124 IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 51, NO. 1, JANUARY 2003 Set-Membership Binormalized Data-Reusing LMS Algorithms Paulo S. R. Diniz, Fellow, IEEE, and Stefan Werner, Member, IEEE Abstract—This paper presents and analyzes novel data selec- tive normalized adaptive filtering algorithms with two data reuses. The algorithms [the set-membership binormalized LMS (SM-BN- DRLMS) algorithms] are derived using the concept of set-mem- bership filtering (SMF). These algorithms can be regarded as gen- eralizations of the recently proposed set-membership NLMS (SM- NLMS) algorithm. They include two constraint sets in order to con- struct a space of feasible solutions for the coefficient updates. The algorithms include data-dependent step sizes that provide fast con- vergence and low-excess mean-squared error (MSE). Convergence analyzes in the mean squared sense are presented, and closed-form expressions are given for both white and colored input signals. Sim- ulation results show good performance of the algorithms in terms of convergence speed, final misadjustment, and reduced computa- tional complexity. Index Terms—Adaptive filter, data-selective, normalized data- reusing algorithms, set-membership filtering. I. INTRODUCTION T HE least mean square (LMS) algorithm has gained popularity due to its robustness and low computational complexity. The main drawback of the LMS algorithm is that the convergence speed depends strongly on the eigenvalue spread of the input-signal correlation matrix [1]. To overcome this problem, a more complex recursive least squares (RLS) type of algorithm can be used. However, the faster conver- gence of the RLS algorithm does not imply a better tracking capability in a time-varying environment [1]. An alternative to speed up the convergence at the expense of low additional complexity is to use the binormalized data-reusing LMS (BNDRLMS) algorithm [2], [3]. The BNDRLMS algorithm, which uses consecutive data pairs in each update, has shown fast convergence for correlated input signals. However, the fast convergence comes at the expense of higher misadjustment because the algorithm utilizes the data even if it does not imply innovation. In order to combat the conflicting requirements of fast convergence and low misadjustment, the objective function of the adaptive algorithm needs to be changed. Set-membership filtering (SMF) [4] specifies a bound on the magnitude of the estimation error. The SMF uses the framework of set-member- ship identification (SMI) [5]–[8] to include a general filtering Manuscript received December 6, 2000; revised August 23, 2002. The asso- ciate editor coordinating the review of this paper and approving it for publication was Dr. Steven T. Smith. P. S. R. Diniz is with the COPPE/Poli/Federal University of Rio de Janeiro, Rio de Janeiro, Brazil. S. Werner is with the Signal Processing Laboratory, Helsinki University of Technology, Helsinki, Finland Digital Object Identifier 10.1109/TSP.2002.806562 problem. Consequently, many of the existing optimal bounding ellipsoid (OBE) algorithms [5], [10]–[13] can be applied to the SMF framework. Most, if not all, of the SMF algorithms feature reduced computational complexity primarily due to (sparse) data-se- lective updates. Implementation of those algorithms essentially involves two steps: 1) information evaluation (innovation check) and 2) update of parameter estimate. If the update does not occur frequently and the information evaluation does not involve much computational complexity, the overall complexity is usually much less than that of their RLS counterparts. It was shown in [9] that the class of adaptive solutions, called set-membership adaptive recursive techniques (SMART), in- clude a particularly attractive OBE algorithm, which is referred to as the quasi-OBE algorithm or the bounding ellipsoidal adaptive constrained least-squares (BEACON) algorithm [13], [14], with a complexity of for the innovation check. In addition, in [9], an algorithm with recursions similar to those of the NLMS algorithm with an adaptive step size was derived. The algorithm known as the set-membership NLMS (SM-NLMS) algorithm, which is further studied in [4], was shown to achieve both fast convergence and low misadjustment. Applications of SMF include adaptive equalization, where it allows the sharing of hardware resources in multichannel communications systems [14], adaptive multiuser detection in CDMA systems [15], [16], and in filtering with deterministic constraints on the output-error sequence [17]. The SM-NLMS algorithm only uses the current input-desired signals in its update. Following the same pattern as the conven- tional NLMS algorithm, the convergence of SM-NLMS algo- rithm will slow down when the input signal is colored. In order to overcome this problem, this paper proposes two versions of an algorithm that uses data pairs from two successive time instants in order to construct a set of feasible solutions for the update. The new algorithms are also data-selective algorithms, leading to a low computational complexity per update. In addition, for correlated input signals, they retain the fast convergence of the BNDRLMS algorithms related to the smart reuse of input-de- sired data pairs. The low misadjustment is obtained due to the data-selective updating utilized by the new algorithms. The idea of data reuse was also exploited in the context of OBE algo- rithms in [12]. The organization of the paper is as follows. Section II reviews the concept of SMF and the SM-NLMS algorithm of [4]. The new algorithms are derived in Section III. Section IV contains analysis of the algorithms in the mean-squared sense, followed by simulations in Section V. Section VI contains the concluding remarks. 1053-587X/03$17.00 © 2003 IEEE

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

124 IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 51, NO. 1, JANUARY 2003
Set-Membership Binormalized Data-ReusingLMS Algorithms
Paulo S. R. Diniz, Fellow, IEEE,and Stefan Werner, Member, IEEE
Abstract—This paper presents and analyzes novel data selec-tive normalized adaptive filtering algorithms with two data reuses.The algorithms [the set-membership binormalized LMS (SM-BN-DRLMS) algorithms] are derived using the concept of set-mem-bership filtering (SMF). These algorithms can be regarded as gen-eralizations of the recently proposed set-membership NLMS (SM-NLMS) algorithm. They include two constraint sets in order to con-struct a space of feasible solutions for the coefficient updates. Thealgorithms include data-dependent step sizes that provide fast con-vergence and low-excess mean-squared error (MSE). Convergenceanalyzes in the mean squared sense are presented, and closed-formexpressions are given for both white and colored input signals. Sim-ulation results show good performance of the algorithms in termsof convergence speed, final misadjustment, and reduced computa-tional complexity.
Index Terms—Adaptive filter, data-selective, normalized data-reusing algorithms, set-membership filtering.
