Problems of Estimation A common problem in statistics is to obtain information about the mean, μ, of a population. For example, we might want to know • the mean age of people in the civilian labor force, • the mean cost of a wedding, • the mean gas mileage of a new-model car, or • the mean starting salary of liberal-arts graduates. If the population is small, we can ordinarily determine μ exactly by first taking a census and then computing μ from the population data. If the population is large, however, as it often is in practice, taking a census is generally impractical, extremely expensive, or impossible. Nonetheless, we can usually obtain sufficiently accurate information about μ by taking a sample from the population. Point Estimate One way to obtain information about a population mean μ is to estimate it by a sample mean x, as illustrated in the next example. EXAMPLE: The U.S. Census Bureau publishes annual price figures for new mobile homes in Manufactured Housing Statistics. The figures are obtained from sampling, not from a census. A simple random sample of 36 new mobile homes yielded the prices, in thousands of dollars, shown in the Table below. Use the data to estimate the population mean price, μ, of all new mobile homes. Solution: We estimate the population mean price, μ, of all new mobile homes by the sample mean price, x, of the 36 new mobile homes sampled. From the Table above, x = x i n = 2278 36 = 63.28 Interpretation: Based on the sample data, we estimate the mean price, μ, of all new mobile homes to be approximately $63.28 thousand, that is, $63,280. An estimate of this kind is called a point estimate for μ because it consists of a single number, or point. 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Problems of Estimation
A common problem in statistics is to obtain information about the mean, µ, of a population.For example, we might want to know
• the mean age of people in the civilian labor force,• the mean cost of a wedding,• the mean gas mileage of a new-model car, or• the mean starting salary of liberal-arts graduates.
If the population is small, we can ordinarily determine µ exactly by first taking a census andthen computing µ from the population data. If the population is large, however, as it oftenis in practice, taking a census is generally impractical, extremely expensive, or impossible.Nonetheless, we can usually obtain sufficiently accurate information about µ by taking a samplefrom the population.
Point Estimate
One way to obtain information about a population mean µ is to estimate it by a sample meanx, as illustrated in the next example.
EXAMPLE: The U.S. Census Bureau publishes annual price figures for new mobile homes inManufactured Housing Statistics. The figures are obtained from sampling, not from a census.A simple random sample of 36 new mobile homes yielded the prices, in thousands of dollars,shown in the Table below. Use the data to estimate the population mean price, µ, of all newmobile homes.
Solution: We estimate the population mean price, µ, of all new mobile homes by the samplemean price, x, of the 36 new mobile homes sampled. From the Table above,
x =
∑
xi
n=
2278
36= 63.28
Interpretation: Based on the sample data, we estimate the mean price, µ, of all new mobilehomes to be approximately $63.28 thousand, that is, $63,280.
An estimate of this kind is called a point estimate for µ because it consists of a single number,or point.
1

Confidence-Interval Estimate
As we know, a sample mean is usually not equal to the population mean; generally, there issampling error. Therefore, we should accompany any point estimate of µ with informationthat indicates the accuracy of that estimate. This information is called a confidence-interval
estimate for µ, which we introduce in the next example.
EXAMPLE: Consider again the problem of estimating the (population) mean price, µ, of all newmobile homes by using the sample data in the Table above. Let’s assume that the populationstandard deviation of all such prices is $7200.
(a) Identify the distribution of the variable x, that is, the sampling distribution of the samplemean for samples of size 36.
(b) Use part (a) to show that 95% of all samples of 36 new mobile homes have the propertythat the interval from x − 2.4 to x + 2.4 contains µ.
(c) Use part (b) and the sample data in the Table above to find a 95% confidence interval forµ, that is, an interval of numbers that we can be 95% confident contains µ.
Solution:
(a) A histogram of the price data in the Table above shows that the prices of new mobilehomes are normally distributed. Because n = 36, σ = 7.2, and prices of new mobile homes arenormally distributed, it follows that
• µx = µ (which we don’t know)• σx = σ/
√n = 7.2/
√36 = 1.2
• x is normally distributedIn other words, for samples of size 36, the variable x is normally distributed with mean µ andstandard deviation 1.2.
