Pronunciation Modeling Lecture 11 Spoken Language Processing Prof. Andrew Rosenberg

Pronunciation Modeling Lecture 11 Spoken Language Processing Prof. Andrew Rosenberg.
Dec 14, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Pronunciation Modeling
Lecture 11
Spoken Language Processing
Prof. Andrew Rosenberg
2
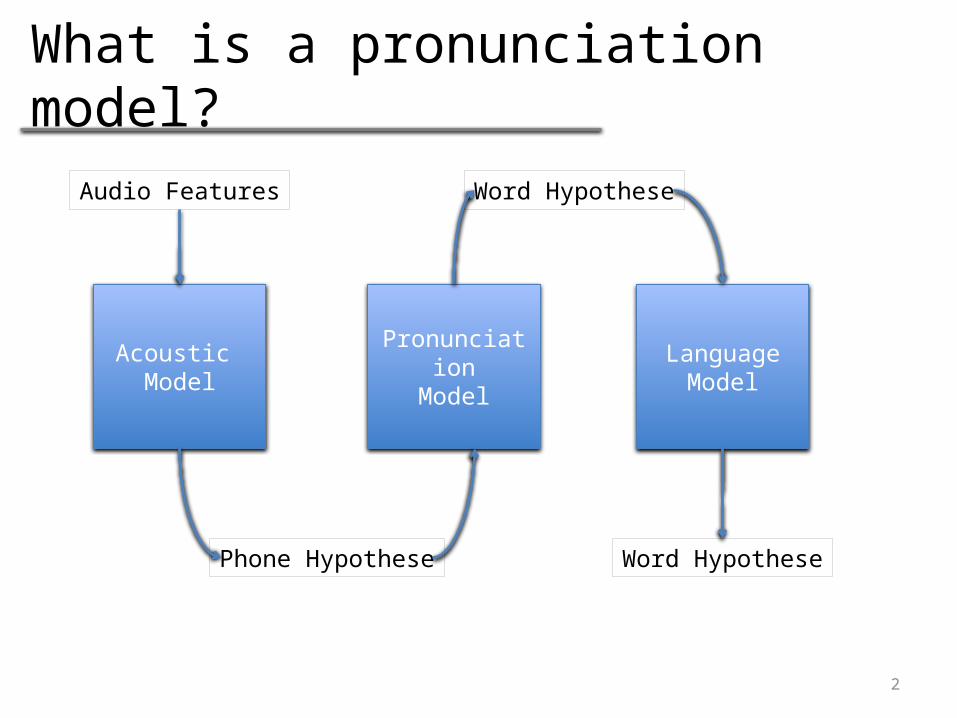
What is a pronunciation model?
Acoustic Model
PronunciationModel
LanguageModel
Audio Features
Phone Hypothese
Word Hypothese
Word Hypothese

3
Why do we need one?
• The pronunciation model defines the mapping between sequences of phones and words.
• The acoustic model can deliver a one-best, hypothesis – “best guess”.
• From this single guess, converting to words can be done with dynamic programming alignment.
• Or viewed as a Finite State Automata.

