Probabilistic Encryption – A Practical Implementation Orhio Mark Creado, Yiling Wang, Xianping Wu, and Phu Dung Le Caulfield School of Information Technology Monash University Melbourne, Australia [email protected], {yiling.wang,xianping.wu,phu.dung.Le}@infotech.monash.edu.au Abstract – This paper aims to provide a practical implementation of a probabilistic cipher by extending on the algorithms by Fuchsbauer, Goldwasser and Micali. We provide details on designing and implementing the cipher and further support our understanding by providing a statistical analysis of our implementation for the key generation, encryption, and decryption times taken by the cipher for key sizes of 1024, 2048, and 4096 bits for varying message spaces of 750, 1500, 3000, and 5000 bits. The concept of 'inter-bit operating time' is introduced for the cipher which calculates time elapsed between two instances of an operation. We show the working of a probabilistic cipher purely from a practical standpoint to justify if its original algorithm is practically implementable. Keywords – Probabilistic Encryption, Probabilistic Cipher, Probabilistic Algorithm, Public-Key Cryptosystem I. INTRODUCTION With the advances in technology, computing is no longer processor intensive. Hence, this has created a need for a more secure mode of communication and data transfer. Cryptography has also evolved from that of a single key cryptosystem to encrypt and decrypt data, to a public key cryptosystem supporting more complex mathematical concepts, which basically form the base of any cryptosystem [1]. One of the main challenges of conventional encryption algorithms still remains in their ability not to encrypt but to decrypt the data. Traditional algorithms such as RSA and ECC tend to be deterministic in nature. This has resulted in the same ciphertext being generated for the same plaintext message each time. This makes it easy for a message, sent more than once, to be subject to a known ciphertext attack, whereby an adversary could randomly guess parts of the same ciphertext. The introduction of trapdoor functions in conjunction with signature algorithms has facilitated a slightly more secure ciphertext and prevented the possibility of message tampering. However, the drawbacks with this approach still remained, but were just made slightly more difficult [2]. With the above flaws in mind, Goldwasser and Micali proposed a new approach towards encryption, which suggested a step away from deterministic algorithms, and dwelled around the concept of introducing ‘randomness’, thereby introducing the idea of dynamic ciphertext for the same plaintext, also known as Probabilistic Encryption (PE). The theory of PE has introduced the concepts of Unapproximable Trapdoor Predicates (UTP), which have been based around the computational infeasibility of solving the Quadratic Residuosity Problem (QRP). The PE utilizes this concept in a bitwise encryption algorithm which encrypts each bit individually, thereby introducing a different ciphertext for the same plaintext value. This concept of randomness, allows for a selected message to be encrypted in many different ways. Hence, theoretically speaking, an adversary would not be able to satisfactorily determine if a given ciphertext represents a possible value with any guaranteed probability, which would be directly dependent on the length of the message being sent [3]. The bitwise approach of PE has been criticized as not feasible to be implemented in practice as it would be impractical due to the message expansion resulting from the encryption of each bit [4]. Many alternative approaches has been suggested which propose the reduction in the ciphertext message expansion either by multiple bit encryption [5], exclusive-or operations with random number generator outputs [6], and also algorithm modifications for faster encryption and decryption [7]. For more details, the reader is referred to the papers by the respective authors. However, all of these are theoretical only since no published research or commercial applications have been made available which shed some light on the practical implementation of PE, so as to be able to benchmark the performance of the cipher versus other commercially available alternatives, such as RSA and ECC. In this paper, we study the logic and basis of the PE model by practically implementing a working demonstration of a Probabilistic Cipher (PC). We provide an analysis of the algorithms behind the cipher based on the performance for the encryption and decryption operations. We further support it with a quantitative analysis pertaining to the performance of the cipher for key sizes of 1024, 2048, and 4096 bits, and for various message lengths of 750, 1500, 3000, and 5000 bits. The paper is structured as follows. Section 2 provides a brief overview of PC and related mathematical concepts. Section 3 outlines the proposed implementation of the cipher. An analysis of the cipher in terms of performance, with a statistical comparison of speed for the key generation, encryption, and decryption operations is shown in Section 4. And in Section 5, we summarize our conclusion and discuss future work. II. PROBABILISTIC ENCRYPTION In this section, we address some of the key aspects which outline the PE model. For a further in-depth understanding of the mathematical concepts mentioned below, the reader is 2009 Fourth International Conference on Computer Sciences and Convergence Information Technology 978-0-7695-3896-9/09 $26.00 © 2009 IEEE DOI 10.1109/ICCIT.2009.216 1130

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Probabilistic Encryption – A Practical Implementation Orhio Mark Creado, Yiling Wang, Xianping Wu, and Phu Dung Le
Caulfield School of Information Technology Monash University
Melbourne, Australia [email protected], {yiling.wang,xianping.wu,phu.dung.Le}@infotech.monash.edu.au
Abstract – This paper aims to provide a practical implementation of a probabilistic cipher by extending on the algorithms by Fuchsbauer, Goldwasser and Micali. We provide details on designing and implementing the cipher and further support our understanding by providing a statistical analysis of our implementation for the key generation, encryption, and decryption times taken by the cipher for key sizes of 1024, 2048, and 4096 bits for varying message spaces of 750, 1500, 3000, and 5000 bits. The concept of 'inter-bit operating time' is introduced for the cipher which calculates time elapsed between two instances of an operation. We show the working of a probabilistic cipher purely from a practical standpoint to justify if its original algorithm is practically implementable.
