Application of Scalable Visual Sensitivity Profile in Image and Video Coding Qian Chen, Guangtao Zhai, Xiaokang Yang, and Wenjun Zhang ISCAS,2008

Qian Chen, Guangtao Zhai, Xiaokang Yang, and Wenjun Zhang ISCAS,2008.
Dec 19, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Application of Scalable Visual Sensitivity Profile in Image and Video Coding
Qian Chen, Guangtao Zhai, Xiaokang Yang, and Wenjun ZhangISCAS,2008

Outline
Introduction Scalable visual sensitivity profile
(SVSP) SVSP in noise-shaping SVSP in ROI coding of JPEG2000 SVSP in ROI scalable video coding Conclusion

Introduction
Computational visual attention models have been developed over the last 20 years and have already facilitated various aspects of the evolution in visual communication systems.
Its important applications is to enhance the image and video compression algorithms perceptually.
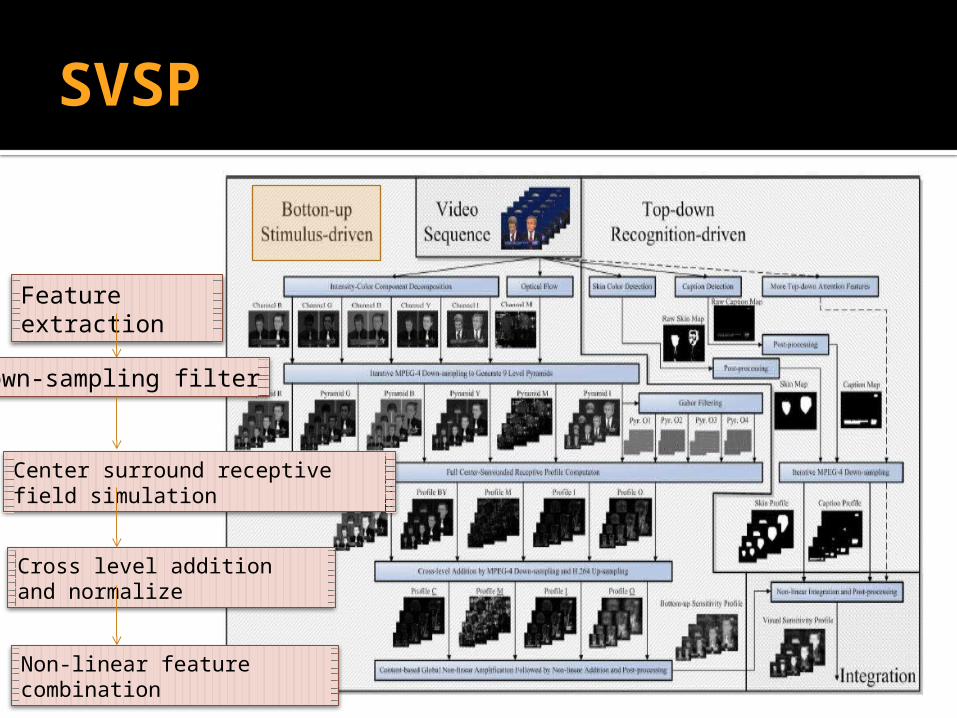
SVSP
Feature extraction
down-sampling filter
Center surround receptive field simulation
Cross level addition and normalize
Non-linear feature combination

SVSP (1)
Low-level Feature Detection Intensity channel :
Color channels :
Orientation channel :
motion channel :optical flow
Gabor filter

SVSP (2)
By iteratively down-sampling for L times of these channels
,we can create pyramids for each of these channels of the framei
Center-surround Receptive Field Simulation
c ∈ [0, 8], s = c + δ,δ ∈ [−3,−2,−1, 1, 2, 3] and s is thrown away if s ∈ [0, 8].

