1 O. Teytaud *, S. Gelly *, S. Lallich **, E. Prudhomme ** *Equipe I&A-TAO, LRI, Université Paris-Sud, Inria, UMR-Cnrs 8623 **Equipe ERIC, Université Lyon 2 Email : [email protected], [email protected], [email protected], [email protected] Quasi-random resampling

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
O. Teytaud *, S. Gelly *,
S. Lallich **, E. Prudhomme **
*Equipe I&ATAO,
LRI, Université ParisSud,
Inria, UMRCnrs 8623
**Equipe ERIC,
Université Lyon 2
Email : [email protected], [email protected],
[email protected]lyon2.fr, [email protected]lyon2.fr
Quasirandom resampling

2
What is the problem ?
Many tasks in AI are based on random resamplings :● crossvalidation● bagging● bootstrap● ...
Resampling is timeconsuming● crossvalidation for choosing hyperparameters● bagging in huge datasets
==> we want to have with n resamplings the same result than with N>>n resamplings

3
A typical exampleYou want to learn a relation x> y on a huge ordered dataset.
The dataset is too large for your favorite learner.
A traditional solution is subagging : average 100 learnings performed on random subsamples (1/20) of your dataset
We propose : use QRsampling to average only 40 learnings.

4
Organization of the talk
(1) why resampling is MonteCarlo integration
(2) quasirandom numbers
(3) quasirandom numbers in strange spaces
(4) applying quasirandom numbers in resampling
(5) when does it work and when doesn't it work ?

5
Why resampling is MonteCarlo integration
What is MonteCarlo integration :
E f(x) ⋲ sum f(x(i)) / n
What is crossvalidation:
Errorrate ⋲ E f(x) sum f(x(i)) / n⋲where f(x) = error rate with the partitionning x

6
An introduction to QRnumbers
(1) why resampling is MonteCarlo integration
(2) quasirandom numbers
(3) quasirandom numbers in strange spaces
(4) applying quasirandom numbers in resampling
(5) when does it work and when doesn't it work ?

7
QRnumbers
(2) quasirandom numbers (less randomized numbers)
We have seen that resampling is MonteCarlo integration,
now we will see how MonteCarlo integration has been strongly improved.

8
Quasirandom numbers ?
Random samples in [0,1]^d can be notsowell distributed> error in MonteCarlo integration O(1/n) with n the
number of points
Pseudorandom samples ⋲ random samples (we try to be very close to pure random)
Quasirandom samples O(1/n) within logarithmic factors> we don't try to be as close as possible to random
> number of samples much smallerfor a given precision

Quasi-random = low discrepancy ?
Discrepancy = Max |Area – Frequency |

A better discrepancy ?
Discrepancy2 = mean ( |Area – Frequency |2 )

