Rule Extraction From Trained Neural Networks Brian Hudson University of Portsmouth, UK

Rule Extraction From Trained Neural Networks
Jan 06, 2016
Rule Extraction From Trained Neural Networks. Brian Hudson University of Portsmouth, UK. Advantages High accuracy Robust Noisy data Disadvantages Lack of comprehensibilty. Artificial Neural Networks. Trepan. - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Rule Extraction From Trained Neural Networks
Brian HudsonUniversity of Portsmouth, UK

Artificial Neural Networks
Advantages High accuracy Robust Noisy data
Disadvantages Lack of comprehensibilty

Trepan A method for extracting a decision tree from
an artificial neural network (Craven, 1996). The tree is built by expanding nodes in a
best first manner, producing an unbalanced tree.
The splitting tests at the nodes are m-of-n tests e.g. 2-of-{x1, ¬x2, x3}, where the xi are Boolean
conditions The network is used as an oracle to answer
queries during the learning process.

Splitting Tests Start with a set of candidate tests
binary tests on each value for nominal features
binary tests on thresholds for real-valued features
Find optimal splitting test by a beam search, initializing beam with candidate test maximizing the information gain.

Splitting Tests To each m-of-n test in the beam and each
candidate test, apply two operators: m-of-(n+1) e.g. 2-of-{x1, x2} => 2-of-{x1, x2, x3} (m+1)-of-(n+1) e.g. 2-of-{x1, x2} => 3-of-{x1, x2, x3}
Admit new tests to the beam if they increase the information gain and differ significantly (chi-squared) from existing tests.

Data Modelling The amount of training data reaching
each node decreases with depth of tree. TREPAN creates new training cases by
sampling the distributions of the training data empirical distributions for nominal inputs kernel density estimates for continuous inputs
Apply oracle (i.e. neural network) to new training cases to assign output values.

Application to Bioinformatics
Prediction of Splice Junction sites in Eukaryotic DNA

Splice Junction Sites

Consensus Sequences Donor
-3 -2 -1 +1 +2 +3 +4 +5 +6C/G A G | G T A/G A G T
Acceptor-12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1
1
C/T C/T C/T C/T C/T C/T C/T C/T C/T C/T A G | G

EBI Dataset Clean dataset generated at EBI
(Thanaraj, 1999) Donors
training set: 567 positive, 943 negative test set: 229 positive, 373 negative
Acceptors training set: 637 positive, 468 negative test set: 273 positive, 213 negative

Results
C5 ANN TREPAN
Donor Training set 94.2 94.5 92.3 Test set 91.9 93.9 90.7
Acceptor Training set 86.5 86.3 77.7 Test set 84.7 87.5 78.4

TREPAN Donor Tree
3 of {-2=A, -1=G, +3=A, +4=A, +5=G}
Positive869:74
Negative43:533
C/G A G | G T A/G A G T
Yes No

C5 Donor Tree (extract)p5=G p3=C or p3=T => NEGATIVE p3=A p2=G => POSITIVE p2=A p4=A or p4=G => POSITIVE p4=C or p4=T => NEGATIVE p2=C p4=A => POSITIVE else => NEGATIVE p2=T p6=A or p6=G => NEGATIVE p6=C or p6=T => POSITIVE p3=G p4=T => NEGATIVE p4=C p6=T => POSITIVE else => NEGATIVE

Trepan Acceptor Tree1 of {-3=G, -5=G}
NEGATIVE {-3=A}
NEGATIVE
POSITIVENEGATIVE
2 of {+1!=G, -5=G}
C/T … C/T A G | G

Application to Chemoinformatics
1. Learning general rules2. Conformational Analysis3. QSAR dataset

Oprea Dataset 137 diverse compounds Classification
62 leads, 75 drugs 14 descriptors (from Cerius-2)
MW, MR, AlogP Ndonor, Nacceptor, Nrotbond Number of Lipinski violations
T.I. Oprea, A.M. Davis, S.J. Teague & P.D. Leeson, “Is there a difference between Leads & Drugs? A Historical Perspective”, J. Chem. Inf. & Comput. Sci., 41, 1308-1315, (2001).