SVSP(3)
Cross level addition and normalize
Non-linear Feature Combination
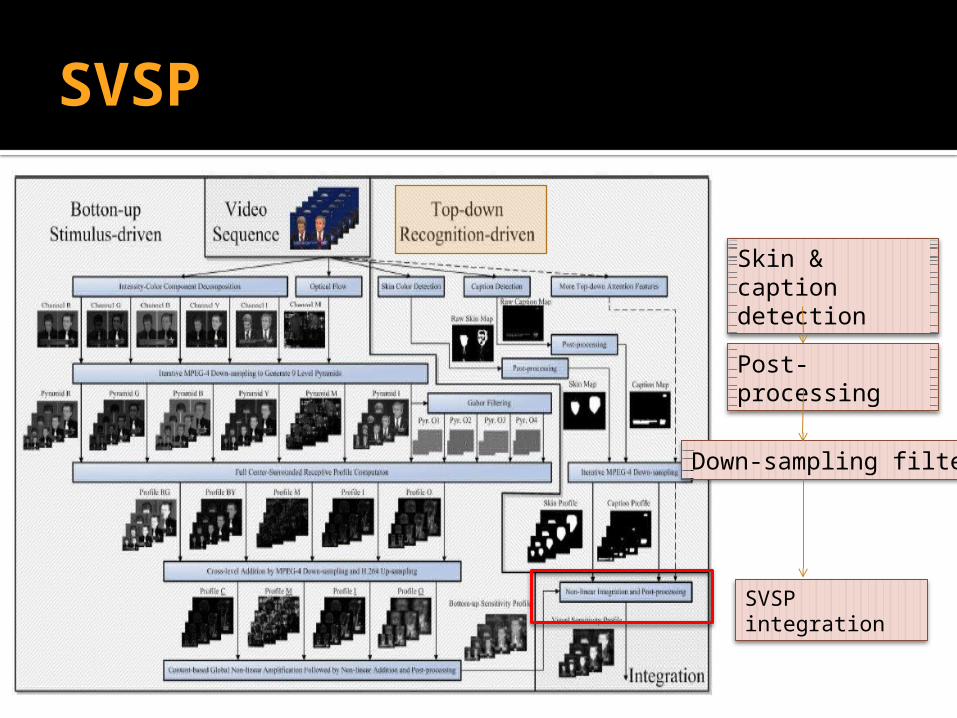
SVSP
Skin & caption detection
Down-sampling filter
SVSP integration
Post-processing

SVSP(4)
Skin Color Detection The skin color area indicates the appearance of
people and often attracts human attention. Hsu’s [5] skin model
Caption Detection Luo’s [6]

SVSP(5)
SVSP integration Considering the fact that human face by its
nature attracts more low-level human attention, we emphasize skin map more and α = 1.5, β = 1.2
Ref.G. T. Zhai, Q. Chen, X. K. Yang, W. J. Zhang,”Scalable Visual Significance Profile Estimation”, submitted to International Conference on Acoustics, Speech, and Signal Processing, April, 2008, Las Vegas, US.

Noise-shaping
To validate the effectiveness of the proposed model. JND (Just-noticeable
distortion/difference) :refers to the visibility threshold below which changes cannot be perceived by human.
Noise shaping is a popular way to evaluate the correctness of JND models.

Noise-shaping
Noise-injection process is :
The proposed VSP-based JND model is :
We will compare it with Chou’s JND model [8] JNDC and the JND model we previously proposed [9] JNDY

Noise-shaping
(a)Luminance of frame 51 in president debate.(b)Chou’s JND model, PNSR=25.99 dB.
(c)Yang’s JND model, PNSR=25.99 dB. (d)proposed VSP-based JND model, PNSR=25.99 dB.

ROI coding of JPEG2000
We define the arbitrary ROIa in an image as areas that take half the top values in .
To generate a rectangular ROIr , we explore a seeded region growing algorithm , seed is placed at the most saliency point in and then expands to surroundings. The stopping criterion is that the pixel value on region borders falls below 60% of the starting seed-value.

