plug-ins,
i.e. pieces of software which can not be run by themselves but complement a main soft-
ware. In SGeMS, plug-ins can be used to add new (geostatistics) tools, add new grid data
structures (faulted stratigraphic grids for example) or define new import/export filters.
1.1 First Steps with SGeMS
1.1.1 A quick tour to the graphical user interface
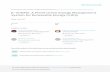
The graphical user interface (GUI) of SGeMS is divided into 3 main parts, see Fig. 1.1:
The Algorithm Panel The user selects in this panel which geostatistics tool to use and
1

Figure 1.1: SGeMS’s graphical interface. The three main panels are highlighted in red.
The top-right panel is the Algorithm Panel, the top-left is the Visualization Panel and the
bottom is the Command Panel
inputs the required parameters (see Fig. 1.2). The top part of that panel shows a
list of available algorithms, e.g. kriging, sequential Gaussian simulation. When
an algorithm from that list is selected, a form containing the corresponding input
parameters appears below the tools list.
The Visualization Panel One or multiple objects can be displayed in this panel, e.g. a
Cartesian grid and a set of points, in an interactive 3-D environment. Visualization
options such as color-maps are also set in the Visualization Panel. The Visualization
Panel is shown in more details in Fig. 1.3.
The Command Panel This panel is not shown by default when SGeMS is started. It
gives the possibility to control the software from a command line rather that from
2

Figure 1.2: The 3 parts of the Algorithm Panel highlighted in red. The top part displays
the list of available tools. The middle part is where the input parameters for the selected
tool are entered.
the GUI. It displays a history of all commands executed so far and provides an input
field where new commands can be typed (see Fig. 1.4). See tutorial 1.1.2 for more
details about the Command Panel.
1.1.2 A simple tutorial
This short tutorial describes a SGeMS session in which ordinary kriging is performed on
a 100 ∗ 130 ∗ 30 Cartesian grid. The data consist of a set of 400 points in 3-D space,
with a rock porosity value associated to each data point. This point-set object is called
porosity data .
The steps involved are the following:
1. Load the data set
3

Figure 1.3: The Visualization Panel. The left-hand side (highlighted in red) controls
which objects (e.g. grids) are visible. It is also used to set display options, such as which
color-map to use.
Figure 1.4: The Command Panel
2. Create a Cartesian grid
3. Select the kriging tool and enter the necessary parameters
4. Display and save the result
4

Loading the data set
The first step is to load the data set into the objects database of SGeMS. Click
Objects | Load Object and select the file containing the data. Refer to section 1.2.1 for a
description of the available data file formats. When the object is loaded a new entry called
porosity data appears in theObjects section of the Visualization Panel, as shown
in Fig. 1.5.
Figure 1.5: Object list after the data set is loaded
Click in the square before the point-set name to display it. Displayed objects have a
little eye painted inside the rectangle before their name. The plus sign before the square
indicates that the object contains properties. Click on the plus sign to display the list
of properties. Click in the square before the property name to paint the object with the
corresponding property (see Fig. 1.6).
Figure 1.6: Showing/hiding an object or a property
5

Creating a grid
The next step is to create the grid on which kriging will be performed. The grid we will
create is a 3-D Cartesian grid with100 ∗ 130 ∗ 30 cells.
Click Objects | New Cartesian Grid to open the grid creation dialog. Enter the di-
mensions of the grid, the coordinates of the origin of the grid, i.e. the lower left corner
(i.e. the grid node with smallestx, y, z coordinates), and the dimensions of each grid cell.
Provide a name for the new grid,working_grid for example. ClickCreate Grid to
create the grid. A new entry calledworking_grid appears in theObjectspanel of the
Visualization Panel, as shown in Fig. 1.7.
Figure 1.7: Object list after the Cartesian grid is created
The object data-base now contains two objects: a point-set with the rock porosity
property, and a Cartesian grid with not yet any property attached. We can proceed to the
kriging run.
Running the kriging algorithm
Select the kriging tool from the list in the Algorithm Panel. A form prompting for the
kriging parameters appears below the algorithms list. You can either type in the para-
meters or load them from a file. Fig. 1.8 shows an example of parameter file for kriging
(refer to section 1.2.2 for a description of the parameter file format and to section 5.0.2
for details on kriging parameters). Using the parameters of Fig. 1.8, ordinary kriging is
performed with an isotropic search ellipsoid of radius50 (section?? describes how to
specify a 3-D ellipsoid in SGeMS) and an isotropic spherical variogram of range30, sill
1, and a nugget effect of0.1 (section??explains how to specify a variogram).
Once all parameters have been entered, click theRun Algorithm button. If some
parameters are not correctly set, they are highlighted in red and a description of the error
will appear if the mouse is left a few seconds on the offending parameter.
6

<parameters> <algorithm name="kriging" />
<Grid_Name value="working_grid" />
<Property_Name value="krig_porosity" />
<Hard_Data grid="porosity data" property="porosity" />
<Kriging_Type type="Ordinary Kriging (OK)" >
<parameters />
</Kriging_Type>
<Max_Conditioning_Data value="12" />
<Search_Ellipsoid value="50 50 50
0 0 0 " />
<Variogram nugget="0.1" structures_count="1" >
<structure_1 contribution="0.9" type="Spherical" >
<ranges max="30" medium="30" min="30" />
<angles x="0" y="0" z="0" />
</structure_1>
</Variogram>
</parameters>
Figure 1.8:Kriging parameter file
If kriging was run with the parameters shown on Fig. 1.8, the grid named
working_grid now contains a new property calledkrig_porosity .
Displaying and saving the result
The algorithmKriging created a new propertykrig_porosity in the grid
working_grid . Click on the plus sign before theworking_grid entry in the objects
list to show the list of properties attached to the grid, and click in the square before the
newly created property to display it. To save the results, clickObject | Save Objectto
open the Save Object dialog. Provide a file name, the name of the object to save, e.g.
working_grid and the file format to use (see section 1.2.1).
It is also possible to save all the objects at once by saving the project (File | Save Project).
7

1.1.3 Automating tasks in SGeMS
Tutorial 1.1.2 showed how to perform a single run of the kriging algorithm. Next, one
would like to study the sensitivity of the algorithm to parameterMax Conditioning Data ,
the maximum number of conditioning data retained for each kriging. The user would like
to vary that number from1 to 50 in increments of1. It would be very impractical to
perform such a study in successive sequences as explained in Tutorial 1.1.2.
SGeMS provides a solution to this problem through its command line interface. Many
actions in SGeMS can either be performed with mouse clicks or by typing a command in
the Command Panel. For example, loading the data set in step 1 of Tutorial 1.1.2 could
have been achieved by typing the following command:
LoadObjectFromFile /home/user/data_file.dat:All
Each command has the following format:
• the name of the command, e.g.LoadObjectFromFile
• a list of parameters, separated by a colon “:”. In the previous example two parame-
ters were supplied: the name of the file to load, and the file formatAll (meaning
that every available file format should be considered).
Every command performed in SGeMS, either typed or resulting from mouse clicks,
is recorded to both the “Commands History” section of the Command Panel and to a file
calledgstlappli history.log . Hence if one does not know a command name, one
can use the GUI to perform the corresponding action and check the command name and
syntax in the command history.
It is possible to combine several commands into a single file and have SGeMS execute
them all sequentially. For the sensitivity study example, one would have to write a “script”
file containing 50 kriging commands, each time changing theMax Conditioning Data
parameter. Note that there are no control structures, e.g. “for” loops, in SGeMS script
files. However there are many programming tools available (Perl, Awk, Shell,. . . ) that
can be used to generate such script file.
8

1.2 File Formats
1.2.1 Objects Files
SGeMS supports two file formats by default to describe grids and sets of points: the
GSLIBformat and the SGeMS binary format.
The GSLIB file format
It is a simple ASCII format used by theGSLIBsoftware (ref ??). It is organized by lines:
• the first line gives the title.
• the second line is a single numbern indicating the number of properties in the
object.
• the n following lines contain the names of each property (one property name per
line)
• each remaining line contains the values of each property (n values per line) sepa-
rated by spaces or tabulations. The order of the property values along each line is
given by the order in which the property names were entered.
Note that the same format is used for describing both point sets and Cartesian grids.
When aGSLIBfile is loaded into SGeMS the user has to supply all the information that
are not provided in the file itself, e.g. the name of the object, the number of cells in each
direction if it is a Cartesian grid.
The SGeMS binary file format
SGeMS can use an uncompressed binary file format to store objects. Binary formats have
two main advantages over ASCII files: they occupy less disk space and they can be loaded
and saved faster. The drawback is a lack of portability between platforms. SGeMS binary
format is self-contained, hence the user need not provide any additional information when
loading such a file.
9

1.2.2 Parameter Files
When an algorithm is selected from the Algorithm Panel (see step 3 of Tutorial 1.1.2),
several parameters are called for. It is possible to save those parameters to a file, and later
retrieve them.
The format of a parameter file in SGeMS is based on the eXtended Markup Language
(XML), a standard formating language of the World Wild Web Consortium (www.w3.org).
Fig. 1.8 shows an example of such parameter file.
In a parameter file, each parameter is represented by an XML element. An element
consists of an opening and a closing tag, e.g.<tag> and</tag> , and one or several
attributes. Following is an example of an element calledalgorithm which contains a
single attribute “name”:
<algorithm name="kriging"> </algorithm>
Elements can themselves contain other elements:
<Variogram nugget="0.1" structures_count="1" >
<structure_1 contribution="0.9" type="Spherical" >
<ranges max="30" medium="30" min="30"> </ranges>
<angles x="0" y="0" z="0"> </angles>
</structure_1>
</Variogram>
Here the elementVariogram contains an elementstructure_1 , which itself
contains two elements:ranges andangles . Each of these elements have attributes.
Note that if an element only contains attributes the closing tag can be abbreviated: in the
previous example, elementranges only contains attributes and could have been written:
<ranges max="30" medium="30" min="30" />
The/> sequence indicates the end of the element
A SGeMS parameter file always has the two following elements:
• elementparameters . It is the root element: it contains all other elements
• elementalgorithm . It has a single attributename which gives the name of the
algorithm for which parameters are specified.
10

All other elements are algorithm-dependent and are described in sections 5 and??.
Such XML formated parameter file has several advantages:
• Elements can be entered in any order
• comments can be inserted anywhere in the file. A comment block starts with<!--
and end with--> . They can span multiple lines. For example:
<!-- An example of a comment block spanning
multiple lines -->
<parameters> <algorithm name="kriging" />
<!-- the name of the working grid -->
<Grid_Name value="working_grid" />
</parameters>
11

Chapter 2
Data Sets & SGeMS EDA Tools
This chapter presents the data sets which will be used to demonstrate the geostatistics
algorithms in the following chapters. It also provides an introduction to the exploratory
data analysis (EDA) tools of the SGeMS software.
Section 2.1 presents the two data sets: one in 2D and one in 3D. The smaller 2D data
set will be used for most of the examples of running geostatistics algorithms. The 3D
data set, which mimics a large deltaic channel reservoir, will be used to demonstrate the
practice of these algorithms on the real and large 3D applications.
Section 2.2 introduces some basic EDA tools, such as histogram, Q-Q (quantile to
quantile) plot, P-P (probability to probability) plot and scatter plot. These EDA tools are
very useful to check/compare both visually and statistically any given data sets.
2.1 The Data Sets
The application example given for each algorithm should be short yet informative, allow-
ing the user to check his understanding of the algorithm and its input-output parameters.
The results of any application based on a specific data set, shouldNOT be extended into
a the general conclusion. Although the SGeMS software was initially designed for reser-
voir modeling, the application examples should stress the generality of the algorithms and
their software implementation.
2.1.1 The 2D data
To be done ...
12

2.1.2 The 3D data
The 3D data set retained in this book is extracted from a layer of Stanford VI, a synthetic
fluvial channel reservoir (Castro et al., 2005). The corresponding SGeMS project is lo-
cated at ‘dataset/stanford6.prj’. This project contains three SGeMS objects:well, grid
andcontainer.
• Thewell object contains the well data set. There are a total of 26 wells (21 verti-
cal wells, 4 deviated wells and 1 horizontal well). The properties associated with
the wells aredensity, binary facies(sand channel or mud floodplain),P-wave im-
pedance, P-wave velocity, permeabilityandporosity. These data can be used as
hard or soft conditioning data for the geostatistics algorithms. Fig. 2.1 shows the
well locations and the porosity distribution along the wells.
• Thegrid object is a cartesian reservoir grid (see its rectangular boundary on Fig. 2.1),
with,
- grid size:150× 200× 80,
- origin point at (0,0,0),
- unit cell size in each x/y/z direction.
This reservoir grid holds the petrophysical properties, currently it contains:
1. Seismic data. The original Stanford VI contains a cube of P-wave seismic
impedance, which is the product of density and P-wave velocity. However for
most geostatistics algorithms such seismic data cannot be used directly as is,
it must be calibrated into, e.g., facies probability distributions. Here, two sand
probability cubes (propertiesP(sand|seis)andP(sand|seis)2) are provided:
one displaying sharp channel boundaries (best quality data, see Fig. 2.2a); and
a second displaying more fuzzy channel boundaries with noise (poor quality
data, see Fig. 2.2b). These probability data will be used as soft data to con-
strain the facies modeling.
2. Region code. Typically a large reservoir would be divided into different re-
gions with each individual region having its own characteristics, for instance,
different channel orientations, channel thickness. The regions associated with
the Stanford VI reservoir are rotation regions (propertyangle) correspond-
ing to different channel orientations (Fig. 2.3), and affinity regions (property
affinity) corresponding to different channel thickness (Fig. 2.4). Each rotation
13

Angle category 0 1 2 3 4 5 6 7 8 9
Angle value (degree) -63 -49 -35 -21 -7 7 21 35 49 63
Table 2.1: Rotation region indicaotrs
Affinity category 0 1 2
Affinity value ([x,y,z]) [0.5, 0.5, 0.5] [ 1, 1, 1 ] [ 2, 2, 2 ]
Table 2.2: Affinity region indicaotrs
region is labeled with an indicator number, and assigned an angle value, see
Table 2.1. The affinity indicators and the attached affinity values are given
in Table 2.2. An affinity value must be assigned for each x/y/z direction; the
smaller the affinity value, the thicker the channel in that direction.
Thisgrid object is used to demonstrate the application examples.
• Thecontainerobject is composed of all the reservoir nodes which are located inside
the channels, hence it is a point set with (x,y,z) coordinates. The user can perform
geostatistics on this channel container, for example, to obtain the within channel
petrophysical properties. In Fig. 2.5 the channel container is represented by all
nodes with value 1.
Although this 3D data set is taken from a reservoir model, it could represent any 3D
spatially-distributed attribute and applications other than reservoir modeling. For exam-
ple, one can interpret each layer of the seismic data cube as satellite measurements defined
over the same area but recorded at different times. The application could then be modeling
landscape change in both space and time.
2.2 The SGeMS EDA Tools
SGeMS software provides some useful exploratory data analysis (EDA) tools, such as
histogram, quantile (Q-Q) plot, probability (P-P) plot, scatter plot, variogram and cross
variogram calculation and fit. In this chapter, the first four elementary tools are presented;
the two latter tools are presented in the next chapter.
14

Figure 2.1: Well locations and the porosity distribution along the wells.
(a) Good quality probability. (b) Poor quality probability.
Figure 2.2: Sand probability cube calibrated from seismic impedance.
Figure 2.3: Angle indicator cube. Figure 2.4: Affinity indicator cube.
15

Figure 2.5: Channel container (nodes with value 1).
All the EDA tools can be invoked through theData Analysis menu from the main
SGeMS graphical interface. Once a specific tool is selected, the corresponding SGeMS
window is popped up. The EDA tool window is independent of the main SGeMS inter-
face, and the user can have multiple windows for each EDA tool.
2.2.1 Common Parameters
The main interface for any of the EDA tools presented in this chapter has 3 main panels
(see Fig. 2.6, Fig. 2.7 and Fig. 2.8):
A. Parameter Panel The user selects in this panel the properties to be analyzed and
the display options. This panel has two pages: ‘Data’ and ‘Display Options’, the
latter being common to all EDA tools;
B. Visualization Panel This panel shows the graphic result of the selected statistics;
C. Statistics Panel This panel displays some relevant statistical summaries.
In the lower part of main interface, there are two buttons:Save as ImageandClose.
The Save as Imagebutton is used to save a graphical visualization (for example his-
togram) into a picture data file in either ‘png’ format or ‘bmp’ format. The user can also
write the statistical summaries and/or paint the grid into the data file by selecting the cor-
responding options in the figure saving dialog box. TheClosebutton is used to close the
current EDA tool interface.
16

Parameters Description
The parameters of the ‘Display Options’ page are listed as follows:
• X Axis: The X axis for variable 1. Only the property value between ‘Min’ and
‘Max’ are displayed in the plot; the values less than ‘Min’ or greater than ‘Max’
still contribute to the statistical summaries. The default values of ‘Min’ and ‘Max’
are the minimum and maximum of the selected Property. TheX Axis can be set to
a logarithmic scale by marking the corresponding check box.
• Y Axis: The Y axis for variable 2. The previous remarks made for theX Axis apply.
The user can modify the parameters through either the keyboard or the mouse. Any
modification through mouse will instantly reflect on the visualization or the statistical
summaries; while the change through keyboard must be inured by pressing the ‘Enter’
key.
2.2.2 Histogram
The histogram tool creates a visual output of the frequency distribution, and displays
some statistical summaries, such as the mean and variance of the selected variable. The
histogram tool is activated by clickingData Analysis|Histogram. Although the pro-
gram will automatically scale the histogram, the user can set the histogram limits in the
Parameter Panel. The mainhistogram interface is given in Fig. 2.6, and the parameters
of the ‘Data’ page are listed below.
Parameters Description
• Object: A cartesian grid or a point set containing variables.
• Property: The values or distribution of a certain variable listed in theObject above.
• bins: The number of classes. The user can change this number through the key-
board, or by clicking the scroll bar. Any value change will be instantly reflected on
the histogram display.
• Clipping Values: Statistical calculation settings. All values less than ‘Min’ and
greater than ‘Max’ are ignored, and any change of ‘Min’ and ‘Max’ will affect the
statistics calculation. The default values of ‘Min’ and ‘Max’ are the minimum and
17

maximum of the selectedProperty. After modifying ‘Min’ and/or ‘Max’, the user
can go back to the default setting by clicking ‘Reset’.
2.2.3 Q-Q plot and P-P plot
The Q-Q plot compares the equal p-values quantiles of two variables; and P-P plot com-
pares the cumulative probability distributions of two variables. The two variables need
not be in the sameObject or have the same number of data. The Q-Q plot and P-P plot are
combined into one program, which can be invoked fromData Analysis|QQ-plot. This
EDA tool generates both a graph in theVisualization Panel and some statistical sum-
maries (mean and variance for each variable) in theStatistics Panel, see Fig. 2.7. The
parameters in the ‘Data’ page are listed below.
Parameters Description
• Analysis Type: Algorithm selection. The user can choose either a Q-Q plot or a
P-P plot.
• Variable 1: The variable selection for the X axis. The user must choose first an
Object, then theProperty name.
• Clipping Values for Variable 1: All values strictly less than ‘Min’ and strictly
greater than ‘Max’ are ignored, any change of ‘Min’ and ‘Max’ will affect the
statistics calculation. The user can go back to the default setting by clicking ‘Reset’.
• Variable 2: The variable selection for the Y axis. The user must choose first an
Object, then theProperty name. Note thatVariable 2 andVariable 1 might be
from different objects.
• Clipping Values for Variable 2: Remarks similar to those forClipping Values for
Variable 1.
2.2.4 Scatter Plot
Thescatterplot tool (executed by clickingData Analysis|Scatter-plot) is used to com-
pare a pair of variables by displaying their bivariate scatter plot and some statistics. All
available data pairs are used to compute the summary statistics, such as the correlation
18

coefficient, the mean and varianace of each variable (see part [C] in Fig. 2.8). To avoid a
crowded figure in theVisualization Panel, only up to 10,000 data pairs are given in the
scatter plot. The parameters in the ‘Data’ page are listed below.
Parameters Description
• Object: A cartesian grid or a point set containing variables. ThisObject must at
least contain two properties.
• Variable 1: The variable property listed in theObject above. This variable is
associated with the X axis.
• Clipping Values for Variable 1: All values strictly less than ‘Min’ and strictly
greater than ‘Max’ are ignored, hence any change of ‘Min’ and ‘Max’ will affect
the statistics calculation. The user can go back to the default setting by clicking
‘Reset’. If Variable 1 has more than 10,000 data, then the ‘Reset’ button can be
used to generate a new scatter plot with a new set of data pairs containing up to
10,000 data.
• Variable 2: The variable property listed in the upperObject. This variable is
associated with the Y axis.Variable 2 must have the same number of data as
Variable 1.
• Clipping Values for Variable 2: Remarks similar to those forVariable 1.
• Options: The choice of visualizing the least square fit line in the scatter plot. The
slope and the intercept are always given below the check box ‘Show Least Square
Fit’.
19