C5 tree
MW <= 380 [ Mode: lead ]
Rule of 5 Violations = 0 [ Mode: lead ]
Hbond acceptor <= 2 [ Mode: lead ] => lead
Hbond acceptor > 2 [ Mode: drug ] => drug
Rule of 5 Violations > 0 [ Mode: lead ] => lead
MW > 380 [ Mode: drug ] => drug

Trepan Oprea Tree1 of { MW<296, MR<85 }
Lead52:3
Unclassified12:49
MW<454
Drug1:20

Conformational Analysis 300 conformations from
5ns MD simulation of rosiglitazone Classified by length of long axis into
Extended – distance > 10A Folded – distance < 10A
8 torsion angles
In house data.

Rosiglitazone
Agonist of PPAR gamma Nuclear Receptor Regulates HDL/LDL and triglycerides Active ingredient of Avandia for Type II
Diabetes
SN
O
O
H
O
NCH3
N
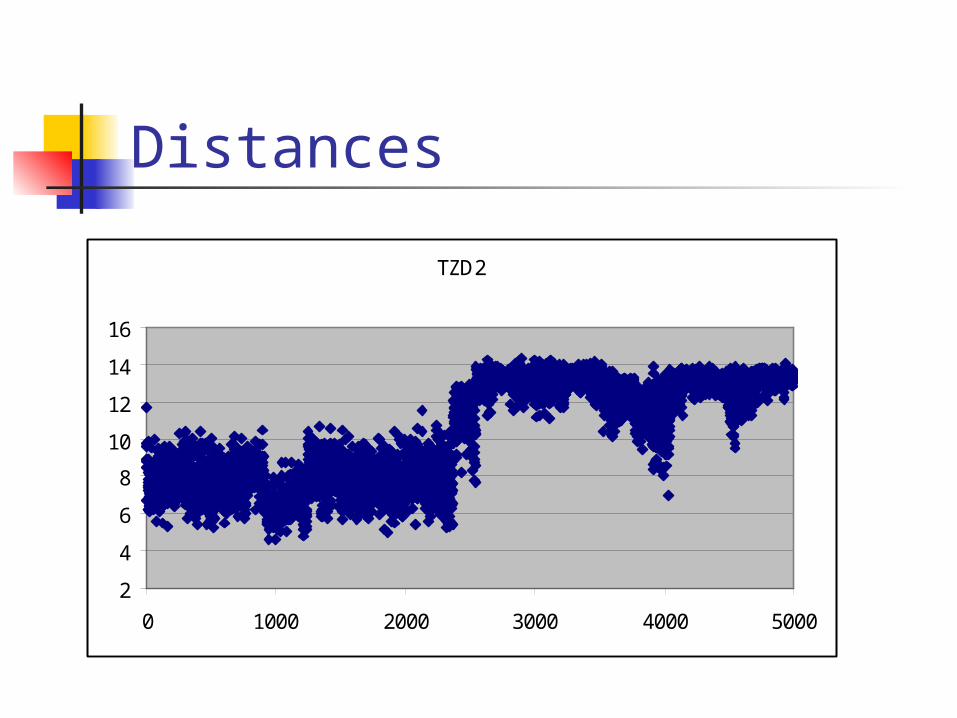
Distances
TZD2
2
4
6
8
10
12
14
16
0 1000 2000 3000 4000 5000

