Research Collection Doctoral Thesis An extensible framework for Web information agents Author(s): Magnanelli, Mario Marco Publication Date: 2001 Permanent Link: https://doi.org/10.3929/ethz-a-004279403 Rights / License: In Copyright - Non-Commercial Use Permitted This page was generated automatically upon download from the ETH Zurich Research Collection . For more information please consult the Terms of use . ETH Library

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript
Research Collection
Doctoral Thesis
An extensible framework for Web information agents
Author(s): Magnanelli, Mario Marco
Publication Date: 2001
Permanent Link: https://doi.org/10.3929/ethz-a-004279403
Rights / License: In Copyright - Non-Commercial Use Permitted
This page was generated automatically upon download from the ETH Zurich Research Collection. For moreinformation please consult the Terms of use.
ETH Library

Diss. ETH No. 14463
An Extensible Framework for WebInformation Agents
A dissertation submitted to the
SWISS FEDERAL INSTITUTE OF TECHNOLOGY
ZÜRICH
for the degree of
Doctor of Technical Sciences
presented by
Mario Marco Magnanelli
Dipl. Informatik-Ing. ETH
born March 27, 1971
citizen of Starrkirch-Wil (SO) and Densbüren (AG), Switzerland
accepted on the recommendation of
Prof. Dr. M.C. Norrie, examiner
Prof. Dr. D.J. Harper, co-examiner
2001

Seite Leer /
Blank leaf

To my family and friends

Seite Leer /
Blank leaf

Abstract
As the Internet is rapidly growing and a huge source for information of any kind, it has
become very time-consuming for a human to locate and extract the interesting informa¬
tion. Therefore, more and more, there are agents running all over the Internet to search
as autonomously as possible for information. However, as the information on the World-
Wide Web is very heterogeneous, it gets harder every day to develop such Web information
agents.
Instead of developing these agents as single applications, we propose a framework, the
Web Agent Toolkit WAT, which lets Web information agents be developed easily and fast.
The main idea in this framework is that users exclusively work with a database during all
development stages. First, they define the application database schema which providesthe space for the results delivered by the agent. Then, they define the agent which means
that they describe what information the agent has to find and in what form it occurs in
a document. In addition to that, the developer sets up some general preferences which
are used to define for example the grade of autonomy of the agent or the periodicity of the
search processes. The agent will be started also by the use of the database and performs the
search process. After it has finished the results will be written to the application database.
Users can then browse the results at their convenience.
To be able to find any sort of information, the agents need to have powerful extraction
mechanisms. We present the methods that allow the agents to extract single information
items as well as to extract semistructured information. For the latter we developed V-Wrap,a method to lay a virtual wrapper over semistructured information. With that wrapper, it is
then possible to access the individual fields and query the whole structure. In addition, we
use the definition given by the user that tells the agent what the structure should look like
to determine the semantics in the interesting information.
When the developer wants to create an agent, he has the possibility to choose from a set
of predefined search objects. Each of these objects can perform the search for a specificinformation item according to the methods described. These objects cover a lot of common
information extraction tasks. However, if this is not enough, thanks to the extensibility of
the system, the user has the possibility to develop and add new search objects with new
specific extraction mechanisms.
A specific part of this thesis is the given to a detailed discussion on how the cooperation
v

between the database and an agent must be organised in order to achieve high efficiency.As the flow of data between these two components is quite high, this is an important part
of the framework.
With this framework, the user has control over an unlimited number of agents from within
one access point and this makes it ideal to do fast prototyping for Web information agent
applications. The developer can easily adapt the settings of the agent between two search
processes and then compare the outcome of these two different searches. With this method,
it is possible to quickly find out what preferences lead to the best possible results.
vi

Zusammenfassung
Weil das Internet äusserst schnell wächst und zu einer fast unerschöpflichen Quelle von
Information wurde, ist es für uns Menschen mittlerweile sehr zeitintensiv geworden, Infor¬
mationen gezielt zu suchen und aufzubereiten. Um dem abzuhelfen gibt es immer mehr
Softwareagenten, welche diese Aufgabe möglichst autonom wahrnehmen sollen. Durch
die Tatsache, dass die Daten im Internet sehr heterogen angelegt sind, wird es aber täglich
schwieriger, solche Intenet-Informationsagenten spezifisch zu entwickeln.
Anstatt nun diese Agenten als spezifische Applikationen zu entwickeln, schlagen wir ein
Framework, das Web Agent Toolkit WAT vor, mit welchem man jegliche solcher Agentenschnell und einfach entwickeln kann. Das spezielle an diesem Framework ist die Tatsache,
dass der Benutzer während des gesamten Entwicklungsprozesses exklusiv nur mit einer
Datenbank arbeitet. Zuerst muss er das Schema der Applikationsdatenbank, in welcher
später die Resultate der Suche gespeichert werden sollen, entwickeln. Dazu definiert er den
Agenten, was vereinfacht gesagt heisst, dass er beschreibt, was der Agent suchen soll, und
wie das auszusehen hat. Hinzu kommen allgemeine Einstellungen wie zum Beispiel der
Grad der Autonomität des Agenten oder die Periode zwischen zwei automatisch gestarteten
Suchprozessen. Der Agent wird danach auch durch die Datenbank gestartet. Nach Beendi¬
gung der Suche werden dann die Resultate in die Applikationsdatenbank geschrieben. Nun
kann sich der Benutzer diese Resultate in der Datenbank ansehen.
Damit so ein Agent möglichst viel Information finden kann, brauchen wir mächtige Extrak¬
tionsmechanismen. Wir beschreiben die Methoden, welche es erlauben, dass die Agentensowohl einzelne Informationen aus den Webseiten extrahieren können, wie auch dass es
möglich ist, halbstrukturierte Informationsblöcke zu analysieren und sie zu zerlegen. Um
letzteres zu erreichen haben wir V-Wrap entwickelt, eine Methode, welche es ermöglichtein virtuelles Gitter um einen solchen Block zu legen und so die einzelnen Inhalte zu erre¬
ichen und die Information aus dem gesamten Block abzufragen. Dazu verwenden wir auch
die Definitionen, welche der Benutzer vorgibt, um dem Agenten mitzuteilen, wie eine rel¬
evante Struktur aussieht, um herauszufinden, welche Semantik dem Block zugrunde liegt.
Bei der Zusammenstellung eines Agenten hat der Entwickler die Möglichkeit, Suchob¬
jekte aus einem vorgegebenen Set auszuwählen. Diese Objekte verkörpern jeweils eine
Suche und Extraktion einer bestimmten Art von Information. Falls diese Objekte jedochnicht genügen, so kann dank der Erweiterbarkeit des Systems ein neues solches Suchobjektentwickelt werden, welches dann die gebrauchten Extraktionsmechanismen beinhaltet.
vu

Ein nicht unerheblicher Teil dieser Arbeit ist der gezielten Diskussion gewidmet, wie die
Zusammenarbeit zwischen der Datenbank und einem Agenten aussehen sollte, damit man
ein hohes Mass an Effektivität erreicht. Da der Datenfluss zwischen diesen beiden Kom¬
ponenten ziemlich intensiv ist, wird dies zu einem wichtigen Teil des Frameworks.
Durch dieses Framework hat der Benutzer die Kontrolle über eine unbeschränkte Anzahl
von verschiedenen Agenten über einen einzigen Zugriffspunkt. Dies ermöglicht auf ideale
Weise ein Prototyping von Internet-Informationsagenten. Zwischen zwei Suchprozesseneines Agenten kann der Entwickler die Einstellungen einfach und gezielt anpassen und
danach die Resultate der beiden Suchprozesse miteinander vergleichen. Mit dieser Meth¬
ode ist es möglich schnell herauszufinden, welche Einstellungen zu den bestmöglichenResultaten führen.
Vlll

Acknowledgements
Now that I have worked hard for four years on this thesis, I would like to thank all those
who contributed to this work in any form.
First of all, I would like to thank my supervisor Prof. Moira C. Norrie for the chance to
work on this interesting thesis and her great support during this time. Thanks to her I never
got lost in the whole topic. And, most important, she always had time when I had to discuss
any new approaches with someone really competent.
I also want to thank Prof. David J. Harper for his very valuable comments about the whole
work. He gave me important remarks and helped me to improve the work significantly.
Of course, my thanks also go to Systor AG which made this work possible, and especiallyto Oliver H. Münster and Arthur Neudeck for their support and positive suggestions for the
direction of the work.
I would like to thank also all my past and present assistant colleagues here at the ETH
Zürich. I think each of them helped me more than once to solve specific problems and the
discussions with them were always valuable.
Finally, I do not want to forget my parents who always gave me the necessary support to go
further in this work and always keep on going. Additionally, I want to thank all my friends,
each one of them has at least a small share of the outcome of this thesis.
IX

Contents
1 INTRODUCTION 1
1.1 Agents and Databases 4
1.2 Contributions of this Thesis 5
1.3 The Structure of this Thesis 8
2 AUTONOMOUS WORK ON BEHALF OF A USER: AGENTS 10
2.1 Agent Technology 10
2.2 General Agent Applications 14
2.2.1 Learning Personal Assistants 14
2.2.2 Mobile Agents 18
2.2.3 Browser Assistants 20
2.2.4 Shopping Agents 21
2.2.5 Robot Agents 21
2.2.6 Information Providing Agents 22
2.3 Agents working together with Databases 24
2.4 Information Extraction in Web Documents 28
2.5 Summary 33
3 ACADEMIA 35
3.1 The Academia System 35
3.1.1 The Components and their Work 36
x

3.1.2 The Connection between Agent and Database 44
3.2 Weaknesses and Disadvantages and their Solutions 45
3.3 Summary 47
4 APPLICATION DATABASES 49
4.1 Requirements Analysis 49
4.2 The OMS Java Data Management Framework 53
4.2.1 The Generic Object Model OM 54
4.2.2 The OMS Database Development Suite 55
4.2.3 The Persistent Object Management Framework OMS Java....
60
4.3 Summary 66
5 AN ARCHITECTURE FOR WEB INFORMATION AGENTS 68
5.1 The Search Process 68
5.1.1 The Components 69
5.1.2 The Organisation of the Databases 72
5.1.3 Initialisation and Start of the Agent 73
5.1.4 The Main Search Process 76
5.1.5 The Handling of the Results and their Analysis 77
5.1.6 Additional Considerations 78
5.2 The Agent System Architecture 80
5.2.1 The Agent Core 81
5.2.2 The Special Agents 85
5.3 Summary 87
6 EXTRACTION OF INFORMATION FROM WEB DOCUMENTS 88
6.1 Extraction of Simple Information Items 90
6.2 Extraction of Semistructured Information 95
xi

6.2.1 Differences in Structured Information 96
6.2.2 XML Documents 99
6.2.3 Our Approach 100
6.2.4 V-Wrap 107
6.3 Rating Extracted Information 110
6.3.1 Confidence Values 110
6.3.2 The upper and lower Thresholds 112
6.3.3 The Rating of Documents 113
6.3.4 The final CV of an Information Item found 113
6.3.5 Comparison to other Work 118
6.4 Evaluation of the Extraction Methods 119
6.4.1 Searching for Email Adresses 120
6.4.2 Searching for Phone Numbers 121
6.4.3 Searching for the Titles of a Person 122
6.4.4 Searching for Publications 123
6.5 Summary 125
7 THE FUSION OF DATABASE AND AGENT APPLICATION 127
7.1 The Fusion as an Ideal 127
7.2 The Web Agent Toolkit WAT 129
7.2.1 The associated Databases and their Contents 130
7.2.2 The Structure of the Agent 133
7.2.3 The Search Process 138
7.2.4 Differences to the Architecture proposed 142
7.3 Agent Application Development with WAT 143
7.3.1 Idea 143
7.3.2 Application Schema 143
xn

7.3.3 Definition of Keys 145
7.3.4 Define the Goals and Create the Agent 146
7.4 Additional Components which support WAT Agents 152
7.4.1 The Message Exchanger 152
7.4.2 The Question Agent 153
7.4.3 Statistics Agents 154
7.4.4 Other supporting Agents 156
7.5 Results of Web Agents created with WAT 157
7.5.1 The Results of WATAcademia 157
7.5.2 The Results of other Agents developed with the WAT 162
7.5.3 Other Benefits and Possibilities to use the WAT 164
7.6 Summary 166
8 CONCLUSIONS AND FURTHER WORK 170
8.1 Summary 170
8.2 Future Work 173
APPENDICES
A The textual Schema of the Configuration Database 176
B The Image Finder Agent 180
BIBLIOGRAPHY 184
Xlll

Chapter 1
INTRODUCTION
Since the invention of the World Wide Web (WWW) [BLCL+94], the amount of data
available on the Web has rapidly grown. It is difficult to determine exactly the number of
pages available [DahOO], but at least we can say that the Web is vast. Consequently, we
have an enormous amount of information and knowledge available on the Web. However,
when it comes to finding the interesting information for a particular problem, it is going to
get harder each day, as the growth of the content on the Web is believed to be exponential.
Finding information has always been an important task. Information leads to knowledge,and knowledge is power. In earlier days, information has been passed orally from gener¬
ation to generation. Later, as people learned to write, information has been written down
which made it more stable. The computer age then has brought us new storage entities
and so we are able to collect information electronically. The technique to connect several
machines in networks which evolved into the Internet, has also brought a change into the
handling of information. We can make information available for millions of other people,in order to share the information and make it easier for it to be accessed by a large amountof people.
But, in fact, the access has not become easier. Due to the explosion of the size of the Web, it
gets more difficult each day to find the information we want. To help us with that task, there
exist a lot of so-called search engines, such as AltaVista, Yahoo or Google. Upon enteringa couple of keywords that hopefully match our desired information, a search engine returns
a list of the best matching Web pages for these keywords. Usually, these engines provide
quite complex query languages to make it possible to narrow down the results to only the
very closest matches that can be found.
Unfortunately, the search engines are also limited in certain ways. First, a Web page must
be found by a search engine in order that it can be indexed and later proposed when it
matches a query. This means that, for every page, a search engine only knows of a snapshotat a certain time. If the content of a Web page changes often, most of the time it will not
be correctly indexed by the search engines. Additionally, new pages must be announced to
the search engines or one of the engine's Web crawlers which just follow all the links on
1

the already indexed pages must find it. For common Web sites, this tends to happen almost
by accident as the Web grows so fast. Even the indexing mechanisms are not able to keep
pace with the growth of the Web. Therefore, some of the indexed pages actually no longerexist or their content has changed since the last indexing took place, or - and this occurs
more often - the page was not found by the search engine at all.
The logical consequences of this can be seen in the problems faced by all of us as we try
to find relevant information for specific needs. In fact, the problem is rather more compli¬cated, as we usually not only look for entire Web pages, but for particular information. For
example, we want to have the telephone number of a friend or we want to know on what
CD a certain song is contained.
We call such a telephone number or that title of a CD an information item. It means that the
information contained in it stands for a complete unit of information that makes sense in
a particular environment. This environment is given by the input values of the search, for
example, it is the name of the person to which the phone number belongs. Such information
items are spread all over the Internet and, in particular, they are also spread over a singleWeb page, but each information item may have its own environment for which it is valid
and makes sense.
For some search tasks we have specific sources, for others we need to start with a common
search engine. And especially in the latter case, the process to find the information takes
a lot of time. Such a typical search process is shown in figure 1.1. This example shows a
result page from a search engine where we have entered the first and the last name of a test
person of whom we want to find a phone number. The first hit leads us to a bibliography
page which contains no phone numbers. The second hit also leads to a bibliography page,
but there is a link named "Home Page" on it. Unfortunately that link contains a URL which
is no longer known. The next hits all lead to very similar bibliography pages until hit 9
which points to an unknown Web address. Page 10 is the first really different page, but it
only shows a library entry and no phone number, too. The search is still unsuccessful until
finally, hit 18 leads to a conference home page where we find a link to a description of a
talk which is given by our test person. On this page, we then find the phone number we
are looking for. If we have been clicking through all the pages according to their ranking,this means we had to look through about 20 pages until we were successful. This is a largeamount of wasted time which we somehow have to prevent.
Additionally, we are often looking for similar things again and again. For example, today,we need the email address of person A, whereas tomorrow, we need the email address of
person B. The processes to find these two email addresses presumably are much the same.
For example, we first are looking for the person's homepage and then we are tracking that
page for the information on the email address or at least for other pages that likely lead
to it. Of course, it makes sense to define this process once in a program and in the future
we just enter for example the name of a person and later receive the corresponding email
address.
As a conclusion, we can assume that most of the search processes performed by users all
2

L brary entry
Figure IIA typical search process to find a phone number
around the world are done more than once, just with different attribute values It therefore
makes sense to capture these processes and parametense them
However, we can go one step further Certain information is needed over and over again
Additionally, this information might change over time, but we only have a use for the most
current one A good example here are phone numbers Since there are telephone numbers
available on the Web, it is possible to always find the most current numbers without havingto call an expensive information service However, we usually do not need the numbers of
many different persons, therefore we may use a small database which contains the entries
of the most important people and their contact information Such a database is supposed to
replace the entries in a filofax and therefore it is important to have it always up to date
But, from time to time, this information changes too, and this usually is not updated auto¬
matically If it concerns a close friend, we might be informed by him and we can adapt the
information m our database within a short period of time, but what if the person does not
give us this new data7 Usually, we first recognise the change when we try to contact some¬
one with the old phone number and find it to be no longer valid - leading to frustration
Now, we would have to search for it again, which may cause even more frustration
3

This example shows that it makes sense to
• capture search processes
• create facilities to manage retrieved data which means to store and organise it as well
as to define how to retrieve it
• automate and repeat search processes to update locally stored data.
1.1 Agents and Databases
We have already mentioned the database as a storage engine for information. Of course,
that is the main task for a database. However, a database does not update itself automat¬
ically. We may think of a simple database containing contact information about people,or statistical information about the weather. It would be very convenient for a user if he
always can see the most current information in such a database at every time. To achieve
this, we can do it by ourselves, but it is rather desirable to have another entity to do this for
us. This entity first of all must only do what the user wants. Additionally, it must have a
certain grade of autonomy to be able to make decisions during such a process so that the
user does not always have to be asked for assistance. We want to save the user time and
not have him spend it in alternative ways of achieving the same result. In addition, this
entity must be pro-active because the expiration date of an information item is not known
in advance. For example, it can check periodically for new and updated information.
This description matches perfectly to the idea of agents. Agents are autonomous entities
which perform tasks received from users or other agents. Agents are able to communicate
with users and other agents in order to process their tasks as fast and correctly as possible.However, the way of achieving a given task does not have to be specified to the agent, as it
should be capable of making its own execution plans.
In our case, we restrict the agent tasks to the problem of finding relevant information on
the World-Wide Web. This means, that for a specific task, the agent is given some inputvalues that it can use to find the desired information. However - and this is rather unusual
- the input values come from a database and not directly from a user. In addition, the
user does not tell the agent when a search has to be started. The agent just has the task to
keep the database as up to date as possible. This means that we want the agent to act as
autonomously as possible in order that the user has a minimum of direct interaction with it.
The user interacts only indirectly via the specification of requests and viewing of results.
Of course, somehow, the agent must know what to look for. In addition to the input values,
there is a definition needed of what information is to be found, and the form that it takes.
It is only natural to put that information also into the database so that the agent can take all
the necessary information to do such a search from one source. This also has the advantagefor the user that he can use only one interface to interact with the agent.
4

So far, this all seems to make sense and we could devise an architecture to define the
interaction between such a database and an agent. However, we want to go further. Until
now, we have only talked of a specific application which works in a specific domain. We
want to make the step forward towards a system with an agent and a database where the
agent is able to work in any domain. The database structure may be changed by the user,
the data to look for may be different for each agent application. This means also that an
agent should be able to operate independent of a particular storage platform as well as a
particular data set which is given by the user. The goal is to create an agent which can
adapt itself to a given storage unit as well as the structure of its data.
Such a system of course needs to be grounded on a sophisticated cooperation between the
two main components. The agent and the database need to be closely coupled in order that
this cooperation can take place as efficiently as possible. Nonetheless, we must not forgetthe user who still has to play the most important role in the whole system. Therefore, we
must not forget about the user's main requirements for such a system. It must be easy for
the user to work with this system and finally, the system should actually save him some
time.
We have now discussed several aspects of a general and flexible framework to find and
extract information from the Web. The resulting system will be rather complex with com¬
ponents that employ a variety of technologies for data storage, Web searching, information
extraction, user feedback, etc. For some tasks, existing technologies could be exploitedand adapted to our needs, while for others new ones have to be developed from scratch.
In the following section, we detail the contribution of this work indicating new conceptsand technologies were developed in the context of this work and where we were able to
use already existing work.
1.2 Contributions of this Thesis
This thesis demonstrates that it is possible to have a single framework for the developmentof Web information agents which search for information relevant to any application. The
main requirement for this was to be able to formulate the search mechanisms in such a
generalised way that they are independent of the search domain. We did this through a
combination of simple approaches that by themselves seem not to provide any specific help,but as part of the whole system, contribute substantially. In addition, we use developed
complex search and extraction mechanisms that are powerful because of their dynamic
handling of the context.
In fact, as usual, it is the developer who has to define a model of the application which
he plans to build. Regarding our work, this means that he has to build a schema of the
application database. This database provides the space to store the information in which
the developer is interested. As we expect it in usual database systems, the system, or rather
the agent behind it, accepts any schema. This means that there is no restriction for the user
5

to work in a specific application domain.
As a second part, the user has to define the agent which shall search for the desired infor¬
mation. Here, the system provides the main components of the agent in a generic form,
i.e. the user only needs to set specific preferences. In this thesis, we define an architecture
for Web information agents which fits to these needs. This architecture was then used to
build the framework for the creation of the agents. Within this extensible framework, it is
possible to create such an open and therefore dynamic agent.
During the agent development phase, the developer has the possibility to adapt a coupleof settings that affect the behaviour of the agent regarding the interaction with the user.
Most important, however, the developer defines what the agent shall look for and how
this information appears. This means that the developer specifies the context in which a
specific information item must occur and a valid form or even format for it. This serves
as a definition of the information item of interest which can be used to detect and extract
information from a document.
One part is given through the application database schema which the agent learns. The
other part has to be given by the developer directly. For each information item of interest,
he defines a search object that tells the agent something about the context in which the
result must occur, what form it must have and where in the application database this infor¬
mation belongs to. We call this the appearance of the information item which is of course
subjective to the developer's meaning, it defines the expectation of the developer.
The system comes up with a comprehensive set of predefined search objects that almost
characterise any form of possible extractable information. This means that the developerdoes not have to define all the search objects from scratch which he needs for a specific
agent application. The developer only has to set some general preferences for each search
object, and these settings let the objects fit best to the new application. Such predefinedsearch objects might for example include an object which looks for a string which must
follow a user-given keyword and only contain characters out of a user-defined set. A spec¬
ification of this would be an email address search object or a telephone number search
object. Nevertheless, the system is extensible so that the developer may define and create
his own search objects as well as extending existing ones. This makes it possible to use the
system for most problem domains when searching for information on the Web.
As already mentioned, the search mechanisms are the key to achieving this framework.
Usually, information search applications are restricted to a specific domain because of the
complexity of information extraction. To give an example, it is obviously quite different to
extract information from some rankings of a sports event or from a text discussing research
results in biology. In our framework, we are able to provide mechanisms that address this
problem.
We have separated the extraction problem into two basic forms. One is the search for singleinformation items which may occur stand-alone as well as in the middle of a sentence. We
use a very simple approach to extract this kind of information, as we try to locate it bylooking for keywords that might occur next to it and, additionally, we try to describe the
6

appearance which means the format and the position of the desired information item as
closely as possible. This approach is relatively simple, but it proves to be very effective.
The other extraction form is the extraction of structured information. This is more difficult
as we cannot rely on looking for any keywords. The sports rankings we mentioned before
usually contain a lot of information which is self-describing for someone who knows about
it. Inside of these rankings, there does not occur any description for specific attributes.
A second and more critical problem comes from the fact that there exist various forms
of structure and depending on the domain, there is even information hidden behind the
structure, for example whether we have a ranking or just a list of entries without semantic
ordering. Finally, the structure is not always that obvious as it may vary between the
entries or even be irregularly formed, because it was created manually which by mistake
led to some errors. The most obvious reason for a variation in the structure lies in a possiblevariation in the information items. However, to have clear clue, we assume that the type of
similar information items is always the same - we do not want to have to check whether an
image in fact contains a text to compare it with a string.
This means in fact that we need a highly dynamic approach to not only extract well struc¬
tured, but also semistructured, information. We therefore have developed the concept of
virtual wrappers. Such a wrapper is laid over semistructured information in order to make
it possible for our agents to access the specific fields. Together with the information given
by the user about the appearance of the desired information, it is possible for the agent to
extract the information independent of the domain.
For the framework to be effective, it is necessary to provide a strong cooperation between
the agent and the database. The idea of using the database for the configuration of the agentas well as for the storage of the results makes it easier for the user to work with the system
as he automatically only has to work with one interface to run any agent or browse throughthe results of a search. This is shown in figure 1.2.
Figure 1.2: The main components and their cooperation
Nevertheless, the traditional roles of agent and database show that these are standing quitein opposition to each other. The database is seen as something robust, large and stable,
whereas typical attributes of an agent are small, flexible and autonomous. Therefore, we
had to bring them as close together as possible without losing any of the properties of these
7

two components. It needed an exact requirement analysis to achieve the best possible result
for that task. We discuss the cooperation therefore in detail, as it is a crucial part of our
system.
1.3 The Structure of this Thesis
In chapter 2, we discuss related research which is important for our work. We start by
talking about agents and their usability. Then, we discuss different agent applications and
detail what we can learn, and in fact use, from these applications. A special section then
examines existing work where agents are working closely together with databases and
where this cooperation is addressed as a specific issue. In addition, we take a look at work
which concentrates on extracting information from Web pages as this is the main task of
our agents.
We start detailing our work in chapter 3 by discussing Academia which was the start of
this thesis. We detail an earlier version of the system to show the problems that have to be
handled in an information search agent. We then propose solutions for this early system
and also discuss the necessary steps to generalise the system in order that it can search for
anything on the Web, and not only for information in a specific domain.
Then, we start concentrating on the components of such a generalised system. In chapter 4,
we want to define the requirements that we need to be fulfilled in the database componentof such a system. Then, as we have chosen the OMS database system, we give an overview
of the system to show the advantages that it brings for us.
In chapter 5, we concentrate on the context in which our system runs. We discuss the tasks
of our specific Web information agent and what it has to be able to find and what not.
Additionally, we detail the workflow in such a system to recognise the most important in¬
terfaces between the different components that constitute that system. Finally, we propose
a specific architecture for our main agent part which is responsible for the discovery and
extraction of information items and discuss the requirements of the different components.
After the tasks of the agent have been defined, in chapter 6 we discuss the search and
extraction mechanisms which are the main features of the agent. We detail the quite simple
approach we use for extracting single information items as well as the more complicatedextraction of semistructured information. For the latter, we also describe our own method
V-Wrap which makes highly dynamic extraction possible. We then discuss the method
used to rate the information extracted in order to make it possible for the agent to decide
about the reliability of a result by itself. At the end of this chapter, we test our extraction
mechanisms by evaluating them on a test set of Web pages.
Chapter 7 is the place where it all comes together. Here, it is described how all of the
techniques described in the previous chapters are brought together, within one system.
First, as a result of the always closer coupling of the two important components, we discuss
the ideal form of a fusion between the agent and the database. Then, we detail the Web
8

Agent Toolkit (WAT) which is the framework for an easy and rapid development of Web
information agents. We also describe the process of developing an application using the
WAT. We then present in detail the additional components of WAT. These components are
agents that do specific tasks that are common to all of the WAT agents, such as messagingor analysing statistics. Finally, we take a critical look at some WAT agents to discuss the
success of our system.
In the final chapter 8, we summarise the results of this thesis and discuss what has been
achieved in the context of Web information agents as a whole. In addition, we take a look
at future work that can be done to improve the WAT.
Finally, in the appendices, we have listed the current schema of the configuration database
which in fact defines how agent applications can be built. Additionally, we added the def¬
inition of an example agent, the ImageFinder which is able to search the Web for picturesof people. This agent is especially successful when looking for celebrities.
9

Chapter 2
AUTONOMOUS WORK ON BEHALF
OF A USER: AGENTS
In this chapter we discuss agents in general. First, we discuss the term agent and show
what properties an agent must have in order to be called an agent. Then, we take a look at
some work that has been done in the area of agents. We focus mainly on agent applicationsand discuss their concepts in order to determine the interesting work for our purposes.
In addition, we want to take agent systems into focus that are used in combination with
one or more database systems. We evaluate the research that has been done in this area
according to our needs, especially how closely the agent and the database are working
together. It is important for us to examine the requirements that were given for a system,because if they differ from our requirements, it is possible that a good approach is not
applicable to our needs. We will see that, in most cases, databases and agents are totally
separated from each other.
Finally, as it is a central part of our work with agents, we also focus on information ex¬
traction and how work in that direction can be used for our purposes. There, we mainlyfocus on systems - which may or may not be agents themselves - that perform the tasks of
information extraction similar to those of our requirements.
2.1 Agent Technology
In this section, we want to summarise agent technology in general and describe the part of
it that is really interesting for our purposes. We also give a definition of what agenthoodmeans in our view.
First, we definitely have to concentrate on what makes a certain system an agent. What
characteristics does an agent have to fulfill in order to be considered one? This is a difficult
question, because there is no single correct answer. In fact, it differs from researcher
10

to researcher. There are a lot of different definitions of the term "agent" around. We
are not seeking another definition, but, by discussing other definitions made, we want to
characterise the agents we use in our work.
An agent itself is a system that tries to fulfill its goals in a complex, dynamic environment.
Usually the agent is also situated in this environment. Of course, the term agent is not
limited to computer science only. In our case, we want to focus on an agent which is some
sort of program, a piece of software. These agents are commonly known as "software
agents", and from now on, when we talk of an agent, we in fact mean a software agent.
The idea of employing agents to delegate computer-based tasks goes back to research byNicholas Negroponte [Neg70] and Alan Kay [Kay84]. There, research was done in the
direction towards an ideal of agents which have human-like communication skills of a very
high level. These agents are able to accept high-level goals and reliably translate these to
low level tasks which are then processed.
Some definitions or characterisations of agents are contained in [WJ95], [JW98], [Mae94],
[Fon93], [RH94], [GK94] and [VB90]. Of course, the statements in these works are not
identical, in fact, sometimes they even disagree with each other in parts, but there are
several common features to be found. We will have a closer look at the definition of an
agent in general and with respect to our view in particular.
A very interesting paper by Franklin and Graesser [FG96] comes up with a taxonomy of
agents. After describing what an agent is, this paper gives a good overview of the different
directions in agent technology and additionally shows some applications for the different
categories. However, we do not want to discuss related work in terms of this taxonomy as,
for our work, we may need features of agents from different categories. We therefore focus
on the features of an agent application, not on its classification.
In our view, the strongest property that makes an agent is autonomy. This fact is accepted in
the whole agent community. The definition of agent autonomy is given in [Cas95]: Agents
operate without the direct intervention of humans or others, and have some kind of control
over their actions and internal state.
Autonomy is the main reason why we as users are interested in agents. The agent should
process a task which we did not want to do ourselves because of the amount of time that
was necessary to do it. So, the user delegates the task to an agent so that it processes the
job autonomously and the user is able to do other work without being interrupted by the
agent. Whenever the user wants, he goes back to the agent and checks the progress of the
work and, when available, the results. Since the main goal is to save the user some time, it
is important that such a system should not require lots of interaction.
In addition, two important properties of an agent are reactivity and pro-activeness, which
make an agent significantly different from a simple piece of software. Reactivity is de¬
scribed in [WJ95] as the property that agents perceive their environment (which may be
the physical world, a user via a graphical user interface, a collection of other agents, the
Internet, or perhaps all of these combined), and respond in a timely fashion to changes
11

that occur in it. Pro-activeness, on the other hand means that agents do not simply act
in response to their environment, but rather are able to exhibit goal-directed behaviour by
taking the initiative.
Another often mentioned feature of agents is communication ability. To discuss this fea¬
ture, first, it is important to recapitulate what type of agent really is of interest for us. We
are mainly dealing with agents working on their own, but, in our prototype system which
is described in section 7.2 we have built some sort of a cooperative agent system which
combines both simple and sophisticated agents. Here, what is important, the system byitself is closed. Some agents must be part of the system so that it is able to work, others can
be plugged in on demand, but only agents that are known by others can work as a part of
this system. There will never be any unknown agents that need to communicate with our
agents and ask for things our agents do not know. Therefore, communication between the
agents is not the central theme for us.
When we talk of typical multi-agent systems, we mean systems in which usually no agentknows of the existence of a particular other agent. So, the agents need to have a strong
ability to communicate in order to forward tasks or ask for information from other agents.These systems are open, which means additional agents can just be placed into the systemwithout the need to announce them to some special instance first. In addition, multi-agent
systems may contain several different instances of the same agent whereas in our prototype,each agent has its own specific task which no other agent in the system is able to fulfill.
In [GK94], it is stated that the criterion for agenthood is that the agent communicates cor¬
rectly in an agent communication language (ACL) as was defined in the ARPA KnowledgeSharing Effort [NFF+91]. The most common such language is the combination of KIF
(Knowledge Interchange Format) [GF92], which is the "inner language" providing the
vocabulary of the language and KQML (Knowledge Query and Manipulation Language)[FWW+93], [LF97], which is the "outer language". However, as the authors ofthat paper
refer mainly to multi-agent systems, we do not take this definition into account.
Communication is important, of course, but not a central task for our agents. We prefer a
weaker definition in this direction as we do not need our agents to have high-end commu¬nication capabilities. We define that agents must have a certain social ability which makes
it possible for them to interact with other agents or humans or even entities like databases
in order to fulfill their tasks. The agent should not necessarily have to operate in terms
of a high-end communication language, the grade of the communication ability is depen¬dent of the environment in which the agent runs. Agents which work on their own must at
least have the possibility to communicate with the user. In fact, this may be simply a well
defined interface to a user program.
These four properties as a weak notion of agents have found currency with a broad range
of researchers. In our work, we were trying to satisfy these properties as far as possible.However, there were other properties discussed to be necessary for reaching agenthood.We claim them as optional, not a must. For example:
12

• Mobility is the ability of an agent to move around electronic networks [Whi94]. This
is an interesting property of multi-agent systems which are spread over several ma¬
chines.
• Veracity is the assumption that an agent will not knowingly communicate false infor¬
mation [Gal88]. This is important too for our work, as a main assumption we make
is that the agents only reflect the information that they find elsewhere.
• Benevolence is the assumption that agents do not have conflicting goals, and that
every agent will therefore always try to do what is asked of it [RG85]. This is tightly
coupled with veracity. Agents must only work on behalf of the users, never againstthem.
• Rationality is also related to the previous two properties. The agent only shall act in
order to achieve its goals, never will act in such a way as to prevent its goals beingachieved - at least insofar as its beliefs permit [Gal88].
• Cooperation is of course necessary whenever we are talking of a multi-agent system,otherwise such a system does not make much sense. However, to enable cooperation,first, social ability is needed. An agent's interaction with a user can also be regardedas a sort of cooperation.
A final property we want to discuss is intelligence. Agent technology is strongly related
to artificial intelligence, therefore the term "intelligent agent" is commonly used. Often,
intelligence is meant to be a property of agents without being named. However, as a simple
example of an agent, we look at a thermostat. Clearly, a thermostat has the four main prop¬
erties that we defined as essential for agenthood, but no one would insist in a thermostat
being intelligent.
Now, to be on the right side, we have to be aware what intelligence really means. It is
beyond the scope of this thesis to discuss the term intelligence, but it is commonly acceptedthat a piece of software is intelligent, if it is able to learn. We interpret that as meaning that
a system which is adaptive, capable of refining its behaviour or of determining facts duringits life time - which it did not know before - is intelligent. This is given for example in
deductive databases or in common knowledge base systems.
We do not want to define intelligence as a necessary property of an agent. It is possible to
give an agent a task which does not require any intelligence by the agent. However, agents
get more interesting whenever they come up with a certain ability to learn. It is simplymore difficult to predict their behaviour.
Having discussed shortly what an agent is, we want to focus more on the applications that
were made using agents. This is the topic of the following section.
13

2.2 General Agent Applications
In this section, we want to give an overview over several other agent applications that have
been developed. Agent research results usually in a large amount of theories, concepts,
approaches and frameworks, but in contrast, not that many working applications are pre¬
sented. Here, we take a short look into general, mostly classic work.
There exist many interesting papers that review a large number of agent applications[JW98], [BZW98], [Mae94], [FG96], [Pet96], [Nwa96], [MM98]. However, we just want
to pick out some specific applications which are interesting for our work. Please note that
we only focus on the agent part of the systems mentioned. We classify the applicationswhich we want to mention in several classes according to the function of the system. We
do this in order to give this description a clear structure.
2.2.1 Learning Personal Assistants
Pattie Maes' Software Agents Group at MIT Media Lab is leading the research in this
section [Mae94]. The idea behind these personal assistants is that they shall be used as
assistants for tools we use every day and which over time require a lot of user effort to be
maintained. Maes calls the agents in this field Interface Agents.
The agents are developed for specific tools and will first be fed with any examples in the
user's mind. For example, considering a news filtering agent, the user feeds the agent with
example articles in which he is interested, then also provides articles that are completely
uninteresting, and the agent then learns from this training set to be able to recommend
interesting articles in the future.
The idea of this approach is that the agent gains experience over time and its actions are
continuously improving. A typical curve of the reliability of the results versus the ongoing
time, while such an agent works, is shown in figure 2.1. The initial reliability of the results
is defined by the training examples that an agent consumes before it is first set in use.
Over time, the agent gets feedback by the user about its hits and misses and by learningfrom these, the results improve. Usually, right after the start, the reliability of the results
improves very fast, as the first feedback has a big impact on the agent. Later, the agent will
come closer to the maximum reliability, and the improvement rate will slow down.
As an extension, the agent can also be fed with feedback in the form of keywords in specificarticles that are important for the user. Another important method for the agent to learn is
to ask the agents of other users which perform the same task. In this case however, there
has to be a whole system in which the agents can communicate with each other. Finally, of
course, an agent can also ask its user for assistance and learn from these hints.
Relevance feedback and information filtering are topics from the field of information re¬
trieval. Generally, information retrieval covers the representation, storage, organisationand accessing of information items [SM83]. The techniques used in the agents discussed
14

Reliabilitya
0
Figure 2.1: Typical curve of reliability of results versus time for Interface Agents
here have mostly been introduced in information retrieval discussions. The algorithmshave simply been adapted to the use in agents where the requirements are commonly more
restricted. For example, agents mostly need to be fast and therefore do not have the time to
search large collections of documents exhaustively. We do not discuss the information re¬
trieval algorithms used here in detail, we only want to give an overview of the functioningof the agents.
Nevertheless, the learning techniques are very interesting for us, because users commonly
accept agents better if they simply tend to act like the user himself rather than if the agentsrun with a complex, barely understandable logic. This has also been proved in user tests
done at the Media Lab.
Now, we want to take a closer look at some of the agents that have been developed in this
area. Although these applications are rather old, the concepts and techniques proposedby these agents have been incorporated successfully within a number of systems and Web
applications since.
Maxims
Electronic mail filtering is quite an obvious field to tackle with agents. Nowadays, our
email addresses are sought by several people or organisations from whom we do not want
to receive mails. We spend a lot of time deleting or storing messages. Maxims [LMM94]is such an agent which assists the user with electronic mail. Maxims learns to prioritise,delete, forward, sort and archive mail messages on behalf of the user.
Maxims' main learning technique is Memory-Based Reasoning [SW86]. The agent contin¬
uously follows the actions of the user while the user deals with electronic mail. The agentmemorises all of the situation-action pairs generated. Situations are described in terms of
a set of features. In Maxims, the agent keeps track of the sender and recipient of a mes-
15

sage, the keywords in the subject line and other components that can be used to distinguishdifferent messages.
Whenever a new situation occurs, the agent compares it to the already stored situations
and tries to find the closest ones. From those, the agent tries to predict the action of the
user. The agent also assigns a confidence level to such a prediction, based on the grade of
similarity of the situation-action pairs that were considered for predicting an action.
There exist two thresholds which can be set by the user. If a prediction has a confidence
level above the "do-it" threshold, then the agent autonomously takes the action on behalf
of the user. On the other hand, if the level is below the "do-it" threshold but above the
"tell-me" threshold, this means that the agent presents its suggestion to the user and waits
for the user's confirmation to automate the action.
This system leaves full control of the degree of autonomy of the agent in the hands of the
user. We think that this is a key factor for a user's acceptance of an agent.
Another advantage of the agent in Maxims is the fact that it is generic. If an application is
scriptable and recordable, this agent can be attached to it. Thanks to that, there are several
possibilities where this agent can provide assistance to a user.
Meeting Scheduling Agent
This possibility was used for creating a meeting scheduling agent [KM93], [Koz93]. This
agent assists the user with the scheduling of meetings, i.e. accept/reject, schedule, resched¬
ule, negotiate meeting times etc.
Also in this case, the behaviour of a user is repetitive, but nevertheless very different for
individual users. For example, some people prefer meetings in the morning while others
want to hold them in the afternoon. Therefore, meeting scheduling is also a perfect exampleof a task which fulfills the criteria for learning interface agents.
The meeting scheduling agent was also very well accepted by users during some tests. The
users liked most the capability of the agent to gain experience and predict, and hence act
more reliably the longer it was in use.
NewT
The next agent in the area of interface agents we want to have a look at is NewT [She94],
[SM93], a system which helps the user filter Usenet Netnews. This agent is definitely oneof the more widely useful agents, because the amount ofnews for some topics is really largeand people seldomly have the time to check them all. So, an agent capable of providingthe user with a small set of documents per day which hopefully have a high relevance to
the user, would be of great interest to many users.
NewT functions as intended above. A user may instantiate different agents for different
16

interesting topics, e.g. one agent for sports news, another one for business news, and so on.
The user then first has to train the agents by feeding them with both relevant and irrelevant
documents and the agent analyses these by performing a full text analysis to retrieve the
words that may be the relevant ones. In addition to that, the agent also tracks the structure
information such as author, subject and so on.
Once the agent has been started, it checks newly arriving articles and recommends the ones
that seem relevant to the user. The user then can give positive or negative feedback for the
articles or portions of them. In addition, the user can give feedback in the form of single
keywords. This feedback then is used for future recommendations to be improved.
The system is meant as an assisting tool for the user, not as a replacement so that the user
never has to track news services by himself again. The agent's limitation to keywords
only is not a limitation. For a deeper semantic analysis of text it would be necessary to
include natural language understanding research, but extensive experimental research has
shown that most advanced NLP methods do not improve information retrieval effectiveness
[A1100].
However, as the user tests have shown, the keyword approach leads to surprisingly goodresults and it is definitely a fast method. This is very important in the case of agents which
have to analyse documents on direct request, i.e. a user enters an explicit request and then
waits for the result.
Ringo
A fourth application from Maes' group works in the area of entertainment selection. The
difference to the other three applications presented is that this application does not work
with content filtering. In addition, it does not assist with a common tool, but instead is a
whole new application by itself.
Shardanand's Ringo [Sha94] is an agent for personalised music recommendation. The
main idea behind Ringo was the social information filtering approach. People that joined
Ringo describe their listening pleasures by rating some music artists. Out of these ratings,the system creates the person's profile. Over time, as the individual rates hopefully more
artists, this profile changes. With social filtering, Ringo uses these profiles to generateadvice to invidual users about what they might be interested in.
Interesting for us, Ringo also includes a user-grown database of musical artists and albums.
This will be further discussed in section 2.3.
The follow-up project of Ringo was HOMR (Helpful Online Music Recommendation Ser¬
vice) before the idea of social information filtering resulted in a spin-off of the MIT Media-
Lab, FireFly [Fir97], [BC98], which developed different recommender agents to be shown
on the Web. FireFly was a huge success story and was later bought by Microsoft.
The agents behind this work are organised as a multi-agent system. Each profile of a user is
modelled as an agent. Whenever the user is interested in a new recommendation, the profile
17

of the user will be compared to all the other user's profiles. The answer then consists of
additional entries from these profiles that are most similar to the original one. AlthoughRingo can be seen as an agent from the family of personal assistants, its techniques cannot
be used for our problem. We want to use a technique that makes it possible for a singleagent to find results without necessarily having to consult other agents. Ringo's success
is highly dependent on having a high number and variation of agents that ensure a better
recommendation. In our system, the possibility that there exist two different agents which
process exactly the same tasks, is very small, therefore we cannot count on that.
2.2.2 Mobile Agents
Many people see mobility as a necessity for agenthood. We instead prefer that agents with
the possibility to be mobile are simply put within a separate class of agents, the mobile
agents. The main emphasis of research here - to move around in networks - requires very
specific techniques. An agent can only move from one system to another, if the other
system allows it and provides a specific mobile agent platform which makes it possible to
receive an agent and let it activate itself to go on with its work. For that, the agent has to
preserve its state and data. Mobile agents therefore are built preferably small and without
carrying a lot of data. If that is granted, the movement between different systems is veryeffective.
Although we stated earlier that our approach does not need any mobility, we discuss mobile
agents, because some work that has been done in this area is nonetheless also interestingfor us. This interest stems from the fact that mobility requires very exact definitions of
agent tasks in order to develop agents. As mobile agents only can move across platformswhich contain client applications that handle the transfers, the agents themselves have to
be built according to a well defined architecture.
In this section, we do not concentrate on specific applications, we focus on two agentarchitectures which come up with specific definitions and programming languages. The
proposed architectures not only contain the ability to move the agents across several ma¬
chines, they also contain communication elements that show possible implementations of
all the demanded communication features.
Aglets
When mobile agents were introduced, IBM started to develop its own system which should
combine Java applet technology with agents, resulting in what IBM calls aglets [OK098],[L098]. The reason for this development lies in the fact that Java [Fla99] is only designedto move applets over a network, but not their data or state of execution.
Therefore, aglets are interesting for people who want to build mobile agents, because theyaugment Java with mainly this possibility. For stationary and stand-alone agent applica¬tions, the language Java itself, for example, provides us with a sufficient set of possibilities.
18

Of course, persistence of data is not given within pure Java. We need this property for
building mobile agents too.
Although we do not need mobility for our agents, we think aglets are a good platform with
which to build agents, whenever these must be mobile and have a strong communication
ability. The aglet API comes up with a built-in communication component which makes it
easy for different aglets to communicate with each other. The communication is based upon
the Agent Transfer Protocol (ATP) [LA97] which was mainly designed for transmitting
agents around a system. As the communication API provides the main basic functionalitythat is proposed in several agent definitions, aglets make agent development remarkablyeasier.
As we have intended before, our agents do not need to be mobile, and they also do not need
strong communication abilities. Therefore, aglets are "oversized" according to our needs.
Telescript
General Magic's [Gen] Telescript is a system for creating and running mobile agents. It is
object-oriented and comes with an interpreted programming language (mainly for securityreasons). Telescript is believed to be the first commercial agent language.
Telescript knows two key concepts in its technology: places and agents. Places are virtual
locations that are occupied by agents. Telescript was developed to support electronic mar¬
ketplace applications and its agents are the providers and consumers of goods. The agentsare mobile software processes which can move from one place to another. While moving,an agent's program and state are encoded and transmitted across a network.
Telescript technology is supported with several components. The language is one of them.
It "is designedfor carrying out complex communication tasks: navigation, transportation,authentication, access control, and so on" [Whi94]. Another component is the Telescriptengine. The engine is the heart of the system. It acts as an interpreter for the Telescriptlanguage, maintains places, schedules agents for execution, manages communication and
agent transport and, finally, provides an interface to other applications. The last main
component is the Telescript protocol set, which is used to perform decoding and encodingof agents to support the transmission between places.
Telescript provides an environment in which it is possible to run agents in a very pure way.
The main features of agenthood are already given and the user can concentrate mainly on
the application. Nonetheless, we decided to develop our own system because we do not
need all of the features in Telescript. We do not need mobility at all, therefore our profitby using Telescript is very small. When looking at Telescript in detail, we see that mobile
agents differ quite strongly from stationary agents, as well as the applications that use one
or the other type of agents are very different from each other.
19

