Revolver: Processor Architecture for Power Efficient Loop Execution Mitchell Haygena, Vignayan Reddy and Mikko H. Lipasti - Padmini Gaur( 13IS15F) Sanchi (13IS20F)

Revolver: Processor Architecture for Power Efficient Loop Execution Mitchell Haygena, Vignayan Reddy and Mikko H. Lipasti -Padmini Gaur( 13IS15F) Sanchi.
Dec 17, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Revolver: Processor Architecture for Power Efficient Loop ExecutionMitchell Haygena, Vignayan Reddy and Mikko H. Lipasti
-Padmini Gaur( 13IS15F) Sanchi (13IS20F)

Contents• The Need• Approaches and Isssues• Revolver: Some basics• Loop Handling
▫ Loop Detection Detection and Training Finite State Machine
• Loop Execution• Scheduler
▫ Units▫ Tag Propagation Unit
• Loop pre-execution• Conclusion• References

The Need
•Per-transistor energy benefit improvement
•Increasing computational efficiency▫Power efficient mobile, server▫Increasing energy contraints
•Elimination of unnecessary pipeline activity
•Managing energy utilization▫Small energy requirements of instruction
execution but Large control overheads

So far: Approaches and Issues
•Pipeline centric instruction caching▫Emphasizing temporal instruction locality
