JURNAL PREDIKSI KELULUSAN SISWA SMK MENGGUNAKAN ALGORITMA K-NN Romadani, Pascasarjana Magister Teknik InformatikaUdinus Vincent Suhartono ,Pascasarjana Magister Teknik Informatika Udinus Catur Suprianto, Pascasarjana Magister Teknik InformatikaUdinus PROGRAM PASCA SARJANA MAGISTER TEKNIK INFORMATIKA UNIVERSITAS DIAN NUSWANTORO SEMARANG 2013

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

JURNAL
PREDIKSI KELULUSAN SISWA SMK MENGGUNAKAN
ALGORITMA K-NN
Romadani, Pascasarjana Magister Teknik InformatikaUdinus
Vincent Suhartono ,Pascasarjana Magister Teknik Informatika Udinus
Catur Suprianto, Pascasarjana Magister Teknik InformatikaUdinus
PROGRAM PASCA SARJANA
MAGISTER TEKNIK INFORMATIKA
UNIVERSITAS DIAN NUSWANTORO
SEMARANG
2013

PREDIKSI KELULUSAN SISWA SMK MENGGUNAKAN
ALGORITMA K-NN
Romadani, Vincent Suhartono, Catur Suprianto
Pascasarjana Teknik Informatika Universitas Dian Nuswantoro
ABSTRACT
Improving the quality of education being one of the important agenda for the government . In
connection with the improvement of the quality of education , various attempts have been made to
improve the quality of teachers , equip educational facilities, improved allocation of education funds
and the implementation of sustainable educational evaluation. Evaluation of learning outcomes by the
Government aimed to assess the achievement of national competency standards , is done in the form of
National Examination . But the natinal examination unsuccessful students always have a negative
impact on students , parents , schools , the Department of Education and educational holder stage .
Therefore it is necessary for data mining students' ability to predict the value of each student before
the national examination takes place . Based on the results of prediction can be made strategic moves
in the national examination unsuccessful students . Research in terms of predicting students'
graduation and college students have a lot to do . In this research, algoroitma prediction using k - NN
is applied to the smk student graduation data is either pass or not pass . This study tested by
comparing the test dataset supporting this study with 11 variables consisting of 10 vaiabel the value of
gender, program expertise , the semester grades 1-5 , the average semester grades , school test scores
, school grades , and 1 pass labels and did not pass . As for further testing using 10 datasets consisting
of 9 vaiabel the value of gender, program expertise , the value of half 1-5 , the average semester ,
school test scores , school grades , and 1 label passed and did not pass . The k - NN classification
method in which a new object is labeled by ( k ) nearest neighbors object . From the test results to
measure the performance of the algorithm using the method of cross validation , confusion matrix and
ROC curves is known that the accuracy is based on 11 variables with k - 1 98.10 % , AUC 0.500 , k - 3
98.20 % , AUC 0.993 , k - 5 98.10 % , AUC 0.996 , k - 7 98.50 % . The value of accuracy with 10
variables with k - 1 98.00 % , AUC 0.500 , k - 3 98.10 % , AUC 0.993 , k - 5 98.10 % , AUC 0.996 , k -
7, 98.40 % , AUC 0.998 . The results of the highest value obtained 98.50 % accuracy on the k - 7 and
AUC of 0.988 with a predicate Excellent Classification.
Keywords : data mining , prediction , k – NN

1. PENDAHULUAN
a) Latar Belakang
Pendidikan merupakan proses yang menerima input berupa siswa dengan tingkat pemahaman yang
rendah, kemudian dilatih melalui beberapa tahap untuk menghasilkan individu-individu yang
berkualitas. Salah satu cara untuk menilai keberhasilan pendidikan adalah dari nilai yang bersangkutan
[1]. Keberhasilan seseorang dalam menempuh ujian dipengaruhi oleh banyak faktor. Ketika nilai ujian
digunakan untuk menentukan kelulusan, maka terjadilah dampak positif dan negative yang terus
diperdebatkan [2]. Ujian Nasional adalah kegiatan pengukuran dan penilaian kompetensi peserta didik
secara nasional pada jenjang SMA, SMK, dan MA. Sedangkan Nilai Ujian Nasional adalah nilai yang
diperoleh oleh peserta didik dalam mengikuti Ujian Nasional. Mata Pelajaran Ujian Nasional SMK
meliputi Bahasa Indonesia, Bahasa Inggris, Matematika dan Teori Kejuruan [3].
Kelulusan peserta Ujian Nasional (UN) SMA/MA/SMK Tahun Ajaran 2010/2011 sebanyak
1.461.941 peserta UN SMA/MA/SMK jumlah peserta yang lulus sebanyak 1.450.498, sedangkan
peserta yang tidak lulus 11.443 peserta [4]. Berdasarkan data evaluasi UN milik Kemdikbud, siswa
yang tidak lulus UN tahun 2011/2012 mencapai 7.579 siswa, dari 1.524.704 peserta UN. Angka
tersebut didapat dari siswa yang nilai akhir rata-ratanya tidak mencapai 5,5 sebanyak 5.300 siswa
(69,4 persen). Juga karena ada satu atau lebih mata pelajaran yang nilainya kurang dari 4 (30,06
persen) [5].
Melihat angka ketidaklulusan UN di atas perlu diadakan upaya-upaya untuk memperkecil angka
ketidaklulusan siswa dalam UN, yaitu dengan melakukan data mining kemampuan siswa. Data mining
digunakan untuk mengubah data menjadi informasi, knowledge dan windom. Data mining digunakan
untuk memprediksi kelulusan setiap siswa SMK sebelum UN berlangsung [3]. Pada penelitian
sebelumnya dalam melakukan prediksi kelulusan dengan menggunakan model algoritma c4.5
dan naïve bayes yang hanya menggunakan 7 parameter sebagai bahan penelitian prediksi
kelulusan. Pada penelitian tentang prediksi kelulusan siswa smk ini akan menggunakan
pendekatan dengan algoritma k-NN, adapun parameter yang digunakan 11 parameter. Klasifikasi algortima k-Nearest Neighbor (k-NN) adalah metode klasifikasi dimana sebuah objek
baru diberi label berdasarkan (k) objek tetangga terdekatnya [6]. k-NN termasuk algoritma supervised
learning dimana hasil dari query instance yang baru diklasifikasikan berdasarkan mayoritas dari
kategori pada k-NN. Sehingga dengan demikian diharapkan penelitian ini dengan menggunakan
algoritma k-NN meningkatkan akurasi yang jauh lebih baik dibandingkan penelitian sebelumnya
dengan menggunakan model algoritma c4.5 dan naïve bayes dengan 7 parameter.
b) Rumusan Masalah
Dari latar belakang masalah di atas, maka penulis merumuskan sebagai berikut :
1. Prediksi kelulusan tidak dapat dilakukan dengan tepat
2. Penelitian sebelumnya parameter yang digunakan hanya melibatkan 7 parameter dengan model
c4.5 dengan akurasi 85,7% dan naïve bayes dengan akurasi 80,85%
c) Tujuan
1. Penelitian ini bertujuan untuk menyediakan model yang lebih tepat untuk melakukan prediksi
kelulusan siswa SMK dengan melakukan prediksi kelulusan siswa SMK dengan algoritma k-nn
2. Penelitian ini bertujuan meningkatkan tingkat akurasi lebih dari 85,7 % dengan melibatkan lebih
dari 11 parameter dengan 10 atribut dan 1 label
d) Manfaat
d.1 Manfaat Bagi Sekolah
1. Untuk mengurangi jumlah ketidak lulusan siswa SMK
2. Membantu pengajar untuk menentukan siswa dan mata pelajaran mana yang perlu dilakukan
tindakan khusus agar siswa tersebut lulus
3. Membantu pengajar untuk menentukan metode pembelajaran terbaik agar diperoleh nilai tertinggi