2.2.3 Browser Assistants
Browser assistants are not performing searches for information on their own. As their
name indicates, they only help the users with their task of finding information. A classic
browser assistant is Henry Lieberman's Letizia [Lie95], [Lie97], which recommends links
according to the user's behaviour.
This concept itself is not useful for our purposes, as our concept is built upon giving exact
information of what we are interested in. We want to serve the user a concrete and correct
information item upon his detailed request. However, there exists one classical browser
assistant which is more interesting in this regard.
WebWatcher
The WebWatcher [AFJM95] is an agent which helps the user to find particular information,such as a paper, a person's homepage, a project homepage, software, course information,
or something else, while he is browsing through the World Wide Web.
After choosing one of the items above, the agent asks the user to supply further informa¬
tion on that specific topic. For example, if a paper is to be found, the user can define an
author, his institution, the title, the conference where it was presented and the subject area.
However, it is not necessary to fill in all the fields.
Then the agent presents the user the Web site from where the user contacted WebWatcher,
with a small difference: The agent highlights the link, which seems most likely to lead
to the desired information. Of course, the user can follow whichever link he likes, but
WebWatcher suggests a link to follow on each page. The agent analyses whether the user
chooses the suggested link or not and changes its suggestions accordingly based on the use
of machine learning techniques. Above the Web Sites, there is also a bar in which the user
may select either "I found it" or "I give up", whenever he wants to end the agent's work;
this also provides the agent with some quality feedback.
Behind the scenes, the agent does the following. When the user clicks on a link, the agentreads the content of this site. It then analyses the links, the meaning of the URLs and the
highlighted text, and gives every link a rating. Consider, for example, the search for a
paper. If the user specifies an author and this name is included in a link, this link would
get a high ranking. After determining the "best" link, the agent sends the user a copy of
the original page where the favourite link is highlighted and all URLs are redirected to the
agent itself, in order to leave the control with WebWatcher.
The concept behind the WebWatcher is very interesting, although it does not always lead
to the desired information. What is common with our requirements is the necessity to rate
the links before the content of the page behind it is known. But in our case, our agent is
not restricted to follow one link only, the agent can search all the promising Web pages
and so the chance to miss the relevant ones is far lower. A very positive aspect of the
WebWatcher, however, is the fact that users always have full control and are free to decide;
20

this is what makes WebWatcher have a rapid user acceptance. Commonly, users want to
have full control over an agent. They tend to not trust artificial intelligences as much as theytrust themselves. This comes mostly from the fact that they do not know the functioning of
such an entity well enough.
2.2.4 Shopping Agents
Shopping agents are very interesting for business applications in the time of electronic
commerce. A first application in this area was Andersen Consulting's BargainFinder[Kru96]. This very simple agent which was accessible from the Web could be used to
compare prices of music compact discs of different retailers.
Shopping agents are very interesting for us, because they need to get information from
other sources, mainly Web pages, to fulfill their tasks. However, as the BargainFinder'saccess to the retailers' pages was strictly hardcoded, this agent's technology is not of use
for us. Whenever the layout of a retailer changes, the user has to program the wrapper
newly. Our agents should be able to act mainly without the user's help.
ShopBot
The ShopBot [DED97] can be seen as the successor of the BargainFinder. In addition to
CDs, it was also capable of comparing software prices. However, the ShopBot is much
more sophisticated than its predecessor.
Unlike the BargainFinder, ShopBot does not work with hardcoded wrappers for its client
pages. The agent is able to learn the content of the retailers' Web pages by querying the
databases behind it. The exact technique is described in section 2.4, where we focus more
on the extraction capabilities of applications. The mechanism which is used in ShopBot is
an ideal approach to extract information from semistructured information.
The only thing a user has to feed ShopBot with are the URLs of interesting retailer sites.
This makes it very dynamic and an ideal tool to do shopping for independent customers.
2.2.5 Robot Agents
The name "Robot Agent" is not an official notation. We simply use it as the notation
of agents that can be imagined as simulated robots. Those systems usually come from
Artificial Intelligence and are used to prove AI concepts. Such applications are not beingdeveloped for the usefulness of the application itself.
Homer
When modelling Homer, Vere and Bickmore argued the following:
21

"The underlying thesis of this work is that AI component research and com¬
puter hardware have in fact progressed to the point where it is now possible,
by a resolute effort, to construct a complete integrated agent." [VB90]
Homer was developed very early, before there were proposals how to use agents, or even
what they shall consist of. Nonetheless, Homer is still a very good example of how to
integrate several capabilities into an agent.
Homer is a simulated robot submarine, which exists in a two-dimensional sea world. Ad¬
ditionally, the world also has a time component. Initially, the agent has only partial knowl¬
edge about its environment which contains a variety of typical objects for a sea world: fish,
birds, piers, boats and so on.
The agent uses a natural language text interface to communicate with the user. Homer
understands a limited subset of English with about an 800 word vocabulary. The user givesinstructions on what Homer must do, mainly to collect pieces and move them around. The
second main capability of Homer is the ability to plan how to achieve the instructions
and then execute the plans, modifying them as required during execution. The agent also
has a limited episodic memory, and using this, is able to answer questions about its past
experiences.
The text interpreter and generator for the communication with users is not very importantfor our purposes, as communication between agent and user does not have to be very
sophisticated. Additionally, our application does not need a full planning engine as our
agent's workflow is predefined.
On the other hand, the episodic memory is an interesting approach. Homer stores all
the information of his actions, perceptions and communications. This information then
is always checked for future situations in order to be able to perform identical actions
again if they proved to be effective in previous situations. This approach can be seen as a
very weak process of learning which was achieved with a comparatively small effort.
2.2.6 Information Providing Agents
Information extraction is the central task of our agents. Therefore, agents that almost onlydo information extraction are very interesting for us.
However, it is questionable if pure information extraction agents really can be named as
agents. We think this is dependent on the wrapping mechanism that is used to extract the
information. If the mechanism is static, meaning that someone defined a fixed wrapper
which can be overlaid to a Web site in order to get the structure and the meaning of it, this
mechanism is simply an extractor program. However, if wrapping is dynamic, meaningthat the mechanism is able to deal with different layouts and contents in the same way,
we see that as a weak form of a combination of reactivity and pro-activeness which were
described in section 2.1.
22

Movie Agent
During the work on this thesis, we supervised the work on the Movie Agent [Sch98] bySchudel. Like ACADEMIA, this is an agent application built for a specific task. Its aim is to
serve the user on request with information about new movies that are showing currently in
the cinemas. The Movie Agent also comes up with a connection to its own database. We
focus on this in section 2.3, here we concentrate only on the agent's work itself. However,
we have to mention that the Movie Agent uses some techniques of ACADEMIA which will
be described in detail in chapter 3.
The process flow of the Movie Agent can be seen in figure 2.2. The system's architecture is
mainly separated in two components. The first component contains a wrapper for a certain
cinema information home page which contains some short information about new movies.
After having extracted the data from this site, the Movie Agent queries the Internet Movie
Database (IMDB) Websites [IMD] about further information about each movie.
The agent then browses in the second part through the corresponding pages at IMDB and
delivers data such as detailed director and cast information, plots or links to other Web sites
that contain trailer files to the user. This second part of the system is much more dynamic as
the agent is capable of extracting the interesting information independent from the layout.In fact, behind the IMDB, there is a large database containing the interesting data which
is presented through HTML documents. The agent is able to handle these documents and
extract the information from it to bring it back into the structured form of a database.
Cinema
Information
Website
querying
Data
querying
Data
Movie Agent
storing
J IMDB
Websites
Data generating HTML
Movie AgentDatabase
IMDB
Figure 2.2: The process flow of the Movie Agent
Further Work by Schudel goes towards a framework for integrating different Web infor¬
mation agents [Sch99]. Within this framework, it is possible to create workflows usingdifferent agents to get the desired results. However, as the user has to define the connection
between two agents by hand, we truly cannot speak of a multi-agent system. For that, it
23

is necessary that the agents were added the possibility to communicate to each other to
process complex tasks by themselves.
2.3 Agents working together with Databases
We have until now discussed various agents that are somehow related to our work, but we
have not yet considered our interest in a tight coupling of the agent with the database. In
this section, we take a closer look at work in this area, however, the coupling of databases
and agents has not yet been a major issue. In existing applications which contain agents and
databases, the connections between them are often not specifically described. Researchers
have not yet paid a lot of attention to that part and, therefore, useful information is rarelyavailable.
Nevertheless, we want to discuss two applications where agents and databases are involved
together. In these applications, the two components are working together more or less
intensively and therefore, with respect to our work, this is worthy of closer examination.
The Movie Agent [Sch98] was already described in section 2.2. It is used to get information
about movies currently being shown in the cinemas. The agent also can be used to fill its
own database with the information found.
The Movie Agent works with the OMS system as its associated database, which is de¬
scribed in section 4.2. The agent itself is able to work without the database. It is written
in Java and needs a special settings file where the user defines whether he wants to use the
associated database or not. Whenever the database is to be used, the user has to start a
specific database server which then listens for requests by the agent. The agent afterwards
communicates with this server through a socket connection to read and write objects. This
technique has previously also been used in the first version [Mag97] of Academia, which
is discussed in chapter 3.
Of course, by using such a socket connection, the system is far away from a tight couplingof agent and database, but it was not the aim of this project to reach that stage. Nevertheless,
the application itself is an ideal example of a system where tight coupling would make
sense: The agent collects information which will be stored entirely into a database where
the user can browse it later on.
We have already discussed MIT's Ringo [Sha94] in section 2.2. A user tells Ringo about
the music acts he likes and Ringo then recommends other music to the user. This is done
using a database to store information about all users. There, the agent looks for users with
similar likes and recommends simply the acts that were listed by these users but have not
been mentioned by the current user.
Compared to the Movie Agent, Ringo is an even better example of an agent working to¬
gether with a database where it makes sense to have a tight coupling. The agent not onlywrites data to the database, it also reads data from it.
24

However, there is no specific information available on the architecture of Ringo with re¬
gard to the database. This means that the connection between agent and database was not
regarded as a critical topic. It seems that the connection was modelled rather simply, for
example by a simple socket connection for communication.
The number of users of the system grew rapidly after it was officially announced on the
Internet in 1994. Ringo was active every hour checking the messages of the users and send¬
ing them new recommendations. Therefore, for Ringo, a detailed sophisticated concept of
the architecture of the connection between the agent and the database not only would have
made sense, it presumably was a very critical factor over time, in order to provide a safe
running of the whole system.
Generally speaking, there exist two types of interaction by an agent with a database, one-
directional and bi-directional information exchange. The Movie Agent is of the one-
directional type, because it only stores information into the database, but it never reads
from it. This type is shown in figure 2.3(a). The opposite case of an agent which onlyreads from a database but never writes to it, is of course possible too. In this case, which is
schematically shown in figure 2.3(b), the database would contain the agent's configuration,or simply some data that is needed to process the agent's tasks.
Agent Agent
(a) Result database (b) Configuration database
Figure 2.3: One-directional interaction between agent and database
Ringo, on the other hand, clearly is of the bi-directional type shown in figure 2.4. It reads
the statistical data from the database and updates the database later when it has processedthe newly arrived inputs of its users.
Although we want to focus on the bi-directional type, the components of Ringo are not
cooperating with each other the way we need it. The agent runs by itself and the database
is only an add-on, In fact, Ringo is also able to work without a database, because the
functionality and the configuration of the system are both part of the agent. The absence of
the database would only affect the accuracy of the recommendations because it has no data
to compare new input with, but the correct functioning of the agent itself is not limited.
This interaction does not require a tighter coupling. There is a difference, if the database
contains configurational information for the agent as is intended in figure 2.4. In this case,
the agent does not know what to do without the database and the database without the
agent is just a static holder of data. Of course, as result information and configuration data
25

Figure 2.4: Bi-directional interaction between agent and database
likely will be of a completely different context, it is possible to work with more than justone database, for example one containing the configurations, and another for storing the
results. This approach will be discussed further in the following chapters.
However, there has been other work performed in which databases and agents work closely
together. An interesting approach is proposed by Larry Kerschberg [Ker97], but he ad¬
dresses large information systems in whole enterprises. He wants to introduce several
cooperating intelligent agent families, so-called knowledge rovers, to process several dif¬
ferent tasks such as supporting users, maintaining active views, mediating between users
and heterogeneous data sources, refining data into knowledge, or roaming the Global Infor¬
mation Infrastructure seeking, locating, negotiating for and retrieving data and knowledge
specific to their mission. In this work, the view is more on the global structure than on the
detailed problem. We focus more on specific single applications which are not in the focus
of Kerschberg's paper.
Other work [GKT95] has been made also in the area of active databases, where brokers, a
special form of software agents, are used together with an active object-oriented database
system to realise a cooperative, process-oriented environment. The authors combine agentsand a database to obtain a system with which it is possible for example to manage work¬
flows.
This approach, again, differs from our requirements. Although the actions can be triggered
by a database in this system, the agents know by themselves what they have to do. A
database cannot influence the configuration of an agent, which is one of our main aims in
this thesis.
On the other hand, the task of our agents is not so complex that we need several different
agents with individual capabilities. In the case of the work mentioned, the agents need a
comprehensive communication language to be able to communicate with each other, or in
other words, they use a true multi-agent system. We simply do not need the features of a
truly multi-agent system to achieve our goals, a single agent provides enough functionality
26

for us.
A final approach we want to discuss is the work done by the IAM at the University of
Southampton. The researchers there have built several interesting systems such as Mi¬
crocosm [DHH+92] and more recently MEMOIR [DHR+98]. The first is a hypermedia
system in which documents are not linked to each other by explicit links but by storinglinks in databases (so-called "linkbases"). However, Microcosm did not explicitly work
with agents.
MEMOIR, however, as a succeeding project of Microcosm, is a recommender system with
an agent-based architecture [PBS+98]. The MEMOIR framework was used to supportresearchers working with large quantities of distributed information in finding both relevant
documents and researchers with related interests. Besides the use of agents, MEMOIR
extended Microcosm's notion of first class links to first class trails which were stored in a
distributed object-oriented database.
The newest approach [EBDHOO] in this family of agent-database systems is built as an
advanced version of the MEMOIR system, with some particular adaptions of the agents. It
is a recommender system for assisting users while browsing. It marks links in documents
when they seem to be especially interesting or absolutely irrelevant according to previous
browsing efforts of the current user or of the other users. The framework involves several
different agents such as the user interface agent which is responsible for the interaction of
the system with the user, the organisational memory agent which manages all the statistics
and provides other agents with statistical information about specific URLs, or the link
service agent which manages a linkbase as in Microcosm to link documents individuallywhenever they are not linked explicitly.
The agents in this framework are using databases to be able to accomplish their tasks.
However, the connections between the agents and the corresponding databases are not very
tight. These connections can be compared to the connection in MIT's Ringo which was
mentioned earlier in this section. The databases are used to store statistical information
and the agents are updating that constantly and use it for further reccommendations. The
role of the databases is very passive, all the actions are initiated by the agents and none bya database.
The recommender system is able to assist in finding information in an intranet and the In¬
ternet too, which is also the aim of our thesis. However, it is only possible to look for whole
documents not for specific information items which we need for our work. Additionally,the system does recommend links based on previous experiences, but not according to the
needs during a new search.
So, for our search mechanism, we have to go another way. We are more interested in
databases and agents working closely together which means that the database has the pos¬
sibility to be more active. We want to have a database which also is able to start an agent
on demand. The systems discussed here mostly do not have this feature, but the reason for
this is more the fact that they do not need to have that to fulfill their tasks.
27

In the following section, we take a closer look at systems which are used mainly to extract
semistructured information which occurs all over Web pages. We need to find a way to
identify information items of interest, and we must have the possibility to extract them.
2.4 Information Extraction in Web Documents
Having discussed general agent technology, we now want to focus on agents or systemsthat in any way do information extraction. Information extraction from documents is a
large field in which researchers have been active since documents existed. In this section,
we not only want to have a closer look into the results of other research, but also to classifythem and outline the needs for our purposes.
The World Wide Web (WWW) is a major source of information about all areas of interest.
This information comes up in various ways. Besides unstructured raw data, there also
exists in many cases well structured information. The reason for this structure may be that
the data behind a Web page is taken from a database and the page is built automatically, or
perhaps because of an exactly organised and structured layout of a human creator.
When we look for information on Web pages, we often lose a lot of time while searchingfor the right document as well as locating the information in the document. Therefore, it is
desirable to automate this process, for example by launching an agent. This agent, however,should not only be able to locate the document, but also to learn how to extract the desired
information from it. This information may be represented in a structured format, so the
agent must "decode" that structure.
Therefore, it is necessary to be able to automate the extraction of semistructured informa¬
tion from Web documents. There are several varieties of Web documents. We are onlysearching in text documents, but there, we have three main variations of documents. First,there are text-only documents. It is not easy to extract structure from text-only documents,but usually, there are few documents of this kind. Another sort of documents are HTML
documents. These are very common nowadays. The third category is the one of XML
documents which are emerging.
We mainly want to focus on the extraction from HTML documents. As said, text-onlydocuments do not often contain structured information, so we want to provide only verybasic functionalities to deal with such documents. On the other hand, it would definitely beeasier for an agent to deal with XML documents as they come up with their own document
type definition. This helps an automated process to learn the semantics. However, the
standard on the Web is still HTML, so we have to concentrate first on information without
additional semantics. Nevertheless, we need an approach which is also able to work with
XML documents.
Of course, there have been many approaches made to solve the tasks mentioned. We want
to discuss them to show what properties we regard the most important for our approach.
28

We also want to classify these works in order to find out the features and characteristics
that are more or less important for our requirements.
We classify these works in various ways: First, we want to distinguish between general
approaches and those which only work for a predefined specific domain. Then we want to
divide these works into single tools and whole systems from which the extraction mech¬
anism is only a subpart. Very important for us is the question of whether a solution is
dynamically or statically oriented. Dynamically means the user has not to give many in¬
puts to the tool in order to receive reliable results - the tool is able to decode the structure of
semistructured information. Statically oriented solutions, on the other hand, need, for ex¬
ample, a wrapper to be created manually in advance so that the extraction mechanism can
come up with results. In the following, we call these three classification axes the domain,
the system and the dynamic factor.
A first specific technique has been used in comparative shopping agents to extract informa¬
tion from specific sites of on-line stores, so-called ShopBots [DED97], which were alreadymentioned in section 2.2. A ShopBot works as follows: The agent is given a URL of the
home page of an on-line store. Starting there, the agent tries to locate a search form to
search for the products that are offered in this store. Usually, such a form is present in
every on-line store. Once this form is found, the agent uses a learning method, as it enters
all information of a single item which most likely will be found in the database. For ex¬
ample, if this shopping agent is used to find music CDs, it will enter a test set containing
keywords such as "Beatles", "White Album" and so on. As a result, the agent will receive
an HTML page which hopefully contains information about the desired item. The agentthen analyses the content and from this learns the general structure of the pages. This is a
direct representation of the database which is behind these Web pages. The agent checks
the position of each attribute, which may result in information such as "first attribute: artist,
included in <B> and </B>; second attribute: title, included in <I> and </I>; etc."
In a further step, when the agent must find an item defined by the user, it only knows some
strings given by the user, but not to which attributes they belong. So the agent uses the
search form, enters all these strings and receives an HTML page containing the information
about the desired item. With the information previously gained in the learning phase,the agent is able to decode the attributes and learns about the price and other additional
information.
This method functions very well, but according to our requirements, there are two main
disadvantages. First, such search forms may exist in almost every on-line store, but not in
common documents of all domains. Second, for every domain of interest, there needs to
be set up another test set of keywords to be able to learn the layout of a newly discovered
site. Our biggest problem is that we do not know always what information is contained in
a newly found pattern. This means that the agent does not know which training set it has
to use. Therefore, this approach is domain oriented, but within a domain, is very dynamic.
Finally, this extraction mechanism is part of a system for which it was specifically created.
Another approach is to develop a language to specify the information to be extracted. This
29

approach has led to promising results and has been used in various forms in [HGMC+97],[BDHS96], [AQM+97], [AMM97], [HKL+98], [KM98] and [HFAN98]. Of course, the
requirements for our system are more complicated than for creating simply a general lan¬
guage to query HTML pages, but some mechanisms may be well applicable to our needs.
In [HGMC+97], there is a very simple script language presented which can be used to
extract semistructured information from HTML documents. This work is a part of the
TSIMMIS project which is intended to integrate heterogeneous data and documents into a
single system, independent of the domain of the data. The user writes a script file which
defines exactly where in an HTML document an information item can be found and then
the processor extracts the information. This leads mostly to correct results but also has
some disadvantages. The user always has to examine an HTML page before it is possibleto extract the information automatically, or to place it into our classification: it is not
dynamic. Additionally, this only will work until the layout of the corresponding document
changes, because the structure of tags and text will then be different and a new script will
have to be written.
The other approaches mentioned present programming languages to query not only Webdocuments but also structured text-only documents in a very convenient way. For our
purposes it is very useful to not be restricted to HTML pages only, but in JEDI [HFAN98],the problem is the same as before, because the user first has to examine the document and
then tell the structure to a program to make it extractable. This makes the approach domain
independent, but not dynamic. The parser, however, was not created for a specific systemand can be integrated in any other system as a tool. A useful feature of the parser is an
implemented fallback mode which prevents the parser from producing cascading errors
following a single false extraction. This makes the extraction more stable even if the user
has not defined the structure well enough.
The WebL programming language [KM98] is a very convenient language to query Web
pages as well as other documents. It is quite similar to the language from JEDI, though weconsider the handling of variables in WebL as more convenient. However, WebL belongsinto the same categories as JEDI, since it is domain independent but the user has to write
the wrapper by himself and therefore it is not dynamic.
FLORID [HKL+98] is an implementation of the deductive object-oriented language F-
logic [KLW95]. It provides declarative semantics to query the Web. Unfortunately,FLORID also needs wrappers defined by hand to access documents and is not dynamic.
Additionally, for our work on Web agents, we prefer an imperative object-oriented lan¬
guage to simplify the integration into our other programs which are mostly written in
Java. A similar approach as in FLORID has been used in the Information Manifold system
[LR096]. This system needs the definition of wrappers for the source sites in order to
be able to query them with a very extensive query language. Unfortunately here too, the
wrapper generation has to be done by the user, but of course, all of these approaches are
not restricted to a specific domain.
There are also the same features and problems in the ARANEUS system [AMM97]. How-
30

ever, this system comes up with various tools that can be used to manage and restructure
data coming from the Web in a convenient way. The main part of the system is the ARA-
NEUS data model which is built based on the structures typically present in Web sites.
With this model, it is possible to describe the scheme of a Web hypertext in the spirit of
databases.
ARANEUS strongly counts on the fact that there exist many documents on the Web that
are automtically built out of data coming from databases. These documents are usually
clearly structured and dynamic. The ARANEUS system provides tools for transformingthese Web sites again to present the data in a schematic format such as a database. So, it
is easier to integrate that data into other applications. However, the user has to provide the
necessary wrappers by himself.
Before using the Lorel language [AQM+97], a document's structure and data is filled into
a database and from there, a graph is created which defines the structure of the document
in question. This makes the subsequent use of Lorel very convenient, but the creation of
the database entries for every new document is rather hard work and therefore not dynamicenough for our purposes. The query language UnQL [BDHS96] is used in a similar way.
Query languages can be used in any domain and they are single tools which can be used in
other systems.
In W4F [SA98], there is a wrapper factory proposed for converting content of HTML sites
into XML documents. To do so, a special language is also defined, but the disadvantage is
the same as before: the user has to define the extraction program, and the XML document
is not created automatically causing the dynamic aspect to fall apart.
A more interesting approach for our purposes is described in the WebOQL system [AM98].
There, an abstract syntax tree for every document of the same family (e.g. HTML) is built
by the same wrapper, whatever the structure of the document might be. There is a query
language provided, which is powerful enough to query these trees in a variety of ways. The
navigation patterns of WebOQL are a generalisation of the path regular expressions of the
Web query language WebSQL [MMM97]. Nevertheless, the semantics of the several nodes
of a specific syntax tree have to be defined by the user and the system does not support the
detection of it. However, this system provides a higher dynamic level than those discussed
previously.
A final very interesting system is the Ariadne system [KMA+98]. Although it also needs
the user to create wrappers for the documents that are to be queried, the assistance by the
system is very comprehensive. The user reads the content of a Web site and enters the
interesting data and its semantics directly into a text file and, afterwards, the system learns
it and creates an automatic wrapper for it, so that it is ready to be queried. However, as
stated before, we do not know the Web sites that our agent has to parse in advance. This
means that the system is only as dynamic as the user is - if the user provides much feedback
to the system, it is powerful, and if the user does not give a reasonable effort to that, the
system will not be very useful. Considering this, it is quite difficult to get good results if
the situation is complex and needs much help from the user.
31

Having discussed all of this related work, we want to have a look at what we can conclude
out of our classification. We can see that it does not make a remarkable difference whether
an extraction mechanism was implemented for a given system or if it has been created as
a single tool to be used in general. Of course, if an extraction tool was built to be used
in a specific system, it means that the requirements were more specific than for a gen¬
eral extraction tool. Nevertheless, the extraction mechanisms themselves are very general.Therefore, in our further evaluation, we put this aspect aside.
The main problem is to combine a dynamic approach with a domain independent one.
Figure 2.5 shows a diagram where we placed the discussed approaches according to their
classification with regard to these two remaining factors. The optimum for our purposes
would be an approach high in the upper right part of figure 2.5. Unfortunately, such an
approach has not yet been realised. Therefore, we have to determine a new way to reach
this goal.
site'1
independent
À
A
domain domain
dependent independent
,o
°x
V
site dependent
Figure 2.5: Classification of related work
Our approach needs to have the dynamics of a ShopBot combined with the domain in¬
dependence of all the other approaches. It seems that we need a knowledge base behind
our agent to be able to learn the semantics, i.e. a ShopBot with stored knowledge of any
possible domain. On the one hand, this would increase the time of procession of the agent,but we want to keep the agent as fast as possible. On the other hand, it is not realistic
that the agent is always able to learn the semantics independent of the information domain.
We cannot prove this explicitly, but the heterogeneity of our main resource, the Web, in
A ShopBot
A Ariadne
WebOQL
O ARANEUS
+ W4F
• JEDI
* WebL
T Manifold
O Lorel
X FLORID
D UnQL
WebSQL
V TSIMMIS
32

addition to the infinite number of possible information domains, strongly points in that
direction.
Because of this, we have to follow another way: first, the user defines what he is interested
in and, with that, he implicitly states the semantics of the information. The agent has to
be able to derive and learn as many as possible facts out of that definition. If these derived
facts do not lead to useful solutions, the agent will have to interact further with the user.
Finally, the agent will be able to come up with reliable results, and if it is able to learn
from the inputs of the user, the next search process will need less interaction with the user,
despite possible changes to the domain of interest. This approach is detailed further in
section 6.2.
2.5 Summary
In this chapter, we focussed on background information related to our work. First, we
explained agent technology in general, where we discussed the definition of agenthood
according to the definitions of several researchers. We consider a software system which
has at least got the properties autonomy, social ability, reactivity and pro-activeness, as
an agent. In addition, an agent may have one or more properties such as mobility, verac¬
ity, benevolence, rationality or cooperation, but we consider these properties as not beingessential for agenthood.
Next, we discussed some agent applications which on the one hand demonstrate the agent
properties defined and which address the issues relevant to our work. We have seen that we
can use certain parts from the work in the area of personal learning assistants. On the other
hand, tools or languages which are used to create mobile agents cannot take us significantlyfurther. Techniques used for browsing assistants and shopping agents, however, are useful
for the processes where our agents have to decide whether they want to follow a link on a
Web page or not and whether the reliability of the results is high enough or not.
After having taken a look at general applications, we examined agents which are working
together with databases, more or less combined. We have seen that the concept of putting
configuration information of agents into a database and letting this data be updated by the
user as well as the agent has not yet been introduced widely. Many agent applicationsare using databases bi-directionally which means that they use the data in a database and
also update it. However, in most cases, this data consisted of statistical information only.Therefore, the issue of achieving a tight coupling of agents and databases has not been
addressed at all.
Finally, we concentrated on related work in the area of semistructured information extrac¬
tion from documents. We classified some of the many existing approaches in this field
according to two main factors. One is site independence - meaning the ability of a systemto extract information correctly independent of the layout of the presented information,
with as little assistance as possible from the user. The other factor is domain independence
33

- the ability to extract information from a Web site independent of the domain of the con¬
tent. For example, can the system be used to extract sports results as well as information
about books?
Our classification showed that these two factors are rarely available within one system.Most existing applications have high domain independence and low site independence,while the ShopBot is the classical application which is highly independent of the site but
very domain dependent. Out of this analysis, we can conclude that we have to combine the
best of both worlds to get a good solution for our problem.
In the following chapter, we want to focus on the "old" ACADEMIA system which has
already been mentioned several times. In this old version, the agent and the database were
separated from each other. By developing this system, we became aware of the necessityof achieving a closer coupling of these two components.
34

Chapter 3
ACADEMIA
In this chapter, we want to detail the ACADEMIA system [Mag97], [MEN98a], [MEN98b].ACADEMIA can be considered as the beginning of this thesis. It was built as an applicationto reduce the work of an academic in finding and updating information about other re¬
searchers. The original system was designed with a strict separation of agent and database.
The agent was the dominating part, while the database was only used as a storage tool.
The early work done in the diploma thesis [Mag97] was an initial investigation and estab¬
lished requirements typical of the category of Web information agents considered. Duringthis work, the basic techniques were identified which in fact are of use for such an agent.This chapter presents a later and improved version of Academia which already solves a
lot of the problems observed in the early version. This version is the final version of the
evolution of Academia as a single stand-alone application.
Academia was planned only as a prototype to demonstrate the functionality of a Web
agent and experiment with discovery and extraction techniques. Therefore performancewas not a major issue in the design of the system and we will not discuss that issue in more
detail.
However, when the system as we describe it in this chapter was finished, we quickly recog¬
nised performance problems. In addition, the configuration of the system was awkward
and tedious. We describe this system in order to give a clearer picture of the problems ex¬
perienced. By fixing these problems, we achieved a constant evolution of the architecture
resulting in the solution presented in this thesis.
3.1 The Academia System
As already stated, ACADEMIA is used to reduce the work of people finding and updating in¬
formation about researchers. People working in a research job usually have many contacts
to people from other universities who are working on similar research topics. Therefore,
35

a database could be used to store these contacts along with addresses and phone numbers.
Even interesting publications and projects may be stored in such a database.
Somehow, this data has to be kept up to date. Some data may be constant, such as the birth-
date of a person or the first name. Other data changes seldomly, such as email addresses or
last names. On the other hand, some of the data such as publications may change more of¬
ten. Corresponding updates in the databases usually occur with significant delay - or even
not at all - since they tend to be based on manual notification by the corresponding person
or detection of outdated information at the time of use e.g. an incorrect phone number. This
can lead to frustration and a lot of work to keep the data up to date.
This is a perfect environment within which to create an agent. The agent works in the back¬
ground and checks the Internet for information about the contact people either periodicallyor on demand. In this way, the agent maintains the database. The user only works with the
database, he does not even have to interact with the agent after having started it once. This
is the task of ACADEMIA.
3.1.1 The Components and their Work
In this section, we detail a version of ACADEMIA implemented using strictly separatedagent and database components. Although it was built as a specific application, during the
work on Academia, we wanted to leave the architecture as open as possible to make it
useful for other applications. The general concepts of this system should be usable in other
applications and, with this aim in mind, the agent was made to be dynamically configurable.Figure 3.1 shows the components of the Academia system and the work flow between
them which we now discuss in more detail.
The Academia database is implemented using the OMS Pro object-oriented database
management system (DBMS) described in section 4.2. OMS provides a graphical browser,full query language and methods which are used to support user operations such as down¬
loading documents. Since the system also supports URLs as a base type, viewing Web
pages and sending email via an Internet browser can be done directly from OMS. Further,since a generic Web interface for OMS is available, the Academia database can also be
accessed through such a browser. These features make OMS a very useful database for our
contact data.
The key contact information in the database consists of person first and last names and
Web addresses. The name is necessary to identify a person, while the address is a generalstarting point for the agent to search for updates. If the user does not know any homepageaddress of a person, the system uses a specific component to find the best possible URLs.
We will describe this component later in this section.
The database also stores general facts about persons such as title, address, photographsand information about research activities including the titles of publications, URLs lead¬
ing to abstracts or a publication file, project titles and URLs of pages containing further
36

IS ISIS IS
WWW Pages\ \
browsing
Figure 3.1: The components of Academia
information on the project.
The user accesses the database directly to retrieve and process information on academic
contacts. Usually this is just a read process, but by entering a new contact giving the full
name of the person only, the user mandates the agent to look for a new contact on the Web,
and the agent will later try to find the desired information. By using this possibility, the user
can look for information about researchers of which he does not yet know anything. This
occurs if the user has been informed by someone that some "Mr. X" might work on similar
topics, but he does not yet know anything more about that person. Instead of searching the
Web by hand, the agent can do that for the user. The information found by the agent can
then be seen as a sort of pre-selection for the user: Either the projects and publications of
the person seem interesting or the user can decide to ignore this person because they prove
to have published in a field that is not of interest.
The Academia agent provides a value-added service by using the information extracted
from Web documents to maintain the database and ensure its currency. The agent may
either update the database directly, or consult with the user as to whether or not it should
perform the updates. An Academia agent usually runs in the background according to the
periodicity specified by the user. A possible period would be to run the agent once every
night, so we only use the CPU at a time when the user usually does not. Nonetheless, in
this way, the data is up to date on a daily basis which is convenient. However, ACADEMIA
might also be used for an ad hoc search of an individual. This can happen, if, for exam¬
ple, the user comes across the name of an unknown researcher and wants to search for
37

information about this person. Therefore, we also want the agent to be fast.
The extraction process of the agent is specified by an extraction profile. For a given appli¬cation system such as Academia, this profile is provided as part of the system. However,
the user could adapt it to search for additional information. For example, if interested in
finger information for a person, the user could add an extraction pattern to the profile to
look for this information too. Definitely, a user needs to be experienced in order to be able
to do so. This means that the user needs to now in which environment such information
occurs and how it is formatted. Additionally, the user has to identify a keyword which
occasionally occurs in combination with this finger information. However, this gets clearer
if we later detail what attributes the extraction profile consists of.
In this version of Academia, the extraction profile is defined in a pure text file. The user
works with a standard text editor and alters the profile whenever necessary. This text file
consists of several lines, each line standing for one specific extraction. Before discussingits detailed composition, we want to describe a search process in detail from the very
beginning.
First, an Academia agent reads the name and Web address of each person in the database
to determine the search domain. If the agent does not find a Web address for a person, it
tries to find a homepage by using the search component mentioned before. In this case,
the only search arguments are the first and last name of the person and, of course, it is not
sure whether relevant documents will even be found. Some names are very common which
means that there exist several other persons having the same name. Therefore, we have
to be aware that the name itself is not exact enough to receive a result which is a hundred
percent reliable.
A second uncertainty comes from the correct spelling of the name. There exist different
spellings for some names, such as for example "Kimberley" or "Kimberly", and even the
name might be changed to a short form, such as "Kim", for example. The worst case
scenario here could be the person using a nick name which is quite different from the
original name.
On first sight, it seems as if the name of a person does not give us very much certainty. To
deal with this uncertainty, we had to define some requirements for the user of ACADEMIA
in advance. First, the user is assumed to be reliable in the spelling of the name of a contact
person, and second the user has to use the most common name which this person uses.
Whenever the user is not sure about these two requirements, he has the possibility to trysearches with all the possible spellings. This is a rather weak solution, but it served our
purposes. However, the agent can now assume that the name of a person is given correctly.
At this point, we want to note that it is easily possible to adapt the search mechanism of
the agent so that it is able to alter spellings in the case of bad or few results being found.
However, the uncertainty increases, because the modified names are even more unreliable
than the ones given by the user. The agent would have to contact the user over and over
again to check whether or not the results found are correct. This is something that from the
very beginning we wanted to avoid.
38

All this means that the search component only has to be aware that the name may lead to
a different person. The first version of ACADEMIA used a simple wrapper around a search
engine such as AltaVista [Alt] or the Metacrawler [SE97] as the search component. The
agent was fed with the first ten results of the search engine's output. The results were
usually quite good, if the person in question was really working in the research area and a
homepage existed. But, whenever there existed many occurences of other persons with the
same name on the Internet or even the first or the last name of a person also had a meaningin one or more natural languages, e.g. the family name "Hammer" also stands for a tool in
english as well as in german, the results were not that useful.
A good example is the search for information on "Bill Gates". This last name itself may
lead to irrelevant pages because of its meaning similar to "doors". In combination with the
first name, however, we can be quite sure to reach information on that man. Nevertheless,
because of Bill Gates being a celebrity, we will also find a lot of information which is not
serious. This may have happened knowingly or not, but this is yet another problem we
cannot take care of.
We therefore developed a special search component for Academia called the HomepageFinder [Sel98]. Altough this tool can be used as a stand-alone application, it was developed
especially to be used by Academia. The Homepage Finder's work flow is shown in figure3.2. This component first contains a wrapper around the Metacrawler search engine, which
is used because it combines the results from several big search engines. The search enginewill be queried with the first and the last name of the person, without requiring them to
occur both or together.
When the 10 best results for a search term list are identified by the Homepage Finder, the
pages are further checked for whether or not they exist and whether or not they contain the
complete name of the person or not. This check algorithm was developed specifically for
the homepage domain. The checks result in a new ranking of the best results and these
are finally returned to the agent. The Homepage Finder also has the possibility to query
additionally the Ahoy! Homepage Finder [SLE97] to receive homepage addresses, but we
do not exclusively use Ahoy! because we want to get as many results as possible. Ahoy is
too restrictive for our purposes, as it usually does only return "true homepages" whereas
also other pages may lead to good results.
Additionally, the Homepage Finder can be fed with other keywords which also will be
entered to the query. This feature can be used to enter additional information about a
person, if it is known. For example, if an attribute of a person is already known, the agentcan use that to receive a better selection of resulting pages. Concretely, if we are interested
in a person working at "ETH Zurich", we can add this term to the search keywords causingsites containing the name of the person and the term "ETH Zurich" to be ranked higher,and with this, the person's homepage at the university will be ranked high.
It is important that the Homepage Finder delivers good results. Academia will not find
correct results if it does not reach a page with information about the person in question.The general homepage finding problem has been approached in a number of other works.
39

Checker
List of good Results
Figure 3.2: The Homepage Finder
Here, we only want to cite the recent work of Craswell et al. [CHROl] which discusses
the finding of a site given the main keywords that should identify the site. This is mainlythe problem we have here, as the name of a person shall be used to identify the homepageof that person. However, the work of Craswell et al. shows that link anchor information
may serve as a better indication of the appropriateness of a document than the document
content itself. In our system, we have the possibility to use this anchor information for
finding related pages when the agent searches a Web document. This is discussed later in
this section as well as in section 6.1.
Basically, the Homepage Finder needs a search engine to work, and our results are depen¬dent on the results given by the chosen search engine. A simple version of the HomepageFinder works quite well for us, therefore we did not go further into the direction of devel¬
oping a significantly better page finder. The results of the Homepage Finder are discussed
in section 7.5.1.
Back to Academia, where the agent now performs a search with each of the pages re¬
turned by the search component. In the case that information is found, the agent later
consults with the user who decides whether this information is reliable or not and should
40

be stored in the database.
Given one or more possible home pages for a person, the agent starts to extract information
from these and referenced pages. Searching home pages is done in two basic ways -
keyword-based and pattern-based search. In the case of keyword-based search, the agent
searches for keywords as specified in the extraction profile. For each keyword, a set of
options is specified which tells the agent what information may be found in proximity to
the keyword.
As an example, we take a look at figure 3.3. In the first line we use the keyword "email" to
find an object of type email. This predefined object type looks for strings with no spaces
and exactly one'
@' in it. In this line, there are a couple of additional preferences given,for example the maximum distance allowed between the keyword and a possible solution
string, and the minimum or maximum length of this solution. The second line is used to
find the title of a person, in this case the title "Professor", whereas the third line, givenwithout an object type, is used to extract a link to follow further. This link shall be found
after the combination of the two words "my" and "work".
KEYWORD Res KWin MaxD NameD FNameD ScndKW ScndKWD MinL MaxL Conf Obj"email" e x 0 0 0 "" 0 8 40 1.0 email
"prof" b x 0 24 10 "" 0 0 0 1.0 title
"my" 1 x 15 0 0 "work" 12 0 0 1.0
Figure 3.3: Part of an extraction profile
Details of the extraction process and the format of the extraction profile are given in sec¬
tion 6.1 - the approach in this early version of ACADEMIA is more or less the same as the
current one which is mainly more efficient. Although such keyword searching is relatively
simple, it has proved effective and is used in Academia to find general information about
a person and also potential links to pages containing publication lists or project descrip¬tions. In section 6.4, we discuss an empiric evaluation of the extraction methods.
Of course, we have also evaluated other techniques that are usable in this context. The
main thing that the keyword approach misses is the semantic interpretation of a whole text.
This information can be tracked by using linguistic analysis of the sentences. However, it
is quite an overhead to search for the semantics just to extract a simple information item,
therefore we have not concentrated on this very much. We further discuss this in chapter 6.
Pattern-based search is used to find information about publications and projects. In most
cases, this information is represented in lists and cannot be extracted by the keyword ap¬
proach. For example, publications are frequently represented within Web documents as an
HTML list with each item giving the authors, title, publication information and one or more
URLs to download the document. The keywords "author" or "title" do not occur explicitly.Our agent therefore tries to detect a recurring pattern in the HTML page which has been
identified as possibly containing a list of publications. This is based on HTML-commands
around text items and the use of lists, tables and different fonts to structure information.
41

The technique to extract information from such sources is commonly known as "extraction
of semistructured information" and our approach to that is described in section 6.2 in detail,
whereas the results of that approach are discussed in section 6.4. The early ACADEMIA
system is running with a similar approach. However, the implementation is not dynamic.The user is only able to look for a publication or a project and the extraction mechanism is
hardcoded for both. This means that it is only possible to extract information from a rather
small part of all the available publication lists as, because the approach is not able to adaptitself to a specific list. As an example consider the pages of the DBLP Computer Science
Bibliography [DBL]. A specific DBLP list is shown in figure 3.4. Although the corre¬
sponding database contains a comprehensive amount of information about publications, it
cannot be parsed by this static extraction approach. The problem lies mainly in the fact
that the entries are separated by the years in which the publications were published and
this relatively small adaptation of a publication list is sufficient to throw the extractor off
track. Additionally, the extraction mechanism is also not able to handle the links to other
authors' publication lists that are included as well. In comparison, the current V-Wrap,which is described in section 6.2.4 is definitely capable of handling much more variation
in structured lists as it works with a highly dynamic implementation. In addition to that, it
is not limited to a specific domain.
As mentioned, the agent starts searching from a potential home page and repeatedly fol¬
lows interesting links to search for further information. In the early version implemented
during the diploma thesis, links were collected in a search list and could be of three types:links that likely lead to general information, to publications or to research topics. The agentsearched each link using the corresponding search technique defined for each type of link.
Common links were searched as intended with the keyword method, whereas publicationand research topic pages were searched for those information items only, as mentioned be¬
fore. However, this is now handled better in the version we describe here. There exists onlyone list of untyped links. In fact, every link will be searched for every possible information
item, but the profiles to extract publication or project information are still working very
differently from the general extraction profiles. The latter profiles are fully parameterised,but the publication and project profiles are static and inflexible.
After the search for one person, a confidence value (CV) is computed for each information
item found based on the reliability of the extraction pattern used to find that item and the
level of corroborating and/or contradictory information found. For example, if the same
telephone number is found in several places, the level of confidence will be high. However,
if different phone numbers are found on different pages, the confidence in each will be low.
These CVs can only be calculated at the end of the search since it is not possible to predictwhen and where items will be found. The method with the CVs has proven effective, so
that it has not changed significantly since this version. It is described in detail in section
6.3.
Once the search is complete, the agent starts the interaction with the database. For every
fact that has a CV greater than the user-specified threshold, the agent writes the fact in
the database and records this action in a log which the user may access to examine the
agent's actions later. For facts which have CVs below the threshold, the agent will later
42

N NetscM>e;BBlF:MoiraC.Norrie
Moira C. Norrie
List of publications from the DBLP Bibho graphv Server
Homepage
25
f~
24
23
20M
Beat Signer. Antonie Erni. Moira C Nome A Personal Assistant for Web Database CachingCASE 2000 64-78
Epaminondas Kapetamos. Moira C Nome. D Fuhrer-Staluc MDDQL A Visual Query Languagefor Metadata Driven Querying VDB 2000
Adrian Kobler. Moira C Nome OMS Java A Persistent Object Management FrameworkL'OBJET 6f31 (2000)
19»
,Lp Epaminondas Kapetamos. Moira C Nome A Frei An Information States Blackboard as an
' BttIntelligent Querying Interface for Snow and Avalanche Data UIDIS1999 32-41
an
I—Andreas Sterner. Adrian Kobler. Moira C Nome OMS/Java Model Extensibility ofOODBMSfor
** Advanced Application Domains CAiSE 1998 115-138
. MoiraC Nome Atenos Pahngims. Alain Wurgler OMS Connect Supporting Muladatabase and* Mobile Working throughDatabaseConnectivity CoopIS 1998 232-240
1»7
Andreas Sterner. Moira C Nome Temporal Object Role Modelimg CAiSE1997 245-258
LoL» Andreas Sterner. Moira C Nome Implementing Temporal Databases m Object-Orientedi S Systems DASFAA1997 381-390
120 j!
19
fl^ SSDHM1997 24-27
16
'j Moira C Nome Data Mining and Modeling in Scientific Databases
MoiraC Nome ManmWunderh Tool Agents ntCoordinatedlnformattonsSystems IS22(2ß)59-77 (1997)
Figure 3.4: An example publication list from DBLP
consult the user who decides whether the fact will be stored or not. The agent stores the
decisions of the user for future reference, thereby avoiding repeatedly asking the user the
same questions. Whenever the user gains more confidence in the agent, he may reduce the
threshold to give the agent greater autonomy.
Regarding the users, we can divide them into different categories according to their use
of the system. There are users that install the system and always use the initial extraction
profile without ever adapting it. This may be because the agent already performs well or
because the user simply is too inexperienced. The only thing which these users may changeare the threshold values or the period of the search runs. The second sort of users are those
which adapt single attributes in the profile. For that, the user has to know about the generalform of some pages in order to be effective. The third and final level of users is when
the user extends the system by adding new search profiles to the existing ones so that the
system increases its extraction possibilities. For this, a user needs to know the system quitewell and must also be aware of the structure and appearance of Web pages in general.
43

3.1.2 The Connection between Agent and Database
We now want to discuss further the connection between the agent and the database. This
approach uses a rather simple method, as shown in figure 3.5. As already mentioned, the
database is implemented in OMS Pro which is implemented in Sicstus Prolog [Swe95].
For the database, there exists a database server written also in Prolog, which has a direct
connection to the database. This server is listening on a predefined port on the system.
Academia
Info
Figure 3.5: Academia's connection between agent and database
The agent, however, is the only active client in the whole system. The database never asks
for a connection to the agent. Whenever there has to be information stored to or read from
the database, the agent connects to the port and makes its request. Either the request is for
the storage of a new information item in which case the server stores the item and simplyreturns a confirmation whenever the task is complete. On the other hand, if the agent wants
to read an information item, for example at the beginning of a search when it needs to know
the names and homepage addresses of the persons, it waits for the answer of the database
server.
Over the socket connection, the agent and the database server send their messages in a
specific database query language designed for ACADEMIA. However, this language is kept
quite simple. There are in fact three main types of requests possible: read and write and
also a specific command to receive all the person's names at once. The first two request
types can only handle one information item at a time, which means that for each attribute
of a person, there is a single request necessary to read or write it.
As the main idea of Academia is to repeatedly check for information of the same persons,
it is clear that the pages found do not change a great deal. Updates of personal pages are
usually done rarely. Therefore, the system uses a quite simple form of caching technique.
Each document which has to be read is checked for three attributes: The date when it
was last modified, the length and a special hashcode. During a search, these values are
compared to the values when the document was last accessed. Whenever at least one of the
values is different, the new page will be searched and otherwise not. This meta data will
also be stored in the database, and there exist two special commands for reading the last
checked page data and storing the new page data.
f "\
Socket DBServer
Connection
>.
^Academia
Database
44

Of course, this method is not a hundred percent safe. On the one hand, there exist many
pages without the "last modified" tag. The other two values do not necessarily have to
change when a page is updated, but this possibility is very small, so we can nearly exclude
this failure. On the other hand, although a document has not changed, it is well possiblethat there exist links to other documents on it, and those may have changed. However, the
system discussed here does not check for that. Nevertheless, periodically, the system is
forced to perform a full search without comparing that meta data. This ensures that while
the results are perhaps not always as good as possible, at least after this periodic full search,
for example once a month, the optimum is reached.
Of course, it is obvious that this system has many weaknesses and disadvantages. In the
following section, we want to discuss these and mention the optimisations we made, as
well as the points where we had to invent new methods to obtain good results.
3.2 Weaknesses and Disadvantages and their Solutions
After having detailed an early ACADEMIA system, we now want to discuss the problemswe had with it. In addition, we describe the optimisations we made and also the problemswe could not solve easily.
This version of Academia has some obvious weaknesses, such as for example the hard-
coded pattern-based extraction mechanism. We were able to develop a dynamic approachto solve that problem. Everything concerning the extraction part of the agent will be dis¬
cussed further in chapter 6. The caching mechanism, to give another obvious example, has
also been completed by implementing a full cache for all of the documents read. It is no
longer necessary to check some document attributes.
Additionally, we wanted to generalise the system, in order to use it for any search task.
First, it was certainly necessary to define the architecture of such a generalised agent. This
architecture is described in chapter 5. Then, we had to determine an abstraction of the
search and extraction part. Another problem was to decide about the way to describe an
agent and, from there, how to construct an agent out of it. This was realised with the Web
Agent Toolkit (WAT) which is described in detail in section 7.2.
Another important feature of the system is its configurability. On the one hand, the global
preferences such as the period between runs or the threshold which sets the measure for
the reliability of information found can be defined in the main configuration file of the
system. On the other hand, it is even possible to configure the search itself by changingthe definition of what the agent should look for. This is changeable within an extraction
configuration file. However, it is definitely not convenient to edit detail preferences in a
file of the form shown in figure 3.3. Here, the user would need at least a manual and has a
tedious task ahead.
Therefore, we have to find another way to manage the configuration of the system. It must
be our main concern to bring the different data closer together. When we go a step further
45

and think of the possibility of a user having more than just one agent working on his behalf,
each agent coming up with another configuration, this is definitely inconvenient as the user
might be lost in the amount of files and databases of which he must keep track. It must be
our goal to concentrate this data in one place only so that it will not be forgotten or even
lost, and also for making the data management easier. If we can store all the data in a single
place and manage it from there, any necessary data recovery can be more easily organised.
The best solution for this problem is to put all the data that is necessary for the system to run
into the database. We already use the database for the storage of the results of the search,
therefore we need it anyway. However, there is no necessity to keep configuration files.
So, we decided to place the whole configuration into an OMS database, too. This requiresthe agent definition to be modelled in a way that it can be represented in a database.
If we use a database to store the configuration, we automatically gain all typical advan¬
tages of database systems in contrast to simple text files. The database system provides
well-organised access to files and helps with recovery mechanisms whenever data appar¬
ently has been lost. It is also very simple to include a history management for storing old
configuration data. This is very interesting if we are in the prototyping phase and want to
find the best possible configuration for a specific agent. Finally, a database offers consis¬
tency, which makes it easier for an agent to work with it.
This decision has another side effect. If the data is all in one place and can be handled
from within a single application, we have the possibility to access it all from within a
single application user interface. Of course, the configuration and result data is different
and the actually used interface for each of them may slightly differ, but in general, it will
look similar. It is already clear, that we need a better user interface to provide the user
with a convenient way to alter the preferences of a search. With this solution, we can
use interfaces of one application only, therefore this access will also be easier. Currently,users are flooded with applications and user interfaces. Therefore, we can also reduce the
number of quite different user interfaces that the user needs to work with.
The conclusion of the requirement to transfer the configuration data into the database is
that the database and the agent have to be coupled more closely together. We do not want
to get a large overhead in processing time because of the transfer of configuration data to
the agent whenever it is necessary. These issues are discussed in chapter 7. The prototypewhich we built to show and prove our concepts is the already mentioned Web Agent Toolkit
(WAT) which is described in section 7.2.
Another major problem of this Academia system is its poor performance which has the
effect that it is not very usable as a real-time application. A complete search for information
on 10 persons lasts several hours. Of course, this is also a problem of the efficiency of the
search. In conjunction with the fact that the database version we use here causes the whole
database to be locked during the period in which the database server is active, this leads
to the problem that it is not possible to access the database frequently, if the agent is set
to check for updates often. This definitely needs a re-engineering of the whole system,
including the database.
46