4
Simplest Pronunciation “model”
• A dictionary.• Associate a word (lexical item,
orthographic form) with a pronunciation.
ACHE EY KACHES EY K SADJUNCT AE JH AH NG K TADJUNCTS AE JH AN NG K T SADVANTAGE AH D V AE N T IH JHADVANTAGE AH D V AE N IH JHADVANTAGE AH D V AE N T AH JH
5
Example of a pronunciation dictionary
6
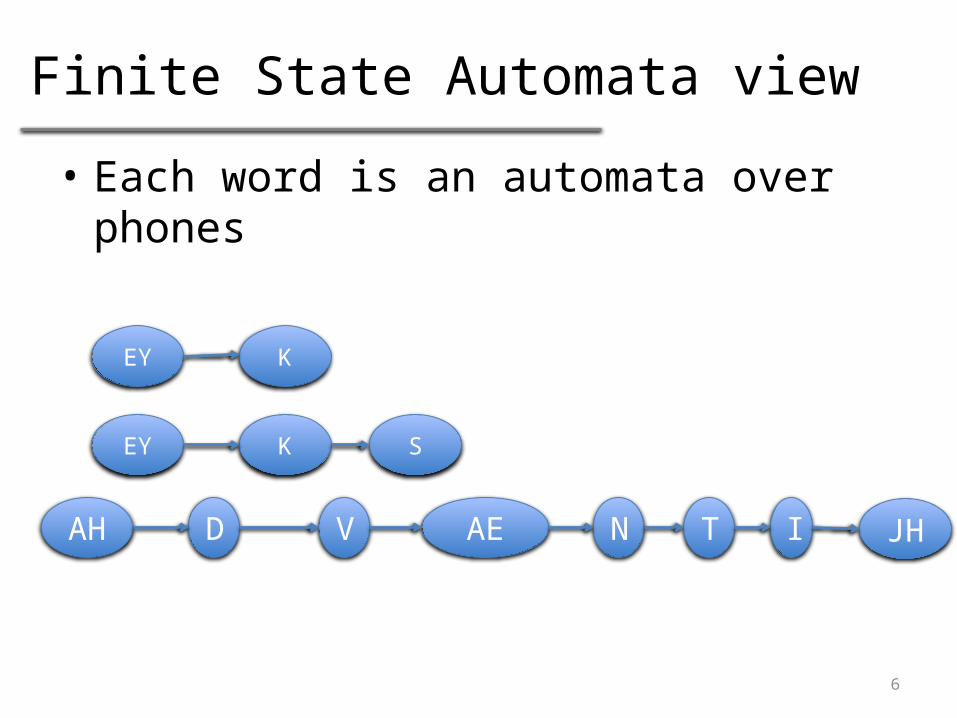
Finite State Automata view
• Each word is an automata over phones
EY K
EY K
AH D V AE N T
S
I JH
7
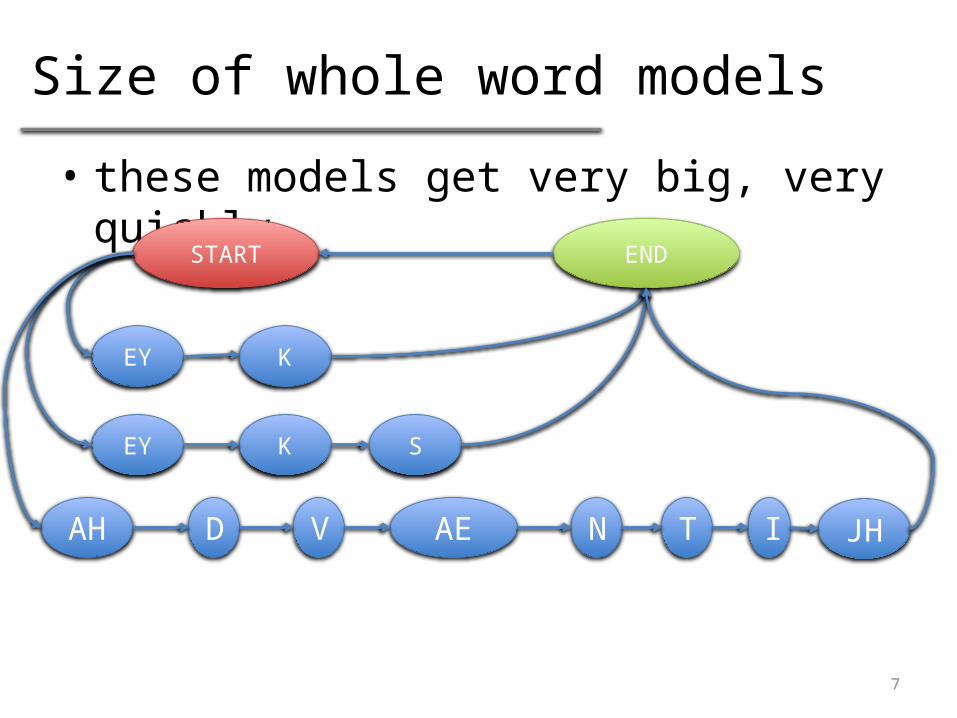
Size of whole word models
• these models get very big, very quickly
EY K
EY K
AH D V AE N T
S
I JH
START END

