Prototype of animated agent for application 1 Elisabetta Bevacqua, Massimo Bilvi, Johan Bos, Piero Cosi, Emanuella Magno Caldognetto, Rob Clark, Catherine Pelachaud, Isabella Poggi, Thomas Rist, Fiorella de Rosis, Markus Schmitt, Mark Steedman, Claus Zinn Distribution: Public MAGICSTER Embodied Believable Agents IST-1999-10982 Deliverable 1.3 September 30, 2002 The deliverable identification sheet is to be found on the reverse of this page.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Prototype of animated agent for application 1
Elisabetta Bevacqua, Massimo Bilvi, Johan Bos,Piero Cosi, Emanuella Magno Caldognetto, Rob Clark,
Catherine Pelachaud, Isabella Poggi, Thomas Rist,Fiorella de Rosis, Markus Schmitt, Mark Steedman, Claus Zinn
Distribution: Public
MAGICSTEREmbodied Believable Agents
IST-1999-10982 Deliverable 1.3
September 30, 2002
The deliverable identification sheet is to be found on the reverse of this page.

Project rf. no. IST-1999-29078Project acronym MAGICSTERProject full title Embodied Believable Agents
Security PublicContractual delivery date M21 = Aug 2002Actual date of delivery September 30, 2002Deliverable number 1.3Deliverable name Prototype of animated agent for application 1Type ReportStatus & version Final 1.0Number of pages 43 (excluding front matter)Contributing WP 1WP/Task responsible UROME
Other contributors All partnersAuthor(s) Elisabetta Bevacqua, Massimo Bilvi, Johan Bos, Piero
Cosi, Emanuella Magno Caldognetto, Rob Clark, CatherinePelachaud, Isabella Poggi, Fiorella de Rosis, Thomas Rist,Markus Schmitt, Mark Steedman, Claus Zinn
EC Project Officer Jakub WejchertKeywords embodied conversational agent, avatar, animationAbstract This Document describes the Prototype of animated agent
for application 1. In particular, it describes the differentphases involved in the computation of the final animationof the agents. This document discusses the method we areusing to resolve conflicts arising when combining severalfacial expressions. We also present our lip and coarticula-tion model.
The partners in MAGICSTER are:University of Edinburgh ICCS EDIN
Universit degli Studi di Roma ”La Sapienza” ROMA
Deutches Forschungszentrum fur Kunstliche Intelligenz DFKI
Swedish Institute of Computer Science SICS
Universit degli Studi di Bari BARI
AvatarMe AME
For copies of reports, updates on project activities and other MAGICSTER-related information, contact:
TheMAGICSTER Project AdministratorUniversity of Edinburgh2 Buccleuch PlaceEdinburgh, Scotland EH8 9LW
Copies of reports and other material can also be accessed via the project’s administration homepage,http://www.ltg.ed.ac.uk/magicster/
c©2002, The Individual Authors
No part of this document may be reproduced or transmitted in any form, or by any means, electronicor mechanical, including photocopy, recording, or any information storage and retrieval system, withoutpermission from the copyright owner.

Prototype of animated agent for application 1
Elisabetta Bevacqua, Massimo Bilvi, Johan Bos,Piero Cosi, Emanuella Magno Caldognetto, Rob Clark,
Catherine Pelachaud, Isabella Poggi, Thomas Rist,Fiorella de Rosis, Markus Schmitt, Mark Steedman, Claus Zinn
September 30, 2002
3

Contents
Executive Summary 1
1 Agent architecture 1
2 The APML parser 1
3 Festival 3
4 Synchronisation of the facial expressions 34.1 Temporal computation of the facial expressions . .. . . . . . . . . . . . . . . . . . . . . 4
4.2 Temporal course of an expression. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
5 Instantiation of the APML tags 7
6 Conflicts resolver 106.1 Definition of Belief Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
6.2 Belief Network for conflicts resolution. . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6.3 Temporal extent of the conflict. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
7 Generation of the facial animation 17
8 The Facial Display Definition Language 188.1 Facial Basis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
8.2 Facial Displays . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
8.3 Blinking and Perlin Noise .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
9 Greta multi-threaded server 23
10 Lip movement 25
11 Lip shapes 2511.1 Visemes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
12 Audio-Visual Speech 26
13 Coarticulation 2713.1 State of the art of coarticulation models. . . . . . . . . . . . . . . . . . . . . . . . . . . 28
14 Lip shape computation 2914.1 Vowels. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
14.2 Consonants. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
14.3 Reproduction of ’VCV sequence. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page ii/43
14.4 Consonantal targets. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
14.4.1 Coarticulation simulation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
14.4.2 Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
14.4.3 Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
15 Conclusion 37
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 1/43
Executive summary
This Document describes the Prototype of animated agent for application 1. In particular, it describes thedifferent phases involved in the computation of the final animation of the agents. This document discussesthe method we are using to resolve conflicts arising when combining several facial expressions. We alsopresent our lip and coarticulation model.
1 Agent architecture
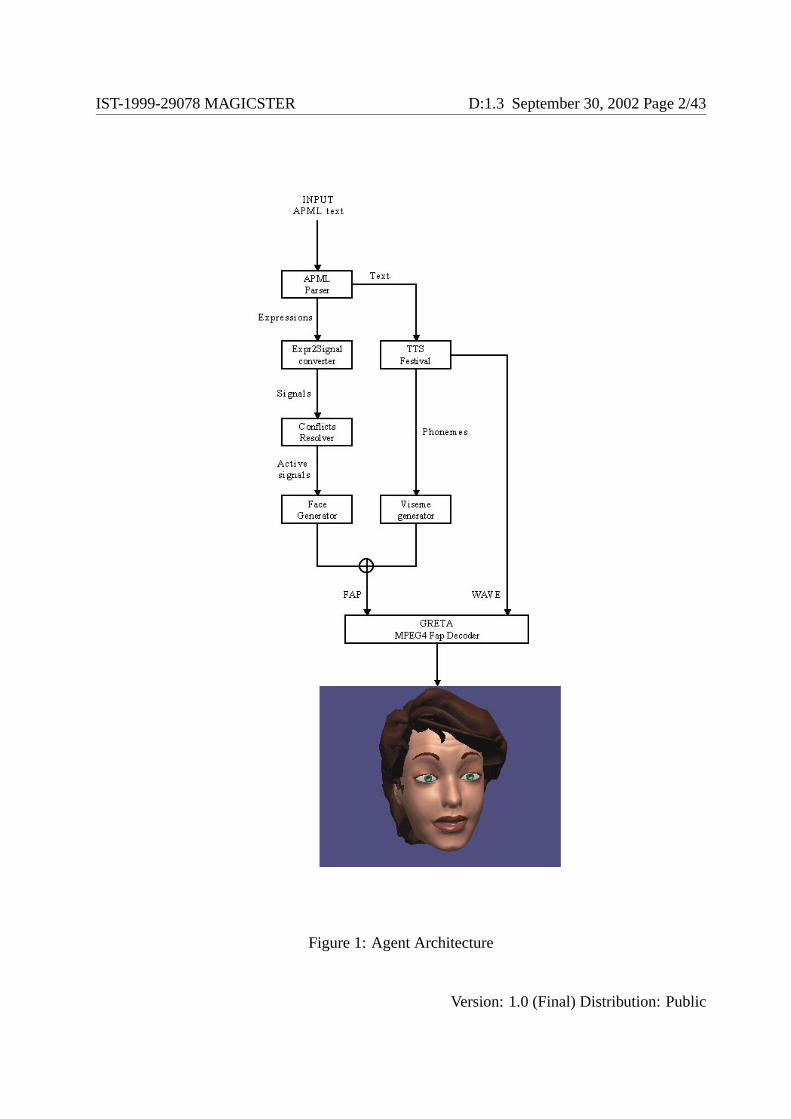
The system described in this document is part of the architecture for believable photo-realistic avatarsin MagiCster, as specified in Deliverable 4.1. The input to the system is a text annotated in APML;this language is described in detail in Deliverable 4.2. The data flow of the general architecture for theanimation of avatar and agent, which was presented in detail in deliverable 1.2, is the following: asdescribed in Deliverable 4.2, the output of the dialogue planner is a text annotated in APML. This text isinterpreted by the engine developed atUROME. The output of this interpretation is a FAP file for the facialanimation (the facial model and its parameters are described in Deliverable 1.2) and a WAV file for theaudio. In this deliverable we are concentrating on the engine created byUROME.
Figure 1 illustrates the detailed architecture of theGretaagent system. It is composed of several moduleswhose main functions are:
• APML Parser : XML parser that validates the input format as specified by the DTD APML.
• Expr2Signal Converter: given a communicative function and its meaning, this module returns thelist of facial signals to activate in order to realize the facial expression.
• TTS Festival: manages the speech synthesis and provides the information needed for the synchro-nisation of the facial expressions to the speech (i.e. a list of phonemes and their duration).
• Conflicts Resolver: resolves the conflicts that may happen when more than one facial signal shouldbe activated on the same facial parts (for example, the co-occurring signals might be “eyebrowraising” and “frown” in the eyebrow region).
• Face Generator: converts the facial signals into the MPEG-4 FAP values needed to animate the3D facial model.
• Viseme Generator: converts each phoneme, provided by Festival, into a set of the FAP valuesneeded for the lip animation.
• MPEG4 FAP Decoder: is an MPEG-4 compliant Facial Animation Engine (described in Deliver-able 1.2).
2 The APML parser
The input to the agent engine is an XML string which contains the text to be pronounced by the agentenriched with XML tags indicating the communicative functions that are attached to the text. The input
Version: 1.0 (Final) Distribution: Public
IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 2/43
Figure 1: Agent Architecture
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 3/43
may be an XML file that is passed directly to the system, or it may be an XML string that is passed viasocket connection. In the latter case, the parser acts as a server waiting for incoming connections on afixed port. Figure 2 provides an example of XML input. The APML parser takes such input and validatesit against the DTD (Document Type Definition) (as defined in Deliverable 4.2). The validation is a processin which the input text is checked with respect to the rules defined by the DTD. These rules define all thepossible elements that we can have in the document, the structure, the attributes, the types of the attributesand so on. The elements of the DTD correspond to the communicative functions described in Deliverable1.2. The next step is to pass the text to be spoken (specified in bold in figure 2) to the Festival speechsynthesiser [5] while the information contained in the markers is stored in a structure that will be usedsubsequently.
<APML><turn-allocation type=”take turn”>Good Morning Mr. Smith.</turn-allocation><affective type=”sorry-for”><performative type=”inform”>I’m sorry to tell you that you have been diagnosed as suffering from a<adjectival type=”small”> mild </adjectival>form of what we call ’angina pectoris’.</performative></affective></APML>
Figure 2: Example of XML input
3 Festival
Festival [5] is described in great detail in Deliverables 2.1 and 2.2. In Greta’s architecture Festival returnsa list of couples(phoneme,duration) for each phrase of APML tagged text. This information is then usedto compute the lip movement and to synchronise the facial expression with speech. An example of textwith the relative phonemes and durations is provided in figure 3. Recently we have developed a versionof the system in which Festival runs as a server on a host (optionally different); communication is madevia socket connection on the default Festival port.
4 Synchronisation of the facial expressions
Facial expressions and speech are tightly synchronised. In our system the synchronisation is implementedat the word level, that is, the timing of the facial expressions is connected to the text embedded between the
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 4/43
Figure 3: Example: text and his list of(phoneme,duration)
Figure 4: Tree structure from XML input
markers. The XML parser returns a tree structure from which we calculate, using the list of the phonemesreturned by Festival, the timings of each individual expression. The leaves of the tree correspond to thetext while the intermediate nodes correspond to facial expressions, except for the root, which correspondsto the APML marker (see Figure 4).