(b) The “95” part of the 68-95-99.7 rule states that, for a normally distributed variable, 95% ofall possible observations lie within two standard deviations to either side of the mean. Applyingthis rule to the variable x and referring to part (a), we see that 95% of all samples of 36 newmobile homes have mean prices within 2 · 1.2 = 2.4 of µ. Equivalently, 95% of all samples of36 new mobile homes have the property that the interval from x − 2.4 to x + 2.4 contains µ.
(c) Because we are taking a simple random sample, each possible sample of size 36 is equallylikely to be the one obtained. From part (b), 95% of all such samples have the property thatthe interval from x − 2.4 to x + 2.4 contains µ. Hence, chances are 95% that the sample weobtain has that property. Consequently, we can be 95% confident that the sample of 36 newmobile homes whose prices are shown in the Table above has the property that the intervalfrom x − 2.4 to x + 2.4 contains µ. For that sample, x = 63.28, so
x − 2.4 = 63.28 − 2.4 = 60.88 and x + 2.4 = 63.28 + 2.4 = 65.68
Interpretation: We can be 95% confident that the mean price, µ, of all new mobile homes issomewhere between $60,880 and $65,680.
2
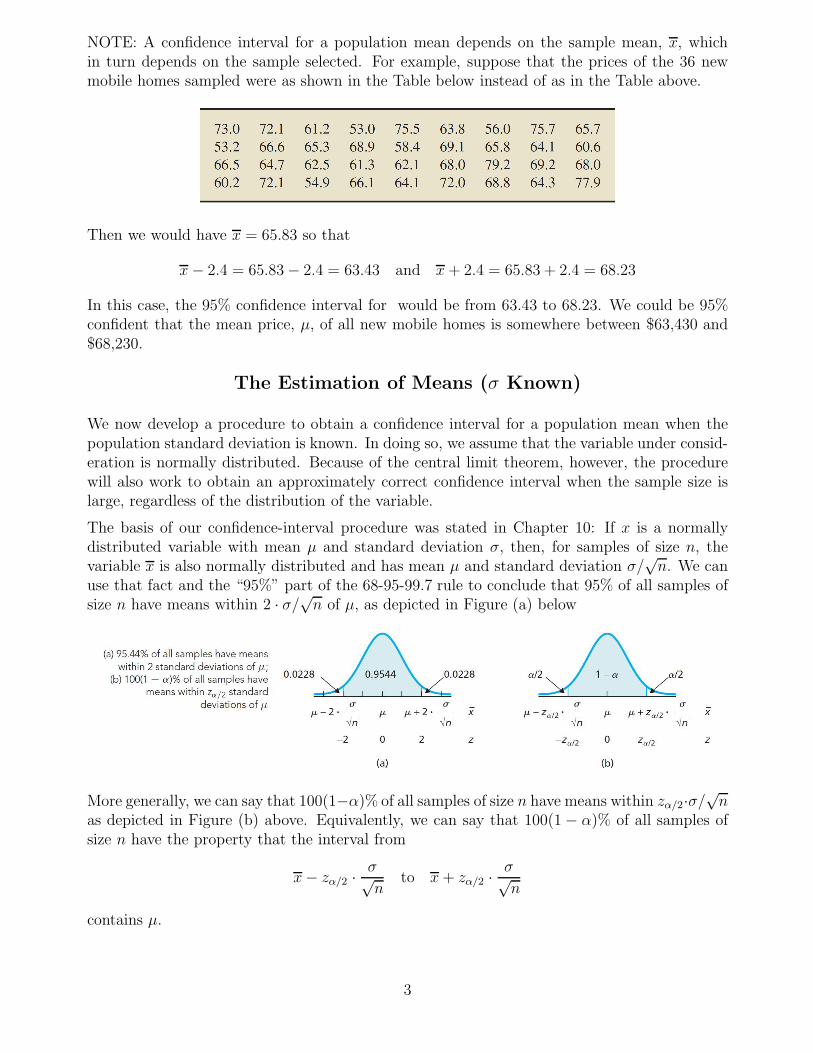
NOTE: A confidence interval for a population mean depends on the sample mean, x, whichin turn depends on the sample selected. For example, suppose that the prices of the 36 newmobile homes sampled were as shown in the Table below instead of as in the Table above.
