1 Sampling-Based Progressive Hedging Algorithms in Two-Stage Stochastic Programming Nezir Aydin * , Alper Murat † , Boris S. Mordukhovich ‡ * Department of Industrial Engineering, Yıldız Technical University, Besiktas/Istanbul, 34349, Turkey † Department of Industrial and Systems Engineering, Wayne State University, Detroit, MI 48202, USA ‡ Department of Mathematics, Wayne State University, Detroit, MI 48202, USA Abstract Most real-world optimization problems are subject to uncertainties in parameters. In many situations where the uncertainties can be estimated to a certain degree, various stochastic programming (SP) methodologies are used to identify robust plans. Despite substantial advances in SP, it is still a challenge to solve practical SP problems, partially due to the exponentially increasing number of scenarios representing the underlying uncertainties. Two commonly used SP approaches to tackle this complexity are approximation methods, i.e., Sample Average Approximation (SAA), and decomposition methods, i.e., Progressive Hedging Algorithm (PHA). SAA, while effectively used in many applications, can lead to poor solution quality if the selected sample sizes are not sufficiently large. With larger sample sizes, however, SAA becomes computationally impractical. In contrast, PHA---as an exact method for convex problems and a very effective method in terms of finding very good solutions for nonconvex problems--suffers from the need to iteratively solve many scenario subproblems, which is computationally expensive. In this paper, we develop novel SP algorithms integrating SAA and PHA methods. The proposed methods are innovative in that they blend the complementary aspects of PHA and SAA in terms of exactness and computational efficiency, respectively. Further, the developed methods are practical in that they allow the analyst to calibrate the tradeoff between the exactness and speed of attaining a solution. We demonstrate the effectiveness of the developed integrated approaches, Sampling-Based Progressive Hedging Algorithm (SBPHA) and Discarding SBPHA (d-SBPHA), over the pure strategies (i.e., SAA). The validation of the methods is demonstrated through two-stage stochastic Capacitated Reliable Facility Location Problem (CRFLP). Key words: stochastic programming; facility location; hybrid algorithms; progressive hedging; sample average approximation. 1. Introduction Most practical problems are subject to uncertainties in problem parameters. There are two major mathematical approaches to modeling uncertainties. The first one applies to deterministic problems, where only admissible regions of uncertain parameter changes are available for decision makers. A natural approach of handle such situations is seeking the guaranteed result in the worst case scenario by using methods of robust optimization and game/minimax theory; see, e.g., Ben-Tal et al. (2009), Bertsimas at al. (2011), and the references therein. The framework of robust and minimax optimization allows us to develop efficient numerical techniques involving generalized differentiation as, e.g., in appropriate versions of nonsmooth Newton methods; see Jeyakumar et al. (2013). However, better results can be achieved as a rule if some stochastic/statistical information is available to measure uncertainties. This paper is devoted to developing the latter approach. Stochastic Programming (SP) methodologies are often resorted for solving problems with uncertainties in parameters either exactly or with a statistical bound on the optimality gap. Beginning with Dantzig’s (1955) introduction of a recourse model, where the solution could be * Corresponding author: Email address: [email protected]; Tel:+90 (212) 383-3029;Fax:+90 (212) 258-5928 Email Adresses: [email protected] (A. Murat), [email protected] (B.S. Mordukhovich)

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Sampling-Based Progressive Hedging Algorithms
in Two-Stage Stochastic Programming
Nezir Aydin*, Alper Murat
†, Boris S. Mordukhovich
‡
*Department of Industrial Engineering, Yıldız Technical University, Besiktas/Istanbul, 34349, Turkey
†Department of Industrial and Systems Engineering, Wayne State University, Detroit, MI 48202, USA
‡Department of Mathematics, Wayne State University, Detroit, MI 48202, USA
Abstract Most real-world optimization problems are subject to uncertainties in parameters. In many
situations where the uncertainties can be estimated to a certain degree, various stochastic
programming (SP) methodologies are used to identify robust plans. Despite substantial advances in
SP, it is still a challenge to solve practical SP problems, partially due to the exponentially increasing
number of scenarios representing the underlying uncertainties. Two commonly used SP approaches
to tackle this complexity are approximation methods, i.e., Sample Average Approximation (SAA),
and decomposition methods, i.e., Progressive Hedging Algorithm (PHA). SAA, while effectively
used in many applications, can lead to poor solution quality if the selected sample sizes are not
sufficiently large. With larger sample sizes, however, SAA becomes computationally impractical.
In contrast, PHA---as an exact method for convex problems and a very effective method in terms of
finding very good solutions for nonconvex problems--suffers from the need to iteratively solve
many scenario subproblems, which is computationally expensive. In this paper, we develop novel
SP algorithms integrating SAA and PHA methods. The proposed methods are innovative in that
they blend the complementary aspects of PHA and SAA in terms of exactness and computational
efficiency, respectively. Further, the developed methods are practical in that they allow the analyst
to calibrate the tradeoff between the exactness and speed of attaining a solution. We demonstrate
the effectiveness of the developed integrated approaches, Sampling-Based Progressive Hedging
Algorithm (SBPHA) and Discarding SBPHA (d-SBPHA), over the pure strategies (i.e., SAA). The
validation of the methods is demonstrated through two-stage stochastic Capacitated Reliable
Facility Location Problem (CRFLP).
Key words: stochastic programming; facility location; hybrid algorithms; progressive hedging;
sample average approximation.
1. Introduction Most practical problems are subject to uncertainties in problem parameters. There are two
major mathematical approaches to modeling uncertainties. The first one applies to deterministic
problems, where only admissible regions of uncertain parameter changes are available for decision
makers. A natural approach of handle such situations is seeking the guaranteed result in the worst
case scenario by using methods of robust optimization and game/minimax theory; see, e.g., Ben-Tal
et al. (2009), Bertsimas at al. (2011), and the references therein. The framework of robust and
minimax optimization allows us to develop efficient numerical techniques involving generalized
differentiation as, e.g., in appropriate versions of nonsmooth Newton methods; see Jeyakumar et al.
(2013). However, better results can be achieved as a rule if some stochastic/statistical information
is available to measure uncertainties. This paper is devoted to developing the latter approach.
Stochastic Programming (SP) methodologies are often resorted for solving problems with
uncertainties in parameters either exactly or with a statistical bound on the optimality gap.
Beginning with Dantzig’s (1955) introduction of a recourse model, where the solution could be
*Corresponding author: Email address: [email protected]; Tel:+90 (212) 383-3029;Fax:+90 (212) 258-5928
Email Adresses: [email protected] (A. Murat), [email protected] (B.S. Mordukhovich)

2
adjusted based on the consequences of random events, the SP area has grown becoming an
important tool for optimization under uncertainty. There is increased attention in the operations
research community in tackling challenging problems with various problem parameter
uncertainties; see, e.g., Lulli and Sen (2006), Topaloglou et al. (2008), Bomze et al. (2010), Peng et
al. (2011), Toso and Alem (2014), Shishebori and Babadi (2015). A common precursor assumption
in applying most of the SP methodologies is that the probability distributions of the random events
are either known, or can be estimated with an acceptable accuracy. For majority of the SP problems,
the goal is to identify a feasible solution that minimizes or maximizes the expected value of a
function over all possible realizations of the random events (Solak, 2007).
The most extensively studied SP models are two-stage models (Dantzig, 1955). In two-stage
SP problems, the decision variables are partitioned into two main sets, where the first stage decision
variables are decided before the uncertain parameters become available. Once the random events
realized, design or operative strategy improvements (i.e., second stage recourse decisions) can be
made at a certain cost. The objective is to optimize the sum of first stage costs and the expected
value of the random second stage or recourse costs (Ahmed and Shapiro, 2002).
An extensive number of solution methods is proposed for solving two-stage SP problems.
These solution methods can be classified as either exact or approximation methods. Both analytical
solution methods as well as methods that algorithmically solve SP problems to yield the optimal
solution are considered as exact solution methods. Because of complexity of SP, several
approximation algorithms in the form of sampling-based methods (Ahmed and Shapiro, 2002) or
heuristic methods (Higle and Sen, 1991) are proposed to take decisions under uncertainty.
When the random variable set is finite with a relatively small number of joint realizations
(i.e., scenarios), a SP can be formulated as a deterministic equivalent program and can be solved
“exactly” via an optimization algorithm (Rockafellar and Wets, 1991). The special structure of this
deterministic equivalent program also calls for the application of large-scale optimization
techniques, e.g., decomposition methods. Such decomposition methods can be categorized into two
types. The first type decomposes the problem by stages as, e.g., L-shaped method (Slyke and Wets,
1969; Birge and Louveaux, 1997), while the second type decomposes the problem by scenarios.
The latter category’s methods are primarily based on Lagrangian relaxation of the non-anticipativity
constraints, where each scenario in the scenario tree corresponds to a single deterministic
mathematical program as, e.g., Progressive Hedging Algorithm (Rockafellar and Wets, 1991;
Lokketangen, and Woddruff, 1996). A subproblem obtained by stage or scenario composition may
include multiple stages in “by-stage” decomposition method and multiple scenarios in “by-
scenario” decomposition methods, respectively (Chiralaksanakul, 2003).
As a popular approximation method, Monte Carlo sampling-based algorithms are commonly
used in solving large scale SP problems (Morton and Popova, 2001). Monte Carlo sampling method
can be deployed within either ‘interior’ or ‘exterior’ of the optimization algorithm. In the ‘interior’
sampling-based methods the computationally expensive or difficult exact computations are replaced
with the Monte Carlo estimates during the algorithm execution (Verweij et al., 2003). In the
‘exterior’ sampling-based methods, the stochastic process is approximated by a finite scenario tree
obtained through the Monte Carlo sampling. The solution to the problem with the constructed
scenario tree is an approximation of the optimal objective function value. The ‘exterior’ sampling
based method is also referred to as the “sample average approximation” method in the SP literature
(see, e.g., Shapiro, 2002).
In this study, we propose a novel algorithm, called Sampling-Based Progressive Hedging
Algorithm (SBPHA), and an improved version of SBPHA (discarding-SBPHA) to solve a class of
two-stage SP problems. A standard formulation of the two-stage stochastic program is (Kall and
Wallace, 1994; Birge and Louveaux, 1997; Ahmed and Shapiro, 2002):
Min𝑥∈𝑋
{𝑔(𝑥) ≔ cT𝐱 + 𝔼[𝜑(𝑥, 𝜉)]} , (1)

3
where
𝜑(𝑥, 𝜉) ≔ inf𝑦∈𝑌
{𝑞𝑇𝑦:𝑊𝑦 ≥ ℎ − 𝑇𝑥} (2)
is the optimal value, and where 𝜉 ≔ (𝑞, 𝑇,𝑊, ℎ) denotes the vector of parameters of the second
stage problem. It is assumed that some or all of the components of 𝜉 are random. The expectation
of (1) is then taken with the respect to the known probability distribution of 𝜉. Problem (1) solves
for the first stage variables, 𝑥 ∈ ℝ𝑛1 , which must be selected prior to any realization of 𝜉, while
problem (2) solves for the second stage variables, 𝑦 ∈ ℝ𝑛2, with a given first stage decision as well
as the realization of 𝜉.
In SBPHA we hybridize Progressive Hedging Algorithm (PHA) and the external sampling-
based approximation algorithm, Sample Average Approximation (SAA), to efficiently solve two-
stage SP problems. While the standard SAA procedure is effective with sufficiently large samples,
the required sample size can be quite large for the desired confidence level. Furthermore, for
combinatorial problems , where the computational complexity increases faster than linearly in the
sample size, SAA is often executed with a smaller sample size by generating and solving several
SAA problems with i.i.d. samples. These additional SAA replications with the same sample size are
likely to provide a better solution in comparison with the best solution found so far. However, by
selecting the best performing sample solution, the SAA procedure effectively discards the
remaining sample solutions, which contain valuable information about problem’s uncertainty. The
main idea of the proposed hybrid method SBPHA is to reuse all the information embedded in
sample solutions by iteratively solving the samples with adding an augmented Lagrangian penalty
term (as in PHA) to find a common solution that all the samples agree on.
The rest of the paper is organized as follows. In §2 we briefly summarize the SAA and PHA
methods and then describe the Sampling-Based Progressive Hedging Algorithm (SBPHA) and its d-
SBPHA modification in detail. In §3 we present the scenario-based capacitated reliable facility
location problem and its mathematical formulation, and then report computational experiments
comparing the solution quality and CPU time efficiency of SAA with those of the proposed hybrid
algorithms (SBPHA and d- SBPHA). We conclude the paper with discussions and future research
directions in §4.
2. Solution Methodology In this section we first summarize PHA and SAA methods. Next we describe the proposed
algorithms (SBPHA and d-SBPHA) in detail.
2.1. Progressive Hedging Algorithm
Most SP problems have key discrete decision variables in one or more of the stages; e.g.,
binary decisions to open a plant (Watson and Woodruff, 2011). Rockafellar and Wets (1991)
proposed a scenario decomposition based method (PHA) that can be used to solve challenging very
large linear or mixed-integer SP problems, especially in cases where effective techniques for
solving individual scenarios exist. While the PHA possesses theoretical converges for SP problems
where all decision variables are continuous, it is used as a heuristic method when some or all
decision variables are discrete (Lokketangen and Woodruff, 1996; Fan and Liu, 2010; Watson and
Woodruff, 2011). Many studies on progressive hedging approach are applied in several fields such
as: lot sizing (Haugen et al., 2001), portfolio optimization (Barro, and Canestrelli, 2005), resource
allocation in network flow (Watson and Woodruff, 2011), operation planning (Gonçalves et al.,
2012), forest planning (Veliz et al., 2014), facility location (Gade et al., 2014), and server location
and unit commitment (Guo et al., 2015).
A standard approach to solve two-stage SP (1)-(2) is by constructing scenario tree via
generating a finite number of joint realizations 𝜉𝑠 for 𝐬 ∈ 𝐒, called ‘scenarios’, and allocating to
each ξs a positive weight 𝑝𝑠 such that ∑ 𝑝𝑠 = 1𝐬∈𝐒 (Shapiro 2008). The generated set, {𝜉1, … , 𝜉𝑆}, of