4.1 Temporal computation of the facial expressions
Let T(E) be a tree built from the XML parser andE be the set of nodes (where a node corresponds to anexpression), we define:∀e∈ E :
• C(e) = the child ofe.
• S(e) = The starting time ofe.
• D(e) = The duration ofe.
• F(e) = The list of phonemes that occurs duringe.
If e is a leaf (i.e. C(e) = /0) thene corresponds to a text span whose duration is given by the sum ofthe durations of the single phonemes that compose the text (see Figure 3). On the other hand, ife is
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 5/43
Figure 5: Computation of an expression duration
Figure 6: Calculation of the starting time
an intermediate node (i.e.C(e) 6= /0, thereforee is an expression), then duration is computed recursivelysumming the durations of all its children (see Figure 5).
∀e∈ E, the durationD(e) is recursively calculated as:
IF C(e) = /0 THEN D(e) = ∑∀ f∈F(e) f
else
D(e) = ∑∀e′∈C(e) D(e′)
If we observe the treeT(E) from left to right we notice that its nodes correspond to facial expressions (ortext spans) successive in time. So, if we redesign the tree as shown in figure 6 we can see that the nodesin the same vertical row have the same starting time. Moreover we see that each of these vertical rowscorresponds to facial expressions occurring over one common text span. So to compute the starting timeand the duration of each facial expression, we perform a pre-scan of the treeT(E) and obtain a listL(E)
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 6/43
Algorithm 1 Computation of the starting time of each expressione in the treeT(E)
L(E) = pre−visit(T(E)) {initialisation of the starting time of the expressione}for all e∈ L(E) do
S(e)← 0end forS← 0for all e∈ L(E) do
S(e)← S{D(e) duration ofegiven by the sum of the phonemes}if “e is a text span”then
S← S+D(e)end if
end for
of text spans. In the variableSwe keep track of the duration of the current text span being examined. Thealgorithm 1 illustrates in pseudo code the procedure for computing the starting time of each expressionein the treeT(E):From the tree shown in Figure 6 we obtain:
L(e) = [1,2,4,7,5,8,3,6].Let S= 0. After scanning the list, we obtain the following starting times:
S(1) = 0, S(2) = 0, S(4) = 0, S(7) = 0
S(5) = D(7), S(8) = D(7)
S(3) = D(7)+D(8), S(6) = D(7)+D(8)
4.2 Temporal course of an expression
Knowing the start time and duration of an expression, the next step is to calculate the course of theexpression intensity. The intensity of the expression is viewed as the amplitude of the facial movements,variable over time, that compose the expression.
Each expression is characterised by three temporal parameters [12]:
• onset: is the time that, starting from the neutral face, the expression takes to reach its maximalintensity.
• apex: is the time during which the expression maintains its maximal intensity.
• offset: is the time that, starting from the maximal intensity, the expression takes to return to neutral.
These parameters are different from expression to expression. For example the “sadness” expression ischaracterised by a longoffset(the expression takes more time to disappear), while the “surprise” expres-sion has a shortonset.
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 7/43
Figure 7: Temporal course of the expression “ surprise” with its respective parametersonset,apexandoffset
The values used for these parameters have been taken from research based on the analysis of facial ex-pressions [14, 39, 2].
It has been showed experimentally that the amplitude of a facial movement is much more complex [14]than a simple decomposition into three linear parameters, but for sake of simplicity and for lack of data,we use such trapezoidal functions to represent the temporal aspects of facial expressions.
5 Instantiation of the APML tags
The APML tags correspond to the meaning of a given communicative function. Thus, the next step is toconvert the markers of an input text into their corresponding facial signals. The conversion is done bylooking up the definition of each tag in the library that contained the lexicon of the type (meaning, facialexpressions) (see Table 1; Deliverable 1.2 contains the complete list of communicative functions we areconsidering). Further details on how each item is stored in the library may be found in Section 8.
Let’s consider the following text:
. . .<affective type=”sorry-for”>I’m sorry to tell you that you have been diagnosed as suffering from aform of what we call ’angina pectoris’.</affective>. . .
This text contains one communicative function represented by the markeraffective whose value issorry-for as specified by the fieldtype. The list of signals for this communicative function is:
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 8/43
Cluster Communicative Function Meaning SignalDeictic & Deictic point in space direction of eyes / head
toward particular point in spaceProperty Adjectival small, tiny, subtle small eye aperture
wide, big, great large eye apertureCertainty uncertain raised eyebrow
Belief certain small frownBelief relation but raised eyebrow
(contrast btw RR)Performative I implore head aside, inner eyebrow up, look at A
I warn tense eyelid, small frown, look at AI order frown, tense lips, chin up, look at AI criticize small frown, mouth grimace, look at A
Intention Topic-comment emphasis raised eyebrow, look atAhead nodblink
Turn-allocation eyes giving turn raised upper eyelidlook at Astart of gesticulation
taking turn look away fromAend of gesticulation
Metacognitive Metacognitive I’m thinking look up sidewayseyelid lowered, look away from A
Affective state Affective anger frown, close tense lipfrown, open tense lip
joy smile, raised cheeksurprise raised eyebrow, large eye aperture,
open mouthsorry-for head aside, inner raised eyebrow central
Table 1: Examples of lexicon pairs
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 9/43
Figure 8: ’Sorry for’ expression
a f f ective(sorry- f or) = {eyebrows up-down, head aside}
Figure 8 illustrates the corresponding expression.
Now let’s consider the following text:
. . .<certainty type=”certainly-not”>I’m sorry to tell you that you have been diagnosed as suffering from aform of what we call ’angina pectoris’.</certainty>. . .
Here, the communicative function is given by the markercertainty with certainly-not as a value. The listof signals for this function is:
certainty(certainly−not) = {frown}
Figure 9 illustrates the expression ofcertainly-not.
In these two examples we have seen two “different” communicative functions that activate “different”signals on the same facial part (eyebrow).
Let consider the following example:
. . .<affective type=”sorry-for”><certainty type=”certainly-not”>I’m sorry to tell you that you have been diagnosed as suffering from aform of what we call ’angina pectoris’.</certainty></affective>. . .
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 10/43
Figure 9: ’Certainly not’ expression
We have two communicative functions that activate in the same time interval two different signals (frownandeyebrows up-down) on the same facial region (eyebrow). So we have a conflict that must be resolvedbefore the animation can be visualised. When a conflict at the level of facial signals is detected, the systemcalls up a special module for the resolution of conflicts (in figure 1 it is termed theConflicts Resolver)that will be described in detail in the section 6. This module determines which signal, among those thatshould be active on the same facial region, should prevail over the others. If we go back to our previousexample,Conflicts Resolver) returns:
resolveconflict(a f f ective(sorry- f or),certainty(certainly−not)) ={frown , head aside}
The resulting expression is shown in Figure 10. As we can see theConflicts Resolverhas decided that thesignalfrown prevails over the signaleyebrows updown.
6 Conflicts resolver
In the previous section we have illustrated a situation in which a conflict between facial signals occurs. Inthis section we describe in detail the architecture of the resolver and the algorithm we use. Few attemptshave been made to combine co-occurring expressions. Often additive rules are applied [7, 30], in whichcase all signals corresponding to the co-occurring communicative functions are added to each other. Re-cently Cassell et al [8] proposed a hierarchical distinction of the signal: only the signal with the highestpriority rule will be displayed. These latter two methods do not allow the combination of several commu-nicative functions to create a complex expression. Our proposal is to applyBelief Networks(BN) to themanagement of this problem. Before proceeding with the description of our system we provide a defini-tion of BNs, which are used extensively in many aspects of the MagiCster research (see the discussion ofAvatar Arena in D2.3, for example).
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 11/43
Figure 10: Expression of ‘sorry-for’, ‘certain’ and combination of both expressions after conflictresolution.
6.1 Definition of Belief Networks
We use Belief Networks in modelling several aspects of the believable agent as uncertainty is typical ofreal domains. In Ball and Breze (2000), belief networks are used to handle uncertainty in the way thatemotions felt are expressed: in this case, the ability of belief networks to handle conflict resolution isexploited. In D3.2, we will see the role that uncertainty plays in modelling the triggering of emotions andwe will extensively use this method to model the mixing and the evolutionary dynamics of the emotions.In the final stages of WP4 we will show how the components mentioned above will be tightly integrated.
Without going into mathematical details, a belief network (or Bayesian network), as employed in Mag-iCster, is built on aDirected Acyclic Graph(DAG), G=(V,E) whose nodes, v in V, represent randomvariablesXv, with finite state spaceχ v. Every random variableXv is described in terms of the condi-tional probability distributionP(Xv|parents(Xv))defined onχ v, whereP(Xv|parents(Xv))reduces to anunconditional distribution ifparents(Xv)=/0. In G the conditioning variables ofXvare represented bypar-ents(Xv). The joint probability, p=pv, defined onχ v, factorizes (recursively) according to the graph, sincep(X)= ∏ p(Xv| parents(Xv)). G is called the independence graph of p, since it captures all (conditional)independence properties of p.
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 12/43
Figure 11: A simple Bayesian network
A net example is illustrated in Figure 11. The set of random variables is{A,B,C} with parents(A) ={B} andparents(C) ={B}. The graph is obviouslydirected(all arcs have a direction) andacyclic (ifwe start from a node and follow the arcs we cannot return to the starting node). The nodes A and C areconditionally independent given B: that isP(A|B,C) = P(A|B). We also haveP(C|B,A) = P(C|B). In thisexample, the joint distribution of the variables is given byP(A,B,C) = P(A|B)*P(B)*P(C|B).
Given a DAG representing a Bayesian Network, evidence on a node v in the network is an instantiationof the corresponding variableXv. If no evidence is inserted in the network, the conditional probability,P(Xv|parents(Xv)), represents the default knowledge in the domain. The marginal probability (also calledprior probability) associated with each variableXv in the network is the belief that an event will occur.If some evidence is observed, the prior probabilities associated with the remaining variables are updated(the new probabilities are also called ‘posterior probabilities’) according to the rules of probability theoryso that equilibrium is reached (Bayesian conflict resolution) .
6.2 Belief Network for conflicts resolution
In this section we look at the technical aspects of the BN. In [31] the reader can find information on thetheoretical foundation of the AN creation; how it is linked to a compositional view of signals and mean-ings; how it can be used to modulate the expression accompanying a sentence; how such a modulationwould allow us to define expressive idiolects to create agents as individual entities with specific behavioursof their own.