Then we would have x = 65.83 so that
x − 2.4 = 65.83 − 2.4 = 63.43 and x + 2.4 = 65.83 + 2.4 = 68.23
In this case, the 95% confidence interval for would be from 63.43 to 68.23. We could be 95%confident that the mean price, µ, of all new mobile homes is somewhere between $63,430 and$68,230.
The Estimation of Means (σ Known)
We now develop a procedure to obtain a confidence interval for a population mean when thepopulation standard deviation is known. In doing so, we assume that the variable under consid-eration is normally distributed. Because of the central limit theorem, however, the procedurewill also work to obtain an approximately correct confidence interval when the sample size islarge, regardless of the distribution of the variable.
The basis of our confidence-interval procedure was stated in Chapter 10: If x is a normallydistributed variable with mean µ and standard deviation σ, then, for samples of size n, thevariable x is also normally distributed and has mean µ and standard deviation σ/
√n. We can
use that fact and the “95%” part of the 68-95-99.7 rule to conclude that 95% of all samples ofsize n have means within 2 · σ/
√n of µ, as depicted in Figure (a) below
More generally, we can say that 100(1−α)% of all samples of size n have means within zα/2·σ/√
nas depicted in Figure (b) above. Equivalently, we can say that 100(1 − α)% of all samples ofsize n have the property that the interval from
x − zα/2 ·σ√
nto x + zα/2 ·
σ√
n
contains µ.
3

EXAMPLE: The Bureau of Labor Statistics collects information on the ages of people in thecivilian labor force and publishes the results in Employment and Earnings. Fifty people in thecivilian labor force are randomly selected; their ages are displayed in the Table below.
Find a 95% confidence interval for the mean age, µ, of all people in the civilian labor force.Assume that the population standard deviation of the ages is 12.1 years.
4

EXAMPLE: The Bureau of Labor Statistics collects information on the ages of people in thecivilian labor force and publishes the results in Employment and Earnings. Fifty people in thecivilian labor force are randomly selected; their ages are displayed in the Table below.
Find a 95% confidence interval for the mean age, µ, of all people in the civilian labor force.Assume that the population standard deviation of the ages is 12.1 years.
Solution: Because the sample size is 50, which is large, and the population standard deviationis known, we can use the Procedure above to find the required confidence interval.
Step 1: For a confidence level of 1 − α, use Table I to find zα/2.
We want a 95% confidence interval, so α = 1 − 0.95 = 0.05. From Table I, zα/2 = z0.05/2 =z0.025 = 1.96.
Step 2: The confidence interval for µ is from
x − zα/2 ·σ
√n
to x + zα/2 ·σ
√n
We know σ = 12.1, n = 50, and, from Step 1, zα/2 = 1.96. To compute x for the data in theTable above, we apply the usual formula:
x =
∑
xi
n=
1819
50= 36.4
to one decimal place. Consequently, a 95% confidence interval for µ is from
36.4 − 1.96 ·12.1√
50to 36.4 + 1.96 ·
12.1√
50
or 33.0 to 39.8.
Interpretation: We can be 95% confident that the mean age, µ, of all people in the civilianlabor force is somewhere between 33.0 years and 39.8 years.
5

Determining the Required Sample Size
If the margin of error and confidence level are given, then we must determine the sample sizeneeded to meet those specifications. To find the formula for the required sample size, we solvethe margin-of-error formula, E = zα/2 · σ/
√n, for n.
EXAMPLE: Consider again the problem of estimating the mean age, µ, of all people in thecivilian labor force.
(a) Determine the sample size needed in order to be 95% confident that µ is within 0.5 year ofthe estimate, x. Recall that σ = 12.1 years.
