Searching through Photographic Databases with QuickLook Gianluigi Ciocca a , Claudio Cusano a , Raimondo Schettini a , Simone Santini b , Andrea de Polo c , and Francesca Tavanti c a Universit` a degl Studi di Milano-Bicocca, Viale Sarca 336, 20126 Milano, Italy b Universidad Aut´onoma de Madrid, C/ Tomas y Valiente 11, 28049 Madrid, Spain c RD multimedia laboratory, Alinari 24 ORE SpA, Largo Alinari 15, 50123 Florence, Italy ABSTRACT We present here the results obtained by including a new image descriptor, that we called prosemantic feature vector, within the framework of QuickLook 2 image retrieval system. By coupling the prosemantic features and the relevance feedback mechanism provided by QuickLook 2 , the user can move in a more rapid and precise way through the feature space toward the intended goal. The prosemantic features are obtained by a two-step feature extraction process. At the first step, low level features related to image structure and color distribution are extracted from the images. At the second step, these features are used as input to a bank of classifiers, each one trained to recognize a given semantic category, to produce score vectors. We evaluated the efficacy of the prosemantic features under search tasks on a dataset provided by Fratelli Alinari Photo Archive. Keywords: Image retrieval, image indexing, semantic gap, prosemantic features 1. INTRODUCTION The need to retrieve visual information from large image and video collections is shared by many application domains, and a wide variety of content-based retrieval methods and systems can be found in the literature. Their capability as general purpose systems is, however, in large part limited by the a-priori definition and setting of the user’s aims (e.g. target search, similarity search, category search); the set of features (visual or textual) used for image indexing; the similarity metric adopted; and the way in which the user may interact with the system in order to express his/her information needs. A survey of some of the most important techniques used in Content-Based Image Retrieval (CBIR) systems can be found in. 1 Many of the existing systems are based on image features derived from computer vision, which can be computed directly and automatically from the images themselves. However simple content-based features could not characterize the images to the degree of generality and sophistication that is required for general-purpose retrieval. In order to come to grip with this problem and to provide satisfactory retrieval performance, different solutions were introduced in the retrieval process. One of these solutions is relevance feedback , 2 which relies on the interaction with the user to provide the system with examples of images relevant to the query. The system then refines its result depending on the selected images. The user’s feedback provides a way to infer short term and case-specific query semantics. Other systems explicitly extract and embed in the retrieval process semantic information about the image content through the use of automatic classification techniques. 3 These techniques can then be employed to automatically annotate the image content with keywords, which are then used for retrieval. If the underlying annotation is reliable, text-based image retrieval can be semantically more meaningful than other retrieval approaches. 4 Concept detection techniques categorize images into general categories such as city, landscape, sunset, forest, sea, etc. . . , using supervised classification. 5 The idea here is that meaning is provided implicitly through the classification of the training set, and it will supplement and integrate the low-level information provided by the features. One of the first attempts to integrate and compare semantic keyword and low-level features into a single CBIR framework is the SIMPLIcity system. 6 A more recent paper 7 defines a new paradigm Gianluigi Ciocca: [email protected], Claudio Cusano: [email protected], Raimondo Schettini: [email protected], Simone Santini: [email protected], Andrea de Polo: [email protected], Francesca Tavanti: [email protected] Multimedia on Mobile Devices 2012; and Multimedia Content Access: Algorithms and Systems VI, edited by Reiner Creutzburg, David Akopian, Cees G. M. Snoek, Nicu Sebe, Lyndon S. Kennedy, Proc. of SPIE-IS&T Electronic Imaging, Vol. 8304, 83040V · © 2012 SPIE-IS&T · CCC code: 0277-786X/12/$18 · doi: 10.1117/12.911976 SPIE-IS&T Vol. 8304 83040V-1 DownloadedFrom:http://proceedings.spiedigitallibrary.org/on05/01/2013TermsofUse:http://spiedl.org/terms

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Searching through Photographic Databases with QuickLook
Gianluigi Cioccaa, Claudio Cusanoa, Raimondo Schettinia, Simone Santinib, Andrea de Poloc,and Francesca Tavantic
aUniversita degl Studi di Milano-Bicocca, Viale Sarca 336, 20126 Milano, ItalybUniversidad Autonoma de Madrid, C/ Tomas y Valiente 11, 28049 Madrid, Spain
cRD multimedia laboratory, Alinari 24 ORE SpA, Largo Alinari 15, 50123 Florence, Italy
ABSTRACT
We present here the results obtained by including a new image descriptor, that we called prosemantic featurevector, within the framework of QuickLook2 image retrieval system. By coupling the prosemantic features andthe relevance feedback mechanism provided by QuickLook2, the user can move in a more rapid and precise waythrough the feature space toward the intended goal. The prosemantic features are obtained by a two-step featureextraction process. At the first step, low level features related to image structure and color distribution areextracted from the images. At the second step, these features are used as input to a bank of classifiers, eachone trained to recognize a given semantic category, to produce score vectors. We evaluated the efficacy of theprosemantic features under search tasks on a dataset provided by Fratelli Alinari Photo Archive.
