Succinct: Fast Interactive Queries Anurag Khandelwal

SF Big Analytics: Introduction to Succinct by UC Berkeley AmpLab
Jan 19, 2017
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Succinct: Fast Interactive Queries
Anurag Khandelwal

Interactive Queries at Scale

Interactive Queries at Scale
Search Tweets by @AMPLab about #Succinct

Interactive Queries at Scale
Search
Regular Expressions
Tweets by @AMPLab about #Succinct
Links to Berkeley or Stanford domains.*(berkeley|stanford)\.edu

Interactive Queries at Scale
Search
Regular Expressions
Range Queries
Tweets by @AMPLab about #Succinct
Links to Berkeley or Stanford domains.*(berkeley|stanford)\.edu
All my Facebook posts between 2013 and 2016

Interactive Queries at Scale
Search
Regular Expressions
Range Queries
Graph Queries
Tweets by @AMPLab about #Succinct
Links to Berkeley or Stanford domains.*(berkeley|stanford)\.edu
All my Facebook posts between 2013 and 2016
Friends of my friends who like trekking

Interactive Queries at Scale
Search
Random Access
Regular Expressions
Range Queries
Graph Queries
Aggregate Queries
Updates
Tweets by @AMPLab about #Succinct
Links to Berkeley or Stanford domains.*(berkeley|stanford)\.edu
All my Facebook posts between 2013 and 2016
Friends of my friends who like trekking

Interactive Queries at Scale
Search
Random Access
Regular Expressions
Range Queries
Graph Queries
Aggregate Queries
Updates
Compute Platforms

Interactive Queries at Scale
Search
Random Access
Regular Expressions
Range Queries
Graph Queries
Aggregate Queries
Updates
Compute Platforms
Query Engines

Interactive Queries at Scale
Search
Random Access
Regular Expressions
Range Queries
Graph Queries
Aggregate Queries
Updates
Compute Platforms
Query Engines
Data Stores

Interactive Queries at Scale

Interactive Queries at ScaleToday’s focus on two main issues:

Interactive Queries at Scale
‣ Performance degradation when data size > memory
Today’s focus on two main issues:

Interactive Queries at Scale
‣ Performance degradation when data size > memory
Today’s focus on two main issues:Th
roug
hput
(O
ps)
0
500
1000
1500
2000
Input Size
1GB 2GB 4GB 8GB 16GB 32GB 64GB 128GB

Interactive Queries at Scale
‣ Performance degradation when data size > memory
Today’s focus on two main issues:Th
roug
hput
(O
ps)
0
500
1000
1500
2000
Input Size
1GB 2GB 4GB 8GB 16GB 32GB 64GB 128GB

Interactive Queries at Scale
‣ Performance degradation when data size > memory
Today’s focus on two main issues:
‣ Handling skewed query workloads
Thro
ughp
ut
(Ops
)
0
500
1000
1500
2000
Input Size
1GB 2GB 4GB 8GB 16GB 32GB 64GB 128GB

Interactive Queries at Scale
‣ Performance degradation when data size > memory
Today’s focus on two main issues:
‣ Handling skewed query workloads
Thro
ughp
ut
(Ops
)
0
500
1000
1500
2000
Input Size
1GB 2GB 4GB 8GB 16GB 32GB 64GB 128GB

Interactive Queries at Scale
‣ Performance degradation when data size > memory
Today’s focus on two main issues:
‣ Handling skewed query workloads
Thro
ughp
ut
(Ops
)
0
500
1000
1500
2000
Input Size
1GB 2GB 4GB 8GB 16GB 32GB 64GB 128GB
Maximum sustainable throughput

Our Solution
BlowFish [NSDI’16]
Succinct [NSDI’15]
SuccinctEncryption
Gra
ph S
tore
KV S
tore
Col
umna
r Sto
re
Row
Sto
re
Uns
truct
ured
Dat
a

Our Solution
‣ Compressed representation → More queries in faster storage
BlowFish [NSDI’16]
Succinct [NSDI’15]
SuccinctEncryption
Gra
ph S
tore
KV S
tore
Col
umna
r Sto
re
Row
Sto
re
Uns
truct
ured
Dat
a

Our Solution
‣ Compressed representation → More queries in faster storage‣ Rich functionality directly on compressed representation
‣ Search, RegEx, Range queries
BlowFish [NSDI’16]
Succinct [NSDI’15]
SuccinctEncryption
Gra
ph S
tore
KV S
tore
Col
umna
r Sto
re
Row
Sto
re
Uns
truct
ured
Dat
a

Our Solution
‣ Compressed representation → More queries in faster storage‣ Rich functionality directly on compressed representation
‣ Search, RegEx, Range queries‣ Flexible support for different data models
BlowFish [NSDI’16]
Succinct [NSDI’15]
SuccinctEncryption
Gra
ph S
tore
KV S
tore
Col
umna
r Sto
re
Row
Sto
re
Uns
truct
ured
Dat
a

Our Solution
‣ Compressed representation → More queries in faster storage‣ Rich functionality directly on compressed representation
‣ Search, RegEx, Range queries‣ Flexible support for different data models
‣ Handles skewed & time-varying workloads
BlowFish [NSDI’16]
Succinct [NSDI’15]
SuccinctEncryption
Gra
ph S
tore
KV S
tore
Col
umna
r Sto
re
Row
Sto
re
Uns
truct
ured
Dat
a

Existing Techniques
SEARCH( )
Example:

Existing Techniques
Data Scans
SEARCH( )
Example:

Existing Techniques
Data Scans
SEARCH( )
Example: Ex: Apache Spark

Existing Techniques
Data Scans
SEARCH( )
Example: Ex: Apache Spark

Existing Techniques
Data Scans
SEARCH( )
Example: Ex: Apache Spark

Existing Techniques
Data Scans
Low storage High Latency
SEARCH( )
Example: Ex: Apache Spark

Existing Techniques
Data Scans Indexes
Low storage High Latency
SEARCH( )
Example: Ex: Apache Spark

Existing Techniques
Data Scans Indexes
Low storage High Latency
SEARCH( )
Example: Ex: Apache Spark Ex: SOLR

Existing Techniques
Data Scans Indexes
Low storage High Latency
SEARCH( )
Example: Ex: Apache Spark Ex: SOLR

Existing Techniques
0, 10, 14, 16, 19, 26, 29
1, 4, 5, 8, 20, 22, 24
2, 15, 17, 27
3, 6, 7, 9, 12, 13, 18, 23 ..
11, 21
Data Scans Indexes
Low storage High Latency
SEARCH( )
Example: Ex: Apache Spark Ex: SOLR