(b) Find a 95% confidence interval for µ if a sample of the size determined in part (a) has amean age of 38.8 years.
Solution:
(a) To find the sample size, we use the Formula above. We know that σ = 12.1 and E = 0.5.The confidence level is 0.95, which means that α = 0.05 and zα/2 = z0.025 = 1.96. Thus
n =(zα/2 · σ
E
)2
=
(
1.96 · 12.1
0.5
)
2
= 2249.79
which, rounded up to the nearest whole number, is 2250.
Interpretation: If 2250 people in the civilian labor force are randomly selected, we can be95% confident that the mean age of all people in the civilian labor force is within 0.5 year ofthe mean age of the people in the sample.
(b) Applying the above Procedure with α = 0.05, σ = 12.1, x = 38.8, and n = 2250, we get theconfidence interval
38.8 − 1.96 ·12.1
√2250
to 38.8 + 1.96 ·12.1
√2250
or 38.3 to 39.3.
Interpretation: We can be 95% confident that the mean age, µ, of all people in the civilianlabor force is somewhere between 38.3 years and 39.3 years.
6

The Estimation of Means (σ Unknown)
What if, as is usual in practice, the population standard deviation is unknown? Then we cannotbase our confidence-interval procedure on the standardized version of x. The best we can do isestimate the population standard deviation, σ, by the sample standard deviation, s; in otherwords, we replace σ by s in the equation
z =x − µ
σ/√
n
and base our confidence-interval procedure on the resulting variable
t =x − µ
s/√
n
which is a value of a random variable having the t-distribution. More specifically, this dis-tribution is called the Student t-distribution or Student’s t-distribution, as it was firstdeveloped by a statistician, W.S.Gosset, who published his work under the pen name “Student.”
There is a different t-distribution for each sample size. We identify a particular t-distributionby its number of degrees of freedom (df). For the studentized version of x, the number ofdegrees of freedom is 1 less than the sample size, which we indicate symbolically by df = n−1.
A variable with a t-distribution has an associated curve, called a t-curve. Although there isa different t-curve for each number of degrees of freedom, all t-curves are similar and resemblethe standard normal curve, as illustrated in the Figure above (right).
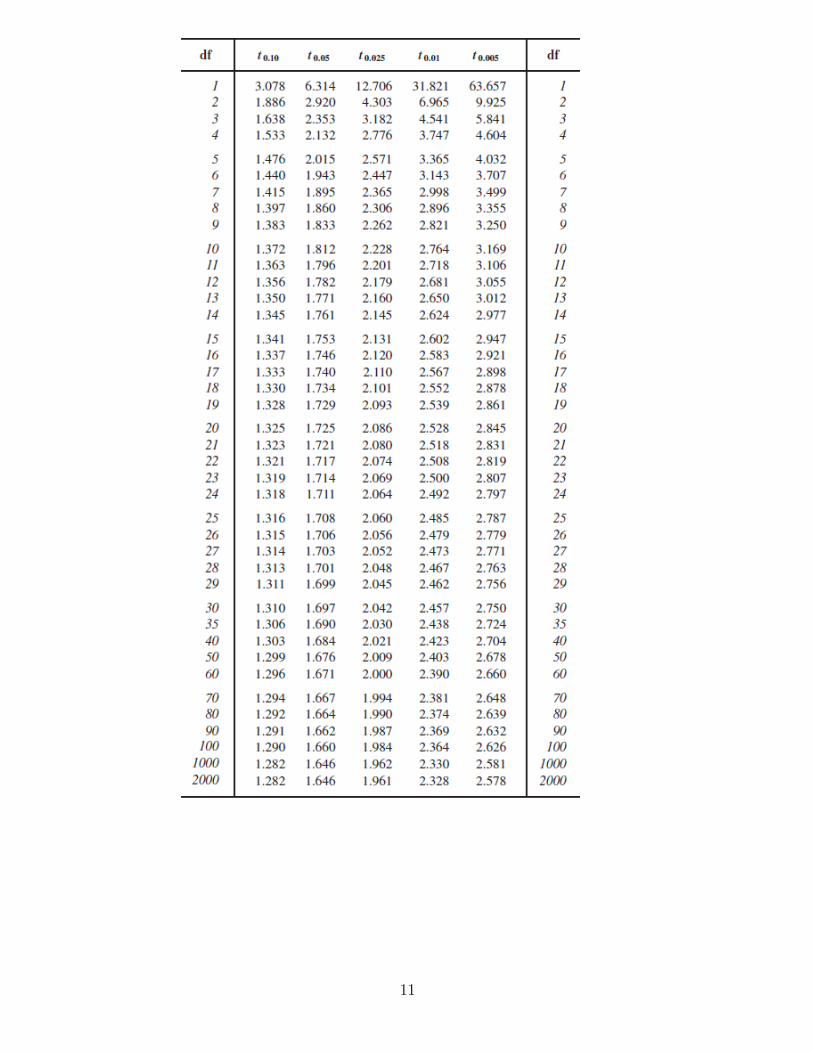
Percentages (and probabilities) for a variable having a t-distribution equal areas under thevariable’s associated t-curve. For our purposes, one of which is obtaining confidence intervalsfor a population mean, we don’t need a complete t-table for each t-curve; only certain areaswill be important. Table II is sufficient for our purposes.
