Research Article Technical Job Recommendation System Using APIs and Web Crawling Naresh Kumar, 1 Manish Gupta , 2 Deepak Sharma, 3 and Isaac Ofori 4 1 Department of Computer Science & Engineering, Maharaja Surajmal Institute of Technology, Janakpuri 110058, New Delhi, India 2 Department of Computer Science & Engineering, Moradabad Institute of Technology, Moradabad 244001, India 3 Department of Information Technology, Jagannath International Management School, Vasant Kunj, New Delhi 110070, India 4 Department of Environmental and Safety Engineering, University of Mines and Technology, Tarkwa, Ghana Correspondence should be addressed to Isaac Ofori; [email protected] Received 22 April 2022; Revised 26 May 2022; Accepted 1 June 2022; Published 21 June 2022 Academic Editor: Arpit Bhardwaj Copyright © 2022 Naresh Kumar et al. is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. ere has been a sudden boom in the technical industry and an increase in the number of good startups. Keeping track of various appropriate job openings in top industry names has become increasingly troublesome. is leads to deadlines and hence important opportunities being missed. rough this research paper, the aim is to automate this process to eliminate this problem. To achieve this, Puppeteer and Representational State Transfer (REST) APIs for web crawling have been used. A hybrid system of Content-Based Filtering and Collaborative Filtering is implemented to recommend these jobs. e intention is to aggregate and recommend appropriate jobs to job seekers, especially in the engineering domain. e entire process of accessing numerous company websites hoping to find a relevant job opening listed on their career portals is simplified. e proposed recommendation system is tested on an array of test cases with a fully functioning user interface in the form of a web application. It has shown satisfactory results, outperforming the existing systems. It thus testifies to the agenda of quality over quantity. 1. Introduction With an increasing number of cash-rich, stable, and prom- ising technical companies/startups on the web [1] which are in much demand right now, many candidates want to apply and work for these companies. ey tend to miss out on these postings because there is an ocean of existing systems that list millions of jobs which are generally not relevant at all to the users. ere is an abundance of choices and not much streamlining. On the basis of the actual skills or interests of an individual, job seekers often find themselves unable to find the appropriate employment for themselves. is system, therefore, approaches the idea from a data point of view, emphasizing more on the quality of the data than the quantity. 1.1. Data Collection. e database used for this system was created using refined and customized data collection tech- niques and methods. is technique helps distinguish the database from the already existing commercially available job databases. Hence, data collection programs have been devel- oped from scratch. Web crawling [2], as well as web scraping, has been used for dataset preparation. By combining web crawling and web scraping, more automation and less hassle were ensured on the Web with less human labor and error. Different types of web crawlers used are as follows: (i) Job Listing Crawler (ii) Ontology-based Crawler (iii) HTML Crawler (iv) API Crawler 1.2. Recommendation System. Recommendation systems proposed in [3] are mechanisms for information filtering that smartly identify and segregate information. ey create smaller chunks out of large amounts of dynamically Hindawi Computational Intelligence and Neuroscience Volume 2022, Article ID 7797548, 11 pages https://doi.org/10.1155/2022/7797548

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Research ArticleTechnical Job Recommendation System Using APIs andWeb Crawling
Naresh Kumar1 Manish Gupta 2 Deepak Sharma3 and Isaac Ofori 4
1Department of Computer Science amp Engineering Maharaja Surajmal Institute of Technology Janakpuri 110058New Delhi India2Department of Computer Science amp Engineering Moradabad Institute of Technology Moradabad 244001 India3Department of Information Technology Jagannath International Management School Vasant Kunj New Delhi 110070 India4Department of Environmental and Safety Engineering University of Mines and Technology Tarkwa Ghana
Correspondence should be addressed to Isaac Ofori ioforiumatedugh
Received 22 April 2022 Revised 26 May 2022 Accepted 1 June 2022 Published 21 June 2022
Academic Editor Arpit Bhardwaj
Copyright copy 2022Naresh Kumar et alis is an open access article distributed under the Creative Commons Attribution Licensewhich permits unrestricted use distribution and reproduction in any medium provided the original work is properly cited
ere has been a sudden boom in the technical industry and an increase in the number of good startups Keeping track of variousappropriate job openings in top industry names has become increasingly troublesome is leads to deadlines and henceimportant opportunities being missedrough this research paper the aim is to automate this process to eliminate this problemTo achieve this Puppeteer and Representational State Transfer (REST) APIs for web crawling have been used A hybrid system ofContent-Based Filtering and Collaborative Filtering is implemented to recommend these jobs e intention is to aggregate andrecommend appropriate jobs to job seekers especially in the engineering domain e entire process of accessing numerouscompany websites hoping to nd a relevant job opening listed on their career portals is simpliede proposed recommendationsystem is tested on an array of test cases with a fully functioning user interface in the form of a web application It has shownsatisfactory results outperforming the existing systems It thus testies to the agenda of quality over quantity
1 Introduction
With an increasing number of cash-rich stable and prom-ising technical companiesstartups on the web [1] which are inmuch demand right now many candidates want to apply andwork for these companies ey tend to miss out on thesepostings because there is an ocean of existing systems that listmillions of jobs which are generally not relevant at all to theusers ere is an abundance of choices and not muchstreamlining On the basis of the actual skills or interests of anindividual job seekers often nd themselves unable to nd theappropriate employment for themselves is systemtherefore approaches the idea from a data point of viewemphasizingmore on the quality of the data than the quantity
11 Data Collection e database used for this system wascreated using rened and customized data collection tech-niques and methods is technique helps distinguish the
database from the already existing commercially available jobdatabases Hence data collection programs have been devel-oped from scratch Web crawling [2] as well as web scrapinghas been used for dataset preparation By combining webcrawling and web scraping more automation and less hasslewere ensured on the Web with less human labor and error
Dierent types of web crawlers used are as follows
(i) Job Listing Crawler(ii) Ontology-based Crawler(iii) HTML Crawler(iv) API Crawler
12 Recommendation System Recommendation systemsproposed in [3] are mechanisms for information lteringthat smartly identify and segregate information ey createsmaller chunks out of large amounts of dynamically
HindawiComputational Intelligence and NeuroscienceVolume 2022 Article ID 7797548 11 pageshttpsdoiorg10115520227797548
generated information A recommendation system has theability to predict whether a specific user will prefer an articleor not based on their profile and its past information [4]
Collaborative filtering [5] makes recommendationsbased on historical user behavior +e model can only beshaped based on the behavior of a single user as well as thebehavior of other individuals who have used the systembefore them Recommendations are based on direct col-laboration from multiple users and then filtered to matchthose who express similar preferences or interests Content-Based recommendations are specific to a specific user as themodel does not use any information about other users on thepage
121 Content-Based Filtering Content-based Filtering [6] isa machine learning technique that makes decisions by takinginto account the similarities in the features of the datapresent Two methods used to decide are as follows
(i) Firstly users provide a list of features out of whichthey can choose whatever they find the best
(ii) Secondly the algorithm can keep track of theproducts that the user has shown interest in the past+ey are appended to the usersrsquo already existingdataContent-based filtering recommenders do not needthe profiles of other users or any foreign data as theydo not greatly influence recommendations [7]
(iii) Collaborative Filtering +e collaborative filteringmethod is based on the historical interlinkages thatare documented among the users and items +emethod tries to forecast the usefulness of articles fora specific user on the articles previously evaluated byfellow users +ese memory-based methods workdirectly with the recorded interaction values and arebased on finding the nearest neighbor for examplefinding the closest user of interest and suggestingthe most popular product
2 Related Work
In recent years tremendous research has been done on thetopic of job recommendations For the completion of thispaper several research articles have been referenced whichwere published recently With the help of this literaturesurvey it was seen that the basic steps involved in most ofthese recommendation systems are as follows
(i) Data acquisition(ii) Data preprocessing(iii) Record recommendation
While several research papers and existing papers gavenumerous insights on the problem statement at hand all ofthem had some of the other elements of such a successful jobrecommendation system being in place creating a scrapingtemplate need to define HTML documents of those websitesfrom where data needs to be collected site navigation tra-versal preparing a system for website navigation and
exploration automating navigation and extraction con-ducting automation for the facts and processed data col-lected computing data and packages from the website +edata acquired has to be saved in tables and databases
+e authors of [1] however only focus on job aggre-gation and not filtering One more limitation of [1] is that itrelies only onHTML scraping to crawl the job listings whichdoes not always work in modern web applications due toclient-side rendering of ReactJS etc +ey propose classifi-cation using Naıve Bayes on search engines A web crawler isused to crawl individual company websites where the jobsare listed For profile matching they use two methods ofmatching semantic similarity tree knowledge matchingand query similarity +ese are integrated based on therepresentation of attributes by students and companies thenthe similarity is evaluated [2] Kethavarapu et al proposedan automatic ontology with a metric to measure similarity(Jaccard Index) and devise a reranking method+e raw dataafter collection goes through preprocessing +e process ofontology creation and mapping is done by calculatingvarious data points to derive alternative semantics which isneeded to create a mapping+emodule dealing with featureextraction is based on TF-IDF similarity and then theindexing and ranking of information by RF algorithm +erankinglisting is achieved by the semantic similarity metric[3] +e authors of [4] focus on content-based filtering andexamining existing career recommender systems +e dis-advantages are the cold start scalability and low behaviorIts process starts with cleaning and building the database andobtaining data attributes +en the cosine similarity func-tion is used to find the correlation between the previous userand the available list
Mishra and Rathi give immense knowledge of the ap-plication domain accuracy measure and have finally com-pared them all However they use third-party aggregators tofetch the jobs and it is well known that these existingaggregators are not always updated +ey cannot fetch jobsdirectly from the company portals [5] Mhamdi et al havedesigneddevised a job recommendation product that aimsto extract meaningful data from job postings on portals+ey use text accumulating methods Resultantly job offersare divided into job groups or clubs based on commonfeatures among them Jobs are matched to job finders basedon their actions [6] +e authors of [7] designed andimplemented a recommender system for online jobsearching by contrasting user and item-based collaborativefiltering algorithms +ey use Log similarity Tanimotocoefficient City block distance and cosine similarity asmethods of calculating similarity Indira and Rathika in theirpaper draw a comparison between interaction and acces-sibility of modern applications toward present conditionsand the trustworthiness of E-Recruitment +e statisticaltools used are Simple Percentage Chi-square CorrelationRegression and ANOVA (One-way ANOVA) [8] Pradhanet al reveal a comparison between exploring relations amidknown features and things describing items [9] A system tomake the proper recommendations based on candidatesrsquoprofile matching as well as saving candidatesrsquo job preferenceshas been proposed in [10] Here mining is done for the rules
2 Computational Intelligence and Neuroscience
predicting the general activities+en recommendations aremade to the target candidate based on content-basedmatching and candidate preferences [10] Manjare et alproposed a specific model (CBF or content-based filtering)and social interaction to increase the relevance of job rec-ommendations Research exhibits high levels of manage-ment and flexibility [11] In [12] matching and collaborativefiltering were used for providing recommendations +eymake a comparison of profile data and take a scoring inorder to rank candidates in the matching technique Con-sequently the score ranking made recruiter decisions easierand more flexible But since the scoring still had a fewproblems with coinciding candidate scores a collaborativefiltering method was used to overcome it
+e authors of [13] take a different spin on the topic byusing modern ML andor DMBI techniques in a RESTfulWeb application +ey filled the difference between theBackend (MongoDB instance) and Frontend (AndroidApplication) using APIs An item-based collaborative fil-tering method for making job recommendations is pre-sented in [14] +ey optimized the algorithm by combiningresume information and position descriptions For opti-mizing the job preference prediction formula historicaldelivery weight is determined by position descriptionsSimilar user weight is computed from resume information[14 15] A system of web scraping for automatic data col-lection from the web using markup HTML and XHTML(classical markup languages) has been presented in [1] +emodule of web scraping technique used by them was elu-cidated by four processes
3 Proposed System
As we have seen the present-day job seeker is faced with anarray of problems before they can find a suitable job forthemselves All existing work is so promising but lacks insome of the other aspects +e need is to eliminate theseissues posed by past research and minimize the weaknessesof the systems +e proposed system is designed to go forthwith developing a fully functional user interface supporting ajob aggregator and recommendation system Every aspect ofthe operation is made from scratch and in a customized sortof manner
Hence the problem statement devised by us as a buildingstarter for the research is as follows
(i) Developing a hybrid model [16] that aggregatesand recommends relevant jobs to the user based ontheir profile skills or interests
(ii) Emphasizing quality over quantity and deliveringonly the most appropriate results to the user +eresults were achieved by applying intelligent filtersand filtering out great amounts of data using ap-propriate parameters
(iii) Recommending jobs to users of any age andbackground in real time based on the popularity ofjobs among the other user base Additionallyallowing users to study job popularity skill
demand grossing market skills etc are discussedin [17 18]
(iv) Finally designing a fully useable and under-standable UI for the Recommender System forpractical usage
(v) +e proposed system consists of the followingthree major modules which are completed as partof this research as follows
(vi) Data collection and preprocessing [19 20] fol-lowed by the unification of the database
(vii) Recommendation of suitable results using a hybridsystem of content-based [21ndash23] and collaborativefiltering
(viii) Development of a fully functional user interface inthe form of a web application
+e flow diagram shown in Figure 1 is used as theproposed system architecture for the modeling process anddemonstrates a high-level design of the entire aggregationand recommendation system +e modules of the proposedarchitecture have been used in the implementation
31 Data Collection and Preprocessing +e data collectionand preprocessing module was further divided into foursubmodules All these modules depicting the different kindsof data needed to be collected as part of this research arecategorized as follows
311 Company Fetching Module +is module is used tofetch and list the top N companies (we started with the top100 companies) based on the rankings on platforms such asCrunch base [24] To get the list of these companies auto-matically the web crawler [25 26] reads and parses the APIcalls of platforms After parsing this module converts the listinto the form of a large JSON array with each element of thearray being an object representing each company
A superset of all potential companies is created +isranking is not completely polished and further filtering is tobe performed Appropriately selected critical parameters areused to further enhance the quality of the database
312 Company Detail Gathering Module +is module isused to collect important deciding details about a particularcompany that will be used to filter the companies from thelist +ese parameters are important to shortlist only the bestcompanies so that irrelevant options are not displayed to theuser +is was done by crawling and scraping the concernedweb listings [27 28] for these companies
+e parameters that have been used to filter out com-panies are series of funding total funding number of in-vestors number of employees (organization size) unicornstatus [29] and latest technology stack
Upon using these parameters a new list of shortlistedcompanies has been created which has fewer results +is isthe final list of this research and recommendation system[30] to work upon
Computational Intelligence and Neuroscience 3
313 Job Listing Fetching Module +is is a very criticalmodule and its function is to scrape and crawl the respectivesources for the job openings of the shortlisted companiesand aggregate them in the database For the course of thisresearch paper new and customized crawlers have beendesigned from scratch instead of using third-party aggre-gators [31 32] Typically all these common aggregators tendto miss out on the latest job listings and a major objective ofthis system is to remove this anomaly +e job listingfetching has been done using the following three types ofcrawling techniques
314 Job Listing Platform Crawling Using this crawler thecrawling was initiated from a set of URLs [32 33] BFStechnique [34] was used to further crawl the rest of the URLs
315 Standalone Company Website Crawling Nowadaysmany companies do not list their job openings on thecommon job listing portals on the web [35ndash49] It wasdecided to individually crawl the API calls [50 51] of thesecompaniesrsquo personal job portals Different companies haddifferent kinds of embedding of the abovementioned joblisting portals Hence a combination of many kinds ofcrawling techniques was used as follows
(o) Ontology-based crawler is being based on the con-cept of ontology and only crawls pages related to agivenspecific topic
(o) API-based crawler is very useful since most of theweb applications in todayrsquos age do not use simpleHTML It is required to make an API crawler that
can intercept API calls of the career pages and fetchthe required result
(o) HTML crawling a lot of older companies that werepart of the final list of shortlisted companies still usedHTML encoding Hence crawling of those companyportals was done using HTML scraping +is is not asingle crawler but a group of crawlers working inparallel traditionally in the same network +istestifies the research that doing this improves theefficiency of the crawler by optimizing the speed
316 Data Fields Unifying Module Data of various jobpostings listed by various platforms as well as standalonecompaniesrsquo job portals is collected +is was done afterculminating a list of the companies that the paper was goingto move ahead with using various filters as mentioned insubmodule C +is concluded the data collection part of theresearch +e job listings achieved as a result of theabovementioned data collection are however not uniform+ere are irregularities in the data with respect to incoherentkey-value sets used by various companies +ey did not havea common schema [52]
For example a company X might label their job de-scription as ldquoJDrdquo company Y could name the same infor-mation under ldquoDetailsrdquo and company Z could name it asldquoRequirementsrdquo With such incoherence and nonunifor-mity the database cannot be directly used for further tasks Itwas hence unified
A procedure was devised for the one-time unification ofthe database for each company [53] It can then be reused forall job listings from that company in the future For eachcompany however this unification needs to be done at leastonce All fields related to the kind of role were unified andnamed ldquoTitlerdquo all fields of job description and requirementswere filed under ldquoDescriptionrdquo etc A total of nine suchheaders or keys were unified +e schema thus obtainedlooked like this
Schema(
job_id Stringtitle Stringdescription Stringlocation Stringcompany Stringplatform Stringapply_url Stringcreated_at Stringupdated_at String
)
As a result of this the unified database with a commonschema is now ready to be used by the filtering algorithm
32 Recommendation System Now the data aggregationand collection part has been implemented and the data hasbeen unified in the database It is ready to be used to rec-ommend jobs to the user +e proposed system calls for ahybrid system of content-based and collaborative filtering
Crawlingcompanies
Scraping jobs
Designing Jobschema
Filteringcompanies
Adding jobs todatabase
Processing jobdescriptions
Content basedfiltering
Collaborativefiltering
User Interface
Figure 1 Proposed system architecture
4 Computational Intelligence and Neuroscience
+e system contrasts this particular hybrid method with thetwo types of filtering used individually to see how the hybridsystem delivers results +ese results are more practicallyvisualized in the web application when the recommenda-tions are listed for the user
(1) Content-based filtering finally provides the recom-mendation of the list of appropriately matching jobsIt is implemented in two ways
(i) Profile-Description Matching In this function-ality the user can be recommended for jobs onthe basis of the user profile that they have fed tothe portal Using a host of algorithms the userprofile is matched against the unified job listingdatabase previously created
(ii) Keyword-Based Searching In this functionalityjobs will be recommended on the basis of explicitsearching by the user +e user will be able toenter the keywords their skills interests or jobareas they are interested in +e system willrecommend jobs after matching those particularkeywords with the job descriptions of companies
+e jobs are listed in the decreasing order of appro-priateness to the user It is unique for each user based ontheir profile Both of these functionalities are achievedthrough content-based filtering cum CBF It attributes torecommend another similar item that the user likes basedon their past actions or clear feedback User profiles are builtusing existing actions or by explicitly asking users abouttheir preferences For new users the latter is a more propertechnique As the system gets trained over time the modelwill learn to recommend the jobs that the user previouslyshowed interest in +is hypothesizes the fact that if a user isinterested in a particular job category they will be interestedin something similar in the future It is true as the skillset of ajobseeker remains more or less static over time Howeverthere can always be room for new additions to their profilesAs mentioned for new users explicitly taking an input oftheir interests or skills or requirements is the best way tomove forward
321 Content-Based Filtering Algorithm After the recom-mender is trained by an array of documents it can tell the listof documents that are more similar to the input document+e training process involves three main steps as follows
(i) Content preprocessing is used to clean all job de-scriptions and user profiles by removing andeliminating all the common English connectors andconjunctions +ese are known as lsquostop wordsrsquo+ese can be lsquoandrsquo lsquocanrsquo lsquobutrsquo lsquoisrsquo lsquohasrsquo etc Inaddition to this it also removed HTML tags that arepresent in the descriptions due to HTML scraping+is is known as HTML tag stripping
(ii) It computes document vectors using the concepts ofTerm Frequency (TF) and Inverse Document Fre-quency (IDF) It gives the count of occurrences ofthe input term in the entire document domain
(iii) Cosine similarity is one of the important elements ofcontent filtering +is similarity is calculated be-tween all vectors in the document
TF and IDF concepts are used to assess the relative valueof documents articles or works +e count of the word in adocument is measured in TF +e recurrence of all docu-ments is the IDF +e effect of high-frequency repetitions inevaluating the exclusion of an object is rejected by the TF-IDF However the mathematical tool log is used to minimizethe impact of any repetitive words when calculating the TF-IDF
+e significance of the word in a document cannot bedetermined by a simple raw number It leads to the following
wtd 1 + log10tftdtftd gt 0
wtd 0otherwise
tftd⟶ wtd
0⟶ 0 1⟶ 1 2⟶ 13 10⟶ 2 1000⟶ 4
(1)
(o) Cosine Similarity For two N-dimensional vectorsrsquocosine values cosine similarity indicates the degreeof similarity between the vectors +e higher thevalues of cosine similarity the closer the two doc-ument vectors in question in similarity +is value istypically between 0 and 1 since there are no negativevectors Equation 2 is used to calculate the cosine
S(Q D) isin QwDw
isin Q2wD
2w
1113969 (2)
where S is the similarity value Q is the document vector 1and D is the document vector 2
What the model does for new users is that it matchesthe userrsquos profile with the job description listed by thecompany in their respective job postings It parses all jobdescriptions looking for matches suitable for the userrsquosprofile Based on these matchings a match percentage or amatch score is calculated Using this score job listings aredisplayed to the user in descending order of their matchpercentage
+is module has been tested on a fair number of testcases and has shown satisfactory results every time Each testcase was catered to mimic the behavior of a different usereach having a separate set of skills and interests
322 Collaborative Filtering In collaborative filtering theidea is to find similar users and recommend to each one ofthem what users similar to them like In this sort of rec-ommendation system instead of using the features of theitem to make recommendations classification of the usersinto clusters of analogous types is done +e system rec-ommends each user on the basis of the preference of itsrespective cluster
+ere are two types of collaborative filtering methods (i)user-based approach and (ii) item-based approach
Computational Intelligence and Neuroscience 5
In the user-based approach the users are the masters ofthe ring If some users have a similar preference they tend tojoin a group Recommendations are given to the user builton the evaluation of items by other users in the same group+ese users share a common taste +e reason for such afilter being chosen in the paper is that the prediction ismainly based on the average weight of recommendationsfrom many people It is located in a single bank from thesame person +e weight allocated to the individual as-sessment determines the relationship between the user andthe other user Pearsonrsquos correlation coefficient was used tomeasure this correlation
(1) Pearson Correlation Coefficient +is correlation methodwas used to compute how much the similarity of mutualusers for particularly two items deviates from the averageratings +e range of the Pearson coefficient varies betweenthe values zero and one +e larger the magnitude of thiscoefficient the higher the correlation between the twodocuments It is depicted in the following equation
P n(isin ab) minus (isin a)(isin b)
n isin a
2minus isin a
21113872 11138731113960 1113961 n isin b
2minus isin b
21113872 11138731113960 11139611113872 1113873
1113969 (3)
where P is the Pearson coefficient and a and b are twoentities
Talking about the implementation of collaborative fil-tering the system generates recommendations for a userbased on users with a similar taste+ere is no normalizationbased on popularity at the moment hence no room for anybias depending on the user profile
Another important assumption made is that the systemis not taking into account any dislikings or spam jobs Inother words the paper takes into account the jobs onlywhich have been recommended by similar users An arraymatrix is defined which is anMlowastNmatrix withM being thenumber of users and N being the jobs+e engine defines theratings of the users in the database It contains only Booleanvalues 0 (not rated) or 1 (recommended or applied) Afterthe function gets the required input in the above format itruns through the collaborative filter algorithm +e algo-rithm effectively generates job recommendations usingJaccard Similarity
(2) Tanimoto Coefficient (Jaccard Index) +e Jaccard Sim-ilarity Index or Tanimoto coefficient is a degree of similaritybetween two sample sets of data +e index arrays are from 0to 1 +e closer to 1 the more similar are the two data sets
(i) Algorithm ndash Hybrid Recommendation System(ii) Input ndash UserU All jobs J
Output ndash Recommended Jobs with respective hybrid scoreStep 1 ndash StartStep 2 ndash Input_desc(U)Step 3 ndash Content_Based_Filtering (U J)
TF-IDF weight determinationif tf[U Ji]gt 0 w[U Ji] SUM(1 log tf[U Ji])
elsew[U Ji] 0
Content_Score w[U Ji]
Cosine similarityCS(U Ji) isin UJiisin U2J2
Content_ScoreContent_Score +CS [U Ji]endStep 4 ndash Collaborative_Filtering (U J)Matrix [U J]
if INTERACT (Ui Jj) TRUEMatrix [Ui Jj] 1
elseMatrix [Ui Jj] 0
Similarity (Ui Jj)RATIO (INTERSECT (Ui Jj) J)Collaborative_ScoreRATIO (N_INTERACT
INTERSECT (N_Similar))end
Step 5 ndash Total_Hybrid_Score (U Ji)ScoreAVERAGE (Collaborative_Score Content_Score)
endStep 6 ndash SORT_JOBS (Total_Hybrid_Score)Step 7 ndash Stop
ALGORITHM 1 Hybrid recommendation system
6 Computational Intelligence and Neuroscience
Jaccard Similarity (Intersection of the two sets of thenumber of observations common in both sets)(Union of thetwo sets or the number in either of the sets)
Equation (4) is a mathematical representation
J(A B) AcapB
AcupB (4)
Using this concept a methodology for computingsimilar jobs based on collaborative filtering [53 54] is de-vised Somemachine learning algorithms can also be devised[55]+e system first finds similar users (who have applied tothe job) and the jobs to which these common users haveapplied Based on the correlation and similarity between thetwo users jobs will be recommended to the current user+at means a job applied by User 2 would be recommendedhigher than the one applied by User 3 if User 1 is moresimilar to User 2 than User 3
323 Hybrid Recommendation System +e concept of ahybrid recommendation system is based on the fact thatcontent-based and collaborative filtering alone does notprovide the best job recommendations to the user +ere-fore a method to combine the two types of filtering andmake the recommendation engine truly hybrid was devisedTo achieve this the system first finds similar users and jobs asdiscussed above in collaborative filtering After this thecorrelation score for the recommended job is computed Tocalculate this the ratio of the number of common jobsbetween the main and suggested user to the number of allcommon jobs present between all the users is taken +isway a score between 0 and 1 is generated Taking the averageof the score computed just above the content-based filteringscore the system produces a final recommendation score foreach job +is way it is possible to rank all top-
recommended jobs to the user based on a hybrid model ofcontent-based and collaborative filtering
4 Algorithm
Algorithmic steps for weight determination content scorecollaborative filtering and hybrid score calculation areshown in Algorithm 1
5 Results and Analysis
Table 1 shows the comparison between the standard existingjob recommendation models in the market (naukricomindeedcom) and existing research papers +e followingparameters were derived from it
Table 2 summarizes the top seven jobs liked by someparticular users in the systemwere analyzed and the content-based and hybrid scores for them were compared as shownin the table
From Figure 2 it is observed that the average percentageincrease in the match score is 5978 In content-basedfiltering it was tried to recommend the jobs as per the userrsquosprofile and resume by parsing all job descriptions andcomputing a match score
