Reyyan Yeniterzi Weakly-Supervised Discovery of Named Entities Using Web Search Queries Marius Pasca Google CIKM 2007

Reyyan Yeniterzi Weakly-Supervised Discovery of Named Entities Using Web Search Queries Marius Pasca Google CIKM 2007.
Dec 29, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Reyyan Yeniterzi
Weakly-Supervised Discovery of Named Entities
Using Web Search Queries
Marius Pasca Google
CIKM 2007

Motivation
Name entities essential during the construction of
knowledge bases from Web helpful in various NLP tasks; like parsing,
coreference resolution … constitute a significant part of the Web
search queries helpful in building verticals in Web search

Previous works
Mining query logs to improve various IR tasks
re-ranking of retrieved documents query expansion spelling correction
Large-scale IE mainly on document collections ignoring the collective knowledge embedded
in noisy search queries This is the first work that applies name
entity finding to Web search query logs

Extraction from Query Logs
Given A set of target classes A set of seed instances
The goal To extract relevant class instances from
query logs Without using
Any domain knowledge Any handcrafted extraction pattern

Overview of the System
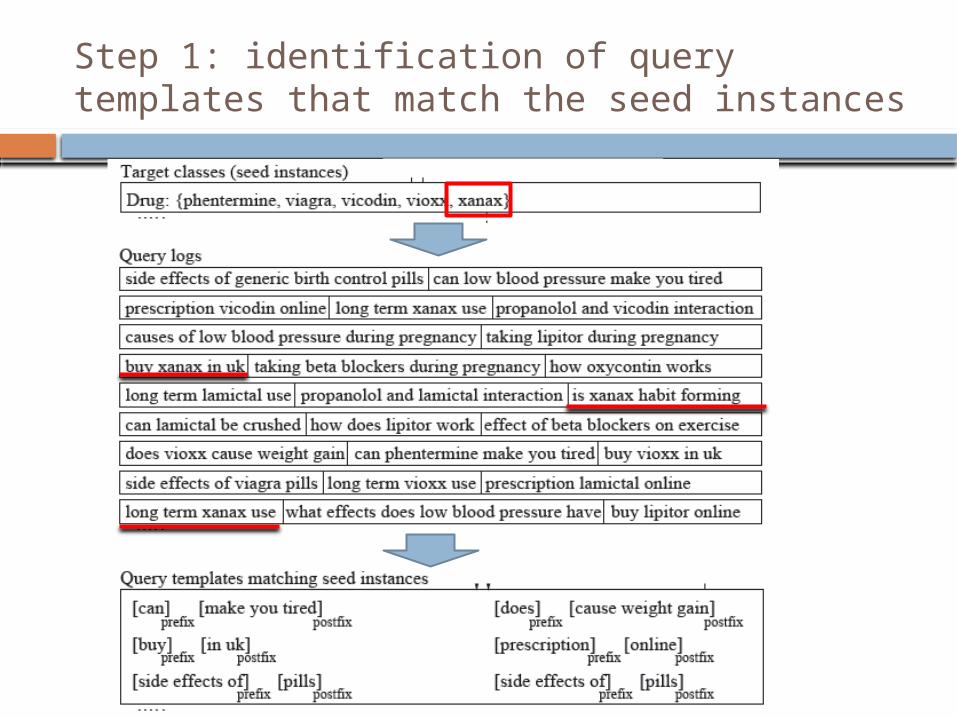
Step 1: identification of query templates that match the seed instances
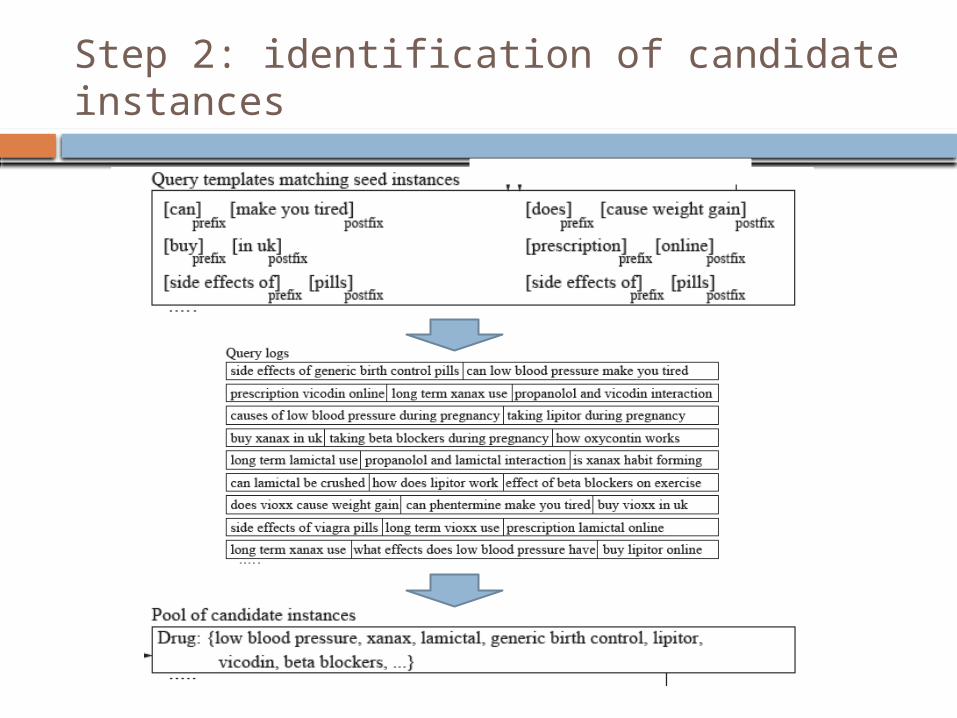
Step 2: identification of candidate instances

