
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


Motivation: Privacy-preserving data mining
Share textual data for mutual benefit, general good or contractual reasonsBut not all of it:
text analytics on private documents
marketplace scenarios [Cancedda ACL 2012]
copyright concerns
1

Motivation: Privacy-preserving data mining
Share textual data for mutual benefit, general good or contractual reasonsBut not all of it:
text analytics on private documents
marketplace scenarios [Cancedda ACL 2012]
copyright concerns
1
Motivation: Privacy-preserving data mining
Share textual data for mutual benefit, general good or contractual reasonsBut not all of it:
text analytics on private documents
marketplace scenarios [Cancedda ACL 2012]
copyright concerns
1

Problem
1 Given n-gram information of a document d , how well can wereconstruct d?
2 If I want/have to share n-gram statistics, what is a good strategy toavoid reconstruction, while preserving utility of data?
2

Example
s = $ a rose rose is a rose is a rose #
2-grams:
$ a 1a rose 3rose rose 1rose is 2is a 2rose # 1
Note that the same 2-grams are obtained starting from:
s = $ a rose is a rose rose is a rose #
s = $ a rose is a rose is a rose rose #
=⇒ Find large chunks of text of whose presence we arecertain
3

Example
s = $ a rose rose is a rose is a rose #2-grams:
$ a 1a rose 3rose rose 1rose is 2is a 2rose # 1
Note that the same 2-grams are obtained starting from:
s = $ a rose is a rose rose is a rose #
s = $ a rose is a rose is a rose rose #
=⇒ Find large chunks of text of whose presence we arecertain
3

Example
s = $ a rose rose is a rose is a rose #2-grams:
$ a 1a rose 3rose rose 1rose is 2is a 2rose # 1
Note that the same 2-grams are obtained starting from:
s = $ a rose is a rose rose is a rose #
s = $ a rose is a rose is a rose rose #
=⇒ Find large chunks of text of whose presence we arecertain
3

Example
s = $ a rose rose is a rose is a rose #2-grams:
$ a 1a rose 3rose rose 1rose is 2is a 2rose # 1
Note that the same 2-grams are obtained starting from:
s = $ a rose is a rose rose is a rose #
s = $ a rose is a rose is a rose rose #
=⇒ Find large chunks of text of whose presence we arecertain
3
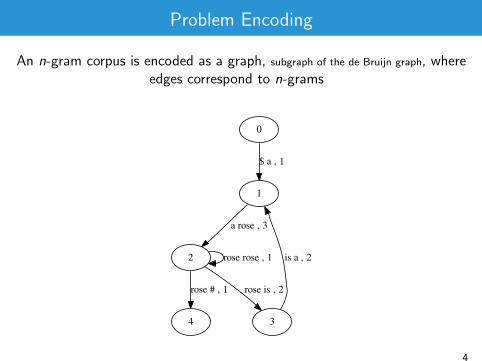
Problem Encoding
An n-gram corpus is encoded as a graph, subgraph of the de Bruijn graph, whereedges correspond to n-grams
0
1
$ a , 1
2
a rose , 3
rose rose , 1
3
rose is , 2
4
rose # , 1
is a , 2
4
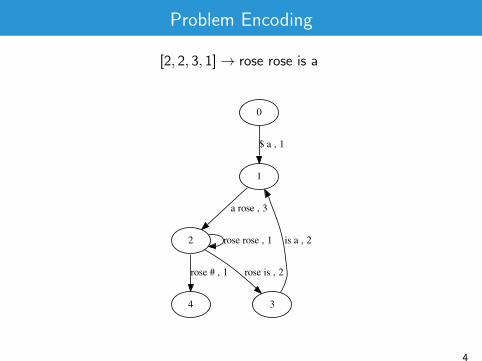
Problem Encoding
[2, 2, 3, 1]→ rose rose is a
0
1
$ a , 1
2
a rose , 3
rose rose , 1
3
rose is , 2
4
rose # , 1
is a , 2
4

Problem encoding
Given such a graph, each Eulerian path gives a plausible reconstruction
Problem: Find those parts that are common in all of them
BEST Theorem, 1951
Given an Eulerian graph G = (V ,E ), the number of different Euleriancycles is
Tw (G )∏v∈V
(d(v)− 1)!
Tw (G ) is the number of trees directed towards the root at a fixed node w
5

