
Search-time Parallelism: Presented by Shikhar Bhushan, Etsy
Jul 13, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


Search-time ParallelismShikhar Bhushan, Etsy Inc. [email protected] @shikhrr
26 million listings
Over 1 million shops

Search Infrastructure at EtsyParallel clusters ‘flip’ & ‘flop’ - dark/live
Listings index:
2013: unsharded Solr, one large JVM
2014: locally sharded Solr, 8 smaller JVM’s big win on latency tail

Speeding up search• Low-level improvements: use less CPU
• Parallelize: use more cores

Amdahl’s law
“The speedup of a program using multiple processors in parallel computing is limited by the time needed for the sequential fraction of the program.”
Wikipedia

ShardingUsing:
• Solr distributed search
• SolrCloud
• Elasticsearchshard0
hash(pk) % num_shards
shard1 shard2 shard3
shard4 shard5 shard6 shard7

Why not shard?New challenges arise once you go distributed, some examples:
• More moving parts and failure modes to deal with
• Missing features with distributed search
• Index statistics on shards can vary, distorting IDF
Tempting to defer sharding if not necessary due to index size.

Segment-level parallelismFully-functioning mini-indexes within your Lucene index.

Collectors!• Hits get accumulated - ‘collected’ by the Collector abstraction.
• Invoked for every hit that matches the Query.
• Has the Scorer available to get the score for current hit if needed.
• Output - e.g. top N hits, number of hits, grouped hits - can be retrieved when done.

Existing solutionIndexSearcher(IndexReaderContext, ExecutorService)
Special-cased for:
TopScoreDocCollector (sort by score)and
TopFieldCollector (arbitrary sort-spec)
Only ships with parallel search support for the above TopDocs collectors.

Not composableDifficult to build parallelization for every possible permutation.
With Solr you may have:
TimeLimitingCollector |— MultiCollector
|— TopScoreDocCollector |— DocSetCollector

Sync considered harmful
collect() called for every single document that matches the query.
Can expect a lot of contention!
protected void search( List<LeafReaderContext> leaves, Weight weight, Collector collector ) throws IOException {
// TODO: should we make this // threaded...? the Collector could be sync'd? // always use single thread:
for (LeafReaderContext ctx : leaves) { // search each subreader …
IndexSearcher.java

Proposed solution
LUCENE-5299 Refactor Collector API for parallelism

API review: Beforepublic interface Collector {
LeafCollector getLeafCollector(LeafReaderContext context) throws IOException;
}
public interface LeafCollector {
void setScorer(Scorer scorer) throws IOException;
void collect(int doc) throws IOException;
boolean acceptsDocsOutOfOrder();
}

New methods: Collectorpublic interface Collector {
LeafCollector getLeafCollector(LeafReaderContext context) throws IOException;
// NEW METHODS:
boolean isParallelizable();
void setParallelized();
void done() throws IOException;
}