d.2 Manfaat Bagi Pengetahuan
Hasil penelitian ini diharapkan dapat untuk memberikan sumbangan model prediksi dengan
pendekatan algoritma data mining untuk prediksi kelulusan siswa SMK
2. TINJAUAN PUSTAKA
2.1 Penelitian yang Relevan
Literatur yang digunakan dalam penelitian yang relevan yaitu : 1). An Artificial Neural Network for
Predicting Student Graduation Outcomes penelitian ini menjelaskan tentang prediksi kelulusan
mahasiswa tepat pada waktunya. Dalam penelitian ini membahas tentang penurunan tingkat kelulusan
mahasiswa yang sangat siginifikan dan menjadi sebuah masalah dalam perguruan tinggi. An Artificial
Neural Network (ANNs) sebagai pengklasifikasian membawa pihak kampus dalam pengembangan,
pelatihan, dan pengujian suatu jaringan syaraf tiruan untuk memprediksi hasil kelulusan mahasiswa.
Tingkat prediktibilitas rata-rata untuk set pelatihan dan uji masing-masing adalah 77 % dan 68 %.
2). Graduation Prediction of Gunadarma University Students Using Algorithm And Naïve Bayes
C4.5 Algorithm penilitian ini untuk mengetahui prediksi kelulusan mahasiswa yang sesuai dengan
waktu studi, diantaranya : NEM SMA, IP semester 1 dan IP semester 2, IPK DNU semester 1 dan 2, gaji
orang tua dan pekerjaan orang tua. Tujuan dari penelitian ini adalah mencari dan menemukan pola yang terdapat
pada data mahasiswa berdasarkan data NEM, IP DNS semester 1, IP DNS semester 2, IPK DNU semester 1-2,
gaji orang tua dan pekerjaan orang tua. metode yang dilakukan dengan mencari akurasi dari masing
masing algoritma kemudian dilakukan perbandingan antara Algoritma Naïve Bayes dan Algoritma
C4.5, dari hasil perbandingan didapat tingkat akurasi ketepatan untuk prediksi menggunakan Naïve
Bayes 80,85% dan prediksi menggunakan C4.5 85,7%.
3). Adaptive Neuro Fuzzy Inference System untuk memprediksi nilai post test mahasiswa pada
jurusan teknik informatika FTIF ITS, dimana penelitian ini dilakukan pada tahun 2012 untuk
mengetahui tingkat pemahaman mahasiswa selama satu semester berlangsung. Pada penelitian
tersebut menggunakan dataset yang berasal dari 2 mata kuliah yang berbeda dengan 4 atribut terdiri
dari nilai kuis 1, nilai kuis 2, nilai UTS, nilai kuis 3 dan 1 nilai UAS yang akan diprediksi, hasil yang
didapat dengan menggunakan iterasi/epoch yang berbeda terlihat bahwa metode ANFIS mencapai
rata-rata error sebesar 0,01 dan RMSE sebesar 0,01 untuk dataset 1. Error tersebut tercapai pada saat
epoch 200. Untuk dataset 2 model mencapai error sebesar 0,06 dan RMSE sebesar 0,07 dengan
menggunakan epoch yang sama, semakin besar jumlah iterasi/epoch maka error yang dihasilkan juga
semakin kecil.
2.2 Landasan Teori
2.2.1 Data Mining
Data mining adalah kegiatan mengesktrasi atau menambang pengetahuan dari data yang berukuran
atau berjumlah besar, informasi inilah yang nantinya sangat berguna untuk pengembangan. Dimana
langkah-langkah untuk melakukan data mining adalah sebagai berikut [7]:
Gambar 1. Data Mining
Adapun tahapan-tahapan dalam proses KDD (Knowledge Discovery in Database) adalah sebagai
berikut :
1. Data Cleaning
Data-data yang tidak relevan itu juga lebih baik dibersihkan karena keberadaannya bisa mengurangi
mutu atau akurasi dari hasil data mining merupakan istilah yang sering dipakai untuk menggambarkan

tahapan ini. Pembersihan data juga akan mempengaruhi performasi dari sistem data mining karena
data yang ditangani akan berkurang jumlah dan kompleksitasnya.
2. Data Integration
Data mining tidak hanya berasal dari suatu database tetapi juga berasal dari beberapa database atau
file teks, integrasi data dilakukan pada atribut-atribut yang mengidentifikasi entitas entitas yang unik
seperti atribut nama, jenis produk, nomor pelanggan dan sebagainya.
3. Data Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk
proses Data Mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada
jenis atau pola informasi yang akan dicari dalam basis data.
4. Data Mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan
menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat
bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses
KDD secara keseluruhan.
5. Pattern Evolution
Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi
dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang
diperoleh tidak sesuai hipotesa, ada beberapa alternative yang dapat diambil seperti menjadikannya
umpan balik untuk memperbaiki proses data mining, mencoba teknik data mining lain yang lebih
sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat. Ada
beberapa teknik data mining yang menghasilkan hasil analisa berjumlah besar seperti analisa prediksi.
Visualisasi hasil analisis akan sangat membantu untuk memudahkan pemahaman dari hasil data
mining.
6. Knowledge
Tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari
hasil analisa yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami
data mining. Karenanya presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami
semua orang adalah satu tahapan yang diperlukan dalam proses data mining.
2.2.2 Prediksi
Data Mining digunakan untuk dapat menyelesaikan masalah dalam kehidupan nyata dengan cara
membangun sebuah model khusus untuk menggambarkan dataset yang di-mined. Pada dasarnya data
mining terdiri dari :
1. Predictive, metode yang menggunakan beberapa variabel yang ada untuk memprediksi nilai masa
depan (belum diketahui) dari variabel lain. Contoh : classification, regression, biases/anomalies
detection.
2. Descriptive, metode yang mengungkapkan pola dalam data, agar mudah diinterpretasikan oleh
pengguna. Contoh : clustering, association rules, sequential patterns.
2.2.3 k-Nearest Neighbor
Klasifikasi algortima k-Nearest Neighbor (k-NN) adalah metode klasifikasi dimana sebuah objek
baru diberi label berdasarkan (k) objek tetangga terdekatnya [6]. KNN termasuk algoritma supervised
learning dimana hasil dari query instance yang baru diklasifikasikan berdasarkan mayoritas dari
kategori pada KNN, prinsip dari algoritma ini yaitu diberi dataset pelatihan (kiri) dan objek baru harus
diklasifikasikan (kanan), jaraknya mengacu pada beberapa jenis kesamaan antara objek baru dan objek
pelatihan pertama kali dihitung, dan objek terdekat atau paling mirip objek (K) kemudian dipilih.
Untuk membangun algoritma ini diperlukan beberapa inputan yaitu [6].
1. Adanya dataset pelatihan