Keywords – Probabilistic Encryption, Probabilistic Cipher, Probabilistic Algorithm, Public-Key Cryptosystem
I. INTRODUCTION
With the advances in technology, computing is no longer processor intensive. Hence, this has created a need for a more secure mode of communication and data transfer. Cryptography has also evolved from that of a single key cryptosystem to encrypt and decrypt data, to a public key cryptosystem supporting more complex mathematical concepts, which basically form the base of any cryptosystem [1].
One of the main challenges of conventional encryption algorithms still remains in their ability not to encrypt but to decrypt the data. Traditional algorithms such as RSA and ECC tend to be deterministic in nature. This has resulted in the same ciphertext being generated for the same plaintext message each time. This makes it easy for a message, sent more than once, to be subject to a known ciphertext attack, whereby an adversary could randomly guess parts of the same ciphertext. The introduction of trapdoor functions in conjunction with signature algorithms has facilitated a slightly more secure ciphertext and prevented the possibility of message tampering. However, the drawbacks with this approach still remained, but were just made slightly more difficult [2].
With the above flaws in mind, Goldwasser and Micali proposed a new approach towards encryption, which suggested a step away from deterministic algorithms, and dwelled around the concept of introducing ‘randomness’, thereby introducing the idea of dynamic ciphertext for the same plaintext, also known as Probabilistic Encryption (PE). The theory of PE has introduced the concepts of Unapproximable Trapdoor Predicates (UTP), which have
been based around the computational infeasibility of solving the Quadratic Residuosity Problem (QRP). The PE utilizes this concept in a bitwise encryption algorithm which encrypts each bit individually, thereby introducing a different ciphertext for the same plaintext value. This concept of randomness, allows for a selected message to be encrypted in many different ways. Hence, theoretically speaking, an adversary would not be able to satisfactorily determine if a given ciphertext represents a possible value with any guaranteed probability, which would be directly dependent on the length of the message being sent [3].
The bitwise approach of PE has been criticized as not feasible to be implemented in practice as it would be impractical due to the message expansion resulting from the encryption of each bit [4]. Many alternative approaches has been suggested which propose the reduction in the ciphertext message expansion either by multiple bit encryption [5], exclusive-or operations with random number generator outputs [6], and also algorithm modifications for faster encryption and decryption [7]. For more details, the reader is referred to the papers by the respective authors. However, all of these are theoretical only since no published research or commercial applications have been made available which shed some light on the practical implementation of PE, so as to be able to benchmark the performance of the cipher versus other commercially available alternatives, such as RSA and ECC.
In this paper, we study the logic and basis of the PE model by practically implementing a working demonstration of a Probabilistic Cipher (PC). We provide an analysis of the algorithms behind the cipher based on the performance for the encryption and decryption operations. We further support it with a quantitative analysis pertaining to the performance of the cipher for key sizes of 1024, 2048, and 4096 bits, and for various message lengths of 750, 1500, 3000, and 5000 bits.
The paper is structured as follows. Section 2 provides a brief overview of PC and related mathematical concepts. Section 3 outlines the proposed implementation of the cipher. An analysis of the cipher in terms of performance, with a statistical comparison of speed for the key generation, encryption, and decryption operations is shown in Section 4. And in Section 5, we summarize our conclusion and discuss future work.