I. INTRODUCTION
T HE least mean square (LMS) algorithm has gainedpopularity due to its robustness and low computational
complexity. The main drawback of the LMS algorithm is thatthe convergence speed depends strongly on the eigenvaluespread of the input-signal correlation matrix [1]. To overcomethis problem, a more complex recursive least squares (RLS)type of algorithm can be used. However, the faster conver-gence of the RLS algorithm does not imply a better trackingcapability in a time-varying environment [1]. An alternativeto speed up the convergence at the expense of low additionalcomplexity is to use the binormalized data-reusing LMS(BNDRLMS) algorithm [2], [3]. The BNDRLMS algorithm,which uses consecutive data pairs in each update, has shownfast convergence for correlated input signals. However, the fastconvergence comes at the expense of higher misadjustmentbecause the algorithm utilizes the data even if it does not implyinnovation. In order to combat the conflicting requirements offast convergence and low misadjustment, the objective functionof the adaptive algorithm needs to be changed. Set-membershipfiltering (SMF) [4] specifies a bound on the magnitude of theestimation error. The SMF uses the framework of set-member-ship identification (SMI) [5]–[8] to include a general filtering
Manuscript received December 6, 2000; revised August 23, 2002. The asso-ciate editor coordinating the review of this paper and approving it for publicationwas Dr. Steven T. Smith.
P. S. R. Diniz is with the COPPE/Poli/Federal University of Rio de Janeiro,Rio de Janeiro, Brazil.
S. Werner is with the Signal Processing Laboratory, Helsinki University ofTechnology, Helsinki, Finland
Digital Object Identifier 10.1109/TSP.2002.806562
problem. Consequently, many of the existing optimal boundingellipsoid (OBE) algorithms [5], [10]–[13] can be applied to theSMF framework.
Most, if not all, of the SMF algorithms feature reducedcomputational complexity primarily due to (sparse)data-se-lectiveupdates. Implementation of those algorithms essentiallyinvolves two steps: 1) information evaluation (innovationcheck) and 2) update of parameter estimate. If the update doesnot occur frequently and the information evaluation does notinvolve much computational complexity, the overall complexityis usually much less than that of their RLS counterparts. Itwas shown in [9] that the class of adaptive solutions, calledset-membership adaptive recursive techniques(SMART), in-clude a particularly attractive OBE algorithm, which is referredto as the quasi-OBE algorithm or the bounding ellipsoidaladaptive constrained least-squares (BEACON) algorithm [13],[14], with a complexity of for the innovation check.In addition, in [9], an algorithm with recursions similar tothose of the NLMS algorithm with an adaptive step size wasderived. The algorithm known as the set-membership NLMS(SM-NLMS) algorithm, which is further studied in [4], wasshown to achieve both fast convergence and low misadjustment.Applications of SMF include adaptive equalization, whereit allows the sharing of hardware resources in multichannelcommunications systems [14], adaptive multiuser detection inCDMA systems [15], [16], and in filtering with deterministicconstraints on the output-error sequence [17].
The SM-NLMS algorithm only uses the current input-desiredsignals in its update. Following the same pattern as the conven-tional NLMS algorithm, the convergence of SM-NLMS algo-rithm will slow down when the input signal is colored. In orderto overcome this problem, this paper proposes two versions of analgorithm that uses data pairs from two successive time instantsin order to construct a set of feasible solutions for the update.The new algorithms are also data-selective algorithms, leadingto a low computational complexity per update. In addition, forcorrelated input signals, they retain the fast convergence of theBNDRLMS algorithms related to the smart reuse of input-de-sired data pairs. The low misadjustment is obtained due to thedata-selective updating utilized by the new algorithms. The ideaof data reuse was also exploited in the context of OBE algo-rithms in [12].
The organization of the paper is as follows. Section II reviewsthe concept of SMF and the SM-NLMS algorithm of [4]. Thenew algorithms are derived in Section III. Section IV containsanalysis of the algorithms in the mean-squared sense, followedby simulations in Section V. Section VI contains the concludingremarks.
1053-587X/03$17.00 © 2003 IEEE

DINIZ AND WERNER: SET-MEMBERSHIP BINORMALIZED DATA-REUSING LMS ALGORITHMS 125
II. SMF
In SMF, the filter is designed to achieve a specified boundon the magnitude of the output error. Assuming a sequence ofinput vectors and a desired signal sequence ,we can write the sequence of estimation errors as
(1)
where and with and . For a properlychosen bound on the estimation error, there are several validestimates of .
Let denote the set of all possible input-desired data pairs( ) of interest. Next, let denote the set of all possible vec-tors that result in an output error bounded bywhenever
. The set , which is referred to as thefeasibility set,is given by
(2)
Assume that the adaptive filter is trained withinput-desireddata pairs . Let denote the set containing all vec-tors for which the associated output error at time instantisupper bounded in magnitude by. In other words
(3)
The set is referred to as theconstraint set, and its boundariesare hyperplanes. Finally, define theexact membership set tobe the intersection of the constraint sets over the time instants
, i.e.,
(4)
It can be seen that thefeasibility set is a subset of theexactmembership set at any given time instant. Thefeasibility setis also thelimiting setof theexact membership set, i.e., the twoset will be equal if the training signal traverses all signal pairsbelonging to .
The idea of SMART is to adaptively find an estimate thatbelongs to the feasibility set. One approach is to apply one ofthe many OBE algorithms, which tries to approximate the exactmembership set with ellipsoids. Another adaptive approachis to compute a point estimate through projections using, forexample, the information provided by the constraint set,like in the set-membership NLMS (SM-NLMS) algorithm con-sidered in the following subsection. It was also shown in [4]that the SM-NLMS algorithm can be associated with an optimalbounding spheroid (OBS).