2. Jarak untuk menghitung kesamaan antara objek
3. Nilai k, yaitu jumlah yang diperlukan objek yang dimiliki dataset pelatihan, berdasarkan
klasifikasi objek baru yang akan dicapai
Tujuan dari algoritma ini adalah mengklasifikasikan objek baru berdasarkan atribut dan training
sample. Classifier tidak menggunakan model apapun untuk dicocokan dan hanya berdasarkan pada
memori.
Jarak Euclidean paling sering digunakan menghitung jarak. Jarak Euclidean berfungsi menguji
ukuran yang bisa digunakan sebagai interpretasi kedekatan jarak antara dua objek yang
dipresentasikan sebagai berikut :
)
2)
1/2 (1)
Keterangan :
Dist (a,b) = jarak Euclidean antara vectori dan vektor
k
ij = komponen ke j dari vector
i
kj = komponen ke j dari vector
k
d = jumlah komponen vectori dan vector
k
semakin besar nilai D akan semakin jauh tingkat keserupaan antara kedua individu dan sebaliknya jika
nilai D semakin kecil maka akan semakin dekat tingkat keserupaan antar individu tersebut.
Nilai k yang terbaik untuk algoritma ini tergantung pada data. Secara umum, nilai k yang tinggi
akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi
semakin kabur. Nilai k yang bagus dapat dipilih dengan optimasi parameter, misalnya dengan
menggunakan cross validation. Kasus khusus dimana klasifikasi diprediksikan berdasarkan training
data yang paling dekat. Langkah-langkah untuk menghitung metode K-Nearest Neighbor :
1. Menentukan parameter K (jumlah tetangga paling dekat)
2. Menghitung kuadrat jarak Euclid (query instance) masing-masing objek terhadap data sampel yang
diberikan
3. Kemudian mengurutkan objek-objek tersebut kedalam kelompok yang mempunyai jarak Euclid
terkecil
4. Mengumpulkan kategori klasifikasi nearest neighbor
5. Dengan menggunakan kategori nearest neighbor yang paling mayoritas maka diprediksikan nilai
query instance yang telah dihitung.
2.2.4 Pengujian K-Fold Cross Validation
K-Fold Cross Validation adalah teknik validasi yang membagi data ke dalam data k bagian dan
kemudian masing masing bagian akan dilakukan proses klasifikasi. Dengan menggunakan K-Fold
Cross Validation akan dilakukan percobaan sebanyak k. tiap percobaan akan menggunakan satu data
testing dan k-1 bagian akan menjadi data training, kemudia data testing itu akan ditukar dengan satu
buah data training sehingga untuk tiap percobaan akan didapatkan data testing yang berbeda beda.
Data training adalah data yang akan dipakai dalam melakukan pembelajaran sedangkan data testing
adalah data yang belum pernah dipakai sebagai pembelajaran dan akan berfungsi sebagai data
pengujian kebenaran atau keakurasian hasil pembelajaran [8].
2.2.5 Evaluasi dan Validasi Metode
1. Confusion Matrix
Confusion Matrix adalah alat (tools) visualisasi yang biasa digunakan pada supervised learning. Tiap
kolom pada matriks adalah contoh kelas prediksi, sedangkan tiap baris mewakili kejadian di kelas
yang sebenarnya [9]. Confusion matrix berisi informasi actual dan prediksi (predicted) pada sistem
klasifikasi. Tabel.. adalah contoh tabel confusion matrix yang menunjukkan klasifikasi dua kelas

Table 1 Confusion Matrix
KLASIFIKASI
YANG BENAR
DIPREDIKSI
+ -
AC
TU
AL
+ (TP) (FN)
- (FP) (TN)
Accuracy : TP + TN
(TP +TN+FP+FN) (2)
Keterangan :
TP = jumlah prediksi yang tepat bahwa instance bersifat negative
FP = jumlah prediksi yang salah bahwa instance bersifat positif
FN = jumlah prediksi yang salah bahwa instance bersifat negative
TN = jumlah prediksi yang tepat bahwa instance bersifat positif
2. Kurva ROC
Kurva ROC menunjukkan akurasi dan membandingkan klasifikasi secara visual. ROC
mengekspresikan confusion matrix. ROC adalah grafik dua dimensi dengan false positives sebagai
garis horizontal dan true positives untuk mengukur perbedaan performasi metode yang digunakan.
ROC Curve adalah cara lain untuk menguji kinerja pengklasifikasian [9]. Sebuah grafik ROC adalah
plot dengan tingkat positif salah (FP) pada sumbu X dan tingkat positif benar (TP) pada sumbu Y.
Titik (0,1) adalah klasifikasi sempurna yang mengklasifikasikan semua kasus positif dan kasus
negative dengan benar, karena tingkat positif salah (FP) adalah 0 (tidak ada), dan tingkat benar (TP)
adalah 1. Titik (0,0) merupakan sebuah klasifikasi yang memprediksi setiap kasus menjadi negative,
sedangkan titik (1,1) sesuai dengan sebuah klasifikasi yang memprediksi setiap kasus menjadi positif.
Titik (1,0) adalah klasifikasi yang tidak benar untuk semua klasifikasi. Dalam banyak kasus,
klasifikasi memiliki parameter yang dapat disesuaikan untuk meningkatkan TP atau penurunan FP.
Setiap pengaturan parameter menyediakan pasangan FP dan TP dan serangkaian pasangan tersebut
dapat digunakan untuk memetakan kurva ROC. Klasifikasi non-parametrik diwakili oleh titik ROC
tunggal, sesuai dengan pasangannya. Performance keakurasian AUC [9] dapat diklasifikasikan
menjadi lima kelompok yaitu :
a. 0.90 – 1.00 = Exellent Clasification
b. 0.80 – 0.90 = Good Clasification
c. 0.70 – 0.80 = Fair Clasification
d. 0.60 – 0.70 = Poor Clasification
e. 0.50 – 0.60 = Failure
2.2.5 Prediksi Kelulusan Siswa SMK Menggunakan k-NN
Dalam menyelesaikan penelitian tentang prediksi kelulusan siswa smk, model yang digunakan
menggunakan k-nn dengan 11 parameter yaitu 10 atribut dan 1 label yang terdiri dari program
keahlian, jenis kelamin, nilai semester-1, semester-2, semester-3, semester-4, semester5, ujian sekolah,
nilai sekolah, dan label Lulus dan Tidak Lulus. Kemampuan algoritma data mining klasifikasi seperti
algortima k-nn. Penelitian ini terdiri dari beberapa tahap seperti terlihat pada kerangka pemikiran.
Permasalahan pada penelitian ini adalah rendahnya tingkat kelulusan siswa SMK.
Untuk itu metode yang digunakan dalam penelitian ini yaitu dengan menggunakan algoritma data
mining yaitu k-NN dalam memecahkan masalah. Pengujian metode dilakukan dengan cara confusion
matrix dan kurva ROC. Untuk menguji metode yang diuji menggunakan tools RapidMiner.