The OMS Pro database system we have used in this work is commonly used as a prototyp¬
ing system, which means that performance is not the most important feature. Therefore,
the search for particular information in the database needs a certain amount of time and
we do not want to concentrate on how the mechanism in the database might be improved.This, however, is a reason for discussing the database we use for our system, and this is the
topic in section 4.1.
Nonetheless, several quite small and easy to implement improvements are possible. First,
a newer version of the database makes it possible to let the database server disconnect
from the database, whenever the database is not used. With this, the database is no longerblocked for such a long time, because during the time in which the agent searches the Web,
the user can access the database. Another improvement would have been to augment the
query language for the database server, in order to make it possible to read and write more
information at once. For example, the agent could collect all the information for a contact
person and - after the whole search process - write all this data back into the database
with only one request. However, it does not make sense to make this query language and
therefore also its use more complex, because the difficulties lie somewhere else.
Our main problem lies in the connection between the agent and the database which con¬
sumes the most time in this process. First, we have to stop using just one connection to
the database during the whole search process of the agent. As we have mentioned, this
becomes possible with a new version of the database. We have to split the connection up
to single sessions for the communication to the database. With this, we can reduce access
problems for the database. On the other hand, the increase in the numbers of sessions au¬
tomatically consumes more time, because the connection process consumes a lot of time,
too. We could use a thread pool consisting of threads that connect to the database, but the
creation of a thread as well as its acquisition whenever it is available also needs time. The
only result of this discussion can be to look for a new sort of connection between the agentand the database - a tighter coupling.
We see that several problems of the old Academia system have their solution in a new
concept to find a closer relationship between the agent and the database. We have even to
try to find not only a tighter coupling but possibly a fusion of the two components.
3.3 Summary
In this chapter, we have been focusing on the early Academia system. This application
rapidly reached its limits due to a lack of performance and efficiency. We have described
the whole system, in order to be able to show the disadvantages and weaknesses of the
architecture.
Academia can be used to find general information about people working in the research
area. This information consists of usual contact data such as postal and email addresses,
titles, birthdates, phone and fax numbers or pictures. Additionally, the system also looks
47

for information on publications written by a person as well as on projects in which the
person has been or is involved.
The agent runs periodically in the background and the user checks for the results in a
database. The idea of the system is that the user does not have to interact with the agent,
only the agent asks for assistance of the user, whenever the agent cannot decide about the
reliability of a result by itself.
We have seen that the connection between the agent and the database is the weakest link in
the whole Academia system. Other problems can be solved quite easily, but the exchangeof information between the agent and the database is an essential part of the system, and
so, it has always to run correctly and be efficient.
In addition, the handling of the system, more precisely the maintenance of the configurationis difficult. This brings up the necessity to integrate the configuration also into a database
and therefore control the agent from there. This makes the cooperation between agent and
database even more important.
These problems tend to lead us in the direction of coupling the agent and database more
tightly - even considering a fusion between them. We saw that it could not be a solution
to work with a simple database server and have the cooperation between the components
running over a socket connection. In the following chapter, we begin with these consider¬
ations by discussing the database part and define our requirements which led us to use the
OMS database management system, and concretely OMS Java. We present the advantagesof the OMS system and describe why this is an ideal system to use for our purposes.
48

Chapter 4
APPLICATION DATABASES
This chapter discusses the use of databases in the context of Web agents. We define the
requirements which a database system must fulfill in order to make the combination with an
agent as powerful as possible. We explain, why these requirements influenced our decision
to use one of the OMS database systems.
In section 4.2, we then describe the main features of the OMS database systems. This
includes a short overview of the OM model which is the underlying model of all the OMS
database management systems and of the ACADEMIA application database in particular.
Finally, we will describe the OMS Java system which is the specific OMS system used in
our prototype.
4.1 Requirements Analysis
In the previous chapter, we described the first version of the ACADEMIA system. This
system consisted mainly of an agent and a database, where the agent interacted frequentlywith the database. When discussing the weaknesses of the system, we determined that
it is necessary to bring these two components closer together in order to achieve better
flexibility, control and performance.
Our main idea was to run the agent by starting and steering it from within a database and
write the search results also into a database. This means that the database in fact consists
of two main parts - the configuration and the application database.
Definition 4.1: A database, in which the configuration data for an agent is stored, is called
a Configuration Database.
Definition 4.2: A database, in which an information agent stores the results found, is called
an Application Database.
Clearly, the database schémas that we use for these two databases are likely to be very
49

different from each other. Therefore the schémas have to be fully separated from each
other, and maybe, this even leads to the use of two separate databases. If a user even plansto run agents for different applications, we expect to have different application databases as
well, and then it makes sense to place the configuration data separate from the applicationdatabases.
The schema of the configuration database has to incorporate the schema of the agent itself.
In this schema, the user must be able to define what the agent shall look for, and how this
information shall appear in order for it to be the information wanted. The main problemhere lies with the agent. The agent's architecture must be easily mappable to a database
schema in order to achieve a system that does not need a lot of conversions of data for¬
mats and so on. In chapter 5, the agent architecture for Web information agents is further
detailed.
As the schema of the agent configuration is highly dependent on the agent architecture, we
want to discuss the details of it later. Anyway, the database will be the starting point for
a user who wants to work with the system and therefore has to provide the possibility to
create a user interface to access the agent's configuration data in as convenient a manner
as possible. The results of a search are also stored in the database and accessed by the user
through the database interface. Therefore, by storing the agent data in the same database,
users can access both configuration and application data through a common applicationinterface.
Of course, a special integrated user interface can always be developed for agent applica¬tions for access to both configuration and application data regardless of where they are
stored. However, this task too will always be simpler if homogeneity prevails and only one
type of storage system is used, thereby ensuring that both systems have the same function¬
ality in terms of API. It is therefore simpler to develop a user interface which is able to
access both types of data. Of course, the most convenient possibility would be to use a
database system which already includes a graphical user interface.
Our goal, which we formulated in chapter 3, is to develop an abstraction of the ACADEMIA
system which then can be used to create different information agents. This has an important
impact on the configuration part of such a system. It implies that we can use just one user
interface to work with all the agents which can be created within this framework. The
schema which describes an agent must be open to contain any schema definition, i.e. it
must be generic.
To give a better overview, we briefly want to discuss the big picture which is our goal. At
the end, we want to have a general system or framework with which we can build Web
information agents. A user shall be able to have several agents working for him. However
usually, they are all working independently of each other although they may have been
executing on a single machine. Figure 4.1 shows this situation schematically. The user has
a number of applications and for each of these applications, there are some agents runningand trying to fill the corresponding application databases with the information items found
on the Internet.
50

Application A Application B Application C
Figure 4.1 : The use of applications and their agents
As it is possible to have more than one agent working for an application database, there
are possibly several agent configurations belonging to one application. All the agents are
built using the same framework, they only differ in their configuration, but - and this is
important - they do not cooperate, because they are all looking for different information
items. Therefore, we have a system ofagents and applications which can work on a single
application database.
On first sight, it seems as if this was not a multi-agent system, because this denotion is
generally used for a system in which the agents cooperate with each other. But, if several
agents are working on a single application database, they can cooperate with each other
indirectly through the database. If one agent finds new or updated results and adds them
to the database, this clearly affects the other agents, because they now may have different
input values for their tasks. In addition, we can talk of a multi-agent system also in a
smaller view. Each application agent by itself can be considered as a multi-agent system
consisting of a main agent and several subagents.
But, we do not want to discuss the agent schema and its contents here, since this is part
of the architechture described in chapter 5. We rather concentrate here only on the re¬
quirements for a database system to be used as the configuration and storage engine for an
agent and describe the particular data management framework that we used. For that, we
only need to have the big picture in mind, because here it is not important how the agents
are built. We assume that the final schema of the agent definition is independent from the
database itself, but there are other aspects which are dependent on the database system
used.
The type of the database system is not very important for the function of the system, it
is more a question of the preference of the developer or user. Anyway, we think object-
51

oriented technology is best suited for our agents, as it supports a higher level of abstraction
and combines actions with data.
The main reason for concentrating on an object-oriented database system, however lies
somewhere else. In chapter 3, we saw that the database itself does not have to process
complex tasks, once the application has been installed for the first time. The complex work
has to be done by the agent. Therefore, in this point, the requirements of the database
system are mostly defined by the implementation and the design of the agent.
We have chosen the Java language to create our agents. Agents, as discussed in section 2.1,
are autonomous pieces of software which are capable of deciding themselves about when
they shall execute their tasks. In addition, they must be independent in terms of how they
plan to fulfill their tasks. Therefore, it is highly recommended to use an object-oriented
language to implement agents, as this matches the idea behind an agent. Given this choice,
it is logical to also use an object-oriented database system. It is simply easier, and hopefullyfaster, to convert result objects of the agent to result objects of the database system. With
this, we can obtain a truly integrated system.
Still, the crucial point in the whole problem is the connection between the two components.We have discussed the fact that we also need a fast connection. This clearly cannot be
matched by a connection over sockets in combination with a specific data manipulation
language for the database as was done in the Academia system described in chapter 3.
First, we must try to omit this specific data manipulation language which costs too much
in processing time. We can do this by choosing a database system which is accessible
through a Java application programming interface (API). In general, this is no problem,as there exist standard APIs for object-oriented database systems as well as for relational
database systems. Most database systems support these. However, as other work shows,
for example [KN99], [KNOOa], connections using JDBC [Ree97], which is the standard
API for relational databases, are very slow, due to the additional network traffic that comes
from the network connection between the JDBC driver and the relational DBMS. Another
factor mentioned before which slows down JDBC connections is of course the necessary
conversion of the objects into table entries and vice versa.
Because of these facts, we finally decided not to use a relational database system. But
still, there are a lot of object-oriented database systems around. Which one best suits our
purpose? This is a difficult question, because it depends on the application itself. Some
database systems are constructed for managing a lot of data, whereas other systems are
more efficient when working with a small amount of data.
We decided to use OMS Java as our database management system and the reason for usingOMS Java lies mainly in the fact, that it is a framework with the possibility of exchangingits storage engine. OMS Java has been built upon various database systems, such as Ob¬
ject Store PSE Pro, Objectivity or even Oracle, to mention a classical relational database
system.
OMS Java, as the name indicates, was built especially for the Java environment. It pro-
52

vides an extensive API that offers operations on objects, collections of objects and also
workspaces. Thanks to the exchangeability of the underlying storage engine, it is possibleto change the database system according to the needs of the application, without affectingthe application's code at all. So, to test an application's functions, it is possible to use
a database system which performs very well with a small amount of data, and when the
system goes live and collects more and more data over time, the data can be transferred to
another database system with better performance for the large data sets in question. OMS
Java provides a middle layer between the application and the storage. It offers the possi¬
bility to integrate any storage engine by adapting a small number of key classes. After this
and the migration of data has been done, the application will run with the same applicationcode as before, but now better adapted to the new amount of data.
Another more practical reason for choosing OMS Java is the fact that the developers of
this system work in the same research group. This means that we were able to discuss
our system requirements and we also had the possibility to take a certain influence duringthe development of OMS Java. By choosing another system, we would not have had this
convenient possibility.
In the following section, we give a more detailed description of OMS Java and its under¬
lying technology. This will show that OMS Java offers a number of features that proved to
be advantageous for our system.
4.2 The OMS Java Data Management Framework
In this section, we detail the database system OMS Java [KobOl] which we use for our
prototype. In fact, it is a Java application framework and therefore provides an ideal data
management platform given our decision to use Java as our agent development language.In addition, we want to describe in more detail the beneficial features that make OMS Java
an excellent database system for our prototype.
A major goal of the OMS Java project was to address two main problems. Frameworks
are often very complex and therefore hard to learn, and they seldomly offer any support
for making application objects persistent. Hence, the goal was to design a framework
which is easy to use, but also offers various and transparent options for persistent object
management.
OMS Java is part of the OMS Database Development Suite [KNW98] which will be further
described in section 4.2.2. All systems in this suite support the generic object model OM.
OMS Java was built with extensibility in mind making it possible to adapt the system for
specific application domains. This, of course, is an important reason why we have chosen it
for our system. In this way, OMS Java was used to develop advanced application systems,
for example a Geographical Information System (GIS) through a combination of model
and architecture extensibility [KNOOb].
Model extensibility stands for the possibility to extend the core object model and its as-
53

sociated languages by new constructs for supporting application specific models such as
temporal and/or spatial ones [SKN98]. On the other hand, architecture extensibility is
achieved through the already mentioned support for exchangeable storage components and
the incorporation of new bulk data structures [KN99].
4.2.1 The Generic Object Model OM
The generic object model OM [Nor95], [Nor93] is a semantic data model that can be used
for all stages of database development [KNW98]. "The goal of semantic data models has
been to represent the semantics of the real world as closely as possible." [SPS+95] The OM
model achieves this through a well-defined two level structure in which collections define
object roles and types define object representations as shown in figure 4.2.
TypeDefinition of Object Representations= Set of Property Specifications
Classification
Semantic Grouping of Objects= Collection of Objects
Figure 4.2: Classification and types
Within OM, it is possible to define various collection constructs and structural constraints
as can be seen in figure 4.3. In addition, by a special form of binary collection construct,
OM supports the representation and processing of associations between objects. An ex¬
ample for this is shown in figure 4.4. Subcollection contraints together with constraints
over subcollections support role modelling in OM. Such constraints apply over all forms
of collections and hence also over associations.
Additionally, there is a general set of operations over collections and associations in terms
of the OM algebra. Other semantic data models such as the extended entity relationshipmodels [Che76] place the emphasis mainly on data description and lack an algebra as
well as concepts for describing the behavioural aspects. Within these models, it is then
necessary to translate the conceptual representation into a lower level target model such as
the relational model [SPS+95]. When using semantic data models which provide concepts
for specifying the behavioural aspects, this translation step can be avoided. In OM, this is
realised through the OM algebra together with the distinction between classification and
typing.
The process of typing in the stage of data model mapping is used for defining the spec¬
ification of objects and associations. In OM, the type level is defined by the eventual
implementation platform. Then, the separation of the classification and type levels makes
it possible to complete the stages of design and prototyping independently of any imple¬mentation decisions.
54
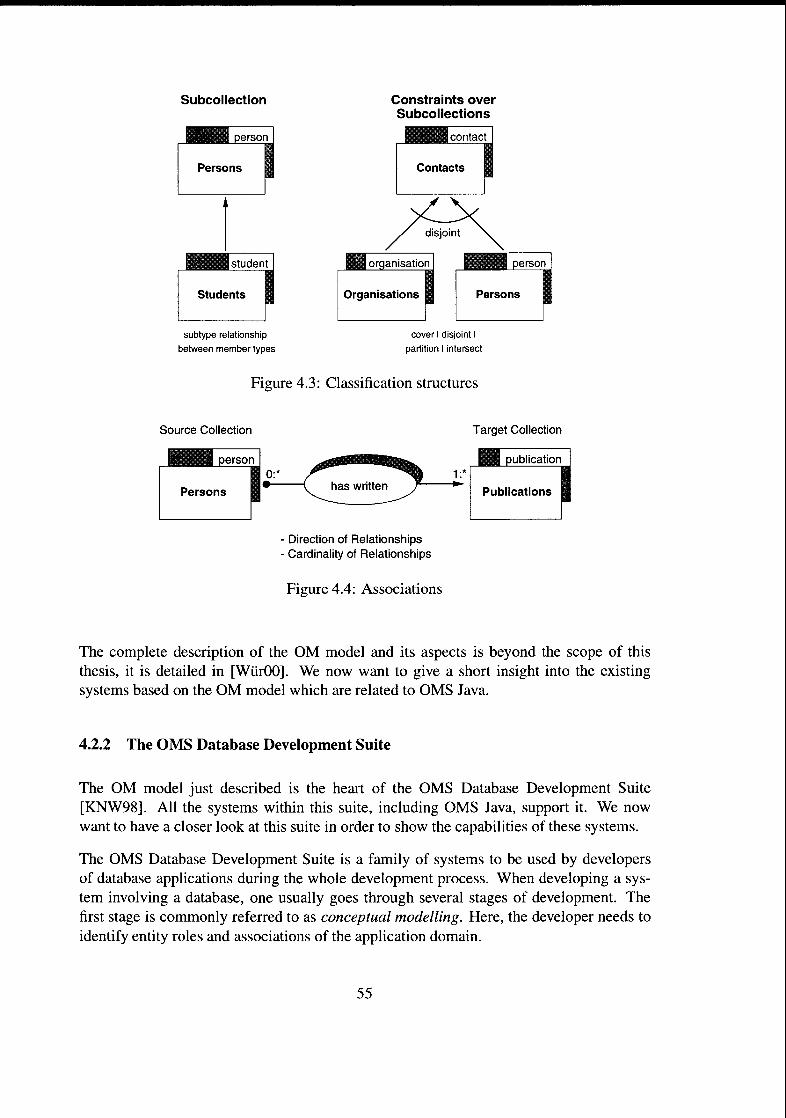
Subcollection Constraints over
Subcollections
Persons
>n
1
Students
nt
subtype relationship
between member types
cover I disjoint I
partition I intersect
Figure 4.3: Classification structures
Source Collection Target Collection
publication
Publications
i
- Direction of Relationships- Cardinality of Relationships
Figure 4.4: Associations
The complete description of the OM model and its aspects is beyond the scope of this
thesis, it is detailed in [WürOO]. We now want to give a short insight into the existing
systems based on the OM model which are related to OMS Java.
4.2.2 The OMS Database Development Suite
The OM model just described is the heart of the OMS Database Development Suite
[KNW98]. All the systems within this suite, including OMS Java, support it. We now
want to have a closer look at this suite in order to show the capabilities of these systems.
The OMS Database Development Suite is a family of systems to be used by developersof database applications during the whole development process. When developing a sys¬
tem involving a database, one usually goes through several stages of development. The
first stage is commonly referred to as conceptual modelling. Here, the developer needs to
identify entity roles and associations of the application domain.
55
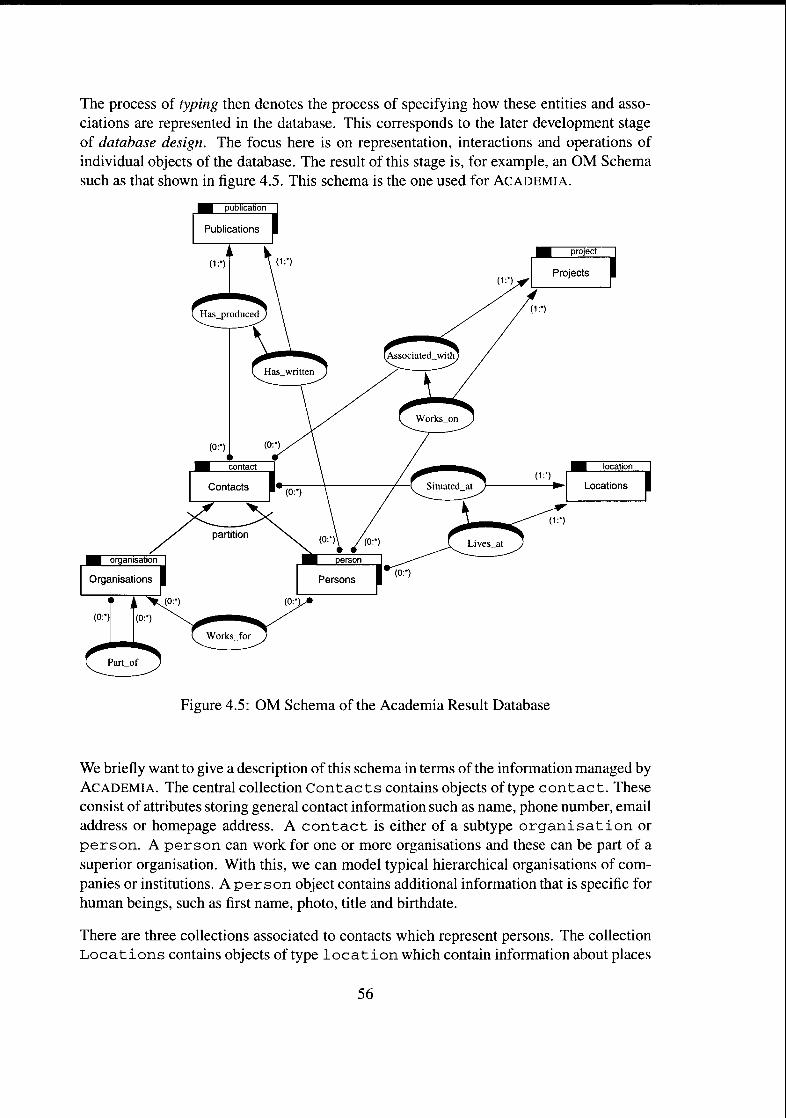
The process of typing then denotes the process of specifying how these entities and asso¬
ciations are represented in the database. This corresponds to the later development stage
of database design. The focus here is on representation, interactions and operations of
individual objects of the database. The result of this stage is, for example, an OM Schema
such as that shown in figure 4.5. This schema is the one used for Academia.
Figure 4.5: OM Schema of the Academia Result Database
We briefly want to give a description of this schema in terms of the information managed byAcademia. The central collection Contacts contains objects of type contact. These
consist of attributes storing general contact information such as name, phone number, email
address or homepage address. A contact is either of a subtype organisation or
person. A person can work for one or more organisations and these can be part of a
superior organisation. With this, we can model typical hierarchical organisations of com¬
panies or institutions. A person object contains additional information that is specific for
human beings, such as first name, photo, title and birthdate.
There are three collections associated to contacts which represent persons. The collection
Locations contains objects of type location which contain information about places
56

where people live, whereas the collection Projects contains project objects with
general information on projects on which a person works or has worked before. This
includes a project title and links to project Web sites. The objects of type publication
which are contained in the collection Publications, on the other hand, contain a title,
other general information about the publication, abstract Web sites and URLs to files that
contain the whole publication, if available.
The associations between the collections are defined including cardinality constraints. For
example, an object in Publications is associated to all the objects from Persons
representing the persons which have co-authored the publication. This information is col¬
lected in the binary collection Has-written which will contain entries where each ob¬
ject of Publications has to occur at least once ("1:*"), combined with any objects of
Persons ("0:*").
The Academia agent is responsible for maintaining most of the information in the collec¬
tions Contacts, Persons, Publications and Projects and the correspondingassociations between them.
The following stage in the development process is to specify the application model plus
type descriptions in the OMS data definition language. Figure 4.6 shows an excerpt of
the data definition for the schema in figure 4.5. The OMS data definition language (DDL)
comprises three main parts corresponding to type, collection and constraint definitions.
The figure shows the definition of the main types in ACADEMIA. Each type consists of a
set of attributes and method definitions. The collections then define the entities of the ap¬
plication. In the constraint part, finally, we find the description of the associations between
entities, the subcollection constraints and the constraints over subcollections. Here, we
define for example that objects in the collection Contacts strictly have to be contained
in either Organisations or Persons by means of the partition constraint.
Once the stage of the data definition is reached, the design phase usually is not yet finished,
because now we have to test the schema for its usability. This is the stage ofprototyping in
which the first product from the OMS database development suite comes into action, the
OMS Pro rapid prototyping system [WürOO].
The user now starts OMS Pro and constructs the schema graphically or he simply can
load the previously defined schema DDL into it. This initialises a database where data
can be input, browsed and queried directly. Prototyping is an iterative process in that a
design may be changed and refined repeatedly. Within OMS Pro, schema evolution is
supported which means that a schema can be examined, extended and revised at any time
during system operation. In fact, a user can work with the same experimental data set
while the application model is refined and revised without having to delete and recreate the
database. In practice, the OMS DDL is used to both specify the schema definitions and the
schema updates. With this, it is easily possible to revise the schema incrementally during
prototyping.
Whenever the initial prototyping of the structure of the system is done, the specification
57

type contact
( name string;
phone string;
fax string;
email url;
www
) ;
set of url;
type organisation subtype of contact
( description : text;
) ;
type person subtype of contact
( firstname string;
title string.
birthdate date;
home.phone : string;
office string;
photo photoflie;
lcq string;
finger url;
age ( ) -> ( years- integer ) ;
work_places :()->( locations;
) ;
set of location ),
type publication
( title string;
author string;
othennfo string;
abstracts set of url;
files
) ;
set of url;
collection Organisations : set of organisation;
collection Publications : set of publication;
collection Part-of : set of (organisation,organisation) ;
collection Works-for : set of (person,organisation) ;
collection Has-written : set of (person,publication);
collection Has_produced : set of (contact,publication);
collection Contacts : set of contact;
collection Persons : set of person;
constraint Works-for association from Persons (0:*) to Organisations (0:*);
constraint Part-of association from Organisations (0:*) to Organisations (0:*);
constraint Has-written association from Persons (0:*) to Publications (1:*);
constraint Has-produced association from Contacts (0:*) to Publications (1:*);
constraint Persons subcollection of Contacts;
constraint Organisations subcollection of Contacts,
constraint Has-written subcollection of Has.produced,
constraint (Persons and Organisations) partition Contacts;
Figure 4.6: Excerpts of the DDL of Academia's Result Database
58

of the database can be completed by adding method and trigger specifications. These
specifications are executable and are given in terms of Prolog rules. They use special OMS
system-defined predicates for access to data, metadata, system calls and dialogue boxes
for the interaction with the user. Thanks to this concept, it is convenient to develop these
specifications. Since they are interpreted, they can be edited and tested directly without
any form of re-compilation.
After the developer is fully content with the database development, he reaches the next
stage of the process, the implementation phase. This involves the mapping of the prototype
database to the chosen implementation platform. It fully depends on the semantic and
functionality gap between OMS Pro and the desired implementation platform, how largethe amount of work to be done for realising the OM model on that platform will be. Ideally,it should be possible to support the application model directly in the target implementation
system. Therefore, there exist also OMS implementation platforms. With these, it can
be demonstrated how higher-level semantic constructs, constraints and operations can be
supported in object-oriented data management systems.
We have used OMS Pro for the initial investigation on Academia. This was convenient as
the schema was under development and the prototyping phase was an important part. On
the other hand, we had to use an interface between our Java agents and the Prolog based
OMS Pro, and as a prototyping system, OMS Pro is developed for single users only. This
was sufficient to prototype basic functionality and operation of our agent. OMS Java soon
seemed to suit better to our purposes as it more addresses performance issues and multi¬
user aspects. However, it was under development as we worked on ACADEMIA, so we
fully developed Academia with OMS Pro.
OMS Java which will be described in more detail in the following section is one of the
OMS implementation platforms. It is a Java application framework based on the OM
model. The migration of the prototype database is quite simple. In addition to the OMS
Data Definition Language which can be used to define an OMS schema, there exists also
the OMS Data Manipulation Language (DML). So, the final schema simply needs to be
exported into a DDL file and the data into a DML file. These files then can be importedinto the implementation platform and methods and triggers are then re-implemented in
Java. In the next section 4.2.3, we also give a short description of the further details which
are necessary to complete application development.
Additionally, we have to mention, that OMS Pro supports a comprehensive high-level,
algebraic query language, AQL, for querying the data as well as the meta data. Every
operand in a system of algebraic query expressions is handled as an object - be it an
integer, an instance of an object type or a collection of objects. This makes AQL fully
orthogonal.
Of course, OMS Pro can be used for general prototyping of database designs. It is not
restricted to be used only when the implementation platform comes also from the OMS
Database Development Suite. If the developer wants to use another object-oriented or rela¬
tional DBMS, OMS Pro comes up with solutions for that case as well. A relational DBMS
59

usually supports SQL statements, and OMS Pro has an export function which generates a
file of the necessary SQL statements to create the database on an RDBMS. For that, the
system maps the conceptual OMS database schema to a relational one. The heuristic used
is similar to general strategies for mapping an object model to a relational model.
In addition, it is of course possible to map an OMS data model to the type system of a
commercial OODBMS. In particular, since many commercial OODBMS vendors claim
their product to be ODMG compliant [CBC+OO] and use the ODMG data model as their
reference object model, OMS Pro provides an export function for ODMG. In fact, with this
export, the system maps an OMS data model to an ODMG object model and creates a file
with instructions in the schema definition language (ODL) of ODMG. Additionally, the
test data is exported into instructions in the Object Interface Language (OIF) of ODMG.
We have given an overview of the OMS Database Development Suite. We have followed
the general development stages in the development of our agent and therefore we tested
a prototype application using the OMS Pro Rapid Prototyping System. We showed whyit is convenient to develop a database using the OMS Pro System. In the next stage, we
use OMS Java as an implementation platform for our agent applications. In the following
section, we describe the persistent object management framework OMS Java.
4.2.3 The Persistent Object Management Framework OMS Java
Having described the OMS Database Development Suite, we move our attention to the data
management framework OMS Java, which is part of the suite. We start by describing its
architecture and then go on to discuss its main features and advantages, which make it not
only a reasonable choice for our work, but also for other applications.
OMS Java can be considered both as a multi-tier object management system and as an
object-oriented application framework for the Java environment. This, of course, makes it a
very reasonable choice when developing applications in Java which need to have persistent
objects.
Figure 4.7 shows the two main components of OMS Java, OMS Java workspace and OMS
Java server. The workspace is the main access point for client applications. It serves them
as the framework by providing the key abstractions for managing application objects in
terms of the constructs of the OM model. The workspace can either be directly part of a
client application or be a middleware component between a client application and an OMS
Java server.
In a given system, one or more OMS Java workspaces can be connected to an OMS Java
server using the Remote Method Invocation Mechanism (Java RMI) for inter-componentcommunication [Dow98]. The server manages all persistent objects of the different
workspaces. Another feature is that it is possible to link the server to one or more database
management systems which are used as storage managers for these objects. The DBMS
can be an ODMG-compliant object-oriented DBMS, a relational DBMS connected to the
60

Client Application
OMS Java
Workspace
Client Application
OMS Java
Workspace
OMS Java
Server
JDBC
RDBMS OODBMS
Figure 4.7: OMS Java Multi-Tier Architecture
server by JDBC, the standard Java data access interface to RDBMSs, or any other DBMS
providing a Java interface. Later, we examine this mapping mechanism in more detail.
The server delegates tasks such as transaction management or data protection to these
DBMSs. Regarding security, most existing DBMSs offer mechanisms for identifyingand veryfing users which means that identification and authentication are handled by the
DBMS. In addition, access control to data - authorisation - is also handled in most cases bythe DBMS. To achieve a truly secure system, the network connections between the various
components must also be made secure. In the case of OMS Java, this has been achieved
within a specific security framework [Ost99].
OMS Java Core System
We already mentioned that OMS Java supports the generic object model OM. Further,
OMS Java provides the same languages as OMS Pro, namely the data definition language
(DDL) and the data manipulation language (DML), as well as the query language AQL. In
OMS Java, components such as the algebra and the various languages can be exchanged or
extended as illustrated in figure 4.8.
The Core System provides functions for managing the important elements according to the
OM model: OM Objects, OM Collections and OM Constraints. Those parts of the system
that are extensible are brought together in the Configuration Component. As an example,
61

QL -*
DDL -•
DML -•
Core System
k k k
t t
OID Algebra Constraints
, , , , , ,
TemporalOID
Temporal
Algebra
TemporalConstraints
Figure 4.8: Extensibility of OMS Java
OMS Java has been extended to support the temporal object model TOM [Ste98].
As already stated in section 4.2.1, the OM model supports object role modelling through a
separation of typing and classification. This is the main requirement for model extensibilitywhich is also a main feature of the OM model. This implies that more than one type
representation can be associated with an object of the application domain. Figure 4.9 givesan example of such an application object.
OM Object
ID: 123
person
Name : Robert Smith
Birthdate: 1957/4/12
student employee
StudID : 4656 EmpID : t0246
Salary : 3200
Figure 4.9: An example for different type representations of an OM Object
Regarding this example, it is possible to access the object with identity 123 through type
person, student or employee, depending on the context. For example, if the ob¬
ject is accessed through the collection Employees, then it is viewed in terms of its em¬
ployee role and hence being of type employee. In the example given, student and
employee are subtypes of type person. Existing type systems of object-oriented pro¬
gramming languages such as Java or C++ do not allow an object to be associated to more
than one subtype. Therefore, application objects are built out of objects at the implemen¬tation level.
62

To achieve these features in OMS Java, the OM model is modelled in a way that the iden¬
tifier of an OM Object is implemented as a separate class ObjectID. An OM Object,on the other hand, can reference any number of OM Instances, for example, OM Object123 references instances of types person, student and employee. The system then
automatically associates the correct instance to the OM Object when accessing it througha specific context, e.g. through a collection. Finally, each OM Instance is specified by ex¬
actly one OM Type, which holds meta information necessary for the system to evaluate
algebra operations and constraints.
The core system, however, manages all application objects, the OM Objects, and all objectsof the core data model OM such as OM Collections and OM Constraints. Any client
application accesses OM Objects through the workspace by using its API. As stated before,
an OM Object can refer to one or more OM Instances. These can be of the following
categories:
• OM Collections
• OM Constraints
• OM Triggers
• OM Types
• OM Simple Instances
The first four categories are obvious, we just want to give an example of an OM SimpleInstance. This category represents the various types of application domain objects which
can be associated to OM Objects. As an example, the following DDL statement defines the
type person:
type person
(
name: String;
);
However, this type has to be linked to a specific Java class. This is done by a simple
mapping information in the beginning of the DDL file:
person: diss.Academia.Person;
This linked Java class may look like this:
public class Person extends OMInstance {
63

private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Now, an instance of class Person represents a specific application object and can be
created, for example, by the following DML statements:
create object personl;
dress personl as person values
(
name = "Robert Smith";
);
The five categories are modelled as subcollections of OM Instances. Each OM Instance
category provides a specific set of functions which can be used by a client application.
OMS Java Storage Management Component
We have already mentioned the storage management component. It is responsible for mak¬
ing application objects persistent when they need to survive beyond the lifetime of an
application process.
Still, the main feature of the storage management component is the possibility to use var¬
ious relational or object-oriented DBMSs for the storage of the application objects. This
means that an application developer can use the OMS Java object management framework
for designing and implementing applications without having to deal with implementation
aspects of storage management.
Two approaches for building the storage management component of OMS Java have been
implemented. One is the Classloader approach [Est99]. Within this approach, all Java
classes are postprocessed at runtime to make them persistent-capable. Although this is
straightforward and fast, there are two major disadvantages: First, not all DBMSs providesuch a mechanism for postprocessing Java classes at runtime. Second, even if such a
mechanism is available, it depends on the DBMS which Java classes can really be made
persistent. For instance, ObjectStore PSE Pro for Java [Odi] supports postprocessing - but
not for all classes. Therefore, there has been implemented another storage managementframework based on the Object Mapping approach.
64

The storage management component of OMS Java which is based on the object mapping
approach is divided into two main parts connected together using Java RMI as shown in
figure 4.10.
CLIENT SERVER
OMObjectManager RMIObjectManager—i Java RMI
RMIObjectJava RMI
RMIAttribute
DBMap RMIMapJava RMI
DBVector RMIVectorJava RMI
DBEnumeration RMIEnumerationJava RMI
Figure 4.10: OMS Java Storage Management Component
The OMObjectManager resides on the client side and is responsible for managing all
application objects. Whenever an object changes its state, it notifies the object man¬
ager, which propagates the changes over the network to the RMIObjectManager.
In a similar manner, application objects are retrieved from the database through the
RMIObj ec tManager. In both cases, the state of an application object is copied to/from
state containers which can be regarded as snapshots of object data. Only these state con¬
tainers are stored in the database. They occur in two types: One for representing the object
identifier, and one for holding the attribute values. So, every application object on the client
side is represented by one or more state container objects on the server side.
Whenever a new DBMS is to be integrated as a storage platform, it is required that all six
interface classes shown in figure 4.10 are implemented using the API of that DBMS. In
most cases, it is necessary to provide a small number of additional classes. The experi¬ences from the integration of various relational and object-oriented DBMSs [KN99] show
that, typically, a total of about ten DBMS specific classes need to be developed for each
integration.
Thanks to a specific eXtreme Design (XD) approach, it is also possible to extend the storage
management component with specific bulk structures. This might not be necessary for most
applications, but for specialist application domains it can be crucial. The common approachto introduce a new data structure would require to implement the structure specifically for
each of the DBMSs to which the OMS Java server supports a link. This is avoided by
65

using the XD approach for specifying bulk data structures as abstract data types in terms
of a metamodel [KobOl].
This short description of the persistent object management system OMS Java shows that
we use a very powerful database within our system. The framework not only provides us
with a rich set of complex data structures for composing application objects, but is also
capable to be linked with several different database management systems which serve as
the storage entity of the framework. This makes OMS Java an excellent choice for our
work.
4.3 Summary
In this chapter, we have discussed the DBMS component of our system. The choice of this
database is very important in achieving an integration of agent and database operation, as
we need to have a fast connection in order to be as effective as possible.
We have chosen the Java language to implement our agents, and this was a major factor
in our decision to use an object-oriented database management system. This led to the
choice of OMS Java which in addition has two other particular advantages: First, it has
an extensive Java API which makes it easy to develop our agents and let them access the
database. Second, the storage engine of OMS Java is exchangeable. OMS Java has alreadybeen implemented upon ObjectStore PSE Pro, Objectivity/DB and Oracle, so the user is
quite free to decide on the DBMS which he wants to use.
To provide the necessary background for our detailed description of the agent model, ar¬
chitecture and operation in later chapters, we also gave an introduction to the OM model
on which OMS Java is based and the OMS Java system itself.
Thanks to a well-defined two level structure in which collections define object roles and
types define object representations, the OM model can be used to represent the semantics
of the real world quite closely.
The main systems of the OMS Database Development Suite are the rapid prototyping sys¬
tem OMS Pro and OMS Java. The suite is based upon the OM model and provides powerfultools for developers of database applications to use them during a whole development pro¬
cess. OMS Pro supports schema evolution, which means that a schema can be examined,
extended and revised with the same data without having to delete and recreate the database.
When the prototyping phase of a database application has been finished, the implementa¬tion phase begins. Here, the user has to map the prototype database to an implementation
platform. In the suite, we have OMS Java as the main platform. Due to the fact, that OMS
Pro and OMS Java support the same data definition and manipulation languages DDL and
DML, it is simple to transfer the database to OMS Java.
Finally, we described OMS Java in more detail to show the advantages which convinced
66

us to use it as the storage component in our system. OMS Java has been built upon sev¬
eral DBMSs, relational as well as object-oriented ones, and thanks to its object mapping
approach, it is relatively simple to add other DBMSs to it. Therefore, a developer who
works with our system in fact is able to use his favourite DBMS underneath OMS Java
which may require a couple of classes to be adapted in order that it cooperates correctlywith OMS Java. The choice of such a specific DBMS depends on the application charac¬
teristics. A user definitely needs a lot of experience to be able to come to a decision. Our
agents, however, will not need any adaption in the code, as they are linked to the OMS Java
framework and not to the DBMS directly.
Having described our requirements for a database system and the choice we made for our
system, we can now go on to the next step, which is to present the general architecture of
an agent which searches for information on the Web. The architecture had to be defined
in a way that the cooperation with the database is very efficient and that the user has the
possibility to configure and run the agents in a simple and convenient way.
67

Chapter 5
AN ARCHITECTURE FOR WEB
INFORMATION AGENTS
Having established the main components in our system, we decided to use Java as our im¬
plementation language for agents and the persistent object management framework OMS
Java. Now, we have to go more into details and examine the general architecture for the
Web agents that we want to build.
However, in the next section, we first want to concentrate on the context, in which our
agents are operating. We do this by discussing a full search process of a Web information
agent. This is important as it is not our goal to create a fully general agent as this is not
realistic. Our goal is rather to create agents for locating information on the Web or in
other resources, as exactly as possible. Afterwards, in section 5.2, we will discuss the
architecture of an agent which achieves our goal.
5.1 The Search Process
Before detailing the architecture of a Web information agent, we must concentrate on the
context in which such an agent is acting. The term "Web information agent" itself does not
say anything in detail about the agent's tasks, but surely, our agent must be able to have
some fixed boundaries in which it can act, so these must be established. We define this
context by discussing a full search process of an agent.
Therefore, we must first discuss the agent and its tasks, before we can propose a generalarchitecture for information search agents which are to be tightly coupled with databases.
We already discussed previously that this coupling has potential benefits in terms of both
convenience of system operation and performance. This combination shall bring many
advantages such as the possibility to locate and manage all agents within a single place.
68

5.1.1 The Components
In chapter 3, we discussed the ACADEMIA system which is used to find information about
researchers published on the Internet. We stated that it is our goal to generalise the system
towards a general agent framework with which it is possible to quickly create agents which
search the Web and perhaps other resources for specific information of any kind. Thus, it
definitely is a good starting point to discuss all the components that are contained within
that system.
The components we have already mentioned are the agent and the database. They both
may occur more than once, but for the moment, we consider each as a single component.
The task of the database is simple - mainly storing data. In addition, we intend to use the
database as the interface of the user to the agent, therefore it makes sense if the database
provides the possibility to develop powerful user interfaces with it, e.g. Web interfaces.
In chapter 4, we already discussed these factors and we decided to use OMS Java as our
database system. It is written in Java and comes with a simple but extensible interface.
In addition, the OMS system has also been Web-enabled [ErnOO], so we could also easilybuild a corresponding Web interface. Another important feature that has been realised for
OMS is the possibility to create XML output [KisOO] [GroOl], which can then be used to
build dynamic Web pages. Thus, OMS Java meets our requirements in this respect.
The agent
Regarding the agent, we have chosen to use the Java language as the development language.As already described in chapters 2 and 4, agents shall be autonomous entities which act on
their own. Additionally, we have stated that our agents may be compositions of several sin¬
gle agents or entities. Therefore it is a good choice to use an object-oriented programming
language to develop our agents, because the object-oriented paradigma also includes the
possibility of adding and subtracting components very easily.
Whenever we are working with data that is not located locally, but rather on the Internet, we
can clearly assume that an enormous time-consuming event is the process of accessing and
downloading documents and not the parsing of them. The only exception here might be the
search for semistructured data and its extraction, but this process is not necessarily needed
for every document. In section 7.5, we will support that assumption with the descriptionof the system's functioning and a description of the agent's results.
Now, what in fact is the task of an agent in our system? First, we want to recall the task
of the agent in the Academia system. The Academia agent receives initial information
in the form of the name of a person and perhaps additionally a URL which defines a Web
page likely to contain the desired information. Whenever this URL is not given, the agent
has to find one or more URLs itself to be able to start the search. Then, the agent searches
the initial Web pages for concrete information or links to other Web pages which may be
of interest. After the search phase has finished, which means that no more links are in the
search queue, the agent writes the information found into the database. In special cases,
69

the agent interacts with the user about what to do and acts according to the user's decision.
So, that is - simply described - the situation of the Academia agent. Where exactly do
we want to generalise? To answer this question, we first concentrate on the information we
want to find. As in Academia, we are interested in specific items or objects which are to
be found on the Web. This includes for example strings, numbers, dates, URLs, picturesor other files. These types may be further specialised, as shown in figure 5.1. A string can
contain just any characters, whereas a phone number is a specific form of string which is
only allowed to contain a specific set of characters.
Strings:
Consisting of any Characters
Phone Numbers:
Strings only consisting of
0123456789+0/ and space character
Figure 5.1: Specialisation / Subtyping
In general, this means that we do not want the agent's architecture to be restricted to onlybe capable of extracting a subset of information. The data which is located in the Internet
can be divided into two main types: Text files and binary files. Text files such as HTML
files can be regarded as a large string where we are looking for small "substrings". Special
formatting enables certain substrings to be considered as URLs or something else, but
mainly, everything is text and we want to be able to extract everything. Binary files usuallyare located behind URLs which serve as their pointers. Binary files can be handled by
specific applications and these applications mostly can be determined by looking at the file
name extension. Binary files are handled as a whole, they will not be split up. Therefore
we can only take their pointers as our reference to them, i.e. in a first step, we only use the
URL that points to a file, not the file itself. And, as seen before, a URL is only a specialisedform of a string.
However, we have not won anything for the main architecture yet. The information items
which are of interest for us must be located by an extraction component of the agent, which
apparently needs to be very powerful, but the conceptual basis of the architecture remains
the same.
The Resources
However, there are also other components involved in the system. Until now, we have
only been talking of Web resources, but the Web is not the only resource we have. When
70

thinking globally, another possible resource is the Usenet where we can access documents.
The Usenet is a large information resource, so it is also of interest to us.
When thinking more locally, we might also want to access data from a local server or
even from locally stored databases. Databases in fact can be everywhere. Even outside
an intranet it is possible to access databases using secure channels, and other databases are
even accessible for free over the Web. The main advantage of databases is the fact that theycontain more semantic information concerning their data. A simple example for that is the
title of a person. In a Web page, the title occurs simply in front of the person's name, as for
example "Prof. Smith" indicates that a person called Smith is a professor. In a database,
we can expect to find an attribute belonging to the person called Smith that is named "title"
and contains the value "Prof." If we have access to a database and can use a powerful
query language, we may find information not only fast but also with a guarantee to havingextracted it correctly.
However, we see that every resource requires different extraction mechanisms. Even, each
database itself probably needs a specific extraction mechanism. With that in mind, we can
also think of other resources which are not explicitly databases, for example simple files
that are stored on another server. We can in fact regard these as a weak form of a database,
without any semantics in it. Even the Usenet can be regarded as a special database with a
specific interface. Therefore, we reduce our resources to two types: The Web pages and
files that are accessible over the Internet or over an intranet and any sort of databases.
The User
Finally, there is one component in our system which we have not yet mentioned, althoughit is the most important one: The users. We refer to the users as a component in the system,
because we want to state that a user is as much a part in our system as the other components.
The users can be divided into three main classes - engineers, administrators and end users.
The engineer is someone who develops a specific application system for which he uses
an agent as described here. To be able to use this agent, the engineer configures it to the
needs of the system to be developed, which also means that he sets the initial schémas and
profiles.
After the system is installed, the second user class comes into action: The administrator
maintains the agent and perhaps even the whole system in a classical way. He creates and
deletes accounts and sets passwords for the end users. The administrator may also alter
the profiles if this leads to better results for the end users. The administrator needs a good
knowledge of the system, in fact, not much less than the engineer.
Usually, the end users only use the system as given and access information that is provided
through the agent. The users may also change their personal agent settings. As is usual in
database systems, it is desirable to provide shared access to the agent and the information it
manages for several users, each perhaps with different preferences and access restrictions.
Now, having identified the components in the system, we start by describing the overall
71

system operation in a classical manner without considering agent/database fusion. We
have seen that we can divide the architecture into four main components which are shown
in figure 5.2. However, the resources are divided into two types. We will discuss the systemin terms of the workflow within it.
set agent preferencesenter data
launch
Resources
User's Databasenew statistics
Agent
evtl look for starting point
information extraction
data found
learn schema & content
Internet/
Intranet
Web Pages
external
Databases
Figure 5.2: The components of a general agent architecture
We have already discussed the different classes of users. In the figure given, we do not
make a distinction between users. The agent has already been built, and now only ad¬
ministrators and end users are working with the system. Here, we define the user as an
administrator and therefore with the maximum authorisation that a user can have in this
phase. Usually, in our system, an end user has the same rights as an administrator. The
difference between them lies within their experience with the system, which means that the
administrator knows better how to change the preferences of an agent in order to improvethe results.
5.1.2 The Organisation of the Databases
We want to start the discussion on the general agent architecture with the database. We have
already stated in chapter 4 that, primarily, the database stores the desired application data,
which is provided either by a user or an agent. However, it also contains the information
that is needed for the agent to do its work. This information includes preferences set by the
users as well as perhaps cached data of previously read Web pages. It is also possible, that
there can be collected statistical data, for example the percentage of Web pages that served
reliable results or the reliability of a single search definition. Most important, the database
contains the definition of the agent's tasks.
As described previously, the data stored consists of application data and data that is re¬
quired for the agent, such as configurational or statistical data. It is possible to divide these
72

two sorts of data by using two databases. If we assume that a user only uses a single ap¬
plication and the corresponding agent, this is a decision that has to be made whenever the
agent system is created. If the database that has to be maintained is likely to remain within
reasonable limits in terms of access load and size, it makes sense to use a single database
for performance reasons. On the other hand, if the data is expected to grow constantly, it
is best to use two separate databases. In this case, the user can work exclusively with the
application data and is not slowed down by a large amount of statistical data that has to be
stored and processed in the same database.
Until now, we have only considered the case where a user works with a single agent appli¬cation. The situation looks rather different if a user, or group of users work with several
agent applications. We already discussed in the previous chapter that we generally will deal
with two different schémas, one for the application data and one for holding configurationaland all other data. Additionally, there is the other goal to achieve a generalisation of the
Academia system in the form of a framework for defining and creating Web information
agents. These two goals lead us to the fact that we will have a configuration database and
an application database for each agent application with the speciality that all the config¬uration databases will be built upon the same schema and the application databases most
likely not. Now, if a user works with several agent applications, this might lead to a largenumber of databases which have to be handled.
This forces us to determine a more detailed definition of the organisation of these databases.
The result is shown in figure 5.3. For each user there will be exactly one configurationdatabase. This database holds all the configurations of the different agent applications that
the user works with. In terms of the OM model which was described in section 4.2.1, this
means that this database contains a collection Agents in which each object stands for a
specific agent application, i.e. it holds the application's definition. One attribute of such an
agent definition object must be a link to the corresponding application database. Because of
the fact that every application database has its own specific schema, every application has a
database of its own. As the agents are not cooperating directly with each other, the systemis not a classical multi-agent system, it is rather a multi-application system. However, as
we have mentioned earlier, the work of an agent may influence the input values of another
agent and therefore such a system is a special form of a multi-agent system.
5.1.3 Initialisation and Start of the Agent
The work and data flow between the components begins with the user. Usually, after the
engineer has installed a new agent application, the agent configuration and general pref¬erences are given and are set in such a way that they will, hopefully, lead to good results.
However, the user has the possibility to change the configuration as well as the agent's pref¬erences. This mainly can be done in the configuration database. There, the user changesthe data according to his wishes. The user is able to perform such a change whenever he
wants. It does not matter whether the agent is running at that moment or not.
The most important job of the user before the first run, however, is not the work with the
73