A. Set-Membership Normalized LMS (SM-NLMS) Algorithm
The set-membership NLMS (SM-NLMS) algorithm derivedin [4] is similar to the conventional NLMS algorithm in form.However, the philosophy behind the SM-NLMS algorithmderivation differs from that of the NLMS algorithm. The basicidea behind the algorithm is that if the previous estimateliesoutside the constraint set , i.e., , the new
Fig. 1. SM-NLMS algorithm.
estimate will lie on the closest boundary of at a min-imum distance, i.e., the SM-NLMS minimizessubject to . This is obtained by an orthogonalprojection of the previous estimate onto the closest boundary of
. A graphical visualization of the updating procedure of theSM-NLMS can be found in Fig. 1. Straightforward calculationleads to the following recursions for :
(5)
with
ifotherwise
(6)
where and denote thea priori error and the time-depen-dent step-size, respectively. The update (5) and (6) resemblethose of the conventional NLMS algorithm, except for the time-varying step-size .
Note that since the conventional NLMS algorithm minimizessubject to the constraint that , it is
a particular case of the above algorithm by choosing the bound. Furthermore, using a step-size in the SM-NLMS
whenever would result in a valid update because thehyperplane with zeroa posteriorierror lies in ; however, theresulting algorithm does not minimize the Euclidean distance.
III. SET-MEMBERSHIPBINORMALIZED DATA-REUSING
LMS ALGORITHMS
The SM-NLMS algorithm in the previous subsection onlyconsidered the constraint set in its update. The SM-NLMSalgorithm has a low computational complexity per update, butits convergence speed appears to follow the trend of the normal-ized LMS algorithm, which depends on the eigenvalue spreadof the input-signal correlation matrix. The exact membershipset defined in (4) suggests the use of more than one con-straint set. In this subsection, two algorithms are derived, re-quiring that the solution belongs to the constraint sets at timeinstants and , i.e., . The recursions ofthe algorithms are similar to the conventional BNDRLMS algo-rithm [2]. The set-membership binormalized data-reusing LMS(SM-BNDRLMS) algorithms can be seen as extensions of theSM-NLMS algorithm that use two consecutive constraint sets

126 IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 51, NO. 1, JANUARY 2003
Fig. 2. SM-BNDRLMS-I algorithm. (a) Orthogonal projection onto the nearest boundary ofH lies withinH , i.e.,w 2 H . No further update. (b)Orthogonal projection onto the nearest boundary ofH ,w lies outsideH . Final solution at the nearest intersection ofH andH .
for each update. The first algorithm presented in Section III-Ais a two-step approach minimizing the Euclidean distance be-tween the old filter coefficients and the new update subjected tothe constraints that the new update lies in both constraint sets
and . The second algorithm presented in Section III-Breduces the computational complexity per update, as comparedwith the first algorithm by choosing a different update strategy.
A. Algorithm I
The first set-membership binormalized data-reusing LMS al-gorithm (SM-BNDRLMS-I) performs an initial normalized stepaccording to the SM-NLMS algorithm. If the solution to the firststep belongs to both constraint sets and , no furtherupdate is required. If the initial step moves the solution out of
, a second step is taken such that the solution is at the in-tersection of and at a minimum distance from .Fig. 2 depicts the update procedure. The SM-BNDRLMS-I al-gorithm minimizes subject to the constraint that
.The solution can be obtained by first performing an orthog-
onal projection of onto the nearest boundary of , just likein the SM-NLMS algorithm
(7)
where and are defined in (6). If , i.e.,, then . Otherwise, a second step is
taken such that the solution lies at the intersection ofandat a minimum distance. The second step in the algorithm
will be in the direction of , which is orthogonal to the firststep, i.e.,
(8)
where
(9)
In summary, the recursive algorithm for is given by
(10)
where
if
otherwise
if and
otherwise.(11)
Remark 1: If the constraint sets and are parallel,the denominator term of the s in (11) will be zero. In thisparticular case, the second step of (10) is not performed to avoiddivision by zero.
It is easy to verify that if the bound of the estimation error ischosen to be zero, i.e., , the update equations will be thoseof the conventional BNDRLMS algorithm with unity step-size[2].
B. Algorithm II
The SM-BNDRLMS-I algorithm in the previous subsectionrequires the intermediate check, that is, if , to de-termine if a second step is needed. This check will add extracomputational complexity. The algorithm proposed below (theSM-BNDRLMS-II) does not require this additional check to as-sure that . Let ( ) denotethe hyperplanes that contain all vectorssuch that
, where are extra variables chosensuch that the bound constraints are valid. That is, if arechosen such that , then .

DINIZ AND WERNER: SET-MEMBERSHIP BINORMALIZED DATA-REUSING LMS ALGORITHMS 127
Fig. 3. General algorithm update.
Consider the following optimization criterion whenever:
subject to
(12)
The pair ( ) specifies the point in wherethe final update will lie; see Fig. 3. In order to evaluate if anupdate according to (12) is required, we need to first check if
. Due to the concept of data reuse together withthe constraint , this check reduces to . Inwhat follows, we first solve for the general update and thereafterconsider a specific choice of the pair ( ), leading to asimplified form.
To solve the optimization problem in (12), we can apply themethod of Lagrange multipliers leading to the following objec-tive function:
(13)
After setting the gradient of (13) to zero and solving for theLagrange multipliers, we get
ifotherwise
(14)
where
(15)
(16)
in which and are thea priori error at iteration and thea posteriorierror at iteration
, respectively.Since always belongs to before a possible update,
we have . Therefore, choosing satisfies. In the same way as in the SM-NLMS and SM-BN-
DRLMS-I algorithms, it is sufficient to choose such that theupdate lies on the closest boundary of, i.e., .
Fig. 4. SM-BNDRLMS-II algorithm.
TABLE ICOMPUTATIONAL COMPLEXITY PER UPDATE.
The above choices lead to the SM-BNDRLMS-II algorithm,where the new estimate will lie at the nearest boundaryof such that thea posteriorierror at iteration ,is kept constant. A graphical illustration of the update proce-dure is shown in Fig. 4. The update equations for the SM-BN-DRLMS-II algorithm are given by
(17)
where
ifotherwise.
(18)
As with the SM-BNDRLMS-I algorithm in the previous sub-section, the problem with parallel constraint sets is avoided byusing the SM-NLMS update of (5) whenever the denominatorin the is zero.