2.3 Kerangka Pemikiran
Gambar 2 Kerangka Pemikiran
3. METODE PENELITIAN
Penelitian adalah mencari melalui proses yang metodis untuk menambahkan pengetahuan itu
sendiri dan dengan yang lainnya, oleh penemuan fakta dan wawasan tidak biasa. Pengertian lainnya,
penelitian adalah sebuah kegiatan yang bertujuan untuk membuat kontribusi orisinal terhadap ilmu
pengetahuan [10]. Dalam konteks sebuah penelitian, pendekatan metode yang digunakan untuk
memecahkan masalah, diantaranya : mengumpulkan data, merumuskan hipotesis atau proposisi,
menguji hipotesis, hasil penafsiran, dan kesimpulan yang dievaluasi secara independen oleh orang lain
[11]. Sementara terdapat empat penelitian yang umum digunakan, diantaranya : Action Research,
Experiment, Case Study, dan Survey. Penelitian ini adalah penelitian eksperimen dengan metode
penelitian sebagai berikut [10]:
MASALAH
Rendahnya tingkat kelulusan siswa SMK
ANALISIS
Prediksi Kelulusan Siswa SMK
EKSPERIMEN
Pengumpulan dan Pengolahan Data Nilai Siswa SMK
PENGUJIAN METODE
Algoritma k-NN
PENGUKURAN
Confusion matrix, kurva ROC
HASIL
Meningkatnya Tingkat Akurasi Dalam Melakukan
Prediksi Kelulusan Siswa SMK

Gambar 3 Tahapan Penelitian
Berikut penjabaran singkat mengenai tahapan penelitian pada gambar 3 :
1. Pengumpulan data
Teknik pengumpulan data ialah teknik atau cara-cara yang dapat digunakan untuk menggunakan data
2. Pengolahan data awal
Data yang telah dikumpulkan maka dilakukan penyelesaian terhadap data tersebut sehingga diperoleh
data yang valid dan berkwalitas. Teknik-teknik yang dilakukan adalah data validation, data
intergration and transformation data size reduction and dicrization.
3. Model Prediksi
Tahapan selanjutnya adalah menentukan metode yang akan digunakan untuk mengolah data yang telah
melalui tahapan pengolahan awal data (preparation data). Model prediksi dengan menggunakan
algoritma klasifikasi
4. Eksperimen dan Pengujian
Pada tahap ini dilakukan percobaan menggunakan metode yang diusulkan dan data yang telah ada.
Pengujian hasil eksperimen dilakukan dengan teknik k-fold cross validation
5. Evaluasi dan Validasi model
Pada tahapan ini dilakukan evaluasi terhadap tingkat akurasi dari metode untuk melihat kinerja
terhadap metode yang digunakan. Teknik yang digunakan adalah menggunakan confusion matrix dan
kurva ROC
3.1 Pengumpulan data
Pada bagian ini dijelaskan tentang bagaimana dan darimana data dalam penelitian ini didapatkan,
ada dua tipe dalam pengumpulan data, yaitu pengumpulan data primer dan pengumpulan data
sekunder. Data primer adalah data yang dikumpulkan pertama untuk melihat apa yang sesungguhnya
terjadi. Data sekunder adalah data yang sebelumnya pernah dibuat oleh seseorang baik di terbitkan
atau tidak (Kothari, 2004). Data yang diperoleh adalah data sekunder karena diperoleh dari database
siswa SMK yang dimiliki oleh SMK yang berada di Kota Cirebon, yaitu melalui Dinas Pendidikan
Kota Cirebon. Data yang diperoleh dalam penelitian ini adalah data kualitatif dan kuantitatif. Data
yang dikumpulkan adalah data siswa SMK kelas XII untuk tahun kelulusan periode tahun ajaran
2012/2013.
3.2 Pengolahan Data Awal
Jumlah data awal yang diperoleh dari pengumpulan data yaitu sebanyak 1200 data, namun tidak
semua atribut digunakan karena harus melalui beberapa tahap pengolahan data awal (preparation
Pengumpulan Data
Pengolahan Data Awal
Model Prediksi
Eksperimen dan Pengujian Metode
Evaluasi dan Validasi Hasil