II. PROBABILISTIC ENCRYPTION
In this section, we address some of the key aspects which outline the PE model. For a further in-depth understanding of the mathematical concepts mentioned below, the reader is
2009 Fourth International Conference on Computer Sciences and Convergence Information Technology
978-0-7695-3896-9/09 $26.00 © 2009 IEEE
DOI 10.1109/ICCIT.2009.216
1130

advised to refer papers specifically on mathematics which address one or more of the concepts discussed.
A. Quadratic Residuosity Problem The foundation of any public key cryptosystem is defined
by the search for a ‘hard problem’ which tends to be a complex mathematical concept in number theory which when attempted to calculate is easy to execute but extremely resource intensive if required to revert [8]. It is for such a hard problem which to execute takes polynomial time to calculate; however to revert the function, the fastest known algorithm takes exponential time. Traditional public key cryptosystems such as RSA is defined by the Integer factorization problem which deals with the factorization of a very large composite number into its two large prime constituents. With increasing computation efficiency, the difficulty of this problem has been dwindling down resulting in the use of larger keys for encryption and decryption. This has made the concept of ECC more appealing as it has been based around finding discrete logarithms of prime numbers over a finite group, and requires smaller key sizes in comparison to RSA [9].
The concept of QRP dwells around finding square roots of a given number modulo N. Let n represent a set of all natural numbers which are less than N but have a multiplicative inverse modulo N. The probabilistic algorithm makes use of the fact that for any given set of numbers in the set n , there exists exactly (# n - 1)/2 numbers which satisfy the following equation:
2 (mod )X A N= (1)
With the exception of 0, for every A that satisfies the above equation is a quadratic residue modulo N, and every X is a square root modulo N. If there does not exist such an X, then A is a quadratic non residue modulo N [10].
Assuming that for any given A, where nA∈ , *RQ is
representative of all the quadratic residues modulo N, and *NRQ is representative of all the quadratic non residues
modulo N; we can use the mathematic concepts of the Legendre Symbol to compute quadratic residues modulo N. Provided P is a prime number, A is an integer, and GCD(A, P) = 1; then applying the Legendre symbol we can obtain the following results [11]:
*
*
1,( )
1,R
NR
if a QAP if a Q
⎧ ∈⎪= ⎨− ∈⎪⎩ (2)
Given ( , ) nA B ∈ , then the following equation holds true:
( ) : ( )( )AB A BP P P
= (3)
Given the limitation that P is required to be prime in order to calculate the Legendre symbol; we can apply the Jacobi Symbol, which is an extension of the Legendre symbol, to
calculate the same. Accounting for this, the Jacobi Symbol has been proven easier to calculate as the factorization of numbers into its prime factors can be avoided which is required to calculate the Legendre symbol. The only stipulation behind the computation of the Jacobi symbol state that N > 0 and N mod 2 = 1. Holding true for composite numbers such as N = P * Q, the following equation holds [12]:
( )( ) : ( )A A AP Q N
= (4)
It should be noted that using the Jacobi symbol does not determine if a passed parameter is a quadratic residue or non residue. Hence, taking into consideration equations 1 – 4, it can be observed that, by using the Jacobi symbol, amongst the non residues obtained there are approximately ( n - 1)/4 elements which will have the Jacobi symbol of 1 but will actually be quadratic non residues modulo N. These elements can further be categorized as Pseudosquares, which form the basis of PE.
Goldwasser and Micali [1] have proven this concept to be semantically secure, due to the computational infeasibility to solve the QRP without knowing the values of P and Q, in other words, the factorization of N; which grows more complex the bigger the size of the prime numbers P and Q.
B. Unapproximable Trapdoor Predicates (UTP) The notion of UTPs was proposed with the idea of
modifying trapdoor functions so as to elude the possibility of an adversary to randomly ‘guess’ parts of the ciphertext message. Since PE follows a bitwise encryption algorithm, it poses an easy target for an adversary to possibly break the cipher for one bit only; however, using UTP’s there is no way for an adversary to computer B(Z) without knowing the trapdoor information. Using the concepts of QRP, discussed above, and B which serves as a trapdoor function that is unapproximable such that anyone can select an X and a Y, so that B(X) = 0 or B(Y) = 1, but only with the knowledge of the trapdoor information can someone given Z, compute B(Z), as it is infeasible to determine a quadratic residue modulo N with no prior knowledge of the factorization of N [4].
III. IMPLEMENTATION
In this section we provide an in-depth understanding towards designing and implementing a PC. We cover our implementation of a basic cipher as conceptualized by its original algorithm supporting bit by bit encryption. Note that the implementation has been executed on Ubuntu 9.10/ Windows Vista Business, Core 2 Duo, T5600 @ 1.83 GHz, 1.5 GB RAM.
