INPE-14439-TDI/1134 RECONHECIMENTO DE FACES USANDO REDES NEURAIS E BIOMETRIA Douglas Rodrigues Oliveira Dissertação de Mestrado do Curso de Pós-Graduação em Computação Aplicada, orientada pelo Dr. Lamartine Nogueira Frutuoso Guimarães, aprovada em 30 de setembro de 2003. INPE São José dos Campos 2006

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

INPE-14439-TDI/1134
RECONHECIMENTO DE FACES USANDO REDES NEURAIS E
BIOMETRIA
Douglas Rodrigues Oliveira
Dissertação de Mestrado do Curso de Pós-Graduação em Computação Aplicada, orientada pelo Dr. Lamartine Nogueira Frutuoso Guimarães, aprovada em 30 de
setembro de 2003.
INPE São José dos Campos
2006

681.3.019 Oliveira, D. R. Reconhecimento de faces usando redes neurais e biometria/
D. R. Oliveira. – São José dos Campos: Instituto Nacional de Pesquisas Espaciais (INPE), 2003.
164 p.; - (INPE-14439-TDI/1134) 1. Reconhecimento de Faces. 2. Biometria. 3. Tipos
Faciais. 4. Morfologia Facial. 5. Redes Neurais. 6. Inteligência Artificial. I.Título.

Aprovado pela Banca Examinadora em cumprimento a requisito exigido para a obtenção do Título de Mestre em Computação Aplicada
Dr. José Demisio Simões da Silva Presidente Dr. Lamartine Nogueira Frutuoso Guimarães Orientador Dra. Sandra Aparecida Sandri Membro da Banca Dr. Walmir Matos Caminhas Membro da Banca
Convidado Candidato: Douglas Rodrigues Oliveira
São José dos Campos, 30 de setembro de 2003.


“Ninguém é igual a ninguém. Todo ser humano é um estranho ímpar”.
Carlos Drummond de Andrade


A meus pais, VICENTE DE PAULO OLIVEIRA e
MARIA DAS GRAÇAS RODRIGUES OLIVEIRA.


AGRADECIMENTOS
Inicialmente, agradeço ao meu orientador Dr. Lamartine pelo empenho, incentivo, compreensão e pelas críticas dispensadas na orientação deste trabalho, mesmo quando outras atividades profissionais e de cunho pessoal lhe exigiam intensa dedicação.
Agradeço aos meus colegas de república, Felipe, Mic e Joubert pelo companheirismo nas dificuldades do dia a dia. Também gostaria de lembrar os colegas conquistados no Laboratório da CAP e em São José dos Campos, Maurício, Fernanda, Élcio, Ana Paula, Fabrício, Talita, Adytia, Aritana, Juliana, Jaciara, Patrícia e todos os que de alguma forma foram fonte de inspiração, apoio e incentivo.
Especialmente, agradeço aos amigos Maurício e Élcio pelos inúmeros
favores e por toda amizade demonstrada por eles e pelas suas respectivas famílias durante o período em que residi em São José dos Campos.
Ao chefe da área de Sistemas Industriais da Açominas S.A., Mário Hermes
de Rezende, pelo incentivo dado para a conclusão desta dissertação e por ter sido extremamente tolerante com a minha necessária dedicação à escrita deste trabalho. Aos colegas de empresa Marlon Gouvea e Eduardo Vieira que deram contribuições importantes para escrita desta dissertação.
Ao Instituto Nacional de Pesquisas Espaciais e à CAP, pelo apoio, consideração e empenho em prover seus alunos com as condições necessárias para o desenvolvimento da pesquisa científica. Especialmente gostaria de citar: Dr. Haroldo e Dr. Demísio que por tantas vezes me receberam e buscaram os órgãos de financiamento para obtenção de bolsas para os alunos da CAP.
Minha profunda gratidão a Rafaella, cujo carinho, compreensão e auxílio,
buscando referências bibliográficas na área de Fonoaudiologia, também foram de grande valia para este trabalho.
Finalmente, agradeço à minha mãe e a meus irmãos, pelo amor e incentivo,
e ao meu pai, que sempre me apoiou em todas as etapas e decisões que tomei em relação a este mestrado.


RESUMO
O reconhecimento de faces é uma das ações mais corriqueiras no dia a dia de um ser vivo inteligente. Esta atividade executada com tanta naturalidade por organismos vivos, tem despertado o interesse de pesquisadores que trabalham com Visão Computacional e Inteligência Artificial. Esta dissertação tem por objetivo pesquisar a viabilidade de um sistema híbrido aplicado ao reconhecimento facial, mesclando características dos métodos geométricos para o reconhecimento de faces, aos métodos de inteligência computacional. Para a extração das métricas de componentes e regiões da face, usadas no método geométrico, foram feitos estudos sobre a anatomia da face humana usados em ortodontia, fonoaudiologia e reconstituição maxilo-facial. Estes estudos visaram a determinação de pontos de referência existentes na face e suas relações de interdependência para construir uma representação para as faces a serem analisadas. As medidas dos componentes e regiões faciais foram usadas na construção de vetores numéricos que identificam as faces de forma singular. Estes vetores de características métricas foram usados para treinar redes neurais, encarregadas de realizar o reconhecimento. Foram usadas, nos testes de reconhecimento, 37 imagens frontais de faces humanas de homens e mulheres adultos. Medidas de desempenho são utilizadas sob diversas condições (presença de ruído e imagens não vistas na etapa de treinamento), para ilustrar a viabilidade do sistema híbrido proposto, bem como a eficiência das métricas usadas para representar as faces.


FACE RECOGNITION USING NEURAL NETWORKS AND BIOMETRY
ABSTRACT
The recognition of faces is one of the simplest actions on a daily basis of an intelligent and living being. This activity performed so naturally by living organisms has been attracting the interest of researchers who work with Computer Vision and Artificial Intelligence. This dissertation has as the objective to study the feasibility of a system based on Neural Network and Biometry applied to face recognition, mixing characteristics of geometric methods for face recognition to computer intelligence methods. For the extraction of measurements of components and regions of the face, used in geometric method studies were developed of the anatomy of the human face used in orthodontist work, phonoaudiology and maxillary facial reconstitution. These studies seek to determine the existing reference points on faces and its interdependent relation to construct a representation of the faces to be analyzed. The components’ measurements and facial regions were used to construct numerical vectors, which identity the faces in a singular way. These vectors of characteristics were used for training neural networks, which are in charge of performing the recognition. 37 frontal face images of adult men and women were used. Performance measurements are used under various conditions (presence of noise and images not-seen during the training phase) in order to illustrate the feasibility of the proposed hybrid system as well as the efficiency of the metrics used to represent the faces.


SUMÁRIO
Pág.
LISTA DE FIGURAS
LISTA DE TABELAS
CAPÍTULO 1 - INTRODUÇÃO ................................................................................. 21
1.1. A Detecção de Faces...................................................................................... 23
1.2. O Reconhecimento de Faces ........................................................................ 26
1.3. Métodos Geométricos para Reconhecimento Facial ................................. 28
1.4. Objetivos desta dissertação .......................................................................... 31
1.5. Aplicações ...................................................................................................... 32
1.6. Organização ................................................................................................... 33
CAPÍTULO 2 - MÉTODOS CONEXIONISTAS NÃO LINEARES ....................... 35
2.1. Redes Neurais Artificiais .............................................................................. 36 2.1.1. Introdução ................................................................................................... 36 2.1.2. Definições ................................................................................................... 37
2.2. Redes multicamadas não- lineares ............................................................... 42 2.2.1. O processo de aprendizado ......................................................................... 44
2.3. Implementando um reconhecedor neural .................................................. 47 2.3.1. Etapa de descrição ...................................................................................... 48 2.3.2. Etapa de reconhecimento ............................................................................ 50
2.4. Conclusões ..................................................................................................... 51
CAPÍTULO 3 - MORFOLOGIA DA FACE HUMANA .......................................... 53
3.1. Introdução ..................................................................................................... 53
3.2. Arquitetura do Esqueleto Facial ................................................................. 56
3.3. Antropometria Facial ................................................................................... 59 3.3.1. Pontos Craniométricos ................................................................................ 60 3.3.2. Medidas Lineares ........................................................................................ 62 3.3.3. Índice Facial................................................................................................ 63
3.4. Estética Facial ............................................................................................... 65 3.4.1. Tipos Morfológicos .................................................................................... 66 3.4.2. Estruturas e Referências Faciais ................................................................. 71 3.4.3. Análise Facial ............................................................................................. 71
CAPÍTULO 4 - METODOLOGIA APLICADA ....................................................... 77
4.1. Introdução ..................................................................................................... 77

4.2. Descrição das etapas ..................................................................................... 78
4.3. Descrição das estruturas utilizadas ............................................................. 88
CAPÍTULO 5 - TESTES REALIZADOS ................................................................ 101
5.1. Testes realizados na rede da etapa de Reconhecimento .......................... 104
5.2. Testes da rede de associação a padrões conhecidos ................................. 128
5.3. Discussão sobre os testes realizados .......................................................... 133 5.3.1. As Métricas Usadas para Representação Facial ....................................... 134 5.3.2. Método conexionis ta Não- Linear Usado .................................................. 137
5.4. Resultados Obtidos ..................................................................................... 139 5.4.1. Comparação entre índices de reconhecimento ......................................... 140
5.5. Aplicabilidade do Trabalho ....................................................................... 141
CAPÍTULO 6 - CONCLUSÕES E PERSPECTIVAS PARA TRABALHOS FUTUROS ........................................................................................ 143
Perspectivas para trabalhos futuros ..................................................................... 148
REFERÊNCIAS BIBLIOGRÁFICAS ...................................................................... 149

LISTA DE FIGURAS
Pág.
1.1 - Etapas iniciais do processo de Visão Computacional, obtendo como resultado
parcial uma imagem contendo o objeto de interesse do sistema.. ...................... 22
1.2 - Etapas finais do processo de Visão Computacional. .............................................. 22
1.3 - Etapas do problema de reconhecimento automático de faces. .............................. 26
2.1 - Funcionamento básico de um elemento de processamento em uma rede neural
artificial. ................................................................................................................. 36
2.2 - Exemplo de topologias básicas de redes neurais .................................................... 38
2.3 - Camadas de uma rede neural artificial multicamadas. ........................................... 41
2.4 - Topologia de rede multicamada para extração de características. ......................... 43
3.1 - Regiões da face. ...................................................................................................... 55
3.2 - Arquitetura do esqueleto facial. .............................................................................. 57
3.3 - . Linhas de Resistência da mandíbula. ................................................................... 59
3.4 - Pontos craniométricos. ........................................................................................... 61
3.5 - Face Euriprosópica ................................................................................................. 64
3.6 - Face Leptoprosópica. .............................................................................................. 64
3.7 - A face humana segundo a concepção artística de Dürer. ....................................... 67
3.8 - Tipos faciais segundo Madame Schimmelpennick em seu livro "Ciência da
Beleza". ............................................................................................................... 68

3.9 - Tipos morfológicos segundo a classificação de Claud Sigaud. .............................. 69
3.10 - Posição natural da cabeça. .................................................................................... 72
3.11 - Tópicos a serem avaliados na visão frontal. ......................................................... 73
3.12 - Divisão da face em duas partes. ........................................................................... 73
3.13 - Divisões verticais da face. .................................................................................... 75
3.14 - Proporção 1:1 da distância vertical do subnasal à margem cutânea do vermelhão
do lábio inferior e deste ao tecido mole do mento .............................................. 76
4.1 - Tratamento de imagens buscando realçar características de interesse. .................. 79
4.2 - Coleta da medida do primeiro terço da face. .......................................................... 81
4.3 - Coleta da medida do segundo terço da face. .......................................................... 81
4.4 - Coleta da medida do terceiro terço da face. ........................................................... 81
4.5 - Coleta da medida da largura do olho. ..................................................................... 82
4.6 - Coleta da medida da altura do olho. ....................................................................... 83
4.7 - Coleta da medida da largura do nariz. .................................................................... 83
4.8 - Coleta da medida da altura do nariz. ...................................................................... 84
4.9 - Coleta da medida da largura da boca. ..................................................................... 84
4.10 - Coleta da medida da altura da boca. ..................................................................... 85
4.11 - Coleta da medida da largura da face .................................................................... 85
4.12 - Coleta da medida da altura da face. ...................................................................... 85

4.13 - Medidas puras dos componentes e regiões faciais do banco de imagens da
Açominas. ........................................................................................................... 90
4.14 - Medidas puras dos componentes e regiões faciais do banco de imagens de Yale. ..
................................................................................................................................ 90
4- 15 - Análise de componentes e Regiões da Face Banco de Imagens da Açominas. ......
................................................................................................................................ 92
4.16 - Relações entre componentes e Regiões da Face. (Banco de Imagens da
Açominas). .......................................................................................................... 93
4.17 - Esquema de funcionamento do sistema de reconhec imento facial. ..................... 96
4.18 - Relações métricas que mais variaram. ................................................................. 97
4.19 - Relações métricas que menos variaram. ............................................................... 98
5.1 - Curva de aprendizado usando relações métricas do Grupo1. ............................... 105
5.2 - Curva de aprendizado usando relações métricas do Grupo2. ............................... 107
5.3 - Curva de aprendizagem das métricas do Grupo5. ................................................ 111
5.4 - Curva de aprendizagem para padrões com baixa interferência de cabelo,
cavanhaque e barba (Grupo5.1). ...................................................................... 117
5.5 - Curva de aprendizagem das métricas do Grupo5.2. ............................................. 121
5.6 - Curva de aprendizagem das métricas do Grupo5.3. ............................................ 126
5.7 - Curva de aprendizagem dos 8 padrões da Classe 3. ............................................. 129
5.8 - Dificuldades de determinação do primeiro terço da face. ................................... 135
5.9 - Dificuldade de localização da região mentoniana, usada na determinação da altura
da face e do 3º terço facial. .................................................................................. 136

A1 – Iniciando novo projeto de rede neural..................................................................157 A.2 – Projeto XOR com as respectivas janelas de configuração...................................158 A.3 – Conteúdo do arquivo XOR.cf..............................................................................159 A.4 – Conteúdo do arquivo XOR.data..........................................................................160 A.5 – Conteúdo do arquivo XOR.data..........................................................................161 A.6 – Arquitetura da rede criada...................................................................................162 A.7 – Janela de parâmetros de treinamento da rede......................................................162 A.8 – Gráfico de evolução do erro médio quadrático....................................................163

LISTA DE TABELAS
Pág.
4-1 - Classificação facial segundo o índice facial apresentado..................................... 86
4-2 - Métricas das 22 faces do corpo de funcionários da açominas s.a ........................ 88
4-3 - Métricas das 15 faces do banco de faces da universidade de yale. ....................... 89
4-4a - Relações normalizadas dos 22 funcionários da açominas s.a. ............................ 94
4-4b - Relações normalizadas da 15 faces da universidade de yale. ............................. 95
5-1 - Distribuição das faces dentro das 5 classes. ....................................................... 102
5-2 - Relações métricas usadas para representar as faces. ......................................... 103
5-3 - Grupos de relações métricas usados no treinamento. ......................................... 104
5-4 - Resposta da rede aos padrões usados no treinamento (usando o grupo1) ......... 106
5-5 - Resposta da rede a padrões totalmente desconhecidos (usando o grupo1) ........ 106
5-6 - Comparação entre o acréscimo de 1 relação específica no vetor de identificação
(grupo2 x grupo3 x grupo4). ............................................................................... 108
5-7 - Resposta da rede aos padrões usados no treinamento (usando o grupo5) ......... 112
5-8 - Resposta da rede a padrões totalmente desconhecidos (usando o grupo5) ........ 113
5-9 - Resposta da rede a padrões conhecidos acrescidos de ruído (usando o grupo5)115
5-10 - Resposta da rede aos padrões usados no treinamento (usando o grupo5.1) .... 118
5-11 - Resposta da rede a padrões totalmente desconhecidos (usando o grupo5.1). .. 119
5-12 - Resposta da rede a padrões conhecidos acrescidos de ruído (usando o grupo5.1).
...................................................................................................................................... 120
5-13 - Resposta da rede aos padrões usados no treinamento (usando o grupo5.2) .... 122
5-14 - Resposta da rede a padrões totalmente desconhecidos (usando o grupo5.2). .. 122
5-15 - Resposta da rede a padrões conhecidos acrescidos de ruído (usando o grupo5.2).
...................................................................................................................................... 124
5-16 - Índice de acerto dos grupos em presença de ruídos. ......................................... 127
5-17 - Índice de acerto dos 8 grupos para 15 padrões desconhecidos, não presentes no
treinamento....................................................................................................... 127
5-18 - Relações métricas que compõem os padrões de emtrada da rede da etapa2.... 129
5-19 - Resposta da rede aos padrões usados no treinamento da classe 3. .................. 130

5-20 - Resposta da rede a padrões conhecidos acrescidos de ruído (etapa 2 de
reconhecimento). .............................................................................................. 131
5-21 - Resultados obtidos para as outras 4 classes (etapa 2 de reconhecimento)....... 132

21
CAPÍTULO 1
INTRODUÇÃO
O reconhecimento de faces é uma das ações mais corriqueiras no dia a dia de um ser vivo
inteligente. Esta atividade executada com tanta naturalidade por organismos vivos, tem
despertado o interesse de pesquisadores que trabalham com Visão Computacional e
Inteligência Artificial.
O intuito desses pesquisadores é construir sistemas artificiais que sejam aptos a realizar o
reconhecimento de faces humanas a fim de empregar esta capacidade nas mais diversas
atividades, como por exemplo: sistemas de vigilância, controles de acesso, definições
automáticas de perfis, entre outras. Pesquisas também vêm sendo desenvolvidas por
cientistas da computação no campo de reconhecimento de expressões faciais, para o
emprego em interfaces homem x máquina. Sistemas capazes de interpretar expressões de
raiva, tristeza ou alegria de seus usuários teriam grande aplicabilidade nos estudos de
interação Homem x Computador (Tian et al., 2001).
Devido à grande variedade existente de rostos humanos é muito difícil realizar um
casamento perfeito de padrões para o efetivo reconhecimento de um rosto, seguindo a
metodologia clássica usada em reconhecimento de padrões. Dificuldades como as
transformações a que um rosto pode estar sujeito, (óculos, maquiagem, barba, bigode, etc.)
interferem na confiabilidade das respostas dadas. A solução (Manjunath et al., 1992) para o
problema de reconhecimento de rostos pode englobar desde uma correlação simples de um
modelo facial versus o rosto em questão, até sofisticados sistemas baseados em
características.
A fim de solucionar esses problemas, o processo de Visão Computacional se divide em
etapas distintas, conforme ilustrado nas figuras 1.1 e 1.2 (Marr, 1982).

22
FIGURA 1.1 - Etapas iniciais do processo de Visão Computacional, obtendo como resultado parcial uma imagem contendo o objeto de interesse do sistema. FONTE: Oliveira (1997), p. 1.
No esquema mostrado na Figura 1.1, a aquisição da imagem pode ser feita usando-se um
scanner ou uma câmera. A imagem adquirida pode ser submetida a um pré-processamento,
através de técnicas de Processamento Digital de Imagens, (Fu et al., 1987) (Gonzalez e
Wintz, 1992) com a finalidade de filtrar ruídos, ajustar níveis de iluminação, entre outros
detalhes. A etapa de segmentação visa localizar os objetos e pontos relevantes presentes na
imagem, selecionando-se estas regiões de interesse. A partir da aquisição destas regiões,
passa-se a trabalhar de forma comum aos problemas clássicos de reconhecimento de
padrões, como mostra a Figura1.2.
FIGURA 1.2 - Etapas finais do processo de Visão Computacional. FONTE: Oliveira (1997), p. 2.
Após a etapa de segmentação tem-se a imagem do objeto, necessitando-se então da
determinação dos critérios para sua descrição de forma representativa. É preciso definir
quais as métricas e as relações entre elas, para que seja possível identificar o objeto.
Finda a etapa de descrição, o objeto é codificado em um vetor numérico denominado de
padrão ou vetor de características. Estes padrões, representando o objeto em questão, são
Imagem
Imagem
Aquisição Pré-processamento Segmentação
Objeto
Descrição Reconhecimento
Objeto
Padrão
Resposta

23
analisados um a um por um algoritmo de reconhecimento, que os separará em grupos
seguindo um determinado critério especial, definido na fase de descrição.
A última etapa do processo responde se o objeto em questão – um rosto humano por
exemplo – foi reconhecido ou não pelo sistema, e ainda qual a sua classificação em relação
aos objetos de mesma natureza.
1.1. A Detecção de Faces
Segundo (Sung et al., 1994), o reconhecimento de faces está diretamente relacionado à
detecção de tais objetos dentro das imagens apresentadas como entrada de um sistema
reconhecedor. Uma primeira etapa para um reconhecedor automático de faces é portanto a
detecção da presença de um rosto na imagem e, a partir daí, a comparação de tal rosto com
os modelos conhecidos pelo sistema.
Do ponto de vista acadêmico, a detecção de rostos é interessante devido ao desafio
representado por essa classe de objetos naturalmente estruturados, mas ligeiramente
deformáveis. Há muitas outras classes de objetos e fenômenos no mundo real que
compartilham de características similares às do rosto, como por exemplo as diferentes
grafias manuais e impressas da letra “A“, anomalias de um tumor em uma imagem MRI
(Interpretação por Ressonância Magnética) e defeitos de materiais em uma linha de
produção industrial.
Portanto, avanços obtidos em estudos de detecção de rostos podem ser aplicados em outras
atividades afins.
Segundo (Ben-Yacoub et al., 1999) a confiabilidade e o tempo de resposta de um sistema
de detecção de rostos influencia diretamente no desempenho e emprego desse sistema.
Pode-se definir a detecção de rostos, de acordo com (Sung et al., 1994), como a
determinação da existência ou não de um rosto na imagem e uma vez encontrado este

24
objeto, sua localização deve ser apontada através de um enquadramento ou retornando as
suas coordenadas dentro da imagem.
Sung et al. (1994) afirma ainda que a detecção de rostos é dificultada por três principais
razões enumeradas a seguir.
A primeira dessas razões afirma que embora a maioria dos rostos apresente estruturas
semelhantes, com as mesmas características faciais básicas (olhos, boca, nariz,
sobrancelhas, etc) e dispostas aproximadamente nas mesmas configurações de espaço, pode
haver um grande número de componentes não rígidos e texturas diferentes entre as faces.
Estes elementos de variabilidade são resultantes das diferenças básicas entre os rostos
humanos – pessoas podem apresentar o nariz mais adunco que outras, lábios mais ou menos
carnudos, olhos mais ou menos “puxados” etc. Outros fatores relevantes são as
flexibilizações causadas no rosto pelas expressões faciais.
O segundo ponto que dificulta a detecção de faces está relacionado com a presença de
adornos, como óculos ou bigodes, os quais podem estar presentes ou totalmente ausentes
em uma face. Estes adornos podem, quando presentes, ocultar características faciais básicas
importantes à detecção do rosto através do surgimento de sombras ou reflexos.
A terceira dificuldade na detecção de faces é a não previsibilidade das condições da
imagem em ambientes sem restrições de iluminação, cores e objetos de fundo. Devido ao
fato das faces apresentarem estruturas tridimensionais, a mudança na distribuição de fontes
de luz pode criar ou esconder sombras na face, resultando em uma variabilidade maior que
as manipuláveis em imagens bidimensionais.
Para tratar os problemas relacionados às dificuldades de detecção de faces, basicamente
existem três abordagens principais: (1) o uso da correlação das imagens capturadas com
modelos pré-existentes, (2) modelos deformáveis e (3) imagens espaciais invariantes.

25
Na correlação entre imagens e modelos fixos trabalha-se com o “casamento de filtros”
(matched filters). Nessa abordagem, registra-se a diferença medida entre um modelo
padrão fixo e a parte avaliada da imagem candidata naquele instante. O resultado da
convolução é a diferença entre o fragmento avaliado e o padrão. Quanto menor essa
diferença, maior a probabilidade da imagem candidata corresponder ao padrão procurado.
A suposição adotada por essa abordagem é de que o grau de elementos não rígidos de sub-
características da face (olhos, nariz, boca entre outros) seja pequeno o suficiente, a ponto de
ser descrito de forma adequada por poucos modelos fixos. Num estágio posterior, a técnica
infere a presença de faces analisando as inter-relações entre as sub-características
encontradas.
A abordagem de modelos deformáveis é similar, em princípio, à abordagem clássica de
correlação de modelos, exceto pelo fato de se comparar formas com componentes não-
rígidos. Esta abordagem (Yuille et al., 1992) faz uso de curvas e superfícies parametrizadas
para modelar os elementos não rígidos da face além de sub-características como olhos,
nariz e lábios. De acordo com (Sung et al., 1994) as curvas parametrizadas e superfícies são
fixadas elasticamente em um modelo global, permitindo uma menor variação posicional
entre as características faciais. O processo de combinação tenta alinhar o modelo com uma
ou mais partes da imagem pré-processada, como por exemplo os picos, vales ou bordas.
As premissas adotadas pela abordagem de imagens invariantes assumem que embora as
faces possam apresentar grandes variações na aparência, devido a diferentes razões, há
algumas relações espaciais comuns nestas imagens, possivelmente únicas para todos os
padrões de face. Um esquema baseado nesta abordagem observa um conjunto de brilhos
invariantes existentes entre as diferentes partes da face (Sinha, , 1994). Também nota-se
que enquanto a iluminação e outras mudanças podem alterar significativamente o nível de
brilho em diferentes partes da face, a estrutura ordinal local de distribuição de brilho
permanece praticamente sem modificações. Por exemplo, a região dos olhos de uma face

26
está quase sempre mais escura que a região das bochechas e da testa, exceto sob certas
condições particulares de iluminação.
Para a localização de uma face usando essa abordagem são avaliadas as partes claras e
escuras do modelo em comparação com a imagem candidata. Se todos os pares de regiões
claras e escuras entre os objetos comparados, bem como suas inter-relações coincidirem,
caracteriza-se então a presença de um rosto na imagem.
Esta dissertação de mestrado irá partir da premissa que há uma face na imagem estudada e
esta face está em posição bem definida dentro da imagem, evitando-se assim a etapa de
detecção. Entretanto, muitos dos conceitos e técnicas usadas para a detecção de uma face
dentro de uma imagem serão de grande importância para este trabalho, como será visto
mais à frente.
Para maiores detalhes sobre metodologias e abordagens para a detecção de rostos em
imagens seguem as referências (Lien et al., 2000), (Ben-Yacoub et al., 1999), (Han et al.,
1997), (Rowley et al., 1995), (Sung et al., 1994).
1.2. O Reconhecimento de Faces
O reconhecimento de faces é uma particularização (Oliveira, 1997) do problema geral de
reconhecimento de padrões. Portanto, pode ser ilustrado por um diagrama como o mostrado
na Figura 1.3.
FIGURA 1.3 - Etapas do problema de reconhecimento automático de faces.
FONTE: Oliveira (1997).
Face
Padrão
Reconhecimento Identificação Categorização
Descrição Reconhecimento
Resposta

27
Em geral a entrada do módulo de descrição é uma imagem de face na escala esperada,
tendo seus tons de cinza normalizados de acordo com um intervalo definido. Deste modo,
tem-se uma imagem de face contida em uma matriz de dimensões m x n, contendo os
valores de tons de cinza em cada pixel. Usando essa representação da face, forma-se um
vetor v de comprimento L definido como sendo L = mn. Tal vetor v contém os valores dos
pixels da imagem.
Uma coleção de faces, onde cada uma delas é representada por meio de um vetor, formará
o conjunto de faces que deverá ser reconhecido pelo sistema. A esse conjunto, dá-se o
nome de conjunto de treinamento, sendo aqui representado por TΦ . Dessa forma, para se
identificar N faces diferentes, o conjunto TΦ de vetores v deve ser o seguinte:
{ }NT vvvv ,...,,, 321=Φ (1.1)
O sistema de reconhecimento deverá passar por uma etapa de treinamento, usando o
conjunto TΦ . Um outro conjunto T'Φ deve ser definido, contendo representações de faces
conhecidas e desconhecidas para o sistema. Tal conjunto será usado na etapa de validação
do sistema de reconhecimento, que responderá sobre as novas faces apresentadas.
{ }NT vvvvvvv ...,,,,,, '33
'22
'11
' =Φ (1.2)
O tipo de resposta esperada do sistema de reconhecimento pode variar de acordo com a
aplicação. Pode-se verificar se a pessoa, cuja face v1’ se encontra no conjuto T'Φ , é
reconhecida pelo sistema (Oliveira, 1997). Pode-se listar dentro das imagens pertencentes
ao conjunto de treinamento as que mais se assemelham com a imagem apresentada. É
possível ainda retornar o nome associado à face representada pelo vetor v1’, indicar o seu
sexo, sua raça ou expressão facial.

