Programming for High Performance Computers John M. Levesque Director Cray’s Supercomputing Center Of Excellence

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Programming for High Performance Computers
John M. Levesque
Director
Cray’s Supercomputing Center
Of
Excellence

Outline
• Building a Petascale Computer• Challenges for utilizing a Petascale System
– Utilizing the Core– Utilizing the Socket – Scaling to 100,000 cores
• How one programs for the Petascale System• Conclusion

Petascale Computer
• First we need to define what we mean by a “Petascale computer”– Google already has a Petaflop on their floor
• Embarrassingly Parallel Application
– My Definition• Petascale computer is a computer system that
delivers a sustained Petaflop to a several “real science” applications

A Petascale Computer Requires:
• A state-of-the-art Commodity Micro-processor
• An ultra-fast proprietary Interconnect
• A sophisticated LWK Operating System to stay out of the way of application scaling
• Efficient messaging between processors– MPI may not be efficient enough!!
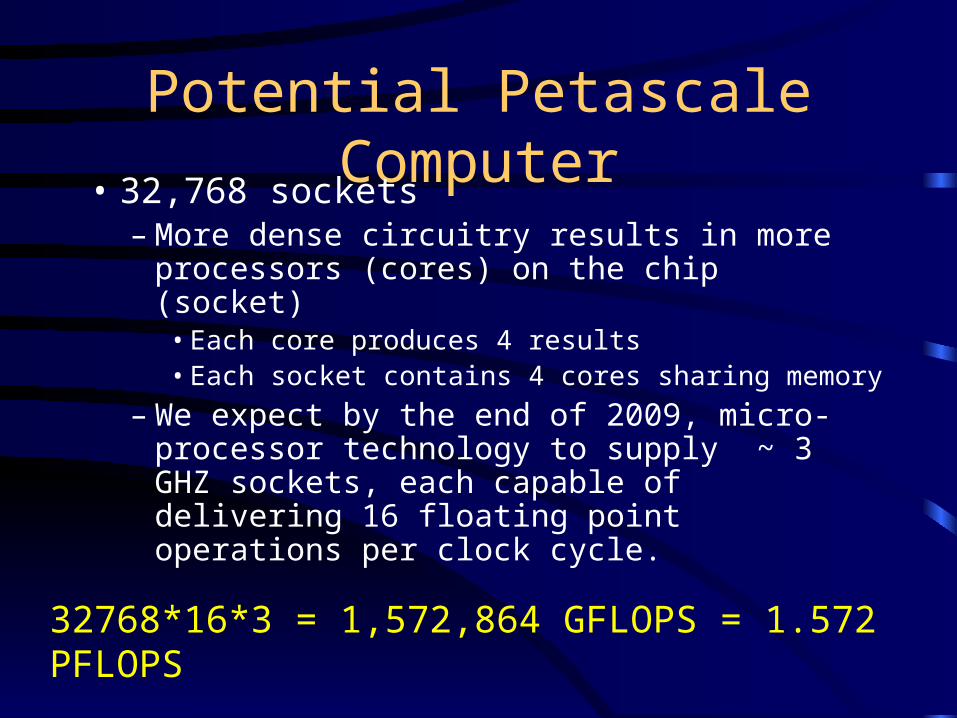
Potential Petascale Computer• 32,768 sockets
– More dense circuitry results in more processors (cores) on the chip (socket)
• Each core produces 4 results• Each socket contains 4 cores sharing memory
– We expect by the end of 2009, micro-processor technology to supply ~ 3 GHZ sockets, each capable of delivering 16 floating point operations per clock cycle.
32768*16*3 = 1,572,864 GFLOPS = 1.572 PFLOPS

Petascale Challenge for Interconnect
• Connect 32,768 Sockets together with an interconnect that has 2-3 microseconds latency across the entire system
• Supply a cross-section bandwidth to facilitate ALLTOALL communication across the entire system

Petascale Challenge for Programming
• Use as 131,072 Uni-processors or 32,768 4-way Shared Memory sockets– MPI across all the processors
• Hard on Socket Memory bandwidth and injection bandwidth into the network
– MPI between sockets and OpenMP across socket
• Hybrid programming is difficult