New methods: LeafCollectorpublic interface LeafCollector {
void setScorer(Scorer scorer) throws IOException;
void collect(int doc) throws IOException;
boolean acceptsDocsOutOfOrder();
// NEW METHOD:
void leafDone() throws IOException;
}
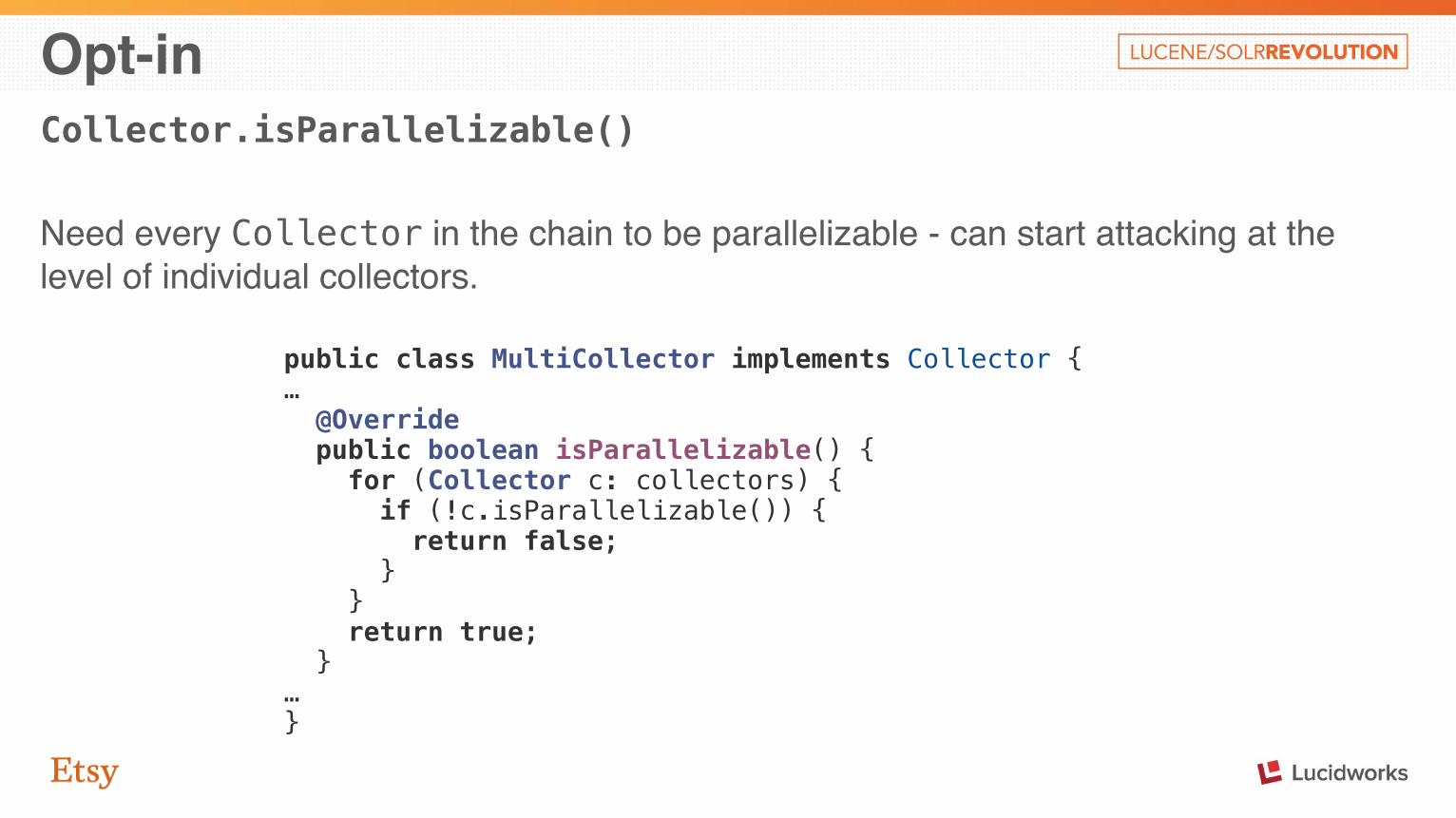
Opt-inCollector.isParallelizable()
Need every Collector in the chain to be parallelizable - can start attacking at the level of individual collectors.
public class MultiCollector implements Collector { … @Override public boolean isParallelizable() { for (Collector c: collectors) { if (!c.isParallelizable()) { return false; } } return true; } … }

Don’t penalize serialCollector.setParallelized()
‘Heads-up’ to the Collector whether collection will be parallelized, so it can adapt in case the parallelism-friendly approach has unnecessary cost in the serial case.

Non-blocking constructsGuarantee to always execute on primary search thread
(existing)LeafCollector Collector.getLeafCollector()
(new)void LeafCollector.leafDone() void Collector.done()
=> safe places to act on shared mutable state

New search strategyIndexSearcher(IndexReaderContext, SearchStrategy)
IndexSearcher.search() factored into:
• SerialSearchStrategy
• ParallelSearchStrategy(Executor e, int parallelism) • parallelism used to throttle maximum concurrent tasks at the request-level

Parallel search - not just collection• Scoring is thread-safe and segment-level.
• Collection is also segment-level, but typically computes its outcome as shared state
between leafs e.g. TopDocs over your index.
• By making Collector API parallelism-friendly, we can parallelize search as a whole.