28
Portanto, segundo (Oliveira, 1997) pode-se dividir as possíveis respostas do sistema de
reconhecimento automático em três tipos: o reconhecimento propriamente dito, a
identificação e a categorização de faces.
O reconhecimento consiste em confirmar se uma imagem de face é conhecida pelo sistema.
Não é necessário realizar a ligação da face a um nome e sim atribuir- lhe uma classificação:
conhecida ou desconhecida.
A identificação deve realizar o reconhecimento e associar uma identidade à face
apresentada.
Já a categorização, compreende as tarefas de identificação de sexo, raça ou estado
emocional da imagem apresentada. Ela pode também ser aplicada na definição de qual o
tipo facial a face se encaixa, segundo um padrão de estética adotado.
Nesta dissertação de mestrado serão abordadas as atividades de reconhecimento e
identificação de faces, como está descrito nos capítulos 4 e 5.
O próximo tópico trata de uma das metodologias aplicadas ao reconhecimento facial usadas
nesta dissertação.
1.3. Métodos Geométricos para Reconhecimento Facial
A primeira tentativa reportada de automatização do reconhecimento de faces, conforme
(Oliveira, 1997), foi realizado por W. Bledsoe na década de 60. Inicialmente, em (Chan e
Bledsoe, 1965) e mais tarde em (Bledsoe, 1966), onde é descrito um sistema semi-
automático de reconhecimento de faces. Bledsoe usou marcações feitas à mão em
fotografias indicando cantos dos olhos, boca e queixo. Após a extração dessas
características o vetor de medidas era submetido a um algoritmo de classificação numérica.
Um dos objetivos deste trabalho é substituir o uso desse algoritmo de classificação
numérica por uma ferramenta inteligente, aqui representada pelas redes neurais. O uso de

29
métodos inteligentes visa tornar o sistema de reconhecimento capaz de absorver pequenas
variações ocorridas no momento da coleta de medidas faciais. Espera-se portanto que o
sistema aqui proposto seja mais robusto a falhas e responda de forma mais confiável, pois
estarão sendo combinadas as vantagens dos métodos geométricos (robustez a variação de
iluminação e escala por exemplo) e as características das redes neurais (não linearidade,
mapeamento de entrada e saída, adaptabilidade, tolerância a falhas, capacidade de
generalização, entre outras). Uma tentativa de padronizar as características que deveriam
ser extraídas de uma imagem de face para seu reconhecimento, foi realizada por uma
equipe dos Laboratórios Bell e apresentada em (Goldstein et al., 1971). Porém, o vetor de
características definido por eles para identificar uma face era baseado em parâmetros como
por exemplo tamanho dos lábios e das orelhas, além de outras características não
geométricas e bastante subjetivas como a tonalidade do cabelo.
Ainda na década de 70, (Kanade, 1973) automatizou completamente a etapa de descrição
facial. Usando um robusto detector de características (construído a partir de módulos
simples usados dentro de uma estratégia “backtracking”), um vetor de 16 características
geométricas foi extraído de uma imagem de face binarizada. Análises de variações dentro
de uma mesma classe e entre classes diferentes de informações revelaram que alguns
parâmetros eram menos eficientes que outros, reduzindo assim a dimensionalidade do
vetor. Tal método chegou a atingir 75% de acerto no reconhecimento facial em uma base de
dados formada por 20 faces diferentes. Foram usadas duas imagens por pessoa, sendo a
primeira imagem a referência inicial e a segunda usada para teste. Já na década de 90, o
trabalho de (Kanade, 1973) foi revisto por (Brunelli e Poggio, 1991).
Brunelli e Poggio (1991) usaram o trabalho de Kanade como base para suas pesquisas. Os
procedimentos computacionais usados por eles não seguiram todo o rigor do trabalho de
Kanade, mas a base de dados usada por Brunelli e Poggio foi mais abrangente em termos
de diversidade de faces, pois o banco de faces era composto por 47 pessoas.

30
Foram usadas quatro instâncias para representar cada pessoa. As características usadas para
representar a face levavam em conta a simetria existente na face humana. O vetor era
composto por 35 medidas referentes aos olhos, sobrancelhas, nariz, boca, queixo e formato
da face.
Os diferentes métodos geométricos chegaram a atingir taxas de acerto de 90% para um
conjunto fixo e não muito grande de faces, segundo o levantamento realizado por (Oliveira,
1997). Entretanto, em muitos casos não era avaliada a capacidade do sistema de identificar
imagens ainda não vistas de faces conhecidas, pois as imagens empregadas na avaliação do
sistema eram as mesmas utilizadas na etapa de construção.
Os trabalhos do grupo de Vicki Bruce (Bruce et al., 1993), (Burton et al., 1993) e (Bruce e
Humphreys, 1994) tratam dos fundamentos psicológicos de utilizar uma abordagem
geométrica para o reconhecimento facial. Após rever a literatura sobre reconhecimento de
objetos e de faces, Bruce sugere diferenças básicas entre o processo humano de
reconhecimento de faces e o reconhecimento de objetos em geral. Afirma-se que a
identificação de objetos é baseada em suas partes e fortemente fundamentada na análise de
arestas, enquanto o reconhecimento de faces parece ser resultado de uma análise mais
global das formas e fundamentado em informações de textura (Bruce e Humphreys, 1994).
A partir de experiências, afirma-se em Bruce e Humphreys(1994) que as codificações feitas
pelo ser humano, relativas a objetos e faces, são processadas em áreas diferentes e de
maneiras diferentes no córtex cerebral. Estas descobertas levaram às abordagens baseadas
em características que trabalham com estruturas existentes no córtex visual. A abordagem
baseada em características pode fazer uso de "Wavelets" , em especial as "“Wavelets de
Gabor” para a extração dessas características e ainda usa uma arquitetura de grafos (grafos
topológicos, grafos elásticos, etc) para a representação da face, como pode ser visto em
(Manjunath, 1992), (Wiskott et al., 1996) dentro de aplicações voltadas para o
reconhecimento de faces e em (Lyons et al, 1998), (Lyons et al, 2000) no reconhecimento
de expressões faciais.

31
Esta dissertação também tem por objetivo principal explorar as métricas faciais tomando
por base os estudos anatômicos relacionados com a odontologia, reconstituição maxilo-
facial e fonoaudiologia, visando o reconhecimento de faces humanas. Os trabalhos
estudados até então para a confecção desta dissertação apresentam medidas características
da face, tomadas a partir de pontos faciais muitas vezes subjetivos, não havendo uma
padronização de quais são realmente as medidas relevantes para o discernimento de rostos.
Não se estabelece também ligações de tais medidas com sexo e raça do modelo.
Procura-se também neste trabalho, analisar a viabilidade de uma abordagemque faça uso de
uma metodologia antiga, como é o caso dos métodos geométricos, combinado a novas
tendências como as redes neurais artificiais.
1.4. Objetivos desta Dissertação
Conforme já mencionado no sub-tópico 1.1, esta dissertação irá partir da premissa que há
uma face na imagem estudada e esta face está em posição bem definida dentro da imagem,
evitando-se assim a etapa de detecção.
O objetivo principal desta dissertação é demonstrar a viabilidade de um sistema de
reconhecimento facial, usando uma rede neural multicamadas, tendo como entrada um
vetor composto pelas relações métricas entre componentes e regiões da face. Tais relações
métricas são obtidas com base no estudo da anatomia facial, usando as mesmas referências
e pontos chaves utilizados em ortodontia, fonoaudiologia e reconstituição maxilo-facial.
Os alvos de estudo deste trabalho podem ser listados como se segue:
• Verificar as dificuldades existentes na extração de características faciais
relevantes à tarefa de reconhecimento, buscando-se uma forma de orientar ou
alertar para a escolha correta das métricas mais aptas para esta tarefa.

32
• Explorar as métricas faciais tomando por base os estudos anatômicos relacionados
com a odontologia e fonoaudiologia, visando o reconhecimento de faces humanas.
• Verificar a viabilidade de substituir, em um sistema de reconhecimento facial, o
uso de algoritmos de classificação numérica por uma ferramenta inteligente, aqui
representada pelas redes neurais, buscando um sistema mais robusto a variações
causadas por expressões faciais diferentes ou mesmo causadas por ruídos durante
a etapa de coleta de dados.
• Analisar a viabilidade de uma abordagem que mescle uma metodologia antiga,
como os métodos geométricos, a novas tendências como as redes neurais
artificiais.
1.5. Aplicações
Embora o reconhecimento de rostos familiares, ou a identificação de semelhanças entre
fisionomias faciais, seja uma tarefa realizada pelos seres vivos inteligentes com certa
tranqüilidade e exatidão, o processo para a realização dessa tarefa ainda não é
completamente compreendido.
Estudos foram realizados descobrindo-se que partes do cérebro são usadas no
reconhecimento de faces. Porém, tais estudos não respondem como essas faces são
representadas internamente dentro de um cérebro. Não respondem também a questões
relativas a que partes da face são essenciais para o seu reconhecimento; qual o motivo para
haver tanta confusão por parte dos ocidentais em diferenciar faces de orientais; que
características e padrões exatos atribuem uma estética agradável a um rosto.
Apenas responder a estes questionamentos já seria uma boa aplicação para um estudo sobre
faces humanas e reconhecimento facial. Porém, há outros motivos para se realizar pesquisas
sobre o reconhecimento de faces e sobre as características relacionadas ao rosto humano.

33
O uso de sistemas de reconhecimento facial aplicado ao controle de acessos, ou na busca de
pessoas suspeitas em um grupo, é de grande aplicabilidade por se tratar de uma forma
menos invasiva, comparando-se a métodos como o scan de retina ou verificação de
impressões digitais. Mesmo que tais sistemas de reconhecimento baseados em faces não
sejam absolutamente infalíveis, até o momento, sempre é possível solicitar o auxílio
humano para validar a decisão ou classificação no reconhecimento de um rosto. Tal
situação seria inviável para um exame de retina.
A iteração homem X máquina também seria privilegiada por sistemas que reconhecessem
faces. Poder-se-ia definir perfis de usuários apenas identificando sua face. Atitudes
diferentes poderiam ser tomadas para determinados usuários, tendo em vista uma estimativa
de sua idade, expressão facial de raiva ou dor, ou ainda sabendo seu sexo.
A seguir será descrito como está organizada esta dissertação.
1.6. Organização
Esta dissertação está dividida em 6 partes, da seguinte forma.
O Capítulo 2 apresenta uma explanação sobre redes neurais e sobre seu uso na tarefa de
reconhecimento facial. É mostrada uma implementação realizada por (Oliveira, 1994)
usando redes neurais artificiais não lineares, com extração implícita de características úteis
ao reconhecimento facial.
No Capítulo 3 introduz-se os conceitos de morfologia facial, usados para a determinação
dos pontos chaves localizados na face. Tais referências são empregadas na criação dos
vetores caraterísticos de cada face. Neste capítulo são mostrados em detalhes a arquitetura
óssea da face, características referentes a pontos específicos do esqueleto facial,
interferência do esqueleto facial com a forma apresentada pelo rosto, além da forma de
obtenção das métricas usadas neste trabalho.

34
O Capítulo 4 descreve a metodologia utilizada para a extração das características da face, as
métricas obtidas através desta metodologia, bem como a estrutura e funcionamento
interligado das redes neurais usadas para o reconhecimento facial.
No Capítulo 5 são apresentados os resultados e a metodologia usada nos testes, incluindo os
parâmetros da rede e ruídos inseridos nos padrões de entrada para a realização dos testes.
Finalmente, são apresentadas as conclusões e perspectivas para trabalhos futuros.

35
CAPÍTULO 2
MÉTODOS CONEXIONISTAS NÃO LINEARES
As expressões faciais são os mais poderosos, naturais e imediatos meios para os seres
humanos comunicarem suas emoções e intenções. Freqüentemente as emoções são
expressas pela face antes mesmo de serem verbalizadas (Tian et al, 2001). Muitos trabalho
(Lien et al., 2000), (Tian et al., 2000a), (Bartlett et al., 1999), (Cohn et al., 1999), (Donato
et al., 1999), (Fukui e Yamaguchi, 1998), (Black e Yacoob, 1995), têm sido desenvolvidos
buscando construir sistemas computacionais capazes de compreender e usar esta forma
natural de comunicação.
Embora as expressões faciais sejam úteis e de grande interesse para a área de interação
homem x máquina, sob o ponto de vista do reconhecimento facial, elas formam um grande
obstáculo. Juntamente com as variações de iluminação, posição da face, escala, tamanho e
orientação da cabeça, as expressões faciais tornam extremamente complexa a tarefa do
reconhecimento facial. Graças a estas particularidades, uma mesma face pode ser
considerada completamente diferente para um sistema automático de reconhecimento.
Como uma tentativa de contornar, ou pelo menos minimizar, estas influências são usadas
neste trabalho as redes neurais artificiais, buscando usar sua capacidade de generalização,
dentre outras habilidades, para efetuar um reconhecimento facial eficiente.
O presente Capítulo faz uma descrição sobre os métodos conexionistas, especificamente
sobre redes neurais artificiais, descrevendo seus componentes, exemplificando possíveis
arquiteturas e também descrevendo o funcionamento de uma rede multicamadas. Também é
descrita aqui uma implementação realizada por (Oliveira, 1994) de um reconhecedor neural
de faces.

36
2.1. Redes Neurais Artificiais
(Oliveira, 1997) afirma que a partir da década de 80, os modelos conexionistas passaram a
ser uma ferramenta comum para a solução de problemas em diversos campos, sendo
principalmente representados pelas redes neurais artificiais não- lineares.
Este sub-tópico apresentará a descrição básica do funcionamento de uma rede neural,
mostrando vantagens e desvantagens do uso de métodos generalistas. Apresentará também
um modelo neural usado por (Oliveira, 1994) na solução do problema de reconhecimento
automático de faces.
2.1.1. Introdução
As Redes Neurais Artificiais representam uma tecnologia que possui raízes em muitas
disciplinas: neurociência, matemática, estatística, física, ciência da computação e
engenharia. (Haykin, 20011)
Uma rede neural artificial é um modelo computacional capaz de, entre outras funções,
armazenar, classificar padrões, realizar interpolação de funções não- lineares e apresentar
soluções heurísticas para problemas de otimização. Isso é conseguido através de um
processo denominado aprendizado. O aprendizado pode ser representado pela Figura 2.1,
onde o ambiente fornece alguma informação para um elemento de aprendizagem.
FIGURA 2.1 – Modelo simples de aprendizagem de máquina. FONTE: Haykin (2001), p. 61.
Ambiente
Elemento de aprendizagem
Base de conhecimento
Elemento de desempenho

37
O elemento de aprendizagem utiliza, então, esta informação para aperfeiçoar a base de
conhecimento, e finalmente o elemento de desempenho utiliza a base de conhecimento para
executar a sua tarefa. Normalmente, a informação que o ambiente fornece para a máquina é
imperfeita, resultando que o elemento de desempenho não sabe previamente como
preencher os detalhes ausentes ou ignorar os detalhes que não são importantes. Portanto, a
máquina opera inicialmente por suposição e depois recebe alimentação do elemento de
desempenho. O mecanismo de realimentação permite que a máquina avalie suas hipóteses e
as revise, se necessário (Haykin, 2001).
A aprendizagem de máquina envolve dois tipos bastante diferentes de processamento de
informação: o indutivo e o dedutivo. No processamento de informação indutivo, padrões
gerais e regras são determinados a partir dos dados brutos e da experiência. Por outro lado,
no processamento de informação dedutivo são utilizadas regras gerais para determinar fatos
específicos. A aprendizagem baseada em similaridade utiliza indução, enquanto que a
prova de um teorema é uma dedução baseada em axiomas conhecidos e em outros teoremas
existentes. A aprendizagem baseada em explanação utiliza tanto a indução quanto a
dedução (Haykin, 2001).
2.1.2. Definições
A operação realizada por uma rede neural é feita através de uma associação de elementos
de processamento e conexões. O elemento básico de um processamento de uma rede neural
é chamado de neurônio, ou nodo. A Figura 2.2 (Haykin, 2001) mostra o diagrama básico do
funcionamento de um neurônio artificial.

38
FIGURA 2.2 - Modelo não linear de um neurônio artificial. FONTE: Adaptado de Haykin (2001), p. 36.
Um neurônio é uma unidade de processamento de informação que é fundamental para a
operação de uma rede neural. Na Figura 2.2 pode-se identificar três elementos básicos do
modelo neuronal (Haykin, 2001):
1) Um conjunto de sinapses ou elos de conexão, cada uma caracterizada por um
peso ou força própria. Especificamente, um sinal xj na entrada da sinapse j
conectada ao neurônio k é multiplicado pelo peso sináptico Wkj. É importante
notar a maneira como são escritos os índices do peso sináptico Wkj. O primeiro
índice se refere ao neurônio em questão e o segundo se refere ao terminal de
entrada da sinapse à qual o peso se refere. Ao contrário de uma sinapse do
cérebro, o peso sináptico de um neurônio artificial pode estar em um intervalo que
inclui valores negativos bem como positivos (Haykin, 2001).
Junção aditiva
Saída yk
( ).ϕ
Wk1
Wkm
.
.
.
Sinais de entrada .
.
.
Wk2
x1
x2
xm
Σ
Bias bk
Pesos sinápticos
Função de ativação

39
2) Um somador para somar os sinais de entrada, ponderados pelas respectivas
sinapses do neurônio; as operações descritas aqui constituem um combinador
linear (Haykin, 2001).
3) Uma função de ativação para restringir a amplitude da saída de um neurônio. A
função de ativação é também referida como função restritiva já que restringe
(limita) o intervalo permissível de amplitude do sinal de saída a um valor finito.
Tipicamente, o intervalo normalizado da amplitude da saída de um neurônio é
escrito como o intervalo unitário fechado [0, 1] ou alternativamente [-1, 1]
(Haykin, 2001).
O modelo neural da Figura 2.2 também inclui um bias aplicado externamente, representado
por bk. O bias bk tem o efeito de aumentar ou diminuir a entrada líquida da função de
ativação, dependendo se ele é positivo ou negativo, respectivamente.
Em termos matemáticos, podemos descrever um neurônio k escrevendo o seguinte par de
equações:
∑ ==
m
j jk jk xwu1 (2.1)
e
( )kkk buy += ϕ (2.2)
onde x1, x2, ..., xm são os sinais de entrada; wk1, wk2, ..., wkm são os pesos sinápticos do
neurônio k; uk é a saída do combinador linear devido aos sinais de entrada; bk é o bias;
( ).ϕ é a função de ativação; e yk é o sinal de saída do neurônio. O uso do bias bk tem o efeito
de aplicar uma transformação afim à saída uk do combinador linear no modelo da Figura
2.2, como mostrado por:

40
kkk buv += (2.3)
O sinal de entrada de um dado neurônio vem de um outro nodo da rede ou de fontes
externas. Esse sinal viaja através das conexões que alimentam os neurônios. Estes
neurônios (Oliveira, 1997) trabalham em paralelo, podendo ser configurados sob a forma de
diferentes arquiteturas.
Os neurônios estão quase sempre dispostos em camadas ou níveis, e a força de cada uma
das conexões que os interliga é expressa por um valor numérico chamado peso.
O “conhecimento” é adquirido pela rede a partir do seu ambiente, através de um processo
de aprendizagem (Haykin, 20011). O processo de aprendizagem nada mais é do que o
ajuste dos pesos sinápticos da rede, de forma ordenada durante a etapa de treinamento, até
que a rede esteja devidamente treinada.
O número de nodos e níveis da rede, além do modo como estes elementos estão dispostos e
conectados, determinam a topologia da rede neural. A definição da topologia de rede a ser
adotada deve estar diretamente ligada à natureza do problema a ser resolvido. Há várias
topologias de redes, cada qual com suas particularidades e aplicações. Alguns tipos destas
topologias são mostrados na Figura 2.3.

41
FIGURA 2.3 – Exemplo de topologias básicas de redes neurais: (a) rede neural feedforward de 1 camada; (b) rede neural feedforward de várias camadas; (c) nodo simples com retro-alimentação; (d) rede recorrente de camada simples; (e) rede recorrente de múltiplas camadas FONTE: adaptado de Lin, C.T. (1996), p. 211.
Outro ponto a ser definido, em se tratando de redes neurais, é o algoritmo a ser usado para
corrigir os pesos das conexões sinápticas. A esse algoritmo dá-se o nome de algoritmo de
treinamento. Assim, a cada rede neural é associada uma estrutura topológica pré-definida
além de um conjunto de técnicas usadas para o treinamento dessa rede. Na fase de
treinamento, os pesos são ajustados de forma a fazer com que a rede aprenda uma dada
tarefa.
Além das arquiteturas mostradas na Figura 2.2, podem ser citadas ainda as redes ANFIS
(Adaptative-Network-based-Fuzzy-Inference), ART (Adaptative Resonance Theory), redes
morfológicas, entre outras. Maiores detalhes sobre arquiteturas e critérios de treinamento de
redes neurais, além de um histórico evolutivo, podem ser encontradas em (Carpenter e

42
Grossberg 1987a,b, 1988,1990), (Haykin, 20011), (Lin, e Lee, 1996), (Senna, 1996),
(Hertz et al., 1991) e (Zurada, 1992).
2.2. Redes Multicamadas Não-Lineares
Pesquisadores com conhecimento em redes neurais artificiais não-lineares começaram a
estudar a possibilidade de aplicação das redes multicamadas não- lineares no tratamento de
faces (Oliveira, 1997). Em (Cottrell e Munro, 1988), afirma-se que assinalar imagens de
faces com diferentes expressões da mesma pessoa é um problema de separação não- linear.
Haykin, 2001As redes multicamadas possuem características importantes como capacidade
de classificação eficiente de padrões, sendo também robustas a entradas ruidosas ou
incompletas. Outra importante característica deste tipo de rede é sua boa generalização,
sendo capaz de realizar separações não- lineares no conjunto de dados.
Em Haykin (2001), diz-se que uma rede generaliza bem quando há um mapeamento de
entrada-saída computado de forma correta (ou aproximadamente correta) para dados de
teste não utilizados na criação ou treinamento da rede. O treinamento de uma rede
multicamadas é feito de forma supervisionada, geralmente por um algoritmo conhecido
como algoritmo de retropropagação do erro (error backpropagation). Este algoritmo é
baseado na regra de aprendizagem por correção do erro. Ao receber uma entrada, a rede é
instruída sobre como deve responder, e a diferença entre a resposta desejada e a obtida é
repassada à rede, servindo como regra de ajuste dos pesos.
A estrutura de uma rede multicamadas lembra a de um grafo bipartido, dirigido e com
pesos. As conexões ligam cada nodo de uma camada a todos os nodos da camada
imediatamente superior a ele, podendo-se ainda deixar alguns nodos sem conexão
caracterizando uma rede parcialmente conectada. As camadas são de três tipos, como pode
ser visto na Figura 2.3.

43
FIGURA 2.3 - Camadas de uma rede neural artificial multicamadas.
Camada de entrada : recebe os dados de entrada. Os nodos nesta camada não realizam
processamento local, pois apenas propagam os dados para os nodos da próxima camada.
Existe apenas uma única camada de entrada em uma rede multicamadas.
Camada de saída : contém a resposta da rede. Após a entrada ser propagada e processada,
os valores de ativação dos nodos desta camada representam a resposta da rede. Assim como
a camada de entrada, a camada de saída é sempre única.
Camada oculta: são as camadas situadas entre as camadas de entrada e de saída. Podem
existir várias camadas ocultas. Em Haykin (2001), afirma-se que para determinados
problemas, como aproximação de funções, é útil o uso de duas camadas ocultas. A primeira
camada oculta se encarrega da extração de características locais enquanto a segunda
camada extrai as características globais. Dessa forma, usando-se duas camadas, o processo
de aproximação (ajuste da curva) se torna mais gerenciável.
Os tamanhos das camadas de entrada e saída são estabelecidos de acordo com as
características do problema a ser tratado. Já o número de nodos das camadas ocultas é
determinado por experiência, dependendo da complexidade do problema (Oliveira, 1997).
Camada de
entrada
Camada
de Saída.
Camada oculta.

44
2.2.1. O processo de aprendizado
A propriedade que é de importância primordial para uma rede neural é a sua habilidade de
aprender a partir de seu ambiente e de melhorar o seu desempenho através de
aprendizagem. A melhoria do desempenho ocorre com o tempo de acordo com alguma
medida preestabelecida. Uma rede neural aprende acerca do seu ambiente através de um
processo interativo de ajustes aplicados a seus pesos sinápticos e níveis de bias. Idealmente,
a rede se torna mais instruída sobre o seu ambiente após cada iteração do processo de
aprendizagem (Haykin, 2001).
Há atividades demais associadas à noção de “aprendizagem” para justificar a sua definição
de forma precisa (Haykin, 2001). Uma definição de aprendizagem segundo o contexto de
redes neurais, adaptada de Mendel e McClarem (1970) é feita a seguir:
“Aprendizagem é um processo pelo qual os parâmetros livres de uma rede neural são
adaptados através de um processo de estimulação pelo ambiente no qual a rede está
inserida. O tipo de aprendizagem é determinado pela maneira pela qual a modificação dos
parâmetros ocorre.”
A definição do processo de aprendizagem implica nos seguintes eventos (Haykin, 2001):
1) A rede neural é estimulada por um ambiente;
2) A rede neural sofre modificações nos seus parâmetros livres como resultado desta estimulação;
3) A rede neural responde de uma maneira nova ao ambiente, devido às modificações ocorridas na sua estrutura interna.
Um conjunto bem estabelecido de regras bem-definidas para a solução de um problema de
aprendizagem é denominado um algoritmo de aprendizagem. Não há um algoritmo único
para o projeto de redes neurais. Basicamente, os algoritmos de aprendizagem diferem entre
si pela forma como é definido o ajuste de um peso sináptico de um neurônio.

45
Em Haykin (2001) são descritas 5 regras de aprendizagem (aprendizado por correção de
erro, aprendizagem baseada em memória, aprendizagem hebbiana, aprendizagem
competitiva e aprendizagem de Boltzmann) básicas para o projeto de redes neurais. Cada
uma das regras citadas tem aplicação mais eficaz em uma determinada tarefa.
Um outro fator a ser considerado é a maneira pela qual uma rede neural, constituída de um
conjunto de neurônios interligados, se relaciona com o seu ambiente. Haykin (2001) explica
dois paradigmas de aprendizado: aprendizado supervisionado e aprendizado não-
supervisionado. A escolha de um ou outro método tem ligação direta à natureza do
problema que se deseja resolver.
Em alguns casos (como heteroassociação, classificação de padrões, reconhecimento de
padrões entre outros) usa-se o paradigma de aprendizagem supervisionada (ou
aprendizagem com um professor). Conceitualmente pode-se considerar o “professor” como
sendo um elemento com um conhecimento sobre o ambiente, sendo este conhecimento
representado por um conjunto de exemplos de entrada-saída. Entretanto o ambiente é
desconhecido pela rede neural de interesse. Portanto, no primeiro passo o professor e a rede
neural são expostos a um vetor de treinamento (i.e., exemplo) retirado do ambiente. Em
virtude do conhecimento prévio apresentado pelo “professor”, ele é capaz de fornecer à
rede uma resposta desejada para aquele vetor de treinamento. Na verdade, a resposta
desejada representa a ação ótima a ser realizada pela rede neural. Os parâmetros da rede são
ajustados sob a influência combinada do vetor de treinamento e do sinal de erro. O sinal de
erro é definido como a diferença entre a resposta desejada e a resposta real da rede. Este
ajuste é realizado passo a passo, iterativamente, com o objetivo de fazer a rede neural
emular o professor (Haykin, 2001). Desta forma, o conhecimento do ambiente disponível
ao professor é transferido para a rede neural através de treinamento, da forma mais
completa possível. Quando esta condição é alcançada, pode-se então dispensar o
“professor” e deixar a rede neural lidar com o ambiente inteiramente por si mesma.