4
scenarios, with the corresponding probabilities 𝑝𝑠, … , 𝑝𝑆 is considered as a representation of the
underlying joint probability distribution of the random parameters. Using this representation, the
expected value function 𝔼[𝜑(𝑥, 𝜉)] can be calculated as 𝔼[𝜑(𝑥, 𝜉)] = ∑ 𝑝𝑠𝜑(𝑥, ξs)𝐬∈𝐒 . By
duplicating the second stage decisions, 𝑦𝑠, for every scenario ξs, i.e., 𝑦𝑠 = 𝑦(ξs) 𝑓𝑜𝑟 𝑎𝑙𝑙 𝐬 ∈ 𝐒, the
two-stage problem (1)-(2) can be equivalently formulated as follows:
Min𝑥,𝑦𝑠,…,𝑦𝑆
cT𝐱 + ∑ 𝑝𝑠𝜑(𝑥, 𝑦𝑠, ξs)𝐬∈𝐒 (3)
𝑥 ∈ X, 𝑦𝑠 ∈ 𝜑(𝑥, ξs) 𝑓𝑜𝑟 𝑎𝑙𝑙 𝐬 ∈ 𝐒,
where ξs ≔ (𝑞𝑠, 𝑇𝑠,𝑊𝑠, ℎ𝑠), 𝐬 ∈ 𝐒, are the corresponding scenarios (Shapiro, 2008). For the sake of
simplicity, the mathematical formulation for each scenario subproblem is denoted by
Min (𝐜𝐱) + 𝑝𝑠(𝐟𝐬𝑦𝑠) (4) s.t (𝐱, 𝐲𝐬) ∈ 𝝋(𝒙, 𝛏𝐬) ∀ 𝐬,
where the first stage decision vector x does not depend on scenario, and where 𝐱𝐬 = 𝐱 𝐟𝐨𝐫 𝐚𝐥𝐥 𝐬 ∈ 𝐒.
Further, 𝒚𝒔 represents second stage decision variables, which are determined given a first stage
decision (𝐱𝒔) and a specific 𝛏𝐬. Finally, 𝐟𝐬 denotes the scenario specific coefficient vectors of the
second stage. Problem (4) is the well-known extensive form of a two-stage stochastic program
(Watson and Woodruff, 2011).
Next we present the pseudo-code of PHA to show how PHA converges to a common solution
taking into account all the scenarios belonging to the original problem. Let 𝝆 be a penalty
factor (𝝆 > 𝟎), 𝝐 be a convergence threshold over the first stage decisions and k be the iteration
number. The basic PHA Algorithm is stated as follows; see, e.g., Watson and Woodruff (2011):
PHA Algorithm
1. 𝒌 ≔ 𝟎
2. For all 𝒔 ∈ 𝑺, 𝒙𝒔𝒌 ≔ 𝒂𝒓𝒈𝒎𝒊𝒏𝒙,𝒚𝒔(𝐜𝐱 + 𝐟𝐬𝒚𝒔): (𝒙, 𝒚𝒔) ∈ 𝝋(𝐱, 𝛏𝐬)
3. ��𝒌 ≔ ∑ 𝒑𝒔𝒙𝒔𝒌
𝒔∈𝑺
4. For all 𝒔 ∈ 𝑺,𝒘𝒔𝒌 ≔ 𝝆(𝒙𝒔
𝒌 − 𝒙𝒌)
5. 𝒌 ≔ 𝒌 + 𝟏
6. For all 𝒔 ∈ 𝑺, 𝒙𝒔𝒌 ≔ 𝒂𝒓𝒈𝒎𝒊𝒏𝒙,𝒚𝒔 (𝐜𝐱 + 𝝎𝒔
𝒌−𝟏𝒙 +𝝆
𝟐‖𝒙 − ��𝒌−𝟏‖
𝟐+ 𝐟𝐬𝒚𝒔) : (𝒙, 𝒚𝒔) ∈ 𝝋(𝐱, 𝛏𝐬)
7. ��𝒌 ≔ ∑ 𝒑𝒔𝒙𝒔𝒌
𝒔∈𝑺 8. For all 𝒔 ∈ 𝑺,𝝎𝒔
𝒌 ≔ 𝝎𝒔𝒌−𝟏 + 𝝆(𝒙𝒔
𝒌 − ��𝒌)
9. 𝝅𝒌 ≔ ∑ 𝒑𝒔‖𝒙𝒔𝒌 − ��𝒌‖𝒔∈𝑺
10. If 𝝅𝒌 < 𝝐, then go to step 5, else terminate
When decision vector 𝐱 is continuous, PHA converges with linear rate to a common solution vector
��, which all the scenarios agree on. However, problem becomes much more difficult to solve when
𝐱 is integer, because integer variables make SP problems nonconvex (Watson and Woodruff, 2011).
Detailed information on behavior of the PHA methodology can be found in Wallace and Helgason
(1991), Mulvey and Vladimirou (1991), Lokketangen and Woodruff (1996), Crainic et al. (2011),
and Watson and Woodruff (2011).
2.2. Sample Average Approximation
The SAA method has become a popular technique in solving large-scale SP problems over
the past decade due to its application ease and scope. It has been shown that feasible solutions
obtained by SAA converge to an optimal solution provide that the sample size is sufficiently large
(Ahmed and Shapiro, 2002). However, even when these sample sizes are quite large, the actual
convergence rate depends on the problem conditioning. Several studies reported successful
applications of SAA to various stochastic programs (Verweij et al., 2003; Kleywegt et al., 2002;

5
Shapiro and Homem-de-Mello, 2001; Fliege and Xu, 2011;Wang et al., 2011; Long et al., 2012; Hu
et al., 2012; Wang et al., 2012; Aydin and Murat, 2013; Ayvaz et al., 2015).
The key idea of the SAA approach to solve SP can be described as follows. A sample
ξ1, … , ξN of N realizations of the random vector ξ is randomly generated, and subsequently the
expected value function 𝔼[𝜑(x, ξ)] is approximated by the sample average
function N−1∑ 𝜑(x, ξ)Nn=1 . In order to reduce variance within SAA, Latin Hypercube Sampling
(LHS) may be used instead of uniform sampling. Performance comparisons of LHS and uniform
sampling, within the SAA scheme, are analyzed in Ahmed and Shapiro (2002). The resulting SAA
problem Minx∈X{gN(x) ≔ cTx + N−1∑ 𝜑(x, ξn)Nn=1 } is then solved by deterministic optimization
algorithms. As N increases, the SAA algorithm converges to the optimal solution of SP (1) as
shown in Ahmed and Shapiro, (2002) and in Kleywegt et al. (2002). Since solving SAA becomes a
challenge with large N, the practical implementation of this algorithm often features multiple
replications of the sampling, solving each of the sample SAA problems, and selecting the best
found solution upon evaluating the solution quality by using the either the original scenario set or a
reference scenario sample set. We now provide a description of the SAA procedure as follows.
SAA Procedure:
Initialize: Generate 𝐌 independent random samples 𝒎 = 𝟏, 𝟐,… ,𝑴 with scenario sets 𝑵𝒎,, where
|𝑵𝒎| = 𝑵. Each sample 𝒎 consists of 𝑵 realizations of independently and identically distributed
(i.i.d.) random scenarios. We also select a reference sample 𝑵′ to be sufficiently large, e.g.,
𝒂𝒔 |𝑵′| ≫ 𝑵.
Step 1: For each sample 𝒎, solve the following two-stage SP problem and record the sample
optimal objective function value 𝒗𝒎 and the sample optimal solution 𝒙𝒎:
𝑴𝒊𝒏𝒙∈𝑿 {𝐜𝐓𝐱 +
𝟏
|𝑵𝒎|∑ 𝝋(𝒙, 𝝃𝒏)𝑵𝒎𝒏=𝟏 }. (5)
Step 2: Calculate the average ��𝑴 of the sample optimal objective function values obtained in Step 1
as follows:
��𝑴 =𝟏
𝑴∑ 𝒗𝒎𝑴𝒎=𝟏 . (6)
Step 3: Estimate the true objective function value ��𝒎 of the original problem for each sample’s
optimal solution. Solve the following problem for each sample by using the optimal first stage
decisions 𝒙𝒎 from step 1:
��𝒎 = 𝐌𝐢𝐧𝐢𝐦𝐢𝐳𝐞∑𝐜𝐓𝐱𝐦 +𝟏
|𝑵′|∑ 𝝋(𝒙𝒎, 𝝃𝒔)𝑵′
𝒔=𝟏 . (7)
Step 4: Select the solution 𝐱𝐦 with the best ��𝒎, i.e., 𝐱𝐒𝐀𝐀 = 𝒂𝒓𝒈𝒎𝒊𝒏𝒎=𝟏,…,𝑴 as the solution
and 𝒗𝑺𝑨𝑨 = 𝐦𝐢𝐧𝒎=𝟏,…,𝑴
��𝒎 as the objective function value of SAA.
Let 𝒗∗denote the optimal objective function value of the original problem (1-2). Then ��𝑴 is an
unbiased estimator of 𝔼[𝒗], which is the expected optimal objective function value of the sample
problems. Since 𝔼[𝒗] ≤ 𝒗∗, the value of ��𝑴 provides a statistical lower bound on 𝒗∗ (Ahmed and
Shapiro, 2002).
When the first and the second stage decision variables in (1) and (2) are continuous, it has
been proved that an optimal solution to the SAA problem solves also the true problem with
probability approaching to one at an exponential rate as 𝑵 increases (Shapiro and Homem-de-

6
Mello, 2001; Ahmed and Shapiro, 2002; Meng and Xu, 2006; Liu and Zhang, 2012; Xu and Zhang,
2013; Shapiro and Dentcheva, 2014). Determining the required minimal sample size 𝑵 is an
important task for SAA applicants, which was investigated by many researchers as in (Kleywegt et
al. 2002; Ahmed and Shapiro, 2002; Shapiro, 2002; Ruszczynski and Shapiro, 2003a).
2.3. Sampling-Based Progressive Hedging Algorithm (SBPHA)
We now describe the proposed SBPHA algorithm, which is a hybridization of the SAA and PHA.
The motivation for this hybridization originates from the final stage of the SAA method (Step 4, in
SAA) where, aft selecting the best performing solution, the rest of the sample solutions are
discarded. This discarding of the (𝑴 − 𝟏) sample solutions results in losses in terms of both
valuable sample information (increasing with M) as well as the effort spent in solving for each
sample’s solution (increasing with N). The proposed SBPHA offers a solution to these losses by
considering each sample SAA problem as though it is a scenario subproblem in the PHA.
Accordingly, in the proposed SBPHA approach, we modify the SAA method by iteratively re-
solving the sample SAA problems while, at the end of each iteration, penalizing deviations from the
probability weighted solution of the samples and the best performing solution to the original
problem (i.e., as in the PHA). Hence, a single iteration of the SBPHA corresponds to the classical
implementation of SAA method.
An important distinction of the SBPHA from classical PHA is the sampling concept and the
size of the subproblems solved. The classical PHA solves many subproblems each corresponding to
a single scenario in the entire scenario set one by one at every iteration, and evaluates the
probability weighted solution using the individual scenario probabilities. In comparison, the
SBPHA solves only a few numbers of subproblems each corresponding to samples with multiple
scenarios and determines the probability weighted solution in a different way than PHA (explained
in detail below). Note that while solving individual sample problems in SBPHA is more difficult
than solving a single scenario subproblem in PHA, SBPHA solves much fewer number of
subproblems. Clearly, SBPHA makes a trade-off between the number of sample subproblems to
solve and the size of each sample subproblem.
We first present the proposed SBPHA algorithm and then describe its steps in detail. For
clarity, we give the notation used precedes the algorithmic steps. Note that for brevity, we only
define the notation that are new or different than those used in the preceding sections:
Notation:
𝒌, 𝒌𝒎𝒂𝒙 : iteration index and maximum number of iterations
𝑷𝒎, ��𝒎 : probability and normalized probability of realization of sample 𝒎,∑ ��𝒎 𝒎∈𝑴 = 𝟏
𝒙𝒎,𝒌 : solution vector for sample 𝒎 at iteration 𝒌
��𝒌 : probability weighted solution vector at iteration 𝒌
��𝒌 : balanced solution vector at iteration 𝒌
𝒙𝒃𝒆𝒔𝒕 : best incumbent solution
��𝒃𝒆𝒔𝒕 : objective function value of the best incumbent solution with respect to 𝑵’
��𝒃𝒆𝒔𝒕𝒌 : objective function value of the best solution at iteration 𝒌 with respect to 𝑵’
𝝎𝒎𝒌 : dual variable vector for sample 𝒎 at iteration 𝒌
𝝆𝒌 : penalty factor at iteration 𝒌

7
𝜷 : update parameter for the penalty factor, 𝟏 < 𝜷 < 𝟐
𝜶𝒌 : weight for the best incumbent solution at iteration 𝒌, 𝟎 ≤ 𝜶 ≤ 𝟏
∆𝜶 : update factor for the weight of the best incumbent solution, 𝟎 ≤ ∆𝜶≤ 𝟎. 𝟎𝟓
𝝐𝜶 : Euclidean norm distance between sample solutions 𝐱𝒎,𝒌 and ��𝒌 at iteration 𝒌
𝝐 : convergence threshold for solution spread
𝒙𝑺𝑩𝑷𝑯𝑨 : best solution found by SBPHA
𝒗𝑺𝑩𝑷𝑯𝑨 : objective function value of the best solution found by SBPHA
The pseudo-code for the Sampling Based Progressive Hedging Algorithm is as follows:
Sampling-Based Progressive Hedging Algorithm (SBPHA) for Two-Stage SP Problems:
1: Initialize: Generate 𝑴 samples, 𝒎 = 𝟏, 𝟐,… ,𝑴 each with 𝑵𝒎 scenarios, where|𝐍𝐦| = 𝐍
2: Generate a reference sample set with 𝐍′ scenarios, where |𝐍′| ≫ 𝐍
3: 𝐤 ≔ 𝟎, 𝛚𝐦𝐤=𝟎 ≔ 𝟎 for ∀𝒎 = 𝟏,… ,𝑴, 𝛂𝐤=𝟎 ≔ 𝟏, and require 𝛒𝐤=𝟎 ≥ 𝟎
4: 𝐏𝐦 ≔ ∏ 𝐩𝐬𝐬∈𝐍𝐦 , ��𝐦 ≔𝐏𝐦
∑ 𝐏𝐦𝐌𝐦=𝟏
, ��: = {��𝐦}∀𝐦
Executing SAA to get initial solution:
5: Execute Steps 1-4 of SAA Algorithm for each m to get 𝐱𝐦
6: 𝐱𝐛𝐞𝐬𝐭 ≔ 𝐱𝐒𝐀𝐀, and ��𝒃𝒆𝒔𝒕 ≔ 𝒗𝑺𝑨𝑨
7: for 𝐦 = 𝟏, 𝟐, . . . , 𝐌, do
8: 𝐱𝒎,𝒌=𝟎 ≔ 𝐱𝐦
9: end for
10: While (𝝐𝒌 ≥ 𝜺 𝐨𝐫 ��𝒌 ≠ 𝒙𝒃𝒆𝒔𝒕), 𝐚𝐧𝐝(𝒌 < 𝒌𝒎𝒂𝒙) do
11: 𝐤 ≔ 𝐤 + 𝟏,
12: ��𝐤 ≔ ��𝐱𝒎,𝒌−𝟏
13: ��𝐤 ≔ 𝛂𝐤��𝐤 + (𝟏 − 𝛂𝐤)𝐱𝐛𝐞𝐬𝐭
14: If 𝛂𝐤−𝟏 = 𝟎, 𝛂𝐤 ≔ 𝛂𝐤−𝟏 else 𝛂𝐤 ≔ 𝛂𝐤−𝟏 − ∆𝛂
15: If 𝐤 ≥ 𝟐,𝛒𝐤 ≔ { 𝛃𝛒𝐤−𝟏 𝐢𝐟 𝛜𝐤 > 𝛜𝐤−𝟏/𝟐
𝛒𝐤−𝟏 𝐨𝐭𝐡𝐞𝐫𝐰𝐢𝐬𝐞, else 𝛒𝐤 ≔ 𝛒𝐤
16: 𝛚𝐦𝐤 ≔ 𝛚𝐦
𝐤−𝟏 + 𝛒𝐤(𝐱𝒎,𝒌−𝟏 − ��𝐤)
Solve each sample (subproblem) with 𝑵𝒎 scenarios:
17: for 𝐦 = 𝟏, 𝟐,… ,𝐌, do
18: [𝒗𝒎,𝒌, 𝐱𝐦,𝐤] ≔ 𝒂𝒓𝒈𝒎𝒊𝒏 {𝒄𝑻𝐱𝐦,𝐤 +𝟏
|𝑵𝒎|∑ 𝝋(𝒙, 𝝃𝒏)𝑵𝒎𝒏=𝟏 + 𝛚𝐦
𝐤 𝐱𝐦,𝐤 +
𝛒𝐤
𝟐‖𝐱𝐦,𝐤 − ��𝐤‖
𝟐} (𝟖)
19: end for
20: 𝝐𝒌: = (∑ ‖𝐱𝒎,𝒌 − ��𝒌‖𝑴𝒎=𝟏 )
𝟏/𝟐
Calculate the performances of solutions got in step 17-19:
21: for 𝐦 = 𝟏, 𝟐, . . , 𝐌, do
22: [��𝒎,𝒌] ≔ 𝐌𝐢𝐧 {𝒄𝑻𝐱𝒎,𝒌 +𝟏
|𝐍′|∑ 𝝋(𝒙, 𝝃𝒔)𝐍′
𝒔=𝟏 } (𝟗)
23: end for
24: ��𝒃𝒆𝒔𝒕𝒌 ≔ 𝐦𝐢𝐧(��𝒎,𝒌)