Fig
ure
2.6:
His
togr
amin
terf
ace
[A]:
para
met
erpa
nel;
[B]:
visu
aliz
atio
npa
nel;
[C]:
stat
istic
spa
nel.
20

Fig
ure
2.7:
Q-Q
plot
inte
rfac
e[A
]:pa
ram
eter
pane
l;[B
]:vi
sual
izat
ion
pane
l;[C
]:st
atis
tics
pane
l.
21

Fig
ure
2.8:
Sca
tter
plot
inte
rfac
e[A
]:pa
ram
eter
pane
l;[B
]:vi
sual
izat
ion
pane
l;[C
]:st
atis
tics
pane
l.
22

Chapter 3
Utilities
3.1 Non-parametric distribution
In SGeMS a non-parametric cumulative distribution function, cdfF (z), is infered from a
set of valuesz1 ≤ . . . ≤ zL which can either be read from a file or from a property.F (z)
is built such that:F (z1) = 1L
andF (zL) = 1 − 1L
. This requires modeling of the tails of
the distributionF (z) if the valuesz1 andzL are not the minimum and maximum values.
The lower tail extrapolation function provides the shape of the distribution between
the minimumzmin and the first valuez1. The options for the lower tail are:
• Z is bounded:F (zmin) = 0. The lower tail ofF is then modeled with a power
model:F (z1)− F (z)
F (z1)=
( z1 − z
z1 − zmin
)ω
∀z ∈]zmin, z1[ (3.1)
The parameterω controls the decrease of the function, with the constraintω ≥ 1.
The greaterω the less likely are low values close tozmin. For ω = 1, all values
betweenzmin andz1 are equally likely.
• Z is not bounded: the lower tail is modeled with an exponential funtion:
F (z) = F (z1) exp(− (z − z1)
2)
∀z < z1 (3.2)
The options for the upper tail extrapolation function are similar but applied to the
interval[zL, zmax].
23

• Z is bounded:F (zmax) = 1. The upper tail ofF is then modeled with a power
model:F (z)− F (zL)
1− F (zL)=
( z − zL
zmax − z1
)ω
∀z ∈]zL, zmax[ (3.3)
The parameterω controls the decrease of the function, with the constraint
ω ∈ [0, 1]. The lower theω value the less likely are extreme values close tozmax.
Forω = 1, all values betweenzL andzmax are equally likely.
• Z is not bounded: the lower tail is modeled by an hyperbolic model
1− F (z)
1− F (zL)=
zL
z∀z > zL (3.4)
All L − 1 intermediary intervals[zi, zi+1] for i = 1, ..., L − 1 are interpolated linearly ,
corresponding to power model withω = 1.
Note: Whenzmin andzmax values are set toz1 andzL, the functional shape of the tail
extrapolation function becomes irrelevant.
Parameters description
1. Reference Distribution: Read the data either from the file [ref on file ] or on the
grid [ref on grid ] .
2. File with reference distribution [filename ]: File containing the reference distribu-
tion in one column without header. Required if [ref on file ] is selected
3. Property with reference distribution: The grid [grid ] and property [property ]
contains the values for the non-parametric distributions
4. Lower Tail Extrapolation : Parametrization of the lower tail. The type of extrapola-
tion function is selected with [LTI function ]. If the power model is selected, the
minimum value [LTI min ] and the parameterω [LTI omega] must be specified. Note
that the minimum [LTI min ] must be less or equal to the minimum datum value as
entered in the reference distribution, and the power omega [LTI omega] must be
greater or equal to 1. The exponential model does not require any parameter.
5. Upper Tail Extrapolation : Parametrization of the upper tail. The type of extrap-
olation fucntion is selected with [UTI function ]. If the power model is selected,
24

the maximum value [UTI max] and the parameterω [UTI omega] must be specified.
Note that the minimum [UTI max] must be greater or equal to the maximum datum
value as entered in the reference distribution, and the power omega [UTI omega]
must be lesser or equal to 1. The hyperbolic model only required the parameter
omega [UTI omega], the upper tail is unbounded.
Histogram Transformation
The algorithmTRANSallows to transform histogram into any other one. For example, the
Gaussian simulation algorithms (SGSIM and COSGSIM), as described in Section 6.1.1
and 6.1.2, assume Gaussian variables. If the attribute of interest is not Gaussian, it is pos-
sible to transform the marginal distribution of that attribute into a Gaussian distribution,
then work on the transformed variable.
The algorithm TRANS transform a property following a source distribution to a new
variable following a target distribution. The transformation of a variableZ with a source
cdf FZ into variableY with target cdfFY is written:
Y = F−1Y
(FZ
(Z
))(3.5)
Note : The transformation of a source distribution to a Gaussian distribution does
not ensure thatY is multivariate Gaussian, only its marginal distribution is. One should
check that the multivariate (or at least bi-variate) Gaussian hypothesis holds forY before
performing Gaussian simulation. If the hypothesis is not appropriate, other algorithms
that do not require Gaussianity, e.g. sequential indicator simulation (SISIM) should be
considered.
Histogram transformation with conditioning data
It is possible to apply a weighting factor to control how much specific values are trans-
formed.
y = z − ω(z − F−1Y (FZ (z)))
Whenω = 0 theny = z, there is no transformation.
25

Whenω = 1 theny = F−1Y (FZ (z))) which is the standard rank transform. The weight
ω can be set equal to the standardized kriging variance. At data locations that kriging
variance is zero, hence there is no transform and the datum value is unchanged. Away
from data locations the kriging variance increases allowing for a larger transform. That
option is to be used for slight adjustment of the marginal distribution. When weights are
used the transform is not rank preserving anymore and would only approximately match
the target distribution.
The histogram transformation algorithm is:
Algorithm 3.1 Histogram transformation1: for Each valuezk to be rank transformeddo
2: Get the quantile from the source histogram associated withzk, pk = FZ(zk)
3: Get the valuesyk from the target distribution associated withpk, yk = F−1Y (pk)
4: if weighted transformationthen
5: Applied weighting to the transform.
6: end if
7: end for
Parameters description
The TRANSalgorithm is activated fromUtilities—trans in the algorithm panel. The
TRANSinterface contains 3 pages: Data, Source and Target (see Figure 3.2). The text
inside [ ] is the corresponding keyword in theTRANSparameter file.
1. Object Name[grid ]: Selection of the grid containing the properties to be transformed
2. Properties[props ]: Properties to be transformed
3. Suffix for output [out suffix ]: The name for each output property consists of the
original name plus the suffix entered here.
4. Local Conditioning [is cond ]: Enables the use of weight for the histogram transfor-
mation
5. Weight Property [cond prop ]: Property with weights for transformation of the his-
togram conditional to data, see Eq. 3.1. The standardized kriging variance is a good
weighting option. Only required ifLocal Conditioning[is cond ] is selected
26

6. Control Parameter [weight factor ]: Value between 0 and 1 adjusting the weights.
Only required ifLocal Conditioning [is cond ] is selected
7. Source histogram[ref type source ]: Define the type of the source histogram.
That histogram may be either non parametric, Gaussian, LogNormal, or Uniform.
Each has its own interface for parameters
8. Gaussian parameters: The mean is given inMean [G mean source ] and the
variance inVariance[G variance source ]
9. LogNormal parameters: The mean is given inMean [LN mean source ] and
the variance inVariance[LN variance source ]
10. Uniform parameters: The minimum value is given inMin [Unif min source ]
and the maximum inMax[Unif max source ]
11. Non Parametric: The non parametric distribution is entered in [nonParamCdf source ],
see 3.1
12. Target histogram[ref type target ]: Define the type of the target histogram. The
histogram may be either non parametric, Gaussian, LogNormal, or Uniform. Each
has its own interface for parameters
13. Gaussian parameters: The mean is given inMean [G mean target ] and the
variance inVariance[G variance target ]
14. LogNormal parameters: The mean is given inMean [LN mean target ] and
the variance inVariance[LN variance target ]
15. Uniform parameters: The minimum value is given inMin [Unif min target ]
and the maximum inMax[Unif max target ]
16. Non Parametric: The non parametric distribution is entered in [nonParamCdf target ],
see 3.1
27

Figure 3.1: Widget for non parametric distribution
(a) Data tab (b) Source tab (c) Target tab
Figure 3.2: User interface forTRANS.
28

Chapter 4
Variograms and variography
Variogram models are used by many geostatistical algorithms; SGeMS allows four basic
models and any positive linear combinations of them, that is the linear model of region-
alization. Linear models of coregionalization are also possible but the software does not
check the permissibility of the model, it is the user responsability. The four basic models
are: the nugget effect model, the spherical model, the exponential model and the Gaussian
model.
nugget effect model
γ(h) =
0 if ‖h‖ = 0
1 otherwise(4.1)
A pure nugget effect model for a variableZ(u) expresses a lack of (linear) depen-
dence between variablesZ(u) andZ(u + h)
spherical model with actual rangea
γ(h) =
32‖h‖a− 1
2(‖h‖
a)3 if ‖h‖ ≤ a
1 otherwise(4.2)
exponential model with practical rangea
γ(h) = 1− exp(−3‖h‖
a
)(4.3)
Gaussian model with practical rangea
γ(h) = 1− exp(−3‖h‖2
a2
)(4.4)
29

Notes: Gaussian models are not permissible for binary indicator variables.
The term variogram is used to designate what is strictly speaking a semi-variogramγ(h)
It is also understood as cross semivariogram depending on the context.
All above models are permissible in 3-D and have a covariance counterpart:
C(h) = C(0)− γ(h)
In SGeMS a variogram model:γ(h) = c0γ(0)(h)+
∑Ll=1 clγ
(l)(h) is characterized by
the following parameters:
• a nugget effectc0γ(0) with nugget constantc0 ≥ 0
• the numberL of nested structures. Each structureγ(l)(h) is then defined by:
– a variance contributioncl ≥ 0
– the type of the variogram: spherical, exponential or Gaussian
– six parameters: the three practical ranges along the main directions of the
anisotropy ellipsoid and the three corresponding rotation angles defining that
ellipsoid. Note that each nested structure can have a different anisotropy.
Example:
Consider the variogram modelγ(h) = 0.3γ(0)(h) + 0.4γ(1)(h) + 0.3γ(2)(h), with:
• γ(0)(h) a nugget with sill0.3
• γ(1)(h) an anisotropic spherical variogram with major range 40, medium range 20
and minor range 5, and anglesα = 45o, β = 0, θ = 0
• γ(2)(h) an isotropic Gaussian variogram of range 200
The corresponding XML parameter file snippet would be:
30

<[Parameter_name] nugget="0.3" structures_count="2" >
<structure_1 contribution="0.4" type="Spherical" >
<ranges max="40" medium="20" min="5" />
<angles x="45" y="0" z="0" />
</structure_1>
<structure_2 contribution="0.3" type="Exponential" >
<ranges max="200" medium="200" min="200" />
<angles x="0" y="0" z="0" />
</structure_2>
</[Parameter_name]>
Where[Parameter_name] is the name of the parameter.
4.1 Modeling variogram in SGeMS
SGeMS offers the computation and modeling of experimental variograms for data both on
regular grids and on point sets. The variogram module is accessible from the Data Analy-
sis—Variogram menu. In addition to the variogram, the experimental covariance and
correlogram can also be calculated. SGeMS only fits permissible models to variograms.
The variography in SGeMS is done in three steps 1) choosing the grid and properties, 2)
calculating the experimental variograms and 3) fitting a model. Step 2) differs depending
whether the properties are to be found on a point set or a grid.
For all steps, the next windows are accessed by clicking onNext.
The parametes for the variogram computation are entered in the second window. That
window takes two forms depending if the property resides on a point set, shown in Figure
4.1(b), or on a cartesian grid 4.1(c).
Selecting properties
The selection of the properties on which to perform the variography is done in the first
window, shown in Figure 4.1(a). The experimental variogram can either be loaded from
a previous session or computed from scratch. When the computation is required, the
user has to specified two properties, termed head and tail. Specifying different properties
for head and tail results in computing their cross-variogram. If it is retrieved from a
31

previous session, then the next window is the modeling window of Figure 4.1(d), the
parametrization window is skipped.
1. Experimental variogram: Either compute the experimental variogram from scratch
or retrieve it from a previous modeling session.
2. Grid and Properties: Select the properties for the experimental varigrams. Specifying
different properties for head and tail results in computing a cross-variogram. Using
the same property for head and tail produces a univariate experimental variogram
Experimental variogram on point set
Calculating experimental variograms on point set is challenging due to the irregularity of
data locations. For a fixed lag and direction, it is unlikely that enough pairs, if any, would
be found to calculate the corresponding variogram. Thus, tolerance on the distance and
angles is introduced such that enough data pairs can be found on a point set. Parameters
3 to 13 shown in Figure 4.1(b) are required when working on a point set. Parameters
entered in this window can be saved for future use.
3. Number of lags: Number of variogram lags to compute
4. Lag separation: Distance between two lags. The experimental variogram will be
computed fromh = 0 to h = Number of lags times the lag separation.
5. Lag tolerance: Tolerance around the lag separation. All pairs of data separated by
Lag separation± lag tolerance would be reported to the same lag.
6. Number of directions: Number of directions along which to compute the experimen-
tal variograms, each with the same number of lags. Each direction is parametrize
by the next four items.
7. Azimuth: Horizontal degrees in angle from North moving clockwise
8. Dip: Vertical gegrees in angle from the horizontal plane, moving clockwise.
9. Tolerance: Half-window angle tolerance.Tolerance on the angle to pair data.
10. Bandwidh: Maximum acceptable deviation from the direction vector..
32

11. Measure type: Choice of the metric to measure bivariate spatial patterns. The op-
tions are: variogram, indicator variogram, covariance and correlogram. The mod-
eling capability of SGeMS permits only to fit a model on variogram and indicator
variogram.
12. Head indicator cutoff: Threshold defining the indicator variable. The value of the
head continuous property is coded one if it is below that threshold, it is zero other-
wise. This field is to be used only for indicator variogram.
13. Tail indicator cutoff : Threshold defining the indicator variable. The value of the tail
continuous property is coded one if it is below that threshold, it is zero otherwise.
This field is to be used only for indicator variogram. Different head and tail thresh-
olds lead paramount to a cross-indicator variogram if the tail and head refer to the
same property, or to a cross-indicator cross-variogram if the head and tail property
are different.
Experimental variogram on cartesian grid
Pairs of data are easier to find on a cartesian grid. Experimental variograms on cartesian
grid does not require tolerance. The computation take advantage of the grid by finding
pairs along discrete direction vector increment,(∆x, ∆y, ∆z), specified by the user. For
example, a direction vector of(1, 0, 0) is horizontal East-West,(1, 1, 0) correponds to
azimuth 45 degree, while(0, 0, 1) is vertical.
Parameters 14 to 18 shown in Figure 4.1(c) are required when the selected head and
tail properties are located on a cartesian grid. Parameters entered in this window can be
saved for future use. The description of parameters without reference number in 4.1(c)
already been described for Figure 4.1(b).
14. Number of lags: Number of variograms lags to consider.
15. Number of directions: Number of discretized direction vectors
16. x: East-West increment
17. y: North-South increment
18. z: Vertical increment
33

Fitting a permissible model
The tools to fit a model to the experimental variogram are shown in Figure 4.1(d). The
figures can be reorganized in the window either manually or by using the menuWindow.
The axes for one or all the plots can be changed from theSettingsmenu. TheFile menu
allows to save or load the variogram model in XML format. The experimental variograms
can also be saved in file from that menu. The last option is to take snapshot for all or for
a particular variogram display.
Right-clicking on any variogram display will toggle the number of pairs next to each
experimental values. When fitting, points with few pairs should be given less considera-
tion.
19. Nugget Effect: Contribution to the sill of the nugget efect
20. Nb of structures: Number of structures for the linear model of regionalization
21. Sill Contribution : Contribution to the sill of that structure
22. Type: Type of variogram for that structure. There are three variogram type: spherical,
exponential and Gaussian.
23. Ranges: Ranges of the variogram. The range can either be changed be manually
entering the value, or by sliding the bar.
24. Angles: Angles defining the anisotropy
34

(a) Property selection (b) Parameters for point set
(c) Parameters for cartesian grid
(d) Model fitting
Figure 4.1: User interface for variogram modeling.
35

Chapter 5
Estimation Algorithms
SGeMS provides several tools for estimating a spatially distributed variableZ(u) from
a limited number of samples. All algorithms rely on the linear, least-square estimation
paradigm called kriging. The kriging estimator can be extended to deal with a variable
whose mean is not stationary, and to the case of multiple covariates (cokriging).
5.0.1 Common Parameters
All estimation algorithms in SGeMS work on a 3-D object, loosely called the estimation
grid: in the current version, that object can either be a Cartesian grid or an unstructured
set of points. When an estimation algorithm is run on an object, a new property containing
the result of the estimation is attached to that object. All estimation algorithms require
the following two parameters:
Parameters description
Grid Name: The grid (or more generally, the object) on which the estimation is to be
performed
Property Name: The name of the new property resulting from the estimation
5.0.2 Kriging
Kriging is a 3-D estimation program for variables defined on a constant volume support.
Estimation can either be performed by simple kriging (SK), ordinary kriging (OK), krig-
36

ing with a polynomial trend (KT) or simple kriging with a locally varying mean (LVM).
SK, OK and KT were introduced in??, p. ??. LVM is another variant of kriging, in
which the meanm(u) is assumed not constant but known for everyu. The kriging prob-
lem consists of finding the weights{λα}, α = 1, . . . , n such that:
V ar( n∑
α=1
λα[Z(uα)−m(uα)]− [Z(u)−m(u)])
is minimum
Example:
Simple kriging is used to estimate porosity in the second layer of Stanford V. Porosity
is modeled by a stationary random function with an anisotropic spherical variogram. Its
expected value, inferred from the well data, is 0.17. The input parameters for algorithm
Kriging are reproduced in Fig. 5.1. Fig. 5.2 shows the estimated porosity field.
<parameters> <algorithm name="kriging" />
<Grid_Name value="layer 2" />
<Property_Name value="krig" />
<Hard_Data grid="layer 2 well data" property="porosity" />
<Kriging_Type type="Simple Kriging (SK)" >
<parameters mean="0.17" />
</Kriging_Type>
<Max_Conditioning_Data value="200" />
<Search_Ellipsoid value="100 100 5
0 0 0 " />
<Variogram nugget="0.2" structures_count="1" >
<structure_1 contribution="0.8" type="Spherical" >
<ranges max="80" medium="40" min="2" />
<angles x="30" y="0" z="0" />
</structure_1>
</Variogram>
</parameters>
Figure 5.1: Simple kriging parameters
37

(a) 3D view
(b) Cross-section 1 (c) Cross-section 2
Figure 5.2: Porosity estimated by simple kriging
Parameters description
1. Hard Data [Hard Data ]: The grid and the name of the property containing the hard
data
2. Kriging Type [Kriging Type ]: Possible types of kriging include: Simple Kriging
(SK), Ordinary Kriging (OK), Kriging with Trend (KT) and Simple Kriging with
Locally Varying Mean (LVM)
38

3. Trend components[Trend ]: The trend components. Possible components are, with
u = (x, y, z): t1(u) = x, t2(u) = y, t3(u) = z, t4(u) = x.y, t5(u) = x.z,
t6(u) = y.z, t7(u) = x2, t8(u) = y2, t9(u) = z2.
The trend is coded by a string of 9 flags, for example the string
“0 1 0 0 0 1 0 1 0’’ would correspond to a trend with componentst2, t6
andt8, i.e. T (u) = α x + β yz + δ y2. Each flag is separated by a space.
4. Local Mean Property [Local Mean Property ]: The property of the simulation grid
containing the non-stationary mean. A mean value must be available at each loca-
tion to be estimated.
5. Max Conditioning Data [Max Conditioning Data ]: The maximum number of con-
ditioning data to be used for kriging at any location
6. Search Ellipsoid [Search Ellipsoid ]: The ranges and angles defining the search
ellipsoid
7. Variogram [Variogram ]: The variogram of the variable to be estimated by kriging
5.0.3 Indicator Kriging
Let Z(u) be a continuous random variable, andI(u, zk) the binary indicator function
defined at cutoffzk:
I(u, zk) =
{1 if Z(u) ≤ zk
0 otherwise
The aim of indicator kriging is to estimate the conditional cumulative distribution function
(ccdf) at any cutoffzk, conditional to data(n):
I∗(u, zk) = E∗(I(u, zk) | (n))
= Prob∗(Z(u) < zk | (n)
)(5.1)
I∗(u, zk) is estimated by the simple kriging estimator:
I∗(u, zk)− E{I(u, zk)} =n∑
α=1
λα
(I(uα, zk)− E{I(uα, zk)}
)EstimatingI∗(u, zk) for different cutoffszk, k =1,. . . ,K, yields a discrete estimate of
the conditional cumulative distribution function at the threshold valuesz1, . . . , zK .
39

