INTRODUCTION 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

INTRODUCTION
1

CHAPTER 1
INTRODUCTION
The main objectives of project is to compare the image from the
image class set, method used to compare the image from the image set is done
through the canonical correlation angle. Canonical angle is defined as the angle
between two dimensional sub-spaces. This is the first time where canonical
angle are used for the comparison. Previously comparison was based on the
method Linear Discriminate analysis. In proposed system is to be developed
through the canonical correlation process .Canonical correlation means
perspective view of images i.e. capturing the image in different view and taking
the Eigen value of the images from the principal component values of all the
images and the value is compared with the source image .Image present in
database will be captured under different angle and under the different condition
the value of the entire image will be taken similarly to the source value
also .the benefits of the canonical angle is robust, efficiency, accuracy.
The proposed face recognition system is based on extracting the
dominating features of a set of human faces stored in the database and
performing mathematical operations on the values corresponding to them.
Hence when a new image is fed into the system for recognition the main
features are extracted and computed to find the distance between the input
image and the stored images.We address the problem of comparing sets of
images for object recognition, where the sets may represent variations in an
object’s appearance due to changing camera pose and lighting conditions.
Canonical Correlations (also known as principal or canonical angles), which can
be thought of as the angles between two d-dimensional subspaces, have recently
attracted attention for image set matching.
2

LITERATURE REVIEW
3

CHAPTER 2
LITERATURE REVIEW
2.1 Integration of Sound Signature in Graphical Password Authentication System
In this project, a graphical password system with a supportive sound
signature to increase the remembrance of the password is discussed. In proposed
work a click-based graphical password scheme called Cued Click Points (CCP)
is presented. In this system a password consists of sequence of some images in
which user can select one click-point per image. In addition user is asked to
select a sound signature corresponding to each click point this sound signature
will be used to help the user in recalling the click point on an image. System
showed very good Performance in terms of speed, accuracy, and ease of use.
Users preferred CCP to Pass Points, saying that selecting and remembering only
one point per image was easier and sound signature helps considerably in
recalling the click points.[1]
2.2 Audiovisual Synchronization and Fusion Using Canonical Correlation Analysis It is well-known that early integration (also called data fusion) is effective
when the modalities are correlated, and late integration (also called decision or
opinion fusion) is optimal when modalities are uncorrelated. In this paper, we
propose a new multimodal fusion strategy for open-set speaker identification
using a combination of early and late integration following canonical correlation
analysis (CCA) of speech and lip texture features. We also propose a method for
high precision synchronization of the speech and lip features using CCA prior to
the proposed fusion. Experimental results show that i) the proposed fusion
strategy yields the best equal error rates (EER), which are used to quantify the
performance of the fusion strategy for open-set speaker identification, and ii)
4

precise synchronization prior to fusion improves the EER; hence, the best EER
is obtained when the proposed synchronization scheme is employed together
with the proposed fusion strategy. We note that the proposed fusion strategy
outperforms others because the features used in the late integration are truly
uncorrelated, since they are output of the CCA analysis.[2]
2.3 Discriminative Learning and Recognition of Image Set Classes Using Canonical Correlations
Many computer vision tasks can be cast as learning problems over vector or
image sets. In object recognition, for example, a set of vectors may represent a
variation in an object’s appearance be due to camera pose changes, non rigid
deformations, or variation in illumination conditions. The objective of this work
is to classify an unknown set of vectors to one of the training classes, each also
represented by vector sets. More robust object recognition performance can be
achieved by efficiently using set information rather than a single vector or
image as input. Whereas most of the previous work on matching image sets for
object recognition exploits temporal coherence between consecutive images,
this study does not make any such assumption. Sets may be derived from sparse
and unordered observations acquired by multiple still shots of a three-
dimensional object or a long term monitoring of a scene, as exemplified, e.g., by
surveillance systems, where a subject would not face the camera all the time. By
this, training sets can be more conveniently augmented in the proposed
framework. [3]
5

SYSTEM ANALYSIS
6

CHAPTER 3
SYSTEM DESIGN
3.1 PROPOSED SYSTEM
The proposed system is consist of the canonical correlation.The system
exhibits very good accuracy as well as other attractive properties such as low
computational matching cost and simplicity of feature selection. In the proposed
project the image is detected using the canonical correlation the input can be
given as number of but in orthogonality of subspaces that is in orthogonal sub
space method it is a restrictive condition, when the number of classes or the
image set is large.LDA has been recognized as a powerful method for face
recognition based on a single face image as input and it is restrictive when
image sets are large that is handled by our project.When they are directly
applied to set classification based on sample matching, they inherit the
drawbacks of the classical nonparametric sample-based methods
7