46
Já em outras situações (extração de características e autoassociação por exemplo) opta-se
pelo uso do aprendizado não-supervisionado. Na aprendizagem não-supervisionada ou
auto-organizada, não há um professor externo ou um crítico para supervisionar o processo
de aprendizado. Em vez disso, são fornecidas condições para realizar uma medida
independente da tarefa da qualidade de representação que a rede deve aprender, e os
parâmetros livres da rede são otimizados em relação a esta medida. Uma vez que a rede
tenha se ajustado às regularidades estatísticas dos dados de entrada, ela desenvolve a
habilidade de formar representações internas para codificar as características da entrada e,
desse modo, de criar automaticamente novas classes (Becker, 1991).
Maiores detalhes sobre os tipos de aprendizado, paradigmas, aplicações bem como
comparativos de desempenho, podem ser encontrados em (Haykin, 2001), (Randall e
Jatinder, 2000) e (Lin e Lee, 1996).
Esta dissertação fará uso do algoritmo de retropropagação do erro para realizar o
treinamento das redes neurais multicamadas, empregadas no reconhecimento facial. Este
algoritmo é baseado na regra de aprendizagem por correção do erro.
Basicamente, a aprendizagem por retropropagação do erro consiste de dois passos através
das diferentes camadas da rede: um passo para frente, a propagação, e um passo para trás, a
retropropagação. No passo para frente, um padrão de atividade (vetor de entrada) é
aplicado aos nós sensoriais da rede e seu efeito se propaga através da mesma. Durante o
passo de propagação, os pesos sinápticos da rede são todos fixos. Durante o passo para trás,
por outro lado, os pesos sinápticos são todos ajustados de acordo com uma regra de
correção de erro. Especificamente, a resposta real da rede é subtraída de uma resposta
desejada (alvo) para produzir um sinal de erro (Haykin, 2001). O objetivo do treinamento é
minimizar o erro médio quadrático entre a saída da rede e a resposta desejada (Zurada,
1992). Este sinal de erro é então propagado para trás através da rede, na direção oposta a
das conexões sinápticas. Os pesos sinápticos são ajustados para fazer com que a resposta

47
real da rede se mova para mais perto da resposta desejada, em um sentido estatístico
(Haykin, 2001).
O processo de aprendizagem realizado com o algoritmo é chamado de aprendizagem por
retropropagação. O próximo tópico ilustra uma implementação possível para um
reconhecedor neural de faces usando uma rede multicamadas treinada por retropropagação.
2.3. Implementando um Reconhecedor Neural
Uma imagem de face é um vetor if de P pixels, sendo que cada um destes pixels pode
apresentar um valor de tom de cinza entre 0 e t . Assim, cada imagem pode ser considerada
um vetor geométrico ifr
, em um espaço P-dimensional Pε , que compreende todas as Pt
imagens representáveis com t tons de cinza.
Como as faces são objetos semelhantes, com olhos, boca e nariz nas mesmas posições
relativas, afirma-se que a distribuição espacial de tons de cinza das imagens de faces faz
com que os vetores ifr
estejam concentrados em um sub-espaço muito menor que
Pε (Turk e Petland, 1991). Portanto, para se representar uma face, a fase de descrição
desta face deve implementar uma redução na dimensionalidade dos vetores ifr
, para uma
distribuição mais concentrada e eficiente.
Após a fase de descrição, cada imagem é codificada em um padrão iP de dimensões muito
menores que as dimensões das imagens originais. Esses padrões podem então ser
processados por um algoritmo de classificação ou agrupamento, que compreende a etapa de
reconhecimento.
Considerando-se então uma rede multicamada não- linear que, de posse de uma imagem if ,
consiga agir de maneira análoga a um compressor de dados. Isto pode ser feito treinando

48
uma rede de três níveis para repetir a imagem de entrada na camada de saída, passando por
uma camada oculta com um número de nodos consideravelmente menor que o número de
pixels da imagem. Se esta rede for capaz de reproduzir imagens de face com um desvio
pequeno, as informações contidas na camada oculta podem ser consideradas como uma
representação reduzida da face. Esta estrutura para compactação foi implementada por
(Oliveira, 1994) e obteve bons resultados comparados aos métodos tradicionais (Oliveira,
1997).
2.3.1. Etapa de Descrição
Uma rede como a mostrada na Figura 2.4 (Oliveira, 1997) treinada com o algoritmo de
retropropagação do erro é capaz de realizar a compactação citada, e pode ser usada para
implementar a etapa de descrição do processo de reconhecimento de faces.
FIGURA 2.4 - Topologia de rede multicamada para extração de características. Apesar de não mostrado na figura para melhor visualização, cada nodo é totalmente conectado com os nodos da camada seguinte. FONTE: Oliveira (1997), p. 29.
Imagem de entrada
Imagem de saída

49
Seja TΦ um conjunto de faces usadas para o treinamento da rede. O conjunto TΦ contém
imagens de face if de N pessoas diferentes, com i variando de 1 ao número total de
pessoas: N.
Para que os dados sejam tratados corretamente pela rede, é preciso que os valores
numéricos em TΦ sejam codificados de modo a não apresentarem uma ordem de grandeza
muito diferente da encontrada nas funções de ativação e dos pesos da rede. Esta modelagem
inicial é um processo que depende da topologia e do tipo de treinamento escolhido para a
rede, e não obedece a um procedimento específico.
No caso específico da aplicação proposta por (Oliveira, 1994), os padrões if apresentam
valores de tons de cinza entre 0 e t, onde t é usualmente igual a 127 ou 255. Sugere-se que
os valores de tons de cinza sejam mapeados de acordo com a imagem da função de ativação
utilizada, tornando os valores de ativação de todos os nodos da rede compreendidos em
uma mesma faixa.
A função sigmoidal escolhida para a rede implementada em (Oliveira, 1994) é mostrada na
equação 2.4, e portanto os tons de cinza originais – de 0 a 127 – foram mapeados em
valores entre 0 e 1. As imagens de face if possuíam dimensões de 64x64, portanto a rede
de compressão tinha 4.096 nodos na camada de saída e de entrada. Após vários testes, a
camada oculta foi fixada em 330 nodos. Os resultados obtidos na compressão podem se
encontrados com detalhes em (Oliveira, 1994).
( )θϕ −−+= ve
v1
1)( (2.4)

50
2.3.2. Etapa de Reconhecimento
A etapa de compactação das imagens de faces presentes no conjunto TΦ , funciona como
um extrator de características relevantes destas faces. Tais características ficaram
codificadas nos pesos da rede. De posse desta rede treinada (Oliveira, 1997) para realizar
compactação de imagens, ou seja, capaz de extrair as características aptas à diferenciação
entre as facesparte-se para a construção de uma rede para reconhecimento de padrões.
Assim, utiliza-se a informação codificada na camada oculta da rede de compressão como
entrada para um classificador.
Esse classificador é uma rede não linear de três camadas, assim como a utilizada para a
extração de características. Apesar disso, existem algumas mudanças na topologia:
• Camada de entrada possui um número de nodos igual ao número utilizado na
camada oculta da rede de extração de características.
• A camada de saída possui N nodos iο , onde i varia de 1 a N e onde N é o número
de pessoas distintas de TΦ .
• A camada oculta deve possuir um número de nodos necessário para a
convergência do treinamento, sendo N-1 uma sugestão para o número inicial de
nodos.
A rede de reconhecimento recebe como entrada os valores de ativação dos nodos da
camada oculta da rede de extração de características, cujos pesos já se encontram fixos após
o treinamento. Treina-se então a rede de reconhecimento através do algoritmo de
retropropagação para realizar a classificação dos padrões.
Cada nodo de saída iο é assinalado a uma pessoa cuja imagem está em TΦ . Assim, ao
receber uma imagem de teste fi, um dos nodos de saída iο deve responder com um valor de

51
ativação sensivelmente maior que os restantes. Quanto mais próximo de 1 for esse valor,
maior a probabilidade de que a pessoa da imagem de teste fi seja a mesma representada na
saída iο , onde i é o nodo com maior resposta.
Após o treinamento da rede de reconhecimento, pode-se construir uma rede única para
realizar a identificação das pessoas em TΦ . Para isso, mantêm-se fixos os pesos entre as
camadas de entrada e oculta da rede de descrição, e concatena-se à camada oculta a rede
treinada para o reconhecimento.
Uma abordagem similar foi proposta em (Bouattour et al., 1992), onde se descreve uma
rede cujos pesos das camadas ocultas são inicializados de modo a filtrar as informações de
entrada. Assim, ao invés da inicialização randômica, a rede implementa filtros conhecidos,
fazendo com que a fase de descrição seja mais robusta e menos sensível a diferenças na
iluminação.
2.4. Conclusões
A implementação do reconhecedor neural de faces mostrada no tópico anterior, usa uma
rede neural para realizar uma decodificação de um conjunto de valores compreendidos
entre 0 e 127, que representam a face da foto, em uma nova representação mais compacta.
Essa nova representação é composta pelos pesos sinápticos da rede neural, obtidos na etapa
de compressão de dados.
Fatores como variações de iluminação influenciam os pixels da imagem (valores
compreendidos entre 0 e 127 que representam a face). Porém, a rede neural, com sua
capacidade de generalização, consegue associar uma ent rada ruidosa (não exatamente igual
à entrada vista na etapa de treinamento) à respectiva saída desejada.
Outra variação que pode interferir no reconhecimento facial é a distância entre a câmera e a
face fotografada. Pode haver distorções na quantidade de pixels que representam um

52
determinado componente facial. Assim, um olho que antes era representado por 9 pixels
dispostos bidimensionalmente 3x3 sob uma determinada distância, pode vir a ser
representado por 4 pixels dispostos 2x2 se a face se aproxima da câmera.
A implementação descrita anteriormente transfere para a rede neural a tarefa de definir e
estruturar a representação da face. Perde-se dessa forma, a noção da importância ou não de
determinado componente ou região específica da face na tarefa de reconhecimento. Na
estrutura mostrada, tem-se uma visão global da face e a partir daí busca-se a representação
mais próxima da face analisada, comparando-se o resultado obtido pela rede com aqueles
conseguidos durante o treinamento.
O sistema híbrido inteligente aplicado ao reconhecimento facial proposto nesta dissertação,
visa mensurar o grau de participação de componentes e regiões da face na tarefa de
reconhecimento facial. O sistema híbrido tem como entrada as relações métricas de
componentes e regiões faciais. Cada conjunto de relações métricas representa uma face.
Dessa forma, busca-se um controle mais refinado de quais os componentes e regiões
realmente contribuem para o sucesso ou insucesso do reconhecimento.
O uso das relações métricas de componentes faciais também visa minimizar a interferência
da variação de distâncias entre câmera e face, bem como variações de iluminação.

53
CAPÍTULO 3
MORFOLOGIA DA FACE HUMANA
As medidas e relações métricas que são usadas nesse trabalho foram pesquisadas de forma
a se encontrar respaldo técnico e embasamento anatômico na obtenção de resultados e
conclusões. Dessa forma, torna-se necessário um conhecimento mínimo da anatomia
estrutural dos componentes faciais para o entendimento do problema e conseqüente
desenvolvimento da dissertação.
As considerações anatômicas expostas a seguir são de extrema importância para o
desenvolvimento desse trabalho, uma vez que elas interferem diretamente na formação
estética da face e podem ser decisivas na diferenciação entre rostos de pessoas distintas.
3.1. Introdução
Segundo (Graziani, 1986), a face tem a forma de uma pirâmide triangular com a base para
baixo que se adapta e articula com a superfície inferior do crânio. É formada por partes
ósseas e partes moles, onde as partes ósseas constituem um arcabouço – o esqueleto facial –
com a função de sustentar as partes moles que a ele se adaptam, formando as várias regiões
superficiais e profundas do rosto. Para se conhecer a face humana é necessário que se avalie
o seu esqueleto e suas partes moles.
Algumas partes do esqueleto facial e pontos importantes de referência craniométrica podem
ser analisadas sem a necessidade de uma radiografia (Graziani, 1986). São estas medidas e
referências, perceptíveis a olho nu, que interessam nesta dissertação, visto que não será
aplicada nenhuma técnica “invasiva” para obtenção das medidas faciais. Serão tomadas
somente as fotos frontais dos modelos a uma distância aproximadamente constante e sob
uma iluminação regular.

54
O esqueleto facial é a estrutura óssea de sustentação da face, formada por um conjunto de
catorze ossos. Esse conjunto é geralmente chamado “maciço facial”. Os ossos que o
compõem estão divididos em seis pares (maxilares superiores, nasais, lacrimais malares,
palatinos e cornetos) e dois ímpares (vômer e mandíbula).
O conjunto é dividido em duas partes, uma superior fixa e outra inferior móvel. A parte
inferior é constituída por um único osso, o maxilar inferior ou mandíbula. A parte superior
compreende todos os demais ossos, os quais se articulam entre si formando uma só peça
que em anatomia se denomina maxilar superior ou maxila.
Os tecidos moles revestem o esqueleto facial. As partes moles são constituídas pela pele,
tecido celular subcutâneo, camadas musculares correspondentes às diversas regiões da face,
vasos e nervos além das glândulas salivares. Uma membrana epitelial reveste internamente
as cavidades formadas entre os ossos (cavidade nasal, cavidade bucal) e as cavidades
existentes no interior dos ossos (seios da face).
Para a conveniênc ia do seu estudo anatômico, a face é dividida arbitrariamente em um
determinado número de regiões. Nos estudos relativos à prótese facial, também
aproveitáveis nos estudos desse trabalho, convém a divisão adotada por Harry Shapiro
mostrada na Figura 3.1 (Graziani, 1986):
1. regiões orbitária (ou palpebral);
2. infra-orbitária;
3. zigomática;
4. nasal;
5. bucal;
6. mentoniana;
7. bucinadora;
8. parotídeo-masseterina;
9. auricular;
10. temporal.

55
FIGURA 3.1 - Regiões da face. FONTE: (Graziani, 1986), p. 6.
Dos tecidos moles que recobrem o esqueleto facial, a pele é um dos mais importantes,
sob o enfoque de prótese restauradora e também sendo um importante tópico para os
estudos aqui realizados. Sob a pele estão situados os músculos da expressão facial, que
são relevantes na diferenciação entre pessoas, através de uma foto frontal. Estes
músculos ainda são úteis em aplicações que objetivem reconhecer expressões faciais.
A Morfologia Facial pode ser melhor estudada quando subdividida em 3 partes:
1) arquitetura do esqueleto facial;
2) antropometria;
3) estética facial.
Nos próximos tópicos a seguir estarão sendo detalhadas cada uma destas partes.

56
3.2. Arquitetura do Esqueleto Facial
O conjunto de quatorze ossos que formam o arcabouço da face constitui uma unidade
funcional, cujos elementos componentes não estão colocados casualmente uns ao lado
dos outros. Eles são dependentes de leis particulares internas e têm uma importante
conexão estrutural. Os ossos do esqueleto facial têm sua arquitetura adaptada às
exigências funcionais: as zonas sobre as quais atuam as maiores forças de pressão e
tração são justamente as mais reforçadas, sob o ponto de vista mecânico (Graziani,
1986).
Fatores como tipo de alimentação, hábitos alimentares e culturais das pessoas e ainda
fatores vinculados à etnia, podem ter influência no desenvolvimento exagerado ou
atrofia de estruturas do esqueleto facial, interferindo por sua vez na forma estética
apresentada pela face. O reforço estrutural, decorrente de tais fatores, pode ocorrer de
duas maneiras: pelo espessamento das lâminas compactas ou pelo espessamento e
condensação das trabéculas esponjosas que formam o esqueleto facial.
No conjunto esqueleto-facial podem ser observados elementos arquitetônicos dispostos
de forma a resistir à ação de poderosos músculos, sendo capazes de suportar as forças
exercidas durante a mastigação (Graziani, 1986). Tais estruturas podem ser
suficientemente desenvolvidas a ponto de caracterizar uma face de forma a diferenciá- la
de outra.
Podem ser verificadas importantes diferenças entre a arquitetura do maxilar superior e a
da mandíbula. Tais particularidades serão descritas a seguir.
Maxilar superior ou Maxila:
O maxilar superior, aqui considerando também os ossos do conjunto facial que se
agregam a ele, se articula com o conjunto crânio-facial por meio de uma série de
sinartroses dotadas de grande eficiência mecânica. Estas sinartroses permitem à maxila
resistir às forças exercidas pela a ação dos músculos mastigadores, além de distribuir
estas forças (Graziani, 1986). O exercício exagerado desses músculos, bem como a

57
ausência de estímulos, pode causar respectivamente hipertrofias ou atrofias que
influenciam no desenho facial. A observação do comportamento dessas estruturas pode
ser um importante diferencial para o discernimento entre pessoas e raças distintas.
Um exemplo de características ligadas a raças ou padrões comportamentais é o arco
supra-orbitário (estrutura 4 da Figura 3.2) super desenvolvidos em algumas raças
primitivas. Segundo (Graziani, 1986), o arco supra-orbitário, é constituído pela arcada
orbitária do frontal. Ele une cada pilar canino (estrutura 1 da Figura 3.2) com o pilar
zigomático (estrutura 2 da Figura 3.2) do respectivo lado. A borda supra-orbitária sofre
o contrachoque das forças da pressão mastigatória. O reforço de tecido compacto do
arco superciliar é uma conseqüência disso, explicando-se o maior desenvolvimento
desse arco em algumas raças humanas primitivas e nos antropóides, (torus supraorbitais)
cuja alimentação exigia maior pressão mastigatória.
FIGURA 3.2 - Arquitetura do esqueleto facial. 1: Pilar canino. 2: Pilar zigomático. 3:
Arco infranasal. 4: Arco supra-orbitário. 5: Arco infra-orbitário. 6: Arco supranasal. FONTE: Graziani (1986), p. 7.

58
A maxila (ou maxilar superior) forma uma armação em forma de pirâmide apoiada à
base do crânio, apresentando pilares de apoio, denominadas linhas de força. Entre esses
pilares formam-se as cavidades orbitárias, nasais e as cavidades pneumáticas acessórias
nasais (ou seios da face). Os pilares são reunidos por arcos de reforço que com eles
constituem a base, o forte da armação. Já os espaços entre eles são frágeis paredes de
cavidades, constituindo verdadeiros espaços mortos, mecanicamente.
O sistema de colunas de sustentação é formado por três pilares principais: 1. Pilar
canino, 2. Pilar zigomático, 3. Pilar pterigóideo. Os pilares canino e zigomático,
podem ser vistos na Figura 3.2, correspondendo às estruturas de número 1 e 2.
A seguir serão descritas algumas particularidades da Mandíbula.
Mandíbula:
A arquitetura da porção móvel do esqueleto facial (Graziani, 1986) – a mandíbula –
diferencia-se bastante da porção fixa. A mandíbula é um osso móvel, isolado, sujeito a
forças de potentes e desenvolvidos músculos. Ela tem, necessariamente, que ser um
osso de grande resistência.
De início, apresenta uma grande linha de resistência, chamada trajetória basilar
(estrutura 1 da Figura 3.3), formada pelo espessamento ao longo da sua borda inferior.
Esta trajetória, conforme vemos na Figura 3.3 , inicia-se no côndilo, caminha para a
borda inferior, passando um pouco adiante do ângulo e depois de caminhar ao longo da
borda inferior, até o nível do canino, curva-se para cima e termina na borda superior, já
na região mentoniana.

59
Região doCônidilo
Regiãomentoniana
FIGURA 3.3 – Linhas de resistência da mandíbula. 1: Trajetória basilar. 2: Trajetória alveolar. 3: Trajetória coronoidal. 4: Trajetória condileana. FONTE: Graziani (1986), p. 8.
A região do mento tem então, quando observada de frente, um sistema de resistência em
forma de “V” invertido, constituindo um reforço à zona mais ameaçada pelas forças de
flexão e na qual pode-se observar fraturas, sobretudo em crianças e em feridos de
guerra.
Outra linha de resistência é observada ao longo do processo alveolar (estrutura 2 da
Figura 3.3), partindo da apófise coronóide, até atingir a linha mediana (trajetória
aveolar). Na apófise coronóide, a linha de resistência destinada à força de tração do
músculo temporal constitui a trajetória coronoidal (estrutura 3 da Figura 3.3).
Finalmente, a trajetória condileana (estrutura 4 da Figura 3.3) assinalada também na
Figura 3.3 , parte do côndilo e toma a direção da borda posterior do ramo ascendente.
3.3. Antropometria Facial
Segundo (Graziani, 1986), os métodos antropométricos têm sido usados em algumas
especialidades da odontologia, como por exemplo em ortodontia, odontologia legal e
prótese restauradora. Alguns pontos e medidas antropológicas são de sumo interesse

60
para a prótese maxilo-facial pois servem de guia para a reconstrução facial, sem
desprezar as características originais da face.
A confecção de uma prótese facial exige que um grande número de detalhes seja levado
em consideração, tais como a estética da face, a sua estrutura óssea e a construção de
formas harmoniosas que se encaixem melhor ao perfil original. Tais medidas e
direcionamentos, usados pelos profissionais de odontologia, são úteis também para a
tarefa de encontrar pontos relevantes ao reconhecimento facial. A seguir serão
detalhadas algumas dessas características.
3.3.1. Pontos Craniométricos
Os pontos e medidas craniométricas (Graziani, 1986) ou mais precisamente,
prosopométricas, permitem o conhecimento exato da forma e dimensões da face,
possibilitando o diagnóstico preciso das deformidades e a apreciação dos detalhes e
variações individuais e raciais.
Os pontos craniométricos estão situados sobre o esqueleto e são utilizados como
referência para as mensurações e as relações crânio-faciais. Infelizmente para essa
dissertação, muitos desses pontos não podem ser precisamente determinados em
indivíduos vivos, ou ainda só são determinados através de raios-X e aparelhos especiais.
Portanto, serão usadas neste trabalho apenas medidas e referências possíveis de se obter
sem a necessidade de métodos invasivos como radiografias ou ressonâncias magnéticas.
A Figura 3.4 mostra a localização de todos pontos craniométricos.

61
FIGURA 3.4 - Pontos craniométricos.
FONTE: Graziani (1986), p. 8.
Outra limitação para a escolha dos pontos craniométricos a serem usados nesta
dissertação é o fato do tecido epitelial e dos músculos da face estarem presentes quando
se analisa uma foto frontal de um indivíduo vivo. Porém, alguns desses pontos
mostrados na Figura 3.4 podem ser determinados com boa precisão através da análise de
imagens frontais da face de indivíduos vivos. Pode-se também estabelecer certas
relações usando estas referências craniométricas e suas relações métricas como é feito
na odontologia. Especialmente neste caso, tais informações serão usadas com a
finalidade de diferenciar indivíduos e não para correções de feições da face.
Dentre os pontos craniométricos que podem ser determinados com certa precisão em
indivíduos vivos e em fotos frontais, seguem-se:
1) Ófrio: situado no meio do diâmetro frontal mínimo (logo acima da glabela).
Corresponde à altura do assoalho endocraniano.
2) Glabela: é uma proeminência situada no osso frontal, entre as duas cristas
superciliares, logo acima da raiz do nariz. No vivo, corresponde às
extremidades internas das sobrancelhas.

62
3) Násio: Situado no cruzamento do plano sagital com a sutura naso-frontal,
podendo ser também determinado no vivo.
4) Gnátio: chamado também ponto mentoniano, situa-se no ponto mais inferior
e mais anterior da mandíbula.
5) Gônio: situado no vértice do ângulo da mandíbula, podendo ser facilmente
determinado no indivíduo vivo;
6) Zigio: ponto lateral mais proeminente da arcada zigomática;
3.3.2. Medidas Lineares
De posse dos pontos craniométricos citados no tópico anterior é possível realizar
algumas medidas lineares importantes a este estudo de reconhecimento, tais como:
• Diâmetro transverso máximo, bizigomático ou bimalar: distância entre os
dois zígios.
• Altura morfológica da face ou naso-mentoniana: distância em projeção que
vai do násio ao gnátio; representa a altura total da face.
• Altura ófrio-alveolar: distância que vai do ófrio ao próstio.
• Altura násio-alveolar: distância entre o násio e o próstio, que corresponde à
altura facial superior.
• Altura nasal: distância entre o násio e o naso-espinhal.
• Largura nasal: distância máxima da abertura nasal.
• Largura interorbitária: distância entre os dois pontos lacrimais.
• Largura orbitária: distância entre o dácrio e a borda externa da órbita.

63
• Altura orbitária: distância entre a borda superior e a borda inferior da órbita,
perpendiculares à linha da largura.
• Diâmetro bigoníaco: distância entre os dois gônios.
• Comprimento do ramo ascendente da mandíbula: distância entre o gônio e o
vértice do côndilo.
Para cirurgias reparadoras e ainda confecção de próteses maxilo-faciais, pode-se contar
com medidas angulares tomadas da face. Neste estudo, tais medidas não são válidas
uma vez que elas devem ser tomadas com o indivíduo em posição perfilada e esta
dissertação se destina a estudos de faces frontais.
3.3.3. Índice Facial
É denominado Índice Facial a relação existente entre a distância násio-gnática,
multiplicada por 100 e dividida pela distância bizigomática (distância entre os dois
zígios).
De acordo com esse índice, tem-se uma classificação das faces em baixas, largas,
médias, altas e estreitas. Temos então indivíduos:
• Hipereuriprosópicos abaixo de 80
• Euriprosópicos de 80 a 85
• Mesoprosópicos de 85 a 90
• Leptoprosópicos de 90 a 95
• Hiperleptoprosópicos acima de 95
O indivíduo Euriprosópico, mostrado na Figura 3.5 tem a face larga, fossas nasais e
abóbada palatina largas e baixas, zigomas salientes e arcadas dentárias largas e curtas.
Há preponderância das medidas transversais.
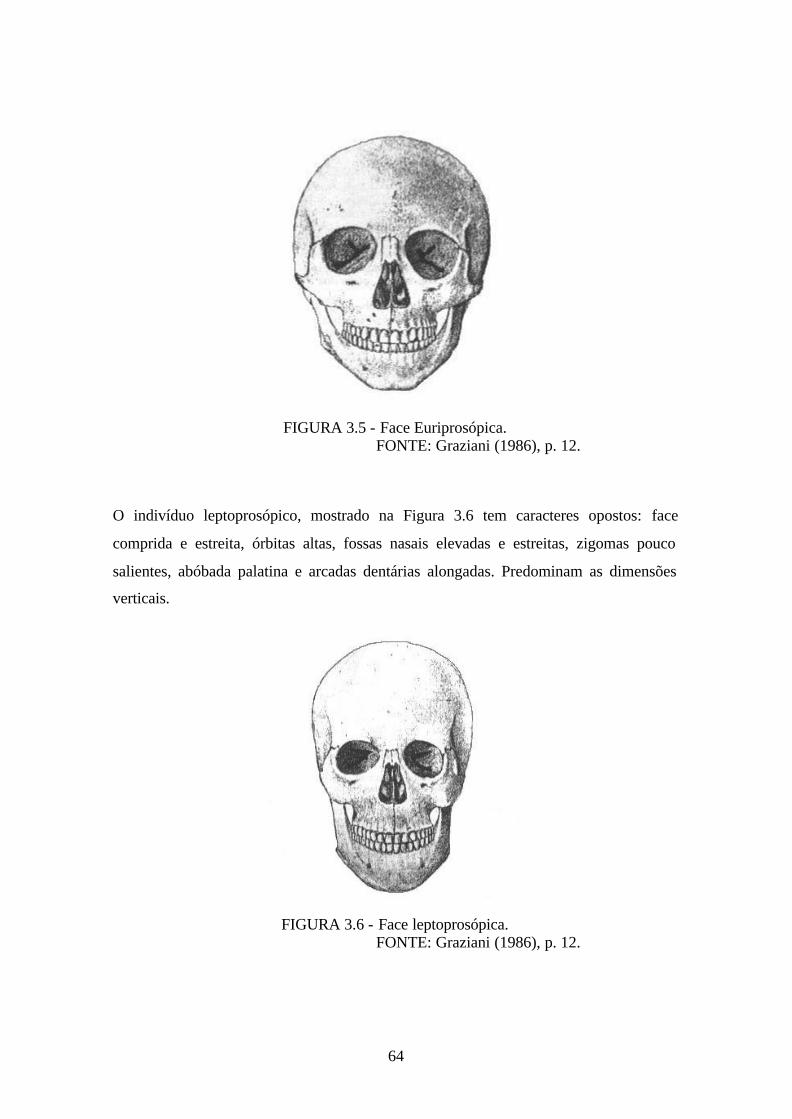
64
FIGURA 3.5 - Face Euriprosópica. FONTE: Graziani (1986), p. 12.
O indivíduo leptoprosópico, mostrado na Figura 3.6 tem caracteres opostos: face
comprida e estreita, órbitas altas, fossas nasais elevadas e estreitas, zigomas pouco
salientes, abóbada palatina e arcadas dentárias alongadas. Predominam as dimensões
verticais.
FIGURA 3.6 - Face leptoprosópica. FONTE: Graziani (1986), p. 12.

65
Os indivíduos mesoprosópicos apresentam características intermediárias àquelas
mostradas nas figuras 3.5 e 3.6. Já os indivíduos que se encontram nos extremos da
classificação segundo o índice facial, apresentam o achatamento facial (indivíduos
hipereuriprosópicos) ou um perfil extremamente comprido (indivíduos
hiperleptoprosópicos) como suas principais características.
3.4. Estética Facial
A estética facial é definida por (Graziani, 1986) como sendo a combinação perfeita de
diferentes partes entre si, formando um todo concorrendo para um mesmo fim. É
importante discernir entre os conceitos do “belo” e do “harmonioso”. A beleza de uma
face muitas vezes é algo subjetivo e depende de questões pessoais e até culturais. Já
uma face harmoniosa, normal, é algo mais palpável e possível de ser conceituado. Pode-
se portanto considerar uma face como normal, quando ela não apresenta grandes
distorções em sua simetria vertical e grandes variações de proporção entre componentes
e regiões. O estudo da face normal e o estudo da arte, em sua relação com a estética e a
beleza facial, são pontos chave para cirurgiões voltados para a reconstituição facial e
certamente fornecem pistas importantes para a diferenciação entre rostos humanos.
O uso de métricas e modelos faciais segundo (Chiche e Pinault, 1996) tem sido
aplicado, no meio clínico, para encontrar uma composição agradável no sorriso,
podendo também ser aplicadas em reconstituições faciais, de modo a criar um arranjo
dos vários elementos estéticos para uma proporção ou relação adequada, conforme os
princípios conhecidos.
Ainda segundo (Chiche e Pinault, 1996), há quatro fatores de composição estética que
podem ser fácil e efetivamente aplicados especificamente ao sorriso. Eles servem para
auxiliar o clínico a determinar a apresentação adequada dos dentes, seu tamanho,
arranjo e orientação em relação à face durante o diagnóstico estético e o tratamento.
Esses fatores são:
• Estruturas e referências: sistema de construção que dá a forma; um padrão para
medir ou construir.

66
• Proporção e idealismo: relação de uma parte com a outra ou com o todo em
relação à grandeza, à quantidade ou ao grau; um padrão de perfeição, beleza ou
excelência.
• Simetria: correspondência de tamanho, forma e posição relativa das partes em
lados opostos de uma linha divisória - ou plano mediano - ou ainda ao redor de
um centro ou eixo.
• Perspectiva e ilusão: técnica ou processo de representar, em um plano ou
superfície curva, a relação espacial de objetos como eles poderiam parecer sob o
nosso olhar.
A intenção deste tópico é estudar as noções de simetria, estruturas e referências
presentes nos elementos de tecido mole que compõem o rosto humano, bem como suas
inter-relações, com o objetivo de se criar uma heurística aplicável à diferenciação de
rostos humanos. Uma vez encontrada essa heurística, poder-se-ia aplicá-la em sistemas
automáticos de reconhecimento de rostos.
Nos tópicos seguintes serão apresentadas mais algumas características úteis à
classificação e diferenciação entre faces humanas.
3.4.1. Tipos Morfológicos
Enquanto estudiosos e artistas estabeleciam as relações da expressão facial com os
estados da alma, e a Estética se preocupou com a harmonia da forma, outros cientistas
trataram de investigar as relações entre os caracteres funcionais ou étnicos, classificando
o aspecto exterior da face em tipos morfológicos (Graziani, 1986).
Diversas classificações sobre tipos morfológicos podem ser encontradas na literatura.
Na renascença, Dürer – artista da época – dividia as formas faciais em seis tipos
diferentes, conforme a Figura 3.7.