8
25: ��𝒃𝒆𝒔𝒕 ≔ { ��𝒃𝒆𝒔𝒕
𝒌 𝒊𝒇 ��𝒃𝒆𝒔𝒕𝒌 < ��𝒃𝒆𝒔𝒕
��𝒃𝒆𝒔𝒕 𝒐𝒕𝒉𝒆𝒓𝒘𝒊𝒔𝒆
26: 𝒙𝒃𝒆𝒔𝒕 ≔ { 𝒂𝒓𝒈𝒎𝒊𝒏𝒎=𝟏,…,𝑴 ��
𝒎,𝒌 𝒊𝒇 ��𝒃𝒆𝒔𝒕𝒌 < ��𝒃𝒆𝒔𝒕
𝒙𝒃𝒆𝒔𝒕 𝒐𝒕𝒉𝒆𝒓𝒘𝒊𝒔𝒆
27: end while
28: 𝐱𝐒𝐁𝐏𝐇𝐀 ≔ 𝒙𝒃𝒆𝒔𝒕, 𝒗𝑺𝑩𝑷𝑯𝑨 ≔ ��𝒃𝒆𝒔𝒕.
The first step in SBPHA’s initialization is to execute the standard SAA procedure (Steps 5-
6). In the initialization step of SBPHA, unlike SAA, we also calculate sample 𝑚’s probability and
normalized probabilities, e.g., Pm and Pm, which are used in to calculate sample m’s probability
weighted average solution xk at iteration k (Step 12). Next, in Step 13, we calculate the samples’
balanced solution (xk) as a weighted average of the average solution (xk) and the incumbent best
solution (xbest). The xbest is initially obtained as the solution to the SAA problem (Step 6) and tgen
updated based on the evaluation of the improved sample solutions and the most recent incumbent
best (Step 26). In calculating the balanced solution (xk), the SBPHA uses a weight factor αk ∈(0,1) to tune the bias between the sample’s current iteration average solution and the best
incumbent solution. High values of αk tend the balanced solution (hence the sample solutions in the
next iteration) to the samples’ average solution, whereas low values tend xk to the incumbent best
solution. There are two alternative implementations of SBPHA concerning this bias tuning, where
the αk can be static by setting ∆α= 0 or dynamically changing over the iterations by setting ∆α> 0
(see Step 14). The advantage of dynamic αk is that, beginning with a large αk, we first prioritize the
sample average solution until the incumbent best solution quality improves. This approach allows
guiding the sample solutions to a consensus sample average initially and then directing the
consensus sample average in the direction of evolving the best solution.
In Step 15, we update the penalty factor ρk depending whether the distance (ϵk) of the
sample solutions from the most recent balanced solution has sufficiently improved. We choose the
improvement threshold as half of the distance in the previous iteration (e.g., ϵk−1) . Similarly, in
Step 16, we update the dual variable (ωmk ) using the standard subgradient method of convex
optimization. Note that the ωmk are the Lagrange multipliers associated with the equivalence of each
sample’s solution to the balanced solution.
In Step 18, we solve each sample problem with additional objective function terms
representing the dual variables and calculate the deviation of the sample solutions from the balanced
solution (i.e., 𝛜𝐤). Step 22 estimates the objective function value of each sample solution in the
original problem using the reference set 𝐍′. Steps 25 and 26 identify the sample solution 𝐱𝐦,𝐤 with
the best ��𝐦,𝐤 in iteration 𝐤 and updates the incumbent best ��𝐛𝐞𝐬𝐭 if there is any improvement. Note
that ��𝐛𝐞𝐬𝐭 is monotonicaly nonincreasing with the SBPHA iterations. Steps 22, and 25-26
correspond to the integration of the SAA method selection of the best performing sample solution.
Rather than terminating with the best sample solution, the proposed SBPHA conveys this
information in the next iteration through the balanced solution. The SBPHA algorithm terminates
when either of the two stopping conditions are met. If the iteration limit is reached 𝐤 ≥ 𝐤𝐦𝐚𝐱 or
when all the sample solutions converge to the balanced solution within a tolerance, then SBPHA
terminates with the best found solution. The worst case solution of the SBPHA is equivalent to the
SAA solution. This can be observed by noting that the best incumbent solution is initialized with
the SAA’s solution and ��𝐛𝐞𝐬𝐭 is monotonicaly nonincreasing with the SBPHA iterations. Hence, the
SBPHA ensures that there is always a feasible solution, which has the same performance or a better
one in comparison with that of SAA.

9
2.4. Discarding-SBPHA (d-SBPHA) for binary-first stage SP problems:
The Discarding-SBPHA approach extends the SBPHA one by finding an improved and
ideally optimal solution to the original problem. The main idea of d-SBPHA is to resolve SBPHA
by adding constraint(s) to the sample subproblems in (8) that prohibits finding the same best
incumbent solution(s) found in earlier d-SBPHA iterations. This prohibition is achieved through
constraints that are violated if 𝐱𝐦,𝐤 overlaps with any of the best incumbent solutions (𝒙𝒃𝒆𝒔𝒕) found
so far in the d-SBPHA iterations. This modification of SBPHA can be considered as a globalization
of SBPHA in the sense that, by repeating the discarding steps, d-SBPHA guarantees to find an
optimal solution, albeit, with infinite number of discarding steps. The d-SBPHA approach initializes
with the 𝒙𝒃𝒆𝒔𝒕 iteration of the SBPHA solution and the SBPHA iteration’s parameter values
(ω,α,ρ…), where this solution is first encountered in the SBPHA iteration history. We now provide
the additional notation and algorithmic steps of d-SBPHA and then describe it in detail.
Additional notation for d-SBPHA
𝐨 : iteration number where d- SBPHA finds a solution for the first time; see below
𝐝, 𝐝𝐦𝐚𝐱 : number discarding iterations and the maximum number of discarding iteration
𝐃 : set of discarded solutions
𝐧𝐃𝐭 : number of binary decision variables that are equal to 1 in discarded solution 𝐃𝐭 ∈ 𝑫
𝐃𝐭𝟏 : set of decision variables that are equal to 1 in discarded solution t
𝐃𝐭𝟎 : set of decision variables that are equal to 0 in discarded solution t
d- SBPHA for binary-first stage SP problems:
1: Initialize: execute Steps 1-28 of SBPHA
2: 𝐱𝐛𝐞𝐬𝐭 ≔ 𝐱𝑺𝑩𝑷𝑯𝑨, 𝑫 ≔ 𝝓, 𝐨 ≔ 𝟎, 𝒅 ≔ 𝟎, 𝐱𝐦,𝐨 ≔ 𝐱𝒎,𝒌, 𝛒𝐨 ≔ 𝛒𝐤, 𝛂𝐨 ≔ 𝛂𝐤
Start d-SBPHA procedure
3: While 𝒅 ≤ 𝒅𝒎𝒂𝒙 do
4: 𝒅 ≔ 𝒅+ 𝟏
5: for 𝐦 = 𝟏, 𝟐,… ,𝐌, do
6: 𝐱𝒎,𝒌 ≔ 𝐱𝐦,𝐨
7: end for
8: 𝛒𝐤 ≔ 𝛒𝐨
9: 𝛂𝐤 ≔ 𝛂𝐨
10: for 𝐦 = 𝟏, , 𝟐, … ,𝐌, do
11: 𝛚𝐦𝐤 ← 𝛚𝐦
𝐨
12: end for
13: 𝑫 ≔ 𝑫⋃{𝐱𝐛𝐞𝐬𝐭} 14: Execute Steps 10-16 of SBPHA
15: for 𝐦 = 𝟏, 𝟐,… ,𝐌 do
16: [𝒗𝒎,𝒌, 𝒙𝒎,𝒌] ≔ 𝐚𝐫𝐠𝐦𝐢𝐧 {𝐜𝐓𝐱𝐦,𝐤 +𝟏
|𝑵𝒎|∑ 𝝋(𝒙, 𝝃𝒏)𝑵𝒎𝒏=𝟏 + 𝛚𝐦
𝐤 𝒙𝒎,𝒌 +𝛒𝐤
𝟐‖𝒙𝒎,𝒌 −
��𝐤‖𝟐} (10)
𝒔. 𝒕. ∑ 𝐱𝐦,𝐤𝐱𝐦,𝐤∈𝑫𝒕𝟏 − ∑ 𝐱𝐦,𝐤𝐱𝐦,𝐤∈𝑫𝒕
𝟎 ≤ 𝒏𝑫𝒕 − 𝟏, ∀𝒕 = 𝟏,… ,𝑫
17: end for
18: Execute steps 20-26 of SBPHA

10
19: 𝐱𝐝𝐝−𝐒𝐁𝐏𝐇𝐀 ≔ 𝐱𝐛𝐞𝐬𝐭, 𝒗𝒅
𝒅−𝑺𝑩𝑷𝑯𝑨 ≔ ��𝒃𝒆𝒔𝒕 20: end while
21: 𝒗𝒃𝒆𝒔𝒕𝒅−𝑺𝑩𝑷𝑯𝑨 ≔ 𝒎𝒊𝒏𝒅=𝟏,…,𝑫 𝒗𝒅
𝒅−𝑺𝑩𝑷𝑯𝑨
22: 𝒙𝒃𝒆𝒔𝒕𝒅−𝑺𝑩𝑷𝑯𝑨 ≔ 𝒙𝒅
𝒅−𝑺𝑩𝑷𝑯𝑨: = 𝒂𝒓𝒈𝒎𝒊𝒏𝒅=𝟏,…,𝑫 𝒗𝒅𝒅−𝑺𝑩𝑷𝑯𝑨
Initialization step of the d-SBPHA is the implementation of the original SBPHA with the
only difference is to set up the starting values of parameters as the values of the SBPHA algorithm,
where the current best solution is found. Also in Step 1, the set of the solutions that are discarded is
updated to prevent the algorithm to reconverge to the same solution. In Steps 2-12, the parameters
are updated. Step 13 updates the set of discarded solutions by including the most recent 𝐱𝐛𝐞𝐬𝐭. Step
14 executes SBPHA steps to update the parameters of sample problems. Note that Step 16 has the
same objective function as in Step 18 of SBPHA with additional discarding constraints that prevent
finding the first-stage solutions that are already found in the preceding d-SBPHA iterations. Step 18
executes steps of SBPHA, which test solutions’ quality and performs the updating of the best
solution according to the SAA approach. The only difference, in Step 20, between d-SBPHA and
SBPHA is that d-SBPHA checks whether the maximum number of discards is reached. If the
discarding iteration limit is reached, then the algorithm reports the solution with the best
performance (in Steps 21 and 22), else continues discarding. Note that with the discarding strategy,
d-SBPHA terminates with a better or the same solution in comparison with SBPHA and is
guaranteed to terminate with an optimal solution that is achieved via infinitely many of discarding
iterations while also discarding the constraints.
2.4.1. Lower bounds on SBPHA and d-SBPHA:
The majority of the computational effort of SBPHA (and d-SBPHA) is spent in solving the
sample subproblems as well as evaluating the first stage decisions in the larger reference set.
Especially, for combinatorial problems with discrete first-stage decisions, the former effort is more
significant than the latter. To improve the computational performance, we propose using a sample
specific lower bound employed while solving the sample subproblems. The theoretical justification
of the proposed lower bound for sample problems is that if the balanced solution does not change,
then the solution of the sample problems is nondecreasing. Hence, one can use the previously found
solution as the optimal lower bound (due to Lagrangian duality in optimization). However, if the
balanced solution changes, then the lower bound of the previous solution is not guaranteed, and thus
the lower bound is removed or a conservative estimate of the lower bound is utilized.
Let 𝐥𝐛𝐦,𝐤 be the lower bound for sample 𝒎 at iteration 𝒌 in SBPHA (or d-SBPHA). In Step
18 in SBPHA (Step 16 in d-SBPHA) a valid cut should be added: 𝐯𝐦,𝐤 ≥ 𝐥𝐛𝐦,𝐤, ∀𝐦,𝐦 = 𝟏,…𝐌,
where 𝐥𝐛𝐦,𝐤 = 𝐜𝐥𝐛𝐥𝐛𝐦,𝐤−𝟏, and 𝟎 ≤ 𝐜𝐥𝐛 ≤ 𝟏, where 𝐜𝐥𝐛 is a tuning parameter to adjust the tightness
of the lower bound. However, 𝐜𝐥𝐛 should not be close to 1 because it might cause infeasible
solutions. There is a trade-off on the value of 𝐜𝐥𝐛. Higher values might cause either infeasible or
suboptimal solutions, lower values does not provide consistent/tight constraints that should help
improving the solution time. In this study, by testing multiple values for 𝐜𝐥𝐛, we suggest applicants
to choose the range of 𝟎. 𝟒 ≤ 𝐜𝐥𝐛 ≤ 𝟎. 𝟔. Providing a justified lower bound to the optimization
problem saves approximately 10%-15% of the solution time.
2.4.2. Characteristics of SBPHAA and d-SBPHA
Here we present and justify several statements characterizing mathematical well-posedness of the
proposed algorithms.