For this two experiments were performed one with theraw job description and the second after processing the jobs+e comparison between the two can be seen in Table 3
Figure 3 clearly shows that the average percentage timereduction after processing the descriptions is 3774
Table 1 Comparing the features of existing systems with the proposed system
SystemsAspects Companies listed
Data collection method JD cleaning Recommendation methodology Real time Jupiter PratilipiReference [2] College campus No Content-based filtering No NA NAReference [25] Single website crawler Yes No No No NoNaukri Direct listing Yes Collaborative No No YesIndeed Direct listing No Collaborative No No NoProposed system Automate crawling Yes Hybrid system Yes Yes Yes
5 10 15 20 250
10987654321
Job_
ID
Rank BeforeRank After
Rank Before vs Rank After
Figure 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Table 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Job_ID Rank before(content)
Rank after(hybrid)
61a29356c062e596f369e488 9 161a293c9c062e596f369e6ad 5 261a293c6c062e596f369e6a1 20 361a2936dc062e596f369e4f4 6 461a29357c062e596f369e491 1 561a293c7c062e596f369e6a4 3 661a2936dc062e596f369e4f7 19 7
Computational Intelligence and Neuroscience 7
Table 4 is an extension of the above experiment and amore important metric was observed ie the match score+e input was the same as the above previous one
Figure 4 shows that job description processing increasesthe chances of the user getting matched to his desired job by10344
6 Conclusion and Future Scope
In this paper Content-Based Filtering and CollaborativeFiltering of recommendations have been compared Addi-tionally an aggregation plus recommender system has beendevised Content-Based Filtering recommends the resultsbased on matching the personal preferences of the user withthe given document whereas collaborative filtering recom-mends based on the preferences of fellow users On eval-uating both of these methods it was concluded that a hybridsystem of both of these overcomes the limitations of both of
Table 3 Comparison of the efficiency of the system with and without preprocessing the job descriptions
User skillsdescription Time taken for the rawjob description (s)
Time taken for the processedjob description (s)
Percentage reductionin time ()
Test case 1mdashfrontend 3338 2087 3748Test case 2mdashbackend 2954 1955 3382Test case 3mdashmachine learning 5107 3669 2816Test case 4mdashDevOps 4628 2952 3621Test case 5mdashproduct management 3848 1807 5304
Table 4 Comparing the ranks of jobs after preprocessing descriptions
User skillsdescription Average match score for raw jobdescription
Average match score for processedjob description
Percentage increase in the matchscore ()
Test case 1mdashfrontend 005629 012358 11954Test casemdash2 backend 004631 009131 9717Test casemdash3 ML 004672 010409 1228Test casemdash4 DevOps 006277 011382 8133Test casemdash5 productmanagement 022237 045107 10285
Time in seconds
Product
DevOps
Machine Learning
Backend
Frontend
Prof
iles
40 600 20
OriginalProcessed
Figure 3 Comparing the efficiency of the system with and without preprocessing the job descriptions
Frontend
Backend
Machine Learning
DevOps
Product
Scor
e
Score (Avg of top 5)
OriginalProcessed
01 02 03 04 0500
Figure 4 Comparing ranks of jobs after preprocessing thedescriptions
8 Computational Intelligence and Neuroscience
them and increases the efficiency of ranking Problems ofcold start sparse database scalability and lack of trendrecommendation [5] have been eliminated +e proposal isto design a Job Recommender system that prioritizes qualityover quantity While there are websites and job listingportals already recommending jobs to job seekers based ontheir profiles this research on aggregate quality recom-mendations has been achieved by crawling selectivelyovercoming the limitations of [1 4 14] A fully functioninguser interface was developed to combine everything togetherto give the user a seamless experience
For this system to be hybrid content-based filtering isrequired which can only recommend jobs based on theuserrsquos current profile It cannot deliver anything surprisingbased on the userrsquos past searches +is paper also usescollaborative filtering which faces well-known problems ofprivacy breaches and cold start +e system has a broadscope that can be used to make it more robust and foolproofFirstly automating the crawling process is required when anew company is added to the database In other wordsremoving the one-time configuration stepprocess to fetchjobs of a particular new company can be done +ese modelscan implement techniques such as KNN in collaborativefiltering Implementing NLP in content-based filtering forbetter and more accurate search matching can be doneAlong with this testing and collecting more user data forbetter performance of the collaborative filtering module isrequired Lastly improving the cleansing process of the jobdescription and using natural language processing are re-quired While using collaborative filtering this work can beimproved by giving different weights to different users basedon their LinkedIn skills
Data Availability
+e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
+e authors declare that they have no conflicts of interest
References
[1] C Slamet R Andrian D S A Maylawati W Darmalaksanaand M A Ramdhani ldquoWeb scraping and Naıve Bayes clas-sification for job search enginerdquo IOP Conference SeriesMaterials Science and Engineering vol 288 no 1 Article ID012038 2018
[2] D V Musale M K Nagpure K S Patil and R F SayyedldquoJob recommendation system using profile matching and webcrawlingrdquo Int J Adv Sci Res Eng Trendsvol 1 2016
[3] U P K Kethavarapu and S Saraswathi ldquoConcept baseddynamic ontology creation for job recommendation systemrdquoProcedia Computer Science vol 85 pp 915ndash921 2016
[4] A S Parihar Y K Gupta Y Singodia V Singh and K SinghldquoA comparative study of image dehazing algorithmsrdquo inProceedings of the 2020 5th International Conference onCommunication and Electronics Systems (ICCES) pp 766ndash771 Coimbatore India 2020 June
[5] R Mishra and S Rathi ldquoEfficient and scalable job recom-mender system using collaborative filteringrdquo in ICDSMLA2019 pp 842ndash856 Springer Singapore 2020
[6] D Mhamdi R Moulouki M Y El Ghoumari M Azzouaziand L Moussaid ldquoJob recommendation based on job profileclustering and job seeker behaviorrdquo Procedia Computer Sci-ence vol 175 pp 695ndash699 2020
[7] V Desai D Bahl S Vibhandik and I Fatma ldquoImple-mentation of an automated job recommendation systembased on candidate profilesrdquo Int Res J Eng Technol vol 4no 5 pp 1018ndash1021 2017
[8] V Indira and S Rathika ldquoA study on E-recruitment and itrsquospresent condition towards job seekersrdquo International Re-search Journal of Engineering and Technology (IRJET) ISSNISSN 2395-0056 vol 7 no 4 pp 3753ndash3758 2020
[9] R Pradhan J Varshney K Goyal and L Kumari ldquoJobrecommendation system using content and collaborative-based filteringrdquo in International Conference on InnovativeComputing and Communications pp 575ndash583 SpringerNature New York NY USA 2022
[10] R G Belsare and V M Deshmukh ldquoEmployment recom-mendation system using matching collaborative filtering andcontent- based recommendationrdquo International Journal ofComputer Applications Technology and Research vol 7 no 6pp 215ndash220 2018
[11] P Manjare J Kumbhar S Ovhal and R Munde ldquoAn ef-fective job recruitment system using content-based filteringrdquoInternational Journal of Engineering amp Technology vol 4no 3 pp 2395ndash0056 2017
[12] C P Akshaya ldquoEnhancement of recommender system usingcollaborative filteringrdquo International Research Journal ofEngineering and Technology vol 5 no 4 pp 2198ndash2200 2018
[13] H Jain and M Kakkar ldquoJob recommendation system basedon machine learning and data mining techniques usingRESTful API and android IDErdquo in Proceedings of the 2019 9thInternational Conference on Cloud Computing Data Science ampEngineering (Confluence) pp 416ndash421 Noida India 2019January
[14] P Yi C Yang C Li and Y Zhang ldquoA job recommendationmethod optimized by position descriptions and resume in-formationrdquo in Proceedings of the 2016 IEEE Advanced In-formation Management Communicates Electronic andAutomation Control Conference (IMCEC) pp 761ndash764 XirsquoanChina 2016 October
[15] H Apaza A A Rubin de Celis Vidal and J E Chire SaireldquoJob recommendation based on curriculum vitae using textminingrdquo in Future of Information and CommunicationConference pp 1051ndash1059 Springer New York NY USA2021
[16] D Nasution and Z Sitorus ldquoEnhance web-based job searchrecommendation system of hybrid-based recommendationrdquoBudapest International Research and Critics Institute (BIRCI-Journal) Humanities and Social Sciences vol 4 no 3pp 7214ndash7221 2021
[17] Q Zhou F Liao L Ge and J Sun ldquoPersonalized preferencecollaborative filtering job recommendation for graduatesrdquo inProceedings of the 2019 IEEE SmartWorld Ubiquitous Intel-ligence amp Computing Advanced amp Trusted ComputingScalable Computing amp Communications Cloud amp Big DataComputing Internet of People and Smart City Innovationpp 1055ndash1062 Leicester UK 2019 August
[18] R Patel and S K Vishwakarma ldquoAn efficient approach for jobrecommendation system based on collaborative filteringrdquo ICT
Computational Intelligence and Neuroscience 9
Systems and Sustainability Proceedings of ICT4SD SpringerNature vol 1 p 169 New York NY USA 2020
[19] Y C Chou and H Y Yu ldquoBased on the application of AItechnology in resume analysis and job recommendationrdquo inProceedings of the 2020 IEEE International Conference onComputational Electromagnetics (ICCEM) pp 291ndash296Singapore 2020 August
[20] D Punitavathi V Shinu S Kumar and V P Sp ldquoOnline joband candidate recommendation systemrdquo International Re-search Journal of Multidisciplinary Technovation vol 1pp 84ndash89 2019
[21] T V Yadalam V M Gowda V S Kumar D Girish andM Namratha ldquoCareer recommendation systems using con-tent based filteringrdquo in Proceedings of the 2020 5th Interna-tional Conference on Communication and Electronics Systems(ICCES) pp 660ndash665 Coimbatore India 2020 June
[22] N Almalis G Tsihrintzis and N Karagiannis ldquoA newcontent-based recommendation algorithm for job recruitingrdquoin Proceedings of the International Conference on InnovativeTechniques and Applications of Artificial Intelligencepp 393ndash398 Springer Corfu Greece 2015 December
[23] J Suharyadi and A Kusnadi ldquoStay at home reservation themitigation step in covid-19 pandemicrdquo International Journalof New Media Technology vol 5 no 2 pp 116ndash120 2018
[24] S R Rimitha V Abburu A Kiranmai andK Chandrasekaran ldquoOntologies to model user profiles inpersonalized job recommendationrdquo in Proceedings of the 2018IEEE Distributed Computing VLSI Electrical Circuits andRobotics (DISCOVER) pp 98ndash103 Mangalore India 2018August
[25] F J M Shamrat Z Tasnim A S Rahman N I Nobel andS A Hossain ldquoAn effective implementation of web crawlingtechnology to retrieve data from the world wide web(WWW)rdquo International Journal of Scientific amp TechnologyResearch vol 9 no 01 pp 1252ndash1256 2020
[26] H Nigam and P Biswas ldquoFrom web scraping to webcrawlingrdquo in Applications of Artificial Intelligence and Ma-chine Learning pp 97ndash112 Springer Singapore 2021
[27] T Karthikeyan K Sekaran D Ranjith and J M BalajeeldquoPersonalized content extraction and text classification usingeffective web scraping techniquesrdquo International Journal ofWeb Portals vol 11 no 2 pp 41ndash52 2019
[28] N Kumar and D Aggarwal ldquoLEARNING-based focusedWEB crawlerrdquo IETE Journal of Research pp 1ndash9 2021
[29] D Rai N Kumar and J Mor ldquoReview on improving per-formance of web crawler and search system ArchitecturerdquoInternational Journal of Advanced Studies of Scientific Re-search vol 3 no 10 2018
[30] T Kamishima S Akaho H Asoh and J Sakuma ldquoRecom-mendation independencerdquo in Proceedings of the Conferenceon Fairness Accountability and Transparency 187-201) NewYork NY USA 2018 January
[31] M Kumar A Bindal R Gautam and R Bhatia ldquoKeywordquery based focused Web crawlerrdquo Procedia Computer Sci-ence vol 125 pp 584ndash590 2018
[32] R Diouf E N Sarr O Sall B Birregah M Bousso andS N Mbaye ldquoWeb scraping state-of-the-art and areas ofapplicationrdquo in Proceedings of the 2019 IEEE InternationalConference on Big Data (Big Data) pp 6040ndash6042 LosAngeles CA USA 2019 December
[33] D Glez-Pentildea A Lourenccedilo H Lopez-Fernandez M Reboiro-Jato and F Fdez-Riverola ldquoWeb scraping technologies in anAPI worldrdquo Briefings in Bioinformatics vol 15 no 5pp 788ndash797 2014
[34] E Uzun ldquoA novel web scraping approach using the additionalinformation obtained from web pagesrdquo IEEE Access vol 8Article ID 61726 2020
[35] M Gupta N Kumar B K Singh and N Gupta ldquoNSGA-III-Based deep-learning model for biomedical search enginerdquoMathematical Problems in Engineering vol 2021 Article ID9935862 8 pages 2021
[36] J Mor N Kumar and D Rai ldquoAn improved crawler based onefficient ranking algorithmrdquo International Journal of Ad-vanced Trends in Computer Science and Engineering vol 8pp 119ndash125 2019
[37] J Mor D Rai and N Kumar ldquoAn XML based web crawlerwith page revisit policy and updation in local repository ofsearch enginerdquo International Journal of Engineering ampTechnology vol 7 no 3 pp 1119ndash1123 2018
[38] J Mor N Kumar and D Rai ldquoResearch on mechanism andchallenges in meta search enginesrdquo International Journal ofInnovative Technology and Exploring Engineering vol 8 no 9pp 281ndash284 2019
[39] N Kumar R Nath and P Kherwa ldquoAn automated frame-work based on TLS to choose best search engine in a particulardomainrdquo International Journal of Computer Applicationvol 83 no 14 pp 42ndash48 2013
[40] J Mor N Kumar and D Rai ldquoEffective presentation ofresults using ranking amp clustering in meta search engineCOMPUSOFTrdquo An International Journal of AdvancedComputer Technology vol 7 no 12 2018
[41] N Kumar and P Dahiya ldquoWeighted similarity page rank animprovement in WPR and WSRrdquo International Journal ofComputer Engineering and Applications vol 11 no VIIIpp 1ndash11 2017
[42] N Kumar and R Nath ldquoA meta search engine approach fororganizing web search results using ranking and clusteringrdquoInternational Journal of Computer 2013
[43] N Kumar D Tyagi and S Awasthi ldquoSurvey on crawlingtechniquesrdquo in Proceedings of the 5th International Conferenceon ldquoComputing for Sustainable Global Developmentpp 2449ndash2455 New Delhi India March 2018
[44] N Kumar ldquoDocument clustering approach for meta searchenginerdquo IOP Conference Series Materials Science and Engi-neering vol 225 Article ID 012291 2017
[45] N Kumar D Tyagi S Awasthi and J Mor ldquoChange de-tection of web page in focused crawling systemrdquo InternationalJournal of Control Heory and Applications vol 10 no 6pp 671ndash676 2017
[46] N Kumar and P Singh ldquoMeta search engine with semanticanalysis and query processingrdquo International Journal ofComputational Intelligence Research ISSN vol 13 no 8pp 0973ndash1873 2017
[47] N Kumar ldquoSegmentation based twitter opinion mining usingensemble learningrdquo International Journal on Future Revolu-tion in Computer Science amp Communication Engineeringvol 3 no 9 2017
[48] R Nath N Kumar and S Tuteja ldquoA survey on reduction ofload on the networkrdquo Intelligent Distributed Computingpp 239ndash249 Springer New York NY USA 2015
[49] N Kumar N N Das D Gupta K Gupta and J BindraldquoEfficient automated disease diagnosis usingmachine learningmodelsrdquo Journal of Healthcare Engineering vol 2021 ArticleID 9983652 13 pages 2021
[50] V Singrodia A Mitra and S Paul ldquoA review on webscrapping and its applicationsrdquo in Proceedings of the 2019International Conference on Computer Communication andInformatics pp 1ndash6 Coimbatore India 2019 January
10 Computational Intelligence and Neuroscience
[51] R Nath and N Kumar ldquoA novel parallel domain focusedcrawler for reduction in load on the networkrdquo InternationalJournal of Computational Engineering Research vol 2 no 7pp 77ndash84 2012
[52] V Shrivastava ldquoA methodical study of web crawlerrdquo Journalof Engineering Research and Application vol 8 no 11 pp 1ndash82018
[53] S Amudha and M Phil ldquoWeb crawler for mining web datardquoInternational Research Journal of Engineering and Technology(IRJET) vol 4 no 2 pp 2395ndash0072 2017
[54] N Nassar A Jafar and Y Rahhal ldquoA novel deep multi-criteria collaborative filtering model for recommendationsystemrdquo Knowledge-Based Systems vol 187 Article ID104811 2020
[55] M Fu H Qu Z Yi L Lu and Y Liu ldquoA novel deep learning-based collaborative filtering model for recommendationsystemrdquo IEEE Transactions on Cybernetics vol 49 no 3pp 1084ndash1096 2018
Computational Intelligence and Neuroscience 11

generated information A recommendation system has theability to predict whether a specific user will prefer an articleor not based on their profile and its past information [4]
Collaborative filtering [5] makes recommendationsbased on historical user behavior +e model can only beshaped based on the behavior of a single user as well as thebehavior of other individuals who have used the systembefore them Recommendations are based on direct col-laboration from multiple users and then filtered to matchthose who express similar preferences or interests Content-Based recommendations are specific to a specific user as themodel does not use any information about other users on thepage
121 Content-Based Filtering Content-based Filtering [6] isa machine learning technique that makes decisions by takinginto account the similarities in the features of the datapresent Two methods used to decide are as follows
(i) Firstly users provide a list of features out of whichthey can choose whatever they find the best
(ii) Secondly the algorithm can keep track of theproducts that the user has shown interest in the past+ey are appended to the usersrsquo already existingdataContent-based filtering recommenders do not needthe profiles of other users or any foreign data as theydo not greatly influence recommendations [7]
(iii) Collaborative Filtering +e collaborative filteringmethod is based on the historical interlinkages thatare documented among the users and items +emethod tries to forecast the usefulness of articles fora specific user on the articles previously evaluated byfellow users +ese memory-based methods workdirectly with the recorded interaction values and arebased on finding the nearest neighbor for examplefinding the closest user of interest and suggestingthe most popular product
2 Related Work
In recent years tremendous research has been done on thetopic of job recommendations For the completion of thispaper several research articles have been referenced whichwere published recently With the help of this literaturesurvey it was seen that the basic steps involved in most ofthese recommendation systems are as follows
(i) Data acquisition(ii) Data preprocessing(iii) Record recommendation
While several research papers and existing papers gavenumerous insights on the problem statement at hand all ofthem had some of the other elements of such a successful jobrecommendation system being in place creating a scrapingtemplate need to define HTML documents of those websitesfrom where data needs to be collected site navigation tra-versal preparing a system for website navigation and
exploration automating navigation and extraction con-ducting automation for the facts and processed data col-lected computing data and packages from the website +edata acquired has to be saved in tables and databases
+e authors of [1] however only focus on job aggre-gation and not filtering One more limitation of [1] is that itrelies only onHTML scraping to crawl the job listings whichdoes not always work in modern web applications due toclient-side rendering of ReactJS etc +ey propose classifi-cation using Naıve Bayes on search engines A web crawler isused to crawl individual company websites where the jobsare listed For profile matching they use two methods ofmatching semantic similarity tree knowledge matchingand query similarity +ese are integrated based on therepresentation of attributes by students and companies thenthe similarity is evaluated [2] Kethavarapu et al proposedan automatic ontology with a metric to measure similarity(Jaccard Index) and devise a reranking method+e raw dataafter collection goes through preprocessing +e process ofontology creation and mapping is done by calculatingvarious data points to derive alternative semantics which isneeded to create a mapping+emodule dealing with featureextraction is based on TF-IDF similarity and then theindexing and ranking of information by RF algorithm +erankinglisting is achieved by the semantic similarity metric[3] +e authors of [4] focus on content-based filtering andexamining existing career recommender systems +e dis-advantages are the cold start scalability and low behaviorIts process starts with cleaning and building the database andobtaining data attributes +en the cosine similarity func-tion is used to find the correlation between the previous userand the available list
Mishra and Rathi give immense knowledge of the ap-plication domain accuracy measure and have finally com-pared them all However they use third-party aggregators tofetch the jobs and it is well known that these existingaggregators are not always updated +ey cannot fetch jobsdirectly from the company portals [5] Mhamdi et al havedesigneddevised a job recommendation product that aimsto extract meaningful data from job postings on portals+ey use text accumulating methods Resultantly job offersare divided into job groups or clubs based on commonfeatures among them Jobs are matched to job finders basedon their actions [6] +e authors of [7] designed andimplemented a recommender system for online jobsearching by contrasting user and item-based collaborativefiltering algorithms +ey use Log similarity Tanimotocoefficient City block distance and cosine similarity asmethods of calculating similarity Indira and Rathika in theirpaper draw a comparison between interaction and acces-sibility of modern applications toward present conditionsand the trustworthiness of E-Recruitment +e statisticaltools used are Simple Percentage Chi-square CorrelationRegression and ANOVA (One-way ANOVA) [8] Pradhanet al reveal a comparison between exploring relations amidknown features and things describing items [9] A system tomake the proper recommendations based on candidatesrsquoprofile matching as well as saving candidatesrsquo job preferenceshas been proposed in [10] Here mining is done for the rules
2 Computational Intelligence and Neuroscience
predicting the general activities+en recommendations aremade to the target candidate based on content-basedmatching and candidate preferences [10] Manjare et alproposed a specific model (CBF or content-based filtering)and social interaction to increase the relevance of job rec-ommendations Research exhibits high levels of manage-ment and flexibility [11] In [12] matching and collaborativefiltering were used for providing recommendations +eymake a comparison of profile data and take a scoring inorder to rank candidates in the matching technique Con-sequently the score ranking made recruiter decisions easierand more flexible But since the scoring still had a fewproblems with coinciding candidate scores a collaborativefiltering method was used to overcome it
+e authors of [13] take a different spin on the topic byusing modern ML andor DMBI techniques in a RESTfulWeb application +ey filled the difference between theBackend (MongoDB instance) and Frontend (AndroidApplication) using APIs An item-based collaborative fil-tering method for making job recommendations is pre-sented in [14] +ey optimized the algorithm by combiningresume information and position descriptions For opti-mizing the job preference prediction formula historicaldelivery weight is determined by position descriptionsSimilar user weight is computed from resume information[14 15] A system of web scraping for automatic data col-lection from the web using markup HTML and XHTML(classical markup languages) has been presented in [1] +emodule of web scraping technique used by them was elu-cidated by four processes
3 Proposed System
As we have seen the present-day job seeker is faced with anarray of problems before they can find a suitable job forthemselves All existing work is so promising but lacks insome of the other aspects +e need is to eliminate theseissues posed by past research and minimize the weaknessesof the systems +e proposed system is designed to go forthwith developing a fully functional user interface supporting ajob aggregator and recommendation system Every aspect ofthe operation is made from scratch and in a customized sortof manner
Hence the problem statement devised by us as a buildingstarter for the research is as follows
(i) Developing a hybrid model [16] that aggregatesand recommends relevant jobs to the user based ontheir profile skills or interests
(ii) Emphasizing quality over quantity and deliveringonly the most appropriate results to the user +eresults were achieved by applying intelligent filtersand filtering out great amounts of data using ap-propriate parameters
(iii) Recommending jobs to users of any age andbackground in real time based on the popularity ofjobs among the other user base Additionallyallowing users to study job popularity skill
demand grossing market skills etc are discussedin [17 18]
(iv) Finally designing a fully useable and under-standable UI for the Recommender System forpractical usage
(v) +e proposed system consists of the followingthree major modules which are completed as partof this research as follows
(vi) Data collection and preprocessing [19 20] fol-lowed by the unification of the database
(vii) Recommendation of suitable results using a hybridsystem of content-based [21ndash23] and collaborativefiltering
(viii) Development of a fully functional user interface inthe form of a web application
+e flow diagram shown in Figure 1 is used as theproposed system architecture for the modeling process anddemonstrates a high-level design of the entire aggregationand recommendation system +e modules of the proposedarchitecture have been used in the implementation
31 Data Collection and Preprocessing +e data collectionand preprocessing module was further divided into foursubmodules All these modules depicting the different kindsof data needed to be collected as part of this research arecategorized as follows
311 Company Fetching Module +is module is used tofetch and list the top N companies (we started with the top100 companies) based on the rankings on platforms such asCrunch base [24] To get the list of these companies auto-matically the web crawler [25 26] reads and parses the APIcalls of platforms After parsing this module converts the listinto the form of a large JSON array with each element of thearray being an object representing each company
A superset of all potential companies is created +isranking is not completely polished and further filtering is tobe performed Appropriately selected critical parameters areused to further enhance the quality of the database
312 Company Detail Gathering Module +is module isused to collect important deciding details about a particularcompany that will be used to filter the companies from thelist +ese parameters are important to shortlist only the bestcompanies so that irrelevant options are not displayed to theuser +is was done by crawling and scraping the concernedweb listings [27 28] for these companies
+e parameters that have been used to filter out com-panies are series of funding total funding number of in-vestors number of employees (organization size) unicornstatus [29] and latest technology stack
Upon using these parameters a new list of shortlistedcompanies has been created which has fewer results +is isthe final list of this research and recommendation system[30] to work upon
Computational Intelligence and Neuroscience 3
313 Job Listing Fetching Module +is is a very criticalmodule and its function is to scrape and crawl the respectivesources for the job openings of the shortlisted companiesand aggregate them in the database For the course of thisresearch paper new and customized crawlers have beendesigned from scratch instead of using third-party aggre-gators [31 32] Typically all these common aggregators tendto miss out on the latest job listings and a major objective ofthis system is to remove this anomaly +e job listingfetching has been done using the following three types ofcrawling techniques
314 Job Listing Platform Crawling Using this crawler thecrawling was initiated from a set of URLs [32 33] BFStechnique [34] was used to further crawl the rest of the URLs
315 Standalone Company Website Crawling Nowadaysmany companies do not list their job openings on thecommon job listing portals on the web [35ndash49] It wasdecided to individually crawl the API calls [50 51] of thesecompaniesrsquo personal job portals Different companies haddifferent kinds of embedding of the abovementioned joblisting portals Hence a combination of many kinds ofcrawling techniques was used as follows
(o) Ontology-based crawler is being based on the con-cept of ontology and only crawls pages related to agivenspecific topic
(o) API-based crawler is very useful since most of theweb applications in todayrsquos age do not use simpleHTML It is required to make an API crawler that
can intercept API calls of the career pages and fetchthe required result
(o) HTML crawling a lot of older companies that werepart of the final list of shortlisted companies still usedHTML encoding Hence crawling of those companyportals was done using HTML scraping +is is not asingle crawler but a group of crawlers working inparallel traditionally in the same network +istestifies the research that doing this improves theefficiency of the crawler by optimizing the speed
316 Data Fields Unifying Module Data of various jobpostings listed by various platforms as well as standalonecompaniesrsquo job portals is collected +is was done afterculminating a list of the companies that the paper was goingto move ahead with using various filters as mentioned insubmodule C +is concluded the data collection part of theresearch +e job listings achieved as a result of theabovementioned data collection are however not uniform+ere are irregularities in the data with respect to incoherentkey-value sets used by various companies +ey did not havea common schema [52]
For example a company X might label their job de-scription as ldquoJDrdquo company Y could name the same infor-mation under ldquoDetailsrdquo and company Z could name it asldquoRequirementsrdquo With such incoherence and nonunifor-mity the database cannot be directly used for further tasks Itwas hence unified
A procedure was devised for the one-time unification ofthe database for each company [53] It can then be reused forall job listings from that company in the future For eachcompany however this unification needs to be done at leastonce All fields related to the kind of role were unified andnamed ldquoTitlerdquo all fields of job description and requirementswere filed under ldquoDescriptionrdquo etc A total of nine suchheaders or keys were unified +e schema thus obtainedlooked like this
Schema(
job_id Stringtitle Stringdescription Stringlocation Stringcompany Stringplatform Stringapply_url Stringcreated_at Stringupdated_at String
)
As a result of this the unified database with a commonschema is now ready to be used by the filtering algorithm
32 Recommendation System Now the data aggregationand collection part has been implemented and the data hasbeen unified in the database It is ready to be used to rec-ommend jobs to the user +e proposed system calls for ahybrid system of content-based and collaborative filtering
Crawlingcompanies
Scraping jobs
Designing Jobschema
Filteringcompanies
Adding jobs todatabase
Processing jobdescriptions
Content basedfiltering
Collaborativefiltering
User Interface
Figure 1 Proposed system architecture
4 Computational Intelligence and Neuroscience
+e system contrasts this particular hybrid method with thetwo types of filtering used individually to see how the hybridsystem delivers results +ese results are more practicallyvisualized in the web application when the recommenda-tions are listed for the user
(1) Content-based filtering finally provides the recom-mendation of the list of appropriately matching jobsIt is implemented in two ways
(i) Profile-Description Matching In this function-ality the user can be recommended for jobs onthe basis of the user profile that they have fed tothe portal Using a host of algorithms the userprofile is matched against the unified job listingdatabase previously created
(ii) Keyword-Based Searching In this functionalityjobs will be recommended on the basis of explicitsearching by the user +e user will be able toenter the keywords their skills interests or jobareas they are interested in +e system willrecommend jobs after matching those particularkeywords with the job descriptions of companies
+e jobs are listed in the decreasing order of appro-priateness to the user It is unique for each user based ontheir profile Both of these functionalities are achievedthrough content-based filtering cum CBF It attributes torecommend another similar item that the user likes basedon their past actions or clear feedback User profiles are builtusing existing actions or by explicitly asking users abouttheir preferences For new users the latter is a more propertechnique As the system gets trained over time the modelwill learn to recommend the jobs that the user previouslyshowed interest in +is hypothesizes the fact that if a user isinterested in a particular job category they will be interestedin something similar in the future It is true as the skillset of ajobseeker remains more or less static over time Howeverthere can always be room for new additions to their profilesAs mentioned for new users explicitly taking an input oftheir interests or skills or requirements is the best way tomove forward