data). Untuk mendapatkan data yang berkualitas, beberapa teknik yang dilakukan adalah sebagai
berikut [12] :
1. Data validation, untuk mengidentifikasi dan menghapus data yang ganjil (outlier/noise), data yang
tidak konsisten, dan data yang tidak lengkap (missing value).
2. Data intergration and Transformation, untuk meningkatkan akurasi dan efisiensi algoritma. Data
yang digunakan dalam penulisan ini bernilai kategorikal. Data ditransformasikan ke dalam tool
rapidminer
3. Data size reduction and dicrization, untuk memperoleh data set dengan jumlah atribut dan record
yang lebih sedikit tetapi bersifat informatif.
3.3 Model Prediksi
Pada tahap ini data dianalisa, dikelompokkan variabel mana yang berhubungan dengan satu sama
lainnya. Setelah data dianalisa lalu diterapkan model model yang sesuai dengan jenis data. Pembagian
data kedalam data latihan (training data) dan data uji (testing data) juga diperlukan untuk pembuatan
model. Model yang diusulkan pada penelitian ini berdasarkan state of the art tentang prediksi
kelulusan siswa SMK dengan mengkomparasikan algoritma data mining, Pada penelitian sebelumnya
dalam melakukan prediksi kelulusan menggunakan 7 parameter dengan tingkat akurasi tertinggi
dicapai 85,7 %, dan masih bisa ditingkatkan dengan menambahkan 4 parameter menjadi 11 parameter
dengan harapan dapat meningkatkan prosentase akurasi prediksi yang didapat.
3.4 Eksperimen dan Pengujian Model / Metode
Dalam penelitian ini akan dilakukan prediksi menggunakan metode klasifikasi data mining. Metode
yang diusulkan untuk pengolahan data siswa adalah penggunaan algoritma klasifikasi k-NN. Data
diolah sesuai dengan algoritma yakni data siswa diolah menggunakan metode algoritma k-NN, setelah
diolah dan menghasilkan model, maka terhadap model yang dihasilkan tersebut dilakukan pengujian
menggunakan k-fold cross validation, kemudian dilakukan evaluasi dan validasi hasil dengan
confusion matrix dan kurva ROC. Berikut gambaran karakteristik dari dari algoritma metode K-
Nearest Neighbor (K-NN) yaitu metode untuk melakukan klasifikasi terhadap objek berdasarkan data
pembelajaran yang jaraknya paling dekat dengan objek tersebut.
4. HASIL PENELITIAN DAN PEMBAHASAN
4.1 Hasil Analisis
Teknik pengumpulan data ialah teknik atau cara-cara yang dapat digunakan untuk menggunakan
data [13]. Dalam pengumpulan data terdapat sumber data, sumber data yang dihimpun langsung oleh
peneliti disebut dengan sumber primer, sedangkan apabila tangan kedua disebut sumber sekunder [13].
Data yang diperoleh adalah data sekunder karena diperoleh dari database siswa yang dimiliki oleh
Dinas Pendidikan Kota Cirebon, yaitu melalui bidang dikmen seksi kurikulum pusat komputer yang
dimiliki oleh dinas tersebut. Data yang diperoleh dalam penelitian ini adalah data kualitatif dan
kuantitatif. Data yang dikumpulkan adalah data siswa sekolah menengah dengan tingkat SMK untuk
tahun kelulusan tahun 2013. Data terkumpul sebanyak 1200 data, dengan atribut, program keahlian,
jenis kelamin, nilai semester 1, semester 2, semester 3, semester 4, semester 5, rata rata semesteran,
ujian sekolah, nilai sekolah, dengan label lulus dan tidak lulus. Sampel data yang diperoleh untuk
penelitian yang sudah melalui beberapa tahapan transformasi dan cleaning dapat dilihat pada Tabel 2.
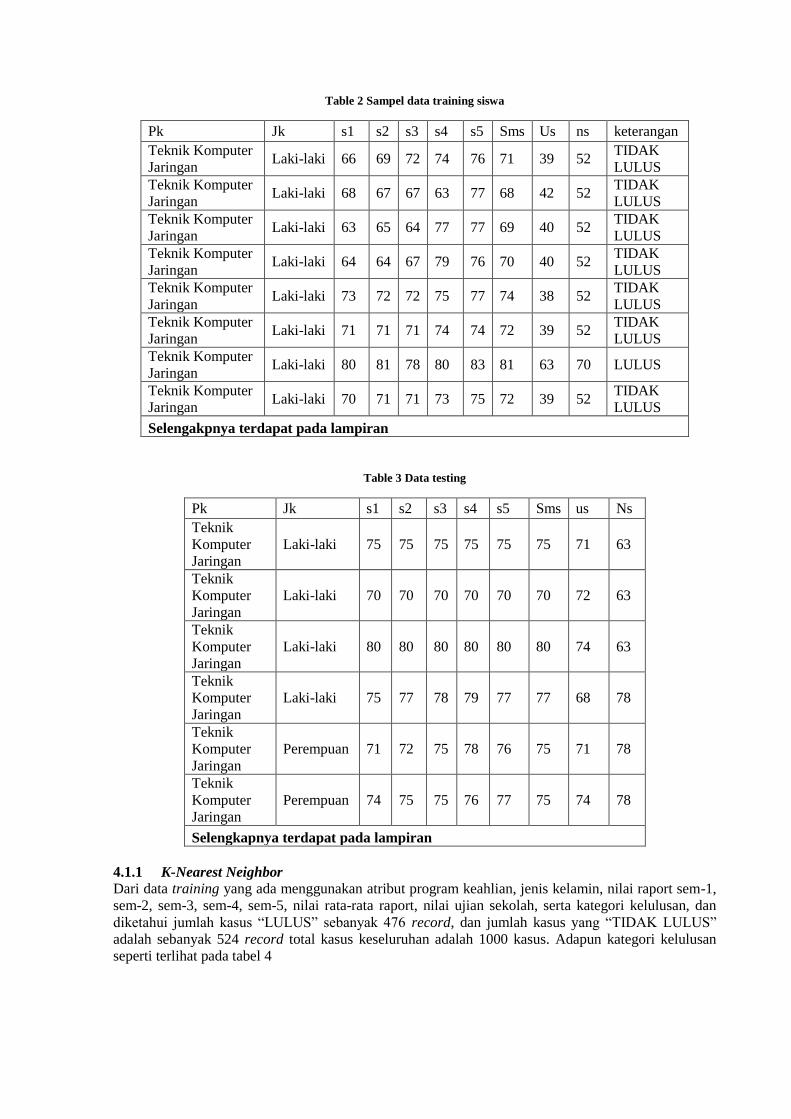
Table 2 Sampel data training siswa
Pk Jk s1 s2 s3 s4 s5 Sms Us ns keterangan
Teknik Komputer
Jaringan Laki-laki 66 69 72 74 76 71 39 52
TIDAK
LULUS Teknik Komputer
Jaringan Laki-laki 68 67 67 63 77 68 42 52
TIDAK
LULUS Teknik Komputer
Jaringan Laki-laki 63 65 64 77 77 69 40 52
TIDAK
LULUS Teknik Komputer
Jaringan Laki-laki 64 64 67 79 76 70 40 52
TIDAK
LULUS Teknik Komputer
Jaringan Laki-laki 73 72 72 75 77 74 38 52
TIDAK
LULUS Teknik Komputer
Jaringan Laki-laki 71 71 71 74 74 72 39 52
TIDAK
LULUS Teknik Komputer
Jaringan Laki-laki 80 81 78 80 83 81 63 70 LULUS
Teknik Komputer
Jaringan Laki-laki 70 71 71 73 75 72 39 52
TIDAK
LULUS
Selengakpnya terdapat pada lampiran
Table 3 Data testing
Pk Jk s1 s2 s3 s4 s5 Sms us Ns
Teknik
Komputer
Jaringan Laki-laki 75 75 75 75 75 75 71 63
Teknik
Komputer
Jaringan Laki-laki 70 70 70 70 70 70 72 63
Teknik
Komputer
Jaringan Laki-laki 80 80 80 80 80 80 74 63
Teknik
Komputer
Jaringan Laki-laki 75 77 78 79 77 77 68 78
Teknik
Komputer
Jaringan Perempuan 71 72 75 78 76 75 71 78
Teknik
Komputer
Jaringan Perempuan 74 75 75 76 77 75 74 78
Selengkapnya terdapat pada lampiran
4.1.1 K-Nearest Neighbor
Dari data training yang ada menggunakan atribut program keahlian, jenis kelamin, nilai raport sem-1,
sem-2, sem-3, sem-4, sem-5, nilai rata-rata raport, nilai ujian sekolah, serta kategori kelulusan, dan
diketahui jumlah kasus “LULUS” sebanyak 476 record, dan jumlah kasus yang “TIDAK LULUS”
adalah sebanyak 524 record total kasus keseluruhan adalah 1000 kasus. Adapun kategori kelulusan
seperti terlihat pada tabel 4