Keywords: Image retrieval, image indexing, semantic gap, prosemantic features
1. INTRODUCTION
The need to retrieve visual information from large image and video collections is shared by many applicationdomains, and a wide variety of content-based retrieval methods and systems can be found in the literature. Theircapability as general purpose systems is, however, in large part limited by the a-priori definition and setting ofthe user’s aims (e.g. target search, similarity search, category search); the set of features (visual or textual)used for image indexing; the similarity metric adopted; and the way in which the user may interact with thesystem in order to express his/her information needs. A survey of some of the most important techniques usedin Content-Based Image Retrieval (CBIR) systems can be found in.1
Many of the existing systems are based on image features derived from computer vision, which can becomputed directly and automatically from the images themselves. However simple content-based features couldnot characterize the images to the degree of generality and sophistication that is required for general-purposeretrieval. In order to come to grip with this problem and to provide satisfactory retrieval performance, differentsolutions were introduced in the retrieval process. One of these solutions is relevance feedback ,2 which relies onthe interaction with the user to provide the system with examples of images relevant to the query. The systemthen refines its result depending on the selected images. The user’s feedback provides a way to infer short termand case-specific query semantics.
Other systems explicitly extract and embed in the retrieval process semantic information about the imagecontent through the use of automatic classification techniques.3 These techniques can then be employed toautomatically annotate the image content with keywords, which are then used for retrieval. If the underlyingannotation is reliable, text-based image retrieval can be semantically more meaningful than other retrievalapproaches.4 Concept detection techniques categorize images into general categories such as city, landscape,sunset, forest, sea, etc. . . , using supervised classification.5 The idea here is that meaning is provided implicitlythrough the classification of the training set, and it will supplement and integrate the low-level informationprovided by the features. One of the first attempts to integrate and compare semantic keyword and low-levelfeatures into a single CBIR framework is the SIMPLIcity system.6 A more recent paper7 defines a new paradigm
Gianluigi Ciocca: [email protected], Claudio Cusano: [email protected], Raimondo Schettini:[email protected], Simone Santini: [email protected], Andrea de Polo: [email protected], Francesca Tavanti:[email protected]
Multimedia on Mobile Devices 2012; and Multimedia Content Access: Algorithms and Systems VI, edited byReiner Creutzburg, David Akopian, Cees G. M. Snoek, Nicu Sebe, Lyndon S. Kennedy, Proc. of SPIE-IS&T Electronic
Imaging, Vol. 8304, 83040V · © 2012 SPIE-IS&T · CCC code: 0277-786X/12/$18 · doi: 10.1117/12.911976
SPIE-IS&T Vol. 8304 83040V-1
Downloaded From: http://proceedings.spiedigitallibrary.org/ on 05/01/2013 Terms of Use: http://spiedl.org/terms

denoted as query-by-semantic-example (QBSE) which combines a query-by-example approach with semanticretrieval
Here we present the results obtained by including within the framework of QuickLook2 image retrieval systema new image descriptor that we called prosemantic feature vector. The framework is based on the feature vectormodel and support a relevance feedback mechanism. With this image descriptor we try to retain the advantagesof using classifiers (the semantics obtained from the annotated training set) without the disadvantages (therestriction to the categories on which it was trained). The feature vector will be embedded into a feature spacein which similarity is defined as a function of the distance, and the search is done using relevance feedback. Byexploiting the relevance feedback mechanism, the user can move through the prosemantic feature space towardthe target image.
The search experiments are performed on a dataset of about 3,000 images provided by Fratelli Alinari PhotoArchive. The prosemantic features are evaluated on this dataset exploiting the QuickLook2 image retrievalsystem.
2. RELEVANCE FEEDBACK RETRIEVAL
The QuickLook2 system allows the user to search an image data base with the aid of sample images, or a user-made sketch, and/or textual descriptions. The system’s response can then be progressively refined by indicatingthe relevance, or non-relevance of the items retrieved. In particular, by exploiting the statistical analysis of theimage feature distributions and of the textual descriptions of the retrieved items the user has judged relevant, ornot relevant, the system is able to identify what features the user has taken into account (and to what extent)in formulating his judgment. It then modifies accordingly the impact of the different visual and textual featuresin the overall evaluation of image similarity, as well as in the formulation of a new single query representing theuser’s information needs.