321 Content-Based Filtering Algorithm After the recom-mender is trained by an array of documents it can tell the listof documents that are more similar to the input document+e training process involves three main steps as follows
(i) Content preprocessing is used to clean all job de-scriptions and user profiles by removing andeliminating all the common English connectors andconjunctions +ese are known as lsquostop wordsrsquo+ese can be lsquoandrsquo lsquocanrsquo lsquobutrsquo lsquoisrsquo lsquohasrsquo etc Inaddition to this it also removed HTML tags that arepresent in the descriptions due to HTML scraping+is is known as HTML tag stripping
(ii) It computes document vectors using the concepts ofTerm Frequency (TF) and Inverse Document Fre-quency (IDF) It gives the count of occurrences ofthe input term in the entire document domain
(iii) Cosine similarity is one of the important elements ofcontent filtering +is similarity is calculated be-tween all vectors in the document
TF and IDF concepts are used to assess the relative valueof documents articles or works +e count of the word in adocument is measured in TF +e recurrence of all docu-ments is the IDF +e effect of high-frequency repetitions inevaluating the exclusion of an object is rejected by the TF-IDF However the mathematical tool log is used to minimizethe impact of any repetitive words when calculating the TF-IDF
+e significance of the word in a document cannot bedetermined by a simple raw number It leads to the following
wtd 1 + log10tftdtftd gt 0
wtd 0otherwise
tftd⟶ wtd
0⟶ 0 1⟶ 1 2⟶ 13 10⟶ 2 1000⟶ 4
(1)
(o) Cosine Similarity For two N-dimensional vectorsrsquocosine values cosine similarity indicates the degreeof similarity between the vectors +e higher thevalues of cosine similarity the closer the two doc-ument vectors in question in similarity +is value istypically between 0 and 1 since there are no negativevectors Equation 2 is used to calculate the cosine
S(Q D) isin QwDw
isin Q2wD
2w
1113969 (2)
where S is the similarity value Q is the document vector 1and D is the document vector 2
What the model does for new users is that it matchesthe userrsquos profile with the job description listed by thecompany in their respective job postings It parses all jobdescriptions looking for matches suitable for the userrsquosprofile Based on these matchings a match percentage or amatch score is calculated Using this score job listings aredisplayed to the user in descending order of their matchpercentage
+is module has been tested on a fair number of testcases and has shown satisfactory results every time Each testcase was catered to mimic the behavior of a different usereach having a separate set of skills and interests
322 Collaborative Filtering In collaborative filtering theidea is to find similar users and recommend to each one ofthem what users similar to them like In this sort of rec-ommendation system instead of using the features of theitem to make recommendations classification of the usersinto clusters of analogous types is done +e system rec-ommends each user on the basis of the preference of itsrespective cluster
+ere are two types of collaborative filtering methods (i)user-based approach and (ii) item-based approach
Computational Intelligence and Neuroscience 5
In the user-based approach the users are the masters ofthe ring If some users have a similar preference they tend tojoin a group Recommendations are given to the user builton the evaluation of items by other users in the same group+ese users share a common taste +e reason for such afilter being chosen in the paper is that the prediction ismainly based on the average weight of recommendationsfrom many people It is located in a single bank from thesame person +e weight allocated to the individual as-sessment determines the relationship between the user andthe other user Pearsonrsquos correlation coefficient was used tomeasure this correlation
(1) Pearson Correlation Coefficient +is correlation methodwas used to compute how much the similarity of mutualusers for particularly two items deviates from the averageratings +e range of the Pearson coefficient varies betweenthe values zero and one +e larger the magnitude of thiscoefficient the higher the correlation between the twodocuments It is depicted in the following equation
P n(isin ab) minus (isin a)(isin b)
n isin a
2minus isin a
21113872 11138731113960 1113961 n isin b
2minus isin b
21113872 11138731113960 11139611113872 1113873
1113969 (3)
where P is the Pearson coefficient and a and b are twoentities
Talking about the implementation of collaborative fil-tering the system generates recommendations for a userbased on users with a similar taste+ere is no normalizationbased on popularity at the moment hence no room for anybias depending on the user profile
Another important assumption made is that the systemis not taking into account any dislikings or spam jobs Inother words the paper takes into account the jobs onlywhich have been recommended by similar users An arraymatrix is defined which is anMlowastNmatrix withM being thenumber of users and N being the jobs+e engine defines theratings of the users in the database It contains only Booleanvalues 0 (not rated) or 1 (recommended or applied) Afterthe function gets the required input in the above format itruns through the collaborative filter algorithm +e algo-rithm effectively generates job recommendations usingJaccard Similarity
(2) Tanimoto Coefficient (Jaccard Index) +e Jaccard Sim-ilarity Index or Tanimoto coefficient is a degree of similaritybetween two sample sets of data +e index arrays are from 0to 1 +e closer to 1 the more similar are the two data sets
(i) Algorithm ndash Hybrid Recommendation System(ii) Input ndash UserU All jobs J
Output ndash Recommended Jobs with respective hybrid scoreStep 1 ndash StartStep 2 ndash Input_desc(U)Step 3 ndash Content_Based_Filtering (U J)
TF-IDF weight determinationif tf[U Ji]gt 0 w[U Ji] SUM(1 log tf[U Ji])
elsew[U Ji] 0
Content_Score w[U Ji]
Cosine similarityCS(U Ji) isin UJiisin U2J2
Content_ScoreContent_Score +CS [U Ji]endStep 4 ndash Collaborative_Filtering (U J)Matrix [U J]
if INTERACT (Ui Jj) TRUEMatrix [Ui Jj] 1
elseMatrix [Ui Jj] 0
Similarity (Ui Jj)RATIO (INTERSECT (Ui Jj) J)Collaborative_ScoreRATIO (N_INTERACT
INTERSECT (N_Similar))end
Step 5 ndash Total_Hybrid_Score (U Ji)ScoreAVERAGE (Collaborative_Score Content_Score)
endStep 6 ndash SORT_JOBS (Total_Hybrid_Score)Step 7 ndash Stop
ALGORITHM 1 Hybrid recommendation system
6 Computational Intelligence and Neuroscience
Jaccard Similarity (Intersection of the two sets of thenumber of observations common in both sets)(Union of thetwo sets or the number in either of the sets)
Equation (4) is a mathematical representation
J(A B) AcapB
AcupB (4)
Using this concept a methodology for computingsimilar jobs based on collaborative filtering [53 54] is de-vised Somemachine learning algorithms can also be devised[55]+e system first finds similar users (who have applied tothe job) and the jobs to which these common users haveapplied Based on the correlation and similarity between thetwo users jobs will be recommended to the current user+at means a job applied by User 2 would be recommendedhigher than the one applied by User 3 if User 1 is moresimilar to User 2 than User 3
323 Hybrid Recommendation System +e concept of ahybrid recommendation system is based on the fact thatcontent-based and collaborative filtering alone does notprovide the best job recommendations to the user +ere-fore a method to combine the two types of filtering andmake the recommendation engine truly hybrid was devisedTo achieve this the system first finds similar users and jobs asdiscussed above in collaborative filtering After this thecorrelation score for the recommended job is computed Tocalculate this the ratio of the number of common jobsbetween the main and suggested user to the number of allcommon jobs present between all the users is taken +isway a score between 0 and 1 is generated Taking the averageof the score computed just above the content-based filteringscore the system produces a final recommendation score foreach job +is way it is possible to rank all top-
recommended jobs to the user based on a hybrid model ofcontent-based and collaborative filtering
4 Algorithm
Algorithmic steps for weight determination content scorecollaborative filtering and hybrid score calculation areshown in Algorithm 1
5 Results and Analysis
Table 1 shows the comparison between the standard existingjob recommendation models in the market (naukricomindeedcom) and existing research papers +e followingparameters were derived from it
Table 2 summarizes the top seven jobs liked by someparticular users in the systemwere analyzed and the content-based and hybrid scores for them were compared as shownin the table
From Figure 2 it is observed that the average percentageincrease in the match score is 5978 In content-basedfiltering it was tried to recommend the jobs as per the userrsquosprofile and resume by parsing all job descriptions andcomputing a match score
For this two experiments were performed one with theraw job description and the second after processing the jobs+e comparison between the two can be seen in Table 3
Figure 3 clearly shows that the average percentage timereduction after processing the descriptions is 3774
Table 1 Comparing the features of existing systems with the proposed system
SystemsAspects Companies listed
Data collection method JD cleaning Recommendation methodology Real time Jupiter PratilipiReference [2] College campus No Content-based filtering No NA NAReference [25] Single website crawler Yes No No No NoNaukri Direct listing Yes Collaborative No No YesIndeed Direct listing No Collaborative No No NoProposed system Automate crawling Yes Hybrid system Yes Yes Yes
5 10 15 20 250
10987654321
Job_
ID
Rank BeforeRank After
Rank Before vs Rank After
Figure 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Table 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Job_ID Rank before(content)
Rank after(hybrid)
61a29356c062e596f369e488 9 161a293c9c062e596f369e6ad 5 261a293c6c062e596f369e6a1 20 361a2936dc062e596f369e4f4 6 461a29357c062e596f369e491 1 561a293c7c062e596f369e6a4 3 661a2936dc062e596f369e4f7 19 7
Computational Intelligence and Neuroscience 7
Table 4 is an extension of the above experiment and amore important metric was observed ie the match score+e input was the same as the above previous one
Figure 4 shows that job description processing increasesthe chances of the user getting matched to his desired job by10344
6 Conclusion and Future Scope
In this paper Content-Based Filtering and CollaborativeFiltering of recommendations have been compared Addi-tionally an aggregation plus recommender system has beendevised Content-Based Filtering recommends the resultsbased on matching the personal preferences of the user withthe given document whereas collaborative filtering recom-mends based on the preferences of fellow users On eval-uating both of these methods it was concluded that a hybridsystem of both of these overcomes the limitations of both of
Table 3 Comparison of the efficiency of the system with and without preprocessing the job descriptions
User skillsdescription Time taken for the rawjob description (s)
Time taken for the processedjob description (s)
Percentage reductionin time ()
Test case 1mdashfrontend 3338 2087 3748Test case 2mdashbackend 2954 1955 3382Test case 3mdashmachine learning 5107 3669 2816Test case 4mdashDevOps 4628 2952 3621Test case 5mdashproduct management 3848 1807 5304
Table 4 Comparing the ranks of jobs after preprocessing descriptions
User skillsdescription Average match score for raw jobdescription
Average match score for processedjob description
Percentage increase in the matchscore ()
Test case 1mdashfrontend 005629 012358 11954Test casemdash2 backend 004631 009131 9717Test casemdash3 ML 004672 010409 1228Test casemdash4 DevOps 006277 011382 8133Test casemdash5 productmanagement 022237 045107 10285
Time in seconds
Product
DevOps
Machine Learning
Backend
Frontend
Prof
iles
40 600 20
OriginalProcessed
Figure 3 Comparing the efficiency of the system with and without preprocessing the job descriptions
Frontend
Backend
Machine Learning
DevOps
Product
Scor
e
Score (Avg of top 5)
OriginalProcessed
01 02 03 04 0500
Figure 4 Comparing ranks of jobs after preprocessing thedescriptions
8 Computational Intelligence and Neuroscience
them and increases the efficiency of ranking Problems ofcold start sparse database scalability and lack of trendrecommendation [5] have been eliminated +e proposal isto design a Job Recommender system that prioritizes qualityover quantity While there are websites and job listingportals already recommending jobs to job seekers based ontheir profiles this research on aggregate quality recom-mendations has been achieved by crawling selectivelyovercoming the limitations of [1 4 14] A fully functioninguser interface was developed to combine everything togetherto give the user a seamless experience
For this system to be hybrid content-based filtering isrequired which can only recommend jobs based on theuserrsquos current profile It cannot deliver anything surprisingbased on the userrsquos past searches +is paper also usescollaborative filtering which faces well-known problems ofprivacy breaches and cold start +e system has a broadscope that can be used to make it more robust and foolproofFirstly automating the crawling process is required when anew company is added to the database In other wordsremoving the one-time configuration stepprocess to fetchjobs of a particular new company can be done +ese modelscan implement techniques such as KNN in collaborativefiltering Implementing NLP in content-based filtering forbetter and more accurate search matching can be doneAlong with this testing and collecting more user data forbetter performance of the collaborative filtering module isrequired Lastly improving the cleansing process of the jobdescription and using natural language processing are re-quired While using collaborative filtering this work can beimproved by giving different weights to different users basedon their LinkedIn skills
Data Availability
+e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
+e authors declare that they have no conflicts of interest
References
[1] C Slamet R Andrian D S A Maylawati W Darmalaksanaand M A Ramdhani ldquoWeb scraping and Naıve Bayes clas-sification for job search enginerdquo IOP Conference SeriesMaterials Science and Engineering vol 288 no 1 Article ID012038 2018
[2] D V Musale M K Nagpure K S Patil and R F SayyedldquoJob recommendation system using profile matching and webcrawlingrdquo Int J Adv Sci Res Eng Trendsvol 1 2016
[3] U P K Kethavarapu and S Saraswathi ldquoConcept baseddynamic ontology creation for job recommendation systemrdquoProcedia Computer Science vol 85 pp 915ndash921 2016
[4] A S Parihar Y K Gupta Y Singodia V Singh and K SinghldquoA comparative study of image dehazing algorithmsrdquo inProceedings of the 2020 5th International Conference onCommunication and Electronics Systems (ICCES) pp 766ndash771 Coimbatore India 2020 June
[5] R Mishra and S Rathi ldquoEfficient and scalable job recom-mender system using collaborative filteringrdquo in ICDSMLA2019 pp 842ndash856 Springer Singapore 2020
[6] D Mhamdi R Moulouki M Y El Ghoumari M Azzouaziand L Moussaid ldquoJob recommendation based on job profileclustering and job seeker behaviorrdquo Procedia Computer Sci-ence vol 175 pp 695ndash699 2020
[7] V Desai D Bahl S Vibhandik and I Fatma ldquoImple-mentation of an automated job recommendation systembased on candidate profilesrdquo Int Res J Eng Technol vol 4no 5 pp 1018ndash1021 2017
[8] V Indira and S Rathika ldquoA study on E-recruitment and itrsquospresent condition towards job seekersrdquo International Re-search Journal of Engineering and Technology (IRJET) ISSNISSN 2395-0056 vol 7 no 4 pp 3753ndash3758 2020
[9] R Pradhan J Varshney K Goyal and L Kumari ldquoJobrecommendation system using content and collaborative-based filteringrdquo in International Conference on InnovativeComputing and Communications pp 575ndash583 SpringerNature New York NY USA 2022
[10] R G Belsare and V M Deshmukh ldquoEmployment recom-mendation system using matching collaborative filtering andcontent- based recommendationrdquo International Journal ofComputer Applications Technology and Research vol 7 no 6pp 215ndash220 2018
[11] P Manjare J Kumbhar S Ovhal and R Munde ldquoAn ef-fective job recruitment system using content-based filteringrdquoInternational Journal of Engineering amp Technology vol 4no 3 pp 2395ndash0056 2017
[12] C P Akshaya ldquoEnhancement of recommender system usingcollaborative filteringrdquo International Research Journal ofEngineering and Technology vol 5 no 4 pp 2198ndash2200 2018
[13] H Jain and M Kakkar ldquoJob recommendation system basedon machine learning and data mining techniques usingRESTful API and android IDErdquo in Proceedings of the 2019 9thInternational Conference on Cloud Computing Data Science ampEngineering (Confluence) pp 416ndash421 Noida India 2019January
[14] P Yi C Yang C Li and Y Zhang ldquoA job recommendationmethod optimized by position descriptions and resume in-formationrdquo in Proceedings of the 2016 IEEE Advanced In-formation Management Communicates Electronic andAutomation Control Conference (IMCEC) pp 761ndash764 XirsquoanChina 2016 October
[15] H Apaza A A Rubin de Celis Vidal and J E Chire SaireldquoJob recommendation based on curriculum vitae using textminingrdquo in Future of Information and CommunicationConference pp 1051ndash1059 Springer New York NY USA2021
[16] D Nasution and Z Sitorus ldquoEnhance web-based job searchrecommendation system of hybrid-based recommendationrdquoBudapest International Research and Critics Institute (BIRCI-Journal) Humanities and Social Sciences vol 4 no 3pp 7214ndash7221 2021
[17] Q Zhou F Liao L Ge and J Sun ldquoPersonalized preferencecollaborative filtering job recommendation for graduatesrdquo inProceedings of the 2019 IEEE SmartWorld Ubiquitous Intel-ligence amp Computing Advanced amp Trusted ComputingScalable Computing amp Communications Cloud amp Big DataComputing Internet of People and Smart City Innovationpp 1055ndash1062 Leicester UK 2019 August
[18] R Patel and S K Vishwakarma ldquoAn efficient approach for jobrecommendation system based on collaborative filteringrdquo ICT
Computational Intelligence and Neuroscience 9
Systems and Sustainability Proceedings of ICT4SD SpringerNature vol 1 p 169 New York NY USA 2020
[19] Y C Chou and H Y Yu ldquoBased on the application of AItechnology in resume analysis and job recommendationrdquo inProceedings of the 2020 IEEE International Conference onComputational Electromagnetics (ICCEM) pp 291ndash296Singapore 2020 August
[20] D Punitavathi V Shinu S Kumar and V P Sp ldquoOnline joband candidate recommendation systemrdquo International Re-search Journal of Multidisciplinary Technovation vol 1pp 84ndash89 2019
[21] T V Yadalam V M Gowda V S Kumar D Girish andM Namratha ldquoCareer recommendation systems using con-tent based filteringrdquo in Proceedings of the 2020 5th Interna-tional Conference on Communication and Electronics Systems(ICCES) pp 660ndash665 Coimbatore India 2020 June
[22] N Almalis G Tsihrintzis and N Karagiannis ldquoA newcontent-based recommendation algorithm for job recruitingrdquoin Proceedings of the International Conference on InnovativeTechniques and Applications of Artificial Intelligencepp 393ndash398 Springer Corfu Greece 2015 December
[23] J Suharyadi and A Kusnadi ldquoStay at home reservation themitigation step in covid-19 pandemicrdquo International Journalof New Media Technology vol 5 no 2 pp 116ndash120 2018
[24] S R Rimitha V Abburu A Kiranmai andK Chandrasekaran ldquoOntologies to model user profiles inpersonalized job recommendationrdquo in Proceedings of the 2018IEEE Distributed Computing VLSI Electrical Circuits andRobotics (DISCOVER) pp 98ndash103 Mangalore India 2018August
[25] F J M Shamrat Z Tasnim A S Rahman N I Nobel andS A Hossain ldquoAn effective implementation of web crawlingtechnology to retrieve data from the world wide web(WWW)rdquo International Journal of Scientific amp TechnologyResearch vol 9 no 01 pp 1252ndash1256 2020
[26] H Nigam and P Biswas ldquoFrom web scraping to webcrawlingrdquo in Applications of Artificial Intelligence and Ma-chine Learning pp 97ndash112 Springer Singapore 2021
[27] T Karthikeyan K Sekaran D Ranjith and J M BalajeeldquoPersonalized content extraction and text classification usingeffective web scraping techniquesrdquo International Journal ofWeb Portals vol 11 no 2 pp 41ndash52 2019
[28] N Kumar and D Aggarwal ldquoLEARNING-based focusedWEB crawlerrdquo IETE Journal of Research pp 1ndash9 2021
[29] D Rai N Kumar and J Mor ldquoReview on improving per-formance of web crawler and search system ArchitecturerdquoInternational Journal of Advanced Studies of Scientific Re-search vol 3 no 10 2018
[30] T Kamishima S Akaho H Asoh and J Sakuma ldquoRecom-mendation independencerdquo in Proceedings of the Conferenceon Fairness Accountability and Transparency 187-201) NewYork NY USA 2018 January
[31] M Kumar A Bindal R Gautam and R Bhatia ldquoKeywordquery based focused Web crawlerrdquo Procedia Computer Sci-ence vol 125 pp 584ndash590 2018
[32] R Diouf E N Sarr O Sall B Birregah M Bousso andS N Mbaye ldquoWeb scraping state-of-the-art and areas ofapplicationrdquo in Proceedings of the 2019 IEEE InternationalConference on Big Data (Big Data) pp 6040ndash6042 LosAngeles CA USA 2019 December
[33] D Glez-Pentildea A Lourenccedilo H Lopez-Fernandez M Reboiro-Jato and F Fdez-Riverola ldquoWeb scraping technologies in anAPI worldrdquo Briefings in Bioinformatics vol 15 no 5pp 788ndash797 2014
[34] E Uzun ldquoA novel web scraping approach using the additionalinformation obtained from web pagesrdquo IEEE Access vol 8Article ID 61726 2020
[35] M Gupta N Kumar B K Singh and N Gupta ldquoNSGA-III-Based deep-learning model for biomedical search enginerdquoMathematical Problems in Engineering vol 2021 Article ID9935862 8 pages 2021
[36] J Mor N Kumar and D Rai ldquoAn improved crawler based onefficient ranking algorithmrdquo International Journal of Ad-vanced Trends in Computer Science and Engineering vol 8pp 119ndash125 2019
[37] J Mor D Rai and N Kumar ldquoAn XML based web crawlerwith page revisit policy and updation in local repository ofsearch enginerdquo International Journal of Engineering ampTechnology vol 7 no 3 pp 1119ndash1123 2018
[38] J Mor N Kumar and D Rai ldquoResearch on mechanism andchallenges in meta search enginesrdquo International Journal ofInnovative Technology and Exploring Engineering vol 8 no 9pp 281ndash284 2019
[39] N Kumar R Nath and P Kherwa ldquoAn automated frame-work based on TLS to choose best search engine in a particulardomainrdquo International Journal of Computer Applicationvol 83 no 14 pp 42ndash48 2013
[40] J Mor N Kumar and D Rai ldquoEffective presentation ofresults using ranking amp clustering in meta search engineCOMPUSOFTrdquo An International Journal of AdvancedComputer Technology vol 7 no 12 2018
[41] N Kumar and P Dahiya ldquoWeighted similarity page rank animprovement in WPR and WSRrdquo International Journal ofComputer Engineering and Applications vol 11 no VIIIpp 1ndash11 2017
[42] N Kumar and R Nath ldquoA meta search engine approach fororganizing web search results using ranking and clusteringrdquoInternational Journal of Computer 2013
[43] N Kumar D Tyagi and S Awasthi ldquoSurvey on crawlingtechniquesrdquo in Proceedings of the 5th International Conferenceon ldquoComputing for Sustainable Global Developmentpp 2449ndash2455 New Delhi India March 2018
[44] N Kumar ldquoDocument clustering approach for meta searchenginerdquo IOP Conference Series Materials Science and Engi-neering vol 225 Article ID 012291 2017
[45] N Kumar D Tyagi S Awasthi and J Mor ldquoChange de-tection of web page in focused crawling systemrdquo InternationalJournal of Control Heory and Applications vol 10 no 6pp 671ndash676 2017
[46] N Kumar and P Singh ldquoMeta search engine with semanticanalysis and query processingrdquo International Journal ofComputational Intelligence Research ISSN vol 13 no 8pp 0973ndash1873 2017
[47] N Kumar ldquoSegmentation based twitter opinion mining usingensemble learningrdquo International Journal on Future Revolu-tion in Computer Science amp Communication Engineeringvol 3 no 9 2017
[48] R Nath N Kumar and S Tuteja ldquoA survey on reduction ofload on the networkrdquo Intelligent Distributed Computingpp 239ndash249 Springer New York NY USA 2015
[49] N Kumar N N Das D Gupta K Gupta and J BindraldquoEfficient automated disease diagnosis usingmachine learningmodelsrdquo Journal of Healthcare Engineering vol 2021 ArticleID 9983652 13 pages 2021
[50] V Singrodia A Mitra and S Paul ldquoA review on webscrapping and its applicationsrdquo in Proceedings of the 2019International Conference on Computer Communication andInformatics pp 1ndash6 Coimbatore India 2019 January
10 Computational Intelligence and Neuroscience
[51] R Nath and N Kumar ldquoA novel parallel domain focusedcrawler for reduction in load on the networkrdquo InternationalJournal of Computational Engineering Research vol 2 no 7pp 77ndash84 2012
[52] V Shrivastava ldquoA methodical study of web crawlerrdquo Journalof Engineering Research and Application vol 8 no 11 pp 1ndash82018
[53] S Amudha and M Phil ldquoWeb crawler for mining web datardquoInternational Research Journal of Engineering and Technology(IRJET) vol 4 no 2 pp 2395ndash0072 2017
[54] N Nassar A Jafar and Y Rahhal ldquoA novel deep multi-criteria collaborative filtering model for recommendationsystemrdquo Knowledge-Based Systems vol 187 Article ID104811 2020
[55] M Fu H Qu Z Yi L Lu and Y Liu ldquoA novel deep learning-based collaborative filtering model for recommendationsystemrdquo IEEE Transactions on Cybernetics vol 49 no 3pp 1084ndash1096 2018
Computational Intelligence and Neuroscience 11

predicting the general activities+en recommendations aremade to the target candidate based on content-basedmatching and candidate preferences [10] Manjare et alproposed a specific model (CBF or content-based filtering)and social interaction to increase the relevance of job rec-ommendations Research exhibits high levels of manage-ment and flexibility [11] In [12] matching and collaborativefiltering were used for providing recommendations +eymake a comparison of profile data and take a scoring inorder to rank candidates in the matching technique Con-sequently the score ranking made recruiter decisions easierand more flexible But since the scoring still had a fewproblems with coinciding candidate scores a collaborativefiltering method was used to overcome it
+e authors of [13] take a different spin on the topic byusing modern ML andor DMBI techniques in a RESTfulWeb application +ey filled the difference between theBackend (MongoDB instance) and Frontend (AndroidApplication) using APIs An item-based collaborative fil-tering method for making job recommendations is pre-sented in [14] +ey optimized the algorithm by combiningresume information and position descriptions For opti-mizing the job preference prediction formula historicaldelivery weight is determined by position descriptionsSimilar user weight is computed from resume information[14 15] A system of web scraping for automatic data col-lection from the web using markup HTML and XHTML(classical markup languages) has been presented in [1] +emodule of web scraping technique used by them was elu-cidated by four processes
3 Proposed System
As we have seen the present-day job seeker is faced with anarray of problems before they can find a suitable job forthemselves All existing work is so promising but lacks insome of the other aspects +e need is to eliminate theseissues posed by past research and minimize the weaknessesof the systems +e proposed system is designed to go forthwith developing a fully functional user interface supporting ajob aggregator and recommendation system Every aspect ofthe operation is made from scratch and in a customized sortof manner
Hence the problem statement devised by us as a buildingstarter for the research is as follows
(i) Developing a hybrid model [16] that aggregatesand recommends relevant jobs to the user based ontheir profile skills or interests
(ii) Emphasizing quality over quantity and deliveringonly the most appropriate results to the user +eresults were achieved by applying intelligent filtersand filtering out great amounts of data using ap-propriate parameters
(iii) Recommending jobs to users of any age andbackground in real time based on the popularity ofjobs among the other user base Additionallyallowing users to study job popularity skill
demand grossing market skills etc are discussedin [17 18]
(iv) Finally designing a fully useable and under-standable UI for the Recommender System forpractical usage
(v) +e proposed system consists of the followingthree major modules which are completed as partof this research as follows
(vi) Data collection and preprocessing [19 20] fol-lowed by the unification of the database
(vii) Recommendation of suitable results using a hybridsystem of content-based [21ndash23] and collaborativefiltering
(viii) Development of a fully functional user interface inthe form of a web application
+e flow diagram shown in Figure 1 is used as theproposed system architecture for the modeling process anddemonstrates a high-level design of the entire aggregationand recommendation system +e modules of the proposedarchitecture have been used in the implementation
31 Data Collection and Preprocessing +e data collectionand preprocessing module was further divided into foursubmodules All these modules depicting the different kindsof data needed to be collected as part of this research arecategorized as follows
311 Company Fetching Module +is module is used tofetch and list the top N companies (we started with the top100 companies) based on the rankings on platforms such asCrunch base [24] To get the list of these companies auto-matically the web crawler [25 26] reads and parses the APIcalls of platforms After parsing this module converts the listinto the form of a large JSON array with each element of thearray being an object representing each company
A superset of all potential companies is created +isranking is not completely polished and further filtering is tobe performed Appropriately selected critical parameters areused to further enhance the quality of the database
312 Company Detail Gathering Module +is module isused to collect important deciding details about a particularcompany that will be used to filter the companies from thelist +ese parameters are important to shortlist only the bestcompanies so that irrelevant options are not displayed to theuser +is was done by crawling and scraping the concernedweb listings [27 28] for these companies
+e parameters that have been used to filter out com-panies are series of funding total funding number of in-vestors number of employees (organization size) unicornstatus [29] and latest technology stack
Upon using these parameters a new list of shortlistedcompanies has been created which has fewer results +is isthe final list of this research and recommendation system[30] to work upon
Computational Intelligence and Neuroscience 3
313 Job Listing Fetching Module +is is a very criticalmodule and its function is to scrape and crawl the respectivesources for the job openings of the shortlisted companiesand aggregate them in the database For the course of thisresearch paper new and customized crawlers have beendesigned from scratch instead of using third-party aggre-gators [31 32] Typically all these common aggregators tendto miss out on the latest job listings and a major objective ofthis system is to remove this anomaly +e job listingfetching has been done using the following three types ofcrawling techniques
314 Job Listing Platform Crawling Using this crawler thecrawling was initiated from a set of URLs [32 33] BFStechnique [34] was used to further crawl the rest of the URLs
315 Standalone Company Website Crawling Nowadaysmany companies do not list their job openings on thecommon job listing portals on the web [35ndash49] It wasdecided to individually crawl the API calls [50 51] of thesecompaniesrsquo personal job portals Different companies haddifferent kinds of embedding of the abovementioned joblisting portals Hence a combination of many kinds ofcrawling techniques was used as follows
(o) Ontology-based crawler is being based on the con-cept of ontology and only crawls pages related to agivenspecific topic
(o) API-based crawler is very useful since most of theweb applications in todayrsquos age do not use simpleHTML It is required to make an API crawler that
can intercept API calls of the career pages and fetchthe required result
(o) HTML crawling a lot of older companies that werepart of the final list of shortlisted companies still usedHTML encoding Hence crawling of those companyportals was done using HTML scraping +is is not asingle crawler but a group of crawlers working inparallel traditionally in the same network +istestifies the research that doing this improves theefficiency of the crawler by optimizing the speed
316 Data Fields Unifying Module Data of various jobpostings listed by various platforms as well as standalonecompaniesrsquo job portals is collected +is was done afterculminating a list of the companies that the paper was goingto move ahead with using various filters as mentioned insubmodule C +is concluded the data collection part of theresearch +e job listings achieved as a result of theabovementioned data collection are however not uniform+ere are irregularities in the data with respect to incoherentkey-value sets used by various companies +ey did not havea common schema [52]