Existing bounds on low-discrepancy-Monte-Carlo
Random > Discrepancy ~ sqrt ( 1/n ) Quasirandom > Discrepancy ~ log(n)^d/n
Koksma & Hlawka :error in MonteCarlo integration < Discrepancy x V
V= total variation (Hardy & Krause)
( many generalizations in Hickernel, A Generalized Discrepancy and Quadrature Error Bound, 1997 )
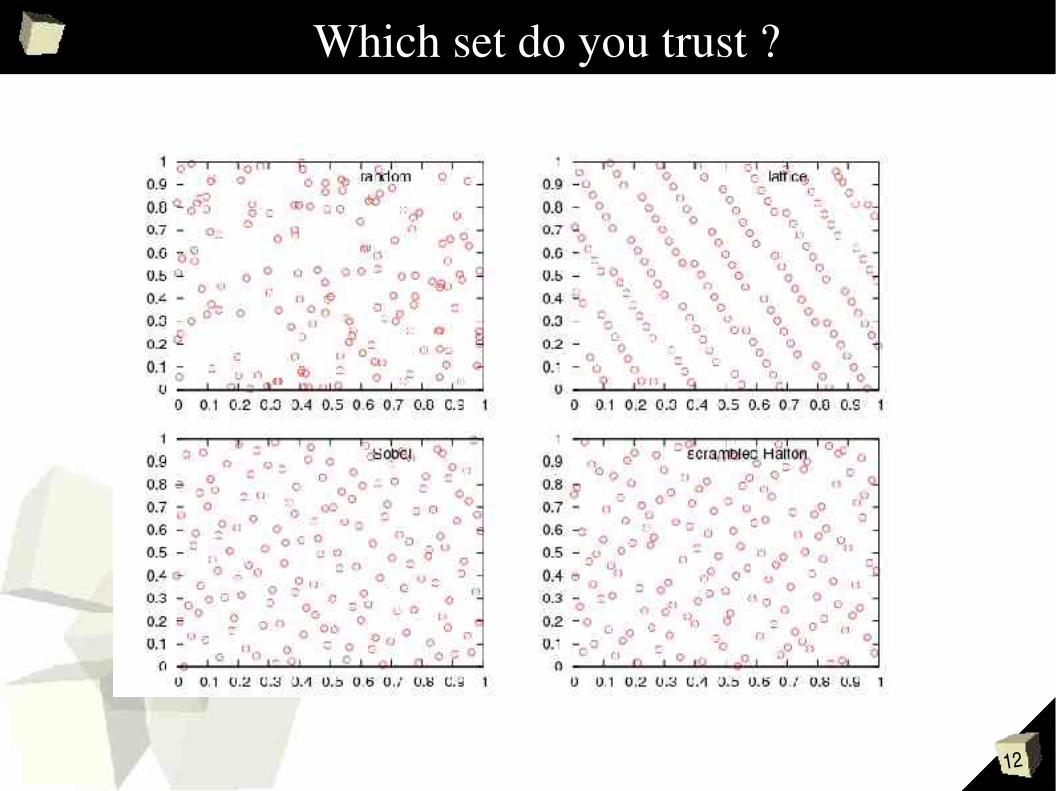
12
Which set do you trust ?

13
Which quasirandom numbers ?
« Haltonsequence with a simple scrambling scheme »
● fast (as fast as pseudorandom numbers) ;● easy to implement ;● available freely if you don't want to implement it.
(we will not detail how this sequence is built here)
(also: Sobol sequence)

14
What else than MonteCarlo integration ?
Thanks to various forms of quasirandom :
● Numerical integration [thousands of papers; Niederreiter 92]