67
FIGURA 3.7 - A face humana segundo a concepção artística de Dürer. FONTE: Graziani (1986), p. 21.
As formas faciais continuaram despertando interesse, como mostrou em 1815 a autora
inglesa Madame Schimmelpennick, em seu livro “Ciência da Beleza”, onde ela
realizava a classificação das faces de acordo com a sua semelhança a 5 formas
geométricas: quadrado, retângulo, círculo, elipse e o triângulo, como mostrado na
Figura 3.8.

68
FIGURA 3.8- Tipos faciais segundo Madame Schimmelpennick em seu livro "Ciência da Beleza". FONTE: Graziani (1986), p. 13.
Já em 1910, Cláudio Sigaud, um médico de Lyon, e ainda Chaillon Mac Auliff em
1912, estabeleceram 4 tipos morfológicos principais:
1) Tipo cerebral;
2) Tipo respiratório;
3) Tipo digestivo;
4) Tipo muscular.
Esses tipos de face são definidos através da criação de 2 linhas de referência na face,
delimitando-a em 3 regiões mostradas na Figura 3.9. A primeira das linhas deve passar
pela raiz do nariz e a segunda pela base do nariz.
Dividida dessa forma, a face passa a ter a parte superior, acima da linha traçada na raiz
do nariz, sendo chamada de cerebral, compreendendo o frontal ao nível dos lóbulos
anteriores do cérebro. O segmento médio, chamado de respiratório é constituído pela
zona do nariz e cavidades sinusais. O seguimento inferior é chamado de digestivo,

69
sendo compreendido pela região da boca, maxilares e arcadas dentárias. Os quatro tipos
de face podem ser vistos na Figura 3.9.
FIGURA 3.9 - Tipos morfológicos segundo a classificação de Claud Sigaud. FONTE: Graziani (1986), p. 13.
O tipo cerebral caracteriza-se pela predominância do segmento superior. A face
apresenta a forma de uma pirâmide invertida, resultando no maior volume do crânio,
sendo que seus contornos estão inscritos em um triângulo de cúspide inferior. É o
indivíduo de face oval alongada, a fronte larga e elevada. Sua maxila, seios maxilares,
boca e mandíbula são de pequenas dimensões.
O tipo respiratório caracteriza-se pela predominância do segmento médio. Nariz, fossas
nasais e cavidades sinusais volumosas, zigomas salientes. Espaço inter-ocular
aumentado, a fronte baixa e estreita. O seu segmento inferior também apresenta altura e
largura reduzidas.
No tipo digestivo a predominância é do segmento inferior. Boca grande, lábios grossos,
dentes largos, mandíbula larga, gônios salientes. Muitas vezes, apresenta prognatismo

70
mandibular. A fronte é estreita e baixa, os olhos quase sempre pequenos e as pálpebras
geralmente infiltradas por tecido adiposo. O segmento médio é de reduzidas proporções.
A face apresenta a forma de um cone truncado ou de um trapézio.
O tipo muscular apresenta os três segmentos iguais, caracterizando-se pela igualdade
das zonas cerebral, respiratória e digestiva. A face tem a forma retangular. É retangular
também a inserção frontal dos cabelos. Possui os limites laterais da fronte no mesmo
plano dos zigomas e da região masseterina. Os olhos, boca e nariz são de dimensões
medianas.
Raramente encontram-se esses tipos faciais sob a sua forma pura, existindo entre eles as
formas de transição (tipos mistos) quase sempre difíceis de serem distinguidos.
Outras classificações faciais são encontradas nos estudos da fonoaudiologia.
Analisando-se os tipos faciais é possível associar a eles certas patologias relacionadas a
distúrbios da fala e distúrbios respiratórios, que por sua vez vêm a interferir na estética
do rosto.
Os tipos de face, segundo a classificação usada em fonoaudiologia, são os seguintes
(DE Felício, 1999):
• Dólico-facial: possuem a musculatura elevadora da mandíbula mais delgada,
quando comparada aos outros dois tipos faciais, sendo a inserção do masseter
próxima ao ângulo da mandíbula e de forma oblíqua. Esse tipo facial apresenta
tendência de crescimento facial no sentido vertical, sendo comum a verificação
de má-oclusão caracterizada por mordida aberta esquelética.
• Bráqui- facial: características inversas às apresentadas pelo dólico-facial, isto é,
sua musculatura elevadora da mandíbula é espessa e sua inserção no corpo da
mandíbula é ampla. A tendência do crescimento da mandíbula é no sentido
horizontal (anti-horário), sendo comum a presença de sobre-mordida.
• Meso-facial: estágio intermediário entre os outros dois tipos de face.

71
3.4.2. Estruturas e Referências Faciais
Segundo Chiche e Pinault, (1996), os artistas desenham dentro de uma estrutura
mensurável geral que é quadrada, retangular ou circular. Esta fórmula é posteriormente
refinada com estruturas internas e pontos de referência imaginários, de modo a
relacionar as partes entre si e a estrutura básica.
Na estética facial, as cirurgias plásticas de reconstrução de partes duras (ósseas) ou
moles (cartilagens, músculos entre outros) do rosto em decorrência de acidentes, má-
formação ou ainda para correção de patologias, devem sempre observar a inter-relação e
harmonia com todas as estruturas que compõem este rosto.
Graziani, (1986) afirma que em presença de uma deformidade maxilofacial, o
especialista deverá estabelecer um padrão de normalidade de acordo com a raça e o tipo
do paciente.
Existem estruturas referencias específicas que são usadas pelos profissionais de estética
para se orientarem no trabalho de reconstrução ou correção facial. Estas mesmas
estruturas e inter-relações são usadas neste trabalho para a tarefa de reconhecimento
dentre pessoas diferentes. Como exemplo de algumas dessas referências, podemos citar:
linhas de referência horizontais, linhas de referência verticais, linha mediana da face,
terços da face entre outros.
A seguir, serão descritos os procedimentos e estratégias para se realizar uma análise
facial.
3.4.3. Análise Facial
O ponto mais importante em uma análise formal da estética facial é a utilização de um
padrão clínico (Suguino et. al, 1996). O modelo é instruído a sentar-se na posição ereta,
olhando para frente na linha do horizonte ou diretamente para um espelho na parede à
sua frente. Esta posição, chamada de posição natural da cabeça, é a que o paciente se
conduz em seu dia-a-dia.

72
A posição natural da cabeça, relação cêntrica (posição mais superior do côndilo), e
postura labial relaxada, devem ser observadas a fim de que os dados possam ser
coletados adequadamente (Suguino et. al, 1996).
Esta é a posição de referência, mostrada na Figura 3.10, que será utilizada nessa
dissertação para que se possa obter dados faciais-esqueléticos confiáveis a fim de
reforçar a segurança e qualidade dos resultados.
FIGURA 3.10 – Posição natural da cabeça. A linha vertical verdadeira é perpendicular ao solo. A horizontal verdadeira é paralela ao solo e definida a partir da pupila dos olhos. FONTE: Suguino et al (1996), p. 87.
Na visão frontal, a face deve ser examinada com os seguintes propósitos (Suguino et. al,
1996):
• Avaliação da simetria bilateral, conforme mostrado na Figura 3.11.A;
• Avaliação das proporções de tamanho da linha mediana até as estruturas
laterais (Figura 3.11.B);
• E avaliação da proporcionalidade vertical (Figura 3.11.C).

73
(A) (B) (C) FIGURA 3.11 – Tópicos a serem avaliados na visão frontal. (A) Análise facial vista
frontal: simetria; (B) Análise facial vista frontal: dimensões laterais; (C) Análise facial vista lateral: proporcionalmente vertical. FONTE: Suguino et al (1996), p. 92.
Inicialmente observa-se a simetria direita e esquerda, traçando-se uma linha vertical
verdadeira (glabela - ponta de nariz e lábios), cruzando perpendicularmente à linha da
visão (horizontal verdadeira) dividindo a face em duas partes como mostrado na Figura
3.12.A (Viazis, 1996).
(A) (B) (C) FIGURA 3.12 – Divisão da face em duas partes. (A) Análise facial vista frontal: linha
vertical verdadeira = simetria; (B) (C) Assimetria aceitável FONTE: Suguino et al (1996), p. 92.

74
Certamente não há face perfeitamente simétrica, contudo a ausência de algumas
assimetrias é necessária para uma boa estética facial (Epker e Fish, 1986).
Essa “assimetria normal”, a qual resulta de uma pequena diferença de tamanho entre os
dois lados de um rosto humano ilustrada na Figura.3.12.B e C, pode ser utilizada para
caracterizar indivíduos diferentes, da mesma forma como é usado para personalizar
exames clínicos ortodônticos.
O balanço geral da face (proporcionalidade vertical) é determinado a seguir, baseado no
equilíbrio dos terços superior, médio e inferior da face, aproximadamente iguais em
altura vertical.
1) Terço Superior da Face – (Linha do Cabelo até as Sobrancelhas)
O terço superior da face é definido como sendo a porção entre a linha da raiz do cabelo
e a linha das sobrancelhas. É altamente variável dependendo do estilo do cabelo, o que o
torna uma medida não tão confiável (Suguino et al., 1996). Contudo, pode-se observar
anormalidades na configuração geral e simetria da calvária, especificamente de áreas
temporal, frontal e sobrancelhas. As anormalidades nestas áreas são freqüentemente
associadas com várias síndromes craniofaciais. Estas áreas usualmente são normais em
deformidades dentofaciais (Epker e Fish, 1986).
2) Terço Médio da Face – Sobrancelhas a Subnasal
O terço médio é definido como a faixa compreendida entre a linha das sobrancelhas e a
base do nariz (linha subnasal) (Suguino et al., 1996), (DE Almeida et al., 1999).
Nesta região, avaliam-se os olhos, as órbitas, o nariz, as bochechas e as orelhas. São
determinadas as medidas das distâncias intercantal e interpupilar. Segundo (Suguino et
al., 1996), o valor médio destas medidas não sofre grandes variações de um indivíduo
para outro, embora pessoas de raça negra freqüentemente apresentem valores maiores
para a distância intercantal e interpupilar. Estes valores são estabelecidos por volta dos 6
a 8 anos de idade e não mudam significantemente após esta época (Epker e Fish, 1986).

75
Juntamente à horizontal verdadeira, a face principal pode ser dividida em três terços:
largura ocular direita, largura nasal e largura ocular esquerda conforme mostra a Figura
3.13.A (Suguino et al., 1996).
A face como um todo, de um olho a outro, em relação à horizontal verdadeira, também
pode ser dividida em terços iguais: largura facial direita, largura da boca e largura facial
esquerda mostrado na Figura 3.13.B (Suguino et al., 1996).
(A) (B) FIGURA 3.13 – Divisões verticais da face.
(A) Largura ocular direita, largura nasal, largura ocular esquerda; (B) Largura facial direita, largura da boca, largura facial esquerda. FONTE: Suguino et al (1996), p. 93.
Na avaliação das bochechas, é observado a eminência malar, borda infraorbital e áreas
paranasais. Finalmente, as orelhas são observadas. A simetria, nível e projeção são
importantes (Suguino et al., 1996).
3) Terço Inferior da Face - Subnasal ao Mento
O terço inferior é definido como a faixa compreendida entre a linha subnasal e o mento
(Suguino et al., 1996), (DE Almeida et al., 1999).

76
O comprimento vertical normal do terço inferior da face é aproximadamente igual ao do
terço médio da face quando existe uma boa estética. Além disso, a proporção da
distância vertical do subnasal ao estômio do lábio superior, e deste ao tecido mole do
mento é em torno de 1:2.
A proporção da distância vertical do subnasal à margem cutânea do vermelhão do lábio
inferior e deste ao tecido mole do mento é de 1:1, como ilustrado na Figura 3.14. Estas
medidas devem ser realizadas com a musculatura facial em repouso.
FIGURA 3.14 - Proporção 1:1 da distância vertical do subnasal à margem cutânea do vermelhão do lábio inferior e deste ao tecido mole do mento. FONTE: Suguino et al (1996), p. 92.
Um outro ponto importante para o exame da face é a avaliação da linha média. A linha
média dentária deveria ser coincidente entre si e com a linha média facial.
O mento é avaliado quanto à sua simetria, relações verticais e morfologia ou forma. A
forma é comparada com o resto da face. Muito freqüentemente o mento é mais
pronunciado do que o resto da face.
Por fim, os ângulos mandibulares são avaliados com atenção para a assimetria e
volume, podendo ser deficientes, normal ou excessivo (Suguino et al., 1996).
Desta forma, completa-se a avaliação estética frontal.

77
CAPÍTULO 4
METODOLOGIA APLICADA
A metodologia usada nesta dissertação visa ressaltar a importância e aplicabilidade das
medidas geométricas da face humana na tarefa de distinção entre diferentes rostos. As
medidas faciais extraídas e usadas aqui seguem padrões anatômicos utilizados em outras
ciências (ortodontia, fonoaudiologia e reconstituição facial) que tratam da beleza
estética, simetrias e anomalias da face humana.
Procura-se, durante todo o trabalho, observar as relações existentes entre a morfologia
do rosto, a raça, o sexo e as anomalias.
Nos próximos tópicos serão descritas as etapas seguidas neste trabalho para executar o
reconhecimento facial.
4.1. Introdução
Como foi visto no Capítulo 1, os métodos geométricos começaram a ser usados no
discernimento de faces na década de 60, chegando a atingir índices de acerto da ordem
de 90%. O interesse por esse método decaiu devido a sua vulnerabilidade, apresentada
na época, em tratar situações adversas como as rotações da imagem, baixa robustez no
tratamento de entradas com ruídos, além da dificuldade de se padronizar quais medidas
e relações eram realmente capazes de realizar a tarefa de reconhecimento facial.
A seguir, descreve-se uma metodologia usada para construir um sistema com base em
redes neurais artificiais e estudos relacionados à biometria capaz de realizar o
reconhecimento de faces. Este sistema proposto combina as vantagens dos métodos
geométricos (robustez a variação de iluminação e escala por exemplo) e as
características das redes neurais (não linearidade, mapeamento de entrada e saída,
adaptabilidade, tolerância à falhas, capacidade de generalização, entre outras).

78
O sistema aqui descrito estuda quais são as métricas relevantes para o reconhecimento
facial, levando em consideração padrões anatômicos faciais ligados ao sexo, raça e
simetria. Descrevem-se também limitações ambientais, heurísticas e o uso de
inteligência computacional, através do uso de redes neurais artificiais, a fim de
aumentar a robustez do sistema, tornando possível a sua aplicação a uma situação real
de reconhecimento de faces.
4.2. Descrição das Etapas
O sistema aqui descrito, parte da premissa que sempre haverá um rosto presente na foto
avaliada. Considera também que a posição desse rosto é bem conhecida. Portanto a
primeira premissa, relacionada à detecção da presença de um rosto na imagem se
encontra satisfeita.
Com relação à aquisição de imagens de faces, foi criado um banco de fotos, contendo
22 faces de funcionários da Açominas S.A. e 15 fotos de faces do banco de imagens
disponibilizadas pela Universidade de Yale. Todas as fotos são de faces em posição
frontal.
As imagens foram coletadas sem grandes variações na iluminação da cena e também
buscando não variar muito a distância entre a pessoa fotografada e a câmera. Entre as
pessoas fotografadas há homens e mulheres adultos de diferentes etnias para garantir
uma coerência do banco de imagens com o mundo real.
Conforme descrito no Capítulo 3, sub-item 3.4.3 referente à análise facial, o modelo é
instruído a sentar-se na posição ereta, olhando para frente na linha do horizonte,
permanecendo com sua expressão facial neutra. Esta posição, chamada de posição
natural da cabeça, é aquela na qual a pessoa normalmente se encontra em seu dia-a-dia.
Após a aquisição das imagens que serão usadas na etapa de extração de características,
inicia-se a fase de tratamento das fotos, com o objetivo de realçar as características de
interesse para o reconhecimento facial. Foram usados filtros construídos com base nas
técnicas de processamento digital de imagens. Esses filtros podem ser aplicados sobre

79
as fotos para melhorar a identificação de arestas e saliências na face, além de
possibilitar o isolamento de texturas que não interessam ou que atrapalhem a coleta das
métricas faciais. A Figura 4.1 mostra um dos filtros implementados sendo aplicado a
uma foto.
FIGURA 4.1 - Tratamento de imagens buscando realçar características de interesse.
A próxima fase, após o tratamento das imagens, é a coleta das métricas faciais. A coleta
das métricas segue as orientações fornecidas no Capítulo 3 desta dissertação, referente a
“Morfologia da Face”. As métricas usadas estão baseadas em pontos de referência
faciais e medidas lineares úteis à ortodontia e reconstituição maxilofacial. São usadas
também características do tecido mole da face visando a distinção de tipos faciais
diferentes como os mostrados nas figuras 3.7, 3.8 e 3.9 do Capítulo 3 .
As 13 medidas coletadas foram as seguintes:
• 1º terço da face (T1);
• 2º terço da face (T2);
• 3º terço da face (T3);
• altura do olho direito (ODY);
• largura do olho direito (ODX);
• altura do olho esquerdo (OEY);
• largura do olho esquerdo (OEX);
• altura do nariz (NY);

80
• largura do nariz (NX);
• altura da boca (BY);
• largura da boca (BX);
• altura da face (FY);
• largura da face (FX).
Estas medidas foram determinadas de forma manual, usando-se o ambiente de coleta de
métricas faciais. Tal ambiente permite que seja posicionada uma linha de referência
sobre a face, variando suas coordenadas X (em caso de coleta de distâncias horizontais)
e Y (em caso de distâncias verticais), de forma a definir a variação de pixels entre o
início e o fim da área ou componente facial medido.
O funcionamento do ambiente de coleta é bem simples. Uma vez que a imagem se
encontra na janela de coleta, pressiona-se o botão de coleta de métricas. Surge neste
momento uma solicitação para o posicionamento da linha que aparece sobre a imagem,
no ponto inicial da região ou componente da face que se deseja medir. A movimentação
da linha é feita através das teclas de setas do teclado ou através dos botões de rolagem
presentes no formulário.
Uma vez posicionada a linha no ponto de início da medida desejada, pressiona-se
novamente o botão de coleta de métricas. O valor da coordenada inicial é então
armazenado e solicita-se que se posicione a linha no ponto final da região de interesse.
Após o posicionamento, pressiona-se o botão de coleta e o valor da coordenada final é
armazenado. De posse dos valores das coordenadas inicial e final de interesse é feita
uma subtração simples e se obtém o valor em pixels da região medida.
A seguir descreve-se como foi determinada cada uma das regiões de interesse na face.
A face humana foi subdividida horizontalmente em 3 regiões chamadas terços faciais. O
primeiro terço (T1) corresponde à distância vertical compreendida entre a linha da raiz
do cabelo e a linha das sobrancelhas como é mostrado na Figura 4.2.

81
FIGURA 4.2 - Coleta da medida do primeiro terço da face.
O segundo terço (T2) da face é a distância vertical compreendida entre a linha das
sobrancelhas e a linha sub-nasal como mostrado na Figura 4.3.
FIGURA 4.3 - Coleta da medida do segundo terço da face.
Finalmente, o terceiro terço (T3) da face é a distância compreendida entre a linha sub-
nasal e a linha mentoniana, (linha tangente ao queixo) como mostrado na Figura 4.4.
FIGURA 4.4 - Coleta da medida do terceiro terço da face.

82
As medidas referentes aos olhos foram tomadas da seguinte forma:
Largura do olho direito (ODX): é a distância horizontal compreendida entre o canto
externo do olho direito e a lateral externa (ou asa) do nariz, como mostrado na Figura
4.5. Evitou-se tomar a distância entre os cantos externos e internos do olho como sendo
a largura ocular, para contornar problemas relativos a rotações da cabeça no momento
da foto. Tais rotações podem ocultar o canto interno do olho.
A medida da largura ocular não é igual para os dois olhos, devido a pequenas variações
de posicionamento que podem ocorrer no momento da foto, ou mesmo por motivos de
assimetria facial. Pequenas diferenças são normais não só comparando-se os olhos, mas
também quando se avalia o lado direito da face em relação ao esquerdo (assimetria
normal da face).
FIGURA 4.5 - Coleta da medida da largura do olho.
Altura do olho direito (ODY): foi definida aqui como a medida vertical compreendida
entre a linha horizontal que passa pela parte visível superior da íris e a linha horizontal
que passa pela parte inferior visível da íris, como mostra a Figura 4.6:

83
FIGURA 4.6 - Coleta da medida da altura do olho.
As métricas referentes ao nariz foram obtidas da seguinte forma:
Largura nasal (NX): é a distância horizontal compreendida entre as partes externas das
narinas, conforme mostrado na Figura 4.7.
FIGURA 4.7 - Coleta da medida da largura do nariz.
Altura do nariz (NY): é a distância vertical compreendida entre a raiz do nariz (linha que
tangencia a parte superior visível da íris) e a linha sub-nasal, mostrado na Figura 4.8.

84
FIGURA 4.8 - Coleta da medida da altura do nariz.
As métricas referentes à boca foram coletadas com se segue:
Largura da boca (BX): é a medida da distância horizontal compreendida entre os cantos
da boca, mostrado na Figura 4.9.
FIGURA 4.9 - Coleta da medida da largura da boca.
Altura da boca (BY): é a medida da distância vertical compreendida entre as linhas
horizontais tangentes ao lábio superior e inferior, como mostrado na Figura 4.10.

85
FIGURA 4.10 - Coleta da medida da altura da boca.
São necessárias ainda as medidas da largura da face (FX), que é representada pela
distância entre os dois zigios, como mostra a Figura 4.11 e a altura da face (FY), que é
definida aqui como a distância násio-mentoniana mostrada na Figura 4.12.
FIGURA 4.11 - Coleta da medida da largura da face
FIGURA 4.12 - Coleta da medida da altura da face.

86
De posse dessas métricas, realiza-se uma classificação prévia do tipo de face com o qual
se está trabalhando. As faces são então classificadas em 5 classes:
• hipereuriprosópico;
• euriprosópico;
• mesoprosópico;
• leptoprosópico;
• hiperleptoprosópico.
A distribuição das faces dentro das 5 classes é feita avaliando-se o índice facial
apresentado pelas faces analisadas. O índice facial é a relação existente entre a altura
facial (distância násio-gnátio ou násio-mentoniana) dividida pela largura facial
(distância bizigomática – distância entre os zígios da face) e multiplicada por 100.
De acordo com esse índice, tem-se a classificação das faces em baixas
(hipereuriprosópico), largas (euriprosópico), médias (mesoprosópico), altas
(leptoprosópico) e estreitas (hiperleptoprosópico) segundo as relações de intervalos
descritas na Tabela 4.1 abaixo:
TABELA 4.1 - Classificação facial segundo o índice facial apresentado.
hipereuriprosópico à abaixo de 80
Euriprosópico à de 80 a 85
Mesoprosópico à de 85 a 90
Leptoprosópico à de 90 a 95
hiperleptoprosópico à acima de 95

87
Cada face será representada por um vetor definido na etapa de estruturação dos vetores
de métricas faciais. Esse vetor será a entrada para a rede de reconhecimento facial.
A etapa de reconhecimento, será realizada em duas fases distintas. A intenção ao dividir
a tarefa de reconhecimento em duas fases complementares segue a estratégia "dividir
para conquistar".
Primeiramente faz-se uma pré-seleção entre os padrões, para se evitar comparar detalhes
entre faces que nada têm em comum. Uma vez separadas as faces em classes distintas,
contendo características em comum, parte-se para a segunda fase, o "ajuste fino", onde
são observados os detalhes de cada uma das faces daquela classe a fim de diferenciá-las.
Na primeira fase deverá ser sinalizado se a face é conhecida ou não. Nessa fase, existem
5 redes neurais independentes, uma para cada classe de face. Cada rede é responsável
por avaliar se a face apresentada na sua entrada é conhecida ou não. Em caso positivo,
ela será submetida à segunda etapa de reconhecimento. Em caso de respostas negativas
apresentadas pelas 5 redes, o padrão será sinalizado como desconhecido e uma ação
referente ao desconhecimento da face será disparada (para o caso de um sistema de
acesso por exemplo, poderia ser solicitada uma senha numérica, ou o auxílio de um
operador humano). Todas as 5 redes terão o mesmo número de neurônios, a mesma
estrutura de camadas, sendo também treinadas com o mesmo algoritmo, o
retropropagação do erro.
A segunda etapa do reconhecimento facial consiste em realizar a associação entre a
entrada, sinalizada como “conhecida” pela fase 1 e uma das faces que estavam presentes
na etapa de treinamento. Apenas uma saída das 5 redes da etapa 1 poderá estar ativa,
pois a entrada deverá ser apresentada a somente uma das 5 redes da etapa 2. As 5 redes
neurais da segunda etapa também são independentes, porém apenas 1 delas pode estar
ativa num dado momento. A configuração das redes dentro de cada etapa é idêntica,
bem como o algoritmo usado no treinamento.
No próximo tópico serão descritas as estruturas usadas nos testes.

88
4.3. Descrição das Estruturas Utilizadas
Durante a etapa de coleta das métricas faciais, foram obtidas 13 medidas de faces de 22
pessoas pertencentes ao corpo de funcionários da Açominas S.A.. Também foram
usadas 15 imagens de faces pertencentes à Universidade de Yale. As métricas dos dois
grupos estão descritas nas Tabelas 4.2 e 4.3 a seguir. A primeira linha da tabela
corresponde à abreviação usada para representar o componente ou região da face, de
acordo com a nomenclatura apresentada no tópico anterior. Já a primeira coluna à
esquerda se refere à identificação de cada face usada. Os valores das medidas são dados
em pixels.
TABELA 4.2 - Métricas das 22 faces do corpo de funcionários da açominas s.ª.
T1 T2 T3 ODX ODY OEX OEY NX NY BX BY FY FX 100365 47 61 62 28 10 27 10 33 43 48 19 106 125 100525 56 79 76 35 12 31 13 48 51 62 20 127 150 100539 48 60 70 27 10 26 10 36 48 51 18 119 117 101604 64 66 70 32 12 27 12 37 52 54 14 124 135 104743 52 62 58 27 10 26 11 36 44 52 15 102 123 107147 49 55 61 29 10 28 9 29 42 46 10 104 105 107879 54 58 63 24 9 26 6 38 46 47 23 111 126 12646 50 62 70 24 10 24 9 38 42 48 13 111 135
304768 60 61 60 29 10 25 9 36 46 42 22 106 118 88643 48 62 58 27 10 25 10 36 48 46 14 106 113
912380 46 56 68 31 12 27 11 43 43 60 28 111 130 100160 59 62 61 25 9 29 10 35 47 53 16 109 122 100270 45 58 71 33 10 31 10 32 41 47 21 112 121 100370 49 58 60 29 10 27 10 35 45 50 12 103 119 100560 46 66 70 27 12 28 12 36 53 48 20 122 117 100636 43 62 65 30 11 27 11 34 49 43 21 112 119 104730 50 67 62 23 11 22 11 42 51 50 16 111 131 104790 42 57 58 23 8 22 8 29 42 46 16 100 98 39609 44 63 60 24 9 23 11 37 49 57 15 110 109 46506 43 72 64 29 10 26 12 44 55 58 10 120 140 50454 47 58 62 29 11 18 10 44 43 54 10 100 131
912715 41 69 63 29 10 25 11 38 53 53 16 115 125

89
TABELA 4.3 - Métricas das 15 faces do banco de faces da universidade de yale.
T1 T2 T3 ODX ODY OEX OEY NX NY BX BY FY FX pessoa1 54 73 84 33 11 33 13 46 57 69 20 140 161 pessoa2 75 83 79 34 13 39 12 47 68 49 18 144 151 pessoa3 50 78 72 33 11 31 11 41 57 60 23 132 139 pessoa4 55 90 78 36 11 34 10 48 67 62 27 144 161 pessoa5 73 83 90 36 10 29 10 43 59 64 19 151 160 pessoa6 53 83 74 38 12 35 10 46 59 64 21 137 163 pessoa7 47 77 83 28 11 32 12 43 57 56 22 140 150 pessoa8 79 89 65 34 14 25 14 47 68 56 21 136 161 pessoa9 56 75 76 36 13 34 14 39 59 54 20 134 145
pessoa10 52 81 77 40 12 28 12 46 57 63 27 140 161 pessoa11 0 79 70 38 14 40 12 45 66 71 17 140 158 pessoa12 80 87 90 35 12 36 12 48 62 79 19 153 161 pessoa13 40 76 68 32 13 26 10 43 58 54 19 126 137 pessoa14 48 87 71 36 8 39 9 49 63 62 21 132 158 pessoa15 53 81 72 35 10 32 11 40 63 63 20 132 155
As Figuras 4.13 e 4.14 mostram uma avaliação gráfica dos valores coletados em ambas
as bases de imagens. Avaliando a curva dos gráficos, é possível notar o comportamento
semelhante apresentado pelos dois grupos de faces. Porém, nota-se que há uma
separabilidade, ainda que pequena, entre as linhas que representam cada pessoa nos
dois bancos de imagens. Com base nesta observação, o objetivo do sistema híbrido
inteligente é conseguir separar as faces usando as informações referentes às medidas
coletadas.