For example a company X might label their job de-scription as ldquoJDrdquo company Y could name the same infor-mation under ldquoDetailsrdquo and company Z could name it asldquoRequirementsrdquo With such incoherence and nonunifor-mity the database cannot be directly used for further tasks Itwas hence unified
A procedure was devised for the one-time unification ofthe database for each company [53] It can then be reused forall job listings from that company in the future For eachcompany however this unification needs to be done at leastonce All fields related to the kind of role were unified andnamed ldquoTitlerdquo all fields of job description and requirementswere filed under ldquoDescriptionrdquo etc A total of nine suchheaders or keys were unified +e schema thus obtainedlooked like this
Schema(
job_id Stringtitle Stringdescription Stringlocation Stringcompany Stringplatform Stringapply_url Stringcreated_at Stringupdated_at String
)
As a result of this the unified database with a commonschema is now ready to be used by the filtering algorithm
32 Recommendation System Now the data aggregationand collection part has been implemented and the data hasbeen unified in the database It is ready to be used to rec-ommend jobs to the user +e proposed system calls for ahybrid system of content-based and collaborative filtering
Crawlingcompanies
Scraping jobs
Designing Jobschema
Filteringcompanies
Adding jobs todatabase
Processing jobdescriptions
Content basedfiltering
Collaborativefiltering
User Interface
Figure 1 Proposed system architecture
4 Computational Intelligence and Neuroscience
+e system contrasts this particular hybrid method with thetwo types of filtering used individually to see how the hybridsystem delivers results +ese results are more practicallyvisualized in the web application when the recommenda-tions are listed for the user
(1) Content-based filtering finally provides the recom-mendation of the list of appropriately matching jobsIt is implemented in two ways
(i) Profile-Description Matching In this function-ality the user can be recommended for jobs onthe basis of the user profile that they have fed tothe portal Using a host of algorithms the userprofile is matched against the unified job listingdatabase previously created
(ii) Keyword-Based Searching In this functionalityjobs will be recommended on the basis of explicitsearching by the user +e user will be able toenter the keywords their skills interests or jobareas they are interested in +e system willrecommend jobs after matching those particularkeywords with the job descriptions of companies
+e jobs are listed in the decreasing order of appro-priateness to the user It is unique for each user based ontheir profile Both of these functionalities are achievedthrough content-based filtering cum CBF It attributes torecommend another similar item that the user likes basedon their past actions or clear feedback User profiles are builtusing existing actions or by explicitly asking users abouttheir preferences For new users the latter is a more propertechnique As the system gets trained over time the modelwill learn to recommend the jobs that the user previouslyshowed interest in +is hypothesizes the fact that if a user isinterested in a particular job category they will be interestedin something similar in the future It is true as the skillset of ajobseeker remains more or less static over time Howeverthere can always be room for new additions to their profilesAs mentioned for new users explicitly taking an input oftheir interests or skills or requirements is the best way tomove forward
321 Content-Based Filtering Algorithm After the recom-mender is trained by an array of documents it can tell the listof documents that are more similar to the input document+e training process involves three main steps as follows
(i) Content preprocessing is used to clean all job de-scriptions and user profiles by removing andeliminating all the common English connectors andconjunctions +ese are known as lsquostop wordsrsquo+ese can be lsquoandrsquo lsquocanrsquo lsquobutrsquo lsquoisrsquo lsquohasrsquo etc Inaddition to this it also removed HTML tags that arepresent in the descriptions due to HTML scraping+is is known as HTML tag stripping
(ii) It computes document vectors using the concepts ofTerm Frequency (TF) and Inverse Document Fre-quency (IDF) It gives the count of occurrences ofthe input term in the entire document domain
(iii) Cosine similarity is one of the important elements ofcontent filtering +is similarity is calculated be-tween all vectors in the document
TF and IDF concepts are used to assess the relative valueof documents articles or works +e count of the word in adocument is measured in TF +e recurrence of all docu-ments is the IDF +e effect of high-frequency repetitions inevaluating the exclusion of an object is rejected by the TF-IDF However the mathematical tool log is used to minimizethe impact of any repetitive words when calculating the TF-IDF
+e significance of the word in a document cannot bedetermined by a simple raw number It leads to the following
wtd 1 + log10tftdtftd gt 0
wtd 0otherwise
tftd⟶ wtd
0⟶ 0 1⟶ 1 2⟶ 13 10⟶ 2 1000⟶ 4
(1)
(o) Cosine Similarity For two N-dimensional vectorsrsquocosine values cosine similarity indicates the degreeof similarity between the vectors +e higher thevalues of cosine similarity the closer the two doc-ument vectors in question in similarity +is value istypically between 0 and 1 since there are no negativevectors Equation 2 is used to calculate the cosine
S(Q D) isin QwDw
isin Q2wD
2w
1113969 (2)
where S is the similarity value Q is the document vector 1and D is the document vector 2
What the model does for new users is that it matchesthe userrsquos profile with the job description listed by thecompany in their respective job postings It parses all jobdescriptions looking for matches suitable for the userrsquosprofile Based on these matchings a match percentage or amatch score is calculated Using this score job listings aredisplayed to the user in descending order of their matchpercentage
+is module has been tested on a fair number of testcases and has shown satisfactory results every time Each testcase was catered to mimic the behavior of a different usereach having a separate set of skills and interests
322 Collaborative Filtering In collaborative filtering theidea is to find similar users and recommend to each one ofthem what users similar to them like In this sort of rec-ommendation system instead of using the features of theitem to make recommendations classification of the usersinto clusters of analogous types is done +e system rec-ommends each user on the basis of the preference of itsrespective cluster
+ere are two types of collaborative filtering methods (i)user-based approach and (ii) item-based approach
Computational Intelligence and Neuroscience 5
In the user-based approach the users are the masters ofthe ring If some users have a similar preference they tend tojoin a group Recommendations are given to the user builton the evaluation of items by other users in the same group+ese users share a common taste +e reason for such afilter being chosen in the paper is that the prediction ismainly based on the average weight of recommendationsfrom many people It is located in a single bank from thesame person +e weight allocated to the individual as-sessment determines the relationship between the user andthe other user Pearsonrsquos correlation coefficient was used tomeasure this correlation
(1) Pearson Correlation Coefficient +is correlation methodwas used to compute how much the similarity of mutualusers for particularly two items deviates from the averageratings +e range of the Pearson coefficient varies betweenthe values zero and one +e larger the magnitude of thiscoefficient the higher the correlation between the twodocuments It is depicted in the following equation
P n(isin ab) minus (isin a)(isin b)
n isin a
2minus isin a
21113872 11138731113960 1113961 n isin b
2minus isin b
21113872 11138731113960 11139611113872 1113873
1113969 (3)
where P is the Pearson coefficient and a and b are twoentities
Talking about the implementation of collaborative fil-tering the system generates recommendations for a userbased on users with a similar taste+ere is no normalizationbased on popularity at the moment hence no room for anybias depending on the user profile
Another important assumption made is that the systemis not taking into account any dislikings or spam jobs Inother words the paper takes into account the jobs onlywhich have been recommended by similar users An arraymatrix is defined which is anMlowastNmatrix withM being thenumber of users and N being the jobs+e engine defines theratings of the users in the database It contains only Booleanvalues 0 (not rated) or 1 (recommended or applied) Afterthe function gets the required input in the above format itruns through the collaborative filter algorithm +e algo-rithm effectively generates job recommendations usingJaccard Similarity
(2) Tanimoto Coefficient (Jaccard Index) +e Jaccard Sim-ilarity Index or Tanimoto coefficient is a degree of similaritybetween two sample sets of data +e index arrays are from 0to 1 +e closer to 1 the more similar are the two data sets
(i) Algorithm ndash Hybrid Recommendation System(ii) Input ndash UserU All jobs J
Output ndash Recommended Jobs with respective hybrid scoreStep 1 ndash StartStep 2 ndash Input_desc(U)Step 3 ndash Content_Based_Filtering (U J)
TF-IDF weight determinationif tf[U Ji]gt 0 w[U Ji] SUM(1 log tf[U Ji])
elsew[U Ji] 0
Content_Score w[U Ji]
Cosine similarityCS(U Ji) isin UJiisin U2J2
Content_ScoreContent_Score +CS [U Ji]endStep 4 ndash Collaborative_Filtering (U J)Matrix [U J]
if INTERACT (Ui Jj) TRUEMatrix [Ui Jj] 1
elseMatrix [Ui Jj] 0
Similarity (Ui Jj)RATIO (INTERSECT (Ui Jj) J)Collaborative_ScoreRATIO (N_INTERACT
INTERSECT (N_Similar))end
Step 5 ndash Total_Hybrid_Score (U Ji)ScoreAVERAGE (Collaborative_Score Content_Score)
endStep 6 ndash SORT_JOBS (Total_Hybrid_Score)Step 7 ndash Stop
ALGORITHM 1 Hybrid recommendation system
6 Computational Intelligence and Neuroscience
Jaccard Similarity (Intersection of the two sets of thenumber of observations common in both sets)(Union of thetwo sets or the number in either of the sets)
Equation (4) is a mathematical representation
J(A B) AcapB
AcupB (4)
Using this concept a methodology for computingsimilar jobs based on collaborative filtering [53 54] is de-vised Somemachine learning algorithms can also be devised[55]+e system first finds similar users (who have applied tothe job) and the jobs to which these common users haveapplied Based on the correlation and similarity between thetwo users jobs will be recommended to the current user+at means a job applied by User 2 would be recommendedhigher than the one applied by User 3 if User 1 is moresimilar to User 2 than User 3
323 Hybrid Recommendation System +e concept of ahybrid recommendation system is based on the fact thatcontent-based and collaborative filtering alone does notprovide the best job recommendations to the user +ere-fore a method to combine the two types of filtering andmake the recommendation engine truly hybrid was devisedTo achieve this the system first finds similar users and jobs asdiscussed above in collaborative filtering After this thecorrelation score for the recommended job is computed Tocalculate this the ratio of the number of common jobsbetween the main and suggested user to the number of allcommon jobs present between all the users is taken +isway a score between 0 and 1 is generated Taking the averageof the score computed just above the content-based filteringscore the system produces a final recommendation score foreach job +is way it is possible to rank all top-
recommended jobs to the user based on a hybrid model ofcontent-based and collaborative filtering
4 Algorithm
Algorithmic steps for weight determination content scorecollaborative filtering and hybrid score calculation areshown in Algorithm 1
5 Results and Analysis
Table 1 shows the comparison between the standard existingjob recommendation models in the market (naukricomindeedcom) and existing research papers +e followingparameters were derived from it
Table 2 summarizes the top seven jobs liked by someparticular users in the systemwere analyzed and the content-based and hybrid scores for them were compared as shownin the table
From Figure 2 it is observed that the average percentageincrease in the match score is 5978 In content-basedfiltering it was tried to recommend the jobs as per the userrsquosprofile and resume by parsing all job descriptions andcomputing a match score
For this two experiments were performed one with theraw job description and the second after processing the jobs+e comparison between the two can be seen in Table 3
Figure 3 clearly shows that the average percentage timereduction after processing the descriptions is 3774
Table 1 Comparing the features of existing systems with the proposed system
SystemsAspects Companies listed
Data collection method JD cleaning Recommendation methodology Real time Jupiter PratilipiReference [2] College campus No Content-based filtering No NA NAReference [25] Single website crawler Yes No No No NoNaukri Direct listing Yes Collaborative No No YesIndeed Direct listing No Collaborative No No NoProposed system Automate crawling Yes Hybrid system Yes Yes Yes
5 10 15 20 250
10987654321
Job_
ID
Rank BeforeRank After
Rank Before vs Rank After
Figure 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Table 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Job_ID Rank before(content)
Rank after(hybrid)
61a29356c062e596f369e488 9 161a293c9c062e596f369e6ad 5 261a293c6c062e596f369e6a1 20 361a2936dc062e596f369e4f4 6 461a29357c062e596f369e491 1 561a293c7c062e596f369e6a4 3 661a2936dc062e596f369e4f7 19 7
Computational Intelligence and Neuroscience 7
Table 4 is an extension of the above experiment and amore important metric was observed ie the match score+e input was the same as the above previous one
Figure 4 shows that job description processing increasesthe chances of the user getting matched to his desired job by10344
6 Conclusion and Future Scope
In this paper Content-Based Filtering and CollaborativeFiltering of recommendations have been compared Addi-tionally an aggregation plus recommender system has beendevised Content-Based Filtering recommends the resultsbased on matching the personal preferences of the user withthe given document whereas collaborative filtering recom-mends based on the preferences of fellow users On eval-uating both of these methods it was concluded that a hybridsystem of both of these overcomes the limitations of both of
Table 3 Comparison of the efficiency of the system with and without preprocessing the job descriptions
User skillsdescription Time taken for the rawjob description (s)
Time taken for the processedjob description (s)
Percentage reductionin time ()
Test case 1mdashfrontend 3338 2087 3748Test case 2mdashbackend 2954 1955 3382Test case 3mdashmachine learning 5107 3669 2816Test case 4mdashDevOps 4628 2952 3621Test case 5mdashproduct management 3848 1807 5304
Table 4 Comparing the ranks of jobs after preprocessing descriptions
User skillsdescription Average match score for raw jobdescription
Average match score for processedjob description
Percentage increase in the matchscore ()
Test case 1mdashfrontend 005629 012358 11954Test casemdash2 backend 004631 009131 9717Test casemdash3 ML 004672 010409 1228Test casemdash4 DevOps 006277 011382 8133Test casemdash5 productmanagement 022237 045107 10285
Time in seconds
Product
DevOps
Machine Learning
Backend
Frontend
Prof
iles
40 600 20
OriginalProcessed
Figure 3 Comparing the efficiency of the system with and without preprocessing the job descriptions
Frontend
Backend
Machine Learning
DevOps
Product
Scor
e
Score (Avg of top 5)
OriginalProcessed
01 02 03 04 0500
Figure 4 Comparing ranks of jobs after preprocessing thedescriptions
8 Computational Intelligence and Neuroscience
them and increases the efficiency of ranking Problems ofcold start sparse database scalability and lack of trendrecommendation [5] have been eliminated +e proposal isto design a Job Recommender system that prioritizes qualityover quantity While there are websites and job listingportals already recommending jobs to job seekers based ontheir profiles this research on aggregate quality recom-mendations has been achieved by crawling selectivelyovercoming the limitations of [1 4 14] A fully functioninguser interface was developed to combine everything togetherto give the user a seamless experience
For this system to be hybrid content-based filtering isrequired which can only recommend jobs based on theuserrsquos current profile It cannot deliver anything surprisingbased on the userrsquos past searches +is paper also usescollaborative filtering which faces well-known problems ofprivacy breaches and cold start +e system has a broadscope that can be used to make it more robust and foolproofFirstly automating the crawling process is required when anew company is added to the database In other wordsremoving the one-time configuration stepprocess to fetchjobs of a particular new company can be done +ese modelscan implement techniques such as KNN in collaborativefiltering Implementing NLP in content-based filtering forbetter and more accurate search matching can be doneAlong with this testing and collecting more user data forbetter performance of the collaborative filtering module isrequired Lastly improving the cleansing process of the jobdescription and using natural language processing are re-quired While using collaborative filtering this work can beimproved by giving different weights to different users basedon their LinkedIn skills
Data Availability
+e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
+e authors declare that they have no conflicts of interest
References
[1] C Slamet R Andrian D S A Maylawati W Darmalaksanaand M A Ramdhani ldquoWeb scraping and Naıve Bayes clas-sification for job search enginerdquo IOP Conference SeriesMaterials Science and Engineering vol 288 no 1 Article ID012038 2018
[2] D V Musale M K Nagpure K S Patil and R F SayyedldquoJob recommendation system using profile matching and webcrawlingrdquo Int J Adv Sci Res Eng Trendsvol 1 2016
[3] U P K Kethavarapu and S Saraswathi ldquoConcept baseddynamic ontology creation for job recommendation systemrdquoProcedia Computer Science vol 85 pp 915ndash921 2016
[4] A S Parihar Y K Gupta Y Singodia V Singh and K SinghldquoA comparative study of image dehazing algorithmsrdquo inProceedings of the 2020 5th International Conference onCommunication and Electronics Systems (ICCES) pp 766ndash771 Coimbatore India 2020 June
[5] R Mishra and S Rathi ldquoEfficient and scalable job recom-mender system using collaborative filteringrdquo in ICDSMLA2019 pp 842ndash856 Springer Singapore 2020
[6] D Mhamdi R Moulouki M Y El Ghoumari M Azzouaziand L Moussaid ldquoJob recommendation based on job profileclustering and job seeker behaviorrdquo Procedia Computer Sci-ence vol 175 pp 695ndash699 2020
[7] V Desai D Bahl S Vibhandik and I Fatma ldquoImple-mentation of an automated job recommendation systembased on candidate profilesrdquo Int Res J Eng Technol vol 4no 5 pp 1018ndash1021 2017
[8] V Indira and S Rathika ldquoA study on E-recruitment and itrsquospresent condition towards job seekersrdquo International Re-search Journal of Engineering and Technology (IRJET) ISSNISSN 2395-0056 vol 7 no 4 pp 3753ndash3758 2020
[9] R Pradhan J Varshney K Goyal and L Kumari ldquoJobrecommendation system using content and collaborative-based filteringrdquo in International Conference on InnovativeComputing and Communications pp 575ndash583 SpringerNature New York NY USA 2022
[10] R G Belsare and V M Deshmukh ldquoEmployment recom-mendation system using matching collaborative filtering andcontent- based recommendationrdquo International Journal ofComputer Applications Technology and Research vol 7 no 6pp 215ndash220 2018
[11] P Manjare J Kumbhar S Ovhal and R Munde ldquoAn ef-fective job recruitment system using content-based filteringrdquoInternational Journal of Engineering amp Technology vol 4no 3 pp 2395ndash0056 2017
[12] C P Akshaya ldquoEnhancement of recommender system usingcollaborative filteringrdquo International Research Journal ofEngineering and Technology vol 5 no 4 pp 2198ndash2200 2018
[13] H Jain and M Kakkar ldquoJob recommendation system basedon machine learning and data mining techniques usingRESTful API and android IDErdquo in Proceedings of the 2019 9thInternational Conference on Cloud Computing Data Science ampEngineering (Confluence) pp 416ndash421 Noida India 2019January
[14] P Yi C Yang C Li and Y Zhang ldquoA job recommendationmethod optimized by position descriptions and resume in-formationrdquo in Proceedings of the 2016 IEEE Advanced In-formation Management Communicates Electronic andAutomation Control Conference (IMCEC) pp 761ndash764 XirsquoanChina 2016 October
[15] H Apaza A A Rubin de Celis Vidal and J E Chire SaireldquoJob recommendation based on curriculum vitae using textminingrdquo in Future of Information and CommunicationConference pp 1051ndash1059 Springer New York NY USA2021
[16] D Nasution and Z Sitorus ldquoEnhance web-based job searchrecommendation system of hybrid-based recommendationrdquoBudapest International Research and Critics Institute (BIRCI-Journal) Humanities and Social Sciences vol 4 no 3pp 7214ndash7221 2021
[17] Q Zhou F Liao L Ge and J Sun ldquoPersonalized preferencecollaborative filtering job recommendation for graduatesrdquo inProceedings of the 2019 IEEE SmartWorld Ubiquitous Intel-ligence amp Computing Advanced amp Trusted ComputingScalable Computing amp Communications Cloud amp Big DataComputing Internet of People and Smart City Innovationpp 1055ndash1062 Leicester UK 2019 August
[18] R Patel and S K Vishwakarma ldquoAn efficient approach for jobrecommendation system based on collaborative filteringrdquo ICT
Computational Intelligence and Neuroscience 9
Systems and Sustainability Proceedings of ICT4SD SpringerNature vol 1 p 169 New York NY USA 2020
[19] Y C Chou and H Y Yu ldquoBased on the application of AItechnology in resume analysis and job recommendationrdquo inProceedings of the 2020 IEEE International Conference onComputational Electromagnetics (ICCEM) pp 291ndash296Singapore 2020 August
[20] D Punitavathi V Shinu S Kumar and V P Sp ldquoOnline joband candidate recommendation systemrdquo International Re-search Journal of Multidisciplinary Technovation vol 1pp 84ndash89 2019
[21] T V Yadalam V M Gowda V S Kumar D Girish andM Namratha ldquoCareer recommendation systems using con-tent based filteringrdquo in Proceedings of the 2020 5th Interna-tional Conference on Communication and Electronics Systems(ICCES) pp 660ndash665 Coimbatore India 2020 June
[22] N Almalis G Tsihrintzis and N Karagiannis ldquoA newcontent-based recommendation algorithm for job recruitingrdquoin Proceedings of the International Conference on InnovativeTechniques and Applications of Artificial Intelligencepp 393ndash398 Springer Corfu Greece 2015 December
[23] J Suharyadi and A Kusnadi ldquoStay at home reservation themitigation step in covid-19 pandemicrdquo International Journalof New Media Technology vol 5 no 2 pp 116ndash120 2018
[24] S R Rimitha V Abburu A Kiranmai andK Chandrasekaran ldquoOntologies to model user profiles inpersonalized job recommendationrdquo in Proceedings of the 2018IEEE Distributed Computing VLSI Electrical Circuits andRobotics (DISCOVER) pp 98ndash103 Mangalore India 2018August
[25] F J M Shamrat Z Tasnim A S Rahman N I Nobel andS A Hossain ldquoAn effective implementation of web crawlingtechnology to retrieve data from the world wide web(WWW)rdquo International Journal of Scientific amp TechnologyResearch vol 9 no 01 pp 1252ndash1256 2020
[26] H Nigam and P Biswas ldquoFrom web scraping to webcrawlingrdquo in Applications of Artificial Intelligence and Ma-chine Learning pp 97ndash112 Springer Singapore 2021
[27] T Karthikeyan K Sekaran D Ranjith and J M BalajeeldquoPersonalized content extraction and text classification usingeffective web scraping techniquesrdquo International Journal ofWeb Portals vol 11 no 2 pp 41ndash52 2019
[28] N Kumar and D Aggarwal ldquoLEARNING-based focusedWEB crawlerrdquo IETE Journal of Research pp 1ndash9 2021
[29] D Rai N Kumar and J Mor ldquoReview on improving per-formance of web crawler and search system ArchitecturerdquoInternational Journal of Advanced Studies of Scientific Re-search vol 3 no 10 2018
[30] T Kamishima S Akaho H Asoh and J Sakuma ldquoRecom-mendation independencerdquo in Proceedings of the Conferenceon Fairness Accountability and Transparency 187-201) NewYork NY USA 2018 January
[31] M Kumar A Bindal R Gautam and R Bhatia ldquoKeywordquery based focused Web crawlerrdquo Procedia Computer Sci-ence vol 125 pp 584ndash590 2018
[32] R Diouf E N Sarr O Sall B Birregah M Bousso andS N Mbaye ldquoWeb scraping state-of-the-art and areas ofapplicationrdquo in Proceedings of the 2019 IEEE InternationalConference on Big Data (Big Data) pp 6040ndash6042 LosAngeles CA USA 2019 December
[33] D Glez-Pentildea A Lourenccedilo H Lopez-Fernandez M Reboiro-Jato and F Fdez-Riverola ldquoWeb scraping technologies in anAPI worldrdquo Briefings in Bioinformatics vol 15 no 5pp 788ndash797 2014
[34] E Uzun ldquoA novel web scraping approach using the additionalinformation obtained from web pagesrdquo IEEE Access vol 8Article ID 61726 2020
[35] M Gupta N Kumar B K Singh and N Gupta ldquoNSGA-III-Based deep-learning model for biomedical search enginerdquoMathematical Problems in Engineering vol 2021 Article ID9935862 8 pages 2021
[36] J Mor N Kumar and D Rai ldquoAn improved crawler based onefficient ranking algorithmrdquo International Journal of Ad-vanced Trends in Computer Science and Engineering vol 8pp 119ndash125 2019
[37] J Mor D Rai and N Kumar ldquoAn XML based web crawlerwith page revisit policy and updation in local repository ofsearch enginerdquo International Journal of Engineering ampTechnology vol 7 no 3 pp 1119ndash1123 2018
[38] J Mor N Kumar and D Rai ldquoResearch on mechanism andchallenges in meta search enginesrdquo International Journal ofInnovative Technology and Exploring Engineering vol 8 no 9pp 281ndash284 2019
[39] N Kumar R Nath and P Kherwa ldquoAn automated frame-work based on TLS to choose best search engine in a particulardomainrdquo International Journal of Computer Applicationvol 83 no 14 pp 42ndash48 2013
[40] J Mor N Kumar and D Rai ldquoEffective presentation ofresults using ranking amp clustering in meta search engineCOMPUSOFTrdquo An International Journal of AdvancedComputer Technology vol 7 no 12 2018
[41] N Kumar and P Dahiya ldquoWeighted similarity page rank animprovement in WPR and WSRrdquo International Journal ofComputer Engineering and Applications vol 11 no VIIIpp 1ndash11 2017
[42] N Kumar and R Nath ldquoA meta search engine approach fororganizing web search results using ranking and clusteringrdquoInternational Journal of Computer 2013
[43] N Kumar D Tyagi and S Awasthi ldquoSurvey on crawlingtechniquesrdquo in Proceedings of the 5th International Conferenceon ldquoComputing for Sustainable Global Developmentpp 2449ndash2455 New Delhi India March 2018
[44] N Kumar ldquoDocument clustering approach for meta searchenginerdquo IOP Conference Series Materials Science and Engi-neering vol 225 Article ID 012291 2017
[45] N Kumar D Tyagi S Awasthi and J Mor ldquoChange de-tection of web page in focused crawling systemrdquo InternationalJournal of Control Heory and Applications vol 10 no 6pp 671ndash676 2017
[46] N Kumar and P Singh ldquoMeta search engine with semanticanalysis and query processingrdquo International Journal ofComputational Intelligence Research ISSN vol 13 no 8pp 0973ndash1873 2017
[47] N Kumar ldquoSegmentation based twitter opinion mining usingensemble learningrdquo International Journal on Future Revolu-tion in Computer Science amp Communication Engineeringvol 3 no 9 2017
[48] R Nath N Kumar and S Tuteja ldquoA survey on reduction ofload on the networkrdquo Intelligent Distributed Computingpp 239ndash249 Springer New York NY USA 2015
[49] N Kumar N N Das D Gupta K Gupta and J BindraldquoEfficient automated disease diagnosis usingmachine learningmodelsrdquo Journal of Healthcare Engineering vol 2021 ArticleID 9983652 13 pages 2021
[50] V Singrodia A Mitra and S Paul ldquoA review on webscrapping and its applicationsrdquo in Proceedings of the 2019International Conference on Computer Communication andInformatics pp 1ndash6 Coimbatore India 2019 January
10 Computational Intelligence and Neuroscience
[51] R Nath and N Kumar ldquoA novel parallel domain focusedcrawler for reduction in load on the networkrdquo InternationalJournal of Computational Engineering Research vol 2 no 7pp 77ndash84 2012
[52] V Shrivastava ldquoA methodical study of web crawlerrdquo Journalof Engineering Research and Application vol 8 no 11 pp 1ndash82018
[53] S Amudha and M Phil ldquoWeb crawler for mining web datardquoInternational Research Journal of Engineering and Technology(IRJET) vol 4 no 2 pp 2395ndash0072 2017
[54] N Nassar A Jafar and Y Rahhal ldquoA novel deep multi-criteria collaborative filtering model for recommendationsystemrdquo Knowledge-Based Systems vol 187 Article ID104811 2020
[55] M Fu H Qu Z Yi L Lu and Y Liu ldquoA novel deep learning-based collaborative filtering model for recommendationsystemrdquo IEEE Transactions on Cybernetics vol 49 no 3pp 1084ndash1096 2018
Computational Intelligence and Neuroscience 11

313 Job Listing Fetching Module +is is a very criticalmodule and its function is to scrape and crawl the respectivesources for the job openings of the shortlisted companiesand aggregate them in the database For the course of thisresearch paper new and customized crawlers have beendesigned from scratch instead of using third-party aggre-gators [31 32] Typically all these common aggregators tendto miss out on the latest job listings and a major objective ofthis system is to remove this anomaly +e job listingfetching has been done using the following three types ofcrawling techniques
314 Job Listing Platform Crawling Using this crawler thecrawling was initiated from a set of URLs [32 33] BFStechnique [34] was used to further crawl the rest of the URLs
315 Standalone Company Website Crawling Nowadaysmany companies do not list their job openings on thecommon job listing portals on the web [35ndash49] It wasdecided to individually crawl the API calls [50 51] of thesecompaniesrsquo personal job portals Different companies haddifferent kinds of embedding of the abovementioned joblisting portals Hence a combination of many kinds ofcrawling techniques was used as follows
(o) Ontology-based crawler is being based on the con-cept of ontology and only crawls pages related to agivenspecific topic
(o) API-based crawler is very useful since most of theweb applications in todayrsquos age do not use simpleHTML It is required to make an API crawler that
can intercept API calls of the career pages and fetchthe required result
(o) HTML crawling a lot of older companies that werepart of the final list of shortlisted companies still usedHTML encoding Hence crawling of those companyportals was done using HTML scraping +is is not asingle crawler but a group of crawlers working inparallel traditionally in the same network +istestifies the research that doing this improves theefficiency of the crawler by optimizing the speed
316 Data Fields Unifying Module Data of various jobpostings listed by various platforms as well as standalonecompaniesrsquo job portals is collected +is was done afterculminating a list of the companies that the paper was goingto move ahead with using various filters as mentioned insubmodule C +is concluded the data collection part of theresearch +e job listings achieved as a result of theabovementioned data collection are however not uniform+ere are irregularities in the data with respect to incoherentkey-value sets used by various companies +ey did not havea common schema [52]
For example a company X might label their job de-scription as ldquoJDrdquo company Y could name the same infor-mation under ldquoDetailsrdquo and company Z could name it asldquoRequirementsrdquo With such incoherence and nonunifor-mity the database cannot be directly used for further tasks Itwas hence unified
A procedure was devised for the one-time unification ofthe database for each company [53] It can then be reused forall job listings from that company in the future For eachcompany however this unification needs to be done at leastonce All fields related to the kind of role were unified andnamed ldquoTitlerdquo all fields of job description and requirementswere filed under ldquoDescriptionrdquo etc A total of nine suchheaders or keys were unified +e schema thus obtainedlooked like this
Schema(
job_id Stringtitle Stringdescription Stringlocation Stringcompany Stringplatform Stringapply_url Stringcreated_at Stringupdated_at String
)
As a result of this the unified database with a commonschema is now ready to be used by the filtering algorithm
32 Recommendation System Now the data aggregationand collection part has been implemented and the data hasbeen unified in the database It is ready to be used to rec-ommend jobs to the user +e proposed system calls for ahybrid system of content-based and collaborative filtering
Crawlingcompanies
Scraping jobs
Designing Jobschema
Filteringcompanies
Adding jobs todatabase
Processing jobdescriptions
Content basedfiltering
Collaborativefiltering
User Interface
Figure 1 Proposed system architecture
4 Computational Intelligence and Neuroscience
+e system contrasts this particular hybrid method with thetwo types of filtering used individually to see how the hybridsystem delivers results +ese results are more practicallyvisualized in the web application when the recommenda-tions are listed for the user