Stupidly parallelizablepublic class TotalHitCountCollector implements Collector {
private int totalHits;
@Override public LeafCollector getLeafCollector(LeafReaderContext context) throws IOException { return new LeafCollector() { private int totalHits = 0; .. @Override public void collect(int doc) throws IOException { totalHits++; } .. @Override public void leafDone() throws IOException { TotalHitCountCollector.this.totalHits += totalHits; } };
} .. @Override public boolean isParallelizable() { return true; }
}

Fun to parallelizeSolr DocSetCollector
populates document ID’s in FixedBitSet(maxDoc) - internally a long[]
To address possible race condition at segment boundaries, when parallelized:
• collect() first and last 64 document ID’s for the segment into LeafCollector-
private longs, all others into shared bitset.
• when leafDone() merge these boundary document ID’s into shared bitset.
leaf docBase maxDoc docId range
0 0 42 [0 -‐ 41]1 42 20 [42 -‐ 61]

Bigger tradeoffsLucene TopScoreDocCollector uses a single priority queue in serial case.
When parallelized:
• More memory: lazy pool of HitQueue - grab when getLeafCollector(), return
when leafDone(), merge when done().
• More computation: in addition to the merge step - less likely to immediately discard
hits that won’t eventually make it, as using multiple priority queues.