The algorithmIndicator Krigingassumes that the marginal probabilitiesE{I(uα, zk)}are constant and known for alluα andzk (Simple Indicator Kriging ref??
Median IK
Estimating a conditional cumulative distribution function at a given locationu requires
the knowledge of the variogram of each of the indicator variablesI(., zk), k =1, . . . , K.
Inference of these K variograms can be a daunting task. Moreover a kriging system has
to be solved for each indicator variable. The inference and computational burden can be
alleviated if two conditions are met:
• the K indicator variables are intrinsically correlated ref(??):
γZ(h) = γI(h, zk) = γI(h, zk, zk′) ∀zk, zk′
where γZ(h) is the variogram of variableZ(u) and γI(h, zk, zk′) is the cross-
variogram between indicator variablesI(., zk) andI(., zk′). All these variograms
are standardized to a unit sill
• All vectors of hard indicator data are complete: there are no missing values as could
result from inequality constraints on theZ value.
When those two conditions are met, it is only necessary to infer one variogramγZ(h) and
only one kriging system has to be solved for all thresholdszk (indeed, the data locations
and the variogram are the same for all thresholds). This simplification is calledmedian
indicator kriging.
Ensuring the validity of the estimated cdf
Since kriging is a non-convex estimator, the cdf values estimated by krigingProb∗(Z(u) < zk
),
k = 1, . . . , K estimated by indicator kriging may not satisfy the properties of a cdfF , that
is:
∀k ∈ {1, ..., K} F (zk) = Prob(Z(u) < zk) ∈ [0, 1] (5.2)
∀zk ≥ zk′ F (zk) ≥ F (zk′) (5.3)
If properties 5.2 and 5.3 are not verified, the programIndicator Kriging modifies the
kriging values so as to ensure the validity of the ccdf. The corrections are performed in 3
steps.
40

1. Upward correction:
• Loop through all the cutoffsz1,. . . ,zK , starting with the lowest cutoffz1.
• At cutoff zk, if the estimated probabilityI∗(Z(u), zk) is not in[I∗(Z(u), zk−1), 1],
reset it to the closest bound
2. Downward correction:
• Loop through all the cutoffsz1,. . . ,zK , starting with the highest cutoffzK .
• At cutoff zk, if the estimated probabilityI∗(Z(u), zk) is not in[0, I∗(Z(u), zk+1)],
reset it to the closest bound
3. The final corrected probability values are the average of the upward and downward
corrections
Categorical Variables
Indicator Krigingcan also be applied to categorical variables, i.e. variables that take a dis-
crete, finite, number of values (also called classes or categories):z(u) ∈ {0, ..., K − 1}.The indicator variable for classk is then defined as:
I(u, k) =
{1 if Z(u) = k
0 otherwise
and the probabilityI∗(u, k) of Z(u) belonging to classk is estimated by simple kriging:
I∗(u, k)− E{I(u, k)} =n∑
α=1
λα
(I(uα, k)− E{I(uα, k)}
)In the case of categorical variables, the estimated probabilities must all be in[0, 1] and
verify:K∑
k=1
P(Z(u = k) | (n)
)= 1 (5.4)
If not, they are corrected as follows:
1. If I∗(Z(u), zk) /∈ [0, 1] reset it to the closest bound. If all the probability values are
lesser or equal to 0, no correction is made and a warning is issued.
2. Standardize the values so that they sum-up to 1:
I∗corrected(Z(u), zk) =
I∗(Z(u), zk)∑Ki=1 I∗(Z(u), zi)
41

Parameters description
1. Hard Data Grid [Hard Data Grid ]: The grid containing the hard data
2. Hard Data Property [Hard Data Property ]: The name of the properties containing
the hard data. If there areK indicators,K properties must be specified. Each
property contains the indicator valuesI(u, k), k = 1,. . . ,K
3. Categorical Variable Flag[Categorical Variable Flag ]: A flag indicating whether
the variable to be kriged is categorical or continuous. If the flag is on (equal to 1),
the variable is assumed categorical
4. Marginal Probabilities [Marginal Probabilities ]: The marginal probabilities of
each indicator. The probability values are separated by one or more space. The first
probability corresponds to the probability of the first indicator and so on.
5. Max Conditioning Data [Max Conditioning Data ]: The maximum number of con-
ditioning data to be used for each kriging
6. Search Ellipsoid [Search Ellipsoid ]: The ranges and angles defining the search
ellipsoid
7. Median IK Flag [Median Ik Flag ]: A flag indicating whether median IK should be
performed
8. Full IK Flag [Full Ik Flag ]: A flag indicating whether full IK should be performed.
If
Median Ik Flag is on/off,Full Ik Flag is off/on
9. Median IK Variogram [Variogram Median Ik ]: The variogram of the indicator vari-
ables used for median IK. IfMedian Ik Flag is off this parameter is ignored
10. Full IK Variogram [Variogram Full Ik ]: The variograms of each indicator vari-
able. IfMedian Ik Flag is on, this parameter is ignored
42

5.0.4 CoKriging
The aim of cokriging is to estimate a variableZ1(u) accounting for data on related vari-
ablesZ2, ..., ZJ+1. The cokriging estimator is given by:
Z∗1(u)−m1(u) =
∑α
λα
[Z1(uα)−m1(uα)
]+
J+1∑j=2
Nj∑βj
λβj
[Zj(uβj
)−mj(uβj)]
(5.5)
Algorithm CoKrigingallows to distinguish between the two cases of simple and ordi-
nary cokriging:
• the meansm1(u), ...,mJ+1(u) are known and constant: simple cokriging
• the means are locally constant but unknown. The weightsλα andλβjmust then
satisfy: ∑α
λα = 1 (5.6)
Nj∑βj
λβj= 0 ∀j ∈ {1, ..., J} (5.7)
Solving the cokriging system calls for the inference and modeling of multiple vari-
ograms: the variogram of each variable and all cross-variograms between any two vari-
ables. In order to alleviate the burden of modeling all these variograms, two models have
been proposed: the Markov Model 1 and the Markov Model 2 ref(??)
For text clarity, we will only consider the case of a single secondary variable (J = 1).
Markov Model 1
The Markov Model 1 (MM1) considers the following Markov-type screening hypothesis:
E(Z2(u) | Z1(u), Z1(u + h)
)= E
(Z2(u) | Z1(u)
)(5.8)
i.e. the dependence of the secondary variable on the primary is limited to the co-located
primary variable.
The cross-variogram (or cross-covariance) is then proportional to the auto-variogram
of the primary variable (??)
C12(h) =C12(0)
C11(0)C11(h) (5.9)
43

WhereC12 is the covariance betweenZ1 and Z2 and C11 is the covariance ofZ1.
Solving the cokriging system under the MM1 model only calls for knowledge ofC11,
hence the inference and modeling effort is the same as for univariate kriging.
Although very congenial the MM1 model should not be used when the support of
the secondary variableZ2 is larger than the one ofZ1, lest the variance ofZ1 would be
underestimated. It is better to use the Markov Model 2 in that case.
Markov Model 2
The Markov Model 2 (MM2) was developed for the case where the volume support of the
secondary variable is larger than that of the primary variable ref(??) . This is often the
case with remote sensing and seismic-related data. The Markov-type hypothesis is now:
E(Z1(u) | Z2(u), Z2(u + h)
)= E
(Z1(u) | Z2(u)
)(5.10)
i.e. the dependence of the primary variable on the secondary is limited to the co-located
secondary variable.
The cross-variogram is now proportional to the variogram of the secondary variable:
C12(h) =C12(0)
C11(0)C22(h) (5.11)
In order for all three covariancesC11, C12 andC22 to be consistent, ref(??) proposed
to modelC11 as a linear combination ofC22 and any permissible residual covarianceCR.
Expressed in term of correlograms (C11(h) = C11(0)ρ11(h)), this is written:
ρ11(h) = ρ212 ρ22(h) + (1− ρ2
12) ρR(h) (5.12)
Parameters description
1. Primary Hard Data Grid [Primary Harddata Grid ]: The grid containing the pri-
mary hard data
2. Primary Variable [Primary Variable ]: The name of the property containing the
primary hard data
3. Assign Hard Data [Assign Hard Data ]: A flag specifying whether the hard data
should be re-located on the simulation grid. See??
44

4. Secondary Hard Data[Secondary Harddata Grid ]: The grid containing the sec-
ondary hard data
5. Secondary Variable[Secondary Variable ]: The name of the property containing
the secondary hard data
6. Kriging Type [Kriging Type ]: Possible types of cokriging include: Simple Kriging
(SK) and Ordinary Kriging (OK). Note that selecting OK while retaining only a
single secondary datum (e.g. when doing co-located cokriging) amounts to com-
pletely ignoring the secondary information : from Eq. (5.7), the weight associated
to the single secondary datum will be 0.
7. SK Means [SK Means]: The mean of the primary and secondary variables. If the
selected kriging type is Ordinary Kriging, this parameter is ignored
8. Co-kriging Type [Cokriging Type ]: The cokriging option. Available options are:
Full Cokriging, Co-located Cokriging with Markov Model 1 (MM1), and Co-located
Cokriging with Markov Model 2 (MM2)
9. Max Conditioning Data [Max Conditioning Data ]: The maximum number of pri-
mary conditioning data to be used for each cokriging
10. Search Ellipsoid - Primary Variable [Search Ellipsoid 1]: The ranges and angles
defining the search ellipsoid used to find the primary conditioning data
11. Primary Variable Variogram [Variogram C11]: The variogram model for the pri-
mary variable
12. Max Conditioning Data [Max Conditioning Data 2]: The maximum number of
secondary conditioning data used for each cokriging. This parameter is only re-
quired if Cokriging Type is set to Full Cokriging
13. Search Ellipsoid - Secondary Variable[Search Ellipsoid 2]: The ranges and an-
gles defining the search ellipsoid used to find the secondary conditioning data. This
parameter is only required if
Cokriging Type is set to Full Cokriging
45

14. Cross-Variogram[Variogram C12]: The cross-variogram between the primary and
secondary variable. This parameter is only required ifCokriging Type is set to
Full Cokriging
15. Secondary Variable Variogram[Variogram C22]: The variogram of the secondary
variable. This parameter is only required ifCokriging Type is set to Full Cokrig-
ing
16. Coefficient of correlation[Correl Z1Z2]: The coefficient of correlation between the
primary and secondary variable. This parameter is only required ifCokriging Type
is set to MM1
17. Coefficient of correlation [MM2Correl Z1Z2]: The coefficient of correlation be-
tween the primary and secondary variable. This parameter is only required if
Cokriging Type is set to MM2
18. Secondary Variable Variogram[MM2Variogram C22]: The variogram of the sec-
ondary variable. This parameter is only required ifCokriging Type is set to MM2.
Note that the variogram of the secondary variable and the variogram of the primary
variable must verify the condition (5.12)
46

Chapter 6
Simulation Algorithms
This chapter presents the collection of stochastic simulation algorithms provided by SGeMS.
Section 6.1 presents the traditional variogram based (two-points) algorithms, such as
SGSIM(Sequential Gaussian Simulation),SISIM(Sequential Indicator Simulation),COS-
GSIM(Sequential Gaussian Co-simulation),COSISIM(Sequential Indicator co-imulation).
SGSIMandCOSGSIMare the choices for most applications with continuous variables,
while SISIMandCOSISMIwould be choice for categorical variables.
Section 6.2 gives detailed descriptions of the two multiple-point simulation (mps) al-
gorithms:SNESIM(Single Normal Equation Simulation) andFILTERSIM(Filter-based
Simulation).SNESIMonly works for categorical variables as involved in facies distribu-
tions, whileFILTERSIMis suited to both continuous and categorical variables.
Each simulation algorithm presented in this chapter is demonstrated with some exam-
ple runs.
6.1 Variogram-based Simulations
This section covers the variogram-based sequential simulation algorithms implemented in
SGeMS. The stochastic realizations from any of these algorithms draw their spatial pat-
terns from input model variograms. Variograms-based algorithms are to be used when the
critical patterns are reasonably amorphous (high entropy) and can be represented by bi-
variate statistics. Cases when variograms fail to reproduce critical spatial patterns should
lead to using the multiple-point geostatistics algorithms described in the next section.
Variogram-based sequential simulations are the most popular stochastic simulation
47

algorithms mostly due to their robustness and ease of conditioning, both for hard and
soft data. Moreover, they do not require rasterized (regular or cartesian ) grid and allow
simulation on irregular grids such as point sets.
SGeMS takes full advantage of this flexibility; all the simulation algorithms in this
section work both on point sets and on cartesian grids. Moreover, the conditioning data
may or may not be on the simulation grid. However, working on point set induces a
performance penalty as the search for neighboring data is significantly more costly than
on a regular (cartesian) grid.
When the simulation grid is cartesian, all algorithms have the option to relocate the
conditioning data to the nearest grid node for increased execution speed. The re-allocation
strategy is to move each datum to the closest grid node. In case two data share the same
closest grid node, the farthest one is ignored.
This section presents first the simulation algorithms requiring some Gaussian as-
sumption: the sequential Gaussian simulationSGSIMand the sequential Gaussian co-
simulationCOSGSIMfor integration of secondary information through a coregionaliza-
tion model. Next, the direct sequential simulationDSSIMis presented,DSSIMdoes not
require any Gaussian assumption but may not reproduce the target distribution. Finally
the implementation of the indicator simulation algorithmsSISIMandCOSISIMare dis-
cussed. These last two algorithms rely on the decomposition of the cumulative distribution
function by a set of thresholds. At any location the probability of exceeding each thresh-
old is estimated by kriging and these propabilities are combined to construct the local
conditional cumulative distribution function (ccdf) from which simulation is performed.
6.1.1 SGSIM: sequential Gaussian simulation
Let Y (u) be a multivariate Gaussian random function with zero mean, unit variance, and
a given variogram modelγ(h). Realizations ofY (u), conditioned to data(n) can be
generated byAlgorithm 6.1.
A non Gaussian random functionZ(u) must first be transformed into Gaussian ran-
dom functionY (u); Z(u) 7→ Y (u). If no analytical model are available, a normal score
transform may be applied. TheAlgorithm 6.1 then becomesAlgorithm 6.2
Using the normal score transform involves more than just transforming and back trans-
forming the data at simulation time. First, the algorithm calls for the variogram of the
normal scorenot of the original data. Only that normal score variogram is guaranteed
48

Algorithm 6.1 Sequential Gaussian Simulation1: Define a random path visiting each node of the grid
2: for Each nodeu along the pathdo
3: Get the conditioning data consisting of both neighboring original data(n) and pre-
viously simulated values
4: Estimate the local conditional cdf as a Gaussian distribution with mean given by a
form of kriging and its variance by the kriging variance
5: Draw a value from that Gaussian ccdf and add the simulated value to the data set
6: end for
7: Repeat for another realization
Algorithm 6.2 Sequential Gaussian Simulation with normal score transform1: Transform the data into normal score space.Z(u) 7→ Y (u)
2: Perform Algorithm 6.1
3: Back transform the Gaussian simulated field into the data space.Y (u) 7→ Z(u)
to be reproduced, not the originalZ-value variogram. However, in many cases the back
transform does not affect adversely the reproduction of theZ-value variogram model. If
required, the SGeMS implementation ofSGSIMcan automatically perform the normal
score transform of the original hard data and back-transform the simulated realizations.
The user must still perform independently the normal score transform of the hard data
with theTRANS, seeAlgorithm 3.1, to calculate and model the normal score variogram.
At each data location the algorithm can either solve a simple kriging, ordinary krig-
ing, kriging with local mean ot kriging with a trend system. Theory only guarantees
reproduction of the variogram with the simple kriging system.
SGSIM with local varying mean
In most cases, the local varying meanzm(u) = E{Z(u)} is given as aZ-value and must
be converted into the Gaussian space, such thatym(u) = E{Y (u)}. Transformingzm(u)
into ym(u) using theFZ and the rank preserving transform
ym(u) = F−1Y
(FZ
(zm(u)
))would not, in all generality, ensure thatym(u) = E{Y (u)}. A better alternative, when
possible, is to get directlyym(u) by direct calibration of the secondary information with
49

the normal score transformy of the primary attributez.
A note on Gaussian spatial law
Gaussian random functions have very specific and consequential spatial structures and
distribution law. Median values are maximally correlated while extreme values are in-
creasingly less correlated. That property is known as destructuration. If the phenomenon
under study is known to have well correlated extreme values, a Gaussian-related simula-
tion algorithm is not appropriate.
Example:
Figure 6.6 shows two conditional realizations on a point set using simple kriging and
normal score transform of the hard data.
Parameters description
TheSGSIMalgorithm is activated fromSimulation—sgsimin algorithm panel. The main
SGSIMinterface contains 3 pages: General, Data and Variogram (see Figure 6.1). The
text inside ‘[ ]’ is the corresponding keyword in theSGSIMparameter file.
1. Simulation Grid Name [Grid Name]: Name of the simulation grid.
2. Property Name Prefix[Property Name]: Prefix for the simulation output. The suffix
real# is added for each realization.
3. # of realizations[Nb Realizations ]: Number of simulations to generate.
4. Seed[Seed]: Seed for the random number generator.
5. Kriging Type [Kriging Type ]: Select the type of kriging system to be solved at each
node along the random path. The simple kriging (SK) mean is set to zero.
6. Hard Data—Object [Hard Data.grid ]: Name of the grid containing the conditioning
data. If no grid is selected, the realizations are unconditional.
7. Hard Data—Property [Hard Data.property ]: Property for the conditioning data.
Only required if a grid has been selected inHard Data—Object[Hard Data.grid ]
50

8. Assign hard data to simulation grid [Assign Hard Data ]: If selected, the hard data
are copied on the simulation grid. The program does not proceed if the copying
fails. This option significantly increases execution speed.
9. Max Conditionning data [Max Conditioning Data ]: Maximum number of data to
be retained in the search neighborhood.
10. Search Ellipsoid Geometry[Search Ellipsoid ]: Parametrization of the search el-
lipsoid.
11. Target Histogram: If used, the data are normal score transformed prior to simulation
and the simulated field is transformed back to the original space.
Use Target Histogram[Use Target Histogram ] flag to use the normal score trans-
form. [nonParamCdf ] parametrize the target histogram (see section 3.1)
12. Variogram [Variogram ]: Parametrization of the normal score variogram.
6.1.2 COSGSIM: Sequential Gaussian co-simulation
COSGSIMallows to simulate a Gaussian variable accounting for secondary information.
Let Y1(u) andY2(u) be two correlated multiGaussian random variables.Y1(u) is called
the primary variable, andY2(u) the secondary variable. TheCOSGSIMsimulation of
the primary variableY1 conditioned to both primary and secondary data is described in
Algorithm 6.3.
Algorithm 6.3 Sequential Gaussian Cosimulation1: Define a path visiting each nodeu of the grid
2: for At each nodeu do
3: Get the conditioning data consisting of neighboring original data, previously sim-
ulated values and secondary data
4: Get the local Gaussian ccdf for the primary attribute, its mean is estimated by a
cokriging estimate and its variance by the cokriging variance.
5: Draw a value from the that Gaussian ccdf and add it to the data set
6: end for
If the primary and secondary variable are not Gaussian, make sure that the trans-
formed variablesY1 andY2 are at least bigaussian. If they are not, another simulation
51

algorithm should be considered,COSISIMfor example (see 6.1.5). If no analytical model
are available for such transformation, a normal score transform may be applied to both
variables. TheTRANSalgorithm only ensures that the respective marginals are Gaussian.
The algorithm 6.3 then becomesAlgorithm 6.4
Algorithm 6.4 Sequential Gaussian Cosimulation for non-Gaussian variable1: TransformZ1 andZ2 into Gaussian variablesY1 andY2, according to Eq. (3.5).
2: Perform AlgorithmAlgorithm 6.3.
3: “Back-transform” the simulated valuesy1,1, ..., y1,N into z1,1, ..., z1,N :
Example:
Figure 6.11 shows two conditional realizations with a MM1-type of coregionalization
and simple cokriging. Both the primary and secondary information are normal score
transformed.
Parameters description
TheCOSGSIMalgorithm is activated fromSimulation—cosgsimin the algorithm panel.
TheCOSGSIMinterface contains 5 pages: General, Primary Data, Secondary Data, Pri-
mary Variogram and Secondary Variogram (see Figure 6.2). The text inside ‘[ ]’ is the
corresponding keyword in theCOSGSIMparameter file.
1. Simulation Grid Name [Grid Name]: Name of the simulation grid.
2. Property Name Prefix[Property Name]: Prefix for the simulation output. The suffix
real# is added for each realization.
3. # of realizations[Nb Realizations ]: Number of simulations to generate.
4. Seed[Seed]: Seed for the random number generator.
5. Kriging Type [Kriging Type ]: Select the type of kriging system to be solved at each
node along the random path.
6. Cokriging Option [Cokriging Type ]: Select the type of coregionalization model:
LMC, MM1 or MM2
52