● Learning [Cervellera et al, IEEETNN 2004, Mary phD 2005]
● Optimization [Teytaud et al, EA'2005]
● Modelizat° of randomprocess [GroweKruska et al,
BPTP'03, Levy's method]
● Path planning [Tuffin]

15
... and how to do in strange spaces ?
(1) why resampling is MonteCarlo integration
(2) quasirandom numbers
(3) quasirandom numbers in strange spaces
(4) applying quasirandom numbers in resampling
(5) when does it work and when doesn't it work ?

16
Have fun with QR in strange spaces
(3) quasirandom numbers in strange spaces
We have seen that resampling is MonteCarlo integration, and how MonteCarlo is replaced by QuasiRandom MonteCarlo.
But resampling is random in a nonstandard space.
We will see how to do QuasiRandom MonteCarlo in nonstandard spaces.
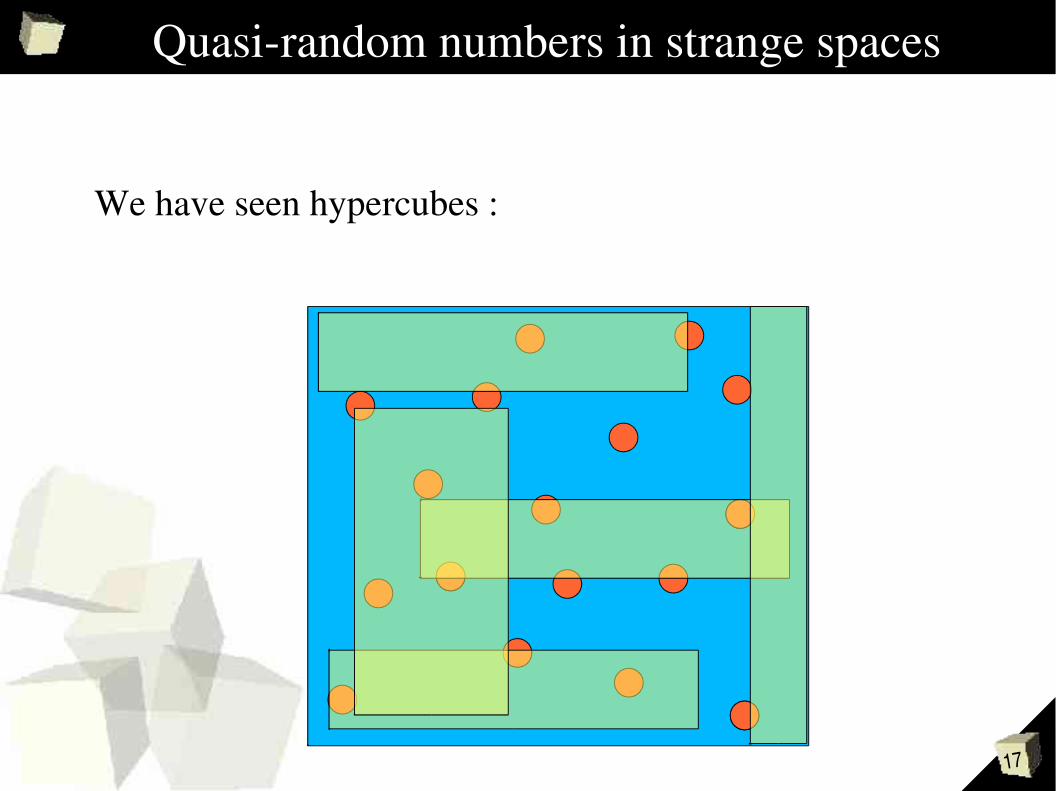
17
Quasirandom numbers in strange spaces
We have seen hypercubes :