A. Logic Our implementation of a PC performs three executions of
the cipher for each operation of key generation, encryption,
1131

and decryption for the following three key sizes: 1024 bits, 2048 bits, and 4096 bits. Since we do not have any published benchmark our assumption remains that the approximate key sizes for RSA versus ECC [13] also apply to our implementation of PC versus ECC. The implementation has three individual aspects: the key generation phase, the encryption phase, the decryption phase. Each aspect of the implementation operates independently of the other and will be covered in brief detail.
In our implementation, the message space considered is representative of the desired lengths of 750, 1500, 3000, and 5000 bits, and is calculated by generating a random point on an ECC curve and then concatenating the x-coordinate of that point to form a message space of the desired length. The required number of points to satisfy the length of the message space for each key length is shown in Table 1. We use this concept to provide a better understanding of our analysis of the graphs which follow in the next chapter.
Key Size – ECC / PC Message Space
750 1500 3000 5000
128/1024 20 39 78 130
160/2048 15 31 62 104
192/4096 13 25 52 86
TABLE 1: REPRESENTATIVE NUMBER OF POINTS (APPROX) ON ECC CURVE FOR SPECIFIC MESSAGE LENGTH VS. KEY SIZE
1) Key Generation Algorithm The key generation phase involves the finding of a
pseudosquare Y to a composite integer N, where N = P * Q, the product of the two prime numbers. The concept for calculating a pseudosquare has not been well documented in any literature that we have come across. The only proposed mode of calculation involves choosing a probabilistic algorithm to select a Y, such that the following equation holds true:
( ) ( ) 1Y YJ JP Q
= = − (5)
Our process for finding a pseudosquare involves the following steps:
• Generate a random bit Y • GCD(Y, N) = 1
• ( ) 1YJN
= , where J is the Jacobi Symbol
• Ensure Eq. 5 holds true From our observation, any Y that can satisfy all of the
above conditions is a probable pseudosquare. Hence we have our private key (P, Q) and we have our public key (N, Y) [10].
The key generation algorithm in our implementation can best be defined by the flowchart in Figure 1.
2) Encryption Algorithm The encryption algorithm follows the same as outlined by
Fuchsbauer [10]. The algorithm works off of the binary representation of the message to be encrypted. For every ‘0’ value bit, the ciphertext outputted by the algorithm is calculated as:
2X modulus N (6)
and for every ‘1’ value bit, the ciphertext outputted by the algorithm is calculated as:
2*Y X modulus N (7)
where Y has been calculated in the key generation phase. The selection of X is randomly selected for each bit in the binary string. The selection of X has to satisfy the following two conditions:
• GCD(X, N) = 1
• ( ) 1YJN
=
The encryption algorithm in our implementation can best be defined by the flowchart in Figure 2.
FIGURE 1: KEY GENERATION ALGORITHM FLOW CHART
1132

3) Decryption Algorithm The decryption algorithm follows the same as outlined by
Fuchsbauer [10]. The algorithm works off of the encrypted message passed in from the encryption phase. According to equations 3 and 4 from section 2, the Jacobi Symbol for the encrypted value, Ex, with either P or Q should be equal; hence in the decryption algorithm we can choose either P or
Q. The algorithm outputs a ‘0’ value bit if ( ) 1ExJP
= and
outputs a ‘1’ value bit for any other value of ( )ExJP
. On
decryption, the algorithm converts the binary string to text. Figure 3 defines the flowchart for the decryption algorithm.
FIGURE 3: DECRYPTION ALGORITHM FLOW CHART
Having provided an understanding of the implementation logic behind the cipher, we now proceed to our analysis of the results obtained from the actual execution of the cipher.
IV. STATISTICAL ANALYSIS
In this section, in terms of statistical analysis we discuss the performance aspect of the cipher. Due to the fact of platform differences and other aspects which could affect cipher performance, we use average values which are calculated based on three executions of the cipher for different keys of the same size. We target the graphs to display a trend rather than making a statement based on our results. The analysis depicted here should be used as a guide for further research and as a potential benchmark for further modifications and development of the algorithms behind the cipher, rather than be considered as actual operating times for the cipher. For a more descriptive definition of our implementation protocol to understand the graphs, please refer to section 3.1. Before proceeding, we first introduce a concept which we use in our analysis.