Figure 5.3: The organisation of the databases
configuration database. The user needs to tell the agent the input values of the search, and
this is done through the application database. In the configuration database, there must
be defined which attributes of the application objects serve as input values. In the case of
Academia where we are searching for persons, a simple approach may be to use the first
and last name of a person as the input values. This means that the user previously has to
define the objects in the application database to limit the search domain to the persons that
he is interested in. The configuration database only contains the information as to how the
search must be done but without specifying the person in question.
In Academia, the user would open the application database first and create person objects
containing the names of the people for which he wants to perform a search. In addition, the
user might enter other data of which he is already sure and this might later help to better
identify the homepage of a person than using only the name.
We want to define names for these objects that serve us with the most important information
for the search:
Definition 5.1: The key application collection is the collection which contains the objectsthat contain the information items that serve as input values for the search.
Definition 5.2: The key object is an object which is a member of the key applicationcollection.
Definition 5.3: The input values are those attributes from a key object that - according to
the user - identify the key object in terms of the search.
In definition 5.3, the addition "in terms of the search" is very important. This means that the
user - commonly an engineer or perhaps an administrator - who defines the input values
states that the chosen attributes define the search domain.
In ACADEMIA, for example, the key application collection is the collection Persons. As
74

already stated, the input values there are the first and the last name. However, the whole
application is not restricted to the search for information on persons. It is completely free
to choose any collection to be the key application collection, whether it be a collection of
animal objects, car objects or furniture objects. Of course, each different type of objects
may require different attributes to be used as input values.
Now, the initial phase has been finished. The next step is to run the agent. There are
two main possibilities. The first one is that the user launches the agent directly through a
specific interface, for example something like a start button in a corner of the screen. This
is the most common way, but we want to get away from that. The alternative way is the
one we prefer: To let the agent run through the database.
This also can happen in two different ways. First, the user can run the agent by calling a
specific method in the database which composes the agent and immediately start it. The
other version is to define a run configuration in which the user sets periodicity and the time
of the first run, and then the database launches the agent according to that, automatically.
So, what happens when the agent is started? The main data flow is shown in figure 5.4.
The idea here is that the agent collects all the information that is stored in the configura¬tion database for this application. This includes general preferences such as the periodic¬
ity of starting a search, the maximum number of pages to be searched and so on. More
importantly, there is the information about what the agent shall look for and where the
corresponding application database is located.
Figure 5.4: The data flow after the launch of the agent
For the agent, this means the following: First, the agent is told what it has to look for and
afterwards, the agent learns the schema of the application database which tells it how the
items it finds are structured in the whole application. We give a simple example: The agent
is instructed to find an email address and a phone number of a person. Then it learns the
75

schema of the application database where the user has defined that in a person object there
is an attribute phone and an attribute set of email. From that, the agent learns that
it has to return all the reliable email addresses that it can find but only one phone number,
in fact, the most reliable one. This learning ability, as it is described here, is a necessary
capability of our framework in order to enable rapid creation of new applications.
5.1.4 The Main Search Process
When the agent has read all this information, the search is about to begin. The agent
connects to the application database which is defined in the configuration data. There,
it reads the input values of the first key object. With these input values, the search will
be started. Of course, after the search for information on that first key object has ended,
the next one will be processed, and so on, until all the objects from the key applicationcollection are processed.
Having read the input values of a specific key object, the agent goes out to the resources.
If the resource is the Internet, the agent needs to have one or more Web pages where the
search starts. In ACADEMIA, we mentioned that this could be given by the user, but we
cannot count on that. The agent must be capable to do more than just parse previously
given Web pages. Therefore, an agent must have a specific component which allows it to
find these start pages. Of course, in a similar way to the definition of what the agent has
to look for, here also the user defines the mechanism which leads to those Web pages with
which to start the search. In ACADEMIA, this is done by the Homepage Finder. If we are
looking for something different than persons, for example, information on furniture, this
would require another component to determine the start pages.
On the other hand, if we want the agent to search a database, we obviously have to providethe agent with direct access to that database. This requires that the agent has a specific
component which is able to handle the access to a database.
At this point, we do not want to give a detailed description of the search process itself. How
the search for the starting point in the Web and the database access shall be done will be
discussed in the following section 5.2 in more detail. Regarding the Web, the agent needs
the possibility to follow links and extract strings, which means, in fact, that the agent needs
a certain knowledge of the syntax of documents that can be accessed on the Web. This
means that the agent needs to have a certain knowledge of HTML. Concerning a database,
the agent must be able to query it and retrieve the interesting information.
However, we must have in mind, that there is one important difference between the search
of the Web and of databases: The structure of Web pages mainly stays the same on the
whole Web, which means that we can have a universal method for querying the documents.
On the other hand, every database can provide a different query language which the agentneeds to know in advance or must have the possibility to learn it. Of course, this comes
from the fact that databases capture more semantics regarding the data. This means that
76

once the agent has learned the query language for a specific database, it can access these
semantics and is more powerful in querying the data.
5.1.5 The Handling of the Results and their Analysis
After a search has ended, the agent has collected some results. What is very important is
that the agent has the capability to decide itself on the reliability of a result. The agent
therefore rates the reliability of each result. If the agent considers it not to be reliable, it
may drop it or, if desired by the user, contact him for feedback about it. The latter is shown
in figure 5.5. In the next section, we detail an agent component which is responsible for
this rating. However, to describe the whole process here, we simply assume that the agent
ends up with reliable results.
reliable
Result
automatic storage
ApplicationDatabase
unreliable
Result
ask for*
Feedback
User
Figure 5.5: The processing of results
We already mentioned the agent's ability to learn the schema of the application database.
This is used now also for the storage of the new data. The agent automatically knows in
which attribute a result has to be stored. Here, it makes sense for the user to define whether
the agent generally shall override old results or if the agent shall contact the user when a
new result has been found which is different from the old database entry. In the latter case,
the user would decide whether the agent shall store or drop the result.
We have not mentioned it yet, but certainly the agent needs a logging mechanism which is
responsible for recording all of its actions. If the user has given the agent a lot of autonomy,
this is necessary so that the user can understand what the agent really has done in a search.
Now, when the search has ended, the user is able to browse the application database and
check for the newly found results. If the user is not pleased with the results then he can
alter the agent definition or the general settings in order to receive a better result next time.
Here, the log serves as a good instrument, as it is possible to see there which results were
77

found but dropped later. With this information and the actual content of the applicationdatabase, the user is able to find out the values of the configuration that have to be adapted.
Therefore, the process to develop a Web information agent with our system will not be
ended after the agent's definition has been set once. As the documents on the Internet are
very heterogeneous, it is never foreseeable which and how many results an agent can find.
This system serves as a prototyping system which allows fast adaption of small details of
the configuration.
Finally, there is one thing in figure 5.2 which we have not mentioned yet. During search
processing, the agent is able to collect a lot of statistical data such as the reliabilities of
the different search definitions. This data also can be used to improve an application. For
example, if an agent should look for phone numbers and birthdates of people, but in fact
never finds any birthdates, the user can be warned about this or the agent even may cancel
the search for birthdates as this only takes time without any outcome.
The statistical data, such as the log information, may also be stored in the configurationdatabase. So, the data of the whole system is accessible in two separate databases without
producing a lot of output files. All agent information can therefore be stored together in
one place.
5.1.6 Additional Considerations
When looking at the whole system, we clearly see that the agent is the core of the system.
It is the only component that interacts with all of the other three components. This requiresthat the agent is continuously able to react to events triggered by other components.
Note that once the agent is launched, the user only interacts directly with the agent when
the agent requests a connection. The user guides the agent only by interacting with the
database. This is an important point of the architecture, because the agent will not be
interrupted while the user changes settings of the agent. It makes sense that the agent uses
the same preferences for a complete search and therefore the agent reads the settings onlyonce at the beginning of a search. The agent should only stop its work in important cases,
for example when the agent has found new information that does not seem to be reliable.
This, however, also will not interrupt the agent immediately; the agent finishes the rest of
the search first and asks the user afterwards. The main feature of our system is the fact that
it really uses the time that it is given instead of waiting for users to interact with it. So, the
agent is not dependent on the user's presence at the screen.
When discussing process time, we also have to mention the idle time in which the agentdoes not process any tasks for the user. This time also can be used by the agent. Here, the
statistics are a good example. Definitely, it is possible to collect a huge amount of statistical
data, and consequently, there are many possibilities to analyse this data. However, this
needs time and we do not have this time during a search process, as it is our goal to return
results as fast as possible, even if the user is not present. Therefore, the agent also may use
78

the idle time to perform such analysis.
Assume the user is a developer who uses an agent to update his contact database. During
workdays, the user works quite hard so the CPU of his machine is always heavily used
when the user really works at his computer. The agent is started once a day in the early
morning. Now, a simple agent can be built which tracks the CPU load. In the evening, after
the user leaves the work place, this agent will notify the contact agent that the CPU is no
longer being heavily used. This is the signal for the contact agent that it now can analysein depth the statistical data of the last search process. Even if this needs a couple of hours,
the user is never disturbed by that and, in fact, is completely unaware of it.
Finally, we want to discuss an important and interesting topic: the search space. This
concerns the agent in several ways. First, consider the resources. Generally, the whole
Internet is the search space, but the user must have the possibility to define the search
space, which means, for example, that he can specify that only Swiss Web sites should be
searched. As other examples, he could define a company's intranet or a single database as
the search space.
As intended, this is not the only way in which the search space is variable. An obvious
example is the scope of the search. This is defined by the agent definition which can be
edited by the user. A processed Web page can only lead to an information item or a link, if
the definition of the result given by the user really matches the one actually located in the
page. For example, if we have defined that we are looking for an email address which must
not be longer than 20 characters, the search scope is strictly restricted to that and the agent
will not return a longer email address, although it might be correct in the semantic context.
Similarly, if we restrict the search for a date to the english date format, we will not find a
date in the american format, although it might semantically match to our search.
Third, the instances in the application database also restrict the search space. As an exam¬
ple, we once again use the Academia system. In the Academia database, a user works
with person objects that represent all of the people working in a given research area of
interest. The ACADEMIA agent then searches the Internet for new information about each
of those persons, e.g. for telephone numbers, email addresses, publications - whatever is
of interest to the user - and stores the information found in the database. The search space
here is restricted to the people for which a search has to be performed. The names of the
persons and optionally specified URLs of their home pages also cut down the search space
in terms of pages to be processed.
It is never the goal of an agent created within this system to perform an exhaustive search.
We must be able to find as much information as possible in a reasonably short time. In
other words, it is the goal of the agent to act according to the 80/20 rule [Zeh91]. The
agent shall find 80 percent of all extractable information within 20 percent of the whole
search time. Later, in the idle time, the agent then could optionally run a more exhaustive
search leading to results which are harder to find.
This completes our overview of the search process and the general agent operation. As
already intended, the agent itself consists of several components, each responsible for an-
79

other task during a search process. In the following section, we want to describe the agent
architecture in more detail.
5.2 The Agent System Architecture
After having described the context in which our Web information agents work and what
the general tasks of the components look like, we now detail the general architecture of
such an agent system.
If we consider the situation presented, the agent has to consist of an agent core, a data
exchange component for the interaction with the databases and several subagents. The
architecture is shown in figure 5.6.
Resource List
Administrator
Result Collector Result
Analyser
0Result
Bag
Feedback/
Questions
Generator
0Feedback
0Question
Summaries
Consulter>
Pattern Learner
Data
Exchange
Component
< >
-7DB Learner
Source List
Web search
Simple Search
Pattern extraction iStart Page Finder
DB searchResource
Access
Handler-7
Summanser
(Patterns, whole
Web Pages, DB's)
Info extractionread
Idle Time Administratorwrite
>Statistics Analyser
^
Logger
^
>Statistics Updater
Agent Core Special Agents
Figure 5.6: The technical architecture of the agent
Before going into further detail, we want to state that this architecture can be implementedin two main ways. First, this can be implemented as a single component. Obviously, this
is not the preferred way if we use an object-oriented programming environment. Therefore
we implement it as a system of several components, in fact, as a multi-agent system. The
agent core is definitely a rather large agent consisting of different components, whereas the
special agents are smaller agents with possibly very simple functions. Of course, there can
exist particular components that do not fully meet the requirements of agents, but here, we
do not make a difference between true agents and other components. However, it must be
80

a goal to make it possible to work with or without these special agents, i.e. they must be
freely pluggable to the system.
5.2.1 The Agent Core
The agent core consists of three main components, the search component, the idle time
administrator and the logger. The first part of the search component is the resource list ad¬
ministrator. This list contains URLs and database locations where interesting information
may be found. Initially, there may be a given starting point for the search from the config¬uration database. If not, the agent calls the subagent start pagefinder, which, according to
the user's definition and the given data, tries to find a Web page as a starting point.
The start page finder is a component which returns a list of URLs out of the input values that
it is given. In Academia, these input values are the first and the last name of a person. The
easiest algorithm there would be to build a wrapper around a search engine. The wrapper
queries the search engine with the input values and extracts the URLs which the enginereturns. Of course, this is able to be improved in many ways. First, if not already done bythe chosen search engine, the searches can be alterated by only searching with subsets of
the given input values. Here, the different results can be compared according to some rules
yet to be determined, and the best ones will be returned. The other possibility is to add a
post-processor component after the search engine's output. This component could analysethe documents behind the returned URLs and cut the selection down to the most relevant
URLs. In chapter 3, we already discussed the Homepage Finder [Sel98] which offers such
a post-processor. Generally speaking, the start page finder must provide a wrapper which
works with different search engines. If the user wants to add a more sophisticated post¬
processing component, which may be very application dependent, the user has to providethat by himself.
Regarding an external database, the agent needs to know not only its location but also the
access method and knowledge about the query language which the database supports. This
information usually has to be given by the user. At least, the user has to provide the location
and a valid account and password, given that the agent already knows how to access the
data with this information.
The next part is the result collector. The result collector gets as input the first unprocessedURL or database address of the resource list administrator. First, the collector searches
the internal summaries database to check whether the requested source was visited and
summarised before. If this is the case, the collector simply uses the results of this summary.
If there is no summary of the source, the collector starts a complete search in the Web or the
database, respectively. Summaries are provided by the summariser which will be discussed
later.
If searching a Web page, the agent performs a simple search and tries to find and extract
patterns according to the profile in the configuration database. What here is called "pattern"
usually is known as semistructured information. If the agent finds such information which
81

is not yet analysed, the subagent pattern learner will be activated to extract the patternand store the content to allow faster result acquisition when the pattern has to be extracted
another time. The pattern learner subagent finally returns the information in a fully struc¬
tured form. The following chapter 6 discusses the search and extraction of information
from Web documents in detail.
Similarly, if an external database is given as a source, and this database was not analysedpreviously, the subagent database learner will be started to look for results. As mentioned
earlier, learning processes will be executed after an entire search process if it is likelyto take significant processing time. Anyhow, the database search consists of a powerful
component which is able to integrate different databases. It must be able to be connected
to a database quickly with little or no help from the user. There exist many products such
as the Fulcrum knowledge server [FKS] which already provide systems with fast access to
several different sources. Similar technology to access databases could also be used by our
agent's database search component.
Next, after having integrated a database, the database learner must be able to query and
finally understand the database. Databases offer a lot of semantics which makes it much
easier to learn their content than to "learn" the Web. However, a single database is very
small in comparison to the Web and - given that we do not talk of really private databases -
sometimes their data is also available somewhere else on the Web. In our prototype, which
is detailed in chapter 7, we did not include the database access and search components. It
is future work to examine these components and implement a prototype component.
After an entry in the list of the source list administrator was processed, the next source in
the list will be searched for new results. This process will be repeated until no unprocessedsource remains in the resource list. Of course, while searching the Web or databases, it
is possible that the agent detects new sources which could be of interest. In that case, the
agent adds these to the list of unprocessed sources, and they will be processed later in the
search. The list functions according to the principle first-in-first-out.
After the search process has ended, the collected results will be analysed within the result
analyser. The analyser decides on the reliability of each information item and, if consid¬
ered reliable, sends it to the data exchange component to store it in the application database.
If there is an information item which does not seem to be reliable enough, the,feedback and
questions composer is activated to ask the user after the search whether it should be stored.
The question composer creates the questions by simply displaying the information item
and giving the user the choice of a couple of predefined answers such as "Store it", "Dropit" or "Ask later". Additionally, it is definitely helpful to provide the context in which this
information item was extracted.
This component does not need to be very complex. In this context, only the determination
of the particular time when this interaction should take place may need a more sophisticatedmechanism. For example, these questions can be asked right after a search process has been
finished by the agent. A more intelligent way is to use the simple agent we have mentioned
in the previous section which is used to find out whether the CPU is heavily used or not.
82

Here, we can use this agent in the opposite way. If the user is not working at his machine,
it does not make sense to ask, as there will perhaps elapse quite a lot of time until the user
gives an answer. Therefore, the agent shall test here, whether there are any keyboard or
mouse interrupts happening. This then indicates that the user is working and is able to
answer quickly, so the question organiser will not be blocked.
We have not yet discussed the result analyser in detail. In the previous section, we have
already stated that the agent needs to be able to learn from the schema of the applicationdatabase. Important for the result analyser, this includes that the agent finds out whether
an attribute consists of a set of values or just a single value. Therefore, if an attribute holds
a set of values, the agent knows that it can simply store all newly found values that are
reliable into the database. On the other hand, if the attribute holds one value, the agent can
store only the most reliable result, although there might be found more that are reliable.
However, we need to find an algorithm that allows the agent to compute a value for the
reliability of a result. This algorithm clearly depends on the search technique. The more
exact a profile for an information item, the higher is the reliability of the result. Therefore,
as we stated that we want to have the possibility to define each single information item that
we are interested in by itself, this has the consequence that the developer of an applicationwill have to define an initial reliability for each search profile of an information item. This
clearly makes sense, as we stated that it is not possible to know the usefulness of a search
profile before the first search has been performed. Therefore, during the prototyping phase,we may have to adapt the reliability values after each test run individually.
There does not exist a perfect algorithm for the evaluation of a result's reliability. Possibly,each application might have its own optimal algorithm. Therefore, we do not want to dis¬
cuss the details about such an algorithm here, we just state that this is a necessity. In chap¬ter 3, we have already described our solution for the ACADEMIA system - the approach
using confidence values. In section 6.3, we will detail the confidence value approach which
we use in our agent applications. It is a further development of the original approach. Our
experiences have shown that this approach is quite independent from a specific application,so we decided to implement it fixed in our framework.
Of course, the reliability of a result also is influenced directly by the page in which it is
found. When was the page created ? The older a page is, the less reliable is the information
in it. Additional information can be gained from the authority of a page. For example, a
university is very interested to always keep its pages up to date, therefore this information
is commonly more reliable.
But, what comes next when the value has been computed? Now, we have to define a way
for the agent to make a decision about the reliability of the result. And here, we only have
three possibilities of what the agent may decide: The result is reliable, the result is not
reliable or the agent is not able to make a decision. In figure 5.7, we see a scale where
these possibilities are shown.
Of course, at the left end of this scale, we have complete unreliability, whereas on the rightside, we have complete reliability. In between, there are the two very important values ti
83

Result is Agent cannot Result is
not reliable decide reliable
H 1 ReliabilityH tu
Figure 5.7: The reliability scale
and tu which separate the three sections from each other. And, these values are defined
strictly - for each result they have the same value. We call them the lower and the upper
threshold:
Definition 5.4: The upper threshold separates the results which the agent considers reliable
from the ones for which the user shall decide about the reliability.
Definition 5.5: The lower threshold separates the results for which the user shall decide
about the reliability from the ones that the agent considers not reliable.
A reliable result is good enough to be stored into the database automatically, whereas an
unreliable result can be dropped by the agent immediately. If the agent cannot decide byitself, it will be the user who has to make a decision about the reliability of the result.
The setting of the threshold values has a high importance and we cannot leave it completelyto the responsibility of the agent. Mainly, it must be the user who sets the thresholds.
Whenever the user has trust in the agent, he will set both values close together. On the
other hand, if the user does not trust the agent that much, he must set the two values far
apart from each other, in order that most decisions fall in between and the agent therefore
must ask the user. Additionally, by moving the threshold to the right, the user states his
belief that the agent very seldomly produces bad results, whereas by moving the values to
the left, this implies that the agent is believed to produce a lot of unreliable results. There
exist some interesting special cases as well with the settings of the values, they are listed
in table 5.1. Note that rmm stands for lowest possible reliability, while rmax denotes the
maximum reliability which is possible.
With the possibility to set these thresholds, the user has almost full control over the agent.
Although the agent defines its own strategy on how to find information, the user can changethe threshold after each search in a very simple way, if he was not content with the way the
agent rated and handled the results. However, the agent might also assist the user in settingthe threshold, this is discussed in chapter 7.4.3.
Usually, we presume that after the prototyping phase, these thresholds do not change fre¬
quently. Therefore, the agent needs a memory in which it can store the user's answers.
84

Situation What it means
^mm — W — ï«
'min W ^ tu <. Vjyiax
'mm "l ^ lu — Tmax
'mm ^ W ^ lu ^ 'max
'mm ^ W — ^u ^ ^rriax
T"min ^ ''l *^ tu — ^max
W ^u 'max
Every result will automatically be considered reliable
Either a result is reliable or the user decides about it
Only the user decides about the reliabilityThe usual case where everything is possibleThe user will never be asked
Either a result is unreliable or the user decides about it
Every result will automatically be considered unreliable
Table 5.1: The different situations in setting the thresholds
In continuous searches, the agent might find the same questionable information again and
again, but the user should not have to answer the same questions repeatedly.
Now, we have described the complete search process for a single object. This will be
repeated as long as there exists an object for which there is a search to perform. Only then
is the search process over and the agent can start to ask the questions.
5.2.2 The Special Agents
In addition to the agent core, there exist several special agents that are used to performindividual tasks that provide added value to the whole system. The agent core is able to do
a search process on his own, but these special agents help to make the tasks of the agent
core easier.
Whenever there is no search process to perform, the idle time administrator controls the
agent. Although this component is located in the agent core because of its close cooperationwith the agent, it can be regarded as a special agent. One task of the idle time administrator
is to manage the list of tasks that have not been done during the last search, because theywould have used too much time. For example, if during a search, the agent detects a
database that was not previously accessed, the DB learner is needed to learn the structure
and content of the database. The DB learner starts immediately and finds out that the
database is very large and it would cost a lot of time to learn it. Therefore, the agentdecides to postpone the learning and goes on with the search. Now, after the search has
ended, the idle time administrator issues the command to execute that search. Of course,
this also works in the same way with the pattern learner. The start pagefinder is the only
component that - if needed - has to run immediately during a search.
Additionally, the idle time administrator has two other tasks to control which run every time
when this administrator is in charge. First, there is the summariser which summarises the
contents of frequently accessed Web pages and stores the results into the home database.
Additionally, the summariser also does this with databases.
A summary contains information on the content of a resource in terms of the agent def-
85

inition, but without specified input values. This means that the summariser performs the
identical search as the search agent with the difference that the input values are filled with
wildcards. If a search profile is defined without any input values, the result will be equalto the result that the agent would extract. On the other hand, if a search profile requires the
occurence of at least one input value, the summariser handles this as if the input value was
found. The result of a summary can be imagined as a table of all possible results found
in a particular resource. If the agent wants to process a resource for which there exists
a summary, the agent only has to check for the occurrence of the input values, the other
attributes of the search are already evaluated. For large resources, this saves a lot of time.
It will be the user who decides when the summariser comes into action. If the user has
no objection to a large configuration database, the summariser will run on every resource
which is accessed. Otherwise, it makes sense to only summarise multiply accessed sources,
as a summary usually consists of a lot of data. We have to bear in mind that a summary has
to be independent of any input values, in contrast to the search which is restricted to some
input values. Therefore, a summary is usually larger than the page itself. On the other
hand, the extraction of information from a summary will be very fast.
Another component to be run by the idle time administrator is the statistics analyser which
analyses the collected statistics to give feedback to the user. Of course to do that, the
feedback and questions composer is also used. In the previous section we have already
given some examples of trackable statistics that the agent can use to give feedback to
the user about inefficient search profiles. Another example is that the agent can track
the answers of the user to questions about the reliability of a result. If the user answers
always "Yes, store it", it might make sense to decrease the upper threshold, as this value
seems to be set incorrectly. However, here we also want the agent only to propose such an
adjustment to the user who then decides whether this shall be done or not.
Finally, the logger is always working. It logs the actions performed during the search
process and the idle time. Of course, the logger is the component which usually updatesstatistical information by calling the statistics updater. It is also possible to implement the
logger as a subagent. However, like the other two main processes of the agent core, the
logger sends its outcome to the exchange component to let it be written into the database.
We have now seen that the data exchange component is used at various points by all of
the main components directly or through the special agents. Therefore, it boosts the per¬
formance of such a framework, if we are able to bring the database closer to the agent. In
chapter 7, we discuss that further.
With this architecture, we have developed a general framework for the development of
many forms of information agent applications. Once an engineer has gained experience in
such a system, he is capable of rapidly creating new applications whenever required.
86

5.3 Summary
In this chapter, we have discussed the whole system in general. First, we have discussed
the context in which the Web information agents are situated. This has several influences
on the architecture of the agents.
Very important in the whole concept is the need to have two different databases. First,
there is the configuration database which holds the information on the agent definition
and the general settings. Further, this database is used to store additional information such
as statistical and log data. Second, for every agent application, we need an applicationdatabase to define the application schema within it and store first the input values and,
after a search, the reliable results.
The agent starts the search after having read all the settings and inputs and searches Web
pages as well as databases. After the search has ended, the agent rates the reliability of
the results and stores the reliable ones in the database. Some other results are rated to be
unreliable and they are dropped immediately by the agent. Additionally, there also will be
some results of which the agent is not able to decide about the reliability. Here, the agent
contacts the user for feedback to decide whether the result shall be stored or dropped. In
fact, this is the only direct contact between the agent and the user. Otherwise, the user onlyinteracts with the database where he for example browses through the results that the agenthas found.
In the previous section, we then discussed the agent's architecture in more detail. Mainly,the database consists of a data exchange component, the agent core and several special
agents that are used to process specific tasks.
The central component, the agent core, consists of three main components. Here, the search
component which organises the whole search processes is of course the most important one.In addition, there are the idle time administrator for doing some tasks during the time in
which no search is processed and the logger which is always active.
We have seen that all components regularly use the data exchange component to exchangedata with the database. Therefore, we definitely lose a lot of time when the cooperation be¬
tween this component and the database is not built well designed. This makes it a necessityto work on a close cooperation between agent and database.
In the following chapter, we describe the search mechanisms of the agent. Definitely, this
is the heart of a Web information agent and we therefore want to discuss it in more detail.
We later describe in section 7.2 how we implemented the architecture mentioned in this
chapter to build our prototype system.
87

Chapter 6
EXTRACTION OF INFORMATION
FROM WEB DOCUMENTS
Regarding our agent, the central part of its work is to extract any kind of desired informa¬
tion from Web documents. In this chapter we want to discuss the two basic mechanisms
that we use to provide a flexible, dynamic configurable agent.
First, as already stated in section 2.4, it is important to emphasise that we do not expect
complete or exact extraction of information. This optimum is difficult to achieve in our
context and also rather expensive. Rather, we aim for some simple mechanisms which do
not necessarily cover all of the relevant information, but at least a significant part of it.
We want to find as much information as possible, and this implies a thorough extensive
search. On the other hand, because we use an agent which has to deliver results as fast as
possible to the user, we also have to be aware that we must find a quick solution. In the
area of general information extraction from documents, we simply cannot achieve both in
perfection. Therefore, for our purposes, we need to find a compromise.
Having these requirements in mind, we exclude linguistical analysis and natural language
processing (NLP) from the possible techniques to use for the extraction of information from
documents. Although linguistical analysis is a good instrument for the processing of texts
and to gain information from it, it is not useful for our purposes, and this not only because
of the processing time. During this thesis, we supervised student projects which focused on
natural language processing for information extraction [Bar98a], [Bar98b]. This projects
highlighted the problems of using this technique, namely the difficulty of creating a robust
and fast parser for the analysis of the sentences. Existing parsers are usually very fast in
parsing short sentences, but whenever the sentences are longer - and we have to count on
that especially in combination with research articles - the parsers are very slow. In addition
to that, the analysis phase of the parser requires a lot of working memory. Bartha's work
showed that it requires a lot of effort to overcome these problems, and it was not possiblein a reasonable amount of time to provide an NLP unit which is fast enough to be used
within our system.
88

However, in future work, it is necessary to study the current approaches in NLP techniquesin much more detail. Other work [A1100] has already shown that lightweight NLP tech¬
niques can be both efficient and effective for information extraction tasks. It is definitelyworth examining these approaches further. We must also examine in more detail how im¬
portant "effectiveness" for our system really is. A user who uses the system only overnightdoes not care whether the system uses time-consuming methods to find results, because he
simply does not notice it. On the other hand, if a user waits for the results, he might preferfaster processing and be prepared to forsake completeness and precision. We decided not
to adopt a linguistic approach in this thesis and rather to try and find something simplerthat functions reasonably well.
For now, it is more important to use a mechanism that lets the user define his needs in a
simple way that is also easy for the agent to interpret. In this way, we achieve fast transfor¬
mation between the interfaces, but, as stated before, our second requirement - exactness -
is not fulfillable if we only regard the other requirement - the performance. Therefore, we
compromise by distinguishing between two sorts of information which we want to be able
to extract.
There is information which is hidden within non-textual structure. For example, repeatingHTML tag patterns can imply that there is a list or a ranking. Other information is ac¬
cessible at the textual level. In this case, we talk of "single information items" or "simpleinformation items" which we are looking for. This can be a telephone number or an email
address. What simple information items really are, is described later in this chapter.
Figure 6.1 shows a typical extraction process schematically. This workflow is quite
straightforward but does not specify anything about the location and the extraction part.In the following section, we discuss how we extract single information items with a rel¬
atively simple approach which nevertheless follows the principle of figure 6.1. However,
if information items are contained in a certain structure, we need a more sophisticated ap¬
proach to perform the extraction. This is described in section 6.2. In section 6.3, we explainthe final part of the extraction process, the rating of extracted information items to decide
automatically whether it is reliable or not. Finally, we want to evaluate our extraction
methods empirically in section 6.4.
Specification Location Extraction Rating
User specifieswhat he wants to
[ find J
Locate a possibleinformation item
in a Web page
Extract the
information item
Rate the
result found
Figure 6.1: The extraction process
89

6.1 Extraction of Simple Information Items
In this section, we discuss the problem of extracting simple information items from docu¬
ments available on the Web. In this context, the word "simple" denotes an information item
that is available in a compact form, without being hidden in a list or split in several piecesthat are separated from each other. As an example, see figure 6.2, which is a homepage
providing information about a researcher. Here, we have such information items contained
within the page. There is the address, which itself can be divided into smaller information
parts, and below that, we see a phone and a fax number, as well as an email address and
another URL to a homepage. Additionally, we have a picture which is also such an infor¬
mation item. In addition, there are information items contained in the text. To name just a
few, there is the year of birth and the degree.
Mario Magnanelli WÉÈëÉIËÈMzK '«
Institute for Information SystemsETH Zentrum, IFWD47.I
8092 Zwick, Switzerland
phone: *41 (0)! 632 7262
fax: +4! (0)1 6321172email. ma%!taneUi@bnf etkz. ch
www: http. //www, inf. etkz ch/personaUmagncsneUt
Mario is developing Internet agents which are responsible for maintaining client databases bygathering information published on the Web. As an example, he developed the Academia agentwhich seeks and extracts information from Web documents about academics, their research
projects and publications. The agent uses a combination of keyword- based and pattern-basedextraction techniques. He is now generalising the system to make it easy to dynamically configurethe agent for other database application systems.
Background
Mario was bom m 1971 in the town of Olten in central Switzerland. He studied Computer Science
at ETH Zurich, obtaining his Diploma (M.Sc.) in 1997 During his studies, he specialised in expert
systems, information retrieval and database systems. He then discovered the possibilities of the
Internet and intelligent agents during his Diploma project. In October 1997, he joined the Institute
for Information Systems as a research assistant funded by SYSTOR AG.
Figure 6.2: An example Web page containing "simple" information items
The extraction of these simple information items is a crucial point for the success of au¬
tonomous extraction of information, because it must be very efficient in order to ensure
good performance. On the other hand, it also must be straightforward in order to provideconvenient handling and make it easily configurable for anyone. A third important point is
that this extraction mechanism must be as generic as possible, because it must be used to
90

extract all sorts of information.
But first, let us have a closer look at the search process which we must try to automate. We
are interested in such a simple information item in the following situation. We have a key
object defined which serves as the anchor for our search. In the case of figure 6.2, this is
the researcher. The key information which is given at the beginning of the search may be
the name of the person. This serves already as a good identification of someone. To keep it
simple, we assume that there is no other key information given, although it clearly would
make sense to define more exactly the person in question. However, this key information
is only one part of the specification phase in the extraction process in figure 6.1. We will
later discuss the tasks there in terms of the schematical extraction process.
Now, the problem is divided into several parts. First, we have a certain belief that the page
which we are searching is relevant for our purpose. As in figure 6.2, it is obvious for a
human that this Web page is the home page of Mario Magnanelli, but for our agent, this is
not that clear. Somehow, the agent has been led to that page and now the agent must have
a measure to decide on the page's reliability. For example, if this page has been given bythe user, the agent should trust the user and therefore believe that the page belongs to the
person in question. On the other hand, if the agent has been following a couple of links
to get to this page, it is not considered so reliable. This issue will be discussed later in
section 6.3. Now, we simply assume to be on a page which is reliable.
For the moment, we deal only with the correct extraction of such an information item.
Now, what do these items have in common? They are all part of a Web page, and they are
there in a textual form, either directly such as the email address in figure 6.2 or indirectlywhich means the situation when we in fact look for a file, such as a picture, then there
exists the link to it in textual form.
With the fact that the information item occurs in textual form on a Web page, we have not
yet achieved anything useful to serve as a specification of what we are interested in. There
is no possibility for an agent to extract such information with only this knowledge. We need
more information. And the simplest information we can use is to define a keyword that has
to occur in proximity to the interesting information. Of course, for each information item
we are looking for, we will have to define a different keyword.
If we look at figure 6.2, we see that this is possible. The phone and the fax number, as
well as the email address are preceeded by their designation, whereas the keyword "www"
points to another homepage. To look for the picture, we could use the file extension, for
example ".jpg" or ".gif" as a keyword, whereas the year of birth follows after the word
"born" and the degree itself, "M.Sc", is usable as a keyword to look for this degree.
The address, however, has no useful keyword, except for the tag with the same name which
may enclose it. However, an address can be placed into a Web page without this tag. So
here the keyword approach does not help that much. On the other hand, an address is
usually well structured and contains several parts such as the street, the zip code or the
town. And each of these elements has a specific look. This is no longer a so called simpleinformation item. Here, we need another approach, with which we are able to extract the
91

whole information in this structure. This approach is described in section 6.2 in more
detail.
Obviously, the keyword only is not reliable enough. While we instinctively would declare
"phone" as a good keyword, "www" seems a little bit unsafe, because almost all URLs
itself have these three letters as part of the host address. And a URL does not have to be a
link to a text, it can link us to a picture or anything else. Unfortunately, that is a fact: For
certain information items, it is much easier to find a reliable keyword, while for others, we
have problems to find one. At least, the keyword serves as a first indicator, we only have
to find more indicators to get a more reliable extraction.
One of these further indicators needs to be the position in which this keyword must be
found. When we look at our example, the keyword "phone" is only useful if it occurs in
the plain text or between formatting tags. Definitely, for our purpose, it does not help us
at all, if this string is incidentally part of a URL in a link tag. Therefore we also check the
position of the keyword. In table 6.1, we see the different positions that we track.
Typea
x
t
h
c
1
k
Description
anywhere in the document
not in a tag (in plain text only)between title tags (<title> and </title>)between any header tags (e.g. <h3> and </h3>)
inside any tag
inside of a link reference tag (in <a href=... >)
in a link anchor (between tags <a> and </a>)
Table 6.1: Possible positions of a keyword in an HTML file
Of course, this is only an excerpt of the positions that we could track, but that set seems to
cover all of our needs. It makes it possible to look for keywords that occur in a link anchor,
as well as for keywords that are especially important because of their position in a title or
a header within a page. However, most of the keywords do have to occur in the plain text
and only seldomly do we need the keyword to be found within a tag. Note that we only
specifically track keywords located in the title tag, in a header or in a link anchor, but we
do not track whether a keyword is located between specific formatting tags such as "<B>"
and "</B>". This does not tell us significantly more than if we only track for the keyword
being located as type "x", which simply means not in a tag.
As stated before, the keyword should point to an information item in which we are inter¬
ested. This relationship must also be defined in terms of the distance, since the proximityof the keyword to the information item is important too. For example, if we are lookingfor a phone number, and we actually detect the keyword "phone" in a Web page, we expect
the number to follow immediately after the keyword. So, we possibly define that the result
shall begin at most 5 characters after the keyword. On the other hand, it is possible, that
there exists an information item which is located anywhere in a page, whenever a certain
92

keyword occurs. It does not necessarily have to be found next to the keyword. In this case,
we set this maximum distance equal to the length of the document.
Another quite simple extension of indicators is to use more than one keyword. This is
helpful if we are looking for information in plain text. In this case, one keyword (or phrase)
may not be enough to represent a good indicator for a certain information item. We givea simple example to illustrate this. If we are interested in finding pictures of somebody's
living place, it is definitely not enough to look for the picture file extension ".jpg" because
this leads us to just any picture. On the other hand, if in the file name, there also occurs the
term "house", the possibility of having found a relevant picture is definitely higher.
But, there is one thing that we have not regarded yet. We have stated that we simply assume
to search a site which is relevant to the key information. This means for example, if we
find a phone number, we can assume that it leads to the telephone of the person in question.
Or, if there is an email address found, it belongs to the person, too. However, it is obvious,
that if this email address contains somehow the name of the person, this makes it much
more reliable. So, for certain keywords, we must also have the possibility to demand the
occurence of parts of the key information in proximity to the keyword.
We give another example to make this clear: If we are looking for the price of a certain
car, we give the brand and the model as key information. If the agent later searches a list
containing a lot of different cars, the keyword "price" or a currency sign leads to all the
prices in the list. However, as we are only interested in one model, we state that the name
ofthat model must occur in close proximity to the price. With this requirement, we receive
only the price that we are looking for.
We now have found several requirements for a successful extraction of information items
from Web pages. They may be useful for every type of information we may be looking
for, therefore they serve as the general specification of the interesting information. On
the other hand, these items can be very different from each other. Of course, an email
address looks totally different from a phone number. Therefore, it makes sense to define
additional extraction mechanisms and properties for each type of information. Figure 6.3
shows the general search algorithm described so far in pseudocode. Here, the extraction
corresponding to the type of the item to be extracted is not shown in detail.
In table 6.2, we list some information types and their specific properties. This defines
mainly how the extracted information item must appear and serves the extraction compo¬
nent of the agent as an important support. The general properties such as the keyword are
not mentioned again. Of course, it is possible to define other types, but with this set we are
able to define an extraction profile for almost every information item.
For each information extraction process of the same type, the predefined properties remain
the same, whereas the optional properties may differ. So, we need for every extraction
component a specific extraction mechanism in addition to the general one. This mechanism
handles these specific properties and the extraction components then are ready to be used
within the agent. In section 7.2, the prototype using this definition is described in detail.
93

document doc
search_profile sp
docposition = 0
x= findjiext (doc, from docposition, find sp.keyword)while (exists (x)) {
if (checkposition(x) = sp.position) {if (is-empty(sp.mputvariables) OR
inputvariables_are_f ound (doc , x, sp.inputvartables) ) {if ( is.empty (sp.morekeywords) OR
morekeywords-are.found (doc i x, sp.morekeywords) ) {x = x+length (sp.keyword)result = extract (doc, x, sp.m axdistance, sp.type)if (valid (result)) sp.add.to
}}
}docposition — x
.results (result)
x— f ind_next {doc, from docposttion,
}
find sp.keyword)
extract(document d, position p, maxdistance m, informat iontype t) {index % = 0
while (p + i < length (d) AND i < m) {res = < .extract-item(document d, start at position (p+i ))
if (valid (res) ) return res
else i = ! -f 1
}}
Figure 6.3: Pseudocode for the extraction of simple information items
As we see in figure 6.2, there is one information type in the given examples which cannot be
extracted using the definitions in table 6.2. This is the degree, "M.Sc", for which we stated
that it is itself to be used as a keyword, and the occurence of it is a sign that the person has
this degree. We define this as the type boolean, for which the result is the keyword itself,
if it is found. In addition to the general properties, there are no other properties to be set.
A good example for the boolean type is the search for a title of a person. As a keyword,we may use "Prof." or "Dr.", and as a property, we state that the name of the person in
question must occur immediately after the keyword. If this is fulfilled, it is reasonable to
assume that the person is a professor or has written a PhD thesis, respectively. Of course,
if both occur, it means that the person has both titles.
Of course, the keyword approach is language-dependent. For example, the keyword
"phone" works in english pages, whereas it will not work in german pages. In these pages,
we usually would have to look for the keyword "tel", which is the prefix and common
abbreviation of "telefon". But also in english itself, the keyword "phone" might not be
enough, it is safer to also search for "tel" which is sometimes used instead. In our ap¬
proach, we can deal with this only in one way. We have to define two extraction profileswith different keywords, whereas the rest of the settings will be identical.
Regarding the schematical extraction process in figure 6.1, we see that the Location means
the finding of the keyword and the required other items that have to occur to indicate the
occurence of an interesting information item. Together with the Extraction, these two
phases are strongly dependent on the Specification. We have not yet discussed the Rating,but this seems to be quite different from the other three phases, therefore we discuss it later.
94

Type Predefined Properties optional PropertiesHTML text min./max. length,
specific character set
plain text no HTML tags min./max. length,
specific character set
phone number only digits and some separators
email address contains one "@", no spaces min./max. length
integer only digits, no spaces range
real only digits, no spaces,
optionally some punctuation
range
date needs specific date parser period
time needs specific time parser period
link returns a URL
image file URL to file with image file extension
video file URL to file with video file extension
audio file URL to file with audio file extension
Table 6.2: Types of information items and their properties
However, in figure 6.4, we see a summary of the necessary information which has to be
given in the specification phase.
With the defined techniques, we are able to extract a lot of information items from Web
sites. The empiric evaluation in section 6.4 and our prototype which is described in sec¬
tion 7.2 verified this and the results of it are discussed in section 7.5. In the next section, we
take a closer look at the problem of extracting semistructured information which occurs in
lists and tables. This extraction is very important because many Web pages are generated
automatically which implies that there is strong repeated structure included. The keyword
approach which we presented here is simply not powerful enough for that.
6.2 Extraction of Semistructured Information
In this section, we want to detail how we dealt with the problem of extracting semistruc¬
tured information on the Web, which is important for our agents to be able to, not onlylocate information in Web documents, but also to extract it. We want to start with a gen¬
eral look at structures in Web pages and afterwards discuss the structures in which we are
95

( define type of information item j
(define keyword j > required
( define valid position of the keyword j
( define second keyworddefine other properties
corresponding the typeoptional
full Specification
Figure 6.4: The necessary parts of the specification phase
interested.
However, the term "semistructured information" or "semistructured data" is not clearlydefined in this context. Generally speaking, it consists of data available in the Internet or
in private intranets where the structure is rather implicit, for example in formatted text.
The structure is not as regular and rigid as in traditional databases. Another specialityin semistructured information is that the data can be in non-traditional formats and the
schema of the data may change often. Of course, when we can deal with semistructured
information, we automatically can deal with fully structured information. And, as there
exists much more semistructured than fully structured information on the Web, we do not
need to find a specific concept for handling structured information.
6.2.1 Differences in Structured Information
An example of an HTML page containing semistructured information is shown in fig¬ure 6.5. It consists of a list of publications where items such as title, author and additional
files are encoded within different HTML tags to define a structure which can easily be
decoded by human beings through its optical impression. The HTML tags, however, also
serve as delimiters of different parts of text for an agent, and this must be our starting pointto not only determine structures, but also learn about the included information. However,
as we see in this figure, the entries are not equally structured since, for example, the first
entry contains a link to a downloadable file of the publication, but the other entries do not
have that. This is the classical case of semistructured information.
We also have to be aware of the domain of sources of interest. For example, if we are onlyinterested in publications as shown in figure 6.5, we can restrict our problem to the very
96