C. Computational Complexity
The computational complexity per update in terms of thenumber of additions, multiplications, and divisions for the threealgorithms are shown in Table I. For the SM-BNDRLMS-I,the two possible update complexities are listed where the firstcorresponds to the total complexity when only the first step isnecessary, i.e., when , and the second correspondsto the total complexity when a full update is needed. Applyingthe SM-BNDRLMS algorithms slightly increases the compu-tational complexity as compared with that of the SM-NLMSalgorithm. However, the SM-BNDRLMS algorithms have areduced number of updates and an increased convergence rate

128 IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 51, NO. 1, JANUARY 2003
as compared to the SM-NLMS algorithm, as verified throughsimulations in Section V. Comparing the complexities of theSM-BNDRLMS-I and SM-BNDRLMS-II algorithms, we notethat the difference in the overall complexity depends on thefrequency the second step is required in Algorithm I. In the op-eration counts, the value of at iteration was assumedunknown. However, once or is known, one cancompute the other using only two additional multiplications,e.g., . The relation between
and has been used in the operation countsof the SM-BNDRLMS algorithms. If update occurs at twosuccessive time instants, and are knownfrom a previous update, and as a consequence, the number ofmultiplications and additions in such updates can be furtherreduced by approximately for the SM-NLMS algorithm and2 for the SM-BNDRLMS algorithms. Finally, note that ifwe continuously estimate and , regardless ofwhether an update is required or not, the SM-BNDRLMS-IIalgorithm will always be more efficient than SM-BNDRLMS-I.These computational savings are crucial in applications wherethe filter order is high and computational resources are limited.
IV. SECOND-ORDER STATISTICAL ANALYSIS
This section addresses the steady-state analysis of theSM-BNDRLMS algorithms.
A. Coefficient-Error Vector
In this subsection, we investigate the convergence behavior ofthe coefficient vector . It is assumed that an unknown FIRis identified with an adaptive filter of the same orderusing the SM-BNDRLMS-II algorithm. The desired response isgiven by
(19)
where is measurement noise, which is assumed here to beGaussian with zero mean and variance. We study the evolu-tion of the coefficient error . The output errorcan now be written as
(20)
The update equations for the adaptive filter coefficients aregiven by
ififif
(21)
where
(22)
As a consequence, the coefficient error at time instantbecomes
ififif
(23)
where
(24)
and
(25)
In the analysis, we utilize the following initial assumptions.AS1) The filter is updated with the probability
, and .Note that the probability will be time-varying be-
cause the variance of the output error depends on themean of the squared coefficient-error vector norm, and forGaussian noise with zero mean and variance, we get
. Since we are interested inthe excess MSE and not the initial transient the followingassumption is made.
AS2)The filter has reached the steady-state value.From (23), we can now write the coefficient error as
(26)
B. Input-Signal Model
In the evaluation of the excess MSE we use a simplifiedmodel for the input-signal vector . The model uses a sim-plified distribution for the input-signal vector by employingreduced and countable angular orientations for the excitation,which are consistent with the first- and second-order statisticsof the actual input-signal vector. The model was used foranalyzing the NLMS algorithm, [18] as well as the BNDRLMSalgorithm [2], and was shown to yield good results.
The input signal vector for the model is
(27)
where
• is 1 with probability 1/2• has the same probability distribution as , and in
the case of white Gaussian input signal, it is a sample ofan independent process with-square distribution withdegrees of freedom, with
• is one of the orthonormal eigenvectors, say { , }.
For a white Gaussian input signal, it is assumed thatis uni-formly distributed such that
(28)
C. Excess MSE for White Input Signals
In this subsection, we investigate the excess MSE in theSM-BNDRLMS algorithms. In order to achieve this goal, wehave to consider a simple model for the input signal vector that

DINIZ AND WERNER: SET-MEMBERSHIP BINORMALIZED DATA-REUSING LMS ALGORITHMS 129
assumes a discrete set of angular orientations. The excess MSEis given by [1]
(29)
where
(30)
is the MSE at iteration , and is the minimum MSE. Withthese equations, we have that
tr cov (31)
For the input-signal model presented in the previous subsec-tion, can be written as
(32)
Conditions and in the model are equivalentto and , respectively, becauseand can only be parallel or orthogonal to each other.
denotes the probability that , anddenotes the probability that . For the
case , the SM-BNDRLMS algorithm will behave likethe SM-NLMS algorithm, which has the excess MSE (seeAppendix A)
(33)
where varies from 1 for binary distribution, to3 for Gaussian distribution, to for a Cauchy distribution [3],[18]. For the case , the expression for the coefficienterror vector also reduces to the same as that of the SM-NLMSalgorithm (see Appendix B), giving
(34)
Combining, we have
(35)
Recall assumptionAS2), where the filter is in steady-state suchthat the probability is constant. The stability and
convergence of (35) holds since . If we let ,the excess MSE becomes
(36)
Assuming the filter has converged to its steady-state value, theprobability of update for white Gaussian input signals is givenby
(37)
where is the complementary Gaussian cumulative distri-bution function given by
(38)
and is the mean of the squared norm of thecoefficient error after convergence. To be able to calculatethe expression in (36), we need, which in turn depends on
. Therefore, consider the following two casesof approximation.
AP1) The variance of the error is lower bounded by the noisevariance, i.e., .Therefore, a simple lower bound is given by
AP2) We can rewrite the variance of the error as, where denotes the dis-
tance between the error atth iteration and the optimalerror. Assuming no update, we have , and with
, we get . Therefore, anupper bound of the probability of update is given by
The approximations of together with (36) are used in thesimulations to estimate the excess MSE for different thresholds
.
D. Excess MSE for Colored Input Signals
When extending the analysis to colored input signals, we maystill use the input-signal model in (27). The angular distribu-tions of will change, i.e., the probabilities and
will be different from those for white input sig-nals. However, as with the case of white input signals, theseprobabilities will not have effect on the final results; see (35).In order to get an expression for the probability of updatefor colored input signals, we assume that the input is correlatedaccording to
(39)
where is a white noise process with zero mean and variance. Straightforward calculations give the autocorrelation matrix
......