Let xI be the representation of the image I. Images can be described by different features so xI is composedof different numerical vectors, each one representing an image characteristic (e.g. color histogram, shape, pros-
emantic features, etc. . . ). We indicate these vectors for image I as x(1)I ,x
(2)I , . . . ,x
(p)I . Given a query Q and a
image I, the dissimilarity between the two representations is computed as a weighted Euclidean distance:
D(Q, I) =1
p
p∑
f=1
D(f)(x(f)Q ,x
(f)I )w(f), (1)
where D(f) and w(f) are the dissimilarity metric and the weight associated to the feature f respectively. Theweights w(f) allow to tune the contribution of each features in the overall similarity measure. The weights aredetermined according to the images selected by the user, and the query Q is computed by the query refinementalgorithm. The dissimilarities are computed between the query and each image in the database. The images mostsimilar to the query are presented to the user sorted by decreasing similarity. For a more detailed description ofthe QuickLook2 system, the reader can refer to8 and.9
The basic idea of the relevance feedback mechanism is that the distribution, in the feature space, of the imagesthat the user has judged relevant (or not relevant) can be used to determine what features the user has takeninto account (and to what extent) in formulating this judgment. With this information, one can accentuate theinfluence of the relevant features in the overall evaluation of image similarity, as well as in the formulation of anew query. The structure of the relevance feedback mechanism is entirely description-independent, that is, theindex can be modified, or extended to include other features without requiring any change in the algorithm aslong as the features can be expressed as numerical vectors. The relevance feedback algorithm works as follows:let R+ the set of relevant images and R− the set of non relevant images. The feature weights are computed as:
w(f) =
⎧⎪⎪⎨
⎪⎪⎩
1ε if ‖R+‖ < 3
1
ε+μ(f)+
if ‖R+‖ ≥ 3 and ‖R−‖ = 0
1
ε+μ(f)+
− α 1
ε+μ(f)∗
otherwise, (2)
SPIE-IS&T Vol. 8304 83040V-2
Downloaded From: http://proceedings.spiedigitallibrary.org/ on 05/01/2013 Terms of Use: http://spiedl.org/terms

Iw9d6z
ExFL9CFOL
669FnL6
ExFL9CFOL
669FnL6
Cp22w6L 1
C922116L
C922116L
I Cp22w6L I
E69[11L62
bL0261119UFIC
L-G6gP9CKFI6A9UC6
6UdIU6
1f6.!6.
Figure 1. Prosemantic features extraction.
where ε and α are positive constants, μ(f)+ is the average of the dissimilarities computed on the f -th feature
between each pair of images in R+, and μ(f)∗ the average of the dissimilarities computed on the f -th feature
between each image in R+ and each image in R−. Negative weights are set to 0. A weight is large if thecorresponding feature is present in all the relevant images while it is small or dampened if the correspondingfeature assumes a broad range of values within the relevant images or if is also present in the non relevant images(viz. it is present in the relevant images but it is not relevant).
In content-based retrieval images are sometimes considered relevant because they resemble the query imagein just some limited sense related to low-level features that are particularly prominent, even if semantically notvery significant. Consequently, after an initial query, a given image may be selected by the user as relevantbecause it has one of the characteristics of the query (e.g. the same color), and another be selected for anothercharacteristics (e.g. the shape), although the two are actually quite different from each other. To cope with thisproblem a method called query refinement is used to compute the query vector. On the basis of the imagesselected by the user, the system formulates a new query that better represents the images of interest to the user,taking into account the features of the relevant images, without allowing any one particular feature value to bias
the query computation. Let x(f)I (k) be the k-th value of the f -th feature of image I. By considering only the
images in the relevant set R+, the query Q is computed as:
Y(f)k = {x(f)
I (k): | x(f)I (k)− x
(f)
Q(k) |≤ 3σ
(f)k }, (3)
x(f)Q (k) =
1
‖Y (f)k ‖
∑
X(f)
I(k)∈Y
(f)
k
x(f)I (k), (4)
where Q is the average query and σ(f)k is the standard deviation of the k-th values in the f -th feature. The
query is thus computed from the feature values that mostly agree with the user selection, while the outliers areremoved from the computation.
3. PROSEMANTIC FEATURES
Figure 1 shows the process of the prosemantic features extraction. Prosemantic features extraction begins bydescribing the images with a suitable set of “low-level” features. As low level features we considered: color meanand standard deviation of the values of the LUV color channels on 9 image subregions, global color histogram inthe RGB color space, statistics about the direction of edges and the descriptors associated to the Scale InvariantFeature Transform.10 More details on how these feature have been computed can be found in.11,12
In order to provide a semantically meaningful information about the content of the images, each feature isused as input to an array of 14 soft classifier, trained to recognize partially overlapping classes. We selected a setof 14 classes: animals, city, close-up, desert, flowers, forest, indoor, mountain, night, people, rural, sea, street,and sunset. Some classes describe the image at a scene level (city, close-up, desert, forest, indoor, mountain,night, rural, sea, street, sunset) other describe the main subject of the picture (animals, flowers, people). Theset of classes is not meant to be exhaustive, or to be able to characterize the content of the images with sufficient
SPIE-IS&T Vol. 8304 83040V-3
Downloaded From: http://proceedings.spiedigitallibrary.org/ on 05/01/2013 Terms of Use: http://spiedl.org/terms

specificity for our purposes. Our intent, here, was to select a variegated set of concepts providing a wide rangeof low-level descriptions of typical scenes. The fact that the categories are overlapping is a practical choicereinforced by an intuition based, in turn, on an analogy. As a matter of praxis, it would be problematic, next toimpossible in fact, to find a reasonably extended collection of categories that show no overlap, not in the leastbecause the very concept of “semantic overlap” is all but well defined, and can be used, at best, as a genericregulative principle.