Problem encoding
Given such a graph, each Eulerian path gives a plausible reconstructionProblem: Find those parts that are common in all of them
BEST Theorem, 1951
Given an Eulerian graph G = (V ,E ), the number of different Euleriancycles is
Tw (G )∏v∈V
(d(v)− 1)!
Tw (G ) is the number of trees directed towards the root at a fixed node w
5

Problem encoding
Given such a graph, each Eulerian path gives a plausible reconstructionProblem: Find those parts that are common in all of them
BEST Theorem, 1951
Given an Eulerian graph G = (V ,E ), the number of different Euleriancycles is
Tw (G )∏v∈V
(d(v)− 1)!
Tw (G ) is the number of trees directed towards the root at a fixed node w
5
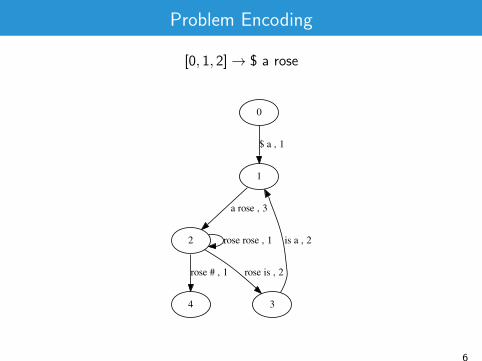
Problem Encoding
[0, 1, 2]→ $ a rose
0
1
$ a , 1
2
a rose , 3
rose rose , 1
3
rose is , 2
4
rose # , 1
is a , 2
6

Definitions
ec(G ): the set of all Eulerian paths of G
given the path c = e1, . . . , en; `(c) = [label(e1), . . . , label(en)]
s(c) = label(e1).label(e2). . . . .label(en) (overlapping concatenation)
Given G , we want G ∗ st:
1 is equivalent:
{s(c) : c ∈ ec(G)} = {s(c) : c ∈ ec(G ∗)}
2 is irreducible:
6 ∃e1, e2 ∈ E ∗ : [label(e1), label(e2)] appears in all `(c), c ∈ ec(G ∗)
Given G ∗ we can just read maximal blocks from the labels.
7

Definitions
ec(G ): the set of all Eulerian paths of G
given the path c = e1, . . . , en; `(c) = [label(e1), . . . , label(en)]
s(c) = label(e1).label(e2). . . . .label(en) (overlapping concatenation)
Given G , we want G ∗ st:
1 is equivalent:
{s(c) : c ∈ ec(G)} = {s(c) : c ∈ ec(G ∗)}
2 is irreducible:
6 ∃e1, e2 ∈ E ∗ : [label(e1), label(e2)] appears in all `(c), c ∈ ec(G ∗)
Given G ∗ we can just read maximal blocks from the labels.
7

Definitions
ec(G ): the set of all Eulerian paths of G
given the path c = e1, . . . , en; `(c) = [label(e1), . . . , label(en)]
s(c) = label(e1).label(e2). . . . .label(en) (overlapping concatenation)
Given G , we want G ∗ st:
1 is equivalent:
{s(c) : c ∈ ec(G)} = {s(c) : c ∈ ec(G ∗)}
2 is irreducible:
6 ∃e1, e2 ∈ E ∗ : [label(e1), label(e2)] appears in all `(c), c ∈ ec(G ∗)
Given G ∗ we can just read maximal blocks from the labels.
7
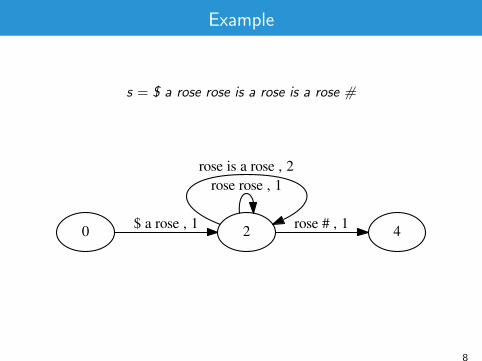
Example
s = $ a rose rose is a rose is a rose #
2
rose rose , 1rose is a rose , 2
4rose # , 10 $ a rose , 1
8

