MILAN - 08TH OF MAY - 2015 PARTNERS Scala in increasingly demanding environments Stefano Rocco – Roberto Bentivoglio DATABIZ

Scala in increasingly demanding environments - DATABIZ
Aug 13, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

MILAN - 08TH OF MAY - 2015
PARTNERS
Scala in increasingly demandingenvironments
Stefano Rocco – Roberto BentivoglioDATABIZ

Agenda
IntroductionCommand Query Responsibility SegregationEvent SourcingAkka persistenceApache SparkReal-time “bidding”Live demo (hopefully)FAQ

1. Introduction

The picture
Highly demanding environments
- Data is increasing dramatically- Applications are needed faster than ever- Customers are more demanding- Customers are becoming more sophisticated- Services are becoming more sophisticated and complex- Performance & Quality is becoming a must- Rate of business change is ever increasing- And more…

Reactive Manifesto
Introduction – The way we see
Responsive
Message Driven
ResilientElastic
Relatore
Note di presentazione
Rensponsive -> The system responds in a timely manner if at all possible Elastic -> The system stays responsive under varying workload Resilient -> The system stays responsive in the face of failure Message Driven -> Reactive Systems rely on asynchronous message-passing to establish a boundary between components that ensures loose coupling, isolation, location transparency, and provides the means to delegate errors as messages

We need to embrace change!
Introduction – The world is changing…

Introduction - Real Time “Bidding”
High level architecture
AkkaPersistence
Input
Output
Cassandra
Kafka
Training PredictionScoring
SparkBatch
Real Time
Action
Dispatch
Publish
Store
Journaling

2. Command Query Responsibility Segregation

Multi-tier stereotypical architecture + CRUD
CQRS
Presentation Tier
Business Logic Tier
Data Tier IntegrationTier
RDBMS
Clie
nt S
yste
ms
Ext
erna
l Sys
tem
s
DTO
/VO
Relatore
Note di presentazione
Remember to mention and explain CRUD

Multi-tier stereotypical architecture + CRUD
CQRS
- Pro- Simplicity- Tooling
- Cons- Difficult to scale (RDBMS is usually the bottleneck)- Domain Driven Design not applicable (using CRUD)
Relatore
Note di presentazione
Simplicity - One could teach a Junior developer how to interact with a system built using this architecture in a very short period of time - the architecture is completely generic. Tooling (Framework) - For instance ORM Scaling - RDBMS are at this point not horizontally scalable and vertically scaling becomes prohibitively expensive very quickly DDD - CRUD => Anemic Model (object containing only data and not behavior)

Think different!
CQRS
- Do we have a different architecture model without heavily rely on:- CRUD- RDBMS transactions- J2EE/Spring technologies stack

Command and Query Responsibility Segregation
Originated with Bertrand Meyer’s Command and Query Separation Principle
“It states that every method should either be a command that performs an action, or a query that returns data to the caller, but not both. In other words, asking a question should not change the answer. More formally, methods should return a value only if they are referentially transparent and hence possess no side effects” (Wikipedia)
CQRS
Relatore
Note di presentazione
Method command => perform an action (MUTATE THE STATE, WE HAVE HERE SIDE EFFECT) query => return data to the caller (NO SIDE EFFECT, IT’S REFERENTIAL TRASPARENT)
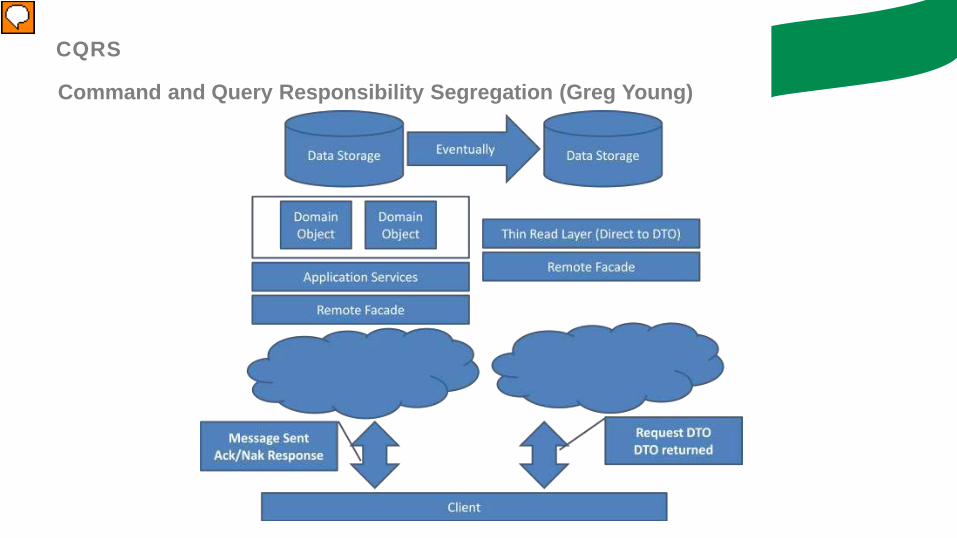
Command and Query Responsibility Segregation (Greg Young)
CQRS
Relatore
Note di presentazione
In this slide you don’t need to introduce Event Sourcing but only to speak about command/write/left side vs query/read/right side