•Capturing loop instruction in buffer▫Inexpensive retrieval for future iterations
•Out-of-order processors: Issues?▫Resource allocation▫Program ordering▫Operand dependency
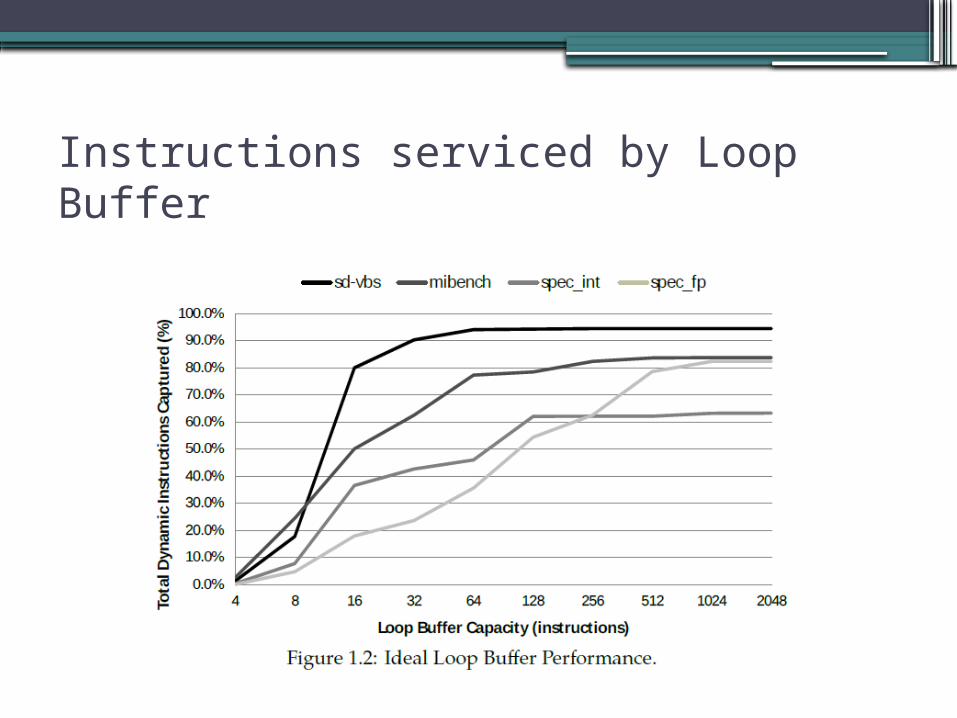
Instructions serviced by Loop Buffer
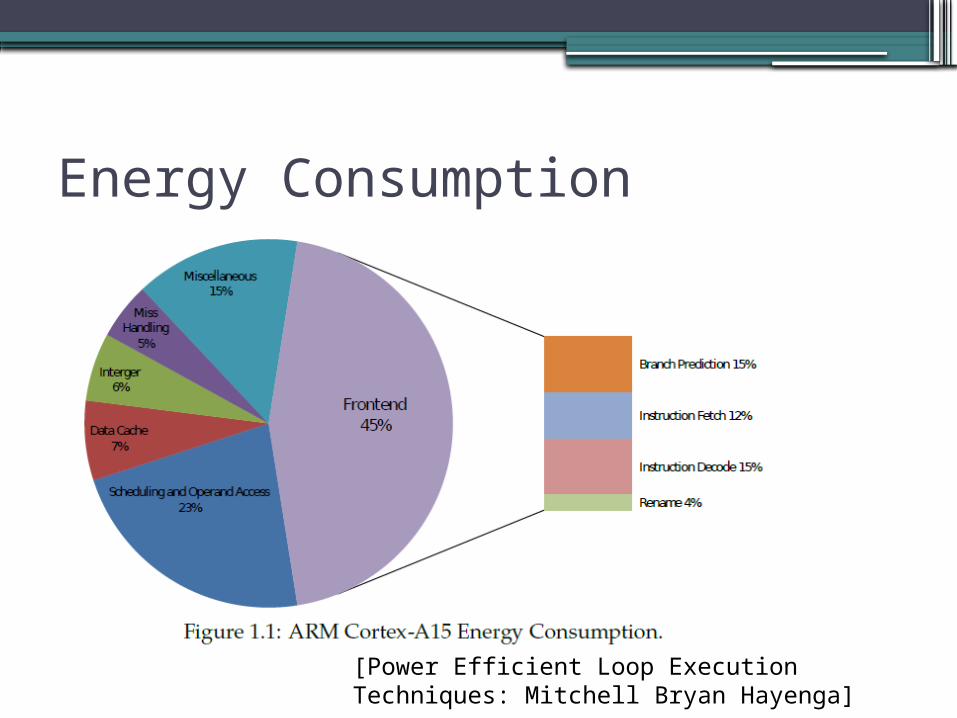
Energy Consumption
[Power Efficient Loop Execution Techniques: Mitchell Bryan Hayenga]
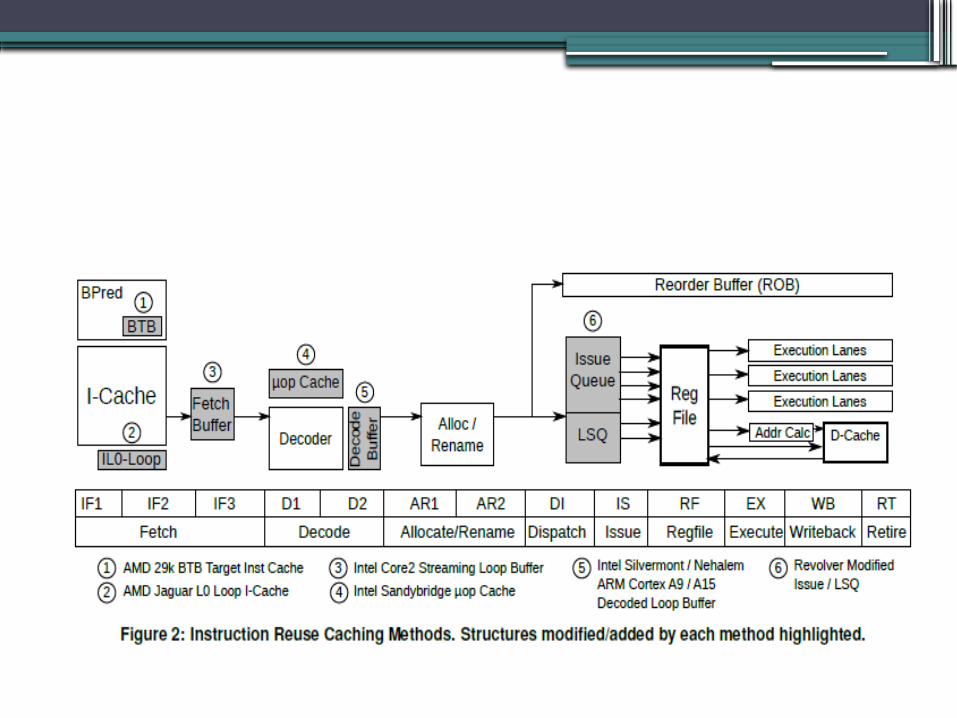

Revolver: An enhanced approach•Out-of-order back-end•Overall design similar to normal
processor•Non-loop instructions
▫Follow normal conventional pipeline•No Register Allocation Table on front-end
instead Tag propagation unit at back-end•Loop mode:
▫Detection and dispatching loop to back-end

The promises
•No additional resource allocation•Energy consumption at front-end
managed•Pre-execution of future iterations•Operand dependence linking moved to
back-end

Loop handling
•Loop detection•Training feedback•Loop execution
▫Wakeup logic▫Tag Propagation Unit
•Load Pre-execution

Loop Detection
•Detection (at) stages:▫Post-execution▫At decode stage
•Enabling loop mode at decode•Calculation of:
▫Start address▫Required resources