In order to collect suitable training samples for the classifiers, we queried various image search engines on theweb with several keywords related to the classes, and downloaded the resulting pictures. The images were thenmanually inspected in order to remove those that did not belong to the classes as well as low quality images.For each class, a set of negative examples was also selected by taking pictures from the other classes. Since theclasses may overlap, a manual inspection was needed to verify that all the selected images were actually negativeexamples.
For each combination of low-level feature and class, a Support Vector Machine (SVM) with a Gaussian kernelhas been trained. There are two parameters that need to be tuned (the cost parameter C and the scale of theGaussian kernel γ), and they have been selected by maximizing the cross validation performance of the resultingclassifier.
At the end of training, we have a distinct SVM for each feature and for each class. Given a new image Q,
represented by the feature vector x(f)Q , the SVM provides a score s(c,f):
s(c,f)(x(f)Q ) = b(c,f) +
∑
I∈T (c)
α(c,f)I y
(c)I exp
(−γ(c,f)‖x(f)
I − x(f)Q ‖2
), (5)
where T (c) is the training set for class c, x(f)I denotes the feature vectors computed on the image I, y
(c)I is
the label in {−1,+1} which indicates whether I is a positive or a negative example, b(c,f) and α(c,f)I are the
parameters determined by the training procedure, and γ(c,f) is the scale parameter of the kernel. The score isexpected to be positive when the image belongs to the class c, and negative otherwise.
Packing together the 56 scores we obtain a compact vector of prosemantic features that we place in a suitablemetric space in order to index the images using relevance feedback.
4. EXPERIMENTAL RESULTS
A quantitative evaluation of the effectiveness of the prosemantic features for target search task can be found inour previous paper.11 Here we are interested in a qualitative evaluation of the proposed prosemantic features“on-the-field” with the contribution of Fratelli Alinari Photo Archive∗ that supplied us a subset of 3,000 imagesextracted from their extensive photo archives.
Founded in Florence in 1852, Fratelli Alinari Photo Archive (now Alinari 24 ORE SpA, part of IL SOLE 24ORE group) is the oldest firm in the world working in the field of photography, the image and communication.The birth of photography and the story of the Firm go hand in hand in their development and growth, asattested by the Alinari owned fund of 5,500,000 photographs, collected in the Alinari Archives. Alinari is aleader in Photographic Publishing, and its Art Printworks or Art Printworks is the only one in the world stillusing the artisan technique of collotype on paper and on silver plate from photographic images. Today Alinari isconstantly updating its on-line photographic repository with over 300,000 images. An important work for longterm preservation, storage and image permanence is ongoing, thanks also to an expert team of skilled techniciansand photographic experts.
The dataset of images supplied to the University of Milano-Bicocca represents a new corpus of color pho-tographs collected by the Alinari team through new photographic campaigns, in order to enrich the traditional19th and early 20th century “vintage” repository with fresh content representing the new photographic genresand tendencies of the 21st century. In particular, the dataset is composed of 3,000 images (b/w and color), mainlyregarding cityscape, landscape, art, painting and sculptures. This dataset has been taken in the center of Italy
∗http://www.alinari.com/
SPIE-IS&T Vol. 8304 83040V-4
Downloaded From: http://proceedings.spiedigitallibrary.org/ on 05/01/2013 Terms of Use: http://spiedl.org/terms

!1irv-ìi
wit
Tio
as rTf
!4,.°.°.
yof¡..
S116SI
Figure 2. A small excerpt of the Alinari image dataset.
(Tuscany region) from locations of high cultural interest such as Firenze, Pisa, and San Giminiano among oth-ers. The images depict sculptures, palaces, plazas, and various other artifacts taken from different perspectivesand sometimes under different illuminations. Some images represent a single object captured from a distance,while other images of the same subject have been taken much more closer (close-up). In some instances, wholepanoramas of the surroundings have been acquired as well. Figure 2 shows a random selection of the images inthe dataset. This dataset has been selected in order to evaluate how QuickLook2 can perform with a specificgenre, with a mix of contemporary color and historical b/w images, and to test if and how it can find images ofspecific objects or part of them.
The experiments have been conducted at the Alinari Archives where a copy of QuickLook2 has been installed.Users have been asked to perform queries without supplying them with a specific task: they were free to choosethe type and aim of their searches. For the purpose of the experiments, image examples are selected only fromthe first page of the retrieved results.