Table 4 Kategori kelulusan berdasarkan nilai sekolah
Prediksi Kategori
<= 69 Tidak Lulus
> 69 Lulus
Data training pada Tabel 5 adalah untuk menentukan apakah siswa dapat dinyatakan lulus atau tidak.
Berikut akan dibahas langkah-langkah perhitungan prediksi kelulusan siswa SMK dengan
menggunakan algoritma K-Nearest Neighbor.
Table 5 Data training nilai siswa SMK
N s1 s2 s3 s4 s5 Us
Y=Klasifikasi X11=1 X12=2 X13=3 X14=4 X15=5 X16=6
1 66 69 72 74 76 39
TIDAK
LULUS
2 68 67 67 63 77 42
TIDAK
LULUS
3 63 65 64 77 77 40
TIDAK
LULUS
4 64 64 67 79 76 40
TIDAK
LULUS
5 73 72 72 75 77 38
TIDAK
LULUS
6 71 71 71 74 74 39
TIDAK
LULUS
7 80 81 78 80 83 63
TIDAK
LULUS
Keterangan :
X11 – X16 = merupakan atribut semester 1-6 pada data training
n = merupakan banyaknya data
Data training ini merupakan data nilai yang akan menentukan “LULUS atau “TIDAK LULUS”
berdasarkan nilai kurang atau tepat 69 (tidak lulus) dan lebih dari 69 (lulus).
Table 6 Data testing
N s1 s2 s3 s4 s5
Us Y=Klasifikasi
X21=1 X22=2 X23=3 X24=4 X25=5 X26=6
1 71 71 71 74 74 62 ?
2 75 78 54 68 68 67 ?
3 66 61 66 66 77 72 ?
4 75 75 75 75 75 69 ?
5 70 70 70 70 70 70 ?
6 75 75 75 75 75 71 ?
7 70 70 70 70 70 72 ?
Keterangan :
X21-X26 = merupakan atribut semester 1-6 pada testing data
n = merupakan banyaknya data