199a
A Web Agent for the Maintenance of a Database of
Academic Contacts
M. MagnaneUi, A. Erni and M. C. Norrie. Informatica,International Journal of Computing and Informatics, Vol. 22,December 1998
Available. |"abstract ] [gnu-compressed Postscript]
Semantic Querying of Scientific Data through a Context
Meta-data Database
E. Kapetanios and M. C. Norrie. ERCIM News No. 35, October
1998
Available: [ ERCIM News On-Line Edition ]
OMS Approach to Database Development throughRapid Prototyping
A. Kobler, M. C. Norrie and A. Würgler. Proc. of8th Workshop on
Information Technologies and Systems (WITS'98), Helsinki,
Finland, December 1998
Available: [abstract ]
Collecting and Querying Medical Information on the
Internet
E. Kapetanios, M. C. Norrie and J. Schilling. INFORMATIK,Journal ofthe Swiss Informations Society, October 1998
Available: [abstract ]
Figure 6.5: An example Web page containing structure
97

specific problem of finding titles and authors, etc., but it must be our goal to have a general
approach which we can use in any domain of interest.
Our preferences lead towards an open solution which can help to extract information with¬
out necessarily knowing any further semantics. Of course, we must exclude the definition
of what must be found. This serves as the only semantics the approach will know. In this
context, we must recall how structure in documents looks like. The structure may be given
by a recuring pattern, for example a list, which is the usual assumed look. On the other
hand, a single entry of a database such as shown in figure 6.6, where the information about
a specific book is shown, also is a form of structured semantics. This makes it definitelyharder to define the location in terms of the exact start and end tags, because we cannot
determine the structure automatically - human help is necessary. When the same pattern
occurs several times one after another, this problem is easier to solve. In that case, we can
find out about the structure automatically.
Design Patterns : Elements of Reusable Object-OrientedSoftware (Addison-Wesley Professional Computing)by Erich Gamma, Richard Helm. Ralph Johnson. John Vhssides, GradyBooch (Designer-)
List Price: $4&SSOur Price: $34.96You Save: $14.99(30%)
Iteifln itatib tAdd to Shopping Cart
| Availability: Usuallyships within 24 hours.
mm
Shopping with us is
100% safe.
diiuliïiltÉëgf
Hardcover - 395 pages 2400 edition (October 1994)Addison-Wesley Pub Co, ISBN 0201633612, Dimensions (in inches) 1 34 x 9 59 x 7 68
Amazon.com Sales Rank: 86
Avg. Customer Review: icfc*rk~k
Number of Reviews 35
Figure 6.6: A view of a single object of a database
Before describing our approach in detail, we once again must characterise our needs. We
use agents to search for information from Web pages and we want them to be able to work
as autonomously as possible. To achieve this, we need a mechanism which is not onlyable to detect the structure but only the semantic content of such information. Structure,
such as shown in figure 6.6, can reliably only be determined by using an approach as used
for the ShopBot which is described in section 2.4. We do not want to concentrate on that,
rather on the extraction of information from structured lists. There, it is possible to find
that structure autonomously without knowing the semantics in detail in advance. However,
this also does not exclude the possibility that we can determine structure, whenever there
is only one entry in a list, such as in the example in figure 6.6.
Our goal is not to query the same page several times which simply changes its data period¬
ically. In the worst case, we have to assume that we only query each page once and never
use it again. The assistance of the user has to be held to a minimum, otherwise we would
98

not be able to use the advantages of agent technology which is mainly used to reduce the
work of the user. The agent should only contact the user when the agent cannot extract
information from a pattern where the agent strongly assumes that it contains interestinginformation. In other words, we want the user to define first what he wants to find and
afterwards, the user will only be contacted again in emergency cases.
6.2.2 XML Documents
For our approach, it should also be desirable not only to find out about a structure in an
HTML document but also in text-only documents. On the other side, our approach also
must be able to use the advantages of XML documents which are fully structured and
come along with the definition of their content, the document type definition (DTD), a
weaker form of semantics. Figure 6.7 shows an example excerpt of an XML document
which definitely would be of interest for Academia.
<person> Moira Nome
<persontitle>Prof</persontit le>
<phone>+41 1 632 7242</phone>
<publication>
<title>A Personal Assistant for Web Database Cachmg</title>
<author>B. Signer</author>
<author>A. Erm</author>
<author>M C. Nome</author>
<published>Proc of CAiSE'00</published>
<address>Stockholm, Sweden</address>
</publication>
<pro]ect>
<title>OMS Database Development Suite</title>
<description>OMS is an object-oriented database management system</description>
</pro]ect>
</person>
Figure 6.7: An excerpt of a possible XML document
We clearly see the structure, and in addition, the tags contain semantic information about
the contents. It seems that this information can be extracted more easily than from an
HTML page. This is correct in terms of the structure as it is given and readable for the
agent. However, the semantic information still is a problem for the agent. Another simple
approach to deal with this is similar to the one with the keywords in section 6.1. We
state in an extraction profile that the keyword "title" in combination to the person, i.e. not
publication or project, leads to the title of the person and we can assume that a correct
extraction will be possible given this input. However, if we are looking for the keyword
"phone" to find the phone number, but the document has a tag called "tel" instead, we
will not find the values. We can deal with that problem in the same way as we did with
the simple extraction in section 6.1, we can provide two extraction definitions, each with
another keyword. Our conclusion concerning XML documents is that we only have the
possibility to get the structure more easily, but not necessarily the content.
A more sophisticated approach is to include a component which tries to "learn" the seman¬
tics in the tags. However, this definitely needs a huge effort and a large knowledge base as
99

well as a strong inference mechanism as a basis. This is beyond the scope of this thesis.
Therefore, in this thesis, we will not deal especially with the way to understand XML
documents. Instead of that, for our purposes, we define XML documents as well structured
documents where we do not have to determine the structure first by ourselves. Of course,
the semantic information about the data which is contained in the tags of XML documents
is not available in pure HTML documents. This is obvious given the case that a specificHTML document was created out of an XML document using an additional style sheet.
For example, an XML tag named "age" which contains the information about a person's
age in the original document will not be available anymore in the HTML document. So, if
we determine a mechanism to extract information from HTML documents, we will end up
with a solution which we can also use to process XML documents, as these do not contain
less semantics as HTML documents.
Note, that when surfing on the Web, there are almost no pure XML documents around.
XML documents are usually hidden behind specific servers and then are presented as
HTML documents. The typical situation is shown in figure 6.8. There is a database which
contains data which will be transformed to XML data. However, it is also possible that the
data is directly stored as XML data. This XML data then will be transformed once againin combination with, for example, an XSL file which contains the information on how the
XML data should be visualised. The result is an HTML document which will be sent to
the client browser. The client therefore usually does not find XML documents on the Web.
This is another reason why we concentrate on HTML or pure textual documents only.
Raw Data or
XML Data
XML page
XSL file
HTML page
Figure 6.8: The transformation of data from a database to a Web document
6.2.3 Our Approach
In non-XML pages, it is a major problem for an agent to determine the semantics of the
content of a pattern. In the ShopBot mentioned in section 2.4, we do not have this problem
100

as every single ShopBot is built for a specific domain and includes the semantic definition
of the desired product. On the other hand, a query language to extract information as for
example WebL described in section 2.4 does by itself not deal with semantics at all. It is
the user who has to provide the semantics when he forms a query.
So we try to adopt an approach in between these two extremes. As we want to give the user
the possibility to extract information of every domain, it is necessary that the user tells us
as exactly as possible what he is interested in. We can then use the user's explanations to
learn about the semantics of this domain.
We give an example from ACADEMIA which was detailed in chapter 3. In this context,
where a Web agent looks for information about researchers, the user is also interested
in publications. Information about publications is typically displayed in lists containing
similarly structured entries which describe a single publication. These lists are a very good
example for our purposes because the structure of the entries is not necessarily alwaysidentical. One publication contains for example a title, authors and information about
where it was published, while another entry comes up with an additional date of publicationand maybe links to an abstract or even a file to download the whole paper.
In Academia, this problem was handled by predefining the possible structure and pro¬
viding it to the agent, but in a general approach, the agent has no information about the
appearance of a publication. Therefore, the user has to give a definition of the expectedor typical form of a publication. The user may specify that a title is a part of the publi¬cation and that this must be a string of a length of 60 characters in average. Additionally,there must exist a part containing the authors where the name of the researcher in questionmust be listed also. All this information gives the agent more information about how a
publication is structured.
Specification Location Structuring
User specifieswhat pattern
he wants to find
Locate a possiblesemistructured
information blockà
Determine the
structure
Analysis Extraction Rating
Determine the
semantic content
Extract the
information
Rate the
result found
-
Figure 6.9: The process to extract semistructured information in Web pages
This example gives the general idea of our approach. Figure 6.9 shows the general work¬
flow for the extraction. Let us now describe it in more detail. The first two phases, Spec¬
ification and Location are effectively identical to the corresponding phases in the generalextraction process shown in figure 6.1, but, before the agent can extract information from
a structured document, it must first be able to determine the Structure which is the task of
phase 3. Then, in the Analysis we try to determine the semantic content of the structure.
If we were successful up to this point, we do the Extraction of the information and finallyrate the results.
We now want to describe the process in the phase where we try to find the structure. Con¬
sidering HTML documents, we have mainly the HTML tags which can define a structure.
See figure 6.10 for an HTML example containing the first two entries of the Web page
101

<BR>
<FONT size=+l> 1998 </FONT>
<HR>
<A NAME="1998i-men-mf"></A>
<FONT size=+l>
<B>A Web Agent for the Maintenance of a Database of Academic Contacts</B>
</FONT>
<BR><BR>
<B>M Magnanelli, A. Erni and M. C. Norrie.</B>
<I>Informatica, Int. Journal of Computing and Informatics, Vol. 22, December 1998</I>
<BR>
Available:
[<a href=" javascript : show( ' 1998i-men-inf .html '
) ">abstract</a>][<a href="docs/1998i-men-mf .ps .gz">gnu-compressed Postscript</a>]<HR>
<A NAME="1998h-knw-wits"X/A>
<FONT size=+I>
<B>Semantic Querying of Scientific Data through a Context Meta-data Database</B>
</FONT>
<BR><BR>
<B>E. Kapetanios and M. C. Norrie.</B>
<I>ERCIM News No. 35, October 1998</I>
<BR>
Available:
[<a href= "http://www. ercim. org/.../en35contents .html">ERCIM News On-Lme Edition</a>]<HR>
Figure 6.10: Part of an HTML publication list
shown in figure 6.5. The HTML tag structure of these two entries is nearly identical. As
already mentioned earlier, there is a difference at the end where, in entry one, two links
exist, but in entry two there is only one. All the other tags exist in both entries. Therefore,
we can combine the HTML structures of both entries to a tag chain shown in figure 6.11.
<A></A><FONT><B></B></FONT><BR><BR><B></B><I></I><BR><AX/A> [<AX/A>] <HR>
Figure 6.11: Two tag chains are combined as one
The notation means that all tags except the ones enclosed in square brackets appear in every
entry. With this method, we can always find a pattern which enables us to divide each entry
into several parts which we can compare with all the corresponding parts in other entries.
Of course, not every document is as well structured as this example. Consider a bibliog¬
raphy site which is updated and extended manually by different people. This might lead
to a result like that shown in figure 6.12, where we see an HTML example with two quitedifferent entries. We can see that the second entry has got only the information about the
authors and the title of their publication, whereas the first entry comes up with a lot of
additional information.
However, this is not only a problem within manually created documents. If the information
comes from a database, this problem can also occur. In fact, the entries in figure 6.12 are
of a different type, the first one denotes a regular publication, whereas the second entry
102

<p>
<B>The extreme Design Framework for Web Object Management</B>
<BR>
<STRONG>A. Kobler and M. C. Norrie.</STRONG>
<I>TOOLS Europe 2001, Workshop on Object-Oriented Databases</I>
<BR>
Zurich, Switzerland, <I>March</I> <B>200K/B>
<P>
<B>Object Data Models: Fundamental Concepts and Issues</B>
<BR>
<STRONG>M. C. Norrie and H. J. Schek.</STRONG>
Figure 6.12: Two quite different entries in an HTML bibliography list
denotes an internal report. This information can be placed in a relational database within a
single table where entry two simply leads to a couple of attributes that will be left empty.
If the automated Web generator builds the Web page, it certainly only uses non-empty
attributes and therefore, as in the figure, the second entry would not have any formatting
tags after the denotion of the authors, as there is no additional information around.
Therefore, we have to deal with the problem that we can have a significant difference in
the tag sequence of the two entries. But what if a document is poorly formatted and does
not contain many HTML tags? Here we have to go a step further and think of a plain text
document. If we write something in plain text, how do we put structure into it? We use
delimiters such as commas, colons, slashes, quotes and so on. Even blanks are often used
to create structure, but as they occur also as natural delimiters between words, it is harder to
distinguish between the natural and the structural blanks without analysing the semantics
of the text.
Therefore, for our purposes, we can replace these delimiters with dummy HTML tagsand then use the same mechanism as above. But, as these delimiters are usually not as
reliable as normal tags, we have to be careful and use them as properly as possible. Here,
we use the approach to categorise the delimiters according to their usability as structural
delimiters. We have analysed several documents and we can conclude that quotes and
brackets are mostly good structural delimiters in lists. On the other hand, colons are not
used frequently, although they seem to be useful as well. Commas as well as dots occur
too often to be good as such delimiters. So, we define initially that quotes and brackets get
a high ranking, colons a medium ranking and commas a low ranking. We do not use dots
at all because they are also too frequently used within abbreviations to be significant. The
system which uses this differentiation may change this while it is running, but our tests
showed that this is a good starting classification.
When we search a document, we always try first to find patterns by only using the givenHTML tags. If we cannot determine a structure which matches our requirements, we start
to replace first the delimiters with the highest ranking by dummy tags and repeat the pattern
detection process. If we are again unsuccessful, we replace the next best delimiters and
so on. In this way, we obtain useful patterns. However, it should not be forgotten that
there exist enough documents with such a poor structure that recuring patterns are not
103

determinable automatically, even with this method. As stated earlier, as we want to achieve
also a high performace, we have to accept the fact that we cannot find all the relevant
information.
We have discussed the problems we face when we want to find structure. Now, we want to
have a deeper look into the actual algorithm we use to determine structure in a sequence of
HTML tags. We begin from the point when we have already determined the starting pointof a list. Let t be the chain of tags beginning with the start tag ti and ending with the final
tag of the page, tn. Note that we take for granted that the page which we search contains
only validated HTML.
The general structure of the algorithm is basically quite simple as shown in figure 6.13. As
we shall explain, the complexities lie in the detail of various parameters. The main idea is
to find a similar chain after the first one. The only thing which is defined is the start tag.
The second tag chain must also begin with the same tag and it must be similar to the chain
which is between the two start tags. As soon as such a second tag chain has been found,
we have determined a recurring pattern, a list of entries.
cur = 1
while (exists (x > cur AND ^x — h )) {reference_chain = chain [ti, . • • # tx-i]
seconcLchain = fincLsimi lar.chain ( to_find = reference .chain,
start_tag = tx)
if exists(seconcLchain) {fincLfurther_chains (to_find = reference .chain)
exit
}else cur= x
}
Figure 6.13: Pseudocode for the determining of a structure in HTML tags
The function "find_further_chains" is rather obvious, as it repeats the procedures for
determining the second tag chain. It is more difficult to determine the function
"find_similar_chain". The easiest form here would be to allow only exact matches, but,
as we have seen before, we would likely not be able to find a lot of structures.
There is no static way to define this similarity comparison. There are several variables that
affect this. For example, we can state the minimum length of a valid chain. Or we can
define a minimum number of chains that must be found. Both definitions make sense, as
a chain consisting of only one tag is not long enough to be a reliable part of a structure in
the context of HTML tags. An example is the tag <br> which is used to break the line.
A sequence of these tags does not mean that there is a reliable structure. In addition, if we
know that we are looking for long lists, it does not make sense to accept a structure with
two entries only, as such a short list is less reliable.
104

These are useful settings, but there is a more important one - the "minimum degree of
similarity" for two chains to be considered similar. As a simple example, it is obvious that
the similarity between the chains <axbxc> and <axbxcxd> is higher than
between <a> and <axb>. And of course, the latter example seems less reliable to stand
actually for two entries of a list. Therefore, we use another variable to define the minimum
degree of similarity. The degree of similarity is computed very simply. We combine two
chains such as those we have seen in the example of figure 6.11. The similarity is given as
the ratio between the number of identical tags to the total number of tags in the combined
chain. The combination in the example has a similarity of 89%.
This algorithm works quite well, but we have to know the starting point of the structure in
advance. This is not that easy, as it usually cannot be determined whether a tag is in fact
the main starting point of a list. However, we use two mechanisms to at least approach this
starting point. The first one is the approach we use in the simple extraction in section 6.1,
namely the keyword approach. For example, if we are looking for a list of publications, it
is likely that the list has a header containing the word "publications" and we take this as a
possible starting point. The other possibility is to assume that the whole page consists of a
list and we start at the beginning of the body part of the HTML document.
As mentioned, we do not know whether we really are at the right starting point. Therefore,
we make the following assumption. We assume to be close to the actual starting point,which means that we try to find a list beginning at this assumed first tag. If we are not
successful, we try to find the list beginning with the following tag and so on. If the structure
we are trying to find is well structured, we will automatically find it. If not, it may be that
the algorithm returns a structure beginning in the middle of the first entry, or that it is not
able to find the structure at all.
In our protoype, some other additional settings have to be defined. We do not want to
discuss all of them here but we give an example of a problem we want to avoid with these
settings. Long publication lists usually contain quite large irregularities in their structure,
for example see figure 6.12. As we do not know for sure where the list begins, we must be
rather restrictive when we want to compare the first two possible chains. If we define that
these two entries must be very similar, e.g. a minimum degree of similarity of 90%, we
lower the possibility that the system finds a starting tag which in fact is in the middle of an
entry. But, as the example shows, there are sometimes entries with much less information
and they would not match to the previous ones given that high similarity setting. This
would mean that the list is not detected up to its end.
We can avoid this by setting an additional minimum degree of similarity for entries which
are only partially similar. In such a case, the system would check this second value, e.g. set
to 40%. If the similarity of this "bad" entry is lower, the system decides to have found the
end. If not, as in our example, the system accepts the entry and looks for the followingone. If this entry is highly similar to the original first one, the system assumes that it is still
in the list and accepts the bad entry as an irregularity. On the other hand, if this final entry
is not similar enough compared to the first similarity setting, the system decides to have
reached the end of the list. Because such irregularities occur quite often, this mechanism
105

significantly improves the search for the correct structure.
With this algorithm to find structures, we achieve very good results, but this is rather the
easier part. It is much harder to detect the semantics of such a pattern which is the task
in the Analysis phase in figure 6.9. As mentioned above, we intend to use the information
given by the user to reach that aim, but first we have to deal with the problem of how the
agent can know that a pattern found contains the information the user is interested in. For
example, if the agent looks for information about publications, it definitely does not make
sense to examine a ranking of a sports event.
To approach a solution ofthat problem, we use two different supporting mechanisms. First,
for every pattern he is interested in, the user has to define additional information as to where
the pattern can occur. The easiest way to do this is by the keyword approach described
in section 6.1. The user gives a simple keyword which may occur as a title to the list.
Commonly, this is a good approach, but we have to take in account that not every such list
needs a title in advance which we can search for a specific keyword. More advanced, the
user could also give information about the further format of the list, such as for examplethe number of entries that are to be expected, the colour of the text and so on.
The second supporting possibility comes up when we ask in which document we have
to look for information. The user does not want the agent to search a page containinginformation of a dentist congress if he is looking for stock quotes. So, as we did in section
6.1, here we simply assume that we only search documents which are believed to contain
relevant information. If the user picks this document and gives it directly to the agent, this
assumption is correct, but if there is an automatic detection of documents, this assumptionis not that certain. Therefore, we will need a way to measure the confidence in a page.
However, we will discuss this problem in detail in section 6.3.
We have pointed out earlier the approach we use to extract the semantics. The combination
of these two leads to a robust approach which is very dynamic. The user shall first define the
look of the information he is interested in, as he believes it appears. Then the agent starts
a search and stores the results found. If the agent detects information that is not reliably
extractable, the user will be contacted for additional assistance to extract the information.
We call this the approach with virtual wrappers, because the agent creates for every Web
page a new wrapper to extract the information contained inside it. In most other systems, as
pointed out in section 2.4, the user is obliged to define wrappers for every page by himself.
Here, the system creates a virtual wrapper which is created according to the structure and
the content expected in a particular page. Usually, for every page, there has to be created a
different wrapper. By using virtual wrappers, we can avoid long processing times.
After the entire automated search process is over, the user checks the solutions found by the
agent. If the user is not content with the results, he can redefine the queries, which results in
different wrapper creation when processing the search the next time. If, for a single query,
there are many incorrect results found, the user may set more exact boundaries. On the
other hand, if there were no results returned, the user may define the corresponding query
less precisely so that it matches easier to a possibly correct pattern and therefore leads to
106

a larger variety of results. Most important, the user is not obliged to search the processedWeb pages by hand to find the exact extraction query. And as it is always this "search byhand" which needs such a long time to achieve exact results - the user could in fact do the
extraction by himself.
It is important to state that the user, of whom we are talking here, has to be an experienceduser to be able to redefine queries efficiently. A user without any background knowledgeof this process might end up with a long trial-and-error phase which does not have to end
up in a useful result.
Anyway, this theoretical concept is not yet sufficient to demonstrate its usefulness, because
of the heterogeneous nature of documents on the Internet. It is impossible to rate it without
having a prototype which delivers the desired results. So, we implemented our concepts in a
system called V- Wrap which we also use inside of our whole system for finding information
on the Internet. In the next section we want to describe this prototype in detail to prove our
concepts of virtual wrappers.
6.2.4 V-Wrap
Having described the concept of how to extract semistructured information from previouslyunknown Web pages using virtual wrappers, we now want to detail the operation of our
prototype.
From now on, we only use the term list, but we want to point out, that we include any
form of structured information such as tables for example. Figure 6.14 shows the V-Wrap
process. For every list the user is interested in, he defines the content and the look of it
as he expects it. Out of this description, we call it the wish list, the agent creates several
search objects, one for each item in the wish list. During the search of a Web page, V-Wrapuses these search objects to create individual virtual wrappers to prepare the extraction of
information from a list.
Web page
Figure 6.14: The V-Wrap process
A search object contains the definition of the information items that must or may occur in
the list as far as the user knows it. This leads to a wrapper that serves the agent exactlythe information that is extractable in the way the user wants it. If such a virtual wrapper
delivers no result, it means that the desired information may not be around or it cannot
be extracted with the description given by the user. We note that the agent only works on
behalf of the user. There is no additional autonomy within this system.
r T
I AgentVWrap
User's
wish list
r1 SI
Search1
r :
\)
107

In the current version, we have included a few types of items that can be used in search
objects: string, integer, float, date or URL. With these types, we cover the most interestinginformation that can be found in lists. Table 6.3 shows these types and their parameters in
an abbreviated EBNF style. We have also tested some types that are specifically used for
extracting financial data such as the currency or the "symbol" which is the denotion of the
abbreviation of a share which is traded at the stock exchange. These quite specific types
make it easy to extract data automatically from any stock data site.
Type Parameters
string [stringpattern] [averagelength] ["needed"]integer [minimum maximum] ["needed"]float [minimum maximum] ["needed"]date ["needed"]URL ["needed"]
Table 6.3: Types of information items in a list and their parameters
String, integer, float and date concentrate on the text in the document whereas URLs are
only searched inside tags. For every item, the user can define an optional identifier. Then,
if the type of the item is string, the user can optionally define a string pattern which must
occur within the searched string and the estimated average length in characters. The latter
is used if there are several candidates in a structure for such a string item. In this case, the
candidate whose average string length comes closest to the given average will be taken.
If the item is of type integer or float, the user may define an optional minimum and max¬
imum value, which defines the boundaries for the numbers which can be accepted. This
is, for example, useful if we are looking for publications with a given year of publication.That year usually is somewhere between 1900 and now, so this helps the agent to reallyfind year numbers and not just any number. Finally, the date and the URL type do not need
any special additional definition. Lastly, all items can optionally be marked with the term
"needed", which means that a specific item must be found in the structure. If the term is
omitted, the item does not necessarily have to occur in a specific structure.
Definition 6.1: An attribute which is marked with the term "needed" is called a requiredattribute.
Of course, the types as we define them can be refined if necessary. An example of these
possibilities can be seen in figure 6.15, where a possible list of publications is defined by
giving its content.
This means that a publication consists of a title field, an authors field and optionally ("need¬ed" is omitted) a year and a URL leading to an abstract. A title item is a string with a lengthof 100 characters on average, while an authors item must contain the string "norrie" and
have a length of 50 characters on average. This later should result in a string containingall the names of the people that are mentioned as having co-authored the publication. A
108

title string 100 needed
authors string norrie 50 needed
year integer 1990 2000
abstract url
Figure 6.15: An example definition of a publication entry
year must be in the range between 1990 and 2000, and the first URL found in an item will
be the link to an abstract of a paper. In other words, we are looking for a list of papers,
where each paper consists of a title and a string denoting the authors and, if determinable,
this paper should have been published in the past ten years. If there is a URL to an abstract
available, we are also interested in it. Finally we only want to get the papers in which one
of the authors is called "Norrie". We see that the search object is defined for a specified
person, because we need not only the person's name to determine the location of the author
field, but also want to limit the results to a certain scope.
There exist also some global settings for a wrapper definition that the user can define. First
of all, as we mentioned in section 6.2, he has to define a keyword which leads to the list
with the keyword extraction method described in section 6.1. In the example above, this
may for example be "publication" or "report". This word can be part of the title of a listing,or it can be combined with a link to a separate document. If this keyword is found in such
a place, the following text or the linked document, respectively, will then be searched for
a recuring pattern and, if found, will be compared to the given definition to determine
whether they match.
Another global setting defines whether the items must occur in the same order as they were
defined by the user or if they can be in any order. The first option of course leads to a lot
faster processing of a structure, as the agent looks for the best position of the first item, and
for the next item it only looks for a position after the previous one. On the other hand, if
the order is not fixed, the agent looks for the best position of the item defined first, then for
the position of the other ones while only searching in free positions. If the tag sequence
that defines the structure is long, this second version may take time, but is much more
dynamic. Regarding the example in figure 6.15, it makes sense to extract also information
from publication lists where the author is given before the title, therefore we can set the
profile as a unordered.
So, the search process is also able to determine the correct positions if the order is not
given as fixed. The user is free to decide on the strategy which V-Wrap uses to extract the
information from a specified list. For example, if the user knows that there exist publicationlists with titles of the reports before the authors and others vice versa, he can choose from
two possible strategies: One is to define the items in the publication list as unordered, the
other is to define two search objects, both with a fixed order, one listing the title item first,
the other the author list. It depends on the complexity of the structures that are found in
the different Web pages that are searched, which of the two strategies leads to a better
performance.
109

To extract as efficient as possible, we might do the following: First, we define a wrapper
with a fixed order of attributes. If it fails to extract information, we can define a second
wrapper with the only difference that the order is not fixed. This second wrapper then is
able to extract the publication information even if the author is the first information of an
entry. Usually, we find the order as defined in the first wrapper and in this case, the search
will be fast.
With virtual wrappers, the agent determines the best extraction structure according to the
user's preferences. Afterwards, the system extracts the matching entries and returns them
to the client application. Of course, the more exact the query given by the user, the more
exact and correct are the wrappers generated and the answers returned gain more reliabilityfor the client. The problem here is that the profile will not be able to extract information
whenever the structure does not fit to the "exact" one. This is compatible to the well-known
information retrieval trade-off between precision and recall. The factor of reliability is
handled in the following section 6.3. But nevertheless, an inexperienced user can specify
queries that will lead to fairly good results.
When the V-Wrap system is used by users with reliable knowledge about the format and lo¬
cation of the desired results, the results show a good rate of locating and extracting reliable
information. When it is set up by an inexperienced user, the rate may not be as high, but it
reaches a acceptable level if the user is aware that he should not restrict the search objecttoo much. So, the user is always motivated to use the agent again and to try to improve it
by redefining the search objects. This change of the settings is done fast and the time to be
invested by the user can be held to a minimum. The user still gains time to use for other
work.
6.3 Rating Extracted Information
In the previous sections, we have discussed how to extract information from Web docu¬
ments. However, we still have not discussed how we want to rate the results, in order to
make it possible for an agent to decide whether information found is reliable or not. A
specific part of this problem is the way the agent moves from one page to another one.
Not every link leads to another page that is really interesting for the current search process.
Therefore, we have introduced the concept of confidence values.
6.3.1 Confidence Values
First, we recapitulate the most important assumption of the two previous sections. We have
stated that we perform an extraction on a page that we believe to be relevant for the search
process. For initial pages that are given by the user or also by another agent process, we can
assume that this is true, as long as we state that it is in the responsibility of the delivering
party to serve relevant results only. The user is interested in good results and therefore
he should only serve Web pages to the agent which he believes to be highly relevant. In
110

addition, if the provider of initial pages is an agent, the user has the control over that agent
and therefore is responsible for serving relevant pages. However, we want to go a step
further and make it possible for the provider of the Web pages to rate these somehow. This
makes it possible to create more flexible agents that serve this input. Most important, these
agents can really assign different degrees of relevances to the documents that they provide.
As mentioned earlier in several examples, the search for different information items is
not equally reliable. For example, the search for a phone number as it is described in
section 6.1 is quite reliable, because, in practice, this depends almost only on the reliabilityof the page which is processed. On the other hand, if we are interested in a picture of a
person, we define that we are interested in a picture object and that in the file name of it,
there must occur the first or the last name of the person. Clearly, as we do not use any image
analysing software, the agent has no idea what in fact is shown on this picture. Therefore,
the reliability of such a result is lower.
This means we have to rate the different search profiles for every interesting information
item according to the reliability we believe in. We have done this using our so-called
confidence values. Each single search profile for the extraction of a single information
item has an associated confidence value (CV) which gives a measure of the reliability of
an extracted information item that results when using that profile.
We refer to the CVs associated with information items as conditional possibilities, i.e.
Definition 6.2: CV(I\S) is the confidence that information item / really occurs given a
search profile S
As we described in section 6.1, a search profile consists of parameters that must be verified
and the most important attribute is the keyword which is the main help for locating an
information item. As an example for this definition, we can describe a search profile which
looks for the keyword "Professor" which has to occur right in front of the name of the
person in question. If this is given, we highly assume that the person in fact is a professorand we set a high CV for this search profile. On the other hand, if we add another search
profile where we only require the last name of the person to occur but not necessarily the
first name, we set a lower CV than for the first search profile. We do this, because the
probability that for example a relative or simply another person is the professor is higher.
The idea of CVs is adapted from certainty factors as defined in [BS 84]. Certainty factors
usually are combined out of some measures of belief and some measures of disbelief in
a fact. But, here lies already the main differences to our approach: We do not have any
measures for disbelief in a result. We only have a certain measure of belief in a result.
This means that we can use a simpler mathematical model to compute our CVs. Another
difference is the range. Certainty factors normally range from -1 (complete uncertainty) to
+1 (complete certainty). As we do not have any measure of disbelief, our CVs range from
0.0 to 1.0. Additionally, we let the user set a threshold which indicates the CV which an
information item has to reach in order to seem reliable to the user. This means, althoughwe use a proper mathematical model with a probabilistic approach to compute the CVs, the
results and how they are in fact evaluated are always fully subjective to the current user.
Ill

Mathematical probabilities are based on the ratio of the number of time a possible event
occurs to all possible outcomes. So, we know that the probability of getting the event
"heads" when throwing a coin is 1/2. In natural sciences we also use probabilities to
state for example the probability of a woman giving birth to twins. Thanks to practicaldata collected within demography, it is possible to define a probability for the event "givebirth to twins" by counting the number of twin births in relation to all births in a relevant
environment. We do not want to define here what such a relevant environment is, but it
is clear that within our system, we do not have anything in that sense, because the Web is
very heterogeneous. A common user does not have any statistics to use, so the values that
will be set cannot be denoted as true probabilities as they are only estimations which are
different for every user. Therefore, we use a special term which intends that it is a value of
the confidence of a user.
In practice, we found many patterns which always led to reliable information items. There¬
fore, it is possible to use percentage values for the CVs to indicate the reliability of the
extraction pattern in terms of the number of cases in which the pattern leads to correct
information items. This also would help to point out the difference of CVs from proba¬bilities. However, in this thesis, we abandon this possibility as computing with percentage
values is not very convenient.
6.3.2 The upper and lower Thresholds
However, as already mentioned, it is not important what values in particular a user wants
to use as confidence values of the search profiles, the main important number is the thresh¬
old. The threshold serves as a possibility for the agent to distinguish between reliable and
unreliable information on behalf of the user. In this way, the user can define the autonomy
of the agent. If the threshold is set low, this means that the agent accepts more results and
returns them as valid to the user or to a database. On the other hand, if the user raises the
threshold, this means that the agent loses the possibility in many cases to decide by itself
whether a result is useful or not. In the case of unreliable results, the agent must ask the
user for assistance.
In our system, we even go a step further. As we have already defined in section 5.2, we
use two thresholds, the lower and the upper threshold. The latter is used as if there was
only one threshold as described before. If the CV of a result is higher than the upper
threshold, the result is rated as reliable. If the CV lies below it, the user has to be asked,
but sometimes, it is possible that the system extracts results that have a very low CV and
we know in advance that it will not be necessary to ask the user for assistance, because the
possibility that the result is true is also quite low. Therefore, we have introduced the lower
threshold. If a CV lies below this threshold, the agent automatically declares the result as
wrong and drops it. Only results with CVs that lie between these two thresholds will be
presented to the user in order to let him decide about the reliability.
112

6.3.3 The Rating of Documents
The last point in this extraction process we have not yet discussed is how the agent moves
from one page to another. In section 6.1, where we described the different types of in¬
formation items, we also discussed the type link. This is exactly what we need here. For
example, we define that we want to follow a link whenever the keyword "publication" oc¬
curs in it. We use the keyword approach described in that section. As stated earlier in this
section, every search profile needs a CV defined by the user. Therefore, in our example,we also have to define a CV for that link extraction profile, and this serves as a rating for
the Web page that we are following behind this link.
As before, we let the user rate the initial Web pages. Usually, if the user provides a Web
page to the agent, he could give it a CV of 1.0, because he hopefully has checked that page
previously. If we use another service or agent which provides the initial Web pages, we let
this component rate the given results. Of course, this means that the user is also responsiblefor this component's rating of the Web pages, and these initial CVs then are also subjectiveto the user.
Again, we want to define this mathematically. When we take Academia which is described
in section 3 as an example, every document the agent searches must be assigned a CV
that indicates how likely it is that information items in this page belong to the processed
person. Generally, this CV rates the reliability that the processed document belongs to the
interesting context.
Definition 6.3: CV(D) is the possibility that document D contains useful information in
the context of interest
As stated before, the initial Web pages which the agent receives from the user or another
agent also get a specific CV between 0.0 and 1.0. In order that the search makes sense, this
value should be above the lower threshold.
6.3.4 The final CV of an Information Item found
To receive the final CV for an occurrence of an information item, we multiply the CV of
the associated extraction profile with the one of the page in which it was found. This can
be likened to the common approach to combine probabilities.
Definition 6.4: CV{I) = CV(D) CV(I\S)
Of course, the pages that should be processed also get their CVs in the same way: We
multiply the CV of the extraction profile that led to the link to that page with the CV of
the page where the link was found. Figure 6.16 shows an example for this computation.The initial Web page A is assigned with a CV of 1.0. In this page, by using a specific link
extraction profile, we found a link which the agent follows. Assume that this link extraction
profile is only assigned a CV of 0.8. Therefore, we compute the reliability of this new page
113

B by assigning it a CV of 1.0 multiplied by 0.8, which means the CV of the new page is
0.8. On this page, the agent was able to extract an information item of type email address.
The email extraction profile that was used for this was assigned a CV of 0.7. This results
in a final CV of that email address E of 0.8 multiplied by 0.7, which results in a CV of
0.56. This final value is later compared with the thresholds to decide what the agent shall
do with that information item.
/s email extraction
profile
CV: 0.7
(klink extraction
profile
CV: 0.8
CV:1.0 CV:0.8 CV: 0.56
Figure 6.16: The computation of final confidence values
When a search process is finished, the work of the agent has not yet ended. At this point,the agent may have collected a couple of information items. It is possible, that certain items
were found more than once. Other items may look very similar but are not identical. The
agent has to handle that before the items are compared to the thresholds.
For every extraction profile, there has to be defined a means of comparing different items
concerning the same information. If two items are equal, we can definitely state that the
reliability of this information is higher than if it would have been found only once. As the
composed CV, we therefore take the probabilistic sum of the CVs of two equal information
items found. Note that we introduce the operator -£ for that operation.
Definition 6.5: CV(I) = CV{IX)+ CV{I2) = CV{h) + CV(I2) - CV(h) CV(I2)
The comparison of two unequal items found is more complex. For example, if we have two
phone numbers, which differ in one single digit, we know that these are different numbers
leading to different telephones. On the other hand, if we have extracted two titles of a book,
which differ in one single letter, it is likely that they belong to the same book and that in
one title there has simply been a typing error.
Definition 6.6: Within each information item type, there have to be defined the similaritycriteria. These let the agent decide whether two different items contain values that can be
regarded as equal. This method is called the similarity comparison.
Therefore, the similarity comparison has to be defined for every single information item
that the user wants to look for. However, we reduce the result of such a comparison to
equal or not equal, as we have to decide whether these two items are equal and should
be combined to one single item, or if they are different and therefore have to be kept as
different items. We do not care about how much two items differ from each other.
114

The similarity comparison will in most cases be quite simple. For numbers, there can
be used the arithmetic comparison, whereas for common strings, we simply can use the
common approach which needs to have all corresponding characters in both strings to be
equal for having string equality. However, in some cases, it is different. For example, for
text parts, such as book titles or quotations, there are typing errors possible. Therefore,
it makes sense in this case to define a specific information item type which inherits most
of its functionality from the general string type, except the similarity comparison. This
now must be a function which for example compares two text parts liguistically to decide
whether they are equal. As a simplification, we also can take a function which allows the
strings to differ in up to a certain low percentage of its corresponding characters to still be
regarded as equal. In Academia, we have implemented the latter which resulted to be
sufficiently exact.
It is not that easy to see what in fact happens, if the agent has found two entries of structured
information. How are these two entries compared to each other? What happens in the case
of partial equality of the items in these entries? Do all the items have to be comparedto the corresponding ones in the other entry? To answer these questions, we first must
recapitulate what structured information really is.
Structured information is a combination of several single information items. This means
especially, that in addition to a general CV for the entire structure, each of these singleinformation items has an additional CV of its own. This makes sense as some of the
attributes of such a structure are easier to find than others. Specifically, this implies that
each single item of a complex information item has to be combined separately with the
corresponding item of the other structured information item.
This is quite complex to understand, therefore we discuss it in terms of an example. As¬
sume that the user is interested in publications and a publication is structured as a title and
a string of authors, both of which are required attributes - they are denoted as "needed".
Further, there should exist another text part which we name "other information". This text
shall contain all the other textual information such as publisher, address or year. Finally, a
publication entry may contain an additional list of links to abstracts or files that contain the
whole publication.
As an attribute of this complex extraction profile we set a general CV in respect to our
confidence in this profile. For our example, we simply set it to 1.0 as we have a highconfidence in this profile. However, as we have already mentioned, there can exist different
CVs for each attribute within this example. These CVs are usually set in relation to the
general CV. We use the following values: 1.0 for title and authors as they are the anchors
of a publication object and they therefore have the same CV as the general profile. In
addition, we set a CV of 0.8 for other information as we have not specified in detail what
this should be and 0.6 for both links to abstracts as well as full text files, because we do
not want to define a very strict profile for these links and simply state that abstracts are
files with the ending "html" and the full text files must have the ending "ps" denoting a
postscript file.
115

Before we discuss the comparison and combination of the single items in detail, we must
define the conditions for considering two structured information items as equal or not. This
is not that easy as a single item can occur exactly once or at least once, or on the other hand,
at most once or in no specific quantity. How do we rate these different item types in terms
of the equality decision of the entire structured information items ? The answer is quite
obvious:
Definition 6.7: Two structured information items are considered equal if and only if all
their required attributes are equal according to their respective comparison definitions as
described by the user.
Taking a look at our example, we see that this is true, if the attributes "title" and "authors",
respectively, both are equal in two different extractions. If we have defined both attributes
as simple strings, this would require them to be equal character by character, but as men¬
tioned before, we use a specific type in which we compare text parts less restrictively.
As a simple example, figure 6.17 shows the concrete combination of two publicationsfound. To explain this, we have to take a look at the definition of this mechanism.
Publication entry A (1 0)
title "OO-Design" (1 0)authors "J Doe and R Smith" (1 0)other info "1997, X-Journal" (0 8)abstracts {"http //www xj com/ood html" (0 6)}files {"http //www xj com/ood ps" (0 6)}
Publication entry B (0 8)^
title "OO-Design" (0 8)authors "J Doe and R Smith" (0 8)other info "Geneva' (0 64)abstracts {"http //www xj com/ood html" (0 48)}files {"http //www oo net/oo-d ps" (0 48)}
Figure 6.17: The joining of two publication items
If all the required attributes are equal, we combine them. Of course, this will be done
attribute by attribute. Here is the definition of how to combine two attributes:
Definition 6.8: Two corresponding attributes will be combined in the following:
• If the attribute has to occur exactly once, i.e. it is required, the content in both
attributes is considered as equal because of definition 6.7, and the new attribute will
get a CV which is the sum of both individual attributes before, according to definition
6.5.
Publication entry C (1 0)
title "OO-Design" (1 0)authors "J Doe and R Smith" (1 0)other info "1997, X-Journal" (0 8)abstracts {"http //www xj com/ood html" (0 792)}
files {"http //www xj com/ood ps" (0 6),
"http //www oo net/oo-d ps" (0 48)}
116

• If the attribute can occur at most once, we will compare the two different contents
according to the comparison definition. If they are equal, they will be combined as
usual, if not, the attribute with the higher CV or, if equal, the one which belongs to
the item which was found earlier, will be taken.
• If the attribute can occur in an undefined number, i.e. we have a simple set, each of
the entries in both will be compared to the other ones according to the comparisondefinition. Those which are unique, remain as they are, the others will be combined
as usual.
For the second case, it is also possible to define that different content may be combined
specifically according to their type. For example, if the contents are of type string, it might
be useful to concatenate the two strings. In some applications, this may make more sense.
Now, we take another look at our example in figure 6.17. Both required attributes are equal,and therefore, the two entries will be considered as pointing to the same publication. The
publication entries now must be combined to a single one. First, the general CV of the new
publication item will be set to the sum of the original ones as defined in definition 6.6. The
required attributes will be taken from the entry where the CV of the items is higher, and
the new CV of each one of it is set also to the sum of the corresponding old ones which
results in a CV of 1.0 each.
Now, we process the third item, "other information". If these two items of the originalentries are equal according to their comparison definition, they will also be joined, which
means we take the content of the one with the higher CV and compute the new CV by the
sum of the old ones. But, if the original items do not match, we only take the one with the
higher CV as the item in the new entry. In our example, the values are different, therefore
we use the one with the higher CV in our combination. We see that definition 6.7 makes
sense: The "other information" is not needed to identify the publication. Therefore, we
decided that it should not be set as required and do not regard it when checking whether
two publication items depict the same publication.
The final two attributes are defined as lists, which means that all the entries in the list that
can be found in both original lists are to be joined. The remaining ones will just be added
to the new list without being changed. Therefore, as the abstracts attributes are equal, theywill be combined as usual, resulting in a CV of 0.792, whereas the combined files attribute
will simply contain both original files entries.
We want to take a look at a more complex example for the joining of lists which is givenin figure 6.18.
In each list, we see the items which each consist of the content and the CV. When joining,
we see that the contents B and C occur in both lists 1 and 2, and therefore they will have to
be combined, CV(BJomed) = CV(BLlstl)j> CV(BL,st2) = 0.65 for B and CV{CJoined) =
CV(CListi)-b CV(Cusn) = 0.72 for C. The remaining items with the contents A, D and
E will just be added to the new list.
117

List 1 List 2
B 0.5
C 0.3
E 0.6
A 0.5
B 0.3
C 0.6
D 0.4
"
Joined List
A 0.5
B 0.65
C 0.72
D 0.4
E 0.6
Figure 6.18: The joining of list items
Now, we have discussed all the mechanisms that we use so that the agent is able to rate
the extracted information on the user's behalf. Although the agent is able to do all the
extraction autonomously, the user has the possibility to influence the final decision of the
agent by setting thresholds as stated earlier.
6.3.5 Comparison to other Work
With the mechanisms shown, we have found a good balance of agent and user responsibil¬
ity. Here, we compare our solution to techniques used in other systems.
We have already mentioned the MYCIN project which uses certainty factors. MYCIN
is in fact an expert system for advising physicians how to treat patients suffering from
bacterial infectious diseases. As input, MYCIN gets patient data, and the output consists
of proposals for diagnosis and therapy. The system does not take decisions autonomously,as the risk for a false diagnosis is too high. This is the main difference to our system, as
our agents make decisions and take actions according to them. An effect of this is our use
of thresholds which makes it possible to assign an action to a certain confidence value.
In addition, the rules in the system are also based on statistical data of patients and their
actual diseases, therefore the system contains real probabilities and not only speculations
by users or developers. We see that the idea of confidence values is based on certaintyfactors, but their use is quite different.
Whenever there need to be made decisions by a program or agents, and the values or
states are vague, there is a mechanism needed which uses thresholds that divide the "goodand the bad" results from each other. There has been various work done which uses this
118

mechanism. As an example, we briefly mention [CMMZ96] where it is necessary to decide
whether two images are similar to each other. There exists a function which rates the
similarity between an image i and a template t, where 0.0 < SimRate(i,t) < 1.0. To
decide whether an image shall be handled as similar or not, the system simply uses a
similarity threshold th, where 0.0 <th< 1.0.
There is another similarity of this work to ours: The so-called similarity rates are not
probabilities either. They are based on a specific function that computes them. However,
in contrast to our approach, the similarity rates are not influenced or even changeable bythe user. The fact that our CVs are changeable by the user makes our system quite specific.
We also want to take a look at an agent which uses thresholds. A good example here is
Maxims which was described in section 2.2.1. This agent helps in filtering emails. The
agent compares an actual situation with previous situations where the agent recorded the
user's actions. For example, the situation is that an email has arrived from Sender X. In
all previous situations where a mail has arrived from this sender, the user deleted it imme¬
diately. Out of that, the agent can determine that it can delete the actual email too. The
actual situation and the previous situations are compared according to a specific similarityfunction. Then there are two similarity thresholds set by the user which decide whether the
agent should immediately perform the best matching action, ask the user about it or not do
anything. The thresholds here are used in a similar manner to our system, but again the
similarity rates are not influenced by the user.
The approach using user-defined CVs is special. Other systems use strictly defined func¬
tions to rate situations or results, or they use probabilities which were defined by a trusted
set of measurements. If a user works with an agent and changes the CVs of the search
profiles according to the correctness of the results of previous search processes, the user
finally will receive a CV which can be compared with a probability. But, as the Web and
its content is so heterogeneous and non-predictable, we cannot define a strict number of
searches which is necessary to provide a sufficient amount of statistical data out of which
we really can compute the true probability of a search profile to lead to a reliable result.
We can only estimate these values. Such a computed value is only true for a search process
which was evaluated before, but not necessarily for a "new" process. It needs a lot of test
cases to get reliable estimations.
6.4 Evaluation of the Extraction Methods
In this section, we discuss the evaluation of our techniques to extract information from
Web documents in practice. As stated previously, it is difficult to undertake a detailed
analysis of the system in terms of absolute or comparative performance. However, clearlyit is desirable to have some measure of performance and in this section we describe the
results of experiments carried out to test the functionality of the extraction mechanisms.
We have decided to use Academia as our test case. We generated a list of persons by
119

taking suggestions from various colleagues which resulted in the names of 53 persons.
Since we wanted to test the extraction process and not the retrieval of the homepages, we
have manually located relevant Web pages of these persons and then we performed an
extraction on these pages. Since for 8 persons, we were not able to find at least one site
with useful information, we had to reduce our test set to 45 persons. In section 7.5, we
discuss the results of the ACADEMIA agent including the search for the homepages for the
same test set of persons.
For each person, we tried to find Web pages which either contain general information
about that person or a list of publications including this person as an author. For some
of the researchers, we found more than one homepage. In total, we found 53 pages with
general information and sometimes included publication information. It is important to
notice that we found such a page for every person at least once. In addition, we found 28
pages containing only publication information. In these 81 pages, we were trying to extract
four main information items: The email address, the telephone number, the titles and the
publications of the person.
The first and the last name of the person serve as the input values in ACADEMIA.
The search profiles were defined in an identical manner to those in a regular search of
Academia. We tested this extraction without having analysed the homepages before¬
hand. This means we did not adjust the profile according to the test pages just to improvethe results in this evaluation.
We want to discuss the results separately for every type of information to extract. If theyare not as good as we expect, we also want to determine the reasons for this and exam¬
ine whether the search profile could be adapted in a way to achieve a better extraction.
Generally, our profile is set rather strict, because we wanted to reach high precision.
6.4.1 Searching for Email Adresses
We use eight profiles to extract the correct email addresses. They are shown in table 6.4
with their most important settings. First, we are looking for the keywords "email" and
"e-mail" and let the agent extract the following email address. As we believe that the
homepage of a person is being searched, we can assume that the following address is reallyan address of the person in question. If an email address can be extracted in this way, we
assign it a confidence value of 0.5, because it is not sure whether this address really belongsto the person in question. CVs are commonly set by rule of thumb. They can be adjustedlater or the system makes a proposal for an adjustment if this seems reasonable. This is
discussed in section 7.4
The next four profiles are similar to the first two ones, except that besides the keyword, the
first or the last name must also occur in the email address to make it valid. Because this
fact is a very reliable indicator that the email address really belongs to the person, we set a
high CV of 0.9.
120

keyword first name? last name? CV
"email" no no 0.5
"e-mail" no no 0.5
"email" yes no 0.9
"e-mail" yes no 0.9
"email" no yes 0.9
"e-mail" no yes 0.9
"mailto:" yes no 0.9
"mailto:" no yes 0.9
Table 6.4: The profile of the search for email addresses
The final two profiles address the links on a Web page which directly open a mail entry
form to send a mail. The email address of the receiver is encoded by a "mailto:" as a prefix.The two profiles are used to search for that prefix as the keyword. One then requires the
first name, the other the last name to be part of the email address. If this is true, we also
assign it a high CV of 0.9. Because the search and extraction of email addresses is very
fast, it is never a problem to use these eight search profiles.
Note the following situation: A person has an email address which contains first and last
name, and this is included in the Web page after the keyword "email". If it is also en¬
coded as a link with the key "mailto:", this will have the effect that five of the profiles will
successfully extract the same email address. One extraction is assigned a CV of 0.5, the
other four 0.9. When these results are combined, we have a final CV of nearly 1.0. This
makes sense as we believe each of the profiles to be one indicator for extracting the correct
information. If the same information can be extracted several times with different profiles,this must increase our confidence in the result.
The results we received for our test set are very promising. There were 51 correct email
addresses on the pages we were searching, and the extraction mechanism was able to cor¬
rectly extract 46 of them. Once we received an incorrect email address because the person
in fact has included an incorrect email address in his homepage. Two extractions failed
because the email address was not given correctly, as they both contained spaces and there¬
fore the extraction mechanism did not accept these as correct email addresses. The final
two failures occured because the email address occured without any preceding keyword.In addition, we received one incorrect email address of a webmaster whose email address
occured after the keyword "email". Because the name of the person in question does not
occur in that address, the CV was only 0.5 which shows the low confidence in that result.
We can definitely say that the result of this test is very good.
6.4.2 Searching for Phone Numbers
The search for phone numbers has been kept simple. We only used two extraction profiles,one to look for the keyword "phone", the other for keyword "tel". Both have the same
121

additional settings which state that a valid telephone number must follow and begin at
most 9 characters after the keyword. Besides the numbers, we also allow the followingcharacters to occur in a valid phone number: '+', '(', ')', '[', ']', '-', V and the space
character.
The result was as follows. There are 35 phone numbers in the test pages which are rele¬
vant. Our agent returned 26 correctly. An extra returned number is incorrect, because the
keyword occurs after the correct number, and after the keyword, there is the fax number
shown. 4 phone numbers do not occur after a keyword, and three times, the keyword is too
far away from the phone number. In one case there were dots included in the number, so
the extractor did not recognize that number as correct.
This means that our extraction mechanism worked exactly in the way it had to. The wrong
results occur because they simply do not match the given extraction profile. However, it is
possible to adapt the profile to optimise the extraction. We can simply increse the maximum
allowed distance between the keyword and the phone number and we may include the dot
in the list of allowed characters in a phone number. If we do this, we receive 30 out of 35
phone numbers which we also rate as a good result.
6.4.3 Searching for the Titles of a Person
The search for titles of a person is quite difficult, because the titles occur in very different
formats in the homepages. It needs several extraction profiles to extract a large number of
them. Nevertheless, we used a simplified search for titles.
First, we are only interested whether a person is a professor or whether the person has
a doctoral degree. Second, we use a very simple profile. We are looking for the terms
"Dr" or "Prof" occurring immediately before either the full name or just the last name
of the person. In the latter case, we assign the extracted value a slightly lower CV. This
extraction profile is usually very successful if we are searching texts that describe meetingsor conferences. In these cases, people are commonly listed together with their title. But,
our test set contains only homepages, and so we knew that the quality of the results mightnot be very good.
The facts show us that in the pages, there are in total 38 references to professor titles and
doctoral degrees. With our extraction profile, we were only able to extract 4 of them.
This was rather dissappointing and so we analysed these references in detail. We found,
as suspected, that titles are given in a large variety of formats. Four times, the title was
given in a form as we expected, e.g. "Prof. John Smith", and the extraction profile was
working perfectly. However, in most cases, people do not list their titles explicitly. For
example, Professor titles are very often given in resumes of people in textual form, e.g.
"she is a professor..." or in a curriculum vitae, there may simply be an entry "1997-presentProfessor at...". Of course, we can define extraction profiles for those examples. As longas we believe that we only search relevant homepages of a person, we can even use simplythe occurrence of the word professor as a hint for a person being professor. If we assign
122