EXAMPLE: For a t-curve with 13 degrees of freedom, determine t0.05; that is, find the t-valuehaving area 0.05 to its right, as shown the Figure below.
7

EXAMPLE: For a t-curve with 13 degrees of freedom, determine t0.05; that is, find the t-valuehaving area 0.05 to its right, as shown in Figure (a) below.
Solution: To find the t-value in question, we use Table II, a portion of which is given below:
The number of degrees of freedom is 13, so we first go down the outside columns, labeled df,to “13.” Then, going across that row to the column labeled t0.05, we reach 1.771. This numberis the t-value having area 0.05 to its right, as shown in Figure (b) above. In other words, for at-curve with df = 13, t0.05 = 1.771.
EXAMPLE: The Federal Bureau of Investigation (FBI) com-piles data on robbery and property crimes and publishes theinformation in Population-at-Risk Rates and Selected Crime
Indicators. A simple random sample of pickpocket offensesyielded the losses, in dollars, shown in the Table on the right.Use the data to find a 95% confidence interval for the meanloss, µ, of all pickpocket offenses.
8

EXAMPLE: The Federal Bureau of Investigation (FBI) com-piles data on robbery and property crimes and publishes theinformation in Population-at-Risk Rates and Selected Crime
Indicators. A simple random sample of pickpocket offensesyielded the losses, in dollars, shown in the Table on the right.Use the data to find a 95% confidence interval for the meanloss, µ, of all pickpocket offenses.
Solution: Because the sample size, n = 25, is moderate, we first need to consider questions ofnormality. To do that, we constructed a histogram that reveals that indeed we have a roughlynormal population. So, we can apply the above Procedure to find the confidence interval.
Step 1: For a confidence level of 1 − α, use Table II to find tα/2 with df= n − 1,
where n is the sample size.
We want a 95% confidence interval, so α = 1−0.95 = 0.05. For n = 25, we have df= 25−1 = 24.From Table II, tα/2 = t0.05/2 = t0.025 = 2.064.
Step 2: The confidence interval for µ is from
x − tα/2 ·s
√n
to x + tα/2 ·s
√n
From Step 1, tα/2 = 2.064. Applying the usual formulas for x and s to the data in the Tableabove gives x = 513.32 and s = 262.23. So a 95% confidence interval for µ is from
513.32 − 2.064 ·262.23√
25to 513.32 + 2.064 ·
262.23√
25
or 405.07 to 621.57.
Interpretation: We can be 95% confident that the mean loss of all pickpocket offenses issomewhere between $405.07 and $621.57.
9

10
11
Related Documents











