Se Não Pode Ser Copiado, Não Existe – By Italo Maia

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Se Não Pode Ser Copiado,Não Existe – By Italo Maia

ScrapingFor Fun And Glory!
BZZ BZZ


VOCÊ
PROGRAMA

DesenvolvedorWeb, Mobile, Desktop
MembroPugCE, ForHacker, DjangoBrasil
GostaPromoção, Ler, Chuva


Esse é muito bom!



BADHTML

BeaufitulSoup
FireBug

Facinho
Referências sem domínioHTTP ErrorsBloqueio de acessoCookiesAutenticaçãoParâmetros dinâmicos
CRAWLING


Como
que faz?
Maneiro!


Obrigado!

Se Não Pode Ser Copiado,Não Existe – By Italo Maia

ScrapingFor Fun And Glory!
BZZ BZZ
Muito bom dia! Sejam bem vindos à mais um Flisol. Que bom que tanta gente conseguiu acordar cedo para ver as primeiras palestras.
O nome da palestra que vou ministrar é Scraping for Fun and Glory; nela, nosso assunto é scraping.

Scraping ou Web Scraping é como chamamos o conjunto de técnicas utilizadas para se extrair informação da internet, como links, imagens ou mesmo texto. O Google, por exemplo, é uma empresa muito famosa que se utiliza dessa técnica fortemente no seu processo de “page ranking” e indexação de conteúdo.

VOCÊ
PROGRAMA
A ideia é se utilizar de um programa, que fará acessos aos sites que possuem a informação que você deseja como se fosse um usuário real. Toda vez que ele acessar uma página, ele vai receber a informação que um usuário receberia em seu navegador, e vai buscar aquilo que é importante e descartar o resto.
Outra habilidade importante que um spider deve ter é a capacidade de seguir links, pois eles podem levá-lo à mais informação útil.

DesenvolvedorWeb, Mobile, Desktop
MembroPugCE, ForHacker, DjangoBrasil
GostaPromoção, Ler, Chuva
Antes de começar, gostaria de falar um pouco de mim. Meu nome é Italo Maia, sou desenvolvedor a 10 anos, possuo projetos em diversas linguagens, muitos deles no github, e tive oportunidade, recentemente, de trabalhar no maior ecommerce do Brasil, onde pude aprender muito sobre o assunto, inclusive, como o scraping é importante para esse tipo de negócio.
Esse ano participei do último python-brasil, em recife, e nele, pude ver o interesse das pessoas sobre o assunto desta palestra. Por isso resolvi compartilhar um pouco do que aprendi ao longo dos anos sobre o assunto aqui.

Meu primeiro contato com scraping foi a muito tempo atrás, quando um americano me pediu um serviço. Ele era um apostador profissional e me pediu um programa capaz de buscar os resultados de partidas esportivas em um site e armazená-los em alguma forma estruturada fácil de ler.
Lembro que não consegui atendê-lo pois meu óculos quebrou no dia seguinte e eu não enxergava a tela do computador no meu antigo monitor. Foi horrível.
Mas lembro também que achei muito interessante a ideia dele, de utilizar informação livremente disponível na internet de forma organizada.