.... . .
...(40)
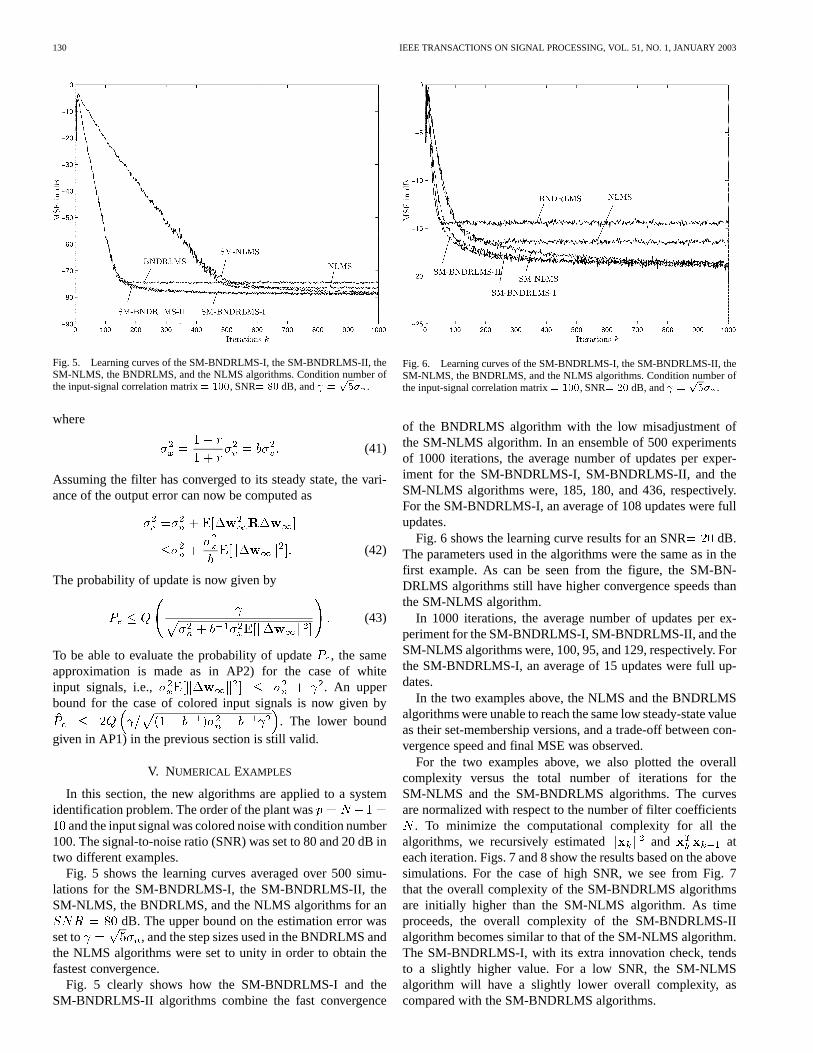
130 IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 51, NO. 1, JANUARY 2003
Fig. 5. Learning curves of the SM-BNDRLMS-I, the SM-BNDRLMS-II, theSM-NLMS, the BNDRLMS, and the NLMS algorithms. Condition number ofthe input-signal correlation matrix= 100, SNR= 80 dB, and =
p5� .
where
(41)
Assuming the filter has converged to its steady state, the vari-ance of the output error can now be computed as
(42)
The probability of update is now given by
(43)
To be able to evaluate the probability of update, the sameapproximation is made as in AP2) for the case of whiteinput signals, i.e., . An upperbound for the case of colored input signals is now given by
. The lower boundgiven in AP1) in the previous section is still valid.
V. NUMERICAL EXAMPLES
In this section, the new algorithms are applied to a systemidentification problem. The order of the plant was
and the input signal was colored noise with condition number100. The signal-to-noise ratio (SNR) was set to 80 and 20 dB intwo different examples.
Fig. 5 shows the learning curves averaged over 500 simu-lations for the SM-BNDRLMS-I, the SM-BNDRLMS-II, theSM-NLMS, the BNDRLMS, and the NLMS algorithms for an
dB. The upper bound on the estimation error wasset to , and the step sizes used in the BNDRLMS andthe NLMS algorithms were set to unity in order to obtain thefastest convergence.
Fig. 5 clearly shows how the SM-BNDRLMS-I and theSM-BNDRLMS-II algorithms combine the fast convergence
Fig. 6. Learning curves of the SM-BNDRLMS-I, the SM-BNDRLMS-II, theSM-NLMS, the BNDRLMS, and the NLMS algorithms. Condition number ofthe input-signal correlation matrix= 100, SNR= 20 dB, and =
p5� .
of the BNDRLMS algorithm with the low misadjustment ofthe SM-NLMS algorithm. In an ensemble of 500 experimentsof 1000 iterations, the average number of updates per exper-iment for the SM-BNDRLMS-I, SM-BNDRLMS-II, and theSM-NLMS algorithms were, 185, 180, and 436, respectively.For the SM-BNDRLMS-I, an average of 108 updates were fullupdates.
Fig. 6 shows the learning curve results for an SNR dB.The parameters used in the algorithms were the same as in thefirst example. As can be seen from the figure, the SM-BN-DRLMS algorithms still have higher convergence speeds thanthe SM-NLMS algorithm.
In 1000 iterations, the average number of updates per ex-periment for the SM-BNDRLMS-I, SM-BNDRLMS-II, and theSM-NLMS algorithms were, 100, 95, and 129, respectively. Forthe SM-BNDRLMS-I, an average of 15 updates were full up-dates.
In the two examples above, the NLMS and the BNDRLMSalgorithms were unable to reach the same low steady-state valueas their set-membership versions, and a trade-off between con-vergence speed and final MSE was observed.