90
Medidas Puras de Componentes e Regiões Faciais - Banco de imagens Açominas -
0
20
40
60
80
100
120
140
160
T1 T2 T3ODX ODY OEX OEY NX NY BX BY
Face
YFa
ceX
Componentes / Regiões
Val
ores
(em
pix
els)
100365
100525
100539
101604
104743
107147
107879
12646
304768
88643
912380
100160
100270
100370
100560
100636
104730
FIGURA 4.13 – Medidas puras dos componentes e regiões faciais do banco de imagens da Açominas.
Medidas Puras de Componentes e Regiões Faciais - Faces do banco de imagens de Yale -
0
20
40
60
80
100
120
140
160
180
Terço
1Te
rço2
Terço
3
OlhoDx
OlhoDy
OlhoEx
OlhoEy
NarizX
NarizY
BocaX
BocaY
Face
YFa
ce X
Componente / Região Facial
Val
ore
s (e
m p
ixel
s)
pessoa1
pessoa2
pessoa3
pessoa4
pessoa5pessoa6
pessoa7
pessoa8
pessoa9pessoa10
pessoa11
pessoa12
pessoa13
pessoa14pessoa15
FIGURA 4.14 – Medidas puras dos componentes e regiões faciais do banco de imagens de Yale.

91
A partir destas medidas, foram criadas relações entre a altura e largura de componentes
da face (olho, nariz e boca) e regiões (T1, T2 e T3) aí presentes. Também foram geradas
métricas relacionando os componentes e as regiões faciais, visando buscar relações
ímpares que sejam capazes de distinguir uma face da outra.
A princípio, pensou-se em realizar todas as combinações possíveis entre as métricas
coletadas, o que resultaria em 78 combinações ( )132 C para alimentar as redes de
reconhecimento. Após a realização de alguns testes preliminares percebeu-se que
determinadas relações estabelecidas eram redundantes. Estas relações ainda
dificultavam o aprendizado da rede, apresentavam alta vulnerabilidade a variações de
aparência e pouco contribuíam para o discernimento das faces.
Desta forma, optou-se por eliminar a avaliação de um dos olhos (OEX e OEY), pois as
informações eram redundantes em relação ao outro olho. Eliminou-se também as
relações onde havia a presença do primeiro terço facial (T1), pois esta métrica se
mostrou muito sensível a variações de penteados.
O número de combinações a serem avaliadas caiu para 45 possibilidades ( )102 C , mas
ainda não era possível determinar quais combinações eram mais aptas à tarefa de
reconhecimento facial.
Através da análise do gráfico de variações dos componentes e regiões da face, mostrado
na Figura 4.15, pode-se perceber quais as medidas que variam mais de pessoa para
pessoa e assim, selecionar de forma mais inteligente quais as relações métricas que
facilitam o trabalho de reconhecimento.

92
FIGURA 4.15 – Análise de componentes e Regiões da Face Banco de Imagens da
Açominas.
A Figura 4.16 mostra o gráfico das relações métricas estabelecidas tomando por base a
variação dos componentes faciais. Nestas relações já estão descartadas as medidas que
apresentam como um de seus elementos, o primeiro terço facial (T1), a largura do olho
esquerdo (OEX) e a altura do olho esquerdo (OEY) .
Análise da Variação dos Componentes e Regiões da Face
0
20
40
60
80
100
120
140
160
1003
65
1005
25
1005
39
1016
04
1047
43
1071
47
1078
79
1264
6
3047
68
8864
3
9123
80
1001
60
1002
70
1003
70
1005
60
1006
36
1047
30
1047
90
3960
9
4650
6
5045
4
9127
15
Identificação das Faces
Val
ores
(em
pix
els)
T1T2T3ODXODYOEXOEYNXNYBXBYFaceYFaceX

93
Avaliação das Relações entre Componentes e Regiões da Face
0,0000
0,2000
0,4000
0,6000
0,8000
1,0000
1,2000
1003
65
1005
25
1005
39
1016
04
1047
43
1071
47
1078
79
1264
6
3047
68
8864
3
9123
80
1001
60
1002
70
1003
70
1005
60
1006
36
1047
30
1047
90
3960
9
4650
6
5045
4
9127
15
Identificação das faces
Val
ore
s n
orm
aliz
ado
s
T2/T3Ox/OyNx/NyBx/ByNx/FxFy/FxT2/FyT3/FyT2/FxT3/Fx
FIGURA 4.16 – Relações entre componentes e Regiões da Face.
Banco de Imagens da Açominas.
As relações mostradas na Figura 4.16 foram definidas com base nas observações
anatômicas da face usadas por outras ciências, na tentativa de estabelecer ligação entre
componentes com relação direta. Não foram avaliadas neste trabalho as relações
existentes entre os componentes, olho X boca, olho X nariz e nariz X boca pois há uma
certa proporcionalidade entre esses elementos, segundo (Graziani, 1986). A princípio,
imagina-se que esta proporcionalidade poderia tornar a informação obtida redundante e
pouco expressiva com base na morfologia facial e nos estudos das medidas e relações
existentes entre estes componentes.
O uso de relações proporcionais, ao invés das medidas puras adquiridas na fase de
coleta das métricas, se deve a preocupação em tornar o sistema menos vulnerável a
variações de distância entre a câmera e a pessoa fotografada. O valor em pixels,
determinado durante uma coleta na imagem, pode variar significativamente com uma

94
aproximação ou afastamento da câmera. Porém a relação entre a altura e largura de um
componente facial e ainda as proporções apresentadas por dois diferentes componentes,
permanecem constantes.
Os valores obtidos das proporções de um componente facial e entre diferentes
componentes foram normalizadas e se encontram descritos nas Tabelas 4.4A e 4.4B a
seguir.
TABELA 4.4A - Relações normalizadas dos 22 funcionários da açominas s.a. Pessoas T2
/T3 ODX /ODY
NX /NY
BX /BY
NX / FX
FY /FX
T2/ FY
T3 /FY
T2 /FX
T3 /FX
100365 0,8746 0,8485 0,7500 0,4356 0,7777 0,8132 0,9251 0,9227 0,8390 0,8290 100525 0,9240 0,8838 0,9198 0,5345 0,9427 0,8120 1,0000 0,9440 0,9055 0,8469 100539 0,7619 0,8182 0,7330 0,4885 0,9064 0,9754 0,8106 0,9279 0,8817 1,0000 101604 0,8381 0,8081 0,6954 0,6650 0,8074 0,8809 0,8557 0,8905 0,8405 0,8667 104743 0,9502 0,8182 0,7996 0,5977 0,8622 0,7953 0,9772 0,8970 0,8666 0,7882 107147 0,8015 0,8788 0,6748 0,7931 0,8136 0,9499 0,8502 0,9252 0,9006 0,9710 107879 0,8183 0,8081 0,8073 0,3523 0,8885 0,8448 0,8400 0,8953 0,7914 0,8357 12646 0,7873 0,7273 0,8842 0,6366 0,8292 0,7885 0,8979 0,9948 0,7896 0,8667
304768 0,9037 0,8788 0,7648 0,3292 0,8988 0,8615 0,9251 0,8929 0,8888 0,8499 88643 0,9502 0,8182 0,7330 0,5665 0,9385 0,8996 0,9403 0,8631 0,9433 0,8579
912380 0,7320 0,7828 0,9773 0,3695 0,9744 0,8189 0,8110 0,9664 0,7406 0,8743 100160 0,9035 0,8418 0,7278 0,5711 0,8451 0,8568 0,9144 0,8828 0,8737 0,8357 100270 0,7261 1,0000 0,7627 0,3859 0,7791 0,8877 0,8325 1,0000 0,8241 0,9808 100370 0,8593 0,8788 0,7601 0,7184 0,8665 0,8301 0,9052 0,9189 0,8380 0,8427 100560 0,8381 0,6818 0,6638 0,4138 0,9064 1,0000 0,8697 0,9051 0,9699 1,0000 100636 0,8479 0,8264 0,6781 0,3530 0,8417 0,9026 0,8899 0,9155 0,8958 0,9130 104730 0,9606 0,6336 0,8048 0,5388 0,9445 0,8126 0,9704 0,8811 0,8793 0,7911 104790 0,8736 0,8712 0,6748 0,4957 0,8718 0,9786 0,9163 0,9149 1,0000 0,9892 39609 0,9333 0,8081 0,7379 0,6552 1,0000 0,9678 0,9207 0,8604 0,9937 0,9201 46506 1,0000 0,8788 0,7818 1,0000 0,9259 0,8220 0,9646 0,8413 0,8842 0,7641 50454 0,8315 0,7989 1,0000 0,9310 0,9895 0,7321 0,9324 0,9780 0,7612 0,7911
912715 0,9735 0,8788 0,7007 0,5711 0,8956 0,8823 0,9646 0,8642 0,9491 0,8424

95
TABELA 4.4B - Relações normalizadas da 15 faces da universidade de yale.
Pessoas T2 /T3
ODX /ODY
NX /NY
BX /BY
NX / FX
FY /FX
T2/ FY
T3 /FY
T2 /FX
T3 /FX
pessoa1 0,5289 0,8690 0,6347 3,0000 0,6667 0,8070 3,4500 0,8261 0,9103 0,8696 pessoa2 0,7811 1,0506 0,7673 2,6154 0,5812 0,6912 2,7222 0,6518 0,9917 0,9536 pessoa3 0,5714 1,0833 0,7912 3,0000 0,6667 0,7193 2,6087 0,6246 0,9398 0,9496 pessoa4 0,5802 1,1538 0,8427 3,2727 0,7273 0,7164 2,2963 0,5498 0,9499 0,8944 pessoa5 0,6674 0,9222 0,6735 3,6000 0,8000 0,7288 3,3684 0,8065 0,8563 0,9438 pessoa6 0,5893 1,1216 0,8192 3,1667 0,7037 0,7797 3,0476 0,7297 0,8991 0,8405 pessoa7 0,4659 0,9277 0,6775 2,5455 0,5657 0,7544 2,5455 0,6095 0,9133 0,9333 pessoa8 1,0000 1,3692 1,0000 2,4286 0,5397 0,6912 2,6667 0,6385 0,9301 0,8447 pessoa9 0,6063 0,9868 0,7207 2,7692 0,6154 0,6610 2,7000 0,6465 0,8569 0,9241 pessoa10 0,5556 1,0519 0,7683 3,3333 0,7407 0,8070 2,3333 0,5587 0,9103 0,8696 pessoa11 0,0000 1,1286 0,8242 2,7143 0,6032 0,6818 4,1765 1,0000 0,9074 0,8861 pessoa12 0,7314 0,9667 0,7060 2,9167 0,6481 0,7742 4,1579 0,9956 0,9499 0,9503 pessoa13 0,4840 1,1176 0,8163 2,4615 0,5470 0,7414 2,8421 0,6805 1,0000 0,9197 pessoa14 0,5562 1,2254 0,8949 4,5000 1,0000 0,7778 2,9524 0,7069 0,9881 0,8354 pessoa15 0,6057 1,1250 0,8216 3,5000 0,7778 0,6349 3,1500 0,7542 0,8222 0,8516
Após a normalização das 10 relações métricas das faces usadas como padrões de
entrada para a rede neural, o próximo passo foi definir a estrutura de rede que
efetivamente fará o papel de reconhecimento das faces.
Para tanto, definiu-se que haveria 2 etapas para o reconhecimento dos rostos como
descrito anteriormente. A primeira etapa caracteriza-se pela sinalização de que a face
apresentada é conhecida ou não. A segunda etapa está relacionada com a associação da
entrada apresentada à rede, com uma das pessoas conhecidas pela rede ativa naquele
momento.
Cada uma das 5 classes de faces, determinadas pelos índices faciais, possui uma rede
especializada em afirmar se o padrão de entrada é conhecido ou não. Se a face
apresentada na entrada da rede é sinalizada como "não conhecida" por todas as 5 redes
da primeira etapa de reconhecimento, a face é imediatamente rechaçada, não chegando a
ser apresentada para nenhuma das 5 redes seguintes. Estas 5 redes da segunda etapa
associam as faces na entrada a padrões aprendidos durante o treinamento. Quando a face
é sinalizada como "conhecida", por mais de uma das 5 redes, ela também é rechaçada.
Caso uma e apenas uma, das 5 redes da etapa de reconhecimento sinalize positivamente,
afirmando que o padrão de entrada é conhecido por ela, as métricas específicas dessa
face são fornecidas como entrada para a segunda rede da classe que manifestou
“conhecê-la”. Essa rede irá então associar a entrada a um de seus padrões conhecidos. A

96
Figura 4.17 abaixo mostra o esquema de funcionamento do sistema de reconhecimento
facial aqui proposto.
FIGURA 4.17 - Esquema de funcionamento do sistema de reconhecimento facial.
Como pode ser visto, através do esquema de funcionamento do sistema de
reconhecimento, as relações métricas usadas como entrada da rede na etapa 1, podem
não ser as mesmas usadas na etapa 2. Isto acontece, porque algumas das relações entre
as métricas faciais, se mostraram mais propícias ao reconhecimento, na primeira etapa,
em comparação à associação das entradas aos padrões aprendidos pela rede, na segunda
etapa.
Foram usados vetores de 5 posições para as redes da camada de reconhecimento e
vetores de 7 posições para as redes da camada de associação. Chegou-se a esse número
de relações métricas, usadas como entradas, após a realização de vários testes usando as
37 faces do banco de imagens desta dissertação e avaliando os gráficos de relações entre
as métricas.
Métricas Faciais
Classe1
Classe3
Classe2
Classe4
Classe5
Saída do sistema de reconhecimento
facial
Redes da etapa de reconhecimento
Redes da etapa de associação das entradas conhecidas aos padrões da
respectiva classe selecionada
Entrada para a camada de rede de
reconhecimento
Entrada para a camada de rede de associação
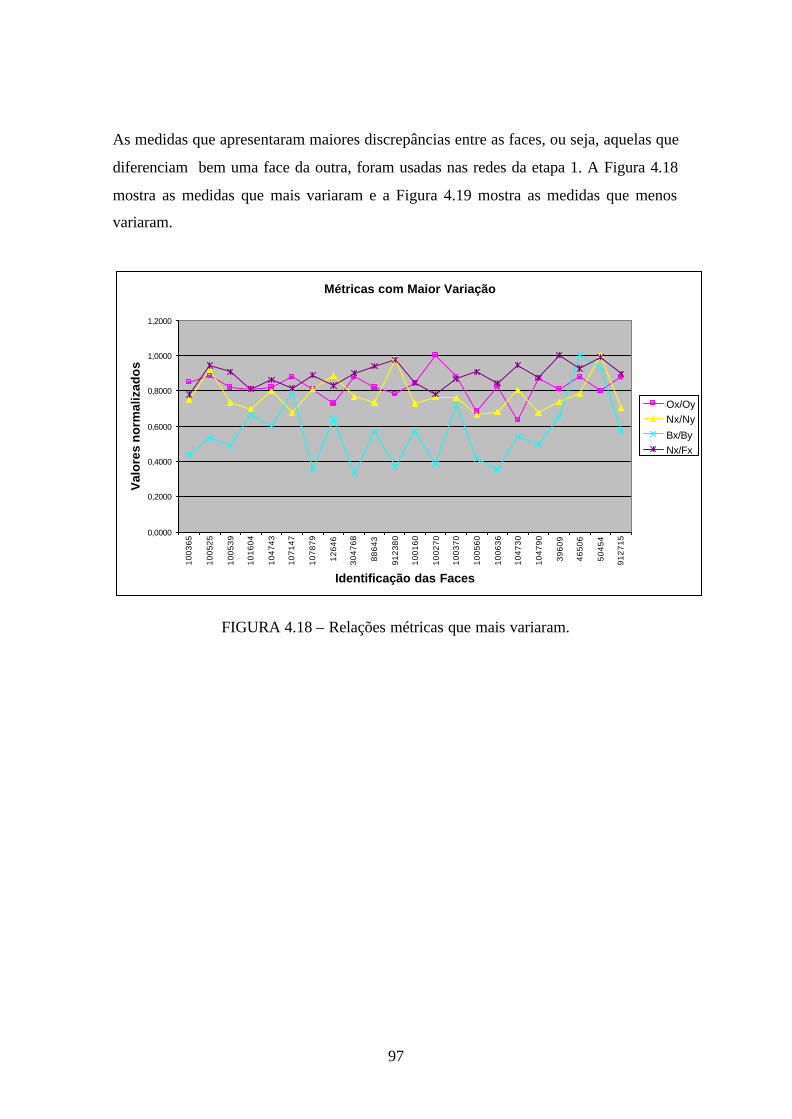
97
As medidas que apresentaram maiores discrepâncias entre as faces, ou seja, aquelas que
diferenciam bem uma face da outra, foram usadas nas redes da etapa 1. A Figura 4.18
mostra as medidas que mais variaram e a Figura 4.19 mostra as medidas que menos
variaram.
Métricas com Maior Variação
0,0000
0,2000
0,4000
0,6000
0,8000
1,0000
1,2000
1003
65
1005
25
1005
39
1016
04
1047
43
1071
47
1078
79
1264
6
3047
68
8864
3
9123
80
1001
60
1002
70
1003
70
1005
60
1006
36
1047
30
1047
90
3960
9
4650
6
5045
4
9127
15
Identificação das Faces
Val
ore
s n
orm
aliz
ado
s
Ox/OyNx/Ny
Bx/ByNx/Fx
FIGURA 4.18 – Relações métricas que mais variaram.

98
FIGURA 4.19 – Relações métricas que menos variaram.
A rede neural da camada de reconhecimento é uma rede multicamadas "feedforward"
com 5 entradas, 4 neurônios na camada oculta e 1 neurônio na camada de saída. Além
das 4 relações que mais variaram, mostradas na Figura 4.18, usou-se entre outras, a
relação FY/FX pois ela também se mostrou muito útil para o discernimento entre faces
por se tratar da altura e largura da própria face.
Para a rede da segunda camada foi usada uma rede multicamadas "feedforward" com 7
entradas, 6 neurônios na camada oculta e 4 neurônios na camada de saída. O algoritmo
usado para o treinamento em ambas as redes foi o algoritmo de retropropagação do
erro, implementado internamente no simulador neural T-LEARN.
O Anexo I traz maiores informações sobre o funcionamento e recursos apresentados
pelo T-LEARN.
As medidas usadas nesta etapa foram na sua maioria, as apresentadas na Figura 4.19 e
ainda a relação BX/BY, que se mostrou bastante apta para realizar diferenciação entre
Métricas com menor Variação
0,0000
0,2000
0,4000
0,6000
0,8000
1,0000
1,2000
1003
65
1005
25
1005
39
1016
04
1047
43
1071
47
1078
79
1264
6
3047
68
8864
3
9123
80
1001
60
1002
70
1003
70
1005
60
1006
36
1047
30
1047
90
3960
9
4650
6
5045
4
9127
15
Identificação das Faces
Val
ore
s n
orm
aliz
ado
s
T2/T3
Fy/Fx
T2/Fy
T3/Fy
T2/Fx
T3/Fx

99
diferentes faces. BX/BY trata da relação entre a largura e a altura da boca do modelo,
que pode variar significativamente de pessoa para pessoa.
O próximo capítulo descreve os testes realizados com o sistema de reconhecimento
facial aqui proposto.

100

101
CAPÍTULO 5
TESTES REALIZADOS
Os testes descritos neste capítulo foram elaborados com o intuito de demonstrar a
viabilidade do uso do sistema híbrido inteligente aqui proposto, no reconhecimento de
faces frontais.
Durante os testes foram usadas faces frontais de homens e mulheres adultos, totalizando
um conjunto de 37 padrões divididos em 2 grupos. Um primeiro grupo de 22 faces foi
utilizado, sendo subdividido em 5 classes, de acordo com o índice facial obtido na
etapa de extração das métricas faciais.
Estas faces, em suas respectivas classes, foram usadas para treinar as redes neurais da
etapa de reconhecimento e também da etapa de associação. As 15 faces do segundo
grupo foram usadas para verificar a capacidade da rede em rejeitar faces totalmente
desconhecidas.
Os passos para a execução dos testes seguiram as etapas descritas no tópico 4.2 dessa
dissertação.
As 22 faces usadas no treinamento ficaram distribuídas dentro das 5 classes
especificadas, como mostra a Tabela 5.1.

102
TABELA 5.1 - Distribuição das faces dentro das 5 classes.
Código
Classe 1 FACE BAIXA
Classe 2
FACE LARGA
Classe 3
FACE MÉDIA
Classe 4
FACE ALTA
Classe 5
FACE ESTREITA 100365 x 100525 x 100539 x 101604 x 104743 X 107147 x 107879 x 12646 X 304768 x 88643 x 912380 x 100160 x 100270 x 100370 x 100560 x 100636 x 104730 x 104790 x 39609 x 46506 x 50454 x 912715 x Total de
Faces por Classe 1 2 8 6 5
As relações métricas usadas como componentes dos vetores de identificação das faces
nos testes são mostradas na Tabela 5.2.

103
Convencionou-se aqui, ao se referir às relações entre largura e altura dos olhos, boca e
nariz, chamá-las de relações entre componentes locais da face. As relações entre os
terços faciais, altura e largura da face são chamadas de relações entre componentes
globais da face.
TABELA 5.2 – Relações métricas usadas para representar as faces.
ODX / ODY
Relações entre medidas de componentes locais. NX / NY
BX / BY
Relação entre medida de componente local e global. NX / FX
FY / FX
T2 / FY
Relações entre medidas de componentes globais. T3 / FY
T2 / FX
T3 / FX
T2 / T3
As relações métricas da Tabela 5.2 foram agrupadas, formando vetores capaz de
representar individualmente cada face. Algumas combinações de componentes locais e
globais se mostraram mais eficientes que outras na tarefa de representar a face de forma
ímpar, evitando confusões ao sinalizar se um rosto é conhecido ou não. Essa capacidade
fica visível ao se avaliar o número de iterações necessárias para se treinar a rede, como
poderá ser visto nos testes realizados no próximo tópico.
As relações métricas usadas como componentes dos vetores de identificação das faces
também estão descritas na Tabela 5.2.
Os testes nas redes da etapa 1 e 2 ocorreram em separado. Foram realizados testes
inserindo erros na aquisição das medidas, aqui representados por acréscimo de pixels
nas medidas horizontais e verticais da métricas puras, visando verificar a tolerância das
redes à entradas com medidas distorcidas. Também foram feitos testes usando faces
que não estiveram presentes na etapa de treinamento para a validação do sistema, como
será visto nos tópicos seguintes.

104
5.1. Testes Realizados na Rede da Etapa de Reconhecimento
Durante os testes, procurou-se verificar quais as relações métricas que melhor se
adaptam à tarefa de sinalizar a "familiaridade" ou "não-familiaridade" de uma face
humana. Para tanto foram avaliadas 8 combinações de métricas faciais compondo o
padrão de entrada da rede.
A avaliação de quais as relações métricas mais propícias ao reconhecimento facial foi
realizada usando o conjunto de faces da Classe 3, contendo 8 faces sinalizadas como
"conhecidas" e ainda outras 6 faces tomadas aleatoriamente entre as demais classes
representando padrões "não conhecidos".
A escolha da Classe 3 para a realização dos testes foi devido ao seu maior número de
padrões, de acordo com a classificação feita pelo índice facial.
Os 8 conjuntos de relações métricas que compõem os padrões de entrada da rede da
etapa 1 são mostradas na Tabela 5.3.
TABELA 5.3 – Grupos de relações métricas usados no treinamento.
Grupo1: OX/OY NX/NY BX/BY
Grupo2: OX/OY NX/NY BX/BY FY/FX
Grupo3: OX/OY NX/NY BX/BY T2/T3
Grupo4: OX/OY NX/NY BX/BY NX/FX
Grupo5: OX/OY NX/NY BX/BY NX/FX FY/FX
Grupo5.1: OX/OY NX/NY BX/BY NX/FX T2/FX
Grupo5.2: T3/FX T2/FX T3/FY T2/FY FY/FX
Grupo5.3: BX/BY NX/FX T3/FY T2/FY FY/FX
Inicialmente, foram tomadas 3 relações métricas dentre àquelas que apresentaram maior
variação de face para face durante a análise gráfica da Figura 4.16. As 3 medidas usadas
a princípio foram OX/OY (relação entre a largura e a altura do olho direito), NX/NY
(relação entre a largura e a altura do nariz), BX/BY (relação entre a largura e a altura da

105
boca). Acredita-se, com base na análise gráfica, que usando estas relações métricas , a
tarefa de discernimento se torne mais fácil.
A seguir serão descritos os testes realizados com cada um dos grupos mostrados na
Tabela 5.3.
Grupo1
Usando as 3 métricas do Grupo1 foi possível treinar a rede neural da etapa 1, fazendo
com que a rede aprendesse a sinalizar os 8 padrões pertencentes à Classe 3 como sendo
"conhecidos" e os 6 padrões das outras classes como "não conhecidos".
A curva de aprendizado é mostrada na Figura 5.1.
FIGURA 5.1 – Curva de aprendizado usando relações métricas do Grupo1.
Para analisar a robustez das relações métricas presentes no Grupo1, foram coletadas as
mesmas medidas das 15 faces do banco de imagens da Universidade de Yale. As
medidas destes 15 padrões não foram apresentados à rede nem como exemplos de
padrões "conhecidos" nem como exemplo de padrões "não conhecidos".
As Tabelas 5.4 e 5.5 abaixo mostram os resultados do treinamento em relação aos
padrões vistos durante o aprendizado e aqueles não vistos.

106
TABELA 5-4 – Resposta da rede aos padrões usados no treinamento (usando o Grupo1).
Padrão Saída desejada Saída obtida Status Classe3 1 0.990 OK! Classe3 1 1.000 OK! Classe3 1 0.984 OK! Classe3 1 1.000 OK! Classe3 1 0.955 OK! Classe3 1 1.000 OK! Classe3 1 0.997 OK! Classe3 1 0.987 OK!
Estranho1 0 0.000 OK! Estranho2 0 0.018 OK! Estranho3 0 0.045 OK! Estranho4 0 0.018 OK! Estranho5 0 0.006 OK! Estranho6 0 0.006 OK!
A Tabela 5.4 mostra a saída desejada definida como 1 (face conhecida) para os
primeiros 8 padrões pertencentes à Classe3. É mostrado também, para os 6 padrões
seguintes que não pertencem à classe avaliada, a saída definida como 0 (face
desconhecida). O limiar adotado para considerar uma saída como 1, foi definido como
valores iguais ou acima de 0,5. Os valores inferiores a 0,5 são considerados 0. A quarta
coluna apresenta o "Status" do reconhecimento. Como pode ser observado, a rede
respondeu corretamente aos 14 padrões.
TABELA 5.5 – Resposta da rede a padrões totalmente desconhecidos (usando o Grupo1)
Padrão Saída desejada Saída obtida Status Estranho1 0 0.631 ERRO! Estranho2 0 1.000 ERRO! Estranho3 0 0.997 ERRO! Estranho4 0 0.996 ERRO! Estranho5 0 0.000 OK! Estranho6 0 0.718 ERRO! Estranho7 0 1.000 ERRO! Estranho8 0 1.000 ERRO! Estranho9 0 0.202 OK! Estranho10 0 1.000 ERRO! Estranho11 0 0.000 OK! Estranho12 0 0.000 OK! Estranho13 0 1.000 ERRO! Estranho14 0 1.000 ERRO! Estranho15 0 0.000 OK!

107
A Tabela 5.5 possui a mesma estrutura e interpretação definidas para a Tabela 5.4.
Avaliando-se a coluna "Status", percebe-se que a rede não consegue sinalizar
corretamente para os 15 padrões que não estavam presentes na etapa de treinamento.
Usando o vetor formado pelos componentes do Grupo1, a rede se mostrou capaz de
aprender corretamente os 14 padrões vistos no treinamento, sinalizando corretamente
para cada um deles. Porém a rede não possui informações em quantidade e qualidade
suficientes para sinalizar que todos os 15 padrões não presentes na etapa de aprendizado
são faces "não conhecidas".
Grupo2
A próxima bateria de testes foi realizada usando o Grupo2. Este grupo possui um
diferencial: a relação entre a altura e a largura da face (FY / FX) que não estava presente
no grupo anterior.
Usando a estrutura da rede e os parâmetros citados no início deste capítulo, a rede não
converge até a iteração de número 1.000.000, como mostra a Figura 5.2a. Após algumas
tentativas, alterando-se o parâmetro da taxa de aprendizado de 0.07 para 0.12, a rede
converge rapidamente como mostrado na Figura 5.2b.
(A) (B)
FIGURA 5.2 – Curva de aprendizado usando relações métricas do Grupo2.
A rede, com este novo vetor de identificação, aprende os 14 padrões apresentados na
etapa de treinamento e erra apenas 5 faces das 15 que não estavam presentes na etapa de
treinamento.