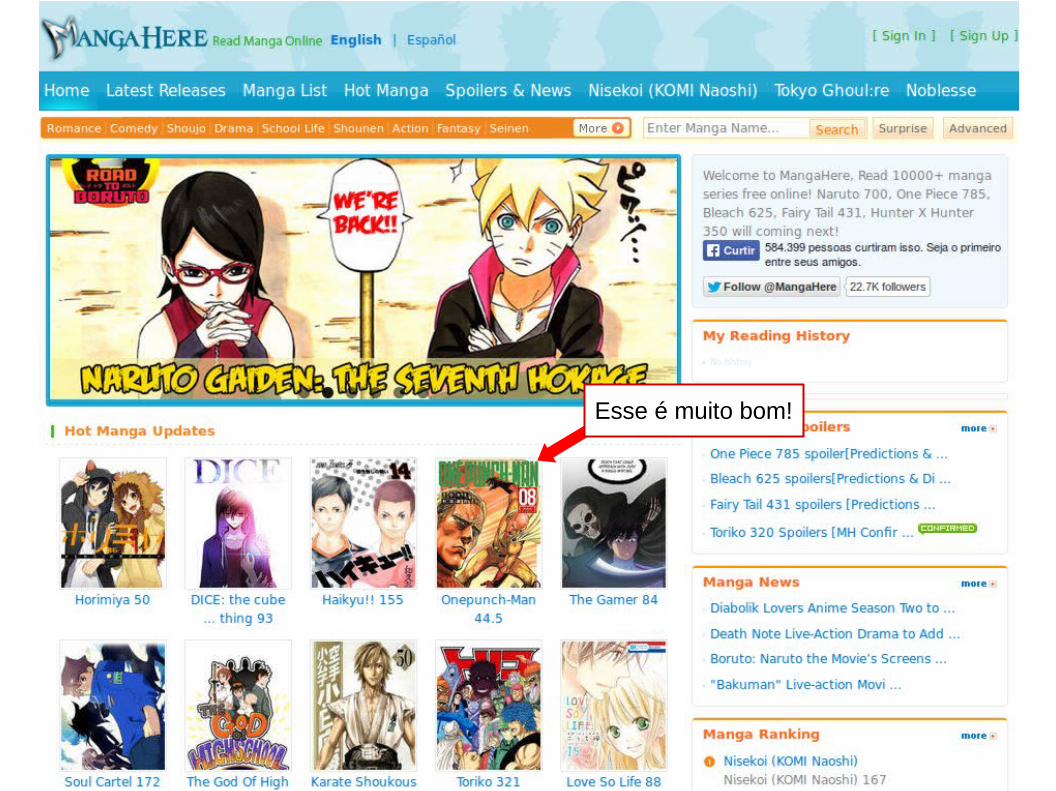
Se vocês prestaram atenção no terceiro slide, vão lembrar que eu disse que gosto de ler. Bem, eu gosto de ler e de colecionar coisas e, na internet, existem muitos sites que te permitem ler quadrinhos online, mesmo aqueles que ainda não foram publicados no brasil, como o mangafox, mangahere e mangapanda.
Sou um grande fã de quadrinhos e sempre tive o hábito de lê-los. Esse tipo de site foi um grande achado para mim.
Esse é muito bom!
Acontece que ler quadrinhos online não é tão divertido quando sua Internet não é tão boa. A página pode não carregar quando você tenta mudá-la ou você pode receber um erro de carregamento qualquer. Lembro que eu tinha Velox na época …
Nesse período, resolvi me aventurar a fazer um aplicativo que buscasse o meu quadrinho predileto no site e baixasse o capítulo que eu quisesse em um formato adequado, como cbz ou cb7.