such an extraction profile a low CV, this would perfectly fit. But there are even other hints.
If a person is a dean of an university, the possibility of this person being a professor is also
very high.
The other title we want to find is the doctoral degree. The problem here is quite similar
as there are different degrees which are doctoral degrees. However, we have seen that the
keyword "degree" is also very interesting for our purposes. Often, this keyword procèdesthe academical or doctoral degree of a person. On the other hand, if someone is a professor,this is often written after the keyword "position".
We see that this case is not easy to solve, as we cannot provide a single generic extraction
profile that fits to everything. We have extended the search profile for that it covers the
possibilities mentioned before. This resulted in a much better result, as we were able to
extract more than 70% of the titles that were somehow listed. We rate this as sufficient to
state that our approach also fits to this problem.
6.4.4 Searching for Publications
The search for publications is the most difficult one. In all test pages that we searched,
a total of 1097 publications were found. Generally, each page had a completely different
structure for this information so that it was simply impossible to have both high recall and
precision within an extraction. We have used two main approaches to locate a publicationsection within a page. The first is to look for a specific keyword and then presume that
shortly after this keyword, a publication list is starting. For this approach, we have been
looking for the keywords "publications", "papers", "reports" and "books". The second
approach is to assume that the whole page may be a publication list and to find a structure
inside of it.
Whenever such a section was found, we were looking for the entry structure which is
shown in figure 6.19. We are looking for a title consisting in average of 65 characters.
Second, we want to find a field containing the authors, which in average also must contain
65 characters. Additionally, this field must contain the name of the person in question.Both the title and the author field must be found in the structure. Then, if available, we try
to extract a field which in average may consist of 100 characters. This is simply considered
as any additional information, for example the conference where the paper was presentedor the name of the book in which it appears. Finally, we are interested in any number of
abstract and file links that belong to the publication entry. We state that a link to an abstract
must contain the sequence ".htm" which lets us presume that it is a link to another HTML
page. A link to a file must contain the sequence ".p" which matches to the file endings
".pdf" and ".ps" which are the most common used file formats for papers. In addition to
these definitions, we also state that these values may be in any order, so that we cover the
case where the author field is first just as well as the case where the title comes first.
We wanted to use only a minimum of extraction profiles to not cause the processing time to
be too long. On the other hand, it is quite strict and will definitely not lead to a high recall
123
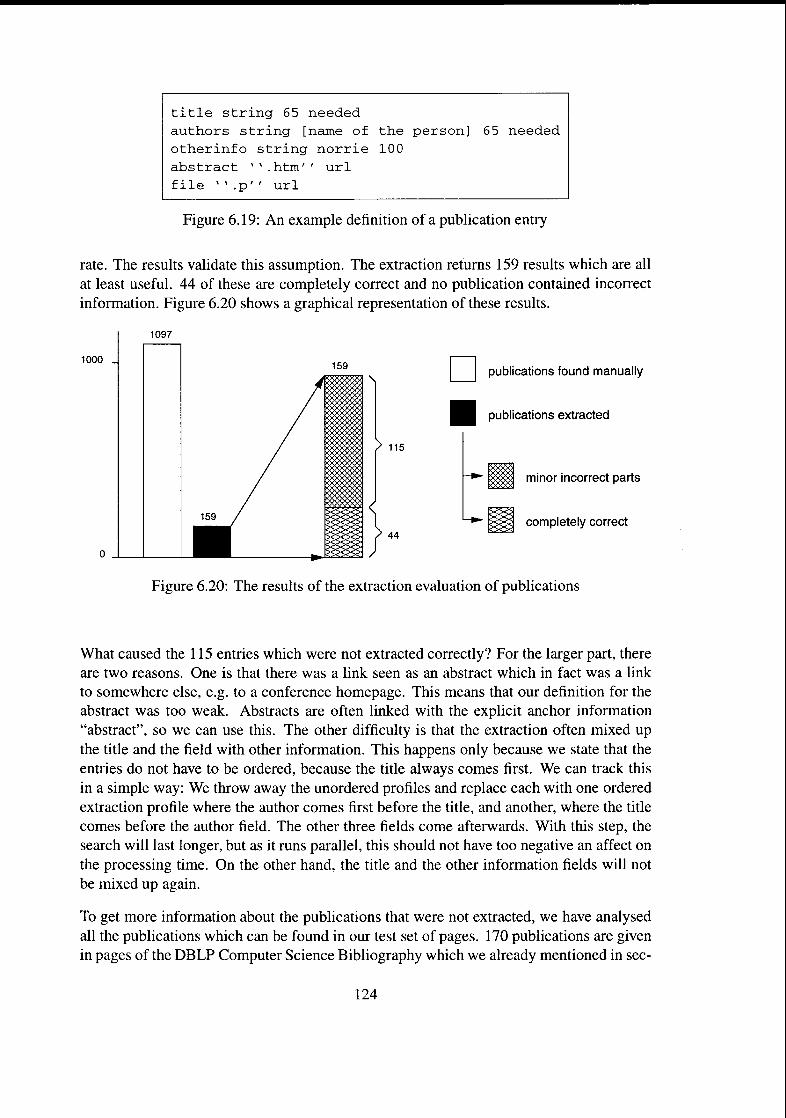
title string 65 needed
authors string [name of the person] 65 needed
otherinfo string norrie 100
abstract xx.htm'' url
file *'.p'' url
Figure 6.19: An example definition of a publication entry
rate. The results validate this assumption. The extraction returns 159 results which are all
at least useful. 44 of these are completely correct and no publication contained incorrect
information. Figure 6.20 shows a graphical representation of these results.
1097
1000_
D publications found manually
publications extracted
minor incorrect parts
completely correct
Figure 6.20: The results of the extraction evaluation of publications
What caused the 115 entries which were not extracted correctly? For the larger part, there
are two reasons. One is that there was a link seen as an abstract which in fact was a link
to somewhere else, e.g. to a conference homepage. This means that our definition for the
abstract was too weak. Abstracts are often linked with the explicit anchor information
"abstract", so we can use this. The other difficulty is that the extraction often mixed up
the title and the field with other information. This happens only because we state that the
entries do not have to be ordered, because the title always comes first. We can track this
in a simple way: We throw away the unordered profiles and replace each with one ordered
extraction profile where the author comes first before the title, and another, where the title
comes before the author field. The other three fields come afterwards. With this step, the
search will last longer, but as it runs parallel, this should not have too negative an affect on
the processing time. On the other hand, the title and the other information fields will not
be mixed up again.
To get more information about the publications that were not extracted, we have analysedall the publications which can be found in our test set of pages. 170 publications are givenin pages of the DBLP Computer Science Bibliography which we already mentioned in sec-
124

tion chapter 3. We have noted there that it is not easy to grab the structure correctly from
these Web pages. This is because in the structure, we must not use links (tag <A>) as
structure delimiters. In DBLP pages all author names are linked to their specific publica¬tion list, so if the link tag was regarded as a delimiter, it would split up the author field.
Therefore we need another specification to extract DBLP pages. Nevertheless, the extrac¬
tion profile was able to extract a small set of publication information from these pages.
Additionally, we have also seen that almost 500 publication entries are in lists which do
not provide enough structure to extract information from them in a generic way. This
means that they contain almost no HTML tags which are usable as field delimiters and the
punctuation which we may want to use instead is not useful either. It is possible to lower
the specification when two tag pattern chains can be combined which lets the agent extract
more entries, but at a lower precision.
Most of the rest of the publications are extractable. If the specification of the entry as well
as the combination of tag patterns is made less strict, the recall immediately increases,
whereas the precision will be slightly lowered. We have also noticed another interestingfact. In most cases except the DBLP pages, the extraction profile was either able to extract
all the publication entries of a list or none. This means that whenever a structure is detected,
it covers the whole publication list and not just a part.
We have also tested the discussed improvements which have brought us to a recall rate
near 50%. For some people in the test set, we searched more than one page which means
that we in fact only had about 900 different papers to find, and the recall rate was in fact
at a level of about 60%. The precision was also reasonable. We are mainly interested in
authors and the title, while the other information is not equally important to us and may
contain some wrong information. Only considering the title and the abstract, we received
a precision of nearly 80%.
Generally, we regard these tests as an approval for our approach on how to extract infor¬
mation from Web pages. The simple extraction is very successful indeed, whereas the
extraction of semistructured information simply is more difficult. It needs more time to
adjust the settings for that the extraction can be optimised.
6.5 Summary
In this chapter, we have discussed the extraction techniques that our agents use to extract
information from Web pages. We are mainly focussing on HTML documents, but with our
approaches, it is also possible to search plain text documents and XML documents.
We have two main sorts of information contained in Web pages. On the one hand, singleinformation pieces, we also have called them "simple" information, are spread all over a
page. On the other hand, structured information which is mostly contained in lists or tables
does not occur that often. However, there is usually more information contained in it.
125

To extract simple information items, we use a straightforward approach which uses a user-
defined keyword for every item as an anchor to locate the item. Together with that keyword,the user has also to define other parameters of which some are dependent on the type of
the information. These settings result in an extraction profile for each item which the agent
should find. We also have defined a set of types of items which may be sought, for example
phone number, email address or a link.
On the other hand, we need a more complex approach to extract structured information
from lists or tables. Our approach must be very dynamic in order to be capable of extracting
a lot of information without having to interrupt the user.
Therefore, we have invented the concept of virtual wrappers, where the user gives the agent
as much information as possible about a list to be parsed. This information consists also
of a keyword which tells the agent where in particular he should look for information.
Additionally, the user can also define some other settings similar to the ones that are set in
a simple extraction profile for a single information item.
The agent then tries to find a structure within the relevant part of a Web page. Usually,the agent examines the HTML tags, because they are frequently used to make structure
viewable for Internet users. In addition, the agent also tries to find a structure when the
HTML tags alone do not form a structure by using punctuation as a form of dummy tags.
When the agent has found the structure, the agent consults the second part of the user's def¬
initions, the look of the single items which must or can occur in an entry of the list. This
description is the same as if the user was searching for a single information item. How¬
ever, with this description, the agent tries to locate the position of the items in the whole
entry. Whenever this is possible, the agent has finished the wrapper and the information in
these lists is easily accessible. We also have detailed a prototype, V-Wrap, which does the
wrapping for such a list.
In section 6.3, we have described how the agent moves from one page to another and uses
the concept of "confidence values" (CV) to rate the reliability of extracted information
items. The user has the ability to set an upper and a lower threshold which decide about
regarding an information item as reliable or not. When the CV of an information item lies
between those thresholds, the user will even be asked for assistance in this decision.
Finally, we have evaluated the extraction approaches empirically. We have seen that the
simple extraction is not only very precise, it also can bring a high recall rate. On the
other hand, it can be difficult to adjust the settings for an extraction of semistructured data.
However, data which is really structured can be extracted anyway. The better the data is
structured, the more precise the results will be.
126

Chapter 7
THE FUSION OF DATABASE AND
AGENT APPLICATION
In the chapters so far, we have shown a system architecture for an information search
agent working in cooperation with a database that holds not only the data found, but also
the preferences of the agent. We have also discussed the features and tasks of each of
the four main components in this system. However, in a given system architecture, these
components do not have to be partitioned as presented so far. In this chapter, we first
address the issue of how the main components in an ideal system could interact with each
other, and then we concentrate on our prototype.
While the user and the resources are fully independent components, the databases and the
agent work together intensively. For reasons of convenience and efficiency, the user must
be capable of working with these two components through one single interface, otherwise,
the possibility of acceptance of such a system is quite limited. The coupling we have used
between these two components until now is not sufficient. In the following section, we
discuss the fusion of these two components. After that, in section 7.2, we describe the core
Web Agent Toolkit (WAT) in detail, before explaining the process in which we developa new agent application with the WAT in section 7.3. We then describe in section 7.4
additional components that we have developed to support the WAT and improve its results.
This is followedby section 7.5, in which we discuss the results of agent applications created
with the WAT. This is necessary to show the usefulness of the WAT.
7.1 The Fusion as an Ideal
As indicated previously, we propose to have not only a coupling as described in [MNOO]
but a fusion of database and agent. The architecture can be seen in figure 7.1. We will now
explain this approach and the underlying idea in detail.
This figure looks quite simple, and it really is simple. Of course, it is not that simple to
127

Resources
Individual Users
browsingenter input data
set agent's preferenceslaunch search process
Il n_
show new data
questions / feedback
evtl look for starting point
information extraction
data found
learn schema & content
Agent Database
Figure 7.1: An architecture where agent and database are merged
Internet /
Intranet
Web Pages
external
Databases
achieve in practice. In the figure, the agent and the database are merged and therefore, we
have been able to reduce the number of arrows compared to figure 5.2. Arrows, in fact,
stand for interactions and whenever there are interactions, we need interfaces. In other
words: This approach at least needs fewer interfaces.
In addition to the previously mentioned advantage of a single interface for the user facili¬
tated by this approach, the whole communication between agent and database can be much
faster, and this improves the performance of the whole system. The object transfer between
the configuration database which contains the agent's settings, the agent and the applica¬tion database is possible in a more direct way. It seems that there is no need to optimisethe system in a way that connections to the database are to be limited to a few accesses per
search process because of their high cost of process time.
Of course, this architecture is not usable for every possible database system and agent
type. The most significant component of this system with respect to possible integrationof agent and database is the database, as there has to exist the possibility to integrate an
agent system. This means that the database system must preferably support the languagein which the agent system was implemented and also provide a convenient application
programming interface (API) to use its functions.
We decided in chapter 4 to use the OMS Java object-oriented database management system
for our prototype, because it is implemented in the well known language Java and providesan extensive and convenient API which fits best to our agents which are also written in
Java. In addition, by using OMS Pro to develop the application database schema, we have
a powerful prototyping tool to make fast development possible.
The agents can be developed with the Web Agent Toolkit (WAT) which is described in more
detail in the next section. Here, we want to discuss a system which combines a database
and a fully functional agent.
The system works as follows. The user only works in the environment of OMS Java.
He starts a database browser and works with his application database. For example, this
database can be a contacts database such as that described for Academia in chapter 3.
128

There, the user has stored contacts information such as telephone numbers or email ad¬
dresses of several people. When done, the user starts the agent configuration database for
the contacts database. In this database, the user has defined what contact information he
wants the agent to look for on the Web. For example, the user may have defined that the
agent shall look for email addresses of the people registered in the contacts database.
Whenever the user thinks an update of the contacts database makes sense, he starts the
agent and the agent immediately starts searching the Web for updated information. What¬
ever the agent finds is then stored in the contacts database, if the information is reliable
enough. After the agent has processed its search, the user can browse again the contacts
database to see the currently available information from the Web.
Ofcourse, such a system needs several boundaries to be set by the user. An important pointis that the user must tell the agent what it has to do whenever it detects updated information,
for example when it finds an email address that is different from the one already stored in
the database. There are three possibilities: First, the agent simply overwrites the old values
without notifying the user. Then, the same is possible including a notice to the user. Finally,the agent can ask the user about the action to perform. The user sets this main preference
according to his trust in the agent's abilities. If the agent is reliable, the user usually givesmore autonomy to it. These possibilities were discussed in detail before in section 5.1.
The system concept presented above is a truly ideal one. In reality, it does not seem possibleto achieve this exactly as we have discussed it here. We have been talking of a fusion
between agent and database. We could achieve this, if we use OMS Java and build in the
search process as a specific method of the application database, but we do not want to
go that far. It might be desirable to use the agent without having to use the database, for
example if we quickly want to search for the email address of a single person.
Therefore, we state again that in fact, we still have two components each of which could
be used independently. However, by using the techniques described, we achieve a close
cooperation which we regard as a weaker form of a fusion, as the interaction between the
agent and the database is very close and easily achievable.
In the following section, we give a more detailed view of our prototype, the Web AgentToolkit (WAT) that can be used to define and create Web information agents using a
database which mainly corresponds to the concept we described here, without a completefusion. Whenever an agent is defined, it can easily be started and maintained through the
GUI of that database.
7.2 The Web Agent Toolkit WAT
This section describes the Web Agent Toolkit WAT which was developed using the generalarchitecture for information agents proposed in chapter 5. The main goal of WAT was
to make it possible to create agents that are capable of working together with databases
without the need to spend a lot of time setting up the interfaces between these two parts.
129

Additionally, it was also a goal to making it possible to use the database as the interface to
the agent. Therefore WAT also contains the necessary interfaces to interact with the OMS
Java database system. Now, we want to describe the whole system in detail.
7.2.1 The associated Databases and their Contents
First, to explain the WAT, we must recall the database part once again. It can be divided
into two main parts. One is the configuration database, which is given with a fixed schema.
The agent engineer fills this database with the data that defines the preferences of the agent,
including the definition of the search information.
The other part is the application database. Here, the engineer defines the schema of the
information to be found by the agent. For example, in the case of a simple person imagefinder agent, this database would contain the definition of person objects containing the
attributes name and image, where the image itself may be modelled as a collection of
URLs. Initially, the user of the image finder would create some objects and enter the
names of the persons of whom he wants to find pictures.
The Configuration Database
Definition 7.1: The configuration database contains the description of the information to
be searched for. Therefore, the agent gets its instructionsfrom that database.
The schema of this database is shown in figure 7.2. It looks quite simple, and that really was
the idea behind it. The application developer should not have to struggle with dozens of
different collections while trying to develop a new agent. Appendix A shows the completeschema definition in the OMS Data Definition Language (DDL) format, as used to build
the configuration database within OMS Java.
The main collection of this database is the collection Agents which contains objects of type
WATAgent. Each such object represents the main object of a single Web information agentand contains general preference attributes such as the thresholds or the maximum number
of links to be searched or - most important, of course - the location of the corresponding
application database.
Related to this main object, there exist four different types of objects that define the entire
work of the agent: At most one URLRetriever, also at most one URLAnalyser, several
input and several output objects. These are contained in collections with the correspondingnames and those are associated through binary collections to the WATAgent object, all with
the corresponding cardinality constraints.
The URLRetriever object is used to determine the starting point of the search. Related to
this is the URLAnalyser object which is responsible for analysing the results in combi¬
nation with the start pages. After a search process, it determines those start pages which
contain results that the agent classifies as reliable. In a future search process for the same
130
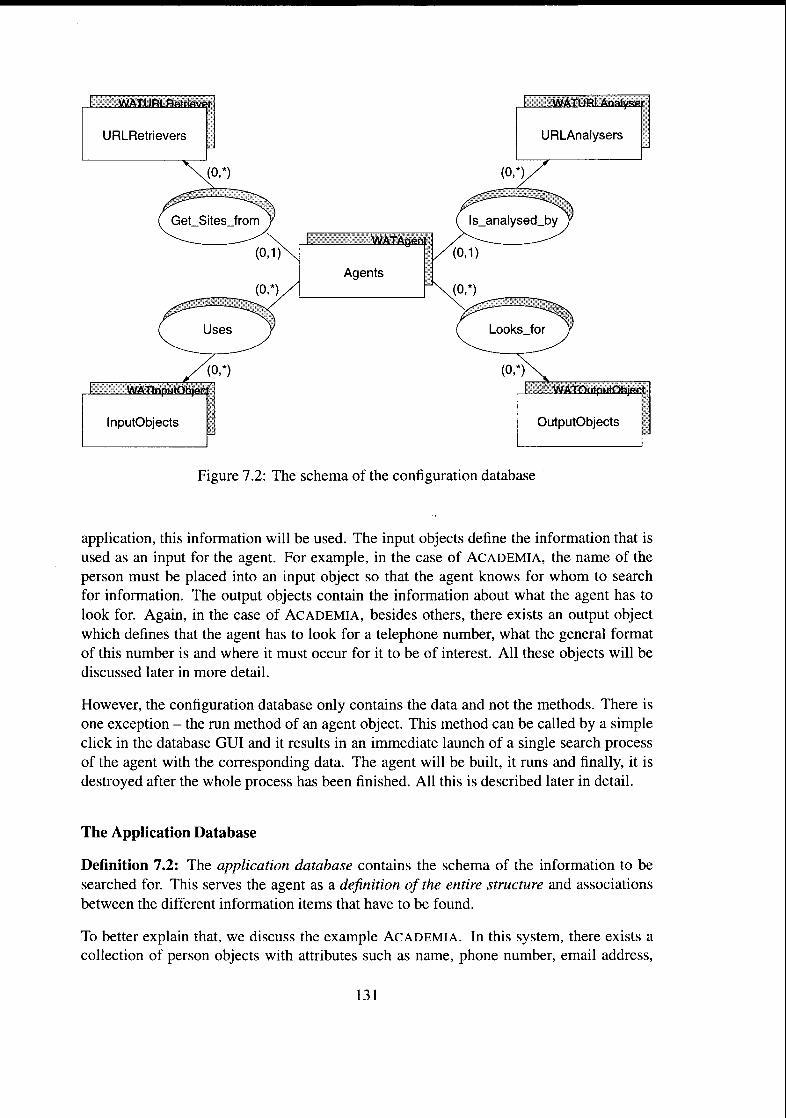
WAT! >R1 Batrtevnr
URLRetrievers
WftTOftt Analysai
URLAnalysers
(0,*)
WATfopwtOhjfttf
InputObjects
WATAge
Agents
WATOutpirtOhjai^
OutputObjects
Figure 7.2: The schema of the configuration database
application, this information will be used. The input objects define the information that is
used as an input for the agent. For example, in the case of ACADEMIA, the name of the
person must be placed into an input object so that the agent knows for whom to search
for information. The output objects contain the information about what the agent has to
look for. Again, in the case of Academia, besides others, there exists an output objectwhich defines that the agent has to look for a telephone number, what the general format
of this number is and where it must occur for it to be of interest. All these objects will be
discussed later in more detail.
However, the configuration database only contains the data and not the methods. There is
one exception - the run method of an agent object. This method can be called by a simpleclick in the database GUI and it results in an immediate launch of a single search process
of the agent with the corresponding data. The agent will be built, it runs and finally, it is
destroyed after the whole process has been finished. All this is described later in detail.
The Application Database
Definition 7.2: The application database contains the schema of the information to be
searched for. This serves the agent as a definition of the entire structure and associations
between the different information items that have to be found.
To better explain that, we discuss the example ACADEMIA. In this system, there exists a
collection of person objects with attributes such as name, phone number, email address,
131

URL of the home page and so on. The schema of this database has been shown in fig¬
ure 4.5. Related to the person objects, there may exist publication and project objectswithin separate collections. These objects represent information about publications that
the corresponding person produced and his associated projects, respectively. Figure 7.3
contains an example of three concrete objects that are related to each other.
person
name: Kapetaniosfirstname: Epaminondas
phone: +41 (0)1 632 7261
email: kapetanios®inf.ethz.ch
project
title: Second Opinion System
homepage: {http://sos.inf.ethz.ch/}
Çhas written
publication
title: Context-Based Querying of Scientific Data: Changing Querying Paradigms?otherinfo: Proc. 3rd IEEE Metadata Conference, Maryland, USA, April 1999
abstract: {http://www.globis.ethz.ch/publications/1999a-knb-meta.html}file: {http://computer.org/conferen/proceed/meta/1999/papers/59/ekapetanios.html}
Figure 7.3: Three concrete objects in ACADEMIA and their associations
The user builds this schema according to the way he wants the results to be presented. The
only restriction is that there exists some sort of key with which the objects that contain
attributes which must be filled by an agent can be identified. This is necessary for each
agent which shall run for an application.
In Academia, these are the attributes surname and forename of a person object. If a
person's name is given, this should lead to exactly one person object, and from that, there
are the exactly defined relations to publication and project objects. Clearly, this assumptiondoes not match the real world as there may exist many different people with the same name.
However, we use this as a simplification of the problem and it is effective within a restricted
search domain where the number of people being considered is reduced.
However, if we face the problem that we are interested in information of two different
people having the same name, we must alter the agent for that we can add other attributes
to the key attributes that make it possible to clearly identify the person we are looking for.
For example, we could use the city in which a person lives or is working, if that is fine
enough for a given problem. If that is not sufficient, we may try a search by adding the
birth date and so on, but the more attributes we add as key attributes, the less results will be
found, because for example the birth date almost never is part of a researcher's home page.
The main idea is that we must adapt the agent to a given situation. A user may work with
132

Academia in its current form and possibly never faces a problem, because the names of
the persons in question are specific enough to only lead to correct or no results. For an
example, consider figure 7.4. Here, we have a schema of a quite simple music database.
We see that an artist can play an unlimited number of songs, whereas to each song, there
exists exactly one artist. Therefore, we can think of an agent which looks for songs of
any given artists. This means that the key attributes of the artist object, for example the
name, serve as the input for that agent. On the other hand, a song can be a part of different
albums. Therefore, with the name of a song as an input, we could create an agent which
looks for the names of the albums which contain that song. In the same way, an album
contains a couple of songs, and a third agent might search the Web for the content of an
album. All these agents use as input the key information of different objects. Regardingthe whole schema, in fact, there is no key object, but, for smaller excerpts of it, there are.
For each agent application, we need to have this key information.
Figure 7.4: A schema excerpt of a music database
The application database also does not contain any methods used by the agent, but it is
bound to the corresponding agent definition by the input and output objects. These point to
specific attributes or objects in the application database. In Academia, for example, there
exists one input object which points to the attribute "surname" of the person object and
another input object points to the attribute "forename". The output object "email address"
points to the corresponding attribute in the person object, whereas the "homepage" pointsto an attribute which denotes a set ofURLs which tells the agent that more than one link can
be found. The output object "publication" is an object that points to a whole publication
object. Note that the input and output objects are related to each other through the keyattributes. These are defined in the input objects and are used by the output objects to find
information.
7.2.2 The Structure of the Agent
And now, where is the agent? The agent itself is dynamically built out of the agent
definition data that comes from the configuration database. Our prototype consists of a
framework of Java classes which represent the objects that we create in the configura¬tion database, i.e. mainly the classes Agent, URLRetriever, URLAnalyser, InputObjectand OutputObject. These classes contain the methods that let them be used to process the
search. In the following, we take a closer look at these classes by going through the process
that is launched when a user starts the run method of an agent object in the configurationdatabase. This creation process is shown in figure 7.5.
133

Agent Definition Database
URLRetrievers URLAnalysers
Get Sites from Is analysed by
Agents
Uses Looks for
InputObjects OutputObjects
Java-Instance of Agent
/ • name
• maxLinks
• maxSearchDepth
\
\
• urIAnalyser
^ • url Retriever
__— c • InputObjectsCollection
_
-c^ • OutputObjectsCollection
Figure 7.5: The creation of the Java instances of an agent
The WATAgent
The run method mainly copies the data of the agent definition to the Java objects and
runs the configured agent. In the case of the agent object itself, this is quite simple. The
attributes are copied into an instance of class WATAgent. This data is used as simple
preferences for the agent: The location of the application database, a maximum number of
links to be processed, threshold values and so on.
The URLRetriever
The URLRetriever is more complex. Here, the data contains information that must be used
to create further objects. The URLRetriever class is an interface that provides an API to
retrieve URLs. The concrete class can be built by the user, for example, a wrapper for the
AltaVista search engine. This wrapper may take keywords as an input and retrieve a set
of URLs that were delivered by AltaVista to the given keywords. The data in the agent
definition object contains the name of this concrete retriever class which will be called byreflection whenever the retriever is called. Other attributes are the IDs of the necessary
input objects which deliver the search keywords, as well as the confidence value that the
delivered pages will be assigned initially. This is a simpler form than that described in
section 6.3, as we rate all pages delivered by a single retriever with the same confidence
value. We do not differentiate between different inputs here. Nonetheless, our experiencewith this method was good, as the retriever mostly finds the relevant pages and filters out
the irrelevant ones.
We detail the retriever's input objects in the case of Academia. In advance, the user has
134

built some person objects in the application database and filled in the names of the persons
of interest in the search process. When building the Java instance of the URLRetriever,
the builder gets the input objects "surname" and "forename". They point to the person
object's attributes surname and forename. The agent then takes the first person object,reads these two attributes and forwards these contents as input values to the retriever. After
the complete search for this person is over, the agent takes the next person object and
continues as in the first. With that mechanism, the input values are set anew for each
person object to process.
The example of a wrapper for the AltaVista search engine given before is already imple¬mented. We provide a couple of predefined wrappers to use for determining start pages,
but we did not build static wrappers. We have used the fact that result pages from search
engines are always structured. We therefore have built a dynamic wrapper using V-Wrapwhich was described in section 6.2.4. V-Wrap makes it easy to extract the correct URLs
from any search engine result page. The main thing the user has to deliver to the wrapper
is to provide the URL of the entry form of a new search engine and the wrapper quickly is
able to extract the results.
The URLAnalyser
The next stage in building the agent is to consider the URLAnalyser object. The creation
of the corresponding Java instance is quite similar to that of the URLRetriever. The URL¬
Analyser class is also an interface providing an application programming interface for a
specific URLAnalyser class that the user can implement according to his needs. As the
URLAnalyser does its analysis at the end of a search process, its results can first be used
when the search for a person is performed the second time.
The URLAnalyser we use does a rather simple job. For every information item that the
agent has found and considered reliable, it determines the original start page which some¬
how led the agent to the result. Either the result was on the start page itself, or it was found
by following one or more links found on the start page. Each URL in the resulting list was
originally delivered by the URLRetriever at the begin of the search.
Of course, as with the URLRetriever, these start pages are dependent on the input values.
When storing the URLs, the input values must also be stored along with them. In the case
of Academia, we would have to assign the first and the last name of a person to these
start pages.
Usually, the list retrieved by the URLAnalyser is smaller than the list of the URLRetriever,
because not all pages which this component retrieves lead to results. The idea now is to
have a certain time out variable in the general setting of the agent. For each search process
which is started before the time out is over, the URLRetriever will not be used, but instead
the list of URLs stored by the URLAnalyser will be processed. This is useful if the URL¬
Retriever uses a special class to analyse the results that are retrieved from a search engine.This analysis can be time consuming and in order to save time, this should not be done
in every search process. As changes or additions to the URLs of researchers homepages
135

tend to be infrequent, in the case of an agent such as ACADEMIA which executes daily, this
value may be set to one week. After the week is over, the URLRetriever will start againwhen the next search is started, and the time out starts again. In this way, new Web pages
can be found every week once.
The Input Objects
We have already briefly mentioned the use of the input objects. An input object is a sort
of a place holder for an input value which we have discussed in section 5.1.3. This means
that input objects stand for the values that are used somewhere during the search process
as input parameters to find a result. As mentioned before, the URLRetriever usually needs
input values to get initial pages to search. Generally, the key attributes of a search which
we described earlier in this section are the input values. They are not only used to find the
starting pages, we also may need them in a particular search for an information item. As an
example, take the title of a person. Usually, on a Web page, we will not find the keyword"title" which leads us to some academic titles of a person. Instead, titles occur in plaintexts, mostly immediately before the name of the person, as in the sentence "Professor
Strieker is a member of the ACM". Therefore, to detect a title, the agent looks for the
combination of the title and the name of a person.
In the WAT, we previously defined four different types of input objects to be used without
further programming. There is a boolean, an integer, a real and a string type. In fact,
until now, we never used anything else than the string type, but that solely depends on the
application.
The Output Objects
Now, we have the retriever, the analyser and the input objects, but the agent does not yet
know what to look for. This information is given in the output objects. Our prototype
provides several subtypes of output objects complying with the type of information that
should be found. There exist so-called single output objects of type text, integer, image and
so on, each of which has its own concrete method to extract the corresponding information
from Web pages. These output objects are built in a way that they contain the predefined
properties that we defined in table 6.2. The optional properties that we also mentioned
in that table then can be set and adapted by the user. The output object types are also
contained in the agent definition schema in appendix A. Table 7.1 lists the correspondingJava classes and points out certain specialities.
In figure 7.6, we give two examples of output objects in ACADEMIA. The object in fig¬ure 7.6(a) looks for a phone number by searching for the keyword "phone" which must
occur in plain text, not as part of a tag. The phone number must be placed at most 6 char¬
acters after the keyword and a successful extraction receives a CV of 1.0. Such an informa¬
tion item found corresponds to the attribute named "phone" in the application database's
corresponding key object. The object in figure 7.6(b) looks for the title "Professor" - usu¬
ally abbreviated as "Prof" which also is the keyword to look for. An extraction is valid
136
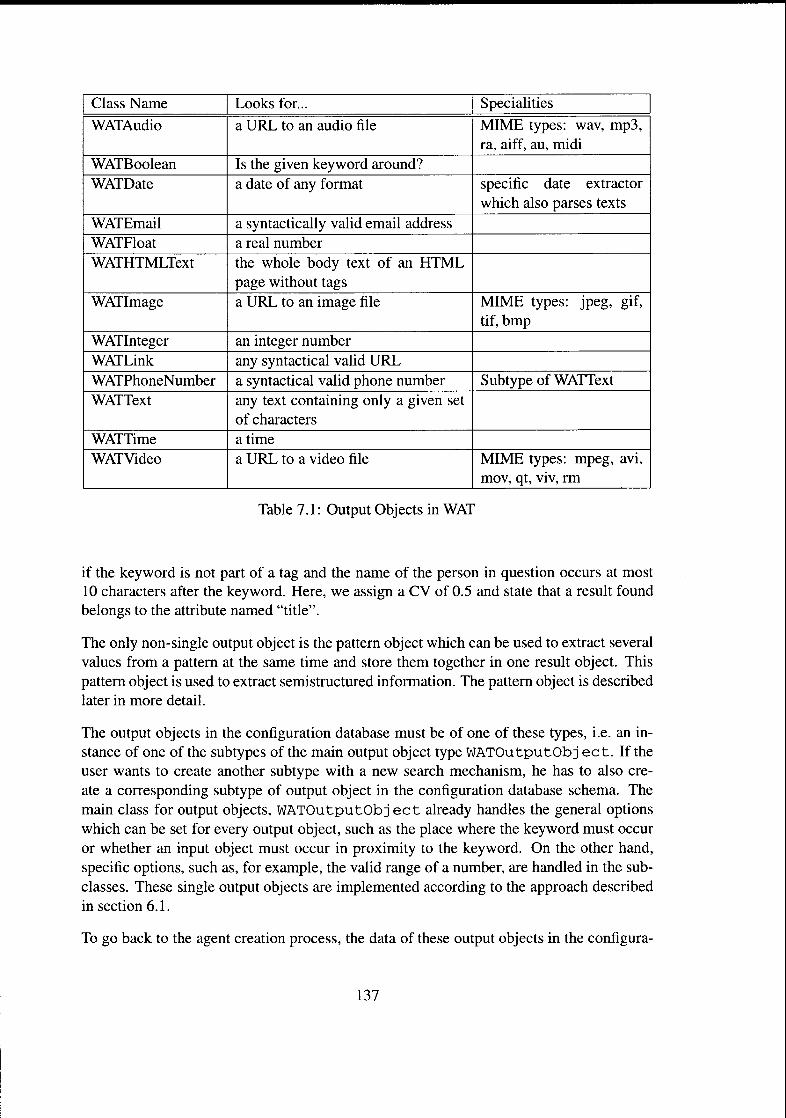
Class Name Looks for... Specialities
WATAudio a URL to an audio file MIME types: wav, mp3,
ra, aiff, au, midi
WATBoolean Is the given keyword around?
WATDate a date of any format specific date extractor
which also parses texts
WATEmail a syntactically valid email address
WATFloat a real number
WATHTMLText the whole body text of an HTML
page without tags
WATImage a URL to an image file MIME types: jpeg, gif,tif, bmp
WATInteger an integer number
WATLink any syntactical valid URL
WATPhoneNumber a syntactical valid phone number Subtype of WATText
WATText any text containing only a given set
of characters
WATTime a time
WATVideo a URL to a video file MIME types: mpeg, avi,
mov, qt, viv, rm
Table 7.1 : Output Objects in WAT
if the keyword is not part of a tag and the name of the person in question occurs at most
10 characters after the keyword. Here, we assign a CV of 0.5 and state that a result found
belongs to the attribute named "title".
The only non-single output object is the pattern object which can be used to extract several
values from a pattern at the same time and store them together in one result object. This
pattern object is used to extract semistructured information. The pattern object is described
later in more detail.
The output objects in the configuration database must be of one of these types, i.e. an in¬
stance of one of the subtypes of the main output object type WATOutputObj ec t. If the
user wants to create another subtype with a new search mechanism, he has to also cre¬
ate a corresponding subtype of output object in the configuration database schema. The
main class for output objects, WATOutputObj ect already handles the general optionswhich can be set for every output object, such as the place where the keyword must occur
or whether an input object must occur in proximity to the keyword. On the other hand,
specific options, such as, for example, the valid range of a number, are handled in the sub¬
classes. These single output objects are implemented according to the approach described
in section 6.1.
To go back to the agent creation process, the data of these output objects in the configura-
137

WATPhoneNumber
keyword: "phone"location: not in a tagmaxdistance: 6
confidence value: 1.0
result: "phone"
WATBoolean
keyword: "prof"location: not in a tag
input: {name,10}confidence value: 0.5
result: "title"
(a) Looks for phone number (b) Looks for title "Professor"
Figure 7.6: Two example output objects in ACADEMIA
tion database is simply copied to the Java instances mentioned. This data includes also the
other input objects which are used as input parameters to successfully extract the desired
information. For example, the output object in figure 7.6(b) defines that the agent must
look for the keyword "prof" in a Web page and the name of the person must occur subse¬
quently. Therefore, the corresponding input object is also used as an optional parameter in
the output objects.
7.2.3 The Search Process
Once the necessary instances for the agent are built, the agent starts the search. Figure 7.7
shows the way information passes during the search procès, while figure 7.8 shows the
process in pseudocode. We once again describe this using Academia as an example.
First, the URLAnalyser is called. If there has been a previous search process, the URL¬
Analyser has stored the original URLs from the link list which then led to the reliable
results. If the agent still has an empty source link list after the URLAnalyser has com¬
pleted its processing, it starts the URLRetriever. The URLRetriever uses its Java retriever
class to somehow find URLs to a certain set of input objects. In the case of ACADEMIA,
this class retrieves a number of URLs from the search engine "Raging Search" [Rag] which
in our tests has proven to deliver the best results in this context. Then, the class does some
postprocessing with the URLs, i.e. testing them to determine if they are still valid and re¬
ally of interest for Academia's purposes. This means testing whether this URL leads to
the home page of the person for which the search process is underway. This is done bythe same Homepage Finder which has been described in chapter 3. The Homepage Finder
simply has been integrated into the whole retrieving process. A certain number of resultingURLs are then added to the source link list: a maximum amount can be set by the user.
At this stage, the agent hopefully has got some URLs in the source link list. If not, the
search process ends here - we do not have any Web sites and therefore cannot look for
information. In this case, the user would have to reconsider the definition of the URLRe¬
triever. However, if there is at least one URL, the information search agent starts its main
work.
138

Agent
• urIAnalyser
• urIRetriever
• InputObjectsCollection
• OutputObjectsCollection
• source link list ^- -.
• result list^
URLAnalyser
c URLRetriever
i /
' /
find source links
input*> OutputObject
find new links & results
Figure 7.7: The exchange of information in a WAT agent
The agent now takes the first URL in the source link list and fetches the document behind
it. Now the output objects come into use. Each output object is fed with the content of the
document and they start searching it in parallel. While some will fail to find their assigned
keyword in the document, other objects with a commonly used word as their keyword will
have a lot more to do to check all its occurrences and try to extract possible results.
There are two main sorts of results. On the one hand, we receive concrete results such as,
for example, phone numbers that have to be stored in the database. On the other hand,
there exists another class of special output objects: The output objects of type "linklist".
The URLs that are found by these objects are not entered into the application database but
rather are added to the source link list in order to extend the search to other Web sites in
addition to the original ones that come from either the URLAnalyser or the URLRetriever.
In addition to these linklist objects, there exist also "normal" URL objects which extract
URLs from pages to store them in the application database. For example, images are
commonly retrieved as URLs.
A specific form of "common" output objects are the pattern objects. We now discuss these
in more detail. The pattern object is the only composite output object available. As stated
before, in the case of Academia, there exists a publication object which is, in fact, such a
pattern output object. A pattern output object is a composition of several other output ob¬
jects - single or other composite ones. All of the output objects contained in it are believed
to be tightly bound together. For the publication object, this makes sense: A publicationcontains a title, some authors and other attributes to identify it properly. Additionally, this
information should usually be found together, not like the contact information of a user
which may be found spread over different sources.
139

start-links = []
result-list = []
for_each object in WATInputObjects {obj ect. get_input-values ( )
}if (retrieving.timeout not passed) {
start-links = URLAnalyser .get_stored_links ( )
}if (start_links = [] ) {
start_links = URLRetriever. retrieve-links ( )
}while (not (start-links = [])) {
current-link = extract_first_link(start-links)
document = read(current_link)
for_each object in WATOutputObject {object .get_input_values_from_WATInputObjects ( )
results = object.extract(document)
for_each entry in results {if (is_of_type_linklist (entry) ) {
start-links. add_link(entry)
} else {result-list .add_result (entry)
}
}}
}analyse_results(result-list)
URLAnalyser. store_original_start_pages (result-list)
Figure 7.8: Pseudocode for the search process
For pattern objects, the definition functions as follows. Concerning the application
database, the user defines the pattern object and its attributes. If the user wants to tell
the agent that a specific attribute may have several different values, such as, for example,that it is possible that there are different URLs from which a specific paper is download¬
able, the user defines that this attribute can contain a set of results and not only a singlevalue. In the configuration database, the user first defines the attributes of such an object.In figure 7.9, this is shown schematically for an example in Academia.
In the case of a publication object, the user typically needs a text object that stands for the
t i 11e of the paper and another text object that shall look for the author information. In
combination to the person for which this search will be processed, this object must be de¬
fined to also contain the surname ofthat person in the author field in order for it to be valid.
In the example, the user has also set a certain range of the length of these two attributes,
as well as specifying that they both have to occur exactly once in one publication object.
Additionally, we use a text object for information about where the paper was published,
140
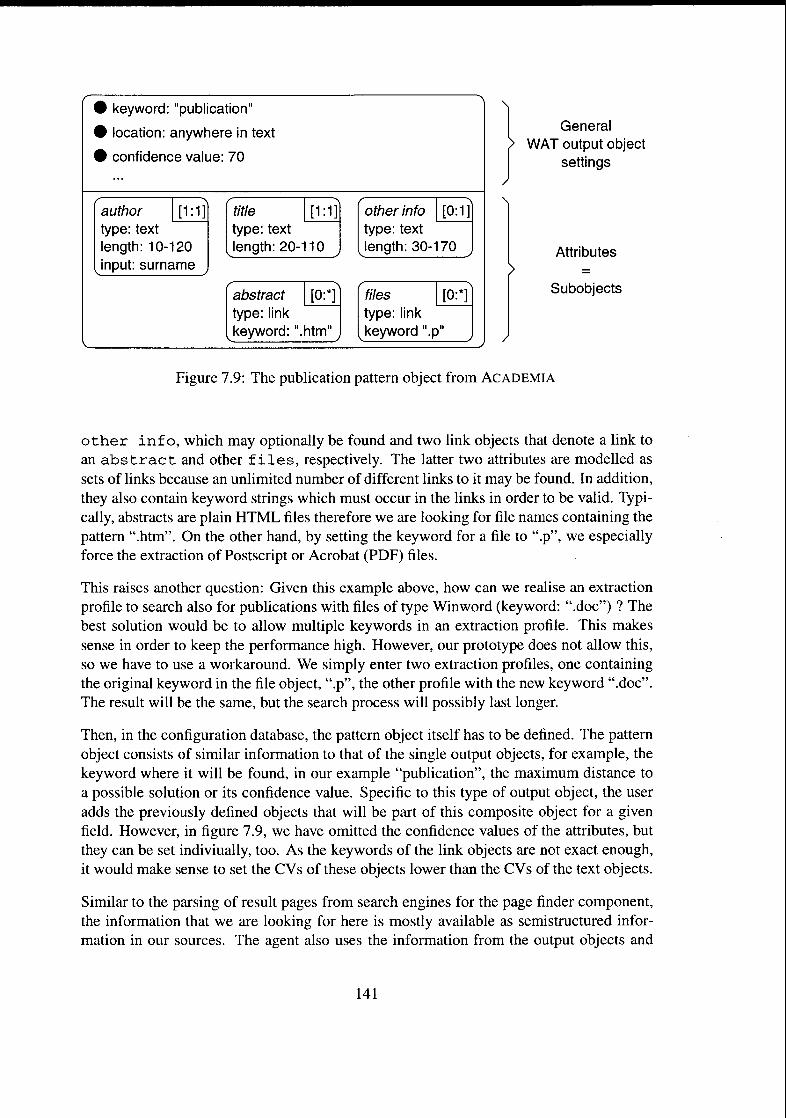
9 keyword: "publication"
9 location: anywhere in text
# confidence value: 70
fauthor [1:1]] title [1:1]] other info [0:1]
/
type: text
length: 10-"
input: surne
20
ime
type: text
length: 20-110,
type: text
Jength: 30-170
abstract [0:*f files [0:*]l
v_
type: link
keyword: ". htm"
type: link
keyword ".p»",
General
> WAT output object
settings
Attributes
Subobjects
Figure 7.9: The publication pattern object from Academia
other info, which may optionally be found and two link objects that denote a link to
an abstract and other files, respectively. The latter two attributes are modelled as
sets of links because an unlimited number of different links to it may be found. In addition,
they also contain keyword strings which must occur in the links in order to be valid. Typi¬
cally, abstracts are plain HTML files therefore we are looking for file names containing the
pattern ".htm". On the other hand, by setting the keyword for a file to ".p", we especiallyforce the extraction of Postscript or Acrobat (PDF) files.
This raises another question: Given this example above, how can we realise an extraction
profile to search also for publications with files of type Winword (keyword: ".doc") ? The
best solution would be to allow multiple keywords in an extraction profile. This makes
sense in order to keep the performance high. However, our prototype does not allow this,
so we have to use a workaround. We simply enter two extraction profiles, one containingthe original keyword in the file object, ".p", the other profile with the new keyword ".doc".
The result will be the same, but the search process will possibly last longer.
Then, in the configuration database, the pattern object itself has to be defined. The pattern
object consists of similar information to that of the single output objects, for example, the
keyword where it will be found, in our example "publication", the maximum distance to
a possible solution or its confidence value. Specific to this type of output object, the user
adds the previously defined objects that will be part of this composite object for a givenfield. However, in figure 7.9, we have omitted the confidence values of the attributes, but
they can be set indiviually, too. As the keywords of the link objects are not exact enough,it would make sense to set the CVs of these objects lower than the CVs of the text objects.
Similar to the parsing of result pages from search engines for the page finder component,
the information that we are looking for here is mostly available as semistructured infor¬
mation in our sources. The agent also uses the information from the output objects and
141

the V-Wrap system which builds wrappers around semistructured information in order to
query its content to decode the source and retrieve the results. V-Wrap is described in detail
in section 6.2.4.
After all output objects have searched a Web page, the new results found are collected and
the new links are added to the source link list. Using a first-in-first-out method, the agent
then takes the next unprocessed URL from this list and processes another search. This
process will be repeated until the source link list is empty. At that time, the agent analyses
the collected results and afterwards enters them into the application database, asks the user
about them or drops them immediately according to their reliability as measured by the
confidence value. The confidence value is used in exactly the same way as it is described
in section 6.3.
The results which belong in the application database will be stored according to the user's
settings. Either all results are stored, whether there was different data already stored or not,
or the user is prompted about what to do with differences to the already existing records,
this fully depends on the user's setting.
The often mentioned Academia was the first agent to be created with WAT and it worked
in the same way as the original system, yet it was much more convenient to handle. At
the beginning, the results were the same as in the old system, but it was possible to easily
improve the results by adjusting some preferences of output objects. In section 7.5, we will
discuss the results of other agent applications that were created with WAT.
7.2.4 Differences to the Architecture proposed
During the development of this concrete implementation, there arose certain specific prob¬lems which were not quite handled according to the architecture proposed. The reason for
this lies mostly in the fact that, in practice, things do not match the theory completely. We
also had to add other functions where it made sense in order to obtain a more complete
functionality.
One main thing here is the fact that the WAT system currently only supports the search of
Web pages. Although, in general, the extraction of information from Web pages is more
difficult, we have concentrated on that, only. As we have seen in section 6.2, Web pages
already provide us with much information coming from databases. Therefore, we have
postponed the realisation of access to database systems. This is a future task which will be
discussed further in section 8.2.
The WAT can be used stand-alone, but currently, it does not provide a sophisticated graphi¬cal user interface. It is therefore recommended to run it together with the OMS Java system
which serves as the database and also provides all the necessary interfaces to the user. All
functions of the WAT can be controlled through the database and this provides a convenient
means of using the system.
We now show in the following section how the WAT must be handled in order to create an
142

agent application. After that, we describe a couple of especially created components and
tools that we have used in cooperation with the WAT agents, in section 7.4.
7.3 Agent Application Development with WAT
After having described the Web Agent Toolkit WAT, we want to take a closer look into
the development process of Web agents created with the WAT. We want to point out the
necessary steps in detail. This section not only will show the whole process, but also can
be used as a tutorial for the creation of applications with the WAT. The main phases of this
process are shown in figure 7.10. In this section, we will describe this process from the
point of view of a developer and we also detail his needs and thoughts during the process.
Idea
—».
r \
Application Schema
m.
Definition of Keys
m.
Define Goals
—»•
Create Agent
User has an idea
for what he wants
to search,
Determine the
structure of the
application DB j
Determine the
key obiects of
the application
Define what shall be
found and how that
appears in the Web
Define the agent
(Search objects,
Retriever, etc )
Figure 7.10: The phases of a development process
7.3.1 Idea
As stated in the previous section, the WAT can be used for prototyping. This means that the
user has an idea for a concrete application and this shall be built quickly within the WAT
and then tested efficiently in order to find out whether it makes sense to develop a specificinformation agent for the application.
Here, we want to discuss a rather simple example, an image finder, in fact, a celebrity
image finder. The main idea is that the user feeds the agent with the name of a person,
and the agent then searches the Web for pictures of this person. Within this agent, we are
only looking for one sort of information items - pictures - and this makes the development
process easier to explain.
7.3.2 Application Schema
The second step is the development of the application schema, or, in other words, the designof the application database. In our case, this schema is quite simple: We will model the
application data as a collection Persons containing objects of type person which at least
consist of the attributes name, f irstname and photos. This is shown in the format of
the OMS Data Definition Language (DDL) in figure 7.11. This DDL file also contains the
mapping of the types that occur in the OMS database to the Java types as they can be used
in client applications.
143