11
Proposition 1 (Equivalence): SBPHA is equivalent to SAA if the algorithm is executed only one
time. Further, SBPHA is equivalent to PHA if the samples are mutually exclusive and their union is
the entire scenario set.
Proof: We proceed with verifying the tow statements of the proposition as formulated.
For SAA: If SBPHA terminated at Step 1, then 𝐱𝐒𝐁𝐏𝐇𝐀 = 𝐱𝐒𝐀𝐀, and 𝐯𝐒𝐁𝐏𝐇𝐀 = 𝐯𝐒𝐀𝐀. This allows us
to conclude that SBPHA is equivalent to SAA.
For PHA: Under specified assumptions and for 𝐌 = 𝐒 and 𝐍𝐦=𝟏,…,𝐌 = 𝟏, we have SBPHA=PHA.
Let us further consider a two-stage SP problem with finitely many scenarios 𝛏𝐬, 𝐬 = 𝟏,… , 𝐒, so that
each scenario occurs with probability 𝐩𝐬, where ∑ 𝐩𝐬 = 𝟏𝐒𝐬=𝟏 . Treating SBPHA with samples as the
individual scenarios, e.g., 𝐌 = 𝐒 and 𝐍𝐦=𝟏,…,𝐌, = 𝟏 for 𝐦 ≠ 𝐦′, we can conclude that 𝐏𝐦 = 𝐩𝐬. If the weight for the best incumbent solution and the update factor for the weight of the best
incumbent solution are equal to 1 and 0, respectively, at every iteration (𝛂𝐤 ≔ 𝟏, ∆𝛂= 𝟎), then
��𝐤: = ��𝐤 ≔ ∑ 𝐩𝐬𝐱𝐬𝐤
𝐬∈𝐒 and 𝐱𝐒𝐁𝐏𝐇𝐀 = 𝐱𝐏𝐇𝐀 and 𝐯𝐒𝐁𝐏𝐇𝐀 = 𝐯𝐏𝐇𝐀. □
Proposition 2 (Convergence): SBPHA algorithm converges and terminates with the best solution
found at an earlier iteration.
Proof: We prove this by contradiction. Assume that SBPHA finds, at iteration 𝐤, the best solution
as 𝐱𝐛𝐞𝐬𝐭 = 𝐱∗. Suppose that the SBPHA algorithm converges to a solution 𝐱′ ≠ 𝐱𝐛𝐞𝐬𝐭 which has a
worse objective value than 𝐱∗, with respect to the reference scenario set. Note that the convergence
yields ��𝐤 = ��𝐤−𝟏 = 𝐱′, while assuming that 𝐤𝐦𝐚𝐱 = ∞ and 𝜺 = 𝟎. In the last update we must have
the equality ��𝐤 = 𝐱′ = 𝛂𝐤𝐱′ + (𝟏 − 𝛂𝐤)𝐱𝐛𝐞𝐬𝐭 . Since 𝛂𝐤 < 𝟏, this equality is satisfied if and only
if 𝐱′ = 𝐱𝐛𝐞𝐬𝐭, which is a contradiction. □
Proposition 3: The SBPHA and 𝐝-SBPHA algorithms have the same convergence properties as
SAA with respect to the sample size.
Proof: It is showed in Ahmed and Shapiro (2002) and Ruszczynski and Shapiro (2003b) that SAA
converges with probability one (w.p.1) to optimal solution of the original problem as sample size
increases to infinity (𝐍 → ∞). Since Step 1 in SBPHA is the implementation of SAA and that
SBPHA does converge to the best solution found (Proposition 2), we can simply argue that SBPHA
and d-SBPHA converges to optimal solution of the original problem, as SAA does with increasing
sample size. Furthermore, since SBPHA and d-SBPHA guarantee a better or same solution quality
as SAA provides, we can conjecture that SBPHA and d-SBPHA have more chance to reach the
optimality than SAA with a given number of samples and sample size.
Proposition 4: The d-SBPHA algorithm converges to the optimum solution as 𝐝 → ∞.
Proof: Given that d-SBPHA is not allowed finding the same solution in the worst case, the d-
SBPHA iterates as many times as the number of feasible solutions (infinite in the continuous and
finite in the discrete case) for the first stage decisions before it finds an optimal solution. Note that
the proposed algorithm is effective for the problems where the first stage decision variables are
binary.
Clearly, as the number of discarding constraints added increases linearly with the number
discarding iterations, the resulting problems become more difficult to solve. However, in our

12
experiments for a particular problem type, we observed that, in the vast majority of experiments, d-
SBPHA finds an optimal solution in less than 10 discarding iterations.
3. Experimental Study Let us now describe the experimental study performed to investigate the computational and
solution quality performance of the proposed SBPHA and d-SBPHA for solving two-stage SP
problems. We benchmark the results of SBPHA and d-SBPHA with those of SAA. All the
algorithms are implemented in Matlab R2010b, and integer programs are solved with CPLEX 12.1.
The experiments are conducted on a PC with Intel(R) Core 2 CPU, 2.13 GHz processor and 2.0 GB
RAM running on Windows 7 OS. Next we describe the test problem, Capacitated Reliable Facility
Location Problem (CRFLP), in Section 3.1 and experimental design in Section 3.2. In Section 3.3,
we report on the sensitivity analysis results for SBPHA and d-SBPHA’s performance with respect
to algorithm’s parameters. In Section 3.4, we present and discuss the benchmarking results.
3.1. Capacitated Reliable Facility Location Problem (CRFLP)
Facility location is a strategic supply chain decision requiring significant investments to
anticipate and plan for uncertain future events (Owen and Daskin, 1998; Melo et al., 2009). An
example of such uncertain supply chain events is the disruption of facilities that are critical for the
ability to efficiently satisfy the customer demand (Schütz, 2009). These disruptions can be either
natural disasters, i.e., earthquake, floods, or man-made as terrorist attacks (Murali et al., 2012),
labor strikes, etc. For a detailed review of uncertainty considerations in facility location problems,
the reader is referred to Snyder (2006) and Snyder and Daskin (2005). Snyder and Daskin (2005)
developed a reliability-based formulation for the Uncapacitated Facility Location Problem (UFLP)
and the p-median problem (PMP). More recently, Shen et al. (2011) studied a variant of the reliable
UFLP called uncapacitated reliable facility location problem (URFLP). The authors proposed
efficient approximation algorithms for URFLP using the special structure of the problem. Several
studies were applied to UFLP, such as Pandit (2004), Arya et al. (2004), Resende and Werneck
(2006), Yun et al. (2014), An et al. (2014). However, approximations that are employed in UFLP
cannot be applied to the general class of facility location problems such as Capacitated Reliable
Facility Location Problem (CRFLP). Li et al. (2013) developed Lagrangian relaxation-based (LR)
solution algorithms for the reliable P-median problem (RPMP) and the reliable uncapacitated fixed-
charge location problem (RUFL). Albareda-Sambola et al. (2015) proposed two mathematical
formulations and developed a metaheuristic based algorithm to minimize total travel cost in a
network, where facilities are subject to probabilistic failures. The model they considered is also a
reliable p-median type problem.
In practice, capacity decisions are considered jointly with the location decisions. Further, the
capacities of facilities often cannot be changed (at least with a reasonable cost) in the event of
disruption. Following the facility failure, customers can be assigned to other facilities only if these
facilities have sufficient available capacity. Thus capacitated reliable facility location problems are
more complex than their uncapacitated counterparts (Shen et al., 2011). Gade (2007) applied SAA
in combination with a dual decomposition method to solve CRFLP. Later, Aydin and Murat (2013)
proposed a swarm intelligence based SAA algorithm to solve CRFLP.
We now introduce the notation used for the formulation of CRFLP. Let 𝐹𝑅 and 𝐹𝑈 denote the
set of possible reliable and unreliable facility sites, respectively, 𝐹 = 𝐹𝑅⋃𝐹𝑈 denote the set of all
possible facility sites including the emergency facility, and 𝒟 denote the set of customers. Let 𝑓𝑖 be
the fixed cost for locating facility 𝑖 ∈ 𝐹, which is incurred if the facility is opened, and 𝒹𝑗 be the
demand for customer 𝑗 ∈ 𝒟. Further, 𝑐𝑖𝑗 denotes the cost of satisfying each unit demand of customer
𝑗 from facility 𝑖 and includes such variable cost drivers as transportation, production, etc. There are
failure scenarios where the unreliable facilities can fail and become incapacitated to serve any
customer demand. In such cases, demand from customers needs to be allocated between the

13
surviving facilities and emergency facility (fe) subject to capacity availability. Each unit of demand,
which is satisfied by the emergency facility, causes a large penalty (ℎ𝑗) cost. This penalty can be
incurred due to either finding an alternative source, or due to the lost sale. Finally, the facility 𝑖 has
a limited capacity and can serve at most 𝑏𝑖 units of demand.
We formulate the CRFLP as a two-stage SP problem. In the first stage, the location decisions
are made before the random failures of the located facilities. In the second stage, following the
facility failures, the customer-facility assignment decisions are made for every customer given the
facilities that have not failed. The goal is to identify the set of facilities to be opened while
minimizing the total cost of open facilities as well as the expected cost of meeting demand of
customers from the surviving facilities and the emergency facility. In the scenario-based
formulation of CRFLP, let 𝑠 denote a failure scenario and the set of all the failure scenarios is 𝑆. Let
𝑝𝑠 be the occurrence probability of scenario 𝑠 and ∑ 𝑝𝑠 = 1𝑠∈𝑆 . Further, let 𝑘𝑖𝑠 indicate whether the
facility 𝑖 survives (then 𝑘𝑖𝑠 = 1) and 𝑘𝑖
𝑠 = 0 otherwise. For instance, in the case of independent
facility failures, we have |𝑆| = 2|𝐹𝑈| possible failure scenarios.
The binary decision variable 𝑥𝑖 specifies whether facility 𝑖 is opened, and the variable 𝑦𝑖𝑗𝑠
specifies the rate of demand of customer 𝑗 is satisfied by facility 𝑖 in scenario 𝑠. The scenario-based
formulation of the CRFLP as a two-stage SP is as follows:
Minimize ∑𝑓𝑖𝑖∈𝐹
𝑥𝑖 +∑𝑝𝑠∑∑𝑑𝑗𝑐𝑖𝑗𝑦𝑖𝑗𝑠
𝑖∈𝐹𝑗∈𝐷
𝑠∈𝑆
(11)
subject to
∑𝑦𝑖𝑗𝑠
𝑖∈𝐹
= 1 ∀𝑗 ∈ 𝐷, 𝑠 ∈ 𝑆, (12)
𝑦𝑖𝑗𝑠 ≤ 𝑥𝑖 ∀𝑗 ∈ 𝐷, 𝑖 ∈ 𝐹, 𝑠 ∈ 𝑆, (13)
∑𝑑𝑗𝑗∈𝐷
𝑦𝑖𝑗𝑠 ≤ 𝑘𝑖
𝑠𝑏𝑖 ∀𝑖 ∈ 𝐹, 𝑠 ∈ 𝑆, (14)
𝑥𝑖 ∈ {0,1} ∀𝑖 ∈ 𝐹, (15) 𝑦𝑖𝑗𝑠 ∈ [0,1] ∀𝑗 ∈ 𝐷, 𝑖 ∈ 𝐹, 𝑠 ∈ 𝑆. (16)
The objective function in formulation (11) minimizes the total fixed cost of opening facilities
and the expected second stage cost of satisfying customer demand through lasting and emergency
facility. Constraints (12) ensure that demand of each customer is fully satisfied by either open
facilities, or the emergency facility in every failure scenario. Constraints (13) ensure that a
customer’s demand cannot be served from a facility that is not opened in every failure scenario.
Constraints (14) prevent the assignment of any customer to a facility if it is failed and also ensure
the total demand assigned the facility does not exceed its capacity in every failure scenario.
Constraints (15) enforces integrality of location decisions and (16) ensure that demand satisfaction
rate for any customer-facility pair is within [0, 1].
3.2. Experimental Setting
We used the test data sets provided in Zhan (2007) which are also used in Shen et al. (2011)
for URFLP. In these data sets, the coordinates of site locations (facilities, customers) are i.i.d and
sampled from U[0,1] × U[0,1]. The sets of customer and facility sites are identical. The customer
demand is also i.i.d., sampled from U[0,1000], and rounded to the nearest integer. The fixed cost of
opening an unreliable facility is i.i.d. and sampled from U[500,1500], and rounded to the nearest
integer. For the reliable facilities, we set the fixed cost to 2,000 for all facilities. The variable
costs cij for customer j and facility i (excluding the emergency facility) are chosen as the Euclidean
distance between sites. We assign a large penalty cost, (20), ℎ𝑗 for serving customer j from
emergency facility. Zhan (2007) and Shen et al., (2011) consider URFLP and thus their data sets do

14
not have facility capacities. In all our experiments, we selected identical capacity levels for all
facilities, i.e., bi=1,..,|F| = 2,000. Datasets used in our study is given in Appendix B Table 9.
In generating the failure scenarios, we assume that the facility failures are independently and
identically distributed according to the Bernoulli distribution with probability qi, i.e., the failure
probability of facility i. We experimented with two sets of failure probabilities; first set of
experiments consider uniform failure rates, i.e., qi∈FU = q where q = {0.1, 0.2, 0.3}, and the
second set of experiments consider bounded non-uniform failure rates i.e. qi, where qi ≤ 0.3. We
restricted the failure probabilities with 0.3 since larger failure rates are not realistic. The reliable
facilities and emergency facility are perfectly reliable, i.e., qi∈(FR∪fe) = 1. Note that in the case,
where qi∈FU = 0, corresponds to the deterministic fixed-charge facility location problem. The
failure scenarios s ∈ S are generated as follows. Let Ffs ⊂ FU denote the facilities that are failed,
and Fr∈FUs ≡ FU\Ff
s be the set of surviving facilities in scenario s. The facility indicator parameter in
scenario s become kis=0 if i ∈ Ff
s, and kis=1 otherwise, e.g., if i ∈ Fr
s ∪ FR ∪ {fe}. The probability of
scenario s is then calculated by ps = q|Ffs|(1 − q)|Fr
s|.
In all the experiments, we used |𝒟| = FU⋃FR = 12 + 8 = 20 sites, which gives us is a
large-sized CRFLP problem that is more difficult to solve than the uncapacitated version (URFLP).
The size of the failure scenario set is |S| = 4,096. The deterministic equivalent formulation has 20
binary xi and 1,720,320 = |F| × |D| × |S| = 21 × 20 × 4,096 continuous yijs variables. Further,
there are 1,888,256 = 81,920 + 1,720,320 + 86,016 = |D| × |S| + |F| × |D| × |S| + |F| × |S| constraints corresponding to constraints (12)--(14) in the CRFLP formulation. Hence, the size of the
constraint matrix of the deterministic equivalent MIP formulation is 1,720,320 × 1,888,256 which
cannot be tackled with exact solution procedures (e.g., branch-and-cut or column generation
methods). Note that while solving LPs with this size is computationally feasible, the presence of the
binary variables makes the solution a daunting task. We generated sample sets for SAA and the
SBPHA (and d-SBPHA) by randomly sampling from U[0,1] as follows. Given the scenario
probabilities, ps, we calculate the scenario cumulative probability vector {p1, (p1 + p2),… , ( p1 +
p2 +⋯+ p|S|−1), 1}, which has |S| intervals. We first generate a random number and then select
the scenario corresponding to the interval containing the random number. We tested the SAA,
SBPHA, and d-SBPHA algorithms with varying number of samples (M) and sample sizes (N). Whenever possible, we use the same sample sets for all the three methods. We select the reference
set (N′) as the entire scenario set, i.e., N′ = S, which is used to evaluate the second stage
performance of a solution. We note that this is computationally tractable due to a relatively small
number of scenarios and that the second stage problem is an LP. In cases of large scenario set or
integer second stage problem, one should select N′ ≪ S.
3.3. Parameter Sensitivity
In this subsection, we analyze the sensitivity of SBPHA with respect to the weight for the
best incumbent solution parameter (α), penalty factor (ρ), and update parameter for the penalty
factor (β). Recall that α determines the bias of the best incumbent solution in determining the
samples’ balanced solution, which is obtained as a weighted average of the best incumbent solution
and the samples’ probability weighted solution. The parameter ρ penalizes the Euclidean distance of
a solution from the samples’ balanced solution and β is the multiplicative update parameter for ρ
between two iterations. In all these tests, we set (M, N) = (5, 10) and q = 0.3 unless otherwise
stated. We experimented with two α strategies, static and dynamic α. We solved in total 480 (=10 replications × 48 parameter settings) problem instances.
The summary results of solving CRFLP using 10 independent sample sets (replications)
with static strategy α=0.6, β = {1.1,1.2,1.3,1.4,1.5,1.8}, and ρ = {1,20,40,80,200} are presented in
Table 1. The detailed results of the 10 replications of Table 1 together with the detailed replication