Para esse programa, utilizei apenas a bibliotecas padrão do python e foi até fácil. Acredito que essa abordagem direta é a forma mais simples de se realizar scraping de um site específico do qual você saiba exatamente a informação de que precisa.
O código para fazer o scraping de um site de quadrinhos costuma ser bem simples, mas independente da biblioteca que você vai utilizar, a primeira coisa a se fazer para um scraping bem sucedido, visto que você não pretende usar uma abordagem generalista, é conhecer o site.
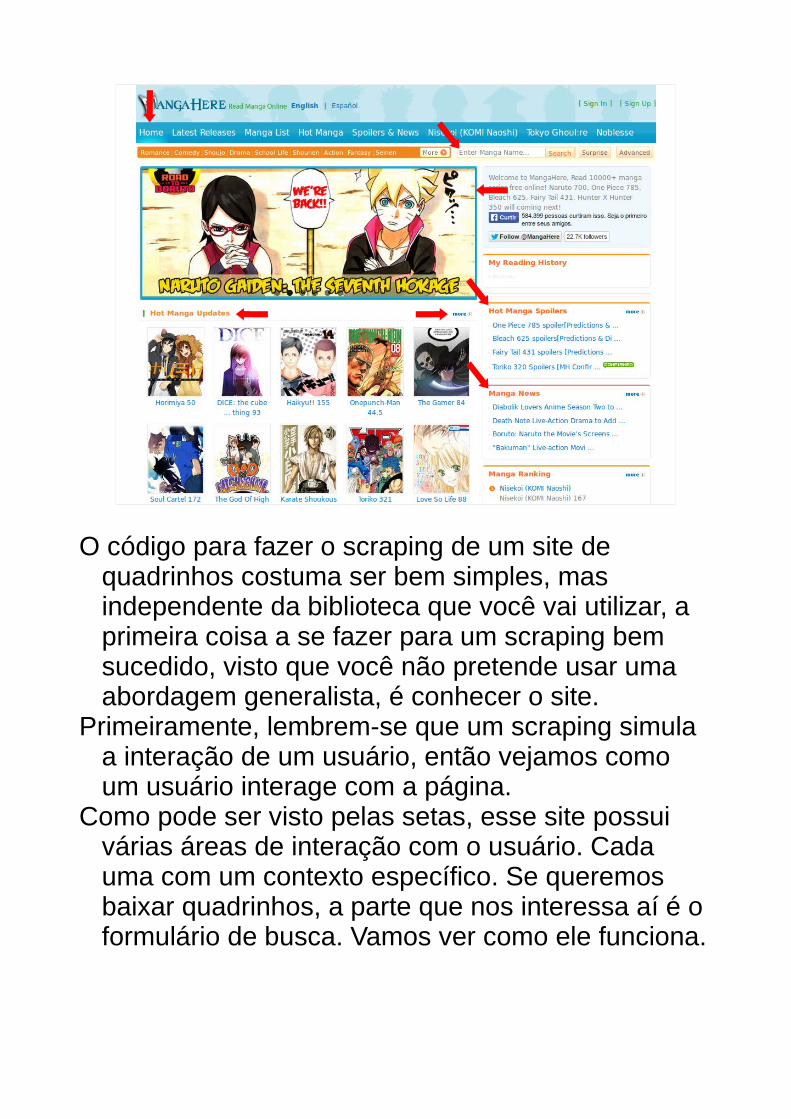
Primeiramente, lembrem-se que um scraping simula a interação de um usuário, então vejamos como um usuário interage com a página.
Como pode ser visto pelas setas, esse site possui várias áreas de interação com o usuário. Cada uma com um contexto específico. Se queremos baixar quadrinhos, a parte que nos interessa aí é o formulário de busca. Vamos ver como ele funciona.