Step 3: internal representation of candidate instances
query: prefix candidate_instance postfix entry: prefix postfix
weight of an entry = frequency of the query
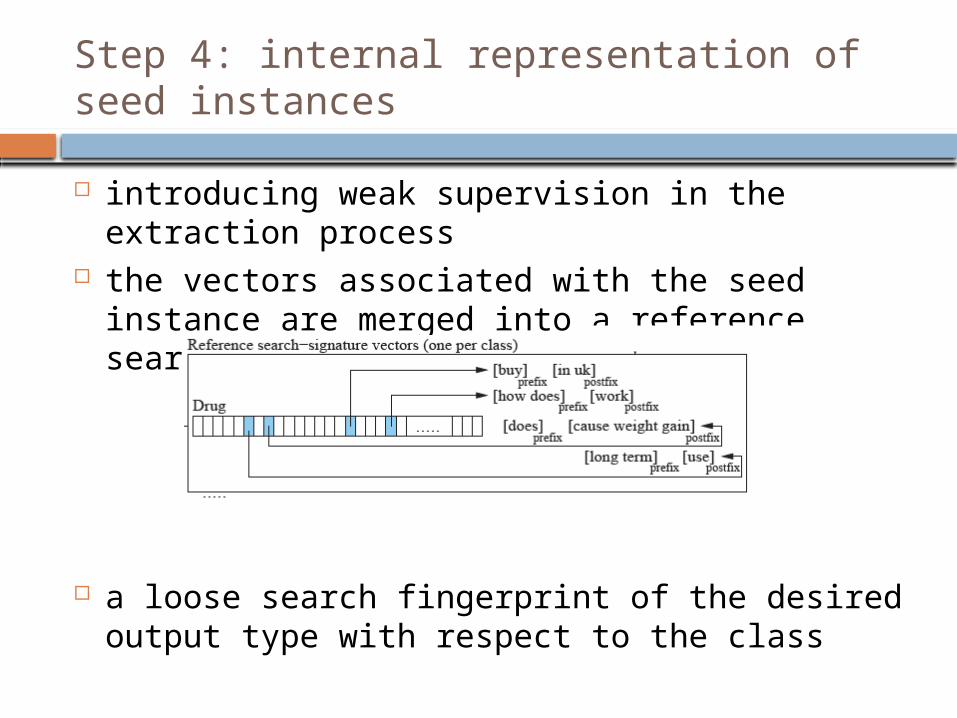
Step 4: internal representation of seed instances
introducing weak supervision in the extraction process
the vectors associated with the seed instance are merged into a reference search-signature vector
a loose search fingerprint of the desired output type with respect to the class

Step 5: instance ranking
ranking based on the similarity score (computed with Jensen-Shannon) between each candidate vector and class vector