3.2 EXISTING SYSTEM
In the existing system comparison was based on the method Linear
Discriminate analysis.Parametric distributed based(model based) and Non-
parametric sampled base , constrained mutual sub-space method,
Orthogonal sub-space method Whereas most of the previous work on matching
image sets for object recognition exploits temporal coherence between
consecutive images.
8

SYSTEM REQUIREMENTS
9

CHAPTER 4
SYSTEM REQUIREMENTS
4.1 HARDWARE REQUIREMENTS
Processor : Any Processor above 733 MHz’s
Ram : 512MB.
Hard Disk : 40 GB.
Compact Disk : 602 MB.
Input device : Standard Keyboard and Mouse.
Output device : VGA and High Resolution Monitor.
Clock speed : 550MHz
Cache Memory : 512KB
Monitor : Color Monitor
4.2 SOFTWARE REQUIREMENTS
Operating System : Windows XP
Techniques : JDK 1.6
Front End : Java, swing
10

SYSTEM DESIGN
11

CHAPTER 5
SYSTEM DESIGN
5.1 ARCHITECTURAL DIAGRAM
Fig.No 5.1- ARCHITECTURAL DIAGRAM
12

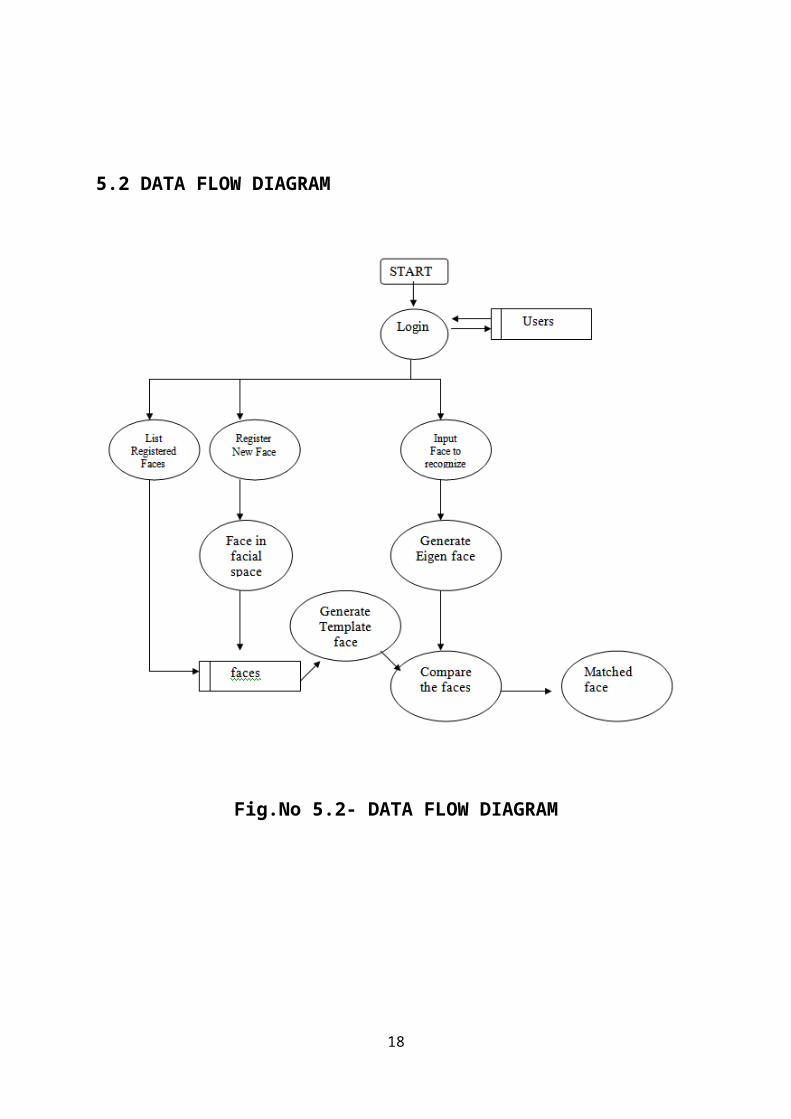
5.2 DATA FLOW DIAGRAM
Fig.No 5.2- DATA FLOW DIAGRAM
13