Detection and Training
•Key mechanisms:▫Detection logic at front-end -> dispatched▫Feedback by back-end: Profitability of loops
•Profitability▫Disabling future loop-mode
•Detection control▫Loop Detection Finite State Machine
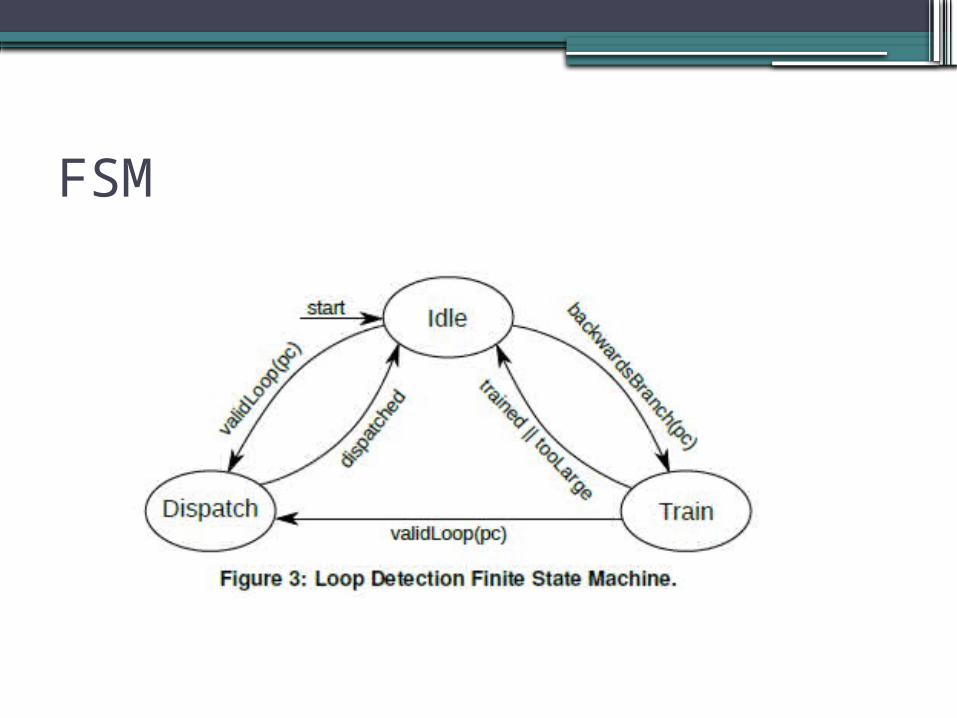
FSM

FSM states
•Idle: Through decode until valid/profitable loop or PC-relative backward branch/jump detection
•Profitability logged in Loop Address Table•LAT records:
▫Composition and profitability•Profitable loop dispatched•Backward jump/ branch and No loop
▫Train State

•Train state: ▫Records start address▫End address▫Allowable unroll factor
•Resources required added to LAT•Loop ends -> Idle state•In dispatch state the decode logic guides
the dispatch of loop instructions into the out of order backend.

•Disabling loop mode on:▫System calls▫Memory barriers▫Load-store linked conditional pair

Training Feedback• Profitability
▫4-bit counter▫Default value =8▫Loop mode enabling if value>=8▫Dispatched loop unrolled more than twice, +2▫Else, -2▫Mis-prediction other than fall-through,
profitability set = 0• Disabled loops:
▫Front-end increments by 1 for 2 sequential successful dispatch

Loop: Basic idea•Unrolling loop:
▫Depending on back-end resources▫As much as possible▫Eliminating additional resource use after
dispatch•Loop instruction stays in issue queue,
executes till completion of iteration•Maintaining provided resources across
multiple executions•Load-store queues modified maintaining
program order

Contd..
•Proper access of destination and source register
•Loop exit:▫Removing instructions from back-end▫Loop fall-trough path dispatch

Loop execution: Let’s follow• Green: Odd numbered• Blue: Even numbered• Pointers:
▫ Program order maintenance: loop_start, loop_end
▫ Oldest uncommitted entry: commit

Loop execution, contd..
•Commiting:▫Start to end▫Wrapping to start: next loop iteration▫Resetting issue queue entries for next loop
iteration▫Load queue entries invalidated▫Store queue entries:
Passed to write-buffer Immediate reuse in next iteration Cannot write to buffer -> stall (very rare)