Available Services
- The service has been split into:- Command → Write side service
- Query → Read side service
CQRS
Change status Status changed
Get status Status retrieved
Relatore
Note di presentazione
Explaining with others words/figures the meaning of Command and Query

Main architectural properties
- Consistency- Command → consistent by definition- Query → eventually consistent
- Data Storage- Command → normalized way- Query → denormalized way
- Scalability- Command → low transactions rate- Query → high transactions rate
CQRS
Relatore
Note di presentazione
Main properties of CQRS

3. Event Sourcing

Storing Events…
Event Sourcing
Systems today usually rely on- Storing of current state- Usage of RDBMS as storage solution
Architectural choices are often “RDBMS centric”
Many systems need to store all the occurred events instead to store only the updated state

Commands vs Events
Event Sourcing
- Commands- Ask to perform an operation (imperative tense)- Can be rejected
- Events- Something happened in the past (past tense)- Cannot be undone
State mutationCommand validation
Command received Event persisted
Relatore
Note di presentazione
An event is something that has happened in the past.

Command and Event sourcing
Event Sourcing
An informal and short definition...
Append to a journal every commands (or events) received (or generated) instead of storing the current state of the application!
Relatore
Note di presentazione
Remember to speak about the append on journal
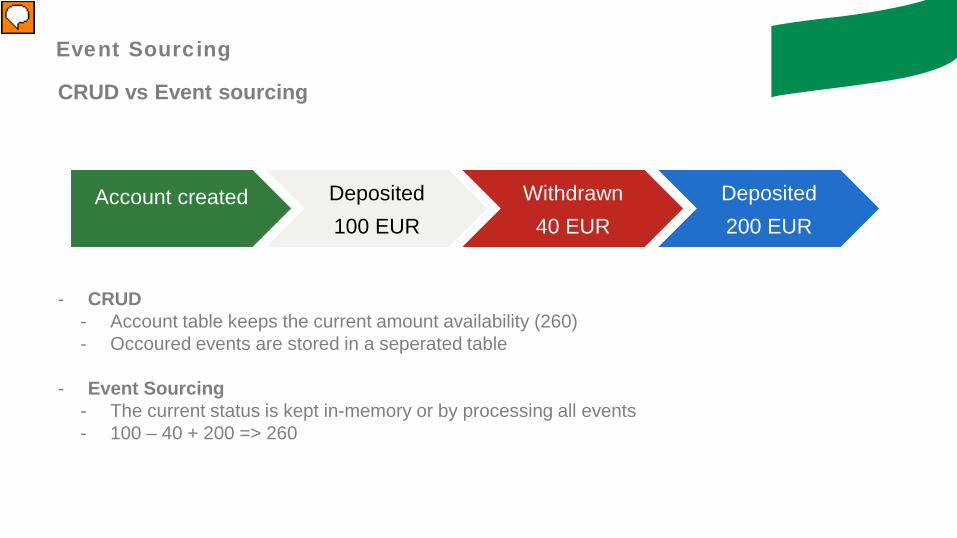
CRUD vs Event sourcing
Event Sourcing
Deposited 100 EUR
Withdrawn40 EUR
Deposited200 EUR
- CRUD- Account table keeps the current amount availability (260)- Occoured events are stored in a seperated table
- Event Sourcing- The current status is kept in-memory or by processing all events- 100 – 40 + 200 => 260
Account created
Relatore
Note di presentazione
Remember to the audience that having an append we don’t have deletion but we have events with opposite sign