(1) Content-based filtering finally provides the recom-mendation of the list of appropriately matching jobsIt is implemented in two ways
(i) Profile-Description Matching In this function-ality the user can be recommended for jobs onthe basis of the user profile that they have fed tothe portal Using a host of algorithms the userprofile is matched against the unified job listingdatabase previously created
(ii) Keyword-Based Searching In this functionalityjobs will be recommended on the basis of explicitsearching by the user +e user will be able toenter the keywords their skills interests or jobareas they are interested in +e system willrecommend jobs after matching those particularkeywords with the job descriptions of companies
+e jobs are listed in the decreasing order of appro-priateness to the user It is unique for each user based ontheir profile Both of these functionalities are achievedthrough content-based filtering cum CBF It attributes torecommend another similar item that the user likes basedon their past actions or clear feedback User profiles are builtusing existing actions or by explicitly asking users abouttheir preferences For new users the latter is a more propertechnique As the system gets trained over time the modelwill learn to recommend the jobs that the user previouslyshowed interest in +is hypothesizes the fact that if a user isinterested in a particular job category they will be interestedin something similar in the future It is true as the skillset of ajobseeker remains more or less static over time Howeverthere can always be room for new additions to their profilesAs mentioned for new users explicitly taking an input oftheir interests or skills or requirements is the best way tomove forward
321 Content-Based Filtering Algorithm After the recom-mender is trained by an array of documents it can tell the listof documents that are more similar to the input document+e training process involves three main steps as follows
(i) Content preprocessing is used to clean all job de-scriptions and user profiles by removing andeliminating all the common English connectors andconjunctions +ese are known as lsquostop wordsrsquo+ese can be lsquoandrsquo lsquocanrsquo lsquobutrsquo lsquoisrsquo lsquohasrsquo etc Inaddition to this it also removed HTML tags that arepresent in the descriptions due to HTML scraping+is is known as HTML tag stripping
(ii) It computes document vectors using the concepts ofTerm Frequency (TF) and Inverse Document Fre-quency (IDF) It gives the count of occurrences ofthe input term in the entire document domain
(iii) Cosine similarity is one of the important elements ofcontent filtering +is similarity is calculated be-tween all vectors in the document
TF and IDF concepts are used to assess the relative valueof documents articles or works +e count of the word in adocument is measured in TF +e recurrence of all docu-ments is the IDF +e effect of high-frequency repetitions inevaluating the exclusion of an object is rejected by the TF-IDF However the mathematical tool log is used to minimizethe impact of any repetitive words when calculating the TF-IDF
+e significance of the word in a document cannot bedetermined by a simple raw number It leads to the following
wtd 1 + log10tftdtftd gt 0
wtd 0otherwise
tftd⟶ wtd
0⟶ 0 1⟶ 1 2⟶ 13 10⟶ 2 1000⟶ 4
(1)
(o) Cosine Similarity For two N-dimensional vectorsrsquocosine values cosine similarity indicates the degreeof similarity between the vectors +e higher thevalues of cosine similarity the closer the two doc-ument vectors in question in similarity +is value istypically between 0 and 1 since there are no negativevectors Equation 2 is used to calculate the cosine
S(Q D) isin QwDw
isin Q2wD
2w
1113969 (2)
where S is the similarity value Q is the document vector 1and D is the document vector 2
What the model does for new users is that it matchesthe userrsquos profile with the job description listed by thecompany in their respective job postings It parses all jobdescriptions looking for matches suitable for the userrsquosprofile Based on these matchings a match percentage or amatch score is calculated Using this score job listings aredisplayed to the user in descending order of their matchpercentage
+is module has been tested on a fair number of testcases and has shown satisfactory results every time Each testcase was catered to mimic the behavior of a different usereach having a separate set of skills and interests
322 Collaborative Filtering In collaborative filtering theidea is to find similar users and recommend to each one ofthem what users similar to them like In this sort of rec-ommendation system instead of using the features of theitem to make recommendations classification of the usersinto clusters of analogous types is done +e system rec-ommends each user on the basis of the preference of itsrespective cluster
+ere are two types of collaborative filtering methods (i)user-based approach and (ii) item-based approach
Computational Intelligence and Neuroscience 5
In the user-based approach the users are the masters ofthe ring If some users have a similar preference they tend tojoin a group Recommendations are given to the user builton the evaluation of items by other users in the same group+ese users share a common taste +e reason for such afilter being chosen in the paper is that the prediction ismainly based on the average weight of recommendationsfrom many people It is located in a single bank from thesame person +e weight allocated to the individual as-sessment determines the relationship between the user andthe other user Pearsonrsquos correlation coefficient was used tomeasure this correlation
(1) Pearson Correlation Coefficient +is correlation methodwas used to compute how much the similarity of mutualusers for particularly two items deviates from the averageratings +e range of the Pearson coefficient varies betweenthe values zero and one +e larger the magnitude of thiscoefficient the higher the correlation between the twodocuments It is depicted in the following equation
P n(isin ab) minus (isin a)(isin b)
n isin a
2minus isin a
21113872 11138731113960 1113961 n isin b
2minus isin b
21113872 11138731113960 11139611113872 1113873
1113969 (3)
where P is the Pearson coefficient and a and b are twoentities
Talking about the implementation of collaborative fil-tering the system generates recommendations for a userbased on users with a similar taste+ere is no normalizationbased on popularity at the moment hence no room for anybias depending on the user profile
Another important assumption made is that the systemis not taking into account any dislikings or spam jobs Inother words the paper takes into account the jobs onlywhich have been recommended by similar users An arraymatrix is defined which is anMlowastNmatrix withM being thenumber of users and N being the jobs+e engine defines theratings of the users in the database It contains only Booleanvalues 0 (not rated) or 1 (recommended or applied) Afterthe function gets the required input in the above format itruns through the collaborative filter algorithm +e algo-rithm effectively generates job recommendations usingJaccard Similarity
(2) Tanimoto Coefficient (Jaccard Index) +e Jaccard Sim-ilarity Index or Tanimoto coefficient is a degree of similaritybetween two sample sets of data +e index arrays are from 0to 1 +e closer to 1 the more similar are the two data sets
(i) Algorithm ndash Hybrid Recommendation System(ii) Input ndash UserU All jobs J
Output ndash Recommended Jobs with respective hybrid scoreStep 1 ndash StartStep 2 ndash Input_desc(U)Step 3 ndash Content_Based_Filtering (U J)
TF-IDF weight determinationif tf[U Ji]gt 0 w[U Ji] SUM(1 log tf[U Ji])
elsew[U Ji] 0
Content_Score w[U Ji]
Cosine similarityCS(U Ji) isin UJiisin U2J2
Content_ScoreContent_Score +CS [U Ji]endStep 4 ndash Collaborative_Filtering (U J)Matrix [U J]
if INTERACT (Ui Jj) TRUEMatrix [Ui Jj] 1
elseMatrix [Ui Jj] 0
Similarity (Ui Jj)RATIO (INTERSECT (Ui Jj) J)Collaborative_ScoreRATIO (N_INTERACT
INTERSECT (N_Similar))end
Step 5 ndash Total_Hybrid_Score (U Ji)ScoreAVERAGE (Collaborative_Score Content_Score)
endStep 6 ndash SORT_JOBS (Total_Hybrid_Score)Step 7 ndash Stop
ALGORITHM 1 Hybrid recommendation system
6 Computational Intelligence and Neuroscience
Jaccard Similarity (Intersection of the two sets of thenumber of observations common in both sets)(Union of thetwo sets or the number in either of the sets)
Equation (4) is a mathematical representation
J(A B) AcapB
AcupB (4)
Using this concept a methodology for computingsimilar jobs based on collaborative filtering [53 54] is de-vised Somemachine learning algorithms can also be devised[55]+e system first finds similar users (who have applied tothe job) and the jobs to which these common users haveapplied Based on the correlation and similarity between thetwo users jobs will be recommended to the current user+at means a job applied by User 2 would be recommendedhigher than the one applied by User 3 if User 1 is moresimilar to User 2 than User 3
323 Hybrid Recommendation System +e concept of ahybrid recommendation system is based on the fact thatcontent-based and collaborative filtering alone does notprovide the best job recommendations to the user +ere-fore a method to combine the two types of filtering andmake the recommendation engine truly hybrid was devisedTo achieve this the system first finds similar users and jobs asdiscussed above in collaborative filtering After this thecorrelation score for the recommended job is computed Tocalculate this the ratio of the number of common jobsbetween the main and suggested user to the number of allcommon jobs present between all the users is taken +isway a score between 0 and 1 is generated Taking the averageof the score computed just above the content-based filteringscore the system produces a final recommendation score foreach job +is way it is possible to rank all top-
recommended jobs to the user based on a hybrid model ofcontent-based and collaborative filtering
4 Algorithm
Algorithmic steps for weight determination content scorecollaborative filtering and hybrid score calculation areshown in Algorithm 1
5 Results and Analysis
Table 1 shows the comparison between the standard existingjob recommendation models in the market (naukricomindeedcom) and existing research papers +e followingparameters were derived from it
Table 2 summarizes the top seven jobs liked by someparticular users in the systemwere analyzed and the content-based and hybrid scores for them were compared as shownin the table
From Figure 2 it is observed that the average percentageincrease in the match score is 5978 In content-basedfiltering it was tried to recommend the jobs as per the userrsquosprofile and resume by parsing all job descriptions andcomputing a match score
For this two experiments were performed one with theraw job description and the second after processing the jobs+e comparison between the two can be seen in Table 3
Figure 3 clearly shows that the average percentage timereduction after processing the descriptions is 3774
Table 1 Comparing the features of existing systems with the proposed system
SystemsAspects Companies listed
Data collection method JD cleaning Recommendation methodology Real time Jupiter PratilipiReference [2] College campus No Content-based filtering No NA NAReference [25] Single website crawler Yes No No No NoNaukri Direct listing Yes Collaborative No No YesIndeed Direct listing No Collaborative No No NoProposed system Automate crawling Yes Hybrid system Yes Yes Yes
5 10 15 20 250
10987654321
Job_
ID
Rank BeforeRank After
Rank Before vs Rank After
Figure 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Table 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Job_ID Rank before(content)
Rank after(hybrid)
61a29356c062e596f369e488 9 161a293c9c062e596f369e6ad 5 261a293c6c062e596f369e6a1 20 361a2936dc062e596f369e4f4 6 461a29357c062e596f369e491 1 561a293c7c062e596f369e6a4 3 661a2936dc062e596f369e4f7 19 7
Computational Intelligence and Neuroscience 7
Table 4 is an extension of the above experiment and amore important metric was observed ie the match score+e input was the same as the above previous one
Figure 4 shows that job description processing increasesthe chances of the user getting matched to his desired job by10344
6 Conclusion and Future Scope
In this paper Content-Based Filtering and CollaborativeFiltering of recommendations have been compared Addi-tionally an aggregation plus recommender system has beendevised Content-Based Filtering recommends the resultsbased on matching the personal preferences of the user withthe given document whereas collaborative filtering recom-mends based on the preferences of fellow users On eval-uating both of these methods it was concluded that a hybridsystem of both of these overcomes the limitations of both of
Table 3 Comparison of the efficiency of the system with and without preprocessing the job descriptions
User skillsdescription Time taken for the rawjob description (s)
Time taken for the processedjob description (s)
Percentage reductionin time ()
Test case 1mdashfrontend 3338 2087 3748Test case 2mdashbackend 2954 1955 3382Test case 3mdashmachine learning 5107 3669 2816Test case 4mdashDevOps 4628 2952 3621Test case 5mdashproduct management 3848 1807 5304
Table 4 Comparing the ranks of jobs after preprocessing descriptions
User skillsdescription Average match score for raw jobdescription
Average match score for processedjob description
Percentage increase in the matchscore ()
Test case 1mdashfrontend 005629 012358 11954Test casemdash2 backend 004631 009131 9717Test casemdash3 ML 004672 010409 1228Test casemdash4 DevOps 006277 011382 8133Test casemdash5 productmanagement 022237 045107 10285
Time in seconds
Product
DevOps
Machine Learning
Backend
Frontend
Prof
iles
40 600 20
OriginalProcessed
Figure 3 Comparing the efficiency of the system with and without preprocessing the job descriptions
Frontend
Backend
Machine Learning
DevOps
Product
Scor
e
Score (Avg of top 5)
OriginalProcessed
01 02 03 04 0500
Figure 4 Comparing ranks of jobs after preprocessing thedescriptions
8 Computational Intelligence and Neuroscience
them and increases the efficiency of ranking Problems ofcold start sparse database scalability and lack of trendrecommendation [5] have been eliminated +e proposal isto design a Job Recommender system that prioritizes qualityover quantity While there are websites and job listingportals already recommending jobs to job seekers based ontheir profiles this research on aggregate quality recom-mendations has been achieved by crawling selectivelyovercoming the limitations of [1 4 14] A fully functioninguser interface was developed to combine everything togetherto give the user a seamless experience
For this system to be hybrid content-based filtering isrequired which can only recommend jobs based on theuserrsquos current profile It cannot deliver anything surprisingbased on the userrsquos past searches +is paper also usescollaborative filtering which faces well-known problems ofprivacy breaches and cold start +e system has a broadscope that can be used to make it more robust and foolproofFirstly automating the crawling process is required when anew company is added to the database In other wordsremoving the one-time configuration stepprocess to fetchjobs of a particular new company can be done +ese modelscan implement techniques such as KNN in collaborativefiltering Implementing NLP in content-based filtering forbetter and more accurate search matching can be doneAlong with this testing and collecting more user data forbetter performance of the collaborative filtering module isrequired Lastly improving the cleansing process of the jobdescription and using natural language processing are re-quired While using collaborative filtering this work can beimproved by giving different weights to different users basedon their LinkedIn skills
Data Availability
+e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
+e authors declare that they have no conflicts of interest
References
[1] C Slamet R Andrian D S A Maylawati W Darmalaksanaand M A Ramdhani ldquoWeb scraping and Naıve Bayes clas-sification for job search enginerdquo IOP Conference SeriesMaterials Science and Engineering vol 288 no 1 Article ID012038 2018
[2] D V Musale M K Nagpure K S Patil and R F SayyedldquoJob recommendation system using profile matching and webcrawlingrdquo Int J Adv Sci Res Eng Trendsvol 1 2016
[3] U P K Kethavarapu and S Saraswathi ldquoConcept baseddynamic ontology creation for job recommendation systemrdquoProcedia Computer Science vol 85 pp 915ndash921 2016
[4] A S Parihar Y K Gupta Y Singodia V Singh and K SinghldquoA comparative study of image dehazing algorithmsrdquo inProceedings of the 2020 5th International Conference onCommunication and Electronics Systems (ICCES) pp 766ndash771 Coimbatore India 2020 June
[5] R Mishra and S Rathi ldquoEfficient and scalable job recom-mender system using collaborative filteringrdquo in ICDSMLA2019 pp 842ndash856 Springer Singapore 2020
[6] D Mhamdi R Moulouki M Y El Ghoumari M Azzouaziand L Moussaid ldquoJob recommendation based on job profileclustering and job seeker behaviorrdquo Procedia Computer Sci-ence vol 175 pp 695ndash699 2020
[7] V Desai D Bahl S Vibhandik and I Fatma ldquoImple-mentation of an automated job recommendation systembased on candidate profilesrdquo Int Res J Eng Technol vol 4no 5 pp 1018ndash1021 2017
[8] V Indira and S Rathika ldquoA study on E-recruitment and itrsquospresent condition towards job seekersrdquo International Re-search Journal of Engineering and Technology (IRJET) ISSNISSN 2395-0056 vol 7 no 4 pp 3753ndash3758 2020
[9] R Pradhan J Varshney K Goyal and L Kumari ldquoJobrecommendation system using content and collaborative-based filteringrdquo in International Conference on InnovativeComputing and Communications pp 575ndash583 SpringerNature New York NY USA 2022
[10] R G Belsare and V M Deshmukh ldquoEmployment recom-mendation system using matching collaborative filtering andcontent- based recommendationrdquo International Journal ofComputer Applications Technology and Research vol 7 no 6pp 215ndash220 2018
[11] P Manjare J Kumbhar S Ovhal and R Munde ldquoAn ef-fective job recruitment system using content-based filteringrdquoInternational Journal of Engineering amp Technology vol 4no 3 pp 2395ndash0056 2017
[12] C P Akshaya ldquoEnhancement of recommender system usingcollaborative filteringrdquo International Research Journal ofEngineering and Technology vol 5 no 4 pp 2198ndash2200 2018
[13] H Jain and M Kakkar ldquoJob recommendation system basedon machine learning and data mining techniques usingRESTful API and android IDErdquo in Proceedings of the 2019 9thInternational Conference on Cloud Computing Data Science ampEngineering (Confluence) pp 416ndash421 Noida India 2019January
[14] P Yi C Yang C Li and Y Zhang ldquoA job recommendationmethod optimized by position descriptions and resume in-formationrdquo in Proceedings of the 2016 IEEE Advanced In-formation Management Communicates Electronic andAutomation Control Conference (IMCEC) pp 761ndash764 XirsquoanChina 2016 October
[15] H Apaza A A Rubin de Celis Vidal and J E Chire SaireldquoJob recommendation based on curriculum vitae using textminingrdquo in Future of Information and CommunicationConference pp 1051ndash1059 Springer New York NY USA2021
[16] D Nasution and Z Sitorus ldquoEnhance web-based job searchrecommendation system of hybrid-based recommendationrdquoBudapest International Research and Critics Institute (BIRCI-Journal) Humanities and Social Sciences vol 4 no 3pp 7214ndash7221 2021
[17] Q Zhou F Liao L Ge and J Sun ldquoPersonalized preferencecollaborative filtering job recommendation for graduatesrdquo inProceedings of the 2019 IEEE SmartWorld Ubiquitous Intel-ligence amp Computing Advanced amp Trusted ComputingScalable Computing amp Communications Cloud amp Big DataComputing Internet of People and Smart City Innovationpp 1055ndash1062 Leicester UK 2019 August
[18] R Patel and S K Vishwakarma ldquoAn efficient approach for jobrecommendation system based on collaborative filteringrdquo ICT
Computational Intelligence and Neuroscience 9
Systems and Sustainability Proceedings of ICT4SD SpringerNature vol 1 p 169 New York NY USA 2020
[19] Y C Chou and H Y Yu ldquoBased on the application of AItechnology in resume analysis and job recommendationrdquo inProceedings of the 2020 IEEE International Conference onComputational Electromagnetics (ICCEM) pp 291ndash296Singapore 2020 August
[20] D Punitavathi V Shinu S Kumar and V P Sp ldquoOnline joband candidate recommendation systemrdquo International Re-search Journal of Multidisciplinary Technovation vol 1pp 84ndash89 2019
[21] T V Yadalam V M Gowda V S Kumar D Girish andM Namratha ldquoCareer recommendation systems using con-tent based filteringrdquo in Proceedings of the 2020 5th Interna-tional Conference on Communication and Electronics Systems(ICCES) pp 660ndash665 Coimbatore India 2020 June
[22] N Almalis G Tsihrintzis and N Karagiannis ldquoA newcontent-based recommendation algorithm for job recruitingrdquoin Proceedings of the International Conference on InnovativeTechniques and Applications of Artificial Intelligencepp 393ndash398 Springer Corfu Greece 2015 December
[23] J Suharyadi and A Kusnadi ldquoStay at home reservation themitigation step in covid-19 pandemicrdquo International Journalof New Media Technology vol 5 no 2 pp 116ndash120 2018
[24] S R Rimitha V Abburu A Kiranmai andK Chandrasekaran ldquoOntologies to model user profiles inpersonalized job recommendationrdquo in Proceedings of the 2018IEEE Distributed Computing VLSI Electrical Circuits andRobotics (DISCOVER) pp 98ndash103 Mangalore India 2018August
[25] F J M Shamrat Z Tasnim A S Rahman N I Nobel andS A Hossain ldquoAn effective implementation of web crawlingtechnology to retrieve data from the world wide web(WWW)rdquo International Journal of Scientific amp TechnologyResearch vol 9 no 01 pp 1252ndash1256 2020
[26] H Nigam and P Biswas ldquoFrom web scraping to webcrawlingrdquo in Applications of Artificial Intelligence and Ma-chine Learning pp 97ndash112 Springer Singapore 2021
[27] T Karthikeyan K Sekaran D Ranjith and J M BalajeeldquoPersonalized content extraction and text classification usingeffective web scraping techniquesrdquo International Journal ofWeb Portals vol 11 no 2 pp 41ndash52 2019
[28] N Kumar and D Aggarwal ldquoLEARNING-based focusedWEB crawlerrdquo IETE Journal of Research pp 1ndash9 2021
[29] D Rai N Kumar and J Mor ldquoReview on improving per-formance of web crawler and search system ArchitecturerdquoInternational Journal of Advanced Studies of Scientific Re-search vol 3 no 10 2018
[30] T Kamishima S Akaho H Asoh and J Sakuma ldquoRecom-mendation independencerdquo in Proceedings of the Conferenceon Fairness Accountability and Transparency 187-201) NewYork NY USA 2018 January
[31] M Kumar A Bindal R Gautam and R Bhatia ldquoKeywordquery based focused Web crawlerrdquo Procedia Computer Sci-ence vol 125 pp 584ndash590 2018
[32] R Diouf E N Sarr O Sall B Birregah M Bousso andS N Mbaye ldquoWeb scraping state-of-the-art and areas ofapplicationrdquo in Proceedings of the 2019 IEEE InternationalConference on Big Data (Big Data) pp 6040ndash6042 LosAngeles CA USA 2019 December
[33] D Glez-Pentildea A Lourenccedilo H Lopez-Fernandez M Reboiro-Jato and F Fdez-Riverola ldquoWeb scraping technologies in anAPI worldrdquo Briefings in Bioinformatics vol 15 no 5pp 788ndash797 2014
[34] E Uzun ldquoA novel web scraping approach using the additionalinformation obtained from web pagesrdquo IEEE Access vol 8Article ID 61726 2020
[35] M Gupta N Kumar B K Singh and N Gupta ldquoNSGA-III-Based deep-learning model for biomedical search enginerdquoMathematical Problems in Engineering vol 2021 Article ID9935862 8 pages 2021
[36] J Mor N Kumar and D Rai ldquoAn improved crawler based onefficient ranking algorithmrdquo International Journal of Ad-vanced Trends in Computer Science and Engineering vol 8pp 119ndash125 2019
[37] J Mor D Rai and N Kumar ldquoAn XML based web crawlerwith page revisit policy and updation in local repository ofsearch enginerdquo International Journal of Engineering ampTechnology vol 7 no 3 pp 1119ndash1123 2018
[38] J Mor N Kumar and D Rai ldquoResearch on mechanism andchallenges in meta search enginesrdquo International Journal ofInnovative Technology and Exploring Engineering vol 8 no 9pp 281ndash284 2019
[39] N Kumar R Nath and P Kherwa ldquoAn automated frame-work based on TLS to choose best search engine in a particulardomainrdquo International Journal of Computer Applicationvol 83 no 14 pp 42ndash48 2013
[40] J Mor N Kumar and D Rai ldquoEffective presentation ofresults using ranking amp clustering in meta search engineCOMPUSOFTrdquo An International Journal of AdvancedComputer Technology vol 7 no 12 2018
[41] N Kumar and P Dahiya ldquoWeighted similarity page rank animprovement in WPR and WSRrdquo International Journal ofComputer Engineering and Applications vol 11 no VIIIpp 1ndash11 2017
[42] N Kumar and R Nath ldquoA meta search engine approach fororganizing web search results using ranking and clusteringrdquoInternational Journal of Computer 2013
[43] N Kumar D Tyagi and S Awasthi ldquoSurvey on crawlingtechniquesrdquo in Proceedings of the 5th International Conferenceon ldquoComputing for Sustainable Global Developmentpp 2449ndash2455 New Delhi India March 2018
[44] N Kumar ldquoDocument clustering approach for meta searchenginerdquo IOP Conference Series Materials Science and Engi-neering vol 225 Article ID 012291 2017
[45] N Kumar D Tyagi S Awasthi and J Mor ldquoChange de-tection of web page in focused crawling systemrdquo InternationalJournal of Control Heory and Applications vol 10 no 6pp 671ndash676 2017
[46] N Kumar and P Singh ldquoMeta search engine with semanticanalysis and query processingrdquo International Journal ofComputational Intelligence Research ISSN vol 13 no 8pp 0973ndash1873 2017
[47] N Kumar ldquoSegmentation based twitter opinion mining usingensemble learningrdquo International Journal on Future Revolu-tion in Computer Science amp Communication Engineeringvol 3 no 9 2017
[48] R Nath N Kumar and S Tuteja ldquoA survey on reduction ofload on the networkrdquo Intelligent Distributed Computingpp 239ndash249 Springer New York NY USA 2015
[49] N Kumar N N Das D Gupta K Gupta and J BindraldquoEfficient automated disease diagnosis usingmachine learningmodelsrdquo Journal of Healthcare Engineering vol 2021 ArticleID 9983652 13 pages 2021
[50] V Singrodia A Mitra and S Paul ldquoA review on webscrapping and its applicationsrdquo in Proceedings of the 2019International Conference on Computer Communication andInformatics pp 1ndash6 Coimbatore India 2019 January
10 Computational Intelligence and Neuroscience
[51] R Nath and N Kumar ldquoA novel parallel domain focusedcrawler for reduction in load on the networkrdquo InternationalJournal of Computational Engineering Research vol 2 no 7pp 77ndash84 2012
[52] V Shrivastava ldquoA methodical study of web crawlerrdquo Journalof Engineering Research and Application vol 8 no 11 pp 1ndash82018
[53] S Amudha and M Phil ldquoWeb crawler for mining web datardquoInternational Research Journal of Engineering and Technology(IRJET) vol 4 no 2 pp 2395ndash0072 2017
[54] N Nassar A Jafar and Y Rahhal ldquoA novel deep multi-criteria collaborative filtering model for recommendationsystemrdquo Knowledge-Based Systems vol 187 Article ID104811 2020
[55] M Fu H Qu Z Yi L Lu and Y Liu ldquoA novel deep learning-based collaborative filtering model for recommendationsystemrdquo IEEE Transactions on Cybernetics vol 49 no 3pp 1084ndash1096 2018
Computational Intelligence and Neuroscience 11

+e system contrasts this particular hybrid method with thetwo types of filtering used individually to see how the hybridsystem delivers results +ese results are more practicallyvisualized in the web application when the recommenda-tions are listed for the user
(1) Content-based filtering finally provides the recom-mendation of the list of appropriately matching jobsIt is implemented in two ways
(i) Profile-Description Matching In this function-ality the user can be recommended for jobs onthe basis of the user profile that they have fed tothe portal Using a host of algorithms the userprofile is matched against the unified job listingdatabase previously created
(ii) Keyword-Based Searching In this functionalityjobs will be recommended on the basis of explicitsearching by the user +e user will be able toenter the keywords their skills interests or jobareas they are interested in +e system willrecommend jobs after matching those particularkeywords with the job descriptions of companies
+e jobs are listed in the decreasing order of appro-priateness to the user It is unique for each user based ontheir profile Both of these functionalities are achievedthrough content-based filtering cum CBF It attributes torecommend another similar item that the user likes basedon their past actions or clear feedback User profiles are builtusing existing actions or by explicitly asking users abouttheir preferences For new users the latter is a more propertechnique As the system gets trained over time the modelwill learn to recommend the jobs that the user previouslyshowed interest in +is hypothesizes the fact that if a user isinterested in a particular job category they will be interestedin something similar in the future It is true as the skillset of ajobseeker remains more or less static over time Howeverthere can always be room for new additions to their profilesAs mentioned for new users explicitly taking an input oftheir interests or skills or requirements is the best way tomove forward
321 Content-Based Filtering Algorithm After the recom-mender is trained by an array of documents it can tell the listof documents that are more similar to the input document+e training process involves three main steps as follows
(i) Content preprocessing is used to clean all job de-scriptions and user profiles by removing andeliminating all the common English connectors andconjunctions +ese are known as lsquostop wordsrsquo+ese can be lsquoandrsquo lsquocanrsquo lsquobutrsquo lsquoisrsquo lsquohasrsquo etc Inaddition to this it also removed HTML tags that arepresent in the descriptions due to HTML scraping+is is known as HTML tag stripping
(ii) It computes document vectors using the concepts ofTerm Frequency (TF) and Inverse Document Fre-quency (IDF) It gives the count of occurrences ofthe input term in the entire document domain
(iii) Cosine similarity is one of the important elements ofcontent filtering +is similarity is calculated be-tween all vectors in the document
TF and IDF concepts are used to assess the relative valueof documents articles or works +e count of the word in adocument is measured in TF +e recurrence of all docu-ments is the IDF +e effect of high-frequency repetitions inevaluating the exclusion of an object is rejected by the TF-IDF However the mathematical tool log is used to minimizethe impact of any repetitive words when calculating the TF-IDF
+e significance of the word in a document cannot bedetermined by a simple raw number It leads to the following
wtd 1 + log10tftdtftd gt 0
wtd 0otherwise
tftd⟶ wtd
0⟶ 0 1⟶ 1 2⟶ 13 10⟶ 2 1000⟶ 4
(1)
(o) Cosine Similarity For two N-dimensional vectorsrsquocosine values cosine similarity indicates the degreeof similarity between the vectors +e higher thevalues of cosine similarity the closer the two doc-ument vectors in question in similarity +is value istypically between 0 and 1 since there are no negativevectors Equation 2 is used to calculate the cosine
S(Q D) isin QwDw
isin Q2wD
2w
1113969 (2)
where S is the similarity value Q is the document vector 1and D is the document vector 2
What the model does for new users is that it matchesthe userrsquos profile with the job description listed by thecompany in their respective job postings It parses all jobdescriptions looking for matches suitable for the userrsquosprofile Based on these matchings a match percentage or amatch score is calculated Using this score job listings aredisplayed to the user in descending order of their matchpercentage
+is module has been tested on a fair number of testcases and has shown satisfactory results every time Each testcase was catered to mimic the behavior of a different usereach having a separate set of skills and interests
322 Collaborative Filtering In collaborative filtering theidea is to find similar users and recommend to each one ofthem what users similar to them like In this sort of rec-ommendation system instead of using the features of theitem to make recommendations classification of the usersinto clusters of analogous types is done +e system rec-ommends each user on the basis of the preference of itsrespective cluster
+ere are two types of collaborative filtering methods (i)user-based approach and (ii) item-based approach
Computational Intelligence and Neuroscience 5
In the user-based approach the users are the masters ofthe ring If some users have a similar preference they tend tojoin a group Recommendations are given to the user builton the evaluation of items by other users in the same group+ese users share a common taste +e reason for such afilter being chosen in the paper is that the prediction ismainly based on the average weight of recommendationsfrom many people It is located in a single bank from thesame person +e weight allocated to the individual as-sessment determines the relationship between the user andthe other user Pearsonrsquos correlation coefficient was used tomeasure this correlation
(1) Pearson Correlation Coefficient +is correlation methodwas used to compute how much the similarity of mutualusers for particularly two items deviates from the averageratings +e range of the Pearson coefficient varies betweenthe values zero and one +e larger the magnitude of thiscoefficient the higher the correlation between the twodocuments It is depicted in the following equation