trunk (serial) vs patch (serial) Task QPS baseline StdDev QPS parcol StdDev Pct diff HighSloppyPhrase 175.08 (11.5%) 156.12 (12.7%) -10.8% ( -31% - 15%) LowSloppyPhrase 368.89 (11.5%) 337.39 (14.5%) -8.5% ( -30% - 19%) LowSpanNear 367.40 (13.3%) 336.12 (24.5%) -8.5% ( -40% - 33%) LowPhrase 364.59 (13.2%) 336.56 (15.2%) -7.7% ( -31% - 23%) HighPhrase 125.30 (13.6%) 116.24 (12.2%) -7.2% ( -29% - 21%) MedSpanNear 147.73 (13.6%) 137.15 (20.3%) -7.2% ( -36% - 30%) MedSloppyPhrase 414.70 (16.5%) 386.07 (13.6%) -6.9% ( -31% - 27%) LowTerm 2288.63 (17.4%) 2138.57 (12.7%) -6.6% ( -31% - 28%) Respell 62.78 (86.4%) 58.80 (76.0%) -6.3% ( -90% - 1143%) MedPhrase 350.78 (14.0%) 331.50 (12.5%) -5.5% ( -28% - 24%) HighTerm 779.36 (10.0%) 740.42 (11.8%) -5.0% ( -24% - 18%) PKLookup 238.68 (10.9%) 226.79 (12.8%) -5.0% ( -25% - 20%) OrHighMed 369.05 (11.2%) 351.05 (12.2%) -4.9% ( -25% - 20%) MedTerm 1166.96 (14.6%) 1116.42 (13.2%) -4.3% ( -27% - 27%) AndHighMed 616.82 (12.9%) 590.46 (13.8%) -4.3% ( -27% - 25%) AndHighHigh 155.12 (22.9%) 150.33 (22.2%) -3.1% ( -39% - 54%) Prefix3 522.67 (14.9%) 508.08 (13.4%) -2.8% ( -27% - 29%) OrHighLow 233.72 (11.6%) 227.83 (11.9%) -2.5% ( -23% - 23%) AndHighLow 982.58 (16.0%) 966.78 (13.2%) -1.6% ( -26% - 