Como “faria” meu amigo Yuki, a melhor forma de descobrir como algo funciona é apertando o botão. Para descobrir como buscar um quadrinho no site, escrevi um texto no campo de busca e apertei no botão buscar. Notem que URL foi alterada com o valor da busca mais um path diferente. Isso nos diz que a busca utiliza um formulário de GET e o parâmetro “search” é utilizado pela controller que responde essa requisição.
Já podemos codificar alguma coisa!

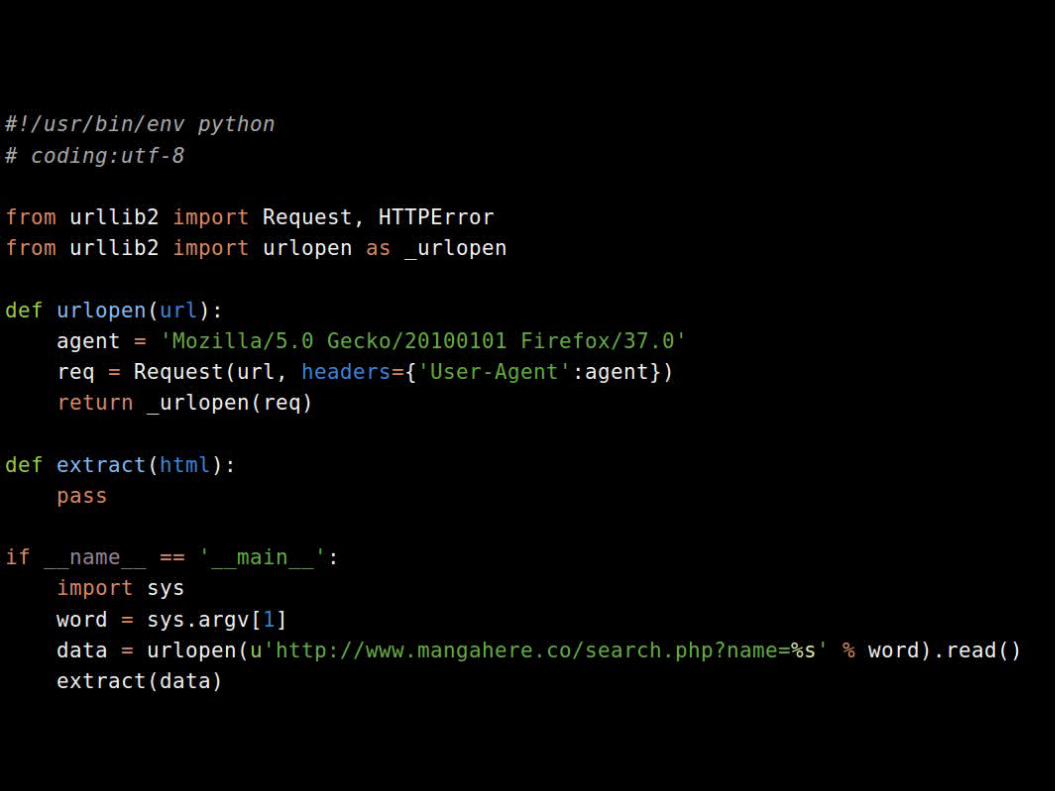
No nosso código exemplo, criamos um urlopen especial, que sobrescreve o user-agent e o utilizamos para realizar uma consulta utilizando o path que descobrimos no slide anterior. No caso acima, sobrescrevemos o user-agent para deixar claro para o site com que trabalhamos que não somos um robô, mesmo lo sendo.
Note que extract está vazio. Ele é a função que vamos utilizar para extrair a informação que desejamos. No caso, a lista de quadrinhos encontrada a partir de nossa palavra.