5.3 USE CASE DIAGRAM
Fig.No 5.3 Use Case Diagram
14

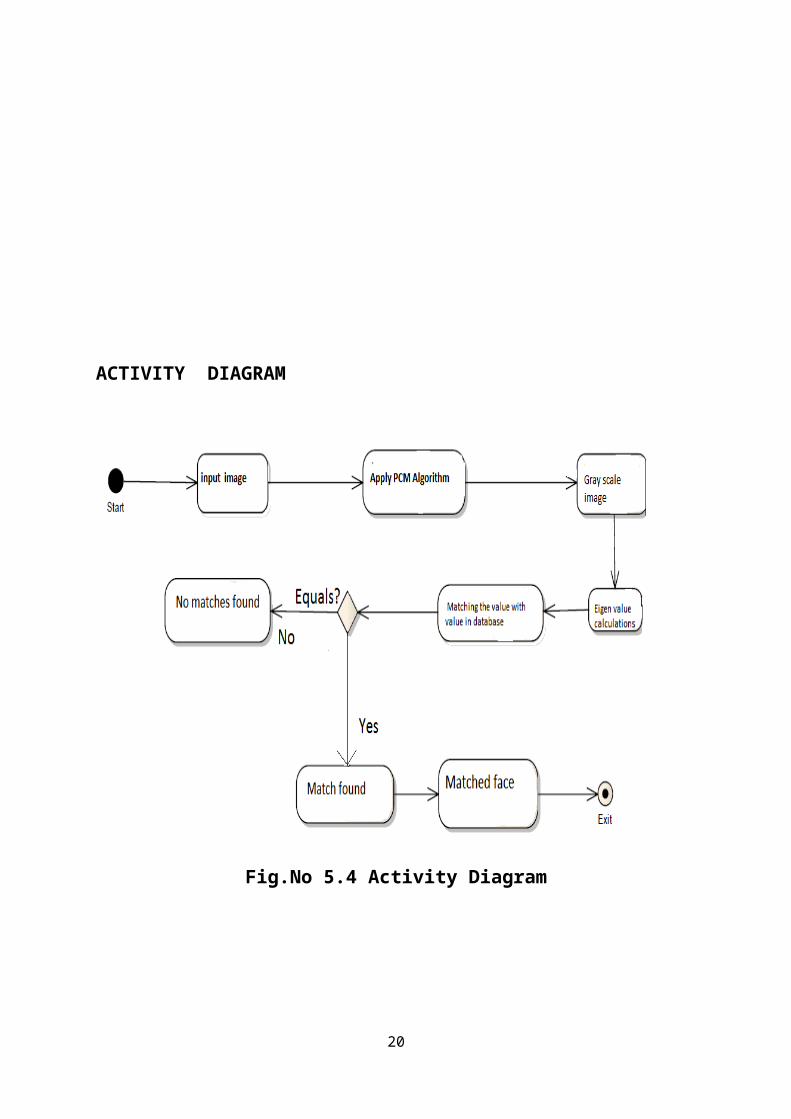
ACTIVITY DIAGRAM
Fig.No 5.4 Activity Diagram
15

METHODOLOGY
16

CHAPTER 6
METHODOLOGY
The ultimate aim of the proposed system is to provide service to the
customers. They need to get trained to use the newly proposed system. Hence
developing a system without the user’s feedback will lead to discard of the
system. So Rapid Application model was used to develop the system.
A rough interface of the system is given to the users for their feedback
and suggestions. Then the modifications are done. But as the system evolved
and after a series of interactions and demonstrations, the user felt comfortable
with the newly developed system.
The system went through the following stages:
The software request is evaluated
Product requirements are collected
Design specification for the prototype is prepared
Prototype software is developed, tested and refined
Prototype is given to the user, who tested the system any gave
suggestions for further refinement
17
The process during the development of the software using the RAD model is
Fig.No 6.1 Requirement Analysis
6.1 PCA Algorithm
Principal Component Analysis (PCA) is a statistical method under the
broad title of factor analysis. The purpose of PCA is to reduce the large
dimensionality of the data space (observed variables) to the smaller intrinsic
dimensionality of feature space (independent variables), which are needed to
describe the data economically. This is the case when there is a strong
correlation between observed variables. The jobs which PCA can do are
prediction, redundancy removal, feature extraction, data compression, etc.
Because PCA is a known powerful technique which can do something in the
linear domain, applications having linear models are suitable, such as signal
processing, image processing, system and control theory, communications, etc.
The main idea of using PCA for face recognition is to express the large 1-
D vector of pixels constructed from 2-D face image into the compact principal
18