Our BN includes the following types of nodes (see figure 12):
communicative functions : These nodes correspond to the communicative functions listed in Deliverable1.2: performative, certainty, belief-relation, emotion, topic-comment, turn-taking, metacognitive.
facial parts : These are the eyes, eyebrows and mouth, and head, which is distinguished by head move-ment and head direction. For example, the values we provide for the eyebrows are: raised, frown,up-down, and neutral (where by up-down we mean the eyebrows are raised as well as pulled to-gether). The values we allow for the mouth are: lip tense, smile, lip corner down, and neutral.
performative dimensions : The performatives that we define in the lexicon number around 20. Per-
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 13/43
Figure 12: Belief Network linking facial communicative functions and facial signals
formatives may be described along a small set of dimensions which are ‘power-relationship’, ‘inwhose interest is the requested action’, ‘degree of certainty’, ‘type of social encounter’, ‘affectivestate’ [33]. Performatives may be characterised by specifying values for each of these dimensions.However, our goal here is not to attempt a full characterisation of performatives, rather to considerthe subset of dimensions that have been described as relevant to the characterisation of performa-tives [33]. We have singled out two dimensions among the five: ‘power relationship’ and ‘in whichinterest is the requested action’. In the BN we call them, respectively, ‘dominance’ (whose val-ues are submissive, neutral, dominant) and ‘orientation’ (whose values are self-oriented, neutral,other-oriented). These dimensions allow us to differentiate performatives not as for their mean-ing (which strictly requires five dimensions) but for the facial parts that are used to express theperformative, and in which conflict may arise (see figure 13). Indeed, a common feature of theperformatives whose value on the orientation dimension is ‘other-oriented’ is a ‘head nod’: perfor-matives of this category are, for example, ‘praise’, ‘approve’, ‘confirm’, and ‘agree’. On the otherhand, ‘submissive’ and ‘self-oriented’ performatives (e.g. ‘implore’) show inner eyebrow raising,while ‘self-oriented’, and ‘dominant/neutral’ performatives (such as ‘order’, ‘criticise’, ‘disagree’,‘refuse’) have a frown in common. In our BN, the two dimensions are represented as intermediarynodes (thus simplifying the construction of the BN), which are linked to the leaf (signal) nodes. Forexample the performative ‘implore’ is characterised as being ‘submissive’ and in ‘self-oriented’,‘advice’ as being ‘neutral’ and ‘other-oriented’, ‘order’ as being ‘dominant’ and ‘self-oriented’.On the one hand this allows us to study how common features of performatives prevail in the finalfacial expressions; on the other hand, it also helps us in reducing the number of entry nodes in theBN.
emotion dimensions : The number of emotions we are considering is 30 [29]. Using the same reasoningas for the performatives, we define emotion along few dimensions. These dimensions are ‘valence’(positive or negative) and ‘time’ (past, current and future) [28]. Valence is commonly used todifferentiate emotions. Examples of positive emotions are ‘joy’, ‘happy-for’, ‘satisfaction’, and‘like’, while examples of negative emotions are ‘anger’, ‘sadness’, ‘fear’, ‘dislike’, and ‘reproach’.The dimension ‘time’ refers to the time at which the event that triggers the emotion is happening[28]. ‘Fear’ or ‘distress’ refer to an event that might happen in the future, while ‘sadness’ or‘resentment’ are due to events that happened in the ‘past’. ‘Disgust’ is due to an event happeningat the ‘current’ time. Furthermore this representation allows one to characterise emotions basedon their facial expressions. ‘Tense lips’ are common to the negative emotions (envy, jealousy,
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 14/43
Figure 13: Cluster of performatives along the dimensions ‘dominance’ and ‘orientation’
anger, fear) while a ‘frown’ will characterise negative emotions happening at the ‘current time’ (forexample anger). ‘Positive’ emotions are often distinguished by a ‘smile’ (e.g. ‘joy’, ‘happy-for’,‘satisfaction’, ‘gratitude’).
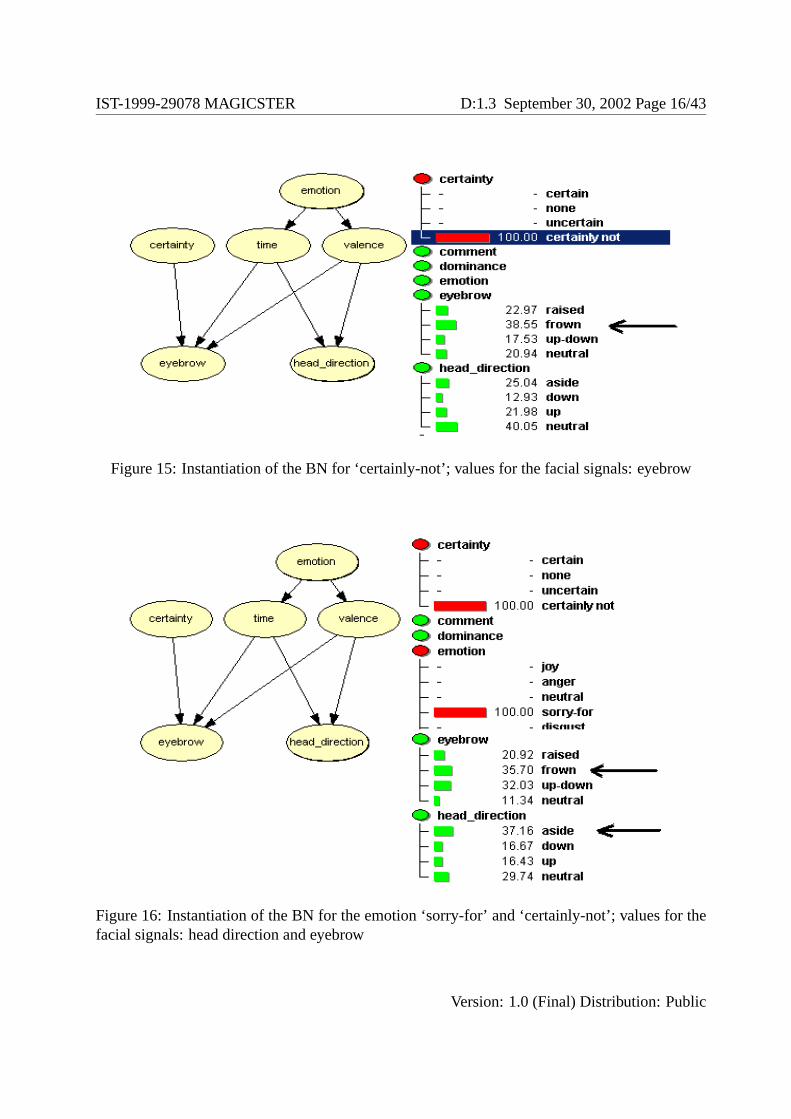
The final expression of the face, corresponding to a set of communicative functions occurring on the sametext span, is obtained by combining the values for each part or expressive parameter that is involved in theexpression of each communicative function. This method allows us to combine expressions at a finer leveland to resolve possible conflicts at the signal level. When a conflict is encountered, the BN initialised thecommunicative function concerned at 100. The BN delivers the probabilities that each signal (involved inboth communicative functions) has to be selected to form the new expression. For example, the expressionresulting from the combination of the performative function ‘I am sorry-for’ (‘oblique eyebrow’ + ‘headaside’) with the certainty function ‘certainly not’ (frown) will simply be ‘frown’ + ‘head aside’; that is, itcuts off the ‘I am sorry-for’ signal at the eyebrow level (See Figure 10). Figure 16 illustrates the result.The emotion ‘sorry-for’ and the certainty ‘certainly-not’ are initialised at 100 by the BN. Knowing whichemotion has been selected, the values of the intermediate nodes ‘valence’ and ‘time’ are computed (thevalues are shown in the figure). The value of the eyebrows for resolution of the signal conflicts is thenoutput by the BN. As shown in the figure, ‘frown’ receives the higher probability. If only the ‘sorry-for’emotion is to be expressed on the face, the value with higher probability is the up-down eyebrow signal(see figure 14). In the same way, with only the ‘certainly-not’ function, the eyebrow will most probablyfrown (see figure 15).
Let us now look at an example where one expression definitely prevails over another. Note the differencebetween ‘certain’ and ‘comment’. Both are expressed through eyebrows, but the former is through a‘small frown’, the latter through an ‘eyebrow raising’. The result of the BN is that the ‘certain’ meaning
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 15/43
Figure 14: Instantiation of the BN for the emotion ‘sorry-for’; values for the facial signals: headdirection and eyebrow
is suppressed, while the ‘comment’ is displayed.
Turning to the mouth region, suppose one has to praise somebody while one is also sad. Praise is usuallyshown by a smile, raised eyebrows and a large head nod while sadness involves lowering the lip corners,looking down, and up-down eyebrows. Having both functions as input, the values of the signals with thehighest probability will be: up-down eyebrows, lower lip corners, look down and a large head nod.
6.3 Temporal extent of the conflict
The conflict resolution is applied to every interval(a,b) on which two (or more) signals should be activeon the same facial region. LetS1 andS2 two signals in conflict and let(a1,b1) and(a2,b2) be the respectiveintervals on which they occur. Then we always have:
a1≤ a2∧b2≤ b1 or a2≤ a1∧b1≤ b2
The temporal intervals of overlapping expressions are embedded in each other; they cannot be interleavedin a single markup file due to the use of XML specifications, that is we cannot have:
<TAG1>. . .<TAG2>. . .</TAG1>. . .</TAG2>
Version: 1.0 (Final) Distribution: Public
IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 16/43
Figure 15: Instantiation of the BN for ‘certainly-not’; values for the facial signals: eyebrow
Figure 16: Instantiation of the BN for the emotion ‘sorry-for’ and ‘certainly-not’; values for thefacial signals: head direction and eyebrow
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 17/43
Figure 17: Instantiation of the BN for the emotion ‘sadness’ and the performative ‘praise’; valuesfor the facial signals: head movement, mouth shape, head direction and eyebrow
Figure 18: Interval of conflict between two signals
Let’s consider the example in figure 18. If a conflict arises between the two signals in the same facialregion, it has to be in the interval(a,b). The resolver will decide, according to the results output bythe BN, whether to deactivate theS2 signal (Figure 19 (a)) or to deactivate “partially” (that is only inthe interval(a,b)) the S1 signal (Figure 19 (b)). As we can see in figure 19 (b), theS1 signal has beendeactivated during the time interval(a,b).
7 Generation of the facial animation
After resolving potential conflicts between the facial signals, we proceed with the animation generationfor the agent. The animation is obtained by converting each facial signal into the corresponding facialparameter, the FAPs as defined by the facial animation player. This one is compliant with the MPEG-4standard and is fully described in Deliverable 1.2.
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 18/43
Figure 19: Various possibilities for the deactivation of a signal on a given interval during theconflict resolution
8 The Facial Display Definition Language
In this section we describe the language we have developed to define and to store facial expressions. Theformalism allows us to create a “facial display dictionary” which can easily be expanded.
8.1 Facial Basis
In our system we distinguish “facial basis” (FB) from “facial display” (FD). An FB involves one facial partsuch as the eyebrow, mouth, jaw, eyelid and so on. FB includes also facial movements such as nodding,shaking, turning the head and movement of the eyes. Each FB is defined as a set of MPEG-4 compliantFAP parameters:
FB = { f ap3 = v1, . . . . . . . . . , f ap69= vk};
wherev1,. . . ,vk specify the intensity value for the FAPs 3-68 (we do not consider the FAP 1 and FAP 2associated, respectively, with the six ”universal” facial expressions of emotion and with visemes).An FB can also be defined as a combination of FBs by using the ’+’ operator in this way:
FB′ = FB1 +FB2;
whereFB1 andFB2 can be:
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 19/43
Figure 20: The combination of “raiseleft” FB (left) and “raiseright” FB (centre) produces“raise eyebrows” FB (right)
• Previously defined FB’s
• an FB of the form:
{ f ap3 = v1, . . . . . . . . . , f ap69= vk}
Let us consider theraising eyebrowsmovement. We can define this movement as a combination ofleftandright raising eyebrow. Thus, in our language, we have:
raise eyebrows= raise le f t+ raise right;
whereraise left andraise right are defined, respectively, as:
raise le f t = { f ap31= 50, f ap33= 100, f ap35= 50};
and
raise right = { f ap32= 50, f ap34= 100, f ap36= 50};
Figure 20 illustrates the resultingraise eyebrowsFB.