15
results with static strategy for α={0.6,0.7,0.8} and dynamic strategy ∆α = {0.02,0.03,0.05} are
presented in Appendix A, Table 5.
The first column in Table 1 shows the α strategy and its parameter value. Note that in the
dynamic strategy, we select the initial value as αk=0 = 1 in Appendix A, Table 5. The second and
third columns show penalty factor (ρ) and update parameter for the penalty factor (β), respectively.
The objective function values for 10 replications (each replication consists of M = 5 samples) are
reported in columns 4 − 13 (shown only for replications 1, 2 and 10 in Table 1 and detailed results
are shown in Appendix A, Table 5). The first column under the “Objective” heading presents the
average objective function value across 10 replications, and the second column under the
“Objective” heading presents the optimality gap (i.e., gap1) between the average replication
solution and the best objective function value found, which is 8995.08†, while the third and fourth
columns under the “Objective” heading present the minimum and maximum objective values across
10 replications. Average objective function value and gap1 are calculated as follows:
vRepAverage
=1
Rep∑ vr
SBPHARepr=1 , (17)
Gap1 =vRepAverage
−v∗
v∗× 100%, (18)
where Rep is the number of replications, e.g., Rep = 10 in this section’s experiments.
In the last column, we report on the computational (CPU) time in seconds for tests. The
complete results on CPU times are provided in Appendix A, Table 6. First observation from Table 1
is that SBPHA is relatively insensitive to the α strategy employed and the parameter settings
selected. Secondly, we observe that the performance of SBPHA with different parameter settings
depends highly on the sample (see Table 5). As seen in replication 7 of Table 5, most of the
configurations show good performance as they all obtain the optimal solution. Further, as the ∆α
increases, the best incumbent solution becomes increasingly more important leading to the
decreased computational time. While some parameter settings exhibit good performance in solution
quality, their computational times are also higher, and vice versa.
Table 1: Summary objective function results for solving 10 replications of CRFLP with
different parameter settings
Alpha(α) Rho (ρ) Replication 𝒗𝒃𝒆𝒔𝒕 Objective Time (s)
Strategy/
Parameter
Start
Update
Parameter(β)
1 2 … 10
Average
Gap1
(%) Min Max
Average
Static/
α=0.6
1 1.8 9,825 9,032 … 9,515 9,358 4.0 8,995 10,006 470.4
20 1.2 9,751 9,104 … 9,483 9,316 3.6 8,995 10,006 786.6
20 1.5 9,547 9,271 … 9,332 9,361 4.1 9,024 10,006 483.8
40 1.3 9,547 8,995 … 9,404 9,335 3.8 8,995 10,006 498.5
40 1.4 9,528 9,271 … 9,586 9,337 3.8 9,024 10,006 474.6
80 1.1 9,362 8,995 … 9,112 9,177 2.0 8,995 9,528 801.1
80 1.2 9,547 9,032 … 9,167 9,134 1.5 8,995 9,547 565.0
200 1.1 9,362 9,287 … 9,096 9,251 2.8 8,995 10,006 442.9
In selecting the parameter settings for SBPHA, we are interested in a parameter setting that
offers a balanced trade-off between the solution quality and the solution time. In order to determine
such parameter settings, we developed a simple, yet effective, parameter configuration selection
index. The selection criterion is the product of average gap1 and CPU time. Clearly, smaller the
† The best solution is obtained by selecting the best among all the SBPHA solutions (e.g., out of 480 solutions) and
the the time-restricted solution of the CPLEX. The latter solution is obtained by solving the deterministic equivalent
using CPLEX method with %0.05 optimality gap tolerance and 10 hours (36,000 seconds) of time limit until either the
CPU time-limit is exceeded or the CPLEX terminates due to insufficient memory.

16
index value, the better is the performance of the corresponding parameter configuration. To
illustrate, using the results of the first row in Table 1, the index of static α = 0.6, with starting
penalty factor (ρ) = 1 and penalty factor update β = 1.8, is calculated as 19.00 (= 4.039% ×470.4). Parameter selection indexes corresponding to all 480 experiments are shown in Table 2.
According to the aggregate results in Table 2 (the ‘Total’ row at the bottom), the static α = 0.7
setting is the best, the static α = 0.6 is the second best while dynamic α with ∆α= 0.03 provides the
third best performance. Hence, we use only these α parameter configurations in our experiments. In
terms of penalty parameter configuration, we select the best setting, i.e., starting penalty factor
(ρ) = 200 and penalty factor update β = 1.1 for all the α parameter configurations. Note that by
selecting a larger starting penalty factor, SBPHA would converge faster but the quality of the
solution converged would be lower. Therefore, we restricted our experiments in terms of penalty
factor to be at most 200 (ρ).
Further, among all the experiments, the best parameter configuration in terms of index is
with static α = 0.6, when starting penalty factor ρ = 80 and update parameter (β) = 1.2. In Table
1 and Table 5, this configuration of parameter selection provides the best average gap performance
and a good CPU time performance. Hence, we also included this parameter configuration in our
computational performance experiments.
Table 2: Index for Parameter Selection
Rho (ρ) Dynamic α Static α
Start Update
Parameter(β) Δα=0.02 Δα=0.03 Δα=0.05 α=0.6 α=0.7 α=0.8 Total
1 1.8 18.95 18.52 25.28 19.00 18.89 25.17 125.8
20 1.2 26.58 22.53 26.33 28.07 16.54 23.88 143.9
20 1.5 13.30 18.37 20.20 19.66 17.09 18.65 107.3
40 1.3 14.58 14.78 24.30 18.83 18.83 18.14 109.5
40 1.4 20.23 18.49 18.03 18.02 14.32 15.12 104.2
80 1.1 21.73 21.62 24.26 16.23 17.67 17.02 118.5
80 1.2 15.88 17.92 21.27 8.70 17.83 20.33 101.9
200 1.1 14.75 12.09 14.77 12.59 13.48 11.98 79.6
Total: 146.0 144.3 174.5 141.1 134.6 150.3
In the remainder of the computational experiments we used sample size and number
as (M. N) = (5. 10). which enables the SBPHA to search the solution space while maintaining
computational time efficiency.
3.4. Computational Performance of SBPHA and d-SBPHA
In this subsection, we first show the performance of d-SBPHA on improving the solution
quality of SBPHA and then compare the performances of SAA and the proposed d-SBPHA
algorithm. In the remainder of the experiments, with a certain abuse of the optimality definition, we
refer to the best solution as the “exact solution”. This solution is obtained by selecting the best
amongst all the SBPHA, d-SBPHA, and SAA solutions and the time-restricted solution of CPLEX.
3.4.1. Analyzing d-SBPHA and SBPHA
Figure 1shows an effect of discarding strategy on the solution quality for different facility
failure probabilities. In all figures, results are based on the average of 10 replications. The
optimality gap (shown as ‘Gap’) is calculated as in (18) but substituting vrSBPHA with vbest.r
d−SBPHA in
(17) to calculate vRepAverage
. The first observation is that d-SBPHA not only improves the solution
quality but also finds an optimal solution in most facility failure probability cases. When failure
probability is q = 0.1, d-SBPHA converges to an optimal solution in less than 5 discarding

17
iterations with all the parameter configurations (Figure 1a). When q = 0.2, d-SBPHA converges to
an optimal solution in all the static α strategies in less than 5 discarding strategies and less
than 0.2% optimality gap with dynamic α strategy (Figure 1b).
0,0%
0,1%
0,1%
0,2%
0,2%
0,3%
0,3%
0,4%
0,4%
0,5%
Gap
Solution Quality Improvement with Discarding for q=0.1
Static α=0.6,ρ=200,β=1.1
Static α=0.7,ρ=200,β=1.1
Static α=0.6,ρ=80,β=1.2
Dynamic Δα=0.03,ρ=200,β=1.1
0,0%
0,2%
0,4%
0,6%
0,8%
1,0%
1,2%
1,4%
1,6%
Gap
Solution Quality Improvement with Discarding for q=0.2
Static α=0.6,ρ=200,β=1.1
Static α=0.7,ρ=200,β=1.1
Static α=0.6,ρ=80,β=1.2
Dynamic Δα=0.03,ρ=200,β=1.1
0.0%
0.5%
1.0%
1.5%
2.0%
2.5%
3.0%
Gap
Solution Quality Improvement with Discarding for q=0.3
Static α=0.6,ρ=200,β=1.1
Static α=0.7,ρ=200,β=1.1
Static α=0.6,ρ=80,β=1.2
Dynamic α=0.03,ρ=200,β=1.1
0.0%
0.5%
1.0%
1.5%
2.0%
2.5%
3.0%
3.5%
Gap
Solution Quality Improvement with Discarding for q random
Static α=0.6,ρ=200,β=1.1
Static α=0.7,ρ=200,β=1.1
Static α=0.6,ρ=80,β=1.2
Dynamic Δα=0.03,ρ=200,β=1.1
Figure 1: Effect of discarding strategy on the solution quality for CRFLP with facility failure
probabilities (a) q = 0.1. (b) q = 0.2. (c) q = 0.3. and (d) when q is random.
Further, when failure probability is 0.3, d-SBPHA is not able converge to an optimal
solution; however, it converges to solutions that are less than 1% away from the optimal one on
average (Figure 1c). Note that these results are based on the average of 10 replications, and at least
5 out of 10 replications are converged to the optimal solution in all the parameter configurations.
Detailed results are provided in the next section.
Finally, when failure probability is randomized, d-SBPHA converges to an optimal solution
in 10 or less discarding iterations, with three out of the four selected parameter configurations and
less than 0.5% gap (Figure 1d). Hence, we conclude that discarding improves the solution
performance while the improvement rates depend on the parameter configuration and the problem
parameters. The reader is referred to Table 7 in Appendix A for detailed results.
Next, we present the CPU time performance of d-SBPHA for 10 discarding iterations
(Figure 2). Note that the time plotted is cumulative over discarding iterations. The time of each
discarding iteration is based on average of 10 replications and is reported in seconds.
First observation here is that the CPU time is linearly increasing. Further, the solution time
is similar for all the facility failure probabilities (Figure 2 a, b, c and d) with all the parameter
configurations.
(a)
(c)
(b)
(d)

18
0
200
400
600
800
1,000
1,200
1,400
1,600
Time (s)
Computational Time for q=0.1
Static α=0.6,ρ=200,β=1.1
Static α=0.7,ρ=200,β=1.1
Static α=0.6,ρ=80,β=1.2
Dynamic Δα=0.03,ρ=200,β=1.10
200
400
600
800
1,000
1,200
1,400
1,600
Time (s)
Computational Time for q=0.2
Static α=0.6,ρ=200,β=1.1
Static α=0.7,ρ=200,β=1.1
Static α=0.6,ρ=80,β=1.2
Dynamic Δα=0.03,ρ=200,β=1.1
0
200
400
600
800
1,000
1,200
1,400
1,600
1,800
Time (s)
Computational Time For q=0.3
Static α=0.6,ρ=200,β=1.1
Static α=0.7,ρ=200,β=1.1
Static α=0.6,ρ=80,β=1.2
Dynamic Δα=0.03,ρ=200,β=1.10
200
400
600
800
1,000
1,200
1,400
1,600
Time (s)
Computational Time For q random
Static α=0.6,ρ=200,β=1.1Static α=0.7,ρ=200,β=1.1Static α=0.6,ρ=80,β=1.2Dynamic Δα=0.03,ρ=200,β=1.1
Figure 2: CPU time performance of discarding strategy for CRFLP with facility failure
probabilities (a) q = 0.1. (b) q = 0.2. (c) q = 0.3, and (d) when q is random.
All the results are presented in Appendix A in Table 8. One main reason for linearly
increasing CPU time is that d-SBPHA makes use of the previously encountered solution
information. In particular, d-SBPHA does not test the reference sample (N′) performance of any
first stage solution that is encountered and already tested before. This is achieved by maintaining a
library of first stage solutions and corresponding reference sample (N′) performance in a dynamic
table.
3.4.2. SAA, SBPHA and d-SBPHA Tests. Comparisons
In this subsection, we compare performances of SBPHA, d-SBPHA, and SAA. First, we
analyze the performance of the proposed SBPHA and d-SBPHA with respect to that of the exact
method and the SAA method with different sample sizes (N) and number of samples (M). Here, for
the sake of simplicity and to explain clearer, we randomly selected a parameter configuration with
α = 0.7, ρ = 200, and β = 1.1, which is not either the worst or the best parameter configuration.
Table 3 and Table 4 illustrate these benchmark results for q ={0.1, 0.2, 0.3, and random}, for one of the replications. Then the average results across all the
replications are shown in Figure 3. The second column for SAA shows the number of samples and
sample size. i.e., ( M, N). For d-SBPHA, it shows the number of replications r, (M, N), and the
number of discarding iterations (d). Note that when the number of discarding iterations d = 0,
d-SBPHA becomes SBPHA. Third column, F∗, indicates the solution convergence for each method.
For instance, with q = 0.1 and (M,N) = (5, 10), the SAA solution is to open facilities F∗ ={1, 2, 8, 10, 12}, SBPHA opens facilities F∗ = {1, 2, 4, 10, 12}, both 2-SBPHA and the exact
(optimal) solution open facilities F∗ = {1, 2, 10, 11, 12}.
(a)
(d)
(b)
(c)

19
The fourth column presents the objective function value for SAA, SBPHA, d-SBPHA and
the exact method, i.e., vSAA, vSBPHA, vbestd−SBPHA, and v∗, respectively. The fifth column presents the
CPU time and the sixth column shows the optimality gap (Gap2) measures. Reported time for
d-SBPHA is the average time of the converged solution that is found during the discarding
iterations. Gap2 for SAA, SBPHA, and d-SBPHA uses the optimal solution value v∗, and it is
defined by
Gap2 =
{
vSAA−v∗
v∗x100% for SAA,
vSBPHA−v∗
v∗x100% for SBPHA,
vbestd−SBPHA−v∗
v∗x100% for d − SBPHA.
(19)
Table 3: Solution quality and CPU time performances of the SAA, SBPHA, and d-SBPHA
for CRFLP with facility failure probabilities q = 0.1 and q = 0.2.
q=0.1 q=0.2
Method M-N F* Best
Objective
Time
(sec.)
Gap2
(%) F* Best
Objective
Time
(sec.)
Gap2
(%)
SA
A
5-10 1,2,8,10,12 6,115 53 2.1 1,2,4,11,12 10,055 59 35.0
5-25 1,2,8,10,12 6,115 132 2.1 1,2,7,8,10,12 7,856 152 5.5
5-40 1,2,4,11,12 6,047 208 1.0 1,2,4,7,11,12 7,762 326 4.2
5-50 1,2,4,11,12 6,047 307 1.0 1,2,8,10,11,12 7,649 325 2.7
5-75 1,2,10,11,12 5,990 695 0.0 1,2,4,8,11,12 7,706 741 3.5
10-
10
1,2,8,10,12 6,115 94 2.1 1,3,4,8,10,12 8,465 122 13.7
10-
25
1,2,4,11,12 6,047 267 1.0 1,2,3,4,10,12 7,856 277 5.5
10-
40
1,2,4,11,12 6,047 445 1.0 1,2,4,7,11,12 7,762 646 4.2
10-
50
1,2,4,11,12 6,047 638 1.0 1,2,8,10,11,12 7,649 676 2.7
10-
75
1,2,10,11,12 5,990 1,430 0.0 1,2,8,10,11,12 7,649 1,636 2.7
20-
10
1,2,8,10,12 6,115 174 2.1 1,4,5,8,11,12 8,450 236 13.5
20-
25
1,2,4,11,12 6,047 526 1.0 1,2,7,8,10,12 7,856 558 5.5
20-
40
1,2,4,11,12 6,047 874 1.0 1,2,8,10,11,12 7,649 1,222 2.7
20-
50
1,2,4,11,12 6,047 1,340 1.0 1,2,4,10,11,12 7,614 1,368 2.2
20-
75
1,2,10,11,12 5,990 2,791 0.0 1,2,4,10,11,12 7,614 3,348 2.2
q=0.1 q=0.2
Static α=0.7,ρ=200, β=1.1 Static α=0.7,ρ=200, β=1.1
Method r x M-N,d F*
Best
Objective
Time
(sec.)
Gap2
(%) F*
Best
Objective
Time
(sec.)
Gap2
(%)
d-S
BP
HA
1x5-10, 0 1,2,4,10,12 6,106 183 1.9 1,2,4,5,11,12 7,447 331 0.0
1x5-10, 1 1,2,10,11,12 5,990 309 0.0 1,2,4,5,11,12 7,447 437 0.0
1x5-10, 2 1,2,10,11,12 5,990 387 0.0 1,2,4,5,11,12 7,447 669 0.0
2x5-10, 0 1,2,10,11,12 5,990 323 0.0 1,2,4,5,11,12 7,447 976 0.0
2x5-10, 1 1,2,10,11,12 5,990 652 0.0 1,2,4,5,11,12 7,447 1,211 0.0
2x5-10, 2 1,2,10,11,12 5,990 810 0.0 1,2,4,5,11,12 7,447 1,713 0.0
3x5-10, 0 1,2,10,11,12 5,990 529 0.0 1,2,4,5,11,12 7,447 1,159 0.0
3x5-10, 1 1,2,10,11,12 5,990 932 0.0 1,2,4,5,11,12 7,447 1,506 0.0
3x5-10, 2 1,2,10,11,12 5,990 1,168 0.0 1,2,4,5,11,12 7,447 2,309 0.0
Exact - 1,2,10,11,12 5,990 >>10,800 - 1,2,4,5,11,12 7,447 >>14,400 -