Existing Techniques
0, 10, 14, 16, 19, 26, 29
1, 4, 5, 8, 20, 22, 24
2, 15, 17, 27
3, 6, 7, 9, 12, 13, 18, 23 ..
11, 21
Data Scans Indexes
Low storage High Latency
SEARCH( )
Example: Ex: Apache Spark Ex: SOLR

Existing Techniques
0, 10, 14, 16, 19, 26, 29
1, 4, 5, 8, 20, 22, 24
2, 15, 17, 27
3, 6, 7, 9, 12, 13, 18, 23 ..
11, 21
Data Scans Indexes
Low storage High Latency
High storage Low Latency
SEARCH( )
Example: Ex: Apache Spark Ex: SOLR

Succinct

Succinct
Succinct

Succinct
Succinct

Succinct
Queries executed directly on the
compressed representation
Succinct

Succinct
Queries executed directly on the
compressed representation
Low Storage Low Latency
Succinct

Succinct
Queries executed directly on the
compressed representation
Low Storage Low Latency
SuccinctWhat makes Succinct unique

Succinct
Queries executed directly on the
compressed representation
Low Storage Low Latency
SuccinctWhat makes Succinct unique
No additional indexes
Query responses embedded in the compressed
representation

Succinct
Queries executed directly on the
compressed representation
Low Storage Low Latency
SuccinctWhat makes Succinct unique
No additional indexes
Query responses embedded in the compressed
representation
No data scans Functionality of indexes

Succinct
Queries executed directly on the
compressed representation
Low Storage Low Latency
SuccinctWhat makes Succinct unique
No additional indexes
Query responses embedded in the compressed
representation
No data scans Functionality of indexes
No decompression
Queries directly on the compressed representation (except for data access queries)

Succinct
Queries executed directly on the
compressed representation
Low Storage Low Latency
Succinct

Succinct
Queries executed directly on the
compressed representation
Low Storage Low Latency
Succinct Scale
In-memory data sizes >= memory capacity

Succinct
Queries executed directly on the
compressed representation
Low Storage Low Latency
Succinct Scale
In-memory data sizes >= memory capacity
Complex queries
Search, range, random access, RegEx

Succinct
Queries executed directly on the
compressed representation
Low Storage Low Latency
Succinct Scale
In-memory data sizes >= memory capacity
Complex queries
Search, range, random access, RegEx
Interactivity
Avoids data scans and decompression

Succinct Data Representation

Succinct Data Representation
Builds on a large body of theory work

Succinct Data Representation
Builds on a large body of theory work
Suffix Arrays

Succinct Data Representation
Builds on a large body of theory work
Suffix Arrays
‣ Strong functionality (search)

Succinct Data Representation
Builds on a large body of theory work
Suffix Arrays
‣ Strong functionality (search) ‣ No structure

Succinct Data Representation
Builds on a large body of theory work
Suffix Arrays
‣ Strong functionality (search) ‣ No structure
Compression?

Succinct Data Representation
Builds on a large body of theory work
Suffix Arrays
‣ Strong functionality (search) ‣ No structure
Compression?
‣ Sample the suffix array

Succinct Data Representation
Builds on a large body of theory work
Suffix Arrays
‣ Strong functionality (search) ‣ No structure
Compression?
‣ Sample the suffix array
‣ Store set of pointers to compute unsampled values on the fly

Succinct Data Representation
Builds on a large body of theory work
Suffix Arrays
‣ Strong functionality (search) ‣ No structure
Compression?
‣ Sample the suffix array
‣ Store set of pointers to compute unsampled values on the fly
Possesses structure that enables compression!

Succinct Data Model

Succinct Data Model
‣ Unstructured data
‣ Key-value stores (Voldemort, Dynamo)
‣ Document store (Elasticsearch, MongoDB)
‣ Tables (Cassandra, BigTable)
‣ And many more ....
Unified Interface

Succinct Data Model
‣ Unstructured data
‣ Key-value stores (Voldemort, Dynamo)
‣ Document store (Elasticsearch, MongoDB)
‣ Tables (Cassandra, BigTable)
‣ And many more ....
Unified Interface
With all the powerful queries on values, documents, columns

Data Model & FunctionalityFor unstructured data:

Data Model & Functionality
Original Input Succinct
For unstructured data:

Data Model & Functionality
Original Input Succinct
SEARCH( ) = {0, 10, 14, 16, 19, 26, 29}
Search: returns offsets of arbitrary strings in uncompressed file
For unstructured data:

Data Model & Functionality
Original Input Succinct
SEARCH( ) = {0, 10, 14, 16, 19, 26, 29}
For unstructured data:
Extract(0, 5) = { , , , , }
Extract: returns data at arbitrary offsets in uncompressed file

Data Model & Functionality
Original Input Succinct
SEARCH( ) = {0, 10, 14, 16, 19, 26, 29}
For unstructured data:
Extract(0, 5) = { , , , , }
COUNT( ) = 7
Count: returns count of arbitrary strings in uncompressed file

Data Model & Functionality
Original Input Succinct
SEARCH( ) = {0, 10, 14, 16, 19, 26, 29}
For unstructured data:
Extract(0, 5) = { , , , , }
COUNT( ) = 7
Append( , , , , )
Append: appends arbitrary strings to uncompressed file

Data Model & Functionality
Original Input Succinct
SEARCH( ) = {0, 10, 14, 16, 19, 26, 29}
For unstructured data:
Extract(0, 5) = { , , , , }
COUNT( ) = 7
Append( , , , , )
Range Queries, REGULAR EXPRESSIONS

Unifying the Data Models

Unifying the Data Models

Unifying the Data Models

Unifying the Data Models

Unifying the Data Models
SEARCH(Column1, )

Unifying the Data Models
SEARCH(Column1, )SEARCH( )

Succinct Architecture

Succinct Architecture
Multi-store Architecture

Succinct Architecture
SuccinctStore
Multi-store Architecture

Succinct Architecture
SuccinctStore
SuffixStore
Multi-store Architecture

Succinct Architecture
SuccinctStore
SuffixStore
LogStore
Multi-store Architecture

Succinct Architecture
SuccinctStore
SuffixStore
LogStore
Data APPENDS
Multi-store Architecture

Succinct Architecture
SuccinctStore
SuffixStore
LogStore
Data APPENDS
Multi-store Architecture

Succinct Architecture
SuccinctStore
SuffixStore
LogStore
Data APPENDS
Multi-store Architecture