P n(isin ab) minus (isin a)(isin b)
n isin a
2minus isin a
21113872 11138731113960 1113961 n isin b
2minus isin b
21113872 11138731113960 11139611113872 1113873
1113969 (3)
where P is the Pearson coefficient and a and b are twoentities
Talking about the implementation of collaborative fil-tering the system generates recommendations for a userbased on users with a similar taste+ere is no normalizationbased on popularity at the moment hence no room for anybias depending on the user profile
Another important assumption made is that the systemis not taking into account any dislikings or spam jobs Inother words the paper takes into account the jobs onlywhich have been recommended by similar users An arraymatrix is defined which is anMlowastNmatrix withM being thenumber of users and N being the jobs+e engine defines theratings of the users in the database It contains only Booleanvalues 0 (not rated) or 1 (recommended or applied) Afterthe function gets the required input in the above format itruns through the collaborative filter algorithm +e algo-rithm effectively generates job recommendations usingJaccard Similarity
(2) Tanimoto Coefficient (Jaccard Index) +e Jaccard Sim-ilarity Index or Tanimoto coefficient is a degree of similaritybetween two sample sets of data +e index arrays are from 0to 1 +e closer to 1 the more similar are the two data sets
(i) Algorithm ndash Hybrid Recommendation System(ii) Input ndash UserU All jobs J
Output ndash Recommended Jobs with respective hybrid scoreStep 1 ndash StartStep 2 ndash Input_desc(U)Step 3 ndash Content_Based_Filtering (U J)
TF-IDF weight determinationif tf[U Ji]gt 0 w[U Ji] SUM(1 log tf[U Ji])
elsew[U Ji] 0
Content_Score w[U Ji]
Cosine similarityCS(U Ji) isin UJiisin U2J2
Content_ScoreContent_Score +CS [U Ji]endStep 4 ndash Collaborative_Filtering (U J)Matrix [U J]
if INTERACT (Ui Jj) TRUEMatrix [Ui Jj] 1
elseMatrix [Ui Jj] 0
Similarity (Ui Jj)RATIO (INTERSECT (Ui Jj) J)Collaborative_ScoreRATIO (N_INTERACT
INTERSECT (N_Similar))end
Step 5 ndash Total_Hybrid_Score (U Ji)ScoreAVERAGE (Collaborative_Score Content_Score)
endStep 6 ndash SORT_JOBS (Total_Hybrid_Score)Step 7 ndash Stop
ALGORITHM 1 Hybrid recommendation system
6 Computational Intelligence and Neuroscience
Jaccard Similarity (Intersection of the two sets of thenumber of observations common in both sets)(Union of thetwo sets or the number in either of the sets)
Equation (4) is a mathematical representation
J(A B) AcapB
AcupB (4)
Using this concept a methodology for computingsimilar jobs based on collaborative filtering [53 54] is de-vised Somemachine learning algorithms can also be devised[55]+e system first finds similar users (who have applied tothe job) and the jobs to which these common users haveapplied Based on the correlation and similarity between thetwo users jobs will be recommended to the current user+at means a job applied by User 2 would be recommendedhigher than the one applied by User 3 if User 1 is moresimilar to User 2 than User 3
323 Hybrid Recommendation System +e concept of ahybrid recommendation system is based on the fact thatcontent-based and collaborative filtering alone does notprovide the best job recommendations to the user +ere-fore a method to combine the two types of filtering andmake the recommendation engine truly hybrid was devisedTo achieve this the system first finds similar users and jobs asdiscussed above in collaborative filtering After this thecorrelation score for the recommended job is computed Tocalculate this the ratio of the number of common jobsbetween the main and suggested user to the number of allcommon jobs present between all the users is taken +isway a score between 0 and 1 is generated Taking the averageof the score computed just above the content-based filteringscore the system produces a final recommendation score foreach job +is way it is possible to rank all top-
recommended jobs to the user based on a hybrid model ofcontent-based and collaborative filtering
4 Algorithm
Algorithmic steps for weight determination content scorecollaborative filtering and hybrid score calculation areshown in Algorithm 1
5 Results and Analysis
Table 1 shows the comparison between the standard existingjob recommendation models in the market (naukricomindeedcom) and existing research papers +e followingparameters were derived from it
Table 2 summarizes the top seven jobs liked by someparticular users in the systemwere analyzed and the content-based and hybrid scores for them were compared as shownin the table
From Figure 2 it is observed that the average percentageincrease in the match score is 5978 In content-basedfiltering it was tried to recommend the jobs as per the userrsquosprofile and resume by parsing all job descriptions andcomputing a match score
For this two experiments were performed one with theraw job description and the second after processing the jobs+e comparison between the two can be seen in Table 3
Figure 3 clearly shows that the average percentage timereduction after processing the descriptions is 3774
Table 1 Comparing the features of existing systems with the proposed system
SystemsAspects Companies listed
Data collection method JD cleaning Recommendation methodology Real time Jupiter PratilipiReference [2] College campus No Content-based filtering No NA NAReference [25] Single website crawler Yes No No No NoNaukri Direct listing Yes Collaborative No No YesIndeed Direct listing No Collaborative No No NoProposed system Automate crawling Yes Hybrid system Yes Yes Yes
5 10 15 20 250
10987654321
Job_
ID
Rank BeforeRank After
Rank Before vs Rank After
Figure 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Table 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Job_ID Rank before(content)
Rank after(hybrid)
61a29356c062e596f369e488 9 161a293c9c062e596f369e6ad 5 261a293c6c062e596f369e6a1 20 361a2936dc062e596f369e4f4 6 461a29357c062e596f369e491 1 561a293c7c062e596f369e6a4 3 661a2936dc062e596f369e4f7 19 7
Computational Intelligence and Neuroscience 7
Table 4 is an extension of the above experiment and amore important metric was observed ie the match score+e input was the same as the above previous one
Figure 4 shows that job description processing increasesthe chances of the user getting matched to his desired job by10344
6 Conclusion and Future Scope
In this paper Content-Based Filtering and CollaborativeFiltering of recommendations have been compared Addi-tionally an aggregation plus recommender system has beendevised Content-Based Filtering recommends the resultsbased on matching the personal preferences of the user withthe given document whereas collaborative filtering recom-mends based on the preferences of fellow users On eval-uating both of these methods it was concluded that a hybridsystem of both of these overcomes the limitations of both of
Table 3 Comparison of the efficiency of the system with and without preprocessing the job descriptions
User skillsdescription Time taken for the rawjob description (s)
Time taken for the processedjob description (s)
Percentage reductionin time ()
Test case 1mdashfrontend 3338 2087 3748Test case 2mdashbackend 2954 1955 3382Test case 3mdashmachine learning 5107 3669 2816Test case 4mdashDevOps 4628 2952 3621Test case 5mdashproduct management 3848 1807 5304
Table 4 Comparing the ranks of jobs after preprocessing descriptions
User skillsdescription Average match score for raw jobdescription
Average match score for processedjob description
Percentage increase in the matchscore ()
Test case 1mdashfrontend 005629 012358 11954Test casemdash2 backend 004631 009131 9717Test casemdash3 ML 004672 010409 1228Test casemdash4 DevOps 006277 011382 8133Test casemdash5 productmanagement 022237 045107 10285
Time in seconds
Product
DevOps
Machine Learning
Backend
Frontend
Prof
iles
40 600 20
OriginalProcessed
Figure 3 Comparing the efficiency of the system with and without preprocessing the job descriptions
Frontend
Backend
Machine Learning
DevOps
Product
Scor
e
Score (Avg of top 5)
OriginalProcessed
01 02 03 04 0500
Figure 4 Comparing ranks of jobs after preprocessing thedescriptions
8 Computational Intelligence and Neuroscience
them and increases the efficiency of ranking Problems ofcold start sparse database scalability and lack of trendrecommendation [5] have been eliminated +e proposal isto design a Job Recommender system that prioritizes qualityover quantity While there are websites and job listingportals already recommending jobs to job seekers based ontheir profiles this research on aggregate quality recom-mendations has been achieved by crawling selectivelyovercoming the limitations of [1 4 14] A fully functioninguser interface was developed to combine everything togetherto give the user a seamless experience
For this system to be hybrid content-based filtering isrequired which can only recommend jobs based on theuserrsquos current profile It cannot deliver anything surprisingbased on the userrsquos past searches +is paper also usescollaborative filtering which faces well-known problems ofprivacy breaches and cold start +e system has a broadscope that can be used to make it more robust and foolproofFirstly automating the crawling process is required when anew company is added to the database In other wordsremoving the one-time configuration stepprocess to fetchjobs of a particular new company can be done +ese modelscan implement techniques such as KNN in collaborativefiltering Implementing NLP in content-based filtering forbetter and more accurate search matching can be doneAlong with this testing and collecting more user data forbetter performance of the collaborative filtering module isrequired Lastly improving the cleansing process of the jobdescription and using natural language processing are re-quired While using collaborative filtering this work can beimproved by giving different weights to different users basedon their LinkedIn skills
Data Availability
+e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
+e authors declare that they have no conflicts of interest
References
[1] C Slamet R Andrian D S A Maylawati W Darmalaksanaand M A Ramdhani ldquoWeb scraping and Naıve Bayes clas-sification for job search enginerdquo IOP Conference SeriesMaterials Science and Engineering vol 288 no 1 Article ID012038 2018
[2] D V Musale M K Nagpure K S Patil and R F SayyedldquoJob recommendation system using profile matching and webcrawlingrdquo Int J Adv Sci Res Eng Trendsvol 1 2016
[3] U P K Kethavarapu and S Saraswathi ldquoConcept baseddynamic ontology creation for job recommendation systemrdquoProcedia Computer Science vol 85 pp 915ndash921 2016
[4] A S Parihar Y K Gupta Y Singodia V Singh and K SinghldquoA comparative study of image dehazing algorithmsrdquo inProceedings of the 2020 5th International Conference onCommunication and Electronics Systems (ICCES) pp 766ndash771 Coimbatore India 2020 June
[5] R Mishra and S Rathi ldquoEfficient and scalable job recom-mender system using collaborative filteringrdquo in ICDSMLA2019 pp 842ndash856 Springer Singapore 2020
[6] D Mhamdi R Moulouki M Y El Ghoumari M Azzouaziand L Moussaid ldquoJob recommendation based on job profileclustering and job seeker behaviorrdquo Procedia Computer Sci-ence vol 175 pp 695ndash699 2020
[7] V Desai D Bahl S Vibhandik and I Fatma ldquoImple-mentation of an automated job recommendation systembased on candidate profilesrdquo Int Res J Eng Technol vol 4no 5 pp 1018ndash1021 2017
[8] V Indira and S Rathika ldquoA study on E-recruitment and itrsquospresent condition towards job seekersrdquo International Re-search Journal of Engineering and Technology (IRJET) ISSNISSN 2395-0056 vol 7 no 4 pp 3753ndash3758 2020
[9] R Pradhan J Varshney K Goyal and L Kumari ldquoJobrecommendation system using content and collaborative-based filteringrdquo in International Conference on InnovativeComputing and Communications pp 575ndash583 SpringerNature New York NY USA 2022
[10] R G Belsare and V M Deshmukh ldquoEmployment recom-mendation system using matching collaborative filtering andcontent- based recommendationrdquo International Journal ofComputer Applications Technology and Research vol 7 no 6pp 215ndash220 2018
[11] P Manjare J Kumbhar S Ovhal and R Munde ldquoAn ef-fective job recruitment system using content-based filteringrdquoInternational Journal of Engineering amp Technology vol 4no 3 pp 2395ndash0056 2017
[12] C P Akshaya ldquoEnhancement of recommender system usingcollaborative filteringrdquo International Research Journal ofEngineering and Technology vol 5 no 4 pp 2198ndash2200 2018
[13] H Jain and M Kakkar ldquoJob recommendation system basedon machine learning and data mining techniques usingRESTful API and android IDErdquo in Proceedings of the 2019 9thInternational Conference on Cloud Computing Data Science ampEngineering (Confluence) pp 416ndash421 Noida India 2019January
[14] P Yi C Yang C Li and Y Zhang ldquoA job recommendationmethod optimized by position descriptions and resume in-formationrdquo in Proceedings of the 2016 IEEE Advanced In-formation Management Communicates Electronic andAutomation Control Conference (IMCEC) pp 761ndash764 XirsquoanChina 2016 October
[15] H Apaza A A Rubin de Celis Vidal and J E Chire SaireldquoJob recommendation based on curriculum vitae using textminingrdquo in Future of Information and CommunicationConference pp 1051ndash1059 Springer New York NY USA2021
[16] D Nasution and Z Sitorus ldquoEnhance web-based job searchrecommendation system of hybrid-based recommendationrdquoBudapest International Research and Critics Institute (BIRCI-Journal) Humanities and Social Sciences vol 4 no 3pp 7214ndash7221 2021
[17] Q Zhou F Liao L Ge and J Sun ldquoPersonalized preferencecollaborative filtering job recommendation for graduatesrdquo inProceedings of the 2019 IEEE SmartWorld Ubiquitous Intel-ligence amp Computing Advanced amp Trusted ComputingScalable Computing amp Communications Cloud amp Big DataComputing Internet of People and Smart City Innovationpp 1055ndash1062 Leicester UK 2019 August
[18] R Patel and S K Vishwakarma ldquoAn efficient approach for jobrecommendation system based on collaborative filteringrdquo ICT
Computational Intelligence and Neuroscience 9
Systems and Sustainability Proceedings of ICT4SD SpringerNature vol 1 p 169 New York NY USA 2020
[19] Y C Chou and H Y Yu ldquoBased on the application of AItechnology in resume analysis and job recommendationrdquo inProceedings of the 2020 IEEE International Conference onComputational Electromagnetics (ICCEM) pp 291ndash296Singapore 2020 August
[20] D Punitavathi V Shinu S Kumar and V P Sp ldquoOnline joband candidate recommendation systemrdquo International Re-search Journal of Multidisciplinary Technovation vol 1pp 84ndash89 2019
[21] T V Yadalam V M Gowda V S Kumar D Girish andM Namratha ldquoCareer recommendation systems using con-tent based filteringrdquo in Proceedings of the 2020 5th Interna-tional Conference on Communication and Electronics Systems(ICCES) pp 660ndash665 Coimbatore India 2020 June
[22] N Almalis G Tsihrintzis and N Karagiannis ldquoA newcontent-based recommendation algorithm for job recruitingrdquoin Proceedings of the International Conference on InnovativeTechniques and Applications of Artificial Intelligencepp 393ndash398 Springer Corfu Greece 2015 December
[23] J Suharyadi and A Kusnadi ldquoStay at home reservation themitigation step in covid-19 pandemicrdquo International Journalof New Media Technology vol 5 no 2 pp 116ndash120 2018
[24] S R Rimitha V Abburu A Kiranmai andK Chandrasekaran ldquoOntologies to model user profiles inpersonalized job recommendationrdquo in Proceedings of the 2018IEEE Distributed Computing VLSI Electrical Circuits andRobotics (DISCOVER) pp 98ndash103 Mangalore India 2018August
[25] F J M Shamrat Z Tasnim A S Rahman N I Nobel andS A Hossain ldquoAn effective implementation of web crawlingtechnology to retrieve data from the world wide web(WWW)rdquo International Journal of Scientific amp TechnologyResearch vol 9 no 01 pp 1252ndash1256 2020
[26] H Nigam and P Biswas ldquoFrom web scraping to webcrawlingrdquo in Applications of Artificial Intelligence and Ma-chine Learning pp 97ndash112 Springer Singapore 2021
[27] T Karthikeyan K Sekaran D Ranjith and J M BalajeeldquoPersonalized content extraction and text classification usingeffective web scraping techniquesrdquo International Journal ofWeb Portals vol 11 no 2 pp 41ndash52 2019
[28] N Kumar and D Aggarwal ldquoLEARNING-based focusedWEB crawlerrdquo IETE Journal of Research pp 1ndash9 2021
[29] D Rai N Kumar and J Mor ldquoReview on improving per-formance of web crawler and search system ArchitecturerdquoInternational Journal of Advanced Studies of Scientific Re-search vol 3 no 10 2018
[30] T Kamishima S Akaho H Asoh and J Sakuma ldquoRecom-mendation independencerdquo in Proceedings of the Conferenceon Fairness Accountability and Transparency 187-201) NewYork NY USA 2018 January
[31] M Kumar A Bindal R Gautam and R Bhatia ldquoKeywordquery based focused Web crawlerrdquo Procedia Computer Sci-ence vol 125 pp 584ndash590 2018
[32] R Diouf E N Sarr O Sall B Birregah M Bousso andS N Mbaye ldquoWeb scraping state-of-the-art and areas ofapplicationrdquo in Proceedings of the 2019 IEEE InternationalConference on Big Data (Big Data) pp 6040ndash6042 LosAngeles CA USA 2019 December
[33] D Glez-Pentildea A Lourenccedilo H Lopez-Fernandez M Reboiro-Jato and F Fdez-Riverola ldquoWeb scraping technologies in anAPI worldrdquo Briefings in Bioinformatics vol 15 no 5pp 788ndash797 2014
[34] E Uzun ldquoA novel web scraping approach using the additionalinformation obtained from web pagesrdquo IEEE Access vol 8Article ID 61726 2020
[35] M Gupta N Kumar B K Singh and N Gupta ldquoNSGA-III-Based deep-learning model for biomedical search enginerdquoMathematical Problems in Engineering vol 2021 Article ID9935862 8 pages 2021
[36] J Mor N Kumar and D Rai ldquoAn improved crawler based onefficient ranking algorithmrdquo International Journal of Ad-vanced Trends in Computer Science and Engineering vol 8pp 119ndash125 2019
[37] J Mor D Rai and N Kumar ldquoAn XML based web crawlerwith page revisit policy and updation in local repository ofsearch enginerdquo International Journal of Engineering ampTechnology vol 7 no 3 pp 1119ndash1123 2018
[38] J Mor N Kumar and D Rai ldquoResearch on mechanism andchallenges in meta search enginesrdquo International Journal ofInnovative Technology and Exploring Engineering vol 8 no 9pp 281ndash284 2019
[39] N Kumar R Nath and P Kherwa ldquoAn automated frame-work based on TLS to choose best search engine in a particulardomainrdquo International Journal of Computer Applicationvol 83 no 14 pp 42ndash48 2013
[40] J Mor N Kumar and D Rai ldquoEffective presentation ofresults using ranking amp clustering in meta search engineCOMPUSOFTrdquo An International Journal of AdvancedComputer Technology vol 7 no 12 2018
[41] N Kumar and P Dahiya ldquoWeighted similarity page rank animprovement in WPR and WSRrdquo International Journal ofComputer Engineering and Applications vol 11 no VIIIpp 1ndash11 2017
[42] N Kumar and R Nath ldquoA meta search engine approach fororganizing web search results using ranking and clusteringrdquoInternational Journal of Computer 2013
[43] N Kumar D Tyagi and S Awasthi ldquoSurvey on crawlingtechniquesrdquo in Proceedings of the 5th International Conferenceon ldquoComputing for Sustainable Global Developmentpp 2449ndash2455 New Delhi India March 2018
[44] N Kumar ldquoDocument clustering approach for meta searchenginerdquo IOP Conference Series Materials Science and Engi-neering vol 225 Article ID 012291 2017
[45] N Kumar D Tyagi S Awasthi and J Mor ldquoChange de-tection of web page in focused crawling systemrdquo InternationalJournal of Control Heory and Applications vol 10 no 6pp 671ndash676 2017
[46] N Kumar and P Singh ldquoMeta search engine with semanticanalysis and query processingrdquo International Journal ofComputational Intelligence Research ISSN vol 13 no 8pp 0973ndash1873 2017
[47] N Kumar ldquoSegmentation based twitter opinion mining usingensemble learningrdquo International Journal on Future Revolu-tion in Computer Science amp Communication Engineeringvol 3 no 9 2017
[48] R Nath N Kumar and S Tuteja ldquoA survey on reduction ofload on the networkrdquo Intelligent Distributed Computingpp 239ndash249 Springer New York NY USA 2015
[49] N Kumar N N Das D Gupta K Gupta and J BindraldquoEfficient automated disease diagnosis usingmachine learningmodelsrdquo Journal of Healthcare Engineering vol 2021 ArticleID 9983652 13 pages 2021
[50] V Singrodia A Mitra and S Paul ldquoA review on webscrapping and its applicationsrdquo in Proceedings of the 2019International Conference on Computer Communication andInformatics pp 1ndash6 Coimbatore India 2019 January
10 Computational Intelligence and Neuroscience
[51] R Nath and N Kumar ldquoA novel parallel domain focusedcrawler for reduction in load on the networkrdquo InternationalJournal of Computational Engineering Research vol 2 no 7pp 77ndash84 2012
[52] V Shrivastava ldquoA methodical study of web crawlerrdquo Journalof Engineering Research and Application vol 8 no 11 pp 1ndash82018
[53] S Amudha and M Phil ldquoWeb crawler for mining web datardquoInternational Research Journal of Engineering and Technology(IRJET) vol 4 no 2 pp 2395ndash0072 2017
[54] N Nassar A Jafar and Y Rahhal ldquoA novel deep multi-criteria collaborative filtering model for recommendationsystemrdquo Knowledge-Based Systems vol 187 Article ID104811 2020
[55] M Fu H Qu Z Yi L Lu and Y Liu ldquoA novel deep learning-based collaborative filtering model for recommendationsystemrdquo IEEE Transactions on Cybernetics vol 49 no 3pp 1084ndash1096 2018
Computational Intelligence and Neuroscience 11

In the user-based approach the users are the masters ofthe ring If some users have a similar preference they tend tojoin a group Recommendations are given to the user builton the evaluation of items by other users in the same group+ese users share a common taste +e reason for such afilter being chosen in the paper is that the prediction ismainly based on the average weight of recommendationsfrom many people It is located in a single bank from thesame person +e weight allocated to the individual as-sessment determines the relationship between the user andthe other user Pearsonrsquos correlation coefficient was used tomeasure this correlation
(1) Pearson Correlation Coefficient +is correlation methodwas used to compute how much the similarity of mutualusers for particularly two items deviates from the averageratings +e range of the Pearson coefficient varies betweenthe values zero and one +e larger the magnitude of thiscoefficient the higher the correlation between the twodocuments It is depicted in the following equation
P n(isin ab) minus (isin a)(isin b)
n isin a
2minus isin a
21113872 11138731113960 1113961 n isin b
2minus isin b
21113872 11138731113960 11139611113872 1113873
1113969 (3)
where P is the Pearson coefficient and a and b are twoentities
Talking about the implementation of collaborative fil-tering the system generates recommendations for a userbased on users with a similar taste+ere is no normalizationbased on popularity at the moment hence no room for anybias depending on the user profile
Another important assumption made is that the systemis not taking into account any dislikings or spam jobs Inother words the paper takes into account the jobs onlywhich have been recommended by similar users An arraymatrix is defined which is anMlowastNmatrix withM being thenumber of users and N being the jobs+e engine defines theratings of the users in the database It contains only Booleanvalues 0 (not rated) or 1 (recommended or applied) Afterthe function gets the required input in the above format itruns through the collaborative filter algorithm +e algo-rithm effectively generates job recommendations usingJaccard Similarity
(2) Tanimoto Coefficient (Jaccard Index) +e Jaccard Sim-ilarity Index or Tanimoto coefficient is a degree of similaritybetween two sample sets of data +e index arrays are from 0to 1 +e closer to 1 the more similar are the two data sets
(i) Algorithm ndash Hybrid Recommendation System(ii) Input ndash UserU All jobs J
Output ndash Recommended Jobs with respective hybrid scoreStep 1 ndash StartStep 2 ndash Input_desc(U)Step 3 ndash Content_Based_Filtering (U J)
TF-IDF weight determinationif tf[U Ji]gt 0 w[U Ji] SUM(1 log tf[U Ji])
elsew[U Ji] 0
Content_Score w[U Ji]
Cosine similarityCS(U Ji) isin UJiisin U2J2
Content_ScoreContent_Score +CS [U Ji]endStep 4 ndash Collaborative_Filtering (U J)Matrix [U J]
if INTERACT (Ui Jj) TRUEMatrix [Ui Jj] 1
elseMatrix [Ui Jj] 0
Similarity (Ui Jj)RATIO (INTERSECT (Ui Jj) J)Collaborative_ScoreRATIO (N_INTERACT
INTERSECT (N_Similar))end
Step 5 ndash Total_Hybrid_Score (U Ji)ScoreAVERAGE (Collaborative_Score Content_Score)
endStep 6 ndash SORT_JOBS (Total_Hybrid_Score)Step 7 ndash Stop
ALGORITHM 1 Hybrid recommendation system
6 Computational Intelligence and Neuroscience
Jaccard Similarity (Intersection of the two sets of thenumber of observations common in both sets)(Union of thetwo sets or the number in either of the sets)
Equation (4) is a mathematical representation
J(A B) AcapB
AcupB (4)
Using this concept a methodology for computingsimilar jobs based on collaborative filtering [53 54] is de-vised Somemachine learning algorithms can also be devised[55]+e system first finds similar users (who have applied tothe job) and the jobs to which these common users haveapplied Based on the correlation and similarity between thetwo users jobs will be recommended to the current user+at means a job applied by User 2 would be recommendedhigher than the one applied by User 3 if User 1 is moresimilar to User 2 than User 3
323 Hybrid Recommendation System +e concept of ahybrid recommendation system is based on the fact thatcontent-based and collaborative filtering alone does notprovide the best job recommendations to the user +ere-fore a method to combine the two types of filtering andmake the recommendation engine truly hybrid was devisedTo achieve this the system first finds similar users and jobs asdiscussed above in collaborative filtering After this thecorrelation score for the recommended job is computed Tocalculate this the ratio of the number of common jobsbetween the main and suggested user to the number of allcommon jobs present between all the users is taken +isway a score between 0 and 1 is generated Taking the averageof the score computed just above the content-based filteringscore the system produces a final recommendation score foreach job +is way it is possible to rank all top-
recommended jobs to the user based on a hybrid model ofcontent-based and collaborative filtering
4 Algorithm
Algorithmic steps for weight determination content scorecollaborative filtering and hybrid score calculation areshown in Algorithm 1
5 Results and Analysis
Table 1 shows the comparison between the standard existingjob recommendation models in the market (naukricomindeedcom) and existing research papers +e followingparameters were derived from it
Table 2 summarizes the top seven jobs liked by someparticular users in the systemwere analyzed and the content-based and hybrid scores for them were compared as shownin the table
From Figure 2 it is observed that the average percentageincrease in the match score is 5978 In content-basedfiltering it was tried to recommend the jobs as per the userrsquosprofile and resume by parsing all job descriptions andcomputing a match score
For this two experiments were performed one with theraw job description and the second after processing the jobs+e comparison between the two can be seen in Table 3
Figure 3 clearly shows that the average percentage timereduction after processing the descriptions is 3774
Table 1 Comparing the features of existing systems with the proposed system
SystemsAspects Companies listed
Data collection method JD cleaning Recommendation methodology Real time Jupiter PratilipiReference [2] College campus No Content-based filtering No NA NAReference [25] Single website crawler Yes No No No NoNaukri Direct listing Yes Collaborative No No YesIndeed Direct listing No Collaborative No No NoProposed system Automate crawling Yes Hybrid system Yes Yes Yes
5 10 15 20 250
10987654321
Job_
ID
Rank BeforeRank After
Rank Before vs Rank After
Figure 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Table 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Job_ID Rank before(content)
Rank after(hybrid)
61a29356c062e596f369e488 9 161a293c9c062e596f369e6ad 5 261a293c6c062e596f369e6a1 20 361a2936dc062e596f369e4f4 6 461a29357c062e596f369e491 1 561a293c7c062e596f369e6a4 3 661a2936dc062e596f369e4f7 19 7
Computational Intelligence and Neuroscience 7
Table 4 is an extension of the above experiment and amore important metric was observed ie the match score+e input was the same as the above previous one
Figure 4 shows that job description processing increasesthe chances of the user getting matched to his desired job by10344
6 Conclusion and Future Scope
In this paper Content-Based Filtering and CollaborativeFiltering of recommendations have been compared Addi-tionally an aggregation plus recommender system has beendevised Content-Based Filtering recommends the resultsbased on matching the personal preferences of the user withthe given document whereas collaborative filtering recom-mends based on the preferences of fellow users On eval-uating both of these methods it was concluded that a hybridsystem of both of these overcomes the limitations of both of
Table 3 Comparison of the efficiency of the system with and without preprocessing the job descriptions
User skillsdescription Time taken for the rawjob description (s)
Time taken for the processedjob description (s)
Percentage reductionin time ()
Test case 1mdashfrontend 3338 2087 3748Test case 2mdashbackend 2954 1955 3382Test case 3mdashmachine learning 5107 3669 2816Test case 4mdashDevOps 4628 2952 3621Test case 5mdashproduct management 3848 1807 5304
Table 4 Comparing the ranks of jobs after preprocessing descriptions
User skillsdescription Average match score for raw jobdescription
Average match score for processedjob description
Percentage increase in the matchscore ()
Test case 1mdashfrontend 005629 012358 11954Test casemdash2 backend 004631 009131 9717Test casemdash3 ML 004672 010409 1228Test casemdash4 DevOps 006277 011382 8133Test casemdash5 productmanagement 022237 045107 10285
Time in seconds
Product
DevOps
Machine Learning
Backend
Frontend
Prof
iles
40 600 20
OriginalProcessed
Figure 3 Comparing the efficiency of the system with and without preprocessing the job descriptions
Frontend
Backend
Machine Learning
DevOps
Product
Scor
e
Score (Avg of top 5)
OriginalProcessed
01 02 03 04 0500
Figure 4 Comparing ranks of jobs after preprocessing thedescriptions
8 Computational Intelligence and Neuroscience
them and increases the efficiency of ranking Problems ofcold start sparse database scalability and lack of trendrecommendation [5] have been eliminated +e proposal isto design a Job Recommender system that prioritizes qualityover quantity While there are websites and job listingportals already recommending jobs to job seekers based ontheir profiles this research on aggregate quality recom-mendations has been achieved by crawling selectivelyovercoming the limitations of [1 4 14] A fully functioninguser interface was developed to combine everything togetherto give the user a seamless experience
For this system to be hybrid content-based filtering isrequired which can only recommend jobs based on theuserrsquos current profile It cannot deliver anything surprisingbased on the userrsquos past searches +is paper also usescollaborative filtering which faces well-known problems ofprivacy breaches and cold start +e system has a broadscope that can be used to make it more robust and foolproofFirstly automating the crawling process is required when anew company is added to the database In other wordsremoving the one-time configuration stepprocess to fetchjobs of a particular new company can be done +ese modelscan implement techniques such as KNN in collaborativefiltering Implementing NLP in content-based filtering forbetter and more accurate search matching can be doneAlong with this testing and collecting more user data forbetter performance of the collaborative filtering module isrequired Lastly improving the cleansing process of the jobdescription and using natural language processing are re-quired While using collaborative filtering this work can beimproved by giving different weights to different users basedon their LinkedIn skills
Data Availability
+e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
+e authors declare that they have no conflicts of interest
References
[1] C Slamet R Andrian D S A Maylawati W Darmalaksanaand M A Ramdhani ldquoWeb scraping and Naıve Bayes clas-sification for job search enginerdquo IOP Conference SeriesMaterials Science and Engineering vol 288 no 1 Article ID012038 2018
[2] D V Musale M K Nagpure K S Patil and R F SayyedldquoJob recommendation system using profile matching and webcrawlingrdquo Int J Adv Sci Res Eng Trendsvol 1 2016
[3] U P K Kethavarapu and S Saraswathi ldquoConcept baseddynamic ontology creation for job recommendation systemrdquoProcedia Computer Science vol 85 pp 915ndash921 2016
[4] A S Parihar Y K Gupta Y Singodia V Singh and K SinghldquoA comparative study of image dehazing algorithmsrdquo inProceedings of the 2020 5th International Conference onCommunication and Electronics Systems (ICCES) pp 766ndash771 Coimbatore India 2020 June
[5] R Mishra and S Rathi ldquoEfficient and scalable job recom-mender system using collaborative filteringrdquo in ICDSMLA2019 pp 842ndash856 Springer Singapore 2020