Scheduler: Units
•Wake-up array▫Identifying Ready instructions
•Select logic▫Arbitration between reading instructions
•Silo instruction▫Producing the opcode and physical
identifiers of selected instruction
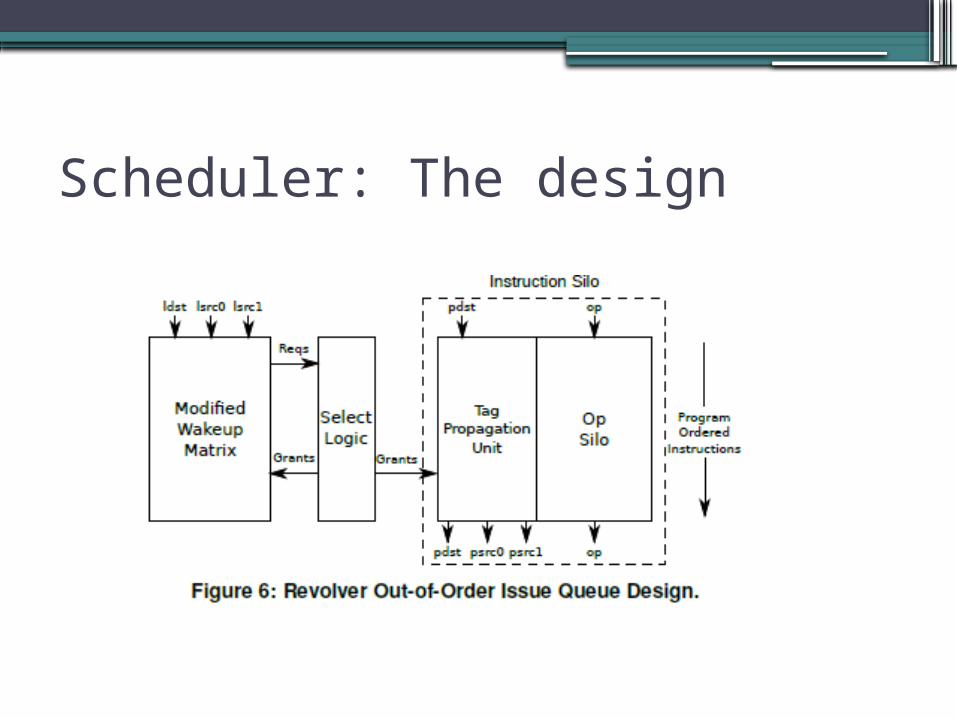
Scheduler: The design

Scheduler: The concept
•Managed as queue•Maintains program order among entries•Wakeup array
▫Utilizes logical register identifiers▫Position dependence
•Tag Propagation Unit (TPU)▫Physical register mapping

Wakeup Logic: Overview
•Observes generated results:▫Identifying new instructions capable of
being executed•Program based ordering•Broadcast of logical register identifier
▫No need for renaming▫No physical register identifier in use

Wakeup: The design

Wake up array
• Rows: Instructions• Columns: Logical registers• Signals:
▫ Request▫ Granted▫ Ready

Wakeup operation
•Allocation into wake up array▫Marking logical source and destination
registers•Unscheduled instruction
▫Deassert downstream register column▫Preventing younger, dependent instructions
from waking up•Request sent when:
▫Receiving all necessary source register broadcasts
▫Ready source registers

•Select grants the request:▫Asserting downstream ready▫Waking up younger dependent instructions
•Wakeup logic cell:▫2 state bits: sourcing/producing logical
register

The simple logic

An example with dependence

Tag Propagation Unit (TPU)
•No renaming!•Maps physical register identifier to logical
registers•Enables reuse of physical register
▫As no additional resources▫Physical register management
•Possible speculative execution of next loop iterations

Next loop iteration??
•Impossible if: Instruction only has access to single physical
destination register•Speculative execution:
▫Alternative physical register identifier needed
•Solution: 2 physical destination registers▫Alternative writing between 2

With 2 destination registers
•Double Buffering▫Maintaining previous state while
speculative computation▫N+1 commits, reusing destination register
of iteration N on iteration N+2▫No instruction dependence in N and N+2▫Speculative writing in output register
allowed