A. Inter-Bit Operating Time More specifically to our implementation, we coin the
term ‘inter-bit operating time’ to refer to the time taken
FIGURE 2: ENCRYPTION ALGORITHM FLOW CHART
1133
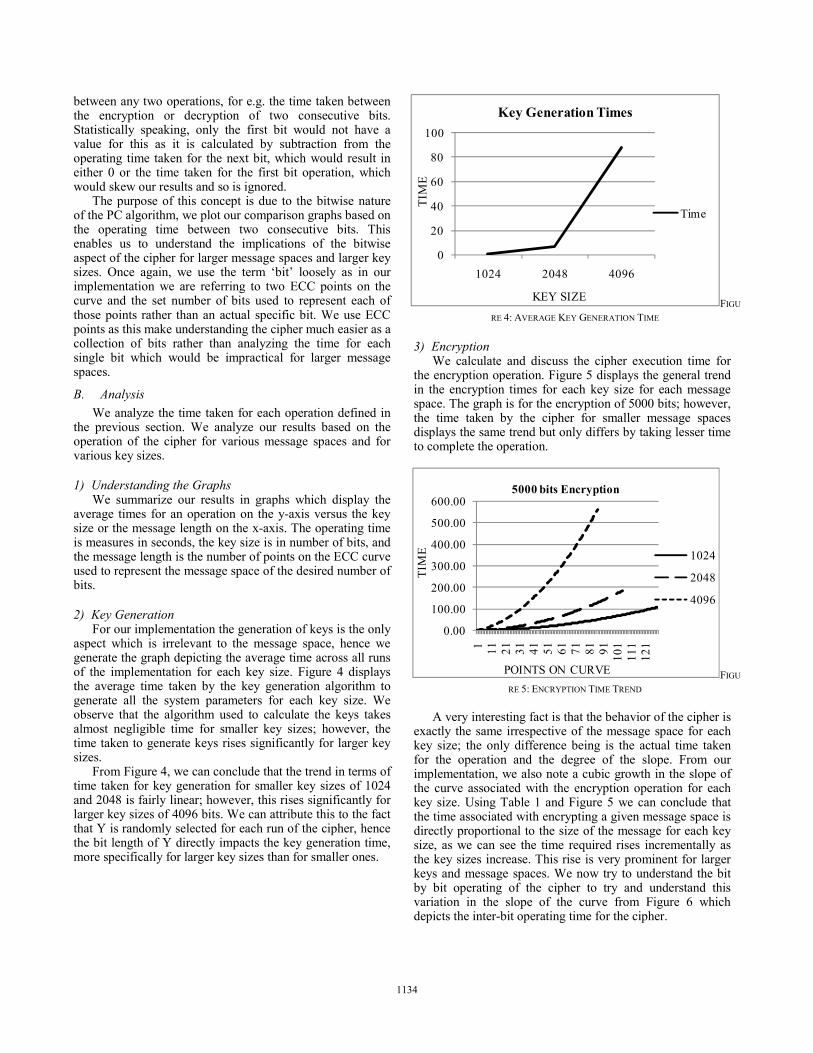
between any two operations, for e.g. the time taken between the encryption or decryption of two consecutive bits. Statistically speaking, only the first bit would not have a value for this as it is calculated by subtraction from the operating time taken for the next bit, which would result in either 0 or the time taken for the first bit operation, which would skew our results and so is ignored.
The purpose of this concept is due to the bitwise nature of the PC algorithm, we plot our comparison graphs based on the operating time between two consecutive bits. This enables us to understand the implications of the bitwise aspect of the cipher for larger message spaces and larger key sizes. Once again, we use the term ‘bit’ loosely as in our implementation we are referring to two ECC points on the curve and the set number of bits used to represent each of those points rather than an actual specific bit. We use ECC points as this make understanding the cipher much easier as a collection of bits rather than analyzing the time for each single bit which would be impractical for larger message spaces.
B. Analysis We analyze the time taken for each operation defined in
the previous section. We analyze our results based on the operation of the cipher for various message spaces and for various key sizes.
1) Understanding the Graphs
We summarize our results in graphs which display the average times for an operation on the y-axis versus the key size or the message length on the x-axis. The operating time is measures in seconds, the key size is in number of bits, and the message length is the number of points on the ECC curve used to represent the message space of the desired number of bits.
2) Key Generation
For our implementation the generation of keys is the only aspect which is irrelevant to the message space, hence we generate the graph depicting the average time across all runs of the implementation for each key size. Figure 4 displays the average time taken by the key generation algorithm to generate all the system parameters for each key size. We observe that the algorithm used to calculate the keys takes almost negligible time for smaller key sizes; however, the time taken to generate keys rises significantly for larger key sizes.