Succinct on Apache Spark

Queries on Compressed RDDs

Queries on Compressed RDDs
New FunctionalitiesDocument store, Key-Value store
search on documents, values

Queries on Compressed RDDs
New FunctionalitiesDocument store, Key-Value store
search on documents, values
Faster operations on RDDs
random access, filters avoid scans

Queries on Compressed RDDs
New FunctionalitiesDocument store, Key-Value store
search on documents, values
Faster operations on RDDs
random access, filters avoid scans
More in-memory Compressed RDDsno decompression
overheads

Unstructured data using SuccinctRDD

import edu.berkeley.cs.succinct._ Import classes
Unstructured data using SuccinctRDD

import edu.berkeley.cs.succinct._
val rdd = ctx.textFile(…).map(_.getBytes)
val succinctRDD = rdd.succinct
Load data & compress using Succinct
Unstructured data using SuccinctRDD

import edu.berkeley.cs.succinct._
val rdd = ctx.textFile(…).map(_.getBytes)
val succinctRDD = rdd.succinct
val offsets = succinctRDD.search("Berkeley") Find all occurrences of “Berkeley”
Unstructured data using SuccinctRDD

import edu.berkeley.cs.succinct._
val rdd = ctx.textFile(…).map(_.getBytes)
val succinctRDD = rdd.succinct
val count = succinctRDD.count("Berkeley")
val offsets = succinctRDD.search("Berkeley")
Count #occurrences of “Berkeley”
Unstructured data using SuccinctRDD

import edu.berkeley.cs.succinct._
val rdd = ctx.textFile(…).map(_.getBytes)
val succinctRDD = rdd.succinct
val bytes = succinctRDD.extract(50, 100)
val count = succinctRDD.count("Berkeley")
val offsets = succinctRDD.search("Berkeley")
Extract 100 bytes from offset 50
Unstructured data using SuccinctRDD

Key-Value Store using SuccinctKVRDD

import edu.berkeley.cs.succinct.kv._ Import classes
Key-Value Store using SuccinctKVRDD

import edu.berkeley.cs.succinct.kv._
val kvRDD = rdd.zipWithIndex.map(t => (t._2, t._1.getBytes))
val succinctKVRDD = kvRDD.succinctKV Load data & compress using Succinct
Key-Value Store using SuccinctKVRDD

import edu.berkeley.cs.succinct.kv._
val kvRDD = rdd.zipWithIndex.map(t => (t._2, t._1.getBytes))
val succinctKVRDD = kvRDD.succinctKV
val keys = succinctKVRDD.search("Berkeley") Find all keys for values that contain “Berkeley”
Key-Value Store using SuccinctKVRDD

import edu.berkeley.cs.succinct.kv._
val kvRDD = rdd.zipWithIndex.map(t => (t._2, t._1.getBytes))
val succinctKVRDD = kvRDD.succinctKV
val value = succinctKVRDD.get(0)
val keys = succinctKVRDD.search("Berkeley")
Get value for key 0
Key-Value Store using SuccinctKVRDD

Evaluation

Evaluation
Dataset Wikipedia dataset
~40GB data

Evaluation
Dataset
Cluster
Wikipedia dataset
~40GB data
Amazon EC2, 5 machines, 30GB RAM each

Evaluation
Dataset
Cluster
Workload
Wikipedia dataset
~40GB data
Amazon EC2, 5 machines, 30GB RAM each
Search queries, 1-10,000 occurrences

Evaluation
Dataset
Cluster
Workload
Systems
Wikipedia dataset
~40GB data
Amazon EC2, 5 machines, 30GB RAM each
Search queries, 1-10,000 occurrences
Spark, Elasticsearch

Evaluation
Dataset
Cluster
Workload
Systems
Wikipedia dataset
~40GB data
Amazon EC2, 5 machines, 30GB RAM each
Search queries, 1-10,000 occurrences
Spark, Elasticsearch
Caveats Absolute numbers are dataset dependent

Evaluation: Search

Evaluation: Search
Takeaway: Succinct on Apache Spark is 2.5x faster than Elasticsearch while being 2.5x more space efficient.(Data fits in memory for all systems)

Support for Regular Expressions

Support for Regular Expressions
Applications Data Cleaning
Information Extraction
Bioinformatics
Document Stores

Support for Regular Expressions
Applications
Operators
Data Cleaning
Information Extraction
Bioinformatics
Document Stores
Union, Concat, Wildcard, Repeat

Support for Regular Expressions
Applications
Operators
Data Cleaning
Information Extraction
Bioinformatics
Document Stores
Union, Concat, Wildcard, Repeat
Example .*(berkeley|stanford)\.edu

Support for Regular Expressions

Support for Regular Expressions
val matches = succinctRDD.regexSearch(".*(berkeley|stanford)\.edu")
Find all matches for the RegEx “.*(berkeley|stanford)\.edu”
SuccinctRDD

Support for Regular Expressions
val matches = succinctRDD.regexSearch(".*(berkeley|stanford)\.edu")
Find all matches for the RegEx “.*(berkeley|stanford)\.edu”
SuccinctRDD
val matchKeys = succinctKVRDD.regexSearch(".*(berkeley|stanford)\.edu")
Find all keys for values that contain the RegEx “.*(berkeley|stanford)\.edu”
SuccinctKVRDD

Evaluation: RegEx

Evaluation: RegEx

Evaluation: RegEx
Takeaway: Succinct significantly speeds up RegEx queries even when all the data fits in memory for all systems.

Succinct on Apache Spark

Succinct on Apache Spark
Already in use at Elsevier Labs

Succinct on Apache Spark
Already in use at Elsevier Labs
‣ Use case: Annotation Search

Succinct on Apache Spark
Already in use at Elsevier Labs
‣ Use case: Annotation Search
Documents

Succinct on Apache Spark
Already in use at Elsevier Labs
‣ Use case: Annotation Search
Documents
1, sentence, (0, 15) 2, word, (0, 4) 3, word, (5, 10) 4, word, (11, 15)
Annotations

Succinct on Apache Spark
Already in use at Elsevier Labs
‣ Use case: Annotation Search
Documents
1, sentence, (0, 15) 2, word, (0, 4) 3, word, (5, 10) 4, word, (11, 15)
Annotations
“Find sentences that talk about open problems in research”

Succinct on Apache Spark
Already in use at Elsevier Labs
‣ Use case: Annotation Search
Documents
1, sentence, (0, 15) 2, word, (0, 4) 3, word, (5, 10) 4, word, (11, 15)
Annotations
(remains|is|still)(unknown|unclear|uncertain)within<sentence>RegEx Annotation
“Find sentences that talk about open problems in research”