8
Potential problems
• Every word in the training material and test vocabulary must be in the dictionary
• The dictionary is generally written by hand• Prone to errors and inconsistencies
ACHE EY KACHES EY K SADJUNCT AE JH AH NG K TADJUNCTS AE JH AN NG K T SADVANTAGE AH D V AE N T IH JHADVANTAGE AH D V AE N IH JHADVANTAGE AH D V AE N T AH JH
9
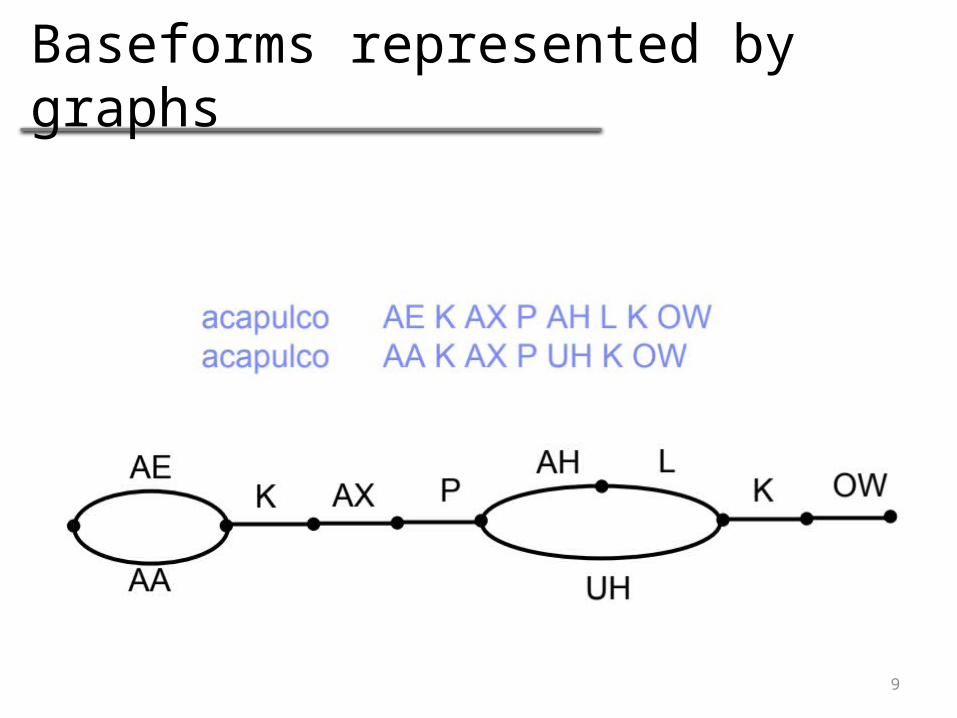
Baseforms represented by graphs
10
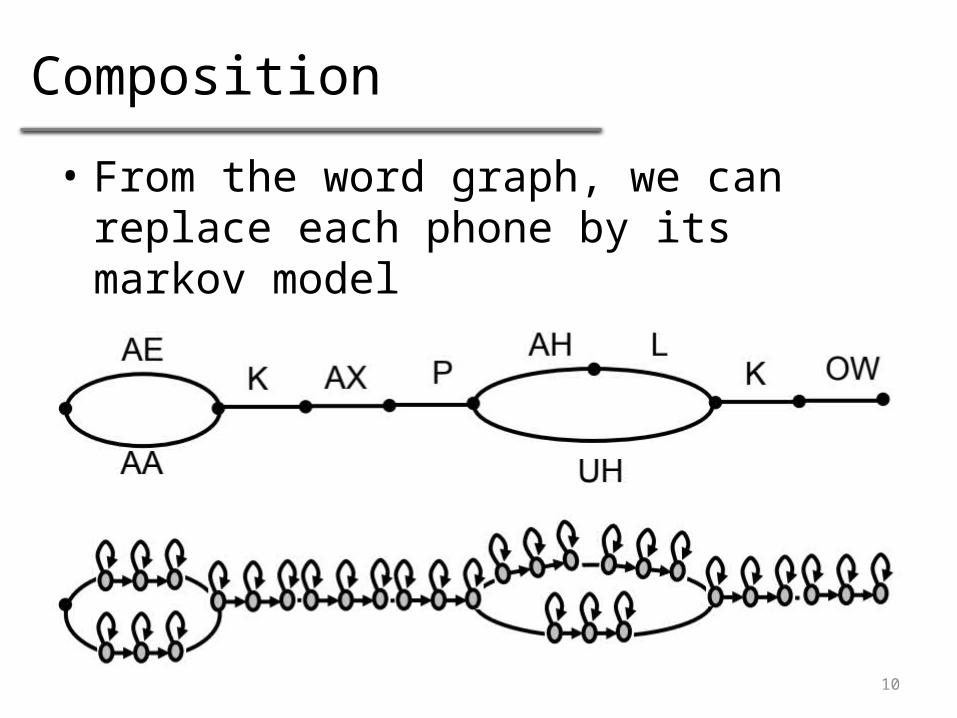
Composition
• From the word graph, we can replace each phone by its markov model