For the two examples above, we also plotted the overallcomplexity versus the total number of iterations for theSM-NLMS and the SM-BNDRLMS algorithms. The curvesare normalized with respect to the number of filter coefficients
. To minimize the computational complexity for all thealgorithms, we recursively estimated and ateach iteration. Figs. 7 and 8 show the results based on the abovesimulations. For the case of high SNR, we see from Fig. 7that the overall complexity of the SM-BNDRLMS algorithmsare initially higher than the SM-NLMS algorithm. As timeproceeds, the overall complexity of the SM-BNDRLMS-IIalgorithm becomes similar to that of the SM-NLMS algorithm.The SM-BNDRLMS-I, with its extra innovation check, tendsto a slightly higher value. For a low SNR, the SM-NLMSalgorithm will have a slightly lower overall complexity, ascompared with the SM-BNDRLMS algorithms.
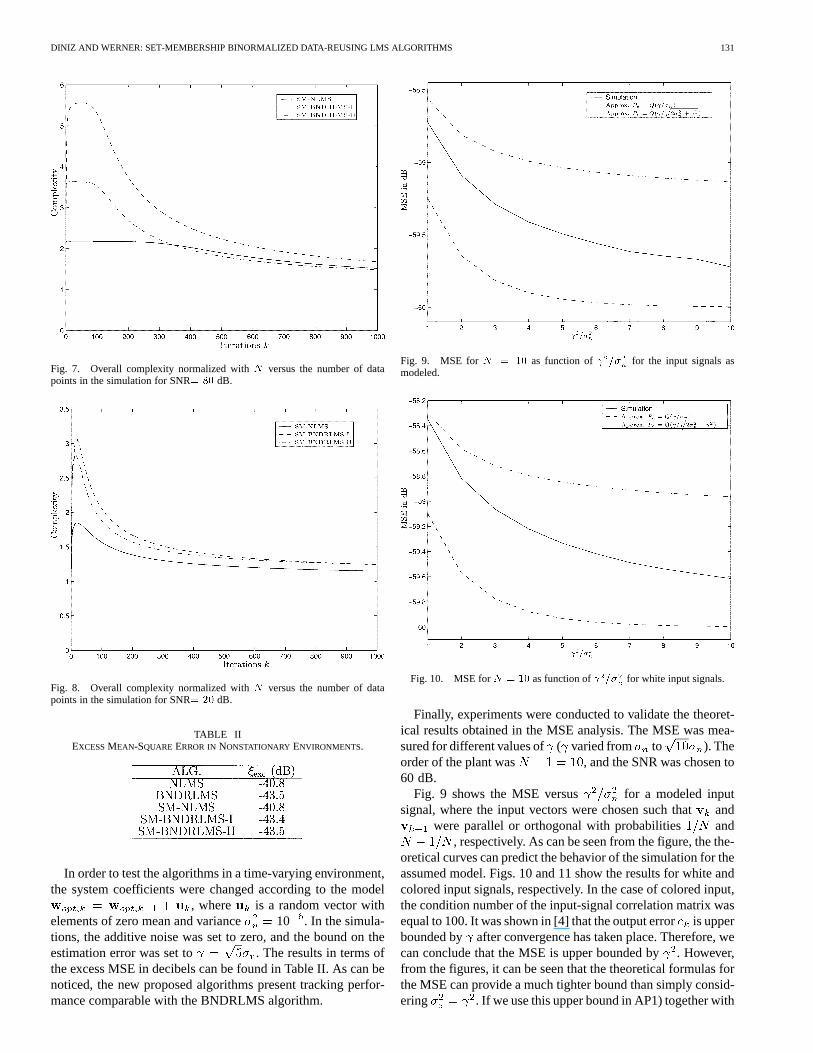
DINIZ AND WERNER: SET-MEMBERSHIP BINORMALIZED DATA-REUSING LMS ALGORITHMS 131
Fig. 7. Overall complexity normalized withN versus the number of datapoints in the simulation for SNR= 80 dB.
Fig. 8. Overall complexity normalized withN versus the number of datapoints in the simulation for SNR= 20 dB.
TABLE IIEXCESSMEAN-SQUARE ERROR INNONSTATIONARY ENVIRONMENTS.
In order to test the algorithms in a time-varying environment,the system coefficients were changed according to the model
, where is a random vector withelements of zero mean and variance 10 . In the simula-tions, the additive noise was set to zero, and the bound on theestimation error was set to . The results in terms ofthe excess MSE in decibels can be found in Table II. As can benoticed, the new proposed algorithms present tracking perfor-mance comparable with the BNDRLMS algorithm.
Fig. 9. MSE forN = 10 as function of =� for the input signals asmodeled.
Fig. 10. MSE forN = 10 as function of =� for white input signals.
Finally, experiments were conducted to validate the theoret-ical results obtained in the MSE analysis. The MSE was mea-sured for different values of( varied from to ). Theorder of the plant was , and the SNR was chosen to60 dB.