20
Table 4: Solution quality and CPU time performances of the SAA, SBPHA and d-SBPHA
for CRFLP with facility failure probabilities 𝑞 = 0.3 and 𝑞 random.
q=0.3 q random
Method M-N F* Objective Time
(sec.)
Gap2
(%) F* Objective Time
(sec.)
Gap2
(%)
SA
A
5-10 1,2,4,7,10,12 11,877 119 32.0 2,4,5,11,12 7,609 52 12.2
5-25 1,2,4,5,8,10,12 9,798 342 8.9 2,5,8,10,11,12 7,310 116 7.8
5-40 1,2,7,8,10,11,12, 9,658 815 7.4 1,2,4,10,11,12 6,979 236 2.9
5-50 1,2,4,5,10,11,12 9,645 1,378 7.2 2,4,5,8,11,12 7,169 291 5.7
5-75 1,2,8,10,11,12,14 9,083 4,570 1.0 2,3,4,5,10,12 7,016 816 3.5
10-10 1,2,4,11,12,14 9,839 236 9.4 2,4,5,11,12 7,609 99 12.2
10-25 1,2,4,7,8,10,12 9,744 708 8.3 1,2,4,10,11,12 6,979 234 2.9
10-40 1,2,11,12,14,18 9,096 2,044 1.1 1,2,4,5,10,12 6,887 474 1.6
10-50 1,2,11,12,14,18 9,096 3,468 1.1 1,2,4,5,10,12 6,887 696 1.6
10-75 1,2,8,10,11,12,14 9,083 7,746 1.0 2,4,5,10,11,12 6,780 1,550 0.0
20-10 1,2,4,11,12,14 9,839 487 9.4 2,4,5,10,12 7,598 201 12.1
20-25 1,2,7,8,10,11,12, 9,658 1,509 7.4 1,2,4,10,11,12 6,979 481 2.9
20-40 1,2,11,12,14,18 9,096 3,960 1.1 2,4,5,10,11,12 6,780 893 0.0
20-50 1,2,11,12,14,18 9,096 6,367 1.1 2,4,5,10,11,12 6,780 1,359 0.0
20-75 1,2,4,10,11,12,14 8,995 13,867 0.0 2,4,5,10,11,12 6,780 2,824 0.0
q=0.3 q random
Static α=0.7,ρ=200, β=1.1 Static α=0.7,ρ=200, β=1.1
Method rxM-N,d F* Objective Time
(sec.)
Gap2
(%) F* Objective Time
(sec.)
Gap2
(%)
d-S
BP
HA
1x5-10, 0 1,2,4,10,11,12,20 9,024 422 0.3 2,4,5,7,10,12 7,263 250 7.1
1x5-10, 1 1,2,4,10,11,12,20 9,024 456 0.3 2,4,5,10,11,12 6,780 467 0.0
1x5-10, 2 1,2,4,10,11,12,20 9,024 490 0.3 2,4,5,10,11,12 6,780 590 0.0
2x5-10, 0 1,2,4,10,11,12,20 9,024 804 0.3 1,2,4,5,10,12 6,887 603 1.5
2x5-10, 1 1,2,4,10,11,12,14 8,995 999 0.0 2,4,5,10,11,12 6,780 901 0.0
2x5-10, 2 1,2,4,10,11,12,14 8,995 1,203 0.0 2,4,5,10,11,12 6,780 1,270 0.0
3x5-10, 0 1,2,4,10,11,12,14 8,995 1,503 0.0 2,4,5,10,11,12 6,780 1,000 0.0
3x5-10, 1 1,2,4,10,11,12,14 8,995 2,093 0.0 2,4,5,10,11,12 6,780 1,470 0.0
3x5-10, 2 1,2,4,10,11,12,14 8,995 2,442 0.0 2,4,5,10,11,12 6,780 1,951 0.0
Exact - 1,2,4,10,11,12,14 8,995 >>21,600 - 2,4,5,10,11,12 6,780 >>10,800 -
Table 3 and Table 4 show that with larger sample sizes the objective function on the SAA
objective function is not always monotonously decreasing while the CPU time increases
exponentially. The observation about the time is in accordance with those in Figure 3. SAA finds
the optimal solution only when N = 75 for q = 0.1 and cannot find the optimal solution for q = 0.2
with any of M-N configurations. SAA also finds the optimal solution for q = 0.3 only when M=20
and N=75 in more than 13,000 seconds and shows a relatively good performance for random q
when M=20. Finally, d-SBPHA finds the optimal solution in all the facility failure probabilities.

21
α=0.6ρ=200β=1.1
α=0.7, ρ=200,β=1.1
α=0.6, ρ=80, β=1.2
Δα=0.03, ρ=200,β=1.1
0
100
200
300
400
500
600
700
800
0%
5%
10%
15%
20%
N=10 N=25 N=40 N=50 N=75CPU
Time(sec.)Gap
d -SBPHA vs SAA for q=0.1
SAA Objectived-SBPHA Objectived-SBPHA TimeSAA Time
α=0.6, ρ=200, β=1.1
α=0.7, ρ=200, β=1.1
α=0.6, ρ=80, β=1.2
Δα=0.03, ρ=200, β=1.1
0
100
200
300
400
500
600
700
800
900
0%
2%4%
6%8%
10%12%
14%16%
18%20%
N=10 N=25 N=40 N=50 N=75 CPU Time(sec.)
Gap
d-SBPHA vs SAA for q=0.2d-SBPHA ObjectiveSAA Objectived-SBPHA TimeSAA Time
α=0.6, ρ=200, β=1.1
α=0.7, ρ=200, β=1.1
α=0.6, ρ=80, β=1.2
Δα=0.03, ρ=200, β=1.1
04008001,2001,6002,0002,4002,8003,2003,6004,000
0%3%5%8%
10%13%15%18%20%23%25%
N=10 N=25 N=40 N=50 N=75
CPU Time(sec.)
Gap
d-SBPHA vs SAA for q=0.3
d-SBPHA ObjectiveSAA Objectived-SBPHA TimeSAA Time
α=0.6, ρ=200, β=1.1
α=0.7, ρ=200, β=1.1
α=0.6, ρ=80, β=1.2
Δα=0.03, ρ=200, β=1.1
0
100
200
300
400
500
600
700
800
0%
2%
4%
6%
8%
10%
12%
14%
N=10 N=25 N=40 N=50 N=75 CPU Time(sec.)
Gap
d-SBPHA vs SAA for q random
d-SBPHA Objective SAA Objective d-SBPHA Time SAA Time
Figure 3: Effect of sample size on the solution quality and CPU time performance of SAA
in comparison with d-SBPHA for CRFLP with facility failure probabilities (a) q = 0.1, (b) q = 0.2,
(c) q = 0.3, and (d) q random.
Results for d-SBPHA (d = 10) in Figure 3 are for all the four parameter settings; the first
setting is for static α = 0.6, ρ = 200 and β = 1.1, the second one is for static α = 0.7, ρ = 200 and
β = 1.1, third setting is for static α = 0.6, ρ = 80 and β = 1.2, and fourth one is for dynamic
Δα = 0.03, ρ = 200 and β = 1.1.
In Figure 3, we present the CPU time and solution quality performances of SAA for
N={10, 25, 40, 50, 75} sample sizes and compare them with that of the proposed d-SBPHA in
which d = 10 and N=10 in solving CRFLP with failure probabilities q = {0.1, 0.2, 0.3, random}. We use 5 (M) samples in both SAA and four different parameter configurations in the proposed
method. Different number of samples would increase the solution time of SAA and SBPHA.
However, as seen from the results, SBPHA already captures the optimal solution in the majority of
experiments with only five samples in less time than the SAA. Therefore, increasing number of
samples would not make any difference for the comparison of SAA and SBPHA in terms of their
performances. The obtained results indicate that the sample size effect the SAA’s CPU time. In
particular, the CPU time of the SAA is growing exponentially. Furthermore, in none of the failure
probability cases, the solution quality performance of SAA has converged to that of d-SBPHA. The
solution quality of all the four configurations of the proposed d-SBPHA are either optimal or near
optimal. The gap in Figure 3 is calculated as in Figure 1 and the CPU time of d-SBPHA shows the
average CPU time when the converged solution is found during the discarding iterations.
(a) (b)
(c) (d)

22
4. Conclusion In this study, we have developed hybrid algorithms for two-stage SP problems. The
proposed algorithms provide hybridization of two existing methods. The first one is the Monte
Carlo sampling-based algorithm, which is called SAA. The SAA method gives us an attractive
approximation for SP problems when the number of uncertain parameters increases. The second
algorithm is PHA, which is an exact solution methodology for SP problems. The research presented
in this study mainly addresses two issues that arise when using SAA and PHA methods
individually: lack of effectiveness in solution quality of SAA and lack of efficiency in
computational time of PHA.
4.1. Summary of Study and Contributions
The first proposed algorithm is called SBPHA, which is the integration of SAA and PHA.
This integration considers each sample as a small deterministic problem and employs the SAA
algorithm iteratively. In each iteration, the non-anticipativity constraints is injected into the solution
process by introducing penalty terms in the objective that guides the solution of each sample to the
samples' balanced solution and to ensure that non-anticipativity constraints are satisfied. The two
key parameters of SBPHA are the weight of the best incumbent solution and the penalty factor.
The weight for the best incumbent solution adjusts the importance given to samples’ best
found solution and to the most recent average sample solution in calculating the balanced solution.
The penalty factor modulates the rate at which the sample solutions converge to the samples’
balanced solution. Given that the best found solution improves over time, we propose two strategies
for the weight of the best incumbent solution: static versus dynamic strategy.
We first conduct experiments for sensitivity analysis of the algorithm with respect to the
parameters. The results show that the SBPHA's solution quality performance is relatively
insensitive to the choice of strategy for the weight of the best incumbent solution. i.e., both the
static and dynamic strategies are able to converge to an optimal solution. SBPHA is able to
converge to an optimal solution even with small number of samples and small sample sizes.
In addition to the sensitivity experiments, we compare the performances of SBPHA and d-
SBPHA with SAA's. These results show that the SBPHA and d-SBPHA are able to improve the
solution quality noticeably with reasonable computational effort compared to SAA. Further,
increasing SAA's sample size to match the solution quality performance of SBPHA or d-SBPHA
requires significant computational effort, which is not affordable in many practical instances.
The contributions of this research are as follows:
Contribution 1: Developing SBPHA, which provides a configurable solution method that
improves the sampling-based methods’ accuracy and PHA’s efficiency for two-stage stochastic
programming problems.
Contribution 2: Enhancing SBPHA for SPs with binary first stage decision variables. The
improved algorithm is called Discarding-SBPHA (d-SBPHA). It is analytically proved that SBPHA
leads us to an optimal solution to the mentioned problems when the number of discarding iterations
approaches to infinity.
There are four possible avenues of the future research on SBPHA. The first opportunity is to
investigate the integration of alternative solution methodologies in order to improve the
convergence rate and solution quality, such as Stochastic Decomposition (SD), Stochastic Dual
Dynamic Programming (SDDP), L-Shaped decomposition. The second extension is the research on
applications of the d-SBPHA to the SPs that have linear first-stage decision variables. Another
extension is the investigation on developing a general strategy for the SBPHA and d-SBPHA
specific parameters in order to reduce the computational effort spent on the parameter sensitivity
steps. Finally, the adaptation of the ideas of d-SBPHA to multistage stochastic programs seems to
yet another productive future research opportunity.

23
Acknowledgements. Research of the third author was partly supported by the USA National
Science Foundation under grants DMS-1007132 and DMS-1512846 and by the USA Air Force
Office of Scientific Research grant 15RT0462.