7. Primary Hard Data Grid [Primary Harddata Grid ]: Selection of the grid for the
primary variable. If no grid is selected, the realizations are unconditional.
8. Primary Property [Primary Variable ]: Selection of the hard data property for the
primary variable.
9. Assign hard data to simulation grid [Assign Hard Data ]: If selected, the hard data
are copied on the simulation grid. The program does not proceed if the copying
fails. This option significantly increases execution speed.
10. Primary Max Conditionning data [Max Conditioning Data 1]: Maximum num-
ber of primary data to be retained in the search neighborhood.
11. Primary Search Ellipsoid Geometry [Search Ellipsoid 1]: Parametrization of
the search ellipsoid for the primary variable.
12. Target Histogram: If used, the primary data are normal score transformed prior to
the simulation and the simulated field is transformed back to the original space.
Transform Primary Variable [Transform Primary Variable ] flag to use the nor-
mal score transform. [nonParamCdf primary ] parametrize the primary variable tar-
get histogram (see section 3.1).
13. Secondary Data Grid[Secondary Harddata Grid ]: Selection of the grid for the
secondary variable.
14. Secondary Property[Secondary Variable ]: Selection of the data property for the
secondary variable.
15. Secondary Max Conditionning data[Max Conditioning Data 2]: Maximum num-
ber of secondary data to be retained in the search neighborhood.
16. Secondary Search Ellipsoid Geometry[Search Ellipsoid 2]: Parametrization of
the search ellipsoid for the secondary variable.
17. Target Histogram: If used, the primary data are normal score transformed prior to
the simulation and the simulated field is transformed back to the original space.
Transform SecondaryVariable [Transform Secondary Variable ] flag to use the
normal score transform. [nonParamCdf secondary ] parametrizes the secondary
variable target histogram (see section 3.1).
53

18. Variogram for primary variable [Variogram C11]: Parametrization of the normal
score variogram for the primary variable.
19. Cross-variogram between primary and secondary variables[Variogram C12]:
Parametrization of the cross-variogram for the normal score primary and secondary
variables. Required ifCokriging Option [Cokriging Type ] is set toFull Cokrig-
ing
20. Variogram for secondary variable [Variogram C22]: Parametrization of the nor-
mal score variogram for the secondary variable. Required ifCokriging Option
[Cokriging Type ] is set toFull Cokriging
21. Coef. Correlation Z1,Z2: Coefficient of correlation between the primary and sec-
ondary variable. Only required ifCokriging Option [Cokriging Type ] is set to
MM1 or MM2 . The correlation keyword is [Correl Z1Z2] for the MM1 coregion-
alization, and [MM2Correl Z1Z2] for the MM2 coregionalization.
22. Covariance for secondary variable[MM2Variogram C22]: Parametrization of the
normal score variogram for the secondary vaiable. Required ifCokriging Option
[Cokriging Type ] is set toMM2
6.1.3 DSSIM: Direct Sequential Simulation
The direct sequential simulation algorithmDSSIM performs simulation of continuous
attributes without prior indicator coding or Gaussian transform. It can be shown that the
only condition for the model variogram to be reproduced is that the ccdf has for mean and
variance the simple kriging estimate and variance. The shape of the ccdf does not matter,
it may not even be the same for each node. The drawback is that there is no guarantee that
the marginal distribution is reproduced.
One solution is to post-process the simulated realizations with a rank transform al-
gorithm to identify the target histogram, see algorithmTRANSin section 3.1. This may
affect variogram reproduction. The second alternative is to set the shape of the local ccdf,
at all locations along the path, such that the marginal distribution is approximated at the
end of each realization.
SGeMS offers two potential distributions type for the first alternative; the ccdf is either
a uniform distribution or a lognormal distribution. Neither of these distributions would
54

produce realizations that have either uniform or lognormal marginal distributions, thus
some rank transformation may be required to identify the target marginal histogram.
For the second alternative, the method proposed by Soares (2001) is implemented.
The ccdf is sampled from the data marginal distribution, modified to be centered on the
kriging estimate with spread equal to the kriging variance. The resulting shape of each lo-
cal ccdf differs from location to location. The method gives reasonable results for a target
symmetric (even multi-modal) distribution, but less so for a highly skewed distribution;
in this latter case the first option of a log-normal ccdf type followed by a rank tranform
may give better results.
Algorithm 6.5 Direct Sequential Simulation1: Define a random path visiting each nodeu of the grid
2: for Each locationu along the pathdo
3: Get the conditioning data consisting of both neighboring original data and previ-
ously simulated values
4: Define the local ccdf with its mean and variance given by the kriging estimate and
variance.
5: Draw a value from that ccdf and add the simulated value to the data set
6: end for
Example:
Figure 6.8 shows two conditional realizations on a point set using the Soares method and
simple kriging. A local varying mean with the Soares method is used in Figures 6.9.
Parameters description
TheDSSIMalgorithm is activated fromSimulation—dssimin the upper part of algorithm
panel. The mainDSSIM interface contains 3 pages: General, Data and Variogram (see
Figure 6.3). The text inside ‘[ ]’ is the corresponding keyword in theDSSIMparameter
file.
1. Simulation Grid Name [Grid Name]: Name of the simulation grid.
2. Property Name Prefix[Property Name]: Prefix for the simulation output. The suffix
real# is added for each realization.
55

3. # of realizations[Nb Realizations ]: Number of simulations to generate.
4. Seed[Seed]: Seed for the random number generator.
5. Kriging Type [Kriging Type ]: Select the form of kriging system to be solved at each
node along the random path.
6. SK mean[SK mean]: Mean of the attribute. Only required ifKriging Type [Kriging Type ]
is set to Simple Kriging(SK).
7. Hard Data—Object [Hard Data.grid ]: Name of the grid containing the conditioning
data. If no grid is selected, the realizations are unconditional.
8. Hard Data—Property [Hard Data.property ]: Property for the conditioning data.
Only required if a grid has been selected inHard Data—Object[Hard Data.grid ]
9. Assign hard data to simulation grid [Assign Hard Data ]: If selected, the hard data
are copied on the simulation grid. The program does not proceed if the copying
fails. This option significantly increases execution speed.
10. Max Conditionning data [Max Conditioning Data ]: Maximum number of data to
be retained in the search neighborhood.
11. Search Ellipsoid Geometry[Search Ellipsoid ]: Parametrization of the search el-
lipsoid.
12. Distribution type [cdf type ]: Select the type of cdf to be build at each location
along the random path
13. LogNormal parameters: Only activated ifDistribution type [cdf type ] is
set toLogNormal. Parametrization of the global lognormal distribution, the
mean is specified byMean[LN mean] and the variance byVariance[LN variance ].
14. Uniform parameters: Only activated ifDistribution type [cdf type ] is set to
Uniform . Parametrization of the global Uniform distribution, the minimum is
specified byMin [U min ] and the maximum byMax[U max].
15. Soares Distribution[nonParamCdf ]: Only activated ifDistribution type [cdf type ]
is set toSoares. Parametrization of the global distribution from which the lo-
cal distribution is sampled (see section 3.1).
56

16. Variogram [Variogram ]: Parametrization of the variogram. For this algorithm, the
sill of the variogram is a critical information and should not be standardized to 1.
6.1.4 SISIM : sequential indicator simulation
Sequential indicator simulationSISIMcombines the indicator formalism with the sequen-
tial paradigm to simulate non-parametric continuous or categorical distributions. In the
continuous case, at every location along the path a non parametric ccdf is built using
the kriging estimate from the neighboring indicator data. For the categorical case, the
probability for each category to occur is estimated by kriging.
The indicator formalism used with the sequential indicator simulation (Algorithm 6.6)
does not requires any Gaussian assumption. Instead, it is assumed that the ccdf be built by
estimating the sequence of probabilities of exceeding a finite set of threshold values. The
more thresholds are retained, the more detailed the conditional cumulative distribution
function is. The indicator formalism removes the need for normal score transform, but
may require an additional modeling effort.
This version ofSISIM does not require any prior indicator coding of the data, all
coding is done internally for both the continuous and the categorical cases. Interval or
incomplete data may also be entered but need to be pre-coded.
When modeling a set of indicator variograms, the user is warned that not all combi-
nation of variograms can be reproduced. For example, if a field has three categories, the
spatial patterns of the third category is completely determined by the variogram models
of the first two.
Continuous variable
The algorithmSISIM relies on indicator kriging to infer the local ccdf values. The con-
tinuous indicator variable is defined as:
i(z(u), zk) =
{1 if z(u) ≤ zk
0 otherwise
Two types of kriging can be used for indicator simulation. The full IK option requires
a variogram model for each threshold. The median IK option only requires the variogram
model for the median threshold, all other variograms are assumed proportional to that
single model.
57

While bothSGSIMandSISIMwith median IK requires a single variogram, they pro-
duce different outputs and spatial patterns. The difference is that the extreme values of
a random field with a median IK regionalization would be more spatially correlated than
with theSGSIMalgorithm.
For continuous attributesSISIMimplementsAlgorithm 6.6.
Sampling the estimated distribution function
At each location to be simulated, the ccdfFZ(u) is estimated at all threshold values
z1, . . . , zK . However sampling fromFZ(u) as described in step 7 ofAlgorithm 6.6 re-
quires the knowledge ofFZ(u)(z) for all z ∈ D. In SISIMFZ(u) is interpolated as follows:
F ∗Z(u)(z) =
φlti (z) if z ≤ z1
F ∗Z(u)(z1) + z−zk
zk+1−zk
(F ∗
Z(u)(z2)− F ∗Z(u)(z1)
)if zk ≤ z ≤ zk + 1
1− φuti(z) if zk+1 ≤ z, ω > 0, ω ∈ R(6.1)
whereF ∗Z(u)(zk) = i∗(u, zk) is estimated by indicator kriging andφlti (z) andφuti(z) are
respectively the lower and upper tail extrapolation chosen by the user and described in
section 3.1. Values between thresholdszi andzi+1 are interpolated linearly, hence are
drawn from a uniform distribution in the interval[zi, zi+1].
Categorical variables
If Z(u) is a categorical variable which only takes the integer values{1, . . . , K}, Algo-
rithm 6.6 is modified as described inAlgorithm 6.7.
The categorical indicator variable is defined by:
i(u, k) =
{1 if Z(u) = k
0 otherwise
For the categorical case, the median IK option would indicates that all categories share
the same variogram.
58

Algorithm 6.6 SISIM - continuous variables1: Choose a discretization of the rangeD of Z(u): z1, . . . , zK
2: Define a path visiting all locations to be simulated
3: for For each locationu along the pathdo
4: Retrieve the neighboring conditioning data :z(uα), α = 1, . . . , N
5: Turn each datumz(uα) into a vector of indicator values:
v(uα) =[i(z(uα), z1
), . . . , i
(z(uα), zK
)].
6: Estimate the indicator random variableI(u, zk) for each of theK thresholds values
by solving a kriging system.
7: The estimated valuesi∗(u, zk) = Prob∗(Z(u) ≤ zk), after correction of order-
relation problems, define an estimate of the ccdfFZ(u) of the variableZ(u).
8: Draw a value from that ccdf and assign it as a datum at locationu.
9: end for
9: Repeat the previous steps to generate another simulated realization
Algorithm 6.7 SISIM - categorical variable1: Define a path visiting all locations to be simulated
2: for For each locationu along the pathdo
3: Retrieve the neighboring categorical conditioning data:
z(uα), α = 1, . . . , N
4: Turn each datumz(uα) into a vector of indicator data values:
v(uα) =[i(z(uα), z1
), . . . , i
(z(uα), zK
)].
5: Estimate the indicator random variableI(u, k) for each of theK categories by
solving a simple kriging system.
6: The estimated valuesi∗(u, k) = Prob∗(Z(u) = k), after correction of order-
relation problems, define an estimate of the discrete conditional probability density
function (cpdf)fZ(u) of the categorical variableZ(u). Draw a realization fromf
and assign it as a datum at locationu.
7: end for
8: Repeat the previous steps to generate another realization
Example:
Figure 6.10 shows two conditional realizations on a point set with a median IK regional-
ization. Nineteen thresholds were selected.
59

Parameters description
The SISIM algorithm is activated fromSimulation—sisimin the algorithm panel. The
main SISIM interface contains 3 pages: General, Data and Variogram (see Figure 6.4).
The text inside ‘[ ]’ is the corresponding keyword in theSISIMparameter file.
1. Simulation Grid Name [Grid Name]: Name of the simulation grid.
2. Property Name Prefix[Property Name]: Prefix for the simualtion output. The suffix
real# is added for each realization.
3. # of realizations[Nb Realizations ]: Number of simulations to generate.
4. Seed[Seed]: Seed for the random number generator.
5. Categorical variable [Categorical Variable Flag ]: Indicates if the data are cate-
gorical or not.
6. # of tresholds/classes[Nb Indicators ]: Number of classes if the flag [Categorical Variable Flag ]
is selected or number of threshold values for continuous attributes.
7. Threshold Values / Classes[Thresholds ]: Threshold values in ascending order. That
field is required only for continuous data.
8. Marginal probabilities [Marginal Probabilities ]:
If continuous Probability to be below each of the above threshold. The entries
must be monotonically increasing.
If categorical Proportion for each category. The first entry correspond to category
0, the second to category 1, ...
9. Lower tail extrapolation [lowerTailCdf ]: Parametrize the lower tail of the cumula-
tive distribution function for continuous attributes.
10. Upper tail extrapolation [upperTailCdf ]: Parametrize the upper tail of the cumu-
lative distribution function for continuous attributes.
11. Indicator kriging type : If Median IK [Median Ik Flag ] is selected, the program
uses median indicator kriging to estimate the ccdf. Otherwise, ifFull IK [Full Ik Flag ]
is selected, one IK system is solved for each threshold/class
60

12. Hard Data Grid [Hard Data Grid ]: Grid containing the conditioning hard data
13. Hard Data Property [Hard Data Property ]: Conditioning data for the simulation
14. Assign hard data to simulation grid[Assign Hard Data ]: If selected, the hard data
are copied on the simulation grid. The program does not proceed if the copying
fails. This option significantly increases execution speed.
15. Interval Data — Object: codedprops Grid containing the interval data. Cannot be
used ifMedian IK [Median Ik Flag ] is selected.
16. Interval Data — Properties: codedgrid Properties with the interval and soft data.
These data must already be properly coded and are all found on the grid [coded grid ].
There must be [Nb Indicators ] properties selected.
17. Max Conditioning data [Max Conditioning Data ]: Maximum number of data to
be retained in the search neighborhood.
18. Search Ellipsoid Geometry[Search Ellipsoid ]: Parametrization of the search el-
lipsoid.
19. Variogram [Variogram ]: Parametrization of the indicator variograms. Only one
variogram is necessary ifMedian IK [Median Ik Flag ] is selected. Otherwise there
are [Nb Indicators ] indicator variograms.
6.1.5 COSISIM: Sequential Indicator Cosimulation
The algorithmCOSISIMextends theSISIMalgorithm to handle secondary data. At the
difference ofSISIM, data must already be coded prior to usingCOSISIM. The algorithm
does not differentiate between hard and interval data; for any given threshold both are
located on the same property. If no secondary data are selected, the algorithmCOSISIM
performs a traditional sequential indicator simulation.
The secondary data are integrated using the Markov-Bayes algorithm. As with the
primary attribute, the secondary information must be coded into indicators before it is
used. The Markov-Bayes calibration coefficients are not internally computed and must be
given as input. SGeMS allows using the Markov-Bayes algorithm with both a Full IK or
a median IK regionalization model.
61

A note on conditioning
As opposed toSISIM, COSISIMdoes not exactly honor hard data for a continuous at-
tribute. The algorithm would honor these data in the sense that the simulated values would
be inside the correct threshold interval. It is not possible to retrieve exactly continuous
data values since these were never provided to the program. A possible post-processing is
to copy the conditioning hard data values over the simulated nodes once the realizations
are finished.
Example:
TO DO: example with cosisim
Parameters description
The COSISIMalgorithm is activated fromSimulation—cosisimin the algorithm panel.
The mainCOSISIMinterface contains 3 pages: General, Data and Variogram (see Figure
6.5). The text inside ‘[ ]’ is the corresponding keyword in theCOSISIMparameter file.
1. Simulation Grid Name [Grid Name]: Name of the simulation grid.
2. Property Name Prefix[Property Name]: Prefix for the simulation output. The suffix
real# is added for each realization.
3. # of realizations[Nb Realizations ]: Number of simulations to generate.
4. Seed[Seed]: Seed for the pseudo random number generator.
5. Categorical variable [Categorical Variable Flag ]: Indicates if the data are cate-
gorical or not.
6. # of tresholds/classes[Nb Indicators ]: Number of classes if the flag [Categorical Variable Flag ]
is selected or number of threshold values for continuous attributes.
7. Threshold Values / Classes[Thresholds ]: Threshold values in ascending order, there
must be [Nb Indicators ] values entered. That field is only for continuous data.
8. Marginal probabilities [Marginal Probabilities ]:
62

If continuous Probability to be below each of the above threshold. The entries
must be monotonically increasing.
If categorical Proportion for each category. The first entry correspond to category
0, the second to category 1, ...
9. Lower tail extrapolation [lowerTailCdf ]: Parametrize the lower tail of the ccdf for
continuous attributes.
10. Upper tail extrapolation [upperTailCdf ]: Parametrize the upper tail of the ccdf for
continuous attributes.
11. Kriging Type [Kriging Type ]: Select the type of kriging system to be solved at each
node along the random path.
12. Indicator kriging type : If Median IK [Median Ik Flag ] is selected, the program
uses median indicator kriging to estimate the cccdf. IfFull IK [Full Ik Flag ] is
selected, there are [Nb Indicators ] IK systems solved at each location, one for
each threshold/class
13. Hard Data Grid [Primary Hard Data Grid ]: Grid containing the conditioning hard
data
14. Hard Data Indicators Properties [Primary Indicators ]: Conditioning primary
data for the simulation. There must be [Nb Indicators ] properties selected, the first
one being for class 0, the second for class 1, and so on. IfFull IK [Full Ik Flag ]
is selected, a location may not be informed for all thresholds.
15. Primary Max Conditionning data [Max Conditioning Data Primary ]: Maximum
number of primary indicator data to be retained in the search neighborhood.
11. Primary Search Ellipsoid Geometry [Search Ellipsoid 1]: Parametrization of
the search ellipsoid for the primary variable.
16. Soft Data Grid [Secondary Harddata Grid ]: Grid containing the conditioning soft
data indicators. If no grid is selected, a univariate simulation is performed.
17. Soft Data Indicators Properties[Secondary Indicators ]: Conditioning secondary
data for the simulation. There must be [Nb Indicators ] properties selected, the first
63

one being for class 0, the second for class 1, and so on. IfFull IK [Full Ik Flag ]
is selected, a location need not be informed for all thresholds.
18. Search Ellipsoid Geometry[Search Ellipsoid Primary ]: Parametrization of the
search ellipsoid for the primary indicator data.
19. B(z,IK) for each indicator [Bz Values ]: Parameters for the Markov Bayes Model,
one B-coefficient value must be entered for each indicator. Only required if sec-
ondary data are used.
20. Secondary Max Conditionning data[Max Conditioning Data Secondary ]: Max-
imum number of secondary indicator data to be retained in the search neighborhood.
21. Secondary Search Ellipsoid Geometry[Search Ellipsoid 1]: Parametrization of
the search ellipsoid for the secondary data indicators.
22. Variogram [Variogram ]: Parametrization of the indicator variograms. Only one
variogram is necessary ifMedian IK [Median Ik Flag ] is selected. Otherwise there
are [Nb Indicators ] indicator variograms.
64