9
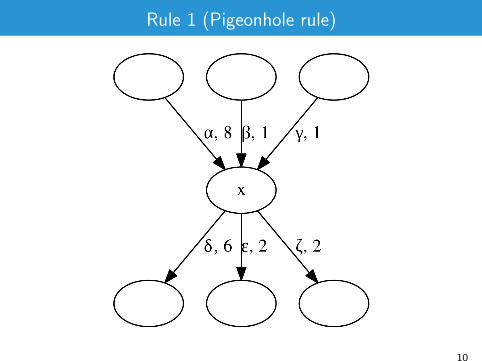
Rule 1 (Pigeonhole rule)
α.δ occurs at least 4 times
10
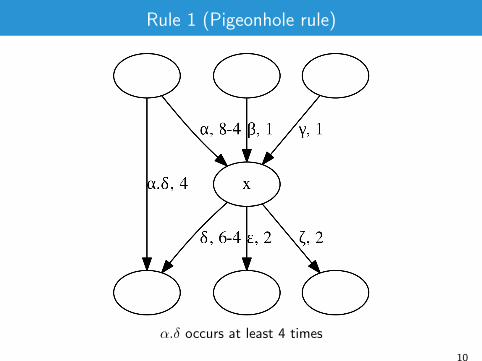
Rule 1 (Pigeonhole rule)
α.δ occurs at least 4 times
10
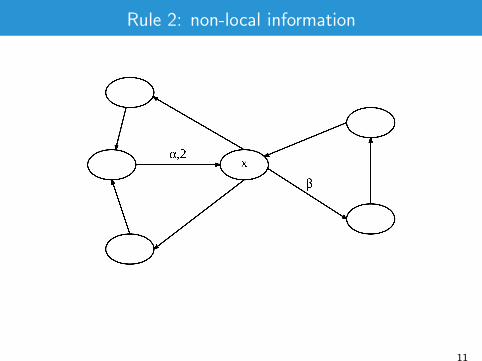
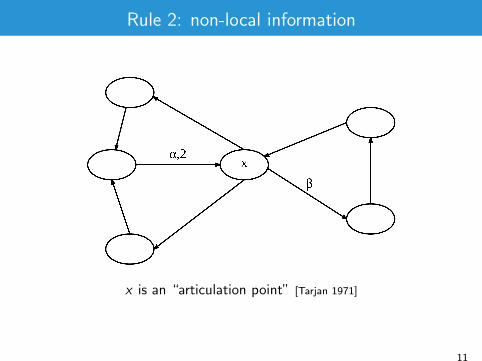
Rule 2: non-local information
x is an “articulation point” [Tarjan 1971]
α.β occurs at least once
11
Rule 2: non-local information
x is an “articulation point” [Tarjan 1971]
α.β occurs at least once
11
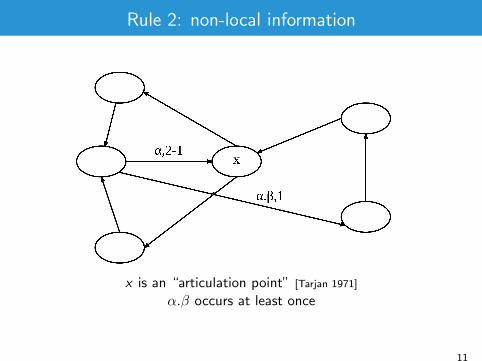
Rule 2: non-local information
x is an “articulation point” [Tarjan 1971]
α.β occurs at least once
11
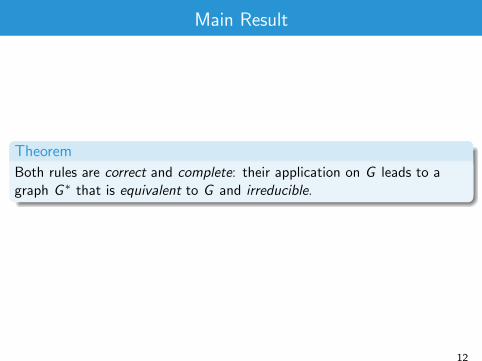
Main Result
Theorem
Both rules are correct and complete: their application on G leads to agraph G ∗ that is equivalent to G and irreducible.
12
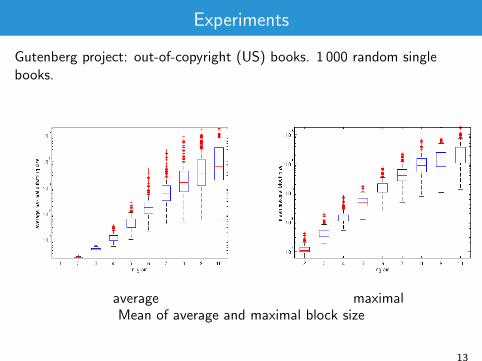
Experiments
Gutenberg project: out-of-copyright (US) books. 1 000 random singlebooks.
average maximalMean of average and maximal block size
13
Experiments
Gutenberg project: out-of-copyright (US) books. 1 000 random singlebooks.
average maximalMean of average and maximal block size
13

