Semantic Web: Comparison of SPARQL implementations Rafal Malanij Mat.No: B0105363 Thesis Project for the partial fulfilment of the requirements for the Master Degree in Advanced Computer Systems Development. University of The West of Scotland School of Computing 29th September 2008

Rafal_Malanij_MSc_Dissertation
Aug 07, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Semantic Web:Comparison of SPARQL
implementations
Rafał MałanijMat.No: B0105363
Thesis Project for the partial fulfilment of the requirements for the Master Degreein Advanced Computer Systems Development.
University of The West of ScotlandSchool of Computing
29th September 2008

Abstract
The Semantic Web is the revolutionary approach to publishing data in the Internet proposed years
ago by Tim Berners-Lee. Unfortunately the deployment of the idea became more complex than
it was assumed. Although the data model for the concept is well established recently a query
language has been announced. The specification of SPARQL was a milestone on the way to fulfil
the vision, but the implementation attempts show that there is a need for further research in the
area. Some of the products are already available. This thesis is evaluating five of them using the
data set based on DBpedia.org. Firstly each of the packages is described taking into consideration
the documentation, the architecture and usability. The second part is testing the ability to load
efficiently a significant amount of data and afterwards to compute in reasonable time results of
the sample queries, which includes the most important structures of the language. The conclusion
shows that although some of the packages seem to be very advanced and complex products, they
still have some problems with processing queries based on basic specification. The Semantic Web
and its key technologies are very promising, but they need some more stable implementations to
become popular.
1

CONTENTS
Contents
Table of contents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
List of Figures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
List of Tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1. Semantic Web. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.1. Origins of the Semantic Web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.2. From the Web of documents to the Web of data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3. World Wide Web model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.4. The Semantic Web’s Foundations – the Layer Cake . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.5. The Semantic Web – Today and in the Future . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2. SPARQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.1. RDF – data model for Semantic Web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.2. Querying the Semantic Web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2.1. Semantic Web as a distributed database . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2.2. Semantic Web queries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.3. The SPARQL query language for RDF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.4. Implementation model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.5. SPARQL’s syntax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.6. Review of Literature about SPARQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3. The implementations of SPARQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.1. Testing methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.1.1. DBpedia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.1.2. Ontology and test queries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.2. OpenRDF Sesame 2.1.2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
2

CONTENTS
3.2.1. Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
3.2.2. Documentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
3.2.3. Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3.2.4. Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
3.2.5. Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
3.3. OpenLink Virtuoso 5.0.6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
3.3.1. Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
3.3.2. Documentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
3.3.3. Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
3.3.4. Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
3.3.5. Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
3.4. Jena Semantic Web Framework 2.5.5 with ARQ 2.2, SDB 1.1 and Joseki 3.2 . . . . . . 93
3.4.1. Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
3.4.2. Documentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
3.4.3. Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
3.4.4. Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
3.4.5. Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
3.5. Pyrrho DBMS 2.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
3.5.1. Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
3.5.2. Documentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
3.5.3. Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
3.5.4. Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
3.5.5. Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
3.6. AllegroGraph RDFStore 3.0.1 Lisp Edition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
3.6.1. Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
3.6.2. Documentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
3.6.3. Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
3.6.4. Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
3.6.5. Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
Bibliography . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
3

LIST OF FIGURES
List of Figures
1.1. W3C’s Semantic Web Logo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.2. Semantic Web’s “layer cake” diagram Source: http://www.w3.org/2007/03/layerCake.png,
[12.02.2008] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1. Structure of RDF triple, after Passin (2004). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.2. RDF statements. Source: DBpedia (http://www.dbpedia.org), RDF/XML vali-
dated by http://www.rdfabout.com/demo/validator/validate.xpd, [12.03.2008] . . . . 22
2.3. RDF graph. Based on: DBpedia (http://www.dbpedia.org), [12.03.2008] . . . . . . . . . 24
2.4. RDF statements in Turtle syntax. Source: DBpedia (http://www.dbpedia.org),
[12.03.2008] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.5. The history of SPARQL’s specification. Based on SPARQL Query Language for
RDF (2008) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.6. SPARQL implementation model. Source: Herman (2007a) . . . . . . . . . . . . . . . . . . . . . 32
2.7. The process of transforming calendar data from XHTML extended by hCalendar
microformat into RDF triples. Source: GRDDL Primer (2007). . . . . . . . . . . . . . . . . . 35
2.8. Simple SPARQL query with the result. Source: DBpedia (http://www.dbpedia.org),
[12.04.2008] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.9. Application of CONSTRUCT query result form with the results of the query seri-
alized in Turtle syntax. Source: DBpedia (http://www.dbpedia.org), [12.04.2008] . . 38
2.10. SPARQL query presenting universities with its number of students, number of
staff and optional name of the headmaster with some filtering applied. Below are
the results of the query. Source: DBpedia (http://www.dbpedia.org), [20.04.2008] . 39
2.11. Structure of RDF tuple, after Cyganiak (2005b). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
2.12. Selection (𝜎) and projection (𝜋) operators, after Cyganiak (2005b). . . . . . . . . . . . . . . 44
4

LIST OF FIGURES
2.13. SPARQL query transformed into relational algebra tree, after Cyganiak (2005b). . . 45
3.1. The status of datasets interlinked by the Linking Open Data project. Source:
http://richard.cyganiak.de/2007/10/lod/lod-datasets/, [12.06.2008]. . . . . . . . . . . . . . . 57
3.2. Querying on-line DBpedia SPARQL endpoint with Twinkle. . . . . . . . . . . . . . . . . . . . 61
3.3. Query testing full-text searching capabilities. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3.4. Selective query with UNION clause. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3.5. Query with numerous selective joins. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.6. Query with nested OPTIONAL clauses. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.7. CONSTRUCT clause creating new graph. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.8. ASK query that evaluates the graph. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.9. Query returning all available triples for the particular resource. . . . . . . . . . . . . . . . . . 65
3.10. Two versions of GRAPH queries. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
3.11. Architecture of Sesame. Source: User Guide for Sesame 2.1 (2008). . . . . . . . . . . . . . 68
3.12. The interface of Sesame Server. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
3.13. Sesame Console with a list of available repositories. . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3.14. Sesame Workbench – exploring the resources in the repository based on a native
storage. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
3.15. Graph comparing loading times for OpenRDF Sesame using different storages. . . . 76
3.16. Graph comparing execution times of testing queries against different repositories. . 79
3.17. Architecture of Virtuso Universal Server. Source: Openlink Software (2008). . . . . . . 83
3.18. OpenLink Virtuoso Conductor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
3.19. OpenLink Virtuoso’s SPARQL endpoint. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
3.20. Interactive SPARQL endpoint with visualisation of one of the test queries. . . . . . . . . 87
3.21. Architecture of Jena Semantic Web Framework version 2.5.5. Source: Wilkinson,
Sayers, Kuno & Reynolds (2004). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
3.22. Graph comparing loading times for SDB using different backened. . . . . . . . . . . . . . . 99
3.23. Graph comparing average loading times for SDB using different backened. . . . . . . . 103
3.24. Querying SDB repository using command line. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
3.25. Joseki’s SPARQL endpoint. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
3.26. Architecture of Pyrrho DB. Source: Crowe (2007). . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
3.27. Evaluation of the first test query against Pyrrho DBMS using provided RDF client. 113
5

LIST OF FIGURES
3.28. Pyrrho Database Manager showing local database sparql with the data stored in
Rdf$ table. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
3.29. High-level class diagram of AllegroGraph. Source: AllegroGraph RDFStore (2008).119
3.30. The process of loading AllegroGraph server and querying a repository using Alle-
gro CL environment. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
3.31. Graph comparing average loading times the best performing configurations. . . . . . . 133
6

LIST OF TABLES
List of Tables
3.1. Summary of loading data into OpenRDF Sesame. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
3.2. Summary of evaluating test queries on OpenRDF Sesame. . . . . . . . . . . . . . . . . . . . . . 78
3.3. Summary of loading data into OpenLink Virtuoso. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
3.4. Summary of evaluating test queries on OpenLink Virtuoso. . . . . . . . . . . . . . . . . . . . . 90
3.5. Summary of loading data using SDB. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
3.6. Summary of evaluating test queries on repositories managed by SDB. . . . . . . . . . . . . 106
3.7. Summary of evaluating test queries against Pyrrho Professional. . . . . . . . . . . . . . . . . 116
3.8. Summary of loading data into AllegroGraph repository. . . . . . . . . . . . . . . . . . . . . . . . 123
3.9. Summary of evaluating test queries on AllegroGraph RDFStore. . . . . . . . . . . . . . . . . 125
3.10. Summary of loading data into tested implementations – configurations that had
the best performance for each implementation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
3.11. Summary of performing test queries – configurations that had the best perfor-
mance for each implementation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
7

INTRODUCTION
Introduction
In the late 1980’s the Internet was becoming internationally established. However retrieving in-
formation from remote computer systems was a challenge due to the lack of unified protocol
for accessing information. In the same time Tim Berners-Lee, a physicist in CERN Laboratory in
Switzerland, started to work on a protocol that would allow easier access to information distributed
over many computers. In 1989, with help from Robert Cailliau, Tim Berners-Lee published a pro-
posal for the new service - World Wide Web. That was the beginning of the revolution. Within a
few years WWW became the most popular service in the Internet.
In 1994 Tim Berners-Lee launched a World Wide Web Consortium (W3C) that started to work on
standardising the technologies that were to extend the functionality of WWW. That was the time
when webpages became dynamic, but the “golden years” were to come soon. WWW was spotted
by the business community and the revolution was spread around the world.
Now we can truly say that hyperlinks have revolutionised our life - the way we publish infor-
mation, media, the way we buy and sell goods, the way we communicate. Almost everybody in
developed countries has personalised email address and treats the Internet as regular tool that helps
in everyday life. We can undoubtedly agree that the Internet is one of the pillars of the revolution
that is transforming the developed world into a knowledge-driven society.
However some visionaries claim that this is not yet the Web of data and information. The meaning
of today’s Web content is only accessible for humans. Although search engines have become very
powerful tools, the quality of the search results is relatively low. What is more, the results contains
only links to webpages, where possibly the information may be found. Users still play the main
role in processing information published in the Internet.
Tim Berners-Lee was aware of all the imperfections of the Web. In the end of the 1990’s he pro-
posed the extension to the current Web that he called the Semantic Web. The specialists announced
8

INTRODUCTION
a revolution – Web 3.0. However the implementation of that vision turned out to be more complex
than expected. The revolution was replaced by evolution.
In this thesis I will focus on one of the aspects of Semantic Web – handling semantic data. Firstly
the vision of the Semantic Web along with basic technologies will be presented. Then I will
examine what expectations derive from the Semantic Web’s foundation for the technologies that
will be responsible for accessing data on the Web. In the following chapter the W3C’s approach,
SPARQL query language, will be presented together with a short introduction into semantic data
model and the problem of querying the Semantic Web. SPARQL will be discussed in details
including the syntax, the implementation models and a review of available literature about the
technology. The practical part of the research will involve a review of a number of available
implementations of SPARQL, which are going to be a subject of some basic usability tests. Firstly
the methodology will be presented together with a description of the data set used for testing. Then
each of examined implementations will be reviewed and tested presenting the findings. Finally the
implementations will be compared when possible and some conclusion will be drawn.
9

SEMANTIC WEB
1. Semantic Web
“The Semantic Web is not a separate Web
but an extension of the current one,
in which information is given well-defined meaning,
better enabling computers and people to work in cooperation.”
(Berners-Lee, Hendler & Lassila 2001)
1.1. Origins of the Semantic Web
The above quotation comes from one of the best known articles about the Semantic Web1 – “The
Semantic Web” published in the year 2001 in Scientific American. It is considered as the initia-
tor of the “semantic revolution” in IT. In fact, due to its popularity, a worldwide discussion has
emerged and some implementation efforts have commenced, but the first ideas were presented by
Tim Berners-Lee earlier in his book, “Weaving the Web: Origins and Future of the World Wide
Web” (Berners-Lee & Fischetti 1999).
Figure 1.1: W3C’s Semantic Web Logo
From the very beginning he was thinking about
the Web as the universal network, where docu-
ments will be connected to each other by their
meaning in a way that enables automatic process-
ing of information. In “Weaving the Web” he
summarised not only his work on developing the Web in the current form, but he was also try-
ing to answer the questions about the future of the Web.1Google Scholar finds it cited in 5304 articles what gives it a first place for searching phrase “semantic web”.
Source: http://scholar.google.co.uk/scholar?hl=en&lr=&q=semantic++web&btnG=Search. Retrieved on 2008.01.29.
10

SEMANTIC WEB
Even before his article in Scientific American, Tim Berners-Lee and scientists gathered around
the World Wide Web Consortium (W3C) started to work on technologies that will form the basis
for the Semantic Web in the future2. They were presenting the vision in numerous lectures around
the world and supporting initiatives for deploying these technologies in some specific knowledge
areas. The first document, “Semantic Web Roadmap” (Berners-Lee 1998), where ideas about the
architecture were described, was published in September 1998.
1.2. From the Web of documents to the Web of data
The word “semantics”, according to Encyclopedia Britannica Online3, means “the philosophical
and scientific study of meaning”. The keyword is the word “meaning”.
The current version of the Web, that was implemented in 1990’s, is based on the mechanism of
linking between documents published on web servers. However despite its universality, the mech-
anism of hyperlinks does not allow a transfer of the meaning of the content between applications.
That inability prevents computers from using the Web content to automate everyday activities.
Computers just do not understand the information they are processing and displaying so human
involvement is needed to put the information into context and thus exchange semantics between the
systems. That problem also occurs while exchanging data between the computer systems used in
business. Different standards of storing data in applications require the use of custom-built parsers
– this increases costs and complexity or may lead to many extraction errors and data inconsistency.
The Semantic Web vision envisages that computers should be able to search, understand and use
the information they process with a little help from additional data. However there are different
ideas what that vision involves. Passin (2004, p.3) states 8 of them. The most important from the
perspective of that thesis is the vision of the Semantic Web as a distributed database. According
to Berners-Lee, Karger, Stein, Swick & Weitzner (2000), cited in Passin (2004), the Semantic
Web is about to present all the databases and logic rules allowing them to interconnect and create
a large database. Information should be easily accessed, linked and understood by computers.2First working draft of RDF specification was published in October 1997. RDF Model and Syntax specification was
released as W3C Recommendation a year later, in February 1999.3Encyclopedia Brytannica Online, http://www.britannica.com/eb/article-9110293/semantics. Retrieved on
2008.01.29.
11

SEMANTIC WEB
Data should be connected by relations to its meaning.
That goal can be achieved by extending the existing databases by additional descriptions of data,
usually called meta data. That supplementary information enables advanced indexing and discov-
ery of decentralised information. Moreover, searching and retrieval of information will be auto-
mated by software agents. These are dedicated applications that communicate with other services
and agents on the Web, and with the help of artificial intelligence can provide improved results or
even follow certain deduction processes. The machine-readable data will be accessible as services
over the Web that will allow computers to discover and process easily all the required information.
What is more the great amount of data that is available outside databases, e.g. static webpages,
will be understandable by machines due to semantic annotations and defined vocabularies.
1.3. World Wide Web model
Today’s model of the World Wide Web is based on a few simple principles. The most basic one
assumes that when a Web document links to another, the linked document can be considered as a
resource. In the Semantic Web, resources are identified using unique Uniform Resource Identifier
(URI). In the current Web, resources such as files or web pages are identified by standardised
Uniform Resource Locators (URLs), which are a kind of URIs, but extended with the description
of its primary access method (e.g. http:// or ftp://). The concept of URI says that resources
may represent tangible things like files and non-tangible ideas or concepts, which even does not
have to exist, but can be thought about. What is more, the resources can be fixed or change
constantly and they are still represented by the same URI.
Over the Web the messages are being sent using the HTTP protocol4, which consists of a small
set of commands and makes it easy to implement in all kind of network software (web servers,
browsers). Although some extensions, like cookies or SSL/TLS encryption layer, are being used,
the original version of protocol does not support security or transaction processing.
Another principle of the WWW is its decentralisation and scalability. Every computer connected
to the Internet can host a web server, and this makes the Web easily extendible. There is no central4Hypertext Transfer Protocol (HTTP) – communication protocol used to transfer information between client and
server deployed in application layer (according to TCP/IP model). It was originally proposed by Tim Berners-Lee in
1989.
12

SEMANTIC WEB
authority that maintains the infrastructure. What is more, every request from client to server is
treated independently. The HTTP protocol is stateless, and this makes it possible to cache the
responses and decrease network traffic.
The Web is open – resources can be added freely. It is also incomplete, and this means that
there is no guarantee that every resource is always accessible. That implies the next attribute –
inconsistency. The information published on-line does not have to be always true. It is possible
that two resources can easily deny each other. Resources are also constantly changing. Due to
the features of HTTP protocol and utilisation of caching servers it may happen that there are two
different versions of the same resource. These aspect raise a very serious requirement on software
agents that attempt to draw conclusions from data found on the Web.
1.4. The Semantic Web’s Foundations – the Layer Cake
The Semantic Web, as an extension of the current Web, should follow the same rules as the current
model. According to that all resources should use URIs to represent objects. The Semantic Web
refers also to non-addressable resources that cannot be transferred via the network. Currently that
feature was not used as the most popular URIs – URLs, were referring to tangible documents. The
basic protocol should continue to have a small set of commands and retain no state information.
It should remain decentralised, global and operate with inconsistent and incomplete information
with all the advantages of caching of information.
The W3C, as the main organisation that is developing and promoting standards for the Seman-
tic Web, has created their own approach to its architecture. The first overview was presented in
Berners-Lee (1998) and it has been evolving together with the evolution and development of the
technologies involved. W3C published a diagram presenting the structure and dependencies be-
tween them. All the technologies are shown as layers where higher ones depend on underlying
technologies. Each layer is specialised and tends to be more complex than the layers below. How-
ever they can be developed and deployed relatively independently. The diagram is known as the
“Semantic Web layer cake”.
Description of the layers depicted in Figure 1.4 are as follows:
∙ URI/IRI — According to the Semantic Web vision all the resources should have their identi-
13

SEMANTIC WEB
Figure 1.2: Semantic Web’s “layer cake” diagram Source:http://www.w3.org/2007/03/layerCake.png, [12.02.2008]
fiers encoded using URIs. The Internationalized Resource Identifier (IRI) is a generalisation
of URI extended by support for Universal Character Set (Unicode/ISO 10646).
∙ Extensible Markup Language (XML) — General-purpose markup language that allows to
encode user-defined structures of data. In the Semantic Web XML is used as a framework
to encode data but provides no semantic constraints on its meaning. XML Schema is used
to specify the structure and data types used in particular XML documents. XML is a stable
technology commonly used for exchanging data. It became a W3C Recommendation in
February 1998.
∙ Resource Description Framework (RDF) — a flexible language capable of describing data
and meta data. It is used to encode a data model of resources and relations between them
using XML syntax. RDF was introduced as a W3C Recommendation a year later than XML,
in February 1999. Semantic data models can be also serialized in alternative notations like
Turtle, N-Triples or TriX.
∙ RDF Schema (RDFS) — Used as a framework for specifying basic vocabularies in RDF
documents. RDFS is built on top of RDF that extends it by a few additional classes describ-
ing relations and properties between resources.
14

SEMANTIC WEB
∙ Rule: Rule Interchange Format (RIF) — It is a family of rule languages that are used for
exchanging rules between different rule-based systems. Each RIF language is called a “di-
alect” to facilitate the use of the same syntax for similar semantics. Rules exchanged by
using RIF may depend on or can be used together with RDF and RDF Schema or OWL data
models. RIF is a relatively new initiative: the W3C’s RIF Working Group was formed in
November 2005 and first working drafts were published on 30 November 2007.
∙ Query: SPARQL — A query language designed for RDF that also includes specification
for accessing data (SPARQL Protocol) and representing the results of SPARQL queries
(SPARQL Query Results XML Format).
∙ Ontology: Web Ontology Language (OWL) — Used to define vocabularies and to specify
the relations between words and terms in particular vocabularies. RDF Schema can be
employed to construct simple ontologies. However OWL was the language designed to
support advanced knowledge representation in the Semantic Web. OWL is a family of 3
sublanguages: OWL-DL and OWL-Lite based on Description Logics and OWL-Full, which
is a complete language. All three languages are popular and used in many implementations.
OWL became a W3C Recommendation in February 2004.
∙ Logic — Logical reasoning draws conclusions from a set of data. It is responsible for apply-
ing and evaluating rules, inferring facts that are not explicitly stated, detecting contradictory
statements and combining information from distributed sources. It plays a key role in gath-
ering information in the Semantic Web
∙ Proof — Used for explaining inference steps. It can trace the way the automated reasoner
deducts conclusions, validate it and, if needed, adjust the parameters.
∙ Trust — Responsible for authentication of services and agents together with providing ev-
idence for the reliability of data. This is a very important layer as the Semantic Web will
achieve its full potential only when there is a trust in its operations and the quality of data.
∙ Crypto — Involves the deployment of Public Key Infrastructure, which can be used to au-
thenticate documents with digital signature. It is also responsible for secure transfer of
information.
15

SEMANTIC WEB
∙ User Interface and Applications — This layer encompasses tools like personal software
agents that will interact with end-users and the Semantic Web together with Semantic Web
Services, which are able to communicate between each other to exchange data and provide
value for the users.
The diagram in Figure 1.4 presents the most recent version of the architecture. The original archi-
tecture was single-stacked – the layers were placed one after another (except the security layer).
However the years of research on the particular technologies has shown that it is impossible to
separate the layers. Kifer, de Bruijn, Boley & Fensel (2005) discuss the interferences between
technologies also taking into consideration the technologies that were not developed by W3C
(e.g. SWRL5, SHOE6). The conclusion is that the multi-stack architecture is a better way of show-
ing the different features of the technological basis for the rule and ontology layers.
Antoniou & van Harmelen (2004, p.17) suggest that two principles should be followed when
considering the diagram: downward compatibility and upward partial understanding. The first
one assumes that applications operating on certain layers should be aware and able to use the
information written at lower levels. Upward partial understanding says that applications should at
least partially take advantage of information available at higher layers.
1.5. The Semantic Web – Today and in the Future
Although the Semantic Web has strong foundations in research results, not all of the technologies
presented in Figure 1.4 are yet developed and implemented. Only RDF(S)/XML and OWL stan-
dards are stable and implementations are available. SPARQL and RIF have appeared quite recently
and the implementations are in development phase. The higher layers are still under research.
The existing technologies are becoming popular. There are many tutorials and books that explain5Semantic Web Rule Language (SWRL) – proposal for Semantic Web rules interchange language that combines
simplified OWL Web Ontology Language (OWL DL and OWL Lite) with RuleML. The specification was created by
National Research Council of Canada, Network Inference and Stanford University and submitted to W3C in May 2004.
Source: http://www.w3.org/Submission/SWRL/. Retrieved on: 16.02.2008.6Simple HTML Ontology Extension (SHOE) – small extension to HTML that allows to include machine-
processable meta data in static webpages. SHOE was developed around 1996 by James Handler and Jeff Heflin.
Source: http://www.cs.umd.edu/projects/plus/SHOE/. Retrieved on: 16.02.2008.
16

SEMANTIC WEB
how to deploy the RDF or create ontologies. Developers are working within active communities
(e.g. http://www.semanticweb.org/). There are many implementations that support the RDF model
including editors, stores for datasets and programming environments7. Some of them are commer-
cial products (e.g. Siderean’s Seamark Navigator used by Oracle Technology Network portal8),
some are being developed by Open Source communities, e.g. Sesame.
Also a number of vocabularies and ontologies have been developed. Very popular vocabularies
are Dublin Core9 and Friend of a Friend10, which were created by non-commercial initiatives11.
Health care and life sciences is a sector where the need for integrating diverse and heterogeneous
datasets evoked the creation of the first large ontologies, e.g. GeneOntology12 that describes genes
and gene product attributes or The Protein Ontology Project13 that classifies a knowledge about
proteins. Other disciplines are also developing their ontologies, like eClassOwl14 that classifies
and describes products and services for e-business or WordNet15 – a semantic lexicon for English
language. We can find ontologies that integrate data from environmental sciences (e.g. climatol-
ogy, hydrology, oceanography) or are deployed in a number of e-government initiatives16. Another
source of meta data has arisen along with Web 2.0 portals known as social software. The commu-
nities of contributors (folksonomies) interested in particular information, describe it with tags or
keywords and publish it on-line. Although tagging offers a significant amount of structured data it
is being developed to meet different goals than ontologies, which are defining data more carefully,
taking into consideration relations and interactions between datasets.
Despite its wider adoption, the OWL family needs more reliable tools that support modelling and
application of ontologies that might be used by non-technical users. On the other hand we cannot
just choose any URI and search existing data stores – the data exposure revolution has not yet
happened (Shadbolt, Berners-Lee & Hall 2006).7The list of all implementations is available on W3C Wiki – http://esw.w3.org/topic/SemanticWebTools.8Source: OTN Semantic Web (Beta), http://www.oracle.com/technology/otnsemanticweb/index.html, 2008.02.25.9Dublin Core Metadata Initiative, http://www.dublincore.org/
10The Friend of a Friend (FOAF) project, http://www.foaf-project.org/11There are webpages where available vocabularies are listed, e.g. SchemaWeb (http://www.schemaweb.info/).12GeneOntology, http://www.geneontology.org/13The Protein Ontology Project, http://proteinontology.info/14eClassOwl, http://www.heppnetz.de/projects/eclassowl/15WordNet, http://wordnet.princeton.edu/16Integrated Public Sector Vocabulary was created in United Kingdom, http://www.esd.org.uk/standards/ipsv. Re-
trieved on 1.03.2008.
17

SEMANTIC WEB
According to Herman (2007b) the Semantic Web, once only of interest of academia, has been
already spotted by small businesses and start-ups. Now the idea is becoming attractive to large
corporations and administration. Major companies offer tools or systems based on the Semantic
Web concept. Adobe has created a labelling technology that allows meta data to be added to most
of their file formats17. Oracle Corporation is not only supporting RDF in their products but is also
using RDF as a base for their Press Room18. The number of companies that are participating in
W3C Semantic Web Working Groups is increasing. Corporate Semantic Web was chosen by Gart-
ner in 2006 as the top emerging technology that will improve the quality of content management,
system interoperability and information access. They predict that it will take 5 to 10 years for
Semantic Web technology to become reliable (Espiner 2006).
Although RDF and OWL are gaining popularity there is some criticism around these technologies.
It is unclear how to extract RDF data from relational databases. It is possible to do it semi-
automatically, but current mechanisms still require a huge amount of data to be manually corrected.
Also there will be an increase in costs of preparing data if it has to be published in format accessible
for machines (RDF) and adjusted for humans to read. The XML syntax of RDF itself is not human-
friendly. To overcome that problem the GRDDL19 mechanism was created. It potentially allows
binding between XHTML and RDF with the use of XSLT.
Another concern is about censorship, as semantic data will be easily accessible, it will be also easy
to filter data or block it thoroughly. Authorities may control the creation and viewing of controver-
sial information as its meaning will be more accessible for automated content-blocking systems.
Also the popularity of FOAF profiles with geo-localisation will decrease users’ anonymity.
There is still a need to develop and standardize functionalities like simpler ontologies, the support
for fuzzy logic and rule based reasoning. There are some initiatives like RIF to regulate auto-
mated reasoning, but there is a lack of standards in that field. Different knowledge domains are
implementing different approaches to inference – the most suitable in particular cases. Also the
shape of the layers responsible for trust, proof and cryptography still remains a puzzle. Developing17Extensible Metadata Platform (XMP) is supported by major Adobe’s products like Adobe Acrobat, Adobe Photo-
shop or Adobe Illustrator. Adobe has also published a toolkit that allows integrating XMP into other applications. XMP
Toolkit is available under the BSD licence. Source: http://www.adobe.com/products/xmp/index.html18Oracle Press Releases, http://pressroom.oracle.com/19Gleaning Resource Descriptions from Dialects of Language (GRDDL), became a W3C Recommendation on
11.09.2007, http://www.w3.org/TR/grddl/. Retrieved on 1.03.2007.
18

SEMANTIC WEB
ontologies is an additional challenge as interoperability, merging and versioning remains unclear.
Antoniou & van Harmelen (2004, p.225) finds the problem with ontology mapping as probably
the most complicated, as there is no central control over application of standards and technologies
during modelling ontologies in open Semantic Web environment.
The Semantic Web vision itself was also criticised. Even Tim Berners-Lee recently said that even
though the idea is simple, it still remains unrealized (Shadbolt et al. 2006). Walton (2006, p.109)
raises the layered model for discussion as the present shape imply certain difficulties for the design
of software agents – providing a unified view of independent layers might be a challenge.
The Semantic Web, like the current Web, relies on the principle that people provide reliable con-
tent. Other important aspects are the fundamental design decisions and their consequences in
creating and deploying standards. Both are being fulfilled – particular communities are working
on RDF datasets and there is a broad discussion about each of the layers of the Semantic Web
focused around W3C Working Groups. As Shadbolt et al. (2006) says, the Semantic Web con-
tributes to Web Science, a science that is concerned with distributed information systems operating
on global scale. It is being encouraged by the achievements of Artificial Intelligence, data mining
and knowledge management.
19

SPARQL
2. SPARQL
2.1. RDF – data model for Semantic Web
The vision of the Semantic Web required new approach to handling data and metadata while it
came to applications. To meet the expectations, W3C in October 1997 published a working draft
for a new universal language to form a basis for the Semantic Web. The Resource Description
Framework (RDF) is providing a standard way to describe, model and exchange information about
resources. It was created as a high-level language and thanks to its low expressiveness, the data is
more reusable. RDF Model and Syntax Specification became W3C recommendation in February
1999. The current version of the specification was published in February 2004. The RDF is in
fact a data model encoded with XML-based syntax. It provides a simple mechanism to make
statements about resources. RDF has a formal semantics that is the basis for reasoning about the
meaning of an RDF dataset.
The RDF statements are usually called triples as they consist of three elements: subject (re-
source), predicate (property) and object (value). The triples are similar to simple sentences with
subject-verb-object structure. The structure of an RDF triple can be represented as a logical for-
mula 𝑃 (𝑥, 𝑦) where binary predicate 𝑃 relates object 𝑥 to object 𝑦. Figure 2.1 depicts its struc-
ture (Passin 2004).
(
𝑠𝑢𝑏𝑗𝑒𝑐𝑡⏞ ⏟ town1 ,
𝑝𝑟𝑒𝑑𝑖𝑐𝑎𝑡𝑒⏞ ⏟ name ,
𝑜𝑏𝑗𝑒𝑐𝑡⏞ ⏟ ”Paisley” )⏟ ⏞
𝑡𝑟𝑖𝑝𝑙𝑒
Figure 2.1: Structure of RDF triple, after Passin (2004).
The subject of a triple is a resource identified by an URI. An URI reference is usually presented
20