108
Apesar da necessidade da mudança da taxa de aprendizagem para evitar a estagnação da
rede na etapa de aprendizado, fica claro que o aumento de mais uma informação no
conjunto de relações que representam a face, dá maior capacidade de discernimento à
rede.
Grupo3 e Grupo4
Os testes usando o Grupo3 e o Grupo4 visam avaliar o potencial das outras duas
relações usadas, em comparação com a relação FY/FX (altura facial / largura facial)
pertencente ao Grupo2. O resultado da comparação entre FY / FX (altura facial / largura
facial), T2 / T3 (2º terço da face / 3º terço da face ) e NX / FX (largura do nariz / largura
da face) está mostrado na Tabela 5.6.
TABELA 5.6 – Comparação entre o acréscimo de 1 relação específica no vetor de identificação (grupo2 x grupo3 x grupo4).
Tópicos avaliados FY/FX T2/T3 NX/FX Converge com erro médio quadrático menor que 0.02? Sim Sim Sim
Aprende os 14 padrões apresentados no treinamento? Sim Sim Sim Nº de erros (15 faces não presentes no treinamento). 5 4 1 Nº de iterações necessárias para atingir erro mínimo. 235186 492854 921321
Através dos resultados mostrados na Tabela 5.6, nota-se a maior eficiência do Grupo4,
contendo a relação NX/FX, em diferenciar corretamente os padrões que não estavam
presentes no treinamento. Isso mostra que o Grupo4 possui maior capacidade de
generalização do que os apresentados pelos Grupos 2 e 3.
Os parâmetros usados no treinamento da rede, foram alterados apenas quando usou-se o
Grupo2, a fim de evitar a estagnação da rede na etapa de aprendizado. Os demais grupos
foram treinados usando os mesmos parâmetros padrão, descritos a seguir.
Percebe-se durante a comparação dos Grupos 2, 3 e 4 que determinadas relações
métricas têm a capacidade de tornar a rede mais apta para a tarefa de diferenciar entre
padrões faciais "conhecidos” e "não conhecidos". Isto pode ser visto através da
substituição da relação T2/T3 pela relação NX/FX. Só com a mudança dos parâmetros,

109
o número de erros cometidos na avaliação das faces não presentes no treinamento foi
reduzido de 4 erros para apenas 1.
Usando a rede treinada com o Grupo4, que apresentou o melhor índice de acerto até o
momento, foram feitas algumas experiências variando-se o número de neurônios
buscando uma melhor resposta em relação às faces não presentes na etapa de
aprendizagem. Durante tais testes, ao aumentar o número de neurônios da camada
escondida de 5 para 6 neurônios, o número de padrões identificados de forma errada
subiu de 1 para 2. E ao subtrairmos 1 neurônio, o número de erros sobe de 1 para 11
erros em 15 padrões apresentados.
Portanto, a estrutura proposta a seguir fica sendo, para esta dissertação, a mais adequada
para o reconhecimento. Outros testes também foram realizados com a rede recebendo
outros padrões de entrada. Porém o número de acertos mais significativos foram
atingidos com a estrutura descrita a seguir.
A arquitetura final das redes da etapa 1, responsáveis por sinalizar se o padrão
apresentado é conhecido ou não é a seguinte:
o Número total de neurônios: 5; o Arquitetura: rede multicamadas de 5 entradas, 4 neurônios ocultos, 1 neurônio
de saída; o Alimentação da rede: "feedforward"; o Algoritmo de aprendizado: "Retropropagação do erro".
Os parâmetros usados no treinamento foram:
o Taxa de aprendizado usada no treinamento: 0.07; o Momentum: 0.8; o Erro Médio Quadrático: inferior a 0.02; o Semente inicial para os pesos: 5 .
Vale ressaltar que o número de neurônios usados na camada oculta pode variar em caso
de aumento do número de padrões a serem aprendidos em cada classe. Assim, os 4
neurônios que para este caso são suficientes para realizar a tarefa de sinalizar se um
determinado padrão é "conhecido" ou "não conhecido", podem ser insuficientes para

110
realizar a mesma tarefa, se a classe avaliada contiver mais de 8 padrões aprendidos
como "conhecidos" e 6 como "não conhecidos".
Para as redes da etapa 2, responsáveis pela associação do padrão sinalizado como
“conhecido” ao um padrão mais “parecido” da classe ativa, foi definido, após a
realização de vários testes, a configuração ótima que se segue:
o Número total de neurônios: 10; o Arquitetura: rede multicamadas de 7 entradas, 6 neurônios ocultos, 4 neurônios
de saída; o Alimentação da rede: "feedforward"; o Algoritmo de aprendizado: "Retropropagação do erro".
Os parâmetros usados no treinamento foram:
o Taxa de aprendizado usada no treinamento: 0.07; o Momentum: 0.8; o Erro Médio Quadrático: inferior a 0.02; o Semente inicial para os pesos: 5.
Cada uma das 5 redes independentes dessa etapa possui 4 neurônios de saída. Esta
estrutura possibilita a cada uma dessas redes, mapear 16 padrões de face seguindo a
codificação binária (0000, 0001, 0010, etc) associada a cada padrão. A capacidade total
de mapeamento da estrutura de rede apresentada é de 80 faces, sendo 16 faces em cada
uma das 5 classes.
Em casos onde o número de padrões a serem reconhecidos ultrapasse 16 faces, será
necessário um número maior de neurônios de saída além de um aumento também no
número de neurônios da camada oculta.
Para o próximo teste, usando o Grupo5, foi acrescentada mais uma informação ao
padrão de entrada da rede. Usou-se o Grupo4 como base, para verificar se apenas a
inclusão de uma nova informação seria suficiente para se obter um ganho significativo
no índice de acerto da rede.
Grupo5

111
Avaliando o conjunto de métricas pertencentes ao Grupo5, percebe-se, através da Figura
5.3, que a aprendizagem da rede é muito rápida.
FIGURA 5.3 - Curva de aprendizagem das métricas do Grupo5.
A rede convergiu em 480544 iterações, apresentando um erro médio quadrático de
0.020349. Os 14 padrões foram aprendidos com sucesso pela rede, como mostra a
Tabela 5.7 a seguir.

112
TABELA 5.7 - Resposta da rede aos padrões usados no treinamento (usando o Grupo5).
Padrão Saída desejada Saída obtida Status Classe3 1 0.984 OK! Classe3 1 0.981 OK! Classe3 1 0.990 OK! Classe3 1 1.000 OK! Classe3 1 0.981 OK! Classe3 1 0.966 OK! Classe3 1 0.983 OK! Classe3 1 0.990 OK! Estranho 0 0.000 OK! Estranho 0 0.017 OK! Estranho 0 0.007 OK! Estranho 0 0.023 OK! Estranho 0 0.044 OK! Estranho 0 0.000 OK!
A Tabela 5.7 mostra a sinalização correta da rede para os 8 padrões pertencentes à
Classe3 e também para os 6 padrões pertencentes a outras classes, sinalizados como
"não conhecidos", como pode ser observado analisando a coluna "Status".
Avaliando-se a saída da rede para os 15 padrões não presentes na etapa de treinamento,
obteve-se o seguinte resultado mostrado na Tabela 5.8:

113
TABELA 5.8 - Resposta da rede a padrões totalmente desconhecidos (usando o Grupo5)
Padrão
Saída esperada
Saída obtida
Status
Descrição do erro
1 0 0.000 OK!
2 0 0.000 OK!
3 0 0.000 OK!
4 0 0.014 OK!
5 0 0.000 OK!
6 0 0.000 OK!
7 0 0.000 OK!
8 0 0.000 OK!
9 0 0.000 OK!
10 0 0.000 OK!
11 0 0.142 OK!
12 0 0.043 OK!
13 0 0.000 OK!
14 0 0.379 OK!
15 0 0.000 OK!
Fica claro, através da análise dos resultados mostrados na Tabela 5.8, que o acréscimo
da informação FY / FX (altura facial / largura facial) no vetor de identificação da face
torna a representação do padrão avaliado mais específico, possibilitando um índice de
acerto maior quando são apresentados os 15 padrões que não estavam presentes no
treinamento.
Um novo teste, a partir do Grupo5, será realizado para se avaliar a resposta da rede a
ruídos durante a coleta das métricas.
A fim de simular erros durante a coleta das medidas faciais, são inseridos ruídos (aqui
representados pelo acréscimo de pixels) em medidas horizontais e verticais de
componentes e regiões da face. A Tabela 5.9 ilustra este teste.
Na coluna "Pixels adicionados" informa-se em quantas unidades as medidas faciais,
descritas na coluna "Medidas afetadas", estão sendo incrementadas. Após a introdução
do erro, as relações métricas "contaminadas" são usadas para validar a rede já

114
devidamente treinada. Foram criados 22 tipos diferentes de “contaminação” nas
medidas faciais, através de incrementos de pixels em medidas verticais e horizontais dos
padrões. Estas contaminações (erros inseridos na aquisição das medidas) foram
aplicadas aos 14 padrões faciais usados nesta dissertação, gerando portanto 308 novos
padrões (308 = 22 * 14).
O número de erros cometidos pela rede está indicado na coluna "Nº de erros em 14
padrões" e a coluna "Descrição do erro" informa o tipo de engano cometido pela rede.
Pode-se verificar o resultado da avaliação de robustez da rede neural usando as
”medidas contaminas”, através da Tabela 5.9 a seguir.

115
TABELA 5.9 - Resposta da rede a padrões conhecidos acrescidos de ruído (usando o Grupo5)
Pixels adicionados
Medidas afetadas
Nº de erros em 14 padrões
Descrição do erro
Inserindo ruído em medidas verticais
1 pixel T2; T3; Fy 1 Reconheceu 1 "face não conhecida".
2 pixels T2; T3; Fy 1 Reconheceu 1 "face não conhecida".
3 pixels T2; T3; Fy 1 Reconheceu 1 "face não conhecida".
4 pixels T2; T3; Fy 1 Reconheceu 1 "face não conhecida".
5 pixels T2; T3; Fy 1 Reconheceu 1 "face não conhecida".
Inserindo ruído em medidas horizontais
1 pixel Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
2 pixels Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
3 pixels Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
4 pixels Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
5 pixels Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
Inserindo ruído em medidas verticais e horizontais
1 pixel T2; T3; Fy; Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
2 pixels T2; T3; Fy; Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
3 pixels T2; T3; Fy; Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
4 pixels T2; T3; Fy; Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
5 pixels T2; T3; Fy; Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
10 pixels T2; T3; Fy; Nx; Bx; Fx 2 Reconheceu 1 "face não conhecida". Não reconheceu 1 "face conhecida".
Adicionando os ruídos aleatórios nas respectivas medidas verticais e horizontais
8 3 6 2 4 8 T2; T3; Fy; Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
4 7 3 7 4 5 T2; T3; Fy; Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
8 16 12 12 14 14 T2; T3; Fy; Nx; Bx; Fx 2 Reconheceu 1 "face não conhecida". Não reconheceu 1 "face conhecida".
14 4 0 16 8 8 T2; T3; Fy; Nx; Bx; Fx 1 Reconheceu 1 "face não conhecida".
6 21 18 9 0 0 T2; T3; Fy; Nx; Bx; Fx 5 Reconheceu 2 "face não conhecida". Não reconheceu 3 "face conhecida".
20 0 12 20 16 8 T2; T3; Fy; Nx; Bx; Fx 2 Reconheceu 1 "face não conhecida". Não reconheceu 1 "face conhecida".

116
Os testes foram separados pela inserção de “contaminação” em medidas verticais,
horizontais e medidas verticais e horizontais juntas. Foram inseridos ainda
“contaminações” representadas por acréscimo escolhidas aleatoriamente nas medidas
informadas na coluna de "Medidas afetadas".
A cada novo ruído inserido nas respectivas métricas foram gerados 14 novos padrões,
sendo 8 da Classe3 e 6 padrões pertencentes às outras classes. Aos 8 padrões da Classe3
a rede deveria sinalizar como "conhecidos" e aos outros 6 padrões, pertencentes às
outras classes, a sinalização deveria ser "não conhecidos".
A rede, usando as relações do Grupo5, cometeu 29 erros de classificação em 308
padrões apresentados, totalizando um índice médio de acerto de 90,58%.
Embora a rede tenha atingido um índice médio de acerto muito bom, houve vários casos
de sinalizações positivas indevidas para faces "não conhecidas", após a inserção de
ruídos. A esta situação, dá-se o nome de falso-positivo. Para a situação inversa, onde
faces "conhecidas" são indevidamente sinalizadas como "não-conhecidas", dá-se o
nome de falso-negativo.
Isto mostra que se esse grupo de métricas fosse usado para controlar o acesso de pessoas
a um dado local, pessoas não autorizadas conseguiriam ter acesso à área restrita. Isto
aconteceria desde que um ruído ou um erro durante a aquisição das medidas faciais
distorcesse, de forma favorável ao invasor, as métricas faciais como simulado pela
“contaminação” das medidas (erro na aquisição das medidas).
No pior caso, (onde ocorreram 2 falso-positivos e 3 falso-negativos em 14 padrões
apresentados) considerando que uma distorção no momento da coleta das métricas
faciais favorecesse a falsa identificação de um estranho, este teria 14,29% de chances de
entrar em um local restrito sem autorização. Haveria também 21,43% de chances de um
indivíduo autorizado ser barrado. Já para o melhor caso atingido pela rede (onde ocorreu
1 erro em 14 padrões apresentados), as chances do indivíduo não autorizado obter
acesso caem para 7,14% usando o conjunto de métricas do Grupo5.

117
Grupo5.1
O Grupo5.1 possui estrutura básica similar ao Grupo5, trocando-se apenas a relação
FY/FX pela relação T2/FX a fim de avaliar o desempenho da rede com uma relação
métrica que não sofresse influência de cabelo, barba ou cavanhaque. Os resultados estão
apresentados a seguir.
A curva de aprendizagem usando o Grupo5.1 é mostrada na Figura 5.4:
FIGURA 5.4 - Curva de aprendizagem para padrões com baixa interferência de cabelo, cavanhaque e barba.
A rede convergiu em 447077 iterações, com erro médio quadrático de 0.020111 e
aprendendo todos os padrões, como mostrado na Tabela 5.10.
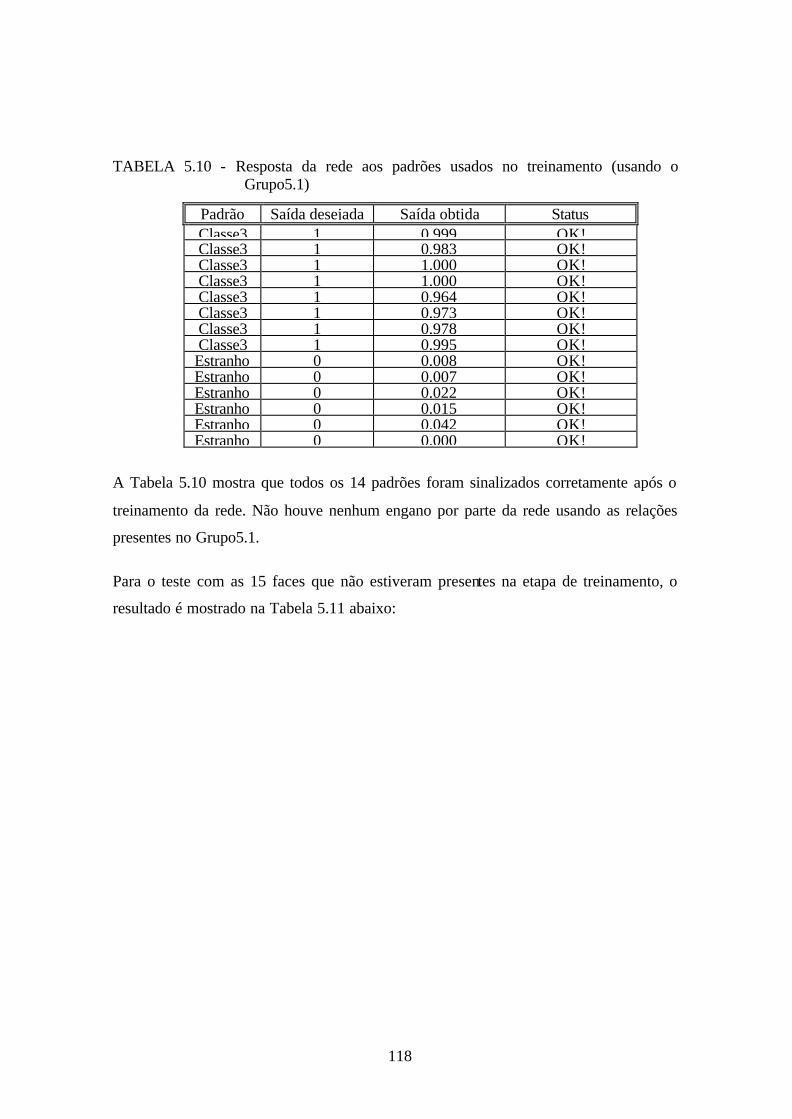
118
TABELA 5.10 - Resposta da rede aos padrões usados no treinamento (usando o Grupo5.1)
Padrão Saída desejada Saída obtida Status Classe3 1 0.999 OK! Classe3 1 0.983 OK! Classe3 1 1.000 OK! Classe3 1 1.000 OK! Classe3 1 0.964 OK! Classe3 1 0.973 OK! Classe3 1 0.978 OK! Classe3 1 0.995 OK! Estranho 0 0.008 OK! Estranho 0 0.007 OK! Estranho 0 0.022 OK! Estranho 0 0.015 OK! Estranho 0 0.042 OK! Estranho 0 0.000 OK!
A Tabela 5.10 mostra que todos os 14 padrões foram sinalizados corretamente após o
treinamento da rede. Não houve nenhum engano por parte da rede usando as relações
presentes no Grupo5.1.
Para o teste com as 15 faces que não estiveram presentes na etapa de treinamento, o
resultado é mostrado na Tabela 5.11 abaixo:

119
TABELA 5.11 - Resposta da rede a padrões totalmente desconhecidos (usando o Grupo5.1).
Padrão
Saída esperada
Saída obtida
Status
Descrição do erro
1 0 0.000 OK!
2 0 0.000 OK!
3 0 0.000 OK!
4 0 0.013 OK!
5 0 0.000 OK!
6 0 0.000 OK!
7 0 0.000 OK!
8 0 0.000 OK!
9 0 0.000 OK!
10 0 0.000 OK!
11 0 0.000 OK!
12 0 0.000 OK!
13 0 0.000 OK!
14 0 0.113 OK!
15 0 0.000 OK!
O Grupo 5.1 se mostrou muito bom para sinalizar como "não conhecidos", os 15
padrões que não estiveram presentes na etapa de treinamento e não pertenciam à
Classe3, como mostra a coluna "Status" da Tabela 5.11.

120
A Tabela 5.12 apresenta os resultados obtidos usando os padrões que estavam presentes
na etapa de treinamento, acrescidos de ruído.
TABELA 5.12 - Resposta da rede a padrões conhecidos acrescidos de ruído (usando o Grupo5.1).
Pixels
adicionados
Medidas afetadas
Nº de erros em 14
padrões
Descrição do erro
Inserindo ruído em medidas horizontais
1 pixel Nx; Bx; Fx 0
2 pixels Nx; Bx; Fx 0
3 pixels Nx; Bx; Fx 0
4 pixels Nx; Bx; Fx 0
5 pixels Nx; Bx; Fx 0
10 pixels Nx; Bx; Fx 0
Adicionando os ruídos aleatórios nas respectivas medidas verticais e horizontais
6 2 8 Nx; Bx; Fx 0
3 7 5 Nx; Bx; Fx 0
12 12 14 Nx; Bx; Fx 0
0 16 8 Nx; Bx; Fx 0
18 9 0 Nx; Bx; Fx 5 Reconheceu 3 "faces não conhecidas". Não reconheceu 2 "faces conhecidas".
12 20 8 Nx; Bx; Fx 2 Reconheceu 2 "faces não conhecidas".
Como os valores verticais, que eram "contaminados" com os ruídos, não pertencem ao
Grupo5.1, exceto a medida T2, não se avaliou a inserção de ruídos em relações verticais
para este grupo.
Para este grupo de métricas, o índice médio de acerto foi de 95,83%. No pior caso
observado considerando que uma distorção no momento da coleta das métricas faciais
favorecesse a falsa identificação de um estranho, este teria 21,43% de chances de
acessar um local restrito. Haveria ainda 14,29% de chances de pessoas autorizadas
serem barradas.

121
Embora o índice médio de acerto do Grupo5.1 tenha sido melhor que o apresentado pelo
Grupo5, haveria maior possibilidade de um estranho acessar indevidamente uma área
restrita, se fossem usadas as métricas do Grupo5.1.
Grupo5.2
As relações métricas que compõem o Grupo5.2 são formadas por regiões globais da
face. Não há a participação de componentes locais como olhos, nariz ou boca entre os
elementos presentes nestas relações.
Este grupo foi formado com a finalidade de avaliar a capacidade das medidas globais
em diferenciar faces, sem a participação de componentes locais. Os resultados são
mostrados a seguir.
A curva de aprendizagem da rede usando o Grupo5.2 é descrita na Figura 5.5 abaixo:
FIGURA 5.5 - Curva de aprendizagem das métricas do Grupo5.2.
A rede convergiu em 954106 iterações, apresentando um erro médio quadrático de
0.020197. Todos os 14 padrões apresentados à rede foram aprendidos como mostra a
Tabela 5.13 a seguir.

122
TABELA 5.13 - Resposta da rede aos padrões usados no treinamento (usando o Grupo5.2)
Padrão Saída desejada Saída obtida Status Classe3 1 0.996 OK! Classe3 1 0.979 OK! Classe3 1 1.000 OK! Classe3 1 1.000 OK! Classe3 1 0.957 OK! Classe3 1 1.000 OK! Classe3 1 0.986 OK! Classe3 1 0.999 OK! Estranho 0 0.001 OK! Estranho 0 0.043 OK! Estranho 0 0.000 OK! Estranho 0 0.000 OK! Estranho 0 0.026 OK! Estranho 0 0.010 OK!
A Tabela 5.14 mostra o comportamento da rede para padrões não vistos no treinamento.
TABELA 5.14 - Resposta da rede a padrões totalmente desconhecidos (usando o Grupo5.2).
Padrão
Saída esperada
Saída obtida
Status
Descrição do erro
1 0 0.000 OK!
2 0 0.000 OK!
3 0 0.000 OK!
4 0 0.000 OK!
5 0 0.000 OK!
6 0 0.854 ERRO! Reconheceu "desconhecido"
7 0 0.000 OK!
8 0 0.594 ERRO! Reconheceu "desconhecido"
9 0 0.000 OK!
10 0 0.000 OK!
11 0 0.000 OK!
12 0 0.000 OK!
13 0 0.000 OK!
14 0 0.007 OK!
15 0 0.000 OK!

123
Como pode ser observado nas Tabelas 5.13, os 14 padrões foram aprendidos
corretamente durante a etapa de treinamento. Não há erros ao sinalizar os membros da
Classe3 e os que não pertencem a esta classe, como descrito na coluna "Status".
A Tabela 5.14 mostra que houve 2 falso-positivos cometidos pela rede ao identificar
como "conhecidos" 2 dos 15 padrões que não pertencem à Classe3 e não estiveram
presentes na etapa de treinamento da rede, totalizando um erro de 13,33% do total de
faces analisadas.
A Tabela 5.15 mostra os resultados do Grupo5.2 aplicado ao reconhecimento de faces
que estiveram presentes na etapa de treinamento, mas agora se encontram
"contaminadas" com ruídos.

124
TABELA 5.15 - Resposta da rede a padrões conhecidos acrescidos de ruído (usando o Grupo5.2).
Pixels adicionados
Medidas afetadas
Nº de erros em 14
padrões
Descrição do erro
Inserindo ruído em medidas verticais 1 pixel T2; T3; Fy 0 2 pixels T2; T3; Fy 0 3 pixels T2; T3; Fy 0 4 pixels T2; T3; Fy 0 5 pixels T2; T3; Fy 0
Inserindo ruído em medidas horizontais 1 pixel Nx; Bx; Fx 0 2 pixels Nx; Bx; Fx 0 3 pixels Nx; Bx; Fx 0 4 pixels Nx; Bx; Fx 0 5 pixels Nx; Bx; Fx 0
Inserindo ruído em medidas verticais e horizontais 1 pixel T2; T3; Fy; Nx; Bx; Fx 0 2 pixels T2; T3; Fy; Nx; Bx; Fx 0 3 pixels T2; T3; Fy; Nx; Bx; Fx 0 4 pixels T2; T3; Fy; Nx; Bx; Fx 0 5 pixels T2; T3; Fy; Nx; Bx; Fx 0 10 pixels T2; T3; Fy; Nx; Bx; Fx 1 Não reconheceu 1 "face conhecida"
Adicionando os ruídos aleatórios nas respectivas medidas verticais e horizontais 8 3 6 2 4 8 T2; T3; Fy; Nx; Bx; Fx 0 4 7 3 7 4 5 T2; T3; Fy; Nx; Bx; Fx 0 8 16 12 12 14 14 T2; T3; Fy; Nx; Bx; Fx 3 Não reconheceu 1 "face conhecida"
Reconheceu 2 "faces não conhecidas".
14 4 0 16 8 8 T2; T3; Fy; Nx; Bx; Fx 0 6 21 18 9 0 0 T2; T3; Fy; Nx; Bx; Fx 5 Não reconheceu 3 "faces
conhecidas" Reconheceu 2 "faces não conhecidas".
20 0 12 20 16 8 T2; T3; Fy; Nx; Bx; Fx 0

125
Este grupo de métricas apresentou o índice médio de acerto igual a 97,08%. No pior
caso observado, um estranho teria 14,29% de chances de acessar um local restrito, se
suas métricas fossem adulteradas favoravelmente por ruídos ou erros durante a etapa de
coleta de medidas. Haveria ainda 21,43% de chances de pessoas autorizadas serem
barradas.
Embora o índice médio de acerto do Grupo5.2 tenha sido o melhor, comparando com o
Grupo5 e com o Grupo 5.1, sua capacidade em barrar faces aprendidas como "não
conhecidas" em presença de erros durante a aquisição das métricas se mostra igual à
apresentada pelo Grupo5. Já a capacidade de suas métricas em sinalizar como "não
conhecidos" os 15 padrões que não estiveram presentes na etapa de treinamento (e eram
"não conhecidos") se mostrou inferior à dos outros 2 grupos.

126
Grupo5.3
Por fim, para demonstrar indícios de que a escolha do conjunto de relações também
influencia na capacidade de discernimento entre as faces e não somente o número de
entradas, foram realizados os testes com o Grupo5.3.
Este grupo é formado por relações entre componentes faciais e globais. A
predominância é de relações entre regiões globais da face, assim como o Grupo5.2. O
que diferencia é a presença de 1 relação mista (NX/FX – largura no nariz pela largura da
face) e 1 relação entre medidas locais (BX/BY – largura pela altura da boca). Os
parâmetros usados para este grupo foram os mesmos usados nos testes anteriores. Os
resultados são mostrados abaixo.
FIGURA 5.6 - Curva de aprendizagem das métricas do Grupo5.3.
Como pode ser visto pela curva de aprendizado mostrada na Figura 5.6, o Grupo5.3
parece não conter as relações métricas mais adequadas para a tarefa de reconhecimento,
usando-se mesmas condições e parâmetros de treinamento válidas para os demais
grupos.
Percebe-se claramente que não há uma tendência de convergência da curva de
aprendizagem da rede para os padrões usando as relações deste grupo.

127
Os índices de acerto atingidos utilizando-se os 4 últimos grupos em presença de ruído,
estão resumidos na Tabela 5.16 a seguir.
Tabela 5.16 – Índice de acerto dos grupos em presença de ruídos.
Grupo Erro médio quadrático
Nº de iterações
Nº de erros
Total de padrões apresentados
% média de acertos
Grupo5
0.020349 480544 29 308 90,58% Grupo5.1
0.020111 447077 7 168 95,83% Grupo5.2
0.020197 954106 9 308 97,08% Grupo5.3 Rede não converge usando os mesmos parâmetros
dos demais grupos
Foram apresentados os 14 padrões de teste para cada inserção de ruídos. E foram
testados 22 grupos de ruídos, totalizando 308 ocorrências no caso dos Grupos 5 e 5.2.
Para o Grupo 5.1 foram testados 12 grupos de ruídos apenas, totalizando 168 padrões
apresentados à rede.
Os índices de acerto atingidos para os 15 padrões que não pertencem à Classe 3 e não
estavam na etapa de treinamento, encontram-se na Tabela 5.17. Foram comparados os 8
grupos de métricas apresentados anteriormente na Tabela 5.3.
TABELA 5.17 – Índice de acerto dos 8 grupos para 15 padrões desconhecidos, não presentes no treinamento.
Grupo Nº de erros Nº de
padrões % média de
acertos
Grupo1 10 15 33,33%
Grupo2 5 15 66,67%
Grupo3 4 15 73,33%
Grupo4 1 15 93,33%
Grupo5 0 15 100%
Grupo5.1 0 15 100%
Grupo5.2 2 15 86,67%
Grupo5.3 Rede não converge usando os mesmos parâmetros
dos demais grupos

128
Os valores mostrados na Tabela 5.17 se referem às respostas apresentadas pela rede aos
15 padrões "não conhecidos" e não usados na etapa de treinamento, para cada um dos 8
grupos de métricas. Estes resultados estão ligados às Tabelas 5.5, 5.6, 5.8, 5.11, 5.14
desta dissertação.
Avaliando-se os resultados dos testes, verifica-se que uma aplicação onde não se deseja
permitir que pessoas não autorizadas tenham acesso a um determinado local, as métricas
dos Grupos 5 e 5.1 se mostraram mais confiáveis quando comparadas às métricas do
Grupo 5.2, para este conjunto de faces utilizado nos testes.
No próximo tópico serão apresentados os testes e resultados obtidos pela rede
responsável por associar faces classificadas como "conhecidas", na etapa 1, à face com
relações métricas mais próximas aprendidas durante a fase de treinamento.
5.2. Testes da Rede de Associação a Padrões Conhecidos
Nesta etapa avalia-se a confiabilidade da rede em mapear um conjunto de entradas em
um valor previamente aprendido. Como foi descrito anteriormente no sub-tópico 4.3
desta dissertação, há 5 redes nesta segunda etapa, sendo cada uma delas responsável por
mapear padrões da sua classe específica.
Os testes abaixo foram realizados usando as 5 classes obtidas do conjunto de 22 faces
do banco de imagens da Açominas S.A. Após o treinamento da rede, foram inseridos
ruídos nas métricas faciais, com a finalidade avaliar o desempenho do mapeamento das
faces realizado pela rede.
Cada face de determinada classe foi codificada previamente em uma combinação de 4
dígitos formados por 0's e 1's. E esta codificação foi fornecida à rede como saída
desejada na etapa de treinamento.
Na validação da rede, os 4 dígitos que codificam a face são obtidos das 4 saídas da rede
desta etapa. Assim, a saída 0001 representa uma face, a saída 0010 representa outra face
e assim por diante.