We can also increase or decrease the intensity of a single facial basis by using the operator ’*’:
FB′ = FB∗c = { f ap3 = v1∗c, . . . . . . . . . , f ap69= vk ∗c};
Where FB is a “facial basis” and ’c’ a constant. The operator ’*’ multiplies each of the FAPS constitutingthe FB by the constant ’c’. For example if we want an eyebrow raising with greater intensity (Figure 21):
large eyebrowsraising= raise eyebrows∗2;
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 20/43
Figure 21: The “raiseeyebrows” FB (left) and the “largeeyebrowsraising” FB (right)
Figure 22: The combination of “surprise” FD (left) and “sadness” FD (centre) produces the“worried” facial display (right)
8.2 Facial Displays
A facial display (FD) corresponds to a facial expression. Every FD is made up of one or more FB’s:
FD = FB1 +FB2 +FB3 + . . . . . .+FBn;
We can define the ’surprise’ facial display in this way:
surprise= raise eyebrows+ raise lids+openmouth;
We can also define a FD as a linear combination of two or more (already) defined facial displays usingthe ’+’ and ’*’ operators. For example we can define the “worried” facial display as a combination of“surprise” (slightly decreased) and “sadness” facial displays (Figure 22):
worried = (surprise∗0.7)+sadness;
8.3 Blinking and Perlin Noise
While speaking with an interlocutor we can see that the face, head or eyes never remain still. They areconstantly in movement, even in an imperceptible manner. These behaviours cannot be simulated by therules specified by the APML language. When an APML tag is instantiated, say to a head turn signal, theagent will turn her head. She will remain in this position until the end of the tag or until a successive tag
Version: 1.0 (Final) Distribution: Public
IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 21/43
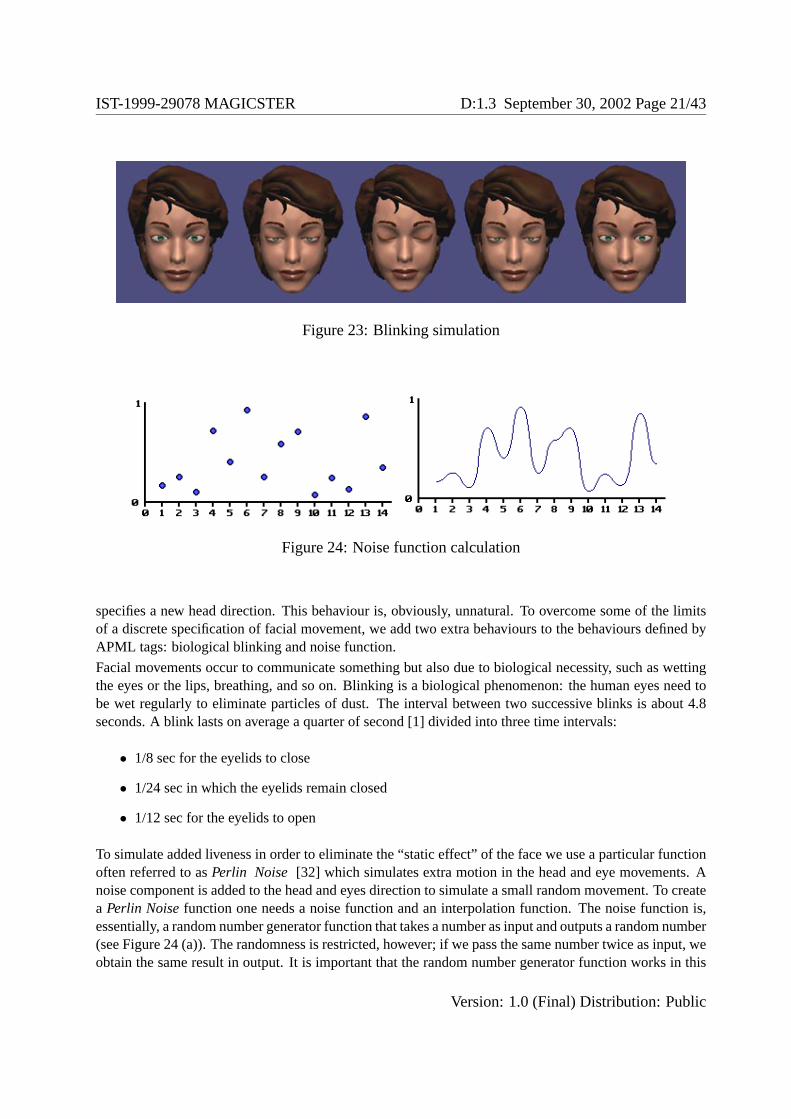
Figure 23: Blinking simulation
Figure 24: Noise function calculation
specifies a new head direction. This behaviour is, obviously, unnatural. To overcome some of the limitsof a discrete specification of facial movement, we add two extra behaviours to the behaviours defined byAPML tags: biological blinking and noise function.
Facial movements occur to communicate something but also due to biological necessity, such as wettingthe eyes or the lips, breathing, and so on. Blinking is a biological phenomenon: the human eyes need tobe wet regularly to eliminate particles of dust. The interval between two successive blinks is about 4.8seconds. A blink lasts on average a quarter of second [1] divided into three time intervals:
• 1/8 sec for the eyelids to close
• 1/24 sec in which the eyelids remain closed
• 1/12 sec for the eyelids to open
To simulate added liveness in order to eliminate the “static effect” of the face we use a particular functionoften referred to asPerlin Noise [32] which simulates extra motion in the head and eye movements. Anoise component is added to the head and eyes direction to simulate a small random movement. To createa Perlin Noisefunction one needs a noise function and an interpolation function. The noise function is,essentially, a random number generator function that takes a number as input and outputs a random number(see Figure 24 (a)). The randomness is restricted, however; if we pass the same number twice as input, weobtain the same result in output. It is important that the random number generator function works in this
Version: 1.0 (Final) Distribution: Public
IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 22/43
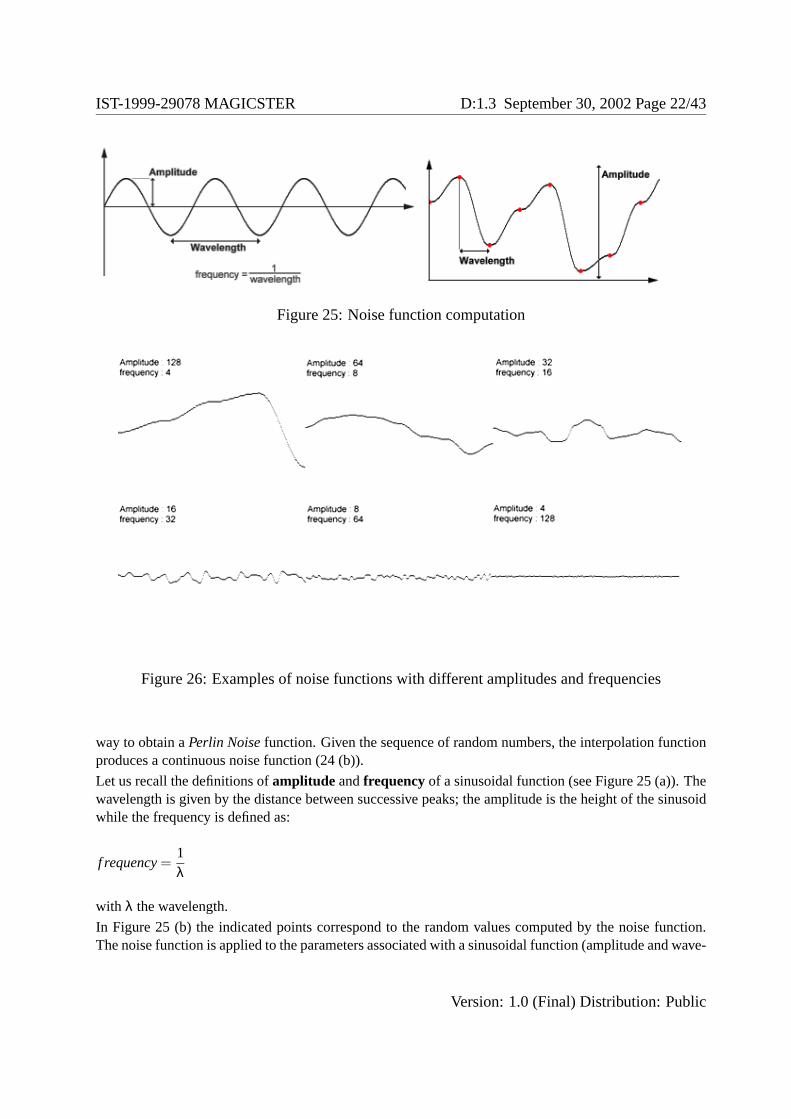
Figure 25: Noise function computation
Figure 26: Examples of noise functions with different amplitudes and frequencies
way to obtain aPerlin Noisefunction. Given the sequence of random numbers, the interpolation functionproduces a continuous noise function (24 (b)).
Let us recall the definitions ofamplitude andfrequencyof a sinusoidal function (see Figure 25 (a)). Thewavelength is given by the distance between successive peaks; the amplitude is the height of the sinusoidwhile the frequency is defined as:
f requency=1λ
with λ the wavelength.
In Figure 25 (b) the indicated points correspond to the random values computed by the noise function.The noise function is applied to the parameters associated with a sinusoidal function (amplitude and wave-
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 23/43
Figure 27: Perlin Noise obtained by adding the functions shown in Figure 26
length). By varying the input parameters, i.e. by varying the amplitude and frequency of the sinusoidalfunction, one can create a series of noise functions (see Figure 26). We can add them up as show in Figure27 to obtain aPerlin Noisefunction. This function is applied to the head direction (i.e. to the three FAPsthat characterise the head direction) as well as to the eye direction. In the future we will change this lastcomputation. To get a proper animation of the eyes, one has to use thePerlin Noisefunction on the pointthe eyes are fixing and to compute the eye direction from this point.
9 Greta multi-threaded server
In the first version, our system suffered from two drawbacks:
• The player was integrated (hard-coded) in the main application.
• The player was blocked while waiting for incoming FAP and WAV files.
In the new architecture we decided to separate some components (the APML parser, Festival and MPEG-4player) into different modules running in a client/server architecture. For the APML parser and Festival wehave chosen a simple blocking server architecture since we use a Windows-based version of Festival whichcannot handle more than one socket connection. This means that the APML parser must wait for Festivalto return the phoneme list. The MPEG-4 player is now able to handle multiple socket connections usingthe multi-threading technique (Figure 28). The player is composed of a main application that computesthe agent animation. We then have a separate thread that acts as a server waiting for incoming connections(e.g. waiting for incoming FAP and WAV files). Each time the server receives a connection a “new”thread for receiving FAP and WAV files is created. After receipt of the files, the thread inserts them in aqueue. This architecture allows us to handle more socket connections (one connection per thread). TheMPEG-4 player reads and plays the first FAP/WAV files available in the queue. This architecture providesthe following advantages:
• The player acts as a separated application running on a (optionally different) host.
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 24/43
• The player has no need to wait for the APML parser to complete its computation and can playFAP/WAV files from the queue while the spawned threads handle the data reception.