Data testing ini merupakan data nilai yang akan diklasifikasikan denga data training untuk
menentukan “LULUS atau “TIDAK LULUS” berdasarkan nilai kurang atau tepat 69 (tidak lulus) dan
lebih dari 69 (lulus). Setelah ada data testing dan data training, lalu menentukan nilai k-nya, contoh
untuk kasus di atas nilai k yang digunakan adalah k = 5
Adapun langkah-langkah menjawab permasalahan di atas, yaitu :
1. Nilai k yang digunakan adalah 5
2. Menghitung kuadrat jarak Euclid (query instance) masing-masing objek terhadap sampel data
yang diberikan dengan menggunakan rumus :
)
2)
1/2 (9)
n =1
Query Instance
= ((X11- X21)2 + (X12- X22)
2 + (X13- X23)
2 + (X14- X24)
2 + (X15- X25)
2 + (X16- X26)
2)
1/2
= ((66-71)2 + (69-71)
2 + (72-71)
2 + (74-74)
2 + (76-74)
2 + (39-62)
2)
1/2
= ((25) + (4) + (1) + (0) + (4) + (529))1/2
= (563)
1/2 = 23,73
n = 2
Query Instance
= ((X11- X21)2 + (X12- X22)
2 + (X13- X23)
2 + (X14- X24)
2 + (X15- X25)
2 + (X16- X26)
2)
1/2
= ((68-75)2 + (67-78)
2 + (67-54)
2 + (63-68)
2 + (77-68)
2 + (42-67)
2)
1/2
= ((49) + (121) + (169) + (25) + (81) + (625))1/2
= (1070)
1/2 = 32,71
n = 3
Query Instance
= ((X11- X21)2 + (X12- X22)
2 + (X13- X23)
2 + (X14- X24)
2 + (X15- X25)
2 + (X16- X26)
2)
1/2
= ((63-66)2 + (65-61)
2 + (64-66)
2 + (77-66)
2 + (77-77)
2 + (40-72)
2)
1/2
= ((9) + (16) + (4) + (121) + (0) + (1024))1/2
= (1065)
1/2 = 32,63
n = 4
Query Instance
= ((X11- X21)2 + (X12- X22)
2 + (X13- X23)
2 + (X14- X24)
2 + (X15- X25)
2 + (X16- X26)
2)
1/2
= ((64-75)2 + (64-75)
2 + (67-75)
2 + (79-75)
2 + (76-75)
2 + (40-69)
2)
1/2
= ((121) + (121) + (64) + (121) + (16) + (841))1/2
= (1284)
1/2 = 35,83
n = 5
Query Instance
= ((X11- X21)2 + (X12- X22)
2 + (X13- X23)
2 + (X14- X24)
2 + (X15- X25)
2 + (X16- X26)
2)
1/2
= ((73-70)2 + (72-70)
2 + (72-70)
2 + (75-70)
2 + (77-70)
2 + (38-70)
2)
1/2
= ((9) + (4) + (4) + (5) + (49) + (1024))1/2
= (1105)
1/2 = 33,24
n = 6
Query Instance
= ((X11- X21)2 + (X12- X22)
2 + (X13- X23)
2 + (X14- X24)
2 + (X15- X25)
2 + (X16- X26)
2)
1/2
= ((71-75)2 + (71-75)
2 + (71-75)
2 + (74-75)
2 + (74-75)
2 + (39-71)
2)
1/2
= ((16) + (16) + (16) + (1) + (1) + (1024))1/2
= (1074)
1/2 = 32,77
n = 7
Query Instance
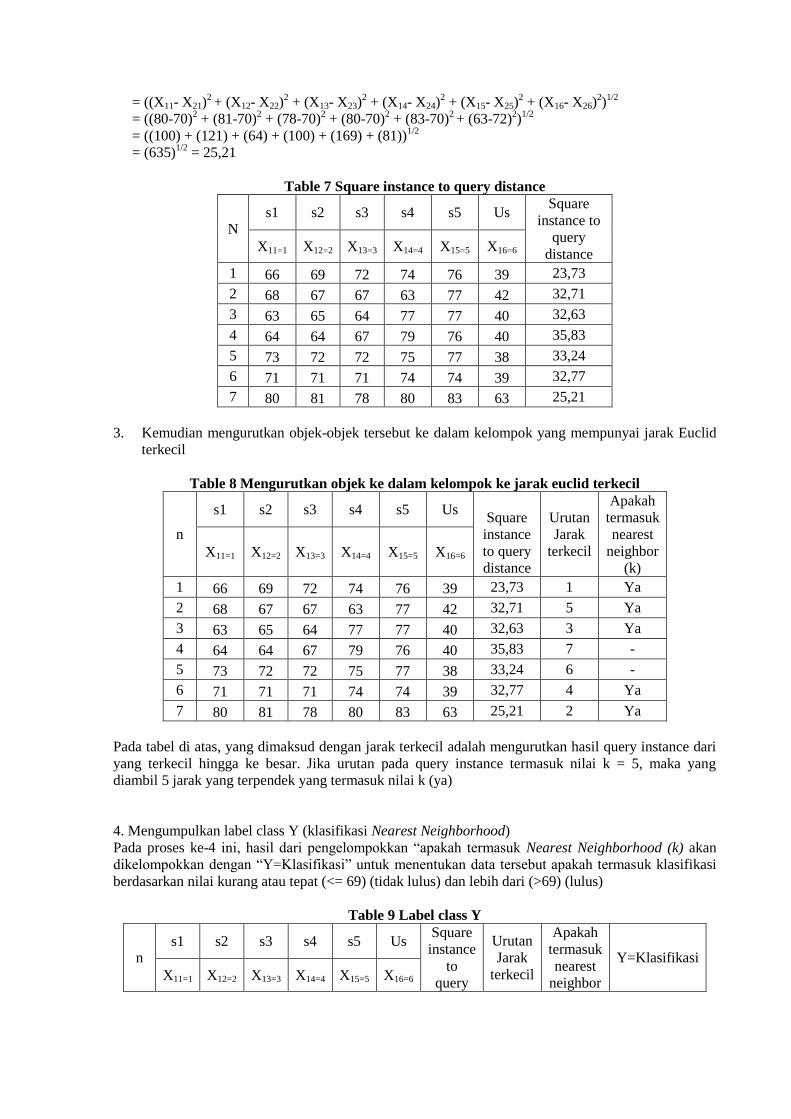
= ((X11- X21)2 + (X12- X22)
2 + (X13- X23)
2 + (X14- X24)
2 + (X15- X25)
2 + (X16- X26)
2)
1/2
= ((80-70)2 + (81-70)
2 + (78-70)
2 + (80-70)
2 + (83-70)
2 + (63-72)
2)
1/2
= ((100) + (121) + (64) + (100) + (169) + (81))1/2
= (635)
1/2 = 25,21
Table 7 Square instance to query distance
N s1 s2 s3 s4 s5 Us
Square
instance to
query
distance X11=1 X12=2 X13=3 X14=4 X15=5 X16=6
1 66 69 72 74 76 39 23,73
2 68 67 67 63 77 42 32,71
3 63 65 64 77 77 40 32,63
4 64 64 67 79 76 40 35,83
5 73 72 72 75 77 38 33,24
6 71 71 71 74 74 39 32,77
7 80 81 78 80 83 63 25,21
3. Kemudian mengurutkan objek-objek tersebut ke dalam kelompok yang mempunyai jarak Euclid
terkecil
Table 8 Mengurutkan objek ke dalam kelompok ke jarak euclid terkecil
n
s1 s2 s3 s4 s5 Us Square
instance
to query
distance
Urutan
Jarak
terkecil
Apakah
termasuk
nearest
neighbor
(k) X11=1 X12=2 X13=3 X14=4 X15=5 X16=6
1 66 69 72 74 76 39 23,73 1 Ya
2 68 67 67 63 77 42 32,71 5 Ya
3 63 65 64 77 77 40 32,63 3 Ya
4 64 64 67 79 76 40 35,83 7 -
5 73 72 72 75 77 38 33,24 6 -
6 71 71 71 74 74 39 32,77 4 Ya
7 80 81 78 80 83 63 25,21 2 Ya
Pada tabel di atas, yang dimaksud dengan jarak terkecil adalah mengurutkan hasil query instance dari
yang terkecil hingga ke besar. Jika urutan pada query instance termasuk nilai k = 5, maka yang
diambil 5 jarak yang terpendek yang termasuk nilai k (ya)
4. Mengumpulkan label class Y (klasifikasi Nearest Neighborhood)
Pada proses ke-4 ini, hasil dari pengelompokkan “apakah termasuk Nearest Neighborhood (k) akan
dikelompokkan dengan “Y=Klasifikasi” untuk menentukan data tersebut apakah termasuk klasifikasi
berdasarkan nilai kurang atau tepat (<= 69) (tidak lulus) dan lebih dari (>69) (lulus)
Table 9 Label class Y
n s1 s2 s3 s4 s5 Us
Square
instance
to
query
Urutan
Jarak
terkecil
Apakah
termasuk
nearest
neighbor
Y=Klasifikasi X11=1 X12=2 X13=3 X14=4 X15=5 X16=6