ROI coding of JPEG2000
(a) Details of the most sensitiveof frame 51 in president debate.
(b) Details of image coded at 0.1bpp witharbitrary ROI defined in VSP, PSNR-Y=27.2dB.
(c) Details of image coded at 0.1bpp with rectangular-shaped ROI defined in SVP, PSNR-Y=32.6dB.
(d)Details of image coded at 0.1bpp without ROI, PSNR-Y=24.0dB.
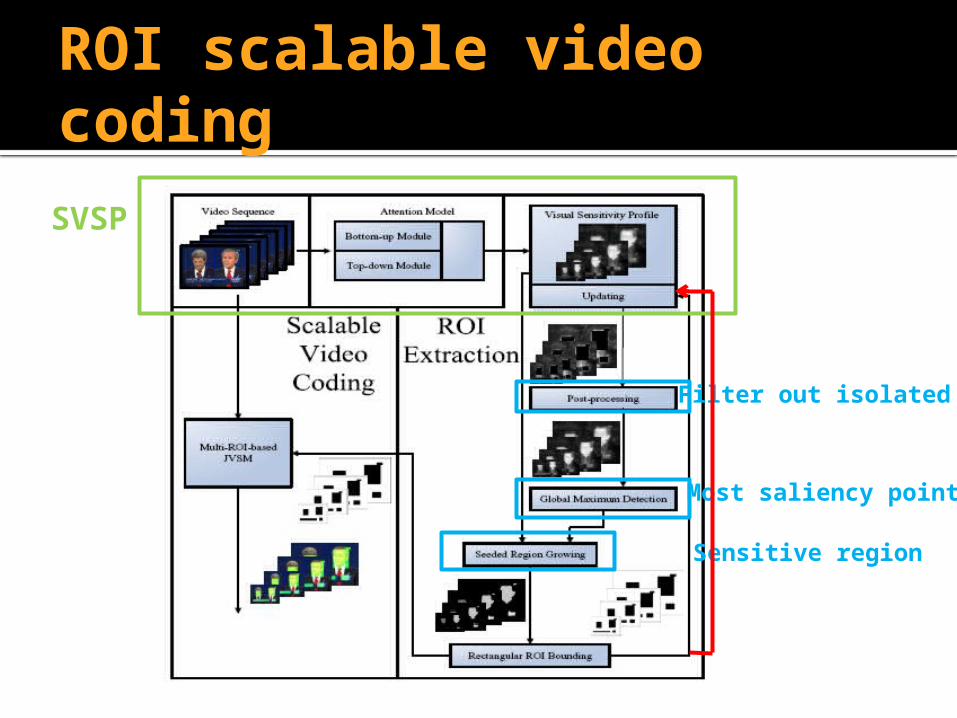
ROI scalable video coding
SVSP
Filter out isolated
Most saliency point
Sensitive region
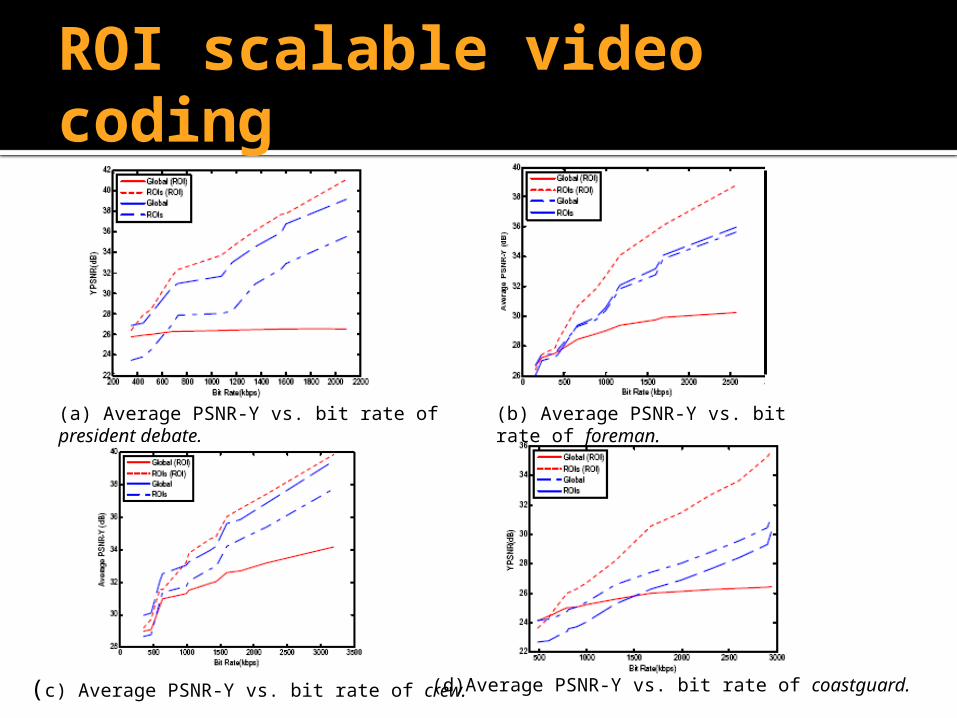
ROI scalable video coding
(a) Average PSNR-Y vs. bit rate of president debate.
(b) Average PSNR-Y vs. bit rate of foreman.
(c) Average PSNR-Y vs. bit rate of crew. (d)Average PSNR-Y vs. bit rate of coastguard.

ROI scalable video coding Visual comparison in saliency area of
frame 60 in president debate, CIF size coded at 900 kbps.
(a)without ROI (b)with SVSP defined ROI

Conclusion
This paper applies the proposed computational model for scalable visual sensitivity profile (SVSP) to image/video processing.
Extensive experimental results have justified the effectiveness of the proposed SVSP model.
Related Documents