11
Automating the construction
• Do we need to write a rule for every word?
• pluralizing?– Where is it +[Z]? +[IH Z]?
• prefixes, unhappy, etc.– +[UH N]– How can you tell the difference between
“unhappy”, “unintelligent” and “under” and “

12
Is every pronunciation equally likely?
• Different phonetic realizations can be weighted.
• The FSA view of the pronunciation model makes this easy.
ACAPULCO AE K AX P AH L K OWACAPULCO AA K AX P UH K OWTHE TH IYTHE TH AXPROBABLY P R AA B AX B L IYPROBABLY P R AA B L IYPROBABLY P R AA L IY

13
Is every pronunciation equally likely?
• Different phonetic realizations can be weighted.
• The FSA view of the pronunciation model makes this easy.
ACAPULCO AE K AX P AH L K OW0.75ACAPULCO AA K AX P UH K OW
0.25THE TH IY
0.15THE TH AX
0.85PROBABLY P R AA B AX B L IY
0.5PROBABLY P R AA B L IY
0.4PROBABLY P R AA L IY
0.1

14
Collecting pronunciations
• Collect a lot of data• Ask a phonetician to phonetically
transcribe the data.• Count how many times each
production is observed.
• This is very expensive – time consuming, finding linguists.

15
Collecting pronunciations
• Start with equal likelihoods of all pronunciations
• Run the recognizer on transcribed speech– forced alignment
• See how many times the recognizer uses each pronunciation.
• Much cheaper, but less reliable

16
Out of Vocabulary Words
• A major problem for Dictionary based pronunciation is out of vocabulary terms.
• If you’ve never seen a name, or new word, how do you know how to pronounce it?– Person names– Organization and Company Names– New words “truthiness”, “hypermiling”,
“woot”, “app”– Medical, scientific and technical terms

17
Collecting Pronunciations from the web
• Newspapers, blog posts etc. often use new names and unknown terms.
• For example:– Flickeur (pronounced like Voyeur) randomly
retrieves images from Flickr.com and creates an infinite film with a style that can vary between stream-of-consciousness, documentary or video clip.
– Our group traveled to Peterborough (pronounced like “Pita-borough”)...
• The web can be mined for pronunciations [Riley, Jansche, Ramabhadran 2009]

18
Grapheme to Phoneme Conversion
• Given a new word, how do you pronounce it.
• Grapheme is a language independent term for things like “letters”, “characters”, “kanji”, etc.
• With a phoneme to grapheme-to-phoneme converter, dictionaries can be augmented with any word.
• Some languages are more ambiguous than others.