[6] D Mhamdi R Moulouki M Y El Ghoumari M Azzouaziand L Moussaid ldquoJob recommendation based on job profileclustering and job seeker behaviorrdquo Procedia Computer Sci-ence vol 175 pp 695ndash699 2020
[7] V Desai D Bahl S Vibhandik and I Fatma ldquoImple-mentation of an automated job recommendation systembased on candidate profilesrdquo Int Res J Eng Technol vol 4no 5 pp 1018ndash1021 2017
[8] V Indira and S Rathika ldquoA study on E-recruitment and itrsquospresent condition towards job seekersrdquo International Re-search Journal of Engineering and Technology (IRJET) ISSNISSN 2395-0056 vol 7 no 4 pp 3753ndash3758 2020
[9] R Pradhan J Varshney K Goyal and L Kumari ldquoJobrecommendation system using content and collaborative-based filteringrdquo in International Conference on InnovativeComputing and Communications pp 575ndash583 SpringerNature New York NY USA 2022
[10] R G Belsare and V M Deshmukh ldquoEmployment recom-mendation system using matching collaborative filtering andcontent- based recommendationrdquo International Journal ofComputer Applications Technology and Research vol 7 no 6pp 215ndash220 2018
[11] P Manjare J Kumbhar S Ovhal and R Munde ldquoAn ef-fective job recruitment system using content-based filteringrdquoInternational Journal of Engineering amp Technology vol 4no 3 pp 2395ndash0056 2017
[12] C P Akshaya ldquoEnhancement of recommender system usingcollaborative filteringrdquo International Research Journal ofEngineering and Technology vol 5 no 4 pp 2198ndash2200 2018
[13] H Jain and M Kakkar ldquoJob recommendation system basedon machine learning and data mining techniques usingRESTful API and android IDErdquo in Proceedings of the 2019 9thInternational Conference on Cloud Computing Data Science ampEngineering (Confluence) pp 416ndash421 Noida India 2019January
[14] P Yi C Yang C Li and Y Zhang ldquoA job recommendationmethod optimized by position descriptions and resume in-formationrdquo in Proceedings of the 2016 IEEE Advanced In-formation Management Communicates Electronic andAutomation Control Conference (IMCEC) pp 761ndash764 XirsquoanChina 2016 October
[15] H Apaza A A Rubin de Celis Vidal and J E Chire SaireldquoJob recommendation based on curriculum vitae using textminingrdquo in Future of Information and CommunicationConference pp 1051ndash1059 Springer New York NY USA2021
[16] D Nasution and Z Sitorus ldquoEnhance web-based job searchrecommendation system of hybrid-based recommendationrdquoBudapest International Research and Critics Institute (BIRCI-Journal) Humanities and Social Sciences vol 4 no 3pp 7214ndash7221 2021
[17] Q Zhou F Liao L Ge and J Sun ldquoPersonalized preferencecollaborative filtering job recommendation for graduatesrdquo inProceedings of the 2019 IEEE SmartWorld Ubiquitous Intel-ligence amp Computing Advanced amp Trusted ComputingScalable Computing amp Communications Cloud amp Big DataComputing Internet of People and Smart City Innovationpp 1055ndash1062 Leicester UK 2019 August
[18] R Patel and S K Vishwakarma ldquoAn efficient approach for jobrecommendation system based on collaborative filteringrdquo ICT
Computational Intelligence and Neuroscience 9
Systems and Sustainability Proceedings of ICT4SD SpringerNature vol 1 p 169 New York NY USA 2020
[19] Y C Chou and H Y Yu ldquoBased on the application of AItechnology in resume analysis and job recommendationrdquo inProceedings of the 2020 IEEE International Conference onComputational Electromagnetics (ICCEM) pp 291ndash296Singapore 2020 August
[20] D Punitavathi V Shinu S Kumar and V P Sp ldquoOnline joband candidate recommendation systemrdquo International Re-search Journal of Multidisciplinary Technovation vol 1pp 84ndash89 2019
[21] T V Yadalam V M Gowda V S Kumar D Girish andM Namratha ldquoCareer recommendation systems using con-tent based filteringrdquo in Proceedings of the 2020 5th Interna-tional Conference on Communication and Electronics Systems(ICCES) pp 660ndash665 Coimbatore India 2020 June
[22] N Almalis G Tsihrintzis and N Karagiannis ldquoA newcontent-based recommendation algorithm for job recruitingrdquoin Proceedings of the International Conference on InnovativeTechniques and Applications of Artificial Intelligencepp 393ndash398 Springer Corfu Greece 2015 December
[23] J Suharyadi and A Kusnadi ldquoStay at home reservation themitigation step in covid-19 pandemicrdquo International Journalof New Media Technology vol 5 no 2 pp 116ndash120 2018
[24] S R Rimitha V Abburu A Kiranmai andK Chandrasekaran ldquoOntologies to model user profiles inpersonalized job recommendationrdquo in Proceedings of the 2018IEEE Distributed Computing VLSI Electrical Circuits andRobotics (DISCOVER) pp 98ndash103 Mangalore India 2018August
[25] F J M Shamrat Z Tasnim A S Rahman N I Nobel andS A Hossain ldquoAn effective implementation of web crawlingtechnology to retrieve data from the world wide web(WWW)rdquo International Journal of Scientific amp TechnologyResearch vol 9 no 01 pp 1252ndash1256 2020
[26] H Nigam and P Biswas ldquoFrom web scraping to webcrawlingrdquo in Applications of Artificial Intelligence and Ma-chine Learning pp 97ndash112 Springer Singapore 2021
[27] T Karthikeyan K Sekaran D Ranjith and J M BalajeeldquoPersonalized content extraction and text classification usingeffective web scraping techniquesrdquo International Journal ofWeb Portals vol 11 no 2 pp 41ndash52 2019
[28] N Kumar and D Aggarwal ldquoLEARNING-based focusedWEB crawlerrdquo IETE Journal of Research pp 1ndash9 2021
[29] D Rai N Kumar and J Mor ldquoReview on improving per-formance of web crawler and search system ArchitecturerdquoInternational Journal of Advanced Studies of Scientific Re-search vol 3 no 10 2018
[30] T Kamishima S Akaho H Asoh and J Sakuma ldquoRecom-mendation independencerdquo in Proceedings of the Conferenceon Fairness Accountability and Transparency 187-201) NewYork NY USA 2018 January
[31] M Kumar A Bindal R Gautam and R Bhatia ldquoKeywordquery based focused Web crawlerrdquo Procedia Computer Sci-ence vol 125 pp 584ndash590 2018
[32] R Diouf E N Sarr O Sall B Birregah M Bousso andS N Mbaye ldquoWeb scraping state-of-the-art and areas ofapplicationrdquo in Proceedings of the 2019 IEEE InternationalConference on Big Data (Big Data) pp 6040ndash6042 LosAngeles CA USA 2019 December
[33] D Glez-Pentildea A Lourenccedilo H Lopez-Fernandez M Reboiro-Jato and F Fdez-Riverola ldquoWeb scraping technologies in anAPI worldrdquo Briefings in Bioinformatics vol 15 no 5pp 788ndash797 2014
[34] E Uzun ldquoA novel web scraping approach using the additionalinformation obtained from web pagesrdquo IEEE Access vol 8Article ID 61726 2020
[35] M Gupta N Kumar B K Singh and N Gupta ldquoNSGA-III-Based deep-learning model for biomedical search enginerdquoMathematical Problems in Engineering vol 2021 Article ID9935862 8 pages 2021
[36] J Mor N Kumar and D Rai ldquoAn improved crawler based onefficient ranking algorithmrdquo International Journal of Ad-vanced Trends in Computer Science and Engineering vol 8pp 119ndash125 2019
[37] J Mor D Rai and N Kumar ldquoAn XML based web crawlerwith page revisit policy and updation in local repository ofsearch enginerdquo International Journal of Engineering ampTechnology vol 7 no 3 pp 1119ndash1123 2018
[38] J Mor N Kumar and D Rai ldquoResearch on mechanism andchallenges in meta search enginesrdquo International Journal ofInnovative Technology and Exploring Engineering vol 8 no 9pp 281ndash284 2019
[39] N Kumar R Nath and P Kherwa ldquoAn automated frame-work based on TLS to choose best search engine in a particulardomainrdquo International Journal of Computer Applicationvol 83 no 14 pp 42ndash48 2013
[40] J Mor N Kumar and D Rai ldquoEffective presentation ofresults using ranking amp clustering in meta search engineCOMPUSOFTrdquo An International Journal of AdvancedComputer Technology vol 7 no 12 2018
[41] N Kumar and P Dahiya ldquoWeighted similarity page rank animprovement in WPR and WSRrdquo International Journal ofComputer Engineering and Applications vol 11 no VIIIpp 1ndash11 2017
[42] N Kumar and R Nath ldquoA meta search engine approach fororganizing web search results using ranking and clusteringrdquoInternational Journal of Computer 2013
[43] N Kumar D Tyagi and S Awasthi ldquoSurvey on crawlingtechniquesrdquo in Proceedings of the 5th International Conferenceon ldquoComputing for Sustainable Global Developmentpp 2449ndash2455 New Delhi India March 2018
[44] N Kumar ldquoDocument clustering approach for meta searchenginerdquo IOP Conference Series Materials Science and Engi-neering vol 225 Article ID 012291 2017
[45] N Kumar D Tyagi S Awasthi and J Mor ldquoChange de-tection of web page in focused crawling systemrdquo InternationalJournal of Control Heory and Applications vol 10 no 6pp 671ndash676 2017
[46] N Kumar and P Singh ldquoMeta search engine with semanticanalysis and query processingrdquo International Journal ofComputational Intelligence Research ISSN vol 13 no 8pp 0973ndash1873 2017
[47] N Kumar ldquoSegmentation based twitter opinion mining usingensemble learningrdquo International Journal on Future Revolu-tion in Computer Science amp Communication Engineeringvol 3 no 9 2017
[48] R Nath N Kumar and S Tuteja ldquoA survey on reduction ofload on the networkrdquo Intelligent Distributed Computingpp 239ndash249 Springer New York NY USA 2015
[49] N Kumar N N Das D Gupta K Gupta and J BindraldquoEfficient automated disease diagnosis usingmachine learningmodelsrdquo Journal of Healthcare Engineering vol 2021 ArticleID 9983652 13 pages 2021
[50] V Singrodia A Mitra and S Paul ldquoA review on webscrapping and its applicationsrdquo in Proceedings of the 2019International Conference on Computer Communication andInformatics pp 1ndash6 Coimbatore India 2019 January
10 Computational Intelligence and Neuroscience
[51] R Nath and N Kumar ldquoA novel parallel domain focusedcrawler for reduction in load on the networkrdquo InternationalJournal of Computational Engineering Research vol 2 no 7pp 77ndash84 2012
[52] V Shrivastava ldquoA methodical study of web crawlerrdquo Journalof Engineering Research and Application vol 8 no 11 pp 1ndash82018
[53] S Amudha and M Phil ldquoWeb crawler for mining web datardquoInternational Research Journal of Engineering and Technology(IRJET) vol 4 no 2 pp 2395ndash0072 2017
[54] N Nassar A Jafar and Y Rahhal ldquoA novel deep multi-criteria collaborative filtering model for recommendationsystemrdquo Knowledge-Based Systems vol 187 Article ID104811 2020
[55] M Fu H Qu Z Yi L Lu and Y Liu ldquoA novel deep learning-based collaborative filtering model for recommendationsystemrdquo IEEE Transactions on Cybernetics vol 49 no 3pp 1084ndash1096 2018
Computational Intelligence and Neuroscience 11

Jaccard Similarity (Intersection of the two sets of thenumber of observations common in both sets)(Union of thetwo sets or the number in either of the sets)
Equation (4) is a mathematical representation
J(A B) AcapB
AcupB (4)
Using this concept a methodology for computingsimilar jobs based on collaborative filtering [53 54] is de-vised Somemachine learning algorithms can also be devised[55]+e system first finds similar users (who have applied tothe job) and the jobs to which these common users haveapplied Based on the correlation and similarity between thetwo users jobs will be recommended to the current user+at means a job applied by User 2 would be recommendedhigher than the one applied by User 3 if User 1 is moresimilar to User 2 than User 3
323 Hybrid Recommendation System +e concept of ahybrid recommendation system is based on the fact thatcontent-based and collaborative filtering alone does notprovide the best job recommendations to the user +ere-fore a method to combine the two types of filtering andmake the recommendation engine truly hybrid was devisedTo achieve this the system first finds similar users and jobs asdiscussed above in collaborative filtering After this thecorrelation score for the recommended job is computed Tocalculate this the ratio of the number of common jobsbetween the main and suggested user to the number of allcommon jobs present between all the users is taken +isway a score between 0 and 1 is generated Taking the averageof the score computed just above the content-based filteringscore the system produces a final recommendation score foreach job +is way it is possible to rank all top-
recommended jobs to the user based on a hybrid model ofcontent-based and collaborative filtering
4 Algorithm
Algorithmic steps for weight determination content scorecollaborative filtering and hybrid score calculation areshown in Algorithm 1
5 Results and Analysis
Table 1 shows the comparison between the standard existingjob recommendation models in the market (naukricomindeedcom) and existing research papers +e followingparameters were derived from it
Table 2 summarizes the top seven jobs liked by someparticular users in the systemwere analyzed and the content-based and hybrid scores for them were compared as shownin the table
From Figure 2 it is observed that the average percentageincrease in the match score is 5978 In content-basedfiltering it was tried to recommend the jobs as per the userrsquosprofile and resume by parsing all job descriptions andcomputing a match score
For this two experiments were performed one with theraw job description and the second after processing the jobs+e comparison between the two can be seen in Table 3
Figure 3 clearly shows that the average percentage timereduction after processing the descriptions is 3774
Table 1 Comparing the features of existing systems with the proposed system
SystemsAspects Companies listed
Data collection method JD cleaning Recommendation methodology Real time Jupiter PratilipiReference [2] College campus No Content-based filtering No NA NAReference [25] Single website crawler Yes No No No NoNaukri Direct listing Yes Collaborative No No YesIndeed Direct listing No Collaborative No No NoProposed system Automate crawling Yes Hybrid system Yes Yes Yes
5 10 15 20 250
10987654321
Job_
ID
Rank BeforeRank After
Rank Before vs Rank After
Figure 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Table 2 Comparing ranks of relevant jobs in content-based andhybrid recommendations
Job_ID Rank before(content)
Rank after(hybrid)
61a29356c062e596f369e488 9 161a293c9c062e596f369e6ad 5 261a293c6c062e596f369e6a1 20 361a2936dc062e596f369e4f4 6 461a29357c062e596f369e491 1 561a293c7c062e596f369e6a4 3 661a2936dc062e596f369e4f7 19 7
Computational Intelligence and Neuroscience 7
Table 4 is an extension of the above experiment and amore important metric was observed ie the match score+e input was the same as the above previous one
Figure 4 shows that job description processing increasesthe chances of the user getting matched to his desired job by10344
6 Conclusion and Future Scope
In this paper Content-Based Filtering and CollaborativeFiltering of recommendations have been compared Addi-tionally an aggregation plus recommender system has beendevised Content-Based Filtering recommends the resultsbased on matching the personal preferences of the user withthe given document whereas collaborative filtering recom-mends based on the preferences of fellow users On eval-uating both of these methods it was concluded that a hybridsystem of both of these overcomes the limitations of both of
Table 3 Comparison of the efficiency of the system with and without preprocessing the job descriptions
User skillsdescription Time taken for the rawjob description (s)
Time taken for the processedjob description (s)
Percentage reductionin time ()
Test case 1mdashfrontend 3338 2087 3748Test case 2mdashbackend 2954 1955 3382Test case 3mdashmachine learning 5107 3669 2816Test case 4mdashDevOps 4628 2952 3621Test case 5mdashproduct management 3848 1807 5304
Table 4 Comparing the ranks of jobs after preprocessing descriptions
User skillsdescription Average match score for raw jobdescription
Average match score for processedjob description
Percentage increase in the matchscore ()
Test case 1mdashfrontend 005629 012358 11954Test casemdash2 backend 004631 009131 9717Test casemdash3 ML 004672 010409 1228Test casemdash4 DevOps 006277 011382 8133Test casemdash5 productmanagement 022237 045107 10285
Time in seconds
Product
DevOps
Machine Learning
Backend
Frontend
Prof
iles
40 600 20
OriginalProcessed
Figure 3 Comparing the efficiency of the system with and without preprocessing the job descriptions
Frontend
Backend
Machine Learning
DevOps
Product
Scor
e
Score (Avg of top 5)
OriginalProcessed
01 02 03 04 0500
Figure 4 Comparing ranks of jobs after preprocessing thedescriptions
8 Computational Intelligence and Neuroscience
them and increases the efficiency of ranking Problems ofcold start sparse database scalability and lack of trendrecommendation [5] have been eliminated +e proposal isto design a Job Recommender system that prioritizes qualityover quantity While there are websites and job listingportals already recommending jobs to job seekers based ontheir profiles this research on aggregate quality recom-mendations has been achieved by crawling selectivelyovercoming the limitations of [1 4 14] A fully functioninguser interface was developed to combine everything togetherto give the user a seamless experience
For this system to be hybrid content-based filtering isrequired which can only recommend jobs based on theuserrsquos current profile It cannot deliver anything surprisingbased on the userrsquos past searches +is paper also usescollaborative filtering which faces well-known problems ofprivacy breaches and cold start +e system has a broadscope that can be used to make it more robust and foolproofFirstly automating the crawling process is required when anew company is added to the database In other wordsremoving the one-time configuration stepprocess to fetchjobs of a particular new company can be done +ese modelscan implement techniques such as KNN in collaborativefiltering Implementing NLP in content-based filtering forbetter and more accurate search matching can be doneAlong with this testing and collecting more user data forbetter performance of the collaborative filtering module isrequired Lastly improving the cleansing process of the jobdescription and using natural language processing are re-quired While using collaborative filtering this work can beimproved by giving different weights to different users basedon their LinkedIn skills
Data Availability
+e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
+e authors declare that they have no conflicts of interest
References
[1] C Slamet R Andrian D S A Maylawati W Darmalaksanaand M A Ramdhani ldquoWeb scraping and Naıve Bayes clas-sification for job search enginerdquo IOP Conference SeriesMaterials Science and Engineering vol 288 no 1 Article ID012038 2018
[2] D V Musale M K Nagpure K S Patil and R F SayyedldquoJob recommendation system using profile matching and webcrawlingrdquo Int J Adv Sci Res Eng Trendsvol 1 2016
[3] U P K Kethavarapu and S Saraswathi ldquoConcept baseddynamic ontology creation for job recommendation systemrdquoProcedia Computer Science vol 85 pp 915ndash921 2016
[4] A S Parihar Y K Gupta Y Singodia V Singh and K SinghldquoA comparative study of image dehazing algorithmsrdquo inProceedings of the 2020 5th International Conference onCommunication and Electronics Systems (ICCES) pp 766ndash771 Coimbatore India 2020 June
[5] R Mishra and S Rathi ldquoEfficient and scalable job recom-mender system using collaborative filteringrdquo in ICDSMLA2019 pp 842ndash856 Springer Singapore 2020
[6] D Mhamdi R Moulouki M Y El Ghoumari M Azzouaziand L Moussaid ldquoJob recommendation based on job profileclustering and job seeker behaviorrdquo Procedia Computer Sci-ence vol 175 pp 695ndash699 2020
[7] V Desai D Bahl S Vibhandik and I Fatma ldquoImple-mentation of an automated job recommendation systembased on candidate profilesrdquo Int Res J Eng Technol vol 4no 5 pp 1018ndash1021 2017
[8] V Indira and S Rathika ldquoA study on E-recruitment and itrsquospresent condition towards job seekersrdquo International Re-search Journal of Engineering and Technology (IRJET) ISSNISSN 2395-0056 vol 7 no 4 pp 3753ndash3758 2020
[9] R Pradhan J Varshney K Goyal and L Kumari ldquoJobrecommendation system using content and collaborative-based filteringrdquo in International Conference on InnovativeComputing and Communications pp 575ndash583 SpringerNature New York NY USA 2022
[10] R G Belsare and V M Deshmukh ldquoEmployment recom-mendation system using matching collaborative filtering andcontent- based recommendationrdquo International Journal ofComputer Applications Technology and Research vol 7 no 6pp 215ndash220 2018
[11] P Manjare J Kumbhar S Ovhal and R Munde ldquoAn ef-fective job recruitment system using content-based filteringrdquoInternational Journal of Engineering amp Technology vol 4no 3 pp 2395ndash0056 2017
[12] C P Akshaya ldquoEnhancement of recommender system usingcollaborative filteringrdquo International Research Journal ofEngineering and Technology vol 5 no 4 pp 2198ndash2200 2018
[13] H Jain and M Kakkar ldquoJob recommendation system basedon machine learning and data mining techniques usingRESTful API and android IDErdquo in Proceedings of the 2019 9thInternational Conference on Cloud Computing Data Science ampEngineering (Confluence) pp 416ndash421 Noida India 2019January
[14] P Yi C Yang C Li and Y Zhang ldquoA job recommendationmethod optimized by position descriptions and resume in-formationrdquo in Proceedings of the 2016 IEEE Advanced In-formation Management Communicates Electronic andAutomation Control Conference (IMCEC) pp 761ndash764 XirsquoanChina 2016 October
[15] H Apaza A A Rubin de Celis Vidal and J E Chire SaireldquoJob recommendation based on curriculum vitae using textminingrdquo in Future of Information and CommunicationConference pp 1051ndash1059 Springer New York NY USA2021
[16] D Nasution and Z Sitorus ldquoEnhance web-based job searchrecommendation system of hybrid-based recommendationrdquoBudapest International Research and Critics Institute (BIRCI-Journal) Humanities and Social Sciences vol 4 no 3pp 7214ndash7221 2021
[17] Q Zhou F Liao L Ge and J Sun ldquoPersonalized preferencecollaborative filtering job recommendation for graduatesrdquo inProceedings of the 2019 IEEE SmartWorld Ubiquitous Intel-ligence amp Computing Advanced amp Trusted ComputingScalable Computing amp Communications Cloud amp Big DataComputing Internet of People and Smart City Innovationpp 1055ndash1062 Leicester UK 2019 August
[18] R Patel and S K Vishwakarma ldquoAn efficient approach for jobrecommendation system based on collaborative filteringrdquo ICT
Computational Intelligence and Neuroscience 9
Systems and Sustainability Proceedings of ICT4SD SpringerNature vol 1 p 169 New York NY USA 2020
[19] Y C Chou and H Y Yu ldquoBased on the application of AItechnology in resume analysis and job recommendationrdquo inProceedings of the 2020 IEEE International Conference onComputational Electromagnetics (ICCEM) pp 291ndash296Singapore 2020 August
[20] D Punitavathi V Shinu S Kumar and V P Sp ldquoOnline joband candidate recommendation systemrdquo International Re-search Journal of Multidisciplinary Technovation vol 1pp 84ndash89 2019
[21] T V Yadalam V M Gowda V S Kumar D Girish andM Namratha ldquoCareer recommendation systems using con-tent based filteringrdquo in Proceedings of the 2020 5th Interna-tional Conference on Communication and Electronics Systems(ICCES) pp 660ndash665 Coimbatore India 2020 June
[22] N Almalis G Tsihrintzis and N Karagiannis ldquoA newcontent-based recommendation algorithm for job recruitingrdquoin Proceedings of the International Conference on InnovativeTechniques and Applications of Artificial Intelligencepp 393ndash398 Springer Corfu Greece 2015 December
[23] J Suharyadi and A Kusnadi ldquoStay at home reservation themitigation step in covid-19 pandemicrdquo International Journalof New Media Technology vol 5 no 2 pp 116ndash120 2018
[24] S R Rimitha V Abburu A Kiranmai andK Chandrasekaran ldquoOntologies to model user profiles inpersonalized job recommendationrdquo in Proceedings of the 2018IEEE Distributed Computing VLSI Electrical Circuits andRobotics (DISCOVER) pp 98ndash103 Mangalore India 2018August
[25] F J M Shamrat Z Tasnim A S Rahman N I Nobel andS A Hossain ldquoAn effective implementation of web crawlingtechnology to retrieve data from the world wide web(WWW)rdquo International Journal of Scientific amp TechnologyResearch vol 9 no 01 pp 1252ndash1256 2020
[26] H Nigam and P Biswas ldquoFrom web scraping to webcrawlingrdquo in Applications of Artificial Intelligence and Ma-chine Learning pp 97ndash112 Springer Singapore 2021
[27] T Karthikeyan K Sekaran D Ranjith and J M BalajeeldquoPersonalized content extraction and text classification usingeffective web scraping techniquesrdquo International Journal ofWeb Portals vol 11 no 2 pp 41ndash52 2019
[28] N Kumar and D Aggarwal ldquoLEARNING-based focusedWEB crawlerrdquo IETE Journal of Research pp 1ndash9 2021
[29] D Rai N Kumar and J Mor ldquoReview on improving per-formance of web crawler and search system ArchitecturerdquoInternational Journal of Advanced Studies of Scientific Re-search vol 3 no 10 2018
[30] T Kamishima S Akaho H Asoh and J Sakuma ldquoRecom-mendation independencerdquo in Proceedings of the Conferenceon Fairness Accountability and Transparency 187-201) NewYork NY USA 2018 January
[31] M Kumar A Bindal R Gautam and R Bhatia ldquoKeywordquery based focused Web crawlerrdquo Procedia Computer Sci-ence vol 125 pp 584ndash590 2018
[32] R Diouf E N Sarr O Sall B Birregah M Bousso andS N Mbaye ldquoWeb scraping state-of-the-art and areas ofapplicationrdquo in Proceedings of the 2019 IEEE InternationalConference on Big Data (Big Data) pp 6040ndash6042 LosAngeles CA USA 2019 December
[33] D Glez-Pentildea A Lourenccedilo H Lopez-Fernandez M Reboiro-Jato and F Fdez-Riverola ldquoWeb scraping technologies in anAPI worldrdquo Briefings in Bioinformatics vol 15 no 5pp 788ndash797 2014
[34] E Uzun ldquoA novel web scraping approach using the additionalinformation obtained from web pagesrdquo IEEE Access vol 8Article ID 61726 2020
[35] M Gupta N Kumar B K Singh and N Gupta ldquoNSGA-III-Based deep-learning model for biomedical search enginerdquoMathematical Problems in Engineering vol 2021 Article ID9935862 8 pages 2021
[36] J Mor N Kumar and D Rai ldquoAn improved crawler based onefficient ranking algorithmrdquo International Journal of Ad-vanced Trends in Computer Science and Engineering vol 8pp 119ndash125 2019
[37] J Mor D Rai and N Kumar ldquoAn XML based web crawlerwith page revisit policy and updation in local repository ofsearch enginerdquo International Journal of Engineering ampTechnology vol 7 no 3 pp 1119ndash1123 2018
[38] J Mor N Kumar and D Rai ldquoResearch on mechanism andchallenges in meta search enginesrdquo International Journal ofInnovative Technology and Exploring Engineering vol 8 no 9pp 281ndash284 2019
[39] N Kumar R Nath and P Kherwa ldquoAn automated frame-work based on TLS to choose best search engine in a particulardomainrdquo International Journal of Computer Applicationvol 83 no 14 pp 42ndash48 2013
[40] J Mor N Kumar and D Rai ldquoEffective presentation ofresults using ranking amp clustering in meta search engineCOMPUSOFTrdquo An International Journal of AdvancedComputer Technology vol 7 no 12 2018
[41] N Kumar and P Dahiya ldquoWeighted similarity page rank animprovement in WPR and WSRrdquo International Journal ofComputer Engineering and Applications vol 11 no VIIIpp 1ndash11 2017
[42] N Kumar and R Nath ldquoA meta search engine approach fororganizing web search results using ranking and clusteringrdquoInternational Journal of Computer 2013
[43] N Kumar D Tyagi and S Awasthi ldquoSurvey on crawlingtechniquesrdquo in Proceedings of the 5th International Conferenceon ldquoComputing for Sustainable Global Developmentpp 2449ndash2455 New Delhi India March 2018
[44] N Kumar ldquoDocument clustering approach for meta searchenginerdquo IOP Conference Series Materials Science and Engi-neering vol 225 Article ID 012291 2017
[45] N Kumar D Tyagi S Awasthi and J Mor ldquoChange de-tection of web page in focused crawling systemrdquo InternationalJournal of Control Heory and Applications vol 10 no 6pp 671ndash676 2017
[46] N Kumar and P Singh ldquoMeta search engine with semanticanalysis and query processingrdquo International Journal ofComputational Intelligence Research ISSN vol 13 no 8pp 0973ndash1873 2017
[47] N Kumar ldquoSegmentation based twitter opinion mining usingensemble learningrdquo International Journal on Future Revolu-tion in Computer Science amp Communication Engineeringvol 3 no 9 2017
[48] R Nath N Kumar and S Tuteja ldquoA survey on reduction ofload on the networkrdquo Intelligent Distributed Computingpp 239ndash249 Springer New York NY USA 2015
[49] N Kumar N N Das D Gupta K Gupta and J BindraldquoEfficient automated disease diagnosis usingmachine learningmodelsrdquo Journal of Healthcare Engineering vol 2021 ArticleID 9983652 13 pages 2021
[50] V Singrodia A Mitra and S Paul ldquoA review on webscrapping and its applicationsrdquo in Proceedings of the 2019International Conference on Computer Communication andInformatics pp 1ndash6 Coimbatore India 2019 January
10 Computational Intelligence and Neuroscience
[51] R Nath and N Kumar ldquoA novel parallel domain focusedcrawler for reduction in load on the networkrdquo InternationalJournal of Computational Engineering Research vol 2 no 7pp 77ndash84 2012
[52] V Shrivastava ldquoA methodical study of web crawlerrdquo Journalof Engineering Research and Application vol 8 no 11 pp 1ndash82018
[53] S Amudha and M Phil ldquoWeb crawler for mining web datardquoInternational Research Journal of Engineering and Technology(IRJET) vol 4 no 2 pp 2395ndash0072 2017
[54] N Nassar A Jafar and Y Rahhal ldquoA novel deep multi-criteria collaborative filtering model for recommendationsystemrdquo Knowledge-Based Systems vol 187 Article ID104811 2020
[55] M Fu H Qu Z Yi L Lu and Y Liu ldquoA novel deep learning-based collaborative filtering model for recommendationsystemrdquo IEEE Transactions on Cybernetics vol 49 no 3pp 1084ndash1096 2018
Computational Intelligence and Neuroscience 11
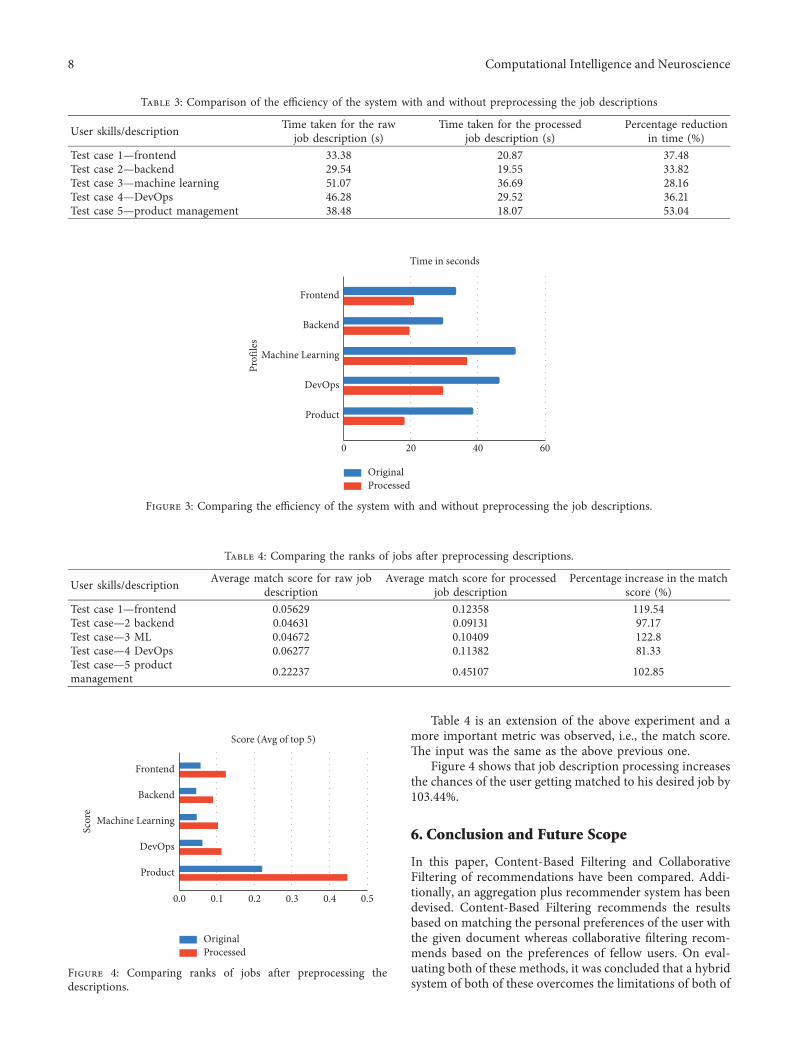
Table 4 is an extension of the above experiment and amore important metric was observed ie the match score+e input was the same as the above previous one
Figure 4 shows that job description processing increasesthe chances of the user getting matched to his desired job by10344
6 Conclusion and Future Scope
In this paper Content-Based Filtering and CollaborativeFiltering of recommendations have been compared Addi-tionally an aggregation plus recommender system has beendevised Content-Based Filtering recommends the resultsbased on matching the personal preferences of the user withthe given document whereas collaborative filtering recom-mends based on the preferences of fellow users On eval-uating both of these methods it was concluded that a hybridsystem of both of these overcomes the limitations of both of
Table 3 Comparison of the efficiency of the system with and without preprocessing the job descriptions
User skillsdescription Time taken for the rawjob description (s)
Time taken for the processedjob description (s)
Percentage reductionin time ()
Test case 1mdashfrontend 3338 2087 3748Test case 2mdashbackend 2954 1955 3382Test case 3mdashmachine learning 5107 3669 2816Test case 4mdashDevOps 4628 2952 3621Test case 5mdashproduct management 3848 1807 5304
Table 4 Comparing the ranks of jobs after preprocessing descriptions
User skillsdescription Average match score for raw jobdescription
Average match score for processedjob description
Percentage increase in the matchscore ()
Test case 1mdashfrontend 005629 012358 11954Test casemdash2 backend 004631 009131 9717Test casemdash3 ML 004672 010409 1228Test casemdash4 DevOps 006277 011382 8133Test casemdash5 productmanagement 022237 045107 10285
Time in seconds
Product
DevOps
Machine Learning
Backend
Frontend
Prof
iles
40 600 20
OriginalProcessed
Figure 3 Comparing the efficiency of the system with and without preprocessing the job descriptions
Frontend
Backend
Machine Learning
DevOps
Product
Scor
e
Score (Avg of top 5)
OriginalProcessed
01 02 03 04 0500
Figure 4 Comparing ranks of jobs after preprocessing thedescriptions
8 Computational Intelligence and Neuroscience
them and increases the efficiency of ranking Problems ofcold start sparse database scalability and lack of trendrecommendation [5] have been eliminated +e proposal isto design a Job Recommender system that prioritizes qualityover quantity While there are websites and job listingportals already recommending jobs to job seekers based ontheir profiles this research on aggregate quality recom-mendations has been achieved by crawling selectivelyovercoming the limitations of [1 4 14] A fully functioninguser interface was developed to combine everything togetherto give the user a seamless experience
For this system to be hybrid content-based filtering isrequired which can only recommend jobs based on theuserrsquos current profile It cannot deliver anything surprisingbased on the userrsquos past searches +is paper also usescollaborative filtering which faces well-known problems ofprivacy breaches and cold start +e system has a broadscope that can be used to make it more robust and foolproofFirstly automating the crawling process is required when anew company is added to the database In other wordsremoving the one-time configuration stepprocess to fetchjobs of a particular new company can be done +ese modelscan implement techniques such as KNN in collaborativefiltering Implementing NLP in content-based filtering forbetter and more accurate search matching can be doneAlong with this testing and collecting more user data forbetter performance of the collaborative filtering module isrequired Lastly improving the cleansing process of the jobdescription and using natural language processing are re-quired While using collaborative filtering this work can beimproved by giving different weights to different users basedon their LinkedIn skills
