Semi-Supervised Learning with Graphs Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Semi-Supervised Learning with Graphs
Xiaojin (Jerry) Zhu
School of Computer ScienceCarnegie Mellon University
1

Semi-supervised Learning
• many problems involve classification
• classifiers need labeled data to train
• labeled data scarce, unlabeled data abundant
• Traditional classifiers cannot use unlabeled data.
My interest (semi-supervised learning): Develop classification
methods that can use both labeled and unlabeled data.
2

Motivating example 1: speech recognition
• classify sounds into words
• need sounds / word transcript pairs (labeled data) to train
• hard to obtain: transcription slow.
I 400 times real-time at phonetic level
I 10 times real-time at word level
• unlabeled data: sounds alone, easy to get.
I record the radio
I call center
• unlabeled data useful?
3

Motivating example 2: parsing
• classify sentences into parse trees
NP VP
PN VB NP PP
DET N P NP
DET N
S
I saw a falcon with a telescope
• need sentence / parse tree pairs (treebank, labeled data) to
train, hard to construct treebank (Hwa, 2003):
I English 40,000 sentences, 5 years; Chinese 4,000 sentences, 2 years
• unlabeled data: sentences without annotation, very easy to
get. Useful?
4

Motivating example 3: video surveillance
• classify images into identities
• need image / identity pairs (labeled data) to train
• typically only a few images are labeled
• unlabeled images abundant. Useful?
5

The message
Unlabeled data can improve classification.
6

Why unlabeled data might help
example: classify astronomy vs. travel articles
• articles represented by content word occurrence vectors
• article similarity measured by content word overlap
d1 d3 d4 d2
asteroid • •bright • •comet •
yearzodiac
...airport
bikecamp •
yellowstone • •zion •
7

Why labeled data alone might fail
d1 d3 d4 d2
asteroid •bright •comet
yearzodiac •
...airport •
bike •camp
yellowstone •zion •
• no overlap!
• tends to happen when labeled data is scarce
8

Unlabeled data are stepping stones
d1 d5 d6 d7 d3 d4 d8 d9 d2
asteroid •bright • •comet • •
year • •zodiac • •
...airport •
bike • •camp • •
yellowstone • •zion •
• observe direct similarity from features: d1 ∼ d5, d5 ∼ d6 etc.
• assume similar features ⇒ same label
• labels propagate via unlabeled articles, indirect similarity
9

Unlabeled data are stepping stones
• arrange l labeled and u unlabeled(=test) points in a graph
I nodes: the n = l + u points
I edges: the direct similarity Wij, e.g. number of overlapping words.(in general: a decreasing function of the distance ||xi − xj||)
• want to infer indirect similarity (with all paths)
d1
d2
d4
d3
10

One way to use labeled and unlabeled data(Zhu and Ghahramani, 2002)
• input: n× n graph weights W
labels Yl ∈ {0, 1}l
• create matrix Pij = Wij/∑
Wi.
• repeat until f converges
I clamp labeled data fl = Yl
I propagate f ← Pf
• f converges to a unique solution, the harmonic function.
0 ≤ f ≤ 1, “soft labels”
11

An electric network interpretation(Zhu, Ghahramani and Lafferty, ICML2003)
• harmonic function f is the voltage at the nodes
I edges are resistors with R = 1/W
I 1 volt battery connects to labeled nodes
• indirect similarity: similar voltage if many paths exist
+1 volt
wijR =ij
1
1
0
12

Closed form solution for the harmonic function
• define diagonal degree matrix D, Dii =∑
Wi·define graph Laplacian matrix ∆ = D −W
fu = −∆uu−1∆ulYl
• ∆ graph version of the continuous Laplacian operator
∇2 = ∂2
∂x2 + ∂2
∂y2 + ∂2
∂z2
• harmonic: ∆f = 0 with Dirichlet boundary conditions on
labeled data
• currents in-flow = out-flow at any node (Kirchoff’s law)
• average of neighbors: fu(i) =∑
j∼i Wijf(j)∑j∼i Wij
13

Text categorization with harmonic functions
accuracy
baseball PC religion
hockey Mac atheism
50 labeled articles, about 2000 unlabeled articles. 10NN graph.
14

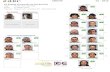
Digit recognition with harmonic functions
• pixel-wise Euclidean distance
not similar indirectly similar
with stepping stones
15

Digit recognition with harmonic functions
accuracy
1 vs. 2 10 digits
50 labeled images, about 4000 unlabeled images, 10NN graph
16

Practical concerns about harmonic functions
• does it scale?
I closed form involves matrix inversion fu = −∆uu−1∆ulYl
I O(u3), e.g. millions of crawled web pages
• solution 1: use iterative methods
I the label propagation algorithm (slow)
I loopy belief propagation
I conjugate gradient
• solution 2: reduce problem size
I use a random small unlabeled subset (Delalleau et al. 2005)
I harmonic mixtures
17