19
Grapheme to Phoneme conversion
• Goal: Learn an alignment between graphemes (letters) and phonemes (sounds)
• Find the lowest cost alignment.• Weight rules, and learn contextual variants.
T E X - T
T EH K S T
T E X T - - - - -
- - - - T EH K S T

20
Grapheme to Phoneme Difficulties
• How to deal with Abbreviations– US CENSUS– NASA, scuba vs. AT&T, ASR– LOL– IEEE
• What about misspellings?– should “teh” have an entry in the dictionary?– If we’re collecting new terms from the web,
or other unreliable sources, how do we know what is a new word?

21
Application of Grapheme to Phoneme Conversion
• This Pronunciation Model is used much more often in Speech Synthesis than Speech Recognition
• In Speech Recognition we’re trying to do Phoneme-to-Grapheme conversion– This is a very tricky problem.– “ghoti” -> F IH SH– “ghoti” -> silence

22
Approaches to Grapheme to Phoneme conversion
• “Instance Based Learning”– Lookup based on a sliding window of 3
letters– Helps with sounds like “ch” and “sh”
• Hidden Markov Model– Observations are phones– States are letters

23
Machine Learning for Grapheme to Phoneme Conversion
• Input:– A letter, and surrounding context, e.g. 2
previous and 2 following letters
• Output:– Phoneme
24
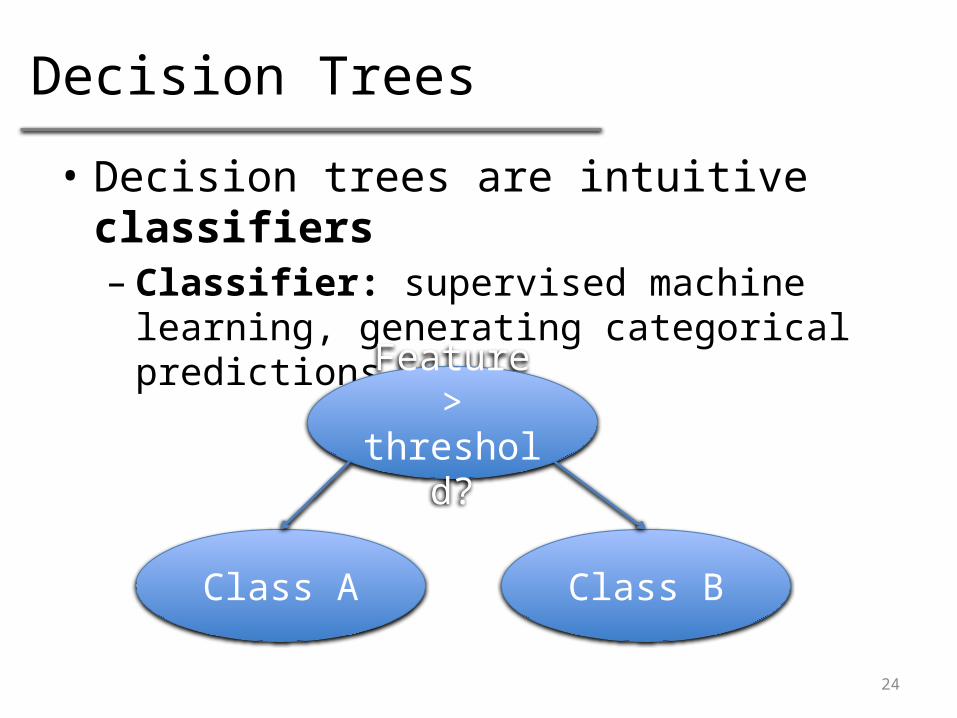
Decision Trees
• Decision trees are intuitive classifiers– Classifier: supervised machine
learning, generating categorical predictions
Feature > threshold?
Class A Class B
25
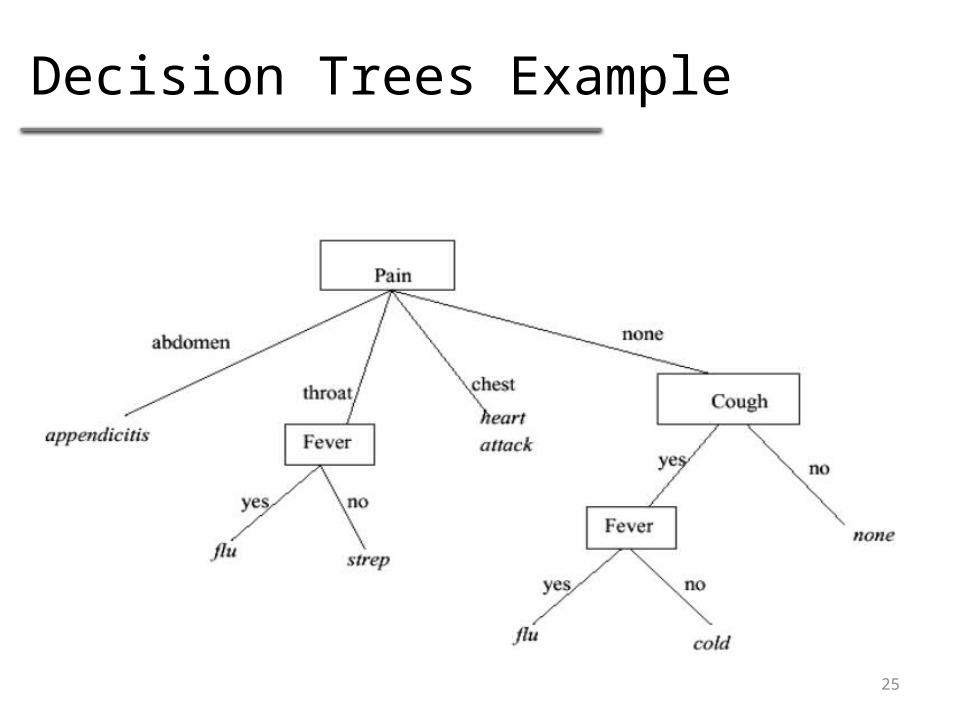
Decision Trees Example

26
Decision Tree Training
• How does the letter “p” sound?• Training data
– P loophole, peanuts, pay, apple– F physics, telephone, graph, photo– ø apple, psycho, pterodactyl,
pneumonia
• pronunciation depends on context