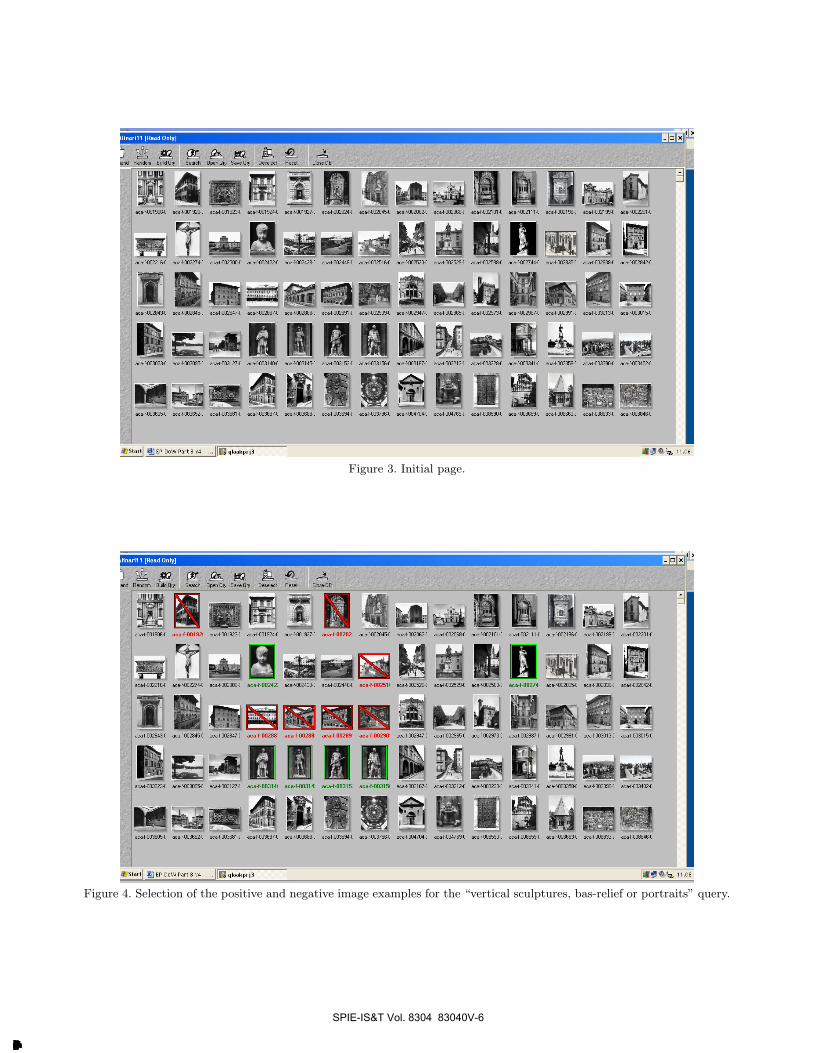
Figures 3, 4, 5, and 6 show an example of image retrieval on the Alinari dataset with the QuickLook2 systemexploiting the prosemantic features. Figure 3 shows the initial page. At the beginning the system shows thepictures sorted according to the identification code assigned by Alinari. As a result, the initial page is composedof black and white pictures only. The objective in this example was to retrieve images showing vertical sculptures,bas-relief or portraits. Thus, the query corresponds to a composite category search. It must be pointed out thatthe query is a very challenging one since the prosemantic features contains no information whatsoever about theconcepts of “vertical”, “sculptures” ad so on. Since these concepts are not directly embedded in the features,they must be indirectly deduced by the system from the image examples and the relevance feedback mechanism.
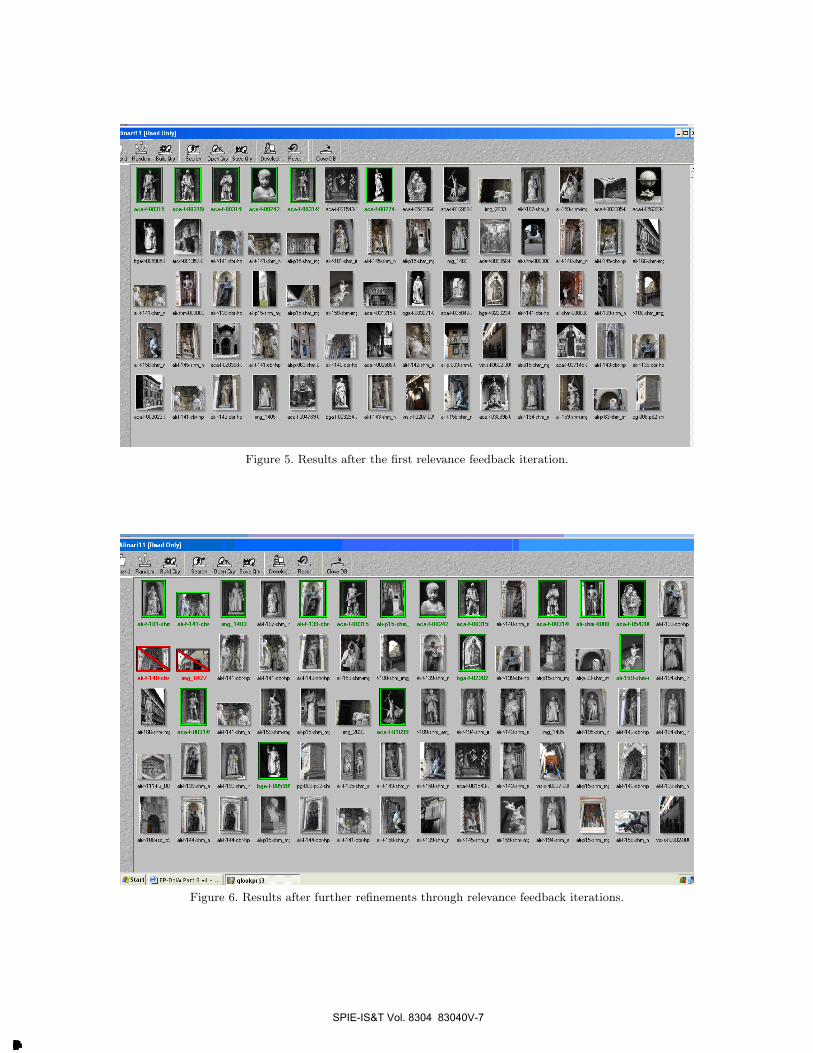
Figure 4 shows the positive/relevant images (with green bounding box) and the negative/non relevant imagesselected by the user. Negative images corresponds mostly to buildings while the positive images are of sculptures.It should be noted that only a subset of the available positive images and negative images in the page have beenselected. Figure 5 shows the results of the first relevance feedback iteration. It can be seen that now the retrievedimages are both the black and white and color ones. More images satisfying the initial query have been found,while the negative images are greatly reduced in number. The large number of different relevant images allowsthe user to strengthen his idea of the query by selecting images having different pictorial characteristics. Thisis shown in Figure 6 where the results obtained after another iteration are more coherent with the query as therelevant images are ranked in the first rows.