From Figure 4, we can conclude that the trend in terms of time taken for key generation for smaller key sizes of 1024 and 2048 is fairly linear; however, this rises significantly for larger key sizes of 4096 bits. We can attribute this to the fact that Y is randomly selected for each run of the cipher, hence the bit length of Y directly impacts the key generation time, more specifically for larger key sizes than for smaller ones.
0
20
40
60
80
100
1024 2048 4096
Key Generation Times
Time
KEY SIZE
TIM
E
FIGU
RE 4: AVERAGE KEY GENERATION TIME
3) Encryption We calculate and discuss the cipher execution time for
the encryption operation. Figure 5 displays the general trend in the encryption times for each key size for each message space. The graph is for the encryption of 5000 bits; however, the time taken by the cipher for smaller message spaces displays the same trend but only differs by taking lesser time to complete the operation.
0.00
100.00
200.00
300.00
400.00
500.00
600.00
1 11 21 31 41 51 61 71 81 91 101
111
121
1024
2048
4096
5000 bits Encryption
POINTS ON CURVE
TIM
E
FIGU
RE 5: ENCRYPTION TIME TREND
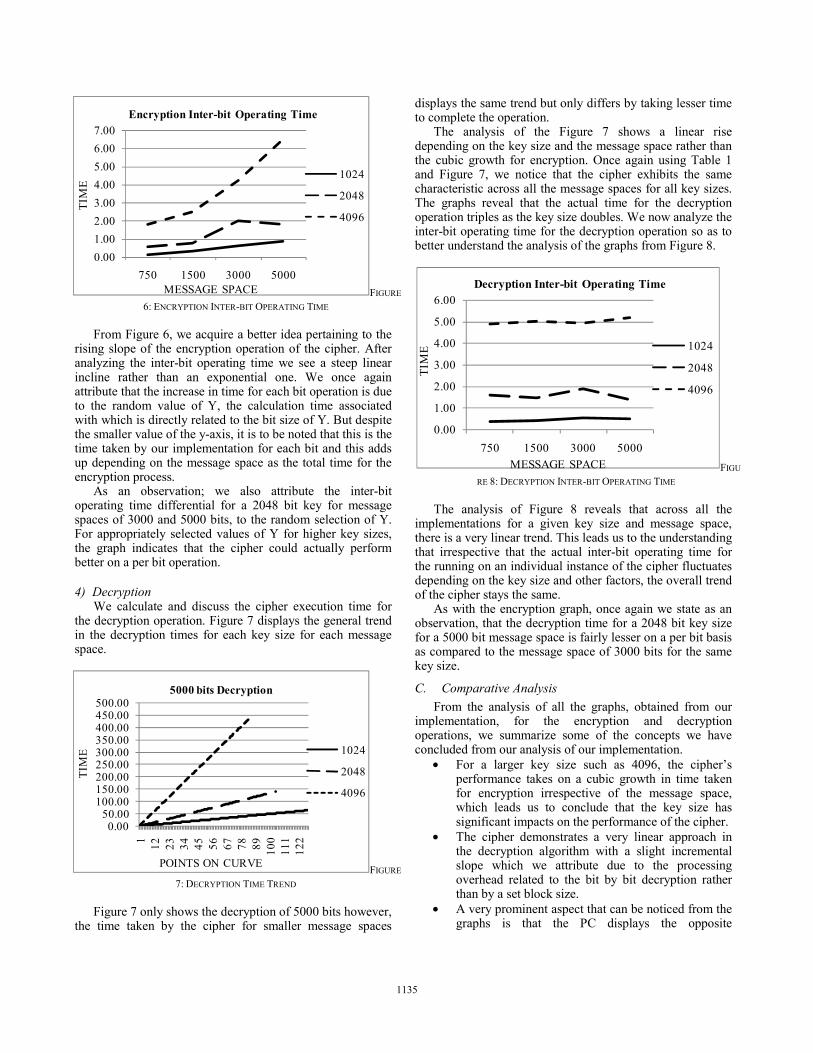
A very interesting fact is that the behavior of the cipher is exactly the same irrespective of the message space for each key size; the only difference being is the actual time taken for the operation and the degree of the slope. From our implementation, we also note a cubic growth in the slope of the curve associated with the encryption operation for each key size. Using Table 1 and Figure 5 we can conclude that the time associated with encrypting a given message space is directly proportional to the size of the message for each key size, as we can see the time required rises incrementally as the key sizes increase. This rise is very prominent for larger keys and message spaces. We now try to understand the bit by bit operating of the cipher to try and understand this variation in the slope of the curve from Figure 6 which depicts the inter-bit operating time for the cipher.