Figure 28: Greta server architecture
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 25/43
10 Lip movement
Another of our goals is to create a natural talking face with lip-readable movements. The sub-contractor,CNR of Padova, provided us with real data extracted from a speaker with an opto-electronic system thatapplies passive markers to the speaker face. We have approximated the data using a neural network model.In the next sections we describe our computational model of lip movements and the coarticulation ruleswe have included. Our model is based on some phonetic-phonological considerations of the parametersdefining the labial orifice, and on identification tests for visual articulatory movements.
Speech intelligibility and speech perception by hearers improve when considering visual signals as wellas audio [35, 36]. Communication between humans is done not only via verbal language, but also throughour use of intonation, gaze, hand gesture, body movement, and facial expression. Some information maybe transmitted by audio and visual signals together, and this redundancy is exploited [22, 6]. For example,a question can be marked by any one of the following signals: the voice pitch, a raised eyebrow or ahead direction, or by a combination of these signals. But also, the interpretation of a signal from onemodality can be modulated by other co-occurring signals. For instance a raised eyebrow coinciding witha high ending tone is interpreted as a question mark signal rather than as the emotional signal of surprisein American-English [12].
Signals from visual and audio channels complement each other. The complementary relation betweenaudio and visual cues helps in ambiguous situations. Indeed, some phonemes can be easily confusedacoustically (e.g. /m/ and /n/) but can be easily differentiated visually (/m/ is accompanied by lip closurewhile /n/ is not). Looking at a face while talking improves human perception [26, 4, 37]. People, especiallythose who are hard of hearing, make use of gesture information to perceive speech. Similarly, speechrecognition performance when combining the audio and visual channels is higher than when only onechannel is used [35].
Our system includes two modules: the coarticulation rules and the converter of the phonetically relevantparameters (PRPs) into facial action parameters (FAPs). The input text is sent to Festival where it isdecomposed into a sequence of phonemes with their duration. These temporal values are used to ensurethe correct synchronisation of the lip movements. From this sequence of phonemes the system computesthe lip shape: it first looks at which visemes are involved and then applies coarticulation rules. Oursystem defines lip shapes using labial parameters that have been determined to be phonetically relevantparameters. These parameters need to be transformed into FAPs to drive the facial animation. Acousticallysynchronised animation is obtained by composing the audio and animation streams.
In the next section, we first provide background information on the articulatory characteristics of lipmovement during speech, looking at the definition of visemes and of phonologically and phoneticallyrelevant labial parameters. We pay particular attention to the effect of coarticulation, and we then presentour coarticulation model.
11 Lip shapes
The computation of lip shape during speech is not as straightforward as one might expect. Indeed, asimple mapping between single speech sounds and unique associated lip shapes does not exist. The samelip movements are involved in producing a variety of different speech sounds. As a consequence, manywords look alike even though they sound different.
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 26/43
11.1 Visemes
Since many phonemes can not be differentiated based on audio signals (such as voiced, voiceless or nasal),Fisher [15] introduced the notion of visual phonemes (visemes). Phonemes are clustered based on theirvisual similarity. A viseme may not be viewed as theoretically founded but rather as an experimentalconcept; a distinction similar to the one existing between allophone and phoneme [4]. Research has beendone to cluster vowels and consonants based on their visual similarity. This relation of similarity doesnot necessarily correspond to the relation linking acoustic similar phonemes. Consonants with differentvoicing or nasal properties are easily confused visually while consonants differing in place of articulationare quite recognisable (such as /p/ and /b/ (lip closure) as well as /f/ and /v/ (lower lip to upper teeth)(cited in [4])). However, vowels are not so easily grouped by similarity. For some languages, the roundingparameter is the most important parameter of distinction among vowels [4].
12 Audio-Visual Speech
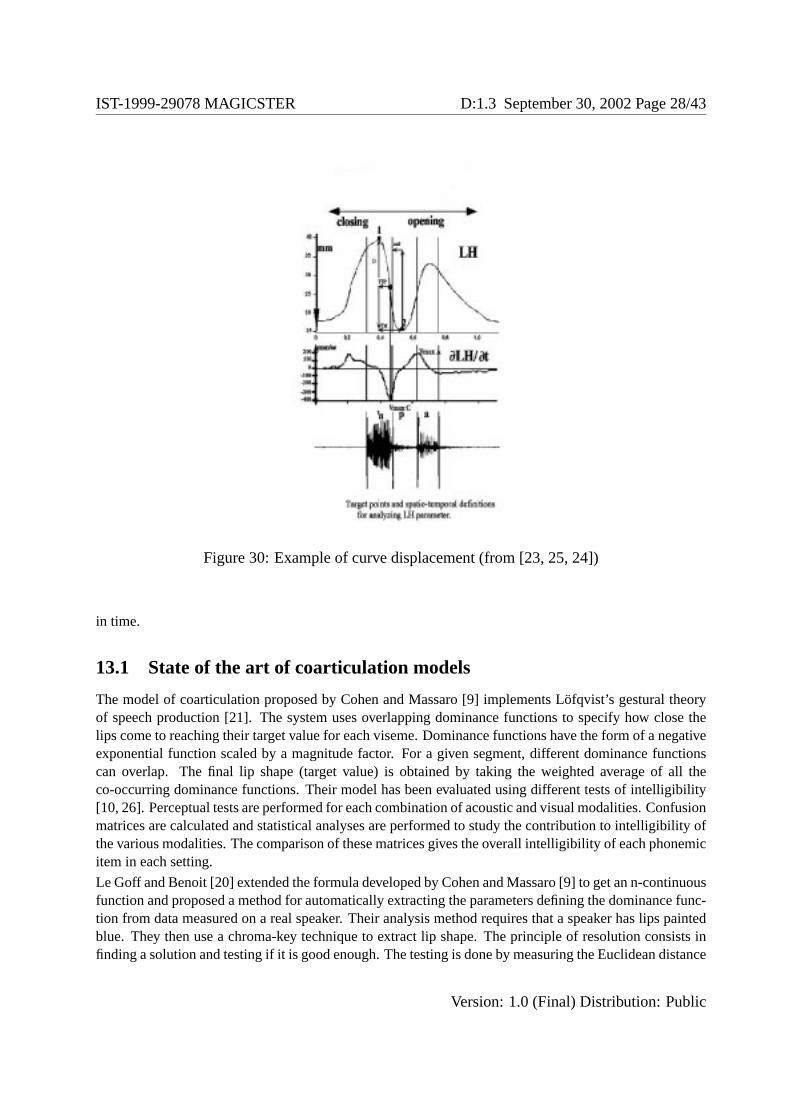
The lip movements of a real speaker have been recorded at the Istituto di Fonetica e Dialettologia-C.N.R.of Padova, sub-contractor ofUROME, by means of ELITE (see figure 29). ELITE is an opto-electronicsystem that applies passive markers to the speaker’s face [23, 25, 24]. It records the acoustic signal as wellas the displacement and velocity of the markers, every 1/10th on a second, producing displacement curves(see figure 30). Markers have been placed on seven spots on the face: one marker on each lip corner, oneon each ear, one on the chin, one on the mid upper lip and one on the mid lower lip. The first two markersallow one to get the lip width; the next two to get information on the global head motion; the marker onthe chin gives information on the jaw action; the last two markers provide values on, respectively, theupper and lower lip protrusion. The articulatory characteristics of Italian vowel and consonant targets inthe ’VCV context were quantified from 4 subjects, repeating each item 5 times. (’V stands for stressedvowel, C for consonant, V for unstressed vowel.)
Research has shown that only a few parameters are necessary to describe lip shapes [17, 4, 11]. Theseparameters are able to describe each cluster of visually confused phonemes (visemes). Five parametershave been found to be phonetically and phonologically relevant: lip height (LH), lip width (LW), upperlip protrusion (UP), lower lip protrusion (LP), and jaw (JAW) [24]. For the moment we have decided toconcentrate on these 5 parameters.
Even though the data was recorded for 4 subjects, we are currently using only one subject saying thesentence once. There is a lot of variation in the lip movement during speech production among subjectsand even with repetitions by a single subject. The average lip shape of the 4 speakers repeating thesentences 5 times loses the characteristic information for each viseme.
The original data were produced by Italian speakers, so we have information on Italian visemes and we usethese data to generate lip shapes for different languages. Each language has its own set of visemes as wellas its coarticulation models [4, 3, 19]. But several aspects of the system allow us to overcome the diversity.First of all, Festival can synthesise different languages (English, Italian, French...). For each of theselanguages, Festival proposes a conversion scheme for any input text into the set of phonemes appropriatefor the current language. Moreover, we are using a mathematical representation of the coarticulationphenomenon which has several parameters that allows us to simulate several coarticulation influence types.
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 27/43
Figure 29: The ELITE system (from [23, 25, 24])
13 Coarticulation
The primary units of word are segments, which are the smallest indivisible entities. A succession ofsegments gives the internal structure of a word. However, there is no clear boundary between segmentsin a word. A word is not made up of a succession of discrete units but rather as a continuous streamof segments. Finding a boundary in acoustics and in articulation is not possible. Only a perceptiblechange in acoustics and/or in articulation distinguishes successive segments in a word. This effect is calledcoarticulation. Coarticulation arises from the temporal overlap of successive articulatory movements,which cause the boundaries between articulatory units to become less prominent.
As we have already mentioned segments are not emitted sequentially but rather they affect each other ina non-linear fashion [16]. Lofqvist [21] integrated this result in his model. The influence of a segmentover an articulator can be represented by a dominance function [21]. A dominance function is establishedfor each speech articulator. Such a function specifies the time-invariant influence (that is the dominance)that an articulator can have over the articulators involved in the production of preceding or succeedingsegments. That is, it simulates the behaviour of an articulator over time: before a certain time the segmenthas no influence over the articulator; after it starts, the maximum influence appears at the maximum ofthe dominance curve; finally the curve decreases, meaning that the effect of the segment on the articulatorlessens. The amplitude and field of influence of each dominance function depend on the segment and onthe articulator. For a sequence of segments, the dominance functions for a given articulator may overlap
Version: 1.0 (Final) Distribution: Public
IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 28/43
Figure 30: Example of curve displacement (from [23, 25, 24])
in time.
13.1 State of the art of coarticulation models
The model of coarticulation proposed by Cohen and Massaro [9] implements Lofqvist’s gestural theoryof speech production [21]. The system uses overlapping dominance functions to specify how close thelips come to reaching their target value for each viseme. Dominance functions have the form of a negativeexponential function scaled by a magnitude factor. For a given segment, different dominance functionscan overlap. The final lip shape (target value) is obtained by taking the weighted average of all theco-occurring dominance functions. Their model has been evaluated using different tests of intelligibility[10, 26]. Perceptual tests are performed for each combination of acoustic and visual modalities. Confusionmatrices are calculated and statistical analyses are performed to study the contribution to intelligibility ofthe various modalities. The comparison of these matrices gives the overall intelligibility of each phonemicitem in each setting.
Le Goff and Benoit [20] extended the formula developed by Cohen and Massaro [9] to get an n-continuousfunction and proposed a method for automatically extracting the parameters defining the dominance func-tion from data measured on a real speaker. Their analysis method requires that a speaker has lips paintedblue. They then use a chroma-key technique to extract lip shape. The principle of resolution consists infinding a solution and testing if it is good enough. The testing is done by measuring the Euclidean distance
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 29/43
between the synthesised curve and the original one. If the distance is too large, the process is repeated. Arelaxation method is used to optimise the different variables iteratively. It uses the dichotomy principlesapplied to each parameter and looks for the minimum of the distance function between the synthesisedand real curves. The computation of the minimum is done by looking at the partial derivative of the tar-get parameter function for each parameter. They have evaluated their extraction method following twoapproaches [20]: a quantitative evaluation test, based on measurements to test if the movements producedare correct or not; and a qualitative evaluation test, an approach based on a perceptual test to check howthe visual information is perceived.