(a) General tab (b) Data tab (c) Variogram tab
Figure 6.1: User interface forSGSIM.
65

(a) General tab (b) Primary data tab (c) Secondary data tab
(d) Primary variogram tab(e) Secondary vari-
ogram tab for the
linear model of
coregionalization
(f) Secondary variogram
tab for the MM2 core-
gionalization
Figure 6.2: User interface forCOSGSIM.
66

(a) General tab (b) Data tab (c) Variogram tab
Figure 6.3: User interface forDSSIM.
67

(a) General tab (b) Data tab (c) Variogram tab
Figure 6.4: User interface forSISIM.
(a) General tab (b) Data tab (c) Variogram tab
Figure 6.5: User interface forCOSISIM.
68

(a) Realization #1 (b) Realization #2
Figure 6.6: Two realizations withSGSIM.
(a) Realization #1 (b) Realization #2
Figure 6.7: Two realizations withSGSIMand local varying mean.
69

(a) Realization #1 (b) Realization #2
Figure 6.8: Two realizations withDSSIM.
(a) Realization #1 (b) Realization #2
Figure 6.9: Two realizations withDSSIMand local varying mean.
70

(a) Realization #1 (b) Realization #2
Figure 6.10: Two realizations withSISIMand the median IK regionalization, 19 thresh-
olds are used in this example.
(a) Realization #1 (b) Realization #2
Figure 6.11: Two realizations withCOSISIMwith the Markov Model 1 (MM1) coregion-
alization.
71

6.2 Multiple-point Simulation algorithms
Before the introduction of multiple-point geostatistics, two families of simulation algo-
rithms for facies modeling were available: pixel-based and object-based. The pixel-based
algorithms build the simulated realizations one pixel at a time, thus providing great flex-
ibility for conditioning to data of diverse support volumes and diverse types. Pixel-based
algorithms may, however, be slow and have difficulty reproducing complex geometric
shapes, particularly if simulation of these pixel values is constrained only by two-point
statistics, such as a variogram or a covariance. Object-based algorithms build the realiza-
tions by dropping onto the simulation grid one object or pattern at a time, hence they can
be fast and faithful to the geometry of the object. However, they are difficult to condition
to local data of different support volumes, particularly when these data are dense as in the
case for seismic surveys.
SGeMS does not provide yet any program for object-based simulation, whether con-
ditional or non-conditional. Such programs are available in many free and commercial
softwares, such as ‘fluvsim’ (Deutsch and Tran, 2002), ‘SBED’.
The multiple-point simulation concept proposed by Journel (1992) and first imple-
mented by Guardiano and Srivastava (1992), combines the strengths of the previous two
classes of simulation algorithms. It operates pixel-wise with the conditional probabilities
for each pixel value being lifted as conditional proportion from a training image depicting
the geometry and distribution of objects deemed to prevail in the actual field. That train-
ing image (TI), a purely conceptual depiction, can be built using object-based algorithms.
Whatmpsdoes is to morph theTI so that it honors all local data.
6.2.1 SNESIM
The originalmps implementation by Guardiano and Srivastava (1992) was much too
slow, for it asked a new rescan of the wholeTI at each new simulation node, to retrieve
the required conditional proportion from which to draw the simulated value.mpsbecame
practical with theSNESIMimplementation of Strebelle (2000). InSNESIM, theTI is
scanned only once and all conditional proportions available in theTI are stored in a
smart search tree data structure, from which they can be retrieved fast.
TheSNESIMalgorithm contains two main parts, the contruction of a search tree where
all training proportions are stored, and the simulation part itself where these proportions
are read and used to draw the simulated values.
72

Search tree construction
A search templateτJ is defined byJ vectorshj, j = 1, . . . , J radiating from a cen-
tral nodeu0. The template is thus constituted by J nodes (u0 + hj, j = 1, . . . , J).
That template is used to scan the training image for all training patternspat(u′0) =
{t(u′0); t(u
′0 + hj), j = 1, . . . , J}, whereu′
0 is any central node of theTI; t(u′0 + hj)
is the training image value at grid nodeu′0 + hj. All these training patterns are stored in
a search tree data structure (Strebelle, 2000), such that one can retrieve easily:
1. the total number (n) of patterns with exactly the sameJ valuesDJ = {dj, j = 1, . . . , J}.One such pattern would be{t(u′
0 + hj) = dj, j = 1, . . . , J};
2. for those patterns, the number (nk) which features a specific valuet(u′0) = k,
(k = 0, . . . , K − 1) at the central locationt(u′0),
whereK is the total number of categories. The ratio of these two numbers give the
proportion of training patterns identifying the central valuet(u′0) = k among all those
identifying theJ “data” valuest(u′0 + hj) = dj:
P (t(u′0) = k|DJ) =
nk
n, k = 0, . . . , K − 1. (6.2)
Single grid simulation
The SNESIMsimulation proceeds one pixel at a time following a random path visiting
all the nodes within the simulation gridG of one realizationre. Hard data have been
relocated to the closest nodes ofG, and these data-informed nodes are not visited thus
ensuring data exactitude. For all other nodes, the algorithm of sequential simulation (in-
ternal re. ??) is used.
At each simulation nodeu, the search templateτJ is used to retrieve the conditional
data eventdev(u) which is defined as
devJ(u) = {z(s)(u + h1), . . . , z(s)(u + hJ)}, (6.3)
wherez(s)(u + hj) is an informed nodal value in theSNESIMrealization; such value
could be either an original hard datum value or a previously simulated value. Note that
there can be any number of uninformed nodal values among theJ possible locations of
the templateτJ centered atu.
73

Next, find the numbern of training patterns which have the same values asdev(u)
from the search tree. Ifn is lesser than a fixed thresholdcmin (the minimum number
of replicates), define the smaller data eventdevJ−1(u) by dropping the furthest away
informed node fromdevJ(u), and repeat the search. This step is repeated untiln ≥ cmin.
Let J ′ (J ′ ≤ J) the data event size for whichn ≥ cmin.
The conditional probability from which the nodal valuez(s)(u) is drawn, is modeled
as:
P (Z(u) = k|devJ(u)) ≈ P (Z(u) = k|devJ ′(u))
= P (t(u′0) = k|devJ ′(u)).
This probability is conditional to up toJ data values found with the search templateτJ .
Algorithm 6.8 describes the simplest version of theSNESIMalgorithm with aK-category
variableZ(u) valued in{0, . . . , K − 1}.
Algorithm 6.8 Simple single gridSNESIM1: Define a search templateτJ
2: Construct a search treeTr specific to templateτJ
3: Relocate hard data to the nearest simulation grid node and freeze them during simu-
lation
4: Define a random path visiting all locations to be simulated
5: for Each locationu along the pathdo
6: Find the conditioning data eventdevJ(u) defined by templateτJ
7: Retrieve the conditional probability distribution ccdfP (Z(u) = k|devJ(u)) from
search tree
8: Draw a simulated valuez(s)(u) from that conditional distribution and add it to the
data set
9: end for
The search-tree stores all training replicates{t(u′0); t(u
′0 + hj), j = 1, . . . , J}, and
allows to retrieve the conditional probability distribution of step 7 inO(J). This speed
comes at the cost of a possibly large RAM memory demand. LetNTI be the total number
of locations in the training image. No matter the data event sizej, there can not be more
thanNTI different data events in the training image; thus an upper-bound of the memory
demand of the search tree is:
Memory Demand≤ min(KJ , NTI)
74

whereKJ is the total number of possible data value combinations withK categories and
J nodes.
Multiple grid simulation
The multiple grid simulation approach (Tran, 1994) is used to capture large scale struc-
tures with a search templateτJ with a reasonably small number of nodes. Denote byG
the 3D Cartesian grid on which simulation is to be performed, defineGg as thegth sub-set
of G such that:G1=G andGg is obtained by down-samplingGg−1 by a factor of 2 along
each of the three coordinate directions:Gg is the sub-set ofGg−1 obtained by retaining
every other node ofGg−1. Gg is called thegth level multi-grid. Fig. 6.12 illustrates a
simulation field which is divided into 3 multiple grids.
Figure 6.12: Three multiple grids (coarsest, medium and finest)
In thegth subgridGg, the search templateτJ is correspondingly rescaled by a factor
2g−1 such that
τ gJ = {2g−1h1, . . . , 2
g−1hJ}
Templateτ gJ has the same number of nodes asτJ but has a much greater spatial ex-
tent, hence allows capturing large-scale structures without increasing the search tree size.
Fig. 6.13 shows a fine template of size3× 3 and the expanded coarse template in the2nd
level coarse grid.
During simulation, all nodes simulated in the previous coarser grid are frozen, i.e.
they are not revisited.Algorithm 6.9 describes the implementation of multiple grids in
SNESIM.
75

Figure 6.13: Multi-grid search template (coarse and fine)
Algorithm 6.9 SNESIMwith multiple grids1: Choose the numberNG of multiple grids
2: Start at the coarsest gridGg, g = NG.
3: while g > 0 do
4: Relocate hard data to the nearest grid nodes in current multi-grid
5: Build a new templateτ gJ by re-scaling templateτJ .
6: Build the search treeTrg using the training image and templateτ gJ
7: Simulate all nodes ofGg as inAlgorithm 6.8
8: Remove the relocated hard data from current multi-grid ifg > 1
9: Move to next finer gridGg−1 (let g = g − 1).
10: end while
Anisotropic template expansion
To get thegth coarse grid, both the base search template and the simulation grid are
expanded by a constant factor2g−1 in all 3 directions. This expansion is thus ‘isotropic’,
and used as default.
The expansion factor in each direction can be made different. Thegth coarse gridGg
is defined by retaining everyf gx nodes, everyf g
y nodes and everyf gz nodes in the X, Y, Z
directions, respectively.
The corresponding search templateτ gJ is re-scaled as:
τ gJ = {f g · h1, . . . , f
g · hJ},
wheref g = {f gx , f g
y , f gz }. Note that the total numberJ of template nodes remains the
same for all grids. This ‘anisotropic’ expansion calls for the expansion factors to be input
through theSNESIMinterface.
Let i = X,Y, Z and 1 ≤ g ≤ G (G ≤ 10), then the requirement for the input
anisotropic expansion factors are:
76

1. all expansion factors (f gi ) must be positive integers;
2. expansion factor for the finest grid must be 1 (f 1i ≡ 1);
3. expansion factor for the(g − 1)th multi-grid must be smaller than or equal to that
for thegth multi-grid (f g−1i ≤ f g
i );
4. expansion factor for the(g − 1)th multi-grid must be a factor of that for thegth
multi-grid (f gi mod f g−1
i = 0).
For example, valid expansion factors for three multiple grids are:
1 1 1 1 1 1 1 1 1
2 2 1 or 4 2 2 or 3 3 1
4 4 2 8 4 2 9 6 2.
A sensitivity analysis of the anisotropic expansion parameter should be performed before
any application.
Marginal distribution reproduction
It is sometimes desirable that the histogram of the simulated variable be close to a given
target distribution, e.g. the sample histogram. There is however no constraint inSNESIM
as described inAlgorithm 6.8 or Algorithm 6.9 to ensure that such target distribution be
reproduced. It is recommended to select a training image whose histogram is reasonably
close to the target marginal proportions.SNESIMcan correct the conditional distribution
function read at each nodal location from the search tree (step 7 ofAlgorithm 6.8) to
gradually gear the histogram of the up-to-now simulated values towards the target.
Let pck, k = 0, . . . , K − 1, denote the proportions of values in classk simulated so
far, andptk, k = 0, . . . , K − 1, denote the target proportions. Step 7 ofAlgorithm 6.8 is
modified as follows:
1. Compute the conditional probability distribution as originally described in step 7 of
Algorithm 6.8.
2. Correct the probabilitiesP(Z(u) = k | devJ(u)
)into:
P ∗(Z(u) = k | devJ(u))
= P(Z(u) = k | devJ(u)
)+
ω
1− ω∗ (pt
k − pck)
77

whereω ∈ [0, 1) is the servosystem intensity factor. Ifω = 0, no correction is
performed. Conversely, ifω → 1, reproducing the target distribution entirely con-
trols the simulation process, at the risk of failing to reproduce the training image
geological structures.
If P ∗(Z(u) = k | devJ(u))
/∈ [0, 1], it is reset to the closest bound. All updated
probability values are then rescaled to sum up to 1:
P ∗∗(Z(u) = k | devJ(u))
=P ∗(Z(u) = k | devJ(u)
)∑Kk=1 P ∗
(Z(u) = k | devJ(u)
)A similar procedure can be called to reproduce a given vertical proportion curve for
each horizontal layer. The vertical proportion should be provided in input as a 1D property
with number of nodes in X and Y directions equal to 1, and the number of nodes in the Z
direction equal to that of the simulation grid.
Soft data integration
Soft (secondary) data may be available to constrain the simulated realizations. The soft
data are typically obtained by remote sensing techniques, such as seismic data. Often soft
data provide exhaustive but low resolution information over the whole simulation grid.
SNESIMcan account for such secondary information. The soft dataY (u) must be first
calibrated into probability dataP(Z(u) = k|Y (u)
), k = 0, . . . , K − 1 as presence or
absence of a certain categoryk centered at locationu, whereK is the total number of
categories.
The Tau model (Journel, 2002) is used to integrate conditional probabilities coming
from the soft data and the training image. The conditional distribution function of step 7 of
Algorithm 6.8, P(Z(u) = k | devJ(u)
), is updated intoP
(Z(u) = k | devJ(u), Y (u)
)using the following formula:
P(Z(u) = k | devJ(u), Y (u)
)=
1
1 + x, (6.4)
x is calculated asx
a=
( b
a
)τ1( c
a
)τ2 , τ1, τ2 ∈ (−∞, +∞), (6.5)
78

wherea, b, c are defined as:
a =1− P
(Z(u) = k
)P
(Z(u) = k
)b =
1− P(Z(u) = k | devJ(u)
)P
(Z(u) = k | devJ(u)
)c =
1− P(Z(u) = k | Y (u)
)P
(Z(u) = k | Y (u)
)P
(Z(u) = k
)is the target marginal proportion of categoryk. The two weightsτ1 and
τ2 account for the redundancy (Krishnan, 2004) between the soft dataY (u) and the local
conditioning data eventdevJ(u), respectively. The default values areτ1 = τ2 = 1.
Step 7 ofAlgorithm 6.8 is then modified as follows:
1. Estimate the probabilityP(Z(u) = k | devJ(u)
)as described inAlgorithm 6.8
2. Compute the updated probabilityP(Z(u) = k | devJ(u), Y (u)
)using Eq. 6.4
3. Draw a realization from the updated distribution function
Subgrid concept
As described earlier in sectionSingle grid simulation (page 73), wheneverSNESIMcan
not find enough training replicates of a given data eventdevJ , it will drop the furthest node
in devJ and repeat searching until the number of replicates is≥ cmin. This data dropping
procedure not only decreases the quality of pattern reproduction, but also significantly
increases CPU cost.
The subgrid concept is proposed to alleviate the data dropping effect. Fig. 6.14.1
shows eight contiguous nodes of a 3D simulation grid, also seen as the 8 corners of a cube
(Fig. 6.14.2). Among them, nodes 1 and 8 belong to subgrid 1; nodes 4 and 5 belongs
to subgrid 2, and all other nodes belong to subgrid 3. Fig. 6.14.3 shows the subgrid idea
in 2 dimensions. The simulation is performed first over subgrid 1, then subgrid 2 and
finally over subgrid 3. This subgrid simulation concept is applied to all multiple grids
except the coarsest grid. Fig. 6.14.4 shows the 3 subgrids over the2nd multi-grid, where
‘A’ denotes the1st sub-grid nodes, ‘B’ denotes the2nd sub-grid nodes, and ‘C’ denotes
the3rd sub-grid nodes.
79

Figure 6.14: Subgrid concept: (1) 8 close nodes in 3D grid; (2) 8 nodes represented in the
corners of a cubic; (3) 4 close nodes in 2D grid; (4) 3 subgrids in the2nd multi-grid
In the1st subgrid of thegth multi-grid, most of the nodes (of type A) would have been
already simulated in the previous coarse(g + 1)th multi-grid: with the default isotropic
expansion, 80% of nodes are already simulated in the previous coarser grid in 3D and
100% of them in 2D. In that1st subgrid, the search template is designed to only use the A
type nodes as conditioning data, hence the data event is almost full. Recall that the nodes
previously simulated in the coarse grid are not resimulated in this subgrid.
In the2nd subgrid, all the nodes marked as ‘A’ in Fig. 6.14.4 are now informed by a
simulated value. In this subgrid, the search templateτJ is designed to use only the A type
nodes, but conditioning includes in addition theJ ′ closest B type nodes; the default is
J ′ = 4. In total, there areJ + J ′ nodes in the search templateτ for that2nd subgrid. The
left plot of Fig. 6.15 shows the2nd subgrid nodes and the template nodes of a simple 2D
case with isotropic expansion: the basic search template of size 14 is marked by the solid
circles, theJ ′ = 4 additional conditioning nodes are marked by the dash circles. Note
that the data event captured by the basic template nodes (solid circles) is always full.
When simulating over the3rd subgrid, all nodes of both the1st and the2nd subgrids
(ot types A and B) are fully informed with simulated values. In that3rd subgrid, the base
templateτJ is designed to search only nodes of types A and B as conditioning data. Again,
80

Figure 6.15: Simulation nodes and search template in subgrid (left:2nd subgrid; right:
3rd subgrid)
theJ ′ nearest nodes of type C in the current subgrid are used as additional conditioning
data. In the right plot of Fig. 6.15, the basic search template for the3rd subgrid is marked
by solid circles, theJ ′ = 4 additional conditioning nodes are marked by dash circles.
The subgrid approach mimics a stagger grid, such that more conditioning data can
be found during simulation in each subgrid, thus the conditional data event is more con-
sistent with the training image patterns. Hence the geological structures present in that
training image would be better reproduced in the simulated realizations. It isstrongly
recommended to use this subgrid concept for 3D simulation.Algorithm 6.9 is modified
as shown inAlgorithm 6.10.
Node re-simulation
The other solution for reducing the data dropping effect is to re-simulate those nodes
which are simulated with a number of conditioning data less than a given threshold.
SNESIMrecords the numberNdrop of data event nodes dropped during simulation. After
simulation on each subgrid of each multiple grid, those nodes withNdrop larger than a
threshold are de-allocated, and pooled into a new random path. ThenSNESIMis per-
81

Algorithm 6.10 SNESIMwith multi-grids and subgrid concept1: for Each subgrids do
2: Build a combined seach templateτ sJ,J ′ = {hi, i = 1, . . . , . . . , (J + J ′)}.
3: end for
4: Choose the numberL of multiple grids to consider
5: Start with the coarsest gridGg, g = L.
6: while g > 0 do
7: Relocate hard data to the nearest grid nodes in current multi-grid
8: for Each subgrids do
9: Build a new geometrical templateτ g,sJ,J ′ by re-scaling templateτ s
J,J ′.
10: Build the search treeTrg,s using the training image and templateτ gJ,J ′
11: Simulate all nodes ofGg,s as inAlgorithm 6.8
12: end for
13: Remove the relocated hard data from current multi-grid ifg > 1
14: Move to next finer gridGg−1 (let g = g − 1).
15: end while
formed again along this new random path. This post-processing technique (Remy, 2001)
improves the simulated realization to a certain extent, in particular it can only improve
small scale features.
In the currentSNESIM, a percentageP of nodes along each of the original random
path are to be re-simulated, withP ∈ [0, 50%] being input through theSNESIMinterface.
Accounting for local non-stationarity
Any training image should be reasonably stationary so that meaningful statistics can be
inferred by scanning it. It is however possible to introduce some non-stationarity in the
simulation by accounting for local rotation and local scaling of an otherwise stationary
TI. SNESIMprovides two approaches to handle such non-stationary simulation: (1)
modify locally the training image; (2) use different training images. The first approach is
presented in this section; the second will be detailed in the next sectionRegion concept
(page 84).
The simulation fieldG can be divided into several rotation regions, each region asso-
ciated with a rotation angle. Letri (i = 0, . . . , Nrot − 1) be the rotation angle about the
82