Succinct on Apache Spark
Already in use at Elsevier Labs
‣ Use case: Annotation Search
Documents
1, sentence, (0, 15) 2, word, (0, 4) 3, word, (5, 10) 4, word, (11, 15)
Annotations
https://spark-packages.org/package/amplab/succinct
(remains|is|still)(unknown|unclear|uncertain)within<sentence>RegEx Annotation
“Find sentences that talk about open problems in research”

Problem: Skewed Query Workloads

Problem: Skewed Query Workloads
Load distribution across partitions is often non-uniform

Problem: Skewed Query Workloads
‣ Succinct: Larger fraction of queries in main memory
‣ Challenge: skewed load across shards?
‣ Challenge: time varying loads?
Load distribution across partitions is often non-uniform

Problem: Skewed Query Workloads
‣ Succinct: Larger fraction of queries in main memory
‣ Challenge: skewed load across shards?
‣ Challenge: time varying loads?
‣ E.g.: Memcached + MySQL deployment @ Facebook
Load distribution across partitions is often non-uniform

Problem: Skewed Query Workloads
Load distribution across partitions is often non-uniform

Problem: Skewed Query Workloads
Load distribution across partitions is often non-uniform

Selective Replication
Problem: Skewed Query Workloads
Load distribution across partitions is often non-uniform
Traditional approach:

Selective Replication
Problem: Skewed Query Workloads
Load distribution across partitions is often non-uniform
#Rep
licas
Traditional approach:

Selective Replication
Problem: Skewed Query Workloads
Load distribution across partitions is often non-uniform
#Rep
licas #Replicas α Load
Traditional approach:

Selective Replication
Problem: Skewed Query Workloads
Load distribution across partitions is often non-uniform
#Rep
licas #Replicas α Load
Coarse grained
Traditional approach:

Selective Replication
Problem: Skewed Query Workloads
Load distribution across partitions is often non-uniform
#Rep
licas #Replicas α Load
Coarse grained 1-2× throughput → 2× storage
Traditional approach:

Succinct + BlowFish

Succinct + BlowFish

Succinct + BlowFish

Succinct + BlowFish
Storage
Throughput

Succinct + BlowFish
Storage
Throughput
Indexes

Succinct + BlowFish
Storage
Throughput
Scans
Indexes

Succinct + BlowFish
Storage
Throughput
Scans
Indexes
Succinct

Succinct + BlowFish
Storage
Throughput
Scans
Indexes
SuccinctStorage-Performance tradeoff curve for each partition

Succinct + BlowFish
Storage
Throughput
Scans
Indexes
SuccinctStorage-Performance tradeoff curve for each partition

BlowFish: Layered Sampled Array

Recap: Succinct stores a sampled suffix array
BlowFish: Layered Sampled Array

Recap: Succinct stores a sampled suffix array
BlowFish: Layered Sampled Array
Unsampled values computed on the fly

OriginalSampled Array 9 15 3 0 12 8 14 5
Recap: Succinct stores a sampled suffix array
BlowFish: Layered Sampled Array
Rate = 2
Unsampled values computed on the fly

OriginalSampled Array 9 15 3 0 12 8 14 5
Recap: Succinct stores a sampled suffix array
BlowFish: Layered Sampled Array
Rate = 2
Unsampled values computed on the fly

OriginalSampled Array 9 15 3 0 12 8 14 5
9 12RATE = 8
Recap: Succinct stores a sampled suffix array
BlowFish: Layered Sampled Array
Rate = 2
Unsampled values computed on the fly

OriginalSampled Array 9 15 3 0 12 8 14 5
9 12RATE = 83 14RATE = 4
Recap: Succinct stores a sampled suffix array
BlowFish: Layered Sampled Array
Rate = 2
Unsampled values computed on the fly

OriginalSampled Array 9 15 3 0 12 8 14 5
9 12RATE = 83 14RATE = 4
15 0 8 5RATE = 2
Recap: Succinct stores a sampled suffix array
BlowFish: Layered Sampled Array
Rate = 2
Unsampled values computed on the fly

OriginalSampled Array 9 15 3 0 12 8 14 5
9 12RATE = 83 14RATE = 4
15 0 8 5RATE = 2
Different combination of layers
Recap: Succinct stores a sampled suffix array
BlowFish: Layered Sampled Array
Rate = 2
Unsampled values computed on the fly

OriginalSampled Array 9 15 3 0 12 8 14 5
9 12RATE = 83 14RATE = 4
15 0 8 5RATE = 2
Different combination of layers Different points on tradeoff curve
Recap: Succinct stores a sampled suffix array
BlowFish: Layered Sampled Array
→
Rate = 2
Unsampled values computed on the fly

OriginalSampled Array 9 15 3 0 12 8 14 5
9 12RATE = 83 14RATE = 4
15 0 8 5RATE = 2
Different combination of layers Different points on tradeoff curve
Recap: Succinct stores a sampled suffix array
BlowFish: Layered Sampled Array
→
Rate = 2
Layer Additions and Deletions
Unsampled values computed on the fly

OriginalSampled Array 9 15 3 0 12 8 14 5
9 12RATE = 83 14RATE = 4
15 0 8 5RATE = 2
Different combination of layers Different points on tradeoff curve
Recap: Succinct stores a sampled suffix array
BlowFish: Layered Sampled Array
→
Rate = 2
Layer Additions and Deletions Move along tradeoff curve→
Unsampled values computed on the fly

BlowFish: Technical Details

BlowFish: Technical Details‣ How should partitions share cache on a server?

BlowFish: Technical Details‣ How should partitions share cache on a server?