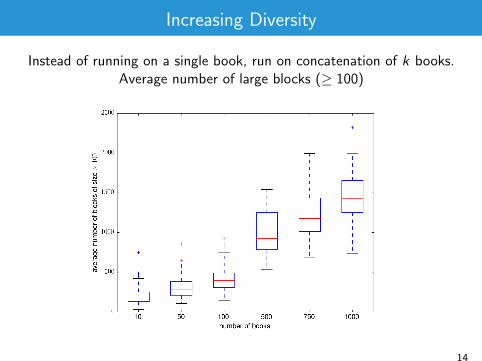
Increasing Diversity
Instead of running on a single book, run on concatenation of k books.
Average number of large blocks (≥ 100)
14
Increasing Diversity
Instead of running on a single book, run on concatenation of k books.Average number of large blocks (≥ 100)
14

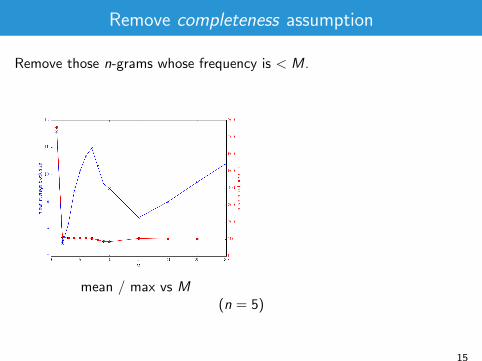
Remove completeness assumption
Remove those n-grams whose frequency is < M.
mean / max vs M
error rate vs M
(n = 5)
15
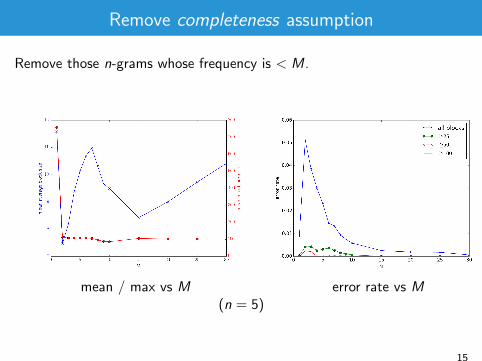
Remove completeness assumption
Remove those n-grams whose frequency is < M.
mean / max vs M
error rate vs M
(n = 5)
15
Remove completeness assumption
Remove those n-grams whose frequency is < M.
mean / max vs M error rate vs M(n = 5)
15

A better noisifying strategy
Instead of removing n-grams, add strategically chosen n-grams
removing edges vs adding edges
16
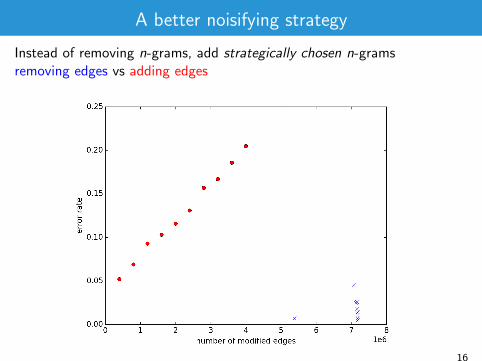
A better noisifying strategy
Instead of removing n-grams, add strategically chosen n-gramsremoving edges vs adding edges
16
Keep utility
Removing
17
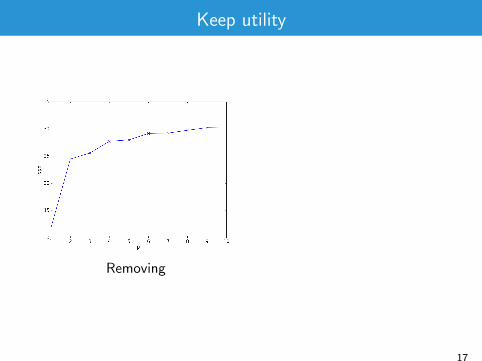
Keep utility
Removing
17
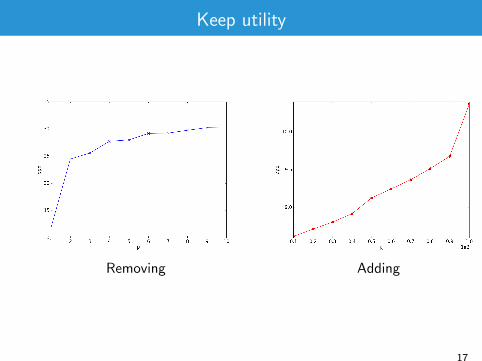
Keep utility
Removing Adding
17