components of the feature space. This is called eigenspace projection.
Eigenspace is calculated by identifying the eigenvectors of the covariance
matrix derived from a set of fingerprint images (vectors).
6.2 Eigenface Method
The most common method to perform face recognition is the eigenface
method. It can be broken down into a few relatively simple steps.
1. First, the system is generally trained with a database of sample images.
All of the training images are converted to grayscale. These training
images are then averaged on a pixel-by-pixel basis (or cell-by-cell basis),
in order to come up with a single average face, or “temple face: of the
same size as the training images.
2. Second, the training images are each compared to the “template face” to
calculate the “eigen face” for each of the training images. Eigenface (or
sometimes eigenvector) is really just a fancy mathematical name for the
differences between the template face and training image. These
eigenfaces are stored in an array to be accessed later, during the
comparison step.
3. Third, the image to recognize is input and converted to gray scale. An
eigenface for this image is calculated and passed into the final step.
4. Finally, the program compares the test eigenface to all of the stored
training eigenface. The difference between each pixel of the respective
eigenfaces in accumulated into a single number called the “eigenface
difference”. The training image with the lowest eigen difference is
selected as the most likely match to the input image.
19
6.3 JAVA
Java is an object-oriented programming language developed by
Sun Microsystems, Inc. It is modeled after C++, and was designed to be small,
simple, and portable across platforms and operating systems at the source level
and at the binary level. Java programs, which include applets and applications,
can therefore run on any machine that has the Java Virtual Machine, JVM,
installed.
6.3.1 ADVANTAGES OF JAVA
Java has significant advantages over other languages and
environments that make it suitable for just about any programming task.The
advantages of Java are as follows:
Java is easy to learn.
Java was designed to be easy to use and is therefore easy to write,
compile, debug, and learn than other programming languages.
Java is object-oriented.
This allows you to create modular programs and reusable code.
Java is platform-independent.
One of the most significant advantages of Java is its ability to move
easily from one computer system to another. The ability to run the same
program on many different systems is crucial to World Wide Web software, and
Java succeeds at this by being platform-independent at both the source and
binary levels.
Because of Java's robustness, ease of use, cross-platform capabilities
and security features, it has become a language of choice for providing
worldwide Internet solutions.
20

6.3.2 JDBC API
JDBC is a set of java API for executing SQL statements. This API
consists of a set of classes and interfaces to enable programmers to write pure
Java Database applications. Java Database Connectivity (JDBC) provides a
database-programming API for Java programs. Java Soft created the JDBC-
ODBC bridge driver that translates the JDBC API to the ODBC API. It is used
with ODBC drivers.
The JDBC API is a java API for accessing virtually any kind of
tabular data. JDBC stands for “Java Database Connectivity”. The JDBC API
consists of a set of classes and interfaces written in the java programming
language that provides a standard API for tool/database developers and makes it
possible to write industrial strength database applications using an all-java API.
The JDBC API makes it easy to send SQL statements to relational
database systems and supports all dialects of SQL. But the JDBC 2.0 goes
beyond SQL, also making it possible to interact with other kinds of data
sources, such as files containing tabular data. The value of the JDBC API is that
an application can access virtually any data source and run on any platform with
a java virtual machine. In other words, with the JDBC API, it isn’t necessary to
write one program to access a Sybase database, another program to access on
Oracle database, another program to access an IBM DB2 database and so on.
One can write a single program using the JDBC API and the program will be
able to send SQL or other statements to the appropriate data source. And, with
an application written in the java programming language, one doesn’t have to
worry about writing different applications to run on different platforms.
The combination of the Java platform and the JDBC API lets a
programmer write once and run anywhere, anytime.
21