24
APPENDIX A: Results for SBPHA and d-SBPHA
Table 5: Objective function values of test samples
Alpha(α) Rho Replication (r) Objective
Strategy/
Parameter
Start
(ρ)
Update
Parameter(β) 1 2 3 4 5 6 7 8 9 10 Average
Gap
(%) Min Max
Dynamic/
Δα=0.02
1 1.8 9,362 9,167 9,254 9,703 9,490 9,713 9,024 9,254 9,161 9,287 9,341 3.9 9,024 9,713
20 1.2 9,825 9,167 9,124 9,083 9,448 9,713 8,995 9,083 9,167 9,254 9,286 3.2 8,995 9,713
20 1.5 9,319 9,167 9,266 9,344 9,545 9,183 8,995 9,266 9,161 9,167 9,241 2.7 8,995 9,545
40 1.3 9,528 9,024 8,995 9,547 9,478 9,362 8,995 9,083 9,161 9,138 9,231 2.6 8,995 9,547
40 1.4 9,319 9,167 9,266 9,828 9,490 9,347 8,995 9,271 9,161 9,839 9,368 4.1 8,995 9,839
80 1.1 9,825 9,032 8,995 9,208 9,478 9,221 9,024 9,083 9,124 9,287 9,228 2.6 8,995 9,478
80 1.2 9,825 9,167 8,995 9,345 9,478 9,221 8,995 9,083 9,161 9,096 9,236 2.7 8,995 9,478
200 1.1 9,345 9,167 8,995 9,398 9,448 9,333 8,995 9,083 9,161 9,316 9,224 2.5 8,995 9,448
Dynamic/
Δα=0.03
1 1.8 9,528 8,995 9,024 9,637 9,490 9,713 9,024 9,288 9,471 9,287 9,346 3.9 8,995 9,713
20 1.2 9,362 9,024 8,995 9,528 9,412 9,370 9,024 9,288 9,221 9,280 9,250 2.8 8,995 9,528
20 1.5 9,825 9,292 9,266 9,467 9,490 9,713 8,995 9,254 9,161 9,138 9,360 4.1 8,995 9,713
40 1.3 9,528 9,167 9,032 9,112 9,490 9,383 8,995 9,254 9,161 9,287 9,241 2.7 8,995 9,490
40 1.4 9,825 9,292 9,032 9,467 9,478 9,713 8,995 9,254 9,221 9,326 9,360 4.1 8,995 9,713
80 1.1 9,825 9,024 8,995 9,362 9,448 9,369 8,995 9,083 9,083 9,167 9,235 2.7 8,995 9,448
80 1.2 9,528 9,104 8,995 9,944 9,478 9,221 8,995 9,112 9,161 9,287 9,283 3.2 8,995 9,944
200 1.1 9,825 9,167 8,995 9,112 9,448 8,995 9,024 9,083 9,161 9,138 9,195 2.2 8,995 9,448
Dynamic/
Δα=0.05
1 1.8 9,825 9,347 9,083 10,006 9,700 9,362 9,024 9,715 9,292 9,693 9,505 5.7 9,024 10,006
20 1.2 9,362 9,104 9,210 9,715 9,539 9,515 9,024 9,161 9,292 9,183 9,310 3.5 9,024 9,715
20 1.5 9,825 9,032 9,288 10,006 9,562 9,362 8,995 9,838 9,167 9,136 9,421 4.7 8,995 10,006
40 1.3 9,679 9,266 9,210 10,006 9,490 9,183 8,995 9,838 9,471 9,167 9,430 4.8 8,995 10,006
40 1.4 9,825 9,266 9,271 9,788 9,562 9,221 8,995 9,254 9,221 9,136 9,354 4.0 8,995 9,788
80 1.1 9,825 8,995 8,995 9,362 9,292 9,221 8,995 9,838 9,221 9,287 9,303 3.4 8,995 9,838
80 1.2 9,362 9,104 8,995 10,006 9,545 9,498 9,024 9,838 9,161 9,167 9,370 4.2 8,995 10,006
200 1.1 9,825 9,167 8,995 9,658 9,490 9,221 9,024 9,254 9,167 9,083 9,288 3.3 8,995 9,658
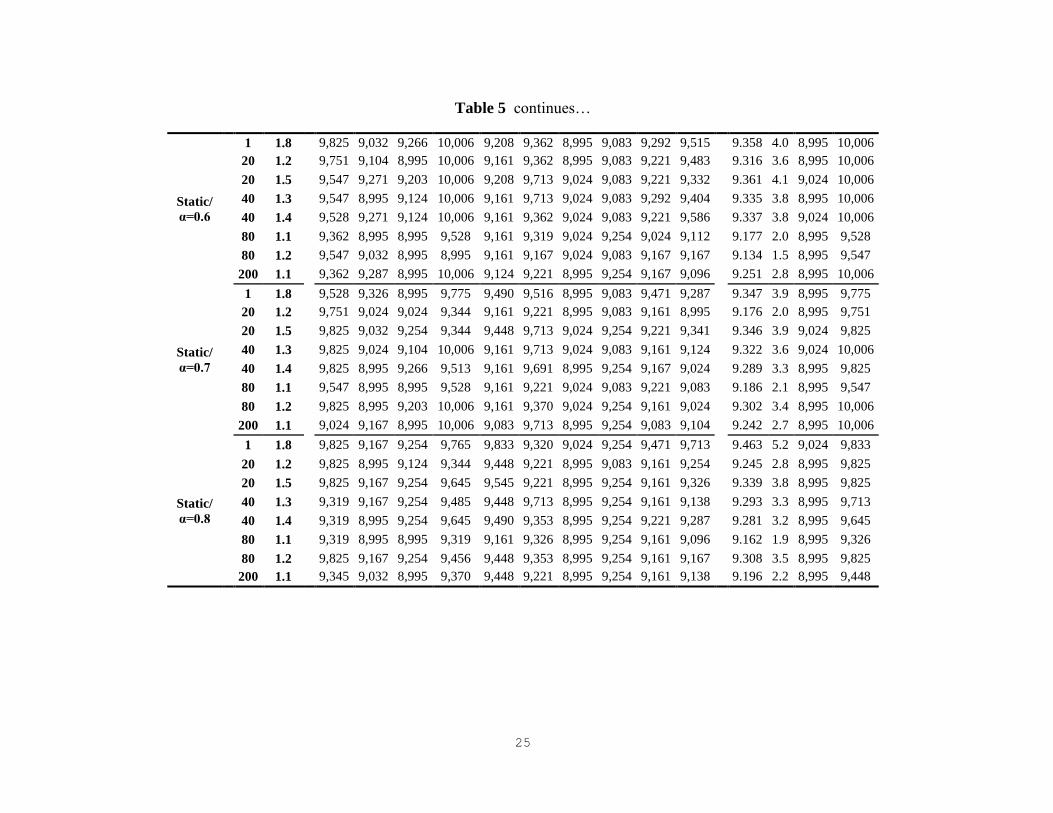
25
Table 5 continues…
Static/
α=0.6
1 1.8 9,825 9,032 9,266 10,006 9,208 9,362 8,995 9,083 9,292 9,515 9.358 4.0 8,995 10,006
20 1.2 9,751 9,104 8,995 10,006 9,161 9,362 8,995 9,083 9,221 9,483 9.316 3.6 8,995 10,006
20 1.5 9,547 9,271 9,203 10,006 9,208 9,713 9,024 9,083 9,221 9,332 9.361 4.1 9,024 10,006
40 1.3 9,547 8,995 9,124 10,006 9,161 9,713 9,024 9,083 9,292 9,404 9.335 3.8 8,995 10,006
40 1.4 9,528 9,271 9,124 10,006 9,161 9,362 9,024 9,083 9,221 9,586 9.337 3.8 9,024 10,006
80 1.1 9,362 8,995 8,995 9,528 9,161 9,319 9,024 9,254 9,024 9,112 9.177 2.0 8,995 9,528
80 1.2 9,547 9,032 8,995 8,995 9,161 9,167 9,024 9,083 9,167 9,167 9.134 1.5 8,995 9,547
200 1.1 9,362 9,287 8,995 10,006 9,124 9,221 8,995 9,254 9,167 9,096 9.251 2.8 8,995 10,006
Static/
α=0.7
1 1.8 9,528 9,326 8,995 9,775 9,490 9,516 8,995 9,083 9,471 9,287 9.347 3.9 8,995 9,775
20 1.2 9,751 9,024 9,024 9,344 9,161 9,221 8,995 9,083 9,161 8,995 9.176 2.0 8,995 9,751
20 1.5 9,825 9,032 9,254 9,344 9,448 9,713 9,024 9,254 9,221 9,341 9.346 3.9 9,024 9,825
40 1.3 9,825 9,024 9,104 10,006 9,161 9,713 9,024 9,083 9,161 9,124 9.322 3.6 9,024 10,006
40 1.4 9,825 8,995 9,266 9,513 9,161 9,691 8,995 9,254 9,167 9,024 9.289 3.3 8,995 9,825
80 1.1 9,547 8,995 8,995 9,528 9,161 9,221 9,024 9,083 9,221 9,083 9.186 2.1 8,995 9,547
80 1.2 9,825 8,995 9,203 10,006 9,161 9,370 9,024 9,254 9,161 9,024 9.302 3.4 8,995 10,006
200 1.1 9,024 9,167 8,995 10,006 9,083 9,713 8,995 9,254 9,083 9,104 9.242 2.7 8,995 10,006
Static/
α=0.8
1 1.8 9,825 9,167 9,254 9,765 9,833 9,320 9,024 9,254 9,471 9,713 9.463 5.2 9,024 9,833
20 1.2 9,825 8,995 9,124 9,344 9,448 9,221 8,995 9,083 9,161 9,254 9.245 2.8 8,995 9,825
20 1.5 9,825 9,167 9,254 9,645 9,545 9,221 8,995 9,254 9,161 9,326 9.339 3.8 8,995 9,825
40 1.3 9,319 9,167 9,254 9,485 9,448 9,713 8,995 9,254 9,161 9,138 9.293 3.3 8,995 9,713
40 1.4 9,319 8,995 9,254 9,645 9,490 9,353 8,995 9,254 9,221 9,287 9.281 3.2 8,995 9,645
80 1.1 9,319 8,995 8,995 9,319 9,161 9,326 8,995 9,254 9,161 9,096 9.162 1.9 8,995 9,326
80 1.2 9,825 9,167 9,254 9,456 9,448 9,353 8,995 9,254 9,161 9,167 9.308 3.5 8,995 9,825
200 1.1 9,345 9,032 8,995 9,370 9,448 9,221 8,995 9,254 9,161 9,138 9.196 2.2 8,995 9,448

26
Table 6: Computational time of test samples
Alpha(α)
Rho (ρ)
Replication (r)
Time (s)
Strategy/
Parameter
Start
Update
Parameter(β)
1 2 3 4 5 6 7 8 9 10
Average
Dynamic/
Δα=0.02
1 1.8
371 518 641 546 445 534 663 448 360 394
492.0
20 1.2
568 777 1,183 823 753 907 992 738 654 833
822.8
20 1.5
346 428 620 472 447 590 547 596 376 440
486.1
40 1.3
395 517 761 580 566 630 505 592 467 549
556.1
40 1.4
370 452 624 495 464 556 505 579 384 450
487.8
80 1.1
551 746 1,090 895 815 952 959 827 779 795
840.8
80 1.2
386 518 799 657 574 695 625 604 484 577
592.0
200 1.1
435 458 720 613 581 742 503 667 488 588
579.5
Dynamic/
Δα=0.03
1 1.8
379 468 629 489 415 512 664 426 349 421
475.1
20 1.2
575 782 1,135 696 767 914 995 653 680 742
794.0
20 1.5
319 447 613 411 424 512 555 468 346 431
452.7
40 1.3
391 484 715 552 515 706 616 502 446 484
541.1
40 1.4
337 447 629 394 426 508 505 459 382 466
455.3
80 1.1
515 729 1,115 823 771 1,089 863 726 768 710
810.9
80 1.2
388 546 767 531 501 649 612 568 479 568
560.9
200 1.1
346 401 696 579 537 777 449 556 515 595
545.0
Dynamic/
Δα=0.05
1 1.8
393 439 646 356 387 499 648 384 329 381
446.4
20 1.2
641 688 1,026 784 653 876 914 704 568 656
751.0
20 1.5
348 398 586 405 385 469 531 372 354 418
426.6
40 1.3
409 524 702 458 451 581 584 427 415 471
502.2
40 1.4
340 466 613 523 366 523 497 391 379 423
452.0
80 1.1
477 660 1,051 836 630 794 814 520 649 652
708.2
80 1.2
398 491 701 478 467 603 577 402 499 488
510.4
200 1.1
304 376 639 483 439 509 403 472 398 508
453.2
Static/ α=0.6
1 1.8
399 533 638 385 390 519 627 444 349 419
470.4
20 1.2
649 740 1,229 554 709 797 967 710 675 837
786.6
20 1.5
391 462 632 315 408 426 508 410 876 410
483.8
40 1.3
439 475 754 346 463 518 588 485 425 491
498.5
40 1.4
379 424 633 306 366 456 457 410 369 945
474.6
80 1.1
670 665 1,206 741 720 413 692 688 816 1,402
801.1
80 1.2
450 430 789 410 438 599 508 1,023 449 554
565.0
200 1.1
421 390 698 269 370 499 373 400 427 582
442.9
Static/ α=0.7
1 1.8
393 452 658 451 440 562 634 456 349 441
483.6
20 1.2
641 726 1,209 706 762 1,046 976 681 721 768
823.5
20 1.5
355 407 625 373 435 510 525 386 364 404
438.5
40 1.3
442 476 780 412 464 531 578 481 441 571
517.6
40 1.4
385 403 631 432 389 449 510 364 383 436
438.2
80 1.1
683 673 1,235 804 704 903 802 795 764 976
834.0
80 1.2
415 473 832 375 458 618 535 447 508 563
522.4
200 1.1
491 385 730 311 536 482 390 420 558 601
490.4
Static/ α=0.8
1 1.8
384 461 654 458 469 540 671 433 356 416
484.2
20 1.2
623 816 1,251 746 838 996 1,017 732 695 885
859.8
20 1.5
459 414 642 503 462 596 565 410 405 417
487.4
40 1.3
405 506 737 580 558 582 623 464 460 555
547.0
40 1.4
459 411 630 517 458 561 510 417 376 412
475.1
80 1.1
744 682 1,302 891 929 1,210 910 661 796 1,046
917.2
80 1.2
452 523 750 615 590 726 618 461 490 623
584.8
200 1.1
458 421 753 600 546 601 452 471 477 589
536.5

27
Table 7: Average objective function value of 10 replications for each parameter configuration
over discarding
q=0.1 q=0.2
Static α Dynamic α Static α Dynamic α
Replications
α=0.6
ρ=200
β=1.1
α=0.7
ρ=200
β=1.1
α=0.6
ρ=80
β=1.2
Δα=0.03 ρ=200
β=1.1
α=0.6
ρ=200
β=1.1
α=0.7
ρ=200
β=1.1
α=0.6
ρ=80
β=1.2
Δα=0.03
ρ=200 β=1.1
No Discard 6,002 6,007 6,002 6,015 7,554 7,511 7,557 7,541
1-Discard 5,990 5,996 5,990 6,008 7,540 7,502 7,520 7,487
2-Discard 5,990 5,993 5,990 5,990 7,520 7,451 7,484 7,476
3-Discard 5,990 5,993 5,990 5,990 7,463 7,447 7,464 7,476
4-Discard 5,990 5,990 5,990 5,990 7,458 7,447 7,447 7,476
5-Discard 5,990 5,990 5,990 5,990 7,458 7,447 7,447 7,476
6-Discard 5,990 5,990 5,990 5,990 7,447 7,447 7,447 7,470
7-Discard 5,990 5,990 5,990 5,990 7,447 7,447 7,447 7,470
8-Discard 5,990 5,990 5,990 5,990 7,447 7,447 7,447 7,470
9-Discard 5,990 5,990 5,990 5,990 7,447 7,447 7,447 7,470
10-Discard 5,990 5,990 5,990 5,990 7,447 7,447 7,447 7,459
Exact
Solution
5,990 - - - 7,447 - - -
q=0.3 q random
Static α Dynamic α Static α Dynamic α
Replications
α=0.6
ρ=200
β=1.1
α=0.7
ρ=200
β=1.1
α=0.6
ρ=80
β=1.2
Δα=0.03 ρ=200
β=1.1
α=0.6
ρ=200
β=1.1
α=0.7
ρ=200
β=1.1
α=0.6
ρ=80
β=1.2
Δα=0.03
ρ=200 β=1.1
No Discard 9,251 9,242 9,134 9,195 6,851 6,938 6,862 6,987
1-Discard 9,220 9,059 9,109 9,116 6,842 6,859 6,861 6,927
2-Discard 9,137 9,057 9,081 9,113 6,822 6,859 6,861 6,801
3-Discard 9,100 9,057 9,081 9,110 6,801 6,812 6,820 6,790
4-Discard 9,067 9,033 9,076 9,081 6,790 6,801 6,810 6,790
5-Discard 9,057 9,033 9,067 9,081 6,790 6,801 6,800 6,790
6-Discard 9,057 9,033 9,067 9,065 6,790 6,790 6,800 6,790
7-Discard 9,057 9,033 9,067 9,065 6,790 6,790 6,800 6,790
8-Discard 9,057 9,033 9,059 9,065 6,790 6,780 6,800 6,790
9-Discard 9,057 9,033 9,059 9,065 6,780 6,780 6,800 6,780
10-Discard 9,057 9,024 9,056 9,065 6,780 6,780 6,800 6,780
Exact
Solution
8,995 - - - 6,780 - - -