Conclusions
How well can textual documents be reconstructed from their list ofn-grams
Resilience to standard noisifying approach
Better noisifying by adding (instead of removing) n-grams
18

Questions?
19

Appendix
20
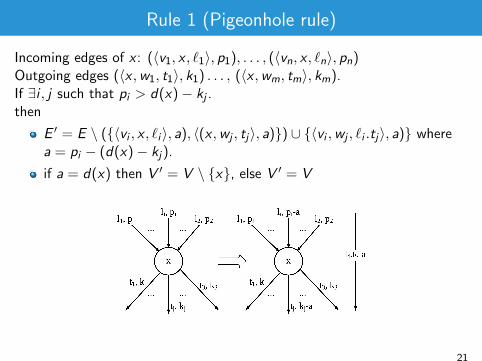
Rule 1 (Pigeonhole rule)
Incoming edges of x : (〈v1, x , `1〉, p1), . . . , (〈vn, x , `n〉, pn)Outgoing edges (〈x ,w1, t1〉, k1) . . . , (〈x ,wm, tm〉, km).If ∃i , j such that pi > d(x)− kj .then
E ′ = E \ ({〈vi , x , `i 〉, a), 〈(x ,wj , tj〉, a)}) ∪ {〈vi ,wj , `i .tj〉, a)} wherea = pi − (d(x)− kj).
if a = d(x) then V ′ = V \ {x}, else V ′ = V
21
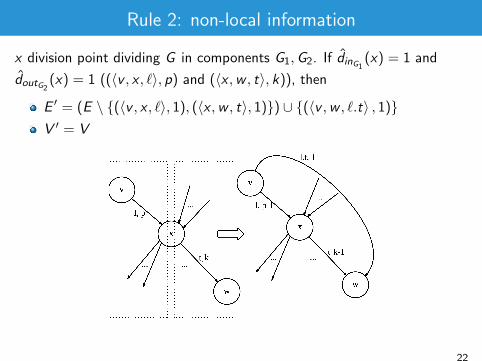
Rule 2: non-local information
x division point dividing G in components G1,G2. If d̂inG1 (x) = 1 and
d̂outG2 (x) = 1 ((〈v , x , `〉, p) and (〈x ,w , t〉, k)), then
E ′ = (E \ {(〈v , x , `〉, 1), (〈x ,w , t〉, 1)}) ∪ {(〈v ,w , `.t〉 , 1)}V ′ = V
22
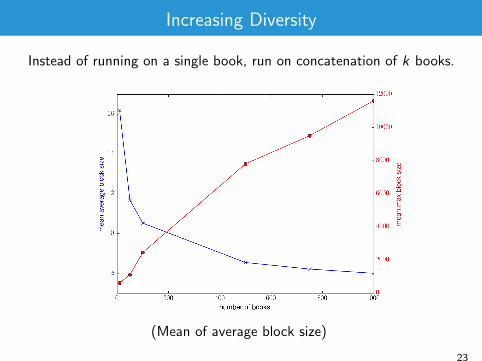
Increasing Diversity
Instead of running on a single book, run on concatenation of k books.
(Mean of average block size)
23
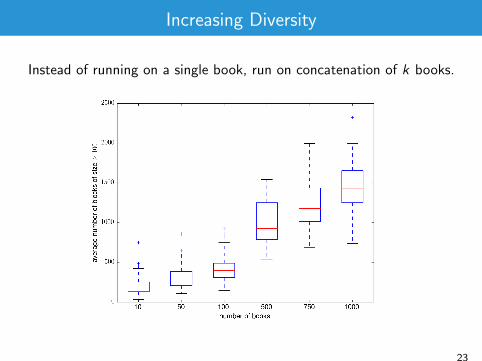
Increasing Diversity
Instead of running on a single book, run on concatenation of k books.
23
Related Documents