Harmonic mixtures(Zhu and Lafferty, 2005)
• fit unlabeled data with a mixture model, e.g.
I Gaussian mixtures for images
I multinomial mixtures for documents
• use EM or other methods
• M mixture components, here
M = 30 � u ≈ 1000
• learn soft labels for the mixture
components, not the unlabeled
points
18

Harmonic mixtureslearn labels for mixture components
• assume mixture component labels λ1, · · · , λM
• labels on unlabeled points determined by the mixture model
I The mixture model defines responsibility R: Rim = p(m|xi)
I f(i) =∑M
m=1 Rimλm
• learn λ such that f is closest to harmonic
I convex optimization
I closed form solution λ = −(R>∆uuR
)−1R>∆ulYl
19

Harmonic mixtures
−2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2.5−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
mixture component labels λ follow the graph
20

Harmonic mixturescomputational savings
• computation on unlabeled data
I harmonic mixtures
fu = −R(R>∆uuR︸ ︷︷ ︸M×M
)−1R>∆ulYl
I original harmonic function
fu = −(∆uu︸︷︷︸u×u
)−1∆ulYl
• harmonic mixtures O(M3), much cheaper than O(u3)
Harmonic mixtures can handle large problems.
21

From harmonic functions to kernels
• harmonic functions too specialized?
• I will show you the kernel behind harmonic function
I general, important concept in machine learning.
I used in many learning algorithms, e.g. support vector machines
I on the graph: symmetric, positive semi-definite n× n matrix
• I will then give you an even better kernel.
22

The kernel behind harmonic functions
K = ∆−1
• covariance matrix
• Kij = indirect similarity
I The direct similarity Wij may be small
I But Kij will be large if many paths between i, j
• K can be used with many kernel machines
I K + support vector machine = semi-supervised SVM
23

Kernels should encourage smooth eigenvectors
• graph spectrum ∆ =∑n
k=1 λkφkφ>k
• small eigenvalue, smooth eigenvector∑i∼j Wij(φk(i)− φk(j))2 = λk
• smooth eigenvectors good for semi-supervised learning
• kernels encourage smooth eigenvectors with large weights
Laplacian ∆ =∑
k λkφkφ>k
harmonic kernel K = ∆−1 =∑
k1λk
φkφ>k
24

General semi-supervised kernels
• ∆−1 not the only semi-supervised kernel, may not be the best
• General principle for creating semi-supervised kernels
K =∑
i r(λi)φiφ>i
• r(λ) should be large when λ is small, to encourage smooth
eigenvectors.
• Specific choices of r() lead to known kernels
I harmonic function kernel r(λ) = 1/λ
I diffusion kernel r(λ) = exp(−σ2λ)I random walk kernel r(λ) = (α− λ)p
• Is there a best r()? Yes, as measured by kernel alignment.
25

Alignment measures kernel quality
• measures kernel by its alignment to the labeled data Yl
align(K, Yl) =〈Kll, YlY
>l 〉
‖ Kll ‖ · ‖ YlY >l ‖
• extension of cosine angle between vectors
• high alignment related to good generalization performance
• leads to a convex optimization problem
26

Finding the best kernel(Zhu, Kandola, Ghahramani and Lafferty, NIPS2004)
• the order constrained semi-supervised kernel
max r align(K, Yl)subject to K =
∑i riφiφ
>i
r1 ≥ · · · ≥ rn ≥ 0
• order constraints r1 ≥ · · · ≥ rn encourage smoothness
• convex optimization
• r nonparametric
27

The order constrained kernel improvesalignment and accuracy
text categorization (religion vs. atheism), 50 labeled and 2000
unlabeled articles.
• alignment
kernel order harmonic RBF
alignment 0.31 0.17 0.04
• accuracy with support vector machines
kernel order harmonic RBF
accuracy 84.5 80.4 69.3
We now have good kernels for semi-supervised learning.
28

Other research (1)Graph hyperparameter learning
• what if we don’t know Wij?
• set up hyperparameters Wij = exp(−
∑d
(xid−xjd)2
αd
)• learn α with Bayesian evidence maximization
100
150
200
250
100
150
200
250
126
128
130
132
134
136
138
140
142
144
average 7 average 9 learned α
29

Other research (2)Sequences and other structured data
(Lafferty, Zhu and Liu, 2004)
y’
x’
y
x
• what if x1 · · ·xn form sequences?
speech, natural language
processing, biosequence analysis,
etc.
• conditional random fields (CRF)
• kernel CRF
• kernel CRF + semi-supervised
kernels
30