(vertical) Z-axis in theith regionRi, whereNrot is the total number of regions for rota-
tion, andR0∪· · ·∪RNrot−1 = G. In SNESIMthe azimuth rotation is limited to be around
the Z-axis, and the angle is measured in degree increasing clockwise from the Y-axis.
The simulation gridG can also be divided into a set of scaling regions, each re-
gion associated with scaling factors in X/Y/Z directions. Letf j = {f jx, f j
y , f jz} (j =
0, . . . , Naff − 1) be the scaling factors, also called affinity ratios, in thejth regionSj,
whereNaff is number of regions for scaling,S0 ∪ · · · ∪ SNaff−1 = G, andf jx, f j
y , f jz
are the affinity factors in the X/Y/Z directions, respectively. All affinity factors must be
positive∈ (0, +∞). The smaller the affinity factor, the larger the extent of the geological
structure in that direction. An affinity factor equal to 1 means no training image scaling.
Note that inSNESIM, the numbersNrot of rotation regions andNaff of scaling regions
can be independent one from another, allowing overlap of rotation regions with scaling
regions.
GivenNrot rotation regions andNaff affinity regions, the total number of new training
images after scaling and rotation isNrot ·Naff . Correspondingly, one search tree must be
constructed using templateτJ for each of the new training imageTIi,j defined as:
TIi,j(u) = Θi · Λj · TI(u),
whereu is the node in the training image,Θi is the rotation matrix for rotation regioni,
andΛj is scaling matrix for affinity regionj:
Θi =
cos ri sin ri 0
− sin ri cos ri 0
0 0 1
Λj =
1/f jx 0 0
0 1/f jy 0
0 0 1/f jz
.
Nrot = 1 means rotate the stationaryTI globally, which can be also achieved by speci-
fying a global rotation angle. SimilarlyNaff = 1 corresponds to a global scaling of the
TI.
The correspondingSNESIMalgorithm is described inAlgorithm 6.11.
This option can be very memory demanding as one new search tree has to be built for
each scaling factorfj and for each rotation angleri. Practice has shown that it is possible
to generate fairly complex models using a limited number of regions: a maximum of 5
rotation regions and 5 affinity regions is sufficient in most cases.
83

Algorithm 6.11 SNESIMwith locally varying azimuth and affinity1: Define a search templateτJ
2: for Each rotation regioni do
3: for Each affinity regionj do
4: Construct a search treeTri,j for training imageTIi,j using templateτJ
5: end for
6: end for
7: Relocate hard data to the nearest simulation grid nodes
8: Define a random path visiting all locations to be simulated
9: for Each locationu along the pathdo
10: Find the conditioning data eventdevJ(u) defined by templateτJ
11: Locate the region indices(i, j) of locationu
12: Retrieve the conditional probability distribution ccdfP (Z(u) = k|devJ(u)) from
the corresponding search treeTri,j
13: Draw a simulated valuez(s)(u) from that conditional distribution and add it to the
data set
14: end for
Region concept
The rotation and affinity concepts presented in the previous section allow to account only
for limited non-stationarity in that the geological structures in the different subdomains
are similar except for orientation and size. In more difficult cases, the geological struc-
tures may be fundamentally different from one zone or region to another, calling for
different training images in different regions, see R1,R2 and R3 in Fig. 6.16. Also, parts
of the study field may be inactive (R4 in Fig. 6.16), hence there is no need to perform
SNESIMsimulation in those locations, and the target proportion should be limited to only
the active cells. The region concept allows such flexibility.
The simulation gridG is first divided into a set of subdomains (regions)Gi, i =
0, . . . , NR − 1, whereNR is the total number of regions, andG0 ∪ · · · ∪ GNR−1 = G.
Perform normalSNESIMsimulation for each active region with its specific training image
and its own parameter settings. The regions can be simulated in any order, or can be
simulated simultaneously through a random path visiting all regions.
Except for the first region, simulation in one region can be conditioned to values previ-
ously simulated in other regions, such as to reduce discontinuity across region boundaries.
84

Figure 6.16: Simulation with region concept: each region is associated to a specificTI.
The simulated result not only contains the property values in the current region, but also
the property copied from the other conditioning regions. For instance in Fig. 6.16, when
region 2 (R2) is simulated conditional to the propertyre1 in region 1 (R1), the simulated
realizationre1,2 contains the property in both R1 and R2. Next the propertyre1,2 can
be used as conditioning data to performSNESIMsimulation in region 3 (R3), which will
result in a realization over all active areas (R1+R2+R3).
Target distributions
SNESIMallows three kinds of target proportions: a global target proportion, a vertical
proportion curve and a soft probability cube. Three indicatorsI1, I2, I3 are defined as
follows:
I1 =
1 a global target is given
0 no global target is given
I2 =
1 a vertical proportion curve is given
0 no vertical proportion curve is given
I2 =
1 a probability cube is given
0 no probability cube is given
85

There are in total23 = 8 possible options. TheSNESIMprogram proceeds as follows,
according to the given option:
1. I1 · I2 · I3 = 1, [global target, vertical proportion curve and probability cube all
given]: SNESIMignores the global target, and checks consistency between the soft
probability cube and the vertical proportion. If they are not consistent, a warning
is prompted in the background DOS console, and the program continues running
without waiting for correction of the inconsistency. The local conditional proba-
bility distribution (ccdf) is updated first for the soft probability cube using the Tau
model, then the servosystem is enacted using the vertical probability values as target
proportion for each layer.
2. I1 · I2 · (1− I3) = 1, [global target, vertical proportion curve, no probability cube]:
SNESIMignores the global target, and corrects the ccdf with the servosystem using
the vertical probability value as target proportion for each layer.
3. I1 · (1− I2) · I3 = 1, [global target, no vertical proportion curve, probability cube]:
SNESIMchecks the consistency between the soft probability cube and the global
target proportion. If they are not consistent, a warning is prompted and the program
continues running without correction of the inconsistency. The ccdf is updated first
for the soft probability cube using the Tau model, then the servosystem is enacted
to approach the global target proportion.
4. I1 ·(1−I2) ·(1−I3) = 1, [global target, no vertical proportion curve, no probability
cube]:SNESIMcorrects the ccdf with the servosystem to approach the global target
proportion.
5. (1− I1) · I2 · I3 = 1, [no global target, vertical proportion curve, probability cube]:
Same as case 1.
6. (1−I1) ·I2 ·(1−I3) = 1, [no global target, vertical proportion curve, no probability
cube]: Same as case 2.
7. (1−I1) ·(1−I2) ·I3 = 1, [no global target, no vertical proportion curve, probability
cube]:SNESIMgets the target proportion from the training image, then checks the
consistency between the soft probability cube and that target proportion. If they are
not consistent, a warning is prompted and the program continues running without
86

correction of the inconsistency. The ccdf is updated first for the soft probability
cube using the Tau model, then the servosystem is enacted to approach the target
proportion.
8. (1− I1) · (1− I2) · (1− I3) = 1, [no global target, no vertical propportion curve, no
probability cube]:SNESIMgets the target proportion from the training image, then
correct the ccdf with the servosystem to approach the global proportion.
Parameters description
TheSNESIMalgorithm is activated fromSimulation|snesimstd in the upper part of al-
gorithm panel. The mainSNESIMinterface contains 4 pages: ‘General’, ‘Conditioning’,
‘Rotation/Affinity’ and ‘Advanced’ (see Fig. 6.17). TheSNESIMparameters will be pre-
sented page by page in the following. The text inside ‘[ ]’ is the corresponding keyword
in theSNESIMparameter file.
1. simulation grid name [GridSelector Sim]: The name of grid on which simulation
is to be performed
2. property name prefix [Property NameSim]: The name of the property to be simu-
lated
3. # of Realizations[Nb Realizations ]: Number of realizations to be simulated
4. Seed[Seed]: A large odd number to initialize the pseudo-random number generator
5. Training Image | Object [PropertySelector Training.grid ]: The name of the
grid containing the training image
6. Training Image | Property [PropertySelector Training.property ]: The training
image property, which must be a categorical variable whose value must be between
0 andK − 1, whereK is the number of categories
7. # of Categories[Nb Facies ]: The numberK of categories contained in the training
image.
8. Target Marginal Distribution [Marginal Cdf ]: The target category proportions, must
be given in sequence from category 0 to categoryNb Facies -1. The sum of all tar-
get proportions must be 1
87

Figure 6.17:SNESIMmain interface.
A. General; B. Conditioning; C. Region; D. Advanced
88

9. # of Nodes in Search Template[Max Cond]: The maximum numberJ of nodes con-
tained in the search template. The larger theJ value, the better the simulation
quality if the training image is correspondingly large, but the more demanding the
computer memory. Usually, around 40 nodes in 2D and 60 nodes in 3D with multi-
grid option can create fairly good models
10. Search Template Geometry[Search Ellipsoid ]: The ranges and angles defining
the ellipsoid used to search for neighboring conditioning data. The search template
τJ is automatically built from the search ellipsoid retaining theJ closest nodes
11. Hard Data | Object [Hard Data.grid ]: The grid containing the hard conditioning
data. The hard data object must be a point set. The default input is ‘None’, which
means no hard conditioning data is used
12. Hard Data | Property [Hard Data.property ]: The property of the hard condition-
ing data, which must be a categorical variable with values between 0 andK − 1.
This parameter is ignored when no hard conditioning data is selected
13. Use Probability Data Calibrated from Soft Data[Use ProbField ]: This flag indi-
cates whether the simulation should be conditioned to prior local probability cubes.
If marked, performSNESIMconditional to prior local probability information. The
default is not to use soft probability cubes.
14. Soft Data | Choose Properties[ProbField properties ]: Selection for the soft
probability data. One property must be specified for each categoryk. The prop-
erty sequence is critical to the simulation result: thekth property corresponds to
P(Z(u) = k | Y (u)
). This parameter is ignored ifUse ProbField is set to 0. Note
that the soft probability data must be given over the same simulation grid defined in
(1)
15. Tau Values for Training Image and Soft Data[TauModelObject ]: Input two Tau
parameter values: the first Tau value is for the training image, the second Tau value
is for the soft conditionig data. The default Tau values are ‘1 1’. This parameter is
ignored ifUse ProbField is set to 0
16. Vertical Proportion | Object [VerticalPropObject ]: The grid containing the ver-
tical proportion curve. This grid must be in 1D dimension: number of cells in X
89

and Y directions must be 1, and the number of cells in Z direction must be the same
as that of the simulation grid. The default input is ‘None’, which means no vertical
proportion data is used
17. Vertical Proportion | Choose Properties[VerticalProperties ]: Select one and
only one proportion for each categoryk. The property sequence is critical to the
simulation result. This parameter is ignored whenVerticalPropObject is ‘None’
18. Use Azimuth Rotation[Use Rotation ]: The flag to use the azimuth rotation concept
to handle non-stationary simulations. If marked (set as 1), then use rotation concept.
The default is unmarked
19. Use Global Rotation[Use Global Rotation ]: To rotate the training image with a
single azimuth angle. If marked (set as 1), a single angle must be specified in
‘Global Rotation Angle’
20. Use Local Rotation[Use Local Rotation ]: To rotate the training image for each re-
gion. If selected, a rotation angle must be specified for each region inRotation categories .
Note thatUse Global Rotation andUse Local Rotation are mutually exclusive
21. Global Rotation Angle[Global Angle ]: The global rotation angle given in degree.
The training image will be rotated by that angle prior to simulation. This parameter
is ignored ifUse Global Rotation is set to 0
22. Property with Azimuth Rotation Categories [Rotation property ]: The property
containing the coding of the rotation regions, must be given over the same simu-
lation grid as defined in (1). The region code ranges from 0 toNrot − 1 where
Nrot is the total number of regions. The angles corresponding to all the regions are
specified byRotation categories
23. Rotation Angles per Category[Rotation categories ]: The angles, expressed in
degrees, corresponding to each region. The angles must given in sequence separated
by space. This parameter is ignored ifUse Global Rotation is set to 0
24. Use Scaling[Use Affinity ]: The flag to use the affinity concept to handle non-
stationary simulations. If marked (set as 1), use the affinity concept. The default is
unchecked
90

25. Use Global Affinity [Use Global Affinity ]: The flag to indicate whether to scale
the training image with same constant factors in each X/Y/Z direction. If marked
(set as 1), three affinity values must be specified in ‘Global Affinity Change’
26. Use Local Affinity [Use Local Affinity ]: To scale the training image for each
affinity region. If set to 1, three affinity factors must be specified for each region.
Note thatUse Global Affinity andUse Local Affinity are mutually exclusive
27. Global Affinity Change [Global Affinity ]: Input three values (separated by spaces)
for the X/Y/Z directions, respectively. If the affinity value in a certain direction is
f , then the category width in that direction is1/f times the original width
28. Property with Affinity Changes Categories[Affinity property ]: The property
containing the coding of the affinity regions, must be given over the same simulation
grid as defined in (1). The region code ranges from 0 toNaff − 1 whereNaff is
the total number of affinity regions. The affinity factors should be specified by
Affinity categories
29. Affinity Changes for Each Category[Affinity categories ]: Input the affinity
factors in the table: one scaling factor for each X/Y/Z direction and for each region.
The region index (the first column in the table) is actually the region indicator plus
1
30. Min # of Replicates[Cmin]: The minimum number of training replicates of a given
conditioning data event to be found in the search tree before retrieving the condi-
tional probability. The default value is 1.
31. Servosystem Factor[Constraint Marginal ADVANCED]: A parameter (∈ [0, 1]) which
controls the servosystem correction. The higher the servosystem parameter value,
the better the reproduction of the target category proportions. The default value is
0.5.
32. Re-simulated Nodes Percentage[revisit nodes prop ]: A parameter indicating
the proportion∈ [0%, 50%] of nodes which will be re-simulated at each multigrid.
The default value is15%.
33. # of Multigrids [Nb Multigrids ADVANCED]: The number of multiple grids to con-
sider in the multiple grid simulation. The default value is 3.
91

34. Debug Level[Debug Level ]: The option controls the output in the simulation grid.
The larger the debug level, the more outputs fromSNESIM:
• If 0, then only the final simulation result is output (default value);
• If 1, then a map showing the number of nodes dropped during simulation is
also output;
• if 2, then intermediate simulation results are output in addition to the outputs
from options 0 and 1.
35. Use sub-grids[Subgrid choice ]: The flag to divide the simulation nodes on the
current multi-grid into three groups to be simulated in sequence. It isstrongly
recommended to use this option for 3D simulation
36. Previously simulated nodes[Previously simulated ]: The number of nodes in cur-
rent subgrid to be used for data conditioning. The default value is 4. This parameter
is ignored ifSubgrid choice is set to 0
37. Use Region[Use Region ]: The flag indicates whether to use the region concept. If
marked (set as 1), performSNESIMsimulation with the region concept; otherwise
performSNESIMsimulation over the whole grid
38. Property with Region Code[Region Indicator Prop ]: The property containing
the coding of the regions, must be given over the same simulation grid as defined
in (1). The region code ranges from 0 toNR − 1 whereNR is the total number of
regions
39. List of Active regions [Active Region Code]: The list of region (or regions when
simulate multple regions simultaneously) to be simulated. If simulation with mul-
tiple regions, the input region codes should be separated by spaces
40. Condition to Other Regions[Use Previous Simulation ]: The option to perform
region simulation conditional to data from other regions
41. Property of Previously Simulated Regions[Previous Simulation Pro ]: The prop-
erty simulated in the other regions. The property can be different from one region
to another. See sectionRegion concept(page 84)
92

42. Isotropic Expansion[expand isotropic ]: The flag to use isotropic expansion method
for generating the series of cascaded search templates and multiple grids
43. Anisotropic Expansion[expand anisotropic ]: The flag to use anisotropic factors
for generating a series of cascaded search templates and multiple grids
44. Anistropic Expansion Factors[aniso factor ]: Input an integer expansion factor
for each X/Y/Z direction and for each multiple grid in the given table. The first
column of the table indicates the multiple grid level, the smaller the number, the
finer the grid. This option is not recommended to beginners
Examples
This section presents four examples showing how theSNESIMalgorithm works with
categorical training images with or without data conditioning, for both 2D and 3D simu-
lations.
1. Example 1: 2D unconditional simulation
Fig. 6.18(a) shows a channel training image of size150× 150. This training image
contains four facies: mud background, sand channel, levee and crevasse. The facies
proportions are 0.45, 0.2, 0.2 and 0.15 respectively. An unconditionalSNESIMsim-
ulation is performed with this training image using a maximum of 60 conditioning
data. The search template is isotropic in 2D with isotropic template expansion. Four
multiple grids are used to capture the large scale channel structures. Fig. 6.18(b)
gives oneSNESIMrealization, whose facies proportions are 0.44, 0.19, 0.2 and
0.17 respectively. It is seen that the channel continuities and the facies attachment
sequence are reasonably well reproduced.
2. Example 2: 3D simulation conditioning to well data and soft seismic data
In this example, the large 3D training image of Fig. 6.19(a) is created with the
object-based program ‘fluvsim’ (Deutsch and Tran, 2002). The dimension of this
training image is150 × 195 × 30, and the facies proportions are 0.66, 0.30 and
0.04 for mud background, sand channel and crevasse, respectively. The channels
are oriented in the North-South direction with varying sinuosity and width.
The simulated field is of size100×130×10. Two vertical wells, five deviated wells
and two horizontal wells were drilled during an early production period. Those
93

(a) Four categories training image (b) OneSNESIMrealization
Figure 6.18: Four facies training image and oneSNESIMsimulation
(black: mud facies; dark gray: channel; light gray: levee; white: crevasse)
wells provide hard conditioning data at the well locations, see Fig. 6.19(b). One
seismic survey was collected, and calibrated from the well hard data into soft prob-
ability cubes for each facies as shown in Fig. 6.19 (c)-(e).
For theSNESIMsimulation, 60 conditioning data nodes are retained in the search
template. The three major axes of the search ellipsoid are of size 20, 20 and 5, re-
spectively. The angles of azimuth, dip and rake are all zero. Four multiple grids are
used with isotropic template expansion. The subgrid concept is adopted with 4 ad-
ditional nodes in the current subgrid for data conditioning. OneSNESIMrealization
conditioning to both well hard data and seismic soft data is given in Fig. 6.19(f).
This simulated field has channels orientated in the NS direction, with the high sand
probability area (light gray to white in Fig. 6.19(d)) having more sand facies. The
simulated facies proportions are 0.64, 0.32 and 0.04 respectively.
3. Example 3: 2D hard conditioned simulation with affinity and rotation regions
In this example,SNESIMis performed with scaling and rotation to account for local
non-stationarity. The simulation field is the last layer of Fig. 6.19(b), which is di-
vided into three affinity regions (Fig. 6.20(a)) and three rotation regions (Fig. 6.20(b)).
For the channel training image of Fig. 6.20(c) which is the4th layer of Fig. 6.19(a),
the channel width in each affinity region (0, 1, 2) is extended by a factor of 2, 1 and
0.5, respectively; and the channel orientation in each rotation region (0, 1, 2) is0o,
−60o and60o, respectively. Fig. 6.20(d) gives oneSNESIMrealization conditioned
94

(a) Three categories training image (b) Well conditioning data
(c) Probability of mud facies (d) Probability of channel facies
(e) Probability of crevasse facies (f) OneSNESIMrealization
Figure 6.19: Three facies 3D traning image (black: mud facies; gray: channel; white:
crevasse), well hard data, facies probability cubes and oneSNESIMrealization. Graphs
(c)-(f) are given for the same slices: X=12, Y=113, Z=4
95

to the well data using both the affinity and rotation regions. It is seen that the chan-
nel width varies from one region to another; and the channels between regions are
well connected.
(a) Affinity region (b) Rotation region
(c) Three facies 2D training image (d) OneSNESIMrealization
Figure 6.20: Affinity and rotation regions (black: region 0; gray: region 1; white: region
2); three facies 2D training image and oneSNESIMsimulation (black: mud facies; gray:
sand channel; white: crevasse)
4. Example 4: 2D simulation with soft data conditioning
In this last example, the simulation grid is again the last layer of Fig. 6.19(b). Both
the soft data and well hard data from that layer are used to for data conditioning.
Fig. 6.21(a) gives the mud probability field. Fig. 6.20(c) is used as training image.
The search template is isotropic with 60 nodes. Four multiple grids are retained
with isotropic template expansion.SNESIMis run for 100 realizations. Fig. 6.21
(c)-(e) present 3 realizations: the channels are well connected in the NS direction;
96

and their locations are consistent with the soft probability data (see the dark area in
Fig. 6.21(a) for the channel). Fig. 6.21(b) gives the mud facies probability obtained
from the simulated 100 realizations, this E-type probability is consistent with the
input mud probability Fig. 6.21(a).
(a) Probability of mud facies (b) Experimental mud probability
(c) SNESIMrealization 12 (d) SNESIMrealization 27 (e) SNESIMrealization 78
Figure 6.21: Mud facies probability, experimental mud probability from 100SNESIM
realizations and threeSNESIMrealizations (black: mud facies; gray: sand channel; white:
crevasse)
97