BlowFish: Technical Details‣ How should partitions share cache on a server?
Low Threshold

BlowFish: Technical Details‣ How should partitions share cache on a server?
High ThresholdLow Threshold

BlowFish: Technical Details‣ How should partitions share cache on a server?
High ThresholdLow Threshold

BlowFish: Technical Details‣ How should partitions share cache on a server?
‣ How should partitions share cache across servers?
High ThresholdLow Threshold

BlowFish: Technical Details‣ How should partitions share cache on a server?
‣ How should partitions share cache across servers?
‣ How should requests be scheduled across replicas?
High ThresholdLow Threshold

BlowFish: Technical Details‣ How should partitions share cache on a server?
‣ How should partitions share cache across servers?
‣ How should requests be scheduled across replicas?
Unified Solution: Back-pressure style scheduling
High ThresholdLow Threshold

BlowFish: Technical Details‣ How should partitions share cache on a server?
‣ How should partitions share cache across servers?
Cache proportional to load,
‣ How should requests be scheduled across replicas?
Unified Solution: Back-pressure style scheduling
High ThresholdLow Threshold

BlowFish: Technical Details‣ How should partitions share cache on a server?
‣ How should partitions share cache across servers?
Cache proportional to load,
‣ How should requests be scheduled across replicas?
Unified Solution: Back-pressure style scheduling
without explicit coordination
High ThresholdLow Threshold

BlowFish: Technical Details‣ How should partitions share cache on a server?
‣ How should partitions share cache across servers?
‣ How should requests be scheduled across replicas?
Unified Solution: Back-pressure style scheduling
1.5x higher throughput than Selective Replication,
High ThresholdLow Threshold

BlowFish: Technical Details‣ How should partitions share cache on a server?
‣ How should partitions share cache across servers?
‣ How should requests be scheduled across replicas?
Unified Solution: Back-pressure style scheduling
1.5x higher throughput than Selective Replication,
within 11% of maximum possible throughput
High ThresholdLow Threshold

Succinct +
BlowFish

‣ Standalone system (prototyped & tested)
Succinct +
BlowFish

‣ Standalone system (prototyped & tested)
‣ Spark Package: Succinct on Apache SparkSuccinct +
BlowFish

‣ Standalone system (prototyped & tested)
‣ Spark Package: Succinct on Apache Spark
‣ As libraries
‣ C++, Java, Scala
‣ for ease of integration
Succinct +
BlowFish


Backup Slides

Array of Suffixes (AoS)
banana$(Input)

Array of Suffixes (AoS)
banana$
banana$anana$nana$ana$na$a$$
Suffixes
(Input)

Array of Suffixes (AoS)
banana$
banana$anana$nana$ana$na$a$$
Suffixes
$a$
ana$anana$
banana$na$
nana$Array of
Suffixes (AoS)
lexi
cogr
aphi
cal o
rder
(Input)

AoS to Input (AoS2Input) Array
$a$
ana$anana$
banana$na$
nana$AoS
6
AoS2Input
531042
b
Input
0123456
anana$

AoS to Input (AoS2Input) Array
$a$
ana$anana$
banana$na$
nana$AoS
6
AoS2Input
531042
b
Input
0123456
anana$
locations of suffixes(suffix array)

AoS to Input (AoS2Input) Array
$a$
ana$anana$
banana$na$
nana$AoS
6
AoS2Input
531042
b
Input
0123456
anana$
locations of suffixes(suffix array)

AoS to Input (AoS2Input) Array
$a$
ana$anana$
banana$na$
nana$AoS
6
AoS2Input
531042
b
Input
0123456
anana$
locations of suffixes(suffix array)

Example: search(“an”)
$a$
ana$anana$
banana$na$
nana$AoS
6
AoS2Input
531042
b
Input
0123456
anana$
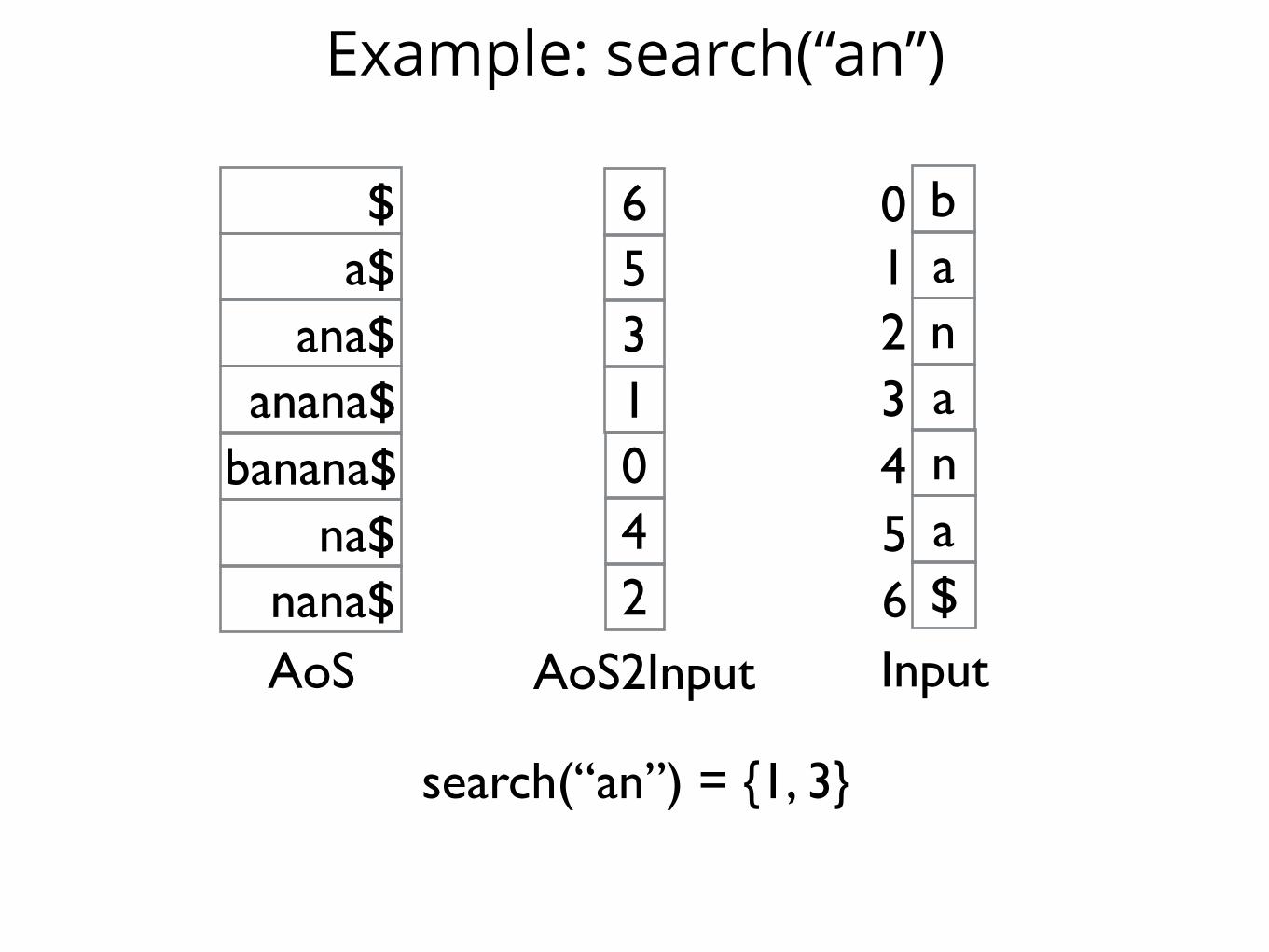
Example: search(“an”)
$a$
ana$anana$
banana$na$
nana$AoS
6
AoS2Input
531042
b
Input
0123456
anana$
search(“an”) = {1, 3}