18
... but we need something else !
Sample of points > QR sample of points
Sample of samples > QR sample of samples

19
Quasirandom points in strange spaces
Fortunately, some QRpoints exist also in various spaces.

20
Why not in something isotropic ?
How to do it in the sphere ? Or for gaussian distributions ?

21
For the gaussian : easy !
Generate x in [0,1]^d by quasirandom
Build y: P( N < y(i) ) = x(i)
It works because distrib = product of distrib(y(i))
What in the general case ?

22
Ok !
generate x in [0,1]^d
define y(i) such that P(t<y(i) | y(1), y(2), ..., y(i1))=x(i)
Ok !

23
However, we will do that
●We do not have better than this general method for the strange distributions in which we are interested
●At least we can prove the O(1/n) property (see the paper)
●Perhaps there is much better
●Perhaps there is much simpler

24
The QRnumbers in resampling
(4) applying quasirandom numbers in resampling
we have seen that resampling is MonteCarlo integration,that we were able of generating quasirandom points for any distribution in continuous domains;
==> it should work==> let's see in details how to move the problem to the continuous domain

25
QRnumbers in resampling
A very particular distribution for QRpoints : bootstrap samples. How to move the problem to continuous spaces ?
y(i) = x(r(i)) where r(i) = randomly uniformly distributed in [[1,n]] ==> this is discrete
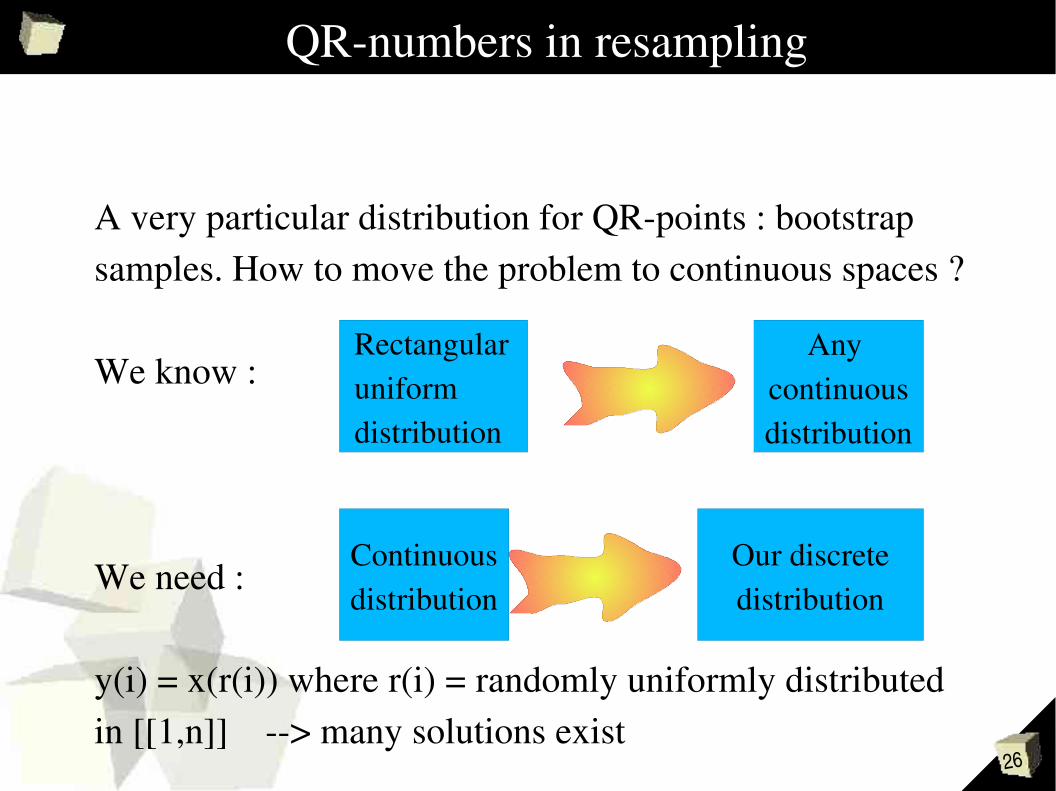
26
QRnumbers in resampling
A very particular distribution for QRpoints : bootstrap samples. How to move the problem to continuous spaces ?
We know :
We need :
y(i) = x(r(i)) where r(i) = randomly uniformly distributed in [[1,n]] > many solutions exist
Rectangularuniformdistribution
Any continuousdistribution
Continuousdistribution
Our discretedistribution

27
What are bootstrap samples ?
Our technique works for various forms of resamplings : subsamples without replacement (randomCV, subagging)
subsamples with replacement (bagging, bootstrap)
random partitionning (kCV).
W.l.o.g., we present here the sampling of n elements in a sample of size n with replacement (= bootstrap resampling).
(usefull in e.g. Bagging, bias/variance estimation...)

28
A naive solution
y(i) = x(r(i))
r(1),...,r(n) = ceil( n x qr ) where qr [0,1]^n
QR in dimension n with n the number of examples.
0.1 0.9 0.84 0.9 0.7
X

29
A naive solution
y(i) = x(r(i))
r(1),...,r(n) = ceil( n x qr ) where qr [0,1]^n
QR in dimension n with n the number of examples.
0.1 0.9 0.84 0.9 0.7
X
X

30
A naive solution
y(i) = x(r(i))
r(1),...,r(n) = ceil( n x qr ) where qr [0,1]^n
QR in dimension n with n the number of examples.
0.1 0.9 0.84 0.9 0.7
X
X X

31
A naive solution
y(i) = x(r(i))
r(1),...,r(n) = ceil( n x qr ) where qr [0,1]^n
QR in dimension n with n the number of examples.
0.1 0.9 0.84 0.9 0.7
X
X
X X X

32
A naive solution
y(i) = x(r(i))
r(1),...,r(n) = ceil( n x qr ) where qr [0,1]^n
QR in dimension n with n the number of examples.
0.1 0.9 0.84 0.9 0.7==> (1, 0,0,1,3)
X
X
X X X

33
A naive solution
y(i) = x(r(i))
r(1),...,r(n) = ceil( n x qr ) where qr [0,1]^n
QR in dimension n with n the number of examples.
==> all permutations of ( 0.1, 0.9, 0.84, 0.9, 0.7) lead to the same result !
X
X
X X X

34
...which does not work.
In practice it does not work better than random.
Two very distinct QRpoints can lead to very similar resamples (permutation of a point lead to the same sample).
We have to remove this symetry.

35
A less naive solution
z(i) = number of times x(i) appears in the bootstrap sample
z(1) = binomialz(2) | z(1) = binomialz(3) | z(1), z(2) = binomial...z(n1) | z(1), z(2),...,z(n2) = binomialz(n) | z(1), z(2), ..., z(n) = constant
==> yes, it works !==> moreover, it works for many forms of resamplings and not only bootstrap !