Main properties
- There is no delete- Performance and Scalability
- “Append only” model are easier to scale- Horizontal Partitioning (Sharding)- Rolling Snapshots - No Impedance Mismatch- Event Log can bring great business value
Event Sourcing
Relatore
Note di presentazione
Main properties of CQRS

4. Akka persistence

Introduction
We can think about it as
AKKA PERSISTENCE = CQRS + EVENT SOURCING
Akka Persistence

Main properties
- Akka persistence enables stateful actors to persiste their internal state- Recover state after
- Actor start- Actor restart
- JVM crash- By supervisor
- Cluster migration
Akka Persistence

Main properties
- Changes are append to storage- Nothing is mutated
- high transactions rates- Efficient replication
- Stateful actors are recovered by replying store changes- From the begging or from a snapshot
- Provides also P2P communication with at-least-once message delivery semantics
Akka Persistence

Components
- PersistentActor → persistent stateful actor- Command or event sourced actor- Persist commands/events to a journal
- PersistentView → Receives journaled messages written by another persistent actor- AtLeastOnceDelivery → also in case of sender or receiver JVM crashes- Journal → stores the sequence of messages sent to a persistent actor- Snapshot store → are used for optimizing recovery times
Akka Persistence

Code example
class BookActor extends PersistentActor {
override val persistenceId: String = "book-persistence"
override def receiveRecover: Receive = {case _ => // RECOVER AFTER A CRASH HERE...
}
override def receiveCommand: Receive = {case _ => // VALIDATE COMMANDS AND PERSIST EVENTS HERE...
}}
type Receive = PartialFunction[Any, Unit]
Akka Persistence

5. Apache Spark
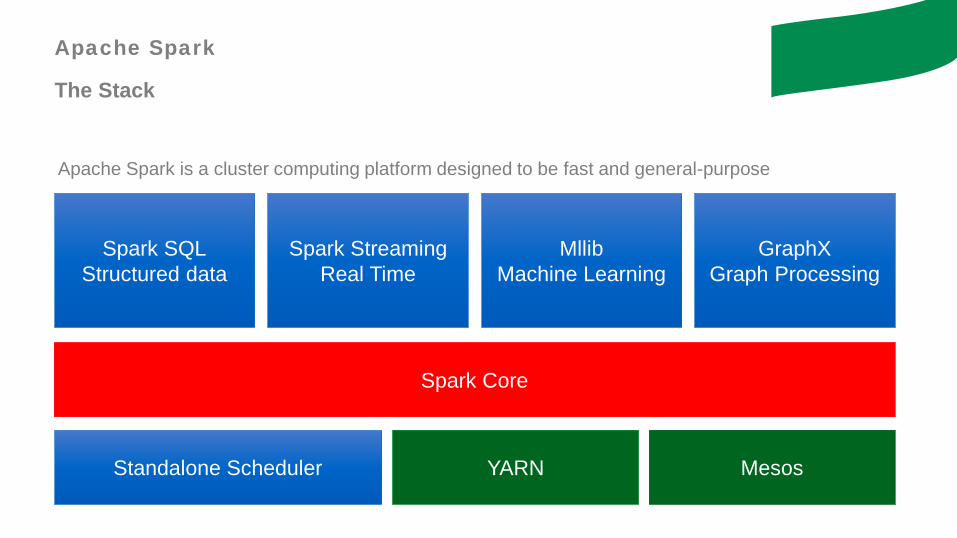
Apache Spark is a cluster computing platform designed to be fast and general-purpose
Spark SQLStructured data
Spark StreamingReal Time
MllibMachine Learning
GraphXGraph Processing
Spark Core
Standalone Scheduler YARN Mesos
Apache Spark
The Stack