BADHTML
Ao trabalhar com informações extraídas de um site, você deve estar ciente de duas coisas:
1 – scripts e estilos não serão executados, a menos que você crie o ambiente necessário para executá-lo. PhantomJS é uma boa sugestão para esses casos.
2 – Se você está trabalhando com HTML, saiba que a chance desse HTML estar mal formado é altíssima. Por isso, utilize bibliotecas capazes de “relevar” um HTML mal formado, como lxml.html ou beautifulsoup.

BeaufitulSoup
FireBug
Para o extract, vamos utilizar uma biblioteca chamada beautifulsoup e uma ferramenta chamada firebug.
O firebug acredito ser conhecido da maioria. Ele permite analisar o HTML, estilos, DOM e cabeçalhos de uma interação com um site. Também te permite executar scripts em um console próprio, o que é muito útil.
O BeautifulSoup, por sua vez, é uma biblioteca para buscar informação em HTML. Ela é muito fácil de usar, bem documentada e consegue trabalhar com HTML mal formado, mesmo os mais “tortos” não são um grande problema.

Facinho
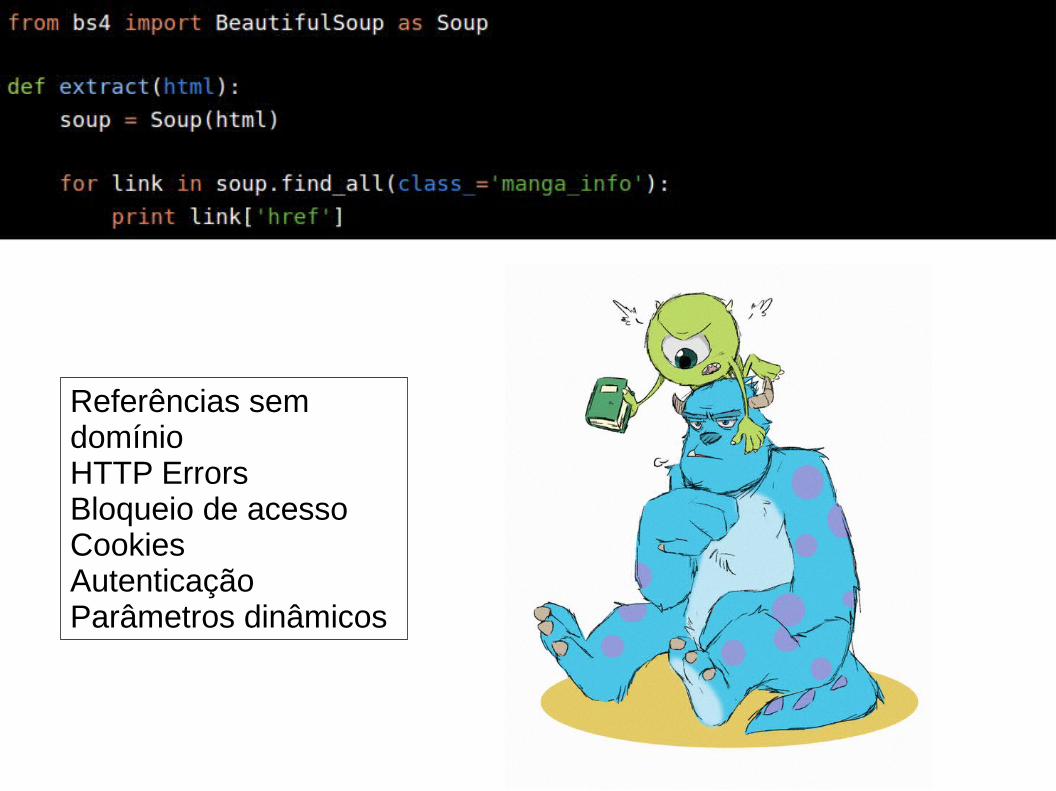
Na página com a lista de resultados que recebemos para nossa consulta, procuramos os links que direcionam para a página do quadrinho que desejamos ler. Visualmente, é bem fácil encontrar os tais links, eles estão bem no