36
With dimensionreduction it's better
Put x(i)'s in k clustersz(i) = number of times an element of cluster i appears in the bootstrap sample
z(1) = binomialz(2) | z(1) = binomialz(3) | z(1), z(2) = binomial...z(k1) | z(1), z(2),...,z(k2) = binomialz(k) | z(1), z(2), ..., z(k) = constant
(then, randomly draw the elements in each cluster)

37
Let's summarize
Put x(i)'s in k clustersz(i) = number of times an element of cluster i appears in the bootstrap sample
z(1) = binomialz(2) | z(1) = binomial...z(k) | z(1), z(2), ..., z(k) = constant
we quasirandomize this z(1),...,z(k)
Then, we randomly draw the elements in each cluster.

38
Let's conclude
(1) why resampling is MonteCarlo integration
(2) quasirandom numbers
(3) quasirandom numbers in strange spaces
(4) applying quasirandom numbers in resampling
(5) when does it work and when doesn't it work ?

39
Experiments
In our (artificial) experiments :● QRrandomCV is better than randomCV● QRbagging is better than bagging● QRsubagging is better than subagging● QRBsfd is better than Bsfd (a bootstrap)
But QRkCV is not better than kCV
kCV already has some derandomization: each point appears the same number
of times in learning

40
A typical exampleYou want to learn a relation x> y on a huge ordered dataset.
The dataset is too large for your favorite learner.
A traditional solution is subagging : average 100 learnings performed on random subsets (1/20) of your dataset
We propose : use QRsampling to average only 40 learnings.
Or do you have a better solution for choosing 40 subsets of 1/20 ?

41
Conclusions
Therefore:● perhaps simpler derandomizations are enough ?● perhaps in cases like CV in which « symetrizing » (picking each example the same number of times) is easy, this is useless ?
For bagging, subagging, bootstrap, simplifying the approach is not so simple
==> now, we use QRbagging, QRsubagging and QRbootstrap instead of bagging, subbagging and bootstrap

42
Further work
Realworld experiments (in progress, for DPapplications)
Other dimension reduction (this one involves clustering)Simplified derandomization methods (jittering, antithetic variables, ...)
Random clustering for dimension reduction ?(yes, we have not tested, sorry ...)

Low Discrepancy ?
Random > Discrepancy ~ sqrt ( 1/n ) Quasirandom > Discrepancy ~ log(n)^d/n
Koksma & Hlawka :error in MonteCarlo integration < Discrepancy x V
V= total variation (Hardy & Krause)
( many generalizations in Hickernel, A Generalized Discrepancy and Quadrature Error Bound, 1997 )

Dimension 1
● What would you do ?

Dimension 1
● What would you do ?

Dimension 1
● What would you do ?

Dimension 1
● What would you do ?

Dimension 1
● What would you do ?

Dimension 1
● What would you do ?

Dimension 1
● What would you do ?● --> Van Der Corput● n=1, n=2, n=3...● n=1, n=10, n=11, n=100, n=101, n=110...● x=.1, x=.01, x=.11, x=.001, x=.101, ...

Dimension 1 more general
● p=2, but also p=3, 4, ...
but p=13 is not very nice :

Dimension n
● x --> (x,x) ?
Dimension n
● x --> (x,x') ?

Dimension n : Halton
● x --> (x,x') with prime numbers
Dimension n+1 : Hammersley
● x --> (n/N,x,x') but --> closed sequence

Dimension n : the trouble
● There are not so many small prime numbers

Dimension n : scrambling(when random comes back)● Pi(p) : [1,p-1] --> [1,p-1]● Pi(p) applied to ordinate with prime p

Dimension n : scrambling
● Pi(p) : [1,p-1] --> [1,p-1] (randomly chosen)
● Pi(p) applied to ordinate with prime p (there is much more complicated)
Related Documents







![Resampling: The New Statistics - USDapps.usd.edu/coglab/psyc792/resampling/Resampling-Colloquium2.pdfResampling: The New Statistics Frank Schieber ... [5 6 7 8 9 10 11 12 13 14 15];](https://static.cupdf.com/doc/110x72/5b3499c67f8b9ae1108e64d7/resampling-the-new-statistics-the-new-statistics-frank-schieber-5-6-7-8.jpg)