SPIE-IS&T Vol. 8304 83040V-5
Downloaded From: http://proceedings.spiedigitallibrary.org/ on 05/01/2013 Terms of Use: http://spiedl.org/terms
512, Pr, te0rand Random Build pry Search bpon Dy Sava by Deselect Reset Close DE
warn 1 [Read Only]
aoald019066 awM019206 aoald01923A ace+001921d e'a1M927.1 Me1.002026[ axlAlAüf
aw1d02216f aw1d022] E aw1d023oIH awldON22. aced 0024381 saNPLH& o14702516f
awld02B43E aWd02B4S awld02B4]S awld02B81S awld02B88f awld02B91S aced 002339f
aw1d030236 aw1d030956 auld03121S awld031406 awld031456 aw1001I536 awld03156f
acaldo36o acaldo3652S cepW3681S acaldo3681S acaldo36881 acaldo36941 acaldo3196f
aW1320:24 awfL020686 a ald021016 awl-0o
.11g
el-002196 ace4q021991 a ald021016
ece4132521X ace4025291 aw1d025H E aw1d0214
Aktieiex4023114 ex4.1023651 aw1d023/3f aw1d0298] ex10029S1L ea11.0331
aca4032167 t eanómx eta ra03ê2az aoarao
gAawldo335H1 aca40)3391f carAW@[
aca /0088161
4i®I11acaldo4]o4f acaldo4]691 acaldoE59o1 acaldo8659f acaldo86i a I0088
d la EP-DoW Part ---- Mn glookprj3 3j,DCa 11.0
7 Pr, FR,lana Fanaom aula 9ry 9,81,8 CPanOo bava 9, Re
upue1
aw1d019001 cal -00192 1923
a
a.:a Close DB
0702 8.M10020456 wad-00206Z( 8cald030686 a e10021015 aw1002
aw1d030
000 cal -00242 ace( 0021718( 8.1002448-0 atol -0025511 awld
0881d03095f aa4J03127 - ca-i-003111 a-i-00314' 881-0031
a.1-0036051 a.1-003652- a.1-003681
1
4 1
ece10121 aw1d021996 8.1-002]II1[
ace 1 00252 f aw1002588f 8881-0027 raNOLB'Ad aw1d020425
tY
aw1002965f aw1002973f aw100298][ aa1033313f et a40730154
un
aw1003681t aw1003681 8.1'00369
d tart EP-0oW Part B v4 -...II 91ookp133
a.1-003]96
e8400]16)d eaN0332134 rice1032284 aab6W1E aw1d0335H aWl®f
a.1008833
ra10034024
j _Ia.1L04]04f a.1004]69( a. 1L0859 L a.1008659( a.1008663 a.1008816(
110 'XL 11 .08
Figure 3. Initial page.
Figure 4. Selection of the positive and negative image examples for the “vertical sculptures, bas-relief or portraits” query.