SPARQL
in URL style extended by fragment identifier – the part of the URI that follows “#”1. A fragment
identifier relates to some portion of the resource. Also different URI schemes and its variations are
allowed, however the generic syntax has to remain as defined. The whole URI should be unique but
not necessarily should enable access to resource. The problem with URI arises with names of the
objects that are not unique – the mechanism allows anyone to make statements about any resource.
Another technique to identify a resource is to refer to its relationships with other resources. The
RDF accepts resources that are not identified by any URI. These resources are known as blank
nodes or b-nodes and are given internal identifiers, which are unique and not visible outside the
application. Blank nodes can only stand as subjects or objects in particular triple.
Predicates are special kind of resources, also identified by URIs, that describe relations between
subjects and objects. Objects can be named by URIs or by constant values (literals) represented by
character strings. These are the only elements that can be represented by plain string. Plain literals
are strings extended by optional language tag. Literals extended by datatype URI are called typed
literals. Objects are the only elements that can be represented by plain strings. Literals can be
extended by the definition of the datatype, then the whole structure is called typed literal. RDF,
unlike database systems or programming languages, does not have built-in datatypes – it bases on
ones inherited from XML Schema2, e.g. integer, boolean or date. The use of externally defined
datatypes is allowed, but in practice not popular (Manola & Miller 2004).
The full triples notation requires that URIs are written as the complete name in angle brack-
ets. However many RDF applications uses the abbreviated forms for convenience. The full URI
reference is usually very long (e.g. <http://dbpedia.org/resource/Paisley>). It
is shortened to prefix and resource name (e.g. dbpedia:Paisley). Prefix is assigned to the
namespace URI. That mechanism is derived from XML syntax and is known as XML QNames3.
1The Uniform Resource Indetifier (URI) is defined by RFC 3986. The generic syntax is URI = scheme ":"
hier-part [ "?" query ] [ "#" fragment ]. Source: http://tools.ietf.org/html/rfc3986, [05.05.2008].2The XML Schema datatypes are defined in W3C Recommendation “XML Schema Part 2: Datatypes” (Avail-
able at: http://www.w3.org/TR/2001/REC-xmlschema-2-20010502/), which is a part of specification of XML Schema
language.3The QNames mechanism is described in “Using Qualified Names (QNames) as Identifiers in XML Content” avail-
able at: http://www.w3.org/2001/tag/doc/qnameids.html.
21

SPA
RQ
L
<?xml version="1.0"?><rdf:RDFxmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns:rdfschema="http://www.w3.org/2000/01/rdf-schema#"xmlns:ns="http://xmlns.com/foaf/0.1/"xmlns:property="http://dbpedia.org/property/">
<rdf:Description rdf:about="http://dbpedia.org/resource/Paisley"><rdfschema:label xml:lang="en">Paisley</rdfschema:label><ns:img rdf:resource="http://upload.wikimedia.org/wikipedia/en/0/0d/RenfrewshirePaisley.png" /><ns:page rdf:resource="http://en.wikipedia.org/wiki/Paisley" /><rdfschema:label xml:lang="pl">Paisley (Szkocja)</rdfschema:label><property:reference rdf:resource="http://www.paisleygazette.co.uk" /><property:latitude rdf:datatype="http://www.w3.org/2001/XMLSchema#double">55.833333</property:latitude><property:longitude rdf:datatype="http://www.w3.org/2001/XMLSchema#double">-4.433333</property:longitude></rdf:Description>
<rdf:Description rdf:about="http://dbpedia.org/resource/University_of_the_West_of_Scotland"><property:city rdf:resource="http://dbpedia.org/resource/Paisley" /><property:name xml:lang="en">University of the West of Scotland</property:name><property:established rdf:datatype="http://www.w3.org/2001/XMLSchema#integer">1897</property:established><property:country rdf:resource="http://dbpedia.org/resource/Scotland" /></rdf:Description>
<rdf:Description rdf:about="http://dbpedia.org/resource/William_Wallace"><property:birthPlace rdf:resource="http://dbpedia.org/resource/Paisley" /><property:death rdf:datatype="http://www.w3.org/2001/XMLSchema#date">1305-08-23</property:death><ns:name>William Wallace</ns:name></rdf:Description>
</rdf:RDF>
Figure 2.2: RDF statements. Source: DBpedia (http://www.dbpedia.org), RDF/XML validated byhttp://www.rdfabout.com/demo/validator/validate.xpd, [12.03.2008]
22

SPARQL
Figure 2.2 presents a number of triples serialized in RDF/XML syntax using the most basic struc-
tures. The preamble of the listing contains the XML Declaration that declares the namespaces
(QNames) that are used in the document. Every subject is placed in <rdf:Description> tag.
It is extended by URI placed in rdf:about attribute. Predicates are called property elements
and they are placed within subject tag. Subject can contain one or multiple outgoing predicates.
In Figure 2.2 every subject has a number of properties. Each property has the type of relation
stated and the name of the object as attribute. Properties can also be extended by the datatype or
language attributes.
There are many methods of representing RDF statements. They can be encoded in XML syntax,
but a graph-based view is a very popular representation. The RDF graph model is a collection
of triples represented as a graph, where subjects and objects are depicted as graph nodes and
predicates are represented by arc directed from the subject node to object node. The example
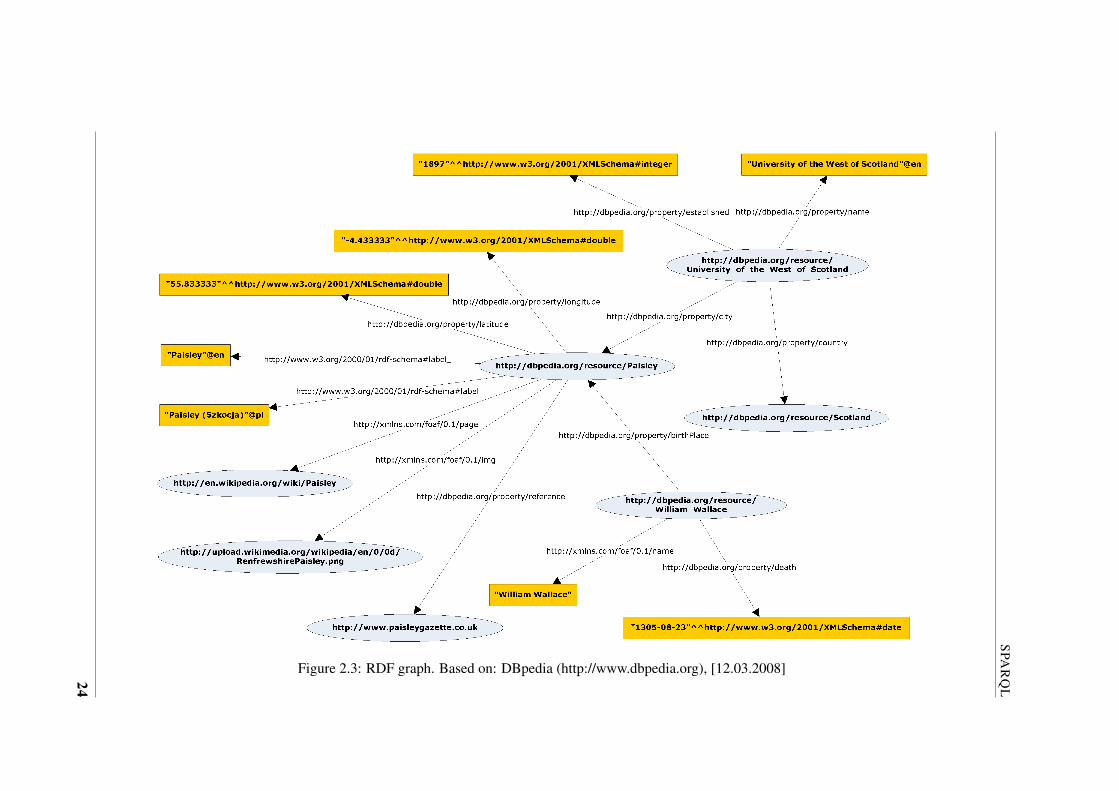
of RDF graph is presented in Figure 2.3. In that case triples from Figure 2.2 were transformed
into graph. The nodes referenced by URIs are shown in oval-shaped figures. Literals are written
within rectangles. Every arc has the URI of the relationship stated. Graph-based view, due to its
simplicity, is used for explaining the concept of triple.
The other popular serialization formats for RDF are Notation3 (N3), JSON or Turtle. The RDF
triples from Figure 2.2 encoded in Turtle syntax are presented in Figure 2.4. In that case, the triples
are shown in actual subject-verb-object format. Turtle syntax is very straightforward. Every triple
is written in one line ended by dot sign. Long URIs can be replaced by short prefix names declared
using @prefix directive. Literals are simply extended by language suffix or by datatype URI.
Turtle allows some abbreviations – when more than one triple involves the same subject it can be
stated only once followed by the group of predicate-object pairs. A similar operation can be done
when subject and predicate are constant.
23
SPA
RQ
L
Figure 2.3: RDF graph. Based on: DBpedia (http://www.dbpedia.org), [12.03.2008]24

SPARQL
@PREFIX dbpedia: <http://dbpedia.org/resource/> .@PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> .@PREFIX foaf: <http://xmlns.com/foaf/0.1/> .@PREFIX dbpedia_prop: <http://dbpedia.org/property/> .@PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> .
dbpedia:Paisley rdfs:label "Paisley"@en .dbpedia:Paisley foaf:img
<http://upload.wikimedia.org/wikipedia/en/0/0d/RenfrewshirePaisley.png> .dbpedia:Paisley foaf:page <http://en.wikipedia.org/wiki/Paisley> .dbpedia:Paisley rdfs:label "Paisley (Szkocja)"@pl .dbpedia:Paisley dbpedia_prop:reference <http://www.paisleygazette.co.uk> .dbpedia:Paisley dbpedia_prop:latitude "55.833333"ˆˆxsd:double .dbpedia:Paisley dbpedia_prop:longitude "-4.433333"ˆˆxsd:double .
dbpedia:University_of_the_West_of_Scotland [dbpedia_prop:city dbpedia:Paisley;dbpedia_prop:name "University of the West of Scotland"@en;dbpedia_prop:established "1897"ˆˆxsd:integer;dbpedia_prop:country dbpedia:Scotland ] .
dbpedia:William_Wallace dbpedia_prop:birthPlace dbpedia:Paisley .dbpedia:William_Wallace dbpedia_prop:death "1305-08-23"ˆˆxsd:date .dbpedia:William_Wallace foaf:name "William Wallace" .
Figure 2.4: RDF statements in Turtle syntax. Source: DBpedia (http://www.dbpedia.org),[12.03.2008]
The RDF has a few more interesting features. One of them is reification that provides the possi-
bility to make statements about other statements. Reification of the statements can provide infor-
mation about its creator or usage. It might be also used in process of authenticating the source
of information. Another feature is the possibility to create containers and collections of resources
that can be used for describing groups of things. Containers, according to the requirements, can be
represented by a group of resources or literals with defined order as an option or by a group where
members are alternatives to each other. A collection is also a group of elements but it is closed –
once created it cannot be extended by any new members.
The RDF provides a simple syntax for making statements about resources. However to define
the vocabulary that will be used in a particular dataset there is a need to use RDF Vocabulary
Description Language better known as RDF Schema (RDFS). The RDFS provides a means for
describing classes of resources and defining their properties. In addition, a hierarchy of classes
can be built. Similar to object-oriented programming every resource is an instance of one or more
classes described with particular properties.
The RDFS does not have its own syntax – it is expressed by the predefined set of RDF resources.
25

SPARQL
The resources are identified with the prefix http://www.w3.org/2000/01/rdf-schema#
usually abbreviated to rdfs: QName prefix. To understand the special meaning of the RDFS
graph the application has to provide such features, otherwise it is processed as a regular RDF
graph.
Although the RDF is supported by W3C it is not the only solution for the Semantic Web.
Passin (2004, p.60) gives an example of Topic Maps as an ISO standard4 for handling semi-
structured data. Topic Maps were originally designed for creating indexes, glossaries, thesauri
and similar. However, their features made them applicable in more demanding domains. Topic
Maps are based on a concept of topics and associations between topics and their occurrences. All
structures have to be defined in ontologies of Topic Maps. The topics are represented with empha-
sis on the collocation and the navigation – it is easier to find the particular information and browse
closely related topics. Topic Maps can be applied as a pattern for organizing information. They
can be implemented using many technologies using native XML syntax for Topic Maps (XTM)
or even RDF. Their features make them well suited to be a part of the Semantic Web even though
they are not supported by W3C.
The RDF is a language that refers directly and unambiguously to a decentralized data model and
unlike XML it is straightforward to differentiate information from the syntax. However, that
technology has some limitations. According to Jorge Cardoso (2006) RDF with RDFS is not able
to express the equivalence between terms defined in independent vocabularies. The cardinality and
uniqueness of terms cannot be preserved. What is more the disjointness of terms and unions of
classes are impossible to express with the limited functionality of RDF. There is also no possibility
to negate statements. Antoniou & van Harmelen (2004, p.68) points out another limitation –
RDF is using only binary predicates but in certain cases, it would be more natural to model a
relation with more than two arguments. In addition, the concept of properties and reification
can be misleading for the modellers. Finally, the XML syntax of RDF, being very flexible and
accessible for machine processing, is hardly comprehensible for humans.
Despite of all the disadvantages the RDF retains a good balance between complexity and expres-
siveness. What is more it has become a de facto world standard for the Semantic Web, and is
heavily supported by W3C and developers around the world.4Topic Maps were developed as ISO standards which is formally known as ISO/IEC 13250:2003.
26

SPARQL
2.2. Querying the Semantic Web
2.2.1. Semantic Web as a distributed database
One of the visions of the Semantic Web says that it is able to provide a common way to access,
link and understand data from different sources available on-line. The Web will become a large
interlinked database. This revolutionary approach challenges the current state of knowledge in
managing data. Currently Relational Database Management Systems (RDBMS) are some of the
most advanced software ever written. They are the largest data resources in the world. Over
30 years of experience in research and implementations has resulted in use of sophisticated mech-
anisms like query optimization, clustering or retaining ACID properties5. Now the principles of
the Semantic Web imply the need of implementing new technologies for managing semantic data.
The Semantic Web has its basic data model – RDF. Passin (2004, p.25) says that RDF data model
can be compared to Relational Data Model. In relational databases, data is organized in tables,
where every row is identified by primary key and has a defined structure. A collection of attributes
that forms a row is called a tuple. Every tuple can be divided into a number of RDF triples
where the primary key becomes the subject. Tuples can be transformed into triples, but the reverse
operation might not be possible. In general, RDF data model is less structured than database.
Every table in the relational model has its defined structure which cannot be extended6 – data
is structured and the number of attributes (properties) is known. RDF allows adding new triples
extending the information about the resource. The triples can be partitioned between different
nodes, even the ones that are not accessible. An RDBMS maintains consistency across all the data
that it manages. Walton (2006) calls this the closed-world assumption, where everything that is
not defined is false. On the contrary, in the Semantic Web, false information has to be specified
or they are just unknown – this is an open-world model. Thanks to that, RDF is more flexible.
However, such an assumption implies the possibility of inconsistency and missing information.
The results of the query vary with the availability of datasets. The returned information can be
only partial, and its size and computing time is unpredictable.5Atomicity, Consistency, Isolation, Durability (ACID) are the basic properties that should be fulfilled by Database
Management System (DBMS) to ensure that transactions are processed reliably.6In fact every RDBMS permits the modifications of the table structure (ALTER TABLE command), but altering
data model in such a way is not a regular operation so in that case can be omitted.
27

SPARQL
Walton (2006) claims that the Semantic Web data is more network structured than relational. In
RDBMS, data is defined in the relation between static tables. Queries are performed on a known
number of tables using set-based operations. In RDF, the data model before querying dataset,
has to be separated from the whole Web of constantly changing stores. The constant change of
asserted data implies that the results of the queries might be incomplete or even unavailable. What
is more, Semantic Web knowledge can be represented in different syntactic forms (RDF with
RDFS, OWL), which results in extended requirements for query languages as they have to be
aware of the underlying representation. In addition, the structure of the datasets will be unknown
to the querying engines, so they will have to rely on specified web services that will perform the
required selection on their behalf.
The Semantic Web principles put very strict constraints on the services that will manage and query
semantic data. The RDF data model ensures simplicity and flexibility so the responsibility for the
results of the queries will be borne by the query languages and automated reasoners.
2.2.2. Semantic Web queries
The new data model that was designed for the Semantic Web required new technologies that
would allow queries on semantic datasets. New query languages were needed to enable higher-
level application development. The inspiration came from well established RDB Management
Systems and Structured Query Language (SQL) that is used there for extracting relational data.
However, the relational approach could not be directly translated into the semantic data model.
The RDF data model with its graph-like model, blank nodes and semantics made the problem
more complex. The query language has to understand the semantics of RDF vocabulary to be able
to return correct information. That is why XML query languages, like XQuery or XPath, turned
out to be insufficient as they operate on lower level of abstraction than RDF (Figure 1.4).
To effectively support the Semantic Web, a query the language should have the following proper-
ties (Haase, Broekstra, Eberhart & Volz 2004):
∙ Expressiveness — specifies how complicated queries can be defined in the language. Usu-
ally the minimal requirement is to provide the means proposed by relational algebra.
∙ Closure — assumes that the result of the operation become a part of the data model, in the
28

SPARQL
case of RDF model, the result of the query should be in a form of graph.
∙ Adequacy — requires that query language working on particular data model use all its con-
cepts.
∙ Orthogonality — requires that all operations can be performed as independent from the
usage context.
∙ Safety — assumes that every syntactically correct query returns definite set of results.
Query languages for RDF were developed in parallel with RDF itself. Some of them were closer to
the spirit of relational database query languages, some were more inspired by rule languages. One
of the first ones was rdfDB, a simple graph-matching query language that became an inspiration
for several other languages. RdfDB was designed as a part of an open-source RDF database with
the same name. One of the followers is Squish that was designed to test some RDF query language
functionalities. Squish was announced by Libby Miller in 20017. It has several implementations,
like RDQL and Inkling8. RQL bases on functional approach, that supports generalized path ex-
pressions9. It has a syntax derived from OQL. RQL evolved into SeRQL. RDQL is a SQL-like
language derived from Squish. It is a quite safe language that offers limited support for datatypes.
RDQL had submission status in W3C but never became a recommendation10. A different approach
was used in the XPath-like query language called Versa11, where the main building block is the
list of RDF resources. RDF triples are used in traversal operations, which return the result of the
query. Another language is Triple12, a query and transformation language, QEL, a query-exchange
language developed as a part of Edutella project13 that is able to work across heterogeneous repos-
itories, and DQL14, which is used for querying DAML+OIL knowledge bases. Triple and DQL
represents rule-based approach.7RDF Squish query language and Java implementation available at: http://ilrt.org/discovery/2001/02/squish/,
[02.05.2008]8Inkling Architectural Overview available at: http://ilrt.org/discovery/2001/07/inkling/index.html, [02.05.2008]9RQL: A Declarative Query Language for RDF available at:
http://139.91.183.30:9090/RDF/publications/www2002/www2002.html, [02.05.2008]10http://www.w3.org/Submission/2004/SUBM-RDQL-20040109/11Specification of Versa is available at: http://copia.ogbuji.net/files/Versa.html, [02.05.2008].12Triple’s homepage is available at: http://triple.semanticweb.org/ , [02.05.2008]13Edutella is a p2p network that enables other systems to search and share semantic metadata. Homepage is available
at: http://www.edutella.org/edutella.shtml, [02.05.2008].14Specification of DQL is available at: http://www.daml.org/2003/04/dql/dql, [02.05.2008].
29

SPARQL
The variety of RDF query languages developed by different communities resulted in compatibility
problems. What is more, according to Gutierrez, Hurtado & Mendelzon (2004), different imple-
mentations were using different query mechanisms that have not been a subject of formal studies,
so there were doubts that some of them might behave unpredictably. W3C was aware of all that
weaknesses. To decrease redundancy and increase interoperability between technologies W3C had
formed in February 2004 an RDF Data Access Working Group (DAWG) that aimed to recommend
a query language, which would become a worldwide standard. DAWG divided the task into two
phases. At the beginning, they wanted to define the requirements for the RDF query language.
They reviewed the existing implementations and wanted to choose a query language that would
be a starting point for the further work in the next phase. In the second phase they prepared a
formal specification together with test cases for the RDF query language (Prud’hommeaux 2004).
In October 2004, the First Working Draft of SPARQL Query Language was published.
2.3. The SPARQL query language for RDF
DAWG worked on SPARQL specification for more than a year. After six official Working Drafts15,
in April 2006, DAWG published a W3C Candidate Recommendation for SPARQL Query Lan-
guage for RDF. However, the community involved in developing a new standard pointed out a
several weaknesses of that version of SPARQL specification and it was returned to Working Draft
status in October 2006. After a few months and one more working Draft the specification reached
a status of Candidate Recommendation in June 2007. When the exit criteria stated in the document
were met (e.g. each SPARQL feature needed to have at least two implementations and the results
of the test was satisfying), the specification went smoothly to Proposed Recommendation stage in
November 2007. Finally, the SPARQL Query Language for RDF became a W3C recommendation
on 15th of January 2008.
The word SPARQL is an acronym of SPARQL Protocol and RDF Query Language (SPARQL
15The official W3C Technical Report Development Process assumes that work on every document starts from the
Working Draft. After positive feedback from the community there is a Candidate Recommendation being published.
When the document gathers satisfying implementation experience it moves to Proposed Recommendation status. This
mature document is waiting for the approval from W3C Advisory Committee. The last stage is the W3C Recommen-
dation, which ensures that the document is a W3C standard. Source: World Wide Web Consortium Process Document
(2005)
30

SPARQL
Figure 2.5: The history of SPARQL’s specification. Based on SPARQL Query Language for RDF(2008)
Frequently Asked Questions 2008). In fact the SPARQL query language is closely related to two
other W3C standards: SPARQL Protocol for RDF16 and SPARQL Query Results XML Format17.
Although SPARQL is a W3C standard there are twelve open issues waiting to be resolved by
DAWG.
The SPARQL query language has an SQL-like syntax. Its queries use required or optional graph
patterns and return a full subgraph that can be a basis for the further processing. SPARQL uses
datatypes and language tags. Patterns can be also matched with the required functional constraints.
Additional features include sorting the results and limiting their number or removing duplicates.
SPARQL does not have the complete functionality that was requested by its users. Some of the
features are being implemented as SPARQL extensions. To avoid inconsistency between imple-
mentations W3C keeps a list of official SPARQL Extensions on their Wiki18. The list contains
a number of missing features including the proposal for insert, update and delete features for
SPARQL, creating subqueries or using aggregation functions.16SPARQL Protocol for RDF defines a remote protocol for transmitting SPARQL queries and receiving their results.
It became a W3C Recommendation in January 2008. The specification is available at: http://www.w3.org/TR/rdf-
sparql-protocol/.17SPARQL Query Results XML Format specify the format of XML document representing the results of SELECT
and ASK queries. It was recognized as W3C recommendation in January 2008. The specification is available at:
http://www.w3.org/TR/rdf-sparql-XMLres/.18The list is available at: http://esw.w3.org/topic/SPARQL/Extensions, [06.04.2008].
31

SPARQL
2.4. Implementation model
SPARQL can be used for querying heterogeneous data sources that operates on native RDF or has
an access to RDF dataset via middleware. The model of possible implementations is presented in
Figure 2.4. Middleware in that case is mapping the SPARQL query into SQL, which operates on
RDF data fitted into relational model. The main advantage of that approach is the possibility of
using the advanced features of RDBMS and benefitting from the years of experience in managing
huge amounts of data. However, the approach still requires the semantic data to be accessible
as an RDF model. Nowadays a great amount of data is still being stored in relation model. To
make it accessible it would have to be transformed into RDF data model, which would be time
consuming and may not be always possible. Most of the current computer systems operate on the
data encapsulated in relational model and revolution in such approach is very unlikely. One of the
suggested solutions is the automatic transformation of relational data into the Semantic Web with
the help of Relational.OWL (de Laborda & Conrad 2005).
Figure 2.6: SPARQL implementation model. Source: Herman (2007a)
Relational.OWL is an application independent representation format based on OWL language that
describes the data stored in relational model together with the relational schema and its semantic
32

SPARQL
interpretation. The solution consists of three layers: Relational.OWL on the top, ontology created
with Relational.OWL to represent database schema and data representation on the bottom, which
is based on another ontology. It can be applied to any RDBMS. Relational data represented by
Relational.OWL is accessible like normal semantic data, so can be queried by SPARQL. The
main advantage of such approach is the possibility of publishing relational data in the Semantic
Web with almost no cost of transforming them to RDF. What is more the changes of data stored
relationally together with its schema are automatically transferred to its semantic representation.
However all the imperfections of database schema affect the quality of the generated ontology.
To avoid that, Relational.OWL can be extended with additional manual mapping as described in
Perez de Laborda & Conrad (2006). In that case, the possibility to generate a graph from the query
results is being used. The subgraph involves the manual adjustments of the original ontology.
Such a dataset is mapped to the target ontology and is free from the drawbacks of Relational.OWL
automatic mapping.
The technology is still under development. de Laborda & Conrad (2005) indicates only the pos-
sibility of representing relational data as a mature feature. Further studies will be directed into
supporting data exchanges and replication.
A similar approach is found in the D2RQ language (Bizer, Cyganiak, Garbers & Maresch 2007).
This is a declarative language that describes mappings between relational data and ontologies. It
is based on RDF and formally defined by D2RQ RDFS Schema
(http://www.wiwiss.fu-berlin.de/suhl/bizer/D2RQ/0.1). The language does
not support Data Modification Language, the mappings are available in read-only mode. D2RQ is
a part of the wider solution called D2RQ Platform. Apart from the implementation of the language,
the Platform includes the D2RQ Engine, which translates queries into SQL, and the D2R Server,
which is an HTTP server with extended functionality including support for SPARQL.
Another interesting implementation of such approach is Automapper (Matt Fisher & Joiner 2008).
The tool is a part of a wider architecture that processes SPARQL query over multiple data sources
and returns combined query result. Automapper uses D2RQ language to create data source ontol-
ogy and mapping instance schema, both based on a relational schema. These ontologies are used
for decomposing a semantic query at the beginning of processing and translating SPARQL into
SQL just before executing it against RDBMS. To decrease the number of variables and statements
33

SPARQL
used in processing a query and to improve performance, Automapper uses SWRL rules that are
based on database constraints. The solution is available in Asio Tool Suite, a software package for
managing data created by BBN Technologies19.
The implementations mentioned above are not the only ones available. The community gath-
ered around MySQL is working on SPASQL20, a SPARQL support built into the database. Data
integration solutions, like DartGrid or SquirellRDF21, are also available. Finally the all-in-one
suits, like OpenLink Virtuoso Universal Server22, can be used for query non-RDF data stores with
SPARQL or other Semantic Web query languages.
Mapping relational databases, while having indisputable advantages, has also some limitations.
Data in RDBMS very often are messy and they do not conform to widely accepted database design
principles. To meet the expectations and provide high quality RDF data the mapping language has
to be very expressive. It should have a number of features, like sophisticated transformations,
conditional mappings, custom extensions and ability to cope with data organized at different level
of normalization.
Future users expect the data to be highly integrated and highly accessible. RDF datasets that has
relational background are still not reliable. There is a need of some studies over mechanisms of
querying multiple data sources, data sources discovery or schema mapping as the current solutions
based on RDF and OWL are insufficient.
Using a bridge between SPARQL and RDBMS is the most demanding problem, but the applica-
tions will seriously increase the availability of semantic data. However, as depicted in Figure 2.4,
it is not the only medium that SPARQL can query. Being very powerful RDF is a bit messy tech-
nology. What is more embedding it into XHTML is rather useless as applications built around
HTML do not recognise it. In addition, transforming data already available in XHTML would
need significant amount of work. To simplify the process of embedding semantic data into web
pages W3C started to work on set of extensions to XHTML called RDFa23. RDFa is a set of at-
tributes that can be used within HTML or XHTML to express semantic data (RDFa Primer 2008).19BBN Technologies, http://www.bbn.com/.20SPASQL: SPARQL Support In MySQL, http://www.w3.org/2005/05/22-SPARQL-MySQL/XTech.21SquirellRDF, http://jena.sourceforge.net/SquirrelRDF/.22Openlink Virtuoso Universal Server Platform, http://www.openlinksw.com/virtuoso/.23The first W3C Working Draft was published in March 2006. For the time of writing RDF has still the same status
– the latest Working Draft was published in March 2008.
34

SPARQL
It consists of meta and link attributes that are already existing in XHTML version 1 and a
number of new ones that are being introduced by XHTML version 2. RDFa attributes can extend
any HTML element, placed on document header or body, creating a mapping between the element
and desired ontology and make it accessible as an RDF triple. The attributes does not affect the
browser’s display of the page as HTML and RDF are separated. The most important advantage
of RDFa is that there is no need to duplicate data publishing it in human-readable format and in
machine-readable metadata. There are no standards of publishing RDFa attributes, so every pub-
lisher can create their own ones. Another benefit is the simplicity of reusing the attributes and
extending the already existing ones with new semantics.
RDFa in some cases is very similar to microformats. However when each microformat has defined
syntax and vocabulary, RDFa is only specifying the syntax and rely on vocabularies created by
publishers or independent ones like FOAF or Dublin Core.
Microformat is the approach to publishing metadata about the content using HTML or XHTML
with some additional attributes specific for each format. Every application that is aware of these
attributes can extract semantics from the document they were embedded in. They do not affect
other software, e.g. web browsers. There are a number of different microformats, most of them
developed by community gathered around Microformats.org. A very popular one is XFN, which
is a way to express social relationships with the usage of hyperlinks. Other common microfor-
mats are hCard and hCalendar, which are the way to embed information based on vCard24 and
iCalendar25 standards in documents.
Figure 2.7: The process of transforming calendar data from XHTML extended by hCalendar mi-croformat into RDF triples. Source: GRDDL Primer (2007).
SPARQL is also able to query documents, which has some semantic information embedded in the
content using e.g. microformats. To process a query over such document SPARQL engine need to24vCard electronic business card is common standard, defined by RFC 2426 (http://www.ietf.org/rfc/rfc2426.txt), for
representing people, organizations and places.25iCalendar is a common format for exchanging information about events, tasks, etc. defined by RFC 2445
(http://tools.ietf.org/html/rfc2445).
35

SPARQL
know the “dialect” that was used for encoding metadata. Being aware of the barrier, W3C started
to work on universal mechanism of accessing semantics written in non-standard formats. At the
end of 2006, they introduced mechanism for Gleaning Resource Descriptions from Dialects of
Languages (GRDDL). GRDDL introduced a markup that indicates if the document includes data
that complies with the RDF data model, in particular documents written in XHTML and generally
speaking in XML. The appropriate information is written in the header of the document. Another
markup links to the transformation algorithm for extracting semantics from the document. The
algorithm is usually available as XSLT stylesheet. The SPARQL engine extracts the metadata
from the document, applying transformations fetched from the relevant file, and presents data as
in the RDF data model. The process of transforming metadata encoded in a specific “dialect” into
RDF is depicted in Figure 2.7.
SPARQL together with some related technologies was designed to be a unifying point for all
the semantic queries. SPARQL engines will be able to serve dedicated applications and other
SPARQL endpoints providing information that they can extract from the documents that are di-
rectly accessible for it. Some implementations of this mechanism already exist. One of them is the
public SPARQL endpoint to DBpedia26 that is able to return data from other semantic datastores
that are linked to its dataset.
2.5. SPARQL’s syntax
SPARQL is a pattern-matching RDF query language. In most cases, the query consists of set of
triple patterns called basic graph pattern. The patterns are similar to RDF triples. The difference
is that each of the elements can be set as a variable. That pattern is matched against RDF dataset.
The result is a subgraph of original dataset where all the constant elements of patterns are matched
and the variables are substituted by data from matched triples. The pair of variable and RDF data
matched to the variable is called a “binding”. The number of related bindings that form a row in
the result set is known as the “solution”.
The SPARQL basic syntax is very similar to SQL – it starts with SELECT clause called projection,
which identifies the set of returned variables, and ends with WHERE clause providing a basic graph
pattern. Variables in SPARQL are indicated by $ or ? prefixes. Similarly to Turtle syntax URIs26DBpedia public SPARQL endpoint is available at: http://dbpedia.org/sparql, [02.05.2008].
36