Example: search(“an”)
$a$
ana$anana$
banana$na$
nana$AoS
6
AoS2Input
531042
b
Input
0123456
anana$
search(“an”) = {1, 3}

Example: search(“an”)
$a$
ana$anana$
banana$na$
nana$AoS
6
AoS2Input
531042
b
Input
0123456
anana$
search(“an”) = {1, 3}

Example: search(“an”)
$a$
ana$anana$
banana$na$
nana$AoS
6
AoS2Input
531042
b
Input
0123456
anana$
search(“an”) = {1, 3}

Example: search(“an”)
$a$
ana$anana$
banana$na$
nana$AoS
6
AoS2Input
531042
b
Input
0123456
anana$
search(“an”) = {1, 3}

Example: search(“an”)
$a$
ana$anana$
banana$na$
nana$AoS
6
AoS2Input
531042
b
Input
0123456
anana$
search(“an”) = {1, 3}

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
3

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
3

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
36

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
36

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
2
36

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
2
36

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
36

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$0123456
aaabnn
4056312
36

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$0123456
aaabnn
4056312
Store only the first character(entire suffix can be computed
“on the fly” using Next Pointer Array (NPA))
36

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$0123456
aaabnn
4056312
36

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$0123456
aaabnn
4056312
36
a

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$0123456
aaabnn
4056312
36
an

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$0123456
aaabnn
4056312
36
an

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$0123456
aaabnn
4056312
36
ana

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$0123456
aaabnn
4056312
36
ana

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$0123456
aaabnn
4056312
36
ana$

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$0123456
aaabnn
4056312
36
ana$

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$0123456
aaabnn
4056312
36

Next Pointer Array: Reducing AoS Size
$a$
ana$anana$
banana$na$
nana$AoS
0123456
NPA
405
12
AoS NPA
$a
b
n
4056312
0123456
AoS NPA
$0123456
aaabnn
4056312
36

Reducing the size of AoS2Input
6
AoS2Input
5
0
2
4
NPA
056312
0123456
31
4

Reducing the size of AoS2Input
6
AoS2Input
5
0
2
4
NPA
056312
0123456
31
4

Reducing the size of AoS2Input
6
AoS2Input
5
0
2
4
NPA
056312
0123456
31
4

Reducing the size of AoS2Input
6
AoS2Input
5
0
2
4
NPA
056312
0123456
31
4
AoS2Input NPA
4056312
6
0
2
0123456
3

Reducing the size of AoS2Input
6
AoS2Input
5
0
2
4
NPA
056312
0123456
31
4
AoS2Input NPA
4056312
6
0
2
0123456
3
Store only a few sampled values(unsampled values computed
“on the fly” using NPA)

Reducing the size of AoS2Input
6
AoS2Input
5
0
2
4
NPA
056312
0123456
31
4
AoS2Input NPA
4056312
6
0
2
0123456
3
Store only a few sampled values(unsampled values computed
“on the fly” using NPA)

Reducing the size of AoS2Input
6
AoS2Input
5
0
2
4
NPA
056312
0123456
31
4
AoS2Input NPA
4056312
6
0
2
0123456
3
Store only a few sampled values(unsampled values computed
“on the fly” using NPA)

Compressing NPA
Increasing sequence of integers(values for suffixes starting with
same character)
Can be compressed(E.g., using run-length encoding)
$
a
b
n
4
0
5
6
3
1
2

Compressing NPA
Increasing sequence of integers(values for suffixes starting with
same character)
Can be compressed(E.g., using run-length encoding)
Succinct uses a 2-dimensional representation of NPA
$
a
b
n
4
0
5
6
3
1
2

Compressing NPA
Increasing sequence of integers(values for suffixes starting with
same character)
Can be compressed(E.g., using run-length encoding)
Succinct uses a 2-dimensional representation of NPA
$
a
b
n
4
0
5
6
3
1
2

Compressing NPA
Increasing sequence of integers(values for suffixes starting with
same character)
Can be compressed(E.g., using run-length encoding)
Succinct uses a 2-dimensional representation of NPA
- better compressibility
$
a
b
n
4
0
5
6
3
1
2

Compressing NPA
Increasing sequence of integers(values for suffixes starting with
same character)
Can be compressed(E.g., using run-length encoding)
Succinct uses a 2-dimensional representation of NPA
- better compressibility- avoids binary search on AoS (lower latency)
$
a
b
n
4
0
5
6
3
1
2

Compressing NPA
Increasing sequence of integers(values for suffixes starting with
same character)
Can be compressed(E.g., using run-length encoding)
Succinct uses a 2-dimensional representation of NPA
- better compressibility- avoids binary search on AoS (lower latency)- enables wider range of queries (E.g., RegEx)
$
a
b
n
4
0
5
6
3
1
2

Compressing NPA
Increasing sequence of integers(values for suffixes starting with
same character)
Can be compressed(E.g., using run-length encoding)
Succinct uses a 2-dimensional representation of NPA
- better compressibility- avoids binary search on AoS (lower latency)- enables wider range of queries (E.g., RegEx)
$
a
b
n
4
0
5
6
3
1
2

Compressing NPA
Increasing sequence of integers(values for suffixes starting with
same character)
Can be compressed(E.g., using run-length encoding)
Succinct uses a 2-dimensional representation of NPA
- better compressibility- avoids binary search on AoS (lower latency)- enables wider range of queries (E.g., RegEx)
See upcoming NSDI paper!
$
a
b
n
4
0
5
6
3
1
2