SCHEMA ImageDE5;
string = java.lang. String;
photofile = org.omsj ava.basetype OMPhotofile;
person: diss .omsJava.result.ImageFinder Person;
type person
( name : string,
firstname : string,
photos :
);
set of photofile;
collection Persons : set of person,
END ImageDB;
Figure 7.11: The DDL of the Image Finder Application Database
The classes of the base types string and photofile already exist in Java. The
String class is provided by the common Java API, whereas the OMPhotofile class
is provided by the OMS Java package. The class Person, however, does not exist. There¬
fore, the developer has to write this class by himself. Figure 7.12 shows a possible imple¬mentation for this class.
For our example, this Java class is easy to create. Most important, each such class which
is to be persistent must extend the class OMSIns tance. Then, for each attribute which
shall be visible in the OMS Java type, we need a corresponding get and a set method. For
the name and the first name, this is very simple. The attribute photos, however, is a bit
more complex. Since it is defined in the DDL as a set of photofile, the attribute
has to be of class OMCollection, which is the corresponding Java class to hold a set of
values. Of course, the user is free to add other attributes and methods to this class, here we
just show the minimal requirements to have our three persistent attributes visible.
Our example application database is rather simple. As another example, the ACADEMIA
application database is much more complex as it consists of several different collections
which are involved in the agent's search process. This comes into effect whenever the
developer uses pattern objects to find information. The result from a search with a pattern
object always is an object of its own, and not only an attribute of an object. This is the
consequence of the fact that a pattern object results from a combined search for different
attributes of a whole object, as it is described in section 7.2 in more detail.
144

public class Person extends OMSInstance {
private String name;
private String firstname;
private OMCollection photos;
public String getName() {return name;
}
public String getFirstname() {return firstname;
}
public OMCollection getPhotos() {return photos ;
}
public void setName(String lName) {name = lName;
}
public void setFirstname(String lFirs tname) {firstname = lFirstname;
}
public void setPhotos(OMCollect Lon lPhotos) {photos = lPhotos;
}}
Figure 7.12: The Java Class Person
7.3.3 Definition of Keys
Back to our example, here we do not have such a complex database. When the applicationdatabase is designed and created, the developer comes to the next step in the process: The
definition of the keys. Here, the user has to study the application database and determine
the input values. In our case, obviously, the input values consist of the name and the
firs tname. We want to search for pictures of people and the name of a person serves as
the key value of this search.
The tasks in this phase are quite obvious, as the user commonly already knows the key
objects since the first phase, the idea. But, it is necessary that now, we once again examine
the application schema and verify that our input values really are non-ambiguous regarding
the information items we want to find. As a simple example for this, consider we want to
145

create a genealogy application in which we search for information about several members
of a family. Here, it is not sufficient to use only the surname as an input value, as in families
usually most of the people have the same surname.
We are aware that our celebrity finder will not be able to differentiate between two celebri¬
ties having the same name or between a celebrity and a non-celebrity. However, it is rather
unlikely to have two celebrities with the same name and if there are non-celebrities with the
same name as a celebrity, this does not affect us greatly, because usually, pages of celebri¬
ties are found more easily than those of another person with the same name. However, it
is important that the developer be aware of the consequence that such assumptions might
have on the results.
7.3.4 Define the Goals and Create the Agent
These two phases can be regarded together as one since both strongly influence the defini¬
tion of the search objects. We therefore discuss them together.
All the other attributes of the object which contains the key values and the objects of
different collections are potential output objects. Here, this only includes the attribute
photos. Of course, it is not necessary to define all attributes as input or output objects.
It is possible to have different agents too, which search for other information in the same
application database. In addition, some attributes and objects only can be entered manually,
because the corresponding information might not be found on the Internet at all. However,
these values are not relevant for the agent.
Now, the developer has to build the agent. The easiest way to do that is to write the
whole definition in the OMS data manipulation (DML) format and afterwards import that
into OMS. Appendix B shows the whole definition of this agent. We will now describe it in
detail. However, it is possible to build such an agent manually within the OMS system. The
handling of the OMS system is described in [WürOO], here we only want to concentrate on
the objects and their contents, not how to create them.
We now describe the components of a concrete WAT agent. We start with the heart of
the agent, the object watAgent. This object stands for the agent itself and contains gen¬
eral settings such as for example the name of the agent. The most important attribute
is resultDB which contains the path to the application database which we have built
before. The other very important values are the thresholds, upperthreshold and
lowerthreshold. The developer here sets some initial values - it is meant that the
user of the application later adapts these to his needs.
The remaining values are less important. The developer is able to specify a separate con¬
figuration file which may contain other settings that are not relevant for the agent itself.
Additionally, there is the possibility to define a maximum number of links to be searched
and a maximum depth of the search which will be accepted. With these two values, the
user has the possibility to let the search end earlier whenever there are actually a lot of
146

links to be checked, because the developer assumes the best links are found early, anyway.
Finally, the attributes overwrite, memory and alwaysask are used for the agent to
know what to do with results when writing them to the database. Shall the agent overwrite
old results automatically or shall the user be asked for permission? Shall the agent store the
answers of the user in order to never ask the same questions more than once? And, shall the
agent always ask the user whether a result is valid or shall the agent strictly act according
to the threshold values? This last attribute may be of use for sceptical users which do not
want to change the thresholds but want to test the agent before really using them.
Now, we want to define the input objects as they usually are needed for all the other objects
in a WAT agent. As stated before, the key values for this agent application are name and
f irstname. These can be mapped straightforwardly to the fact that we need exactly two
input objects. Obviously, these input objects must both be of type watlnputString.
The important values are the ID which is necessary to identify an input object for the
other objects and the value. The latter contains the information on the object and the
specific attribute which contains such key information. For the name input object, we
therefore set this value to "person.name", stating that this key value comes from the person
object's attribute name. During the search, this information will later be used to read the
corresponding values in the application database. The two input objects finally have to
be added to the collection InputObj ect s and the associations between the watAgent
and the input objects have to be added to the binary collection Uses.
Next, we have to define the watURLRetriever. Here we must declare the class which
contains the crawler mechanism - a wrapper for a search engine or something else. This
class has to be written by the developer, but there are a number of crawlers already given,
such as the Homepage Finder, which was described in chapter 3. There can be added an
unrestricted number of crawlers to the attribute crawlers, but usually, one is enough.
Additionally very important is the attribute inputs which will be filled with the IDs of
the input objects that point to the key values of the search. In this case, we use both
input objects created before. In addition, we need some general settings describing the
maximumnumber ofresults and the combinationType which defines the way in which
the different input values have to be combined for the search. Table 7.2 shows the possible
values and their meaning. Then, the developer can set a range in percent which depicts the
maximum difference, in the relevance of a resulting page to the best page found in order to
be valid, if the retriever mechanism contains a relevance evaluation. Finally, the developer
sets the initial confidence value which will be given to the pages found by the retriever.
It is assumed that the retriever only returns relevant results, therefore we do not make a
distinction in the relevance of these documents. For the future, it makes sense to add that
feature to the retriever.
The retriever we have defined, of course, has to be added to the collection
URLRetrievers and the association between the watAgent and the retriever has to
be defined too.
Just as we need to define a retriever, we also need a URL analyser in the form of
a watOriginalURLsAnalyser. The current URL analyser which we use is very
147

Type Value DescriptionANY
ALL
PHRASE
0
1
2
at least one of the input values must occur
all input values must occur in a page
the page must contain the input values as a phrase
Table 7.2: The possible values of the attribute combinationType
simple, as we have already discussed in section 7.2. We only need the IDs of the in¬
put values that serve as the keys for the search. These are the same as for the re¬
triever. Similar to the retriever object, the URL analyser has to be added to the collection
OriginalURLsAnalysers and the association to the watAgent has also to be made.
Finally, we have to define the output objects, those which tell the agent what it has to look
for. We can divide these into two sorts: The output objects which are used to find results
and those which are used to find further pages to search. We first want to concentrate on
the former ones.
We are interested only in photos of a person. Regarding HTML pages which we are search¬
ing, this means that we in fact have to look for links to pictures. For that, we can use the
predefined output object watlmage, which can be used to find correct URLs that pointto files that are likely to be pictures. This is done by checking the file extension. Now, we
must think what else must be given to consider a URL to a picture file as a reliable one
for a specific search. In fact, we have the problem, that we do not use any image recog¬
nition software (it is possible to extend the watlmage object for that, but here we ignore
that) .Therefore, the only thing which gives us a hint that an image might contain a pictureof a specific person, is that the first or last name of a person is contained in the link or the
file name. Concrete examples for this hypothesis can be seen in figure 7.13. This figurecontains two HTML excerpts which in the context of a search for information on "Robert
Smith" possibly point to photos of this person.
...This is a photo of <A HREF=:"sit• jpg ">Robert Smith</A>...
...Look at this picture: <IMG SRC= 'smithl jpg"> . . .
Figure 7.13: Two HTML snippets that show or link to a picture of a person
Now, the task is to find a way to define as few output objects as possible to be able to
extract as much reliable results as possible. The biggest problem is to find a good keywordfor which the agent shall look. The name itself cannot be used as the main keyword,because for this, the system needs a fixed string. In the example given, we could look for
the keywords "photo" and "picture", but then we also would need objects that look for
"image" for example. Even, the keyword denoting an image file does not have to occur at
all. There is a much better keyword which occurs in most cases, the file extension ".jpg" !
The JPEG format is widely used for photos as it saves a lot of storage space. By looking
148

for this keyword, we will be able to locate a lot of the image files and we then can look
further for the name to be part of the file name or the anchor information. Of course, we
can use the same technique for the location of GIF-files which are used for smaller images.
This helps us to cover most of the images available on Web pages.
Having found that keyword, it is quite clear that we need one output object which looks
for the last name being a part of the file name, one to look for the last name being a part
of the highlighted link string and additionally two other output objects doing the same
search for the first name. An output object that is responsible for the first mentioned task
is shown in figure 7.14. Obviously, we build four output objects that only differ from each
other in the content of the attribute inputObjectsSpecs. This attribute consists of
two values. One value is the id of the corresponding input object, whereas maxDist
means the maximum distance from the location of the keyword where the input object's
string shall be found. A negative value means the string shall occur before the keyword.
Therefore, the example in figure 7.14 looks for an image URL with the last name in the file
name.
create object injname 1 ;
dress object in_namel as input values (
id = name ;
maxDist = -15 ;
);
create object picl ;
dress object picl as watObject values (
id = image1 ;
active = true ;
) ;
dress object picl as watOutputObj ect values (
keyword = ".jpg" ;
confidence - 1.0 ;
where = c ;
otherKeywords = \\ ,
inputObjectsSpecs == [injnamel] ;
resultName = photos ;
) i
dress object picl as watSingleOutputObj ect;
dress object picl as watlmage values (
maxDist = 0 ;
);
insert into collection OutputObjects : [picl] ;
insert into association Looks_for : [( agent,picl)] ;
Figure 7.14: The definition of an output object that looks for images
149

In table 7.3, we can see all four combinations of these input values and what URLs theywill help to extract. The whole definition of the Image Finder is shown in appendix B.
Note that file names or links that contain the full name of the person will result in two
result matches. The joining of these identical results will later result in a higher confidence
value as if there was only either the first or the last name found. This clearly makes sense.
id maxDist What will be extracted
name
firstname
name
firstname
-15
-15
20
20
an image URL with the last name in the file name
an image URL with the first name in the file name
an image URL behind a link containing the last name
an image URL behind a link containing the first name
Table 7.3: The input values and their meaning for the extraction of image URLs
The other values that have to be set include resultName which always has to be set to
"photos". With that, the agent knows where the results have to be stored. Then, where
has to be set to "c" meaning, as described in section 6.1, that the keyword has to be located
inside a tag, which obviously must be the case. With this, we will locate embedded pictures
as well as links to images, otherKeywords will be left empty as we do not need further
keywords. However, it is quite similar to the input values to set additional keywords. There
exists a specific type keyword which contains the two values keyword and maxDist
which denote the other keyword that has to be found in proximity to the original keywordand the maximum distance that is allowed.
Another attribute is specific to the watlmage object, maxDist. This denotes the maxi¬
mum distance of the URL to be extracted from the keyword. Because the keyword ".jpg"is already a part of the URL we are interested in, we set this value to 0. The final attribute
to set is the confidence which denotes the belief of the developer that a result which
can be found with an output object is reliable. As described in section 6.3, these values are
always subjective to the user. In the example in appendix B, we have set all the confidence
values to 1.0 as we assume all output objects to be equally reliable. In fact, because the
image finder is built up so simply that, we have always used the same confidence values.
This changes very quick when we are looking for different results. It might for examplebe possible to also include output objects that look for photos without requiring the name
of the person to occur. Such results, however, are far less reliably pictures of the person in
question. Therefore these objects would have to receive much smaller confidence values.
So far, we could start the agent and search for pictures, but the agent would only search the
Web pages that are provided by the retriever. Usually, celebrities have fan Web sites with
several galleries which are reachable from some index page. If the retriever only delivers
a couple of different index pages, we never would reach the galleries. Therefore, we also
need output objects that look for further pages to search.
As we have stated in the previous section, these output objects are of type watLink and
they need to have resultName set to "LinkList". Now, what objects do we want to
150

build? First, as stated before, we are looking for galleries. And, if these are around, there
will be a link from an index page to a gallery. So, the most obvious object to create will
be one to look for the keyword "gallery" which must be part of a link anchor, and then, the
URL behind it will be added to the source list. This output object does not need any further
attributes to be set specifically.
However, it is not necessary that the word "gallery" be highlighted as a link - it is possiblethat it, for example, occurs as a header before a link. Therefore, we also create a second
link output object which looks for the keyword "gallery" to occur before a link. We do
this by setting the attribute maxDist to a value of 80 which means the agent will extract
any link that occurs at maximum 80 characters after the keyword. Here, we also set the
attribute where to "x", denoting that the keyword may be located anywhere in the whole
text. In addition to looking for the keyword "gallery", we of course could create further
search objects that only differ from the keyword. For example, we can use the keywords
"pictures" or "images".
Now, we have objects that look explicitly for galleries, but not every page contains an
explicit gallery. Therefore, we also need to have link output objects that are more open. The
absolutely open possibility is to chose the keyword ".htm" without any further restrictions.
This would in fact mean that the agent follows every link to HTML pages. Together with
the attribute maxSearchDepth of the watAgent which is set to 1, this leads to the
search of every original page delivered by the retriever and every page which is directly
linked by one of the original pages. This is a possibility, but it means an exhaustive and
quite possibly exaggerated search because the pages that are of interest to us - those with
pictures - usually only are one part of all pages of fan sites. Most important, these pages
contain a lot of banners for any sort of advertising. The pages behind these banners are
not relevant at all for our search. Therefore we want to restrict the given proposal a bit by
requiring the first or the last name of the person to be part of the file name. We achieve this
by adding the first two input values shown in table 7.3.
However, this is only one possible development process made by a developer. We do not
want to declare this one as the best, not even as the only one. It depends solely on the
developer. Maybe, this is a first definition of an agent and, during the test phase, this
definition will again change. It is possible that the developer chooses to also look for
GIF image files and therefore, he adds another four watlmage output objects, almost
equal to the four already described, but now with the keyword ".gif". After testing this,
the developer might see that there are a lot of additional GIF files found, most of them
correct, but some advertisement banners as well. Therefore, the developer then starts the
development of an extension class of the simple watlmage output object, one called for
example watPortrait. In the corresponding Java class, the developer now can program
an additional method which assures that a portrait has to have a certain aspect ratio. With
this, all the banners which are usually far wider than high, will no longer be considered as
valid results.
We see that during the development process of an agent application, we may never find
a final optimum version. This is a general feature of information agents that search the
151

Web, just because of the heterogeneous data that is available on the Web. Therefore, it is
important to have a framework with which rapid prototyping of such an agent is possible.
Now, we have described a typical development process. We did not discuss the results
which this agent application was able to produce, this will be discussed in section 7.5.
First, in the following section, we will describe some additional components which can
also be seen as subagents that help to improve the work of a WAT agent.
7.4 Additional Components which support WAT Agents
By now, we have described the Web Agent Toolkit and how it is used to develop a new agent
application. Now, we want to describe a couple of components and tools that we developed
which are used in cooperation with aWAT agent and how they help us to improve the results
of the system. The specific retriever applications such as the Homepage Finder which was
described in chapter 3 can also be seen as such components, but as they are so close to a
WAT agent that, we regard them as a part of the agent itself.
However, there are other components which were first introduced in the work of Foser
[Fos99] which was developed under our supervision. We have adapted and enhanced these
and want to mention them here, briefly. Mainly, these components include a message
service for the communication between these components and the agents, a question agent
and a couple of statistics analysers.
7.4.1 The Message Exchanger
Let us first discuss the Message Exchanger. If we want to add other agent components
to the system which are not bound so close to the WAT agent as the retriever component,
we need the different components to have social ability, which means that they need to
be able to communicate with each other. Therefore, we have first developed the Message
Exchanger which is responsible for the transfer of the messages from one agent to another.
By using a specific component for the exchange of messages, we make sure that the com¬
munication between the components is regulated and kept to a simple format. However,
the Message Exchanger is a way of outsourcing most of the communication abilities of the
agents to another component. In the future, it is definitely planned to develop specific com¬
munication components which can be added to the agents to make them "communication-
capable". However, by now, we rely on the simpler possibility of using a centralised mes¬
sage service.
The function of the Message Exchanger is very simple, it is shown schematically in figure
7.15. Every agent or component has first to identify itself at the Message Exchanger in
order to have access to its services. After that, the agent may fetch messages that were sent
to it or it creates and sends a new message. A message consists of the attributes receiver,
152

subject, send and expiration date and body. As long as the body information is serialisable,
everything can be sent thanks to this definition.
login & identification
Message
Exchanger
login & identification
access granted / \ access grantedAgent A
V
Component C
fetch messages for Agent A send new message to XY
Figure 7.15: The functioning of the Message Exchanger
The meaning behind the service is that the string in the subject shall serve as a sign for the
receiver of what should be done with the body. In fact, a receiver always has to know the
type of message in advance, in order to know how to handle it. This may seem a strong
restriction of the service, but with intelligent mechanisms, it is possible to also sort of
"teach" a receiver how to handle unknown messages. In the following, when we describe
other components, we also will see how the messaging functions concretely. However, we
do not want to discuss the Message Exchanger in more detail, as this is not important for
our work.
7.4.2 The Question Agent
Another specialised service is the Question Agent. We already stated that there may be
results which have a confidence value between the lower and the upper threshold. This
means that the WAT agent has to ask the user whether this result shall be regarded as
reliable or not. But, we also stated that the WAT agent shall not be interrupted by such
events. Rather, the question shall be presented to the user when he works at the terminal
and the CPU load of the system is not too high. This makes it ideal to develop the question
manager as a specific agent.
The flow of a question from aWAT agent to the user through the Question AgentA is shown
in figure 7.16. At some time during their search process, agents X and Y independent
from each other have to ask the user for assistance. They send the question in the form
of a message to the Message Exchanger. Whenever there are no WAT agents running,
which means that the CPU is not used that intensively, the Question Agent fetches both
questions from the Message Exchanger. Whenever the Question Agent detects that the
user is working - by tracking the keyboard and mouse interrupts - it asks the questions to
the user.
The method of returning answers to the agents is just the other way round. As soon as
the Question Agent has received an answer to a certain question, it sends a message con¬
taining the answer to the Message Exchanger for the corresponding agent. Whenever the
agent starts another search process, it first checks for its messages and therefore receives
153

WAT Agent X
WAT Agent Y
©
send message for Q
(contains Question A)
Message
Exchanger
send message for Q \ / fetch messages for Q
User
asks user questions A&B Iff)whenever time is right
(contains Question B)Question Agent Q
Figure 7.16: The flow of the questions from WAT agents to the user
the answer and handles it according to the user's wish. This whole process is shown in
figure 7.17.
The Question Agent shows that it brings us many advantages to introduce additional ser¬
vices in the form of other agents. Like this, it is possible to optimise the whole schedulingof the system according to external influences such as the presence or absence of the user
or the CPU load of the system.
7.4.3 Statistics Agents
In section 5, we also discussed about specific collectors and analysers of statistical data.
These components are also ideal for building them as autonomous components in this
system. One of these analysers is the Web Page Analyser. This agent analyses the Web
pages that are delivered by the retriever to a WAT agent to improve the results in the future.
The Web Page Analyser works quite simply. For an agent, it checks all the pages that
have been delivered by the corresponding retriever component. All the words excluding
stop words are then counted and listed separately. For every word, the ratio "number of
pages containing the word" to "number of pages analysed" is computed. When the user
wants to use this agent, he sets a minimum reliability value for that ratio. Whenever there
are words with a ratio greater than this value, the Web Page Analyser considères them
relevant for the reliability of the start pages retrieved by the retriever. For example, in
the case of ACADEMIA, this agent determined a high ratio for the words "information"
and "research". In the future, by adding these words to the input values of the retriever
component, the precision of the retriever can be improved.
This simple algorithm has the advantage that it is independent of the domain and hence
usable for any agent. The algorithm behind it uses the fact that in a WAT agent's search
154

User
© gives answers A & B
Question Agent Q
send message for X
(contains Answer A)
send message for Y
(contains Answer B)
fetch messages for XWAT Agent X
Message
Exchanger®
fetch messages for YWAT Agent Y
Figure 7.17: The flow of the answers from the user to the WAT agents
process, the retriever always looks for pages from a specific domain. And in such a domain,
there are certain words that occur more than others. It works better, of course, the more
search processes for different input objects have been started. Different to the other two
previously discussed agents, this agent can be activated or deactivated for every WAT agent,
just according to the user's wish.
Another statistical agent is the Keyword Observer. This agent analyses the keywords that
are used by the output objects. In fact, this agent tracks three numbers:
• Uses: How many pages were searched?
• KWHits: In how many pages has this keyword been found?
• Results: How many times has this keyword led to a result?
With this data, the agent tracks the usefulness of an output object and the confidence in
its results. There exist different factors that indicate that a keyword is useful or not, for
example the ratio KWHits/Uses. If this is small, this means that the agent only seldomlyfinds the keyword in a page, nonetheless, every page is searched for it. The user can set
a threshold for this ratio in the Keyword Observer which lets the agent filter out output
objects which are not useful. Whenever such an object is found, the agent formulates a
question to the user which recommends the deactivation of the object and asks whether the
user really wants to do that. This question will be asked by using the Message Exchanger
as well as the Question Agent.
Other ratios serve as indicators for the reliability in an output object's results. For example,
the ratio Results/KWHits is a direct rate for the efficiency of an output object and with
that also a rate for the confidence which we may have in a result. Similar to the usefulness
155

tracking, the agent also recommends the user that the confidence value could be adapted
and proposes a specific adaption which the user can accept or refuse.
However, we want to state that the algorithms described here do not have to be mathemat¬
ically correct. They may work for one WAT agent but not for another. It is always the
responsibility and the trust of the user which leads to the activation or deactivation of such
an agent. On the other side, the user may create another keyword observer which uses
other ratios for its analysis. Here, we only want to point out the possibilities for a user.
The final analyser we have implemented is the Threshold Observer. Opposite to tracking
the confidence values of output objects, we also can rate the confidence thresholds. For that,
we track it when a user accepts or drops a result which had a confidence value between the
two thresholds. In addition, we track the average confidence values of the automatically
stored and dropped results.
For example, if the user answers a high percentage rate of the results positive, this means
that the upper threshold seems to be too high. However, with this algorithm and the reverse
one for the lower threshold, we only have the possibility to bring both thresholds closer
together, but not apart. This is due to the fact that the user only rates the results that have
confidence values between the two thresholds. Therefore, to make the Threshold Observer
more effective, the user would have to rate all the results, including those which, in fact,
could be stored or dropped already by the agent. Like the Keyword Observer, the Threshold
Observer also does not work according to a strong defined mathematical model, it is well
possible to develop a better threshold observer.
7.4.4 Other supporting Agents
Like the described analysers, there might be other agents very useful for our purposes.
One example is a sort of a Synonym Finder. When the user includes a phone number
output object to a search and sets its keyword attribute to "tel", meaning the abbreviation
of "telephone", the user might not be aware that the keyword "phone" might be much
more effective. Therefore, this synonym finder works with a large database containing
information about synonyms and starts alternative searches by setting the keywords of
output objects to different synonyms. The user afterwards will be confronted with the most
promising results and will be asked whether the keywords shall be adapted.
We see that there are a lot of possibilities of additional components which can do helpful
work for our WAT agents. We have only presented a few possibilities. However, as we have
now fully outlined the work ofWAT agents and also the different components which help
to improve the results, we now want to take a look at the quality of the results of different
WAT agents. We do this in the following section.
156

7.5 Results of Web Agents created with WAT
In this section, we want to take a critical look at the usefulness of the Web agent toolkit
WAT in practice. We have already stated that the WAT is meant to be used as a prototyping
system for developers who want to create a specific Web information agent. With the WAT,
it is possible to build such an agent quickly and also changes in the search profile are easy
to be made. However, is the result really useful?
We have stated our restrictions in the previous sections. Every agent needs to be built upon
a schema in which there exist key attributes that identify the whole search process within
the given domain. Whenever this is granted, the WAT can be used. From now on, it lies
in the responsibility and the skills of the developer, whether it is possible to develop the
desired agent. Either the developer uses the predefined search objects or he has to develop
new ones if the predefined do not match the needs of the application.
We must bear in mind that the WAT does not help do wonders. The information that we
are looking for must occur somewhere on the Web, and it must be reachable for the agent.
A WAT agent will never be able to find a URL which is nowhere linked on other Web sites.
Besides Academia, we have also created a couple of other WAT agents. In this section,
we want to discuss the results that the WAT agents were able to find. This will give us a
measure for the usefulness of the Web agent toolkit.
7.5.1 The Results of WATAcademia
We have already mentioned that the results of WATAcademia are at least as good as the
results of the original application. In fact, it is much easier to adapt WATAcademia over
time, for example if the user wants to add the search for another attribute such as the
number of the room in which a person works. The WAT agent is adapted quickly as soon
as the search object is defined.
However, it is clear that the Web Agent Toolkit is not useful for users which do not know the
Internet and have no idea about the data that is located there. If a WAT application shall be
developed for inexperienced users, this is only possible, if an administrator is around who
is able not only to alter some preferences of the objects but also to add new search objects
according to end user's wishes. The WAT is definitely too complex for inexperienced users.
However, in the future, this problem could be accessed by creating powerful wizards that
guide a user through the development process.
Figure 7.18 gives an example of the success ofWATAcademia. All the tested person objects
only contained the name of the person in question before the search was started. While the
results for the first person are not surprising as that person comes from our research group,
the other person is from another university and was tested without having checked his
Web site beforehand. Note, that we have omitted the confidence values as they are solely
dependent from the user's preferences.
157

Person 's name Gabrio Rivera
email : rivera@inf. ethz.ch
fax: +41 (0)1 632 1172
phone : +41 (0)1 632 7267
photo http'//www inf.ethz.ch/department/IS/globis/PICS/gabrio.gif
publ : [title: OMX-FS. An Extended File System Architecture Based on a Generic
Object Model,
author : G. Rivera and M.C. Norrie,
otherinfo' Proc. Joint Modular Languages Conference (JMLC 2000), September 2000
publ.:
J
[title: IDEOMS: An Integrated Document Environment based on OMS
Object-Oriented Database System,
author : G. Rivera, M. C. Norrie and A. Sterner,
otherinfo: 4th Doctoral Consortium at 9th Conf. on Advanced Information
Systems Engineering (CAiSE'97), Barcelona, Spain. June 1997,
abstracts [http://www.mf.ethz.ch/. . . /globis/REPORTS/ 1997f-rns-doccaise.html] ,
files:
]
[ftp://ftp.inf.ethz.ch/.../papers/is/globis/1997f-rns-doccaise.ps]
Person 's name: Rolf Pfeifer
title: Prof
title: Dr
email : pfeifer@if : umzh ch
fax: (0041) 1
phone : 41 - 1 - 635 43 20/31
photo: http://www. neuroscience.unizh.ch/e/images/groups/pfeifer.jpg
publ.: [author Rolf Pfeifer,
title: Teaching powerful ideas with autonomous mobile robots,
otherinfo "Journal of Computer Science Eduation, Vol. 7, No. 2.",
abstracts : [ftp://ftp lfi.unizh.ch/pub/institute/.../html/96.11/index.html] ,
files :
]
[ftp://ftp.ifi.unizh.ch/pub/institute/.../96.ll.ps gz]
publ. . [author Rolf Pfeifer,
title: Cheap Designs: Exploiting the Dynamics of the System-environment
Interaction. Three Case Studies on Navigation,
otherinfo:
l
Technical Report 94.01,
publ. :
J
[author Pfeifer, R., Blumberg, B., Meyer, J.-A., and Wilson, S. (eds.), 1998
From Animals to Animats,
title: Cambridge, Mass.: MIT Press.,
j
(totally 17 publications)
Figure 7.18: Two results that were found by WATAcademia
158

We definitely can be content with the results of the search for the first person. We have
checked the sources in the Web and the information that is shown here is the complete
information which is available. In other words: We have reached a precision- and a recall-
rate of 1. The second result, however, is not that perfect. The fax number is not complete
and the phone number seems to contain too many numbers. And finally, the last publication
seems not to be extracted correctly. We now have to ask: Does that mean that the qualityof WATAcademia is low?
When looking at the log files ofthat search, we immediately see that the relevant documents
were actually searched, no important page was missing. The phone number was in fact
correctly extracted, but Prof. Pfeifer has two different numbers and the agent did not know
that this string in fact contains two different phone numbers. The fax number is definitely
not a correct one, however, when we look at the settings we made for the fax output object,
we see that we have set a range of length between 6 and 100. This is definitely too wide,
we have to adapt these numbers at least to 10 and 30, respectively. The wrong publication
extraction, finally, is the result of an insufficient extraction profile that was provided to the
agent. We therefore can state that all three errors occured because of a wrong or too inexact
extraction profile. The WAT agent only worked according to our definitions and these were
not correct.
As in a prototyping step, we now can adapt the output objects. The problem with the fax
number can be corrected by adjusting the settings - a new search returns the correct num¬
ber, whereas the phone number extraction algorithm would have to be enhanced in order
to be able to recognise the given string as actually two phone numbers. The publication
problem also might require an enhancement in the pattern extraction algorithm. But in fact,
for that entry, the agent returned a very low confidence value which was lower than all the
other results, which means, in a common search process, this result will be dropped by the
agent anyway.
Of course, as the extraction of publications is more complicated than that of single infor¬
mation items such as phone numbers, the agent usually does not find all the publicationsthat are visible on the Web. But, as stated earlier, this is not the goal of the WAT, as it shall
be used as a framework with which it is possible to quickly create agents from various dif¬
ferent domains. If a specific WAT agent has a low recall rate, the problem usually lies in the
extraction profile given by the user and some small adaptions may improve search results
significantly. If a WAT agent reaches a high recall rate, this means that it is ready to go into
production. This, in turn, means that it makes sense to build a specific application with it,
where the developer may add specific extraction mechanisms that are highly dependent on
the domain of this application. This can help to raise the recall rate once again.
In section 6.4, we have discussed the extraction from homepages of a test set of researchers.
We now want to take a look at WATAcademia's results when searching for information
about the same people. The main difference is the fact that WATAcademia does not know
the correct homepages in advance. For the evaluation of our extraction methods, we only
had to extract from relevant Web pages. But now, we do a full search in WATAcademia.
Once again, we only concentrate on email address, phone number, title and publications.
159

We use an application schema which defines that we only want to find one email address
and one phone number for each person, whereas the title attribute is a set which means we
are interested in both titles, Professor and Doctor. Finally, we want to extract all publica¬tions a person has authored.
We have seen that the extraction is quite good when extracting from the relevant pages only.
Therefore, here we have to find out whether the relevant pages are found by WATAcademia.
If not, we may receive either no or incorrect results. If the relevant pages are found, we
assume that we receive almost the same results as we received in section 6.4. We used
the Homepage Finder which we described in chapter 3, based on the search engine Rag¬
ing [Rag].
The results delivered by the Homepage Finder have the quality expected. In the extraction
evaluation, we tested a total of 53 homepages belonging to a total of 45 persons. The
Homepage Finder found 44 of them. For the 8 pages which could not be found, there
were other results returned which in some cases also lead to correct results. However,
the Homepage Finder often returns more than one URL.This can also lead to irrelevant
pages which do not belong to the person in question and can therefore result in incorrect
extractions. In this context, the confidence values are an essential instrument to rate the
extracted information.
The results are as follows. For 39 out of the 45 persons, the system returned their correct
email address. Three email addresses were incorrect, because the system found a home¬
page of a different person having the same name. For the remaining three persons, we
were not even able to find a personal email address by hand, therefore it is correct that the
system returned no email address in these cases.
The search for phone numbers showed very positive results. The system returned 26 correct
results and 6 incorrect ones. This is very good, because the extraction profile for a phone
number, as described in section 6.4, is only successful if we search a relevant page. The
extraction profile is defined to extract any phone number found on a page after the keyword
"phone" or "tel". The reason for the quality of this result lies in the Homepage Finder
which is able to return in most cases the actual homepage of a person in ranking position 1.
The remaining cases where the system did not return a phone number was due to a varietyof reasons. In most of the cases, there is no phone number of the person available on the
Web. Rarely, the format of the phone number is incorrect.
The result in the search for titles was even better than in the pure extraction testing. The
system returned 14 correct Professor or Doctor titles. The reason for this is simple. The
Homepage Finder usually returns 4 or 5 pages which likely contain relevant information
about the person in question. Therefore the system had more sources for the extraction. In
this case, this increases the chance of finding a title. We have used the simple extraction
profile to extract these titles. In section 6.4, we describe how the results can be improved.
The most interesting test was the search for publications. We used the same simple extrac¬
tion profile described in the extraction evaluation. The system returned 268 publicationswhich are useful. Some of them have the previously described problem that the title and
160
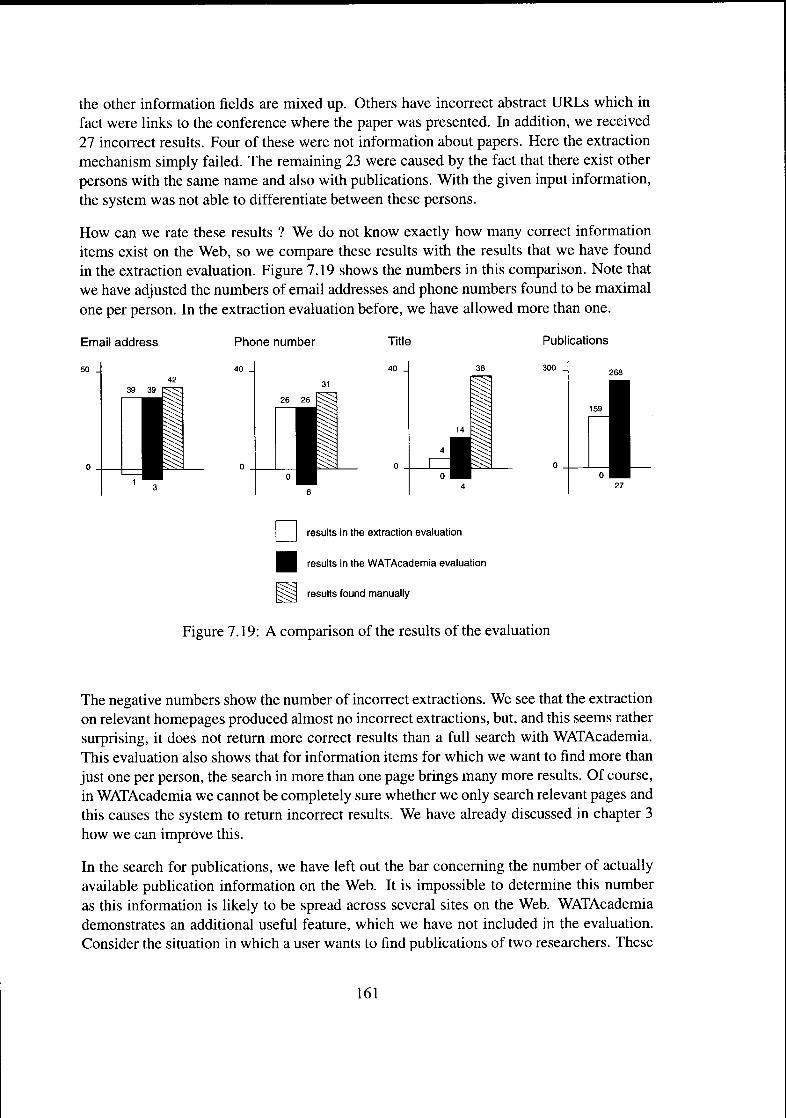
the other information fields are mixed up. Others have incorrect abstract URLs which in
fact were links to the conference where the paper was presented. In addition, we received
27 incorrect results. Four of these were not information about papers. Here the extraction
mechanism simply failed. The remaining 23 were caused by the fact that there exist other
persons with the same name and also with publications. With the given input information,
the system was not able to differentiate between these persons.
How can we rate these results ? We do not know exactly how many correct information
items exist on the Web, so we compare these results with the results that we have found
in the extraction evaluation. Figure 7.19 shows the numbers in this comparison. Note that
we have adjusted the numbers of email addresses and phone numbers found to be maximal
one per person. In the extraction evaluation before, we have allowed more than one.
Email address Phone number Title
40_
38
14
II0 i B^?
4
Publications
300_
D
^
results in the extraction evaluation
results in the WATAcademia evaluation
results found manually
Figure 7.19: A comparison of the results of the evaluation
The negative numbers show the number of incorrect extractions. We see that the extraction
on relevant homepages produced almost no incorrect extractions, but, and this seems rather
surprising, it does not return more correct results than a full search with WATAcademia.
This evaluation also shows that for information items for which we want to find more than
just one per person, the search in more than one page brings many more results. Of course,
in WATAcademia we cannot be completely sure whether we only search relevant pages and
this causes the system to return incorrect results. We have already discussed in chapter 3
how we can improve this.
In the search for publications, we have left out the bar concerning the number of actually
available publication information on the Web. It is impossible to determine this number
as this information is likely to be spread across several sites on the Web. WATAcademia
demonstrates an additional useful feature, which we have not included in the evaluation.
Consider the situation in which a user wants to find publications of two researchers. These
161

two researchers actually work closely together and they have published a lot ofjoint papers.
Now, it is possible that the system searches the homepage of each one of the researchers.
On the first homepage, there is absolutely no publication information, but on the homepage
of the second person, there is a long list of publications. Of course, many of the papers in
there also have the first researcher as an author. If the system writes this information into
the application database, the system also recognizes that the first researcher is an author of
some of the papers, and also enters associations from the first researcher to these papers.
These results show us that our approach not only works, but also that the WAT system with
its components brings added value to the user. We now want to disuss the results when
using the WAT system with applications other than Academia.
7.5.2 The Results of other Agents developed with the WAT
However, until now, we have only discussed the results of WATAcademia, and this cannot
be proof enough for the usability of the system. Other applications that we tested included
the ImageFinder which we already described in section 7.3. This agent serves links to
images of people where their first and last name have to be given. The ImageFinder is
able to produce a lot of results when tested for celebrities, although the concept of finding
images of a person just by knowing their name is quite weak. The ImageFinder is an
example for the fact that the simplest agents return the best results. This is of course due
to the fact that simple agents are better foreseeable, it is simpler for the developer to define
the appearance of the results and the pages that contain them.
Another quite simple application is the CarFinder which looks for information about cars.
The agent should find prices, speed limits or weights of cars where the manufacturer and
name serve as the input. The CarFinder was surprisingly effective, but the fact that there
are different sellers with different prices and numbers about the characteristics makes it
almost impossible for the agent to find the "true" values. An interesting extension might be
to let the CarFinder look for the lowest priced car only. This is not yet implemented in the
Web Agent Toolkit. WAT agents either look for all the results they can find for an attribute
or only for one which will be that in which the agent has the highest confidence. However,
it is simply a need to extend the querying possibilities of a WAT agent so that there is a
possibility to look for aggregate values such as the lowest available price of a car.
Until now, we have only discussed applications in which we run only one WAT agent. Let
us now take a look at a more complex application in which we run more than one agent
to fetch the information from the Web. A good example application is the music database
which we already mentioned in section 7.2. Figure 7.20 shows an excerpt of the whole
schema of that database.
There are a lot of quite small information agents imaginable for that schema. For example,
an agent which searches the homepages of record labels for new albums. Another possi¬
bility is an agent which looks for album names and tries to extract the songs contained on
them. Another agent might look for fan or homepages of artists and extract the names of
162

artist
Artists
(0,*)
(o,*) fl..
T-% (1,1)'
Played_byv
( Plays 1
(0,*)
I musicaLinstrument
Musicaljnstruments
sonp
Songs
(0,*)
(0,*)
(1.1)
audio, cd
Audio CDs
(0*> ^Part.of^ (1 *>
(0,*)
Track_Numbers
album
Albums
(0,*)
(0,*)
recordjat»i"
Record_Labels
Figure 7.20: A larger schema excerpt of the music database
the songs that they play. There are a lot of different agents possible and we have built two
of then.
First, we have created a song information agent. As an input, this agent simply takes the
title of a song and tries to find the duration and the lyrics of it, as well as sound files of it.
For that, the agent searches pages delivered by a search engine to find lyrics and duration
as well as two sources of sound files. This means, unlike other agents, that we use three
different sources for the retriever.
The quality of this agent is dependent on the song. This agent only uses the song title but
not the artist as an input value. This means that songs that have been interpreted by several
different artists or simply have a quite common title will not necessarily lead to the correct
data. For example, the song "Knockin' on heaven's door" leads to many different songs
that were not all interpreted by the desired artist. On the other hand, when searching for
the song "Everything counts", we received 6 files which included 5 different versions of
the same song by the same artist. However, the duration that is extracted mainly depends
on the version of the song that is found, because the agent does not have any instruction to
differentiate between original versions and remixes. Finally, the lyrics extraction profile is
kept very simple. We only look for pages that contain the lyrics of the song in question and
nothing more. With this method, pages that contain all the lyrics of an entire album will
not be considered.
It is easy to see that the level of quality of these results has the same reason as the
WATAcademia agent. Generally, we do not provide the agent with information which
is exact enough, and this leads to results that are not that reliable. Here, the solution lies
also in optimising the extraction profile. This first might include the addition of the name
of the artist to the input values. With this step, we automatically can exclude a lot of in¬
correct pages and hence incorrect results. The lyrics extraction profile of course also has
to be improved, although this will not be that easy. Lyrics usually consist of a block of text
without necessary clear borders to the rest of an HTML page. However, it is possible and
might just need more time for a comprehensive analysis of the situation and the realisation
163

of the improvements.
7.5.3 Other Benefits and Possibilities to use the WAT
The WAT framework is open, and it is possible to introduce new output objects to extract
anything we want. As soon as a developer has an idea as to what shall be searched and
how the interesting information appears, the creation of an agent can begin. However, the
system is not only extensible in terms of the search objects that it uses. The framework can
also be extended to integrate the agent into other applications.
If it seems to make sense, the agent can be hardcoded in Java, e.g. for increasing the
performance. As the whole framework is written in Java, this is not very difficult, we do
not have to define the agent in the database. Of course, this will only be done for agent
applications which have to be fully optimised in the prototype phase as it is no longer so
convenient to adapt the agent. Similarly, we can redirect the output of an agent to produce
output in another format rather than writing results into a database.
Another specific feature of the system is the automatic production of output in an XML
format. For every search process, the system produces two XML files, one containing the
definition of the agent, and another containing the results of the search. The document
type definitions of those two files are fixed, therefore it is possible to easily implement
applications which can understand any of those XML files. Of course, if desired, a user
also can extend the system with another specific output format.
What are these features good for? For some applications, it might not be necessary to de¬
velop a specific application after the prototyping phase, for example because performanceis not important. To give a concrete example, when we were contacted by other researchers
to give them more information about the earlier ACADEMIA agent and its results, it seemed
as a good idea to make Academia available online. However, the old version was far away
from being Web-enabled, this would have required us to alter a lot of things to make that
possible. In the mean time, the OMS system has been Web-enabled [ErnOO], but we in
fact only wanted to focus on the results and therefore, it was not necessary at all to use a
database behind that Web application. We only wanted to provide an entry page in which a
user can enter the name of the person in question, and somehow, the agent will be executed
before presenting the results to the user.
When we introduced WAT, we automatically created an easy solution for that problem as
we could build fixed agents as a Java object, as well as redirect the output. With that, we
created WebAcademia [Web] and WAPAcademia [MagOO] which can be used via a Web
browser and a mobile phone, respectively.
Figure 7.21 shows the entry page of WebAcademia, the Web application of Academia.
The user enters the first and the last name of the person for a search and also his email
address. This is necessary, as a specific search might last 1 minute or in extreme cases up
to a couple of hours. There is no possibility to foresee that, so it does not make sense to
164

uphold a direct connection from the client to the server for hours. As soon as the user has
started the search, the connection will be closed and on the server-side, the agent starts the
search. Whenever the agent has finished, the results will be sent to the user by email.
Hie Edit View Go Bookmarks Options Directory Window Help
4»B** t
Location: Jittp //ww globxs etàa ch/AGans/MiDEMia/
What's New?: What's Cool? Destinations] Netsearch People Software)
Figure 7.21 : The entry form of WebAcademia
There is also a speciality which differs from a common WAT agent. As the user who
requested the search does not set any preferences for agent operation, we decided not to let
the agent drop any results. The agent returns everything he finds and additionally returns
the confidence values and declares their meaning.
WAPAcademia of which figure 7.22 shows a part of the entry form and figure 7.23 shows
the three parts of a single result is in fact a light version of WATAcademia. The display of a
WAP browser which is commonly a mobile telephone is usually quite small, so it does not
make sense to present long lists of publications. We have reduced the output objects to onlylook for phone and fax number, email address, title and birthdate. These information items
usually can be extracted quickly and therefore WAPAcademia can uphold a connection
between the client and the server before returning the results to the client.
165

Figure 7.22: The entry form of WAPAcademia
Figure 7.23: A result in WAPAcademia in three parts
We have seen that the WAT framework is highly flexible and also extensible in many ways.
We therefore are convinced in its usability in many ways, although, the use of it as a proto¬
typing system for Web information agents remains its main task. However, it is important
to bear in mind that the success of an agent is always highly dependent on the user input.
7.6 Summary
In this chapter, we have discussed the framework which realises the concepts developedwithin this thesis. The Web Agent Toolkit (WAT) is not only the prototype which proves
our concepts from the earlier chapters, but also a useful tool for the development of Web
information agents.
We began this chapter by discussing the possibility to bring the database and the agent
even closer to each other than the architecture proposed in chapter 5. We have discussed
the ideal of a fusion of these two components. However, this is not realistic, and therefore
we rather concentrate on a close cooperation between agent and database.
The WAT is the prototype for our concepts, it is a framework to easily and quickly create
Web information agents. These agents are built from within a database where they can
also be started. The database actually comprises two parts - a configuration database and
a so-called application database.
166

Before starting the agent, the user has to enter the input values for a search. In case of
ACADEMIA, this would be the name of a person. When the agent is started, it collects the
information from these two databases to learn about its specific search task. After the agent
has finished the search, the results will be written to the application database, where the
user can then browse them.
The WAT has built in the tight coupling between the agent and the databases. It is flexi¬
ble and can be used for any search domain, as long as the desired information occurs on
the Web. The main use of WAT is for the prototyping of Web information agents. The
developer of a specific agent always has to check the quality of the results after a search.
Together with the log files, it is possible to track the pages which were searched and what
was really found on them. The developer can then quickly adapt the settings of the output
objects that define the search. Without having to re-compile anything, the developer can
start another search to see whether the agent has been improved. The developer works on
the WAT agent until he is fully content with the results, and this is the point where the
developer knows all the facts to develop a specific agent application according to the char¬
acteristics of this search domain. This makes sense as the WAT is a general framework that
does not guarantee an optimal performance for any agent.
By describing the ImageFinder WAT agent, we have shown how to build such an agent.
The main points in this development process begin with the definition of the core WAT
Agent and some general settings. Then, the developer has to define, how the agent gets
the initial pages where the search shall be started, and also, how these pages have to be
analysed after a search in order to differ between relevant and irrelevant start pages in a
future search for the same person. These two components are called the Retriever and the
OriginalURLsAnalyser. Finally, the search is defined by the input objects which define the
input values for the search and the output objects which tell the agent what has to be found
and how that is expected to appear in the Web pages.
The WAT comes up with a given set of output objects which can be used without havingto program a single line of code. These objects include an email object, a picture objector a link object to name but a few. However, for new applications, it may be necessary to
introduce new output objects, and then, the developer has to program the correspondingJava class which contains the information how this object shall extract any results.
We have also described several add-ons to the framework which increase the possibilitiesof the system. First, there is the Message Exchanger which is a component that handles
all the communication between the agents and other components. Another important agent
is the Question Agent which organises all the interaction that a component in the system
wants to do with the user. Every component in the system may compose a question for the
user and send this to the Question Agent using the Message Exchanger. Then, the Question
Agent tracks the availability of the user and poses the questions. Every answer finally will
be sent back to the component which asked the question, so that this component can act
according to the user's decision.
In addition, the system contains a couple of statistics agents that analyse certain parts of
167

the search processes and try to find improvements in the input values or settings of the
WAT agents. The Web Page Analyser tracks all the start pages that a retriever delivered
for its WAT agent. These pages will be searched for words that occur in most of them,
because these words might serve as additional evidence for the relevance of a start page
in the search domain of a single WAT agent. These words in the future then can be used
by the retriever in order to improve the precision of its results. Additionally, there are the
Keyword Observer and the Threshold Observer, which track the usability and the success
of the keywords that are used in the output objects, and the optimal setting of the thresholds,
respectively. The system is extensible and new statistics agents can be easily introduced.
When we took a critical look at the quality of several WAT agents, we had to conclude
that the success of a WAT agent is highly dependent on the developer. As it is usuallynot known in advance how the desired information really is presented on the Internet, it is
quite difficult to define a new agent. Therefore, a newly created WAT agent usually does
not provide a high rate of good results when run for the first time.
Therefore, the prototyping phase is very important. A developer has to check the results of
a search and analyse the situation exactly whenever the precision and/or the recall rate are
poor. Perhaps, the agent just needs some adaptions in the settings of the output objects, but
in specific cases, it might be necessary to improve the extraction algorithms of an output
object or even to develop a new output object. This analysis and continuous update leads to
a step-by-step improvement of the results until the developer is content with the outcome
of an agent.
We have described some agents that we have built, some of which are very successful
such as WATAcademia, and others may need further improvement. However, we have seen
that it is always possible to work on an agent and increase precision and recall. For that,
the developer mainly has to concentrate on two questions: Are the relevant pages part of
the start pages delivered by the retriever? And: Are the extraction profiles exact enough?Whenever the developer is able to answer both with "yes", the prototyping phase has been
finished and the developer can take the next step.
When a WAT agent is optimised, the developer has to decide whether the results are good
enough. In other words, does the agent return enough results? If not, this means that the
desired information is not around in the Internet and we can forget about the automated
search. On the other hand, if sufficient results are found, this means that the prototyping
phase has resulted in a fully usable agent and the search concept behind it is successful.
The developer can now decide to build a specific agent application, free from WAT. This
makes sense whenever performance is important or many people have to access the agent
concurrently.
The examples of WebAcademia and WAPAcademia show that it is also possible to build
applications with a WAT agent itself. Whenever an application is used only for a one-off
search, this means we no longer need the whole construct with database and agent, and it
might be a solution to stay with the WAT agent instead of building a new specific agent. We
therefore can create a fixed version of that agent and redirect the output to any file of any
168

format as required. With that concept, we built the Web and the WAP application to use
Academia. Although the latter is quite small and looks only for a subset of the attributes
of WebAcademia, the results are good and at least WebAcademia is used regularly.
169