SPARQL
can be abbreviated using PREFIX keyword and prefix label with a definition of the namespace.
If the namespace occurs in multiple places, it can be set as a base URI. Then relative URIs, like
<property/>, are resolved using base URI. Triple patterns can be abbreviated in the same way
as in Turtle syntax – a common subject can be omitted using “;” notation and a list of objects
sharing the same subject and predicate can be written in the same line separated by “,”. The
query results can contain blank nodes, which are unique in the subgraph and indicated by “ :”
prefix.
The simple query to find a name of the university in Paisley from the dataset presented in Figure 2.4
is shown in Figure 2.8
BASE <http://dbpedia.org/>PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>PREFIX dbpedia: <property/>
SELECT DISTINCT ?city ?uninameWHERE {
?city rdfs:label "Paisley (Szkocja)"@pl .?uni dbpedia:city ?city .?uni dbpedia:established "1897"ˆˆxsd:integer .?uni dbpedia:name ?uniname .}
city uninamehttp://dbpedia.org/resource/Paisley University of the West of Scotland
Figure 2.8: Simple SPARQL query with the result. Source: DBpedia (http://www.dbpedia.org),[12.04.2008]
SPARQL has a number of different query result forms. SELECT is used for obtaining variable
bindings. Another form is CONSTRUCT that returns an RDF dataset build on the graph pattern that
is applied to the subgraph returned by the query. This feature can be used to create RDF subgraphs
that become a base for the further processing, e.g. Relational.OWL is using it to map automatically
created ontology based on relational schema into desired ontology. Figure 2.9 presents the usage
of CONSTRUCT clause to build a subgraph according to required pattern.
Another two forms are ASK and DESCRIBE. First of them returns a boolean value that indicates
if the query pattern matches the RDF graph or not. The usage of the ASK clause is similar to
the SELECT clause, the only difference is that there is no specification of returned variables.
DESCRIBE is used to obtain all triples from RDF dataset that describe the stated URI.
37

SPARQL
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>PREFIX dbpedia: <http://dbpedia.org/property/>
CONSTRUCT {?uni <http://dbpedia.org/property/located_in> ?city.?uni <http://dbpedia.org/property/has_name> ?uniname }
WHERE {?city rdfs:label "Paisley (Szkocja)"@pl .?uni dbpedia:city ?city .?uni dbpedia:established "1897"ˆˆxsd:integer .?uni dbpedia:name ?uniname .}
Returned RDF subgraph serialized in Turtle:
<http://dbpedia.org/resource/University_of_the_West_of_Scotland><http://dbpedia.org/property/located_in> <http://dbpedia.org/resource/Paisley>;<http://dbpedia.org/property/has_name> "University of the West of Scotland"@en.
Figure 2.9: Application of CONSTRUCT query result form with the results of the query serializedin Turtle syntax. Source: DBpedia (http://www.dbpedia.org), [12.04.2008]
Every query language should provide possibilities to filter the results returned by the generic query.
SPARQL uses FILTER clause to restrict the result by adding filtering conditions. Using condi-
tions SPARQL can filter the values of the strings with regular expressions defined in XQuery 1.0
and XPath 2.0 Functions and Operators (2007) W3C specification. Also a subset of functions and
operators used in XPath27 is available – all the arithmetic and logical functions comes from that
language. However SPARQL introduces a number of new operators, like bound(), isIRI()
or lang(). All of them are described in detail in the SPARQL Query Language for RDF (2008).
There is also a possibility to use external functions defined by an URI. That feature may be used
to perform transformations not supported by SPARQL or for testing specific datatypes.
After applying filters, SPARQL returns the result of graph pattern matching. However, the list of
query solutions is in random order. Similarly to SQL, SPARQL provides a means to modify the set
of results. The most basic modifier is ORDER BY clause that orders the solutions according to the
chosen binding. The solutions can be ordered ascending, using ASC() modifier, or descending
indicated by DESC() modifier.
It is common that the solutions in result dataset are multiplied. The keyword DISTINCT ensures
that only unique triples are returned. The REDUCED modifier has similar functionality. However27XML Path Language (XPath) is a language to address parts of the XML document. It provides a possibilities to
perform operations on strings, numbers or boolean values. XPath is now available in version 2.0, which is a W3C
Recommendation since January 2007. Source: XML Path Language (XPath) 2.0 (2007)
38

SPARQL
when DISTINCT ensures that duplicate solutions are eliminated, REDUCED allow them to be
eliminated. In that case the solution occurs at least once, but not more than when not using the
modifier. Another two modifiers affect the number of returned solutions. The keyword LIMIT
defines how many solutions will be returned. The OFFSET clause determines the number of
solutions after which the required data will be returned. The combination of these two modifiers
returns a particular number of solutions starting at the defined point.
BASE <http://dbpedia.org/>PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>PREFIX dbpedia: <property/>SELECT DISTINCT ?uniname ?countryname ?no_students ?no_staff ?headnameWHERE {{?uni dbpedia:type <http://dbpedia.org/resource/Public_university>.?uni dbpedia:country ?country.?country rdfs:label ?countryname.?uni dbpedia:undergrad ?no_students.?uni dbpedia:staff ?no_staff.?uni rdfs:label ?uniname.
FILTER (xsd:integer(?no_staff) < 2000).FILTER (regex(str(?country), "Scotland") || regex(str(?country),"England")).FILTER (lang(?uniname)="en")FILTER (lang(?countryname)="en")}OPTIONAL{?uni dbpedia:head ?headname}
}ORDER BY DESC(?no_students)LIMIT 5
uniname countryname no students no staff headnameNapier University Scotland 11685 1648
University of the West of Scotland Scotland 11395 1300 Professor Bob BeatyUniversity of Stirling Scotland 6905 1872 Alan Simpson
Aston University England 6505 1,000+Heriot-Watt University Scotland 5605 717 Gavin J Gemmell
Figure 2.10: SPARQL query presenting universities with its number of students, number of staffand optional name of the headmaster with some filtering applied. Below are the results of thequery. Source: DBpedia (http://www.dbpedia.org), [20.04.2008]
Supporting only basic graph patterns in some cases might be a very serious limitation. SPARQL
provides mechanisms to combine a number of small patterns to obtain more complex set of triples.
The simplest one is a group graph pattern where all stated triple patterns have to match against
given RDF dataset. Group graph pattern is presented in Figure 2.8. A result of graph pattern match
can be modified using OPTIONAL clause. The RDF data model is a subject of constant change, so
39

SPARQL
assumption of full availability of desired information is too strict. Opposite to group graph pattern
matching OPTIONAL clause allows to extend the result set with additional information without
eliminating the whole solution if that particular information is inaccessible. When the optional
graph pattern does not match, the value is not returned and the binding remains empty. If there
is a need to present a result set that contains a set of alternative subgraphs, SPARQL provides a
way to match more than one independent graph pattern in one query. This is done by employing
UNION clause in the WHERE clause that joins alternative graph patterns. The result consists of the
sequence of solutions that match at least one graph pattern.
Finally, the SPARQL can restrict the source of the data that is being processed. RDF dataset always
consists of at least one RDF graph, which is a default graph and does not have any name. The
optional graphs are called named graphs and are identified by URI. SPARQL is usually querying
the whole RDF dataset, but scope of the dataset can be limited to a number of named graphs. The
specification of RDF dataset is set by URI using FROM clause, which indicates the active dataset.
The representation of the resource identified by URI should contain the required graph – this can
be e.g. a file with a RDF dataset or another SPARQL endpoint. If a combination of datasets is
referred to by the FROM keyword, the graphs are merged to form a default RDF graph. To query
a graph without adding it to the default dataset, the graph should be referred to by FROM NAMED
clause. In that case the relation between RDF dataset and named graph is indirect, named graph
remains independent to the default graph. To switch between the active graphs SPARQL uses the
GRAPH clause. Only triple patterns that are stated inside the clause are matched against the active
graph. Outside the clause, the triple patterns are matched against the default graph. GRAPH clause
is very powerful. It can be used not only to provide solutions from specific graphs, but is also very
useful for the right graph containing desired solution.
SPARQL is a technology that the whole community was waiting for. Its official specification
regulates the access to RDF datastores which will result in increased popularity of the whole
concept and cause SPARQL to be regarded as not just the technology for academia, but as the
stable solution that is worth implementing in common data access tools.
However the current specification of SPARQL does not fully met the requirements. The com-
munity has pointed out the lack of data modification functions as one of the most serious issues.
Another problem is an inability to use cursors caused by the stateless character of the proto-
40

SPARQL
col. SPARQL does not allow computing or aggregating results. This has to be done by external
modules. What is more, querying collections and containers may be complicated, which may be
especially inconvenient while processing OWL ontologies. Finally the lack of support for fulltext
searching is quite problematic.
Apart from that SPARQL is a significant step on the way to the Semantic Web, but also a starting
point for the research on the higher layers of the Semantic Web “layer cake” diagram. However
there is a place for improvement and further research. W3C should consider starting to work on
the next version of SPARQL Query Language.
2.6. Review of Literature about SPARQL
SPARQL Query Language for RDF is a relatively new technology. Indisputably it is gaining
popularity within the Semantic Web community, but there is still little research so far on the
language itself and its implementability. Google Scholar returns only 2030 search results for the
word “sparql”. This is almost nothing comparing to the number of search results when looking for
the word “rdf” – 237000, or documents related to “semantic web” – 34400028. Google Scholar is
not an objective source of knowledge – the number of results may vary depending on date and if the
local version of the search engine is used. However it shows how big is the difference in popularity
between stable RDF and brand-new SPARQL. What is more the number of publications where
SPARQL query language and the implementation issues are being under research is very small.
Usually SPARQL appears in the context of the complex architecture that is being implemented to
solve a particular problem with the means provided by the Semantic Web.
The first complete study of the requirements that semantic query language has to meet was done
in “Foundations of Semantic Web Databases” (Gutierrez et al. 2004). According to the paper,
the new features of RDF, like blank nodes, reification, redundancy and RDFS with its vocabulary,
need a new approach to queries in comparison to relational databases. The authors at the beginning
propose the notion of normal form for RDF graphs. The notion is a combination of core and closed
graphs. A core graph is one that cannot be mapped into itself. An RDFS vocabulary together with
all the triples it applies to is called a closed graph. The problem is the redundancy of triples. The
authors describe an algorithm that allows reduction of the graph. Even so computing the normal28The test was performed using http://scholar.google.pl on 6.05.2008.
41

SPARQL
and reduced forms of the graph is still very difficult. On that theoretical background a formal
definition of RDF query language is given. A query is a set of graphs considered within a set of
premises with some of the elements replaced by variables limited by a number of constraints. The
answer to a query is a separate and unique graph. A very important property that every query
language should have is the possibility to compose complex queries from the results of the simpler
ones (compositionality). A union or merge of single answers can achieve this. In the first case,
the existing blank nodes have unique names, while in merging the result sets the names of the
blank nodes have to be changed. The union operation is more straightforward and can create data
independent queries. The merge operator is more useful for querying several sources. Finally, the
authors discuss the complexity of answering queries.
Similar theoretical deliberations on semantic query language can be found in “Semantics and
Complexity of SPARQL” (Perez, Arenas & Gutierrez 2006a). However this time the authors start
from the RDF formalization done in Gutierrez et al. (2004) to examine the graph pattern facility
provided by SPARQL. Although the features of the SPARQL seem to be straightforward, in com-
bination they create increased complexity. According to the authors, SPARQL shares a number of
constructs with other semantic query languages. However, there was still a need to formalize the
semantics and syntax of SPARQL. The authors consider graph pattern matching facility limited
to one RDF data set. They start by defining the syntax of a graph pattern expression as a set of
graph patterns related to each other by 𝐴𝑁𝐷, 𝑈𝑁𝐼𝑂𝑁 , 𝑂𝑃𝑇𝐼𝑂𝑁𝐴𝐿 operators and limited by
𝐹𝐼𝐿𝑇𝐸𝑅 expression. Then they define the semantics of the query language. It turns out that op-
erators 𝑈𝑁𝐼𝑂𝑁 and 𝑂𝑃𝑇𝐼𝑂𝑁𝐴𝐿 makes the evaluation of the query more complex. There are
two approaches for computing answers to graph patterns. The first one uses operational seman-
tics what means that the graphs are matched one after another using intermediate results from the
preceding matchings to decrease the overall cost. The second approach is based on bottom up eval-
uation of the parse tree that minimizes the cost of the operation using relational algebra. Relational
algebra can be easily applied to SPARQL, however there are some discrepancies. The lack of con-
straints in SPARQL makes the 𝑂𝑃𝑇𝐼𝑂𝑁𝐴𝐿 operator not fully equal to its relational counterpart
– left outer join. Further issues are null-rejecting relations, which are impossible in SPARQL, and
Cartesian product that is often used in SPARQL. Finally, the authors state the normal form of an
optional triple pattern that should be followed to design cost-effective queries. It assumes that
all patterns that are outside optional should be evaluated before matching the optional patterns.
42

SPARQL
Similar conclusion are drawn while evaluating graph patterns with relational algebra in Cyganiak
(2005b).
The authors of Perez et al. (2006a) continue their studies on semantics of SPARQL in “Semantics
of SPARQL” (Perez, Arenas & Gutierrez 2006b). The goal of this technical report was to update
the original publication with the changes introduced by W3C Working Draft published in October
2006. The authors extend the definitions of graph patterns stated in the previous paper and discuss
the support for blank nodes in graph patterns and bag/multiset semantics for solutions. At the
beginning, the authors state the basic definitions of RDF and basic graph patterns. Then they
define syntax and semantics for the general graph patterns. They also include the GRAPH operator,
which defines the default graph that is matched against the query. Another extension to Perez et al.
(2006a) is the semantics of query result forms. SELECT and CONSTRUCT clauses are also being
discussed. Finally, the definition of graph patterns is extended by the support for blank nodes and
bags. The main problem they indicate is the increased cardinality of the solutions. They finish
the report with two remarks about query entailment, which was not fully defined at the time of
writing.
The author of “A relational algebra for SPARQL” (Cyganiak 2005b) does not focus on the generic
definition of SPARQL queries. He transforms SPARQL into relational algebra, which is an in-
termediate language for the evaluation of queries that is widely used for analysing queries on the
relational model. Such an approach has significant advantages – it provides knowledge about query
optimization for SPARQL implementers, makes the SPARQL support in relational databases more
straightforward and simplifies the further analyses on the queries over distributed data sources. The
author presents only queries over basic graph. Some special cases are also considered, however
the filtering operator still has to be put under research.
At the beginning author assumes that RDF graph can be presented as a relational table with 3
columns corresponding to ?𝑠𝑢𝑏𝑗𝑒𝑐𝑡, ?𝑝𝑟𝑒𝑑𝑖𝑐𝑎𝑡𝑒 and ?𝑜𝑏𝑗𝑒𝑐𝑡. Each triple is stored as a separate
record. There is also a new term introduced. An RDF tuple, which example is presented in
Figure 2.11, is a container that maps a number of variables to RDF terms and is also known as
RDF solution. Tuple is an universal term used in relational algebra. Every variable present in a
tuple is said to be bound. A set of tuples forms an RDF relation. The relations can be transformed
into triples and form a data set.
43

SPARQL
𝑡 =
⎧⎪⎪⎨⎪⎪⎩?𝑝𝑒𝑟𝑠𝑜𝑛 −→ <http://example.org/people#Bob>?𝑛𝑎𝑚𝑒 −→ "Bob"?𝑒𝑚𝑎𝑖𝑙 −→ <mailto:[email protected]>?𝑎𝑔𝑒 −→ "42"
Figure 2.11: Structure of RDF tuple, after Cyganiak (2005b).
In the following part, the author defines the relational algebra operators in terms of SPARQL.
The selection (𝜎) is an unary operator that selects only those tuples of a relation that satisfy the
condition. It is expressed by the FILTER operator or is filtered by the graph relation. Both
examples are presented in Figure 2.12. Projection (𝜋) and rename (𝜌) operators are usually used
together to restrict a relation to a subset of attributes and rename them if needed. In Figure 2.12
the ?𝑠𝑢𝑏𝑗𝑒𝑐𝑡 is the only attribute selected and it is renamed to ?𝑝𝑒𝑟𝑠𝑜𝑛.
𝜎?𝑎𝑔𝑒≥ 42∨ bound(?𝑒𝑚𝑎𝑖𝑙)(𝑅)
𝜎?𝑝𝑟𝑒𝑑𝑖𝑐𝑎𝑡𝑒 = ex:email(𝑅)
𝜋?𝑝𝑒𝑟𝑠𝑜𝑛← ?𝑠𝑢𝑏𝑗𝑒𝑐𝑡(𝑅)
Figure 2.12: Selection (𝜎) and projection (𝜋) operators, after Cyganiak (2005b).
Other two important operators are the inner join (◁▷) and left outer join (o). First of them computes
the Cartesian product of the tuples from both data sets that are going to be joined and eliminates
the combinations where the shared attribute is not equal. The shared attribute has to be bound
in both tuples. Left outer join also joins two relations on the shared attribute, however the result
contains also the tuples from the first data set that has no matching in the second. Finally the
author defines one more operator – union (∪), which unlike in regular algebra does not require to
have all the attributes bounded. An example translation from SPARQL to relational tree, where
all defined operators are used, is depicted in Figure 2.6. The order of transformation plays an
important role due to cost effectiveness and accuracy – matching optional part before the required
patterns could produce inappropriate results. At the beginning of the processing, the projection and
rename operations are performed to eliminate redundant tuples. Then two sets of tuples are joined
using inner join, this step involves also UNION operations and matching against different graphs
using GRAPH clause. In the next step the solutions are extended by the tuples from OPTIONAL
clause using left outer join. Finally the FILTER conditions are applied. This operation cannot be
44

SPARQL
performed with lower precedence as the conditions can use variables from the whole group. The
order of the FILTER clauses does not matter.SELECT ?name ?emailWHERE {
?person rdf:type foaf:Person .?person foaf:name ?name .OPTIONAL { ?person foaf:mbox ?email }}
Figure 2.13: SPARQL query transformed into relational algebra tree, after Cyganiak (2005b).
The relational algebra operations can be simply translated into SQL statements. The author firstly
assumes that SPARQL queries, which are recursive from its nature, will require some nested state-
ments. The possible implementation should benefit from a number of SQL features available in
RDBMSs. The author suggests three solutions. The biggest advantage of the temporary tables that
store intermediate solutions is the possibility to reuse them in different part of the query processing
or process them by external software. This gives a possibility to employ extension functions or
externally defined datatypes. Nested SELECT statements are processed inside the RDBMS what
makes it much easier to implement using relational algebra. However the performance of these
queries might not be acceptable. The last solution is the usage of bracketed JOINs, what means
that aliases of the triple tables are joined in the SQL statement with the right order using JOIN and
LEFT JOIN operators. This solution is hard to implement due to the complexity of the statement
that has to be computed automatically, however the performance is satisfying.
45

SPARQL
In the next section the author discusses the mapping of the particular operation into SQL. Projec-
tion and rename operations are very straightforward to translate as the simple column aliases in
SELECT statement are being used. The selection heavily depends on the datatype interpretation
employed in the database. Generally it is being done be extending SELECT statement by WHERE
clause. Inner join operation in most of the cases can be translated into NATURAL JOIN used in
SQL. However, the situation when one of the variables is unbound requires more complex solu-
tion. In SQL a NULL value causes the tuple to be rejected. SPARQL only rejects the rows where
variables are bound to different values in both data sets. One of the possibilities is to track the
unbound variables and during translation test it against the IS NULL condition. The author pro-
vides a number of rules that states which operation preserve the bound/unbound property during
translation. Left outer join translation is translated similarly to inner join. To perform SPARQL’s
UNION operation the corresponding SQL operator can be used. The only difference is the re-
quirement to fill the appropriate column from one data set with NULL values as the variables in
SPARQL query does not have to exist in both data sets. The problem with such approach is the
performance of such operation. To summarize the mapping from relational algebra to SPARQL
the author discusses the possibilities to simplify the SELECT statements used in JOIN operations.
This can be done by RDBMS query optimizer and significantly improve the processing times.
Although transforming SPARQL queries to SQL statements seems to be quite straightforward
there are some exceptions that have to be considered. The author points out that at the time of
writing SPARQL’s semantics was not strictly defined and that was leading to ambiguities. One
of them, mentioned above, is the difference in indicating unknown values. Relational model has
precisely defined list of attributes. Every tuple must correspond with that list either having appro-
priate values or special value NULL that simply means “unknown”. SPARQL does not have any
special value for specifying unknown data – the variable is left unbound. That problem is espe-
cially emerging while processing OPTIONAL graph patterns when such variables are unbound in
some solutions and has to be expressed using relational algebra. The situation is also affecting
JOIN operations. If the attribute used for joining data set is unbound on one side, the value from
the other side is treated as the result. In regular relational algebra NULL on any of the sides is
causing the tuple to be rejected. The OPTIONAL clause is causing some more problems. In the
case where at least two optional graph patterns are nested one inside another and variables are used
inside the inner one and outside the optional graph pattern, one of the left joins may fail. There
46

SPARQL
is no simple solution for such case. The author leaves it as the matter of the further studies. The
last problem that is being addressed is the scope of the filtering. The SPARQL semantics allows to
use the FILTER expression anywhere in the query. In some cases, the query cannot be translated
without considering the exact intention of filtering tuples. The author shows that sometimes using
left outer join is more appropriate than applying simple selection. However, this operation needs
much wider studies that remain as future work.
The author of the above paper has also published a “Note on database layouts for SPARQL
datastores” (Cyganiak 2005a), where he summarizes some lessons learnt while implementing a
SPARQL datastore. The engine was called sparql2sql. It was build on top of ModelRDB, which
at the time of writing, was database backend for Jena Semantic Web Framework. Considering the
weaknesses of this storage the author propose some recommendations for the future implementa-
tions.
At the beginning, the author points out the mismatch for the schema normalization between simple
queries and complex ones. ModelRDB uses denormalized schema decreasing the number of JOIN
operations and significantly improving the performance of simple graph matching. However, more
sophisticated SPARQL queries always perform a number of joins – using normalized schema
does not increase the number substantially. What is more denormalized columns contain long
string values that has to be processed several times. Normalizing tables results in the decrease
of read operations as the joins are made over key columns usually populated by sequences of
integers. Another aspect is the higher selectivity of the SPARQL queries comparing to regular
graph matching. In normalized schema, joins are performed on the key columns and the actual
values are read in the last stage of the processing. This also improves the processing times. Finally,
the space used by normalized database is usually much lower as the long strings used for encoding
nodes are stored only once. Other tables are operating only on numerical values that represent
the nodes, what is known as primary and foreign key relation. Although some testing proved that
normalized view is faster for complex queries, denormalized schema remains a better solution
for the simple graph matching. The implementers should consider this while planning the most
suitable approach.
The support for basic graph patterns also requires different level of indexing in the database.
ModelRDB has a combined index on Subject and Predicate and a separate one on Object column.
47

SPARQL
To effectively handle a number of graphs, the column with graph names should be indexed as well.
In addition, the schema that ModelRDB is using for storing triples in tables is very complicated
– parts of the node are indexed using additional metadata what require sophisticated expressions
during extraction process. The encoding gets more complicated when prefixing is being used. Due
to such approach, the role of database engine in testing values is minimised. However, it is proved
that pushing as many operations down to the RDBMS significantly improves the performance, e.g.
if the query is processed in database the result modifying operations (e.g. ORDER BY, LIMIT)
could be performed there not employing application logics.
Further recommendations are made while considering the database layout. In ModelRDB all
graphs are kept in the same table. However, such approach is efficient only for named graphs.
Thanks to that the queries that go through all named graphs are much more effective as the
RDBMS has to read only one indexed table. Following that approach default graph should be
stored in separate table. What is more SPARQL queries clearly distinguish patterns over named
graphs from the ones over default graph so the approach is more reasonable. It also makes the SQL
queries simpler and decreases the size of the queries. The author suggests creating an independent
graph in a form of a table with references to the graph nodes. The table can be very helpful in
discarding empty graphs during query processing, especially when a number of datasets are stored
in a single database. In such table, graphs should be identified using the same encoding as regular
triples. In ModelRDB database layout the same encoding for graphs and triples cannot be used
when several data sets are stored in one database because of one graph name table. The situation
requires graphs to be extended by additional dataset identifiers what simply complicates the query
computation. Finally, the author considers the functionality that is not officially supported by the
specification of SPARQL. Jena supports creating and deleting graphs. However this operation
has to be performed by Java code, which modifies the appropriate metadata about the model. To
simplify the operation the metadata should be also accessible for SQL.
At the end of the report, the author briefly discusses the impact of reified statements on RDF
datasets. ModelRDB uses a dedicated table for storing statements about other statements that
reduces the storage required during query processing. When a normalized schema is being used
such approach is not effective as the performance benefit does not compensate the cost of the
increased query complexity.
48

SPARQL
Very similar recommendations were published in related technical report “SPARQL query pro-
cessing with conventional relational database systems” (Harris & Shadbolt 2005). This time the
authors present conclusions that were drawn during the implementation of SPARQL query inter-
face in 3store RDF storage system. The previous version of 3store was optimised for RDQL and
basic specification of RDF. Version 3 has a new data model for RDF representation and SPARQL
engine implemented. At the time of writing there were at least three similar solutions that author
refers to: Federate, Jena and Redland. However, none of them fully supported SPARQL specifi-
cation using translation to relational expressions and computing them in the underlying RDBMS.
3store is build in three-layer model that can be characterized as RDF Syntax, RDF Representa-
tion and RDBMS which is the unified storage for classes and instances. The implementation goal
was to transform RDF expressions to SQL queries that perform a large number of join operations
across a small number of tables. According to the author, this approach significantly reduces query
execution times.
The database schema used in 3store is not completely denormalized as Cyganiak (2005a) suggests.
Resources and literals are kept in a single table. That approach enables inner joins operations
however makes the table very large. To minimise the string comparison, resources and literals
are internally identified by 64-bit hash function. To avoid the situation when two strings are
similar, but in fact has different role and should be distinguished (e.g. URI and literal), special
hash algorithm based on MD5 function was implemented. Additional algorithm is responsible for
detecting and informing about possible hash collisions for RDF nodes during insert operation. The
database schema of 3store is based on four tables. TRIPLES table stores a representation of RDF
triples. Every tuple consist of the hashes for the subject, predicate and object extended by a GRAPH
identifier. Table SYMBOLS stores the actual values of the triples. Tuples are identified by hashes
and contains string representation of the symbol as it appears in RDF documents, foreign keys to
datatype and language tables and the value of the string computed to one of the datatypes – integer,
datetime or floating. That mechanism assumes that at the time of creating the tuple the value is
computed according to RDF datatype and stored in appropriate column. Thanks to that SQL
processing does not have to perform ad-hoc cast operation which might be time consuming, but
uses value in appropriate datatype. Two other tables, DATATYPE and LANGUAGE are dictionary
tables used to join with the SYMBOLS table.
One of the design principles of 3store was to benefit from the database query optimizer by pass-
49

SPARQL
ing the most of the query execution process down to the RDBMS. The author presents sample
SPARQL queries translating them to relational algebra and finally to SQL. The transformation of
simple graph patterns is very straightforward. When the query contain multiple graph patterns the
TRIPLES table has to be joined recursively according to certain algorithm. The interesting step
of both processings is the usage of temporary tables as suggested in Cyganiak (2005b). These
tables store the hashes of variables that form the result. In the final step, the intermediate table
is joined with dictionary tables to present the appropriate textual values of the variables and to
serialize them in required format.
The author presents similar approach to process OPTIONAL operator as in Cyganiak (2005b).
According to him simple optional graph patterns can be handled by left outer join of relational
algebra. Like in regular patterns matching, the intermediate results are stored in temporary tables.
However, more complex queries with nested clauses require algorithms that are more sophisti-
cated. Testing values with FILTER clause can be much more demanding than transformations
of graph patterns, due to the design of database schema for 3store. In case of simple constraints
the intermediate results has to be joined with textual representation of hash values and then the
values can be evaluated. However, there are some cases that make the transformation impossi-
ble. FILTER clause can contain the references to external functions or constraints that cannot be
expressed using relational algebra. The solution is to implement algorithms that will be able to
compute the results using temporary tables or that will perform the final processing in the applica-
tion layer. Another problem is caused by optional clause and constraints on variables not present
in that clause. The processing engine has to identify such case and transfer that condition to final
processing step, when definitive evaluation is performed. Similar situation appears when the con-
straint is stated outside the OPTIONAL clause – the processing has to be detached from the overall
query execution or delayed until the last stage.
The optimisation of the SPARQL query processing is a complex matter. The goal of the imple-
mentation is to use RDBMS query optimizer for processing the whole queries. Simple graph
patterns can be easily translated to relational algebra. However, the exceptions described in the
paper and derived from the specification of RDF and SPARQL require some more sophisticated
transformations performed in the application layer. The author gives an example of substituting
intermediate table into the results expression with appropriate renaming.
50

SPARQL
Finally, the author presents some areas for future development. He points out the necessity of
fully supporting the SPARQL query language as at the time of writing not all the features were
implemented. In addition, the optimisation of handling SPARQL graphs is the matter of further
studies. The next version of 3store will also support RDFS reasoning.
Different approach to the process of translating SPARQL queries to SQL is suggested in “Rela-
tional Nested Optional Join for Efficient Semantic Web Query Processing” (Chebotko, Atay, Lu
& Fotouhi 2007). However, instead of solving the problems caused by differences in semantics of
SPARQL and SQL, the authors propose a new relational operator – nested optional join (NOJ) that
improves the performance of processing optional graph patterns by RDBMSs. They point out the
OPTIONAL patterns as especially liable for correctness and efficiency issues during translation.
As described in the previous papers, root cause is the semantics of nested optional graph patterns
– no obligation to bound variables, possibility to share variables across the query and the nesting
of optional patterns. Cyganiak (2005b) and Harris & Shadbolt (2005), being aware of the draw-
backs, are using left outer joins (LOJ) for evaluating optional patterns as it seems to be the most
straightforward solution. However, the authors of this paper suggest a new extension to relational
algebra – nested optional joins. Firstly, they present an example query, which uses regular left
outer join, with its translation to relational algebra and analysing its limitations. Then they start
defining new operator with the specification of special kind of relation – twin relation, which is
a pair of conventional relations with identical relational schemas but disjoint sets of tuples. Then
a conversion operator is presented, which transforms a twin relation to conventional one. Having
the new relation, they define new operator as a join of two twin relations that results in another
twin relation. The result tuple consist of two parts, optional and regular. The optional part is just
copied to the result set without any joins on the preceding steps. The biggest advantages of this
approach is the effective processing of tuples that are having unbounded variables and elimination
of NOT NULL check which is normally used to minimize the impact of inconsistencies between
SPARQL and SQL. Finally, they discuss the properties of nested optional join.
In the next section, the authors propose three algorithms for processing nested optional join in
RDBMSs based on conventional ones. Nested-loops nested optional join (NL-NOJ) is based on
nested-loops join. The slight modification includes the requirement of higher cardinality during
the iteration over tuples and linear processing in the final stage. Sort-merge nested optional join
(SM-NOJ) is a bit more complicated and is executed in three stages. First stage sort the tuples
51