meio da tela. Para encontrar os links no HTML, utilizamos a ferramenta de inspeção do Firebug. Clicamos nela e depois na estrutura com o link para o quadrinho; no frame do HTML, o trecho de código que possui aquele link é aberto. Agora basta analisar a estrutura e decidir quais os critérios de seleção para os links. É como se você tivesse que decidir quais regras CSS são necessárias para aplicar um estilo, só que com o BeautifulSoup!
Dica: Você pode utilizar o Jquery pelo console para testar se suas regras de seleção funcionam.
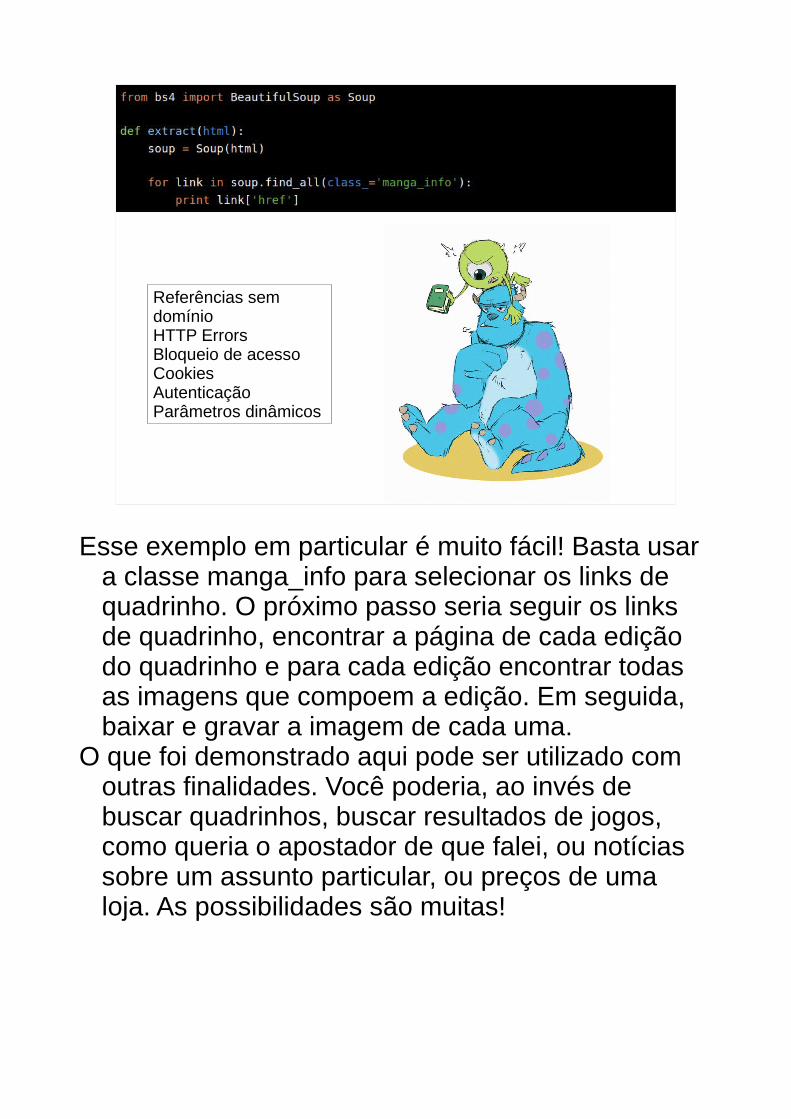
Referências sem domínioHTTP ErrorsBloqueio de acessoCookiesAutenticaçãoParâmetros dinâmicos
Esse exemplo em particular é muito fácil! Basta usar a classe manga_info para selecionar os links de quadrinho. O próximo passo seria seguir os links de quadrinho, encontrar a página de cada edição do quadrinho e para cada edição encontrar todas as imagens que compoem a edição. Em seguida, baixar e gravar a imagem de cada uma.
O que foi demonstrado aqui pode ser utilizado com outras finalidades. Você poderia, ao invés de buscar quadrinhos, buscar resultados de jogos, como queria o apostador de que falei, ou notícias sobre um assunto particular, ou preços de uma loja. As possibilidades são muitas!