6.3.3 FUNCTIONALITY OF JDBC API
The JDBC API supports three-tier model for database access. In
the three-tier model, commands are sent to a “middle tier” of services, which
then sends the commands to the data source. The data source processes the
commands and sends the results back to the middle tier, which then sends them
to the user.
JDBC URLs allow driver writers to encode all necessary
connection information within them. This makes it possible, for example, for an
applet that wants to talk to a given database to open the database connection
without requiring the user to do any system administration chores.
JDBC URLs allow a level of indirection. This means that the JDBC
URL may refer to a logical host or database name that is dynamically translated
to the actual name by a network naming system. This allows system
administrators to avoid specifying particular hosts as part of the JDBC name.
There are a number of different network name services such as DNS, NIS and
DCE and there is no restriction about which ones can be used.
22

SYSTEM IMPLEMENTATION
23

CHAPTER 7
SYSTEM IMPLEMENTATION
Implementation is the stage of the project where the theoretical design is
turned into a working system. At this stage the main work load and the major
impact on the existing system shifts to the user department. If the
implementation is not carefully planned and controlled, it can cause chaos and
confusion.
Implementation includes all those activities that take place to convert from
the old system to the new one. The new system may be totally new, replacing an
existing manual or automated system or it may be a major modification to an
existing system. Proper implementation is essential to provide a reliable system
to meet the organization requirements.
The process of putting the developed system in actual use is called system
implementation. The system can be implemented only after thorough testing is
done and it is found to be working according to the specifications. The system
personnel check the feasibility of the system. The most crucial stage is
achieving a new successful system and giving confidence on the new system for
the user that it will work efficiently and effectively. It involves careful planning,
investigation of the current system and its constraints on implementation. The
system implementation has three main aspects. They are education and training,
system testing and changeover.
The implementation stage involves following tasks.
Careful planning
Investigation of system and constraints
Design of methods to achieve the changeover.
Training of the staff in the changeover phase
Evaluation of the changeover method
24

7.1 Implementation Procedures
Implementation of software refers to the final installation of the package
in its real environment, to the satisfaction of the intended users and the
operation of the system. The people are not sure that the software is meant to
make their job easier. In the initial stage they doubt about the software but we
have to ensure that the resistance does not build up as one has to make sure that.
The active user must be aware of the benefits of using the system
Their confidence in the software built up
Proper guidance is impaired to the user so that he is comfortable in using
the application
Before going ahead and viewing the system, the user must know that for
viewing the result, the server program should be running in the server. If the
server object is not running on the server, the actual processes will not take
place.
7.2 User Training
To achieve the objectives and benefits expected from the proposed
system it is essential for the people who will be involved to be confident of their
role in the new system. As system becomes more complex, the need for
education and training is more and more important.
Education is complementary to training. It brings life to formal training
by explaining the background to the resources for them. Education involves
creating the right atmosphere and motivating user staff. Education information
can make training more interesting and more understandable.
25

7.3 Training on the Application Software
After providing the necessary basic training on the computer awareness,
the users will have to be trained on the new application software. This will give
the underlying philosophy of the use of the new system such as the screen flow,
screen design, type of help on the screen, type of errors while entering the data,
the corresponding validation check at each entry and the ways to correct the
data entered. This training may be different across different user groups and
across different levels of hierarchy.
7.4 Operational Documentation
Once the implementation plan is decided, it is essential that the user of
the system is made familiar and comfortable with the environment. A
documentation providing the whole operations of the system is being
developed. Useful tips and guidance is given inside the application itself to the
user. The system is developed user friendly so that the user can work the system
from the tips given in the application itself.
26

APPENDIX 1
SAMPLE CODE
27

APPENDIX 1
SAMPLE CODE
//FaceRecog.java
import java.lang.*;
import java.io.*;
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
class FaceRecog extends JFrame implements ActionListener
{
static Icon[ ] Cfaces = {
new ImageIcon("images\\train\\face16a.jpg"),
new ImageIcon("images\\train\\face17b.jpg"),
new ImageIcon("images\\train\\face12b.jpg"),
new ImageIcon("images\\train\\face15a.jpg"),
new ImageIcon("images\\train\\face13a.jpg"),
};
JFrame frmMain=new JFrame("Face Recognition ");
JLabel lblTestPath=new JLabel("TestPath:");
JTextField txtTestPath=new JTextField("images\\test\\face16d.pgm");
String s1=txtTestPath.getText();
28