SPARQL
from both relations according to join attributes. Then the tuples satisfying the join attribute are
merged into regular part of the result set. Tuples without matching are placed in the optional part.
This step is using backtracking which reduce the time used for scanning the matching triples. In
the final step the tuples from optional part of the original relation are added to result set with
NULL values substituted for unbound variables. The last proposed algorithm is simple hash nested
optional join (SH-NOJ). In the first step the hashes of the first twin relation are being computed
over the join attributes and placed in hash table. Then for each tuple from the second relation hash
is being prepared. If the join condition is satisfied the tuples from both relations are merged and
placed in the result set. If the tuple contains unbounded variables they are substituted with NULL
values and placed in the optional part of the result set. Finally, the rest of the tuples from the
optional part of the relation are placed in the result set. The important note is that the hash table
should be prepared from the relation that contain the smallest number of distinct values of the join
conditions.
In the next section, the authors describe the performance tests they conducted using NOJ algo-
rithms in comparison to conventional left outer join implementations. They implemented the
algorithms using in-memory representation of twin relations. For more objective results the cor-
responding left outer joins algorithms were also implemented using the same technologies. The
WordNet ontology was used as a dataset. Finally the authors has created a set of nine SPARQL
queries with a various levels of nesting OPTIONAL clauses, reasonable size of the result sets and
some common patterns to show the performance changes. The translation of SPARQL queries into
SQL was decomposed into two steps. During query preparation, all query patterns are evaluated
and the results are stored in the initial relations. Query evaluation is the part where the actual joins
are performed.
When comparing execution times of the queries using NL-NOJ and NL-LOJ it turned out that the
NL-NOJ is faster. However, the performance difference for simple queries and for queries with
low cardinality is not significant. Both algorithms should be used for highly selective queries. The
comparison of both sort-merge join algorithms showed the advantage of NOJ operator, however
the performance differences are slight. The reason is that the sort-merge join has lower bound than
corresponding nested-loops join, what is emphasized by the low selectivity of the queries. SH-
NOJ and SH-LOJ turned out to behave close to linear lower bound for joins with low cardinality
and the differences in processing time are very small. However, the authors pointed out that in
52

SPARQL
the case when the higher number of I/O operations is involved, SH-NOJ may be more efficient.
The comparison of all three NOJ algorithms showed that SH-NOJ and SM-NOJ has comparable
efficiency, which is much higher than NL-NOJ. SH-NOJ turned out to be the most efficient and
almost twice faster than NL-NOJ. The final experiment was an evaluation of NOJ algorithms
performance in comparison to different cardinalities. The authors define a join selectivity factor
(JSF) which represents the ratio of the cardinality of the join result to the Cartesian product of
both relations. Testing algorithms with different JSF showed that NL-NOJ is the least efficient
algorithm for the low selectivity queries. The execution times for SH-NOJ and SM-NOJ are
comparable. However when the query has high JSF value the NL-NOJ algorithm is much more
effective. In that case the cost of hashing or sorting is enough significant to have negative impact
on the performance.
In the summary the authors discuss briefly the research problems that they would like to focus on.
Apart from the incorporation of NOJ into SPARQLtoSQL algorithm and implementation of its
index-based version they want to go much further – explore the possibilities of defining relational
algebra only for RDF query processing.
The developers of the Asio Tool Suite29, which incorporates also Automapper (Matt Fisher &
Joiner 2008), were involved in the works on the Semantic Web implementations since the very
beginning. Taking into consideration their experience, one of them published a short analysis
of requirements that universal interface to RDBMS should meet to support semantic queries. In
“Suggestions for Semantic Web Interfaces to Relational Databases” (Dean 2007) the author starts
from a brief description of development of the Semantic Web interface to RDBMS. The effort
needed for creating solution dedicated to particular database schema turned out to be significant.
In result, they started to work on a generic tool that will be able to represent every schema in the
Semantic Web with lower development costs using SWRL and ontology mapping. They found out
that to make relational data commonly accessible in the Semantic Web the method of exposing
data should be well designed and standardized. The general mechanism of creating representation
should allow automatic and dynamic derivation of metadata from database schema, what would
make it insensitive for schema changes and technology independent. The author suggests a number
of features that such universal interface should provide. One of the requirements is resolvable URI,29Asio Tool Suite is a set of applications that supports integration and discovery of information using means provide
by the Semantic Web. Source: http://asio.bbn.com/, [15.05.2008].
53

SPARQL
which assumes that every URI should lead to representation of particular entities with primary keys
preserved. The foreign keys should be used for encoding properties from internal or external data.
The mapping should support various access methods and efficiently translate queries into SQL.
Finally, the security model should be created taking into consideration the requirements of limited
access to RDBMS objects and user verification.
Creating a standard mapping from the Semantic Web to relational model is very complicated.
However the author indicates the areas where the standardization is possible in the near future.
That includes the mapping between SPARQL and SQL and secure web service interfaces.
SPARQL query language is gaining popularity. W3C recognizes 14 implementations of SPARQL
in SPARQL Query Language Implementation Report (2008). That document is a summary of
review that W3C made at the time when SPARQL Specification was changing status from Can-
didate Recommendation to Proposed Recommendation in November 2007. The implementations
were tested against RDF Data Access Working Group’s query language test suite. Each test was
designed to evaluate at least one detailed property of SPARQL. The results from the particular
groups of functionalities are aggregated and give an overview about overall support for the partic-
ular feature by the implementation. The highest mark is 1.0, which is a percentage of all passed
test cases. At that time only ARQ30 was fully supporting SPARQL receiving the best marks. The
next one on the list was Pyrrho DBMS31 with only one result below 1.0. The latest version of
the report32 covers 15 implementations of SPARQL. After half a year from the original report two
more implementations achieved the best score – Algae233 and OpenRDF Sesame34.
W3C’s SPARQL Query Language Implementation Report (2008) does not cover all available so-
lutions. There is a number of implementations that are a part of wider architectures or just small
modules extending the functionality of RDF storages. However, this report is the most acknowl-
edged publication that simply evaluates the support of SPARQL query language.
30ARQ is a query engine for Jena Semantic Web Framework available at: http://jena.sourceforge.net/ARQ/.31Pyrrho DBMS is a compact relational database management system that supports native RDF and SPARQL being
also a SPARQL server. It is available at: http://www.pyrrhodb.com/, [20.05.2008].32SPARQL Query Language Implementation Report is being periodically updated. The latest version was published
on 16.04.2008 and is available at: http://www.w3.org/2001/sw/DataAccess/tests/implementations, [20.05.2008].33Algae2 is a query interface to RDF storage system available at: http://www.w3.org/1999/02/26-
modules/User/Algae-HOWTO, [20.05.2008].34Sesame is a very flexible Open Source RDF framework that supports a number of query languages developed by
the OpenRDF community. It is available at: http://www.openrdf.org/, [20.05.2008].
54

THE IMPLEMENTATIONS OF SPARQL
3. The implementations of SPARQL
3.1. Testing methodology
SPARQL is a recent technology that is recognized as one of the key milestones on the way to the
Web 3.01. Although the number of partial implementations were available at the time of publishing
the standard and nowadays SPARQL Query Language Implementation Report (2008) recognizes
15 of them, there are not many commercial products that became very popular as a solution for
managing data where SPARQL query language is one of the major technologies. What is more
a number of technical and conference papers point out the weaknesses of the specification and
future areas of research. There are still some implementation challenges that software engineers
have to face before the applications will be as stable as the popular RDBMSs.
The goal of the implementation part of the project is to present a number of applications that
support SPARQL, perform several tests using a popular ontology and evaluate them considering
the high-level overview of its architecture, the documentation, available support from the vendor
or the community and the ease of deployment. The ontology used for testing will be based on an
extract from DBpedia. The evaluation will be done from the perspective of the user that has an
overview of Semantic Web technologies but is not a specialist in the area, what means that either
low-level design or performance related issues would not be discussed. What is more the different
functionalities provided by the solutions and its maturity makes it impossible to compare them.
Every test attempt requires individual approach. Some of the tests will have to be adjusted to the
current limitations or even cancelled due to some imperfections of the implementation.
The list of the implementations that are going to be reviewed includes OpenRDF Sesame 2.1.2,1Web 3.0 is a term that refers to the future of the WWW. It follows the naming standard introduced by the current
revolution of the Web – Web 2.0, a trend in technology (e.g. Ajax) and web design that is based on user created content.
55

THE IMPLEMENTATIONS OF SPARQL
OpenLink Virtuoso 5.0.6, Jena Semantic Web Framework 2.5.5 with ARQ 2.2, SDB 1.1 and Joseki
3.2, Pyrrho DBMS 2.0 and AllegroGraph RDFStore 3.0.1 Lisp Edition. Sesame is one of the lead-
ing open source RDF storages with support of SPARQL. OpenLink Virtuoso is an open source
edition of the Virtuoso Universal Server – the product that combines the functionalities of the
middleware and database engine. Jena Semantic Web Framework is one of the first frameworks
for developing Semantic Web applications. ARQ, Joseki and SDB are subprojects of Jena that pro-
vides additional functionalities. Pyrrho DBMS is a very compact database with a native support
of RDF and SPARQL. Finally, AllegroGraph RDFStore is one of the most serious commercial
products in the area that supports AI programming. All the implementations are listed in SPARQL
Query Language Implementation Report (2008), however most of them still does not fully comply
with the specification of SPARQL. Majority of them is written in Java or use Java-based compo-
nents, but there are some other technologies involved – .NET Framework or Common Lisp envi-
ronment. In addition, the ways of storing data varies from external RDBMS to specific disk-based
storages.
The applications will be installed and tested on a separate server operated by Red Hat Enterprise
Linux version 5.0 (kernel version 2.6.18). Testing environment includes Sun Java 6.0 (1.6.06),
MySQL version 5.0.22, PotgreSQL version 8.1.4, Apache Tomcat version 6.0.16 and Mono JIT
compiler version 1.0.6. The required software is going to be set up on the machine powered
by AMD Athlon 1GHz (x86 architecture) with 384Mb of RAM memory and 120Gb of storage.
The server will be connected to the Internet via 1Mbit ADSL line through a separate router. The
installation and testing will be managed from another machine – a laptop powered by Intel Pentium
3.06GHz with 768Mb of RAM memory and operated by Windows XP Professional Edition SP2
with Firefox 2.0.0.15 and Internet Explorer 7.0.573.11 as the Internet browsers.
3.1.1. DBpedia
DBpedia is an open source project that aims to extract semantically rich data from the current
content of Wikipedia. Even though Wikipedia is the largest publicly available encyclopædia, it
only offers regular full text searching. That limitation makes it a source of raw data rather than a
source of knowledge. The problem can be resolved with the use of the Semantic Web technolo-
gies. DBpedia community extracts data from the Wikipedia and converts it into the structured
56

THE IMPLEMENTATIONS OF SPARQL
knowledge stored in the RDF. The data set is freely available on-line and can interconnect with
other domains. What is more the community is involved in the W3C Linking Open Data project2,
which is publishing various open datasets and interlinking them using RDF relations. Figure 3.1
shows the datasets and links between them that are already available. DBpedia is one of the core
sources of RDF data for the project.
Figure 3.1: The status of datasets interlinked by the Linking Open Data project. Source:http://richard.cyganiak.de/2007/10/lod/lod-datasets/, [12.06.2008].
Currently available DBpedia’s dataset, version 3.0 from 1st of April 2008, is based on an extract
from various language versions of Wikipedia (e.g. English, Polish, German) that was done in
January 2008. It describes around 2.18 million of resources with 218 million of triples. Every
resource in the dataset is described by a label, short and long version of abstract, link to the
Wikipedia’s page and to depicting image, if available. All information is originally available in
English, but if the resource exists in the regional versions, it is also presented. The resources are
classified using three schemas: Wikipedia Categories represented by the SKOS Vocabulary3, the2More information about the project is available on the project’s wiki:
http://esw.w3.org/topic/SweoIG/TaskForces/CommunityProjects/LinkingOpenData, [12.06.2008].3Simple Knowledge Organization System (SKOS) is the W3C project that is working on the specification and
57

THE IMPLEMENTATIONS OF SPARQL
YAGO Classification4 and WordNet links. Most of the additional facts about the resources are
derived from the Wikipedia’s infoboxes – the dataset contains about 22.8 million of such triples.
DBpedia also includes references to external datasets, as visible in Figure 3.1. Another useful part
of the dataset are the geographical coordinates of approximately 293 000 geographic locations.
DBpedia dataset can be downloaded from the project’s website or accessible on-line using a nu-
merous interfaces, like DBpedia SPARQL endpoint or OpenLink’s iSPARQL Query tool. The
dataset can be freely downloaded and used thanks to its licensing model – GNU Free Documen-
tation License, which allows distribution and modification of documents either commercially or
non-commercially.
3.1.2. Ontology and test queries
Due to limited capacity, only a subset of DBpedia’s dataset will be considered for testing pur-
poses. The first set of files considered for loading contained 113 494 213 triples. Unfortunately,
the amount of data was too big for the testing environment. Regarding to that the expected results
were evaluated and the set of predicates that are used in the processing was stated. Using the list
only, the files that contains required predicates were chosen. The set contained 35 128 737 triples.
That amount was extended by an extract of triples from the omitted DBpedia data files that contain
a word “Paisley” and five other files that contained additional unique relations. The dataset con-
tained 37 970 186 triples in total, which were merged into one file at the size of 5 897 915 630 bytes.
The first tests using Sesame 2.2 and MySQL showed that the amount of data is far exceeding the
capabilities of the server – the loading process had to be stopped after 24 hours. The further reduc-
tions were necessary. Another set of URI, which creates the result set of the queries, was laid down
and used for reducing the number of triples in the largest file – infoboxproperties en.nt.
What is more, the additional data files were removed from the data set except the file containing
triples that include the word “Paisley”. That set was recreated taking into consideration all omitted
standards such as thesauri, classification schemas, taxonomies that will be able to support Knowledge Management
Systems.4Yet Another General Ontology (YAGO) is a semantic knowledge base that stores entities and relations that are au-
tomatically extracted from the Wikipedia and unified with the WordNet. Currently YAGO stores about 1.7 million en-
tities which are involved into 14 million of relations. Source: http://www.mpi-inf.mpg.de/ suchanek/downloads/yago/,
[12.06.2008].
58

THE IMPLEMENTATIONS OF SPARQL
files from the original data set. Filtering the triples was performed using grep command. Finally,
the following files containing data needed for the test queries will be loaded into the evaluated
implementations:
∙ articlecategories en.nt — links all entries available in Wikipedia to categories defined us-
ing SKOS vocabulary. Contains 6 136 876 triples with the file size of 980 826 612 bytes.
∙ articles label en.nt — titles of all articles in English. Contains 2 390 513 triples with the
file size of 291 030 062 bytes. All resources available in DBpedia are included in the file,
what means that together with SKOS Vocabulary it contains more than two million of unique
triples.
∙ articles label fr.nt — titles of the articles available in French. Contains 293 388 triples
with the file size of 34 646 881 bytes.
∙ articles label pl.nt — titles of the articles that are available in Polish. Contains 179 748
triples with the file size of 20 925 708 bytes.
∙ categories label en.nt — labels for the articles’ categories. Contains 312 422 triples with
the file size of 44 353 206 bytes.
∙ infobox en.nt — information extracted from infoboxes of English version of Wikipedia.
The original file contains 22 820 839 triples (3 218 768 028 bytes), which had to be signif-
icantly reduced. The output file (infobox en.reduced.nt) contains 269 355 triples with the
file size of 40 300 966 bytes.
∙ infoboxproperties en.nt — definitions of properties used in infoboxes. Contains 65 612
triples with the file size of 8 856 957 bytes.
∙ links gutenberg en.nt — links the writers described in DBpedia to their corresponding
data in Project Gutenberg. Contains 2 510 triples with the file size of 450 969 bytes.
∙ links quotationsbook en.nt — links persons from the dataset with their data available in
Quotationsbook5. Contains 2 523 triples with the file size of 322 580 bytes.5Quotationsbook is one of the most popular portals that provides famous quotations. Available at:
http://quotationsbook.com/.
59

THE IMPLEMENTATIONS OF SPARQL
∙ persondata de.nt — information about persons extracted from German version of Wikipedia
expressed using FOAF vocabulary. Contains 569 051 triples with the file size of 69 431 850
bytes.
∙ shortabstract en.nt — short abstracts (max. 500 characters long) of articles in English.
Contains 2 180 546 triples with the file size of 735 378 536 bytes.
∙ shortabstract pl.nt — short abstracts (max. 500 characters long) of articles that are avail-
able also in Polish. Contains 179 742 triples with the file size of 66 025 464 bytes.
Additionally the file with triples containing the word “Paisley” and URIs of the resources that are
used for evaluating the results sets will be loaded to increase the number of unique predicates.
The extract is based on the files removed from the original data set. Additional triples will com-
plicate the query evaluation. The file paisley.nt contains 1 494 603 triples and has the size of
217 096 501 bytes. One of the test queries requires a remote graph available on-line. Regarding
to that a small file (32 triples, 4892 bytes) will be uploaded to the server of Warsaw School of
Economics and made accessible via standard HTTP protocol6.
The whole dataset that is going to be used during evaluation of implementations contains 14 076 889
triples in total. The particular files are going to be loaded separately using the means provided by
the application. The size of the whole data set is 2 509 646 292 bytes. In case of any issues caused
by the architecture of the application or limited capacity, the data files will be splitted into smaller
files and loaded partially. In addition, the loading will be done with the default configuration of
the applications and the background RDBMSs. No performance related improvements will be ap-
plied, however when the setup prevents from interrupted testing, it will be manually adjusted. In
the final evaluation loading times will be presented and some conclusions will be drawn regarding
the simplicity of the process, timings and the overview of the structure of the storage.
After loading the files, the capability of handling complicated SPARQL queries will be evaluated.
The applications will be tested against the set of eight queries. Each of them is testing different
feature of SPARQL regarding the implementation details, which has the most significant impact
on the response time, e.g. using hash functions for identifying URIs improves significantly join
operations. The correctness of the queries was tested using DBpedia SPARQL endpoint and the6File is available at: http://akson.sgh.waw.pl/∼rm28708/geo.nt
60

THE IMPLEMENTATIONS OF SPARQL
Figure 3.2: Querying on-line DBpedia SPARQL endpoint with Twinkle.
queries were validated using on-line SPARQLer Validator7. The evaluation will take into con-
sideration only the timings. The accuracy of the result sets will not be compared to the expected
results returned by DBpedia endpoint as the data set used for testing is only a subset of the original
DBpedia. However when the results will significantly differ from the expected it will be noted.
The applications with already loaded DBpedia data set will be queried in two ways – using the
provided client and external application, Twinkle. Twinkle 2.0 is an open source graphical inter-
face for ARQ SPARQL query engine. It allows connecting to local or remote data sets and fully
supports SPARQL. However, one of the required functionalities was missing – the interface had to
be slightly modified to display query-processing time. Twinkle is written in Java and distributed
under Gnu Public License. It is freely available at: http://www.ldodds.com/projects/twinkle/. The
timings obtained using client software and Twinkle will be compared and discussed.
The objective of the first query presented in Figure 3.3 is to check the full-text searching capabil-
ities. It filters out all the objects that do not have the word “Paisley” in plain literals. The query
returns both subject and object regardless of its language. The test dataset contains short abstracts
in English, Polish and French.7SPARQLer Validator is an on-line SPARQL validator based on Joseki. It is available at:
http://www.sparql.org/validator.html, [16.05.2008].
61

THE IMPLEMENTATIONS OF SPARQL
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>SELECT *WHERE {
?res rdfs:comment ?abstr.FILTER regex(str(?abstr), "Paisley")}
Figure 3.3: Query testing full-text searching capabilities.
BASE <http://dbpedia.org/>PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>PREFIX owl: <http://www.w3.org/2002/07/owl#>PREFIX dbpedia: <property/>
SELECT DISTINCT *WHERE {
{{?place dbpedia:gaelicName ?name.?person dbpedia:birthPlace ?place.?person dbpedia:death ?date.}
UNION{?place dbpedia:gaelicName ?name.?person dbpedia:cityofbirth ?place.?person dbpedia:death ?date}
FILTER (regex(str(?name),"Paislig\"")).}OPTIONAL {
?person owl:sameAs ?ref.}
FILTER (xsd:date(?date) > xsd:date("1800-01-01")).}
ORDER by ?person
Figure 3.4: Selective query with UNION clause.
The second query depicted in Figure 3.4 contains a union of two similar graph patterns, which
are returning the URI of the persons that were born in the specific place and the date of their
death. The difference is in using other DBpedia’s properties – either dbpedia:birthPlace
or dbpedia:cityofbirth. The place has to have dbpedia:gaelicName property, which
value (Paislig) is forced by the FILTER clause. Also the dataset that comes from the joined graphs
should be optionally extended with reference to other datasets by owl:sameAs. Finally, the date
of the persons’ death should be later than ‘‘1800-01-01’’.
The third query presented in Figure 3.5 is performing a number joins on a several relations. It
should test the ability to optimize complicated selective query and perform the most cost-effective
62

THE IMPLEMENTATIONS OF SPARQL
BASE <http://dbpedia.org/>PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>PREFIX skos: <http://www.w3.org/2004/02/skos/core#>PREFIX dbpedia: <property/>
SELECT DISTINCT ?leader_name ?uniname ?cnameWHERE {
?uni dbpedia:country ?country;rdfs:label ?uniname.
?country rdfs:label ?cname.?person dbpedia:almaMater ?uni;
rdfs:label ?leader_name.?person skos:subject ?category.?category rdfs:label ?cat_name.FILTER regex(str(?cat_name), "Current national leaders").FILTER (langMatches( lang(?uniname), "en")).FILTER (langMatches( lang(?leader_name), "fr")).FILTER (lang(?cname)="pl").}
ORDER BY ?leader_name DESC(?uniname) ?cname
Figure 3.5: Query with numerous selective joins.
joins. The query is selecting universities in the countries, and then selecting people that were
studying at the universities. Finally, the URIs of the persons are joined with SKOS vocabulary.
The query is highly selective – the person has to belong to category which is named “Current
national leaders” and the appropriate labels has to be returned in different languages.
BASE <http://dbpedia.org/>PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>PREFIX dbpedia: <property/>
SELECT *WHERE {
?country rdfs:label "Scotland"@en.?company dbpedia:headquarters ?country.
OPTIONAL {?company dbpedia:airline ?name.OPTIONAL {?company dbpedia:alliance ?alliance.?alliance rdfs:label ?all_name.FILTER (lang(?all_name)="en")}
}}
Figure 3.6: Query with nested OPTIONAL clauses.
The query presented in Figure 3.6 is testing the performance of processing nested optionals. The
query is checking the URIs of the companies that have their headquarters in Scotland. Optionally
it returns the name of the company if it is an airline. The inner optional is returning the URI and
63

THE IMPLEMENTATIONS OF SPARQL
name of the alliance if the airline is involved in any. The name of the alliance has to be written in
English.
BASE <http://dbpedia.org/>PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>PREFIX skos: <http://www.w3.org/2004/02/skos/core#>PREFIX dbpedia: <property/>
CONSTRUCT {?person <isLeading> ?country}WHERE {
?uni dbpedia:country ?country.?person dbpedia:almaMater ?uni.?person skos:subject ?category.?category rdfs:label ?cat_name.FILTER regex(str(?cat_name), "Current national leaders").}
ORDER BY ?country ?uni ?person
Figure 3.7: CONSTRUCT clause creating new graph.
The CONSTRUCT query presented in Figure 3.7 is very similar to query depicted in Figure 3.5 –
from the same graph pattern it is supposed to create a separate dataset with the predicate that do
not exist in the original DBpedia dataset. The query engine should return the triples in the N3 or
the RDF format, which shows the countries and their national leaders.
PREFIX dbpedia: <http://dbpedia.org/property/>PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
ASK {?person dbpedia:birthPlace ?place.?place rdfs:label "Paisley"@en.?person dbpedia:deathPlace ?place.?person rdfs:label ?name.FILTER regex(str(?name), "Wilson").}
Figure 3.8: ASK query that evaluates the graph.
ASK query result form should return a boolean value that indicates if the graph pattern matches
the RDF dataset. The query presented in Figure 3.8 evaluates if there is a person in DBpedia
dataset that has a word ”Wilson” in the names and was born (dbpedia:birthPlace) and died
(dbpedia:deathPlace) in the same place. The place should have the label in English equal
to the word “Paisley”. The result of the query should be serialized in SPARQL Query Results
XML Format.
64

THE IMPLEMENTATIONS OF SPARQL
PREFIX dbpedia: <http://dbpedia.org/property/>PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>DESCRIBE ?cityWHERE {<http://dbpedia.org/resource/Alexander_Wilson> dbpedia:birthPlace ?city.}
Figure 3.9: Query returning all available triples for the particular resource.
The DESCRIBE query result form should return an RDF graph that describes the particular re-
source or list of resources. The query presented in Figure 3.9 is checking the resource name of the
birth place of Alexander Wilson
(<http://dbpedia.org/resource/Alexander Wilson>) and returns all available triples
with the selected URI as the subject or the object of the relation.
The test created for evaluating the capability of using remote graphs was divided into two steps.
The first query presented in Figure 3.10 is using the graph stated in the FROM clause
(<http://akson.sgh.waw.pl/∼rm28708/geo.nt>) as the default graph. The graph
pattern is checking the latitude and longitude of the city of Paisley
(<http://dbpedia.org/resource/Paisley>) and returns the URI of the places that
are based near Paisley. The selection is made using filtering clause that removes from the result set
the places that are not within the range of 0.04 considering latitude and 0.1 considering longitude.
The second query is extended by the usage of local and remote graphs. Remote graph is stated
using FROM NAMED clause while the local data set is defined by FROM clause. The graph pattern
from the previous query creates a main part of the second query, but this time it is preceded with
the GRAPH clause, which changes an active graph for matching the following graph pattern. The
results of the inner subquery matched against the remote graph should be used as a part of the outer
query resolved using local graph. Finally the query should return the labels of the places based
near Paisley, which are defined in http://akson.sgh.waw.pl/∼rm28708/geo.nt. De-
pending on the implementation the query might be slightly changed, e.g. the names of the graphs
can be adjusted.
65

THE IMPLEMENTATIONS OF SPARQL
PREFIX geo: <http://www.w3.org/2003/01/geo/wgs84_pos#>PREFIX foaf: <http://xmlns.com/foaf/0.1/>PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>SELECT ?placeFROM <http://akson.sgh.waw.pl/˜rm28708/geo.nt>WHERE {
<http://dbpedia.org/resource/Paisley> geo:lat ?PaisleyLat .<http://dbpedia.org/resource/Paisley> geo:long ?PaisleyLong .?place geo:lat ?lat .?place geo:long ?long .FILTER (?lat <= ?PaisleyLat + 0.04 &&?long >= ?PaisleyLong - 0.1 &&?lat >= ?PaisleyLat - 0.04 &&?long <= ?PaisleyLong + 0.1)
}
PREFIX geo: <http://www.w3.org/2003/01/geo/wgs84_pos#>PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>SELECT ?place ?nameFROM <http://dbpedia.org>FROM NAMED <http://akson.sgh.waw.pl/˜rm28708/geo.nt>WHERE {GRAPH <http://akson.sgh.waw.pl/˜rm28708/geo.nt> {
<http://dbpedia.org/resource/Paisley> geo:lat ?PaisleyLat .<http://dbpedia.org/resource/Paisley> geo:long ?PaisleyLong .?place geo:lat ?lat .?place geo:long ?long .FILTER (?lat <= ?PaisleyLat + 0.04 &&?long >= ?PaisleyLong - 0.1 &&?lat >= ?PaisleyLat - 0.04 &&?long <= ?PaisleyLong + 0.1)
}?place rdfs:label ?name}
Figure 3.10: Two versions of GRAPH queries.
3.2. OpenRDF Sesame 2.1.2
Sesame is an open source RDF storage system that was originally developed by Aduna Soft-
ware8 as a part of the EU research project On-To-Knowledge9. After the project’s completion,
Aduna started cooperation with NLnet Foundation and Ontotext to continue the development of
Sesame. The community of developers gathered around OpenRDF website was created to support8Aduna Software, http://www.aduna-software.com/.9On-To-Knowledge-Project was a research project conducted between 1999 and 2002 and supported by EU. The
main goal was to develop tools and methods for employing ontologies in knowledge management systems. More
information is available at: http://www.ontoknowledge.org/, [25.05.2008].
66

THE IMPLEMENTATIONS OF SPARQL
the project. Currently Sesame is being developed as a community-based project with Aduna as a
technical leader.
Sesame 2.1.2 is the newest stable version of the system. Recently a significant step forward was
made. Sesame 2.x series replaced 1.x series introducing the revised architecture, performance
improvements, new functionalities and support for Java version 5. One of the new features was
support for SPARQL query language together with SPARQL protocol and SPARQL Query Results
XML Format.
Sesame is an open source project available under Aduna BSD-style licence. It was designed with
W3C open standards. The community support is available at OpenRDF website (http://www.openrdf.org).
Aduna Software offers commercial support under Aduna Commercial License.
Sesame can be freely downloaded from the SourceForge repository10 – appropriate links are pro-
vided at OpenRDF download page. The sourcecode is available at SVN repository hosted by
Aduna11.
3.2.1. Architecture
Sesame is a framework built in Java that supports the storage and querying of RDF. It has very flex-
ible architecture that reflects inferencing, multiple storage mechanisms and RDF triples formats
together with a number of query languages and query result formats. Sesame offers a JDBC-
like Repository API12, low-level storage API and RESTful HTTP interface with the support of
SPARQL Protocol for RDF. Apart from SPARQL query language Sesame implements SeRQL,
RQL and RDF Schema inferencer. RDF triples can be stored in disk-based and memory-based
RDF stores or using every RDBMS that supports JDBC.
Figure 3.11 depicts Sesame’s architecture with the dependencies of its components. Sesame, as
RDF storage, has its features derived from the characteristics of RDF data model. On top of the
RDF model, there are three components: Sail API, RIO and HTTPClient. Sail (Storage And Infer-10SourceForge.net is a source code repository that became the most popular portal for developers to control and
manage open source projects. It is a commercial venture operated by Sourceforge, Inc.11Aduna’s SVN repository: https://src.aduna-software.org/svn/org.openrdf/ [25.05.2008].12Application Programming Interface (API) is an interface that operating system, library or service provides for
external applications that are intended to use its functionality.
67

THE IMPLEMENTATIONS OF SPARQL
Figure 3.11: Architecture of Sesame. Source: User Guide for Sesame 2.1 (2008).
ence Layer) API abstracts the details of storage and inferencing used by Sesame and allows using
various independent storages and inferencers. RIO (RDF I/O) is a set of RDF parsers and writers
for different RDF serializations. HTTPClient handles connections made by remote HTTP Servers.
Repository API is the main API that can be used for interaction with the framework. It offers a
number of methods for handling data files, querying, extracting and manipulating data. The two
implementations of the API presented in Figure 3.11 are SailRepository and HTTPRepository.
On the top of the architecture, there is a HTTP server that allows connecting with Sesame over
HTTP protocol. Every component can be used independently, however the most general-purpose
component is the Repository API.
The open source community has prepared a number of tools and extensions for Sesame. Elmo has
been just released in stable 1.0 version. It is a toolkit for creating the Semantic Web applications
using Sesame and the most popular independent ontologies, like FOAF or Dublin Core. The list of
extensions to Sesame is quite long. It contains additional inferencing engines, modules for Drupal
and Protege and a long list of libraries for popular programming languages, like Python, Perl, PHP,
that simplify the integration of Sesame.
3.2.2. Documentation
The documentation of Sesame is published on-line on community’s website and attached to pack-
age containing the binaries. On the website, the most extended is the section for Sesame 1.x series.
However as there is no backward compatibility between the series this documentation is useless
for deploying 2.x series. There are three manuals available for Sesame 2.x. The most basic is the
68