CRAWLING
Caso, o que você precisa é vasculhar um conjunto de sites à procura de informação, o que você está precisando é um crawler.
Crawlers são software que se utilizam de programas chamados spiders ou web spiders para extrair informação de um conjunto de sites. Spiders são programas especialistas de busca e extração de informação, como programas de scrapers, contudo, não lidam com a parte de persistência de informação ou gerenciamento de outros spiders.
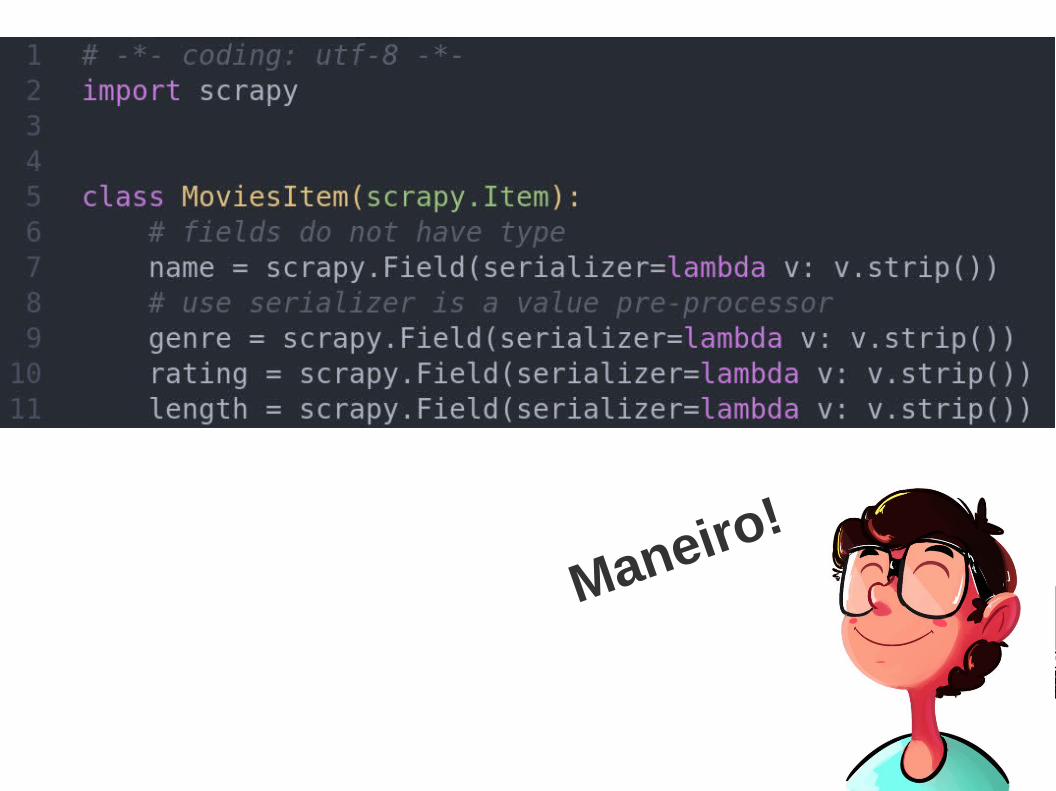
Os robôs de indexação do google, por exemplo, são crawlers conhecidos. Ao contrário de um programa de scraping, não é interessante escrever seu próprio crawler sem uma ferramenta especializada para o trabalho. Uma muito famosa, o scrapy, merece sua atenção.
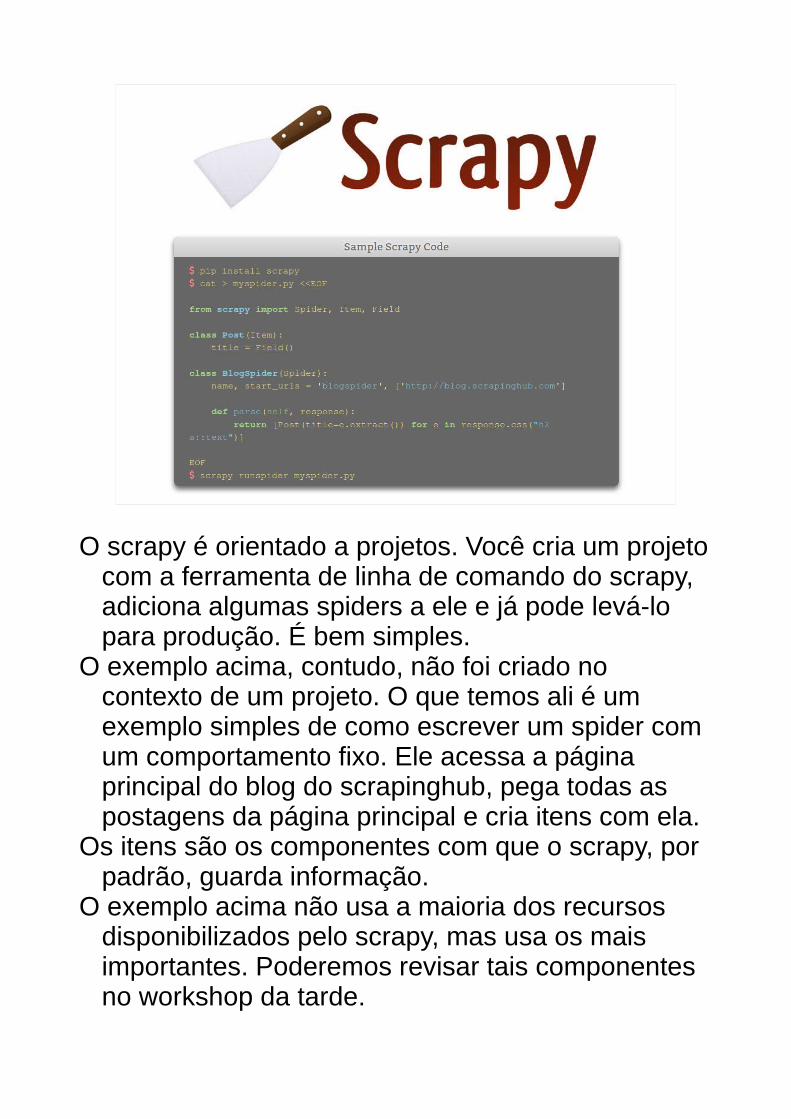
O scrapy é orientado a projetos. Você cria um projeto com a ferramenta de linha de comando do scrapy, adiciona algumas spiders a ele e já pode levá-lo para produção. É bem simples.
O exemplo acima, contudo, não foi criado no contexto de um projeto. O que temos ali é um exemplo simples de como escrever um spider com um comportamento fixo. Ele acessa a página principal do blog do scrapinghub, pega todas as postagens da página principal e cria itens com ela.
Os itens são os componentes com que o scrapy, por padrão, guarda informação.
O exemplo acima não usa a maioria dos recursos disponibilizados pelo scrapy, mas usa os mais importantes. Poderemos revisar tais componentes no workshop da tarde.

Como
que faz?

Maneiro!


Obrigado!
Related Documents