129
As 7 relações métricas que compõem os padrões de entrada da rede são apresentadas na
Tabela 5.18.
TABELA 5.18 – Relações métricas que compõem os padrões de emtrada da rede da etapa2.
Relações Bx/By Nx/Fx Fy/Fx T2/Fy T3/Fy T2/Fx T3/Fx
A curva de aprendizagem para as 8 faces pertencentes à Classe 3 é mostrada na Figura
5.7:
FIGURA 5.7 - Curva de aprendizagem dos 8 padrões da Classe 3.
O erro médio quadrático obtido foi de 0.019988 após 397957 iterações.
Apresentando-se novamente à rede, o conjunto de padrões usados durante a etapa de
treinamento, percebe-se que todos os padrões foram aprendidos, como é mostrado na
Tabela 5.19.

130
TABELA 5.19 - Resposta da rede aos padrões usados no treinamento da classe 3.
Padrão Saída desejada Saída obtida Status 1 0 0 0 1 0.000 0.000 0.011 0.999 OK! 2 0 0 1 0 0.000 0.017 0.988 0.014 OK! 3 0 0 1 1 0.000 0.011 0.981 1.000 OK! 4 0 1 0 0 0.000 0.990 0.012 0.008 OK! 5 0 1 0 1 0.000 0.990 0.021 0.987 OK! 6 0 1 1 0 0.007 1.000 0.983 0.009 OK! 7 0 1 1 1 0.000 0.984 1.000 0.988 OK! 8 1 0 0 0 0.992 0.008 0.001 0.000 OK!
A Tabela 5.19 mostra na coluna "Saída desejada" a codificação estabelecida para cada
padrão da Classe3. Usando-se esta codificação binária é possível representar até 16
faces para cada classe.
A coluna "Saída obtida" mostra a resposta da rede aos padrões usados no treinamento
após os pesos já estarem fixos. Os valores na saída da rede serão considerados 1 se
forem maiores ou iguais a 0,5. Serão considerados 0 aqueles valores inferiores a 0,5.
Percebe-se então, avaliando-se a coluna "Status", que a rede aprendeu os 8 padrões
vistos no treinamento.
A Tabela 5.20 mostra a saída da rede quando são apresentados os padrões
"contaminados" com ruídos.

131
TABELA 5.20 - Resposta da rede a padrões conhecidos acrescidos de ruído (etapa 2 de reconhecimento).
Pixels adicionados
Medidas afetadas
Nº de erros em 8
padrões
Descrição do erro
Inserindo ruído em medidas verticais 1 pixel T2; T3; Fy 0 2 pixels T2; T3; Fy 0 3 pixels T2; T3; Fy 0 4 pixels T2; T3; Fy 0 5 pixels T2; T3; Fy 0
Inserindo ruído em medidas horizontais 1 pixel Nx; Bx; Fx 0 2 pixels Nx; Bx; Fx 0 3 pixels Nx; Bx; Fx 0 4 pixels Nx; Bx; Fx 0 5 pixels Nx; Bx; Fx 0
Inserindo ruído em medidas verticais e horizontais 1 pixel T2; T3; Fy; Nx; Bx; Fx 0 2 pixels T2; T3; Fy; Nx; Bx; Fx 0 3 pixels T2; T3; Fy; Nx; Bx; Fx 0 4 pixels T2; T3; Fy; Nx; Bx; Fx 0 5 pixels T2; T3; Fy; Nx; Bx; Fx 0
10 pixels T2; T3; Fy; Nx; Bx; Fx 1 Não associou a entrada a nenhuma face
Adicionando os ruídos aleatórios nas respectivas medidas verticais e horizontais 8 3 6 2 4 8 T2; T3; Fy; Nx; Bx; Fx 0 4 7 3 7 4 5 T2; T3; Fy; Nx; Bx; Fx 0
8 16 12 12 14 14 T2; T3; Fy; Nx; Bx; Fx 0
14 4 0 16 8 8 T2; T3; Fy; Nx; Bx; Fx 0 6 21 18 9 0 0 T2; T3; Fy; Nx; Bx; Fx 2
Confundiu 1 face, associando as métricas de entrada à face errada Não mapeou a entrada a nenhuma face
20 0 12 20 16 8 T2; T3; Fy; Nx; Bx; Fx 1 Não mapeou a entrada a nenhuma face
A média de acertos atingida pela rede, avaliando os padrões da Classe 3, foi de 97,73%.

132
A coluna "Medidas afetadas", a exemplo do que ocorre nos testes da etapa 1, mostra
quais as medidas que serão contaminadas com o número de pixels descritos na coluna
"Ruído". A coluna "Nº de erros em 8 padrões", informa o número de equívocos
cometidos pela rede ao classificar os 8 padrões da Classe3 contaminados com os ruídos.
Por fim, a coluna "Descrição do erro" mostra qual o equívoco cometido pela rede na
tarefa de associação (associação errada entre a face avaliada e uma das faces aprendidas
ou a não associação da face avaliada a nenhuma das faces aprendidas).
Os 8 padrões da Classe 3 foram apresentados a cada inserção de um novo conjunto de
ruídos.
A Tabela 5.21 mostra os resultados obtidos para todas as 5 classes, seguindo o mesmo
padrão de testes com ruídos descritos na Tabela 5.20.
TABELA 5.21 - Resultados obtidos para as outras 4 classes (etapa 2 de reconhecimento).
Classe Nº padrões por Classe
Nº de erros Nº padrões submetidos à
rede
% média de acertos
1 1 0 22 100
2 2 0 44 100
3 8 4 176 97,73
4 6 0 132 100
5 5 1 110 99,10
A primeira coluna da Tabela 5.21 informa qual a Classe avaliada. A coluna “Nº Padrões
por Classe” informa quantas faces foram enquadradas em cada Classe específica, de
acordo com o índice facial. A coluna "Nº de erros" informa quantos erros ocorreram ao
se introduzir os 22 tipos de erros na etapa de aquisição das métricas faciais dos 14
padrões avaliados. Esta coluna informa o número de erros observados em relação ao
número total de padrões submetidos à rede para a dada Classe. Na coluna “Nº de
padrões submetidos à rede” tem-se o total de padrões apresentados à rede em cada

133
Classe na etapa de aquisição das métricas, após a contaminação com os 22 tipos de erros
já mencionados. Dessa forma, a Classe 1 que continha 1 padrão, após a contaminação
com 22 tipos de erros passou a ter 22 padrões apresentados à sua rede específica (22 = 1
padrão * 22 tipos de erros avaliados), seguindo-se o mesmo raciocínio para as demais
classes. Por fim a coluna "% média de acerto" informa o índice de acerto para cada
Classe individualmente, avaliando os erros em relação ao total de padrões apresentados
para a Classe específica.
Não foram feitas outras combinações referentes às métricas usadas para representar as
faces nesta segunda etapa, pois os resultados até aqui alcançados já mostram que é
possível realizar o reconhecimento de faces usando-se as relações métricas definidas
neste trabalho.
A avaliação de outros conjuntos de relações nas 2 etapas é proposta como possível
trabalho futuro, juntamente com outros testes no capítulo final desta dissertação.
O próximo tópico é dedicado aos comentários a respeito dos testes realizados.
5.3. Discussão Sobre os Testes Realizados
O foco desta dissertação foi a utilização de métricas faciais para o reconhecimento de
faces. Buscou-se mostrar a viabilidade do uso dessas medidas para reconhecer um rosto.
Os estudos vistos durante o desenvolvimento desta dissertação sobre reconhecimento
facial usam poucos recursos geométricos para a tarefa de reconhecimento, por acreditar
que as medidas de componentes faciais, por si só, são incapazes de efetuar o
discernimento eficiente entre faces distintas.
Os resultados atingidos, apresentados nos tópicos 5.1 e 5.2 desta dissertação, mostram
que uma vez escolhidas as métricas faciais e relações proporcionais adequadas e
usando-se a capacidade de generalização das redes neurais, é possível a diferenciação
entre rostos "conhecidos" e "não conhecidos", através de um sistema que combine
características geométricas de representação facial e características presentes em redes

134
neurais artificiais, como o proposto por este trabalho. Tal sistema também se mostra
apto para mapear uma face apresentada na entrada da rede, na face mais semelhante
aprendida na fase de treinamento.
Desta forma, o sistema aqui proposto pode certamente ser usado como ferramenta de
reconhecimento ou como apoio a outros sistemas baseados em metodologias diferentes
como álgebra linear, modelos deformáveis e filtros baseados em wavelets, a fim de se
atingir um bom índice de acerto no reconhecimento facial.
No próximo tópico serão descritos alguns comentários sobre detalhes do uso das
métricas faciais no reconhecimento facial.
5.3.1. As Métricas Usadas para Representação Facial
A imagem contendo uma face é a informação básica que deve ser trabalhada por um
sistema de reconhecimento automático de faces. As representações mais usuais em
sistemas desse tipo são feitas através de matriz de pixels (informações de iluminação),
modelos tridimensionais ou até mesmo por uma mistura das duas formas (Oliveira,
1997).
A partir da imagem de entrada devem ser extraídas características para a representação
do rosto de forma manipulável pelo sistema de reconhecimento. A extração dessas
características pode ser feita de 2 formas: implícita ou explícita (Oliveira, 1997).
A extração implícita é utilizada por todos os métodos que fazem uso de algoritmos de
categorização implícitos ou que usem propriedades da imagem para gerar
representações sem se basear em informações locais de componentes.
Já a extração explícita compreende os métodos que partem de características
previamente estabelecidas, tais como medidas entre pontos-chaves utilizados pelos
métodos geométricos. A extração explícita de características foi o método adotado por
esta dissertação, buscando o embasamento na anatomia facial para a determinação das
relações métricas que representam individualmente cada face.

135
Através da extração explícita de características visou-se determinar quais dos
componentes e áreas da face eram realmente importantes para o discernimento facial.
Os componentes dos vetores, usados para representar a face durante as 2 etapas de
reconhecimento, foram escolhidos levando-se em consideração as dificuldades
encontradas em se mensurar tais regiões. Algumas áreas e componentes da face se
mostraram muito suscetíveis a variações do tipo: corte de cabelo ou presença de barba,
bigode e cavanhaque.
Foi observado que determinados cortes de cabelo impediam a determinação correta do
1º terço facial, pois a franja obstruía a determinação da linha da raiz do cabelo, como
mostrado na Figura 5.8.A. A determinação do 1º terço da face também se mostrou
imprecisa em casos onde o modelo é calvo, ilustrado na Figura 5.8.B.
(A) (B)
FIGURA 5.8 - Dificuldades de determinação do primeiro terço da face. (A) Linha da raiz do cabelo é ocultada pela franja. (B) Encontra-se a dificuldade de determinar o ponto de início da linha da raiz do cabelo.
Outro problema encontrado foi a determinação da linha tangente à região
mentoniana, usada na determinação do 3º terço e da altura facial. Neste caso, ilustrado
na Figura 5.9, a dificuldade é causada pelo uso de barba ou cavanhaque que cobre e
prolonga o queixo, impedindo-se a determinação da linha tangente a esta região.

136
FIGURA 5.9 - Dificuldade de localização da região mentoniana, usada na determinação da altura da face e do 3º terço facial.
Através destas observações, optou-se por não utilizar as medidas extraídas do 1º terço
da face. Para o caso da altura facial, assumiu-se que a linha deveria ser tangente ao final
da face. Caso houvesse a presença de barba ou cavanhaque, a linha seria tangente ao
final desse adorno. Não foi possível descartar esta região pois ela é usada na
determinação da altura facial, sendo uma das medidas necessárias à determinação do
índice facial.
Determinadas métricas apresentaram maior adaptabilidade que outras, quando avaliado
o seu desempenho nas 2 etapas que compõem o reconhecimento facial aqui descrito.
A principal estratégia usada neste trabalho foi a classificação de faces com formatos
variados em grupos com características básicas semelhantes, através da determinação do
índice facial. Dessa forma, não foram feitas comparações entre faces totalmente
diferentes ("faces baixas" comparadas a "faces estreitas" por exemplo) usando os
componentes apropriados para a tarefa de ajuste fino, como algumas das relações
métricas usadas nesta dissertação (ODX/ODY, NX/NY, NX/FX, entre outras).
As redes não convergiam em testes realizados antes dessa classificação pois um
conjunto de características próprias de uma face sofria interferência do conjunto de
características do outro tipo de face. Os ajustes feitos nos pesos da rede, para atender ao
reconhecimento de faces de uma dada classe, não eram os mesmos ajustes necessários
para o reconhecimento de outra classe distinta. Por isso a rede não aprendia os padrões.
Isso mostra que em certas situações, os detalhes ou certas particularidades dos
componentes faciais são um diferencial importante na tarefa de discernimento entre uma

137
face "conhecida" e o "não conhecida". Porém uma pré-seleção de grupos de faces com
características gerais similares deve ser feita antes do treinamento para um melhor
aprendizado.
A seguir serão feitas algumas observações sobre a rede neural usada no sistema de
reconhecimento facial.
5.3.2. Método Conexionista Não-Linear Usado
Segundo (Haykin, 2001) o poder de generalização de uma rede neural está diretamente
relacionado com a sua estrutura maciçamente paralela e distribuída. A generalização se
refere ao fato da rede produzir saídas adequadas para entradas que não estavam
presentes durante o treinamento. É a chamada "aprendizagem".
A generalização é uma das principais características que tornam as redes neurais aptas à
tarefa de reconhecimento facial. Esta característica pôde ser percebida durante os testes,
como mostram os resultados apresentados nas Tabelas 5.5, 5.6, 5.8, 5.11 e 5.14.
Durante toda a fase de testes a estrutura da rede foi alterada na busca de uma
configuração que atendesse à tarefa de reconhecimento. A capacidade de adaptação das
redes também foi testada alterando-se os parâmetros de aprendizagem, experimentando-
se novas combinações de métricas faciais, novos erros mínimos aceitáveis, degradando-
se a estrutura da rede para verificar a interferência causada nos resultados, entre outros
experimentos.
A boa tolerância a falhas apresentada pelas redes neurais também foi alvo de testes
realizados neste trabalho. Esta característica pôde ser avaliada durante os testes de
tolerância a falhas, no processo de aquisição de dados, como mostram especificamente
os resultados das Tabelas 5.9, 5.12, 5.15, 5.20 e 5.21. Nestes testes, variou-se de forma
controlada os valores das métricas de componentes da face, observando-se até quando,
com o aumento dos níveis de ruído, a rede ainda conseguiria obter a resposta correta nos
neurônios de saída.

138
Foi observado que o desempenho da rede degrada suavemente sob condições de
operação adversas. Devido à natureza distribuída da informação armazenada na rede
(Haykin, 2001), o dano que por ventura venha a ser causado em sua estrutura deve ser
extenso para que a resposta global seja degradada seriamente.
O papel da rede neural neste sistema foi substituir as comparações entre padrões de
faces utilizando algoritmos de classificação numérica, por um sistema inteligente capaz
de lidar com pequenos erros e presença de ruídos, realizando ainda assim, um
reconhecimento eficiente. Os testes realizados comprovaram que as redes neurais são
uma boa ferramenta para tratar a inexatidão e variabilidade dos padrões faciais. Através
do uso das redes neurais, pequenas variações de expressão observadas na face do
modelo podem ser desconsideradas no momento de verificar se uma face é conhecida
ou não. Esta informação adulterada não impede a realização do reconhecimento facial
correto, como foi visto nos testes com inserção de ruídos.
A configuração final da rede, capaz de realizar o reconhecimento nas etapas 1 e 2, foi
atingida após uma série de testes envolvendo várias combinações de métricas
representando as faces.
Na etapa 1, apenas 1 neurônio na camada de saída é suficiente para informar se o padrão
facial de entrada é conhecido ou não. Já o número de neurônios da camada oculta deve
ser alterado para casos onde o número de faces seja superior aos 14 padrões usados
aqui. Sugere-se um aumento gradativo de neurônios na camada escondida, bem como de
relações métricas (na composição do vetor de identificação) que garantam a unicidade
de cada face a fim de que a rede continue com um bom índice de acerto.
Na etapa 2, foram usados 4 neurônios de saída, o que torna cada rede capaz de
representar até 16 faces. Em casos onde o número de faces por classe for maior que 16,
o número de neurônios da camada oculta, os número de neurônios da camada de saída,
bem como o número de elementos que representem a face, devem ser alterados. Novos
neurônios devem ser adicionados à rede (e novas relações métricas acrescentadas ao
vetor de identificação das faces), na medida em que sejam aumentados o número de
faces de cada classe e o desempenho da rede comece a cair.

139
O aumento no número de neurônio se justifica pelo fato da rede ter a necessidade de
armazenar informações das novas faces, distribuídas nos pesos dos novos neurônios. A
necessidade de novas informações para representar um número maior de faces é
justificada pelo fato da rede precisar de novos critérios de desempate para realizar o
reconhecimento facial.
A seguir serão comentados os resultados obtidos nos testes.
5.4. Resultados Obtidos
Os índices de reconhecimento obtidos durante a fase de testes e apresentados nas
Tabelas 5.16 e 5.17 mostram que o uso de métricas faciais aplicadas ao reconhecimento
facial é viável para pequenos grupos de faces.
Utilizando-se apenas um conjunto de 13 medidas (apresentadas nas Tabelas 4.2 e 4.3 )
extraídas de fotos frontais e estabelecendo as relações proporcionais entre tais medidas
(mostradas nas Tabelas 4.4A e 4.4B), foi possível diferenciar entre faces "conhecidas" e
"não conhecidas". Também foi possível associar ao vetor de métricas faciais na entrada
da rede, a codificação da face que mais se assemelhou a esse vetor dentro do conjunto
de padrões vistos na fase de aprendizado.
Foram obtidas médias de acerto acima de 95% nas redes da etapa 1 (mostradas nas
Tabelas 5.6 e 5.16), para padrões vistos na fase de treinamento acrescidos de ruídos.
Também nesta etapa foram alcançados índices de acerto superiores a 85%, quando
apresentados padrões que não estavam presentes na fase de treinamento (mostrado na
Tabela 5.17).
Para as redes da etapa 2 de reconhecimento, os acertos foram superiores a 97%
(conforme as Tabelas 5.20 e 5.21). As variações nos índices de acerto se devem ao uso
de um vetor contendo um grupo com relações métricas mais ou menos aptas para
discernir entre as várias faces avaliadas.
Os resultados obtidos reforçam a idéia de que a definição de um vetor de características
baseado em pontos chaves da face (como os pontos craniométricos ou mesmo outros

140
pontos anatômicos usados em odontologia e reconstituição facial) é robusto o suficiente
para ser aplicado ao reconhecimento de faces, dentro de um grupo limitado de pessoas.
Um ponto importante observado nos testes refere-se à estratificação das faces a serem
reconhecidas dentro de grupos com características semelhantes. Esta estratificação deve
ser realizada para que sejam comparadas, usando as relações métricas de ajuste fino
mostradas nesta dissertação, somente aquelas faces com as mesmas características
globais. Assim tem-se um aprendizado rápido das características das faces de cada
grupo.
Fica claro ainda que deve-se escolher bem os componentes faciais para se extrair as
métricas e definir apropriadamente as relações entre elas. Dessa forma assegura-se uma
boa representação das particularidades de cada face, tornando o discernimento entre
estes padrões mais fácil.
5.4.1. Comparação entre Índices de Reconhecimento
Segundo (Oliveira, 1997), os estudos realizados por (Bledsoe, 1966), (Goldestein et
al.1971), (Kanade, 1973), (Brunelli e Poggio, 1991) utilizando métodos geométricos
aplicados ao reconhecimento facial obtive ram índices de acerto que variaram enter 45 e
90% de acerto.
Alguns desses estudos usavam marcações feitas à mão em fotos de faces frontais,
indicando os cantos dos olhos, boca, nariz e queixo, como as realizadas nesta
dissertação. Porém não era levado em consideração as características dos pontos
craniométricos e as relações lineares existentes entre estes pontos. As comparações
entre as medidas que representavam as faces (determinando se um vetor de medidas
características pertencia ou não a uma determinada face) eram realizadas por algoritmos
de classificação numérica.
Os índices de reconhecimento obtidos nesta dissertação (acima de 90%), apresentam um
forte indício de que o uso de um conhecimento prévio sobre a anatomia facial, levando
em consideração suas particularidades na escolha das métricas para representar a face,

141
são um ponto importante para se realizar um reconhecimento eficiente. Outro ponto a
ser considerado é o uso de redes neurais em substituição dos algoritmos de classificação
numérica. Através do uso das redes neurais, pode-se trabalhar melhor a imperfeição
ocorrida na coleta das métricas.
Não se está afirmando aqui que o sistema híbrido proposto nesta dissertação é melhor
ou pior do que os descritos em trabalhos anteriores. Esta afirmação não poderia ser feita
uma vez que os testes não foram realizados usando-se o mesmo número de padrões, as
mesmas faces, sob as mesmas condições de iluminação e resolução.
O que se quer mostrar é que o uso de uma heurística na determinação dos pontos a
serem medidos na face e a aplicação de métodos inteligentes na comparação dessas
medidas, geram bons índices de acerto no reconhecimento facial, como podem ser visto
se comparados apenas os índices de reconhecimento dos testes aqui apresentados com
os índices vistos em outros trabalhos.
O próximo tópico apresenta possíveis aplicações para este trabalho.
5.5. Aplicabilidade do Trabalho
Avaliando-se os resultados desta dissertação, conclui-se que é viável a implementação
de um sistema híbrido de reconhecimento automático de faces, se o mesmo for guiado
pela aplicação que se deseja.
Se a aplicação desejada for um sistema de controle de acesso, usando o reconhecimento
da faces, espera-se colaboração daqueles que vão utilizar tal sistema. Portanto
preocupações do tipo: posicionamento da face de forma correta em frente a câmera de
aquisição de imagens, expressão facial neutra apresentada pelo usuário no momento da
validação do acesso, presença ou ausência de adornos como óculos por exemplo, não
representam grandes problemas pois os usuários estarão cientes das exigências para o
perfeito funcionamento do sistema. Assim, as faces dificilmente estarão em uma
posição diferente da esperada, estando ainda a uma distância conhecida da câmera.

142
O ambiente de aquisição das imagens é perfeitamente controlável, no que se refere a
luminosidade, ou presença de objetos que possam ocultar partes de interesse da face a
ser analisada. Como o número de pessoas que terá acesso a um determinado local não
deve ser muito grande, um sistema com as características do sistema híbrido
apresentado nesta dissertação, atenderia às necessidades exigidas para o controle de
acesso a determinados ambientes.
Para o caso de reconhecimento de faces de criminosos, dentro de uma banco de fotos, as
características referentes ao posicionamento frontal da face, controle de iluminação e
"background" também atenderiam às necessidades de funcionamento do sistema
híbrido. Porém o grande número de faces presentes em um banco de fotos policial,
geralmente em torno de milhares, pode ser um elemento que dificultaria o
reconhecimento.
A melhor estratégia para este caso, seria uma estratificação das faces em número maior
de classes que o apresentado nesta dissertação. Dessa forma, diminuir-se- ia o número de
elementos presentes em cada classe de faces. Para o caso onde a rede não consiga
determinar exatamente a face procurada, ela poderá apontar a face que mais se
assemelha ao objetivo, segundo as métricas avaliadas.
Além das aplicações citadas acima, que podem ser satisfeitas pelo sistema híbrido, ainda
é possível utilizá- lo como apoio para outros sistemas de reconhecimento facial, fazendo
com que ele gere um parecer paralelo e depois se compare os dois resultados obtidos.
Em caso de duplo positivo, isto é, ambos os sistemas reconheceram a face, uma dada
ação poderia ser executada. Caso pelo menos um dos sistemas apresentasse resposta
divergente, uma nova verificação poderia ser exigida, ou então uma intervenção humana
solicitada. E em caso de duplo negativo, a ação correspondente ao "não
reconhecimento" seria disparada.
O sistema aqui proposto pode ainda ser adaptado para determinação de sexo, raça,
auxílio em análises faciais buscando por problemas de assimetria facial, auxílio a
ortodontia entre outras aplicações.

143
CAPÍTULO 6
CONCLUSÕES E PERSPECTIVAS
PARA TRABALHOS FUTUROS
Esta dissertação apresenta um protótipo de avaliação para a construção de um sistema
híbrido inteligente, direcionado ao reconhecimento de faces. Tal sistema procura
mesclar as características locais e globais da face, usadas nos métodos geométricos, com
a capacidade de generalização e robustez à falhas, observadas nos métodos inteligentes
baseados em redes neurais artificiais.
A aplicação dos métodos geométricos ao reconhecimento facial teve início na década de
60. Eram usadas medidas de componentes e regiões da face, coletadas manualmente,
para formar um vetor de medidas características que representaria cada padrão de forma
única. A escolha das características a serem medidas era feita de forma subjetiva, não
havendo nenhuma explicação lógica ou embasamento teórico para escolher este ou
aquele componente facial. Além disso, a comparação feita entre dois vetores,
verificando se tais representações faziam referência à mesma face, era feita através de
algoritmos de classificação numérica. Esta forma de comparação era altamente
suscetível a variações causadas por ruídos ou por imperícia no momento da coleta de
medidas.
Buscou-se neste trabalho, levantar embasamentos científicos para auxiliar na escolha
dos componentes a serem examinados na face. Observou-se também, quais medidas
deveriam ser consideradas para se realizar o reconhecimento facial. Estudos foram
realizados sobre a morfologia da face humana, buscando encontrar pontos de referência
que justificassem a escolha deste ou daquele componente, para se extrair as medidas
responsáveis por representar uma face de forma única.
Os fundamentos seguidos aqui para determinar os pontos de referência, componentes e
medidas faciais relevantes para o reconhecimento de faces foram encontrados em
estudos anatômicos da área de ortodontia, fonoaudiologia e reconstituição maxilo-facial.

144
Avaliando-se as referências destas ciências, descobriu-se que as faces podem ser
estratificadas em classes, de acordo com a determinação do seu índice facial. Este
índice, que é composto pela razão entre a altura facial e a distância bizigomática, pode
ser determinado sem dificuldades e de forma satisfatoriamente precisa em fotos de faces
frontais. Ainda nos estudos realizados sobre a anatomia facial, foram encontrados
pontos de referência sobre o esqueleto da face (denominados pontos craniométricos) e
relações entre estes pontos (denominadas medidas lineares). Estas relações são usadas
por profissionais de ortodontia e reconstituição maxilo-facial em exames, tratamentos e
cirurgias corretivas.
O uso destes pontos de referência durante os testes aqui realizados, bem como o uso das
medidas lineares estabelecidas entre eles, mostrou-se eficiente na formação de vetores
capazes de representar faces de forma única, possibilitando assim o seu reconhecimento.
Após este estudo, um dos problemas apontados originalmente para o uso dos métodos
geométricos (subjetividade na determinação de quais medidas devem ser usadas para
representar uma face) pôde ser resolvido. Adotou-se como referência, para a
determinação das medidas características de uma face, o uso dos pontos craniométricos
e das medidas lineares existentes entre eles. Todos os pontos de referência usados aqui
estão presentes em todas as faces humanas e são possíveis de serem determinados sem
maiores problemas.
O segundo problema, apontado em estudos anteriores sobre os métodos geométricos, foi
a vulnerabilidade a ruídos. Originalmente os métodos geométricos usavam algoritmos
de classificação numérica para a comparação entre 2 vetores, a fim de determinar se
ambos eram referentes à mesma face. Foi proposto nesta dissertação a substituição
desses algoritmos por métodos baseados em inteligência computacional.
Para tornar a tarefa de reconhecimento facial mais simples, este trabalho usou a
estratégia "dividir para conquistar". Tal estratégia prega a quebra de problemas grandes
e de difícil solução, em problemas menores que apresentem soluções mais
simplificadas.