Reference search-signature vectors A series of queries that can be asked about
instances of a class
Given a set of candidate phrases, the system guess which candidate phrases are more likely to belong to the target class by looking at the queries
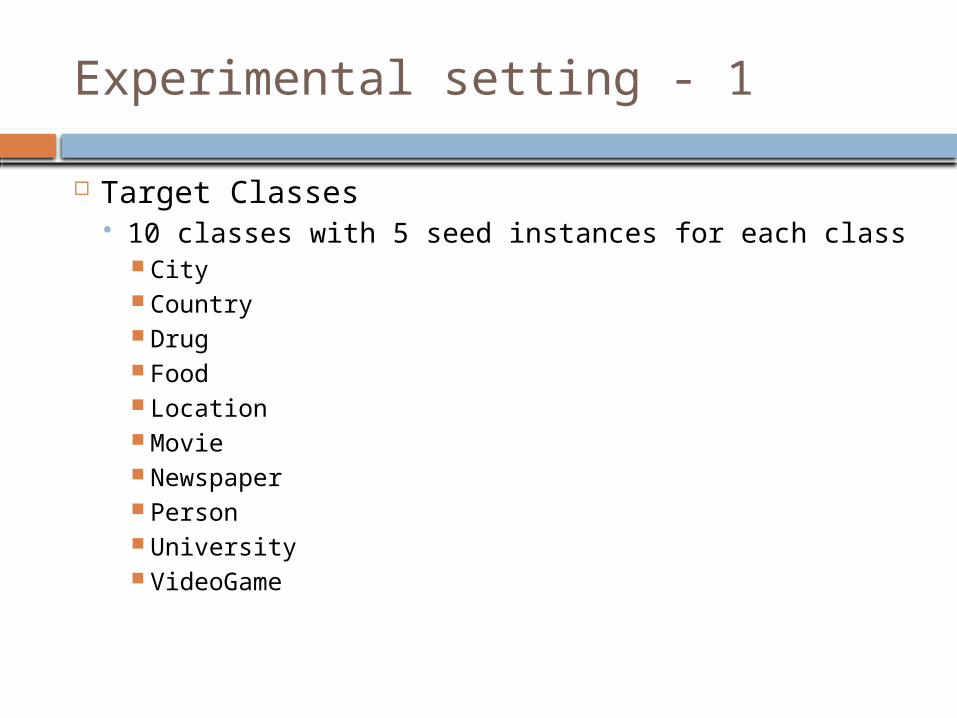
Experimental setting - 1
Target Classes 10 classes with 5 seed instances for each class
City Country Drug Food Location Movie Newspaper Person University VideoGame