1134
0.001.002.003.004.005.006.007.00
750 1500 3000 5000
1024
2048
4096
Encryption Inter-bit Operating Time
MESSAGE SPACE
TIM
E
FIGURE
6: ENCRYPTION INTER-BIT OPERATING TIME
From Figure 6, we acquire a better idea pertaining to the rising slope of the encryption operation of the cipher. After analyzing the inter-bit operating time we see a steep linear incline rather than an exponential one. We once again attribute that the increase in time for each bit operation is due to the random value of Y, the calculation time associated with which is directly related to the bit size of Y. But despite the smaller value of the y-axis, it is to be noted that this is the time taken by our implementation for each bit and this adds up depending on the message space as the total time for the encryption process.
As an observation; we also attribute the inter-bit operating time differential for a 2048 bit key for message spaces of 3000 and 5000 bits, to the random selection of Y. For appropriately selected values of Y for higher key sizes, the graph indicates that the cipher could actually perform better on a per bit operation.
4) Decryption
We calculate and discuss the cipher execution time for the decryption operation. Figure 7 displays the general trend in the decryption times for each key size for each message space.
0.0050.00
100.00150.00200.00250.00300.00350.00400.00450.00500.00
1 12 23 34 45 56 67 78 89 100
111
122
1024
2048
4096
5000 bits Decryption
POINTS ON CURVE
TIM
E
FIGURE
7: DECRYPTION TIME TREND
Figure 7 only shows the decryption of 5000 bits however, the time taken by the cipher for smaller message spaces
displays the same trend but only differs by taking lesser time to complete the operation.
The analysis of the Figure 7 shows a linear rise depending on the key size and the message space rather than the cubic growth for encryption. Once again using Table 1 and Figure 7, we notice that the cipher exhibits the same characteristic across all the message spaces for all key sizes. The graphs reveal that the actual time for the decryption operation triples as the key size doubles. We now analyze the inter-bit operating time for the decryption operation so as to better understand the analysis of the graphs from Figure 8.
0.00
1.00
2.00
3.00
4.00
5.00
6.00
750 1500 3000 5000
1024
2048
4096
Decryption Inter-bit Operating Time
MESSAGE SPACE
TIM
E
FIGU
RE 8: DECRYPTION INTER-BIT OPERATING TIME
The analysis of Figure 8 reveals that across all the implementations for a given key size and message space, there is a very linear trend. This leads us to the understanding that irrespective that the actual inter-bit operating time for the running on an individual instance of the cipher fluctuates depending on the key size and other factors, the overall trend of the cipher stays the same.
As with the encryption graph, once again we state as an observation, that the decryption time for a 2048 bit key size for a 5000 bit message space is fairly lesser on a per bit basis as compared to the message space of 3000 bits for the same key size.
C. Comparative Analysis From the analysis of all the graphs, obtained from our
implementation, for the encryption and decryption operations, we summarize some of the concepts we have concluded from our analysis of our implementation.
• For a larger key size such as 4096, the cipher’s performance takes on a cubic growth in time taken for encryption irrespective of the message space, which leads us to conclude that the key size has significant impacts on the performance of the cipher.
• The cipher demonstrates a very linear approach in the decryption algorithm with a slight incremental slope which we attribute due to the processing overhead related to the bit by bit decryption rather than by a set block size.
• A very prominent aspect that can be noticed from the graphs is that the PC displays the opposite
1135

characteristics of traditional ciphers such as RSA and ECC. From the curves we conclude that the time taken for encryption is directly proportional to the key size and the message space being encrypted. However, for decryption, for larger key sizes over larger message spaces, the time taken to decrypt is actually shorter than the time taken to encrypt the data.
• We attribute the above fact to the random selection of Y; since for similar sized key constituent prime numbers P and Q, the decryption algorithm takes almost the same or lesser time to decrypt the same number of bits for a key size as does the encryption algorithm. This leads us to believe that the only cost to the decryption algorithm is the doubling up adding of inter-bit operating time due to the bitwise operation of the cipher.
• We executed our implementation under the Windows Vista operating system and obtained fairly the same results only with a slight increase in the time taken for key generation, encryption, and decryption operation; however, the trend of Figure 4-8 remained the same. We conclude from this that external factors such as choice of operating system, hardware specifications etc. do affect the performance of the cipher.