Evaluation: Storage Footprint10 node 150GB cluster

Evaluation: Storage Footprint
server itself but currently does this in the background.
Limitations. The current Succinct prototype suffersfrom three main limitations. It requires manually han-dling: (1) coordinator failure; (2) fault tolerance anddata durability; and (3) adding new servers to an exist-ing cluster. However, none of these limitations are fun-damental. Succinct could use traditional solutions likeZooKeeper [36] for maintaining multiple coordinatorreplicas with a consistent view. Fault tolerance and datadurability can be achieved using standard replication-based or erasure-code-based [35] techniques. Finally,since each SuccinctStore contains multiple partitions,adding a new server simply requires moving some par-titions from existing servers to the new server and up-dating pointers at servers. We plan to incorporate theseand evaluate associated overheads in the near future.
7 Evaluation
This section explores whether Succinct design and algo-rithms meet Succinct’s goal of supporting fast queries bypushing more data in memory and by operating directlyon compressed data. We perform an end-to-end evalua-tion of Succinct’s memory footprint (§7.1), throughput(§7.2) and latency (§7.3).
Compared systems. We evaluate Succinct using theNoSQL interface extension as described in §5, sinceit requires strictly more operations than queries onflat files. We compare Succinct against several open-source and industrial systems: (1) MongoDB [6] ver-sion 2.6.4 and Cassandra [37] version 2.0.10 with in-dexes; (2) HyperDex [26] version 1.2 with metadata;and (3) DB-X, one of the industrial columnar-store withdata scans. For HyperDex, we encountered a bug alsoencountered by other users [4] that crashes the sys-tem when the inter-machine latencies are variable. ForDB-X, distributed experiments require access to the in-dustrial version. To that end, we only perform micro-benchmarks for HyperDex and DB-X on a single ma-chine for Workloads A and C.
We configured each of the system for no-failure sce-nario (no fault tolerance). For MongoDB and Cassan-dra, we used the most memory-efficient indexes. Theseindexes do not support substring searches and wildcardsearches. HyperDex and DB-X do not support wildcardsearches. Thus, the evaluated systems provide slightlyweaker functionality than Succinct. Finally, for Suc-cinct, we disabled dictionary encoding to evaluate theperformance of Succinct techniques in isolation.
Datasets and Cluster. We use two multi-attributerecord datasets, one smallKV and one largeKV from
Table 2: Datasets used in our evaluation.
Size (Bytes) #Attr- #RecordsKey Value ibutes (Millions)
SmallKV 8 ≈ 140 15 123–1393
LargeKV 8 ≈ 1300 98 19–200
Table 3: Workloads used in our evaluation. All workloadsuse a query popularity that follows a Zipf distribution with
skewness 0.99, similar to YCSB [22].
Workload Remarks
A 100% Reads YCSB workload C
B 95% Reads, 5% Inserts YCSB workload D
C 100% Search -
D 95% Search, 5% Inserts YCSB workload E
Conviva customers as shown in Table 2. All our experi-ments were performed on Amazon EC2 m1.xlarge ma-chines with 15GB RAM and 4 cores, except for DB-Xwhere we used pre-installed r2.2xlarge instances.
75
150
225
Dat
aS
ize
that
Fit
sin
Mem
ory
(GB
)
SmallKV LargeKV
MongoDB
Cassandra
HyperDex
Succinct
RAM
Figure 12: Succinct pushes more than 10× larger amountof data in memory compared to the next best system, while
providing similar or stronger functionality.
10
10 node 150GB cluster

Evaluation: Storage Footprint
Takeaway: Succinct can push >11x more data in memory
server itself but currently does this in the background.
Limitations. The current Succinct prototype suffersfrom three main limitations. It requires manually han-dling: (1) coordinator failure; (2) fault tolerance anddata durability; and (3) adding new servers to an exist-ing cluster. However, none of these limitations are fun-damental. Succinct could use traditional solutions likeZooKeeper [36] for maintaining multiple coordinatorreplicas with a consistent view. Fault tolerance and datadurability can be achieved using standard replication-based or erasure-code-based [35] techniques. Finally,since each SuccinctStore contains multiple partitions,adding a new server simply requires moving some par-titions from existing servers to the new server and up-dating pointers at servers. We plan to incorporate theseand evaluate associated overheads in the near future.
7 Evaluation
This section explores whether Succinct design and algo-rithms meet Succinct’s goal of supporting fast queries bypushing more data in memory and by operating directlyon compressed data. We perform an end-to-end evalua-tion of Succinct’s memory footprint (§7.1), throughput(§7.2) and latency (§7.3).
Compared systems. We evaluate Succinct using theNoSQL interface extension as described in §5, sinceit requires strictly more operations than queries onflat files. We compare Succinct against several open-source and industrial systems: (1) MongoDB [6] ver-sion 2.6.4 and Cassandra [37] version 2.0.10 with in-dexes; (2) HyperDex [26] version 1.2 with metadata;and (3) DB-X, one of the industrial columnar-store withdata scans. For HyperDex, we encountered a bug alsoencountered by other users [4] that crashes the sys-tem when the inter-machine latencies are variable. ForDB-X, distributed experiments require access to the in-dustrial version. To that end, we only perform micro-benchmarks for HyperDex and DB-X on a single ma-chine for Workloads A and C.
We configured each of the system for no-failure sce-nario (no fault tolerance). For MongoDB and Cassan-dra, we used the most memory-efficient indexes. Theseindexes do not support substring searches and wildcardsearches. HyperDex and DB-X do not support wildcardsearches. Thus, the evaluated systems provide slightlyweaker functionality than Succinct. Finally, for Suc-cinct, we disabled dictionary encoding to evaluate theperformance of Succinct techniques in isolation.
Datasets and Cluster. We use two multi-attributerecord datasets, one smallKV and one largeKV from
Table 2: Datasets used in our evaluation.
Size (Bytes) #Attr- #RecordsKey Value ibutes (Millions)
SmallKV 8 ≈ 140 15 123–1393
LargeKV 8 ≈ 1300 98 19–200
Table 3: Workloads used in our evaluation. All workloadsuse a query popularity that follows a Zipf distribution with
skewness 0.99, similar to YCSB [22].
Workload Remarks
A 100% Reads YCSB workload C
B 95% Reads, 5% Inserts YCSB workload D
C 100% Search -
D 95% Search, 5% Inserts YCSB workload E
Conviva customers as shown in Table 2. All our experi-ments were performed on Amazon EC2 m1.xlarge ma-chines with 15GB RAM and 4 cores, except for DB-Xwhere we used pre-installed r2.2xlarge instances.
75
150
225
Dat
aS
ize
that
Fit
sin
Mem
ory
(GB
)
SmallKV LargeKV
MongoDB
Cassandra
HyperDex
Succinct
RAM
Figure 12: Succinct pushes more than 10× larger amountof data in memory compared to the next best system, while
providing similar or stronger functionality.
10
10 node 150GB cluster

Evaluation: Throughput (95% GET + 5% PUT)
10 node 150GB cluster, uniform random access pattern