THE IMPLEMENTATIONS OF SPARQL
Figure 3.12: The interface of Sesame Server.
Sesame API documentation in the form of Javadoc13, that contains the description of all available
APIs. Sesame 2.x System documentation describes briefly the architecture of Sesame and presents
class diagrams. It also presents the HTTP communication protocol for Sesame. Unfortunately, at
the time of writing the system documentation has not yet been finalized. The most complete is
the user documentation. It contains the overview of Sesame and the installation process. Then the
brief instructions for using console are stated together with introduction to Repository API. The
last part is the comprehensive tutorial of SeRQL.
From the users perspective the installation process and basic manual are the most important parts.
Unfortunately, the user documentation does not describe them in details. Not all the features are
discussed, some of the parameters are not even described. There is no FAQ14 section for Sesame
2.x series. On the other hand, deployment related matters are being discussed on community’s
forum. Generally speaking the documentation still needs some improvements.13Javadoc is a documentation generator for Java APIs provided by Sun Microsystems. It became an industry standard
for documenting Java classes.14FAQ – Frequently Asked Questions
69

THE IMPLEMENTATIONS OF SPARQL
Figure 3.13: Sesame Console with a list of available repositories.
3.2.3. Installation
While downloading Sesame there is a choice between two types of packages – one is the single
jar file that contains all the libraries and can be used as an embedded component. The more
relevant to average user is the complete package (SDK) that contains all libraries (jar files), doc-
umentation and actual Sesame’s applications. Sesame’s Web application is divided into two inde-
pendent servlets – one of them is a Sesame server, the other is a client application called Sesame
Workbench. Sesame Server is responsible for accessing Sesame repositories via HTTP, the client
is an end-user interface that connects to servers and provides querying, viewing and extraction of
RDF stores. The application responsible for managing repositories is Sesame Console. This is
a command-line tool that is used mainly for creating and managing the repositories. Sesame is
written in Java, so it can be deployed on every operation system that supports the language.
Sesame has very low software requirements – only Java 5.0 or newer is needed together with any
Java Servlet Container. The authors recommend using stable version of Apache Tomcat15.15At the time of writing the latest stable version of Apache Tomcat was version 6.0.16. Source:
http://tomcat.apache.org/, [27.05.2008].
70

THE IMPLEMENTATIONS OF SPARQL
Figure 3.14: Sesame Workbench – exploring the resources in the repository based on a nativestorage.
The installation process is very straightforward. At the beginning, the logging implementation has
to be determined and application directory chosen by adding appropriate parameters to environ-
ment variables. Then both applications, Sesame Server and Sesame Workbench, can be deployed
in the servlet container using downloaded WAR files. The repositories can be configured using
Sesame Console. The additional installation step – defining appropriate JDBC driver, is needed
for configuring RDF repository that stores data in RDBMS. Currently Sesame supports MySQL
and PostgreSQL – additional RDBMSs can be configured by creating appropriate template in
SYSTEM repository.
3.2.4. Testing
The testing of Sesame started with an overview of both applications - Server and Workbench.
Sesame Server has very limited functionality. Sesame Workbench is in fact the application that
provides an on-line graphical interface for the repositories. The application is very straightforward
with high usability. However, it is not free from the errors. At the beginning of the tests, it turned
71

THE IMPLEMENTATIONS OF SPARQL
out that sometimes while accessing the Workbench the servlet causes a Java exception on the
container’s side. The investigation showed that one of the small features, the possibility to save a
selected server as a default reference, causes the error. The selection is saved on client’s side in
the form of cookie. While accessing the file the URLRewrite method is not able to process it and
finally the servlet receives null as the server’s URL, which causes exception. The situation was
appearing in both browsers – Mozilla Firefox and Internet Explorer.
OpenRDF Sesame is able to use memory, disk or RDBMS as the storage for its repositories.
Currently only PostgreSQL and MySQL are the only RDBMSs supported – the other databases
needs manually created configuration templates. Both of the RDBMS together with the native
storage were chosen for testing. What is more the Sesame was used to prepare the extract of
DBpedia’s data set that would be the most accurate for the project. It showed that the primary set
of triples has to be significantly reduced due to limited capacity.
The test started with creating the appropriate repository using the console with the MySQL as the
storage. The configuration is very straightforward. It requires adding JDBC driver for MySQL
to the CLASSPATH and creating an empty database with the corresponding user. At this step the
database layout that Sesame creates can be also configured. Sesame is able to store data in a single
table or in separate tables for each predicate. Multiple tables layout used for storing data sig-
nificantly improves query performance, however the large number of tables can lead RDBMS to
higher response times or even a failure. The default maximum number of tables is 256, which value
was used during the testing. After creating the repository the data set containing 37 970 186 triples
merged into one file started to load. The loading process is also very straightforward – it re-
quires the console connected to the Server (http://localhost:8080/sesame/) and an
opened repository. Unfortunately, after 24 hours of processing it turned out that the amount of
data already processed compared to the overall data set is very little. The monitoring showed
that Sesame was loading the data keeping the transaction log. The data itself was storied in My-
ISAM database engine, which is relatively fast. The details of the transactions were storied using
InnoDB, which performance is much lower. What is more the tables created from predicates are
also maintained by the same engine – InnoDB is optimised for insert operations preserving trans-
action isolation not for selections. In fact, the engine was spending much more time in searching
if the triples already exists than on inserting new ones. The processing was stopped and the
data set was reviewed. The testing was restarted using smaller dataset. While loading the first
72

THE IMPLEMENTATIONS OF SPARQL
file (articlecategories en.nt) the same situation happened again. It turned out that the
amount of triples, which can be processed in reasonable time is lower than the actual file was
containing. The file had to be splitted into two smaller data sets and the testing started on a fresh
database. This time the processing has finished. However while loading the second file, which was
taking more than 24 hours, the connection via JDBC has reached the timeout value. This caused
an exception on Sesame Server side and resulted in loading failure. The configuration of MySQL
and Sesame’s repository was changed and the tests were restarted using empty database. The final
results are presented in Table 3.1. Sesame has created 267 tables – 255 of them are predicate-
based tables, 12 are the main tables containing values of URIs, labels, numeric values or language
tags. Sesame creates normalized database layout with the table TRIPLES as the main table. The
values of the URIs or literals are stored in separate dictionary tables. To improve the performance
each relation (predicate) has a dedicated table that stores references to corresponding subjects and
objects together with the information about the contexts. The idea of context in Sesame is used
for organising logical groups of triples, which can be separately processed. During the tests, this
concept will not be used.
While evaluating the results of the test there is no visible trend in the average loading times –
the average time per triple varies from 3,4130ms to 30,1840ms. It can be only presumed that the
number of triples loaded at one time, the size of the file or the number of unique predicates affects
the performance of loading data.
The next loading test was performed with Sesame based on a native storage. The procedure
of creating the repository is even more straightforward comparing to creating database backed
repository. It only requires choosing the name and index patterns that will be used for creating
disk-based indexes. Sesame uses B-Tree indexes based on four keys: subject (s), predicate (p),
object (o) and context (c). By default console suggests using two indexes – spoc and posc.
Creating more indexes may potentially improve query performance, but also requires additional
capacity for maintaining them. The data is stored in the ADUNA DATA directory stated in the
environment configuration.
The load was performed using the same set of files used while testing MySQL. This time the tests
were not disturbed. The loading times are available in Table 3.1. Generally speaking Sesame
is loading data to disk-based storage much more effectively. The reason is that there is no addi-
73

THE IMPLEMENTATIONS OF SPARQL
tional engine responsible for transaction processing. However while interrupted, the loading could
not be rolled back as in RDBMS-backed repositories. This time also there is no correlation be-
tween the size of the file and the average loading time – articlecategories en.part1.nt
with 3 000 000 triples was loaded 6 358 082ms (2.1194ms per triple) while much smaller file,
links quotationsbook en.nt with 2 523 triples, was loaded in 51 735ms (20.5054 ms per
triple). The average loading times varies from 2,1194ms to 25,5857ms per triple.
The last loading test was performed on Sesame with the repository based on PostgreSQL. Before
creating the repository there was a need of installing dedicated JDBC driver and creating appro-
priate user with corresponding database. The configuration was very similar to MySQL-based
repository – apart from connection details, it required stating the maximum number of tables. The
default value was 256.
This time process of loading the files was uninterrupted. PostgreSQL was not reporting any con-
nection timeouts. Loading the first file showed that this combination of the RDBMS and Sesame
is very fast. However while proceeding with the next files the loading was slowing down signif-
icantly. The investigation showed that while the actual operations of inserting and selecting data
are fast, the recurring VACUUM process is causing large amount of I/O operations, what is dramat-
ically slowing down the whole processing. The process is generally responsible for reclaiming
disk space freed after deleting tuples, updating statistics and maintaining transactions. It can be
controlled by adjusting the settings according to the characteristics of the database. During the
test, default values were used. Sesame has created the same set of tables as in MySQL – 267 in
total with 12 containing values of URIs or literals and 255 predicate-based tables. This time also
the average loading times are not depending on the file size or the number of triples – the values
varies from 8.5294ms to 140.4283ms.
74

TH
EIM
PL
EM
EN
TAT
ION
SO
FS
PAR
QL
File No. of triplesMySQL Native storage PostgreSQL
Time (ms) Avg (ms) Time (ms) Avg (ms) Time (ms) Avg (ms)
articlecategories en.part1.nt 3 000 000 47 755 188 15.9184 6 358 082 2.1194 25 588 343 8.5294
articlecategories en.part2.nt 3 136 876 88 794 180 28.3066 16 706 385 5.3258 68 147 566 21.7247
articles label en.nt 2 390 513 16 268 233 6.8053 8 178 421 3.4212 146 450 826 61.2633
articles label fr.nt 293 388 4 446 781 24.7390 3 565 839 19.8380 25 241 699 140.4283
articles label pl.nt 179 748 3 448 541 11.7542 2 463 018 8.3951 14 323 278 48.8203
categories label en.nt 312 422 6 391 322 20.4573 6 630 437 21.2227 35 493 395 113.6072
infobox en.reduced.nt 269 355 919 297 3.4130 1 002 681 3.7225 4 408 939 16.3685
infoboxproperties en.nt 65 612 1 106 935 16.8709 411 573 6.2728 6 852 589 104.4411
links gutenberg en.nt 2 510 52 613 20.9614 42 748 17.0311 91 909 36.6171
links quotationsbook en.nt 2 523 56 248 22.2941 51 735 20.5054 116 125 46.0266
paisley.nt 1 494 603 8 642 147 5.7822 3 643 921 2.4381 17 082 615 11.4295
persondata de.nt 569 051 8 304 793 14.5941 3 734 774 6.5632 20 950 502 36.8166
shortabstract en.nt 2 180 546 31 938 179 14.6469 19 299 840 8.8509 212 680 793 97.5356
shortabstract pl.nt 179 742 5 425 334 30.1840 4 598 827 25.5857 4 425 293 24.6203
Total 14 076 889 223 549 791 76 688 281 581 853 872
Average loading time 15.8806 5.4478 41.3340
Table 3.1: Summary of loading data into OpenRDF Sesame.75

THE IMPLEMENTATIONS OF SPARQL
The comparison of loading times of tested storages is depicted in Figure 3.15. It is easily vis-
ible that Sesame based on PostgreSQL had the lowest performance especially while loading
articles label en.nt and shortabstract en.nt when the average time per triple
was 61.2633ms and 97.5356ms. However the highest time per triple was obtained while loading
articles label fr.nt (140.4283ms) when Sesame based on MySQL and native storage
had significantly lower results – 24.7390ms and 19.8380ms. PostgreSQL loaded all the files in
around 162 hours loading one triple in 41.3340ms. MySQL had much better performance – an
average triple was loaded in 15,8806ms, while the whole dataset was processed in approximately
62 hours. This configuration was very slow while processing two first files containing the rela-
tions between articles and categories. The remaining files were loaded much faster than in the
case of PostgreSQL. Sesame with native storage turned out to be the fastest configuration. It was
loading the triples in the average pace of 5.4478ms per triple. The overall processing time slightly
exceeded 21 hours.
Figure 3.15: Graph comparing loading times for OpenRDF Sesame using different storages.
There is no visible trend in the results of the loading times. It can be only spotted that the files with
76

THE IMPLEMENTATIONS OF SPARQL
diversified predicates, like paisley.nt or infobox en.reduced.nt, were loaded much
faster than the others, even the files with the small number of triples (links gutenberg en.nt
and links quotationsbook en.nt).
After loading the files to all Sesame’s repositories each of them was tested against test queries.
Each repository was queried firstly using the console then using Twinkle. Sesame is able to han-
dle requests done via HTTP protocol – all repositories are easily available on-line. The testing
environment was rebooted before each part of tests. The comparison of query times is depicted in
Figure 3.16.
The query evaluation started with testing Sesame based on MySQL using provided console client.
The first query was evaluated without errors. Unfortunately the second one caused a “Query eval-
uation error” – Sesame was not able to filter date using
http://www.w3.org/2001/XMLSchema#date function and returned an error. After re-
moving the FILTER clause the query was evaluated, however this cannot be counted as success-
fully passed test. The following queries were evaluated correctly presenting reasonable set of
results. However, the last set of queries that are checking the ability to use remote graphs failed
– Sesame was returning empty sets. Even the simplified version of query number eight (without
filtering expression) did not return any values. Evaluating queries using Twinkle started with the
reboot of the server. Then each query was processed using Sesame based on MySQL. The results
of the test were very similar to the previous ones. The first query needed much less time to finish.
The second query returned no results unless removing the FILTER clause. The following queries
were evaluated correctly presenting the expected result sets. However the query number eight has
failed, which was easy to predict. The evaluation time of Sesame based on MySQL measured
using console client and Twinkle are comparable, only the results of processing the first query
shows significant differences.
Evaluating queries using Sesame based on native storage is even simpler than the previous test
– it needs only Sesame server working and a client application. First test was conducted using
provided console. Query number one returned expected results, however computation time was
much higher comparing to MySQL-based repository. The next query failed as in the previous
tests. The remaining queries, except the query number eight, were evaluated successfully returning
reasonable sets of results. Unfortunately, the processing times were much higher than in the
77

THE IMPLEMENTATIONS OF SPARQL
QueryMySQL Native storage PostgreSQL
Console(ms) Twinkle(ms) Console(ms) Twinkle(ms) Console(ms) Twinkle(ms)
Query 1 497 119 155 187 1 038 507 117 485 676 064 678 297
Query 2 × × × × × ×
Query 3 31 934 31 750 246 822 228 766 78 999 80 172
Query 4 1 155 1 234 287 406 2 414 2 688
Query 5 14 918 15 109 20 354 15 984 75 712 76 328
Query 6 402 297 435 406 1 281 782
Query 7 206 785 206 938 4 336 646 3 415 844 64 595 58 547
Query 8a × × × × × ×
Query 8b × × × × × ×
Table 3.2: Summary of evaluating test queries on OpenRDF Sesame.
previous tests, especially while computing results of the query number seven. The same test
conducted using Twinkle brought similar results – all queries, except queries number two and
eight, were processed successfully. The evaluation times are comparable to the ones received
when using console as the client application. However, they are still higher than the results of
Sesame based on MySQL.
The last test involved Sesame based on PostgreSQL RDBMS. It was very similar to the previous
ones considering configuration. At the beginning, the queries were evaluated using provided con-
sole application. The results were similar to the previous tests, however the timings varied. First
query turned out to be a bit slower comparing to MySQL-based repository, but faster than in case
of the native storage. The trend remains stable until the last query, when the processing time is
much lower than in the case of the competitors. The next step was to repeat the test using Twinkle.
Evaluating the query showed that the results are almost the same as when using console. Queries
number three, four and five prove the hypothesis – the differences are very slight. The last queries
were evaluated a bit faster using Twinkle than in previous test. The overall results are higher than
on MySQL-based repository, but significantly lower than in the case of native storage.
Generally speaking the whole test showed that Sesame is not able to process external graphs
and some of the functions inherited from XPath are not supported. Considering the performance
the fastest configuration was Sesame based on MySQL RDBMS. The second place was reached
78

THE IMPLEMENTATIONS OF SPARQL
Figure 3.16: Graph comparing execution times of testing queries against different repositories.
by PostgreSQL-based repository while the native storage was the slowest one. The summary of
processing times are presented in Table 3.2. It has to be pointed out that the native storage had
only two indexes created (spoc and posc)– searching on objects had to be much slower. It
is visible in the results of processing the fifth query, where the searching was based mostly on
subject. The results of evaluating query number one vary – the usage of Twinkle significantly
improves full-text searching. Query number three shows that the repositories are performing well
even when the query is highly selective and involves a large number of triples. In addition, nested
optionals are computed fast, what is shown by query number four. In that case, the native storage
is the fastest one. The evaluation time of the query number five is comparable in the case of the
first two configurations while the PostgreSQL was processing a few times slower. The situation
was probably caused by the slower access to data in the database as the query was processing a
large data set. The value of the ASK query number six was returned in comparable amount of
time, while the processing time of the next query varies significantly. In that case, PostgreSQL-
based Sesame was the fastest configuration that resolved the query, while the native storage needed
approximately sixty times more time for processing the request.
79

THE IMPLEMENTATIONS OF SPARQL
3.2.5. Summary
OpenRDF Sesame is one of the first widely available RDF repositories that allowed storing and ex-
tracting the Semantic Web data. It has recently evolved from a pure RDF storage with the support
of SeRQL or RQL to flexible repository build with W3C standards. An open source community
built through the years of developing the project provides a solid support and increase the quality
of the application. The modular architecture makes the components of the Sesame highly reusable
in other projects. Multiple APIs providing an access to repository with a different level of abstrac-
tion makes it easy to implement Sesame in more complicated information systems. What is more
the front-end applications, like Workbench or console, are providing highly accessible means for
managing and querying repositories stored in Sesame Server. Unfortunately, the components are
not completely free from errors. The documentation of Sesame provides the most basic informa-
tion about the package and short guides for deploying them. The quality is acceptable, however
not all the parts of Sesame are described, like configuration details or detailed description of some
provided functionalities. There is a need of publishing some usage guidelines containing recom-
mended configuration.
The installation of Sesame is straightforward. It provides direct access to repositories through
HTTP protocol, which simplifies the integration with external clients. The repositories can be
created within minutes, however the test showed that the default configuration may not be opti-
mised. Loading data to Sesame based on RDBMSs takes significant amount of time, what might
be improved by changing transaction handling or adjusting file system’s journaling16. It turned out
that a disk-based storage is much faster. However, in the test evaluating query times the situation
has reverted. RDBMS-based repositories were much faster than the native storage. This proves
that the default indexes should be revised before deploying a repository and adjusted to the future
queries. Probably the indexes used by both RDBMS were not optimal and should be also rebuild
taking into consideration performance statistics.
OpenRDF Sesame provides a wide range of functionalities, which can be easily integrated with
other systems. However, it still remains an easy to use RDF repository. The open source code,
availability of community-based and commercial support makes it even more interesting for em-16Journaling is responsible for logging changes made to main file system into separate journal. It allows recovering
data in the case of system crash. Testing environment is based on ext3 file system, which support journaling by default.
80

THE IMPLEMENTATIONS OF SPARQL
ploying the package in larger projects. Unfortunately, the documentation is not fully reliable and
the software itself requires some more testing.
3.3. OpenLink Virtuoso 5.0.6
OpenLink Virtuoso is an open source version of Virtuoso Universal Server developed by OpenLink
Software. The project was launched in 1998 when OpenLink Software has merged its OpenLink
data access middleware with Kubl – a compact, but high performance Object-Relational Database
Management System (ORDBMS)17 developed in Finland. After acquisition, OpenLink started a
transformation of Virtuoso from a set of ODBC drivers extended by Kubl to a fully functional
Virtual DBMS Engine that was able to abstract data access across heterogeneous data sources.
Further on the support for XML technologies was added. In 2001, when the idea of Web Ser-
vices emerged, Service Oriented Architecture (SOA) paradigms were implemented significantly
increasing the functionality. That resulted in a mismatch between the name and the actual feature
set – the Virtuoso became a Universal Server. As Virtuoso Open-Source Edition (2008) says Vir-
tuoso was always ahead of its time. OpenLink started to develop a set of Web 2.0 applications that
were based on Virtuoso Universal Server and offered as separate DataSpaces. In 2005, OpenLink
started to work on incorporating the Semantic Web vision into Virtuoso. Currently Virtuoso Uni-
versal Server is a cross platform virtual database that incorporates the functionalities of web, file
and database server into one product.
Version 5.0.6 of OpenLink Virtuoso was released recently. A year ago significant improvements
were made. Version 4.5.7 was replaced by version 5.0.0, which introduced major changes in
the architecture and a new database engine. Since then the package is under heavy development
bringing new functionalities every 2-3 months.
OpenLink Software apart from a variety of commercial versions of the Virtuoso Universal Server
offers its open source edition. It is licensed under GNU General Public License version 218 with
some exemptions when additional modules are used. Commercial version is a subject of com-17ORDBMS is a relational database management system with object-oriented data model that natively supports
classes in the schema and in the query language.18GNU General Public License (GPL) is a popular free software license originally written by Richard Stallman.
It assumes that the software can be freely used, distributed and modified, however all the improvements have to be
published under the same license.
81

THE IMPLEMENTATIONS OF SPARQL
plicated license model, which depends on planned implementation model, number of clients and
employed CPUs.
Opens source version of Virtuoso can be downloaded from Sourceforge.net. In addition, the CVS
repository with the most recent code is available and is hosted by the same website. Commercial
versions are available at OpenLink Software website through a download section, which offers a
possibility to customize the package according to user’s server configuration.
3.3.1. Architecture
OpenLink Virtuso combines a functionality of middleware and database engine in one universal
server platform. With additional connectors, it can easily integrate data from different sources and
publish them in the Internet.
Very efficient object-relational database engine is the core of the platform. It provides advanced
features like transactional processing or powerful procedural language that can be extended by
code in Java or .NET. The engine is able to take advantage of multi-threading and multiple CPUs.
It provides also hot backup and advanced locking. The built-in web server extends the function-
ality of the database. It can host dynamic pages written in PHP, ASP.NET or other technologies
using external libraries, however the native support is for pages written in VSP – Virtuoso Server
Pages. Web server is designed to support Web Services providing an access to stored procedures
via SOAP and REST protocols and an implementation of UDDI server. Also a number of Web
Services protocols, like WS-Security or WS-BPEL19, is implemented. Virtuoso’s web server pro-
vides also a means for implementing Service Oriented Architecture (SOA). The access to files
stored in Virtuoso is ensured by implemented WebDAV repository. It can be accessed from regu-
lar WebDAV clients provided by popular operating systems. What is more, automatic extraction of
metadata and full text searching is possible for the specified types of files stored in the repository.
All components of Virtuoso have extended support for XML-related technologies including RDF
and SPARQL. XML is a standard way for presenting, storing and exchanging documents between
different data sources. The support for the Semantic Web technologies is under heavy develop-
ment. At the moment of writing Virtuoso was storing RDF natively in the database and support-19The specifications that are usually referred to as WS-* are developed to extend Web Services capabilities and
increase the interoperability.
82

THE IMPLEMENTATIONS OF SPARQL
Figure 3.17: Architecture of Virtuso Universal Server. Source: Openlink Software (2008).
ing SPARQL at the database engine level. SPARQL can be queried from SQL. There is also a
SPARQL endpoint available.
Figure 3.17 depicts the architecture of Virtuoso Universal Server. The biggest difference in the
functionality between commercial and open source edition is a virtual database feature and repli-
cation capabilities. Virtual database provides transparent dynamic access to external databases or
other data sources available in the Internet, like ontologies or metadata extracted from documents.
All the data is available through one Virtuoso platform and is accessible for deployed applications
or in the Internet, depending on the security policy. OpenLink Software proposes a concept of
Data Space as front-ends to integrated data sources. Data Spaces are personalized applications
deployed in Virtuoso that presents semantic data available in the database or derived from other
applications like blogs, wikis or galleries, in the form of Atom 1.0, RSS or RDF. SPARQL or
83

THE IMPLEMENTATIONS OF SPARQL
XPath can easily query them.
3.3.2. Documentation
Virtuoso Universal Server is a very complicated platform that supports a wide range of technolo-
gies. Because of that, all the features should be well documented in the user manual and the
examples of implementations should be presented in various tutorials. Virtuoso meets the require-
ments, but the quality is sometimes questionable.
The documentation of Virtuoso Universal Server is freely available on the company’s website –
http://virtuoso.openlinksw.com/. It is presented in the form of on-line book. Starting with the
overview and installation guide it provides descriptions of all Virtuoso’s functionalities together
with brief specifications of involved technologies. All topics are illustrated on various examples
that give an insight view into the involved technologies. Unfortunately some of the features are
covered very briefly – the reader may have a feeling that the documentation is written for people
that already have some experience with the product. In addition, the organization of the manual is
sometimes chaotic. The linking between related topics is not sufficient.
The examples of implementations are also available on tutorial page. It presents a number of
sample scripts showing the Virtuoso’s functionalities in real applications. Some of the topics are
covered by animated tutorials. The issues encountered by users can be presented on the support
forum. Registered users can also communicate with support provided by OpenLink Software.
However once again all the information are not easily accessible from the main page.
The open source version of Virtuoso has dedicated wiki where the documentation is published.
However apart from the history section, detailed description of functionality and installation guide,
there are only a small number of topics covered there. What is more the articles are either copied
from the documentation of commercial product or presented very briefly. The slight difference in
functionality between open source and commercial edition of Virtuoso makes the documentation
of Virtuoso Universal Server very useful while deploying its free edition, however there are some
inconsistencies that are not emphasized. Open source edition is also supported by mailing list
hosted on Sourceforge.net.
84

THE IMPLEMENTATIONS OF SPARQL
Figure 3.18: OpenLink Virtuoso Conductor.
3.3.3. Installation
OpenLink Virtuoso is available in two packages - the source code in tar.gz format and Windows
binaries. The first package contains all libraries required for compiling the server together with
sources of OpenLink Data Spaces and a number of packages that extend the functionality. That
includes Conductor, a tool for administrating the platform, tutorials, demo database and SPARQL
interfaces. When using binary distribution these packages can be downloaded in precompiled
versions.
Virtuoso can be installed on most popular platforms – Windows, MacOS X and various Unix/Linux
systems (HP/UX, Solaris, AIX and Generic Linux). Installation on Linux has some requirements
about the installed third-party packages like OpenSSL or gperf20. Virtuoso has significant space
requirements – 800Mb in total with all demo applications. When all the dependencies are resolved
the configuration should be performed. In regular case only ./configure script should be per-
formed, but at this point, there is a possibility to include some extensions. Virtuoso can be build20Gperf is a hash function generator available at GNU Project’s website.
85

THE IMPLEMENTATIONS OF SPARQL
Figure 3.19: OpenLink Virtuoso’s SPARQL endpoint.
to host scripts written in Java, .NET, PHP, Perl, Ruby or Python. After successful configuration
the regular compilation can start. The authors of the manual (Virtuoso Open-Source Edition 2008)
state that it should last about 30 minutes on 2GHz machine. On testing environment, the com-
pilation took about 4 hours to complete. The last step, make install command, installs the
compiled binaries to specified directories. At this point, the server is ready to be started. The first
run creates the empty database and installs Conductor package. Conductor is an administration
suite for Virtuoso. The server is available at http://localhost:8890/. The interface al-
lows configuring the modules, installing additional ones and provides direct access to the database
via Interactive SQL module. As the open source version does not provide the full functionality of
Virtuoso Universal Server (e.g. replication or virtual database), some of the tabs in Conductor are
disabled.
Virtuoso provides also a command line tool, isql, that acts as a client to the database. It enables
all the operations on database using SQL or SPARQL. The configuration of the server can be
changed by edition of the INI file placed in the database directory. There is also a SPARQL
endpoint available providing direct access Virtuoso’s RDF repository (Figure 3.19). The data set
86

THE IMPLEMENTATIONS OF SPARQL
can be also queried via Interactive SPARQL endpoint, which provides an Ajax graphical interface
for building queries (Figure 3.20).
Figure 3.20: Interactive SPARQL endpoint with visualisation of one of the test queries.
The installation of Windows binaries is covered by a separate manual. The commercial version of
the platform has an installation guide similar in some points to the open source version, but the
process slightly differs, e.g. license validation or installing Virtuoso as a server daemon.
3.3.4. Testing
The testing of OpenLink Virtuoso started with a short overview of the possible loading methods. It
turned out that the server provides different interfaces that could be used for uploading RDF. One
of the basic is the HTTP Post21 method used for uploading explicit triples via the popular protocol.
Smaller files can be loaded using similar HTTP Put method. Other means include uploading triples21HTTP protocol defines eight methods of communication between host and server. Post method submits the data
for processing on server’s side. Data is placed in the body of the request. HTTP Put method uploads a representation
of a specified resource to the server.
87

THE IMPLEMENTATIONS OF SPARQL
using SPARQL endpoint, WebDAV, Virtuoso Crawler that provides dedicated web interface or
even via SIMILE RDF Bank22. These methods simplify the integration of the server with external
applications and allow creating personalized RDF repositories. However the most universal tool,
which can be also used for uploading the Semantic Web data, is a command line client – isql.
Specific functions that can be executed through that interface allow uploading single triples and
large data sets. By default the triples are loaded into RDF QUAD table incorporated to either default
or specific graph, but can be also stored in users’ schemas or even WebDAV directories as files.
Dbpedia.org is using Virtuoso to publish the whole dataset on-line. The project is using MySQL
as back-end storage and the server as a SPARQL engine. What is more the on-line documentation
of Virtuoso uses the project’s triples in explaining some features of the server. It also contains an
example of script that can be used for automatic loading of larger data sets divided into several
files. The script was originally created for loading DBpedia’s data. The script with some modifi-
cations was used to load the data set prepared for testing purposes. It mainly uses the ttlp mt()
function, which is able to parse triples serialized in Turtle, and perform some additional logging. It
was designed to load data in several parallel threads, however when using CPU with one core it is
more effective to load one file at once. What is more, while loading data in Turtle syntax it might
happen that parallel sessions are failing due to non-reentrant parser. The script is also performing
a checkpoint after each file is loaded to ensure that data is stored in persistent storage.
The loading of the files started with adjusting the loading script. While executed it automatically
searched for the *.nt files in given directory and performed loading. The searching was done
using find command what resulted in non-alphabetical order of files submitted for loading. The
actual order with a summary of results is presented in Table 3.3. The loading process was divided
into two parts – the actual loading and the checkpoint. The first few files were loaded very fast –
the average time was below 1ms per triple. The fifth file, persondata de.nt surpassed that
value. The subsequent files were in various paces – the highest average loading time peaked at
39.1667ms per triple. There is no visible trend in results of loading the data set related to the
file size. However all three files containing relations between articles and labels and both files
presenting short abstracts had much higher average loading times than the others. Commit times22RDF Piggy Bank is a Firefox extension developed within the SIMILE’s project conducted by MIT. It allows creat-
ing a local RDF mashup based on metadata extracted from websites or RDF repositories. Piggy Bank provides means
for searching and sharing local repositories. Source: http://simile.mit.edu/wiki/Piggy Bank, [10.07.2008].
88