Some difficulties may be found with the above method [34], especially for the bilabial stops for whichlabial closure is necessary but is not always maintained if one uses the dominance function. To overcomethese problems, Reveret et al [34] adaptOhman’s coarticulation model [27]. This model suggests thatthere is a dominant stream of vowel gestures on which are superimposed consonant gestures. The authorsfirst determined the appropriate gestures for each vowel and each consonant. Any articulatory parameteris then expressed by an algebraic sum of consonant and vowel gestures [34]. Their model is based onthe analysis of real data of a speaker with several dots on his face that are tracked through time. Theyuse the principal component analysis technique to define a few phonetically relevant parameters. Theseparameters are then transformed into FAP to drive an MPEG-4 compliant facial model [13].
The approach of Pelachaud et al. [30] implements the look-ahead model. Lip movements are viewedaccording to a notion of speech as a sequence of key positions (corresponding to phonemes belonging tonon-deformable clusters) and transition positions (corresponding to phonemes belonging to deformableclusters). The problem is to determine the shape computation of the transition position for which the look-ahead model is well suited. Indeed, this model predicts that any articulatory adjustment starts just after akey-position and lasts until the next one. The transition position receives the same shape as the ’strongest’key-position (’strongest’ meaning lip shapes belonging to the least deformable clusters). Both forwardand backward look-ahead rules are considered by the algorithm. To solve particular problems (certainvisual transitions between segments) which cannot be solved by these two rules, a three-step algorithmis employed. In the first step, the forward and backward coarticulation rules are applied to all clusterswhich are defined as context-dependent. The next step considers the relaxation and contraction timesof the muscles involved. Finally, the program examines the way two consecutive actions are performedgeometrically.
14 Lip shape computation
To compute lip shape we proceed in two stages. The first one consists of using the data provided bythe sub-contractor, CNR of Padova, to characterise each phonetically relevant parameter for the visemesassociated with vowels and consonants. The second stage concerns the computation of coarticulationwhich is done with a mathematical function to simulate the influence of vocalic contexts over consonants.As described above the data represent values over time of five phonetically relevant parameters (LW, UP,LP, LH, JAW) of a speaker saying ’VCV string; the first ’V being stressed while the second is unstressed.The original data correspond to curves that are stored in arrays. Apart from the values of each labialparameter, CNR of Padova provided the acoustic segmentation into V, C, V, marked in the figures byvertical lines. We can see that we may encounter asynchronies of the labial target with the acousticsignal, according to the parameter and/or the phoneme. Furthermore, the different ranges of extension fordifferent parameters have to be stressed: for example, UP and LP variations under 1 mm are evidently not
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 30/43
so relevant.
What we aim to represent are curves of the types shown in Figures 30. We are using interpolating B-spline.The advantages of using B-spline are double: B-spline needs few control points as input and they areC2
continuous giving a smooth shape. Moreover interpolating B-spline ensures the curves will go throughthe control points. The original curves have been sampled every 1/10th sec. Rather than considering thewhole list of sample points which would be too cumbersome for later manipulation of the coarticulationfunction, we decided to represent each curve by a few control points.
In the first section below we present each item individually (consonant, stressed vowel, unstressed vowel);in the following section, we discuss how we simulate sequences of the type ’VCV, and finally of any type.
14.1 Vowels
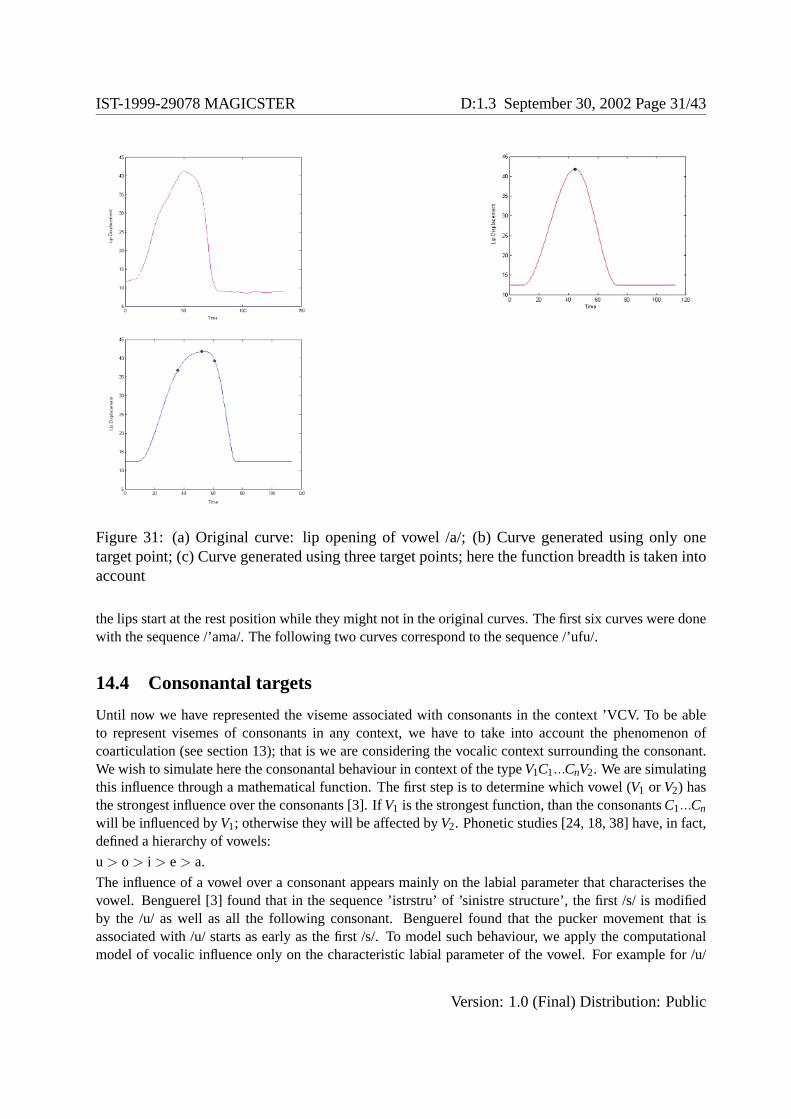
As a first approach we chose as control points the maximum or the minimum of the curve that representsthe vowel (see Figure 31 (a)). We refer to such a point as the target point; a target point corresponds to thetarget position the lips would assume at the apex of the vowel production. Vowels are not fully representedif we consider only one target point for each labial parameter (see Figure 31 (b)). Indeed, the interpolatingspline function intersects the target point without any notion of the shape of the original function and, asa result, of the breadth of the original curve around the target. In all the figures shown in these sections,all the generated curves start with the lips at rest position, unlike the original curves. The rest position forthe lips corresponds to the lips slightly closed.
To get a better representation of the characteristics of a vowel we consider two more points for every labialparameters (see Figure 31 (c)), one on the left of the target point and one on the right. Such values arenot randomly chosen but individuated from the original data in the following way: we select the two extrapoints whose abscissas correspond, respectively, to the median point between the onset of the phonemeand its target and to the median point between its target and the offset of the phoneme. In this way foreach vowel we have 15 points, i.e. three for each lip parameter.
14.2 Consonants
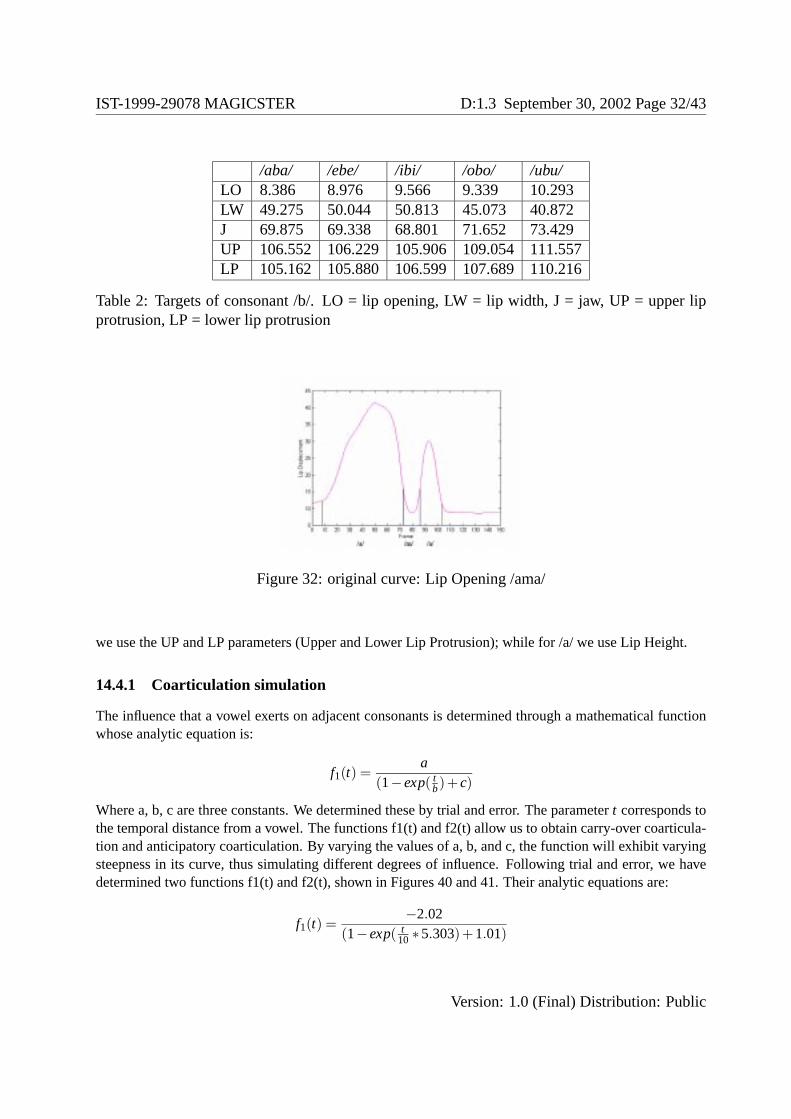
Unlike vowels, to represent consonants we only consider the target point that corresponds to the minimumor the maximum of the curve. Therefore, for each consonant we have five values, one for each lip parame-ter. Often, visemes associated with consonants do not exhibit stable lip shape, rather they strongly dependon the vocalic context, that is on the adjacent vowels: this is one of the manifestations of the phenomenonof coarticulation. To take into account the vocalic context we gathered from the original ’VCV data all thetargets of a consonant in every possible context (/a, e, i, o, u/) that was provided by CNR of Padova. Forinstance, we extracted the target points for the consonant /b/ in the contexts /aba/, /ebe/, /ibi/, /obo/ and/ubu/, thus obtaining 20 targets (see Table 2).
14.3 Reproduction of ’VCV sequence
As a first test, we compare the original curves with the reconstructed curves (see Figures 32 ... 39); theselast curves correspond to the interpolating B-spline defined by the following seven control points: threefor the first vowel + one for the consonant + three for the last vowel. In the following figures, the verticallines separate the visemes temporally in the sequence ’VCV. As mentioned above, in the generated curves
Version: 1.0 (Final) Distribution: Public
IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 31/43
Figure 31: (a) Original curve: lip opening of vowel /a/; (b) Curve generated using only onetarget point; (c) Curve generated using three target points; here the function breadth is taken intoaccount
the lips start at the rest position while they might not in the original curves. The first six curves were donewith the sequence /’ama/. The following two curves correspond to the sequence /’ufu/.
