Probabilistic Fingerprints for Shapes Niloy J. MitraLeonidas Guibas Joachim Giesen Mark Pauly Stanford University MPII Saarbrücken ETH Zurich

Probabilistic Fingerprints for Shapes Niloy J. MitraLeonidas Guibas Joachim GiesenMark Pauly Stanford University MPII SaarbrückenETH Zurich.
Dec 18, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Probabilistic Fingerprints for Shapes
Niloy J. Mitra Leonidas Guibas Joachim Giesen Mark Pauly
Stanford University MPII Saarbrücken ETH Zurich

Introduction
• Shape Analysis and Comparison• shape retrieval, shape clustering, feature selection,
correspondence, compression, re-use, etc
•Question: Are two shapes similar?
≈ ?

Introduction
• More general: Are two shapes similar in parts?• relative size of overlap region partially matching under
rigid motion
• scan alignment
• context-based editing
• shape recognition, etc.
• Efficient tests require compact signatures• database query
• network setting
• fast pre-filtering, etc.

Background
• Methods for global registration• Gelfand, Mitra, Guibas and Pottmann, Robust Global Registration, SGP 2005
• Li and Guskov, Multi-scale Features for Approximate Alignment of Point-based Surfaces, SGP 2005
• Huber and Hebert, Fully Automatic Registration of Multiple 3D Data Sets, CVBVS 2001
• Global shape descriptors• Kazhdan, Funkhouser and Rusinkiewicz, Rotation Invariant Spherical
Harmonic Representation of 3D Shape Descriptors, SGP 2003
• Osada, Funkhouser, Chazelle and Dobkin, Shape Distributions, ACM TOG 2002
• Reuter and Wolter, Laplace-Spectra as fingerprints for shape matching, SPM 2005

Background
• Geometric Hashing• Wolfson, Rigoutsos. Geometric Hashing: An Overview, IEEE Computational
Science and Engineering, 4(4), 1997
• Gal and Cohen-Or, Salient geometric features for partial shape matching and similarity, ACM TOG 2006
• File matching• Broder, Glassman, Manasse, Zweig. Syntactic Clustering of the Web, World
Wide Web Conference, 1997
• Broder, On the Resemblance and Containment of Documents, Sequences 1997
• Schleimer, Wilkerson and Alex Aiken, Winnowing: local algorithms for document fingerprinting, Sigmod, ’03

Probabilistic Fingerprints
• Function such that• Given two shapes S1 and S2, with high probability
• if f(S1) ≠ f(S2) then S1 and S2 are dissimilar
• if f(S1) = f(S2) then S1 and S2 are similar
• f is efficiently computable
• compact, i.e.,
• output sensitive
• localized (partial matching)
• robust to sampling and articulated motion
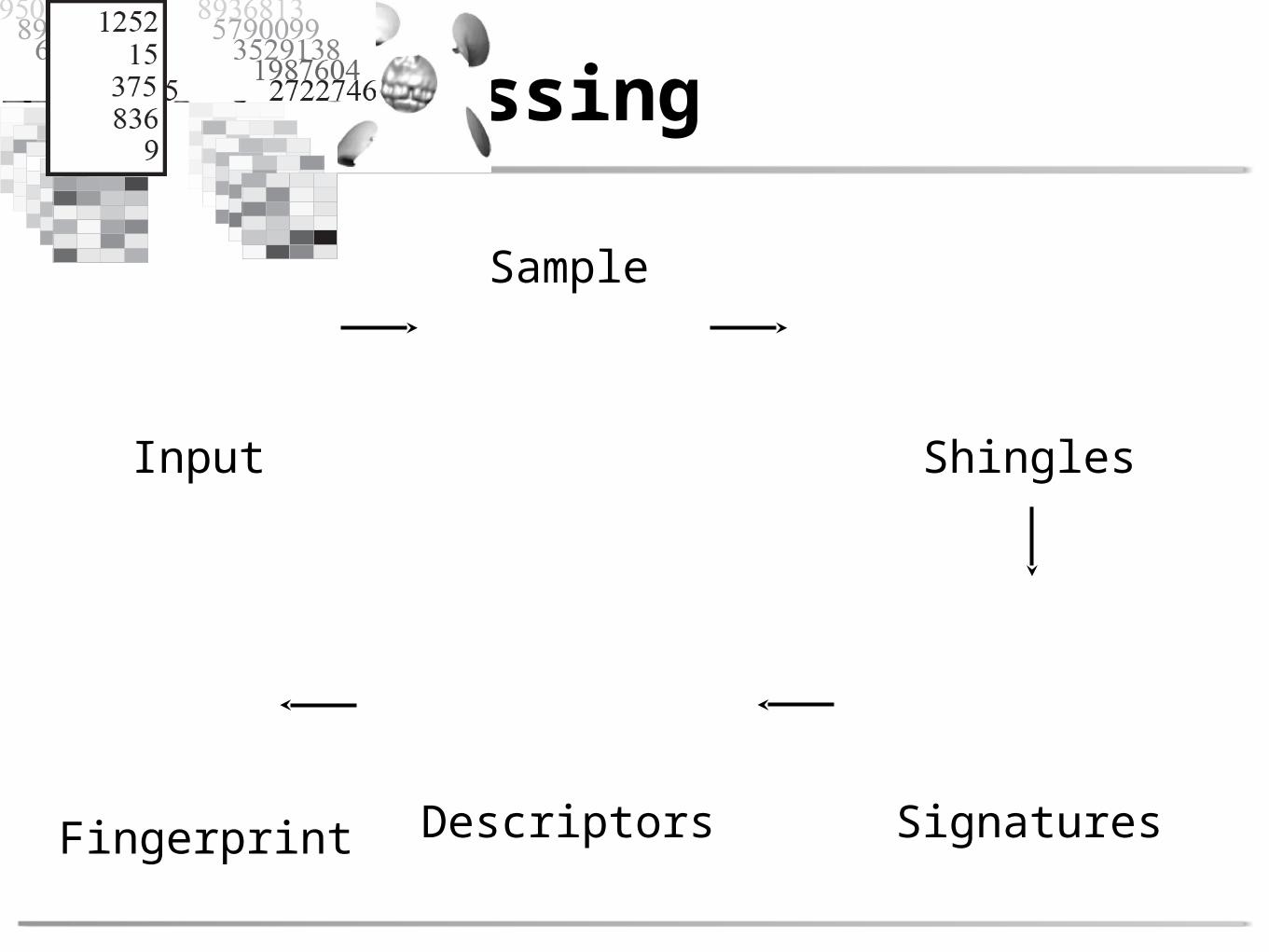
Pre-Processing
Input
Sample
Shingles
SignaturesDescriptorsFingerprint