THE IMPLEMENTATIONS OF SPARQL
File No. of triplesLoading Checkpoint
Time (ms) Avg (ms) Time (ms) Avg (ms)
links quotationsbook en.nt 2 523 755 0.2992 229 0.0908
infobox en.reduced.nt 269 355 83 516 0.3101 1391 0.0052
links gutenberg en.nt 2 510 1181 0.4705 697 0.2777
infoboxproperties en.nt 65 612 21 352 0.3254 2 731 0.0416
persondata de.nt 569 051 659 558 1.1590 5044 0.0089
shortabstract en.nt 2 180 546 34 800 747 15.9596 43 469 0.0199
categories label en.nt 312 422 2 474 279 7.9197 1 637 960 5.2428
articles label fr.nt 293 388 6 735 321 22.9570 2 643 139 9.0090
articlecategories en.part2.nt 3 136 876 7317384 2.3327 385176 0.1228
articles label en.nt 2 390 513 10 235 709 4.2818 6 794 905 2.8424
shortabstract pl.nt 179 742 7 039 908 39.1667 4 270 809 23.7608
articlecategories en.part1.nt 3 000 000 23 690 353 7.8968 627 560 0.2092
articles label pl.nt 179 748 6 801 260 37.8378 5 962 858 33.1734
paisley.nt 1494603 6 609 065 4.4220 2 797 931 1.8720
Total 14 076 889 106 470 388 25 173 899
Average loading time 7.5635 1.7883
Table 3.3: Summary of loading data into OpenLink Virtuoso.
also varied. They were rather related to the actual situation in the file system than to the amount
of processed data. The overall processing time took approximately 36.5 hours with almost 30
hours spent on loading and about 7 hours used for committing. The average triple was loaded in
7.5635ms, while writing it to persistent storage took 1.7883ms.
OpenLink Virtuoso loaded the triples into the main database creating a number of tables using
denormalized schema. Every URI is stored in RDF OBJ table. The explicit triples are stored
in RDF QUAD table containing references to the actual values of URIs. Additional tables. like
RDF DATATYPES or RDF LANGUAGES, improves the performance.
After loading the files the evaluation of the test queries against OpenLink Virtuoso started. The
first set of tests was performed on Virtuoso without performing any special actions, like recreating
89

THE IMPLEMENTATIONS OF SPARQL
indexes. However the documentation advices to adjust and rebuild the indexes which is shown on
DBpedia as an example. In addition, it is recommended to refresh manually the synchronization
between the full text searching index and indexing rules. The summary of query evaluation times
is presented in Table 3.4. The first query testing full text searching capabilities was evaluated
in a very long time – 29 495 710ms, approximately 8 hours. The next query did not manage to
finish, after 24 hours of processing the process was killed manually. The same situation happened
with query number 3, however this time it was stopped after 12 hours. Query number four finally
managed to return the expected results, which took 4 915 957ms. The next query had to be stopped
– after 12 hours of processing there were no results returned. Query number six and seven were
evaluated very quickly comparing to the previous ones. However it has to be stated that in the case
of the unsuccessful queries the compiler did not return any error. Due to low performance of the
database engine, it was decided to stop the processings. Query 8 behaved differently – the first part
returned empty result set. Even the query without filtering clauses returned no results. After some
experiments it turned out that the FROM clause has to be replaced with the FROM NAMED clause.
The documentation advised also granting some additional roles to SPARQL user for allow it using
remote graphs. Finally, the simple query returned the triples from the remote graph. However
when testing the full query number eight it was still resulting in empty data set.
QueryOpenLink Virtuoso OpenLink Virtuoso Indexed
Isql Test 1 (ms) Isql Test 2 (ms) Isql(ms) Twinkle(ms)
Query 1 29 495 710 2 503 160 2 195 937 2 181 203
Query 2 × × 480 1 515
Query 3 × × 12 602 13 813
Query 4 4 915 957 4 785 866 448 390
Query 5 × × 2273 2797
Query 6 138 158 83 156
Query 7 168 804 202 310 962 1 036
Query 8a × × × ×
Query 8b × × × ×
Table 3.4: Summary of evaluating test queries on OpenLink Virtuoso.
90

THE IMPLEMENTATIONS OF SPARQL
All the unsuccessful queries contain a part which employs text searching capabilities. It was
stated in the documentation that very low efficiency while searching strings might be noticed if
the database is not properly indexed. Following the manual the function, which adds the rules for
text indexing, was called. It took 3 315 823ms to finish the operation. Then a proper function was
used to synchronize RDF text indexes manually and the queries were evaluated once again. The
query number one, which only examines text search capabilities, was processed approximately
11 times faster than previously (29 495 710ms versus 2 503 160ms). Surprisingly the next query
did not finish – after five hours of processing it was stopped. The following was stopped after
one hour of void evaluation. Query number four returned expected results in time comparable
to the previous run. The next query did not return any results so the processing was stopped
after two hours. Query six and seven were evaluated with almost the same results as during the
first attempt. Finally, GRAPH queries did not return any results. This time the queries two, three
and five were processing much longer than expected. This is probably because the RDF QUAD
table was not properly indexed and the queries have very complicated execution plans that without
indexes required multiple full table scans.
The next attempt was proceed with the reindexing of triples table and changing its structure. The
layout of the table had to be changed to improve the performance of queries, which are not speci-
fying graph. Following the documentation the temporary table was created as a copy of main table
(99 217 780ms, approximately 27.5 hours). The original RDF QUAD table was dropped, the opera-
tion took 17 590 234ms, and the temporary table was renamed. Finally three bitmap indexes were
created – opgs, pogs, gpos, and text index synchronized. Examining the first query showed
a slight improvement in performance. However the next queries were completed in much shorter
time. Finally, the queries that were failing before, returned the data sets in very reasonable time.
The difference in performance of Virtuoso with and without proper indexing can be observed on
the timings of query number four – the final test shows it could be evaluated approximately 11 000
times faster. The difference is also noticeable in the case of a query number seven, which returned
the result set in about 180 times shorter amount of time. As expected both queries with GRAPH
clauses were not evaluated as required.
The last test was repeated using Twinkle. The results were comparable, however a bit bigger than
when using isql. This can be explained by the delay between the instance of Twinkle and HTTP
server. Using Twinkle for evaluating the queries required a small change in the configuration of
91

THE IMPLEMENTATIONS OF SPARQL
Virtuoso – the original estimated query time (120s) was too low to handle query number one. The
summary of the above tests is presented in Table 3.4.
Generally speaking the test of OpenLink Virtuoso showed that it is offers efficient RDF repository.
Loading process is very straightforward and can be automated. Unfortunately the repository is
not ready to use just after loading is done. The user can be very surprised with the very low
performance at the beginning. Further studies of documentation unveil the actions that has to
be taken to improve the performance. Evaluating the test queries showed that proper indexing
is a prerequisite of efficient querying. Without the indexes, some of the queries were processing
extremely long without any results. After adding bitmap indices, the obtained results were far
smaller than the previous ones. Unfortunately Virtuoso is still not capable for appropriate handling
of GRAPH queries. It can use remote graphs, but queries cannot be complicated or combined with
the local graphs.
3.3.5. Summary
OpenLink Virtuoso is a product with a very interesting history. The previous works on implement-
ing the concept of ORDBMS and a set of multiplatform ODBC drivers resulted in an universal
server that is able to integrate data from various sources – databases, files or the Internet. The
overall picture complements a set of very popular technologies, like XML, support for SOA or
integration with the Internet. Virtuoso heavily supports RDF as one of the main technologies for
exchanging data. Its architecture allows to create single view of corporate data accessible for end
users.
The product is available for a set of popular platforms. The installation on Unix systems involves
configuration and regular compilation. Its open source edition has limited functionality – it does
not allow creating virtual databases. The level of product’s complexity enforces the quality of
documentation. Virtuoso’s manual is so extensive that the navigation between pages sometimes
becomes difficult. Unfortunately, despite its size there are some issues that has not been described
there. Some recommendations are not linked to the main topics and not all functions are covered.
Actually, the configuration of the server sometimes relies on trial and error method.
The testing of Virtuso showed that although the data loading process is rather straightforward, the
proper configuration of the server is a necessity. The data set was loaded relatively fast. However,
92

THE IMPLEMENTATIONS OF SPARQL
the whole process had to be extended by additional creation of proper indexing scheme, which was
not communicated directly in the documentation related to loading. Evaluating queries without the
indices was very time consuming. Any monitoring tool could have minimized this. Right now the
user can only rely on laconic information available in isql. It also turned out that some errors are
not properly described in the documentation and the user can only report them to support. Finally,
the repository turned out to be very efficient RDF storage that provides multiple interfaces for
accessing the data.
Generally speaking OpenLink Virtuoso is a very complex product, that could be employed in
advanced systems. Unfortunately, the quality of the documentation is sometimes questionable.
The performance of the server is very promising, but the optimization of database remains not
fully described. There is also a need for some additional monitoring tools.
3.4. Jena Semantic Web Framework 2.5.5 with ARQ 2.2, SDB 1.1 and Joseki 3.2
Jena Semantic Web Framework is an open source framework that provides means for manipulat-
ing RDF graphs. The development of Jena originally started as a research project at HP Labs. The
Semantic Web Group based in Bristol started to work on Semantic Web technologies since 2000
helping to establish new standards23 and conducting research on the key technologies. Nowa-
days Jena became one of the most popular programming toolkits used for building Semantic Web
applications. A wide community of developers supports it.
ARQ is one of the extensions to Jena that also comes from HP Labs. It is a query engine that
provides an implementation of SPARQL and allows querying Jena’s datasets. ARQ is also used
by Joseki, which provides a web interface for querying RDF using SPARQL. Joseki is another sub-
project of Jena that originates from HP Labs. Although Jena supports natively persistent storage
of its datasets, HP Labs proposed a separate component for more effective RDF storage. SDB
is a SPARQL database for Jena that uses standard RDBMSs to store RDF. It can be used as a
standalone application or managed through Jena.
At the beginning of the year 2008, a version 2.5.5 of Jena Semantic Web Framework has been23HP Labs’ employees are working in a various W3C Working Groups. Andy Seaborne is a member of RDF DAWG
and was an editor of SPARQL specification. Jeremy Carroll and Brian McBride are valid contributors to RDF and OWL
standards. Source: http://www.hpl.hp.com/semweb/standards.htm, [5.06.2008].
93

THE IMPLEMENTATIONS OF SPARQL
released together with version 2.2 of ARQ engine. Joseki is a separate application – its latest
version, 3.2, was released at the beginning of August 2008. SDB is a relatively new project.
Stable version 1.0 of the storage was published at the end of 2007. Recently an improved 1.1
version appeared.
All four projects were launched in HP Labs. However, from the very beginning they were freely
available with no direct commercial versions. The copyrights of these applications belong to
Hewlett-Packard Development Company, but they are licensed under BSD-style licence that as-
sumes free use, modification and redistribution of software with recognition of original copyrights.
The source code of the applications is available in CVS or SVN repositories hosted on Source-
forge.net portal. The appropriate download links are available on the projects’ websites.
3.4.1. Architecture
Jena is a framework written in Java. It provides programming API for handling RDF graphs
serialized in various formats: RDF/XML, N3 and Turtle. Jena has a number of internal reasoners
and also provides a support for using external ones. This is being done by Jena Ontology API,
which acts as an extension to main RDF API. Although the API is language neutral, it can be used
for reasoning over RDFS, OWL and DAML+OIL ontologies.
RDF graphs in Jena are simply abstracted and presented as models. The biggest advantage of
the approach supported by Jena’s rich API is the possibility to manipulate graphs according to
requirements. The graphs can be presented in multiple ways enabling easy navigation through
the structure of the data set. The models can be fed by triples stored in files, databases, inferred
or in-memory graphs. Figure 3.21 presents a simplified architecture of Jena with emphasis on
processing triples from persistent storage. In that case, applications are intended to use a higher
abstraction graphs that are being translated into more specific set of triples and atomic operations
on triple store.
Jena’s models can be easily queried using core API, RDQL or SPARQL. The first method is very
primitive as it is based on listing statements in the model. Two other methods are provided by
ARQ, a query engine for Jena. It can be used for querying local or remote graphs and translating
semantic query languages into SQL. ARQ also provides a programming API, that can be deployed
94

THE IMPLEMENTATIONS OF SPARQL
Figure 3.21: Architecture of Jena Semantic Web Framework version 2.5.5. Source: Wilkinsonet al. (2004).
in external applications. However, it is a part of Jena and can be used from Jena’s API. One of the
stages of processing query is optimization. ARQ query optimizer is employed at the basic graph
pattern generation stage. It uses cost based algorithms for joined triple patterns to reorder triples
in the basic graph patterns and in result minimise the cardinality of intermediate results. Some
features of ARQ go beyond the official SPARQL specification. Apart from SPARQL/Update
extension ARQ supports basic federated query, that executes remotely only part of the query,
GROUP BY queries and aggregations.
ARQ is a part of Joseki – a SPARQL server for Jena. Joseki provides HTTP access to RDF triples
stored in files or external database. It is a J2EE servlet that can work as a standalone application
thanks to the preconfigured Jetty24 web server. Joseki can be also deployed using external web
server, e.g. Tomcat. Joseki can process SPARQL queries on defined datasets or can dynamically
call remote graphs.24Jetty is an open source HTTP and servlet container written in Java. Thanks to its small size and config-
uration capabilities it is often used for providing web services in embedded Java applications. Jetty homepage:
http://jetty.mortbay.com/jetty-6/, [6.06.2008]
95

THE IMPLEMENTATIONS OF SPARQL
SDB is a relatively new software. It is Jena’s component that provides efficient storage for RDF
on the base of regular RDBMSs easily integrating with most of the popular products, e.g. Oracle
10g, MySQL, PostgreSQL, IBM DB2. SDB is generally designed for serving SPARQL queries.
It uses ARQ for querying graphs and can be easily managed through Jena’s API. SDB provides
also a simple API for direct integration with external applications.
Jena and ARQ are integrated components. Joseki and SDB are using ARQ for querying SPARQL
data stores. In addition, Joseki can be configured to use SDB as a data source. All four applications
are interconnected and complement to each other creating a coherent platform for storing and
retrieving triples that can be accessed locally by external application or via Internet.
3.4.2. Documentation
Although all four applications come from the same laboratory, they do not have joint website
neither documentation. The exception is ARQ, which is described as the subsection of Jena’s
website. The documentation for Jena is available only on its website hosted by Sourceforge.net
– http://jena.sourceforge.net/. It contains a description of Jena’s API in the form of manual and
Javadoc and manuals for processing ontologies and using inference engine. There is also a brief
section about tools provided by Jena, list of external tools that were designed for the framework
and a list of HowTo’s that describe solutions for particular problems. ARQ documentation starts
with a tutorial about SPARQL. Similarly, to Jena’s documentation, there is a description of ARQ
API and a short manual about command line utilities provided by ARQ. The following section
contains descriptions of the features derived from SPARQL specification and provided by ARQ
extended with some implementation notes. Finally the documentation provide some examples of
the usage of functionality that is beyond the actual specification of SPARQL – federated queries,
grouping and aggregating results or updating RDF graphs.
Joseki has a separate webpage with all the available documentation – http://www.joseki.org/. The
documentation is very brief. It contains a short “Quick Start” manual, a section about configuration
and a short introduction into the implementation of SPARQL protocol that Joseki supports. The
documentation of SDB is a bit more complex. It is available at Jena’s wiki page hosted by HP
– http://jena.hpl.hp.com/wiki/SDB. What is interesting there is no information about Jena at that
wiki. The documentation starts with installation manual and “Quick Start” section. Further, the
96

THE IMPLEMENTATIONS OF SPARQL
command line tools are described and the detailed configuration of SDB is presented in a few
separate sections. Integration with external applications and with Joseki is covered in the next
section. Finally, there is a user manual about loading and querying data and some database-specific
notes.
The websites of all four applications are simple and have layouts very similar to each other. Most
of them are hosted at the same repository. Generally speaking the quality of the documentation is
acceptable, however the majority is not for the beginners. There is a lack of detailed description
of architecture or suggestions on configurations other than suggested. The good point is that
most of the topics are backed with a number of examples, however not all of them are working
perfectly. The support for all the applications is provided by the community of developers through
a Jena-Dev mailing list hosted by Yahoo.com.
3.4.3. Installation
The applications can be freely downloaded in the form of zip archive. Their requirements are
very low – for operating they need Java 5.0 or newer. In addition, appropriate JDBC driver has to
be installed if any of the packages are going to be used with external RDBMS. In the case of SDB,
the presence of database is obvious. Thanks to the interoperability of Java, the applications can be
installed on almost every operating system.
All the packages are coming with a copy of the documentation available on-line, required libraries
and a set of test cases and examples of implementation. Jena contains ARQ as an internal mod-
ule. The installation on Unix environment is very straightforward – requires setting JENAROOT
environmental variable. Jena provides a test script, which runs regression tests on the installation.
Generally speaking Jena is a library for handling RDF, but the distribution contains a number of
scripts that allows to query the models using ARQ. In addition, Jena provides a command line
utilities that simplify the access to some commonly used functionalities, like testing models or
parsing triples serialized in N3 format and storing models directly in the database. ARQ provides
a similar set of tools for querying models.
The functionality of Jena can be extended using additional packages developed by the community.
The list of them is available on Jena’s website. That includes NG4J providing API for named
graphs or OWL-Tidy, which reports problems with OWL ontologies.
97

THE IMPLEMENTATIONS OF SPARQL
ARQ can be also downloaded as a separate package. It contains ARQ as a jar library and a set
of command line tools. The installation finishes at setting ARQROOT environmental variable and
adding ARQROOT/bin/ directory to PATH variable. The package also contains a test script and
a number of data files for testing purposes with a significant number of examples.
Joseki comes with a preconfigured Jetty web server. The package also contains required li-
braries, including Jena and ARQ, a copy of on-line documentation and data files available for
testing. Installation is also very simple – requires setting up the appropriate environmental vari-
able (JOSEKIROOT) and edition of configuration script. The included script runs the server,
which is available at http://localhost:2020.
SDB to be fully operational requires RDBMS, which is going to be a back-end of the server. The
package contains required libraries – also Jena and ARQ, documentation and a set of testing data.
In addition, a wide range of command line tools is included that allows to manage and query RDF
repositories. The installation steps include setting the appropriate environmental variables and
creating a configuration file. This can be done using the included templates. For integrating SDB
with Joseki the configuration of web server has to include the specification of SDB-implemented
dataset. SDB package also contains a testing script, which is very helpful for checking the config-
uration of RDBMS.
3.4.4. Testing
The testing of Jena with its sub-projects started with the proper installation of the packages. In
fact to create a database-backed RDF repository only SDB has to be installed. The package con-
tains already Jena and ARQ stored in the form of libraries. Creating repository using SDB is very
simple – it requires proper configuration file and execution of one script. SDB supports a num-
ber of database layouts, where layout2/hash and layout2/index are the main ones. In
layout2 SDB creates a database consisting of 4 tables. The main one, Nodes, stores the URIs.
The triples from the default graph with the references to specific URI values are kept in Triples
table. Similar mechanism, but used for storing named graphs, is implemented with Quads ta-
ble. The last table, Prefixes, stores prefixes. Nodes table has two forms - index-based and
hash-based. The difference is in primary keys – the first form uses 4-byte sequences as a primary
key and contains additional column with hash values used for indexing, while the second one uses
98

THE IMPLEMENTATIONS OF SPARQL
only 8-byte hash values for both. The index-based layout is very efficient while loading, but the
hashed form performs better in querying.
Figure 3.22: Graph comparing loading times for SDB using different backened.
SDB supports many popular databases including MS SQL, Oracle, MySQL and PostgreSQL. For
testing purposes two open source RDBMSs were chosen. The tests were performed on MySQL
and PostgreSQL using both main database layouts. First tests were conducted on MySQL with
index-based layout. SDB uses command-line scripts for loading files, what together with bash
scripting simplifies the automation of loading. The documentation suggests creating repository
in three steps – configuration, then loading files and afterwards creating indexes. This is much
more efficient than creating indexes at the beginning. The actual loading is very straightforward,
requires the execution of sdbload script with the file name containing triples. The loader is
using efficient algorithm that divides the data into blocks of 20 000 triples, which are loaded
to mirror tables in database. Afterwards the RDBMS-specific query is copying the data from
temporary tables to the main ones removing the duplicates. SDB loader is reporting the speed
of loading of each chunk of data. What is more at the end it is providing a short summary
with the overall operation time. The loading started without any problems and was proceed-
ing very smoothly. The summary of loading times is presented in Table 3.5. SDB was very
stable until the last two files containing short abstracts of the articles. While proceeding with
99

THE IMPLEMENTATIONS OF SPARQL
shortabstract en.nt SDB was reporting syntax error caused by the escape sequence ∖U.
The triple with the sequence was not loaded into the repository. This situation happened multiple
times. However the most serious error appeared by the end of the processing. The loader returned
an exception caused by one of the Jena’s classes and stopped processing. What is interesting the
investigation showed that the last triple in the file was loaded into repository. It seems like the
loading failed just after finishing processing the data. Because of that the summary was not dis-
played and the overall loading time of the file presented in Table 3.5 is just an estimation based
on speed of loading the last few chunks of data. The same situation happened while proceeding
with similar file, shortabstract pl.nt, which contains abstracts of articles but in Polish.
Firstly some of the triples were not loaded due to illegal escape sequence, then the loading was
not finished correctly due to Jena’s exception. Analysing the statistics of loading data to MySQL
with indexed layout it can be noticed that only 2 files were loaded with speed of around 35ms
per triple (articles label fr.nt and categories label en.nt). Two smallest files,
links gutenberg en.nt and links quotationsbook en.nt, were loaded relatively
slow. This is caused by the loading process – firstly the Java classes has bo initialised, which takes
approximately the same amount of time in every case, then the actual processing and loading of
triples starts. The files containig short abstracts were loaded relatively fast comparing to amount
of text that had to be processed. After loading the files the indexes has to be created. This is being
done using sdbconfig script and in that case took approximately 24 hours.
The following tests included loading files to MySQL with hashed layout and both layouts in Post-
greSQL. They were very similar to the first one and were encountering the same errors. Only
loading times differ. The documentation says that hashed layout is slower than indexed layout
while loading data. However, when comparing loading statistics obtained from tests conducted
using MySQL, the differences are significant. The file articles label fr.nt was loaded
with the speed of 62.0436ms per triple. The fastest one was the first file,
articlecategories en.part1.nt, loaded with the pace of 5.8238ms per triple. Although
the use of hashed layout might result in longer loading, very important factor was the MySQL’s
data file management. SDB is using InnoDB as a database engine for creating repository in
MySQL. InnoDB is a good choice while processing transactions as it ensures advanced trans-
action isolation, however the performance of selections is not impressive. What is more MySQL
keeps the data managed by InnoDB engine in one big data file, what may cause slower perfor-
100

THE IMPLEMENTATIONS OF SPARQL
mance as managing large file requires more I/O operations at the operating system level. After
finished loading the indexes were created, what took approximately 44.5 hours (160 702 181ms).
The tests performed using PostgreSQL encountered the same problems as before. First loading
was performed using indexed layout. It was finished in reasonable time – the lowest speed was
noted while loading articles label fr.nt and shortabstract pl.nt, however the
last file has only estimated loading time. The highest pace was encountered while loading the first
file in the set. The indexes were created after finished loading, what took 793 466ms. The last
test was performed on SDB using PostgreSQL and hash layout. This time the overall loading time
was a bit longer. However the highest time per triple was smaller than previously – 41.5593ms per
triple in the case of categories label en.nt. The lowest time per triple was observed while
processing articlecategories en.part1.nt – 3.0410ms per triple. Creating indexes
after finished loading took 918 804ms.
The comparison of loading times observed while testing SDB is depicted in Figure 3.22. It is
being shown that the fastest configuration was the MySQL with index layout. The overall loading
process took approximately 32 hours with the average speed of 8.2705ms per triple. The same
RDBMS but with hash layout performed much worse achieving the speed of 22.1185ms per triple
and accomplishing the task in approximately 86.5 hours. However in that case there was significant
impact of the architecture’s performance – when the repository was stored in one separate file
for each database using InnoDB engine not the single one for all data, the efficiency would be
much better. This can be observed in the case of PostgreSQL where the difference in processing
speed between the layouts is much lower. PostgreSQL with indexed form has finished loading in
approximately 58,5 hours with the average speed of 14.9706ms per triple. The same RDBMS but
with hash layout finished the processing in 70.5 hours spending 18.0530ms for loading each triple.
Analysing the trends in average loading times it can be spotted, that the first files are processed
faster than the following ones. The probable cause is the size of the database which is increasing
and complicating the searching, especially when there are no indexes. Figure 3.23 shows the com-
parison of average loading times. It can be seen that the properties of data, rather unique in each
file, has an impact on its loading time. There is a visible trend – files with a large number of unique
triples were loaded with the highest speed (infobox en.reduced.nt and paisley.nt).
101

TH
EIM
PL
EM
EN
TAT
ION
SO
FS
PAR
QL
File No. of triplesMySQL Indexed MySQL Hashed PostgreSQL Indexed PostgreSQL Hashed
Time Avg Time Avg Time Avg Time Avg
articlecategories en.part1.nt 3 000 000 8 052 900 2.6843 17 471 300 5.8238 8 438 640 2.8129 9 122 928 3.0410
articlecategories en.part2.nt 3 136 876 11 493 760 3.6641 37 012 782 11.7992 37 060 499 11.8145 25 775 098 8.2168
articles label en.nt 2 390 513 24 206 642 10.1261 88 451 509 37.0011 50 224 367 21.0099 72 050 570 30.1402
articles label fr.nt 293 388 6 451 873 35.8940 11 152 212 62.0436 9 316 316 51.8299 10 343 324 35.2548
articles label pl.nt 179 748 4 352 178 14.8342 6 999 086 23.8561 5 504 439 18.7616 6 441 692 35.8374
categories label en.nt 312 422 11 119 161 35.5902 12 421 024 39.7572 15 229 827 48.7476 12 984 045 41.5593
infobox en.reduced.nt 269 355 1 009 110 3.7464 4 294 236 15.9427 1 808 335 6.7136 3 612 225 13.4106
infoboxproperties en.nt 65 612 540 272 8.2343 1 614 423 24.6056 724 923 11.0486 1 204 855 18.3633
links gutenberg en.nt 2 510 53 317 21.2418 103 162 41.1004 63 205 25.1813 94 324 37.5793
links quotationsbook en.nt 2 523 65 436 25.9358 93 746 37.1566 73 079 28.9651 84 117 33.3401
paisley.nt 1 494 603 3 284 330 2.1975 21 338 703 14.2772 7 536 950 5.0428 18 993 459 12.7080
persondata de.nt 569 051 3 333 169 5.8574 7 221 688 12.6908 5 460 092 9.5951 5 715 237 10.0435
shortabstract en.nt 2 180 546 39 744 200 18.2267 94 981 340 43.5585 59 864 250 27.4538 81 638 880 37.4397
shortabstract pl.nt 179 742 2 715 881 15.1099 8 205 151 45.6496 9 435 071 52.4923 6 069 790 33.7695
Total 14076889 116422229 311360362 210739993 254130544
Average loading time 8.2705 22.1185 14.9706 18.0530
Table 3.5: Summary of loading data using SDB.102

THE IMPLEMENTATIONS OF SPARQL
After loading all the files into repositories and creating indexes each of them was tested using test
queries. The repositories were queried via command line script provided with SDB (sdbquery)
and Twinkle. The script is similar to the previously used. It shows the overall processing time and,
what is especially interesting, all the steps taken to evaluate the query and plan it execution includ-
ing the actual SQL statement passed to the RDBMS. Twinkle itself is using Jena for manipulating
graphs, however to connect it with repositories created by SDB there is a need to use Joseki, an
HTTP interface to RDF storage. Connecting SDB-backed repositories to Joseki is rather straight-
forward, but not well documented. The appropriate Joseki configuration file, that contains details
of dataset that is going to be used, was created using trial and error method. Fortunately it finally
made Joseki to recognise the repositories.
Figure 3.23: Graph comparing average loading times for SDB using different backened.
First set of test queries was processed against repository created on MySQL with index layout
and conducted using command line script. Unfortunately the query number one caused processing
errors. It turned out that SDB decoded the SPARQL query into SQL statement that was returning
the whole dataset as a result. This caused a Java out of memory exception. The default value
for Java’s heap space is 64Mb, however even changing the value to 400Mb was still causing the
error. SDB with Jena was not able to create an efficient query that would be able to perform a
full text searching over the dataset. The following queries were evaluated without any problems.
103

THE IMPLEMENTATIONS OF SPARQL
However processing queries number three and five required significantly more time than in other
cases. They also require a full text searching over a fraction of dataset and a number of joins.
The CONSTRUCT query was the worst performer (14 740 242ms) even though it does not require
so many joins like the query number three (250 924ms). The comparison of the query times is
presented in Table 3.6. Unfortunately when evaluating the GRAPH queries it turned out that SDB
is not able to use external graphs. The simplified query returned some results, however the query
used a graph from internal repository, not the external one. The more complicated version of the
query returned an empty data set. While using Twinkle for querying MySQL-based repository
with index layout the results were comparable. An attempt to process the first of the queries
returns and HTTP error. The following queries are processed without any interruptions. The
timings are also similar. Twinkle is performing better while evaluating simpler queries. When
they are more complicated SDB script is more efficient. However the differences are very slight.
Very interesting situation happens when processing the simplified GRAPH query – Joseki allows
to use external data sources. It only requires a small change in the configuration file. Afterwards
Twinkle passes the query to Joseki servlet which determines if the internal SDB-backed repository
should be used or it should use external data set. The simplified version of the query number eight
returned expected results. Unfortunately the more complicated version, when there is a need to
use external and internal repositories, fails due to internal Joseki error.
Performing the same test on MySQL-backed repository but with hash layout brought the same
results – query number one failed due to Jena’s error and query number eight was fulfilled only
partially while submitted using Twinkle. However the timings differs. The queries number three
and five, which were very time consuming in the previous test, returned the result sets in more
reasonable time – 72 603ms and 4 134ms. This time the query with more joins required more time
than the CONSTRUCT query. It shows that hash layout performs much better while text searching
is required. The other results are comparable to repository built on MySQL with index layout. The
interesting thing is that Twinkle was returning results faster than SDB script, what was completely
opposite to the previous test.
The next test was conducted using repository based on PostgreSQL with indexed layout. In the
case of this RDBMS the procedure is similar, there is only a need to adjust a configuration file
to connect to the database. The errors returned this time were exactly the same as in the previ-
ous tests – queries number one and eight were not successfully processed. The difference was
104

THE IMPLEMENTATIONS OF SPARQL
Figure 3.24: Querying SDB repository using command line.
in performance. This time all the queries were evaluated much longer than in the case of both
configurations based on MySQL. Both queries number two and three needed more than 500s to
complete (543 038ms and 965 835ms). The query number five needed more than 19 hours to finish
(69 147 100ms). When using Twinkle that time was reduced to 55 061 218ms (approximately 15
hours). The following queries were processed in reasonable time, but still much longer than in the
case of MySQL. The same test done using Twinkle returned comparable results except the query
number five. In other queries the external application was a bit slower that internally executed
scripts.
Testing the PostgreSQL-based repository but built with hashed layout returned the same errors
as above. The results of the successfully processed queries were lower in most cases than in the
previous test. It is especially visible in the case of query number two and five. The query number
two was executed in reasonable time (4 324ms). The next query needed 6 810 587ms to complete,
which was much higher than in indexed based layout. The opposite situation was observed in the
case of the query number five when hash layout turned out to be more efficient than index layout.
DESCRIBE query was also executed longer by PostgreSQL with hash layout than with indexed
form. Conducting the same test using Twinkle returned lower results than previously, except the
query number three, when the result set was returned after 7 374 013ms.
105