SPIE-IS&T Vol. 8304 83040V-6
Downloaded From: http://proceedings.spiedigitallibrary.org/ on 05/01/2013 Terms of Use: http://spiedl.org/terms
P, Cl.and Random Build Dry Search Open Dry Save Dry D le
fReset Close DB
ca10031 ea-1-00315i ca10031 I pal-00242. ea-1-00314r aw1061543[ a1-00214 awlA5aID6f awH116999f imy2633 all -19] M1rryjr all 159 ohm im
boa I005985í arc d013500 all < awl CIhmn arroi 5ahpm¿ all 181 ahmjr aull5.ffm_n
all -141 hm al ohm 000005 all all 015 af015ahn_m a4159aFminç ö1II31215f
alM1p15'$bn_m¿ imy1403 aaard090506 a4aFm000005
nurnboa m03mL asr035049L hg rr[z0nd all 1,11
aa1A563091
lyJlY
r145cbdp aW66aFmimç
IIUiF1$alnryn 1100aFmjms
all lí 8 shm_n a11115.9mn aca I 020368 all -141 cbr hp ah p 06 L all -140 chr h aca 1002588 (
aa1d0302 Lr-p imy1405 aa1d04]69l boa 1d03L941 alF143aMry0
shm_n p 003 ohm L v is s 1 1 9 OOi all p15 m mr aca 037145-8 44113 cbr - p all iî rM1p
II it0207 00 aw150aMry0 aa15i0896f afr1194aMryjr aW59aFminE afp63aMryjn p90009ó-Fi
4linaril1 [Read Only]
pand Random Build Qry Search Open Qry Save Qry Deselect Reset Close DB
f,l r.IIÌ
ali -f- 181 -shn ali -f- 141 -cb img_1403 ali1- 187- shm_ir ali -f- 139 -cbr aca- f- 00315 al p15 -shm_ aca -f- 00242: aca -f- 003151
ali -f- 140 -cbr ali-159-shmim5 f-108-shm_img alid-139-shm_n bga-I-02202:
Iali-166-shmim5 aca-f-00314, aliá-141-shm_n ali-p15-shm_mc img_2633
alid-139.cbr-hp
aca -f- 01699' f- 189- shm_am_ ali -f- 194- shm_ir ali -f- 143 -shm_n
l ealid-139.cbr-hp
ali p15 -shm mc ati-p-63-shm_in ali -159 -shm -i ali -f- 194- shm_ir
img_1405 alid-195-shm_ir atid-143-cbrhp aliá-194-shm_ir
aliá-108rsc_p
alid-111-f1u_00 alid-139-shm_n atid-193.shm_ir bga-f-00598! pg-008-p62-shi alid-195-shm_ir alid-143.shm n atid-158.shm n acad-061543d alid-143-shm_n vis.sdi0207.001 atid.140-cbrhp atid.139.shm n
aid-144.shm n atid-144-cbrhp a,p15-shm_mc alid-144-cbr-hp alid-141-cbr-hp alid-158-shm_n alid-139-shm_n alid-145-shm_n a,p15.shm mç atid-158.shm n vis.sdi0602.00,
D Starti j EP -DoW Part B v4 - ... ç glookprj3
Figure 5. Results after the first relevance feedback iteration.
Figure 6. Results after further refinements through relevance feedback iterations.
SPIE-IS&T Vol. 8304 83040V-7
Downloaded From: http://proceedings.spiedigitallibrary.org/ on 05/01/2013 Terms of Use: http://spiedl.org/terms

Table 1. The usability questionnaire administered to the QuickLook2 users. The numerical scale goes from ‘stronglydisagree’ to ‘strongly agree’ (1 → ‘strongly disagree’, 2 → ‘disagree’, 3 → ‘neutral’, 4 → ‘agree’, 5 → ‘strongly agree’).
# Statement 1 2 3 4 5
1. I think that I would like to use this system frequently �2. I found the system unnecessarily complex �3. I thought the system was easy to use �4. I would need the support of a technical person to be able to use this system �5. I found the various functions in this system were well integrated �6. I thought there was too much inconsistency in this system �7. I would imagine that most people would learn to use the system very quickly �8. I found the system very cumbersome to use �9. I felt very confident using the system �
10. I needed to learn a lot of things before I could get going with this system �
11. The queries are executed rapidly �12. Too many iterations are required to obtain acceptable results �13. The system allows effective category searches �14. The system allows effective target searches �15. The system is useful for browsing images �16. The system is useful for the retrieval of images �17. The system user interface is easy to understand �18. The relevance feedback mechanism is too complicated �19. I think that retrieval by image examples is useless �20. Too many positive examples must be selected �21. Too many negative examples must be selected �
Different users tested the system for a few days. A questionnaire in two parts was administered to theseusers in order to collect their impression about the system on the overall and on its functionalities. The firstpart was inspired by the System usability Scale (SUS) questionnaire developed by John Brooke at DEC (DigitalEquipment Corporation).13 It is composed of statements related to different aspects of the experience, andthe subjects were asked to express their agreement or disagreement with a score taken from a Likert scale of5 numerical values: 1 expressing strong disagreement with the statement, 5 expressing strong agreement and3 expressing a neutral answer. The second part of the questionnaire focuses more on the functionalities of theQuickLook2 system and was administered with the same modalities.
The results of the questionnaire are reported in Table 4. The score given by the users are summarizedby majority vote. The results show that on the overall the system perform well. The retrieval capabilities ofQuickLook2 are judged positively as well as its efficiency and efficacy “The system is robust, fast to manage, andspeedy in the query mechanism”. The relevance feedback mechanism coupled with the prosemantic features isefficient and is able to retrieve satisfactory results in few iterations and requiring the users to select a moderateamount of image examples. Retrieval by examples is still considered a plus in a retrieval engine that copemainly with images. With respect to the users’ experiences the weakest point of the system is the graphicaluser interface. Although the selection of the images is quite intuitive, the other components of the user interfacehas been rated poorly. The QuickLook2 system has been designed with a very rough and simple interface. Inparticular users complained about the selection of the query options and proposed some solutions such as:
• “There is not a logic approach to perform a query as the approach is through drop menu and windowsand not through, for example, a wizard navigation tool. The result is that a non experienced user couldhave difficult at the beginning to understand where to start, which bottom to push first, and what to do,or where to go next.”