Apache Spark
The Stack
- Spark SQL: It allows querying data via SQL as well as the Apache Variant of SQL (HQL) and supports many sources of data, including Hive tables, Parquet and JSON
- Spark Streaming: Components that enables processing of live streams of data in a elegant, fault tolerant, scalable and fast way
- MLlib: Library containing common machine learning (ML) functionality including algorithms such as classification, regression, clustering, collaborative filtering etc. to scale out across a cluster
- GraphX: Library for manipulating graphs and performing graph-parallel computation
- Cluster Managers: Spark is designed to efficiently scale up from one to many thousands of compute nodes. It can run over a variety of cluster managers including Hadoop, YARN, Apache Mesos etc. Spark has a simple cluster manager included in Spark itself called the Standalone Scheduler
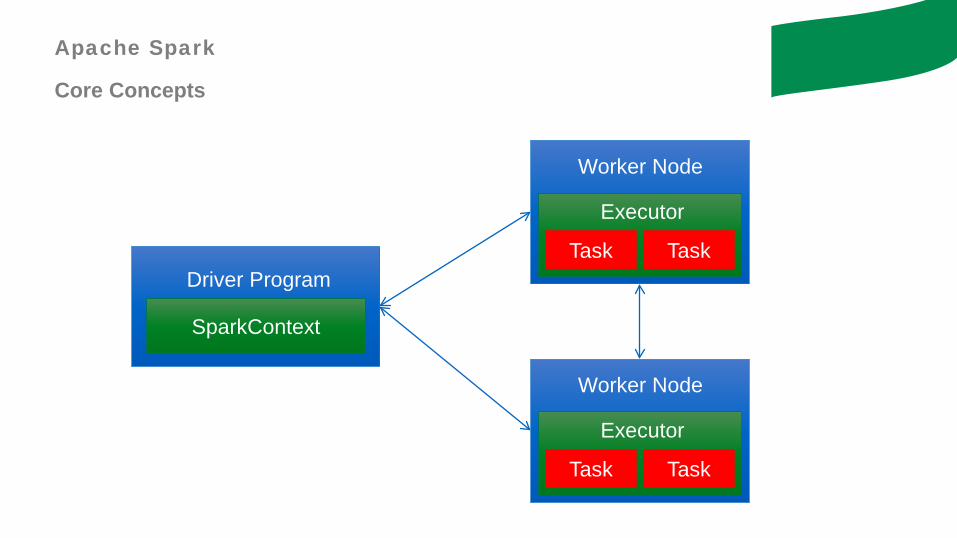
Apache Spark
Core Concepts
SparkContext
Driver Program
Worker Node
Worker Node
Executor
Task Task
Worker Node
Executor
Task Task

Apache Spark
Core Concepts
- Every Spark application consists of a driver program that launches various parallel operations on the cluster. The driver program contains your application’s main function and defines distributed datasets on the cluster, then applies operations to them
- Driver programs access spark through the SparkContext object, which represents a connection to a computing cluster.
- The SparkContext can be used to build RDDs (Resilient distributed datasets) on which you can run a series of operations
- To run these operations, driver programs typically manage a number of nodes called executors

Apache Spark
RDD (Resilient Distributed Dataset)
It is an immutable distributed collection of data, which is partitioned across machines in a cluster. It facilitates two types of operations: transformation and action
-Resilient: It can be recreated when data in memory is lost
-Distributed: stored in memory across the cluster
-Dataset: data that comes from file or created programmatically

Apache Spark
Transformations
- A transformation is an operation such as map(), filter() or union on a RDD that yield another RDD.
- Transformations are lazilly evaluated, in that the don’t run until an action is executed.
- Spark driver remembers the transformation applied to an RDD, so if a partition is lost, that partition can easily be reconstructed on some other machine in the cluster. (Resilient)
- Resiliency is achieved via a Lineage Graph.