THE IMPLEMENTATIONS OF SPARQL
QueryMySQL Indexed MySQL Hashed PostgreSQL Indexed PostgreSQL Hashed
Script Twinkle Script Twinkle Script Twinkle Script Twinkle
Query 1 × × × × × × × ×
Query 2 2 594 1 812 2 397 1 750 543 038 542 593 4324 3891
Query 3 250 924 256 687 72 603 76 265 965 835 973 703 6 810 587 7 374 013
Query 4 2 321 1 781 1 227 750 8 697 8 031 6 929 6 578
Query 5 14 740 242 17 459 236 4 134 3 796 69 147 100 55 061 218 3 967 769 3 972 687
Query 6 717 281 539 203 2 833 3 047 1 534 859
Query 7 2 759 3 406 3 754 7 000 6 722 7 531 23 413 11 359
Query 8a × 453 × 266 × 313 × 266
Query 8b × × × × × × × ×
Table 3.6: Summary of evaluating test queries on repositories managed by SDB.
Generally speaking the indexed layout was performing worse than hashed layout, which was es-
pecially visible in the case of full text searching. Only PostgreSQL is an exception as there were
no significant differences between the layouts. MySQL was processing queries faster than Post-
greSQL especially when comparing hash layout to other configurations. Even though loading data
into MySQL with hash layout was the slowest processing, that combination was able to evaluate
complicated queries in reasonable time. Comparing the results of test conducted using Twinkle
it has to be noticed that in general the timings are lower – Joseki has to use a kind of additional
optimisation before passing the queries to SDB-backed repositories.
3.4.5. Summary
Jena Semantic Web Framework is one of the most popular projects related to the field in the
world. It has been always very innovative thanks to the team which is taking significant part in
the development of the semantic technologies. Jena together with its extensions like ARQ, SDB
and Joseki, became a solid base for the Semantic Web applications. Thanks to its modularity
and openness it can be tailored to the most sophisticated projects. All of the components are under
heavy development – the code is changing almost everyday. Unfortunately there is not much effort
put on creating a consistent version of the product. Jena and its components provide a wide range
of APIs allowing to handle data in various formats and perform reasoning. The graphs that are
106

THE IMPLEMENTATIONS OF SPARQL
Figure 3.25: Joseki’s SPARQL endpoint.
manipulated by Jena can be queried in a number of ways including SPARQL. Here is where ARQ
is used. It can be also implemented into the structure of the external application. The graphs can
be stored in RDBMS using SDB and exposed to the Internet via Joseki. Unfortunately due to its
dynamics the project is not well documented. Every component has its own set of documentation,
which mainly consist of the API description in the form of Javadoc. There are also brief HowTo’s
presenting main functionalities, but some of them are not accurate or complete leaving the user
with limited support. Sometime there is a need to use a trial and error method. The overall quality
of the documentation should be improved. The project itself, together with its components require
more detailed knowledge to be shared for the regular users.
Installation of Jena and its components is very straightforward. It usually requires only setting the
appropriate environmental variables and preparing a configuration file. The packages are freely
available on-line and contain a number of additional scripts and data that can be used for testing
purposes. SDB also requires an JDBC library to be installed. The testing proved that using Jena
with SDB is relatively simple. SDB package contains the scripts that automates the creating
repositories, loading data or querying data set. Setting up Joseki to communicate with SDB is
107

THE IMPLEMENTATIONS OF SPARQL
more demanding. The process of loading data is very user-friendly. Unfortunately it is not perfect
as some of the triples were not loaded and in the case of two files from the data set the process
was interrupted due to Java exceptions. Considering the performance Jena with SDB required a
significant amount of time to finish the loading. The most efficient configuration was MySQL
based repository with index layout. Included scripts allow also to query the repositories. To
provide an external access to the data set Joseki is needed. The testing showed that SDB is not
able to handle full text searching over a large data set. Other queries that also required this type of
searching were evaluated significantly longer than regular ones. It turned out that SDB is not able
to use external graphs. However when employing Joseki as a front-end to SDB external graphs
can be used to some extent. The fastest response time was achieved by the repository set up in
MySQL with hashed layout. PostgreSQL was performing much worse.
Jena is a very innovative project providing a wide range of functionalities. However because of
such dynamics it cannot be perceived as a stable and reliable product. The documentation should
be reviewed and improved. What is more there are still some cases that causes errors – Jena should
have the ability to perform full text searching optimised and handling external graphs should be
improved.
3.5. Pyrrho DBMS 2.0
Pyrrho Database Management System is a very light and efficient RDBMS for .NET framework.
Its development started in 2005 at University of Paisley under the supervision of Professor Mal-
colm Crowe. The name of the application is taken from the name of a Greek philosopher – Pyrrho
from Elis, the founder of the school of scepticism. Pyrrho assumed that the man should live relying
on sense perception and make decisions based on analyzing the reality around. The authors has
followed that approach – Pyrrho DMBS is gathering automatically many additional information
about its operations, what increases the level of truthfulness of the data and simplify the process
of investigating data quality issues.
Pyrrho is available in a number of versions. All of them contain the same database engine and
programming API, but include a different set of tools, which extends the functionality of the
RDBMS. The basic version, Pyrrho Personal Edition, is free to use and it is the most suitable
version for regular applications. Unfortunately, the database file size is limited and there is no
108

THE IMPLEMENTATIONS OF SPARQL
support provided by the developers’ team. Professional Edition is similar in capabilities to the
previous edition, but differs in the default security policy implemented in the web server. There
is an optional support provided. The Enterprise Edition is extended by a set of administrative
tools for managing database files including recovery, backup and creation of files, or enhanced
security. This is a commercial version and it is offered with a technical support. The Datacenter
Edition is another commercial version that is able to work in clustered environment. Thanks to
Pyrrho’s small footprint, it is able to work on mobile devices. Pyrrho Mobile Edition is designed
to work together with an Enterprise Edition – the local copy of data placed on a mobile device
is constantly synchronised with database server. The ability to cache the static data decreases
the network traffic. Beside the closed source editions, the open source version of Pyrrho is also
available. Its functionality is comparable to Professional Edition extended by the implementations
of Java Persistence and SWI-Prolog interfaces. The package contains also the source code of the
database.
Nowadays the development of Pyrrho DBMS has slowed down. The latest version of closed source
edition is 2.0 and was initially published in November 2007. The open source edition reached
version 2.0 in March 2008. However, during the testing the patched versions of both products
were revealed.
Pyrrho RDBMS is an intellectual property of the University of the West of Scotland25. The closed
source versions are licensed under standard end-user licence. Personal and Professional editions
are royalty-free and can be freely used, distributed and incorporated into commercial products.
The open source edition is not licensed under any standard licensing model – the license is the
same as commercial products. A number of unique improvements to database engine that Pyrrho
includes are subject to a patent application.
All editions of Pyrrho DBMS can be easily downloaded from its webpage – http://www.pyrrhodb.org/.
The commercial versions for operating need a license key that can be obtained from the cooperat-
ing portals.25The University of Paisley on 1st of August 2007 merged with Bell College creating Scotland’s largest university –
The University of the West of Scotland.
109

THE IMPLEMENTATIONS OF SPARQL
3.5.1. Architecture
Pyrrho DBMS is a very compact, but efficient database engine written in C# language. It supports
transaction processing preserving ACID properties and employing optimistic concurrency con-
trol26. Transactions are written directly to the storage. In addition, advanced auditing facilities are
provided – Pyrrho preserves the information about the changes made to the database. What is more
the full history of data is kept as the modifications appear to be new rows in the database. The data
is stored in Unicode. Pyrrho besides its small size is a scalable DBMS. It supports multi-threading
and can be deployed on clustered environments.
Pyrrho is a multi-user DBMS. It was designed in the client-server architecture. The communica-
tion is implemented using TCP-based protocol. Pyrrho provides also an access to databases via
built-in web server. However better security is ensured when using provided client tool.
Pyrrho DBMS supports SQL2003 standard of SQL language, which apart from the query capabil-
ities, provides also syntax for creating stored procedures. The external code is not supported. The
Semantic Web technologies were also implemented – the DBMS supports RDF with SPARQL and
queries written in XPath. There is a SPARQL endpoint available through the web server.
Figure 3.26 depicts the high-level overview of Pyrrho’s architecture. The database is usually stored
in one database file with *.pfl extension in the commercial editions and *.osp extension for
the open source version. Database files larger than 32Gb are splitted into segments. The data
is visible at the physical layer in the Log$ virtual tables that shows all data ever written to the
database. These tables can be used to trace back all the changes made to data, as the records
cannot be changed after writing them to the database file. In addition, transaction isolation is
implemented on the physical layer. The actual snapshot of the database is visible in the logical
layer. The SQL processor performs the queries on the logical view of the database preserving
transactions on the physical layer. The database server can be connected by client applications
via HTTP protocol or using Pyrrho connection library supplied in the form of DLL library or Java
package, which is available only in the open source edition. The additional tools available in the
Enterprise edition allow managing database files together with creating and recovering backups,
creating mobile checkpoints and perform security audits.26Optimistic concurrency control is a locking algorithm used in relational databases, which relies on assumption that
the transaction do not conflict with other transactions, so non-exclusive locks are used.
110

THE IMPLEMENTATIONS OF SPARQL
Figure 3.26: Architecture of Pyrrho DB. Source: Crowe (2007).
3.5.2. Documentation
The documentation of Pyrrho DBMS is enclosed to the package with the application in the form
of the MS Word document. It starts with the introduction to the manual and the presentation of the
philosophy of the database. Then the licensing model and the descriptions of particular versions
are presented. The following section presents the installation process and the architecture of the
DBMS. The next chapter presents client utilities, which are included into the package and covers
the SPARQL client interface provided by the DBMS. Then the details of designing and creating
database in Pyrrho are described. This chapter also presents the way SPARQL and RDF is han-
dled by the DBMS. The following chapter discusses the details of developing applications based
on Pyrrho. That mainly includes the different ways of connecting to the DBMS from external
software. Finally, the documentation presents in details the SQL Syntax of Pyrrho and states the
details of system tables used for administration purposes. The following chapters presents the
functionalities and tools specific for more advanced editions of Pyrrho.
The open source edition of Pyrrho contains also a very detailed introduction into the source code
of the DBMS. Every feature is described with the implementation details of the algorithms used
in Pyrrho together with the lists of the implemented classes.
111

THE IMPLEMENTATIONS OF SPARQL
Pyrrho’s website does not provide any additional manuals or documentation apart from the sam-
ple source code. The examples cover using SQL procedures and functions, implementing the
connection from applications written in PHP, ASP.NET, SWI-Prolog or using Java Persistence. In
addition, the SQL reference or the list of system and log tables is also available. What is especially
interesting there is also a summary of informal tests against the TPC Benchmark27.
The quality of the documentation of Pyrrho DBMS is very high. The manual contains descrip-
tions of all the features extended by a number of examples. In addition, the introduction to the
source code might be very helpful in understanding the internal mechanisms and implemented
algorithms. However the reader may find the information in the documentation not perfectly or-
ganised, sometimes scattered in the whole document. Another drawback is the lack of the on-line
version.
3.5.3. Installation
All editions of Pyrrho DBMS are available on-line in zip packages. When downloading one
of the free closed source editions the one receives two sets of binaries – regular .NET version
and application compiled using .NET Compact Framework, which is designed to work on mo-
bile operating systems like Windows CE. Both contain the same functionality, except the web
server, which is not available in the compact version. The package with Pyrrho contains the
server (PyrrhoSvr.exe) and a set of clients. PyrrhoCmd.exe is a command line client.
PyrrhoMgr.exe is a WinForm application that allows browsing a single database including logs
and system tables. It also helps in importing data from external databases. Finally the Rdf.exe
is a client that provides a WinForm interface to interact with the RDF content of Pyrrho. It al-
lows loading and deleting triples. It also works as a SPARQL interface for querying the database
and displaying the results in a number of formats. All of these applications does not need any
installation steps and can be simply executed after downloading.
Pyrrho has very low requirements, only .NET Framework version 2.0 or later is needed for exe-
cuting the binaries. In other operating systems than Windows the Mono framework28 has to be27Transaction Processing Performance Council (TPC) is the non-profit organisation that works on standardisation of
transaction processing and database benchmarks that became very popular in evaluating performance of the database
backed computer systems. They provide an objective performance data to the industry.28Mono is an open source project lead by Novell that implements the Microsoft .NET architecture. It contains .NET
112

THE IMPLEMENTATIONS OF SPARQL
installed, the executables itself are platform-independent. Although Pyrrho can run on every pop-
ular machine, it has a high consumption of main memory. The documentation suggests at least
12Mb of RAM to be installed for the server and for efficient processing additional main memory
of about twice of the size of the database.
3.5.4. Testing
The testing started with loading the data set. At the beginning, some of the imperfections of Pyrrho
was found. The first attempt to launch Pyrrho in the testing environment failed due to the runtime
error. The reconfiguration and reinstallation of Mono framework did not resolved the problem,
so it was decided to continue the testing on the laptop with Windows XP and Microsoft .NET
Framework 3.0 SP1. The testing was intended to be conducted using the Professional and the
Open Source editions. Unfortunately, the Open Source version turned out to be less stable than
the latter one, so the actual tests were done using the Professional edition of Pyrrho.
Figure 3.27: Evaluation of the first test query against Pyrrho DBMS using provided RDF client.
compatible tools and compilers (e.g. C#) and just-in-time runtime engine.
113

THE IMPLEMENTATIONS OF SPARQL
The first step was to load the files. Loading first of the file from the data set
(articlecategories en.nt) was causing “System.OutOfMemoryException” error. That
was because the RDF client is loading the whole file into memory and then allows saving it to
the database. It turned out that Pyrrho needs smaller files with data. The appropriate selection of
triples was made using the same method as applied for preparing paisley.nt file. The data set
contains only triples used in the results of the test queries extracted from the files prepared for test-
ing. The files finally contained 296 267 triples with the size of 46 215 107 bytes. Most of the files
were around 2Mb or less. Only one, infobox en.nt, had the approximate size of 40Mb. The
first file from the data set was loaded successfully. Proceeding the next one caused “RDF excep-
tion: Bad escape sequence” error. The situation occurred while loading few other files. Another
files were causing “Invalid XML content“ errors. Both scenarios with some sample data were sub-
mitted to the support and resulted in a few patches. It also turned out that the version of Pyrrho had
some problems with improper handling of escape sequences (∖u), non matching parenthesis and
∖” characters. All problems had been solved by the support and the improved versions of Pyrrho
were published on the website. The testing was restarted with the updated Professional edition of
RDBMS. Almost all of the files were loaded correctly – the infobox en.nt data file was too
large for the server and was causing “Stack overflow” error. The solution was to partition the file.
Experiments with the file size showed that Pyrrho is able to handle around 30 000 of triples at once
with the size of around 5Mb. The original file was divided into 9 smaller files. Finally the whole
dataset was loaded creating the database file with the size of 26 124 288 bytes.
Pyrrho keeps the triples in one large system table – Rdf$, that contains six columns – subject,
predicate, object, graph, type and value. Every column has a dedicated index. The structure of the
database can be seen using Pyrrho Database Manager (Figure 3.28)
The evaluation of the test queries was done using provided RDF client (Figure 3.27) and Twinkle.
At the beginning of the test it turned out that the name of the database cannot be “sparql” – the
address of the SPARQL endpoint with sparql as the default data set is
http://localhost:8080/sparql/sparql. This configuration causes an error as Twin-
kle connects with Pyrrho via the web server and the last part of the URL defines the default data
set. After changing the name of the database into sparql1 the web server was able to recognize
the data set. The timings were measured during the first and the second execution of the query –
the second value is much lower as the required triples were already loaded into the main memory
114

THE IMPLEMENTATIONS OF SPARQL
Figure 3.28: Pyrrho Database Manager showing local database sparql with the data stored inRdf$ table.
during the first attempt. Unfortunately Pyrrho was not able to proceed all of the queries (Table 3.7).
The first query failed in Twinkle causing exception. The same query submitted using RDF client
returned the correct values. What is more the query processed directly via the Pyrrho’s web server
returned correct data. The situation might be caused by bug in Twinkle. The second query required
a minor adjustment – removing ∖" character. Afterwards it returned the expected values. Query
number three evaluated using Twinkle caused “HttpException: 404 Bad Request”. Processing the
same query with the provided client returned a bit different error. It turned out that the SPARQL
engine obtained literal when it was expecting RDF what caused a “Wrong Types” error. The error
message was a bit laconic and there was no possibility to trace back the exception or check the
data quality. The next query was handled correctly, however its complexity causes higher execu-
tion time. Query number five is based on the logics of the third query. However this time Twinkle
returned a “Query Exception” caused by Jena class. What is interesting the RDF client returned
the correct values of the CONSTRUCT query. This seems to be another incompatibility between
Twinkle and Pyrrho as the same query submitted via the web server’s site returns expected values.
The next query, which is evaluating the verity of the default graph, returns the correct value in
both client applications. Unfortunately, the query seven fails in both of them. Twinkle is returning
“HttpException: 404 Bad Request” error, while RDF client is reporting internal error caused by
115

THE IMPLEMENTATIONS OF SPARQL
RDF client Twinkle Time 1 (ms) Time 2 (ms)
Query 1√
× – –
Query 2√ √
172 94
Query 3 × × – –
Query 4√ √
13 703 12 594
Query 5√
× – –
Query 6√ √
3 922 2 750
Query 7 × × – –
Query 8 × × – –
Table 3.7: Summary of evaluating test queries against Pyrrho Professional.
inability to cast objects from one type to another. The last query that evaluates the possibility to
use external graphs fails as well. Both parts of the query causes similar “HttpException” error,
while the RDF client is returning RDF exception. The final check using web server’s site did not
returned any data, what means that Pyrrho is not able to handle remote graphs.
3.5.5. Summary
Pyrrho DBMS is a very compact multi-purpose database. It is a very promising project charac-
terised by an innovative approach to handling data, which is a subject of patent application. The
product line is established, however the licensing model need some clarifications. The architecture
of the DBMS is providing a wide range of functionalities, but the performance and the memory
consumption should be reconsidered. The documentation of the product is very detailed – it need
some reorganisation to improve the readability, but still offers a description of many details, espe-
cially the part describing the structure of the code enclosed to the open source edition. The lack
of on-line version is a small drawback.
When the architecture of Pyrrho is advanced, the implementation still needs some improvements,
especially in the case of the RDF client. The database server turned out to be quite unstable
causing “Stack overflow” errors. Loading data set using provided tools is very inefficient – the
files have to be relatively small, otherwise the server fails. What is more the interface of the client
is very poor and sometimes misleading – there is no information about the progress of data loading
116

THE IMPLEMENTATIONS OF SPARQL
and the error messages does not give enough information for tracking the error. The client does
not inform about the data quality issues. Some of the ones encountered during the tests had to be
tracked by the support. The evaluation of the queries showed that Pyrrho has some problems with
the built-in SPARQL endpoint and has some problems with handling already loaded RDF data.
Additionally is not able to perform queries over remote graphs.
Pyrrho DBMS is a very interesting implementation due to its size and the functionality. However,
the product needs some more testing to increase the stability and improve the performance.
3.6. AllegroGraph RDFStore 3.0.1 Lisp Edition
AllegroGraph is an efficient disk-based RDF database developed by Franz Inc. The development
of AllegroGraph started in 2004 and was based on the experience gathered through years of im-
proving company’s implementation of the Common Lisp29 language, Allegro CL, and an object
database designed for that environment – AllegroCache. Right now Franz Inc. is one of the lead-
ing suppliers of commercial RDF databases. Together with Allegro CL and other products like
reasoners or ontology modelling software it provides complex solutions for the Semantic Web.
Franz Inc. also provides consulting services and support for ontology-based systems built on their
technologies.
On 19th of May 2008 Franz Inc. announced the release of the version 3.0 of AllegroGraph. It was
called the first Web 3.0 database that provides features like social network analysis, geographic
and spatial data analysis and analysis of points in time.
AllegroGraph is available in two editions – a standalone server written in Java and a server in-
tegrated with Allegro CL environment. Every edition has three versions. The free version has a
limitation of 50 million of stored triples. The Developer version is able to handle up to 600 million
of triples while the Enterprise version has no similar limits. AllegroGraph is designed for 64-bit
architecture and this kind of configurations account for the majority of supported operating sys-
tems. The 32-bit versions are also available, but it is suggested to use them for up to medium sized
databases. All commercial editions can be evaluated for a period of time without any charges.29Common Lisp is a dialect of Lisp programming language. Lisp is the second-oldest high-level programming
language with the beginnings in 1958. It was originally created as a mathematical notation, but became very popular
for Artificial Intelligence programming.
117

THE IMPLEMENTATIONS OF SPARQL
In addition, the AllegroGraph Java API is an open source package licensed under Mozilla Public
License Version 1.1.
The free version of AllegroGraph is licensed by End User Licence Agreement, which restricts the
modification or distribution of the package and which does not offer any support. Commercial
edition of AllegroGraph is distributed under Franz Software Licence Agreement, which generally
distinguishes commercial and non-commercial users taking into consideration further redistribu-
tion of software created using that tool. Every edition requires an appropriate license key that is
being generated on-line and placed into the application’s directory during installation.
AllegroGraph in both available versions can be downloaded after previous registration from the
website of Franz Inc. – http://agraph.franz.com/allegrograph/. The license key can be obtained
on-line using the link provided in the e-mail sent after registration.
3.6.1. Architecture
AllegroGraph is a high-performance RDF persistent storage and application framework for Se-
mantic Web applications. Apart from storing triples, it provides a query engine that supports
SPARQL and Prolog queries. It is also able to perform RDFS/OWL reasoning using internal
reasoner or connecting to external applications.
AllegroGraph supports RDF/XML and N3 as input and output serialization format. To improve
the efficiency of the storage the indices are built after assertion of triples. Additional free text
indices simplify text searching. SPARQL sub-system is called twinql. It provides query optimizer
and support for named graphs. Prolog queries are alternative to SPARQL and can be specified
declaratively. Prolog is a part of native Lisp environment, however the Java version also supports
the queries.
AllegroGraph can be accessed via the implementation of Sesame 2.0 RESTful HTTP protocol
that supports both SPARQL and Prolog. The HTTP Server can be run as a standalone application
or as a part of Allegro CL. It provides a number of extensions including the creation of new
repositories or updating indices. Another way to communicate with the AllegroGraph is a Java
API that implements most of the Sesame and Jena interfaces for accessing RDF repositories. Using
some extensions, it provides an access to all features of the server and simplifies the integration
118

THE IMPLEMENTATIONS OF SPARQL
with the client applications. Finally, AllegroGraph is accessible using Lisp through the same Lisp
environment or connecting to the remote server.
Version 3.0 of AllegroGraph introduced advanced features like support for federated databases and
specialized datatypes that are used for analysing social networks, two-dimensional (geospatial)
and temporal information. AllegroGraph can connect to either local or remote stores. Federation
allows creating a virtual triple store from a number of standalone servers. Such approach simplifies
scalability and manageability of stores. Together with the support of multithreading it improves
the loading and response times.
Figure 3.29: High-level class diagram of AllegroGraph. Source: AllegroGraph RDFStore (2008).
Figure 3.29 depicts an abstract model of AllegroGraph’s classes that show the functionality of
the server. In fact, an open triple store is an instance of one of the classes. Concrete-triple-
store class stands for the real data stored in AllegroGraph. Federated class provides the access to
virtual triple store. Encapsulated-triples-store extends the existing stores by additional information
derived from RDFS/OWL ontologies using reasoners. Finally, AllegroGraph provides an access
to external triple-stores. In fact, the connectors to Oracle and Sesame are still under development.
The instances of all these classes create an integrated RDF database that can be managed and
queried using single interface.
119

THE IMPLEMENTATIONS OF SPARQL
3.6.2. Documentation
The documentation of AllegroGraph RDFStore is available on the company’s website. It starts
with the overview section about the functionalities of the server and supported HTTP protocol.
The following section describes the Java edition of AllegroGraph. It starts from the step-by-step
installation procedure for a various operating systems. Then the configuration file is discussed.
Next part is an introduction to the Java edition. Unfortunately, it is very brief and do not give any
clue on the functionalities of the edition. The more experienced users can explore the Javadocs
documentation that presents AllegroGraph’s API and the implementation of Sesame API.
The following part of the documentation provides a manual for using AllegroGraph Lisp edition.
It starts from the detailed installation manual. The next sections cover all the functionalities of
the server. They provide a number of tutorials about using RDFS, SPARQL, Prolog, Federated
databases and additional specialized datatypes within the Allegro CL environment. Each tuto-
rial contains a list of available functions, which are depicted in a numerous examples. Due to
SPARQL’s importance, the manual contains a few sections about using that query language in
different situations. The final part of the documentation presents a results of LUBM benchmark30
and some remarks about performance tuning of AllegroGraph.
AllegroGraph’s website provides also a Learning Centre. It contains tutorial examples for Java
edition of the server. In fact, these are the source code of the Java classes that implements all the
functionalities provided. There is no description of the usage apart from some remarks about the
installation of AllegroGraph. All the examples can be downloaded as an Eclipse31 project Java
archive.
The documentation of AllegroGraph does not present an equal quality. While the Lisp edition
is described in details, the Java edition has only an API description in Javadoc format and some
example source code, but without any descriptions. The overview of the server is rather messy and
sometimes misleading.30The Lehigh University Benchmark (LUBM) was developed to simplify and standardize the performance evalua-
tion of RDF triple stores. It contains university domain ontology, set of RDF data and test queries and a number of
performance metrics.31Eclipse is an integrated development environment written in Java and supporting that language by default. Its
functionality can be extended by using plug-in modules, e.g. development toolkits for other programming languages.
120

THE IMPLEMENTATIONS OF SPARQL
3.6.3. Installation
AllegroGraph is distributed in a number of versions. It runs on both 32-bit and 64-bit architectures
and the most popular operating systems – Windows, Linux/Unix, Solaris, FreeBSD and MacOS.
There are no special prerequisites for the installation of the server – only Java edition requires
Sun’s Java preinstalled in the version 1.4.2 or later.
The installation procedure for each of the AllegroGrpah’s editions is different. Java edition can
be downloaded as RPM or tar.gz package and contains the documentation, libraries and server
executable. The installation of the Lisp edition in fact starts from the installation of Allegro CL
in one of the available versions. Free version of AllegroGraph contains a free version of Allegro
CL – the Express Edition. The package with Allegro CL contains documentation for that envi-
ronment, libraries and some executables. In fact, the Lisp version of the server contains the same
AllegroGraph Java server application as the Java version.
The Java edition of AllegroGraph has very straightforward installation process. After downloading
the package it has to be unpacked and placed in the desired directory. After that the server is ready
to be started using the AllegroGraphServer executable. The manual suggests reviewing the
configuration file. The installation process of the Lisp edition starts from downloading Allegro CL.
It has to be unpacked and copied to the selected directory. Then the Lisp environment has to be
started using mlisp executable. The authors suggest updating the environment using (require
:update) command. After applying the patches the actual installation of AllegroGraph starts
by using (system.update:install-allegrograph) command. Allegro CL downloads
the latest version of the server and installs it in the application directory. When the operation is
finished the server can be loaded using (require :agraph) command. Both installation
procedures require the license key to be downloaded and placed in the application’s directory.
After installing the AllegroGraph Lisp edition, it can be accessed via Allegro CL interface, which
allows creating and managing triple stores and performing operations on triples. The Java server
can be also started and managed from the Lisp environment.
121

THE IMPLEMENTATIONS OF SPARQL
3.6.4. Testing
Allegro CL environment provides very useful methods for administrating AllegroGraph repos-
itories. Creating repository and loading triples is very straightforward, requires a small set of
commands. For testing purposes it had to be extended by a macro for measuring execution times.
The test started with creating an empty repository. Then the loading has started. The first file,
articlecategories en.part1.nt, was loaded very fast. The macro was showing the real
and CPU times. In addition after loading set of 10 000 triples Allegro was reporting the progress
and average loading time – the indicator was flirting around 4 800 triples per second. Unfortu-
nately, loading the third file, articles label en.nt, failed due to lack of aclmalloc space
left for extending repository. The on-line documentation of AllegroGraph says that aclmalloc()
function is allocating data blocks for the storage in the form of allocation addresses. Unfortunately,
there was no description of any workaround, so the problem was submitted to support team. It
turned out that the error is related to the string dictionary AllegroGraph is using. When the dictio-
nary is close to full the server is trying to extend it by allocating additional blocks. The support
team ensured that the error happens only on 32-bit machines as AllegroGraphs is optimized for
64-bit environments. The only solution is to estimate a total number of unique triples and set
:expected-unique-resources argument while creating new repository.
The first estimates were made using MySQL database created by OpenRDF Sesame. The value
of the attribute was set to 3 000 000 of unique strings and the loading started. The process was
successfull until the paisley.nt file. AllegroGraph was not able to extend the dictionary and
returned an error. The value of estimated unique triples was changed to 10 000 000. That time the
loading stopped on the next to last file – shortabstract en.nt. While creating repositories
with desired values of unique resources interesting situation was observed. Creating repository
with a certain value of the attribute sometimes was failing due to unability to allocate enough
aclmalloc space. Lowering the value was not always directly leading to successful creation
of repository – sometimes a restart of Allegro CL was needed. What is more setting very high
value at the beginning was not possible. When creating repository the value should be relatively
low. Afterwards when loading fails due to lack of space, the repository should be dropped. The
new one should have higher value of the :expected-unique-resources attribute. Those
adjustments should be repeated till all the files are loaded correctly or the highest possible value is
122

THE IMPLEMENTATIONS OF SPARQL
File No. of triplesLoading
Time (ms) Avg (ms)
articlecategories en.part1.nt 3 000 000 509 190 0.1697
articlecategories en.part2.nt 3 136 876 539 022 0.1718
articles label en.nt 2 390 513 530 136 0.2218
articles label fr.nt 293 388 64 005 0.3561
articles label pl.nt 179 748 39 495 0.1346
categories label en.nt 312 422 70 730 0.2264
infobox en.reduced.nt 269 355 53 406 0.1983
infoboxproperties en.nt 65 612 14 226 0.2168
links gutenberg en.nt 2 510 953 0.3797
links quotationsbook en.nt 2 523 888 0.3520
paisley.nt 1494603 279 757 0.1872
persondata de.nt 569 051 116 821 0.2053
shortabstract en.nt 1 904 971 755 000 0.3963
shortabstract pl.nt 179 742 67 026 0.3729
Total 13 801 314 3 040 655
Average loading time 0.2203
Table 3.8: Summary of loading data into AllegroGraph repository.
reached. After a number of experiments the value of the attribute was set at 8 350 000. The previ-
ous value, 10 000 000, could not be achieved. When the repository was created loading had started.
It was uninterrupted until the largest file – shortabstract en.nt. AllegroGraph returned er-
ror about reaching the maximum aclmalloc space after loading 2 070 000 triples. What is
more despite the error the last file containig 179 742 triples was succesfully loaded. Reloading
shortabstract en.nt file retured the same error after completing 1 950 000 triples.
The loading test was not completed successfully. AllegroGraph managed to load 13,801 314 triples
– 275 575 triples are missing from the original dataset. Missing triples are containing short com-
ments about the resources, which are used only for the first of test queries. The number of these
triples is not significant, so it should not have much impact on the evaluation of the rest of test
queries. The summary of loading data set into AllegroGraph repository is presented in Table 3.8.
123