14.4 Consonantal targets
Until now we have represented the viseme associated with consonants in the context ’VCV. To be ableto represent visemes of consonants in any context, we have to take into account the phenomenon ofcoarticulation (see section 13); that is we are considering the vocalic context surrounding the consonant.We wish to simulate here the consonantal behaviour in context of the typeV1C1...CnV2. We are simulatingthis influence through a mathematical function. The first step is to determine which vowel (V1 or V2) hasthe strongest influence over the consonants [3]. IfV1 is the strongest function, than the consonantsC1...Cn
will be influenced byV1; otherwise they will be affected byV2. Phonetic studies [24, 18, 38] have, in fact,defined a hierarchy of vowels:
u > o > i > e> a.
The influence of a vowel over a consonant appears mainly on the labial parameter that characterises thevowel. Benguerel [3] found that in the sequence ’istrstru’ of ’sinistre structure’, the first /s/ is modifiedby the /u/ as well as all the following consonant. Benguerel found that the pucker movement that isassociated with /u/ starts as early as the first /s/. To model such behaviour, we apply the computationalmodel of vocalic influence only on the characteristic labial parameter of the vowel. For example for /u/
Version: 1.0 (Final) Distribution: Public
IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 32/43
/aba/ /ebe/ /ibi/ /obo/ /ubu/LO 8.386 8.976 9.566 9.339 10.293LW 49.275 50.044 50.813 45.073 40.872J 69.875 69.338 68.801 71.652 73.429UP 106.552 106.229 105.906 109.054 111.557LP 105.162 105.880 106.599 107.689 110.216
Table 2: Targets of consonant /b/. LO = lip opening, LW = lip width, J = jaw, UP = upper lipprotrusion, LP = lower lip protrusion
Figure 32: original curve: Lip Opening /ama/
we use the UP and LP parameters (Upper and Lower Lip Protrusion); while for /a/ we use Lip Height.
14.4.1 Coarticulation simulation
The influence that a vowel exerts on adjacent consonants is determined through a mathematical functionwhose analytic equation is:
f1(t) =a
(1−exp( tb)+c)
Where a, b, c are three constants. We determined these by trial and error. The parametert corresponds tothe temporal distance from a vowel. The functions f1(t) and f2(t) allow us to obtain carry-over coarticula-tion and anticipatory coarticulation. By varying the values of a, b, and c, the function will exhibit varyingsteepness in its curve, thus simulating different degrees of influence. Following trial and error, we havedetermined two functions f1(t) and f2(t), shown in Figures 40 and 41. Their analytic equations are:
f1(t) =−2.02
(1−exp( t10 ∗5.303)+1.01)
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 33/43
Figure 33: generated curve: Lip Opening /ama/
Figure 34: original curve: Lip Width /ama/
f1(t) =2.02
(1−exp( t−1010 ∗5.303)−1.01)
The function f is applied to the labial parameters of the consonant between successive vowels. To simplifythe computation, the time interval between the vowels has been normalised. So time t=0 corresponds to theoccurrence ofV1, and time t=1 corresponds toV2. The consonants are placed on the abscissa depending ontheir temporal normalised distance from the vowels. Lett1...tn be their corresponding time. The influenceof a vowel on a consonant is given by the value off (ti). We can see that the functionf will always varybetween 0 and 1, ensuring that the first consonant after (or before for anticipatory coarticulation) willbe strongly influenced while the last vowel will be minimally influenced.f (t) = 0 means no influenceis exercised on the consonant whilef (t) = 1 means the opposite; that is the labial parameters of theconsonant will be equal to the labial parameters of the vowel. As already noted, vowels may show adistinctive behaviour. Based on this, we applied the function of influence over a consonant only on thelabial parameters that characterise the ’strong’ vowel.
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 34/43
Figure 35: generated curve: Lip Width /ama/
Figure 36: original curve: Jaw /ama/
14.4.2 Example
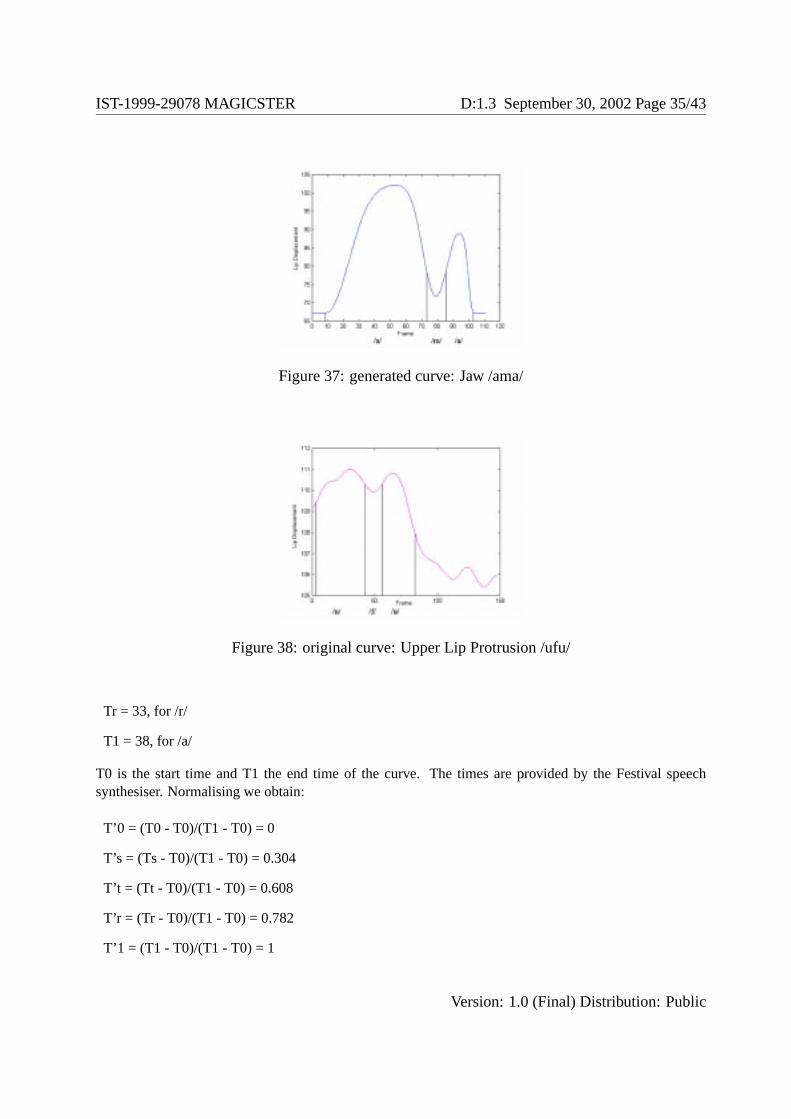
Let us consider the sequence /ostra/ taken from the Italian word ’mostra’ (’show’). The targets for /s/, /r/and /t/ in the contexts /o/ (i.e. /oCo/) and /a/ (i.e. /aCa/) are individuated. We report these values in thetable 3.
Since the vowel /o/ is stronger than /a/, we select the target position of the consonants /s,t,r/ from thecontext /oCo/. Moreover, the viseme associated with /o/ is mainly characterised by its lip protrusionparameters. For example, we compute the influence of the UP parameter (Upper Lip Protrusion) of /o/over the UP parameter of the consonants /s, t, r/. The temporal distances of each consonant from the vowelposition /o/ are:
T0 = 15, for /o/
Ts = 22, for /s/
Tt = 29, for /t/
Version: 1.0 (Final) Distribution: Public
IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 35/43
Figure 37: generated curve: Jaw /ama/
Figure 38: original curve: Upper Lip Protrusion /ufu/
Tr = 33, for /r/
T1 = 38, for /a/
T0 is the start time and T1 the end time of the curve. The times are provided by the Festival speechsynthesiser. Normalising we obtain:
T’0 = (T0 - T0)/(T1 - T0) = 0
T’s = (Ts - T0)/(T1 - T0) = 0.304
T’t = (Tt - T0)/(T1 - T0) = 0.608
T’r = (Tr - T0)/(T1 - T0) = 0.782
T’1 = (T1 - T0)/(T1 - T0) = 1
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 36/43
Figure 39: generated curve: Upper Lip Protrusion /ufu/
Figure 40: carry-over coarticulation
In the ’mostra’ example we have an anticipatory coarticulation, and we employ theF2 function of influ-ence. Figure 42 shows how the curve acts over the sequence /ostra/. The function gives the value 0,958for /s/; which means that /s/ will be influenced 95.89% by the vowel /o/ and, consequently, /a/ exerts aninfluence of 4.2% on the same consonant. If we indicate the target point of the upper lip protrusion pa-rameter in the context /oso/ withoSo and the target value of the same parameter in the context /asa/ withaSa, then the new target of /s/ in the context /osa/ will be:
osa = 0.958∗o so +(1−0.958)∗a sa = 0.958∗110.856+0.042∗106.242= 110.662
Because of the strong influence exerted on /s/ by /o/, the targetosa is almost the same as the targetoso. Inthis case, since /r/ is further away from /o/ than /s/ is, the targetora will be:
osa = 0.51∗o ro +(1−0.49)∗a ra = 0.51∗110.063+0.49∗104.463= 107.318
In the same wayota is calculated. Figures 43 to 47 show the behaviour of each of the five labial parameters
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 37/43
Figure 41: Anticipatory coarticulation
over the sequence /ostra/. The vertical lines delineate the phonemes, whereas the points indicate thetargets. Figure 48 shows the associated visemes.
14.4.3 Algorithm
In summary, for each sequence of typeV1C1...CnV2, the algorithm looks for the two vowels (V1, V2) thatsurround the consonants. It then determines which is the strongest vowel and computes the influenceof this vowel over the consonants for the characteristic labial parameters. In the case of ’istrstru’, thealgorithm will determine that /u/ is the strongest vowel and will modify ’strstr’ along the parametersUP and LP; if /i/ were the strongest vowel, the modification would have been done on the Lip Widthparameters. Once the new target points have been computed, the interpolating B-spline function is usedto obtain a smooth animation.
15 Conclusion
In this deliverable we have presented the Greta agent system which is used in Application 1. In the futurewe are planning to work towards incorporating arm gestures. We are currently working on a gestureplanner, and in parallel we have been developing a language to describe gesture. We are also developingtools to create gestures and to store them in the format described by the language.
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 38/43
/s/ /t/ /r/Context /oso/ Context /oto/ Context /oro/
LO 23.343 23.343 31.211LW 41.085 41.385 41.945J 79.500 79.500 84.633UP 110.856 109.856 110.063LP 109.262 108.262 109.071
Context /asa/ Context /ata/ Context /ara/LO 31.500 33.500 39.211LW 52.152 51.142 50.945J 87.012 89.012 94.633UP 106.242 106.242 104.463LP 104.225 104.225 102.471
Table 3: Targets of consonants /s, t, r/ in different vocalic contexts
Figure 42: Influence of /o/ on the upper lip protrusion (UP) parameter of the consonants /s/, /t/ e/r/.
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 39/43
Figure 43: Behaviour of the Lip Height (LH) for the word /mostra/.
Figure 44: Behaviour of the Lip Width (LW) for the word /mostra/.
Figure 45: Behaviour of the Jaw (J) for the word /mostra/.