6.2.2 FILTERSIM
SNESIMis designed for modeling categories, e.g. facies distributions. It is limited by the
number of categorical variables it can handle.SNESIMis memory-demanding when the
training image is large with a large variety of different patterns.SNESIMdoes not work
for continuous variables. Themps algorithmFILTERSIM, called filter-based simulation
(Zhang, 2006), has been proposed to circumvent these problems. TheFILTERSIMalgo-
rithm is much less memory demanding yet with a reasonable CPU cost, and it can handle
both categorical and continuous variables.
FILTERSIMutilizes linear filters to classify training patterns in a filter score space
of reduced dimension. Similar training patterns are stored in a class characterized by an
average pattern called prototype. During simulation, the prototype closest to the condi-
tioning data event is determined. A pattern from that prototype class is then drawn, and
pasted onto the simulation grid.
Instead of saving faithfully all training replicates in a search tree as doesSNESIM,
FILTERSIMonly saves the central location of each training pattern in memory, hence
reducing RAM demand.
Filters and scores
A filter is a set of weights associated with a specific data configuration/templateτJ =
{u0;hi, i = 1, . . . , J}. Each nodeui of the template is characterized by a relative offset
vectorhi = (x, y, z)i from the template centeru0 and is associated with a specific fil-
ter value or weightfi. The offset coordinatesx, y, z are integer values. For aJ-nodes
template, its associated filter is{f(hi); i = 1, . . . , J}. The filter configuration can be of
any shape: Fig. 6.22.a shows a irregular shaped filter and Fig. 6.22.b gives a cube-shaped
filter of size5× 3× 5.
A search template is used to capture patterns from a training image. The search tem-
plate ofFILTERSIMmust be rectangular of size(nx, ny, nz), wherenx, ny, nz are odd
positive integers. Each node of this search template is recorded by its relative offset to the
centroid.
Fig. 6.22.b shows a search template of size5× 3× 5.
FILTERSIMrequires that the filter configuration be same as the search template, such
that this filter can be applied to the training pattern centered at locationu. The training
98

Figure 6.22: Filter and score: (a) a general template; (b) a cube-shaped template; (c) from
filter to score.
pattern is then summarized by a filter scoreSτ (u):
Sτ (u) =n∑
i=1
f(hi) · pat(u + hi), (6.6)
wherepat(u + hi) is the pattern nodal value.
Fig. 6.22.c illustrates the process of creating a filter score with a 2D filter.
Clearly, one filter is not enough to capture the essential information carried by a given
training pattern. A set ofF filters should be designed to capture the diverse characteristics
of a training pattern. TheseF filters create a vector ofF scores to represent the training
pattern, Eq. 6.6 is rewritten as:
Skτ (u) =
n∑i=1
fk(hi) · pat(u + hi), k = 1, . . . , F (6.7)
Note that the pattern dimension is reduced from the template sizenx ∗ ny ∗ nz to F . For
example a 3D pattern of size11 × 11 × 3 can be described by the 9 default filter scores
proposed inFILTERSIM.
For a continuous training image (TI), the F filters are directly applied to the con-
tinuous values constituting each training pattern. For a categorical training image with
99

K categories, this training image is first transformed intoK set of binary indicators
Ik(u), k = 0, . . . , K − 1,u ∈ TI:
Ik(u) =
{1 if u belongs tokth category
0 otherwise(6.8)
A K-category pattern is thus represented byK sets of binary patterns, each indicating the
presence/absence of one single category at a certain location. TheF filters are applied
to each one of theK binary patterns resulting in a total ofF × K scores. A continuous
training image can be seen as a special case of a categorical training image with a single
categoryK = 1.
Filters definition
FILTERSIMaccepts two filter definitions: the default filters provided byFILTERSIMand
user-defined filters.
By default,FILTERSIMprovide 3 filters (average, gradient and curvature) for each
X/Y/Z direction, with the filters configuration being identical to that of the search tem-
plate. Letni be the template size in thei direction (i denotes either X, Y or Z),mi =
(ni − 1)/2, andαi = −mi, . . . , +mi be the filter node offset in thei direction, then the
default filters are defined as:
• average filter: f i1(αi) = 1− |αi|
mi∈ [0, 1]
• gradient filter: f i2(αi) = αi
mi∈ [−1, 1]
• curvature filter: f i3(αi) = 2|αi|
mi− 1 ∈ [−1, 1]
The default total is 6 filters for a 2D search template and 9 in 3D.
The users can also design their own filters and enter them into a data file. This option
is not recommended to beginners. The filter data file should follow the following format
(see Fig. 6.23):
• The first line must be an integer number indicating the total number of filters in-
cluded in this data file. Starting from the second line, list each filter definition one
by one.
100

• For each filter, the first line gives the filter name which must be a string and the
weight associated to the filter score (this weight is used later for pattern classi-
fication). In each of the following lines, list the offset (x, y, z) of each template
node and its associated weight (f(x, y, z)). The four numbers must be separated by
spaces.
Although the geometry of the user defined filters can be of any shape and any size,
only those filter nodes within the search template are actually retained for the score cal-
culation to ensure that the filter geometry is same as that of the search template. For
those nodes in the search template but not in the filter template,FILTERSIMadds dummy
nodes associated with a zero filter value. There are many ways to create the filters, Princi-
pal Component Analysis (PCA) (Jolliffe, 1986) is one alternative, refer to Zhang (2006)
for more details.
Figure 6.23: Format of user-defined filter.
Pattern classification
Sliding theF filters over aK-category training image will result inFK score maps,
where each local training pattern is summarized by aFK-length vector in the filter score
101

space. In general,FK is much smaller than the size of the filter templateτ , hence the
dimension reduction is significant.
Similar training patterns will have similarFK scores. Hence by partitioning the filter
score, similar patterns can be grouped together. Each pattern class is represented by a
pattern prototypeprot, defined as the point-wise average of all training patterns falling
into that class. A prototype has the same size as the filter template, and is used as the
pattern group ID.
For a continuous training image, a prototype associated with search templateτJ is
calculated as:
prot(hi) =1
c
c∑j=1
pat(uj + hi), i = 1, . . . , J (6.9)
wherehi is theith offset location in the search templateτJ , c is the number of replicates
within that prototype class;uj (i = 1, . . . , c) is the center of a specific training pattern.
For a categorical variable, Eq. 6.9 is applied to each of theK sets binary indicator
maps transformed by Eq. 6.8. Hence a categorical prototype consists ofK proportion
maps, each map giving the probability of a certain category to prevail at a template loca-
tion uj + hi:
prob(hi) ={protk(hi), k = 1, . . . , K
}, (6.10)
whereprotk(hi) = P (Z(u + hi) = k).
For maximal CPU efficiency, a two-step partition approach is proposed:
1. group all training patterns into some rough pattern clusters using a fast classification
algorithm; these rough pattern clusters are called parent classes. Each parent class
is characterized by its own prototype;
2. partition those parent classes that have both too many and too diverse patterns in
it using the same (previous) classification algorithm. The resulting sub-classes are
called children classes. These children classes might be further partitioned if they
contain too many and too diverse patterns. Each final child class is characterized by
its own prototype of type Eq. 6.9.
For any class and corresponding prototype, the diversity is defined as the averaged
filter variance:
V =1
FK
FK∑k=1
ωk · σ2k,l (6.11)
102

where:
ωk ≥ 0 is the weight associated with thekth filter score,∑FK
k=1 ωk = 1. For the
default filter definition,ωk is 3, 2 and 1 for average, gradient and curvature filters, respec-
tively. For the user-defined filters, theωk value for each filter must be specified in the
filter data file (Fig. 6.23);
σ2k = 1
c
∑ci=1(S
ik−mk)
2 is the variance of thekth score value over thec replicates;
mk = 1c
∑ci=1 Si
k,l is the mean value of thekth score value over thec replicates;
Sik is the score of theith replicate ofkth filter score defining the prototype.
The prototypes with diversity higher than a threshold and with too many replicates are
further partitioned.
This two-step partition approach allows finding quickly the prototype closest to the
data event. Without the two-step partition, it would take at each node 3000 distance
comparisons to check all 3000 prototypes (parent and children); while with the two-step
partition, it takes only 50 comparisons to find the best parent prototype among all 50
parent prototype classes, then it takes in average 60 comparisons to find the best child
prototype, thus in average a total of 110 comparisons.
Partition method
Two classification methods are provided: cross partition (Zhang, 2006) and K-Mean clus-
tering partition (Hartigan, 1975). The cross partition consists of partitioning indepen-
dently each individual filter score into equal frequency bins (see Fig. 6.24.a). Given a
score space of dimensionFK, if each filter score is partitioned intoM bins (2 ≤ M ≤10), then the total number of parent classes isMFK . However, because the filter scores
are partitioned independently one from another, many of these classes will contain no
training patterns. Fig. 6.25 shows the results of cross partition in a 2-filter score space
using the proposed two-step approach splitting parent classes into children.
The cross partition approach is fast, however it is rough resulting in many classes
having few or no replicate.
A better partition method using K-Mean clustering is also proposed: given an input
number of clusters, the algorithm will find the optimal centroid of each cluster, and assign
training patterns to a specific cluster according to a distance between the training pattern
and the cluster centroids (see Fig. 6.24.b). This K-Mean clustering partition is one of
103

Figure 6.24: Two classification methods.
the simplest unsupervised learning algorithms; it creates better pattern groups all with
a reasonable number of replicates, however it is slow compared to the cross partition.
Also the number of clusters is critical to both CPU cost and the final simulation results.
Beginning level users are not advised to use this option. Fig. 6.26 shows the results of
K-Mean clustering partition in a 2-filter score space with the proposed two-step approach.
Single grid simulation
After creating the prototype list (for all parents and children) built from all the training
patterns, one can proceed to generate simulated realizations.
The classic sequential simulation paradigm (Deutsch and Journel, 1998) is extended to
pattern simulation. At each nodeu along the random path visiting the simulation gridG, a
search templateτ of same size as the filter template is used to extract the conditioning data
eventdev(u). The prototype closest to that data event, based on some distance function,
is found. Next a patternpat is randomly drawn from that closest prototype class, and is
pasted onto the simulation gridG. The inner part of the pasted pattern is frozen as hard
data, and will not be revisited during simulation on the current (multiple) grid. The simple
single gridFILTERSIMapproach is summarized inAlgorithm 6.12.
104

Figure 6.25: Illustration of cross partition in a 2-filter score space. Each dot represents
a local training pattern; the solid lines show the first parent partition (M = 3); the dash
lines give the secondary children partition (M = 2).
Figure 6.26: Illustration of K-Mean clustering partition in a 2-filter score space. Each dot
represents a local training pattern; the solid lines show the first parent partition (M = 4);
the dash lines give the secondary children partition (M = 3).
Distance definition
A distance function is used to find the prototype closest to a given data eventdev. The
distance betweendev and any prototype is defined as:
d =J∑
i=1
ωi · |dev(u + hi)− prot(u0 + hi)| (6.12)
105

Algorithm 6.12 Simple, Single gridFILTERSIMsimulation1: Create score maps with given filters
2: Partition all training patterns into classes and prototypes in the score space
3: Relocate hard conditioning data into the simulation gridG
4: Define a random path on the simulation gridG
5: for Each nodeu in the random pathdo
6: Extract the conditioning data eventdev centered atu
7: Find the parent prototypeprotp closest todev
8: if protp has children prototype liststhen
9: Find the child prototypeprotc closest todev
10: Randomly draw a patternpat from protc
11: else
12: Randomly draw a patternpat from protp
13: end if
14: Pastepat to the realization being simulated, and freeze the nodes within a central
patch
15: end for
where
J is the total number of nodes in the search templateτ ;
ωi is the weight associated to each template node;
u is the center node of the data event;
hi is the node offset in the search templateτ ;
u0 is the center node location of the prototype.
Given three different data types: original hard data (d = 1), previously simulated values
frozen as hard data (d = 2), other values informed by pattern pasting (d = 3). The above
weightωi is defined as
ωi =
W1/N1 : hard data(d=1)
W2/N2 : patch data(d=2)
W3/N3 : other(d=3)
,
whereWd (d = 1, 2, 3) is the weight associated with data typed, andNd is the number of
nodes of data typed within the data eventdev. It is required thatW1 + W2 + W3 = 1,
andW1 ≥ W2 ≥ W3, to emphasize the impact of hard data and data frozen as hard (inner
106

patch values).
Note that the data eventdev may not be fully informed, thus only those informed
nodes are retained for the distance calculation.
Marginal distribution reproduction
It may be desirable that the mean value (for continuous variables) or the global propor-
tions (for categorical variables) of a simulated realization be reasonably close to a target
mean or proportions. There is however no such constraint inFILTERSIMas described in
Algorithm 6.12. To better reproduce the target, instead of randomly drawing a pattern
from the closest prototype classFILTERSIM introduces a servosystem intensity factor
ω ∈ [0, 1), similar to that used in theSNESIMalgorithm.
• For a continuous variable, letmt be the target mean value, andmc the mean value
simulated so far. Calculate the gear factor:
µ = (mt/mc)ω
1−ω . (6.13)
Before selecting a pattern from the closest prototype classprot, all patterns be-
longing to classprot are sorted in ascending order based on their inner patch mean
values. Those sorted patterns are numbered from 1 toNp, whereNp is the total
number of patterns falling into prototype classprot. If mt > mc, thenµ > 1 which
means a pattern with high mean value should be selected. The larger theω value,
the more control on this pattern selection.
A power function
f(i) =
(i
Np
)µ
(6.14)
is used as the probability function to select the pattern IDi within the sorted pro-
totype class, whereNp is the total number of patterns falling into that prototype
classprot. µ > 1 means the current simulated mean is lower than the target, hence
a pattern with high mean value will be preferentially selected, see Fig. 6.27; vice
versa forµ < 1. If ω = 0, thenµ = 1, this corresponds to a uniform distribution,
resulting in all patterns to be drawn equi-probably, hence no control on the target
mean value. Ifω → 1, the target mean is better reproduced at the risk of failing to
reproduce the training image structures.
Steps 10 and 12 ofAlgorithm 6.12 are modified asAlgorithm 6.13.
107

Figure 6.27: Pattern selection function for target reproduction
• For a binary variable, letpc0, p
c1 denote the proprotions of values simulated so far,
and letpt0, p
t1 denote the target category proprotions. Becausepc
1, pt1 are the current
mean valuemc and the target mean valuemt of the simulated realizations, hence
Eq. 6.13 andAlgorithm 6.13 are used to select the best pattern for reproducing the
target category proportions.
• For a categorical variable with more than 2 categories (K > 2), an indexG(i, k) is
defined to measure the ability to tune thekth category proportion of theith pattern
in the prototype class:
G(i, k) =∣∣(Nsp
ck + Nrq
ki )/(Ns + Nr)− pt
k
∣∣ , i = 1, . . . , Np, k = 0, . . . , K − 1
where
Ns is the number of nodes informed by either hard data or patched simulated
values;
pck is the proportion of values in classk simulated so far;
Nr is the number of nodes within the inner patch template;
qki is the proportion of categoryk in patterni;
ptk is the target proportion of classk;
Np is the number of patterns in the prototype class.
Let H(i) = max {G(i, k); k = 0, . . . , K − 1}, let V1 = max {H(i)} andV2 =
min {H(i)} for i = 0, . . . , Np. If V2 = V1, all patterns in the prototype class are
equi-probably drawn during simulation. Next, define the gear factor as
µ = (V2/V1)ω
1−ω ≤ 1, and useAlgorithm 6.13 to sample the best pattern from the
108

prototype class for better proprotion reproduction.
Algorithm 6.13 Servosystem control on target reproduction1: Compute the gearing factorω
2: Sort the patterns within the closest prototype clas
3: Use Eq. 6.14 to select the ‘best’ pattern for reproducing target mean
Note that only the nodes within the inner patch template are retained for servosystem
control.
Multiple grid simulation
Similar to theSNESIMalgorithm, the multiple grid simulation concept (Tran, 1994) is
used to capture the large scale structures of the training image with a large but coarse
templateτ . In the gth (1 ≤ g ≤ NG) coarse grid, the filters defined on the rescaled
templateτ g are used to calculate the pattern scores. Sequential simulation proceeds from
the coarset grid to the finest grid. All nodes simulated in the coarser grid are re-simulated
in the next finer grid.
The template is expanded isotropically as described in theSNESIMalgorithm (page 75).
TheFILTERSIMmultiple grid simulation is summarized inAlgorithm 6.14.
Algorithm 6.14 FILTERSIMsimulation with multiple grids1: repeat
2: For thegth coarse grid, rescale the geometry of the search template, the inner patch
template and the filter template
3: Create score maps with the rescaled filters
4: Partition the training patterns into classes and corresponding prototypes
5: Define a random path on the coarse simulation gridGg
6: Relocate hard conditioning data into the current coarse gridGg
7: Perform simulation on current gridGg (Algorithm 6.12)
8: If g 6= 1, delocate hard conditioning data from the current coarse gridGg
9: until All multi-grids have been simulated
109

Soft data integration
TheFILTERSIMalgorithm allows users to constrain simulations to soft data defined over
the same simulation grid. The soft data when simulating a continuous variable should be
a spatial trend (local varying mean, internal ref. ??) of the attribute being modeled, hence
only one soft data is allowed with the same unit as that attribute. For categorical training
images, there is one soft data per category. Each soft cube is a probability field indicating
the presence/absence of a category at each simulation grid nodeu, hence there is a total
of K probability cubes,
• The procedure of integrating soft data for continuous variable is described inAlgo-
rithm 6.15. The soft data eventsdev is used to fill in the data eventdev: at any
uninformed locationuj in the data event, set its value to the soft data value at the
same location (dev(uj) = sdev(uj)). Because this soft data contributes to the pro-
totype selection, hence the choice of the sampled pattern is constrained by the local
trend.
• For a categorical variable, the original training image has been internally trans-
formed intoK binary indicator maps (category probabilities) through Eq. 6.8, thus
each resulting prototype is a set ofK probability templates (Eq. 6.10). At each sim-
ulation locationu, the prototype closest to the data eventdev is a probability vector
prob(u). The same search templateτ is used to retrieve the soft data eventsdev(u)
at the locationu. The Tau model (Journel, 2002) is used to integratesdev(u) and
prob(u) pixel-wise at each nodeuj of the search templateτ into a new probability
cubedev∗ (see sectionSoft data integration in SNESIMalgorithm: page 78). A
prototype is found which is closest todev∗, and a pattern is randomly drawn and
pasted onto the simulation grid. The detailed procedure of integrating soft proba-
bility data for categorical attributes is presented inAlgorithm 6.16.
Accounting for local non-stationarity
The same region concept as presented in theSNESIMalgorithm is introduced here to
account for local non-stationarity. It is possible to performFILTERSIMsimulation over
regions, with each region associated with a specific training image and its own parameter
settings. See sectionRegion conceptof the SNESIMalgorithm (page 84) for greater
details.
110

Algorithm 6.15 Data integration for continuous variable1: At each nodeu along the random path, use the search templateτ to extract both the
data eventdev from the realization being simulated, and the soft data eventsdev from
the soft data field
2: if dev is empty (no informed data)then
3: Replacedev by sdev
4: else
5: Usesdev to fill in dev at all uninformed data locations within the search template
τ centered atu
6: end if
7: Usedev to find the closest prototype, and proceed to simulation of the nodeu
Algorithm 6.16 Data integration for categorical variable1: At each nodeu along the random path, use the search templateτ to retrieve both the
data eventdev from the realization being simulated and the soft data eventsdev from
the input soft data field
2: if dev is empty (no informed data)then
3: Replacedev by sdev, and use the newdev to find the closest prototype.
4: else
5: Usedev to find the closest prototypeprot
6: use Tau model to combine prototypeprot and the soft data eventsdev into a new
data eventdev∗ as the local probability map
7: Find the prototype closest todev∗, and proceed to simulation
8: end if
Parameters description
The FILTERSIMalgorithm can be invoked fromSimulation|filtersim std in the upper
part of algorithm panel. Its main interface has 4 pages: ‘General’, ‘Conditioning’, ‘Re-
gion’ and ‘Advanced’ (see Fig. 6.28). TheFILTERSIMparameters is presented page by
page in the following. The text inside ‘[ ]’ is the corresponding keyword in theFILTER-
SIM parameter file.
1. simulation grid name [GridSelector Sim]: The name of grid on which simulation
is to be performed
111

Figure 6.28:FILTERSIMmain interface.
A. General; B. Conditioning; C. Region; D. Advanced
112