Petascale Challenge for Software
• OS must be able to supply required facilities and not be over-loaded with demons that steal cpu cycles and get cores out of sync– The notion of a Light Weight Kernel (LWK)
that only has what is needed to run app• No keyboard demon, no kernel threads, no sockets,
….
Two systems are using this very successfully today, Cray’s XT4 and IBM’s Bluegene

The Programming Challenge
• We start with 1.5 Petaflops and want to sustain > 1 Petaflop– Must achieve 67% of peak across the
entire system• Inhibitors
– On-socket memory bandwidth– Scaling across 131,072 processors; or,– Utilizing OpenMP on socket, Messaging across
system

The Programming Challenge• Inhibitors
– On-socket memory bandwidth• Today we see between 5-80% of sustained performance on the
core. This single core sustained performance is the maximum we will achieve.
– Scaling across 131,072 processors; or,• Today few applications scale as high as 5000 processors
– Utilizing OpenMP on socket, Messaging across system• OpenMP must be used on a very high percentage of the
application; or else, Amdahl’s law applies and peak of Socket may be degraded

Programming Challenge
• Minimize loads/stores and maximize floating point operations– Fortran compilers have been and are extremely
good at optimizing Fortran code– C compilers are hindered by use of pointers
which confuse the compiler’s data dependency analysis – unless one writes C-tran.
– C++ compilers completely give up

Programming Challenge
• 80% of ORNL major science applications are written in Fortran
• University students are being taught about new architectures and C, C++ and Java
• No classes are teaching how to write Fortran and C to take advantage of cache and utilize SSE instructions through the language


Why Fortran?
• Legacy codes are mostly written in Fortran– Compiler writers tend to develop better Fortran optimizations
because of the existing code base• 83% of ORNL’s major codes are Fortran
• Fortran allows the users to relay more information about memory access to the compiler – Compilers can generate better optimized code from Fortran
than from C and C++ code is just awful
• Scientific Programmers tend to use Fortran to get the most out of the system– Even large C++ Frameworks use Fortran computational
kernels

What about new Languages?
• Famous Question– “What languages are going to be used in the
year 2000?”
• Famous Answer– “Don’t know what it will be called; however, it
will look a lot like Fortran”

Seriously
• HPF – High Performance Fortran, was a complete failure. A language was developed that was difficult to compile efficiently. Since use was unsuccessful, programmers quit using the new language before the compiler got better
• ARPA HPCC – Three new language proposals, will they suffer from the HPF syndrome?

The Hybrid Programming Model
• OpenMP on the socket– Master/Slave model
• MPI or CAF or UPC across the system– Single program, Multiple Data (SPMD)
• Few – Multi-instruction, Multiple Data (MIMD)
Co-array Fortran and UPC greatly simplify this into a single programming Model

Shared Memory Programming
• OpenMP– Directives for Fortran and Pragmas for C
• Co-Arrays– User specifies a processor:
• A(I,J)[nproc] = B(I,J)[nproc+1] + C(I,J)
If nproc or nproc+1 is on the socket – this is a storeinto memory, if off processor, it is a remoteMemory store. C always comes from memory

How to create a new Language
• Extend an old one– Co-Array Fortran
• Extension of Fortran
– UPC• Extension of C
• This way the compiler writers only have to address the extension when generating efficient code.


The Programming Challenge
• Scaling to 131,072 processors– MPI is a more coarse grain messaging, requiring hand-
holding between communicating processors• User is protected to some degree
– Co-Array Fortran and UPC are Fortran and C extensions that facilitate low latency “gets” and “puts” into remote memory. These two languages are commonly known as Global Address Space languages, where the user can address all of the memory of the MPP
• User must be cognizant of synchronization between processors

Conclusions• Scientific Programmers must start learning
– how to utilize 100,000s of processors– how to utilize 4-8 cores per socket
• Fortran is the best language to use for– controlling cache usage– utilizing SSE2 instructions required to obtain >1 result per
clock cycle– working with the compiler to get the most out of the core
• GAS languages such as Co-Arrays and UPC facilitate efficient utilization of 100,000s of processors
Related Documents