Evaluation: Throughput (95% GET + 5% PUT)
10 node 150GB cluster, uniform random access pattern

Evaluation: Throughput (95% GET + 5% PUT)
Takeaway: Succinct achieves performance comparable to existing open source systems for queries on primary attributes
10 node 150GB cluster, uniform random access pattern

Evaluation: Throughput (95% SEARCH + 5% PUT)
10 node 150GB cluster, search queries with 1-10K occurrences

Evaluation: Throughput (95% SEARCH + 5% PUT)
10 node 150GB cluster, search queries with 1-10K occurrences

Evaluation: Throughput (95% SEARCH + 5% PUT)
Takeaway: Succinct by pushing more data in faster storage provides performance similar to existing systems for 10-11x larger data sizes.
10 node 150GB cluster, search queries with 1-10K occurrences

Evaluation: RegEx Latency40GB Wikipedia dataset, 5 commonly used RegEx queries
Single EC2 node, 32 vCPUs, 244GB RAM

Evaluation: RegEx Latency40GB Wikipedia dataset, 5 commonly used RegEx queries
Single EC2 node, 32 vCPUs, 244GB RAM

Evaluation: RegEx Latency
Takeaway: Succinct significantly speeds up RegEx queries even when all the data fits in memory for all systems.
40GB Wikipedia dataset, 5 commonly used RegEx queries
Single EC2 node, 32 vCPUs, 244GB RAM

Support for JSON

val ids1 = succinctJsonRDD.search("AMPLab")
Search for JSON documents containing “AMPLab”
Support for JSON

val ids2 = succinctJsonRDD.filter("city", "Berkeley")
val ids1 = succinctJsonRDD.search("AMPLab")
Filter JSON documents where the “city” attribute has value “Berkeley”
Support for JSON

val jsonDoc = succinctJsonRDD.get(0)
val ids2 = succinctJsonRDD.filter("city", "Berkeley")
val ids1 = succinctJsonRDD.search("AMPLab")
Get JSON document with id 0
Support for JSON

Layer Additions & Deletions

9 12RATE = 83 14RATE = 4
15 0 8 5RATE = 2
Layer Additions & Deletions

9 12RATE = 83 14RATE = 4
Layer Additions & Deletions
Layer Deletions: simple

RATE = 2
9 12RATE = 83 14RATE = 4
Layer Additions & Deletions
Layer Addition:

RATE = 2
9 12RATE = 83 14RATE = 4
Unsampled values already computed during query execution
Layer Additions & Deletions
Layer Addition:

RATE = 2
9 12RATE = 83 14RATE = 4
815
Unsampled values already computed during query execution
Layer Additions & Deletions
Layer Addition:
Layers in LSA populated opportunistically!!

Spatial Skew

Spatial SkewLoad distribution across partitions is heavily skewed

Object
Load
1Compressed
Wasted Cache!
Spatial SkewLoad distribution across partitions is heavily skewed
#Replicas α Load
Selective Replication

Spatial SkewLoad distribution across partitions is heavily skewed
#Replicas α Load
Selective Replication
BlowFish
Fractionally change storage just enough to meet load
1Compressed
Uncompressed10
Object
Load

Spatial SkewLoad distribution across partitions is heavily skewed
#Replicas α Load
Selective Replication
BlowFish
Fractionally change storage just enough to meet load
1.5x higher throughput than Selective Replication,
1Compressed
Uncompressed10
Object
Load

Spatial SkewLoad distribution across partitions is heavily skewed
#Replicas α Load
Selective Replication
BlowFish
Fractionally change storage just enough to meet load
1.5x higher throughput than Selective Replication,
within 10% of optimal
1Compressed
Uncompressed10
Object
Load

Changes in Spatial Skew

Changes in Spatial Skew
Study on Facebook Warehouse Cluster
[HotStorage’13]

Changes in Spatial Skew
Transient failures → 90% of failuresStudy on Facebook Warehouse Cluster
[HotStorage’13]

Changes in Spatial Skew
Transient failures → 90% of failures
Replica creation delayed by 15 mins
Study on Facebook Warehouse Cluster
[HotStorage’13]

Changes in Spatial Skew
Transient failures → 90% of failures
Replica creation delayed by 15 mins
Study on Facebook Warehouse Cluster
[HotStorage’13]
Leads to variation in load over time

Changes in Spatial Skew
Transient failures → 90% of failures
Replica creation delayed by 15 mins
Replica#1
Replica#2
Replica#3
Data Partitions Request Queues
Study on Facebook Warehouse Cluster
[HotStorage’13]
Leads to variation in load over time

Changes in Spatial Skew
Transient failures → 90% of failures
Replica creation delayed by 15 mins
Replica#1
Replica#2
Replica#3
Data Partitions Request Queues
Study on Facebook Warehouse Cluster
[HotStorage’13]
Leads to variation in load over time

Changes in Spatial Skew
Transient failures → 90% of failures
Replica creation delayed by 15 mins
Replica#1
Replica#2
Replica#3
Data Partitions Request Queues
Study on Facebook Warehouse Cluster
[HotStorage’13]
Leads to variation in load over time

Changes in Spatial Skew
Replica#1
Replica#2
Replica#3

Changes in Spatial Skew
Replica#1
Replica#2
Replica#3

Changes in Spatial SkewOperation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Replica#1
Replica#2
Replica#3

Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Changes in Spatial Skew
Load
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Replica#1
Replica#2
Replica#3

Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Changes in Spatial Skew
Load Throughput
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Replica#1
Replica#2
Replica#3

Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Changes in Spatial Skew
Load Throughput
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Replica#1
Replica#2
Replica#3

Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Changes in Spatial Skew
Load Throughput
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Replica#1
Replica#2
Replica#3

Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Changes in Spatial Skew
Load Throughput
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Replica#1
Replica#2
Replica#3

Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Changes in Spatial Skew
Load Throughput
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Replica#1
Replica#2
Replica#3

Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Changes in Spatial Skew
Load Throughput
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Replica#1
Replica#2
Replica#3

Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Changes in Spatial Skew
Load Throughput
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Replica#1
Replica#2
Replica#3

Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Changes in Spatial Skew
Load Throughput
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Replica#1
Replica#2
Replica#3

Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Changes in Spatial Skew
Load Throughput
Operation
s / second
0
600
1200
1800
2400
3000
Time (mins)
0 30 60 90 120
Request Queue Siz
e0K
10K
20K
30K
40K
50K
Time (mins)
0 30 60 90 120
Adapts to 3x higher load in < 5 mins
Replica#1
Replica#2
Replica#3
Related Documents