28
Table 8: Average CPU time of 10 replications for each parameter configuration over discarding
q=0.1
q=0.2
Static α
Dynamic α Static α
Dynamic α
Replications
α=0.6
ρ=200
β=1.1
α=0.7
ρ=200
β=1.1
α=0.6
ρ=80
β=1.2
Δα=0.03
ρ=200
β=1.1
α=0.6
ρ=200
β=1.1
α=0.7
ρ=200
β=1.1
α=0.6
ρ=80
β=1.2
Δα=0.03
ρ=200
β=1.1
No Discard
248 250 288
268
333 366 366
380
1-Discard
108 121 106
146
98 101 128
149
2-Discard
124 130 137
143
110 164 108
107
3-Discard
97 116 97
108
131 102 60
77
4-Discard
131 143 114
143
85 106 122
102
5-Discard
88 93 94
109
117 126 114
133
6-Discard
101 146 85
125
103 80 81
110
7-Discard
106 105 98
93
106 106 63
85
8-Discard
75 78 64
103
103 102 88
47
9-Discard
82 86 84
87
89 116 89
93
10-Discard
122 117 97
108
86 76 79
71
Total Time
1,282 1,386 1,263
1,434
1,360 1,444 1,297
1,354
Time (Best
Solution found) 114 160 165
165
515 458 521
523
q=0.3
q random
Static α
Dynamic α Static α
Dynamic α
Replications
α=0.6
ρ=200
β=1.1
α=0.7
ρ=200
β=1.1
α=0.6
ρ=80
β=1.2
Δα=0.03
ρ=200
β=1.1
α=0.6
ρ=200
β=1.1
α=0.7
ρ=200
β=1.1
α=0.6
ρ=80
β=1.2
Δα=0.03
ρ=200
β=1.1
No Discard
430 476 503
533
279 308 302
329
1-Discard
172 210 100
204
133 173 155
157
2-Discard
138 132 78
139
126 148 119
163
3-Discard
107 122 75
137
124 147 109
130
4-Discard
96 116 72
106
78 91 85
88
5-Discard
110 136 76
66
89 100 82
80
6-Discard
117 119 57
68
106 79 73
76
7-Discard
110 102 50
62
108 98 57
95
8-Discard
89 72 50
78
98 120 64
101
9-Discard
97 67 50
52
97 147 65
78
10-Discard
73 65 47
35
83 75 52
88
Total Time
1,540 1,618 1,159
1,479
1,320 1,485 1,162
1,384
Time (Best
Solution found) 648 686 727
692
423 499 373
614
APPENDIX B: Data set used for CRFLP
The first column of Table 9 shows whether the possible facility site is reliable or not. The
second column shows the facility number. The third and fourth columns show the location (lat-
long) of the facility sites. The fifth column presents the demand of the location and the sixth

29
column presents the fix opening cost that is going to be applied if a facility is opened at the
specified location. Finally, the seventh column presents the failure probability if it is a random
failure cases; otherwise all the values in this column (only rows 1-12) are equal. e.g., q = qi =0.1. The emergency cost (demand satisfying cost if the demand is not satisfied from an opened
facility but from emergency. e.g., dummy facility) is 20 and is equal for all the facility sites.
Capacity for all facilities is taken 2000.
Table 9: Data set for CRFLP
Facility
Type No Lat. Long. Demand
Fixed
Cost
Failure
Probability
Un
reli
ab
le
1 0.82 0.18 957 938 0.24
2 0.54 0.70 202 642 0.12
3 0.91 0.72 186 1,230 0.13
4 0.15 0.31 635 1,008 0.11
5 0.74 0.16 737 1,279 0.08
6 0.58 0.92 953 1,431 0.25
7 0.60 0.09 450 1,187 0.29
8 0.37 0.19 188 1,044 0.30
9 0.70 0.52 206 1,466 0.26
10 0.22 0.40 995 989 0.17
11 0.50 0.45 429 948 0.17
12 0.30 0.52 528 585 0.24
Rel
iab
le
13 0.95 0.20 570 2,000 0.00
14 0.65 0.07 938 2,000 0.00
15 0.53 0.11 726 2,000 0.00
16 0.95 0.95 533 2,000 0.00
17 0.15 0.13 565 2,000 0.00
18 0.31 0.40 322 2,000 0.00
19 0.98 0.73 326 2,000 0.00
20 0.59 0.04 663 2,000 0.00
References Ahmed, S. and Shapiro, A. (2002). The sample average approximation method for stochastic
programs with integer recourse. Georgia Institute of Technology. Published electronically in:
http://www.optimization-online.org/DB_HTML/2002/02/440.html
Albareda-Sambola, M., Hinojosa, Y., and Puerto, J. (2015). The reliable p-median problem with
at-facility service. European Journal of Operational Research, 245(3), 656-666.
An, Y., Zeng, B., Zhang, Y., and Zhao, L. (2014). Reliable p-median facility location problem:
two-stage robust models and algorithms. Transportation Research Part B: Methodological, 64,
54-72.
Arya, V., Garg, N., Khandekar, R., Meyerson, A., Munagala, K., and Pandit, V. (2004). Local
search heuristics for k-median and facility location problems. SIAM Journal on Computing,
33(3), 544-562.
Aydin, N., and Murat, A. (2013). A swarm intelligence-based sample average approximation
algorithm for the capacitated reliable facility location problem. International Journal of
Production Economics, 145(1), 173-183.
Ayvaz, B., Bolat. B., and Aydin. N. (2015). Stochastic reverse logistics network design for waste
of electrical and electronic equipment. Resources, Conservation and Recycling (in press);

30
http://dx/doi.org/10.1016/j.resconrec.2015.07.006.
Barro, D., and Canestrelli, E. (2005). Dynamic portfolio optimization: Time decomposition using
the maximum principle with a scenario approach. European Journal of Operational Research,
163(1), 217-229.
Ben-Tal, A., Ghaoui, L.E., and Nemirovski, A. (2009). Robust Optimization. Princeton
University Press. Princeton, NJ.
Bertsimas, D., Brown, D.B., and Caramanis, C. (2011). Theory and applications of robust
optimization. SIAM Reviews, 53:464-501.
Birge, J. R. and Louveaux, F. V. (1997). Introduction to Stochastic Programming. New York.
Bomze, I., Chimani, M., Jünger, M., Ljubić, I., Mutzel, P., and Zey, B. (2010). Solving two-stage
stochastic Steiner tree problems by two-stage branch-and-cut. In Algorithms and Computation
(pp. 427-439). Springer, Berlin.
Chiralaksanakul, A. (2003). Monte Carlo Methods for Multistage Stochastic Programs. PhD
Thesis. University of Texas at Austin.
Crainic, T. G., Fu, X., Gendreau, M., Rei, W., and Wallace, S. W. (2011). Progressive hedging-
based metaheuristics for stochastic network design. Networks, 58(2), 114-124.
Dantzig, G. B. (1955). Linear programming under uncertainty. Management Science 1(3-4): 197-
206.
Fan, T., and Liu, C. (2010). Solving stochastic transportation network protection problem using
the progressive hedging-based method. Network and Spatial Economics 10(2): 193-208.
Fliege, J., and Xu, H. (2011). Stochastic multiobjective optimization: sample average
approximation and applications. Journal of Optimization Theory and Applications, 151(1),
135-162.
Gade, D. (2007). Capacitated facilities location problems with unreliable facilities. Master
Thesis. University of Arkansas.
Gade, D., Hackebeil, G., Ryan, S., Watson, J., Wets, R. J-B., and Woodruff, D. (2015).
Obtaining lower bounds from the progressive hedging algorithm for stochastic mixed-integer
programs. Mathematical Programming, to appear.
Gonçalves, R. E., Finardi, E. C., and da Silva, E. L. (2012). Applying different decomposition
schemes using the progressive hedging algorithm to the operation planning problem of a
hydrothermal system. Electric Power Systems Research, 83(1), 19-27.
Guo, G., Hackebeil, G., Ryan, S. M., Watson, J. P., and Woodruff, D. L. (2015). Integration of
progressive hedging and dual decomposition in stochastic integer programs. Operations
Research Letters, 43(3), 311-316.
Haugen, K. K., Løkketangen, A., & Woodruff, D. L. (2001). Progressive hedging as a meta-
heuristic applied to stochastic lot-sizing. European Journal of Operational Research, 132(1),
116-122.
Higle, J. L., and Sen, S. (1991). Stochastic decomposition: an algorithm for two-stage linear
programs with recourse. Mathematics of Operations Research,16: 650–669.
Hu, J., Homem-de-Mello, T., and Mehrotra, S. (2012). Sample average approximation of
stochastic dominance constrained programs. Mathematical programming, 133(1-2), 171-201.
Jeyakumar, V., Li, G.Y., Mordukhovich, B.S., and Wang, J.H. (2013). Robust best
approximation with interpolation under ellipsoid uncertainty: Strong duality and nonsmooth
Newton methods. Nonlinear Analysis: Theory, Methods and Applications, 81:1-11.
Kall, P., and Wallace S. W. (1994). Stochastic Programming. Wiley, New York.

31
Kleywegt, A. J., Shapiro, A., and Homem-de-Mello, T. (2002). The sample average
approximation method for stochastic discrete optimization. SIAM Journal on Optimization,
12(2), 479-502.
Li, Q., Zeng, B., and Savachkin, A. (2013). Reliable facility location design under disruptions.
Computers & Operations Research, 40(4), 901-909.
Liu, Y., and Zhang, Y. (2012). A note on the sample average approximation method for
stochastic mathematical programs with complementarity constraints. Journal of Mathematical
Analysis and Applications, 393(2), 389-396.
Lokketangen A., and Woodruff, D. L. (1996). Progressive hedging and tabu search applied to
mixed Integer (0.1) multi stage stochastic programming. Journal of Heuristics 2(2): 111-128.
Long, Y., Lee, L. H., and Chew, E. P. (2012). The sample average approximation method for
empty container repositioning with uncertainties. European Journal of Operational Research,
222(1), 65-75.
Lulli, G., and Sen, S. (2006). A heuristic procedure for stochastic integer programs with
complete recourse. European Journal of Operational Research, 171(3), 879-890
Melo, M. T., Nickel, S., and Saldanha-da-Gama, F. (2009). Facility location and supply chain
management: a review. European Journal of Operational Research, 196(2), 401-412.
Meng, F. W., and Xu, H. F. (2006). Exponential convergence of sample average approximation
methods for a class of stochastic mathematical programs with complementarity constraints. J.
Comput. Math, 24(6), 733-748.
Morton, D. and Popova, E. (2001). Monte Carlo simulations for stochastic optimization.
Encyclopedia of Optimization. I. C. A. Floudas and P. M. Pardalos. Kluwer Academic
Publishers, Norwell, MA.
Mulvey, J. M., and Vladimirou, H. (1991). Applying the progressive hedging algorithm to
stochastic generalized networks." Annals of Operations Research 31: 399-424.
Murali, P., Ordóñez, F., and Dessouky, M. M. (2012). Facility location under demand
uncertainty: Response to a large-scale bio-terror attack. Socio-Economic Planning Sciences,
46(1), 78-87.
Owen, S.H., and Daskin, M.S. (1998). Strategic facility location: a review. European Journal of
Operational Research, 111, 423–447.
Pandit, V. (2004). Local search heuristics for facility location problems. DCE, IIT, Delhi.
Peng, P., Snyder, L. V., Lim, A., and Liu, Z. (2011). Reliable logistics networks design with
facility disruptions. Transportation Research Part B: Methodological, 45(8), 1190-1211.
Resende, M. G., and Werneck, R. F. (2006). A hybrid multistart heuristic for the uncapacitated
facility location problem. European Journal of Operational Research, 174(1), 54-68.
Rockafellar R. T., and Wets, R. J.-B. (1991). Scenarios and policy aggregation in optimization
under uncertainty. Mathematics and Operations Research 16: 119-147.
Ruszczynski, A., and Shapiro, A. (2003a). Stochastic Programming Models. Stochastic
Programming. Handbooks in Operations Research and Management Science, 10. Elsevier
Science, Amsterdam.
Ruszczynski, A., and Shapiro, A. (2003b). Monte Carlo Sampling. Handbooks in Operations
Research and Management Science, 10. Elsevier Science, Amsterdam.
Schütz, P., Tomasgard, A., and Ahmed, S. (2009). Supply chain design under uncertainty using
sample average approximation and dual decomposition. European Journal of Operational
Research, 199(2), 409-419.
Shapiro, A. (2002) Statistical inference of multistage stochastic programming problems. Georgia
Institute of Technology. Published electronically in:

32
http://www.optimization-online.org/DB_FILE/2002/01/434.pdf
Shapiro, A. (2008). Stochastic programming approach to optimization under uncertainty.
Mathematical Programming, 112: 183-220.
Shapiro, A., Dentcheva, D., and Ruszczynski, A. (2014). Lectures on Stochastic Programming:
Modeling and Theory. SIAM, Philadelphia, PA.
Shapiro, A., and Homem-de-Mello, T. (2001). On the rate of convergence of Monte Carlo
approximations of stochastic programs. SIAM Journal on Optimization, 11: 76-86.
Shen, Z. J. M., Zhan, R. L., and Zhang, J. (2011). The reliable facility location problem:
Formulations, heuristics, and approximation algorithms. INFORMS Journal on Computing,
23(3), 470-482.
Shishebori, D., and Babadi, A. Y. (2015). Robust and reliable medical services network design
under uncertain environment and system disruptions. Transportation Research Part E:
Logistics and Transportation Review, 77, 268-288.
Slyke, R. M. V., and Wets, R. J.-B. (1969). L-shaped linear programs with applications to
optimal control and stochastic programming. SIAM Journal on Applied Mathematics 17:
638–663.
Snyder, L. V. (2006). Facility location under uncertainty: a review. IIE Transactions, 38(7), 547-
564.
Snyder, L.-V., and Daskin, M. S. (2005). Reliability models for facility location: The expected
failure cost case. Transportation Science 39: 400-416.
Solak, S. (2007). Efficient solution procedures for multistage stochastic formulations of two
problem classes. PhD Thesis. Georgia Institute of Technology.
Topaloglou, N., Vladimirou, H., and Zenios, S. A. (2008). A dynamic stochastic programming
model for international portfolio management. European Journal of Operational Research,
185(3), 1501-1524.
Toso, E. A. V., and Alem, D. (2014). Effective location models for sorting recyclables in public
management. European Journal of Operational Research, 234(3), 839-860.
Veliz, F. B., Watson, J. P., Weintraub, A., Wets, R. J. B., and Woodruff, D. L. (2014). Stochastic
optimization models in forest planning: a progressive hedging solution approach. Annals of
Operations Research, 1-16.
Verweij, B., Ahmed, S., Kleywegt, A. J., Nemhauser, G., and Shapiro, A. (2003). The sample
average approximation method applied to stochastic routing problems: a computational study.
Computational Optimization and Applications, 24(2-3), 289-333.
Wallace, S. W. and Helgason, T. (1991). Structural properties of the progressive hedging
algorithm. Annals of Operations Research 31: 445-456.
Wang, M., Montaz Ali, M., and Lin, G. (2011). Sample average approximation method for
stochastic complementarity problems with applications to supply chain supernetworks.
Journal of Industrial and Management Optimization, 7(2), 317.
Wang, Q., Guan, Y., and Wang, J. (2012). A chance-constrained two-stage stochastic program
for unit commitment with uncertain wind power output. Power Systems, IEEE Transactions
on, 27(1), 206-215.
Watson J. P., and Woodruff, D. L. (2011). Progressive hedging innovations for a class of
stochastic mixed-integer resource allocation problems. Computational Management Science
8: 355-370.
Xu, H., & Zhang, D. (2013). Stochastic Nash equilibrium problems: sample average
approximation and applications. Computational Optimization and Applications, 55(3), 597-
645.

33
Yun, L., Qin, Y., Fan, H., Ji, C., Li, X., and Jia, L. (2014). A reliability model for facility
location design under imperfect information. Transportation Research Part B:
Methodological.
Zhan, R.-L. (2007). Models and algorithms for reliable facility location problems and system
reliability optimization. Doctor of Philosophy. University of Florida.
Related Documents