distance (k)
1 66 69 72 74 76 39 23,73 1 Ya Tidak Lulus
2 68 67 67 63 77 42 32,71 5 Ya Tidak Lulus
3 63 65 64 77 77 40 32,63 3 Ya Tidak Lulus
4 64 64 67 79 76 40 35,83 7 - Tidak Lulus
5 73 72 72 75 77 38 33,24 6 - Tidak Lulus
6 71 71 71 74 74 39 32,77 4 Ya Tidak Lulus
7 80 81 78 80 83 63 25,21 2 Ya Tidak Lulus
Dengan menggunakan kategori Nearest Neighborhod yang paling mayoritas maka dapat diprediksikan
nilai query instance yang telah dihitung. Pada urutan jarak yang terdekat dari dari satu sampai lima
(nilai k=5), maka diketahui ada 7 yang tidak lulus <=69 dan 0 yang lulus >69 pada tabel 9
Setelah diolah maka dilakukan teknik pengujian dengan metode k-fold cross validation pada tools
RapidMiner, pengolahan pengujian untuk metode algoritma k-NN terlihat seperti gambar 4 dibawah
ini :
5. KESIMPULAN DAN SARAN
5.1 Kesimpulan
Dari penelitian yang telah dilakukan pembuatan menggunakan algoritma k-Nearest Neighbor (K-
NN), menggunakan data kelulusan siswa SMK untuk prediksi kelulusan siswa SMK. Metode dengan
algoritma k-nn dapat melakukan prediksi kelulusan siswa SMK serta mampu meningkatkan nilai
akurasi. Untuk mengukur kinerja model digunakan confusion matrix dan kurva ROC, dan diketahui
bahwa metode algoritma k-Nearest Neighbor menghasilkan nilai akurasi tertinggi dengan diperoleh
dengan nilai jarak (k-7) serta menggunakan 11 variabel yaitu 98,50% dan nilai AUC 0,998. Dengan
demikian berdasarkan pengujian metode prediksi yaitu dengan menggunakan model k-NN, jenis
kelamin sebagai salah satu variabel juga memberikan sumbangsih dalam peningkatan nilai akurasi.
5.2 Saran
Untuk keperluan penelitian lebih lanjut mengenai prediksi dengan menggunakan algoritma k-nn
dengan metode klasifikasi dengan menggunakan data kelulusan siswa SMK ini maka disarankan untuk
melakukan penyeleksian atribut dan diperlukan validasi dataset yang benar sehingga dapat
menghasilkan tingkat akurasi dan nilai AUC yang seimbang terhadap metode yang digunakan.
6. PENUTUP
Tesis dengan judul “PREDIKSI KELULUSAN SISWA SMK MENGGUNAKAN ALGORITMA K-
NN” ini dapat penulis selesaikan sesuai rencana karena dukungan dari berbagai pihak yang tidak
ternilai besarnya. Oleh karena itu penulis menyampaikan ucapan terima kasih kepada :
1. Allah SWT yang telah memberikan nikmat dan sehat, sehingga penulis dapat terus melakukan
kajian terhadap Tesis ini
2. Istriku Dian Rosmalinda, anak-anakku A’Rafi Laksmana Dirgantara dan A’Liya Safira
Ramanda atas doa dan dukungannya
3. Kedua orangtua dan Mertua penulis yang selalu mendoakan demi suksesnya studi penulis
4. Bapak Dr.Ir.Edi Noersasongko, M.Kom selaku Rektor Universitas Dian Nuswantoro
5. Bapak Dr.Abdul Syukur, MM selaku Direktur MTI Universitas Dian Nuswantoro
6. Bapak Dr.Ing Vincent Suhartono dan Bapak Catur Supriyanto. M.C.S selaku dosen dan
pembimbing Tesis yang telah memberikan pengetahuan dan bimbingannya dalam penyusunan
Tesis ini
7. Bapak Dadang Sudrajat, M.Kom selaku Ketua STMIK IKMI Kota Cirebon yang memberikan
rekomendasi penulis untuk melanjutkan studi

8. Pimpinan di lingkungan perguruan Al-Irsyad Al-Islamiyyah Kota Cirebon yang telah
memberikan kesempatan bagi penulis untuk melanjutkan studi
9. Ibu Surayah Arfan yang telah membantu memvalidkan dataset nilai siswa
Semua pihak yang telah membantu penulis dan tidak dapat disebutkan satu persatu. Penulis menyadari
adanya keterbatasan penelitian ini, maka kritik, saran, dan masukan yang membangun akan sangat
membantu penulis dalam penelitian selanjutnya. Semoga tulisan ini dapat bermanfaat bagi ilmu
pengetahun dan pembaca.
Semarang, Mei 2013
Penulis
PERNYATAAN ORIGINALITAS
“Saya menyatakan dan bertanggung jawab dengan sebenarnya bahwa Artikel ini adalah hasil karya
saya sendiri kecuali cuplikan dan ringkasan yang masing-masing telah saya jelaskan sumbernya”.
Romadani - P.31.2011.01002
DAFTAR PUSTAKA
[1] B. T. Kuncahyo, R. V. H. Ginardi, I. Arieshanti, T. Informatika, and F. T. Informasi,
“Penerapan Metode Adaptive Neuro-Fuzzy Inference System Untuk Memprediksi Nilai Post
Test Mahasiswa Pada Jurusan Teknik Informatika,” pp. 1–9, 2012.
[2] P. Lptk, D. Pengembangan, and P. Vokasi, “Model Ujian Untuk Menentuka Kelulusan Bagi
Siswa SMK,” pp. 1307–1312, 2007.
[3] T. Elektro, “Data Mining Kemampuan Siswa,” pp. 1–6, 2011.
[4] “kelulusan UN tahun 2011.” [Online]. Available:
http://www.antaranews.com/berita/258487/kelulusan-un-sma-2011-capai-9922-persen.
[5] “Prosentase Kelulusan UN 2012 Meningkat-www.” [Online]. Available:
http://edukasi.kompas.com/read/2012/05/24/2112220/Prosentase.Kelulusan.UN.2012.Meningk
at.
[6] M. K. Jiawei Han, Data Mining Concepts and Techiques, Second. Diane Cerra, 2007, pp. 1–
772.
[7] A. Fadli, “Konsep Data Mining,” pp. 1–9, 2011.
[8] M. A. H. Ian H.Witten, Eibe Frank, Data Mining Practical Machine Learning Tools and
Techniques, Third. 2011, pp. 1–665.
[9] F. Gorunescu, Data Mining Concepts, Models and Techniques. 2011, pp. 1–370.
[10] C. W. Dawson, Projects in Computing and Information Systems, Second. England, 2009.
[11] M. Berndtsson, A Guide for Students in Computer Sciences and Information Systems, Second
Edi. Sweden: Springer Science+Business Media, 2007, pp. 1–162.
[12] C. Vercellis, Business Intelligence : Data Mining and Optimazation for Decision Making.
2009, pp. 1–420.
[13] M. Riduwan, Drs. M.B.A dan DR. Engkos Achmad Kuncoro, SE, Cara Menggunakan dan
Memaknai Analisis Jalur (Path Analysis). Bandung, 2008.
Related Documents