Pre-Processing
Input Sample
• Uniform random sample • guarantee δ-coverage
• avoid arbitrarily dense sampling [Turk 92]
such that

Sample
Pre-Processing
Shingles
• Local surface patches• intersection with ρ-balls
• create sufficient overlap for robust signature estimation, i.e.,

Pre-Processing
Shingles Signatures
• Local signatures should be invariant to• rigid transforms
• sampling & local perturbations
• Examples: Spin images, shape histograms, integral descriptors, etc.

Pre-Processing
DescriptorsSignatures
• Optional: Compressed descriptors• e.g., Rabin’s hashing
• Signature set • multi-set of points in high-dimensional space
• spatial relation of shingles not preserved

Resemblance
80 32 54 76 91 10 11 12 13 14
80 32 54 76 91 10 11 12 13 14

Resemblance

Probabilistic Fingerprint
• Let be random permutations
• Estimate of resemblanceindicator function

Probabilistic Fingerprint
• Estimate of resemblance
• Example: m = 3
8 0 32 54 76 91 1011 1213 14
8 03 25 4769 1 101112 1314
8 03 25 47 6 91 1011 12 1314

Probabilistic Fingerprint
• Estimate of resemblance
8 0 32 54 76 91 1011 1213 14
80 32 54 76 91 10 11 12 13 14
80 32 54 76 91 10 11 12 13 14

Probabilistic Fingerprint
• Estimate of resemblance
8 0 32 54 76 91 1011 1213 14
80 32 54 76 91 10 11 12 13 14
80 32 54 76 91 10 11 12 13 14

Probabilistic Fingerprint
• Estimate of resemblance
80 32 54 76 91 10 11 12 13 14
80 32 54 76 91 10 11 12 13 14
8 03 25 4769 1 101112 1314

Probabilistic Fingerprint
• Estimate of resemblance
8 03 25 4769 1 101112 1314
80 32 54 76 91 10 11 12 13 14
80 32 54 76 91 10 11 12 13 14

Probabilistic Fingerprint
• Estimate of resemblance
80 32 54 76 91 10 11 12 13 14
80 32 54 76 91 10 11 12 13 14
8 03 25 47 6 91 1011 12 1314

Probabilistic Fingerprint
• Estimate of resemblance
80 32 54 76 91 10 11 12 13 14
80 32 54 76 91 10 11 12 13 14
8 03 25 47 6 91 1011 12 1314

Pre-Processing
FingerprintDescriptors
• Probabilistic Fingerprint• reduce using min-hashing
• based on random permutations of universe
• set of ‘random experts’ consistent for all models

Min-Hashing
• Feature selection by random experts• reduces set comparison to element-wise
comparison
• estimate resemblance using m permutations = perform m coin tosses to estimate bias of coin
• Analysis• probabilistic bounds using Markov inequality &
strong Chernoff bound
• relates size of the fingerprint to confidence in estimated resemblance

Data Reduction
Shingles Signatures Descriptors Fingerprint
quantization min hashing
set size remains constant
100k 100k 100k 1k
set reduction

Applications
• Resemblance between partial scans

Applications
• Adaptive feature selection

Applications
• Alignment using adaptive feature selection
scan A scan B final alignment

Applications
• Multiple scans• greedy alignment
using priority queue
• fingerprint matching determines score
• advanced alignment method for verification
• merging fingerprints requires no re-computation

Applications
• Shape distributions

Applications
• Database retrieval

Statistics
• Pre-processing time in seconds:
• Query time: ~ 15 msec on average
• Fingerprint size ~10kb
model #vts. uniform sampl.
spin image
Rabin hash
min-hash
skull 54k 0.8 7.5 0.05 4.5
Caesar 65k 1.4 7.3 0.08 10.3
bunny 121k 1.8 13.8 0.04 2.9
horse 8k 0.7 5.7 0.05 7.3

Remarks & Insights
• Resemblance defined as set operation on signature sets → quantization is crucial
• Random experts effectively extract consistent set of features → requires no explicit correspondence
• Fingerprints do not preserve spatial relation of shingles → false positives are possible
• Few parameters that are easy to tune

Remarks & Insights
• Accumulate local evidence for global inference
• Spatial structure vs. unordered signature set?
• Semantic features vs. random experts?
Thank You!
Related Documents