Chapter 8
CONCLUSIONS AND FURTHER
WORK
We have detailed our work which mainly resulted in a framework for creating Web infor¬
mation agents. In this chapter, we summarise the main concepts introduced in this thesis
and discuss our achievements. In addition, we indicate what can be done in order to im¬
prove the system. This can affect not only the system's features but also its handling for
developers as well as users.
8.1 Summary
As the quantity of information available on the World-Wide Web continues to grow dra¬
matically, Web information agents can play an increasingly important role in the searchingand filtering of information. As we have seen with the example of the Academia agent,
there are possibilities where these types of agents can help to maintain data as well as save
their users a lot of time. Therefore, there is a demand for research in that direction.
However, we wanted to go a step further and not only provide some specific applications,we wanted to develop a general method for developing any Web information agent. As we
have seen, this is not easy as the extraction of information sometimes is heavily dependenton the domain. Therefore, we had to concentrate on the things that are independent of
the domain. The result was a combination and integration of several components and
techniques.
Let us first have a look at the important components that we have described in this thesis.
We summarise what we have brought in and developed by ourselves, where we had the
possibility to adapt ideas already given and also specify existing tools that we could use.
The work in this thesis was mainly to bring together several different concepts and ideas
and integrate them. Table 8.1 lists all these components. We discuss them by going throughthe entire system.
170

Invented Concept of WAT
Implementation of WAT
VWrap
Adapted Web information agent architecture
Concept of the cooperation between agent and database
Extraction of simple information items
Rating of the extraction results
Homepage Finder
All the other add-ons
Used Database (OMS Java)
Table 8.1 : A summary of the important components used in this thesis
Of course, the concept and the implementation of the WAT is an invention of this thesis - it
is the main achievement of this work. However, the architecture on which the WAT is built
cannot be called our invention. Although we have not yet seen a specific Web information
agent architecture, we can state that the concepts we use in ours are derived from general
agent architectures.
The extraction techniques in general are also adaptions of existing techniques. We have
captured and parameterised the extraction processes of a typical Web information agent.
They are the heart of the system. Generally, we saw that there exist two different types of
extractable information - single information items and information which is contained in
a structure. We have isolated these types and were able to find a way to parameterise these
methods to make it possible for a developer to define agents which may search for any kind
of information in Web pages independently of a domain.
The extraction of so-called single information, however, is quite special. The idea behind it,
our so-called "keyword approach" to locate information items, is very simple and therefore
a common approach. However, we have formulated it and shown how deep this approachcan be refined and what benefits are possible by using it. Together with additional attributes
to be set, it is possible to narrow down the results to the most promising ones. On the other
hand, as it was necessary to find a way to "query" semistructured information, we had to
invent VWrap as there does not exist a tool which is highly domain independent as well
as flexible enough to find structures by itself. VWrap is a tool which builds an "ad hoc
wrapper" around the structure. With this, it is possible to efficiently query the structure
and also get information about the semantics it contains. The rating of the results found,
however, is an adaption of existing techniques to provide an optimal solution for our agents.
Several add-ons, especially the Homepage Finder, were developed under our supervision.We integrated them within this system with the adaptions necessary.
Finally, the database is a full component on which we have not done any development.There exist powerful database systems, therefore it was not necessary to do a lot of work
in this area. We simply have chosen OMS Java as it seemed to provide the most benefits
171

for our system. However, the cooperation between agent and database was not a part of
the database, we had to define this by ourselves. The concept as we described it is a
combination of several existing techniques.
Having a look at our achievements in this thesis, we see that we have been able to determine
several benefits from the way we have built the system. The close coupling between agent
and database provides some of these benefits. By using the database not only for the storage
of the results of the agent's search processes, but also for the storage of the settings for the
agent, we were able to maximise two things at once. On the one hand, the agent only has
to interact with one entity which is the database, and on the other hand, the user also needs
to work with only one entity. The latter is a gain as the user does not need to get used to
several different interfaces.
Another huge plus lies in the use of the database for the storage of all data of the system,
results as well as configuration data. With this solution, the data can be kept in one single
place. This makes it easier for a user to keep the overview of the whole data even if he runs
more than one agent. The use of the OMS Java database system provides another benefit,
as it in fact is a framework which can be positioned on top of any storage engine. This
makes it possible for the user to use the underlying storage system that he prefers.
When examining our extraction components, we see a rather special conclusion in this
work, as it presents another example demonstrating that sometimes it is possible that sim¬
ple approaches may lead to extraordinary good results. As stated previously, we do not
necessarily aspire to a recall rate of 100 percent. Therefore it was possible to use the key¬word approach to locate and extract single information items. Although this approach is
not completely reliable, it has proved to be very effective in spite of being a relatively
simple approach.
To do this extraction, the framework provides a set of search objects that can be used to find
specific information items such as for example email addresses or images. Thanks to the
extensibility of the system, a developer can always implement new search objects, if the
predefined ones do not meet the current needs. This prevents the agents from having any
restrictions in their extraction capabilities. A special search object incorporates the search
and extraction of information which is part of structured tables or lists. With the definition
given by the developer about what shall be found, the agent can decide autonomouslywhether an extracted result is really relevant. In the case that the agent cannot decide that,
there is still the option to ask the user for assistance on rating the relevance of a result. And,
as the user has to define thresholds that tell the agent about when a result shall be treated
as relevant or not, the agent is always under full control of the user.
However, we should not forget that a user with no idea about a search process on the
Internet will have problems using the framework. Therefore, we have to use the term
"user" more carefully. A person who works with the WAT to develop a Web information
agent is a developer. Such a person must know how a search on the Web takes place in
order to be able to define what the agent has to find. A developer may not only developbut also fully test an agent, which means that he optimises the settings so that the agent
172

produces nearly optimal results. This results in an agent which can be handed over to an
end user of the system. An end user commonly is an inexperienced user who only will let
it run and does not have to care about any settings. However, as the system makes it easy to
adapt an agent, it is possible for an end user to learn more about the search process duringthe use of an agent and finally improve it by himself by adjusting its settings.
As a consequence of this possibility to adapt an agent, the system is ideal to be used for
prototyping. We have discussed several agent applications where we saw specific lacks
in the search settings. The settings of an agent can easily be adapted between two search
processes without the need to recompile anything. It is therefore convenient to test an agent
and at the same time improve it. However, if the developer has handed over the agent to an
end user, the system still can evolve further.
All these benefits make the framework a powerful tool for developing Web information
agents. We even can state that whenever it is not possible to let a specific agent find
relevant results, the interesting information is not accessible for us or even not around at
all. The only other possibility that is left to explain the failure is that we did not define the
search objects correctly. And as we have seen, they still can be improved further.
8.2 Future Work
Although we are convinced that the Web Agent Toolkit WAT is a powerful and useful tool
for creating Web information agents, this does not mean it is perfect. Like any complex
system, there are many things that can be done to improve the handling and the results that
the WAT is able to produce.
First of all, in section 5.1, we have already mentioned the advantages of also accessingand extracting information from databases. The current version of the WAT is restricted to
the search of documents on the Web, which also may contain Web-enabled content from
databases, but not specifically the databases itself. This would be an important impact on
the extraction, as it is definitely easier to extract information from databases. This relies
mainly on the fact that the structure is already given and therefore the possibility of a false
extraction is minimised.
As we already stated, we first have to provide a mechanism to perform the access to such
databases. Of course, the form of access depends on the database system. Nonetheless,
the key values that are needed for that mostly are the same, as we need information about
an account which mainly consists of a user name and a password. We therefore have to
provide an interface which takes these values as an input and for every database system
which shall be accessed, we write a specific wrapper matching that interface.
However, the more important part is the extraction of the information from the database.
The main idea here is to first ask for the schema of the database. Similar to our approach for
extracting semistructured information, we now must combine the definitions given by the
user with the schema that is found and let the agent try to merge these. For every database,
173

this of course has to be done anew. If an agent is not able to find a full match, it must be
possible to ask the user for assistance. Here, the grade of autonomy of the agent must also
be given by the user. If the user wants the agent to be highly autonomous, the agent tries
to extract information even if it is not quite clear whether the desired information really is
there where assumed. On the other hand, the user can state that the agent must contact him
whenever it is not absolutely clear how the information is to be extracted.
With the addition of possible access to databases, the WAT becomes more interesting to
be used inside of a company, i.e. in an intranet. The WAT here could be used as a sort of
knowledge locating system. However, improvements are not only restricted to the sources
of the search.
Another part which can be added is the automatic generation of code whenever needed. If
the user needs a search object which does not yet exist, it is desirable that the system auto¬
matically generates source code that contains the necessary methods as empty constructs.
Additionally, it would be a big challenge to build a tool, a sort of a wizard which lets the
developer define what and how he wants to extract specific information, and the tool then
generates the corresponding search object by itself.
We also have discussed that for some agents it makes sense to prototype them with the
WAT, but for production, the agent has to be built as a stand-alone application. Here, it
makes sense to generate the necessary code automatically, so that the developer then onlyhas to add a visual interface and the stand-alone agent is ready to run.
The automatic generation of code whenever necessary makes the WAT more useful for
users that are not really developers. They are no longer restricted to use only a predefined
agent and at most adapt some settings with low importance. With this, they also have the
possibility to really make the most of the WAT.
Of course, the user interface to the WAT can be improved as well. In this thesis, we have
concentrated on the framework itself, we have not discussed how the WAT appears visuallyto the user. In fact, we work with a quite simple interface which is a demonstration version
of the actual OMS interface. This interface supports especially the functions that must be
provided by OMS, such as for example the creation of databases and objects as well as a
querying window.
There are also functions that are specific to the WAT which of course are not included in
this demonstration version. We therefore could create a specific user interface in which a
developer is guided through the creation of a specific agent. Here, he first will be presentedthe core agent object and after that also automatically the other necessary objects to set all
the necessary preferences. This will make the creation of a new agent significantly easier
and the WAT will be more attractive for inexperienced users.
Another possibility for an extension of the WAT is to include a linguistics analyser. Such
a component can help to improve the process of determining relevant documents, as it is
possible, together with a knowledge base, to make more complexer concepts about the
content of a Web page. With this we can improve mainly the retriever classes.
174

Additionally, this analyser can help with the extraction itself. Certain information which is
hidden in long sentences will be significantly easier and with more precision extractable.
As an example, take a text which describes the background of a person. With linguistic
analysis, it is much more convenient to extract the information that the person in questionis a professor from the sentence "she has been full Professor since 1996", than if we do
that with the keyword approach.
A linguistics analyser could also be used to create a comprehensive communication com¬
ponent for the agents. The message exchanger described in section 7.4 is definitely worth
extending so that it is also possible for foreign agents to communicate with the system.
This is especially interesting for exchanging results with other search agents which search
other sources that our agents do not know of.
Finally, we can state that a system like the WAT can always be further improved. As the
WAT is built as a system of components, every component by itself has always the potentialof being extended or replaced. This may prove to be vital in the context of the Web which
is continuously evolving. The future may likely bring along new standards and possibilitiesfor the publication and location of information. The easier a system can be adapted to these
changes, the more value it brings to a user.
175

Appendix A
The textual Schema of the ConfigurationDatabase
The following schema is in the OMS Data Definition Language (DDL) format. It can be
used to build the configuration database within OMS Java. At the beginning, it contains
the necessary conversion information to map the OMS objects to Java objects.
SCHEMA WATAgentResourceDB;
string = Java.lang.String;
strmg2 = org. omsjava. basetype. OMStrmg;date = org.omsjava.basetype.OMDate;text = java.lang.String;url = org.omsjava basetype.OMUrl;
photofile = org.omsjava.basetype.OMPhotofile;
mime = org.omsjava.basetype.OMMime;
integer = java.lang.Integer ;
mteger2 = org. oms j ava. basetype. OMInteger;
integer3 = java.lang.Long;
boolean = java.lang.Boolean;real = org.oms]ava.basetype.OMDouble;
watObject: diss.omsJava.detect.WATObject;
watInputObject: diss.omsJava.detect.input.WATInputObject;
watlnputBoolean: diss.omsJava detect.input.WATInputBoolean,
watlnputFloat. diss.omsJava.detect.input.WATInputFloat;
watlnputlnteger: diss.omsJava detect.input.WATInputlnteger;
watlnputstrmg: diss.omsJava. detect. input .WATInputStrmg;
watOutputObject: diss.omsJava.detect.output.WATOutputObject;
watPatternObject: diss.omsJava.detect.output.WATPatternObject,
watSmgleOutputObject : diss. omsJava, detect .output .WATSingleOutputObject;
watAudio: diss.omsJava.detect output.WATAudio;
watBoolean: diss.omsJava.detect.output.WATBoolean;
watDate- diss.omsJava.detect.output.WATDate;watEmail: diss.omsJava.detect.output.WATEmail;watFloat: diss.omsJava.detect.output.WATFloat;
watlmage: diss.omsJava.detect.output.WATImage;
watlnteger. diss.omsJava detect.output.WATInteger,watLmk- diss .omsJava, detect. output .WATLmk;
watText: diss.omsJava.detect.output.WATText,watHTMLText: diss.omsJava.detect.output.WATHTMLText;watTime: diss.omsJava.detect.output.WATTime;watPhoneNumber diss.omsJava.detect.output WATPhoneNumber;
watVideo: diss.omsJava.detect.output.WATVideo;watURLRetnever: diss.omsJava agent.WATURLRetriever;
176

watOriginalURLsAnalyser: diss.omsJava.agent.WATOriginalURLsAnalyser;
watAgent: diss.omsJava.agent.WATAgent;
keywords : diss.omsJava.util.Keyword;
input: diss.omsJava.util.Input ;
type watObject
( id string;active boolean
on ( ) -> ( ) ;
off
);
( ) -> ( ) ;
type watOutputObject subtype of watob
( keyword string;confidence real;
where string;otherKeywords set of keywords ;
inputObjectsSpecs set of input ;
resultName
);
string;
type watlnputobject subtype of watObject
();
type watSingleOutputObject subtype of watOutputObject
();
type watPatternObject subtype of watOutputObject
( searchURL
maxDist
attributes
arities
structureEquality
);
boolean-
integer;
ranking of watOutputObject;
ranking of integer2;
integer;
type watlnputBoolean subtype of watlnputobject
( value : boolean;
);
type watlnputFloat subtype of watlnputobject
( value : real;
type watInputInteger subtype of watlnputobject
( value : integer;
) ;
type watlnputString subtype of watlnputobject
( value : string;
) ;
type watAudio subtype of watSingleOutputObject
( maxDist : integer;
) ;
type watBoolean subtype of watSingleOutputObject
0;
type watDate subtype of watSingleOutputObject
( maxDist
minLength
maxLength
);
integer;
integer;
integer;
type watTime subtype of watSingleOutputObject
( maxDist
minLength
maxLength
);
integer;
integer;
integer;
type watEmail subtype of watSingleOutputObject
( minLength : integer;
177

maxLength : integer;
),
type watFloat subtype of watSingleOutputObject
( maxDist
mm
max
>;
integer;
real;
real;
type watlmage subtype of watSmgleOutputObject
( maxDist : integer;
type watlnteger subtype of watSmgleOutputObject
( maxDist
mm
max
) ;
integer;
mteger3 ;
mteger3 ;
type watLink subtype of watSmgleOutputObject
( maxDist : integer;
type watText subtype of watSmgleOutputObject
( maxDist
minLength
maxLength
charSet
begmCharSet
endCharSet
);
integer;
integer,
integer;
string;
string;
string;
type watHTMLText subtype of watSmgleOutputObject
<>;
type rfatPhoneNumber subtype of watText
(>;
type watVideo subtype of watSmgleOutputObject
( maxDist
>;
integer;
type watURLRetriever
( crawlers
inputs
combmationType
maxNumOfResults
rangeOfResultsconfidence
) ;
set of strmg2;
set of string2;
integer;
integer;
real;
real;
type watOriginalURLsAnalyser
( inputs : set of string2;
) ;
type keywords
( keyword
maxDist
);
type input
( id
maxDist
);
string,
integer;
string;
integer;
type watAgent
( name
resultDB
conflgFile
maxSearchDepth
maxLmks
upperthreshold
string;
string;
string;
integer;
integer;
real,
178

1owerthresho1d
overwrite
memory
alwaysask
run
real;
boolean
boolean
boolean
( ) -> ( ),
collection Agents
collection Get_Sites_from
collection InputObjectscollection Is_analysed_by
collection Looks_for
collection OrigmalURLsAnalyserscollection OutputObjects
collection URLRetrievers
collection Uses
set of watAgent;
set of (watAgent,watURLRetriever) ;
set of watlnputobject;set of (watAgent,watOriginalURLsAnalyser);
set of (watAgent,watOutputObject);set of watOriginalURLsAnalyser;set of watOutputObject;set of watURLRetriever;
set of (watAgent,watlnputobject);
constraint
constraint
constraint
constraint
Get_Sites_from
Is_analysed_by
Looks_for
Uses
association from Agents (0:1)
association from Agents (0:1)
association from Agents (0:*)
association from Agents (0:*)
to URLRetrievers (0 : *);
to OrigmalURLsAnalysersto OutputObjects (0:*);
to InputObjects (0:*);
(0
END WATAgentResourceDB;
179

Appendix B
The Image Finder Agent
The following definition is in the OMS Data Manipulation Language (DML) format. It can
be used to build the Image Finder agent which is described in section 7.3.
create object agent ;
dress object agent as watAgent values (
name = "ImageFinder" ;
resultDB = "/home/magnanel/omsJava/db/imageDB.odb";
configFile = "/home/magnanel/work/cfg/ImageFmder.cfg";
maxSearchDepth = 1 ;
maxLmks = 50 ;
upperthreshold = 0.6 ;
lowerthreshold = 0.2 ;
overwrite = true,
memory = true ;
alwaysask = false ;
);
insert into collection Agents : [agent] ;
create object retriever ;
dress object retriever as watURLRetriever values (
crawlers = ["diss.crawler.wrap.HomePageFmder"] ;
inputs = ["firstname","name"] ;
combinationType = 1 ;
maxNumOfResults = 20 ;
rangeOfResults = 20.0 ;
confidence =1.0,
),
insert into collection URLRetrievers : [retriever] ;
insert into association Get_Sites_from : [(agent,retriever)] ;
create object urlsanalyser ,
dress object urlsanalyser as watOriginalURLsAnalyser values (
inputs = ["firstname","name'] ;
) ;
insert into collection OrigmalURLsAnalysers : [urlsanalyser] ,
insert into association Is_analysed_by • [(agent,urlsanalyser)] ;
create object mput_name ;
dress object mput_name as watObject values (
id = name ;
active = true ;
) ;
dress object input_name as watlnputobject;
180

dress object mput_name as watlnputString values (
value = "person name" ;
) ;
insert into collection InputObjects : [mput_name] ;
insert into association Uses : [(agent,mput_name)]
create object mput_fname ;
dress object mput_fname as watObject values (
id = firstname ;
active = true ;
);
dress object mput_fname as watlnputobject;dress object mput_fname as watlnputString values (
value = "person firstname" ;
) ;
insert into collection InputObjects : [mput_fname]insert into association Uses
. [(agent,mput_fname)]
create object m_namel ;
dress object mnamel as input values (
id = name ;
maxDist = -15 ;
),
create object m_name2 ;
dress object m_name2 as input values (
id = name ;
maxDist = 20 ;
) ;
create object m_fnamel ;
dress object m_fnamel as input values (
id = firstname ;
maxDist - -15 ;
);
create object m_fname2 ;
dress object m_fname2 as input values (
id = firstname ;
maxDist = 20 ;
);
create object linkl ;
dress object lir.kl as watObject values (
id = galleryl ;
active = true ;
>;
dress object lmkl as watOutputObject values (
keyword = gallery ;
confidence =10;
where = k ;
otherKeywords = [] ;
inputObjectsSpecs = [] ;
resultName = "LinkList" ;
);
dress object linkl as watSmgleOutputObject;dress object linkl as watLmk values (
maxDist = 0 ;
);
insert into collection OutputObjects : [linkl] ;
insert into association Looks_for : [(agent,linkl)]
create object lmk2 ;
dress object lmk2 as watObject values (
id = gallery2 ;
active = true ;
);
dress object Unk2 as watOutputObject values (
keyword = gallery ;
181

confidence =1.0,
where = x ;
otherKeywords = [] ;
mputObjectsSpecs = [] ;
resultName = 'LinkList" ;
);
dress object lmk2 as watSmgleOutputObject;dress object link2 as watLink values (
maxDist = 80 ;
),
insert into collection OutputObjects • [lmk2] ;
insert into association Looks_for : [ (agent, lmk2 ) ]
create object lmk3 ;
dress object lmk3 as watObject values (
id = lmk2 ;
active = true ;
);
dress object link3 as watOutputObject values (
keyword = ".htm",
confidence =1.0,
where = 1 ;
otherKeywords = [] ;
mputObjectsSpecs = [in_fnamel] ;
resultName = "LmkList" ;
);
dress object lmk3 as watSmgleOutputObject;dress object lmk3 as watLmk values (
maxDist = -80 ;
) ;
insert into collection OutputObjects : [link3] ,
insert into association Looks_for : [(agent,lmk3)]
create object lmk4 ;
dress object lmk4 as watObject values (
id = linkl ;
active = true,
) ;
dress object lmk4 as watOutputObject values (
keyword = ".htm" ;
confidence = 1.0 ;
where = 1 ;
otherKeywords = [] ;
mputObjectsSpecs = [m_namel] ;
resultName = "LmkList" ;
) ;
dress object lmk4 as watSmgleOutputObject;dress object lmk4 as watLmk values (
maxDist = -80 ;
);
insert into collection OutputObjects : [lmk4] ;
insert into association Looks_for • [(agent,lmk4)]
create object picl ;
dress object picl as watObject values (
id = image1 ;
active = true,
) ;
dress object picl as watOutputObject values (
keyword = ".jpg" ;
confidence = 1.0 ;
where = c ;
otherKeywords = [] ;
mputObjectsSpecs = [m_namel] ;
resultName = photos ;
);
dress object picl as watSmgleOutputObject;dress object picl as watlmage values (
maxDist = 0,
182

),
insert into collection OutputObjects : [picl] ;
insert into association Looks_for : [(agent,picl)]
create object pic2 ;
dress object pic2 as watObject values (
id = image2 ;
active = true ;
);
dress object pic2 as watOutputObject values (
keyword = ".jpg" ;
confidence =10;
where = c ;
otherKeywords = [] ;
mputObjectsSpecs = [m_fnamel] ;
resultName = photos ;
),
dress object pic2 as watSmgleOutputObject;dress object pic2 as watlmage values (
maxDist = 0 ;
);
insert into collection OutputObjects : [pic2] ;
insert into association Looks_for : [(agent,pic2)]
create object pic3 ;
dress object pic3 as watObject values (
id = image3 ;
active = true ;
);
dress object pic3 as watOutputObject values (
keyword = ".jpg" ;
confidence = 1.0 ;
where = c ;
otherKeywords = [ ] ;
inputObjectsSpecs = [in_name2] ;
resultName = photos ;
) ;
dress object pic3 as watSmgleOutputObject;dress object pic3 as watlmage values (
maxDist = 0 ;
);
insert into collection OutputObjects : [pic3] ;
insert into association Looks_for : [(agent,pic3)]
create object pic4 ;
dress object pic4 as watObject values (
id = image4 ;
active = true ;
) ;
dress object pic4 as watOutputObject values (
keyword = ".jpg" ;
confidence = 1.0 ;
where = c ;
otherKeywords = [] ;
mputObjectsSpecs = [m_fname2] ;
resultName = photos ;
);
dress object pic4 as watSmgleOutputObject;dress object pic4 as watlmage values (
maxDist = 0 ;
);
insert into collection OutputObjects : [pic4] ;
insert into association Looks_for : [(agent,pic4)]
183

Bibliography
[AFJM95] R. Armstrong, D. Freitag, T. Joachims, and T. Mitchell. WebWatcher: A
Learning Apprentice for the World Wide Web. In Proc. of the Symposium
on Information Gathering from Heterogeneous, Distributed Environments,
Stanford, California, 1995.
[A1100] J. Allan. Natural Language Processing for Information Retrieval. Tutorial
presented at the NAACL/ANLP Joint Language Technology Conference,
Seattle, April 2000.
[Alt] AltaVista, http://www.altavista.com/.
[AM98] G. O. Arocena and A. O. Mendelzon. WebOQL: Restructuring Documents,
Databases, and Webs. In Proc. of the International Conference on Data
Engineering (ICDE), Orlando, Florida, February 1998.
[AMM97] P. Atzeni, G. Mecca, and P. Merialdo. To Weave the Web. In Proc. of the
23rd International Conference on Very Large Databases (VLDB'97), pages
206-215, Athens, Greece, August 1997.
[AQM+97] S. Abiteboul, D. Quass, J. McHugh, J. Widom, and J. Wiener. The Lorel
Query Language for Semistructured Data. International Journal on DigitalLibraries, l(l):68-88, April 1997.
[Bar98a] G. A. Bartha. A News Agent with Natural Language Processing. Master's
thesis, Institute for Information Systems, Swiss Federal Institute of Technol¬
ogy Zürich, CH-8092 Zürich, Switzerland, September 1998.
[Bar98b] G. A. Bartha. Information Extraction with Natural Language Processing for
the World Wide Web. Group of Global Information Systems, Swiss Federal
Institute of Technology Zürich, February 1998. Semester Project.
[BC98] E. Brynjolfsson and J.-C. Charlet. Firefly Network. Stanford UniversityCase OIT22A, March 1998.
[BDHS96] P. Buneman, S. Davidson, G. Hillebrand, and D. Suciu. A Query Languageand Optimization Techniques for Unstructured Data. In Proc. of the 1996
ACM SIGMOD International Conference on Management of Data, pages
505-516, Montreal, Canada, 1996.
184

[BLCL+94] T. Berners-Lee, R. Cailliau, A. Luotonen, H. Frystyk Nielsen, and A. Secret.
The World-Wide Web. Communications of the ACM, 37(8):76-82, August1994.
[BS84] B. G. Buchanan and E. H. Shortliffe. Rule-Based Expert Systems:The MYCIN Experiments of the Stanford Heuristic Programming Project.
Addison-Wesley, Reading, Massachusetts, 1984.
[BZW98] W. Brenner, R. Zarnekow, and H. Wittig. Intelligent Software Agents: Foun¬
dations and Applications. Springer-Verlag, New York, April 1998.
[Cas95] C. Castelfranchi. Guarantees for Autonomy in Cognitive Agent Architec¬
ture. In M. J. Wooldridge and N. R. Jennings, editors, Intelligent Agents:
Theories, Architectures and Languages (Volume 890 ofLecture Notes in Ar¬
tificial Intelligence), pages 56-70. Springer-Verlag, New York, 1995.
[CBC+00] R. G. G. Cattell, D. K. Barry, R. Catell, M. Berler, J. Eastman, D. Jordan,
C. Russell, O. Schadow, T. Stanienda, and F. Vêlez. The Object Data Stan¬
dard: ODMG 3.0. Morgan Kaufmann Publishers, January 2000.
[Che76] P. P. Chen. The Entity-Relationship Model - Toward a Unified View of Data.
ACM Transactions on Database Systems, 1(1):9—36, 1976.
[CHR01] N. Craswell, D. Hawking, and S. Robertson. Effective Site Finding usingLink Anchor Information. In Proc. of the 24th Annual International ACM
SIGIR Conference on Research and Development in Information Retrieval,
New Orleans, Louisiana, September 2001.
[CMMZ96] W. Chang, D. Murthy, Y Mei, and A. Zhang. Metadatabase and Search
Agent for Multimedia Database Access over Internet. Technical Report 96-
24, Department of Computer Science and Engineering, SUNY Buffalo, Buf¬
falo, New York, December 1996.
[DahOO] M. Dahn. Counting Angels on a Pinhead: Criti¬
cally Interpreting Web Size Estimates. Online Inc.,
http://www.onlineinc.com/onlinemag/OL2000/dahn 1 .html, January 2000.
[DBL] Universität Trier, http://www.informatik.uni-trier.deriey/db/index.html.DBLP Computer Science Bibliography.
[DED97] R. Doorenbos, O. Etzioni, and D.Weld. A Scalable Comparison-Shopping
Agent for the World-Wide Web. In Proc. ofthe 1st International Conferenceon Autonomous Agents, Marina del Rey, California, February 1997.
[DHH+92] H. C. Davis, W. Hall, I. Heath, G. J. Hill, and R. J. Wilkins. Towards an
Integrated Information Environment with Open Hypermedia Systems. In In
ECHT '92: Proc. of the Fourth ACM Conference on Hypertext, pages 181-
190, Milan, Italy, November 1992.
185

[DHR+98] D. C. DeRoure, W. Hall, S. Reich, A. Pikrakis, G. J. Hill, and M. Stairmand.
An open Framework for collaborative distributed Information Management.In Seventh International World Wide Web Conference (WWW7), volume 30,
pages 624-625, Brisbane, Australia, April 1998.
[Dow98] T. B. Downing. Java RMI: Remote Method Invocation. IDG Books, Febru¬
ary 1998.
[EBDHOO] S. El-Beltagy, D. DeRoure, and W. Hall. The Evolution of a Practical Agent-based Recommender System. In Proc. ofthe Workshop on Agent-based Rec¬
ommender Systems, Autonomous Agents 2000, Barcelona, Spain, June 2000.
ACM Press.
[ErnOO] A. Erni. A Generic Agent Frameworkfor Internet Information Systems. PhD
thesis, Swiss Federal Institute of Technology, Department of Computer Sci¬
ence, CH-8092 Zürich, Switzerland, 2000.
[Est99] D. Estermann. Persistent Java Objects. Master's thesis, Institute for In¬
formation Systems, Swiss Federal Institute of Technology Zürich, CH-8092
Zürich, Switzerland, 1999.
[FG96] S. Franklin and A. Graesser. Is it an Agent, or just a Program?: A Taxonomyfor Autonomous Agents. In Proc. of the ECAI'96 Workshop (ATAL). Intel¬
ligent Agents III. Agent Theories, Architectures, and Languages, Budapest,
Hungary, August 1996. Springer-Verlag.
[Fir97] Firefly, http://ai.about.com/compute/ai/library/weekly/aa052797.htm, May1997.
[FKS] Fulcrum Knowledge Server, http://www.hummingbird.com/.
[Fla99] D. Flanagan. Java in a Nutshell, 3rd Edition. O'Reilly & Associates,
November 1999.
[Fon93] L. Foner. What's an Agent, Anyway? A Sociological Case Study.
http://foner.www.media.mit.edu/people/foner/Julia/Julia.html, 1993.
[Fos99] M. Foser. Intelligente Subagenten zur Unterstützung von Internet-
Informationsagenten. Master's thesis, Institute for Information Systems,Swiss Federal Institute of Technology Zürich, CH-8092 Zürich, Switzer¬
land, July 1999.
[FWW+93] T. Finin, J. Weber, G. Wiederhold, M. Genesereth, R. Fritzson, D. McKay,J. McGuire, R. Pelavin, S. Shapiro, and C. Beck. DRAFT Specificationof the KQML Agent-Communication Language. Technical report, The
DARPA Knowledge Sharing Initiative External Interfaces Working Group,June 1993.
186

[Gal88] J. R. Galliers. A Theoretical Framework for Computer Models of Coop¬erative Dialogue, Acknowledging Multi-Agent Conflict. PhD thesis, Open
University, United Kingdom, 1988.
[Gen] General Magic, http://www.generalmagic.com.
[GF92] M. R. Genesereth and R. E. Fikes. Knowledge Interchange Format, Version
3.0 Reference Manual. Computer Science Department, Stanford University,Stanford, California, 1992.
[GK94] M. R. Genesereth and S. P. Ketchpel. Software Agents. Communications ofthe ACM, 37(7):48-53, 1994.
[GKT95] A. Geppert, M. Kradolfer, and D. Tombros. Realization of Cooperative
Agents Using an Active Object-Oriented Database Management System. In
T. Sellis, editor, Proc. of the 2nd Workshop on Rules in databses (RIDS),
volume 985 of Lecture Notes in Computer Science, pages 327-341, Athens,
Greece, September 1995. Springer-Verlag.
[GroOl] M. Grossniklaus. CMServer - An Object-Oriented Framework for Website
Development and Content Management. Master's thesis, Institute for In¬
formation Systems, Swiss Federal Institute of Technology Zürich, CH-8092
Zürich, Switzerland, February 2001.
[HFAN98] G. Huck, P. Fankhauser, K. Aberer, and E. J. Neuhold. JEDI: Extracting and
Synthesizing Information from the Web. In Michael Halper, editor, Proc.
of the 3rd IFCIS International Conference on Cooperative Information Sys¬
tems, CoopIS'98, New York City, New York, August 1998.
[HGMC+97] J. Hammer, H. Garcia-Molina, J. Cho, R. Aranha, and A. Crespo. ExtractingSemistructured Information from the Web. Technical report, Department of
Computer Science, Stanford University, Stanford, California 94305-9040,
1997.
[HKL+98] R. Himmeroder, P.-T. Kandzia, B. Ludasher, W. May, and G. Lausen.
Search, Analysis, and Integration of Web Documents: A Case Study with
FLORID. In Proc. of the International Workshop on Deductive Databases
and Logic Programming (DDLP), Manchester, UK, 1998.
[IMD] The Internet Movie Database, http://us.imdb.com/.
[JW98] N. R. Jennings and M. J. Wooldridge. Applications of Intelligent Agents.In N. R. Jennings and M. J. Wooldridge, editors, Agent Technology: Foun¬
dations, Applications and Markets, pages 3-28. Springer-Verlag, February1998.
[Kay84] A. Kay. Computer Software. Scientific American, 273(3):53-59, 1984.
187

[Ker97] L. Kerschberg. The Role of Intelligent Software Agents in Advanced In¬
formation Systems. In C. Small, P. Douglas, R. G. Johnson, P. J. H. King,and G. N. Martin, editors, Proc. ofAdvances in Databases, 15th British Na¬
tional Conferenc on Databases, BNCOD 15, volume 1271 of Lecture Notes
in Computer Science, pages 1-22, London, United Kingdom, July 1997.
Springer-Verlag. Invited Paper.
[KisOO] M. Kistler. OMS-XML - WAP and HTML Interface based on an XML
Server Component for OMS Java. Master's thesis, Institute for Information
Systems, Swiss Federal Institute of Technology Zürich, CH-8092 Zürich,
Switzerland, 2000.
[KLW95] M. Kifer, G. Lausen, and J. Wu. Logical Foundations of Object-Oriented and
Frame-Based Languages. Journal of the ACM, 42(4):741-843, July 1995.
[KM93] R. Kozierok and P. Maes. A Learning Interface Agent for Scheduling Meet¬
ings. In Proc. of the ACM SIGCHI International Workshop on IntelligentUser Interfaces, pages 81-88, Orlando, Florida, January 1993. ACM Press.
[KM98] T. Kistler and H. Marais. WebL - A Programming Language for the Web. In
Computer Networks and ISDN Systems (Proc. of the WWW7 Conference),volume 30, pages 259-270, Brisbane, Australia, April 1998.
[KMA+98] C. A. Knoblock, S. Minton, J. L. Ambite, N. Ashish, P. J. Modi, I. Muslea,
A. G. Philipot, and S. Tasheda. Modeling Web Sources for Information
Integration. In Proc. of the Fifteenth National Conference on Artificial In¬
telligence, Madison, Wisconsin, 1998.
[KN99] A. Kobler and M. C. Norrie. OMS Java: Lessons Learned from Buildinga Multi-Tier Object Management Framework. In Workshop on Java and
Databases: Persistence Options, OOPSLA'99, Denver, Colorado, October
1999.
[KNOOa] A. Kobler and M. C. Norrie. OMS Java: A Persistent Object ManagementFramework. L'objet, 6(3): 1-15, November 2000.
[KNOOb] A. Kobler and M. C. Norrie. OMS Java: An Open, Extensible Architecture
for Advanced Application Systems such as GIS. In Proc. ofthe International
Workshop on Emerging Technologiesfor Geo-Based Applications, Ascona,
Switzerland, May 2000.
[KNW98] A. Kobler, M. C. Norrie, and A. Würgler. OMS Approach to Database De¬
velopment through Rapid Prototyping. In Proc. of the 8th Workshop on
Information Technologies and Systems, WITS'98, Helsinki, Finland, Decem¬
ber 1998.
[KobOl] A. Kobler. The eXtreme Design Approach. PhD thesis, Swiss Federal In¬
stitute of Technology, Department of Computer Science, CH-8092 Zürich,
Switzerland, February 2001.
188

[Koz93] R. Kozierok. A Learning Approach to Knowledge Acquisition for IntelligentInterface Agents. Master's thesis, Massachusetts Institute of Technology,
Cambridge, Massachusetts, May 1993.
[Kru96] B. Krulwich. The BargainFinder Agent: Comparison Price Shopping on the
Internet. In J. Williams, editor, Agents, Bots, and other Internet Beasties,
pages 257-263. SAMS.NET publishing (Division of Macmillan publishing),
May 1996.
[LA97] D. B. Lange and Y Aridor. Agent Transfer Protocol. IBM Tokyo Research
Laboratory, http://www.trl.ibm.co.jp/aglets/atp/atp.htm, March 1997. Draft.
[LF97] Y Labrou and T. Finin. A Proposal for a new KQML Specification. Tech¬
nical Report TR CS-97-03, Computer Science and Electrical Engineering
Department, University of Maryland Baltimore County, Baltimore, Mary¬land 21250, February 1997.
[Lie95] H. Lieberman. Letizia: An Agent That Assists Web Browsing. In Proc.
of the 1995 International Joint Conference on Artificial Intelligence, pages
924-929, Montreal, Canada, August 1995. Morgan-Kaufmann.
[Lie97] H. Lieberman. Autonomous Interface Agents. In Proc. of the ACM Confer¬
ence on Computers andHuman Interface (CHI-97), Atlanta, Georgia, March
1997.
[LMM94] Y Lashkari, M. Metral, and P. Maes. Collaborative Interface Agents. In
Proc. of the 12th National Conference on Artificial Intelligence, volume 1,
Seattle, Washington, 1994. AAAI Press.
[L098] D. B. Lange and M. Oshima. Programming and Deploying Java Mobile
Agents with Aglets. Addison-Wesley, 1998.
[LR096] A. Y Levy, A. Rajaraman, and J. J. Ordille. Query Answering Algorithmsfor Information Agents. In Proc. of the 13th National Conference on Artifi¬cial Intelligence, AAAI-96, pages 40-47, Portland, Oregon, August 1996.
[Mae94] P. Maes. Agents that Reduce Work and Information Overload. Communi¬
cations of the ACM: Special Issue on Intelligent Agents, 37(7):31^40, July1994. ACM Press.
[Mag97] M. Magnanelli. Maintenance of a Contact Database by an Internet Agent.Master's thesis, Institute for Information Systems, Swiss Federal Institute of
Technology Zürich, CH-8092 Zürich, Switzerland, February 1997.
[MagOO] M. Magnanelli. WAPAcademia. Technical report, Systor AG, Zürich,
Switzerland, December 2000.
[MEN98a] M. Magnanelli, A. Erni, and M. C. Norrie. A Web Agent for the Main¬
tenance of a Database of Academic Contacts. Informatica, International
Journal ofComputing and Informatics, 22(4), December 1998.
189

[MEN98b] M. Magnanelli, A. Erni, and M. C. Norrie. ACADEMIA: An Agent-Maintained Database based on Information Extraction from Web Docu¬
ments. In Proc. of the 14th European Meeting on Cybernetics and SystemsResearch (EMCSR'98), Vienna, Austria, April 1998.
[MM98] M. Magnanelli and O. H. Münster. Software Agents and the Web. Technical
report, Systor AG, Zürich, Switzerland, 1998.
[MMM97] A. O. Mendelzon, G. Miahila, and T. Milo. Querying the World Wide Web.
Journal ofDigital Libraries, 1(1):54—67, 1997.
[MNOO] M. Magnanelli and M. C. Norrie. Databases for Agents and Agents for
Databases. In Proc. of the 2nd Intl. Bi-Conference Workshop on Agent-Oriented Information Systems (AOIS-2000), Stockholm, Sweden, June
2000.
[Neg70] N. Negroponte. The Architecture Machine: Towards a more Human Envi¬
ronment. MIT Press, 1970.
[NFF+91] R. Neches, R. Fikes, T. Finin, T. Gruber, R. Patil, T. Senator, and W R.
Swartout. Enabling Technology for Knowledge Sharing. AI Magazine,
12(3): 16-36,1991.
[Nor93] M. C. Norrie. An Extended Entity-Relationship Approach to Data Manage¬ment in Object-Oriented Systems. In Proc. of the 12th International Con¬
ference on Entity-Relationship Approach, pages 390-401, Arlington, Texas,
December 1993. Springer-Verlag.
[Nor95] M. C. Norrie. Distinguishing Typing and Classification in Object Data Mod¬
els. Information Modelling and Knowledge Bases, vol. VI, 1995. chapter
25, IOS (originally appeared in Proc. of the European-Japanese Seminar on
Information and Knowledge Modelling, Stockholm, Sweden, June 1994).
[Nwa96] H. S. Nwana. Software Agents: An Overview. Knowledge Engineering
Review, 11(3): 1-40, September 1996.
[Odi] Object Store PSE Pro. http://www.odi.com/.
[OK098] M. Oshima, G. Karjoth, and K. Ono. Aglets Specification 1.1 Draft. IBM
Tokyo Research Laboratory, http://www.trl.ibm.co.jp/aglets/specll.html,
September 1998.
[Ost99] C. Osterwalder. Secure Communications with Java RMI. Master's the¬
sis, Institute for Information Systems, Swiss Federal Institute of Technology
Zürich, CH-8092 Zürich, Switzerland, 1999.
[PBS+98] A. Pikrakis, T. Bitsikas, S. Sfakianakis, M. Hatzopoulos, D. C. DeRoure,
W. Hall, S. Reich, G. J. Hill, and M. Stairmand. MEMOIR - Software Agents
190

for Finding Similar Users by Trails. In H. S. Nwana and D. T. Ndumu, ed¬
itors, PAAM98 - The Third International Conference and Exhibition on The
Practical Application of Intelligent Agents and Multi-Agents, pages 453-
466, London, United Kingdom, March 1998.
[Pet96] C. J. Pétrie. Agent-Based Engineering, the Web, and Intelligence. IEEE
Expert, ll(6):24ff, December 1996.
[Rag] Raging Search, http://ragingsearch.altavista.com/.
[Ree97] G. Reese. Database Programming with JDBC and Java. O'Reilly & Asso¬
ciates, July 1997.
[RG85] J. S. Rosenschein and M. R. Genesereth. Deals among Rational Agents. In
Proc. of the 1985 International Joint Conference on Artificial Intelligence
(IJCAI-85), pages 91-95, Los Angeles, California, 1985.
[RH94] M. Roesler and D. T. Hawkins. Intelligent Agents: Software Servants For
An Electronic World (and More!). Online, 18(4): 18-32, 1994.
[SA98] A. Sahuguet and F. Azavant. W4F: a WysiWyg Web Wrapper Factory. Tech¬
nical report, University of Pennsylvania, August 1998.
[Sch98] F. Schudel. Movie Agent. Group of Global Information Systems, Swiss
Federal Institute of Technology Zürich, 1998. Semester Project.
[Sch99] F. Schudel. A Framework for Internet Agents: An Approach towards a
Multimedia Information Finder. Master's thesis, Institute for Information
Systems, Swiss Federal Institute of Technology Zürich, CH-8092 Zürich,
Switzerland, February 1999.
[SE97] E. Selberg and O. Etzioni. The MetaCrawler Architecture for Resource Ag¬
gregation on the Web. IEEE Expert, 12(1):8-14, January 1997.
[Sel98] I. Sele. Homepage Finder. Group of Global Information Systems, Swiss
Federal Institute of Technology Zürich, August 1998. Semester Project.
[Sha94] U. Shardanand. Social Information Filtering for Music Recommendation.
Master's thesis, Massachusetts Institute of Technology, Cambridge, Mas¬
sachusetts, September 1994.
[She94] B. Sheth. A Learning Approach to Personalized Information Filtering.Master's thesis, Massachusetts Institute of Technology, Cambridge, Mas¬
sachusetts, February 1994.
[SKN98] A. Steiner, A. Kobler, and M. C. Norrie. OMS/Java: Model Extensibil¬
ity of OODBMS for Advanced Application Domains. In Proc. of the 10th
International Conference on Advanced Information Systems Engineering,
CAiSE'98, Pisa, Italy, June 1998.
191

[SLE97] J. Shakes, M. Langheinrich, and O. Etzioni. Dynamic Reference Sifting:A Case Study in the Homepage Domain. In Proc. of the 6th International
World Wide Web Conference, Santa Clara, California, April 1997.
[SM83] G. Salton and M. J. McGill. Introduction to Modern Information Retrieval.
Comnputer Science Series. McGraw-Hill, New York, 1983.
[SM93] B. Sheth and P. Maes. Evolving Agents for Personalized Information Fil¬
tering. In Proc. of the Ninth Conference on Artificial Intelligence for Ap¬
plications, pages 345-352, Orlando, Florida, March 1993. IEEE Computer
Society Press.
[SPS+95] S. Spaccapietra, C. Parent, M. Sunye, K. Yetongnon, and A. Dileva. ERC+:
An Object+Relationship Paradigm for Database Applications. In D. C. Rine,
editor, Readings in Object-Oriented Systems and Applications, pages 180—
205. IEEE Press, 1995.
[Ste98] A. Steiner. A Generalisation Approach to Temporal Data Models and their
Implementations. PhD thesis, Swiss Federal Institute of Technology, De¬
partment of Computer Science, CH-8092 Zürich, Switzerland, 1998.
[SW86] C. Stanfill and D. Waltz. Toward Memory-Based Reasoning. Communica¬
tions ofthe ACM, 29(12):1213-1228, November 1986.
[Swe95] Swedish Institute of Computer Science, S-164 28 Kista, Sweden. SICStus
Prolog User's Manual, 1995.
[VB90] S. Vere and T. Bickmore. A basic Agent. Computational intelligence,
6(l):41-60,1990.
[Web] WebAcademia. http://www.globis.ethz.ch/AGENTS/ACADEMIA/.
[Whi94] J. E. White. Telescript Technology: The Foundation for the Electronic Mar¬
ketplace. General Magic White Paper GM-M-TSWP1-1293-V1, 1994.
[WJ95] M. J. Wooldridge and N. R. Jennings. Intelligent Agents: Theory and Prac¬
tice. The Knowledge Engineering Review, 10(2): 115-152,1995.
[WürOO] A. Würgler. OMS Development Framework: Rapid Prototypingfor Object-Oriented Databases. PhD thesis, Swiss Federal Institute of Technology,
Department of Computer Science, CH-8092 Zürich, Switzerland, 2000.
[Zeh91] C. A. Zehnder. Informatik-Projektentwicklung. B.G. Teubner Verlag, Verlagder Fachvereine, Zürich, Switzerland, 1991. 2., überarbeitete und erweiterte
Auflage.
192

Curriculum Vitae
Name : Mario Marco Magnanelli
Birthdate: March 27, 1971
Birthplace: Olten, Switzerland
Citizenship: Starrkirch-Wil (SO) and Densbüren (AG), Switzerland
1977 - 1982 Elementary School in Starrkirch-Wil, Switzerland
1983 - 1991 High School in Olten, Switzerland
1991 Matura Type B
1991 - 1997 Study of Computer Science at the Swiss Federal Institute of Tech¬
nology (ETH) in Zurich
1994 - 1996 Practical Training at Cantonal Bank of Zurich
1997 M.Sc. (Dipl. Informatik-Ing. ETH) in Computer Science
1997 Practical Training at BMW AG, Munich
1997 - 2001 PhD student in the research group for Global Information Systemsat the ETH Zurich (Prof. Dr. Moira C. Norrie) and employee at
SYSTOR AG, Basel as Internet Engineer
193
Related Documents