27
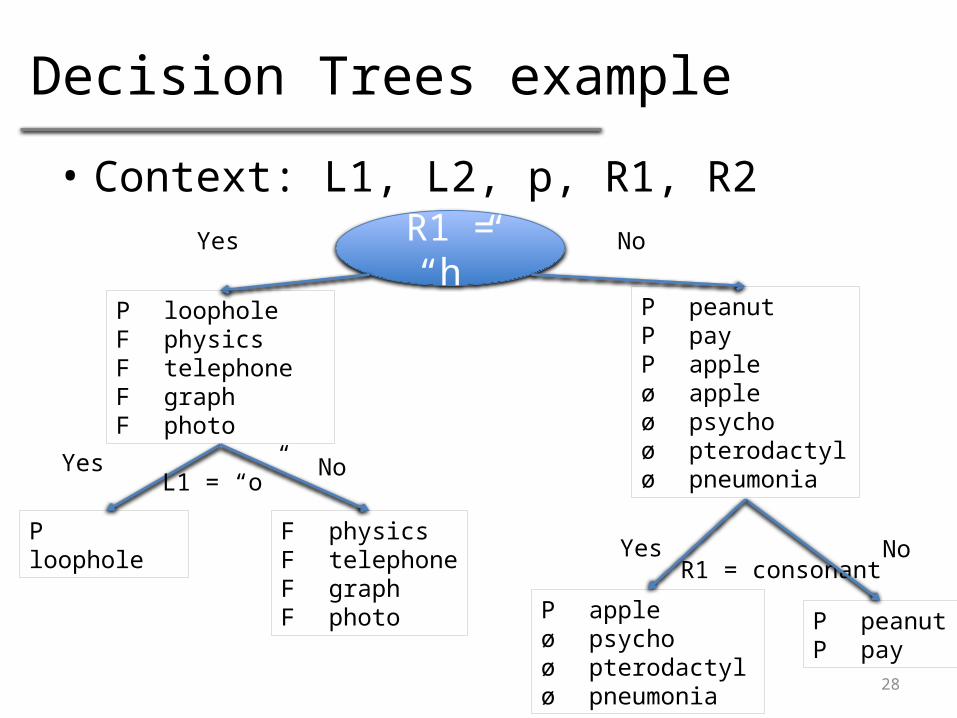
Decision Trees example
• Context: L1, L2, p, R1, R2
R1 = “h”
Yes No
P loopholeF physicsF telephoneF graphF photo
P peanutP payP appleø appleø psychoø psychoøpterodactyløpneumonia
28
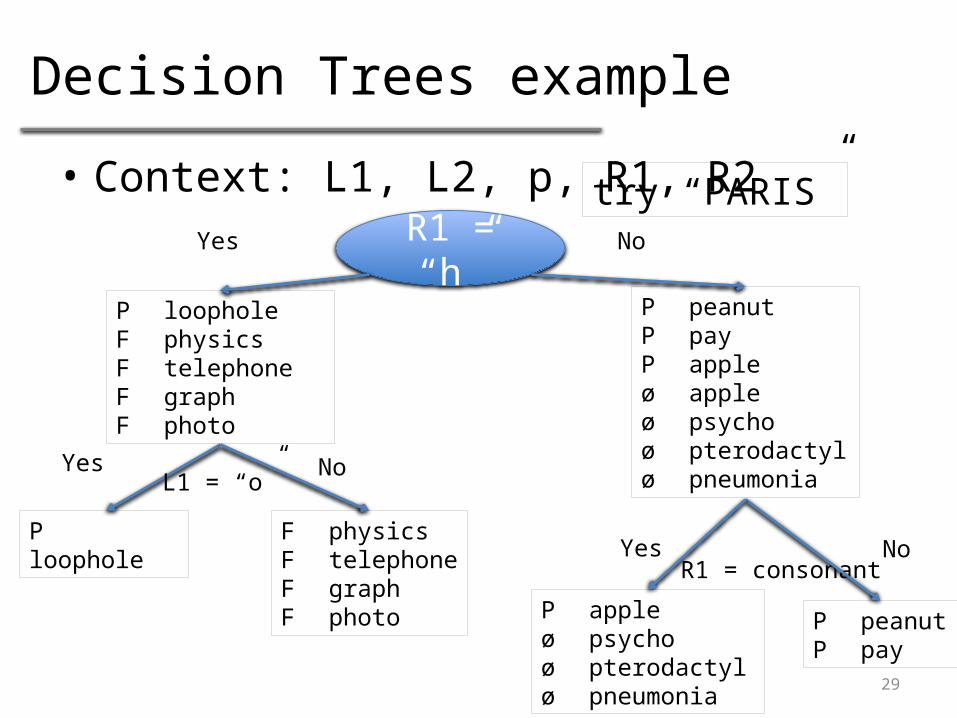
Decision Trees example
• Context: L1, L2, p, R1, R2
R1 = “h”Yes No
P loopholeF physicsF telephoneF graphF photo
P peanutP payP appleø appleø psychoøpterodactyløpneumonia
Yes No
Ploophole
F physicsFtelephoneF graphF photo
L1 = “o”
R1 = consonantNoYes
PpeanutP pay
P appleø psychoø pterodactylø pneumonia
29
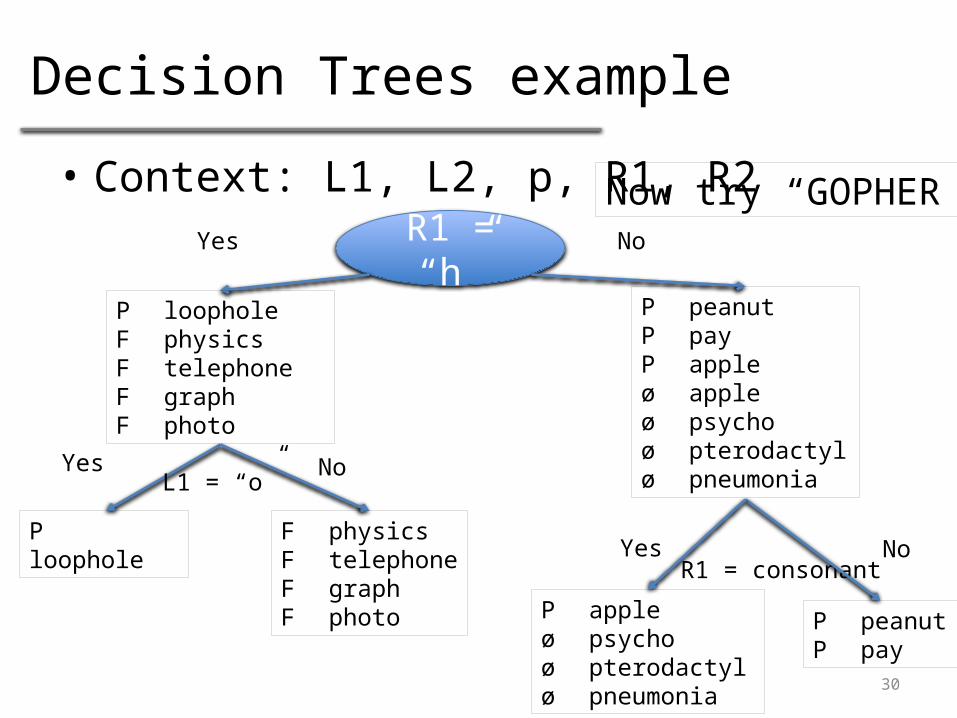
Decision Trees example
• Context: L1, L2, p, R1, R2
R1 = “h”Yes No
P loopholeF physicsF telephoneF graphF photo
P peanutP payP appleø appleø psychoøpterodactyløpneumonia
Yes No
Ploophole
F physicsFtelephoneF graphF photo
L1 = “o”
R1 = consonantNoYes
PpeanutP pay
P appleø psychoø pterodactylø pneumonia
try “PARIS”
30
Decision Trees example
• Context: L1, L2, p, R1, R2
R1 = “h”Yes No
P loopholeF physicsF telephoneF graphF photo
P peanutP payP appleø appleø psychoøpterodactyløpneumonia
Yes No
Ploophole
F physicsFtelephoneF graphF photo
L1 = “o”
R1 = consonantNoYes
PpeanutP pay
P appleø psychoø pterodactylø pneumonia
Now try “GOPHER”

31
Training a Decision Tree
• At each node, decide what the most useful split is.– Consider all features– Select the one that improves the performance
the most
• There are a few ways to calculate improved performance– Information Gain is typically used.– Accuracy is less common.
• Can require many evaluations

32
Pronunciation Models in TTS and ASR
• In ASR, we have phone hypotheses from the acoustic model, and need word hypotheses.
• In TTS, we have the desired word, but need a corresponding phone sequence to synthesize.

33
Next Class
• Language Modeling• Reading: J&M Chapter 4
Related Documents