Apache Spark
Actions
- Compute a result based on a RDD and either return it to the driver program or save it to an external storage system.
- Typical RDD actions are count(), first(), take(n)

Apache Spark
Transformations vs Actions
RDD RDD
RDD Value
Transformations: define new RDDs based on current one. E.g. map, filter, reduce etc.
Actions: return values. E.g. count, sum, collect, etc.

Apache Spark
Benefits
Scalable Can be deployed on very large clusters
Fast In memory processing for speed
Resilient Recover in case of data loss
Written in Scala… has a simple high level API for Scala, Java and Python
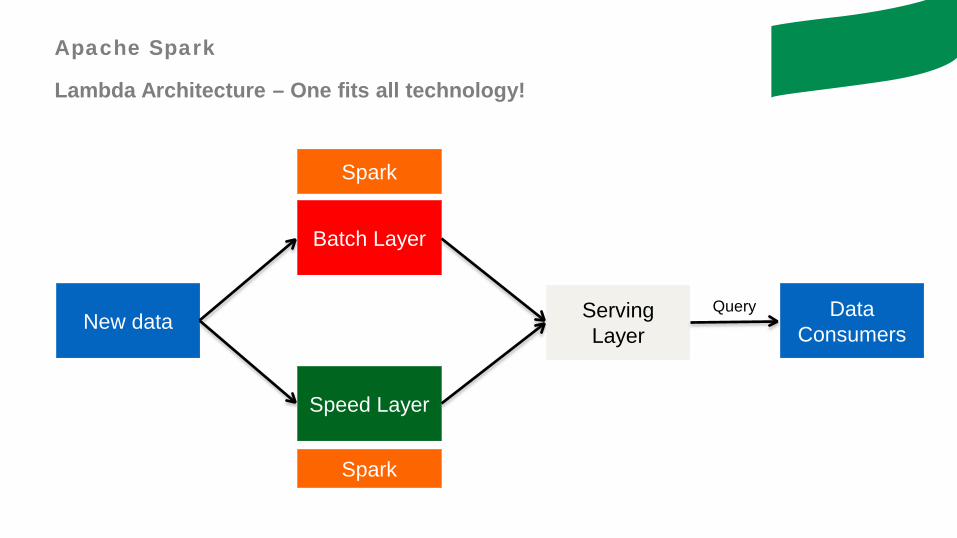
Apache Spark
Lambda Architecture – One fits all technology!
New data
Batch Layer
Speed Layer
Serving Layer
Data Consumers
Query
Spark
Spark
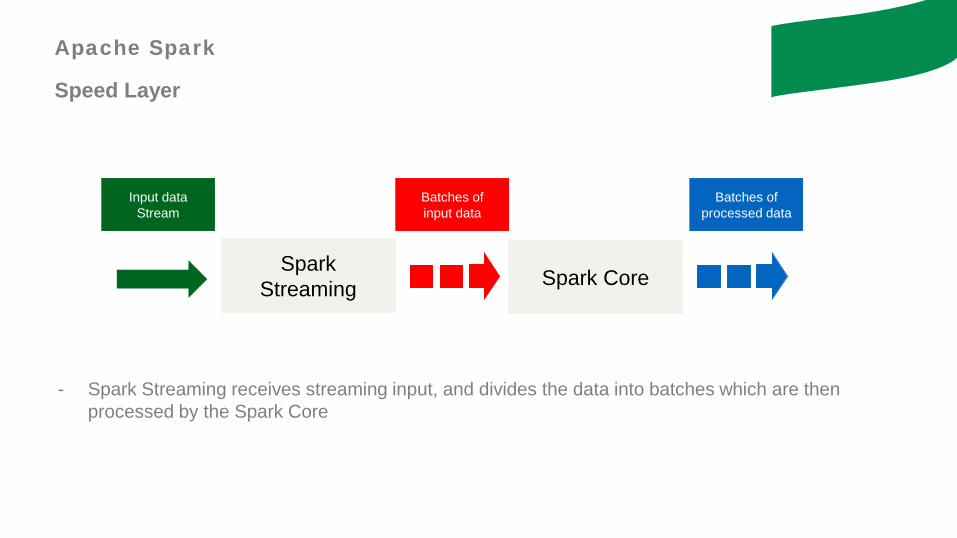
- Spark Streaming receives streaming input, and divides the data into batches which are thenprocessed by the Spark Core
Input data Stream
Batches of input data
Batches of processed data
Spark Streaming Spark Core
Apache Spark
Speed Layer