Version: 1.0 (Final) Distribution: Public
IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 40/43
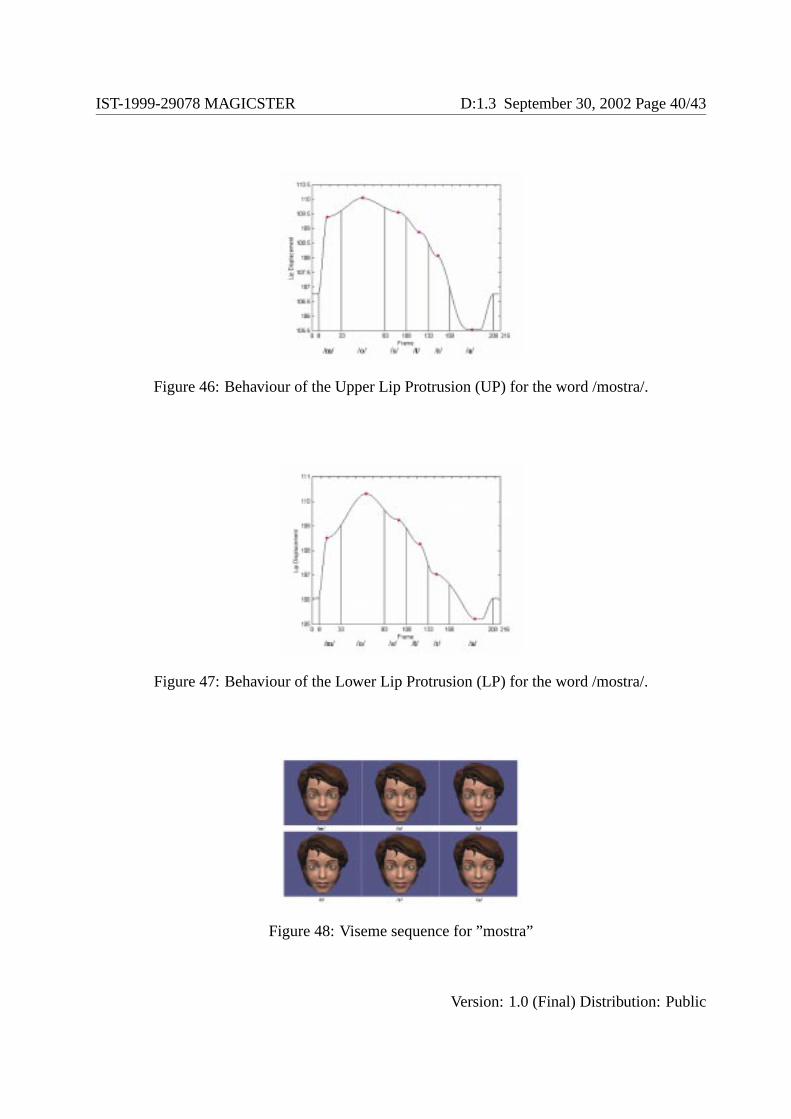
Figure 46: Behaviour of the Upper Lip Protrusion (UP) for the word /mostra/.
Figure 47: Behaviour of the Lower Lip Protrusion (LP) for the word /mostra/.
Figure 48: Viseme sequence for ”mostra”
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 41/43
References
[1] M. Argyle and M. Cook.Gaze and Mutual gaze. Cambridge University Press, 1976.
[2] M.S. Bartlett, J.C. Hager, P. Ekman, and T.J. Sejnowski. Measuring facial expressions by computerimage analysis.Psychophysiology, 36(2):253–263, 1999.
[3] A.P. Benguerel and H.A. Cowan. Coarticulation of upper lip protrusion in french.Phonetica, 30:40–51, 1974.
[4] C. Benoit, T. Lallouache, T. Mohamadi, and C. Abry. A set of french visemes for visual speechsynthesis. InTalking machines: Theories, Models, and Designs, pages 485–504. Elsevier North-Holland, Amsterdam, 1992.
[5] A.W. Black, P. Taylor, R. Caley, and R. Clark. Festival. http://www.cstr.ed.ac.uk/projects/festival/.
[6] D. Bolinger. Intonation and its Part. Stanford University Press, 1986.
[7] J. Cassell, C. Pelachaud, N.I. Badler, M. Steedman, B. Achorn, T. Becket, B. Douville, S. Prevost,and M. Stone. Animated conversation: Rule-based generation of facial expression, gesture andspoken intonation for multiple conversational agents. InComputer Graphics Proceedings, AnnualConference Series, pages 413–420. ACM SIGGRAPH, 1994.
[8] J. Cassell, H. Vilhjalmsson, and T. Bickmore. BEAT : the Behavior Expression Animation Toolkit.In Computer Graphics Proceedings, Annual Conference Series. ACM SIGGRAPH, 2001.
[9] M. M. Cohen and D. W. Massaro. Modeling coarticulation in synthetic visual speech. InM. Magnenat-Thalmann and D. Thalmann, editors,Models and Techniques in Computer Animation,pages 139–156, Tokyo, 1993. Springer-Verlag.
[10] M.M. Cohen, R.L. Walker, and D.W. Massaro. Perception of synthetic visual speech. In D.G.Stork and M.E. Hennecke, editors,Speechreading by Humans and Machines, Models, Systems, andApplications, volume 150 ofComputer and Systems Sciences, pages 153–168, Berlin, 1996. NATOASI Series, Springer-Verlag.
[11] P. Cosi and E. Magno-Caldognetto. Lips and jaws movements for vowels and consonants: Spatio-temporal characteristics and bimodal recognition applications. In D.G. Stork and M.E. Hennecke,editors,Speechreading by Humans and Machines: Models, Systems, and Applications, volume 150of NATO ASI Series. Series F: Computer and Systems Sciences. Springer-Verlag, Berlin, 1996.
[12] P. Ekman. About brows: Emotional and conversational signals. In M. von Cranach, K. Foppa,W. Lepenies, and D. Ploog, editors,Human ethology: Claims and limits of a new discipline: con-tributions to the Colloquium, pages 169–248. Cambridge University Press, Cambridge, England;New-York, 1979.
[13] F. Elisei, M. Odisio, G. Bailly, and P. Badin. Creating and controlling video-realistic talking heads.In Auditory-Visual Speech Processing AVSP’01, pages 90–97, Aalborg, Denmark, September 8-92001.
[14] I.A. Essa and A. Pentland. A vision system for observing and extracting facial action parameters.Proceedings of Computer Vision and Pattern Recognition (CVPR 94), pages 76–83, 1994.
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 42/43
[15] C.G. Fisher. Confusions among visually perceived consonants.Journal Speech Hearing Research,15:474–482, 1968.
[16] C.A. Fowler and E.L. Salztman. Coordination and coarticulation in speech production.Languageand Speech, 36:171–195, 1993.
[17] V. Fromkin. Lip positions in American-English vowels.Language and Speech, 7(3):215–225, 1964.
[18] J. Jeffers and M. Barley.Speechreading (lipreading). C.C. Thomas, Springfield, Illinois, 1971.
[19] R.D. Kent and F.D. Minifie. Coarticulation in recent speech production models.Journal of Phonet-ics, 5:115–135, 1977.
[20] B. LeGoff and C. Benoit. A French speaking synthetic head. In C. Benoit and R. Campbell, editors,Proceedings of the ESCA Workshop on Audio-Visual Speech Processing, Rhodes, Greece, September1997.
[21] A. Lofqvist. Speech as audible gestures.Speech Production and Speech Modeling, pages 289–322,1990.
[22] E. Magno-Caldognetto and I. Poggi. Micro- and macro-bimodality. In C.Benoit and R.Campbell,editors,Proceedings of the Workshop on Audio Visual Speech Perception, Rhodes, September 26-27,1997 1997.
[23] E. Magno-Caldognetto, K. Vagges, and C. Zmarich. Visible articulatory characteristics of the Italianstressed and unstressed vowels. InProceedings of the XIIIth International Congress of PhoneticSciences, volume 1, pages 366–369, Stockholm, 1995.
[24] E. Magno-Caldognetto, C. Zmarich, and P. Cosi. Statistical definition of visual information forItalian vowels and consonants. In D. Burnham, J. Robert-Ribes, and E. Vatikiotis-Bateson, editors,International Conference on Auditory-Visual Speech Processing AVSP’98, pages 135–140, Terrigal,Australia, 1998.
[25] E. Magno-Caldognetto, C. Zmarich, P. Cosi, and F. Ferrero. Italian consonantal visemes: Rela-tionships between spatial /temporal articulatory characteristics and coproduced acoustic signal. InC. Benoit and R. Campbell, editors,Proceedings of the ESCA Workshop on Audio-Visual SpeechProcessing, pages 5–8, Rhodes, Greece, September 1997.
[26] D. Massaro.Perceiving Talking Faces : From Speech Perception to a Behavioral Principle. BradfordBooks Series in Cognitive Psychology. MIT Press, 1997.
[27] S.E.G. Ohman. Numerical model of coarticulation.Journal of Acoustical Society of America,41(2):311–321, 1967.
[28] A. Ortony. On making believable emotional agents believable. In R. Trappl and P. Petta, editors,Emotions in humans and artifacts. MIT Press, Cambridge, MA, in press.
[29] A. Ortony, G.L. Clore, and A. Collins.The Cognitive Structure of Emotions. Cambridge UniversityPress, 1988.
Version: 1.0 (Final) Distribution: Public

IST-1999-29078 MAGICSTER D:1.3 September 30, 2002 Page 43/43
[30] C. Pelachaud, N.I. Badler, and M. Steedman. Generating facial expressions for speech.CognitiveScience, 20(1):1–46, January-March 1996.
[31] C. Pelachaud and I. Poggi. Subtleties of facial expressions in embodied agents.Journal of Visual-ization and Computer Animation, To appear.
[32] K. Perlin. An image synthesizer. InComputer Graphics Proceedings, Annual Conference Series,pages 287–296. ACM SIGGRAPH, 1985.
[33] I. Poggi and C. Pelachaud. Facial performative in a conversational system. In S. Prevost J. Cassell,J. Sullivan and E. Churchill, editors,Embodied Conversational Characters. MITpress, Cambridge,MA, 2000.
[34] L. Reveret, G. Bailly, and P. Badin. MOTHER: A new generation of talking heads providing a flex-ible articulatory control for video-realistic speech animation. In X. Tang B. Yuan, T. Huang, editor,Proceedings of ICSLP’00: International Conference on Spoken Language Processing, volume II,pages 755–758.
[35] A. Risberg and J.L. Lubker. Prosody and speechreading. Technical Report Quaterly Progress andStatus Report 4, Speech Transmission Laboratory, KTH, Stockholm, Sweden, 1978.
[36] C. Schwippert and C. Benoit. Audiovisual intellegibility of an androgynous speaker. In C. Benoitand R. Campbell, editors,Proceedings of the ESCA Workshop on Audio-Visual Speech Processing,Rhodes, Greece, September 1997.
[37] Q. Summerfield. Lipreading and audio-visual speech perception.Philosophical Transactions of theRoyal Society of London, 335(1273):71–78, 1992.
[38] E.F. Walther.Lipreading. Nelson-Hall, Chicago, 1982.
[39] Y. Yacoob and L. Davis.Computer Vision and Pattern Recognition Conference, chapter Computingspatio-temporal representations of human faces, pages 70–75. IEEE Computer Society, 1994.
Version: 1.0 (Final) Distribution: Public
Related Documents