Other research (3)Active learning
(Zhu, Lafferty and Ghahramani, 2003b)
• what if the computer can ask for labels?
• smart queries: not necessarily the most ambiguous points
01
a 0.5
B 0.4
• active learning + semi-supervised learning, fast algorithm
31

Related work in semi-supervised learning
based on different assumptions
method assumptions references
graph similar feature, same label this talk
mincuts (Blum and Chawla, 2001)
normalized Laplacian (Zhou et al., 2003)
regularization (Belkin et al., 2004)
mixture model, EM generative model (Nigam et al., 2000)
transductive SVM low density separation (Joachims, 1999)
co-training feature split (Blum and Mitchell, 1998)
Semi-supervised learning has so far received relatively little attention in statisticsliterature.
32

Some key contributions
• harmonic function formulations for semi-supervised learning
• solving large scale problems with harmonic mixtures
• semi-supervised kernels by spectral transformation of the
graph Laplacian
• kernelizing conditional random fields
• combining active learning and semi-supervised learning
33

Summary
Unlabeled data can improve classification.
The methods have reached the stage where we canapply them to real-world tasks.
34

Future Plans
• continue the research on semi-supervised learning
I structured data
I ranking
I clustering
I explore different assumptions
• application to human language tasks
I speech recognition: acoustic and language modeling
I document categorization
I information extraction
I sentiment analysis
I social networks
35

Future Plans
• explore novel machine learning approaches for
I text mixed with other modalities, e.g. images
I speech and multimodal user interfaces
I graphics
I robotics
• collaboration
36

Thank You
37

References
M. Belkin, I. Matveeva and P. Niyogi. Regularization and Semi-supervisedLearning on Large Graphs. COLT 2004.A. Blum and S. Chawla. Learning from Labeled and Unlabeled Data usingGraph Mincuts. ICML 2001.A. Blum, T. Mitchell. Combining Labeled and Unlabeled Data with Co-training.COLT 1998.O. Delalleau, Y. Bengio, N. Le Roux. Efficient Non-Parametric FunctionInduction in Semi-Supervised Learning. AISTAT 2005.R. Hwa. A Continuum of Bootstrapping Methods for Parsing Natural Languages.2003.T. Joachims, Transductive inference for text classification using support vectormachines. ICML 1999.K. Nigam, A. McCallum, S Thrun, T. Mitchell. Text Classification from Labeledand Unlabeled Documents using EM. Machine Learning. 2000.D. Zhou, O. Bousquet, T.N. Lal, J. Weston, B. Schlkopf. Learning with Localand Global Consistency. NIPS 2003.X. Zhu, J. Lafferty. Harmonic Mixtures. 2005. submitted.X. Zhu, Jaz Kandola, Z. Ghahramani, J. Lafferty. Nonparametric Transforms of
38

Graph Kernels for Semi-Supervised Learning. NIPS 2004.J. Lafferty, X. Zhu, Y. Liu. Kernel Conditional Random Fields: Representationand Clique Selection. ICML 2004.X. Zhu, Z. Ghahramani, J. Lafferty. Semi-Supervised Learning Using GaussianFields and Harmonic Functions. ICML 2003.X. Zhu, J. Lafferty, Z. Ghahramani. Combining Active Learning and Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions. ICML2003 workshop.X. Zhu, Z. Ghahramani. Learning from Labeled and Unlabeled Data with LabelPropagation. CMU-CALD-02-106, 2002.
39

40

41

42

The probabilistic model behind harmonic function
• define a random field p(f) ∝ exp (−E(f))
• energy E(f) =∑
i∼j Wij(fi − fj)2 = f>∆f
• low energy means good label propagation
E(f) = 4 E(f) = 2 E(f) = 1
• if f ∈ {0, 1} discrete, standard Markov random fields
(Boltzmann machines), inference hard
43

The probabilistic model behind harmonic functionGaussian random fields(Zhu, Ghahramani and Lafferty, ICML2003)
• continuous relaxation f ∈ R ⇒ Gaussian random field
• Gaussian random field p(f) is a n-dimensional Gaussian with
precision (inverse covariance) matrix ∆.
p(f) ∝ exp (−E(f)) = exp(−f>∆f
)• harmonic functions are the mean of Gaussian random fields
• Gaussian random fields = Gaussian processes on finite data
44

A random walk interpretationof harmonic functions
• harmonic function fi = P (hit label 1 | start from i)
I random walk from node i to j with probability Pij
I stop if we hit a labeled node
• indirect similarity: random walks have same fate
1
0
i
45

Graph spectrum ∆ =∑n
i=1 λiφiφ>i
46

Learning component label with EM
−2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2.5−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
Labels for the components do not follow the graph.(Nigam et al., 2000)
47
Related Documents