With Double buffering
•Dynamic linkage between dependent instructions and source registers
•Changing logical register mapping▫Overwriting output register column
•Instruction stored in program order:▫Downstream instructions obtain proper
source mapping
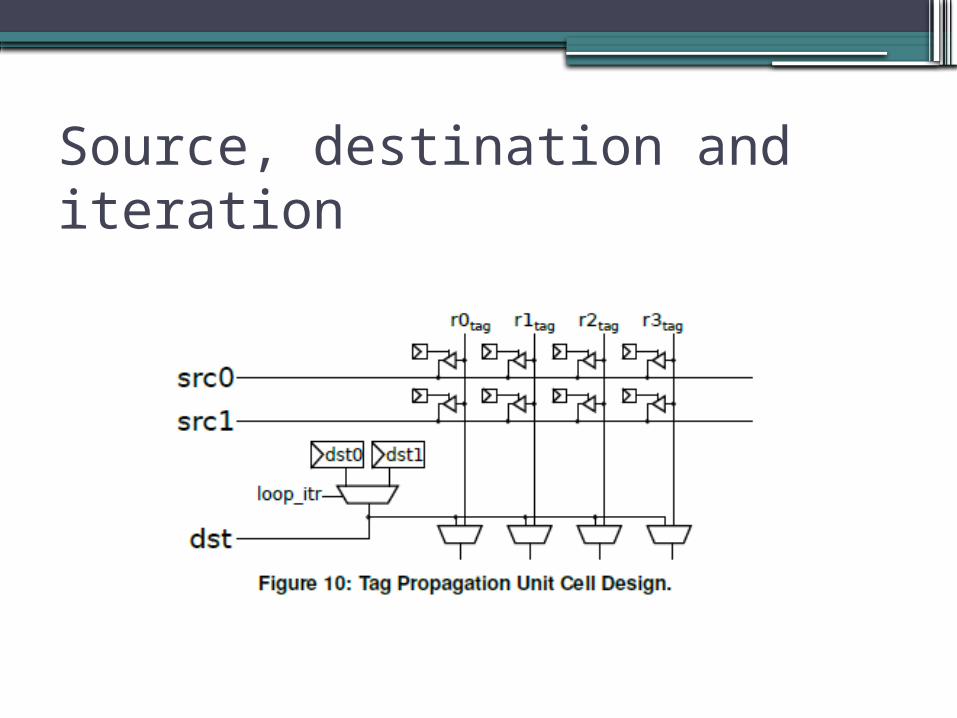
Source, destination and iteration

Register reclamation
•Any instruction misprediction:▫Flushing downstream instructions▫Propagation of mappings to all newly
scheduled instructions•Better than RAT:
▫Complexities reduced

Queue entries: Lifetime
•Received prior to dispatch•Retained till instruction exit from backend•Reused to execute multiple loop iterations
▫Immediate freeing of LSQ upon commit▫Position based age logic in LSQ
•Load queue entries:▫Simply reset for future

Store Queue entries: An extra effort
•Need to write back•Drained into write buffer immediately
between L1 Cache and queue•If cannot write stall
▫Very rare•Wrapping around of commit pointer

Loop pre-execution
•Pre-execution of future loads:▫Parallelization▫Enabling zero-latency loads
No L1 cache access latency•Repeated execution of load till completion
of all iterations•Exploiting recurrent nature of loop:
▫Highly predictable address patterns

Learning from example: String copy
•Copying source array to destination array•Predictable load address•Accessing consecutive bytes from memory•Primary addressing access patterns:
▫Stride▫Constant▫Pointer-based
•Placing simple pattern identification hardware alongside pre-executed load buffers

Stride based addressing
•Most common • Iterating over data array
▫Computing address Δ between 2 consecutive loads
▫Third load matches predicted stride: Stride verification
▫Pre-execution of next load•Constant: A special case of zero-sized stride
▫Reading from same address▫Stack allocated variables/ Pointer aliasing

Pointer based addressing
•Value returned by current load -> next address
•E.g. Linked list traversals

Pre-execution: more..
•Pre-executed load buffer placed between load queue and L1 Cache interface
•Store clashes with pre-executed load▫Invalidating entry▫Coherency maintenance
•Pre-executed loads:▫Speculatively waking up dependent
operations on next cycle•Incorrect address prediction:
▫Scheduler cancels and re-issues operation

Conclusion
•Minimizing energy during loop execution•Elimination of front-end overheads
originating from pipeline activity and resource allocation
•Benefits achieved better than in loop buffers and μop caches
•Pre-execution increases performance during loop execution by hiding L1 cache latencies
•According to research, 5.3-18.3% energy-delay benefit

References•Scheduling Reusable Instructions for Power
Reduction (J. Hu, N. Vijaykrishnan, S. Kim, M. Kandemir, M. Irwin),2004
•Matrix Scheduler Reloaded (P. G. Sassone, J. Rupley, E. Breckelbaum, G. H. Loh, B. Black)
• Instruction Fetch Energy Reduction Using Loop Caches for Embedded Applications with Small Tight Loops (L. H. Lee, B. Moyer, J. Arends)
•Power Efficient Loop Execution Techniques (Mitchell Bryan Hayenga)
Related Documents