145
Optou-se então por quebrar a tarefa de reconhecimento facial em 2 tarefas menores. A
primeira tarefa é verificar se uma determinada face é conhecida. Em caso positivo
inicia-se segunda tarefa, que é a procura (dentro do grupo de faces vistas na etapa de
treinamento) daquela face que mais se assemelha ao padrão analisado no momento.
Foram usadas redes neurais multicamadas, alimentadas adiante e treinadas por
retropropagação do erro, a fim de verificar se um padrão era conhecido ou não (etapa 1).
Usou-se também (etapa 2) outra rede com as mesmas características estruturais, um
número maior de entradas e de neurônios escondidos, para avaliar a similaridade entre
os padrões vistos na etapa de treinamento e o padrão avaliado naquele momento. Cada
uma das cinco classes de faces possui um par dedicado de redes (uma para a etapa 1 e
outra para a etapa 2). O uso da estratégia se mostrou eficaz pois foram obtidos bons
índices de acerto no reconhecimento facial.
A estratificação das faces em diferentes classes contendo padrões com características
semelhantes, antes de apresentá-las às redes neurais, foi importante para otimizar o
aprendizado dessas redes. Foi observado, durante a etapa de testes, que antes de usar a
estratificação em classes, um determinado número de faces era aprendido pela rede sem
maiores problemas. Alterando-se os padrões para um segundo grupo, com o mesmo
número de elementos, a rede apresentava dificuldades em aprendê- los. Mais tarde,
descobriu-se que essa dificuldade estava diretamente ligada às características de faces
pertencentes a classes extremas. Durante a etapa de treinamento, os ajustes feitos para
satisfazer o aprendizado de um determinado padrão de uma classe entravam em
contradição com os ajustes nos pesos para atender o padrão da outra classe. Esta
situação levava a rede a não convergência.
Analisando os testes realizados, pode-se perceber que o emprego de um sistema híbrido
que combina características de métodos geométricos e características de inteligência
computacional, é perfeitamente viável para a tarefa de reconhecimento facial.
Foram alcançados índices de acerto acima de 95% para as redes da etapa 1, avaliando-se
padrões vistos na fase de treinamento acrescidos de ruídos. E foram alcançados índices
de acerto superiores a 85%, quando apresentados padrões que não estava m presentes na

146
fase de treinamento. As redes da etapa 2 de reconhecimento obtiveram acertos
superiores a 97%.
Observou-se durante os testes a influência sofrida por algumas regiões da face a
variações estéticas como cortes de cabelo, presença ou ausência de barba, bigode e
cavanhaque. As regiões mais afetadas por estas variações foram as relações faciais que
envolviam o 1º terço facial (T1), o 3º terço facial (T3) e a altura da face (FY).
Em presença de certos adornos (barba e cavanhaque) ou penteados (com franjas
cobrindo a testa) percebeu-se uma grande dificuldade para a determinação exata dessas
medidas, principalmente na determinação de T1. Foram feitos testes sem o uso de
relações métricas que contivessem essas 3 medidas, e foi possível realizar o
reconhecimento da etapa1 sem problemas. A medida FY foi usada apenas para a
determinação do índice facial, no caso desse teste.
No decorrer dos testes foi possível também perceber que a etapa que deve ser tratada
com mais cuidado é a etapa 1. Nela devem ser usadas as relações que apresentaram
maior poder de diferenciação entre faces, a fim de garantir uma sinalização precisa
sobre a face ser "conhecida" ou "não-conhecida".
O estudo do poder de discernimento de uma relação métrica entre duas medidas pode
ser feita através de uma avaliação gráfica, como foi mostrado no capítulo 4 desta
dissertação. Através da variação apresentada por uma relação métrica entre uma face e
outra, pode-se ter a noção se ela tem um alto poder de diferenciação (quando há
oscilação significativa de face para face) ou não (quando a trajetória da linha
permanecer aproximadamente constante variando-se de face para face).
Avaliando-se a etapa 2 do reconhecimento, observa-se que ela funciona como um ajuste
fino para encontrar um determinado padrão dentro de um conjunto de padrões com
características próximas. Como as características não são exatamente as mesmas, a
tarefa de mapeamento de um padrão em um dos outros padrões do conjunto não se
mostra muito complexa para um número não muito grande de elementos. Para um

147
número maior de elementos do conjunto a idéia de não complexidade se mantém, desde
que existam variações suficientes entre os valores que compõem os padrões.
Deve-se estar atendo ao número de entradas a serem usadas para representar cada face
na etapa 2. Pode-se conseguir um bom índice de acerto usando um número pequeno de
entradas, mas a robustez a ruídos pode ficar comprometida com a redução dos padrões
de desempate.
Ainda com relação à composição dos vetores que representam as faces, o uso das
relações métricas entre medidas de componentes e regiões da face, ao invés do uso das
medidas puras, se mostrou muito útil para eliminar variações que podem existir entre a
distância da face e da câmera no momento da foto. Além disso, cria-se a oportunidade
de aumentar o número de possíveis componentes do vetor que representa a face.
Por fim, podem ser citados como contribuição oferecida por este trabalho os seguintes
tópicos:
• Uso de pontos de referência anatômicos e suas relações na criação de
uma representação facial aplicável à tarefa de reconhecimento;
• Avaliação na substituição de algoritmos numéricos por métodos
inteligentes na tarefa de comparação entre vetores contendo métricas
faciais;
• Avaliação da estratificação de um conjunto de faces em classes menores
antes de iniciar as etapas de treinamento e também na etapa do
reconhecimento facial propriamente dito;
• Avaliação e alertas sobre regiões da face que devem ser evitadas, dentro
do possível, para se representar uma face (devido a suscetibilidade a
variações estéticas);

148
Os artigos publicados durante a confecção deste trabalho estão citados nas referências
bibliográficas (Oliveira e Guimarães, 2001a) e (Oliveira e Guimarães, 2001b).
Perspectivas para trabalhos futuros
Inicialmente deve-se realizar um estudo das melhorias que seriam agregadas ao sistema,
se juntamente com as fotos frontais fossem analisadas também as fotos perfiladas dos
modelos. De posse dessas informações, seria possível também fazer uso de outras
distâncias e ângulos faciais usados pela ortodontia, aplicando-as ao reconhecimento
facial. Dessa forma o sistema híbrido poderia se tornar mais robusto a falhas.
Ainda com relação às métricas faciais, novas combinações poderiam ser testadas na
etapa 2. Deseja-se assim verificar outras medidas que também se mostrem aptas ao
"ajuste fino" do reconhecimento facial feito por esta etapa.
Além desse estudo, outro ponto a ser desenvolvido é a extração automática das métricas
faciais. Dessa forma, seria possível ter a certeza que nenhum conhecimento implícito ao
operador que extrai as métricas está sendo usado na coleta. Uma sugestão para essa
extração automática é a divisão da tela em regiões onde espera-se que estejam presentes
os componentes a serem medidos. A partir dessa divisão, seguida de seguimentações e
filtragens em cada uma das regiões definidas a fim de realçar as características
desejadas, seriam determinados os pontos de interesse e as respectivas medidas entre
eles.

149
REFERÊNCIAS BIBLIOGRÁFICAS
Adhiwiyogo, M., Chong, S., Huang, J., Teo, W.. Fingerprint Recognition [on line]
http://www.andrew.cmu.edu/~jchuang/551/final/fnalreport.html, 1999.
Angelo, N. P., Haertel, V.. Avaliação dos Parâmetros dos Filtros de Gabor na
Classificação Supervisionada de Imagens Digitais, Revista de Informática Teórica e
Aplicada, vol. 9, no 1, Ago. 2002.
Bartlett, M., Hager, J., Ekman, P., Sejnowski, T.. Measuring facial expressions by
computer analysis. Psychophysiology, 36:253-264, 1999.
Ben-Yacoub, S., Fasel, B., Luttin, J.. Fast face detection using MLP and FFT. In
Second International Conference on Audio and Video-Based Biometric Person
Authentication, p. 31-35, 1999.
Bianchini, E. M. G.. Articulação Temporomandibular – Implicações, Limitações e
Possibilidades Fonoaudiológicas, 1 ed, Pró-fono Departamento Editorial. 401 pág.,
2000.
Black, M. J., Yacoob, Y.. Tracking and recognizing rigid and non-rigid motions using
local parametric models of image motion. In Proc. Of International conference on
Computer Vision, pág. 374-381, 1995.
Bledsoe, W. W.. Man-machine facial recognition. Relatório técnico, Panoramic
Research Inc., Palo Alto, CA, 1966.
Bouattour, H., Soulié, F. F., Viennet, E.. Neural nets for human face recognition.
IJCNN92, III:700-704, 1992.
Bruce, V., Burton, A. M., Hanna, E., Healey, P., Mason, O.. Sex discrimination: how do
we tell the difference between male and female faces. Perception, 22:131-152, 1993.

150
Bruce, V., Humphreys, G. W.. Recognizing objects and faces. Visual Cognition, pág.
141-180,1994.
Brunelli, R., Poggio, T.. Face recognition: Features versus templates. Relatório técnico,
I.R.S.T., 1991.
Burton, A. M., Bruce, V., Dench, N.. What's the difference between men and women?
Evidence from facial measurement. Perception, 22:153-176, 1993.
Carpenter, G. A., Grossberg, S.. A massively parallel architecture for a self organizing
neural pattern recognition machine. Comput. Vision Graphics Image Process. 37:54-
115, 1987a.
Carpenter, G. A., Grossberg, S.. ART2: Self-organization of stable category recognition
codes for analog input patterns. Appl. Opt. 26:4919-4930, 1987b.
Carpenter, G. A., Grossberg, S.. The ART of adaptative pattern recognition by a self-
organization neural network. Computer 21(3):77-88, 1988.
Carpenter, G. A., Grossberg, S.. ART3: Hierarchical search using chemicla transmitters
in self-organizing pattern recognition architectures. Neural Networks 3(2):129-152,
1990.
Chan, H., Bledsoe, W. W.. A man-machine facial recognition: some preliminary results.
Relatório técnico, Panoramic Research Inc., Palo Alto, CA, 1965.
Chiche, G. I., Pinault, A.. Princípios Científicos e Artísticos aplicados à Odontologia
Estética, 1 ed, Quintessence Books. 201 pág., 1996.
Cohn, J. F., Zlochower, A. J., Lien, J., Kanade, T.. Automated face analysis by feature
point tracking has high concurrent validity with manual facs coding.
Psychophysiology, 36:35-43, 1999
Cottrell, G. W., Munro, P.. Principal component analysis of images via
backpropagation. Proc. Soc. of Photo-Optical Instr. Eng., 1988.

151
Daugman, J. G.. Complete Discrete 2-D Gabor Transforms by Neural Networks for
Image Analysis and Compression, IEEE Trans. on Acoustics, Speech, and Signal
Processing, vol. 36, no. 7, Jul. 1988.
DE Almeida, R. C., DE Almeida, M. H. C.. A Assimetria Facial no Exame Clínico
Frontal da Face, Revis ta da Sociedade Paulista de Ortodontia – Revista Ortodontia,
vol. 32, no. 2, pp.82 – 86, 1999.
DE Felício, C. M.. Fonoaudiologia Aplicada a Casos Odontológicos – Motricidade Oral
e Audiologia, 1 ed, Pancast Editora Com. e Representações LTDA. 243 pág., 1999.
Donato, G., Bartle, M. S., Hager, J. C., Ekman, P., Sejnowski, T.. Classifying facial
actions. IEEE Trasaction on Pattern Analysis and Machine Intelligence, 21(10):974-
989, Oct 1999.
Epker, B. N., Fish, L.. Evaluation and Treatment Planning. Dentofacial Deformities . v.
1, p. 9, 1986.
Fu, K. S., Gonzales, R., Lee, C.. Robotics: Control, Sensing, Vision and Intelligence.
McGraw-Hill, 1987.
Fukui, K., Yamaguchi, O.. Facial feature point extraction method based on combination
of shape extraction and pattern machine. System and Computers in Japan, 29(6):49-
58, 1998.
Goldstein, H., Lesk.. Identification of human faces. Proceedings IEEE, 59:748, 1971.
Gonzalez, R. C., Winitz, P.. Digital Image Processing. Addison- Wesley Publishing
Company, 1992.
Graziani, M.. Cirurgia Buco-Maxilo-Facial, 7 ed., Guanabara Koogan, 717 pág., 1986.
Han, C. C., Liao, H. Y. M. G., Yu, K. C., Chen, L. H.. Fast face detection via
morphologybased pre-processing. Taipei / Taiwan: Academia Sinica, 1997. 21p.
(TR-IIS-97-001).

152
Haykin, S.. Redes Neurais – princípios e prática, 2 ed., Brookman, 900 pág., 2001.
Hertz, J., Krogh, A., Palmer, R. G.. Introduction to the Theory of Neural Computation,
volume 1 de Computation and neural system series. Allan M. Wylde, 1991.
Kalocsai, P. Malsburg, C. von der and Horn, J.. Face recognition by statistical analysis
of feature detectors. Image And Vision Computing, 18(4):273-278, March 2000.
Kanade, T.. Picture Processing System by Computer Complex and Recognition of
Human Faces. Tese de Doutorado, Dept. of Information Science, Kyoto University,
1973.
Lades, M., Vorbruggen, J.C., Buhmann, J., Lange, J., Malsburg, C. v. d., Wurtz, R. P.,
Konen, W.. Distortion Invariant Object Recognition in the Dynamik Link
Architecture. IEEE Transactions on Computers, vol.42, no.3, p. 300-311, Mar. 1993.
Lampinen, J.; Oja, E.. Distortion tolerant pattern recognition based on self-organizing
feature extraction, IEEE Transactions on Neural Networks, 1995.
Lien, J., Kanade T., Cohn, J. F., Li, C. C.. Detection, tracking, and classification of
action units in facial expression. Journal of Robotics and Autonomous System,
31:131-146, 2000.
Lin, C. T.; Lee, C. S. G.. Neural Fuzzy Systems – A Neuro-Fuzzy Synergism to
Intelligent Systems. New Jersey: Prantice Hall, 797 pág., 1996.
Lyons, M. J., Akamatsu, S., Kamachi, M., Gyoba, J.. Coding Facial Expressions with
Gabor Wavelets, Proceedings, 3rd IEEE International Conference on Automatic Face
and Gesture Recognition, pp. 200-205, Apr. 1998.
Lyons, M. J., Budynek, J., Plante, A., Akamatsu, S.. Classifying Facial Attributes Using
a 2-D Gabor Wavelet Representation and Discriminant Analysis, Proceedings, 4th
International Conference on Automatic Face and Gesture Recognition. 28-30 March,
2000, Grenoble France, IEEE Computer Society, pp. 202-207.

153
Maio, D., Maltoni, D., Rizzi, S.. Topological Clustering Of Maps Using A Genetic
Algorithm. Pattern Recognition Letters, vol. 16, no. 1, pp. 89-96, 1995.
Manjunath, B. S.. Perceptual Grouping and Segmentation Using Neural Networks,
Signal and Image Processing Institute, University og Southern California, 119 pág.,
Dez. 1991.
Manjunath, B. S., Chellappa, R., Malsburg, C. v. d.. A feature based approach to face
recognition. California: Computer Vision Laboratory, Center for Automation
Research , Univ. of Maryland., Janeiro 1992. 35p. (CAR-TR-604 and CS-TR-2834)
Maren, A., Harston, C., Pap, R.. Handbook of Neural Computing Applications.
Academic Press, Inc. San Diego, 1990. 450p.
Marr, D.. Vision. W. H. Freeman & Company, New York, 1982.
McMinn, R. M. H., Hutchings, R. T., Logan, B. M.. Atlas Colorido de Anatomia da
Cabeça e Pescoço, 2 ed., Editora Artes Médicas LTDA, 247 pág., 2000.
Oliveira, D. R., Guimarães, L. N. F.. Sistema Híbrido Inteligente Aplicado ao
Reconhecimento de Faces, Simpósio de Ciências Exatas e da Terra, UNIVAP, São José
dos Campos – SP, 2001a. (painel).
Oliveira, D. R., Guimarães, L. N. F.. Sistema Híbrido Inteligente Aplicado ao
Reconhecimento de Faces, I Workshop de Computação Aplicada (I WORCAP), INPE,
São José dos Campos – SP, 2001b. (painel).
Oliveira, Y. G.. Implemantação de um reconhecedor neural de faces. Projeto Orientado
em Ciência da Computação, 1994.
Oliveira, C., Silva, F., Oliveira, T.. Processamento de Língua Natural: Uma Abordagem
Simbólica ou Conexionista? São José dos Campos: Instituto Nacional de Pesquisas
Espaciais, 1996. 50p. (INPE-5971-PRP/194).

154
Oliveira, Y. G.. Classificação de Metodologias para Reconhecimento Automático de
Faces Humanas. Dissertação de Mestrado, Universidade Federal de Minas Gerais,
1997.
Pedroza, L. C. C., Pedreira, C. E.. Uma Nova Metodologia para Treinamento em Redes
Neurais Multicamadas, vol. 11 no. 1, pp. 49-54, 2000.
Petrelli, E.. Ortodontia Contemporânea, 2 ed., Sarvier, 370 pág., 1993.
Pham, D., Liu, X.. Neural Networks for Identification, Prediction and Control. Springer-
Verlag, 1995, 238p.
Plunkett, K. Elman, J. L.. Exercises in Rethinking Innateness – A Handbook for
Connectionist Simulations, 3 ed., MIT Press/Bradford Books, 313 pág., 1997.
Polikar, R. The Wavelet Tutorial, [on line] <http://www.public.iastate.edu/
%7erpolikar/WAVELETS/WTtutorial.html>, 1995.
Porat, M., Zeevi, Y.. The Generalized Gabor Scheme of Image Representation in
Biological and Machine Vision, IEEE, 1988.
Proffit , W. R.. Diagnóstico e Planejamento de Tratamento. Ortodontia Contemporânea.
p.138, 1991.
Randall S. S., Jatinder N. D. G.. Comparative evaluation of genetic algorithm and
backpropagation for training neural networks, Information Sciences, 2000.
Rempel, E. L.. Reconhecimento de Padrões Invariantes a Rotação Utilizando uma Rede
Morfológica Não-Supervisionada. São José dos Campos: Instituto Nacional de
Pesquisas Espaciais, 2000. 81p. (INPE-7994-TDI/748).
Rowley, H. A., Baluja, S., Kanade, T. Human face detection in visual scenes. Pittsburg:
Carnegie Mellon University, November 1995. 24p. (CMU-CS-95-158R).
Rowley, A. H., Baluja, S., Kanade, T.. Rotation Invariant Neural Netwoar-Based Face
Detection. Technical Report. CMU-CS-97-201, Carnegie Mellon University, 1997.

155
Senna, A. L.. Previsão de qualidade de aglomerados de finos de minério utilizando
redes neurais. Dissertação de Mestrado, Universidade Federal de Minas Gerais, 1996.
Shioyama, T., Wu, H. Mitani, S.. Segmentation with Gabor Filters and Cumulative
Histograms, IEEE, 1999.
Sinha, P.. Object Recognition via Image Invariants: A Case Study. In Investigative
Ophthalmology and Visual Science, vol 35, pp. 1735-1740, May, 1994.
Suguino, R., Ramos, A. L., Tereda, H. H., Furquin, L.Z., Maeda, L., DA Silva Filho, O.
G.. Análise Facial. Revista Dental Press de Ortodontia e Ortopedia Maxilar, vol. 1,
no. 1, pp. 86-107, 1996.
Sung, K.K., Poggio, T.. Example-based Learning for View-based Human Face
Detection. Massachusetts: Massachusetts Institute of Technology, December 1994.
20p. (AIM-1521/C.B.C.L. No 112).
Tian, Y., Kanade, T., Cohn, J.. Recognizing upper face actions for facial expressions
analysis. In Proceedings Of CVPR'2000, pág. 294-301, 2000a.
Tian, Y., Kanade, T., Cohn, J.. Recognizing lower face actions for facial expression
analysis. In Proceedings Of International Conference on Face and Gesture
Recognition, pág. 484-490, Mar. 2000b.
Tian, Y., Kanade, T., Cohn, J. F.. Recognizing Facial Actions by Combining Geometric
Features and Regional Appearance Patterns. Pittsburg: Carnegie Mellon University,
January 2001. 31p. (CMU-RI-TR-01-01).
Viazis, A.D.. Avaliação do Tecido Mole. Atlas de Ortodontia. Princípios e Aplicações
Clínicas. p. 49, 1996.
Wasserman, P.. Neural Computing – Theory and Pratice. Van Nostrand Reinhold. New
York, 1989. 230p.

156
Wiskott, L., Fellous, J.-M.; Kruger, N., Malsburg, C.von.der.. Face recognition by
elastic bunch graph matching. Germany: Institut fur Neuroinformatik, Ruhr-
Universitat Bochum. 1996. 23p. (IR-INI 96-08 / D44780).
Yuille, A., Halliman, P., Cohen, D.. Feature Extraction from Faces using Deformable
Templates. International Journal of Computer Vision, 8 (2): 99-111,1992.
Zurada, J. M.. Introduction to Artificial Neural Systems. St Paul, USA, 1992.
Zhang, Z., Lyons, M., Schuster, M., Akamatsu, S.. Comparison Between Geometric-
Based and Gabor-Wavelets-Based Facial Expression Recognition Using Multi-Layer
Percetron. Proceedings, 3rd IEEE International Conference on Automatic Face and
Gesture Recognition, April 1998, Nara Japan, p. 454-459.

157
APÊNDICE A
O T-learn foi escolhido para ser o simulador neural desta dissertação por ser fácil de
usar e flexível a alterações rápidas de estrutura e parametrização. Além disso, ele possui
uma gama de ferramentas úteis à avaliação e análise das arquiteturas de rede neurais
implementadas.
O simulador de redes neurais T- learn foi programado para ser compatível com diversas
plataformas incluindo Macintoshes, Windows e muitas máquinas UNIX que executam o
X-windows. O T- learn pode ser adquirido via ftp (File Transmission Protocol) anônimo
no endereço: ftp.psych.ox.ac.uk ou pelo endereço http://crl.ucsd.edu/innate.
A seguir será descrito, de forma sucinta, o funcionamento básico do T- learn e de alguns
de seus recursos.
Para iniciar o processo de construção de uma nova rede neural usando o T- learn,
seleciona-se o item “Network” na barra de menu, como mostrado na Figura A1:
FIGURA A1 – Iniciando novo projeto de rede neural.
Após escolher o nome do projeto e a pasta onde deseja armazená- lo, 3 arquivos serão
criados pelo T- learn para gerenciar o projeto. Para ilustrar o processo de criação de uma

158
rede neural com o T- learn, será criada aqui uma rede capaz de solucionar o problema da
porta lógica XOR.
Portanto, após escolher o nome XOR para o projeto, 3 arquivos com o mesmo
nome são automaticamente criados, cada qual com sua função e extensão específica,
como mostrado na Figura A2.
FIGURA A.2 – Projeto XOR com as respectivas janelas de configuração.
Cada janela será usada para a entrada de informações relevantes a diferentes aspectos da
arquitetura da rede e ambiente de treinamento.
A janela referente ao arquivo XOR.cf é usada para definir o número de nodos da rede e
os padrões iniciais de conexão entre estes nodos antes do início do treinamento.
A janela do arquivo XOR.data define quantos são os padrões de entrada da rede, e o
formato através do qual eles estão representados no arquivo.
Por fim, a janela referente ao arquivo XOR.teach define os padrões esperados na saída
da rede, detalhando quantos são estes padrões, e o formato que eles estão representados.
Por convenção, o T- learn necessita que qualquer projeto de simulação possua os 3
arquivos listados anteriormente. Ele espera ainda que estes arquivos possuam as
extensões .cf, .data e .teach. Todos os arquivos pertencentes a um mesmo projeto devem
ter o mesmo nome. As informações do projeto são armazenadas em um arquivo especial
sem extensão criado no momento da escolha do nome do projeto. No caso do exemplo
aqui apresentado, foi criado automaticamente o arquivo XOR. Este arquivo identifica o
projeto e faz a ligação com os outros 3 arquivos específicos para cada função. Para abrir

159
um projeto já existente no T-learn, deve-se abrir este arquivo principal no menu
“Network”, opção “Open Project”, e ele se encarrega de abrir os demais arquivos
específicos (.cf, .data e . teach).
O T-learn é sensível a letras maiúsculas e minúsculas, além de espaços em branco.
Portanto, deve-se estar atento na digitação dos comandos específicos de cada uma das
janelas descritos a seguir.
O arquivo XOR.cf contém 3 sessões:
• A sessão NODES especifica o número total de unidades da rede e
identifica quais nodos executam o papel de entrada e saída da rede.
• A sessão CONNECTIONS especifica como as unidades são
interconectadas.
• A sessão SPECIAL fornece informações que determinam o valor inicial
das conexões e especifica as unidades cujos valores de ativação estão
disponíveis para inspeção.
O arquivo XOR.cf deve ter o conteúdo mostrado na Figura A3.
FIGURA A.3 – Conteúdo do arquivo XOR.cf.
Note que as sessões são delimitadas, sendo escritas em letras maiúsculas e seguidas de
dois pontos “:”. As instruções têm as seguintes funções:

160
“NODES:” define o início do bloco de nodos;
“nodes = 3” define quantos nodos farão parte da rede; “inputs = 2” define o número de entradas da rede; “outputs = 1” define quantos serão os neurônios de saída da rede; “output node is 3” define qual dos neurônios será a saída da rede; “CONNECTIONS:” define o início da sessão que estabelece as conexões entre
nodos; “groups = 0” diz ao T-learn quantos grupos de conexões são restritos a ter o
mesmo valor. Na rede atual, não há nenhuma restrição, portanto define-se que ‘groups = 0’;
“1-2 from i1- i2” define que os neurônios 1 e 2 recebem entradas de i1 e i2; “3 from 1-2” define que o neurônio 3 recebe as saídas dos neurônios 1 e 2 como
entradas; “1-3 from 0” define que os 3 neurônios da rede recebem entradas de um ‘bias’; “SPECIAL:” define o início de uma nova sessão; “selected = 1-3” diz ao T-learn quais unidades estão sendo selecionadas para
impressão especial; “weight-limit = 1.00” define que o intervalo de inicialização dos pesos deve
estar enter 0 e 1. O arquivo XOR.data define os padrões de entrada que serão apresentados ao T-
learn. A entrada dos dados deve ser feita como mostrado na Figura A.4.
FIGURA A.4 – Conteúdo do arquivo XOR.data.
A primeira linha desse arquivo deve ser o comando “distributed”. A linha seguinte
define o número de padrões que devem ser apresentados à rede em i1 e i2, já citados no
arquivo “XOR.cf”.

161
O arquivo XOR.teach é mostrado na Figura A.5. A primeira linha de arquivo segue o
mesmo padrão descrito no arquivo “XOR.data”. A linha seguinte determina a
quantidade de padrões de saída para as respectivas entradas apresentadas no arquivo
“XOR.data”. A cada uma das linhas do arquivo XOR.teach, está relacionada a entrada
presente no arquivo “XOR.data”. Então, para o padrão de entrada “0 0”, espera-se a
saída “0” e assim por diante.
FIGURA A.5 – Conteúdo do arquivo XOR.data.
Desta forma, termina-se a etapa de parametrização da rede. Pode-se verificar a
arquitetura rede criada usando-se o menu “Displays” e escolhendo a opção “Network
Architecture”.
Para a rede construída no exemplo citado aqui, tem-se a arquitetura ilustrada na Figura
A.6.

162
FIGURA A.6 – Arquitetura da rede criada.
Após a definição da estrutura, conexões, padrões de entrada e saídas desejadas, é
necessário definir os parâmetros de treinamento. Isso é feito através do menu
“Networks”, escolhendo-se a opção: “Training options”. A tela de configuração dos
parâmetros de treinamento é mostrada na Figura A.7.
FIGURA A.7 – Janela de parâmetros de treinamento da rede.

163
Através desta tela é possível se configurar os parâmetros de treinamento da rede, tais
como número de épocas, valor do ‘bias’, taxa de aprendizado, momentum, erro médio
quadrático aceitável, etc.
Feitas as devidas configurações, para efetuar o treinamento da rede, através do menu
“Network”, escolhe-se a opção “Train the network”.
Para acompanhar o gráfico de evolução do erro durante o treinamento, seleciona-se
através do menu “Displays”, a opção “Error display”. O gráfico resultante é mostrado
na Figura A.8.
FIGURA A.8 – Gráfico de evolução do erro médio quadrático. A verificação do real aprendizado da rede é feita através do menu “Networks”
escolhendo-se a opção “Verify network has learned”. Nesse momento, são novamente
apresentados à rede os padrões usados no treinamento e são avaliados os valores de
saída apresentados pela rede.
Para o exemplo aqui mostrado, os valores de saída obtidos após 4000 iterações com os
parâmetros usados no treinamento foram:

164
Output activations using XOR-4000.wts and XOR.data (Training Set) 0.023 0.976 0.976 0.030
As saídas mostram que a rede realmente aprendeu os padrões apresentados.
Para a apresentação de padrões que não estavam presentes no treinamento da rede,
formando um conjunto de validação de dados, basta criar um novo arquivo
“novels.data” através do menu “File” opção “New”. Nesse arquivo, seguindo os
mesmos padrões do arquivo “.data”, entra-se com os novos valores. No menu
“Networks”, opção “Testing options” deve-se alterar a opção “Testing set” para “Novel
data” e colocar na caixa de texto ao lado, o nome do arquivo de testes (novels.data aqui
descrito).
Feito isso, para submeter os novos padrões à rede, basta acessar o menu “Networks” e
escolher a opção “Verify network has learned”. O novo conjunto de padrões será
submetido à rede e serão apresentadas as respostas da rede a esses padrões.
O T- learn oferece muitos outros recursos, como análise de componentes principais,
análise de ‘clusters’, verificação gráfica da ativação dos nodos sob a presença dos
padrões de ent rada entre outras ferramentas de análise.
Maiores detalhes do funcionamento e recursos do T- learn podem ser encontrados no
endereço: http://crl.ucsd.edu/innate ou no livro “Exercises in Rethinking Innateness – a
Handbook for Connectionist Simulations”, presente nas referências bibliográficas desta
dissertação.
Related Documents