Data Availability
+e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
+e authors declare that they have no conflicts of interest
References
[1] C Slamet R Andrian D S A Maylawati W Darmalaksanaand M A Ramdhani ldquoWeb scraping and Naıve Bayes clas-sification for job search enginerdquo IOP Conference SeriesMaterials Science and Engineering vol 288 no 1 Article ID012038 2018
[2] D V Musale M K Nagpure K S Patil and R F SayyedldquoJob recommendation system using profile matching and webcrawlingrdquo Int J Adv Sci Res Eng Trendsvol 1 2016
[3] U P K Kethavarapu and S Saraswathi ldquoConcept baseddynamic ontology creation for job recommendation systemrdquoProcedia Computer Science vol 85 pp 915ndash921 2016
[4] A S Parihar Y K Gupta Y Singodia V Singh and K SinghldquoA comparative study of image dehazing algorithmsrdquo inProceedings of the 2020 5th International Conference onCommunication and Electronics Systems (ICCES) pp 766ndash771 Coimbatore India 2020 June
[5] R Mishra and S Rathi ldquoEfficient and scalable job recom-mender system using collaborative filteringrdquo in ICDSMLA2019 pp 842ndash856 Springer Singapore 2020
[6] D Mhamdi R Moulouki M Y El Ghoumari M Azzouaziand L Moussaid ldquoJob recommendation based on job profileclustering and job seeker behaviorrdquo Procedia Computer Sci-ence vol 175 pp 695ndash699 2020
[7] V Desai D Bahl S Vibhandik and I Fatma ldquoImple-mentation of an automated job recommendation systembased on candidate profilesrdquo Int Res J Eng Technol vol 4no 5 pp 1018ndash1021 2017
[8] V Indira and S Rathika ldquoA study on E-recruitment and itrsquospresent condition towards job seekersrdquo International Re-search Journal of Engineering and Technology (IRJET) ISSNISSN 2395-0056 vol 7 no 4 pp 3753ndash3758 2020
[9] R Pradhan J Varshney K Goyal and L Kumari ldquoJobrecommendation system using content and collaborative-based filteringrdquo in International Conference on InnovativeComputing and Communications pp 575ndash583 SpringerNature New York NY USA 2022
[10] R G Belsare and V M Deshmukh ldquoEmployment recom-mendation system using matching collaborative filtering andcontent- based recommendationrdquo International Journal ofComputer Applications Technology and Research vol 7 no 6pp 215ndash220 2018
[11] P Manjare J Kumbhar S Ovhal and R Munde ldquoAn ef-fective job recruitment system using content-based filteringrdquoInternational Journal of Engineering amp Technology vol 4no 3 pp 2395ndash0056 2017
[12] C P Akshaya ldquoEnhancement of recommender system usingcollaborative filteringrdquo International Research Journal ofEngineering and Technology vol 5 no 4 pp 2198ndash2200 2018
[13] H Jain and M Kakkar ldquoJob recommendation system basedon machine learning and data mining techniques usingRESTful API and android IDErdquo in Proceedings of the 2019 9thInternational Conference on Cloud Computing Data Science ampEngineering (Confluence) pp 416ndash421 Noida India 2019January
[14] P Yi C Yang C Li and Y Zhang ldquoA job recommendationmethod optimized by position descriptions and resume in-formationrdquo in Proceedings of the 2016 IEEE Advanced In-formation Management Communicates Electronic andAutomation Control Conference (IMCEC) pp 761ndash764 XirsquoanChina 2016 October
[15] H Apaza A A Rubin de Celis Vidal and J E Chire SaireldquoJob recommendation based on curriculum vitae using textminingrdquo in Future of Information and CommunicationConference pp 1051ndash1059 Springer New York NY USA2021
[16] D Nasution and Z Sitorus ldquoEnhance web-based job searchrecommendation system of hybrid-based recommendationrdquoBudapest International Research and Critics Institute (BIRCI-Journal) Humanities and Social Sciences vol 4 no 3pp 7214ndash7221 2021
[17] Q Zhou F Liao L Ge and J Sun ldquoPersonalized preferencecollaborative filtering job recommendation for graduatesrdquo inProceedings of the 2019 IEEE SmartWorld Ubiquitous Intel-ligence amp Computing Advanced amp Trusted ComputingScalable Computing amp Communications Cloud amp Big DataComputing Internet of People and Smart City Innovationpp 1055ndash1062 Leicester UK 2019 August
[18] R Patel and S K Vishwakarma ldquoAn efficient approach for jobrecommendation system based on collaborative filteringrdquo ICT
Computational Intelligence and Neuroscience 9
Systems and Sustainability Proceedings of ICT4SD SpringerNature vol 1 p 169 New York NY USA 2020
[19] Y C Chou and H Y Yu ldquoBased on the application of AItechnology in resume analysis and job recommendationrdquo inProceedings of the 2020 IEEE International Conference onComputational Electromagnetics (ICCEM) pp 291ndash296Singapore 2020 August
[20] D Punitavathi V Shinu S Kumar and V P Sp ldquoOnline joband candidate recommendation systemrdquo International Re-search Journal of Multidisciplinary Technovation vol 1pp 84ndash89 2019
[21] T V Yadalam V M Gowda V S Kumar D Girish andM Namratha ldquoCareer recommendation systems using con-tent based filteringrdquo in Proceedings of the 2020 5th Interna-tional Conference on Communication and Electronics Systems(ICCES) pp 660ndash665 Coimbatore India 2020 June
[22] N Almalis G Tsihrintzis and N Karagiannis ldquoA newcontent-based recommendation algorithm for job recruitingrdquoin Proceedings of the International Conference on InnovativeTechniques and Applications of Artificial Intelligencepp 393ndash398 Springer Corfu Greece 2015 December
[23] J Suharyadi and A Kusnadi ldquoStay at home reservation themitigation step in covid-19 pandemicrdquo International Journalof New Media Technology vol 5 no 2 pp 116ndash120 2018
[24] S R Rimitha V Abburu A Kiranmai andK Chandrasekaran ldquoOntologies to model user profiles inpersonalized job recommendationrdquo in Proceedings of the 2018IEEE Distributed Computing VLSI Electrical Circuits andRobotics (DISCOVER) pp 98ndash103 Mangalore India 2018August
[25] F J M Shamrat Z Tasnim A S Rahman N I Nobel andS A Hossain ldquoAn effective implementation of web crawlingtechnology to retrieve data from the world wide web(WWW)rdquo International Journal of Scientific amp TechnologyResearch vol 9 no 01 pp 1252ndash1256 2020
[26] H Nigam and P Biswas ldquoFrom web scraping to webcrawlingrdquo in Applications of Artificial Intelligence and Ma-chine Learning pp 97ndash112 Springer Singapore 2021
[27] T Karthikeyan K Sekaran D Ranjith and J M BalajeeldquoPersonalized content extraction and text classification usingeffective web scraping techniquesrdquo International Journal ofWeb Portals vol 11 no 2 pp 41ndash52 2019
[28] N Kumar and D Aggarwal ldquoLEARNING-based focusedWEB crawlerrdquo IETE Journal of Research pp 1ndash9 2021
[29] D Rai N Kumar and J Mor ldquoReview on improving per-formance of web crawler and search system ArchitecturerdquoInternational Journal of Advanced Studies of Scientific Re-search vol 3 no 10 2018
[30] T Kamishima S Akaho H Asoh and J Sakuma ldquoRecom-mendation independencerdquo in Proceedings of the Conferenceon Fairness Accountability and Transparency 187-201) NewYork NY USA 2018 January
[31] M Kumar A Bindal R Gautam and R Bhatia ldquoKeywordquery based focused Web crawlerrdquo Procedia Computer Sci-ence vol 125 pp 584ndash590 2018
[32] R Diouf E N Sarr O Sall B Birregah M Bousso andS N Mbaye ldquoWeb scraping state-of-the-art and areas ofapplicationrdquo in Proceedings of the 2019 IEEE InternationalConference on Big Data (Big Data) pp 6040ndash6042 LosAngeles CA USA 2019 December
[33] D Glez-Pentildea A Lourenccedilo H Lopez-Fernandez M Reboiro-Jato and F Fdez-Riverola ldquoWeb scraping technologies in anAPI worldrdquo Briefings in Bioinformatics vol 15 no 5pp 788ndash797 2014
[34] E Uzun ldquoA novel web scraping approach using the additionalinformation obtained from web pagesrdquo IEEE Access vol 8Article ID 61726 2020
[35] M Gupta N Kumar B K Singh and N Gupta ldquoNSGA-III-Based deep-learning model for biomedical search enginerdquoMathematical Problems in Engineering vol 2021 Article ID9935862 8 pages 2021
[36] J Mor N Kumar and D Rai ldquoAn improved crawler based onefficient ranking algorithmrdquo International Journal of Ad-vanced Trends in Computer Science and Engineering vol 8pp 119ndash125 2019
[37] J Mor D Rai and N Kumar ldquoAn XML based web crawlerwith page revisit policy and updation in local repository ofsearch enginerdquo International Journal of Engineering ampTechnology vol 7 no 3 pp 1119ndash1123 2018
[38] J Mor N Kumar and D Rai ldquoResearch on mechanism andchallenges in meta search enginesrdquo International Journal ofInnovative Technology and Exploring Engineering vol 8 no 9pp 281ndash284 2019
[39] N Kumar R Nath and P Kherwa ldquoAn automated frame-work based on TLS to choose best search engine in a particulardomainrdquo International Journal of Computer Applicationvol 83 no 14 pp 42ndash48 2013
[40] J Mor N Kumar and D Rai ldquoEffective presentation ofresults using ranking amp clustering in meta search engineCOMPUSOFTrdquo An International Journal of AdvancedComputer Technology vol 7 no 12 2018
[41] N Kumar and P Dahiya ldquoWeighted similarity page rank animprovement in WPR and WSRrdquo International Journal ofComputer Engineering and Applications vol 11 no VIIIpp 1ndash11 2017
[42] N Kumar and R Nath ldquoA meta search engine approach fororganizing web search results using ranking and clusteringrdquoInternational Journal of Computer 2013
[43] N Kumar D Tyagi and S Awasthi ldquoSurvey on crawlingtechniquesrdquo in Proceedings of the 5th International Conferenceon ldquoComputing for Sustainable Global Developmentpp 2449ndash2455 New Delhi India March 2018
[44] N Kumar ldquoDocument clustering approach for meta searchenginerdquo IOP Conference Series Materials Science and Engi-neering vol 225 Article ID 012291 2017
[45] N Kumar D Tyagi S Awasthi and J Mor ldquoChange de-tection of web page in focused crawling systemrdquo InternationalJournal of Control Heory and Applications vol 10 no 6pp 671ndash676 2017
[46] N Kumar and P Singh ldquoMeta search engine with semanticanalysis and query processingrdquo International Journal ofComputational Intelligence Research ISSN vol 13 no 8pp 0973ndash1873 2017
[47] N Kumar ldquoSegmentation based twitter opinion mining usingensemble learningrdquo International Journal on Future Revolu-tion in Computer Science amp Communication Engineeringvol 3 no 9 2017
[48] R Nath N Kumar and S Tuteja ldquoA survey on reduction ofload on the networkrdquo Intelligent Distributed Computingpp 239ndash249 Springer New York NY USA 2015
[49] N Kumar N N Das D Gupta K Gupta and J BindraldquoEfficient automated disease diagnosis usingmachine learningmodelsrdquo Journal of Healthcare Engineering vol 2021 ArticleID 9983652 13 pages 2021
[50] V Singrodia A Mitra and S Paul ldquoA review on webscrapping and its applicationsrdquo in Proceedings of the 2019International Conference on Computer Communication andInformatics pp 1ndash6 Coimbatore India 2019 January
10 Computational Intelligence and Neuroscience
[51] R Nath and N Kumar ldquoA novel parallel domain focusedcrawler for reduction in load on the networkrdquo InternationalJournal of Computational Engineering Research vol 2 no 7pp 77ndash84 2012
[52] V Shrivastava ldquoA methodical study of web crawlerrdquo Journalof Engineering Research and Application vol 8 no 11 pp 1ndash82018
[53] S Amudha and M Phil ldquoWeb crawler for mining web datardquoInternational Research Journal of Engineering and Technology(IRJET) vol 4 no 2 pp 2395ndash0072 2017
[54] N Nassar A Jafar and Y Rahhal ldquoA novel deep multi-criteria collaborative filtering model for recommendationsystemrdquo Knowledge-Based Systems vol 187 Article ID104811 2020
[55] M Fu H Qu Z Yi L Lu and Y Liu ldquoA novel deep learning-based collaborative filtering model for recommendationsystemrdquo IEEE Transactions on Cybernetics vol 49 no 3pp 1084ndash1096 2018
Computational Intelligence and Neuroscience 11

them and increases the efficiency of ranking Problems ofcold start sparse database scalability and lack of trendrecommendation [5] have been eliminated +e proposal isto design a Job Recommender system that prioritizes qualityover quantity While there are websites and job listingportals already recommending jobs to job seekers based ontheir profiles this research on aggregate quality recom-mendations has been achieved by crawling selectivelyovercoming the limitations of [1 4 14] A fully functioninguser interface was developed to combine everything togetherto give the user a seamless experience
For this system to be hybrid content-based filtering isrequired which can only recommend jobs based on theuserrsquos current profile It cannot deliver anything surprisingbased on the userrsquos past searches +is paper also usescollaborative filtering which faces well-known problems ofprivacy breaches and cold start +e system has a broadscope that can be used to make it more robust and foolproofFirstly automating the crawling process is required when anew company is added to the database In other wordsremoving the one-time configuration stepprocess to fetchjobs of a particular new company can be done +ese modelscan implement techniques such as KNN in collaborativefiltering Implementing NLP in content-based filtering forbetter and more accurate search matching can be doneAlong with this testing and collecting more user data forbetter performance of the collaborative filtering module isrequired Lastly improving the cleansing process of the jobdescription and using natural language processing are re-quired While using collaborative filtering this work can beimproved by giving different weights to different users basedon their LinkedIn skills
Data Availability
+e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
+e authors declare that they have no conflicts of interest
References
[1] C Slamet R Andrian D S A Maylawati W Darmalaksanaand M A Ramdhani ldquoWeb scraping and Naıve Bayes clas-sification for job search enginerdquo IOP Conference SeriesMaterials Science and Engineering vol 288 no 1 Article ID012038 2018
[2] D V Musale M K Nagpure K S Patil and R F SayyedldquoJob recommendation system using profile matching and webcrawlingrdquo Int J Adv Sci Res Eng Trendsvol 1 2016
[3] U P K Kethavarapu and S Saraswathi ldquoConcept baseddynamic ontology creation for job recommendation systemrdquoProcedia Computer Science vol 85 pp 915ndash921 2016
[4] A S Parihar Y K Gupta Y Singodia V Singh and K SinghldquoA comparative study of image dehazing algorithmsrdquo inProceedings of the 2020 5th International Conference onCommunication and Electronics Systems (ICCES) pp 766ndash771 Coimbatore India 2020 June
[5] R Mishra and S Rathi ldquoEfficient and scalable job recom-mender system using collaborative filteringrdquo in ICDSMLA2019 pp 842ndash856 Springer Singapore 2020
[6] D Mhamdi R Moulouki M Y El Ghoumari M Azzouaziand L Moussaid ldquoJob recommendation based on job profileclustering and job seeker behaviorrdquo Procedia Computer Sci-ence vol 175 pp 695ndash699 2020
[7] V Desai D Bahl S Vibhandik and I Fatma ldquoImple-mentation of an automated job recommendation systembased on candidate profilesrdquo Int Res J Eng Technol vol 4no 5 pp 1018ndash1021 2017
[8] V Indira and S Rathika ldquoA study on E-recruitment and itrsquospresent condition towards job seekersrdquo International Re-search Journal of Engineering and Technology (IRJET) ISSNISSN 2395-0056 vol 7 no 4 pp 3753ndash3758 2020
[9] R Pradhan J Varshney K Goyal and L Kumari ldquoJobrecommendation system using content and collaborative-based filteringrdquo in International Conference on InnovativeComputing and Communications pp 575ndash583 SpringerNature New York NY USA 2022
[10] R G Belsare and V M Deshmukh ldquoEmployment recom-mendation system using matching collaborative filtering andcontent- based recommendationrdquo International Journal ofComputer Applications Technology and Research vol 7 no 6pp 215ndash220 2018
[11] P Manjare J Kumbhar S Ovhal and R Munde ldquoAn ef-fective job recruitment system using content-based filteringrdquoInternational Journal of Engineering amp Technology vol 4no 3 pp 2395ndash0056 2017
[12] C P Akshaya ldquoEnhancement of recommender system usingcollaborative filteringrdquo International Research Journal ofEngineering and Technology vol 5 no 4 pp 2198ndash2200 2018
[13] H Jain and M Kakkar ldquoJob recommendation system basedon machine learning and data mining techniques usingRESTful API and android IDErdquo in Proceedings of the 2019 9thInternational Conference on Cloud Computing Data Science ampEngineering (Confluence) pp 416ndash421 Noida India 2019January
[14] P Yi C Yang C Li and Y Zhang ldquoA job recommendationmethod optimized by position descriptions and resume in-formationrdquo in Proceedings of the 2016 IEEE Advanced In-formation Management Communicates Electronic andAutomation Control Conference (IMCEC) pp 761ndash764 XirsquoanChina 2016 October
[15] H Apaza A A Rubin de Celis Vidal and J E Chire SaireldquoJob recommendation based on curriculum vitae using textminingrdquo in Future of Information and CommunicationConference pp 1051ndash1059 Springer New York NY USA2021
[16] D Nasution and Z Sitorus ldquoEnhance web-based job searchrecommendation system of hybrid-based recommendationrdquoBudapest International Research and Critics Institute (BIRCI-Journal) Humanities and Social Sciences vol 4 no 3pp 7214ndash7221 2021
[17] Q Zhou F Liao L Ge and J Sun ldquoPersonalized preferencecollaborative filtering job recommendation for graduatesrdquo inProceedings of the 2019 IEEE SmartWorld Ubiquitous Intel-ligence amp Computing Advanced amp Trusted ComputingScalable Computing amp Communications Cloud amp Big DataComputing Internet of People and Smart City Innovationpp 1055ndash1062 Leicester UK 2019 August
[18] R Patel and S K Vishwakarma ldquoAn efficient approach for jobrecommendation system based on collaborative filteringrdquo ICT
Computational Intelligence and Neuroscience 9
Systems and Sustainability Proceedings of ICT4SD SpringerNature vol 1 p 169 New York NY USA 2020
[19] Y C Chou and H Y Yu ldquoBased on the application of AItechnology in resume analysis and job recommendationrdquo inProceedings of the 2020 IEEE International Conference onComputational Electromagnetics (ICCEM) pp 291ndash296Singapore 2020 August
[20] D Punitavathi V Shinu S Kumar and V P Sp ldquoOnline joband candidate recommendation systemrdquo International Re-search Journal of Multidisciplinary Technovation vol 1pp 84ndash89 2019
[21] T V Yadalam V M Gowda V S Kumar D Girish andM Namratha ldquoCareer recommendation systems using con-tent based filteringrdquo in Proceedings of the 2020 5th Interna-tional Conference on Communication and Electronics Systems(ICCES) pp 660ndash665 Coimbatore India 2020 June
[22] N Almalis G Tsihrintzis and N Karagiannis ldquoA newcontent-based recommendation algorithm for job recruitingrdquoin Proceedings of the International Conference on InnovativeTechniques and Applications of Artificial Intelligencepp 393ndash398 Springer Corfu Greece 2015 December
[23] J Suharyadi and A Kusnadi ldquoStay at home reservation themitigation step in covid-19 pandemicrdquo International Journalof New Media Technology vol 5 no 2 pp 116ndash120 2018
[24] S R Rimitha V Abburu A Kiranmai andK Chandrasekaran ldquoOntologies to model user profiles inpersonalized job recommendationrdquo in Proceedings of the 2018IEEE Distributed Computing VLSI Electrical Circuits andRobotics (DISCOVER) pp 98ndash103 Mangalore India 2018August
[25] F J M Shamrat Z Tasnim A S Rahman N I Nobel andS A Hossain ldquoAn effective implementation of web crawlingtechnology to retrieve data from the world wide web(WWW)rdquo International Journal of Scientific amp TechnologyResearch vol 9 no 01 pp 1252ndash1256 2020
[26] H Nigam and P Biswas ldquoFrom web scraping to webcrawlingrdquo in Applications of Artificial Intelligence and Ma-chine Learning pp 97ndash112 Springer Singapore 2021
[27] T Karthikeyan K Sekaran D Ranjith and J M BalajeeldquoPersonalized content extraction and text classification usingeffective web scraping techniquesrdquo International Journal ofWeb Portals vol 11 no 2 pp 41ndash52 2019
[28] N Kumar and D Aggarwal ldquoLEARNING-based focusedWEB crawlerrdquo IETE Journal of Research pp 1ndash9 2021
[29] D Rai N Kumar and J Mor ldquoReview on improving per-formance of web crawler and search system ArchitecturerdquoInternational Journal of Advanced Studies of Scientific Re-search vol 3 no 10 2018
[30] T Kamishima S Akaho H Asoh and J Sakuma ldquoRecom-mendation independencerdquo in Proceedings of the Conferenceon Fairness Accountability and Transparency 187-201) NewYork NY USA 2018 January
[31] M Kumar A Bindal R Gautam and R Bhatia ldquoKeywordquery based focused Web crawlerrdquo Procedia Computer Sci-ence vol 125 pp 584ndash590 2018
[32] R Diouf E N Sarr O Sall B Birregah M Bousso andS N Mbaye ldquoWeb scraping state-of-the-art and areas ofapplicationrdquo in Proceedings of the 2019 IEEE InternationalConference on Big Data (Big Data) pp 6040ndash6042 LosAngeles CA USA 2019 December
[33] D Glez-Pentildea A Lourenccedilo H Lopez-Fernandez M Reboiro-Jato and F Fdez-Riverola ldquoWeb scraping technologies in anAPI worldrdquo Briefings in Bioinformatics vol 15 no 5pp 788ndash797 2014
[34] E Uzun ldquoA novel web scraping approach using the additionalinformation obtained from web pagesrdquo IEEE Access vol 8Article ID 61726 2020
[35] M Gupta N Kumar B K Singh and N Gupta ldquoNSGA-III-Based deep-learning model for biomedical search enginerdquoMathematical Problems in Engineering vol 2021 Article ID9935862 8 pages 2021
[36] J Mor N Kumar and D Rai ldquoAn improved crawler based onefficient ranking algorithmrdquo International Journal of Ad-vanced Trends in Computer Science and Engineering vol 8pp 119ndash125 2019
[37] J Mor D Rai and N Kumar ldquoAn XML based web crawlerwith page revisit policy and updation in local repository ofsearch enginerdquo International Journal of Engineering ampTechnology vol 7 no 3 pp 1119ndash1123 2018
[38] J Mor N Kumar and D Rai ldquoResearch on mechanism andchallenges in meta search enginesrdquo International Journal ofInnovative Technology and Exploring Engineering vol 8 no 9pp 281ndash284 2019
[39] N Kumar R Nath and P Kherwa ldquoAn automated frame-work based on TLS to choose best search engine in a particulardomainrdquo International Journal of Computer Applicationvol 83 no 14 pp 42ndash48 2013
[40] J Mor N Kumar and D Rai ldquoEffective presentation ofresults using ranking amp clustering in meta search engineCOMPUSOFTrdquo An International Journal of AdvancedComputer Technology vol 7 no 12 2018
[41] N Kumar and P Dahiya ldquoWeighted similarity page rank animprovement in WPR and WSRrdquo International Journal ofComputer Engineering and Applications vol 11 no VIIIpp 1ndash11 2017
[42] N Kumar and R Nath ldquoA meta search engine approach fororganizing web search results using ranking and clusteringrdquoInternational Journal of Computer 2013
[43] N Kumar D Tyagi and S Awasthi ldquoSurvey on crawlingtechniquesrdquo in Proceedings of the 5th International Conferenceon ldquoComputing for Sustainable Global Developmentpp 2449ndash2455 New Delhi India March 2018
[44] N Kumar ldquoDocument clustering approach for meta searchenginerdquo IOP Conference Series Materials Science and Engi-neering vol 225 Article ID 012291 2017
[45] N Kumar D Tyagi S Awasthi and J Mor ldquoChange de-tection of web page in focused crawling systemrdquo InternationalJournal of Control Heory and Applications vol 10 no 6pp 671ndash676 2017
[46] N Kumar and P Singh ldquoMeta search engine with semanticanalysis and query processingrdquo International Journal ofComputational Intelligence Research ISSN vol 13 no 8pp 0973ndash1873 2017
[47] N Kumar ldquoSegmentation based twitter opinion mining usingensemble learningrdquo International Journal on Future Revolu-tion in Computer Science amp Communication Engineeringvol 3 no 9 2017
[48] R Nath N Kumar and S Tuteja ldquoA survey on reduction ofload on the networkrdquo Intelligent Distributed Computingpp 239ndash249 Springer New York NY USA 2015
[49] N Kumar N N Das D Gupta K Gupta and J BindraldquoEfficient automated disease diagnosis usingmachine learningmodelsrdquo Journal of Healthcare Engineering vol 2021 ArticleID 9983652 13 pages 2021
[50] V Singrodia A Mitra and S Paul ldquoA review on webscrapping and its applicationsrdquo in Proceedings of the 2019International Conference on Computer Communication andInformatics pp 1ndash6 Coimbatore India 2019 January
10 Computational Intelligence and Neuroscience
[51] R Nath and N Kumar ldquoA novel parallel domain focusedcrawler for reduction in load on the networkrdquo InternationalJournal of Computational Engineering Research vol 2 no 7pp 77ndash84 2012
[52] V Shrivastava ldquoA methodical study of web crawlerrdquo Journalof Engineering Research and Application vol 8 no 11 pp 1ndash82018
[53] S Amudha and M Phil ldquoWeb crawler for mining web datardquoInternational Research Journal of Engineering and Technology(IRJET) vol 4 no 2 pp 2395ndash0072 2017
[54] N Nassar A Jafar and Y Rahhal ldquoA novel deep multi-criteria collaborative filtering model for recommendationsystemrdquo Knowledge-Based Systems vol 187 Article ID104811 2020
[55] M Fu H Qu Z Yi L Lu and Y Liu ldquoA novel deep learning-based collaborative filtering model for recommendationsystemrdquo IEEE Transactions on Cybernetics vol 49 no 3pp 1084ndash1096 2018
Computational Intelligence and Neuroscience 11

Systems and Sustainability Proceedings of ICT4SD SpringerNature vol 1 p 169 New York NY USA 2020
[19] Y C Chou and H Y Yu ldquoBased on the application of AItechnology in resume analysis and job recommendationrdquo inProceedings of the 2020 IEEE International Conference onComputational Electromagnetics (ICCEM) pp 291ndash296Singapore 2020 August
[20] D Punitavathi V Shinu S Kumar and V P Sp ldquoOnline joband candidate recommendation systemrdquo International Re-search Journal of Multidisciplinary Technovation vol 1pp 84ndash89 2019
[21] T V Yadalam V M Gowda V S Kumar D Girish andM Namratha ldquoCareer recommendation systems using con-tent based filteringrdquo in Proceedings of the 2020 5th Interna-tional Conference on Communication and Electronics Systems(ICCES) pp 660ndash665 Coimbatore India 2020 June
[22] N Almalis G Tsihrintzis and N Karagiannis ldquoA newcontent-based recommendation algorithm for job recruitingrdquoin Proceedings of the International Conference on InnovativeTechniques and Applications of Artificial Intelligencepp 393ndash398 Springer Corfu Greece 2015 December
[23] J Suharyadi and A Kusnadi ldquoStay at home reservation themitigation step in covid-19 pandemicrdquo International Journalof New Media Technology vol 5 no 2 pp 116ndash120 2018
[24] S R Rimitha V Abburu A Kiranmai andK Chandrasekaran ldquoOntologies to model user profiles inpersonalized job recommendationrdquo in Proceedings of the 2018IEEE Distributed Computing VLSI Electrical Circuits andRobotics (DISCOVER) pp 98ndash103 Mangalore India 2018August
[25] F J M Shamrat Z Tasnim A S Rahman N I Nobel andS A Hossain ldquoAn effective implementation of web crawlingtechnology to retrieve data from the world wide web(WWW)rdquo International Journal of Scientific amp TechnologyResearch vol 9 no 01 pp 1252ndash1256 2020
[26] H Nigam and P Biswas ldquoFrom web scraping to webcrawlingrdquo in Applications of Artificial Intelligence and Ma-chine Learning pp 97ndash112 Springer Singapore 2021
[27] T Karthikeyan K Sekaran D Ranjith and J M BalajeeldquoPersonalized content extraction and text classification usingeffective web scraping techniquesrdquo International Journal ofWeb Portals vol 11 no 2 pp 41ndash52 2019
[28] N Kumar and D Aggarwal ldquoLEARNING-based focusedWEB crawlerrdquo IETE Journal of Research pp 1ndash9 2021
[29] D Rai N Kumar and J Mor ldquoReview on improving per-formance of web crawler and search system ArchitecturerdquoInternational Journal of Advanced Studies of Scientific Re-search vol 3 no 10 2018
[30] T Kamishima S Akaho H Asoh and J Sakuma ldquoRecom-mendation independencerdquo in Proceedings of the Conferenceon Fairness Accountability and Transparency 187-201) NewYork NY USA 2018 January
[31] M Kumar A Bindal R Gautam and R Bhatia ldquoKeywordquery based focused Web crawlerrdquo Procedia Computer Sci-ence vol 125 pp 584ndash590 2018
[32] R Diouf E N Sarr O Sall B Birregah M Bousso andS N Mbaye ldquoWeb scraping state-of-the-art and areas ofapplicationrdquo in Proceedings of the 2019 IEEE InternationalConference on Big Data (Big Data) pp 6040ndash6042 LosAngeles CA USA 2019 December
[33] D Glez-Pentildea A Lourenccedilo H Lopez-Fernandez M Reboiro-Jato and F Fdez-Riverola ldquoWeb scraping technologies in anAPI worldrdquo Briefings in Bioinformatics vol 15 no 5pp 788ndash797 2014
[34] E Uzun ldquoA novel web scraping approach using the additionalinformation obtained from web pagesrdquo IEEE Access vol 8Article ID 61726 2020
[35] M Gupta N Kumar B K Singh and N Gupta ldquoNSGA-III-Based deep-learning model for biomedical search enginerdquoMathematical Problems in Engineering vol 2021 Article ID9935862 8 pages 2021
[36] J Mor N Kumar and D Rai ldquoAn improved crawler based onefficient ranking algorithmrdquo International Journal of Ad-vanced Trends in Computer Science and Engineering vol 8pp 119ndash125 2019
[37] J Mor D Rai and N Kumar ldquoAn XML based web crawlerwith page revisit policy and updation in local repository ofsearch enginerdquo International Journal of Engineering ampTechnology vol 7 no 3 pp 1119ndash1123 2018
[38] J Mor N Kumar and D Rai ldquoResearch on mechanism andchallenges in meta search enginesrdquo International Journal ofInnovative Technology and Exploring Engineering vol 8 no 9pp 281ndash284 2019
[39] N Kumar R Nath and P Kherwa ldquoAn automated frame-work based on TLS to choose best search engine in a particulardomainrdquo International Journal of Computer Applicationvol 83 no 14 pp 42ndash48 2013
[40] J Mor N Kumar and D Rai ldquoEffective presentation ofresults using ranking amp clustering in meta search engineCOMPUSOFTrdquo An International Journal of AdvancedComputer Technology vol 7 no 12 2018
[41] N Kumar and P Dahiya ldquoWeighted similarity page rank animprovement in WPR and WSRrdquo International Journal ofComputer Engineering and Applications vol 11 no VIIIpp 1ndash11 2017
[42] N Kumar and R Nath ldquoA meta search engine approach fororganizing web search results using ranking and clusteringrdquoInternational Journal of Computer 2013
[43] N Kumar D Tyagi and S Awasthi ldquoSurvey on crawlingtechniquesrdquo in Proceedings of the 5th International Conferenceon ldquoComputing for Sustainable Global Developmentpp 2449ndash2455 New Delhi India March 2018
[44] N Kumar ldquoDocument clustering approach for meta searchenginerdquo IOP Conference Series Materials Science and Engi-neering vol 225 Article ID 012291 2017
[45] N Kumar D Tyagi S Awasthi and J Mor ldquoChange de-tection of web page in focused crawling systemrdquo InternationalJournal of Control Heory and Applications vol 10 no 6pp 671ndash676 2017
[46] N Kumar and P Singh ldquoMeta search engine with semanticanalysis and query processingrdquo International Journal ofComputational Intelligence Research ISSN vol 13 no 8pp 0973ndash1873 2017
[47] N Kumar ldquoSegmentation based twitter opinion mining usingensemble learningrdquo International Journal on Future Revolu-tion in Computer Science amp Communication Engineeringvol 3 no 9 2017
[48] R Nath N Kumar and S Tuteja ldquoA survey on reduction ofload on the networkrdquo Intelligent Distributed Computingpp 239ndash249 Springer New York NY USA 2015
[49] N Kumar N N Das D Gupta K Gupta and J BindraldquoEfficient automated disease diagnosis usingmachine learningmodelsrdquo Journal of Healthcare Engineering vol 2021 ArticleID 9983652 13 pages 2021
[50] V Singrodia A Mitra and S Paul ldquoA review on webscrapping and its applicationsrdquo in Proceedings of the 2019International Conference on Computer Communication andInformatics pp 1ndash6 Coimbatore India 2019 January
10 Computational Intelligence and Neuroscience
[51] R Nath and N Kumar ldquoA novel parallel domain focusedcrawler for reduction in load on the networkrdquo InternationalJournal of Computational Engineering Research vol 2 no 7pp 77ndash84 2012
[52] V Shrivastava ldquoA methodical study of web crawlerrdquo Journalof Engineering Research and Application vol 8 no 11 pp 1ndash82018
[53] S Amudha and M Phil ldquoWeb crawler for mining web datardquoInternational Research Journal of Engineering and Technology(IRJET) vol 4 no 2 pp 2395ndash0072 2017
[54] N Nassar A Jafar and Y Rahhal ldquoA novel deep multi-criteria collaborative filtering model for recommendationsystemrdquo Knowledge-Based Systems vol 187 Article ID104811 2020
[55] M Fu H Qu Z Yi L Lu and Y Liu ldquoA novel deep learning-based collaborative filtering model for recommendationsystemrdquo IEEE Transactions on Cybernetics vol 49 no 3pp 1084ndash1096 2018
Computational Intelligence and Neuroscience 11

[51] R Nath and N Kumar ldquoA novel parallel domain focusedcrawler for reduction in load on the networkrdquo InternationalJournal of Computational Engineering Research vol 2 no 7pp 77ndash84 2012
[52] V Shrivastava ldquoA methodical study of web crawlerrdquo Journalof Engineering Research and Application vol 8 no 11 pp 1ndash82018
[53] S Amudha and M Phil ldquoWeb crawler for mining web datardquoInternational Research Journal of Engineering and Technology(IRJET) vol 4 no 2 pp 2395ndash0072 2017
[54] N Nassar A Jafar and Y Rahhal ldquoA novel deep multi-criteria collaborative filtering model for recommendationsystemrdquo Knowledge-Based Systems vol 187 Article ID104811 2020
[55] M Fu H Qu Z Yi L Lu and Y Liu ldquoA novel deep learning-based collaborative filtering model for recommendationsystemrdquo IEEE Transactions on Cybernetics vol 49 no 3pp 1084ndash1096 2018
Computational Intelligence and Neuroscience 11
Related Documents