C5 treeT5 <= 269 [ Mode: extended ]
T5 <= 52 [ Mode: extended ]
T7 <= 185 [ Mode: extended ] => extended
T7 > 185 [ Mode: folded ]
T6 <= 75 [ Mode: folded ] => folded
T6 > 75 [ Mode: extended ]
T5 <= 41 [ Mode: folded ]
T8 <= 249 [ Mode: folded ] => folded
T8 > 249 [ Mode: extended ] => extended
T5 > 41 [ Mode: extended ] => extended
T5 > 52 [ Mode: extended ]
T6 <= 73 [ Mode: extended ]
T8 <= 242 [ Mode: extended ]
T5 <= 7 [ Mode: extended ]
T8 <= 22 [ Mode: extended ] => extended
T8 > 22 [ Mode: folded ] => folded
T5 > 7 [ Mode: extended ] => extended
T8 > 242 [ Mode: extended ] => extended
T6 > 73 [ Mode: extended ] => extended
T5 > 269 [ Mode: folded ] => folded
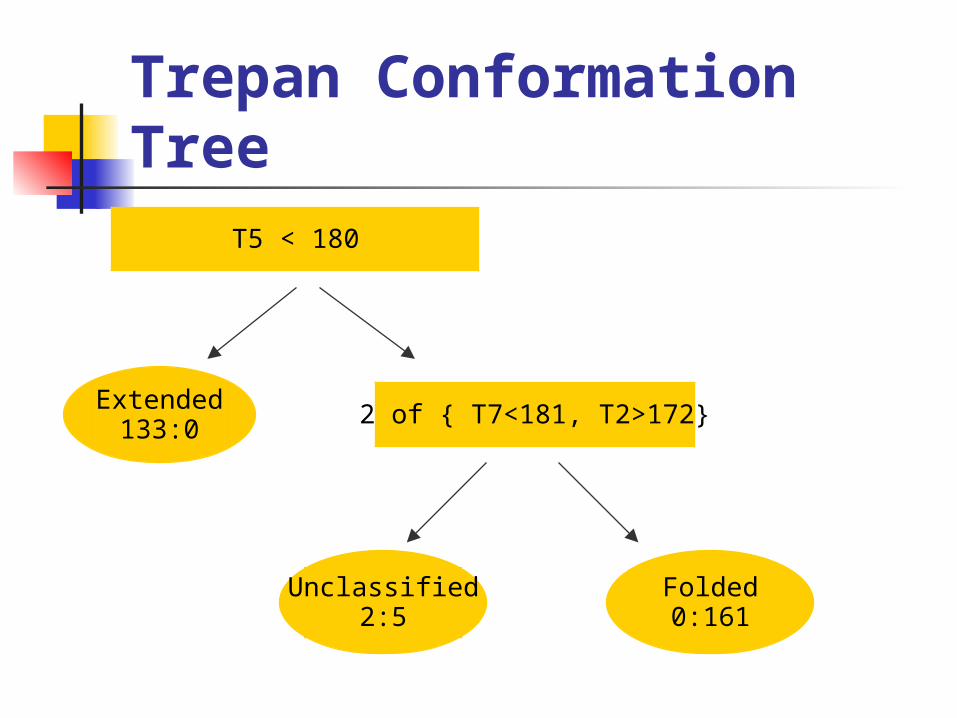
Trepan Conformation Tree
T5 < 180
Extended133:0
Unclassified2:5
2 of { T7<181, T2>172}
Folded0:161

Ferreira Dataset “typical” QSAR dataset 48 HIV-1 Protease inhibitors Activity as pIC50
Low pIC50 < 8.0 High pIC50 > 8.0
14 descriptors (mostly topological)
R. Kiralj and M.M.C. Ferreira, “A-priori Molecular Descriptors in QSAR : a case of HIV-1 protease inhibitors I. The Chemometric Approach”, J. Mol. Graph. & Modell. 21, 435-448, (2003)

Original Results PLS model Activity determined by
X9,X11,X10,X13 R2 = 0.91, Q2=0.85, Ncomps=3

C5 tree
X11 <= 2.5 [ Mode: low ]
X13 <= 16.7 [ Mode: low ] => low
X13 > 16.7 [ Mode: high ] => high
X11 > 2.5 [ Mode: high ] => high

Trepan Ferreira Tree
1 of { X13<16.1, X9<3.4 }
High1:24
X1<552
Low17:1
Low4:1
High0:1
X6<0.04

Accuracy
Dataset C5 ANN TREPANFerreira 91.8% 98.0% 91.8%Oprea 69.3% 68.6% 65.7%Conformer 99.0% 94.4% 94.4%

Conclusions Reasonable Accuracy Comprehensible Rules

Acknowledgements David Whitley. Tony Browne. Martyn Ford. BBSRC grant reference BIO/12005.
Related Documents