SPIE-IS&T Vol. 8304 83040V-8
Downloaded From: http://proceedings.spiedigitallibrary.org/ on 05/01/2013 Terms of Use: http://spiedl.org/terms

• “Probably a wizard that could assist the user on the various operation, along with a graphic interfaceprobably more colorful, without drop down menus, but with simple and direct buttons, and with an on-line help and a virtual assistant tool could push the usability.”
The other recommendations can be summarized as follows: being able to save specific queries, being able topersonalized the access (different users can have different privileges or access different options in the menu), havea statistic function that can send to the system developer institution a log with the bugs/system performance(for remote tracking, performance analysis, improvements). An eye tracking functionalities to detect the userbehavior and evaluate what the user see, where he normally goes or select into the main windows, or even the timethat a user spend between two different queries can provide vital information for future system improvements.Being able to export the query content into a virtual 3D exhibition space, or even into the Cloud, might provideadditional usability possibilities.
5. CONCLUSIONS
In this paper we presented an experimentation where prosemantic features are used within the QuickLook2 imageretrieval system to perform content-based searches in a photo archive provided by Fratelli Alinari.
Employers of Alinari qualitatively evaluated the performance of the system in different retrieval scenarios.The resulting judgments are quite surprising. No criticisms have been raised concerning the system’s capability inidentifying the target concepts or pictures. The only negative observations were related to the user interface, anaspect of the system which was not the focus of the experimentation. In our future work we plan to thoroughlyaddress this issue by providing a more user friendly interface, and by investigating the use of more complexvisualization techniques.
REFERENCES
[1] Smeulders, A. W. M., Worring, M., Santini, S., Gupta, A., and Jain, R., “Content-based image retrievalat the end of the early years,” IEEE Transactions on Pattern Analysis and Machine Intelligence 22(12),1349–1380 (2000).
[2] Zhou, X. S. and Huang, T. S., “Relevance feedback in image retrieval: a comprehensive review,” MultimediaSystems 8(6), 536–544 (2003).
[3] Fan, J., Gao, Y., Luo, H., and Xu, G., “Automatic image annotation by using concept-sensitive salientobjects for image content representation,” in [Proceedings of the 27th annual international ACM SIGIRconference on Research and development in information retrieval ], 361–368 (2004).
[4] Datta, R., Li, J., and Wang, J. Z., “Content-based image retrieval: approaches and trends of the newage,” in [Proceedings of the 7th ACM SIGMM international workshop on Multimedia information retrieval ],253–262 (2005).
[5] Vailaya, A., Figueiredo, M., Jain, A., and Zhang, H.-J., “Image classification for content-based indexing,”IEEE Trans. on Image Processing 10(1), 117–130 (2001).
[6] Wang, J., Li, J., and Wiederhold, G., “SIMPLIcity: Semantics-sensitive integrated matching for picturelibraries,” IEEE Transactions on Pattern Analysis and Machine Intelligence 23(9), 947–963 (2001).
[7] Chang, E., G., K., Sychay, G., and Gang, W., “CBSA: content-based soft annotation for multimodal imageretrieval using bayes point machines,” IEEE Transactions on Circuits and Systems for Video Technol-ogy 13(1), 26–38 (2003).
[8] Ciocca, G., Gagliardi, I., and Schettini, R., “Quicklook2: An integrated multimedia system,” Journal ofVisual Languages & Computing 12(1), 81–103 (2001).
[9] G. Ciocca, I. G. and Schettini, R., “Content based image retrieval and video retrieval using the QuickLooksearch engine,” MultiMedia Information Retrieval , 151–170 (2004).
[10] Lowe, D. G., “Distinctive image features from scale-invariant keypoints,” International Journal of ComputerVision 60(2), 91–110 (2004).
[11] Ciocca, G., Cusano, C., Santini, S., and Schettini, R., “Halfway through the semantic gap: prosemanticfeatures for image retrieval,” Information Sciences 181(22), 4943–4958 (2011).
SPIE-IS&T Vol. 8304 83040V-9
Downloaded From: http://proceedings.spiedigitallibrary.org/ on 05/01/2013 Terms of Use: http://spiedl.org/terms

[12] Ciocca, G., Cusano, C., Santini, S., and Schettini, R., “Prosemantic features for content-based imageretrieval,” in [7th International Workshop on Adaptive Multimedia Retrieval ], (2009).
[13] Brooke, J., “SUS: A Quick and Dirty Usability Scale,” in [Usability Evaluation in Industry ], Jordan, P. W.,Thomas, B., Weerdmeester, B. A., and McClelland, I. L., eds., Taylor & Francis., London (1996).
SPIE-IS&T Vol. 8304 83040V-10
Downloaded From: http://proceedings.spiedigitallibrary.org/ on 05/01/2013 Terms of Use: http://spiedl.org/terms
Related Documents