JButton btRecognize=new JButton("Recognize");
JLabel lblResult=new JLabel("Result:");
JTextArea txtResult=new JTextArea("",4,80);
String som=txtResult.getText();
JScrollPane spResult=new JScrollPane(txtResult);
String Indo;
String sd1;
String sd2;
String tan;
String lis;
int NumFaces;
int MaxFaces=100;
int FaceTemplate[][];
int Faces[][][];
int PcaFaces[][][];
String FaceFileNames[ ];
String tResult="";
//constructor
public FaceRecog()
{
29

frmMain.setDefaultLookAndFeelDecorated(true);
frmMain.setResizable(true);
frmMain.setBounds(0,0,1024,750);
frmMain.getContentPane().setLayout(new GridLayout(5,1));
//frmMain.getContentPane().setLayout();
JPanel p1=new JPanel();
//lblTestPath.setBounds(17,15,100,20);
frmMain.getContentPane().add(p1);
//txtTestPath.setBounds(15,35,170,20);
//frmMain.getContentPane().add(checkTestPath);
JPanel p2=new JPanel();
//lblTestPath.setBounds(17,15,100,20);
p2.add(lblTestPath);
p2.add(txtTestPath);
p2.add(btRecognize);
frmMain.getContentPane().add(p2);
//txtTestPath.setBounds(15,35,170,20);
//frmMain.getContentPane().add(txtTestPath);
JPanel p3=new JPanel();
p3.add(lblResult);
30

p3.add(spResult);
frmMain.getContentPane().add(p3);
txtResult.setEditable(false);
btRecognize.addActionListener(this);
frmMain.setVisible(true);
}
public void actionPerformed(ActionEvent evt)
{
if(evt.getSource()==btRecognize)
{
tResult="";
txtResult.setText("");
train();
test();
}
}
//methods
public void addResultText(String tStr)
{
tResult=tResult+tStr;
31

txtResult.setText(tResult);
//try { Thread.sleep(1000); } catch(Exception err) { }
}
public void train()
{
int xBase,yBase,xSub,ySub;
int xLow,xHigh,yLow,yHigh;
int GrayLevel;
int CellSum,CellAvg;
int i,j;
int xDiv,yDiv;
int BlockWidth,BlockHeight;
int StartX,StartY;
int SizeX,SizeY;
//set system parameters
SizeX=80;
SizeY=80;
xDiv=20;
yDiv=20;
BlockWidth=SizeX/xDiv;
32

BlockHeight=SizeY/yDiv;
FaceTemplate=new int[xDiv][yDiv];
Faces=new int[xDiv][yDiv][MaxFaces];
PcaFaces=new int[xDiv][yDiv][MaxFaces];
FaceFileNames=new String[MaxFaces];
NumFaces=0;
addResultText("Training...");
PGM pgm1=new PGM();
for(i=1;i<=17;i++)
{
for(j=97;j<=98;j++)//'a' to 'b'
{
NumFaces=NumFaces+1;
FaceFileNames[NumFaces]="images\\train\\face"+i+(char)j+".pgm;
PGM_ImageFilter imgFilter=new PGM_ImageFilter();
imgFilter.set_inFilePath(FaceFileNames[NumFaces]);
imgFilter.set_outFilePath("temp.pgm");
imgFilter.resize(SizeX,SizeY);
pgm1.setFilePath("temp.pgm");
pgm1.readImage();
33

for(xBase=0;xBase<=xDiv-1;xBase++)
{
for(yBase=0;yBase<=yDiv-1;yBase++)
{
StartX=xBase*BlockWidth;
StartY=yBase*BlockHeight;
xLow=StartX;
xHigh=StartX+BlockWidth-1;
yLow=StartY;
yHigh=StartY+BlockHeight-1;
CellSum=0;
for(xSub=xLow;xSub<=xHigh;xSub++)
{
for(ySub=yLow;ySub<=yHigh;ySub++)
{
GrayLevel=pgm1.getPixel(xSub,ySub);
CellSum=CellSum+GrayLevel;
}
}
CellAvg=CellSum/(BlockWidth*BlockHeight);
34