2. property name prefix [Property NameSim]: The name of the property to be simu-
lated
3. # of Realizations[Nb Realizations ]: Number of realizations to be simulated
4. Seed[Seed]: A large odd number to initialize the random number generator.
5. Training Image | Object [PropertySelector Training.grid ]: The name of the
grid containing the training image
6. Training Image | Property [PropertySelector Training.property ]: The training
image property, which must be a categorical variable whose value must be between
0 andK − 1, whereK is the number of categories
7. Search Template Dimension[Scan Template ]: The size of the 3D template used to
define the filters. The same template is used to retrieve training patterns and data
events during simulation.
8. Inner Patch Dimension [Patch Template ADVANCED]: The size of the 3D patch of
simulated nodal values frozen as hard data during simulation
9. Continuous Variable [Is Contv ]: A flag indicating that the current training image is
a continuous variable. The variable type must be consistent with ‘Training Image|Property’
10. Categorical Variable[Is Catv ]: A flag indicating that the current training image is
a categorical variable. The variable type must be consistent with ‘Training Image|Property’. Note thatIs Contv andIs Catv are mutually exclusive
11. Target Mean[Marginal Ave]: The mean value of the simulated attribute when work-
ing with continuous variable
12. # of Facies[Nb Facies ]: The total number of categories when working with cate-
gorical variable. This number must be consistent with the number categories in the
training image
13. Target Marginal Distribution [Marginal Cpdf ]: The target category proportions
when working with categorical variable, must be given in sequence from category
0 to categoryNb Facies -1. The sum of all marginal distributions must be 1
113

14. Treat as Continuous Data for Classification[Treat Cate As Cont ]: The flag to
treat a categorical training image as continuous variable for pattern classification
(the simulation is still performed with categorical variable). With this option, the
F filters are directly applied on the training image without having to transform
the categorical variables intoK sets of binary indicators, hence the resulting score
space is of dimensionF instead ofFK, and simulation is faster. Note that this
training image coding will affect the simulation results
15. Hard Data | Object [Hard Data.grid ]: The grid containing the hard conditioning
data. The hard data object must be a point set. The default input is ‘None’, which
means no hard conditioning data is used
16. Hard Data | Property [Hard Data.property ]: The property of the hard condition-
ing data, which must be a categorical variable with values between 0 andK − 1.
This parameter is ignored when no hard data conditioning is selected
17. Use Soft Data[Use SoftField ]: This flag indicates whether the simulation should
be conditioned to prior local soft data. If marked, performFILTERSIMconditional
to soft data. The default is not to use soft data
18. Soft Data | Choose Properties[SoftData properties ]: Selection for local soft
data. For a continuous variable, only one soft conditioning property is allowed
which is treated as a local varying mean. For a categorical variable, select one
and only one property for each category. The property sequence is critical to the
simulation result: thekth property corresponds to thekth category. This parameter
is ignored ifUse ProbField is set to 0. Note that the soft data must be given over
the same simulation grid as defined in (1)
19. Tau Values for Training Image and Soft Data[TauModelObject ]: Input two Tau
parameter values: the first Tau value is for the training image, the second Tau value
is for the soft conditioning data. The default Tau values are ‘1 1’. This parameter
is ignored ifUse SoftField is set to 0. Note thatTauModelObject only works for
categorical variables
20. Use Region[Use Region ]: The flag indicates whether to use region concept. If
marked (set as 1), performSNESIMsimulation with the region concept; otherwise
performFILTERSIMsimulation over the whole grid
114

21. Property with Region Code[Region Indicator Prop ]: The property containing
the coding of the regions, must be given over the same simulation grid as defined
in (1). The region code ranges from 0 toNR − 1 whereNR is the total number of
regions
22. List of Active regions [Active Region Code]: The region to be simulated, or re-
gions when multiple regions are simulated simultaneously. When simulating with
multiple regions, the input region codes should be separated by spaces
23. Condition to Other Regions[Use Previous Simulation ]: The option to perform
region simulation conditional to data from other regions
24. Property of Previously Simulated Regions[Previous Simulation Pro ]: The prop-
erty simulated in the other regions. The property can be different from one region
to another. See sectionRegion concept(page 84)
25. Servosystem Factor[Constraint Marginal ADVANCED]: A parameter (∈ [0, 1]) which
controls the servosystem correction. The higher the servosystem factor, the better
the reproduction of the target mean value (continuous variable) or the category pro-
portions (categorical variable). The default value is 0.5.
26. # of Multigrids [Nb Multigrids ADVANCED]: The number of multiple grids to con-
sider in the multiple grid simulation. The default value is 3.
27. Min # of Replicates for Each Grid [Cmin Replicates ]: A pattern prototype split
criteria. Only those prototypes with more thanCmin Replicates can be further
divided. Input aCmin Replicates value for each multiple coarse grid. The default
value is 10 for each multigrid.
28. Weights to Hard, Patch & Other [Data Weights ]: The weights assigned to differ-
ent data types (hard data, patched data and all other data). The sum of these weights
must be 1. The default values are 0.5, 0.3 and 0.2.
29. Debug Level[Debug Level ]: The flag controls the output in the simulation grid. The
larger the debug level, the more outputs fromFILTERSIMsimulation:
• If 0, then only the final simulation result is output (default value);
115

• If 1, then the filter score maps of the finest grid are also output over the training
image grid;
• if 2, then the intermediate simulation results are output in addition;
• if 3, then the map giving all parent prototypes’ id number is output in addition.
30. Cross Partition [CrossPartition ]: Perform pattern classification with cross parti-
tion method (default option)
31. Partition with K-mea [KMeanPartition ]: Perform pattern classification with K-
mean clustering method. Note that‘Cross Partition’ and ‘Partition with
K-mean’ are mutually exclusive
32. Number of Bins for Each Filter Score | Initialization [Nb Bins ADVANCED]: The
number of bins for parent partition when using cross partition, the default value is
4
33. Number of Bins for Each Filter Score|Secondary Partition[Nb Bins ADVANCED2]:
The number of bins for children partition when using cross partition, the default
value is 2
34. Maximum Number of Clusters| Initialization [Nb Clusters ADVANCED]: The num-
ber of bins for parent partition when using K-mean partition, the default value is 200
35. Maximum Number of Clusters | Secondary Partition [Nb Clusters ADVANCED2]:
The number of bins for children partition when using K-mean partition, the default
value is 2
36. Distance Calculation Based on| Template Pixels[Use Normal Dist ]: With this
option, the distance is defined as the pixel-wise sum of differences between the
data event values and the corresponding prototype values (Eq. 6.12). This is the
default option
37. Distance Calculation Based on| Filter Scores[Use Score Dist ]: With this option,
the distance is defined as the sum of differences between the data event scores
and the pattern prototype scores. This option has not yet been implemented in the
currentFILTERSIMversion. Note thatUse Normal Dist andUse Score Dist are
mutually exclusive
116

38. Default Filters [Filter Default ]: The option to use the default filters provided by
FILTERSIM: 6 filters for a 2D search template and 9 filters for a 3D search template
39. User Defined Filters[Filter User Define ]: The option to use user’s own filter
defintions. Note that‘Default’ and‘User Defined’ are mutually exclusive
40. The Data File with Filter Definition [User Def Filter File ]: Input a data file with
the filter definitions (see Fig. 6.23). This parameter is ignored ifFilter User Define
is set to 0
Examples
In this section,FILTERSIM is run for both unconditional and conditional simulations.
The first three examples demonstrate theFILTERSIMalgorithm with categorical training
images; the last example illustrates the ability of theFILTERSIMalgorithm to handle
continuous variables.
1. Example 1: 2D unconditional simulation
The first example is a four facies unconditional simulation using Fig. 6.18(a) as
training image. The search template is of size23× 23× 1, and the patch template
is of size15× 15× 1. The number of multiple grid is 3, and the minimum number
of replicates for each multiple grid is 10. The pattern classification method is cross
partition with 4 bins and 2 bins for the two-step partition, respectively. The target
proportions were set to the TI’s proportions, see Table 6.1. Fig. 6.29 shows two
FILTERSIMrealizations, which depict a reasonable training pattern reproduction.
The facies proportions for these two realizations are given in Table 6.1. Compared
to theSNESIMsimulation of Fig. 6.18(b), theFILTERSIMalgorithm appears to
better capture the large scale channel structures.
2. Example 2: 2D unconditional simulation with affinity and rotation
In this example, the region concept is used to account for local non-stationarity.
The simulation field is of size100× 130× 1, same as used in the third example of
theSNESIMalgorithm. The 2D training image is given in Fig. 6.20(c). The affinity
regions are given in Fig. 6.20(a), and the rotation regions are given in Fig. 6.20(b).
The region settings are exactly the same as used in the thirdSNESIMexample.
117

mud background sand channel levee crevasse
training image 0.45 0.20 0.20 0.15
SNESIMrealization 0.44 0.19 0.20 0.17
FILTERSIMrealization 1 0.51 0.20 0.17 0.12
FILTERSIMrealization 2 0.53 0.18 0.18 0.11
Table 6.1: Facies proportions of bothSNESIMandFILTERSIMsimulations
Figure 6.29: TwoFILTERSIMrealizations using Fig. 6.18(a) as training image
(black: mud facies; dark gray: channel; light gray: levee; white: crevasse)
FILTERSIMis performed with a search template of size11×11×1, a patch template
of size7×7×1, three multiple grids and 4 bins for the parent partition. Fig. 6.30(a)
shows oneFILTERSIMsimulation using the affinity regions only, which reflects de-
creasing channel width from South to North without significant discontinuity across
the region boundaries. Fig. 6.30(b) shows oneFILTERSIMrealization using only
the rotation regions. Again, the channel continuity is well preserved across the
region boundaries.
3. Example 3: 2D simulation conditioned to hard well data and soft data
A 2D three faciesFILTERSIMsimulation is performed with soft data conditioning.
The problem settings are exactly the same as those used in the fourthSNESIM
example: the probability fields are taken from the last layer of Fig. 6.19 (c)-(e); and
the training image is given in Fig. 6.20(c).FILTERSIMis run for 100 realizations
with a search template of size11 × 11 × 1, a patch template of size7 × 7 × 1,
118

(a) FILTERSIMsimulation with affinity region (b) FILTERSIMsimulation with rotation region
Figure 6.30:FILTERSIMsimulation with affinity regions (Fig. 6.20(a)) and with rotation
regions (Fig. 6.20(a)). In both cases, Fig. 6.20(c) is used as training image. (black: mud
facies; gray: sand channel; white: crevasse)
three multiple grids and 4 bins for the parent partition. Fig. 6.31 (a)-(c) show three
realizations, and Fig. 6.31(d) gives the E-type mud facies probability calculated
from the 100 realizations. Fig. 6.31(d) is consistent with the soft conditioning data
of Fig. 6.21(a). Recall that inFILTERSIMthe soft data is used only for distance
calculation, not directly as a probability field.
4. Example 4: 3D simulation of continuous seismic data
In this last example, theFILTERSIMalgorithm is used to enhance a 3D seismic
image. Fig. 6.32(a) shows a 3D seismic image with a missing zone due to shadow
effect. The whole grid is of size450× 249× 50, and percentage of missing values
is 24.3%. The goal here is to fill in the missing zone by extending the geological
structures present in the neighboring areas. The north part of the original seismic
image is retained as the training image, which is of size150 × 249 × 50, see the
area in the small white rectangular box.
For theFILTERSIMsimulation, the size of the search template is21× 21× 7, the
size of the patch template is15 × 15 × 5, the number of multiple grids is 3, and
the number of bins for parent partition is 3. All available seismic data are used
for hard conditioning. OneFILTERSIMrealization is given in Fig. 6.32(b). The
simulation area is delineated by the white and black lines. The layering structures
are seen to extend from the conditioning area into the simulation area, with the
119

(a) FILTERSIMrealization 18 (b) FILTERSIMrealization 59
(c) FILTERSIMrealization 91 (d) Experimental mud probability
Figure 6.31: ThreeFILTERSIM realizations (black: mud facies; gray: sand channel;
white: crevasse) and E-type mud probability from 100FILTERSIM realizations. The
training image is given as Fig. 6.20(c)
horizontal large scale structures reasonably well reproduced. For comparison, the
2-point algorithmSGSIMis also used to fill in the empty area with a variogram
modeled from the same training image. Fig. 6.32(c) shows oneSGSIMrealization,
in which the layering structures were lost.
120

(a) Simulation grid with conditioning data
(b) Fill-in simulation withFILTERSIM
(c) Fill-in simulation withSGSIM
Figure 6.32:FILTERSIMandSGSIMused to fill in the shadow zone of a 3D seismic cube
121

Chapter 7
Scripting and Commands
7.1 Commands
Most of the tasks performed in SGeMS using the graphical interface, e.g. creating a new
cartesian grid or performing a geostatistics algorithm, can be executed using a command
line. For example, the following command:
NewCartesianGrid mygrid::100::100::10
creates a new cartesian grid called ”mygrid”, of dimensions 100x100x10. Commands can
be entered in the Command Panel. The Command Panel is not displayed by default. To
display it, go to theViewmenu and selectCommands Panel.
To execute a command, type it in the field underRun Command(refered to as the
command line) and press Enter. The SGeMSCommands Historytab shows a log of
all commands performed either from the graphical interface or the command line. The
commands appear in black. Messages are displayed in blue, and warnings or errors in red.
Commands can be copied from the log, pasted to the command line, edited and executed.
Clicking the Run Command button will prompt for a file containing a list of commands
to be executed. Each command in the file must start on a new line and be contained on
a single line. Comments start with a # sign. Use the Help command (just type Help
in the command line) to get a list of all available commands. SGeMS actually keeps
two logs of the commands executed during a session: one is displayed in the SGeMS
Commands History tab, the other one is recorded to a file called ”sgemshistory.log”. This
file is located in the directory where SGeMS was started. It only contains the commands:
messages, warnings and errors are not recorded.
122

Commands are an easy way to automate tasks in SGeMS. They however offer limited
flexibility: there are no control structures such as loops, tests, etc. Hence performing
20 runs of a given algorithm, each time changing a parameter, would require that the 20
commands corresponding to each run are written in the commands file. If more power-
ful scripting capabilities are needed, one should turn to the other automation facility of
SGeMS: Python scripts.
The following is a list of all SGeMS commands with the input parameters. Parameters in
”‘[]”’ are optional.
• Help List all the commands available with SGeMS.
• ClearPropertyValueIf Grid::Prop::Min::Max Set to not-informed
all value of property ”Prop” in grid ”Grid” that are in range [Min,Max ]
• CopyProperty GridSource::PropSource::GridTarget::
PropTarget::Overwrite::isHardData CopyPropSource fromGridSource
to
PropTarget from GridTarget . If optionsOverwrite is set to true, the copy
would overwrite values already onPropTarget . Option isHardData would
set the copied values as hard data.
• DeleteObjectProperties Grid::Prop1::Prop2... Delete all the spec-
ified properties.
• DeleteObjects Grid1::Grid2... Delete the specified objects.
• SwapPropertyToRAM Grid::Prop1::Prop2... Swap the the specified
properties from the random access memory (RAM) to the hard drive.
• SwapPropertyToDisk Grid::Prop1::Prop2... Swap the the specified
properties from the hard drive to the random access memory (RAM).
• LoadProject Filename Load the specified project.
• SaveGeostatGrid Grid::Filename::Filter Save the specified grid on
file. Filter specified the data format: either asciigslibor binarysgems.
• LoadObjectFromFile Filename Load the object from the specified file.
123

• NewCartesianGrid Name::Nx::Ny::Nz[::SizeX::SizeY::SizeZ]
[::Ox::Oy::Oz] Create a new cartesian grid with the specified geometry. The
default pixel size value for [SizeX,SizeY,SizeZ ] is 1 and the default origin
[Ox,Oy,Oz ] is 0.
• RotateCamera x::y::z::angle Rotate the camera.
• SaveCameraSettings Filename Save the position of the camera into
Filename
• LoadCameraSettings Filename Retrieve the camera position from
Filename
• ResizeCameraWindow Width::Height Set the width and the height of the
camera toWidth andHeight
• ShowHistogram Grid::Prop[::NumberBins::LogScale] Display the
histogram of the specified proprety. The number of bins may also be input with
NumberBins ; the default value is 20. The x axis can also be changed to log scale
by settingLogScale to true.
• SaveHistogram Grid::Prop::Filename[::Format]
[::NumberBins][::LogScale][::ShowStats][::ShowGrid] Save the
specified histogram intoFilename with format specified byFormat . The default
format is PNG. WhenShowStats is set to true, it saves the statistics in the file,
ShowGrid adds a grid to the histogram.
• SaveQQplot Grid::Prop1::Prop2::Filename[::Format]
[::ShowStats][::ShowGrid] Save the QQ plot betweenProp1 andProp2
into Filename , the default format is PNG. WhenShowStats is set to true, it
saves the statistics in the file,ShowGrid adds a grid to the QQ-plot.
• SaveScatterplot Grid::Prop1::Prop2::Filename
[::Format][::ShowStats][::ShowGrid][::YLogScale::
XLogScale] Save the scatter plot betweenProp1 andProp2 into Filename ,
the default format is PNG. WhenShowStats is set to true, it saves the statistics
in the file,ShowGrid adds a grid to the scatter plot.
124

• DisplayObject Grid[::Prop] DisplayProp on the viewing window. When
Prop is not specified, only the grid geometry is displayed.
• HideObject Grid RemoveGrid from the viewing window.
• TakeSnapshot Filename[::Format] Take the snapshot of the current view-
ing window and save it intoFilename . The default format is PNG.
• RunGeostatAlgorithm Parameters Run the algorithms specified by
Parameters
7.2 Python script
SGeMS provides a powerful way of performing repetitive tasks by embedding the Python
language. Useful information about Python (including a beginner’s guide, tutorials and
reference manuals) can be found at http://python.org/doc. SGeMS provides a Python
extension modules that allows Python to call SGeMS commands. The module name is
sgems. It offers three functions:
• execute( ’Command’ ) : executes SGeMS command command.
• get_property( ’GridName’, ’PropertyName’ ) : returns a list con-
taining the values of propertyPropertyName of objectGridName .
• set_property( ’GridName’, ’PropertyName’, Data ) : sets the
values of propertyPropertyName of object GridName to the values of list
Data . If objectGridName has no property calledPropertyName a new prop-
erty is created.
The following is a script example that compute the logarithm of values taken from
the property ’samples’ of the grid named ’grid’. It then writes the logarithms to a new
property called ’logsamples’, displays that property and takes a snapshot in PNG format.
import sgems
from math import *
data = sgems.get_property(’grid’,’samples’)
125

for i in range(len(data)) :
if data[i]>0 : data[i] = log(data[i])
else : data[i] = -9966699
sgems.set_property(’grid’,’log_samples’,data)
sgems.execute(’DisplayObject grid::log_samples’)
sgems.execute(’TakeSnapshot log_samples.png::PNG’)
126

Bibliography
Castro, S. A., Caers, J., Mukerji, T., May 2005. The stanford vi reservoir. Report 18 of
stanford center for reservoir forecasting, Stanford, CA.
Deutsch, C. V., Journel, A. G., 1998. GSLIB: Geostatistical Software Library and User’s
Guide, second edition Edition. Oxford, New York.
Deutsch, C. V., Tran, T. T., 2002. Fluvsim: a program for object-based stochastic model-
ing of fluvial depositional system. Computers & Geosciences, 525–535.
Guardiano, F., Srivastava, R. M., September 1992. Multivariate geostatistics: Beyond
bivariate moments. In: Fourth International Geostatistics Congress. Troia.
Hartigan, J. A., 1975. Clustering algorithms. New York, John Wiley & Sons Inc[].
Jolliffe, I. T., 1986. Principal Component Analysis. Springer-Verlag, New York.
Journel, A., 1992. Geostatistics: roadblocks and challenges. In: Soares, A. (Ed.),
Geostatistics-Troia. Vol. 1. Kluwer Academic Publications, pp. 213–224.
Journel, A. G., 2002. Combining knowledge from diverse sources: An alternative to tra-
ditional data independence hypotheses. Mathematical Geology 34 (5), 573–596.
Krishnan, S., 2004. Combining diverse and partially redundant information in the earth
sciences. Phd thesis, Stanford University, Stanford, CA.
Remy, N., May 2001. Post-processing a dirty image using a training image. Report 14 of
stanford center for reservoir forecasting, Stanford University, Stanford, CA.
Strebelle, S., 2000. Sequential simulation drawing structures from training images. Phd
thesis, Stanford University, Stanford, CA.
127

Tran, T., 1994. Improving variogram reproduction on dense simulation grids. Computers
& Geosciences 20 (7), 1161–1168.
Zhang, T., 2006. Filter-based training pattern classification for spatial pattern simulation.
Phd thesis, Stanford University, Stanford, CA.
128
Related Documents