Fig. 9 shows the MSE versus for a modeled inputsignal, where the input vectors were chosen such thatand
were parallel or orthogonal with probabilities and, respectively. As can be seen from the figure, the the-
oretical curves can predict the behavior of the simulation for theassumed model. Figs. 10 and 11 show the results for white andcolored input signals, respectively. In the case of colored input,the condition number of the input-signal correlation matrix wasequal to 100. It was shown in [4] that the output erroris upperbounded by after convergence has taken place. Therefore, wecan conclude that the MSE is upper bounded by. However,from the figures, it can be seen that the theoretical formulas forthe MSE can provide a much tighter bound than simply consid-ering . If we use this upper bound in AP1) together with
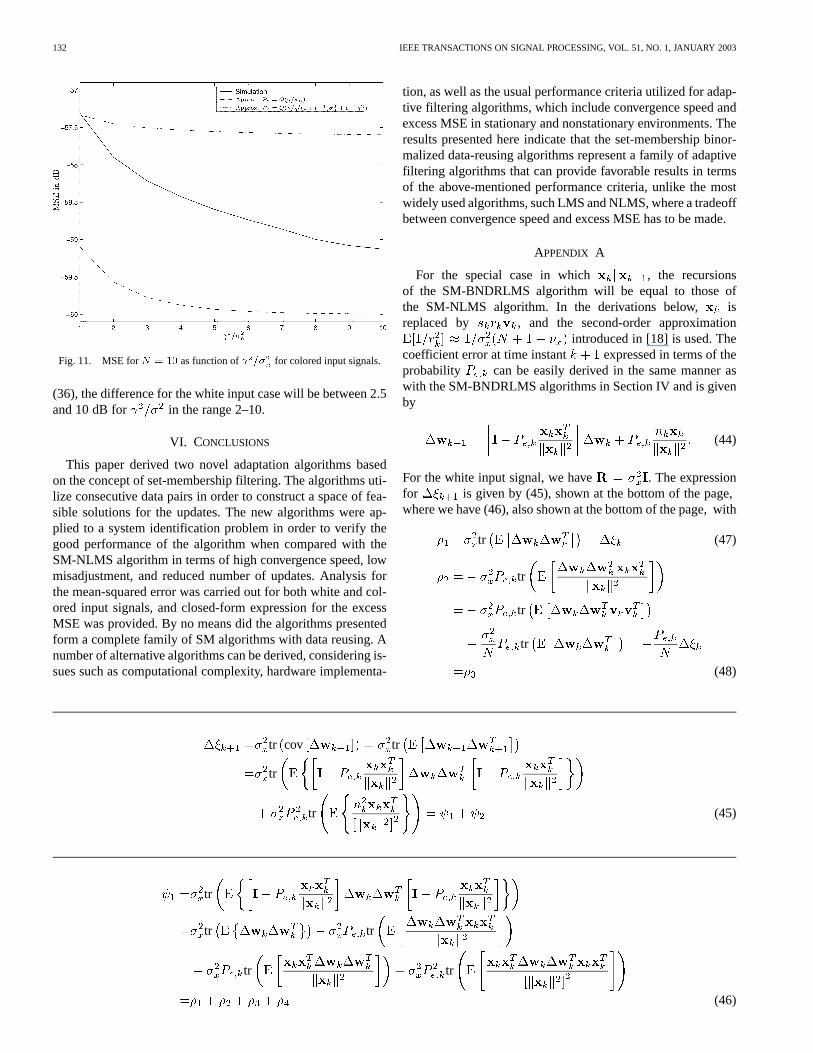
132 IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 51, NO. 1, JANUARY 2003
Fig. 11. MSE forN = 10 as function of =� for colored input signals.
(36), the difference for the white input case will be between 2.5and 10 dB for in the range 2–10.
VI. CONCLUSIONS
This paper derived two novel adaptation algorithms basedon the concept of set-membership filtering. The algorithms uti-lize consecutive data pairs in order to construct a space of fea-sible solutions for the updates. The new algorithms were ap-plied to a system identification problem in order to verify thegood performance of the algorithm when compared with theSM-NLMS algorithm in terms of high convergence speed, lowmisadjustment, and reduced number of updates. Analysis forthe mean-squared error was carried out for both white and col-ored input signals, and closed-form expression for the excessMSE was provided. By no means did the algorithms presentedform a complete family of SM algorithms with data reusing. Anumber of alternative algorithms can be derived, considering is-sues such as computational complexity, hardware implementa-
tion, as well as the usual performance criteria utilized for adap-tive filtering algorithms, which include convergence speed andexcess MSE in stationary and nonstationary environments. Theresults presented here indicate that the set-membership binor-malized data-reusing algorithms represent a family of adaptivefiltering algorithms that can provide favorable results in termsof the above-mentioned performance criteria, unlike the mostwidely used algorithms, such LMS and NLMS, where a tradeoffbetween convergence speed and excess MSE has to be made.
APPENDIX A
For the special case in which , the recursionsof the SM-BNDRLMS algorithm will be equal to those ofthe SM-NLMS algorithm. In the derivations below, isreplaced by , and the second-order approximation
introduced in [18] is used. Thecoefficient error at time instant expressed in terms of theprobability can be easily derived in the same manner aswith the SM-BNDRLMS algorithms in Section IV and is givenby
(44)
For the white input signal, we have . The expressionfor is given by (45), shown at the bottom of the page,where we have (46), also shown at the bottom of the page, with
tr (47)
tr
tr
tr
(48)
tr cov tr
tr
tr (45)
tr
tr tr
tr tr
(46)

DINIZ AND WERNER: SET-MEMBERSHIP BINORMALIZED DATA-REUSING LMS ALGORITHMS 133
where the last equality is true since tr tr .
tr
tr
tr
tr
tr
tr
(49)
tr
tr
(50)
Finally, we get
(51)
APPENDIX B
For the case , (24) and (25) reduce to
(52)
and
(53)
The coefficient error vector in (26) now reduces to
(54)
which is the same as in (44) for the case of the SM-NLMS al-gorithm. Consequently, we get
(55)
REFERENCES
[1] P. S. R. Diniz,Adaptive Filtering: Algorithms and Practical Implemen-tations, Second ed. Boston, MA: Kluwer, 2002.
[2] J. A. Apolinário, M. L. R. de Campos, and P. S. R. Diniz, “The binor-malized data-reusing LMS algorithm,”IEEE Trans. Signal Processing,vol. 48, pp. 3235–3242, Nov. 2000.
[3] J. A. Apolinário, M. L. R. de Campos, P. S. R. Diniz, and T. I. Laakso,“Binormalized data-reusing LMS algorithm with optimized step-size se-quence,”Brazilian Telecommun. J. SBT, vol. 13, pp. 49–55, 1998.
[4] S. Gollamudi, S. Nagaraj, S. Kapoor, and Y. F. Huang, “Set-member-ship filtering and a set-membership normalized LMS algorithm with anadaptive step size,”IEEE Signal Processing Lett., vol. 5, pp. 111–114,Apr. 1998.
[5] E. Fogel and Y. F. Huang, “On the value of information in system identi-fication – bounded noise case,”Automatica, vol. 18, pp. 229–238, 1982.
[6] J. R. Deller, “Set-membership identification in digital signal pro-cessing,”IEEE Acoust., Speech, Signal Processing Mag., vol. 6, pp.4–22, Jan. 1989.