Experimental setting - 2
Data A random sample of 50 million unique fully-
anonymized queries submitted to Google
Evaluation Procedure Top 250 candidates of each class are manually
assigned a correctness label 1 : correct 0 : incorrect
Precision at rank N has been calculated for several N values
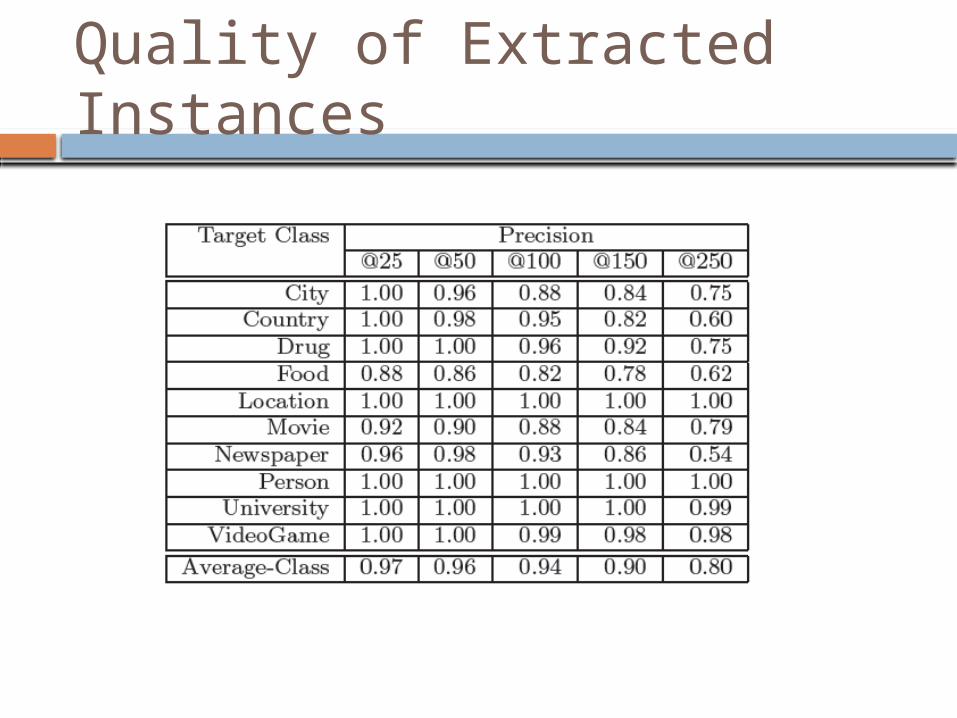
Quality of Extracted Instances
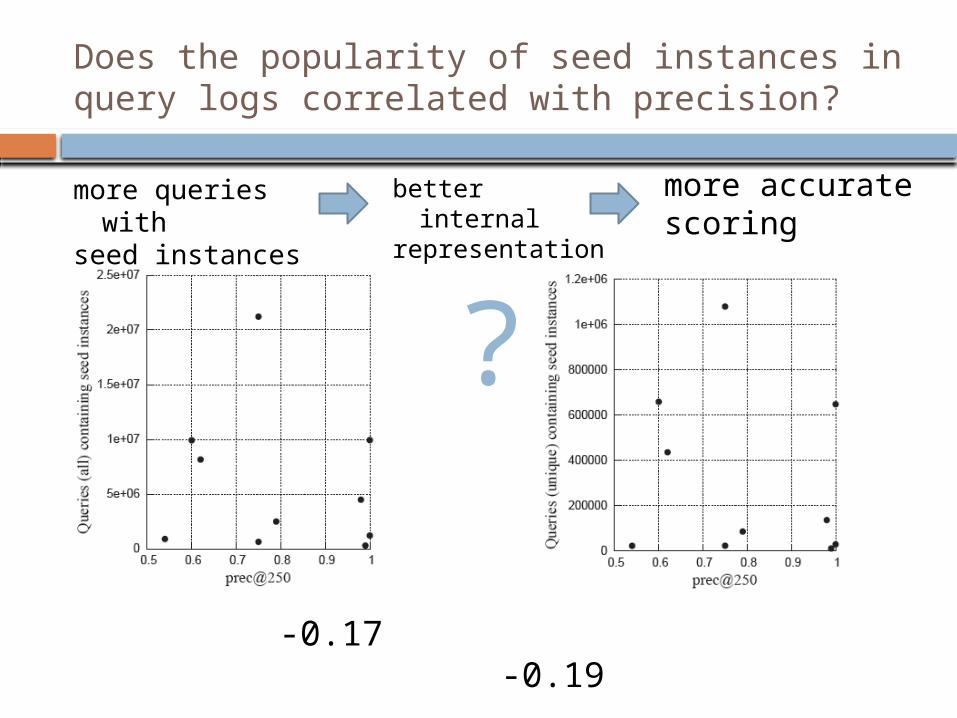
Does the popularity of seed instances in query logs correlated with precision?
-0.17 -0.19
more queries with
seed instances
more accurate scoring
better internal representation
?

Comparing the usefulness of query logs vs. Web documents in NE finding
M. Pasca. Acquisition of categorized named entities for Web search. CIKM 2004 Target classes are incrementally
acquired from Web documents along with their respective instances by using hand crafted extraction patterns (D-patt) Class [such as|including] Instance
Manual one-to-one mapping of chosen target classes with acquired classes

Comparing the usefulness of query logs vs. Web documents in NE finding
Instances extracted from Web documents are also manually evaluated as correct and incorrect
Except City, Newspaper and Country classes, seed based extraction from queries outperformed D-patt in every other class

Conclusion
Search queries, which are thought as noisy, keyword based approximations of underspecified user information needs, proved to be useful in name entity discoveries even with a small set of seed instances with absolute precision (or precision improvement
relative to web based hand crafted system) 0.96 (29%) for prec@50 0.90 (26%) for prec@150 0.80 (15%) for prec@250

Questions ?
Related Documents