32%) IntNRQ 88.57 (15.1%) 87.37 (12.9%) -1.4% ( -25% - 31%) HighSpanNear 92.55 (21.2%) 91.55 (11.7%) -1.1% ( -28% - 40%) Wildcard 226.43 (11.5%) 225.37 (11.3%) -0.5% ( -20% - 25%) Fuzzy2 7.02 (17.1%) 7.02 (19.0%) 0.0% ( -30% - 43%) OrHighHigh 242.44 (14.3%) 243.60 (14.0%) 0.5% ( -24% - 33%) Fuzzy1 9.62 (30.7%) 12.40 (102.9%) 28.9% ( -80% - 234%)
luceneutil with wikimedium500k
SerialSearchStrategy
SEARCH_NUM_THREADS=32
Hardware: 32-core Sandy Bridge
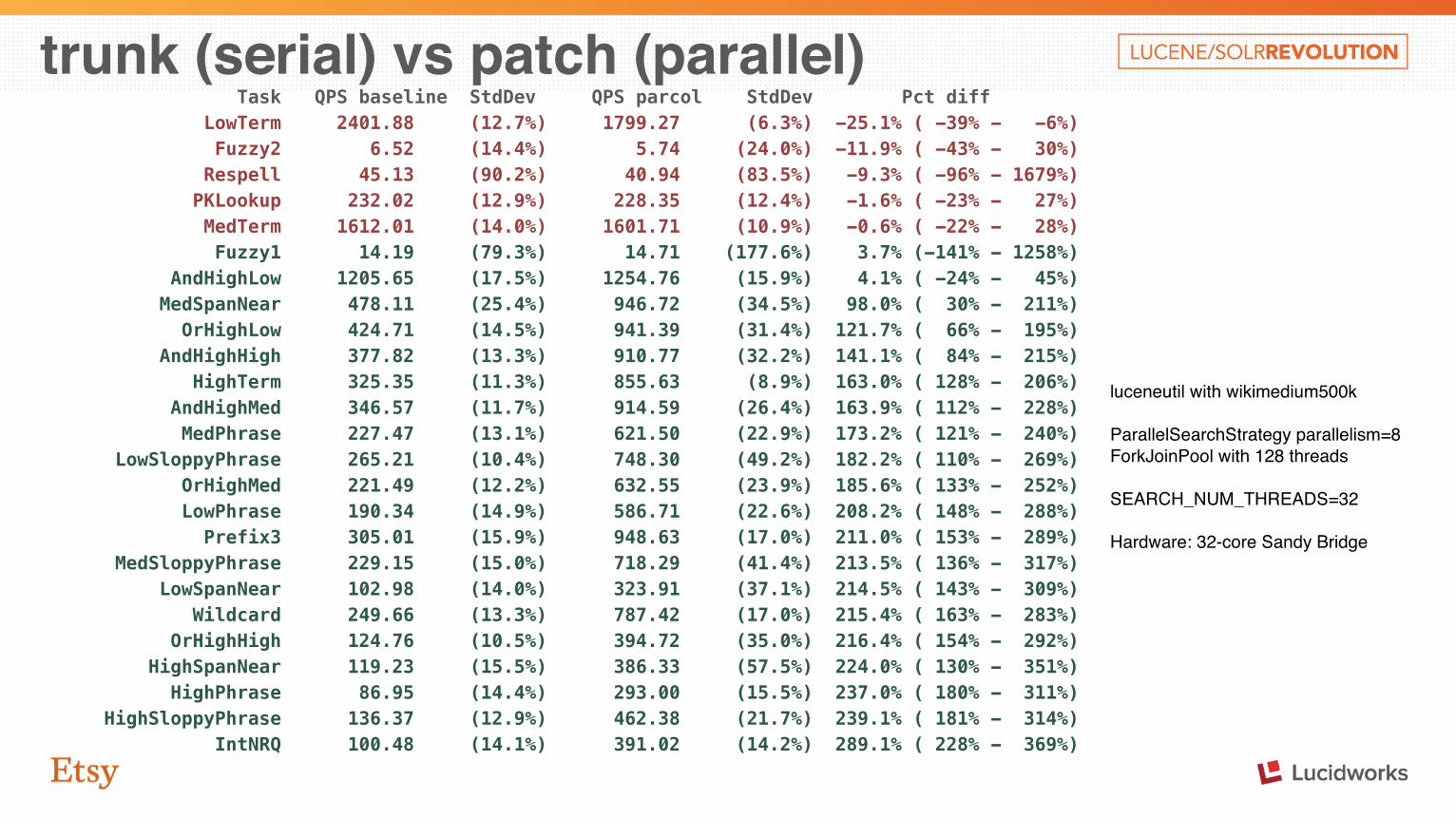
trunk (serial) vs patch (parallel) Task QPS baseline StdDev QPS parcol StdDev Pct diff LowTerm 2401.88 (12.7%) 1799.27 (6.3%) -25.1% ( -39% - -6%) Fuzzy2 6.52 (14.4%) 5.74 (24.0%) -11.9% ( -43% - 30%) Respell 45.13 (90.2%) 40.94 (83.5%) -9.3% ( -96% - 1679%) PKLookup 232.02 (12.9%) 228.35 (12.4%) -1.6% ( -23% - 27%) MedTerm 1612.01 (14.0%) 1601.71 (10.9%) -0.6% ( -22% - 28%) Fuzzy1 14.19 (79.3%) 14.71 (177.6%) 3.7% (-141% - 1258%) AndHighLow 1205.65 (17.5%) 1254.76 (15.9%) 4.1% ( -24% - 45%) MedSpanNear 478.11 (25.4%) 946.72 (34.5%) 98.0% ( 30% - 211%) OrHighLow 424.71 (14.5%) 941.39 (31.4%) 121.7% ( 66% - 195%) AndHighHigh 377.82 (13.3%) 910.77 (32.2%) 141.1% ( 84% - 215%) HighTerm 325.35 (11.3%) 855.63 (8.9%) 163.0% ( 128% - 206%) AndHighMed 346.57 (11.7%) 914.59 (26.4%) 163.9% ( 112% - 228%) MedPhrase 227.47 (13.1%) 621.50 (22.9%) 173.2% ( 121% - 240%) LowSloppyPhrase 265.21 (10.4%) 748.30 (49.2%) 182.2% ( 110% - 269%) OrHighMed 221.49 (12.2%) 632.55 (23.9%) 185.6% ( 133% - 252%) LowPhrase 190.34 (14.9%) 586.71 (22.6%) 208.2% ( 148% - 288%) Prefix3 305.01 (15.9%) 948.63 (17.0%) 211.0% ( 153% - 289%) MedSloppyPhrase 229.15 (15.0%) 718.29 (41.4%) 213.5% ( 136% - 317%) LowSpanNear 102.98 (14.0%) 323.91 (37.1%) 214.5% ( 143% - 309%) Wildcard 249.66 (13.3%) 787.42 (17.0%) 215.4% ( 163% - 283%) OrHighHigh 124.76 (10.5%) 394.72 (35.0%) 216.4% ( 154% - 292%) HighSpanNear 119.23 (15.5%) 386.33 (57.5%) 224.0% ( 130% - 351%) HighPhrase 86.95 (14.4%) 293.00 (15.5%) 237.0% ( 180% - 311%) HighSloppyPhrase 136.37 (12.9%) 462.38 (21.7%) 239.1% ( 181% - 314%) IntNRQ 100.48 (14.1%) 391.02 (14.2%) 289.1% ( 228% - 369%)
luceneutil with wikimedium500k
ParallelSearchStrategy parallelism=8ForkJoinPool with 128 threads
SEARCH_NUM_THREADS=32
Hardware: 32-core Sandy Bridge
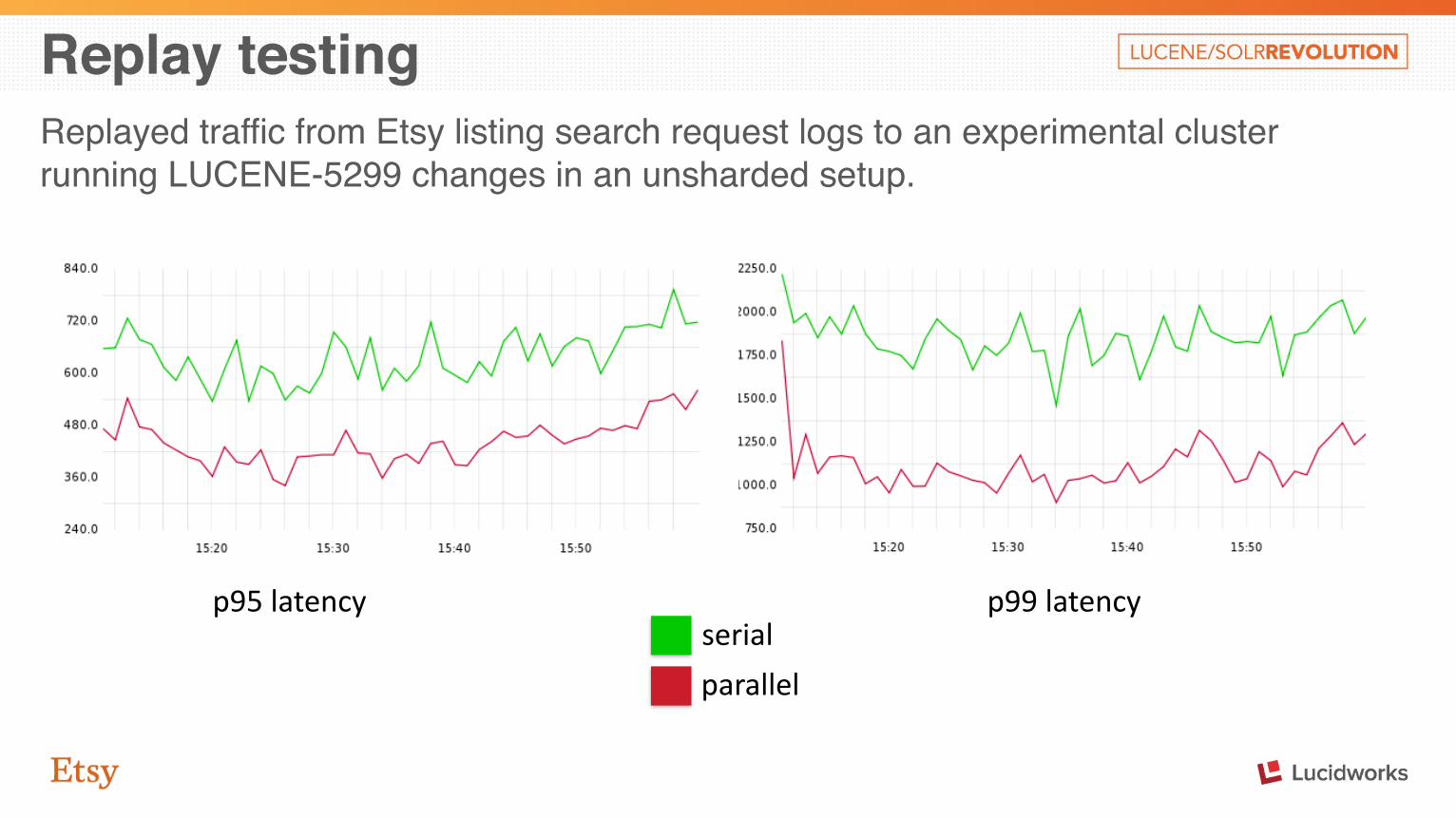
Replay testingReplayed traffic from Etsy listing search request logs to an experimental cluster running LUCENE-5299 changes in an unsharded setup.
p95 latency p99 latencyserial
parallel