[7] J. R. Deller, M. Nayeri, and S. F. Odeh, “Least-squares identificationwith error bounds for real-time signal processing and control,”Proc.IEEE, vol. 81, pp. 815–849, June 1993.
[8] E. Walter and H. Piet-Lahanier, “Estimation of parameter bounds frombounded-error: A survey,”Math. Comput. Simul., vol. 32, pp. 449–468,1990.
[9] S. Gollamudi, S. Nagaraj, and Y. F. Huang, “SMART : A toolbox forset-membership filtering,” inProc. IEEE Eur. Conf. Circuit Theory Des.,1997, pp. 879–884.
[10] S. Dasgupta and Y. F. Huang, “Asymptotically convergent modifiedrecursive least-squares with data dependent updating and forgettingfactor for systems with bounded noise,”IEEE Trans. Inform. Theory,vol. IT-33, pp. 383–392, 1987.
[11] J. R. Deller, M. Nayeri, and M. Liu, “Unifying the landmark develop-ments in optimal bounding ellipsoid identification,”Int. J. Adap. Contr.Signal Process., vol. 8, pp. 43–60, 1994.
[12] D. Joachim, J. R. Deller, and M. Nayeri, “Multiweight optimization inOBE algorithms for improved tracking and adaptive identification,” inProc. IEEE Int. Acoust., Speech Signal Process., vol. 4, Seattle, WA,May 1998, pp. 2201–2204.
[13] J. R. Deller, S. Gollamudi, S. Nagaraj, and Y. F. Huang, “Convergenceanalysis of the QUASI-OBE algorithm and the performance implica-tions,” in Proc. IFAC Int. Symp. Syst. Ident., vol. 3, Santa Barbara, CA,June 2000, pp. 875–880.
[14] S. Gollamudi, S. Nagaraj, S. Kapoor, and Y. F. Huang, “Set-membershipadaptive equalization and updator-shared implementation for multiplechannel communications systems,”IEEE Trans. Signal Processing, vol.46, pp. 2372–2384, Sept. 1998.
[15] S. Kapoor, S. Gollamudi, S. Nagaraj, and Y. F. Huang, “Adaptivemultiuser detection and beamforming for interference suppression inCDMA mobile radio systems,”IEEE Trans. Veh. Technol., vol. 48, pp.1341–1355, Sept. 1999.
[16] S. Nagaraj, S. Gollamudi, S. Kapoor, Y. F. Huang, and J. R. Deller,“Adaptive interference suppression for CDMA systems with aworst-case error criterion,”IEEE Trans. Signal Processing, vol. 48, pp.285–289, Jan. 2000.
[17] S. Nagaraj, S. Gollamudi, S. Kapoor, and Y. F. Huang, “BEACON : Anadaptive set-membership filtering technique with sparse updates,”IEEETrans. Signal Processing, vol. 47, pp. 2928–2941, Nov. 1999.
[18] D. T. M. Slock, “On the convergence behavior of the LMS and the nor-malized LMS algorithms,”IEEE Trans. Signal Processing, vol. 41, pp.2811–2825, Sept. 1993.

134 IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 51, NO. 1, JANUARY 2003
Paulo S. R. Diniz(F’00) was born in Niterói, Brazil.He received the Electronics Eng. degree (CumLaude) from the Federal University of Rio de Janeiro(UFRJ), Rio de Janeiro, Brazil, in 1978, the M.Sc.degree from COPPE/UFRJ in 1981, and the Ph.D.degree from Concordia University, Montreal, QC,Canada, in 1984, all in electrical engineering.
Since 1979, he has been with the Departmentof Electronic Engineering (undergraduate), UFRJ.He has also been with the Program of ElectricalEngineering (graduate), COPPE/UFRJ, since 1984,
where he is presently a Professor. He served as Undergraduate Course Coor-dinator and as Chairman of the Graduate Department. He is one of the threesenior researchers and coordinators of the National Excellence Center in SignalProcessing. From January 1991 to July 1992, he was a Docent Research Asso-ciate with the Department of Electrical and Computer Engineering, Universityof Victoria, Victoria, B.C., Canada. He also holds a visiting Professor positionat Helsinki University of Technology, Helsinki, Finland. From January 2002 toJune 2002, he was a Melchor Chair Professor with the Department of ElectricalEngineering, University of Notre Dame, Notre Dame, IN. His teaching andresearch interests are in analog and digital signal processing, adaptive signalprocessing, digital communications, wireless communications, multiratesystems, stochastic processes, and electronic circuits. He has published severalrefereed papers in some of these areas and wrote the booksAdaptive Filtering:Algorithms and Practical Implementation(Boston, MA: Kluwer, Second Ed.,2002) andDigital Signal Processing: System Analysis and Design(Cambridge,U.K.: Cambridge Univ. Press, 2002: with E. A. B. da Silva and S. L. Netto). Hewas an associate editor of theCircuits, Systems, and Signal Processing Journalfrom 1998 to 2002.
Dr. Diniz was the Technical Program Chair of the 1995 MWSCAS, Rio deJaneiro, Brazil. He has been on the technical committee of several internationalconferences including ISCAS, ICECS, EUSIPCO, and MWSCAS. He hasserved Vice President for region 9 of the IEEE Circuits and Systems Societyand as Chairman of the DSP technical committee of the same Society. Heserved as associate editor for the IEEE TRANSACTIONS ON CIRCUITS AND
SYSTEMS II from 1996 to 1999 and the IEEE TRANSACTIONS ON SIGNAL
PROCESSINGfrom 1999 to 2002. He was a distinguished lecturer of the IEEECircuits and Systems Society for the year 2000 to 2001. He received the Rio deJaneiro State Scientist award from the Governor of the state of Rio de Janeiro.
Stefan Werner (M’02) received the M.Sc. degreein electrical engineering from the Royal Instituteof Technology, Stockholm, Sweden, in 1998, andthe Dr.Tech. degree (with honors) from the SignalProcessing Laboratory, Helsinki University ofTechnology, Helsinki, Finland, in 2002.
His research interests are in multiuser communica-tions and adaptive filtering.
Related Documents