THE IMPLEMENTATIONS OF SPARQL
The loading process was very fast, it lasted approximately 50 minutes. The triples were loaded
with different pace, which varied from 0.1346ms per triple in the case of articles’ labels in Polish
to 0.3963ms per triple while processing short abstracts in English. All the files were processed in
the average speed of 0.2203ms per triple.
Figure 3.30: The process of loading AllegroGraph server and querying a repository using AllegroCL environment.
When the loading test was finished freetext indices were configured by adding the desired predi-
cates to indexing list. In that case two predicates were added, <rdfs:comment> and
<rdfs:label>. The next step required indexing all triples in the repository. AllegroGraph
adds the default indexing schema while creating a new repository, but the actual values has to be
computed after loading triples. The server provides additional functions for indexing only new
triples and managing the indices.
Evaluating test queries started after creating the indices. It was conducted using Allegro CL en-
vironment and Twinkle. The first query, evaluating fulltext searching capabilities, failed due to
upi-not-in-string-table-error error. The online documentation says nothing about
that error but it could be related to loading failure of shortabstract en.nt – the query is
basically iterating on the literals originally placed in the file. Failure in extending space could have
124

THE IMPLEMENTATIONS OF SPARQL
QueryAllegroGraph Conditional
Allegro CL(ms) Twinkle(ms) Allegro CL(ms) Twinkle(ms)
Query 1 × ×
Query 2 × × 398 399
Query 3 × × 5 137 411 1 427 375
Query 4 591 797
Query 5 × × 1 407 239 1 473 828
Query 6 298 453
Query 7 × ×
Query 8a × ×
Query 8b × ×
Table 3.9: Summary of evaluating test queries on AllegroGraph RDFStore.
resulted in inconsistency. AllegrGraph implements additional “magic” predicate (fti:match)
that the manual advices to use instead of regex() function. After redesigning the query, it also
returned the error. The second query has also failed. It turned out that AllegroGraph recognized
xsd:date function as not implemented yet. After removing filtering clause the query returned
correct results, what took 398 399ms. Figure 3.9 presents the summary of query execution times
with an additional column showing processing times of adjusted queries that cannot be counted
as successful. The next query returned empty result set. However after using the predicate on lit-
eral constraints instead of filtering clause the query has completed with the expected results. The
query number four was processed without any error. AllegroGraph seems to be working efficiently
while there is no text searching. Query number five tests the capability to construct a new graph
and contains FILTER clause with the literal constraint – this time it returned very strange result
set containing only definitions of prefixes. What is interesting the next query, which contains the
similar constraint returned the correct value in 298ms. Query number seven behaved similarly to
the first one – it turned out that one of the tuples had not been added to the dictionary, what caused
an inconsistency and finally the processing error. Query number eight, which tests the ability to
use external graphs, did not returned any results.
Evaluating test queries using Twinkle brought similar results. Only queries number four and six
were evaluated successfully. Queries number two, three and five had to be adjusted to obtain
125

THE IMPLEMENTATIONS OF SPARQL
the correct results. The rest of the queries returned processing errors or returned empty data sets
(query number eight).
Summarising the query test it turned out that AllegroGraph has serious problems with performing
SPARQL queries. Two of them failed due to inconsistency in the triple store, which should be
somehow handled by the server. The other ones were mainly unsuccessful due to inefficient text
searching, even though queries with a large number of joins were selective and only a relatively
small set of triples required searching over literals. What is interesting the ASK query, which also
contains regex() function, was performing very well. Nested optionals are supported efficiently,
so it can be presumed that AllegroGraph’s repository has optimised indexes. Finally, the usage of
remote graphs is not properly handled.
3.6.5. Summary
AllegroGraph is a disk-based RDF storage system, which derives from the producer’s experience
in developing Lisp environment supported by separate database. It is available in two versions,
with interface to Allegro CL environment and direct Java API. The Java version is a standalone
server provided with no additional tools. The Lisp version can be handled through Allegro CL,
however it is subject to separate licensing. The usage of Lisp edition seems to be very reasonable
as Lisp programming language provides useful capabilities for AI programming and the Semantic
Web intends to be supported by artificial intelligence. What is more AllegroGraph provides native
support for Prolog and contains internal reasoner. The data serialized in RDF on N3 formats can
be accessed by SPARQL via the built-in web server. AllegroGraph provides also some interesting
non-stadard capabilities, like federated database or additional functions for analysing geographical
data. The architecture of the server was designed to support multithreading with maximum per-
formance in 64-bit environment. The documentation contains basic information about the server
and some manuals for using the provided functionalities. Unfortunately, there is no section about
errors that may appear during exploitation of the storage. Some of the errors encountered during
the testing was briefly described in the documentation of Allegro CL, the manuals of the server
provided no information about them. The overall quality and usability are not satisfactional.
The installation of the server is very straightforward. Creating the storage and the loading of triples
requires only a few functions to be executed. the first impression is very good – AllegroGraphs is
126

THE IMPLEMENTATIONS OF SPARQL
loading data with the pace of 4 500-5 000 triples per second. Unfortunately, it has some significant
problems with allocating the storage while deployed in 32-bit environment. Even though addi-
tional consultations were done and special configuration of the repository was applied, the server
was behaving unpredictably. In fact not all the triples were loaded what resulted in general failure
of the loading test. What is more the server was not able to preserve the consistency of the data,
what caused the failure of some test queries. While evaluating the test queries it turned out that
AllegroGraph is not able to perform text searching effectively even though the free text searching
capability was configured according the the documentation. Even using special predicates did not
shorten the execution times. It turned out that the server is not fully supporting SPARQL and it is
not able to query the remote graphs.
AllegroGraph is a very efficient RDF storage system with some interesting capabilities, however
some architectural problems make it not reliable solution for the Semantic Web. Some function-
ality needs improvements and the documentation requires some precision. However, the speed of
loading and indexing the data has to be recognised.
127

CONCLUSION
Conclusion
The Semantic Web is undoubtedly a revolution comparable to the one that was caused by the
emergence of the World Wide Web. Linking not only documents published in the Internet but
also the information available on-line will make computers assist humans to the extent we cannot
even think about now. The days are coming when our PC will keep the track of our meetings,
organise our travel or easily provide the exact information we want. Tim Berners-Lee announced
the beginning of the web of data. This apparently straightforward idea unfortunately turned out
to be more complex in deployment. Although some of the technologies were established almost
a decade ago, the idea has only reached the unifying logic layer of the Semantic Web layer cake
diagram.
The final specifications of the precedent technologies, SPARQL and RIF, have just been published.
Both are important, but SPARQL is the one that is going to implement the idea of linking data
sources and information over the Web. This query language was designed to meet the requirements
derived from the nature of the WWW and the semantic data model – RDF. SPARQL is able to
operate within the decentralisation, openness and incompleteness of the Internet. These factors
also make implementations of the language very difficult to design. Exposing thousands of data
sets on-line brings the problem of interoperability, scalability and security of data. On one hand,
there is a need to design repositories that will be able to organise, exchange, interlink and provide
an on-line access to information. On the other hand the end user applications, sometimes called
software agents, will have to browse through a mass of information searching for the pieces that
are needed for the particular deduction process. SPARQL, being a query language, but also related
to communication protocol and query results format, is one of the key elements of the structure
providing agents the means for communicating with repositories. It was designed to be a unifying
point for all semantic requests. The challenge is to use the currently available sources of data
and expose them as semantic data. Developers are working on additional standards like GRDDL
128

CONCLUSION
or RDFa that will provide an access to text documents. However the great majority of data is
already available in RDBMSs, which as a mature technology provide a sound platform. What
is more the relational data model can be compared to semantic data model – storing RDF in
relational model is straightforward, but the differences make querying more demanding. This is
the reason why using RDBMS-backed repositories is so popular. There is a lot of industry effort
put on optimising the translation between semantic and relational data in both ways – exposing
automatically relational databases with additional metadata and transforming semantic queries
into SQL statements. Although other solutions are also available, this configuration seems to be
very promising.
There is not much literature about the nature of SPARQL and its impact on the Semantic Web.
Although a number of scientists tried to conduct formal studies over the semantic query language,
a more popular topic for the academia is the implementation of the W3C’s specification. The
review of the literature shows that the implementers are trying to use the methods known from the
current database knowledge, e.g. translating SPARQL queries into relational algebra and using
similar operators as in relational model. However there are some exceptions the model that still
has to be addressed.
Alongside the development of SPARQL, a number of its implementations were growing. Today
we have the choice of around 15 popular software packages. One of the goals of this thesis was to
review a few of them and perform some tests using a data set based on DBpedia. The review part
took into consideration the architecture, documentation of the packages, implementability and the
overall perception of the potential end user. The tests included loading and processing of eight
queries. A separate server was prepared for the implementations. Unfortunately the configuration
turned out to be too slow for handling a data set containing around 114 million of triples. It had
to be reduced to approximately 14 million of triples. However that number was serious enough to
emphasize the differences in architecture and performance of chosen implementations. Although
each test was performed in the same conditions, the differences in timing were significant.
OpenRDF Sesame turned out to be a flexible but stable solution. The availability of APIs and fact
that the solution is built using open standards make it an interesting alternative. It can be easily
deployed on every machine and the included tools make it very straightforward to use for end
users. Unfortunately the documentation is not mature enough and does not contain many of the
129

CONCLUSION
details. OpenLink Virtuoso being an open source version of the commercial product is a much
more complex solution, which supports SPARQL as one of the features. It complies with many
recent standards in the industry and with its many features creates a universal platform for deploy-
ing web applications, although it requires significant capacity. Its rich interface makes it more
accessible to users, however not all the features are well documented. It is worth emphasizing
that the package is under heavy development - the project team is constantly incorporating the
newest technologies available on the market including the ones related to the Semantic Web. Jena
Semantic Web Framework presents a different approach. The project has its origins in academia
and consists of a number of modules that allows manipulation and storage of RDF graphs. Each of
them provides API and can be easily implemented in more complex solutions. As it is still being
under heavy development Jena has become a very up to date solution. However the constant im-
provements make it less stable and cause problems in the integration between packages. Because
of that the documentation is also very limited. Fortunately the components can be easily deployed
and used independently. In contrary Pyrrho DBMS is a consistent product being a very compact
database. Written in .NET framework Pyrrho contains some interesting solutions like advanced
logging, native support for RDF and SPARQL or additional programming interfaces. Thanks to
numerous versions it can be deployed on a wide range of devices, from PDAs to clustered servers.
Some additional tools simplify the administration tasks. Unfortunately the product is very re-
source consuming. The tools turned out to be not stable and the database itself could not manage
the full testing. The DBMS need more internal testings to be done before it can become a reliable
solution. The strong point is the documentation, which briefly describes all advanced functional-
ities of the product. Although sometimes it seems to be not perfectly organised, it provides a lot
of detailed knowledge about the architecture and functionalities of the database. AllegroGraph is
also a database, however it is a single solution designed only for handling RDF. It is a compact
and efficient database server dedicated for 64-bit systems providing functionalities like internal
reasoner, support for analysing social networks or geographical data. Being a standalone server it
provides a Java interface and SPARQL endpoint for integrating it with external applications, but
with no additional tools. The more interesting is the version deployed as a part of Allegro CL
environment that allows using RDF within Prolog or Lisp applications. The documentation of the
server is brief, especially for the Java edition. However it supports the user of the Lisp edition
with the most useful information about the functionalities, but does not provide any known-error
section.
130

CO
NC
LU
SIO
N
File No. of triplesSesame Native Storage OpenLink Virtuoso Jena MySQL Indexed AllegroGraph
Time (ms) Avg (ms) Time (ms) Avg (ms) Time (ms) Avg (ms) Time (ms) Avg (ms)
articlecategories en.part1.nt 3000000 6358082 2.1194 24317913 8.1060 8052900 2.6843 509190 0.1697
articlecategories en.part2.nt 3136876 16706385 5.3258 7702560 2.4555 11493760 3.6641 539022 0.1718
articles label en.nt 2390513 8178421 3.4212 17030614 7.1243 24206642 10.1261 530136 0.2218
articles label fr.nt 293388 3565839 12.1540 9378460 31.9661 6451873 35.8940 64005 0.3561
articles label pl.nt 179748 2463018 13.7026 12764118 71.0112 4352178 14.8342 39495 0.1346
categories label en.nt 312422 6630437 21.2227 4112239 13.1625 11119161 35.5902 70730 0.2264
infobox en.reduced.nt 269355 1002681 3.7225 84907 0.3152 1009110 3.7464 53406 0.1983
infoboxproperties en.nt 65612 411573 6.2728 24083 0.3671 540272 8.2343 14226 0.2168
links gutenberg en.nt 2510 42748 17.0311 1878 0.7482 53317 21.2418 953 0.3797
links quotationsbook en.nt 2523 51735 20.5054 984 0.3900 65436 25.9358 888 0.3520
paisley.nt 1494603 3643921 2.4381 9406996 6.2940 3284330 2.1975 279757 0.1872
persondata de.nt 569051 3734774 6.5632 664602 1.1679 3333169 5.8574 116821 0.2053
shortabstract en.nt 2180546 19299840 8.8509 34844216 15.9796 39744200 18.2267 755000 0.3462
shortabstract pl.nt 179742 4598827 25.5857 11310717 62.9275 2715881 15.1099 67026 0.3729
Total 14076889 76688281 131644287 116422229 3040655
Average loading time 5.4478 9.3518 8.2705 0.2203
Table 3.10: Summary of loading data into tested implementations – configurations that had the best performance for each implementation.
131

CONCLUSION
After finishing the review the testing started. The loading of the prepared data set unveiled a lot of
differences between the solutions related to functionalities and especially performance. Table 3.10
compares the timings obtained by the best performing configuration of each implementation. Un-
fortunately the final results are not fully comparable as not all of the implementations were able to
perform a full load. The amazing performance was presented by AllegroGraph, which managed
to load one triple in about 0.2203ms. Unfortunately the test was not finished due to instability
of the platform. Another repository that is using its internal engine is OpenRDF Sesame based
on the native storage. It was managed to load data with the speed of 5.4478ms per triple which
gave it second place. Sesame turned out to be very stable and easy to use. The only configuration
that uses external RDBMS is SDB based on MySQL with the indexed layout. It was able to load
an average triple in 8.2705ms. Unfortunately some errors were encountered while loading short
abstracts. The slowest solution is OpenLink Virtuoso, which was able to load and commit each
triple with the speed of 9.3518ms per triple. That test was accomplished successfully and thanks
to batch processing was highly automated. Pyrrho DBMS turned out to be very unstable when
loading large files so it could not be compared to other implementations of SPARQL. The data set
had to be very limited and in fact, no timings were collected. The testing also showed that the con-
figurations that were using PotsgreSQL were not efficient while loading data – OpenRDF Sesame
based on PostgreSQL has finished processing after about 161 hours, which was the highest result
obtained during the project.
Taking into consideration a graph showing the average loading times for each file (Figure 3.31) it
can be noticed that in the case of files having a large number of unique triples the loading times
were relatively lower and comparable between the solutions. Relatively lowest average time was
always obtained at the beginning of the test while the repository was almost empty. Handling files
with long literals was also time consuming. In the case of the smallest files the results are very
high, which is always caused by the process of initiating the loading taking the same amount of
time each time the file is loaded.
Performing the test queries draw another interesting conclusions. Each implementation was queried
using standard tool provided by the solution and Twinkle, what showed if the repository could be
queried via Internet. This time there were more failures than in previous test. Only three of the
implementations were able to process the majority of the queries – the comparison of the result
of the best performing configurations is presented in Table 3.11. Starting the test with Sesame
132

CONCLUSION
Figure 3.31: Graph comparing average loading times the best performing configurations.
showed that full text searching over the large repository is very demanding. The evaluation of the
next query proved that the implementation does not fully comply with the SPARQL’s specification.
The following queries were finished successfully, but the last query checking the ability to use ex-
ternal graphs failed. OpenLink Virtuoso was the worst performer, mostly because of the very poor
text searching – the query returned results after approximately 36 minutes. Very interesting re-
sults were obtained while querying the repository before adding proper indexes. The same query
was finished after 491 minutes. The difference is more visible in the case of the query number
two – 480ms comparing to more than 24 hours. The following queries were evaluated at least
twice faster than Sesame until the last query, which failed. The last configuration is Jena based on
MySQL with hashed layout. The testing started with a failure – Jena was not able to compute a
proper query that could be passed down to the database and limit the result set inside the RDBMS.
Although the first query failed, the following ones were evaluated successfully. Unfortunately this
time also the implementation was not able to process the query number eight – only Joseki queried
using Twinkle used external data set, but performing more complicated version of the query failed
causing runtime exception. It turned out that none of the implementations were able to use both in-
ternal and external graphs. Comparing the performance there is no unambiguous leader. Virtuoso
seems to be the fastest repository, but the performance of text searching was the worst. Sesame
133

CONCLUSION
based on MySQL has generally speaking better results than Jena, apart from the query describing
the resource, which was evaluated in much longer time. This time also the configurations based
PostgreSQL obtained worse results. In the case of Jena the difference is significant.
QuerySesame MySQL OpenLink Virtuoso Indexed Jena MySQL Hashed
Console (ms) Twinkle (ms) Isql (ms) Twinkle (ms) Script (ms) Twinkle (ms)
Query 1 497119 155187 2195937 2181203 × ×
Query 2 × × 480 1515 2397 1750
Query 3 31934 31750 12602 13813 72603 76265
Query 4 1155 1234 448 390 1227 750
Query 5 14918 15109 2273 2797 4134 3796
Query 6 402 297 83 156 539 203
Query 7 206785 206938 962 1036 3754 7000
Query 8a × × × × × 266
Query 8b × × × × × ×
Table 3.11: Summary of performing test queries – configurations that had the best performance
for each implementation.
The remaining two implementations could not be compared to the ones described above. Alle-
groGraph, although it managed to load almost all files successfully, failed on the majority of the
queries. It turned out that it can only evaluate two of them without any changes to the original
query. The failures were caused by the inconsistent data due to loading problems and limited sup-
port of the filtering functions specified in the SPARQL’s documentation. What was easy to predict,
AllegroGraph had also problems with external graphs. However the queries that finished success-
fully were performed relatively fast. Another implementation, Pyrrho, has failed the loading test
so there was no possibility to check the performance of the repository. However the compliance
testing could have been performed. Pyrrho has executed successfully most of the queries. How-
ever some of them queried via Twinkle were causing the web server error. The performance cannot
be compared with the test conducted on the remaining implementations.
The testing of the implementations showed that not all of the products are stable enough to handle
larger amounts of data. Some of the failures were caused due to limited capacity, but the others
were the results of the instability of the code. Querying the repositories confirmed that none of the
134

CONCLUSION
tested configurations was fully compliant to SPARQL’s specification, especially when considering
working on external graphs. The performance is also questionable, especially when the query is
based on literal conditions.
Predictions by leading industry specialists suggest that it will be another 5 or 10 years until the
Semantic Web becomes reliable. Although progress is happening almost every day and new tech-
nologies are emerging frequently, the revolution has not yet happened. Data still remains hidden
in the structures of the databases and searching technologies still need some improvement. This
review and testing of a few of the most popular implementations of SPARQL has shown that the
technology is still not reliable. Although they provide a wide range of interesting features, there
are no easy to use tools for average users to deploy their own repository. What is more, the query
engines are still not fully compliant with the specification. SPARQL is a milestone on the way to
the Semantic Web, but both the technology and its implementations needs to become more stable.
135

BIBLIOGRAPHY
Bibliography
AllegroGraph RDFStore (2008).
http://agraph.franz.com/allegrograph/, [12.06.2008]
Antoniou, G. & van Harmelen, F. (2004), A Semantic Web Primer, The MIT Press, Cambridge,
Massachusetts.
ARQ - A SPARQL Processor for Jena (2008).
http://jena.sourceforge.net/ARQ/, [5.06.2008]
Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak, R. & Ives, Z. G. (2007), DBpedia:
A Nucleus for a Web of Open Data, in K. Aberer, K.-S. Choi, N. F. Noy, D. Allemang,
K.-I. Lee, L. J. B. Nixon, J. Golbeck, P. Mika, D. Maynard, R. Mizoguchi, G. Schreiber &
P. Cudre-Mauroux, eds, ‘The Semantic Web, 6th International Semantic Web Conference,
2nd Asian Semantic Web Conference, ISWC 2007 + ASWC 2007, Busan, Korea, November
11-15, 2007’, Vol. 4825 of Lecture Notes in Computer Science, Springer, pp. 722–735.
Baader, F., Horrocks, I. & Sattler, U. (2003), Description Logics as Ontology Languages for the
Semantic Web, in D. Hutter & W. Stephan, eds, ‘Festschrift in honor of Jorg Siekmann’,
Lecture Notes in Artificial Intelligence, Springer-Verlag.
Berners-Lee, T. (1998), Semantic Web road map, Technical report, W3C Design Issues.
http://www.w3.org/DesignIssues/Semantic.html, [10.03.2008]
Berners-Lee, T. & Fischetti, M. (1999), Weaving the Web : The Original Design and Ultimate
Destiny of the World Wide Web by its Inventor, Harper San Francisco.
Berners-Lee, T., Hendler, J. & Lassila, O. (2001), ‘The Semantic Web’, Scientific American
284(5), 34–43.
136

BIBLIOGRAPHY
Berners-Lee, T., Hollenbach, J., Lu, K., Presbrey, J., Prud’hommeaux, E. & Schraefel, M. (2007),
Tabulator redux: Writing into the semantic web. Unpublished.
Berners-Lee, T., Karger, D. R., Stein, L. A., Swick, R. R. & Weitzner, D. J. (2000), Semantic web
development, Technical report, MIT.
http://www.w3.org/2000/01/sw/DevelopmentProposal, [23.04.2008]
Bizer, C. & Cyganiak, R. (n.d.), ‘D2R Server – Publishing Relational Databases on the Semantic
Web’.
Bizer, C., Cyganiak, R., Garbers, J. & Maresch, O. (2007), The D2RQ Platform v0.5.1 - Treating
Non-RDF Relational Databases as Virtual RDF Graphs, Technical report, Freie Universitat
Berlin.
http://www.wiwiss.fu-berlin.de/suhl/bizer/d2rq/spec/20071025/, [10.04.2008]
Chebotko, A., Atay, M., Lu, S. & Fotouhi, F. (2007), Relational nested optional join for effi-
cient semantic web query processing, in G. Dong, X. Lin, W. Wang, Y. Yang & J. X. Yu,
eds, ‘Advances in Data and Web Management, Joint 9th Asia-Pacific Web Conference, AP-
Web 2007, and 8th International Conference, on Web-Age Information Management, WAIM
2007, Huang Shan, China, June 16-18, 2007, Proceedings’, Vol. 4505 of Lecture Notes in
Computer Science, Springer, pp. 428–439.
Connolly, T. M. & Begg, C. E. (2004), Database Systems : A Practical Approach to Design,
Implementation, and Management, 4th edn, Pearson Education.
Crowe, M. (2007), ‘The Pyrrho Database Management System, User’s Manual’.
Cyganiak, R. (2005a), Note on database layouts for SPARQL datastores, Technical Report HPL-
2005-171, Hewlett Packard Laboratories.
Cyganiak, R. (2005b), A relational algebra for SPARQL, Technical Report HPL-2005-170,
Hewlett Packard Laboratories.
de Laborda, C. P. & Conrad, S. (2005), Relational.OWL - A Data and Schema Representation For-
mat Based on OWL, in S. Hartmann & M. Stumptner, eds, ‘Second Asia-Pacific Conference
on Conceptual Modelling (APCCM2005)’, Vol. 43 of CRPIT, ACS, Newcastle, Australia,
pp. 89–96.
137

BIBLIOGRAPHY
de Laborda, C. P. & Conrad, S. (2006), Bringing Relational Data into the Semantic Web us-
ing SPARQL and Relational.OWL, in ‘ICDEW ’06: Proceedings of the 22nd International
Conference on Data Engineering Workshops (ICDEW’06)’, IEEE Computer Society, Wash-
ington, DC, USA, p. 55.
Dean, M. (2007), Suggestions for Semantic Web Interfaces to Relational Databases, in ‘W3C
Workshop on RDF Access to Relational Databases’.
http://www.w3.org/2007/03/RdfRDB/papers/dean.html, [17.05.2008]
Espiner, T. (2006), ‘How will emerging tech affect your company?’, ZDNet.co.uk [Online] .
http://news.zdnet.co.uk/itmanagement/0,1000000308,39280643,00.htm?r=10 [17.02.2008]
Feigenbaum, L., Herman, I., Hongsermeier, T., Neumann, E. & Stephens, S. (2007), ‘The semantic
web in action’, Scientific American 297, 90–97.
GRDDL Primer (2007).
http://www.w3.org/TR/grddl-primer/, [10.04.2008]
Gutierrez, C., Hurtado, C. A. & Mendelzon, A. O. (2004), Foundations of Semantic Web
Databases, in A. Deutsch, ed., ‘Proceedings of the Twenty-third ACM SIGACT-SIGMOD-
SIGART Symposium on Principles of Database Systems, June 14-16, 2004, Paris, France’,
ACM, pp. 95–106.
Haase, P., Broekstra, J., Eberhart, A. & Volz, R. (2004), A comparison of RDF query languages, in
‘Proceedings of the Third International Semantic Web Conference, Hiroshima, Japan, 2004.’.
Harris, S. & Shadbolt, N. (2005), SPARQL query processing with conventional relational database
systems, in M. Dean, Y. Guo, W. Jun, R. Kaschek, S. Krishnaswamy, Z. Pan & Q. Z. Sheng,
eds, ‘Web Information Systems Engineering - WISE 2005 Workshops, WISE 2005 Interna-
tional Workshops, New York, NY, USA, November 20-22, 2005, Proceedings’, Vol. 3807 of
Lecture Notes in Computer Science, Springer, pp. 235–244.
Hendler, J., Berners-Lee, T. & Miller, E. (2002), ‘Integrating Applications on the Semantic Web’,
Journal of the Institute of Electrical Engineers of Japan 122 (10), 676–680.
Herman, I. (2007a), ‘Questions (and Answers) on the Semantic Web’, Conference Slides.
http://www.w3.org/People/Ivan/CorePresentations/SW QA/, [18.02.2008]
138

BIBLIOGRAPHY
Herman, I. (2007b), ‘State of the the Semantic Web’, Conference Slides.
http://www.w3.org/2007/Talks/0424-Stavanger-IH/, [17.02.2008]
Jena - A Semantic Web Framework for Java (2008).
http://jena.sourceforge.net/, [5.06.2008]
Jorge Cardoso (2006), The Syntactic and the Semantic Web, in J. Cardoso, ed., ‘Semantic Web
Services: Theory, Tools and Applications’, IGI Global.
Jos (2008), ‘Joseki - A SPARQL server for Jena’.
http://www.joseki.org/, [5.06.2008]
Kifer, M., de Bruijn, J., Boley, H. & Fensel, D. (2005), A realistic architecture for the semantic
web, in A. Adi, S. Stoutenburg & S. Tabet, eds, ‘Rules and Rule Markup Languages for
the Semantic Web, First International Conference, RuleML 2005, Galway, Ireland, Novem-
ber 10-12, 2005, Proceedings’, Vol. 3791 of Lecture Notes in Computer Science, Springer,
pp. 17–29.
Lee, R. (2004), Scalability report on triple store applications, Technical report, MIT.
Manola, F. & Miller, E. (2004), ‘RDF Primer’.
http://www.w3.org/TR/2004/REC-rdf-primer-20040210/, [10.03.2008]
Matt Fisher, M. D. & Joiner, G. (2008), Use of OWL and SWRL for Semantic Relational Database
Translation, in ‘OWL: Experiences and Directions 2008. Fourth International Workshop
(OWLED 2008 DC)’.
http://www.webont.org/owled/2008dc/papers/owled2008dc paper 13.pdf, [10.04.2008]
McCarthy, P. (2004), ‘Introduction to Jena’.
McCarthy, P. (2005), ‘Search RDF data with SPARQL’.
Motik, B., Horrocks, I. & Sattler, U. (2007), Bridging the gap between OWL and relational
databases, in C. L. Williamson, M. E. Zurko, P. F. Patel-Schneider & P. J. Shenoy, eds,
‘Proceedings of the 16th International Conference on World Wide Web, WWW 2007, Banff,
Alberta, Canada, May 8-12, 2007’, ACM, pp. 807–816.
Openlink Software (2008).
http://openlinksw.com/, [25.05.2008]
139

BIBLIOGRAPHY
OpenRDF Sesame (2008).
http://www.openrdf.org/, [20.05.2008]
Passin, T. B. (2004), Explorer’s guide to the Semantic Web, Manning.
Perez de Laborda, C. & Conrad, S. (2006), Database to Semantic Web Mapping using RDF Query
Languages, in ‘Conceptual Modeling - ER 2006, 25th International Conference on Concep-
tual Modeling, Tucson, AZ, USA’, Lecture Notes in Computer Science, Springer Verlag,
pp. 241–254.
Perez, J., Arenas, M. & Gutierrez, C. (2006a), ‘Semantics and Complexity of SPARQL’.
Perez, J., Arenas, M. & Gutierrez, C. (2006b), Semantics of SPARQL, Technical Report TR/DCC-
2006-17, Universidad de Chile.
Prud’hommeaux, E. (2004), ‘RDF Data Access WG Charter’.
http://www.w3.org/2003/12/swa/dawg-charter, [04.04.2008]
RDFa Primer (2008).
http://www.w3.org/TR/xhtml-rdfa-primer/, [10.04.2008]
SDB - A SPARQL Database for Jena (2008).
http://jena.sourceforge.net/SDB/, [5.06.2008]
Shadbolt, N., Berners-Lee, T. & Hall, W. (2006), ‘The Semantic Web Revisited’, IEEE Intelligent
Systems 21(3), 96–101.
SPARQL Frequently Asked Questions (2008).
http://thefigtrees.net/lee/sw/sparql-faq, [06.04.2008]
SPARQL Query Language for RDF (2008).
http://www.w3.org/TR/rdf-sparql-query/, [06.04.2008]
SPARQL Query Language Implementation Report (2008).
http://www.w3.org/2001/sw/DataAccess/impl-report-ql, [20.05.2008]
Stuckenschmidt, H., Vdovjak, R., Houben, G.-J. & Broekstra, J. (2004), Index structures and al-
gorithms for querying distributed RDF repositories, in S. I. Feldman, M. Uretsky, M. Najork
140

BIBLIOGRAPHY
& C. E. Wills, eds, ‘Proceedings of the 13th international conference on World Wide Web,
WWW 2004, New York, NY, USA, May 17-20, 2004’, ACM, pp. 631–639.
The Pyrrho Database Management System (2008).
http://pyrrhodb.com/, [10.06.2008]
User Guide for Sesame 2.1 (2008).
http://www.openrdf.org/, [20.05.2008]
Virtuoso Open-Source Edition (2008).
http://virtuoso.openlinksw.com/wiki/main/Main/, [25.05.2008]
Walton, C. (2006), Agency and the Semantic Web, Oxford University Press, Inc., New York, NY,
USA.
Wilkinson, K., Sayers, C., Kuno, H. & Reynolds, D. (2004), Efficient RDF storage and retrieval
in jena2, Technical Report HPL-2003-266, Hewlett Packard Laboratories.
World Wide Web Consortium Process Document (2005).
http://www.w3.org/2005/10/Process-20051014/
XML Path Language (XPath) 2.0 (2007).
http://www.w3.org/TR/xpath20/, [20.04.2008]
XQuery 1.0 and XPath 2.0 Functions and Operators (2007).
http://www.w3.org/TR/xpath-functions/, [20.04.2008]
141