ThroughputIn general, system needs to do more work overall, which impacts throughput:• concurrency overhead• context switches• locally optimal choices at the leaf-level• merge cost
serial user cpu % parallel user cpu %
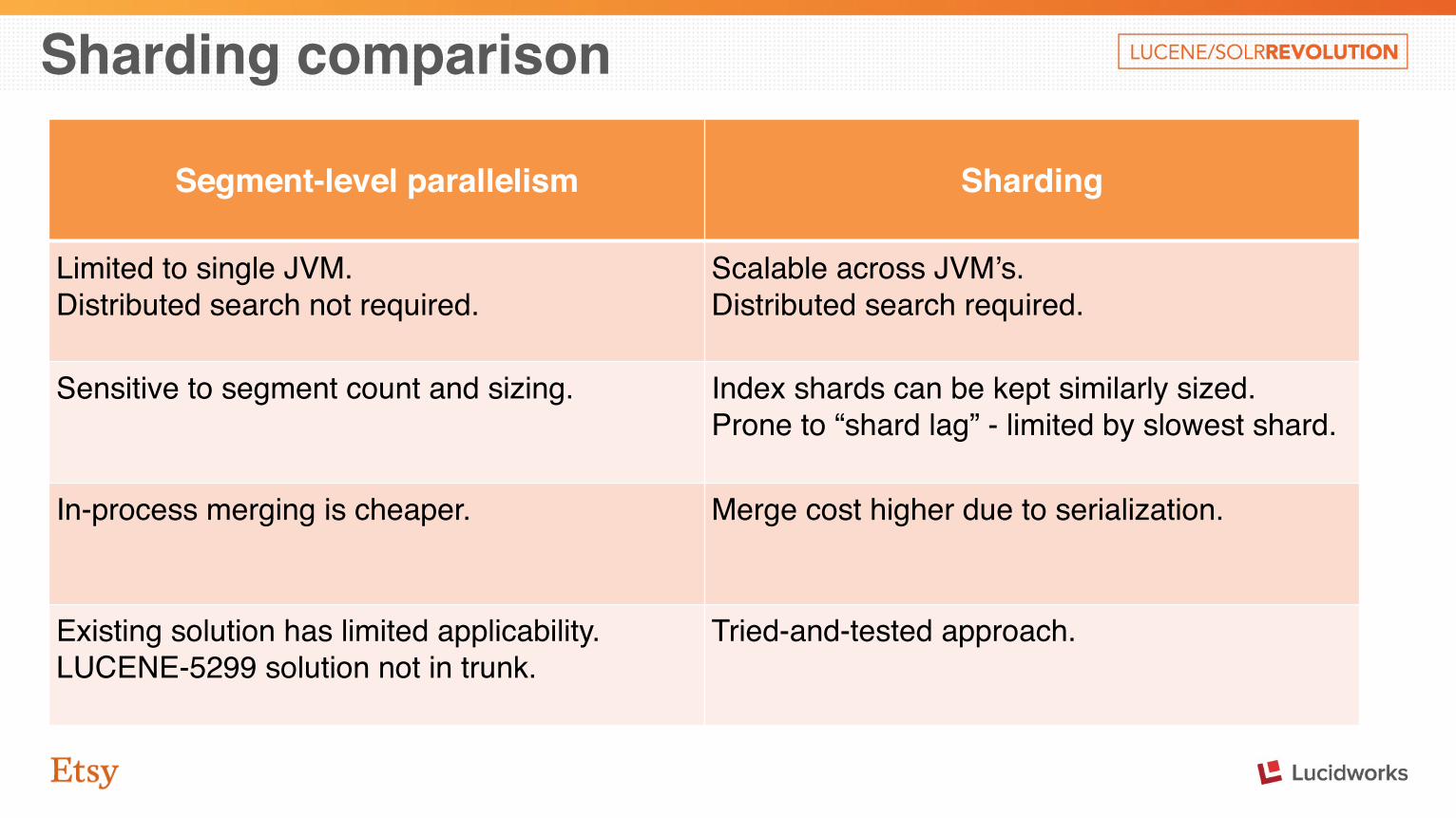
Sharding comparison
Segment-level parallelism Sharding
Limited to single JVM.Distributed search not required.
Scalable across JVM’s.Distributed search required.
Sensitive to segment count and sizing. Index shards can be kept similarly sized.Prone to “shard lag” - limited by slowest shard.
In-process merging is cheaper. Merge cost higher due to serialization.
Existing solution has limited applicability.LUCENE-5299 solution not in trunk.
Tried-and-tested approach.

Not mutually exclusive
Sharding + Segment-level parallelism = ?

Next steps• Figure out whether serial penalty is real.
• Semantics around exceptions during collection and ‘done’ callbacks.
• Lots more collectors can be made parallelizable.
• Your contributions welcome - LUCENE-5299.
• Committer interest especially welcome!

Thanks
Shikhar Bhushan
@shikhrr
codeascraft.com
etsy.com/careers
Related Documents