Faces[xBase][yBase][NumFaces]=CellAvg;
}
}
}
}
for(xBase=0;xBase<=xDiv-1;xBase++)
{
for(yBase=0;yBase<=yDiv-1;yBase++)
{
CellSum=0;
for(i=1;i<=NumFaces;i++)
{
CellSum=CellSum+Faces[xBase][yBase][i];
}
CellAvg=CellSum/NumFaces;
FaceTemplate[xBase][yBase]=CellAvg;
}
}
for(xBase=0;xBase<=xDiv-1;xBase++)
{
35

for(yBase=0;yBase<=yDiv-1;yBase++)
{
for(i=1;i<=NumFaces;i++)
{
PcaFaces[xBase][yBase][i]=Faces[xBase][yBase][i]-
FaceTemplate[xBase][yBase];
}
}
}
PGM pgm2=new PGM();
pgm2.setFilePath("template.pgm");
pgm2.setType("P5");
pgm2.setComment("");
pgm2.setDimension(SizeX,SizeY);
pgm2.setMaxGray(255);
for(xBase=0;xBase<=xDiv-1;xBase++)
{
for(yBase=0;yBase<=yDiv-1;yBase++)
{
StartX=xBase*BlockWidth;
StartY=yBase*BlockHeight;
36

xLow=StartX;
xHigh=StartX+BlockWidth-1;
yLow=StartY;
yHigh=StartY+BlockHeight-1;
for(xSub=xLow;xSub<=xHigh;xSub++)
{
for(ySub=yLow;ySub<=yHigh;ySub++)
{
GrayLevel=FaceTemplate[xBase][yBase];
pgm2.setPixel(xSub,ySub,GrayLevel);
}
}
}
}
pgm2.writeImage();
addResultText("done.");
}
public void test()
{
JLabel pp;
37

int eq1,eq2;
int xBase,yBase,xSub,ySub;
int xLow,xHigh,yLow,yHigh;
int GrayLevel;
int CellSum,CellAvg;
int i,j;
int xDiv,yDiv;
int BlockWidth,BlockHeight;
int StartX,StartY;
int SizeX,SizeY;
//set system parameters
SizeX=80;
SizeY=80;
xDiv=20;
yDiv=20;
BlockWidth=SizeX/xDiv;
BlockHeight=SizeY/yDiv;
int TestFace[][]=new int[xDiv][yDiv];
int TestPcaFace[][]=new int[xDiv][yDiv];
int PcaDiff;
38

int MinPcaIndex;
double TotalPcaDiff,MinPcaDiff;
addResultText("\nTesting...");
PGM pgm1=new PGM();
pgm1.setFilePath(txtTestPath.getText());
pgm1.readImage();
for(xBase=0;xBase<=xDiv-1;xBase++)
{
for(yBase=0;yBase<=yDiv-1;yBase++)
{
StartX=xBase*BlockWidth;
StartY=yBase*BlockHeight;
xLow=StartX;
xHigh=StartX+BlockWidth-1;
yLow=StartY;
yHigh=StartY+BlockHeight-1;
CellSum=0;
for(xSub=xLow;xSub<=xHigh;xSub++)
{
for(ySub=yLow;ySub<=yHigh;ySub++)
39

{
GrayLevel=pgm1.getPixel(xSub,ySub);
CellSum=CellSum+GrayLevel;
}
}
CellAvg=CellSum/(BlockWidth*BlockHeight);
TestFace[xBase][yBase]=CellAvg;
}
}
PGM pgm2=new PGM();
pgm2.setFilePath("diff.pgm");
pgm2.setType("P5");
pgm2.setComment("");
pgm2.setDimension(SizeX,SizeY);
pgm2.setMaxGray(255);
for(xBase=0;xBase<=xDiv-1;xBase++)
{
for(yBase=0;yBase<=yDiv-1;yBase++)
{
StartX=xBase*BlockWidth;
40

StartY=yBase*BlockHeight;
xLow=StartX;
xHigh=StartX+BlockWidth-1;
yLow=StartY;
yHigh=StartY+BlockHeight-1;
for(xSub=xLow;xSub<=xHigh;xSub++)
{
for(ySub=yLow;ySub<=yHigh;ySub++)
{
GrayLevel=TestFace[xBase][yBase];
pgm2.setPixel(xSub,ySub,GrayLevel);
}
}
}
}
for(xBase=0;xBase<=xDiv-1;xBase++)
{
for(yBase=0;yBase<=yDiv-1;yBase++)
{
TestPcaFace[xBase][yBase]=TestFace[xBase][yBase]-
FaceTemplate[xBase][yBase];
41