val numThreads = 1val group = "test"val topicMap = group.split(",").map((_, numThreads)).toMapval conf = new SparkConf().setMaster("local[*]").setAppName("KafkaWordCount")val sc = new SparkContext(conf)val ssc = new StreamingContext(sc, Seconds(2))val lines = KafkaUtils.createStream(ssc, "localhost:2181", group, topicMap).map(_._2)val words = lines.flatMap(_.split(","))val wordCounts = words.map { x => (x, 1L) }.reduceByKey(_ + _)
....
ssc.start()ssc.awaitTermination()
Apache Spark – Streaming word count example
Streaming with Spark and Kafka

6. Real-time “bidding”

Real Time “Bidding”
High level architecture
AkkaPersistence
Input
Output
Cassandra
Kafka
Training PredictionScoring
SparkBatch
Real Time
Action
Dispatch
Publish
Store
Journaling

Apache Kafka
Distributed messaging system
- Fast: Hight throughput for both publishing and subribing- Scalable: Very easy to scale out- Durable: Support persistence of messages- Consumers are responsible to track their location in each log
Producer 1
Producer 2
Consumer A
Consumer B
Consumer C
Partition 1
Partition 2
Partition 3
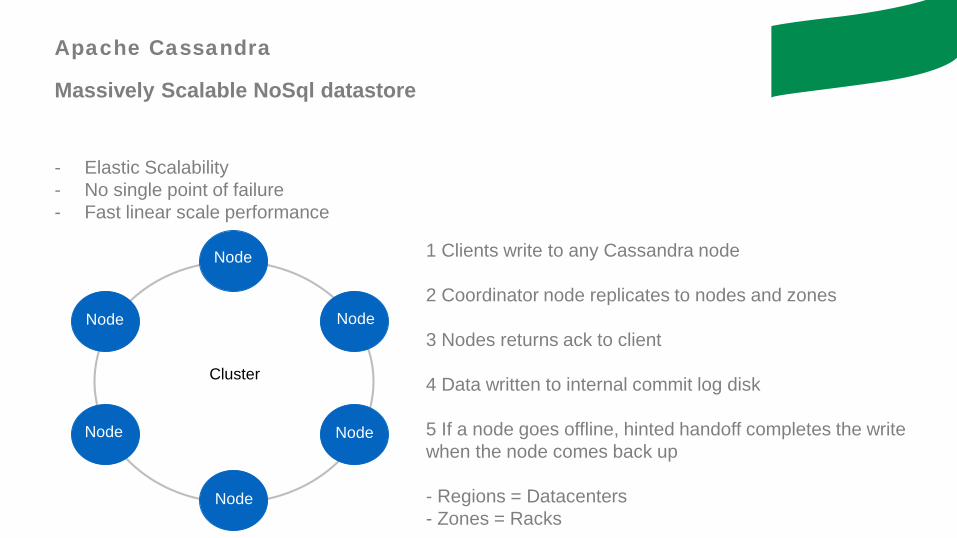
Apache Cassandra
Massively Scalable NoSql datastore
- Elastic Scalability- No single point of failure- Fast linear scale performance
1 Clients write to any Cassandra node
2 Coordinator node replicates to nodes and zones
3 Nodes returns ack to client
4 Data written to internal commit log disk
5 If a node goes offline, hinted handoff completes the writewhen the node comes back up
- Regions = Datacenters- Zones = Racks
Node
Node
Node
Node
Node
Node
Cluster

7. Live demo

MILAN - 08TH OF MAY - 2015
PARTNERS
THANK YOU!Stefano Rocco - @whispurr_it
Roberto Bentivoglio - @robbenti
@DATABIZit
PARTNERS
FAQ
We’re hiring!
Related Documents