V. CONCLUSION
Our main purpose behind this paper has been to provide an insight on the practical implementation of a PC based on its original algorithms and to justify if it would be practically implementable. We have provided details on the mathematical concepts of the cipher and have provided the design for a working model which can be practically implemented. Many proposals have been proposed by Benaloh, Harn and Keisler, Okamoto et al, as well as Blum and Goldwasser, which suggest modifications to the base algorithm so as to reduce the message expansion associated with the PC by introducing multiple bit encryption and other message reduction techniques. Incorporating some of these modifications and doing a statistical analysis against the base algorithms would be the ideal use of this paper. Furthering to this paper, an understanding of the security implications versus varying key sizes would also be a beneficial enhancement. Further to this paper we aim to practically compare the RSA, ECC, and PC to actually provide a comparative analysis of all three ciphers.
In conclusion, we would like to stress that from our analysis and implementation, PC is in fact practically implementable based on its original algorithm and it does offer a significant advantage for smaller message spaces even for larger key sizes. Given the need for a high level of data security, the cipher does prove to be semantically secure in the generation of ciphertext using a probabilistic approach to encryption. The question still remains open to actually being able to incorporate the cipher algorithm by modifying it so as to significantly reduce the encryption time curve for larger message spaces, if possible, the cipher could prove to be very ideal for everyday activities such as website logins; it is however quite feasible for long term storage of data, the only question remains open is if the time taken by the algorithm compensates the data being secured.
REFERENCES 1. Robshaw, M.J.B. and Y.L. Yin (1997) Elliptic Curve Cryptosystems.
An RSA Laboratories Technical Note [cited July 7, 2009], http://www.rsa.com/rsalabs/node.asp?id=2013
2. Menezes, A., P.V. Oorschot, and S. Vanstone, Handbook of Applied Cryptography. 1996 CRC Press.
3. Neto, A.C.d.A. and R.F. Weber (2006) A new probabilistic public key algorithm based on elliptic logarithms. Brazilian Symposium on Information Security and Computing Systems [cited Dec 20, 2008], http://hdl.handle.net/10183/9983
4. Harn, L. and T. Kiesler, An Efficient Probabilistic Encryption Scheme. Information Processing Letters, 1990. 34 p. 123-129.
5. Benaloh, J., Dense Probabilistic Encryption. Proceedings of the Workshop on Selected Areas of Cryptography, 1994 p. 120-128.
6. Blum, M. and S. Goldwasser. An efficient probabilistic public key encryption scheme which hides all partial information. in Proceedings of CRYPTO 84 on Advances in cryptology. 1985. Santa Barbara, California, United States Springer-Verlag New York, Inc.
7. Harn, L. and T. Kiesler, An efficient probabilistic encryption scheme. Inf. Process. Lett., 1990. 34(3) p. 123-129.
8. Saeed, Q., T. Basir, S. Ul Haq, N. Zia, and M.A. Paracha. Mathematical Hard Problems in Modern Public-Key Cryptosystem. in Emerging Technologies, 2006. ICET '06. International Conference on. 2006.
9. Raju, G.V.S. and R. Akbani, Elliptic Curve Cryptosystem and its Applications. Lecture Notes in Computer Science, 1997. 1294 p. 342-356.
10. Fuchsbauer, G.J., An Introduction to Probabilistic Encryption. Osjecki Matematicki List, 2006. 6 p. 37-44.
11. Weisstein, E.W. "Legendre Symbol." From MathWorld--A Wolfram Web Resource. [cited June 1, 2009]; Available from: http://mathworld.wolfram.com/LegendreSymbol.html.
12. Weisstein, E.W. "Jacobi Symbol." From MathWorld--A Wolfram Web Resource. [cited June 1, 2009]; Available from: http://mathworld.wolfram.com/JacobiSymbol.html.
13. Gupta, V., S. Gupta, S. Chang, and D. Stebila. Performance analysis of elliptic curve cryptography for SSL. in Proceedings of the 1st ACM workshop on Wireless security. 2002. Atlanta, GA, USA ACM.
1136
Related Documents








![Practical Chosen Ciphertext Secure Encryption from FactoringDetails of our construction. In 1979 Rabin [42] proposed an encryption scheme based on the \modular squaring" trapdoor permutation](https://static.cupdf.com/doc/110x72/6046c2d96ee227125569f335/practical-chosen-ciphertext-secure-encryption-from-details-of-our-construction.jpg)