}
}
MinPcaDiff=2147483647; //2^32
MinPcaIndex=-1;
for(i=1;i<=NumFaces;i++)
{
TotalPcaDiff=0;
for(xBase=0;xBase<=xDiv-1;xBase++)
{
for(yBase=0;yBase<=yDiv-1;yBase++)
{
TotalPcaDiff=TotalPcaDiff+java.lang.Math.abs(TestPcaFace[xBase]
[yBase]-PcaFaces[xBase][yBase][i]);
System.out.println("min="+MinPcaDiff);
System.out.println("total="+TotalPcaDiff);
}
}
if(MinPcaDiff>TotalPcaDiff)
{
MinPcaDiff=TotalPcaDiff;
MinPcaIndex=i;
42

}
}
pgm2.writeImage();
PGM pgmMatched=new PGM();
pgmMatched.setFilePath(FaceFileNames[MinPcaIndex]);
pgmMatched.readImage();
pgmMatched.setFilePath("matched.pgm");
pgmMatched.writeImage();
addResultText("done.");
//set result
if(MinPcaDiff>15000)
{
addResultText("not Found");
}
else{
addResultText( "\n\nMatched:"+FaceFileNames[MinPcaIndex]);
sd1=FaceFileNames[MinPcaIndex];
lis=sd1.replace("pgm","jpg");
System.out.println(lis);
recyc();
43

}
}
public void recyc( )
{
JButton jb1 = new JButton("", Cfaces[4]);
String s1="images\\train\\face16a.jpg";
String s2="images\\train\\face17b.jpg";
String s3="images\\train\\face12b.jpg";
String s4="images\\train\\face15a.jpg";
String s5="images\\train\\face13a.jpg";
lis=sd1.replace("pgm","jpg");
System.out.println(lis);
boolean beam1=lis.equals(s1);
//System.out.println("hell:"+beam);
System.out.println("helloo:"+beam1);
if(lis.equals(s1))
jb1.setIcon(Cfaces[0]);
else if(lis.equals(s2))
jb1.setIcon(Cfaces[1]);
else if(lis.equals(s3))
44

jb1.setIcon(Cfaces[2]);
else if(lis.equals(s4))
jb1.setIcon(Cfaces[3]);
else if(lis.equals(s5))
jb1.setIcon(Cfaces[4]);
else
jb1.setLabel("Not Found");
JPanel p4=new JPanel(new FlowLayout());
p4.add(jb1);
frmMain.getContentPane().add(p4);
}
public static void main(String args[])
{
new FaceRecog();
}
}
45

APPENDIX - 2
SCREEN SHOTS
46

APPENDIX 2
SCREEN SHOTS
START PAGE
47

SCREEN SHOT 2
SETTING RESULT
48

SCREEN SHOT 3
MATCHED FACE
49

SCREEN SHOT 4
IMAGE NOT FOUND
50

SCREEN SHOT 5
MATCHED FACE
51

CONCLUSION
52

CHAPTER 8
CONCLUSION
Our system is proposed to use Principle Component Analysis in Face
Recognition which eliminates the flaws in the existing system. This system
makes the faces to reduce into lower dimensions and algorithm for PCA is
performed for recognition. The application is developed successfully and
implemented as mentioned above.
53

8.1 FUTURE ENHANCEMENT
The project entitled “Face recognition” helps to recognize the faces.
This system is effective in finding matched face. In future, the application can
be modified by capturing live faces and more precise identification for better
results. The matching accuracy could even be set to higher value for more
matched results. Discrimination and dimension, reducing the dimension of
image and reducing the noise ratio in image Identifying the noise in images and
removal of image noise Implementing the RGB images for source part.
54

BIBLIOGRAPHY
1. H. Hotelling, “Relations between Two Sets of Variates,” Biometrika, vol. 28,
no. 34, pp. 321-372, 1936.
2. A. Bjo¨rck and G.H. Golub, “Numerical Methods for Computing Angles
between Linear Subspaces,” Math. Computation, vol. 27,no. 123, pp. 579-594,
1973.
3. T. Kailath, “A View of Three Decades of Linear Filtering Theory,” IEEE
Trans. Information Theory, vol. 20, no. 2, pp. 146-181, 1974.
4. E. Oja, Subspace Methods of Pattern Recognition. Research Studies
55
Related Documents











